Redis-实践知识
转自极客时间Redis 亚风 原文视频:https://u.geekbang.org/lesson/535?article=681062
Redis最佳实践
普通KEY
Redis 的key虽然可以自定义,但是最好遵循下面几个实践的约定:
格式:[业务名称]:[数据名]:[id] 长度不超过44字节 不包含特殊字符
例如: login:user:10
这样做的好处是
• 可读性强
• 避免key冲突
• ⽅便管理
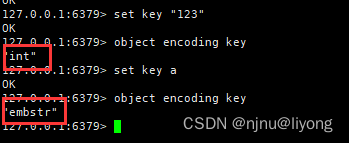
• 节省内存:key是string类型,底层编码包含int、embstr和raw三种。embstr在⼩于44字节使⽤,采⽤连续内存空间,内存占⽤更⼩。
set key "123"
object encoding key

BigKey
什么是bigKey?
- BigKey通常以Key的⼤⼩和Key中成员的数量来综合判定,例如:
- Key本身的数据量过⼤:⼀个String类型的Key,它的值为5 MB(key + val 加在一起 也就是一个Entry)。
- Key中的成员数过多:⼀个ZSET类型的Key,它的成员数量为10,000个。
Key中成员的数据量过⼤:⼀个Hash类型的Key,它的成员数量虽然只有1,000个但这些成员的Value(值)总⼤⼩为100 MB。
推荐值:
单个key的value⼩于10KB。
对于集合类型的key,建议元素数量⼩于1000。
BigKey的问题
• ⽹络阻塞
对Bigkey执⾏读请求时,少量的QPS就可能导致带宽使⽤率被占满,导致Redis实例,乃⾄所在物理机变慢
• 数据倾斜
BigKey所在的Redis实例内存使⽤率远超其他实例,⽆法使数据分⽚的內存资源达到均衡
• Redis阻塞
对元素较多的hash、 list、 zset等做运算会耗时较久,使主线程被阻塞
• CPU压⼒
对BigKey的数据序列化和反序列化会导致CPU的使⽤率飙升,影响Redis实例和本机其它应⽤
BigKey的发现
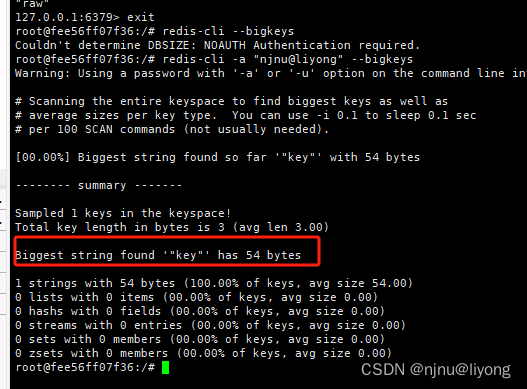
• redis-cli --bigkeys
利⽤ redis-cli提供的–bigkeys参数,可以遍历分析所有key,并返回Key的整体统计信息与每个数据的Top1的big key
redis-cli --bigkeys #扫描bigkeys
这里只得出了最大的key是54bytes,没有统计有那些key占用了多少空间,实际用用价值不大。
memory usage key #使用内存大小 (integer) 112
strlen key #也是使用内存大小
llen list #求内存大小
#最好是使用后面两个命令来求 memory usage性能不好

• scan扫描
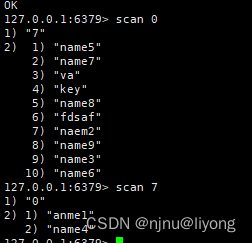
⾃⼰编程,利⽤scan扫描Redis中的所有key,利⽤strlen、hlen等命令判断key的⻓度(此处不建议使⽤MEMORY USAGE)
scan 0 #第一页是0
#第二页则是 返回什么值 往下翻页就是转这个值
scan 7
// 自己编程
final static int STR_MAX_LEN = 10 * 1024;
final static int HASH_MAX_LEN = 1000;@Testvoid testScan() {int maxLen = 0;long len = 0;String cursor = "0";do {// 扫描并获取⼀部分keyScanResult<String> result = jedis.scan(cursor);// 记录cursorcursor = result.getCursor();List<String> list = result.getResult();if (list == null || list.isEmpty()) {break;}// 遍历for (String key : list) {// 判断key的类型String type = jedis.type(key);switch (type) {case "string":len = jedis.strlen(key);maxLen = STR_MAX_LEN;break;case "hash":len = jedis.hlen(key);maxLen = HASH_MAX_LEN;break;case "list":len = jedis.llen(key);maxLen = HASH_MAX_LEN;break;case "set":len = jedis.scard(key);maxLen = HASH_MAX_LEN;break;case "zset":len = jedis.zcard(key);maxLen = HASH_MAX_LEN;break;default:break;}if (len >= maxLen) {System.out.printf("Found big key : %s, ty
pe: %s, length or size: %d %n", key, type, len);}}} while (!cursor.equals("0"));}
• 第三⽅⼯具
利⽤第三⽅⼯具,如 Redis-Rdb-Tools 分析RDB快照⽂件,全⾯分析内存使⽤情况(推荐使用,但是实时性比较差)
• ⽹络监控
⾃定义⼯具,监控进出Redis的⽹络数据,超出预警值时主动告警。直接监控网络数据包。
如何删除BigKey
BigKey内存占⽤较多,即便时删除这样的key也需要耗费很⻓时间,导致
Redis主线程阻塞,引发⼀系列问题。
• redis 3.0 及以下版本
如果是集合类型,则遍历BigKey的元素,先逐个删除⼦元素,最后删除Bigkey
• Redis 4.0以后
Redis在4.0后提供了异步删除的命令:unlink
怎么存储key
例1:⽐如存储⼀个User对象,我们有三种存储⽅式:
⽅式⼀:json字符串
user:1 {"name":"jack","age":21}
优点:
简单粗暴
缺点:
数据耦合,不够灵活
方式二
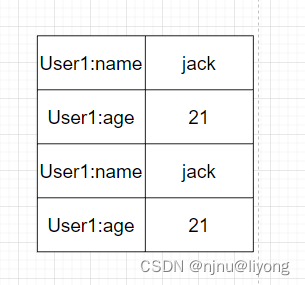
字段打散
user:1:name jack
user:1:age 21
优点:可以灵活访问对象任意字段
缺点:占⽤空间⼤、没办法做统⼀控制
方式三
hset uid name zhonglimo #单字段赋值
hmset uid name zhonglimo age 24 #多字段赋值

优点:底层使⽤ziplist,空间占⽤⼩,可以灵活访问对象的任意字段
缺点:代码相对复杂
实战案例
假如有hash类型的key,其中有100万对field和value,field是⾃增id,这个key存在什么问题?如何优化?

存在的问题:
• hash的entry数量超过500时,会使⽤dict⽽不是ZipList,内存占⽤较多
• 可以通过hash-max-ziplist-entries配置entry上限。但是如果entry过多就会
导致BigKey问题
解决方案一直接将hash进行拆分成String:
存在的问题:
• string结构底层没有太多内存优化,内存占⽤较多
• 想要批量获取这些数据⽐较麻烦
方式二:拆分为⼩的hash,将 id / 100 作为key,将id % 100 作为field,这样每100个元素为⼀个Hash
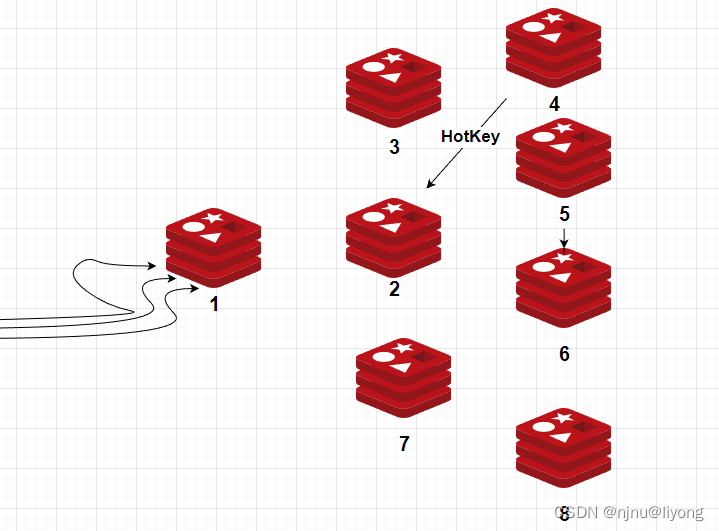
HotKey
比如我有一个redis集群,由于2有一个热键,所有的请都打到了这个机器上有可能这个机器扛不住压力会挂掉,服务因而无法使用。
如果是读:
比如用哈希取模的方法进行路由到不同的机器,但是键也要做同样的拆分因为一个集群不能相同的键。

如果是写,比如秒杀扣库存,每台机器存放100个库存:
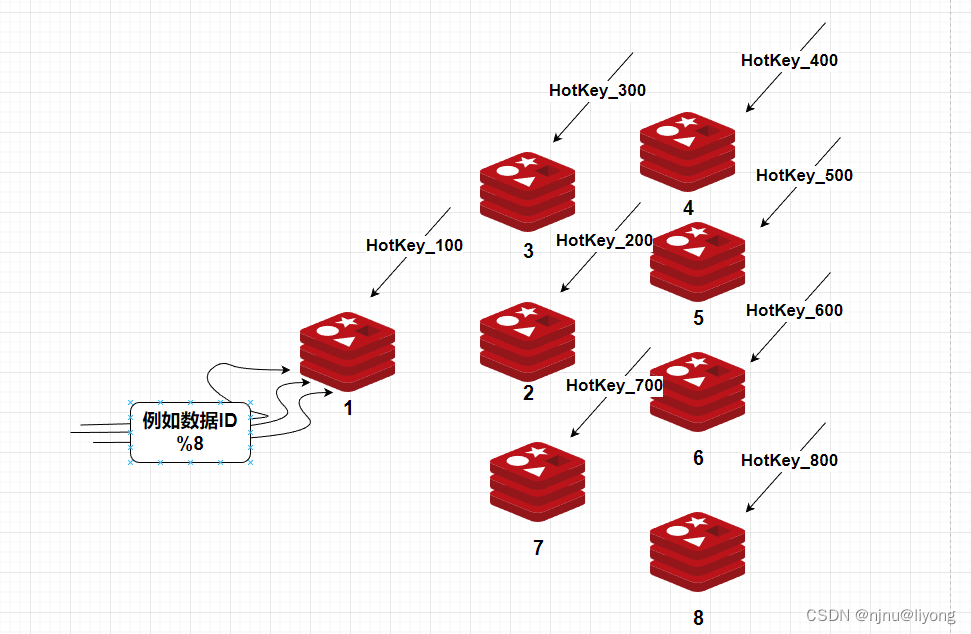
但是如果消耗到最后可能有碎片,比如剩了5个这个时候可以通过限流排队取消耗这些碎片。还有一种解决方案是消耗到剩一些碎片的时候,直接关闭流量,保证不超消费就行。
Pipeline批处理
MSET(不能被打断)虽然可以批处理,但是却只能操作部分数据类型,因此如果有对复杂数据类型的批处理需要,建议使⽤Pipeline功能:
void testPipeline() {Pipline pipeline = jedis.pipelined();for (int i = 1; i <= 10000; i ++) {if (i % 1000 == 0) {pipline.sync();}}
}
注意事项:
• 批处理时不建议⼀次携带太多命令
• Pipeline的多个命令之间不具备原⼦性
MSET/Pipeline这样的批处理需要在⼀次请求中携带多条命令,⽽此时如果Redis是⼀个集群,那批处理命令的多个key必须落在⼀个插槽中,否则就会导致执⾏失败。
解决方案:
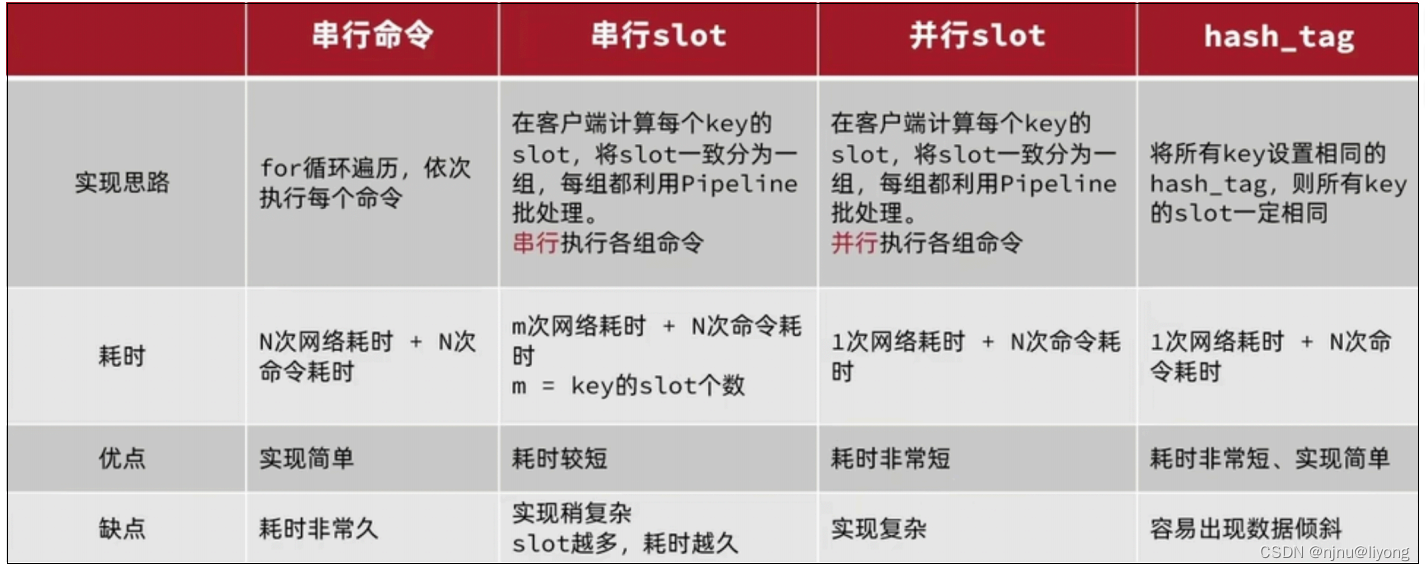
并行Slot在spring中的应用Spring->lettuce or Jedis->MultiKeyCommands
@Override
public RedisFuture<String> mset(Map<K,V> map) {Map<Integer, List<K>> partitioned = SlotHash.partition(codec, map.keySet());if (partitioned.size() < 2) {return super.mset(map);}
}
hash_tag
mset {a}name zhangsan {a}age 12 {a}set male #这个hash Tag可以将key路由到同一个槽中
但是hash_tag 存在数据倾斜的问题,实战中推荐使用并行slot.
RDB 数据文件备份
RDB全称Redis Database Backup file (Redis数据备份⽂件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照⽂件,恢复数据。快照⽂件称为RDB⽂件,默认是保存在当前运⾏⽬录。
#有两种命令
save #由redis主进程来执行RDB,会阻塞所有命令
#fork 出⼀个⼦进程,⼦进程执⾏,不会阻塞 Redis 主线程,默认选项
bgsave #开启子进程执行RDB,避免主进程受到影响
Redis 可以通过创建快照来获得存储在内存⾥⾯的数据在 某个时间点 上的副本。Redis 创建快照之后,可以对快照进⾏备份,可以将快照复制到其他服务器从⽽创建具有相同数据的服务器副本(Redis 主从结构,主要⽤来提⾼Redis 性能),还可以将快照留在原地以便重启服务器的时候使⽤。快照持久化是 Redis 默认采⽤的持久化⽅式,在 redis.conf 配置⽂件中默认有此下配置:
#这些配置是一个或的关系,可以多个都生效,底层执行的都是bgsave 会自动转换为bgsave
save 900 1 #900秒以后如果有一个key变化触发bgsave
save 300 10 #300秒以后如果有10个key变化可以出发bgsave
save 60 10000 #一分钟如果有10000个key发生变化触发bgsave
rdbcompression yes #是否开启压缩,建议不开启,压缩会消耗cpu
dbfilename dump.rdb #rdb文件名称
dir ./ #文件保存目录
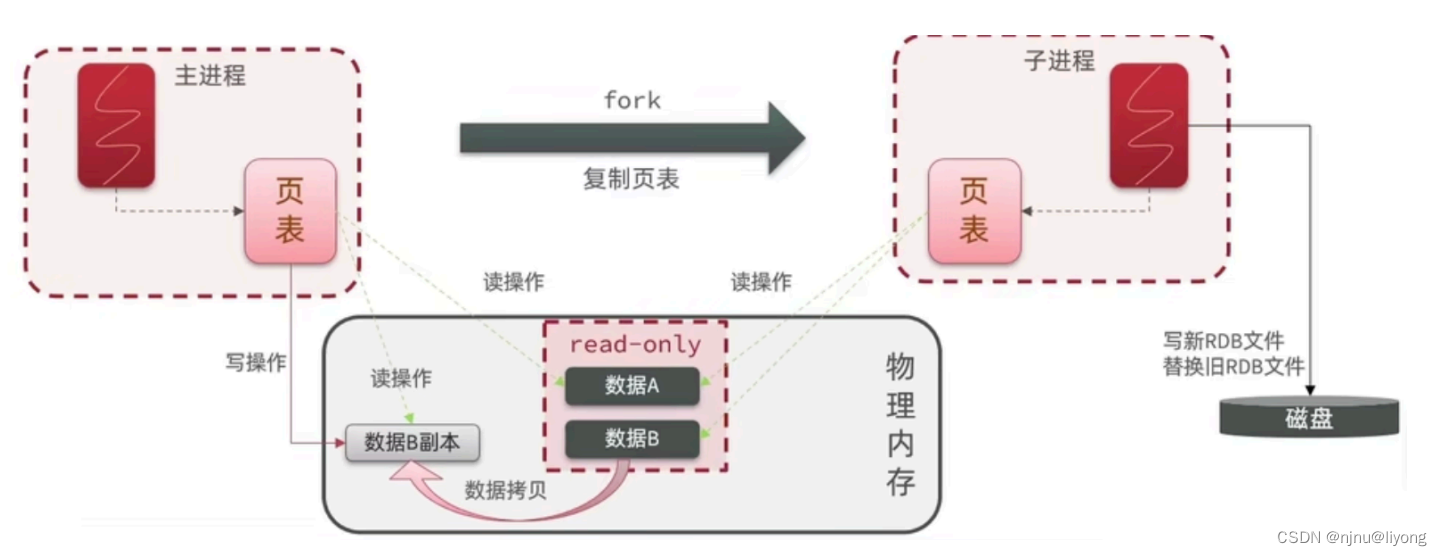
bgsave开始时会fork主进程得到⼦进程,⼦进程共享主进程的内存数据。完成fork后读取内存数据并写RDB ⽂件。fork采⽤的是copy-on-write技术:当主进程执⾏读操作时,访问共享内存;当主进程执⾏写操作时,则会拷⻉⼀份数据,执⾏写操作。
AOF 追加文件
AOF全称为Append Only File(追加⽂件)。Redis处理的每⼀个写命令都会记录在AOF⽂件,可以看做是命令⽇志⽂件。
与快照持久化相⽐,AOF 持久化的实时性更好。默认情况下 Redis 没有开启 AOF⽅式的持久(Redis6.0 之后已经默认是开启了),可以通过 appendonly 参数开启:appendonly yes
开启 AOF 持久化后每执⾏⼀条会更改 Redis 中的数据的命令,Redis 就会将该命令写⼊到 AOF 缓冲区(用户空间) server.aof_buf 中,然后再写⼊到 AOF ⽂件中(此时在内核缓存区),最后再根据持久化⽅式( fsync策略)的配置来决定何时将系统内核缓存区的数据同步到硬盘中的。
只有同步到磁盘中才算持久化保存了,否则依然存在数据丢失的⻛险,⽐如说:系统内核缓存区的数据还未同步,磁盘机器就宕机了,那这部分数据就算丢失了。
AOF ⽂件的保存位置和 RDB ⽂件的位置相同,都是通过 dir 参数设置的,默认的⽂件名appendonly.aof。
AOF 持久化功能的实现分为 5 步:
1 命令追加(append) :所有的写命令会追加到 AOF 缓冲区中。
2 ⽂件写⼊(write) :将 AOF 缓冲区的数据写⼊到 AOF ⽂件中。这⼀步
需要调⽤write函数(系统调⽤),write将数据写⼊到了系统内核缓冲区之
后直接返回了(延迟写)。注意!此时并没有同步到磁盘。
3 ⽂件同步(fsync) :AOF 缓冲区根据对应的持久化⽅式( fsync 策略)
向硬盘做同步操作。这⼀步需要调⽤ fsync 函数(系统调⽤), fsync 针
对单个⽂件操作,对其进⾏强制硬盘同步,fsync 将阻塞直到写⼊磁盘完
成后返回,保证了数据持久化。
4 ⽂件重写(rewrite) :随着 AOF ⽂件越来越⼤,需要定期对 AOF ⽂件
进⾏重写,达到压缩的⽬的。
5 重启加载(load) :Redis 重启时,可以加载 AOF ⽂件进⾏数据恢复。
Linux 系统直接提供了⼀些函数⽤于对⽂件和设备进⾏访问和控制,这些函数被称为系统调⽤(syscall)。
write :写⼊系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会⽴即同步到硬盘。虽然提⾼了效率,但也带来了数据丢失的⻛险。同步硬盘操作通常依赖于系统调度机制,Linux 内核通常为 30s 同步⼀次,具体值取决于写出的数据量和 I/O 缓冲区的状态。
fsync : fsync⽤于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
Redis fsync策略
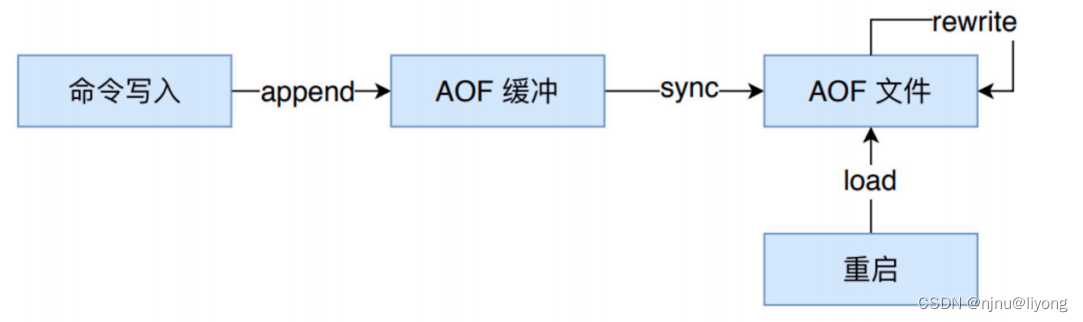
在 Redis 的配置⽂件中存在三种不同的 AOF 持久化⽅式( fsync策略),它们分别是:
• appendfsync always:主线程调⽤ write 执⾏写操作后,后台线程( aof_fsync 线程)⽴即会调⽤ fsync 函数同步 AOF ⽂件(刷盘),fsync 完成后线程返回,这样会严重降低 Redis 的性能
• appendfsync everysec :主线程调⽤ write 执⾏写操作后⽴即返回,由后台线程( aof_fsync 线程)每秒钟调⽤ fsync 函数(系统调⽤)同步⼀次 AOF ⽂件
• appendfsync no :主线程调⽤ write 执⾏写操作后⽴即返回,让操作系统决定何时进⾏同步,Linux 下⼀般为 30 秒⼀次为了兼顾数据和写⼊性能,可以考虑 appendfsync everysec 选项 ,让 Redis 每秒同步⼀次 AOF ⽂件,Redis 性能收到的影响较⼩。⽽且这样即使出现系统崩溃,⽤户最多只会丢失⼀秒之内产⽣的数据。当硬盘忙于执⾏写⼊操作的时候,Redis 还会优雅的放慢⾃⼰的速度以便适应硬盘的最⼤写⼊度。
**Multi Part AOF **
从 Redis 7 开始,Redis 使⽤了 Multi Part AOF 机制。顾名思义,Multi Part AOF 就是将原来的单个 AOF ⽂件拆分成多个 AOF ⽂件。在 Multi Part AOF 中,AOF ⽂件被分为三种类型,分别为:
BASE:表示基础 AOF ⽂件,它⼀般由⼦进程通过重写产⽣,该⽂件最多只有⼀个。
INCR:表示增量 AOF ⽂件,它⼀般会在 AOFRW 开始执⾏时被创建,该⽂件可能存在多个。
HISTORY:表示历史 AOF ⽂件,它由 BASE 和 INCR AOF 变化⽽来,每次 AOFRW 成功完成时,本次 AOFRW 之前对应的 BASE 和 INCR AOF 都将变为 HISTORY,HISTORY 类型的 AOF 会被 Redis ⾃动删除。
当 AOF 变得太⼤时,Redis 能够在后台⾃动重写 AOF 产⽣⼀个新的 AOF ⽂件,这个新的 AOF ⽂件和原有的 AOF ⽂件所保存的数据库状态⼀样,但体积更⼩。
AOF重写
AOF 重写是⼀个有歧义的名字,该功能是通过读取数据库中的键值对来实现的(扫描键值对重新写一个新文件,不会对之前的AOF进行读写),程序⽆须对现有 AOF ⽂件进⾏任何读⼊或写⼊操作。
由于 AOF 重写会进⾏⼤量的写⼊操作,为了避免对 Redis 正常处理命令请求造成影响,Redis 将 AOF 重写程序放到⼦进程⾥执⾏。
AOF ⽂件重写期间,Redis 还会维护⼀个 AOF 重写缓冲区,该缓冲区会在⼦进程创建新 AOF ⽂件期间,记录服务器执⾏的所有写命令。当⼦进程完成创建新 AOF ⽂件的⼯作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF ⽂件的末尾,使得新的 AOF ⽂件保存的数据库状态与现有的数据库状态⼀致。最后,服务器⽤新的 AOF ⽂件替换旧的 AOF ⽂件,以此来完成 AOF ⽂件重写操作。
开启 AOF 重写功能,可以调⽤ BGREWRITEAOF 命令⼿动执⾏,也可以设置下⾯两个配置项,让程序⾃动决定触发时机:
#增长超过多少百分比触发重写
auto-aof-rewrite-percentage 100
#体积多大触发重写
auto-aof-rewrite-min-size 64mb
Redis 7.0 版本之前,如果在重写期间有写⼊命令,AOF 可能会使⽤⼤量内存,重写期间到达的所有写⼊命令都会写⼊磁盘两次。AOF 重写期间的增量数据如何处理⼀直是个问题,在过去写期间的增量数据需
要在内存中保留,写结束后再把这部分增量数据写⼊新的 AOF ⽂件中以保证数据完整性。可以看出来 AOF 写会额外消耗内存和磁盘 IO,这也是 Redis AOF 写的痛点,虽然之前也进⾏过多次改进但是资源消耗的本质问题⼀直没有解决。
阿⾥ Redis 在最初也遇到了这个问题,在内部经过多次迭代开发,实现了 Multi-part AOF 机制来解决,同时也贡献给了社区并随此次 7.0 发布。具体⽅法是采⽤ base(全量数据)+incr(增量数据)独⽴⽂件存储的⽅式。由于 RDB 和 AOF 各有优势,Redis 4.0 开始⽀持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF ⽂件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF ⾥⾯的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
RDB与AOF的对比
RDB ⽐ AOF 优秀的地⽅ :
RDB ⽂件存储的内容是经过压缩的⼆进制数据, 保存着某个时间点的数据集,⽂件很⼩,适合做数据的备份,灾难恢复。AOF ⽂件存储的是每⼀次写命令,类似于 MySQL 的 binlog ⽇志,通常会必 RDB ⽂件⼤很多。当 AOF 变得太⼤时,Redis 能够在后台⾃动重写 AOF。新的 AOF ⽂件和原有的 AOF ⽂件所保存的数据库状态⼀样,但体积更⼩。不过, Redis 7 之前,如果在重写期间有写⼊命令,AOF 可能会使⽤⼤量内存,重写期间到达的所有写⼊命令都会写⼊磁盘两次。使⽤ RDB ⽂件恢复数据,直接解析还原数据即可,不需要⼀条⼀条地执⾏命令,速度⾮常快。⽽ AOF 则需要依次执⾏每个写命令,速度⾮常慢。也就是
说,与 AOF 相⽐,恢复⼤数据集的时候,RDB 速度更快。
AOF ⽐ RDB 优秀的地⽅ :
RDB 的数据安全性不如 AOF,没有办法实时或者秒级持久化数据。⽣成 RDB ⽂件的过程是⽐较繁重的, 虽然 BGSAVE ⼦进程写⼊ RDB ⽂件的⼯作不会阻塞主线程,但会对机器的 CPU 资源和内存资源产⽣影响,严重的情况下甚⾄会直接把 Redis 服务⼲宕机。AOF ⽀持秒级数据丢失(取决 fsync 策略,如果是 everysec,最多丢失 1 秒的数据),仅仅是追加命令到 AOF ⽂件,操作轻量。
RDB ⽂件是以特定的⼆进制格式保存的,并且在 Redis 版本演进中有多个版本的 RDB,所以存在⽼版本的 Redis 服务不兼容新版本的 RDB 格式的问题。AOF 以⼀种易于理解和解析的格式包含所有操作的⽇志。你可以轻松地导出 AOF ⽂件进⾏分析。⽐如,如果执⾏FLUSHALL命令意外地刷新了所有内容后,删除最新命令并重启即可恢复之前的状态。持久化可以保证数据安全,但会带来额外的开销,请遵循下列建议:
• ⽤来做缓存的Redis实例尽量不要开启持久化功能
• 建议关闭RDB持久化功能,使⽤AOF持久化
• 利⽤脚本定期在slave节点做RDB,实现数据备份
• 设置合理的rewrite阈值,避免频繁的bgrewrite
• 配置no-appendfsync-on-rewrite =yes,禁⽌在rewrite期间做aof,避免因
AOF引起的阻塞
部署建议
• Redis实例的物理机要预留⾜够内存,应对fork和rewrite
• 单个Redis实例内存上限不要太⼤,例如8G。可以加快fork的速度(fork是到页如果句柄太大,fork也会很慢)、减少主从同步、数据迁移压⼒
• 不要与CPU密集型应⽤部署在⼀起
• 不要与⾼硬盘负载应⽤⼀起部署。例如:数据库、消息队列
慢查询
慢查询阈值可以通过配置指定:slowlog-log-slower-than:慢查询阈值,单位是微秒。默认是10000(10ms),建议1000(1ms)
慢查询会被放⼊慢查询⽇志中,⽇志的⻓度有上限,可以通过配置指定:slowlog-max-len:慢查询⽇志(本质是⼀个队列)的⻓度。默认是128,建议1000
• slowlog len:查询慢查询⽇志⻓度
• slowlog get n:读取n条慢查询⽇志
• slowlog reset:清空慢查询列表、
Redis 安全设置
Redis会绑定在0.0.0.0:6379,这样将会将Redis服务暴露到公⽹上,⽽Redis如果没有做身份认证,会出现严重的安全漏洞.
漏洞出现的核⼼的原因有以下3点:
• Redis未设置密码
• 利⽤了Redis的config set命令动态修改Redis配置
• 使⽤了Root账号权限启动Redis
为了避免漏洞,这⾥给出⼀些建议:
• Redis⼀定要设置密码
• 禁⽌线上使⽤下⾯命令:keys、 flushall、 flushdb、 config set等命令。可以利⽤rename-command禁⽤。
rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52 #把修改配置的命令重新命名
rename-command KEYS "" #必禁命令,线上用这种查询方式绝对是不对的
rename-command FLUSHALL "" #必禁命令,谁会清除数据呢
rename-command FLUSHDB "" #必禁命令,谁会清除数据呢
rename-command CONFIG "" #可以考虑重命名下
• bind:限制⽹卡,禁⽌外⽹⽹卡访问
• 开启防⽕墙
• 不要使⽤Root账户启动Redis
• 尽量不是有默认的端⼝
Redis内存优化
当Redis内存不⾜时,可能导致Key频繁被删除、响应时间变⻓、QPS不稳定等问题。当内存使⽤率达到90%以上时就需要我们警惕,并快速定位到内存占⽤的原因。
redis info 详解
内存占用

内存缓冲区常⻅的有三种:
复制缓冲区:主从复制的repl-backlog_buf,如果太⼩可能导致频繁的全量复制,影响性能。通过repl-backlog-size来设置,默认1mb。
AOF缓冲区:AOF刷盘之前的缓存区域,AOF执⾏rewrite的缓冲区。⽆法设置容量上限。
客户端缓冲区:分为输⼊缓冲区和输出缓冲区,输⼊缓冲区最⼤1G且不能设置,输出缓冲区可以设置。
通过下面这个命令进行设置:
class 是一个什么,集群的时候配replica

CLIENT LIST #可以通过Client List 定位问题客户端
Redis集群优化
在Redis的默认配置中,如果发现任意⼀个插槽不可⽤,则整个集群都会停⽌对外服务:
cluster-require-full-coverage yes #通过这个配置来进行设置 no 是有个一个插槽不可以也可以使用
集群节点之间会不断的互相Ping来确定集群中其它节点的状态。每次Ping携带的信息⾄少包括:
• 插槽信息
• 集群状态信息
• 集群中节点越多,集群状态信息数据量也越⼤,10个节点的相关信息可能达到1kb,此时每次集群互通需要的带宽会⾮常⾼。
解决途径:
• 避免⼤集群,集群节点数不要太多,最好少于1000,如果业务庞⼤,则建⽴多个集群
• 避免在单个物理机中运⾏太多Redis实例
• 配置合适的cluster-node-timeout值
相关文章:
Redis-实践知识
转自极客时间Redis 亚风 原文视频:https://u.geekbang.org/lesson/535?article681062 Redis最佳实践 普通KEY Redis 的key虽然可以自定义,但是最好遵循下面几个实践的约定: 格式:[业务名称]:[数据名]:[id] 长度不超过44字节 不…...

多维时序 | MATLAB实现SSA-CNN-SVM麻雀算法优化卷积神经网络-支持向量机多变量时间序列预测
多维时序 | MATLAB实现SSA-CNN-SVM麻雀算法优化卷积神经网络-支持向量机多变量时间序列预测 目录 多维时序 | MATLAB实现SSA-CNN-SVM麻雀算法优化卷积神经网络-支持向量机多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | MATLAB实现…...

leetcode160相交链表思路解析
分别让tmp1以及tmp2的结点分别先指向headA以及headB,当遍历完成后,再让tmp1以及tmp2分别指向haedB和headA反转 此处有个问题:为什么if判断句中写tmp1!=nullptr,能够编译通过,但是写tmp1->ne…...

在线分析工具-日志优化
一、概述 针对于大日志文件,统计分析出日志文件的相关指标,帮助开发测试人员,优化日志打印。减少存储成本 二、日志分析指标 重复打印日志:统一请求reqId的重复打印日志打印最多的方法:检测出打印日志最多的方法…...

硬核实战!mysql 错误操作整个表全部数据后如何恢复?附解决过程、思路(百万行SQL,通过binlog日志恢复)
mysql 错误操作整个表全部数据后如何恢复?(百万行SQL,通过binlog日志恢复) 事件起因 事情起因:以为某个表里的数据都是系统配置的数据,没有用户数据,一个字段需要覆盖替换为新的url链接&#x…...

【什么是反射机制?为什么反射慢?】
✅ 什么是反射机制?为什么反射慢? ✅典型解析✅拓展知识仓✅反射常见的应用场景✅反射和Class的关系 ✅典型解析 反射机制指的是程序在运行时能够获取自身的信息。在iava中,只要给定类的名字,那么就可以通过反射机制来获得类的所有…...
PostGreSQL:货币类型
货币类型:money money类型存储固定小数精度的货币数字,小数的精度由数据库的lc_monetary设置决定。windows系统下,该配置项位于/data/postgresql.conf文件中,默认配置如下, lc_monetary Chinese (Simplified)_Chi…...

ESP8266网络相框采用TFT_eSPI库TJpg_Decoder库mixly库UDP库实现图片传送
用ESP8266和TFT_ESPI模块来显示图片数据。具体来说,我们将使用ILI9431显示器作为显示设备,并通过UDP协议将图片数据从发送端传输到ESP8266。最后,我们将解析这些数据并在TFT屏幕上显示出来。在这个过程中,我们将面临一些编程挑战&…...
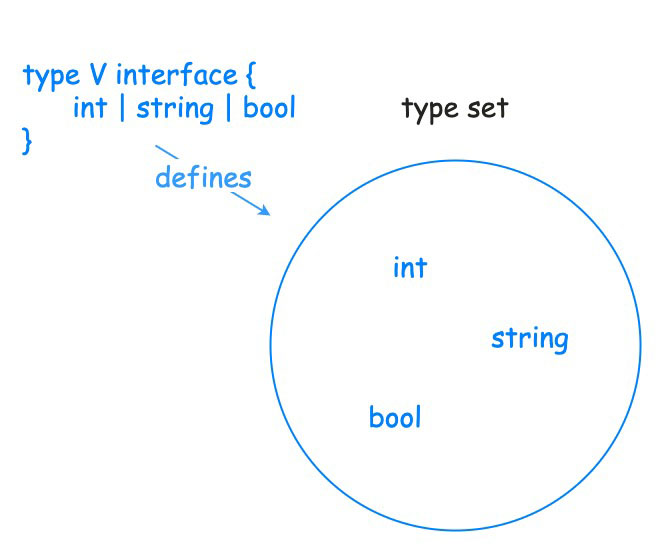
Go 泛型发展史与基本介绍
Go 泛型发展史与基本介绍 Go 1.18版本增加了对泛型的支持,泛型也是自 Go 语言开源以来所做的最大改变。 文章目录 Go 泛型发展史与基本介绍一、为什么要加入泛型?二、什么是泛型三、泛型的来源四、为什么需要泛型五、Go 泛型设计的简史六、泛型语法6.1 …...

python 解决手机拍的书籍图片发灰的问题
老师给发的作业经常是手机拍的,而不是扫描,背景发灰,如果二次打印就没有看了,象这样: 如果使用photoshop 处理,有些地方还是扣不干净,不如python 做的好,处理后如下: 具体…...

【prompt一】Domain Adaptation via Prompt Learning
1.Motivation 当前的UDA方法通过对齐源和目标特征空间来学习域不变特征。这种对齐是由诸如统计差异最小化或对抗性训练等约束施加的。然而,这些约束可能导致语义特征结构的扭曲和类可辨别性的丧失。 在本文中,引入了一种新的UDA提示学习范式࿰…...
视频编辑与制作,添加视频封面的软件
如今,视频已经成为了我们生活中不可或缺的一部分,无论是社交媒体上的短视频,还是电影、电视剧,视频都以其独特的魅力吸引着我们的目光。而在这背后,视频剪辑软件功不可没。今天,我就为大家揭秘一款新一代的…...
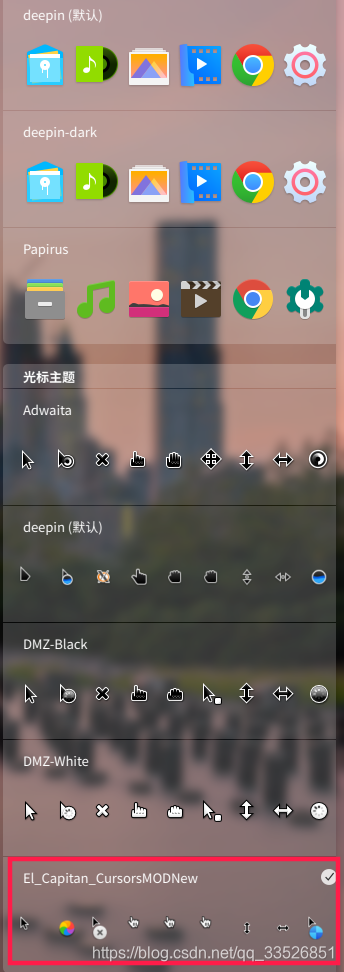
Deepin更换仿Mac主题
上一篇博客说了要写一篇deepin系统的美化教程 先看效果图: 准备工作: 1.你自己 嘻嘻嘻 2.能上网的deepin15.11电脑 首先去下载主题 本次需要系统美化3部分:1.图标 2.光标 3.壁纸 开始之前,请先把你的窗口特效打开,…...

【Flink-Kafka-To-ClickHouse】使用 Flink 实现 Kafka 数据写入 ClickHouse
【Flink-Kafka-To-ClickHouse】使用 Flink 实现 Kafka 数据写入 ClickHouse 1)导入相关依赖2)代码实现2.1.resources2.1.1.appconfig.yml2.1.2.log4j.properties2.1.3.log4j2.xml2.1.4.flink_backup_local.yml 2.2.utils2.2.1.DBConn2.2.2.CommonUtils2.…...

浅谈Redis分布式锁(下)
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 自定义Redis分布式锁的…...

Django Rest Framework框架的安装
Django Rest Framework框架的安装 Django Rest Framework框架的安装 1.DRF简介2.安装依赖3.安装使用pip安装添加rest_framework应用 1.DRF简介 Django REST Framework是Web api的工具包。它是在Django框架基础之上,进行了二次开发。 2.安装依赖 链接python安装 …...
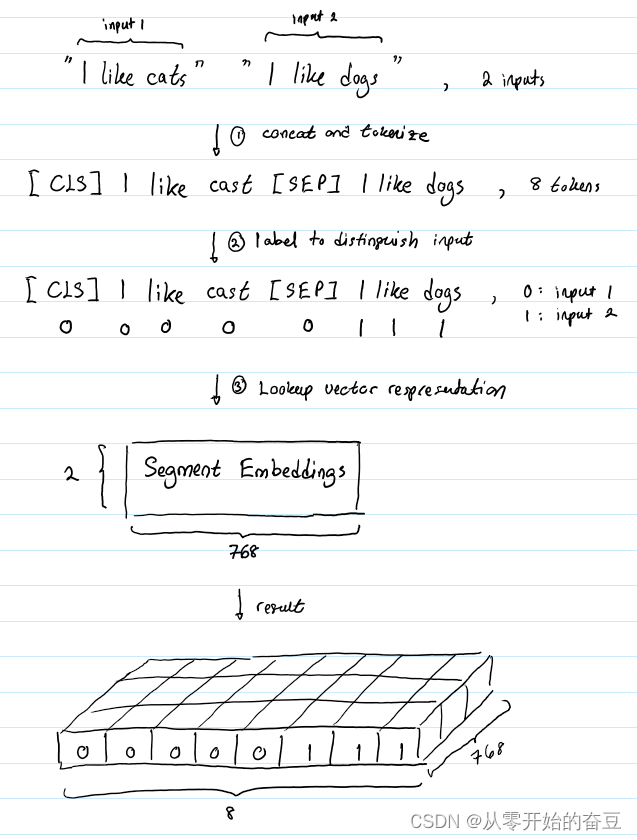
深度学习(七):bert理解之输入形式
传统的预训练方法存在一些问题,如单向语言模型的局限性和无法处理双向上下文的限制。为了解决这些问题,一种新的预训练方法随即被提出,即BERT(Bidirectional Encoder Representations from Transformers)。通过在大规模…...
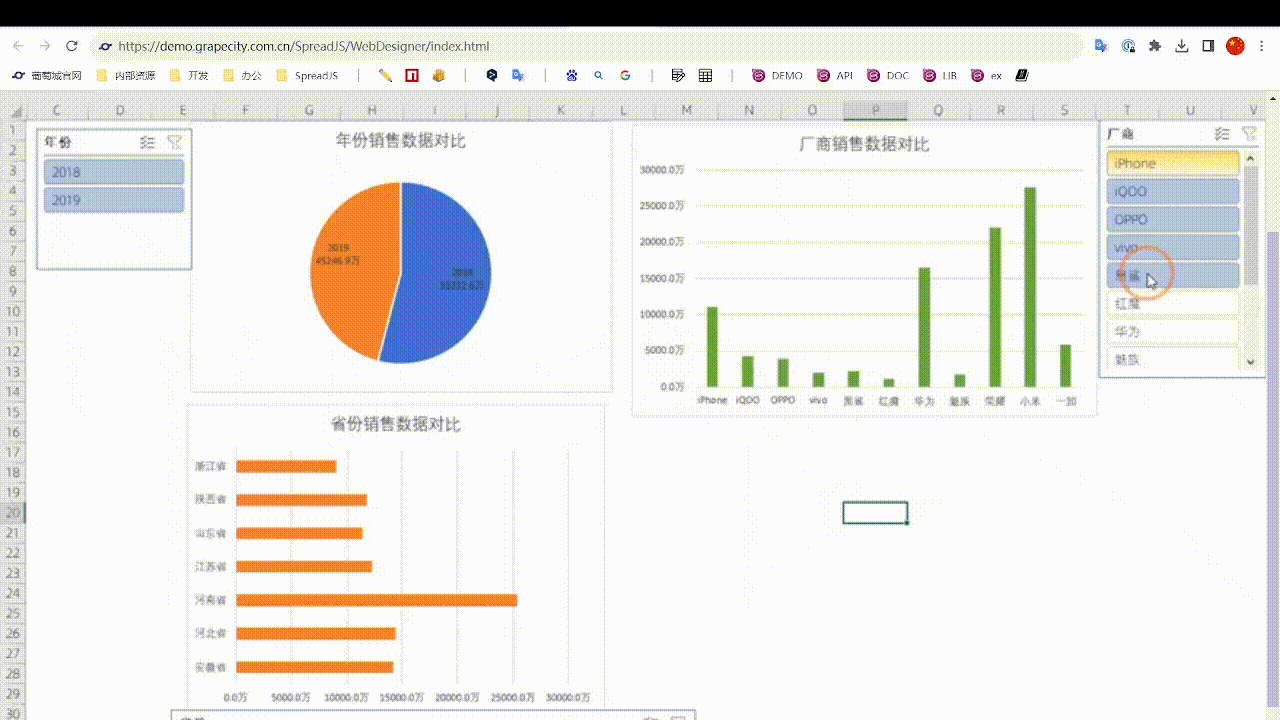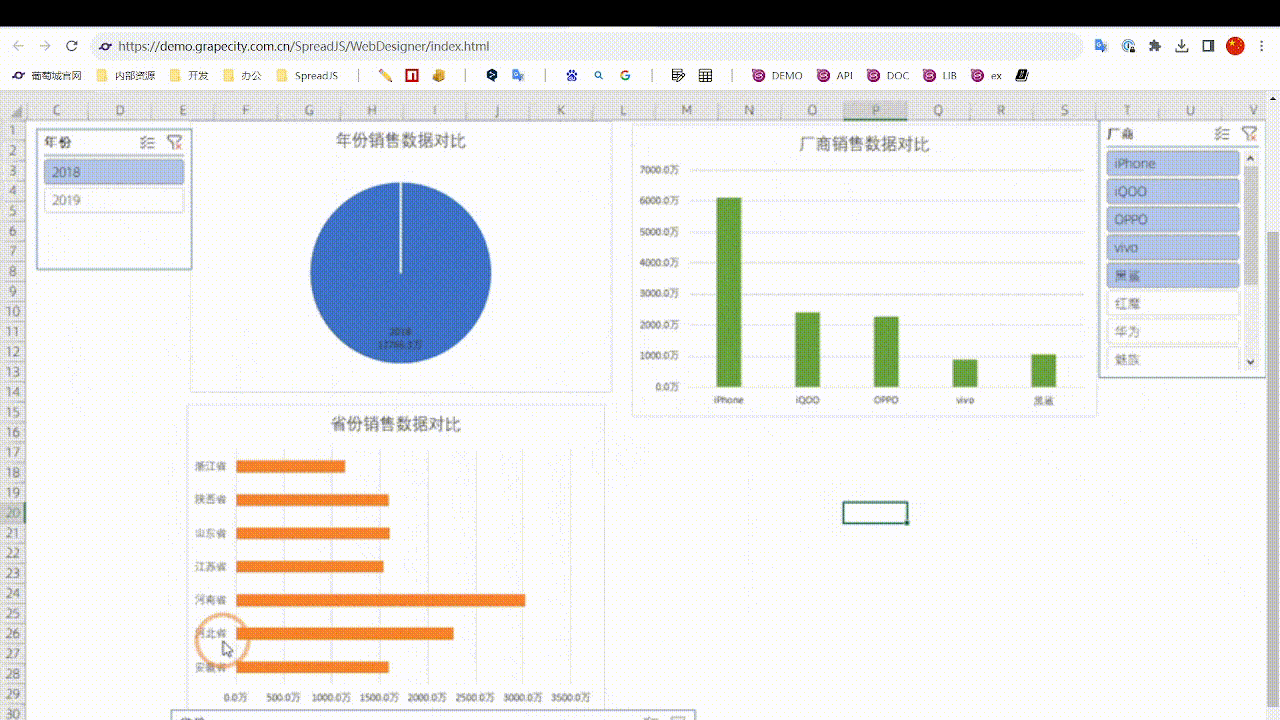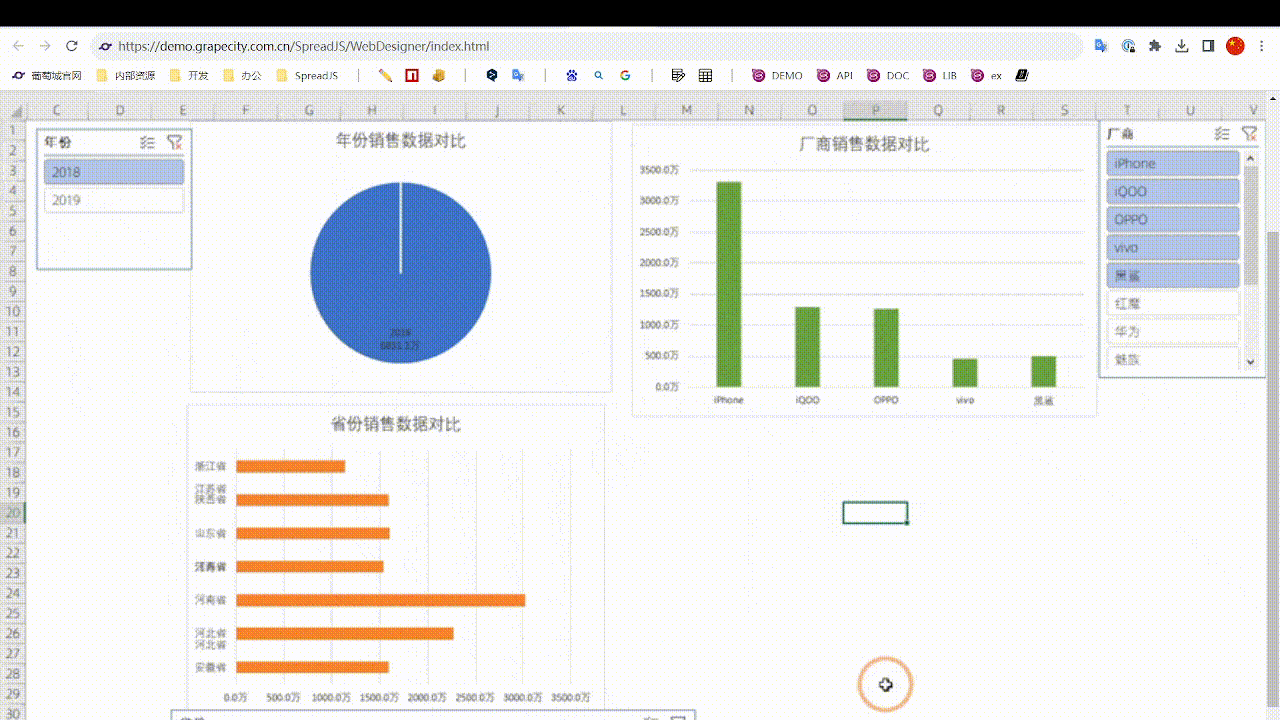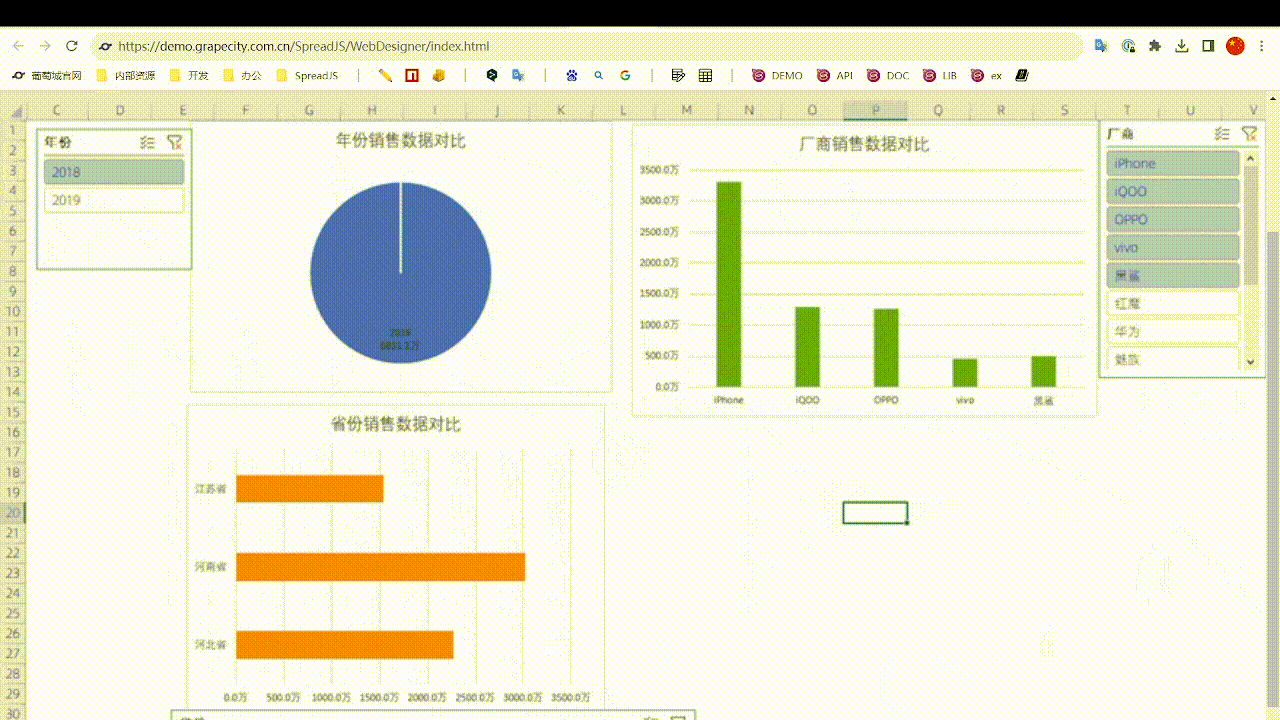
如何用Excel制作一张能在网上浏览的动态数据报表
前言 如今各类BI产品大行其道,“数据可视化”成为一个热门词汇。相比价格高昂的各种BI软件,用Excel来制作动态报表就更加经济便捷。今天小编就将为大家介绍一下如何使用葡萄城公司的纯前端表格控件——SpreadJS来实现一个Excel动态报表: 实…...
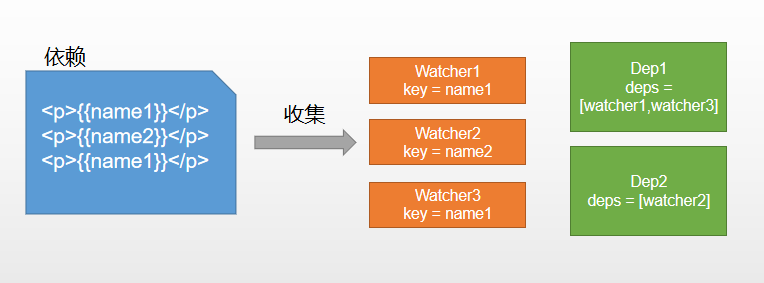
双向数据绑定是什么
一、什么是双向绑定 我们先从单向绑定切入单向绑定非常简单,就是把Model绑定到View,当我们用JavaScript代码更新Model时,View就会自动更新双向绑定就很容易联想到了,在单向绑定的基础上,用户更新了View,Mo…...

鱼眼标定方式
鱼眼作用 人单眼水平视角最大可达156度,垂直方向150度。为了增加可视范围,摄像头可以通过畸变参数扩大视野,一般100度到200度的fov。所以鱼眼是为了看的视野更大,注意在一定分辨率下,fov边缘的像素点稀疏,…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...