MySQL 上亿大表如何优化?
背景
XX 实例(一主一从)xxx 告警中每天凌晨在报 SLA 报警,该报警的意思是存在一定的主从延迟。(若在此时发生主从切换,需要长时间才可以完成切换,要追延迟来保证主从数据的一致性)
XX 实例的慢查询数量最多(执行时间超过 1s 的 SQL 会被记录),XX 应用那方每天晚上在做删除一个月前数据的任务。
分析
使用 pt-query-digest 工具分析最近一周的 mysql-slow.log:
pt-query-digest --since=148h mysql-slow.log | less结果第一部分:
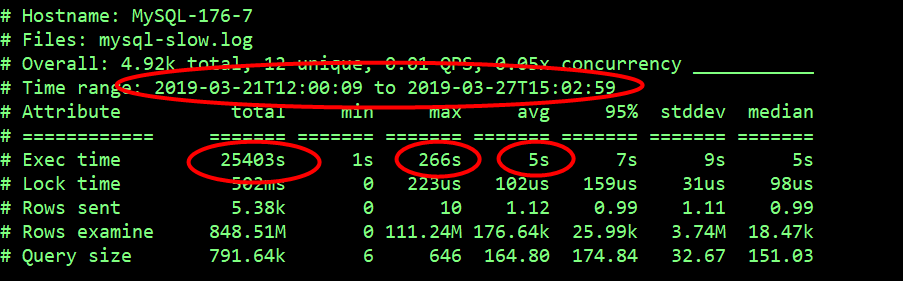
最近一个星期内,总共记录的慢查询执行花费时间为 25403s,最大的慢 SQL 执行时间为 266s,平均每个慢 SQL 执行时间 5s,平均扫描的行数为 1766 万。
结果第二部分:
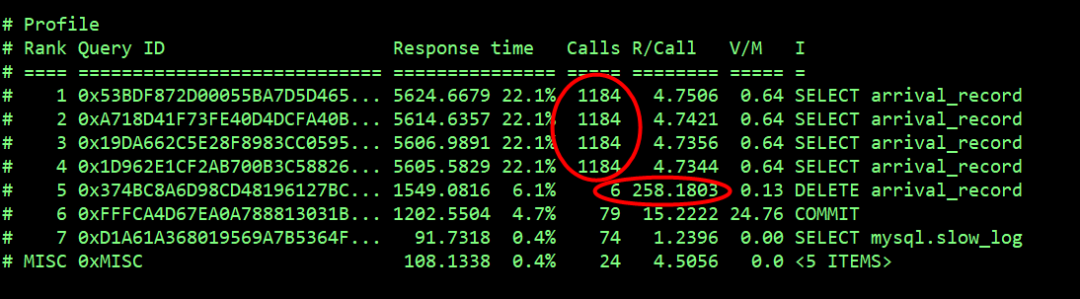
select arrival_record 操作记录的慢查询数量最多有 4 万多次,平均响应时间为 4s,delete arrival_record 记录了 6 次,平均响应时间 258s。
select xxx_record 语句
select arrival_record 慢查询语句都类似于如下所示,where 语句中的参数字段是一样的,传入的参数值不一样:
select count(*) from arrival_record where product_id=26 and receive_time between '2019-03-25 14:00:00' and '2019-03-25 15:00:00' and receive_spend_ms>=0\G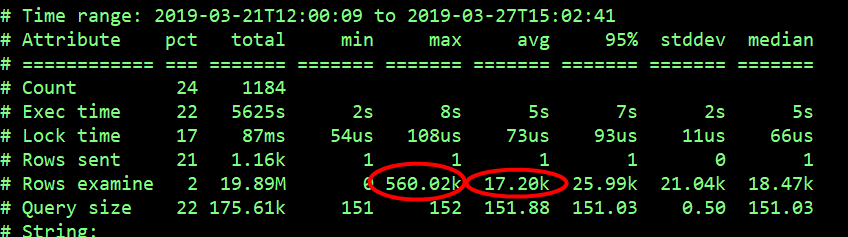
select arrival_record 语句在 MySQL 中最多扫描的行数为 5600 万、平均扫描的行数为 172 万,推断由于扫描的行数多导致的执行时间长。
查看执行计划:
explain select count(*) from arrival_record where product_id=26 and receive_time between '2019-03-25 14:00:00' and '2019-03-25 15:00:00' and receive_spend_ms>=0\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: arrival_record
partitions: NULL
type: ref
possible_keys: IXFK_arrival_record
key: IXFK_arrival_record
key_len: 8
ref: const
rows: 32261320
filtered: 3.70
Extra: Using index condition; Using where
1 row in set, 1 warning (0.00 sec)用到了索引 IXFK_arrival_record,但预计扫描的行数很多有 3000 多万行:
show index from arrival_record;
+----------------+------------+---------------------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------------+------------+---------------------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| arrival_record | 0 | PRIMARY | 1 | id | A | 107990720 | NULL | NULL | | BTREE | | |
| arrival_record | 1 | IXFK_arrival_record | 1 | product_id | A | 1344 | NULL | NULL | | BTREE | | |
| arrival_record | 1 | IXFK_arrival_record | 2 | station_no | A | 22161 | NULL | NULL | YES | BTREE | | |
| arrival_record | 1 | IXFK_arrival_record | 3 | sequence | A | 77233384 | NULL | NULL | | BTREE | | |
| arrival_record | 1 | IXFK_arrival_record | 4 | receive_time | A | 65854652 | NULL | NULL | YES | BTREE | | |
| arrival_record | 1 | IXFK_arrival_record | 5 | arrival_time | A | 73861904 | NULL | NULL | YES | BTREE | | |
+----------------+------------+---------------------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+show create table arrival_record;
..........
arrival_spend_ms bigint(20) DEFAULT NULL,
total_spend_ms bigint(20) DEFAULT NULL,
PRIMARY KEY (id),
KEY IXFK_arrival_record (product_id,station_no,sequence,receive_time,arrival_time) USING BTREE,
CONSTRAINT FK_arrival_record_product FOREIGN KEY (product_id) REFERENCES product (id) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=614538979 DEFAULT CHARSET=utf8 COLLATE=utf8_bin |①该表总记录数约 1 亿多条,表上只有一个复合索引,product_id 字段基数很小,选择性不好。
②传入的过滤条件:
where product_id=26 and receive_time between '2019-03-25 14:00:00' and '2019-03-25 15:00:00' and receive_spend_ms>=0
没有 station_nu 字段,使用不到复合索引 IXFK_arrival_record 的 product_id,station_no,sequence,receive_time 这几个字段。
③根据最左前缀原则,select arrival_record 只用到了复合索引 IXFK_arrival_record 的第一个字段 product_id,而该字段选择性很差,导致扫描的行数很多,执行时间长。
④receive_time 字段的基数大,选择性好,可对该字段单独建立索引,select arrival_record sql 就会使用到该索引。
现在已经知道了在慢查询中记录的 select arrival_record where 语句传入的参数字段有 product_id,receive_time,receive_spend_ms,还想知道对该表的访问有没有通过其他字段来过滤了
神器 tcpdump 出场的时候到了,使用 tcpdump 抓包一段时间对该表的 select 语句:
tcpdump -i bond0 -s 0 -l -w - dst port 3316 | strings | grep select | egrep -i 'arrival_record' >/tmp/select_arri.log获取 select 语句中 from 后面的 where 条件语句:
IFS_OLD=$IFS
IFS=$'\n'
for i in `cat /tmp/select_arri.log `;do echo ${i#*'from'}; done | less
IFS=$IFS_OLDarrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=17 and arrivalrec0_.station_no='56742'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=22 and arrivalrec0_.station_no='S7100'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=24 and arrivalrec0_.station_no='V4631'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=22 and arrivalrec0_.station_no='S9466'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=24 and arrivalrec0_.station_no='V4205'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=24 and arrivalrec0_.station_no='V4105'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=24 and arrivalrec0_.station_no='V4506'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=24 and arrivalrec0_.station_no='V4617'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=22 and arrivalrec0_.station_no='S8356'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=22 and arrivalrec0_.station_no='S8356'select 该表 where 条件中有 product_id,station_no,sequence 字段,可以使用到复合索引 IXFK_arrival_record 的前三个字段。
综上所示,优化方法为:
删除复合索引 IXFK_arrival_record
建立复合索引 idx_sequence_station_no_product_id
建立单独索引 indx_receive_time
delete xxx_record 语句
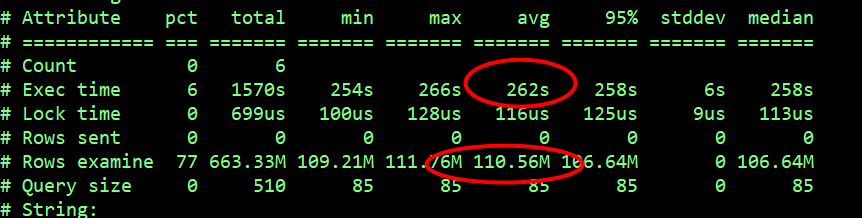
该 delete 操作平均扫描行数为 1.1 亿行,平均执行时间是 262s。
delete 语句如下所示,每次记录的慢查询传入的参数值不一样:
delete from arrival_record where receive_time < STR_TO_DATE('2019-02-23', '%Y-%m-%d')\G执行计划:
explain select * from arrival_record where receive_time < STR_TO_DATE('2019-02-23', '%Y-%m-%d')\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: arrival_record
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 109501508
filtered: 33.33
Extra: Using where
1 row in set, 1 warning (0.00 sec)该 delete 语句没有使用索引(没有合适的索引可用),走的全表扫描,导致执行时间长。
优化方法也是:建立单独索引 indx_receive_time(receive_time)。
测试
拷贝 arrival_record 表到测试实例上进行删除重新索引操作。
XX 实例 arrival_record 表信息:
du -sh /datas/mysql/data/3316/cq_new_cimiss/arrival_record*
12K /datas/mysql/data/3316/cq_new_cimiss/arrival_record.frm
48G /datas/mysql/data/3316/cq_new_cimiss/arrival_record.ibdselect count() from cq_new_cimiss.arrival_record;
+-----------+
| count() |
+-----------+
| 112294946 |
+-----------+
1亿多记录数SELECT
table_name,
CONCAT(FORMAT(SUM(data_length) / 1024 / 1024,2),'M') AS dbdata_size,
CONCAT(FORMAT(SUM(index_length) / 1024 / 1024,2),'M') AS dbindex_size,
CONCAT(FORMAT(SUM(data_length + index_length) / 1024 / 1024 / 1024,2),'G') AS table_size(G),
AVG_ROW_LENGTH,table_rows,update_time
FROM
information_schema.tables
WHERE table_schema = 'cq_new_cimiss' and table_name='arrival_record';+----------------+-------------+--------------+------------+----------------+------------+---------------------+
| table_name | dbdata_size | dbindex_size | table_size(G) | AVG_ROW_LENGTH | table_rows | update_time |
+----------------+-------------+--------------+------------+----------------+------------+---------------------+
| arrival_record | 18,268.02M | 13,868.05M | 31.38G | 175 | 109155053 | 2019-03-26 12:40:17 |
+----------------+-------------+--------------+------------+----------------+------------+---------------------+磁盘占用空间 48G,MySQL 中该表大小为 31G,存在 17G 左右的碎片,大多由于删除操作造成的。(记录被删除了,空间没有回收)
备份还原该表到新的实例中,删除原来的复合索引,重新添加索引进行测试。
mydumper 并行压缩备份:
user=rootpasswd=xxxxsocket=/datas/mysql/data/3316/mysqld.sockdb=cq_new_cimisstable_name=arrival_recordbackupdir=/datas/dump_$table_namemkdir -p $backupdirnohup echo `date +%T` && mydumper -u $user -p $passwd -S $socket -B $db -c -T $table_name -o $backupdir -t 32 -r 2000000 && echo `date +%T` &并行压缩备份所花时间(52s)和占用空间(1.2G,实际该表占用磁盘空间为 48G,mydumper 并行压缩备份压缩比相当高):
Started dump at: 2019-03-26 12:46:04
........Finished dump at: 2019-03-26 12:46:56du -sh /datas/dump_arrival_record/
1.2G /datas/dump_arrival_record/拷贝 dump 数据到测试节点:
scp -rp /datas/dump_arrival_record root@10.230.124.19:/datas多线程导入数据:
time myloader -u root -S /datas/mysql/data/3308/mysqld.sock -P 3308 -p root -B test -d /datas/dump_arrival_record -t 32real 126m42.885s
user 1m4.543s
sys 0m4.267s逻辑导入该表后磁盘占用空间:
du -h -d 1 /datas/mysql/data/3308/test/arrival_record.*
12K /datas/mysql/data/3308/test/arrival_record.frm
30G /datas/mysql/data/3308/test/arrival_record.ibd
没有碎片,和mysql的该表的大小一致
cp -rp /datas/mysql/data/3308 /datas分别使用 online DDL 和 pt-osc 工具来做删除重建索引操作。
先删除外键,不删除外键,无法删除复合索引,外键列属于复合索引中第一列:
nohup bash /tmp/ddl_index.sh &
2019-04-04-10:41:39 begin stop mysqld_3308
2019-04-04-10:41:41 begin rm -rf datadir and cp -rp datadir_bak
2019-04-04-10:46:53 start mysqld_3308
2019-04-04-10:46:59 online ddl begin
2019-04-04-11:20:34 onlie ddl stop
2019-04-04-11:20:34 begin stop mysqld_3308
2019-04-04-11:20:36 begin rm -rf datadir and cp -rp datadir_bak
2019-04-04-11:22:48 start mysqld_3308
2019-04-04-11:22:53 pt-osc begin
2019-04-04-12:19:15 pt-osc stoponline DDL 花费时间为 34 分钟,pt-osc 花费时间为 57 分钟,使用 onlne DDL 时间约为 pt-osc 工具时间的一半。
做 DDL 参考:
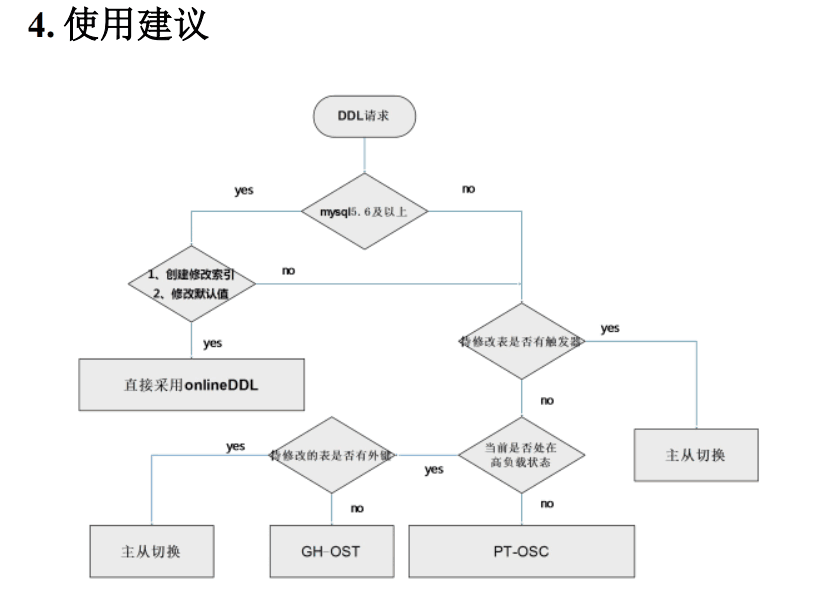
实施
由于是一主一从实例,应用是连接的 vip,删除重建索引采用 online DDL 来做。
停止主从复制后,先在从实例上做(不记录 binlog),主从切换,再在新切换的从实例上做(不记录 binlog):
function red_echo () {local what="$*"echo -e "$(date +%F-%T) ${what}"
}function check_las_comm(){if [ "$1" != "0" ];thenred_echo "$2"echo "exit 1"exit 1fi
}red_echo "stop slave"
mysql -uroot -p$passwd --socket=/datas/mysql/data/${port}/mysqld.sock -e"stop slave"
check_las_comm "$?" "stop slave failed"red_echo "online ddl begin"mysql -uroot -p$passwd --socket=/datas/mysql/data/${port}/mysqld.sock -e"set sql_log_bin=0;select now() as ddl_start;ALTER TABLE $db_.\`${table_name}\` DROP FOREIGN KEY FK_arrival_record_product,drop index IXFK_arrival_record,add index idx_product_id_sequence_station_no(product_id,sequence,station_no),add index idx_receive_time(receive_time);select now() as ddl_stop" >>${log_file} 2>& 1red_echo "onlie ddl stop"red_echo "add foreign key"mysql -uroot -p$passwd --socket=/datas/mysql/data/${port}/mysqld.sock -e"set sql_log_bin=0;ALTER TABLE $db_.${table_name} ADD CONSTRAINT _FK_${table_name}_product FOREIGN KEY (product_id) REFERENCES cq_new_cimiss.product (id) ON DELETE NO ACTION ON UPDATE NO ACTION;" >>${log_file} 2>& 1check_las_comm "$?" "add foreign key error"red_echo "add foreign key stop"red_echo "start slave"
mysql -uroot -p$passwd --socket=/datas/mysql/data/${port}/mysqld.sock -e"start slave"
check_las_comm "$?" "start slave failed"执行时间:
2019-04-08-11:17:36 stop slave
mysql: [Warning] Using a password on the command line interface can be insecure.
ddl_start
2019-04-08 11:17:36
ddl_stop
2019-04-08 11:45:13
2019-04-08-11:45:13 onlie ddl stop
2019-04-08-11:45:13 add foreign key
mysql: [Warning] Using a password on the command line interface can be insecure.
2019-04-08-12:33:48 add foreign key stop
2019-04-08-12:33:48 start slave删除重建索引花费时间为 28 分钟,添加外键约束时间为 48 分钟。
再次查看 delete 和 select 语句的执行计划:
explain select count(*) from arrival_record where receive_time < STR_TO_DATE('2019-03-10', '%Y-%m-%d')\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: arrival_record
partitions: NULL
type: range
possible_keys: idx_receive_time
key: idx_receive_time
key_len: 6
ref: NULL
rows: 7540948
filtered: 100.00
Extra: Using where; Using indexexplain select count(*) from arrival_record where product_id=26 and receive_time between '2019-03-25 14:00:00' and '2019-03-25 15:00:00' and receive_spend_ms>=0\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: arrival_record
partitions: NULL
type: range
possible_keys: idx_product_id_sequence_station_no,idx_receive_time
key: idx_receive_time
key_len: 6
ref: NULL
rows: 291448
filtered: 16.66
Extra: Using index condition; Using where都使用到了 idx_receive_time 索引,扫描的行数大大降低。
索引优化后
delete 还是花费了 77s 时间:
delete from arrival_record where receive_time < STR_TO_DATE('2019-03-10', '%Y-%m-%d')\G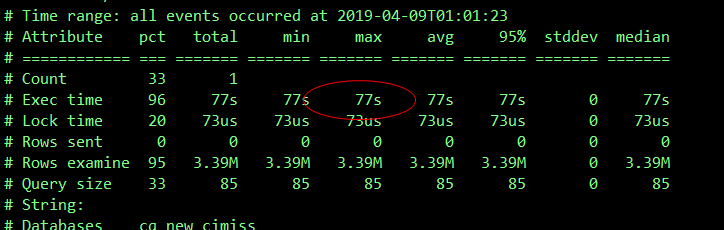
delete 语句通过 receive_time 的索引删除 300 多万的记录花费 77s 时间。
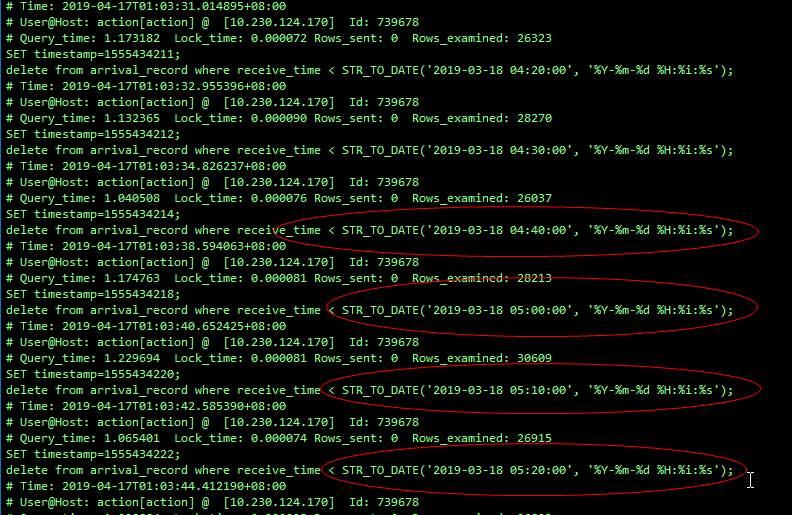
delete 大表优化为小批量删除
应用端已优化成每次删除 10 分钟的数据(每次执行时间 1s 左右),xxx 中没在出现 SLA(主从延迟告警):
另一个方法是通过主键的顺序每次删除 20000 条记录:
#得到满足时间条件的最大主键ID
#通过按照主键的顺序去 顺序扫描小批量删除数据
#先执行一次以下语句SELECT MAX(id) INTO @need_delete_max_id FROM `arrival_record` WHERE receive_time<'2019-03-01' ;DELETE FROM arrival_record WHERE id<@need_delete_max_id LIMIT 20000;select ROW_COUNT(); #返回20000#执行小批量delete后会返回row_count(), 删除的行数
#程序判断返回的row_count()是否为0,不为0执行以下循环,为0退出循环,删除操作完成DELETE FROM arrival_record WHERE id<@need_delete_max_id LIMIT 20000;select ROW_COUNT();
#程序睡眠0.5s总结
表数据量太大时,除了关注访问该表的响应时间外,还要关注对该表的维护成本(如做 DDL 表更时间太长,delete 历史数据)。
对大表进行 DDL 操作时,要考虑表的实际情况(如对该表的并发表,是否有外键)来选择合适的 DDL 变更方式。
对大数据量表进行 delete,用小批量删除的方式,减少对主实例的压力和主从延迟。
相关文章:
MySQL 上亿大表如何优化?
背景XX 实例(一主一从)xxx 告警中每天凌晨在报 SLA 报警,该报警的意思是存在一定的主从延迟。(若在此时发生主从切换,需要长时间才可以完成切换,要追延迟来保证主从数据的一致性)XX 实例的慢查询…...
Git(狂神课堂笔记)
1.首先去git官网下载我们对应的版本Git - Downloading Package (git-scm.com) 2.安装后我们会发现git文件夹里有三个应用程序: Git Bash:Unix与Linux风格的命令行,使用最多,推荐最多 Git CMD:Windows风格的命令行 G…...

「2」指针进阶,最详细指针和数组难题解题思路
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练 🔥座右铭:“不要等到什么都没有了,才下定决心去做” 🚀🚀🚀大家觉不错…...

云服务器是做什么的?云服务器典型的应用场景介绍
云服务器可能是很多企业以及个人上云用户的必选产品了,但是对于初学者或者非专业的用户来说云服务器还是比较陌生的,它到底是干什么的,如此生活中哪些地方可以接触到,这篇文章将详细的介绍云服务器使用的应用场景以及相关的操作 本…...
【论文随笔】Transfer of temporal logic formulas in reinforcement learning
Zhe Xu and Ufuk Topcu. 2019. Transfer of temporal logic formulas in reinforcement learning. In Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI’19). AAAI Press, 4010–4018. 这是一篇将inference和learning结合起来的文章…...

蓝桥杯-货物摆放
蓝桥杯-货物摆放1、题目描述1.1 答案提交1.2 运行限制2、解决方案2.1 方案一:暴力解法(三重循环)2.2 方案二:找出乘机的因子1、题目描述 小蓝有一个超大的仓库,可以摆放很多货物。 现在,小蓝有 n 箱货物要摆放在仓库,每…...

10 种顶流聚类算法 Python 实现(附完整代码)
聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现数据中的有趣模式,例如基于其行为的客户群。 有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。相反,最好探索一系列聚类算法以及每…...

微信小程序第一节 —— 自定义顶部、底部导航栏以及获取胶囊体位置信息。
一、前言 大家好!我是 是江迪呀。我们在进行微信小程序开发时,常常需要自定义一些东西,比如自定义顶部导航、自定义底部导航等等。那么知道这些自定义内容的具体位置、以及如何适配不同的机型就变得尤为重要。下面让我以在iPhone机型&#x…...
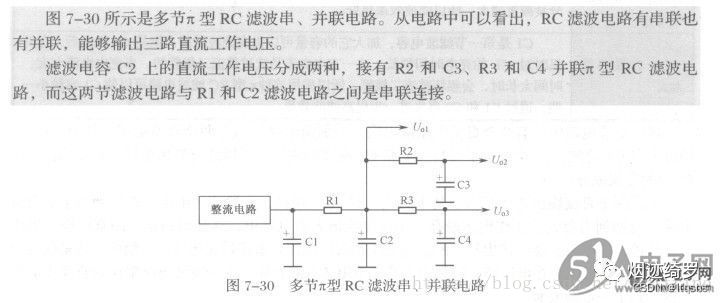
快速吃透π型滤波电路-LC-RC滤波器
π型滤波器简介 π型滤波器包括两个电容器和一个电感器,它的输入和输出都呈低阻抗。π型滤波有RC和LC两种, 在输出电流不大的情况下用RC,R的取值不能太大,一般几个至几十欧姆,其优点是成本低。其缺点是电阻要消耗一些…...
聊聊混沌工程
这是鼎叔的第五十四篇原创文章。行业大牛和刚毕业的小白,都可以进来聊聊。欢迎关注本专栏和微信公众号《敏捷测试转型》,大量原创思考文章陆续推出。混沌工程是一门新兴学科,它不仅仅只是个技术活动,还包含如何设计能够持续协作的…...

做为骨干网络的分类模型的预训代码安装配置简单记录
一、安装配置环境 1、准备工作 代码地址 GitHub - bubbliiiing/classification-pytorch: 这是各个主干网络分类模型的源码,可以用于训练自己的分类模型。 # 创建环境 conda create -n ptorch1_2_0 python3.6 # 然后启动 conda install pytorch1.2.0 torchvision…...

网络协议(九):应用层(域名、DNS、DHCP)
网络协议系列文章 网络协议(一):基本概念、计算机之间的连接方式 网络协议(二):MAC地址、IP地址、子网掩码、子网和超网 网络协议(三):路由器原理及数据包传输过程 网络协议(四):网络分类、ISP、上网方式、公网私网、NAT 网络…...
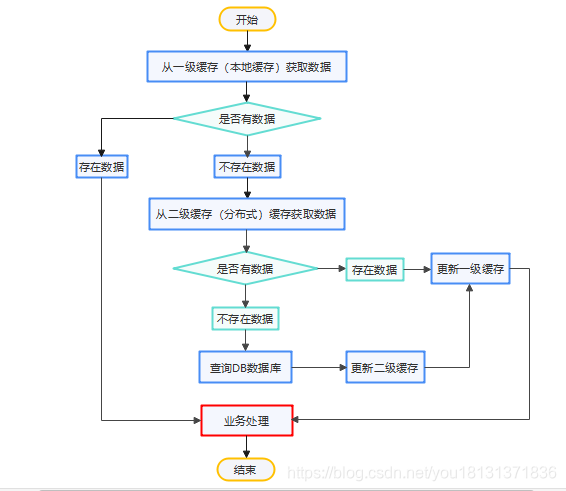
有趣的小知识(三)提升网站速度的秘诀:掌握缓存基础,让你的网站秒开
像MySql等传统的关系型数据库已经不能适用于所有的业务场景,比如电商系统的秒杀场景,APP首页的访问流量高峰场景,很容易造成关系型数据库的瘫痪,随着缓存技术的出现很好的解决了这个问题。 一、缓存的概念(什么是缓存…...

SpringCloud之服务拆分和实现远程调用案例
服务拆分对单体架构项目来说:简单方便,高度耦合,扩展性差,适合小型项目。而对于分布式架构来说:低耦合,扩展性好,但架构复杂,难度大。微服务就是一种良好的分布式架构方案࿱…...
: com.atguigu.dao.UserDao.save)
mybatis: Invalid bound statement (not found): com.atguigu.dao.UserDao.save
问题描述: 1 问题实质: dao层(又叫mapper接口)跟mapper.xml文件没有映射 2 问题原因: 出现这种映射问题的原因分为低级原因和更低级原因两种 更低级原因: (1)dao层的方法和mapper.xml中的方法不一样; (2)mapper中的namespace 值 和对应的dao层entity层不一致 &…...
JavaScript 代码规范
所有的 JavaScript 项目适用同一种规范。JavaScript 代码规范代码规范通常包括以下几个方面:变量和函数的命名规则空格,缩进,注释的使用规则。其他常用规范……规范的代码可以更易于阅读与维护。代码规范一般在开发前规定,可以跟你的团队成员…...

6综合项目 旅游网 【6.我的收藏和收藏排行榜】
我的收藏分析先登录→拿到当前登录的用户信息,从数据库中获取uid和对应uid的rid集合→将rid集合信息展示到我的收藏前台代码判断用户是否登录,传递uid,通过uid查找其对应的rid集合当查询的属性涉及到多张表,则必须使用多表连接&am…...
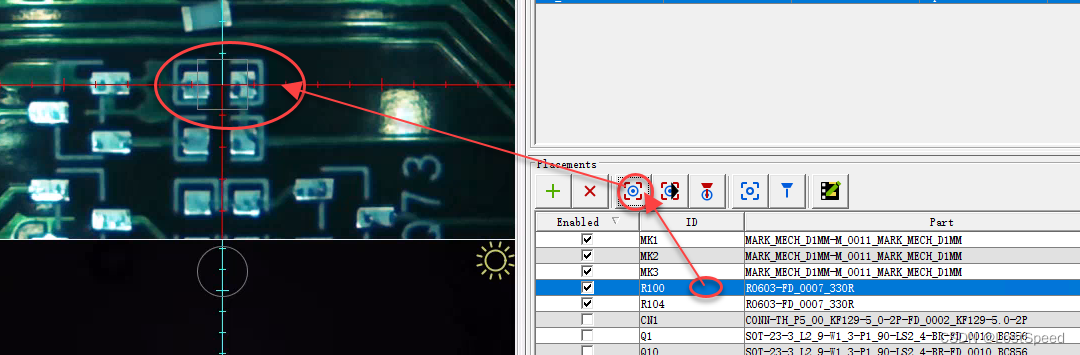
openpnp - error - 微调mark点坐标后,更新板子其他原件其他坐标报错的变通方法
文章目录openpnp - error - 微调mark点坐标后,更新板子其他原件其他坐标报错的变通方法概述想出来一个变通的方法ENDopenpnp - error - 微调mark点坐标后,更新板子其他原件其他坐标报错的变通方法 概述 载入坐标文件后, 指定左下角远点坐标, 然后定位板子上的3个Mark点, 因为…...

借助ChatGPT爆火,股价暴涨又暴跌后,C3.ai仍面临巨大风险
来源:猛兽财经 作者:猛兽财经 C3.ai的股价 作为一家人工智能技术提供商,C3.ai(AI)的股价曾在2021年初随着炒作情绪的增加,达到了历史最高点,但自那以后其股价就下跌了90%,而且炒作情…...

蓝桥杯-数位排序
蓝桥杯-数位排序1、问题描述2、解题思路3、代码实现1、问题描述 小蓝对一个数的数位之和很感兴趣, 今天他要按照数位之和给数排序。当 两个数各个数位之和不同时, 将数位和较小的排在前面, 当数位之和相等时, 将数值小的排在前面。 例如, 2022 排在 409 前面, 因为 2022 的数位…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

CppCon 2015 学习:REFLECTION TECHNIQUES IN C++
关于 Reflection(反射) 这个概念,总结一下: Reflection(反射)是什么? 反射是对类型的自我检查能力(Introspection) 可以查看类的成员变量、成员函数等信息。反射允许枚…...

spring boot使用HttpServletResponse实现sse后端流式输出消息
1.以前只是看过SSE的相关文章,没有具体实践,这次接入AI大模型使用到了流式输出,涉及到给前端流式返回,所以记录一下。 2.resp要设置为text/event-stream resp.setContentType("text/event-stream"); resp.setCharacter…...

Netty自定义协议解析
目录 自定义协议设计 实现消息解码器 实现消息编码器 自定义消息对象 配置ChannelPipeline Netty提供了强大的编解码器抽象基类,这些基类能够帮助开发者快速实现自定义协议的解析。 自定义协议设计 在实现自定义协议解析之前,需要明确协议的具体格式。例如,一个简单的…...
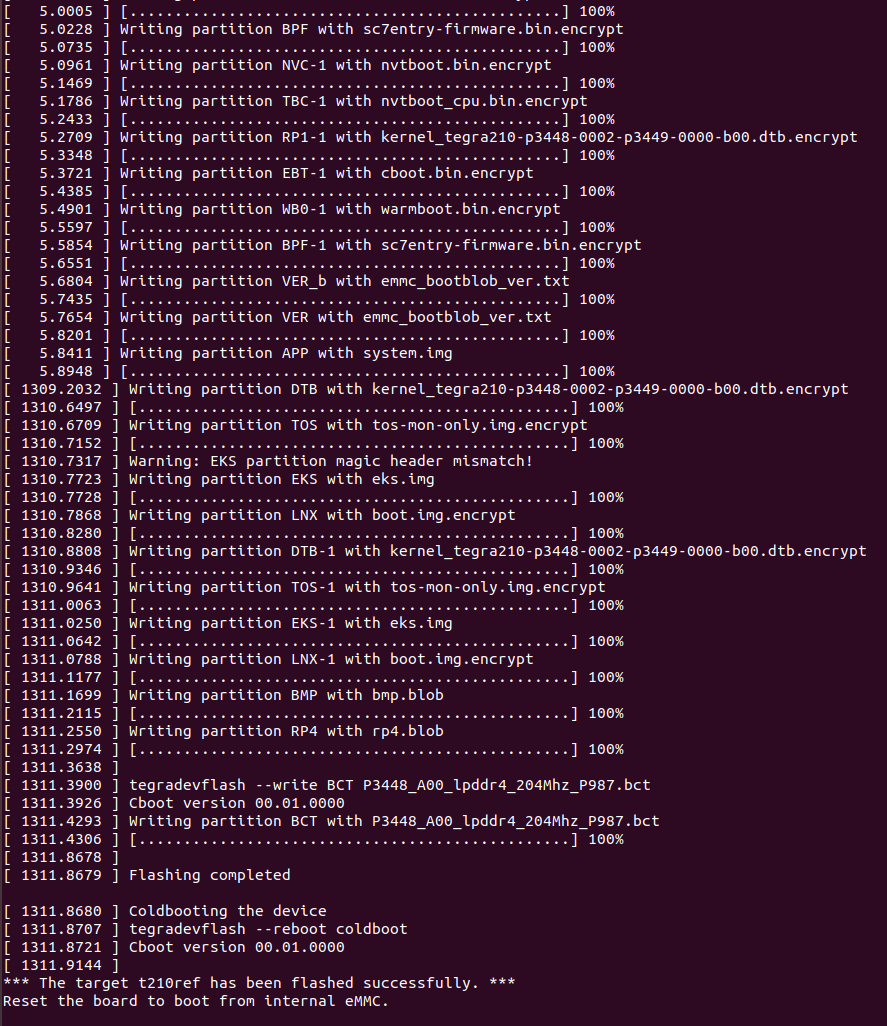
新版NANO下载烧录过程
一、序言 搭建 Jetson 系列产品烧录系统的环境需要在电脑主机上安装 Ubuntu 系统。此处使用 18.04 LTS。 二、环境搭建 1、安装库 $ sudo apt-get install qemu-user-static$ sudo apt-get install python 搭建环境的过程需要这个应用库来将某些 NVIDIA 软件组件安装到 Je…...