docker-compose部署kafka
docker-compose.yml配置
version: "3"
services:kafka:image: 'bitnami/kafka:latest'ports:- '7050:7050'environment:- KAFKA_ENABLE_KRAFT=yes- KAFKA_CFG_PROCESS_ROLES=broker,controller- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER- KAFKA_CFG_LISTENERS=PLAINTEXT://:7050,CONTROLLER://:7051- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://183.56.203.157:7050- KAFKA_BROKER_ID=1- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@0.0.0.0:7051- ALLOW_PLAINTEXT_LISTENER=yeskafka UI界面
docker run -d --name kafka-map -p 8049:8080 -e DEFAULT_USERNAME=admin -e DEFAULT_PASSWORD=admin dushixiang/kafka-map:latest
docker run -p 8080:8080 -e KAFKA_BROKERS=host.docker.internal:9092 docker.redpanda.com/vectorized/console:master-173596f
UI界面总览
https://towardsdatascience.com/overview-of-ui-tools-for-monitoring-and-management-of-apache-kafka-clusters-8c383f897e80
kafka学习
生产者
import org.apache.kafka.clients.producer.Callback
import org.apache.kafka.clients.producer.KafkaProducer
import org.apache.kafka.clients.producer.ProducerConfig
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.common.serialization.StringSerializer
import org.junit.Test
import java.util.*/*** @Description :* @Author xiaomh* @date 2022/8/5 15:58*/
class CustomProducer {//异步发送@Testfun customProducer() {//配置val properties = Properties()//链接kafkaproperties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.nameproperties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name//创建kafka生产者对象val kafkaProducer = KafkaProducer<String, String>(properties)//发送数据for (i in 0 until 5) {//黏性发送,达到设置的数据最大值/时间后,切换分区(不会是当前分区)kafkaProducer.send(ProducerRecord("xiao1", "customProducer,count::$i"))}//关闭资源kafkaProducer.close()}//同步发送@Testfun customProducerSync() {//配置val properties = Properties()//链接kafkaproperties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.nameproperties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name//创建kafka生产者对象val kafkaProducer = KafkaProducer<String, String>(properties)//发送数据for (i in 0 until 5) {//黏性发送,达到设置的数据最大值/时间后,切换分区(不会是当前分区)kafkaProducer.send(ProducerRecord("xiao1", "customProducerSync,count::$i")).get()}//关闭资源kafkaProducer.close()}//回调异步发送@Testfun customProducerCallback() {//配置val properties = Properties()//链接kafkaproperties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.nameproperties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name//创建kafka生产者对象val kafkaProducer = KafkaProducer<String, String>(properties)//发送数据for (i in 0 until 500) {//黏性发送,达到设置的数据最大值/时间后,切换分区(不会是当前分区)kafkaProducer.send(ProducerRecord("xiao1", "customProducerCallback,count::$i"), Callback{ metadata, exception ->if (exception == null) {println("主题:${metadata.topic()},分区:${metadata.partition()}")}})//测试分区策略Thread.sleep(1)}//关闭资源kafkaProducer.close()}//回调异步发送+使用分区@Testfun customProducerCallbackPartitions1() {//配置val properties = Properties()//链接kafkaproperties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.nameproperties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name//创建kafka生产者对象val kafkaProducer = KafkaProducer<String, String>(properties)//发送数据for (i in 0 until 5) {//1.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值//2.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器)//key可以作为producer数据名,让consumer通过key找到kafkaProducer.send(ProducerRecord("xiao1", 1, "", "customProducerCallbackPartitions,count::$i"), Callback{ metadata, exception ->if (exception == null) {println("主题:${metadata.topic()},分区:${metadata.partition()}")}})}//关闭资源kafkaProducer.close()}//回调异步发送+自定义分区@Testfun customProducerCallbackPartitions2() {//配置val properties = Properties()//链接kafka,集群链接使用"183.56.203.157:7050,183.56.203.157:7051"properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.nameproperties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name//关联自定义分区器properties[ProducerConfig.PARTITIONER_CLASS_CONFIG] ="com.umh.medicalbookingplatform.b2bapi.config.MyPartitioner"//创建kafka生产者对象val kafkaProducer = KafkaProducer<String, String>(properties)//发送数据for (i in 0 until 50) {//1.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值//2.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器)//key可以作为producer数据名,让consumer通过key找到kafkaProducer.send(ProducerRecord("xiao1", "felix is strong,count::$i"), Callback{ metadata, exception ->if (exception == null) {println("主题:${metadata.topic()},分区:${metadata.partition()}")}})}//关闭资源kafkaProducer.close()}//自定义配置缓冲区、批次、等待时间、压缩@Testfun customProducerParameters() {//配置val properties = Properties()properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.nameproperties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name//缓冲区大小。默认32,64=33554432x2properties[ProducerConfig.BUFFER_MEMORY_CONFIG] = 33554432//批次大小。默认16kproperties[ProducerConfig.BATCH_SIZE_CONFIG] = 16384//等待时间。默认0properties[ProducerConfig.LINGER_MS_CONFIG] = 1//压缩.压缩,默认 none,可配置值 gzip、snappy、lz4 和 zstdproperties[ProducerConfig.COMPRESSION_TYPE_CONFIG] = "snappy"//创建kafka生产者对象val kafkaProducer = KafkaProducer<String, String>(properties)for (i in 0 until 10) {//1.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值//2.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器)//key可以作为producer数据名,让consumer通过key找到kafkaProducer.send(ProducerRecord("xiao1", "customProducerParameters::$i"), Callback{ metadata, exception ->if (exception == null) {println("主题:${metadata.topic()},分区:${metadata.partition()}")}})}//关闭资源kafkaProducer.close()}//ack、重试次数配置@Testfun customProducerAck() {//配置val properties = Properties()properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.nameproperties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name//ackproperties[ProducerConfig.ACKS_CONFIG] = "1"//重试次数properties[ProducerConfig.RETRIES_CONFIG] = 30//创建kafka生产者对象val kafkaProducer = KafkaProducer<String, String>(properties)for (i in 0 until 10) {//1.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值//2.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器)//key可以作为producer数据名,让consumer通过key找到kafkaProducer.send(ProducerRecord("xiao1", "customProducerAck::$i"), Callback{ metadata, exception ->if (exception == null) {println("主题:${metadata.topic()},分区:${metadata.partition()}")}})}//关闭资源kafkaProducer.close()}//事物@Testfun customProducerTransaction() {//配置val properties = Properties()properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.nameproperties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name//指定事务id,一定要指定!!properties[ProducerConfig.TRANSACTIONAL_ID_CONFIG] = UUID.randomUUID().toString()//创建kafka生产者对象val kafkaProducer = KafkaProducer<String, String>(properties)//开启事务kafkaProducer.initTransactions()kafkaProducer.beginTransaction()try {for (i in 0 until 10) {//1.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值//2.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器)//key可以作为producer数据名,让consumer通过key找到kafkaProducer.send(ProducerRecord("xiao1", "customProducerTransaction::$i"), Callback{ metadata, exception ->if (exception == null) {println("主题:${metadata.topic()},分区:${metadata.partition()}")}})}
// val test: Int = 1 / 0kafkaProducer.commitTransaction()} catch (e: Exception) {kafkaProducer.abortTransaction()} finally {//关闭资源kafkaProducer.close()}}}
消费者
1、一个consumer group中有多个consumer组成,一个 topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个 partition的数据。
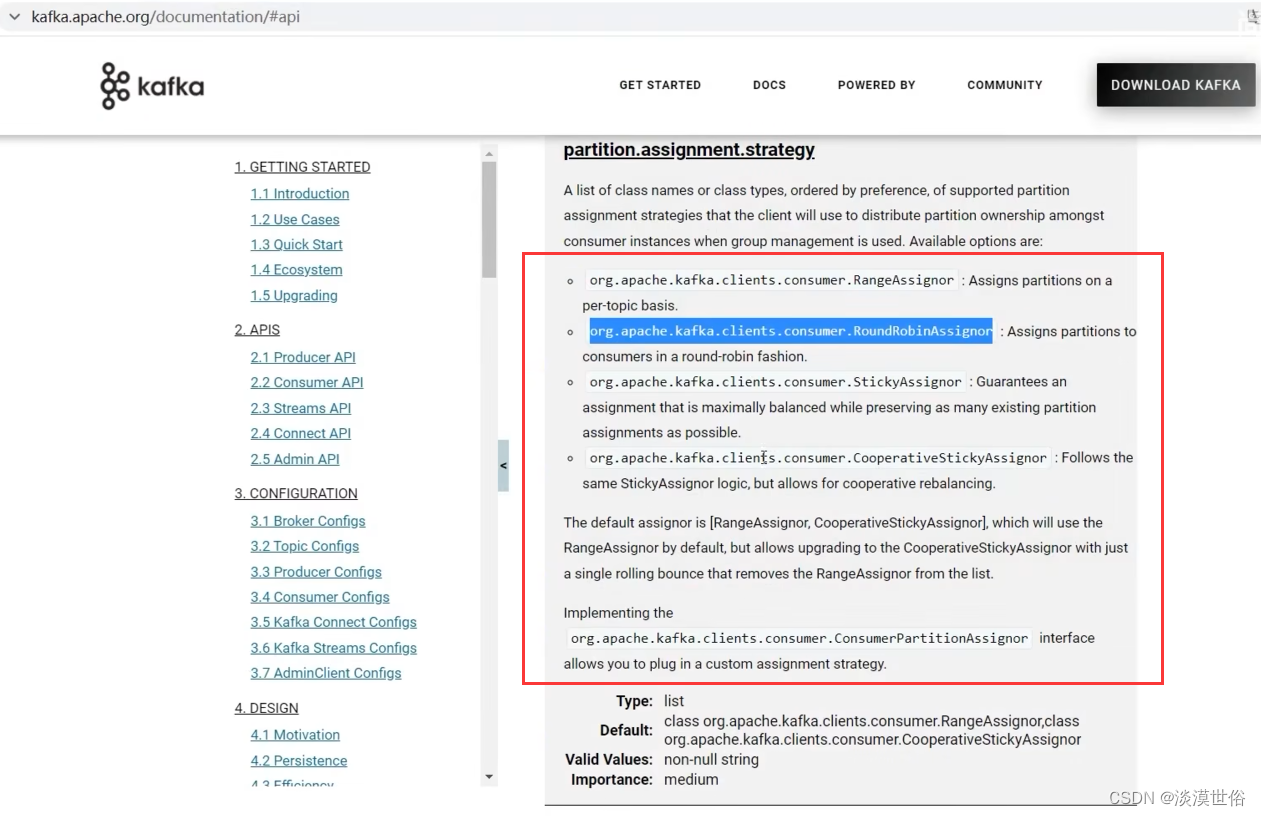
2、Kafka有四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。 可以通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky。Kafka可以同时使用 多个分区分配策略。
3、每个消费者都会和coordinator保持心跳(默认3s),一旦超时 (session.timeout.ms=45s),该消费者会被移除,并触发再平衡; 或者消费者处理消息的过长(max.poll.interval.ms5分钟),也会触发再 平衡
package com.umh.medicalbookingplatform.apiimport com.alibaba.fastjson.parser.ParserConfig
import com.fasterxml.jackson.databind.MapperFeature
import com.umh.medicalbookingplatform.core.audit.SpringSecurityAuditorAware
import com.umh.medicalbookingplatform.core.config.CoreConfiguration
import com.umh.medicalbookingplatform.core.jsonview.JsonViews
import com.umh.medicalbookingplatform.core.properties.ApplicationProperties
import com.umh.medicalbookingplatform.core.utils.ApplicationJsonObjectMapper
import org.jboss.resteasy.client.jaxrs.ResteasyClientBuilder
import org.keycloak.OAuth2Constants
import org.keycloak.admin.client.Keycloak
import org.keycloak.admin.client.KeycloakBuilder
import io.swagger.v3.oas.models.Components
import io.swagger.v3.oas.models.OpenAPI
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
import org.springframework.boot.web.servlet.ServletComponentScan
import org.springframework.cache.annotation.EnableCaching
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Import
import org.springframework.data.domain.AuditorAware
import org.springframework.data.jpa.repository.config.EnableJpaAuditing
import org.springframework.http.MediaType
import org.springframework.http.converter.HttpMessageConverter
import org.springframework.http.converter.ResourceHttpMessageConverter
import org.springframework.http.converter.json.MappingJackson2HttpMessageConverter
import org.springframework.scheduling.annotation.EnableScheduling
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer
import java.security.Security
import java.util.*
import io.swagger.v3.oas.models.info.Info
import io.swagger.v3.oas.models.info.License
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.clients.consumer.ConsumerRecords
import org.apache.kafka.clients.consumer.KafkaConsumer
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.keycloak.adapters.KeycloakConfigResolver
import org.keycloak.adapters.springboot.KeycloakSpringBootConfigResolver
import org.keycloak.adapters.springboot.KeycloakSpringBootProperties
import org.springframework.http.converter.StringHttpMessageConverter
import java.time.Duration
import java.util.concurrent.TimeUnit@EnableJpaAuditing
@EnableCaching
@EnableScheduling
@SpringBootApplication
@Import(CoreConfiguration::class)
@ServletComponentScan("com.umh.medicalbookingplatform")
open class ApiApplication : WebMvcConfigurer {@Autowiredprivate lateinit var appProperties: ApplicationProperties@Autowiredprivate lateinit var keycloakSpringBootProperties: KeycloakSpringBootProperties@Beanfun keycloakConfigResolver(): KeycloakConfigResolver {return KeycloakSpringBootConfigResolver()}@Beanfun fastJson(){ParserConfig.getGlobalInstance().isAutoTypeSupport = true}@Beanfun customConsumer() {//配置val properties = Properties()//连接properties[ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"//反序列化(注意写法:生产者是序列化,消费者是反序列化)properties[ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.nameproperties[ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.name//配置消费者组id(就算消费者组只有一个消费者也需要)//当消费者组ID相同时,表示他们在同一个消费者组//当有三个分区,而消费者组里又有三个消费者时,消费者会各自自动选取一个分区进行消费properties[ConsumerConfig.GROUP_ID_CONFIG] = "test"//1.创建一个消费者val kafkaConsumer = KafkaConsumer<String, String>(properties)//2.定义主题 xiao1val topics = mutableListOf<String>()topics.add("xiao1")kafkaConsumer.subscribe(topics)//3.消费数据while (true) {val consumerRecord: ConsumerRecords<String, String> = kafkaConsumer.poll(Duration.ofSeconds(1))for (msg in consumerRecord) {println("consumer,msg:::$msg")}}}// @Beanfun customConsumerPartition() {//配置val properties = Properties()//连接properties[ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"//反序列化(注意写法:生产者是序列化,消费者是反序列化)properties[ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.nameproperties[ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.name//配置消费者组id(就算消费者组只有一个消费者也需要)//当消费者组ID相同时,表示他们在同一个消费者组properties[ConsumerConfig.GROUP_ID_CONFIG] = UUID.randomUUID().toString()//1.创建一个消费者val kafkaConsumer = KafkaConsumer<String, String>(properties)//2.定义主题对应的分区val topicPartition = mutableListOf<TopicPartition>()topicPartition.add(TopicPartition("xiao1", 1))kafkaConsumer.assign(topicPartition)//3.消费数据while (true) {val consumerRecord: ConsumerRecords<String, String> = kafkaConsumer.poll(Duration.ofSeconds(1))for (msg in consumerRecord) {println("msg:::$msg")}}}@Bean(name = ["keycloakGlobalCmsApi"])fun keycloakGlobalCmsApiInstance(): Keycloak {return KeycloakBuilder.builder().serverUrl(appProperties.keycloakAuthServerUrl)//https://keycloak.umhgp.com/auth.realm(appProperties.keycloakGlobalCmsRealm)//global_cms.clientId(appProperties.keycloakGlobalCmsClient)//global-cms.username(appProperties.keycloakApiUsername)//medical-booking-platform-system-uat.password(appProperties.keycloakApiPassword)//Kas7aAnC76eGVHv5.grantType(OAuth2Constants.PASSWORD).resteasyClient(ResteasyClientBuilder().connectTimeout(10, TimeUnit.SECONDS).readTimeout(10, TimeUnit.SECONDS).connectionPoolSize(100).build()).build()}@Bean(name = ["keycloakGlobalProfileApi"])fun keycloakGlobalProfileApiInstance(): Keycloak {return KeycloakBuilder.builder().serverUrl(appProperties.keycloakAuthServerUrl).realm(appProperties.keycloakGlobalProfileRealm).clientId(appProperties.keycloakGlobalProfileClient).username(appProperties.keycloakApiUsername).password(appProperties.keycloakApiPassword).grantType(OAuth2Constants.PASSWORD).resteasyClient(ResteasyClientBuilder().connectTimeout(10, TimeUnit.SECONDS).readTimeout(10, TimeUnit.SECONDS).connectionPoolSize(100).build()).build()}@Bean(name = ["keycloakBookingSystemApi"])fun keycloakBookingSystemApiInstance(): Keycloak {return KeycloakBuilder.builder().serverUrl(appProperties.keycloakAuthServerUrl).realm(appProperties.keycloakBookingSystemRealm).clientId(appProperties.keycloakBookingSystemClient).username(appProperties.keycloakApiUsername).password(appProperties.keycloakApiPassword).grantType(OAuth2Constants.PASSWORD).resteasyClient(ResteasyClientBuilder().connectTimeout(10, TimeUnit.SECONDS).readTimeout(10, TimeUnit.SECONDS).connectionPoolSize(100).build()).build()}@Bean(name = ["keycloakUmhBookingSystemApi"])fun keycloakBookingSystemUmhApiInstance(): Keycloak {return KeycloakBuilder.builder().serverUrl(appProperties.keycloakAuthServerUrl).realm(appProperties.keycloakUmhBookingSystemRealm).clientId(appProperties.keycloakUmhBookingSystemClient).username(appProperties.keycloakApiUsername).password(appProperties.keycloakApiPassword).grantType(OAuth2Constants.PASSWORD).resteasyClient(ResteasyClientBuilder().connectTimeout(10, TimeUnit.SECONDS).readTimeout(10, TimeUnit.SECONDS).connectionPoolSize(100).build()).build()}@Beaninternal fun auditorProvider(): AuditorAware<UUID> {return SpringSecurityAuditorAware()}@Beanfun customOpenAPI(): OpenAPI? {return OpenAPI().components(Components()).info(Info().title("medical-booking-platform").version("1.5.8").license(License().name("Apache 2.0").url("http://springdoc.org")))}override fun configureMessageConverters(converters: MutableList<HttpMessageConverter<*>>) {
// ActuatorMediaTypes()val supportedMediaTypes = ArrayList<MediaType>()supportedMediaTypes.add(MediaType.APPLICATION_JSON)supportedMediaTypes.add(MediaType.valueOf("application/vnd.spring-boot.actuator.v3+json"))supportedMediaTypes.add(MediaType.TEXT_PLAIN)val converter = MappingJackson2HttpMessageConverter()val objectMapper = ApplicationJsonObjectMapper()objectMapper.setConfig(objectMapper.serializationConfig.withView(JsonViews.Admin::class.java))objectMapper.configure(MapperFeature.DEFAULT_VIEW_INCLUSION, true)converter.objectMapper = objectMapperconverter.setPrettyPrint(true)converter.supportedMediaTypes = supportedMediaTypesconverters.add(0, StringHttpMessageConverter())converters.add(1, converter)converters.add(ResourceHttpMessageConverter())}}fun main(args: Array<String>) {Security.setProperty("crypto.policy", "unlimited")runApplication<ApiApplication>(*args)
}
range(范围)
Kafka 默认的分区分配策略就是 Range + CooperativeSticky,所以不需要修改策 略。
消费者分区操作:7分区2个消费者时
消费者1:消费分区0123
消费者2:消费分区456
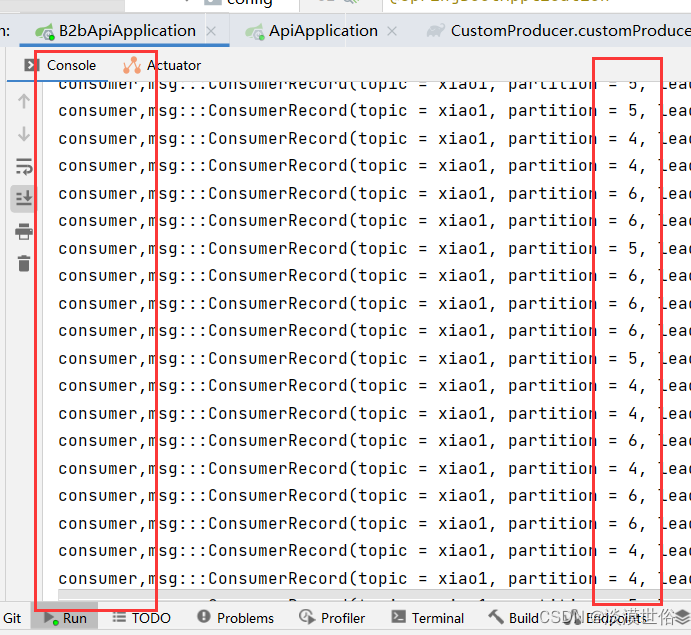
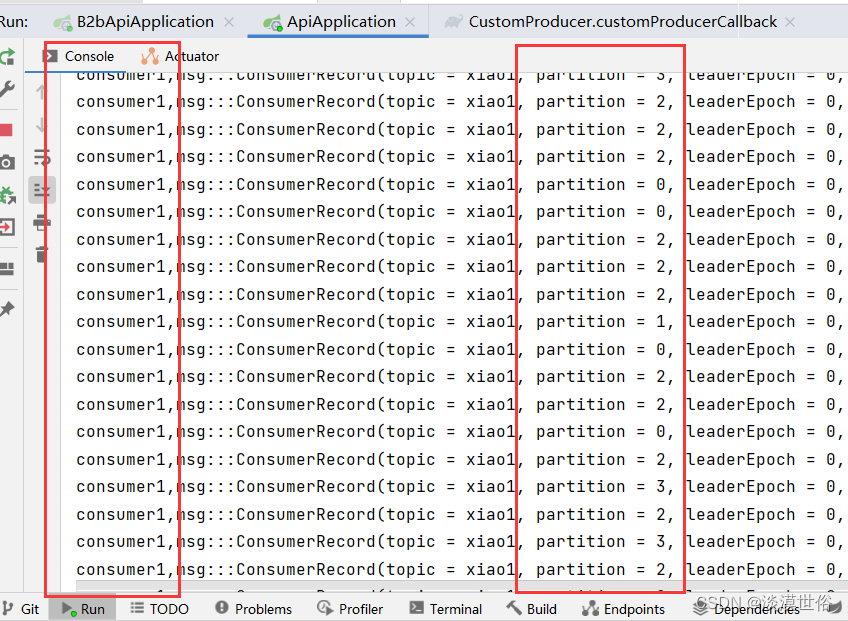

在同一个消费者组,三消费者的情况下,如果其中一个宕机,45秒后会把消费者0需要处理的数据整个搬到消费者1或者消费者2.
结果:Consumer1=01234 或者 Consumer2=01256
随后如果再传输数据,消费者组会根据当前的消费者重新组织分配
Consumer0宕机45秒后再次传数据结果:Consumer1=0123 Consumer2=456
RoundRobin(轮询)
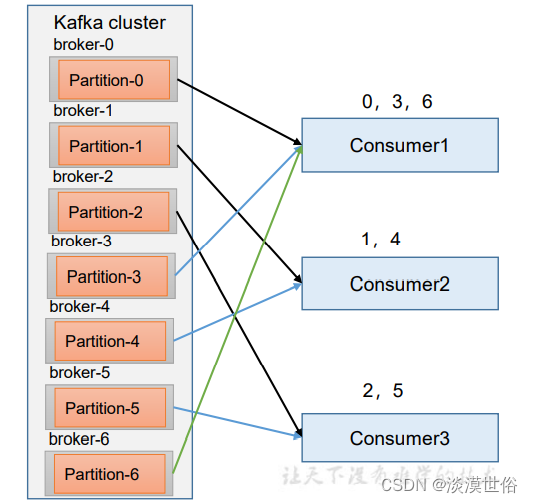
RoundRobin 针对集群中所有Topic而言。 RoundRobin 轮询分区策略,是把所有的 partition 和所有的 consumer 都列出来,然后按照 hashcode 进行排序,最后 通过轮询算法来分配 partition 给到各个消费者。
策略分配的修改
@Beanfun customConsumer() {//配置val properties = Properties()//连接properties[ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"//反序列化(注意写法:生产者是序列化,消费者是反序列化)properties[ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.nameproperties[ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.name//配置消费者组id(就算消费者组只有一个消费者也需要)//当消费者组ID相同时,表示他们在同一个消费者组//当有三个分区,而消费者组里又有三个消费者时,消费者会各自自动选取一个分区进行消费properties[ConsumerConfig.GROUP_ID_CONFIG] = "test"//设置分区分配策略properties[ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG] = "org.apache.kafka.clients.consumer.RoundRobinAssignor"//1.创建一个消费者val kafkaConsumer = KafkaConsumer<String, String>(properties)//2.定义主题 xiao1val topics = mutableListOf<String>()topics.add("xiao1")kafkaConsumer.subscribe(topics)//3.消费数据while (true) {val consumerRecord: ConsumerRecords<String, String> = kafkaConsumer.poll(Duration.ofSeconds(1))for (msg in consumerRecord) {println("consumer,msg:::$msg")}}}
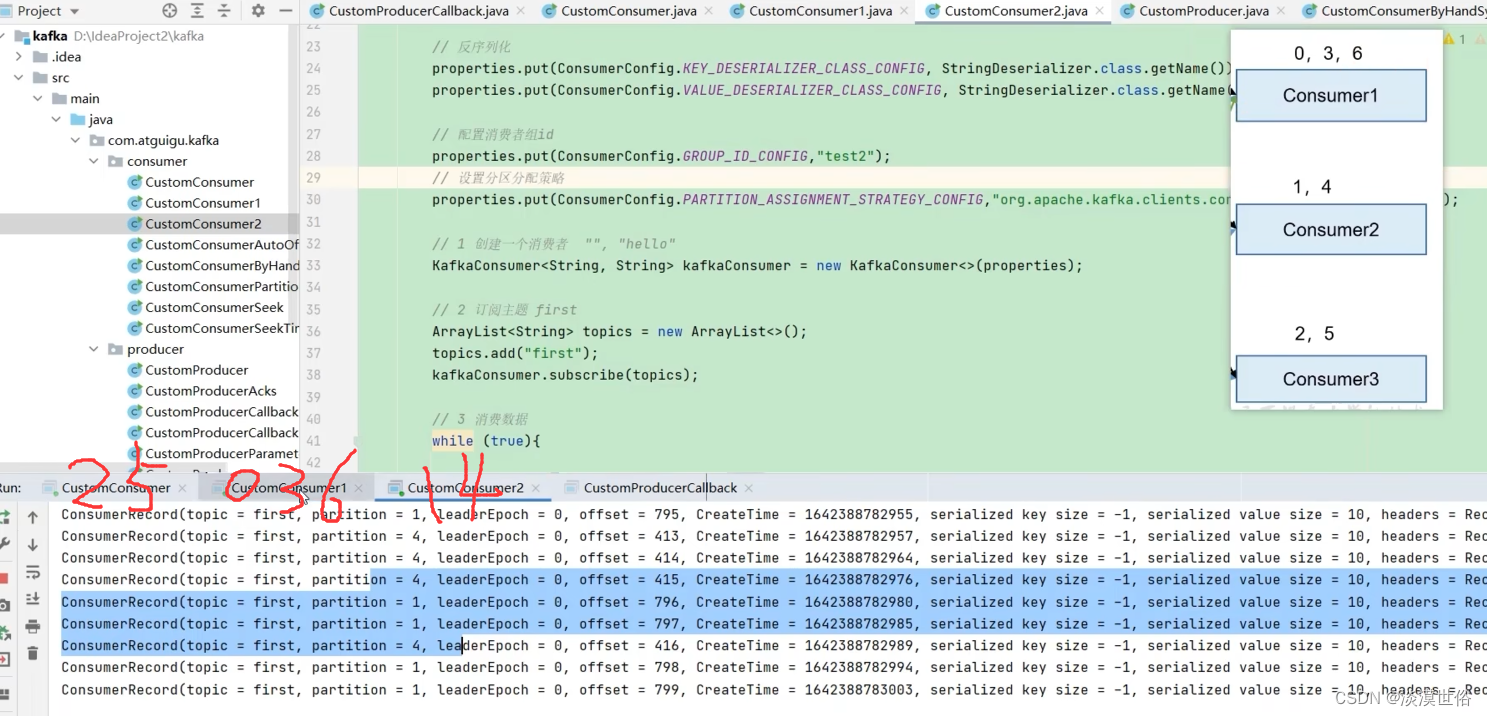

注意:06为一组给到一个消费者,3为一组给到另外一个消费者。45秒后重新发送数据,consumer2:0246,consumer3:135
Sticky (黏性)
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 2、5、3 号分区数据。
2 号消费者:消费到 4、6 号分区数据。
0 号消费者的任务会按照粘性规则,尽可能均衡的随机分成 0 和 1 号分区数据,分别 由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需 要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 2、3、5 号分区数据。
2 号消费者:消费到 0、1、4、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照粘性方式分配。
 随机+均匀
随机+均匀
宕机后分配的消费者和45秒后分配消费者一样
宕机(3消费者变2消费者):1403,235
45秒后2消费者:1403,235
本文转自 https://blog.csdn.net/weixin_52925162/article/details/126280062?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170100111416800225544545%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=170100111416800225544545&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v31_ecpm-8-126280062-null-null.142v96pc_search_result_base9&utm_term=keycloak%20docker-compose&spm=1018.2226.3001.4187,如有侵权,请联系删除。
相关文章:
docker-compose部署kafka
docker-compose.yml配置 version: "3" services:kafka:image: bitnami/kafka:latestports:- 7050:7050environment:- KAFKA_ENABLE_KRAFTyes- KAFKA_CFG_PROCESS_ROLESbroker,controller- KAFKA_CFG_CONTROLLER_LISTENER_NAMESCONTROLLER- KAFKA_CFG_LISTENERSPLAIN…...
Spark与Hadoop的关系和区别
在大数据领域,Spark和Hadoop是两个备受欢迎的分布式数据处理框架,它们在处理大规模数据时都具有重要作用。本文将深入探讨Spark与Hadoop之间的关系和区别,以帮助大家的功能和用途。 Spark和Hadoop简介 1 Hadoop Hadoop是一个由Apache基金会…...
蓝桥杯-Excel地址[Java]
目录: 学习目标: 学习内容: 学习时间: 题目: 题目描述: 输入描述: 输出描述: 输入输出样例: 示例 1: 运行限制: 题解: 思路: 学习目标: 刷蓝桥杯题库日记 学习内容: 编号96题目Ex…...

OSPF多区域配置-新版(12)
目录 整体拓扑 操作步骤 1.基本配置 1.1 配置R1的IP 1.2 配置R2的IP 1.3 配置R3的IP 1.4 配置R4的IP 1.5 配置R5的IP 1.6 配置R6的IP 1.7 配置PC-1的IP地址 1.8 配置PC-2的IP地址 1.9 配置PC-3的IP地址 1.10 配置PC-4的IP地址 1.11 检测R5与PC1连通性 1.12 检测…...
华为---USG6000V防火墙web基本配置示例
目录 1. 实验要求 2. 配置思路 3. 网络拓扑图 4. USG6000V防火墙端口和各终端相关配置 5. 在USG6000V防火墙web管理界面创建区域和添加相应端口 6. 给USG6000V防火墙端口配置IP地址 7. 配置通行策略 8. 测试验证 8.1 逐个删除策略,再看各区域终端通信情况 …...
Ksher H5页面支付实例指导 (PHP实现)
背景 前两天,公司的项目,为了满足泰国客户的支付需求,要求使用 Ksher (开时支付) 对接任务突然就给了鄙人,一脸懵 … 通过了解客户的使用场景、以及参考官网指导 发现:Ksher支付最令人满意的便是 —— 提供了便捷的 支…...
https密钥认证、上传镜像实验
一、第一台主机通过https密钥对认证 1、安装docker服务 (1)安装环境依赖包 yum -y install yum-utils device-mapper-persistent-data lvm2 (2)设置阿里云镜像源 yum-config-manager --add-repo http://mirrors.aliyun.com/do…...

three.js使用精灵模型Sprite渲染森林
效果: 源码: <template><div><el-container><el-main><div class"box-card-left"><div id"threejs" style"border: 1px solid red"></div><div class"box-right&quo…...
什么是数据可视化?数据可视化的流程与步骤
前言 数据可视化将大大小小的数据集转化为更容易被人脑理解和处理的视觉效果。可视化在我们的日常生活中非常普遍,但它们通常以众所周知的图表和图形的形式出现。正确的数据可视化以有意义和直观的方式为复杂的数据集提供关键的见解。 数据可视化定义 数据可视化…...

2022年山东省职业院校技能大赛高职组云计算赛项试卷第二场-容器云
2022年山东省职业院校技能大赛高职组云计算赛项试卷 目录 【赛程名称】云计算赛项第二场-容器云 需要竞赛软件包以及资料可以私信博主! 【赛程名称】云计算赛项第二场-容器云 【赛程时间】2022-11-27 09:00:00至2022-11-27 16:00:00 说明:完成本任务…...

Unity3D 中播放 RTSP 监控视频
【Unity 3D】怎么在 WebGL 中低延迟播放 RTSP 监控 - 简书[Unity 3D] 开箱即食的头部监控厂商 SDK 集成框架 - 简书 Unity3d Windows播放视频(视频流)功能组/插件支持对比_ffmpeg for unity-CSDN博客Unity UMP打包黑屏问题总结-CSDN博客Unity Universal…...

[spark] DataFrame 的 checkpoint
在 Apache Spark 中,DataFrame 的 checkpoint 方法用于强制执行一个物理计划并将结果缓存到分布式文件系统,以防止在计算过程中临时数据丢失。这对于长时间运行的计算过程或复杂的转换操作是有用的。 具体来说,checkpoint 方法执行以下操作&…...

flask文件夹列表改进版--Bug追踪
把当前文件夹下的所有文件夹和文件列出来,允许点击返回上层目录,允许点击文件夹进入下级目录并显示此文件夹内容 允许点击文件进行下载 from flask import Flask, render_template, send_file, request, redirect, url_for import osapp Flask(__name_…...

Elasticsearch之常用DSL语句
目录 1. Elasticsearch之常用DSL语句 1.1 操作索引 1.2 文档操作 1.3 DSL查询 1.4 搜索结果处理 1.5 数据聚合 1. Elasticsearch之常用DSL语句 1.1 操作索引 mapping是对索引库中文档的约束,常见的mapping属性包括: - type:字段数据类…...
鸿蒙实战-库的调用(ArkTS)
整体框架搭建 主页面、本地库组件页面、社区库组件页面三个页面组成,主页面由Navigation作为根组件实现全局标题,由Tabs组件实现本地库和社区库页面的切换。 // MainPage.ets import { Outer } from ../view/OuterComponent; import { Inner } from ..…...

观察者模式学习
观察者模式(Observer Design Pattern)也被称为发布订阅模式(Publish-Subscribe Design Pattern)。在 GoF 的《设计模式》一书中,它的定义是这样的: Define a one-to-many dependency between objects so th…...

人工智能_机器学习078_聚类算法_概念介绍_聚类升维_降维_各类聚类算法_有监督机器学习_无监督机器学习---人工智能工作笔记0118
首先看一下什么是聚类,我们可以进入sklearn的官网去看看 可以看到这里,首先classification 这个分类我们学完了,然后就是regression回归我们也学完了对吧,其实我们现实生活中的,大部分问题就是 这两种问题就可以解决了. 然后我们再来看一个: clustering,这个就是聚类对吧.聚类算…...
基于AR+地图导航的景区智慧导览设计
随着科技的飞速发展,智慧旅游已经成为现代旅游业的一个重要趋势。在这个背景下,景区智慧导览作为智慧旅游的核心组成部分,正逐渐受到越来越多游客的青睐。本文将深入探讨地图导航软件在景区智慧导览中的应用,并分析其为游客和景区…...

git基本指令
下载代码 git clone http://.......设置分支 git checkout 分支名查询当前分支 git checkout打开终端或命令行窗口,进入你要操作的项目目录,执行以下命令,列出所有的分支,这会列出当前代码仓库中的所有分支,用带星号…...

ECMAScript基础入门
ECMAScript(简称ES)是一种标准化了的高级编程语言,它是JavaScript语言的标准化版本,由Ecma International组织发布。ECMAScript描述了JavaScript的语法和核心特性,而JavaScript是实现ECMAScript标准的编程语言。随着We…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...
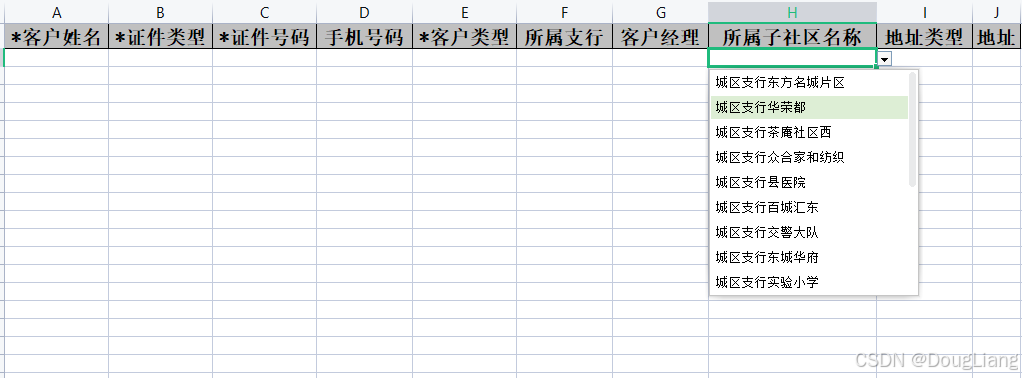
关于easyexcel动态下拉选问题处理
前些日子突然碰到一个问题,说是客户的导入文件模版想支持部分导入内容的下拉选,于是我就找了easyexcel官网寻找解决方案,并没有找到合适的方案,没办法只能自己动手并分享出来,针对Java生成Excel下拉菜单时因选项过多导…...