十二:爬虫-Scrapy框架(上)
一:Scrapy介绍
1.Scrapy是什么?
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架(异步爬虫框架)
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片
Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度
- 异步和非阻塞的区别
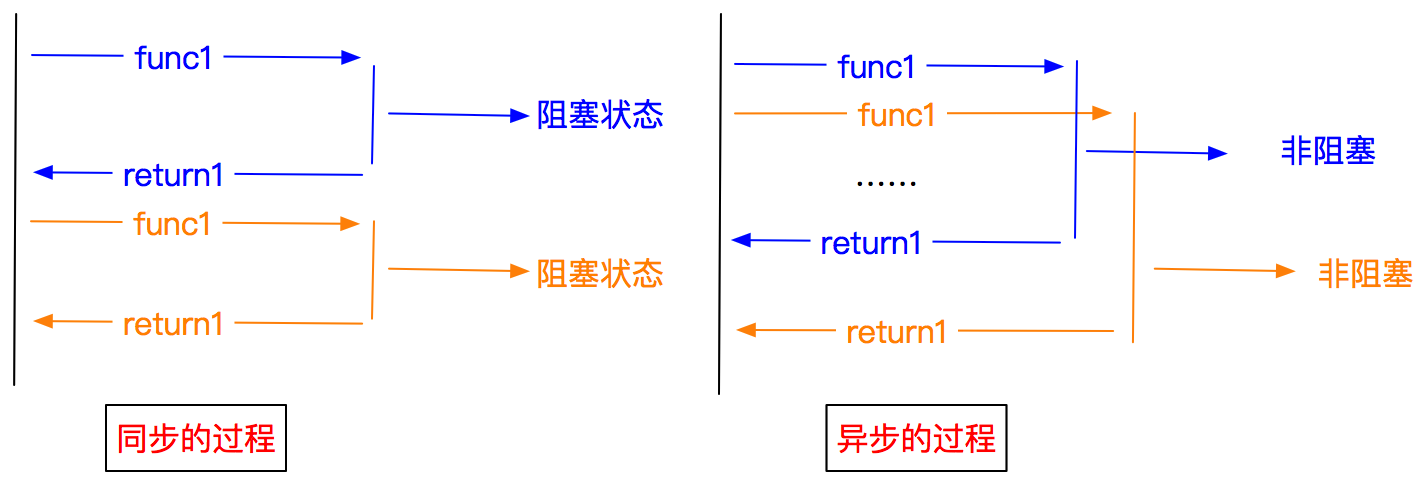
异步:调用在发出之后,这个调用就直接返回,不管有无结果
非阻塞:关注的是程序在等待调用结果时的状态,指在不能立刻得到结果之前,该调用不会阻塞当前线程
2.Scrapy的优势
爬虫必备的技术
- 能够使我们的爬虫程序更加稳定 效率更高(多线程)
- 配置和可扩展性非常强(很灵活)
downloader下载器(基于多线程的) 发送请求 获取响应的
3.Scrapy参考学习
scrapy官方学习网址:https://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
最新的:https://docs.scrapy.org/en/latest/
4.Scrapy的安装
pip install scrapy==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
二:Scrapy工作流程
一种爬虫方式:

另一种爬虫方式:
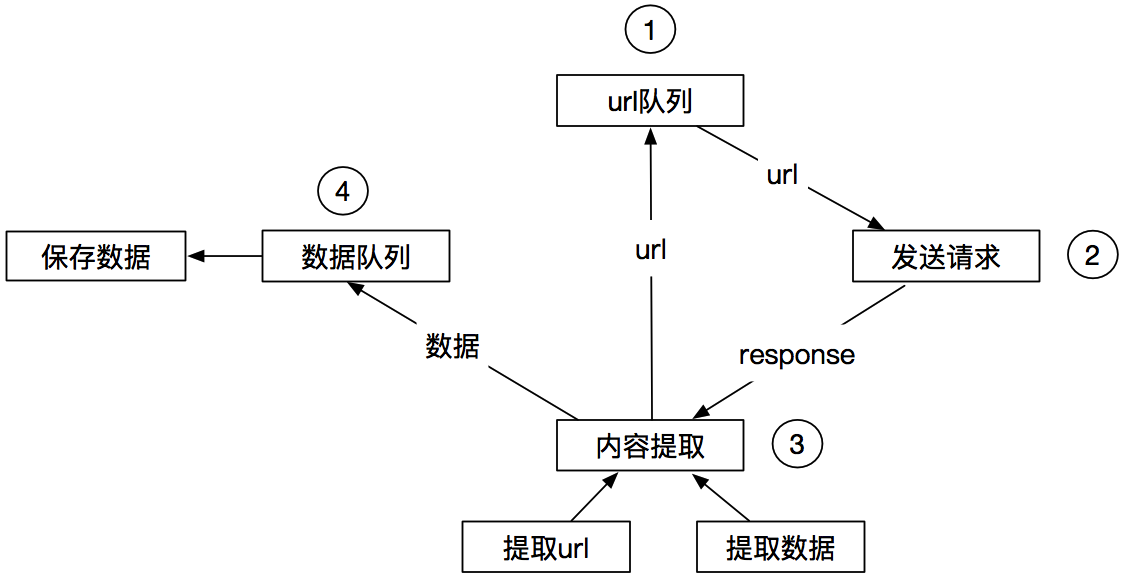
工作流程:

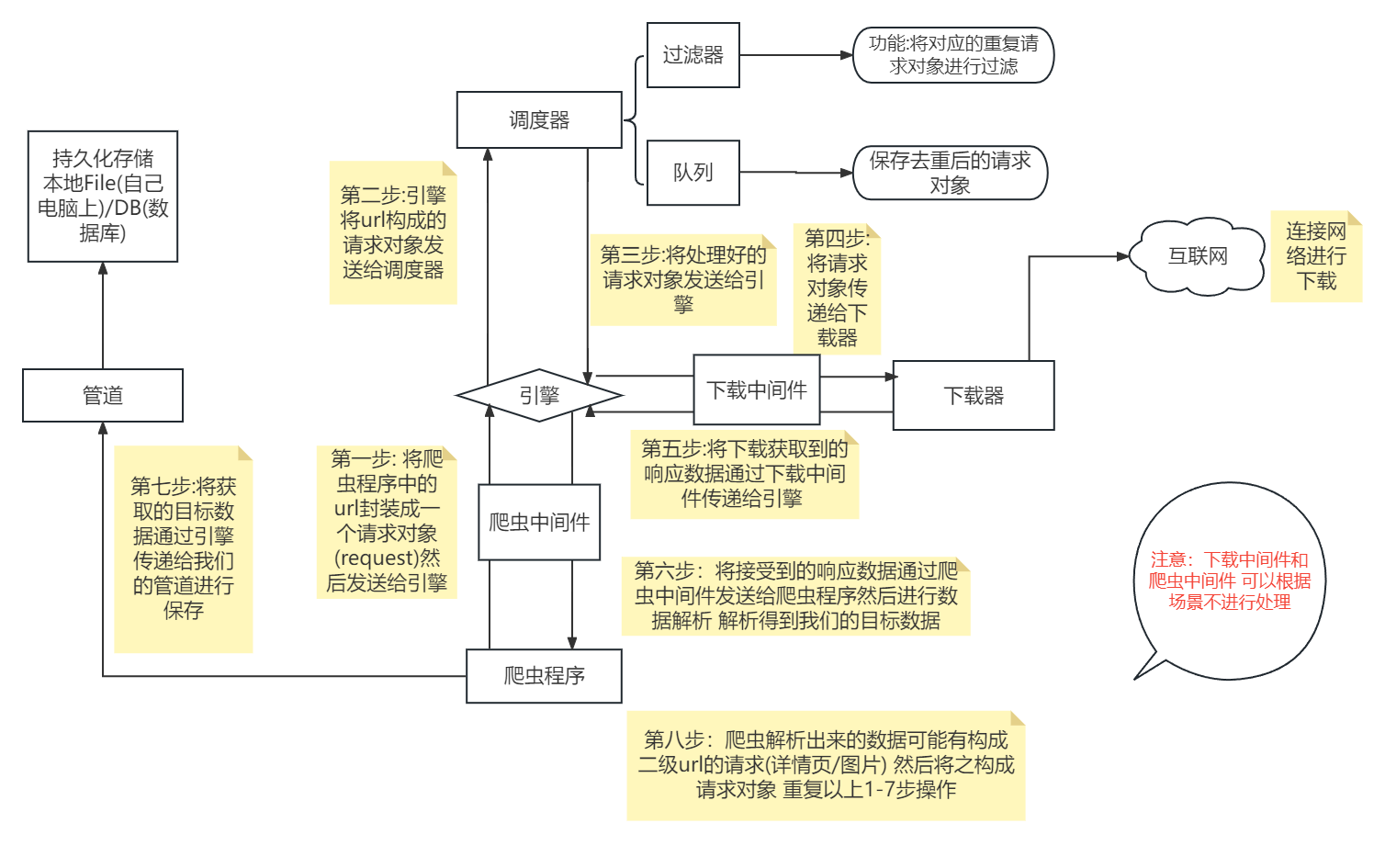
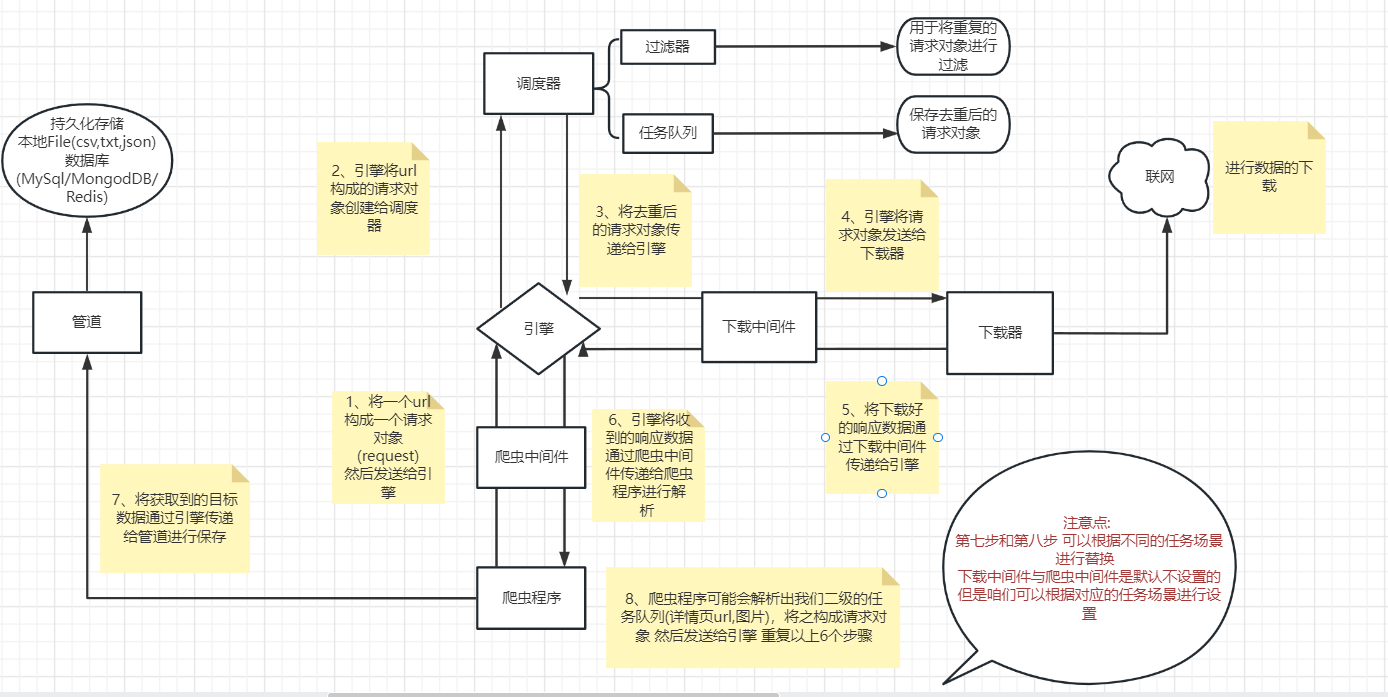
1.各个组件的功能介绍:
Scrapy engine(引擎) | 总指挥:负责数据和信号的在不同模块间的传递 | scrapy已经实现 |
|---|---|---|
Scheduler(调度器) | 一个队列,存放引擎发过来的request请求 | scrapy已经实现 |
Downloader(下载器) | 下载把引擎发过来的requests请求,并返回给引擎 | scrapy已经实现 |
Spider(爬虫) | 处理引擎发来的response,提取数据,提取url,并交给引擎 | 需要手写 |
Item Pipline(管道) | 处理引擎传过来的数据,比如存储 | 需要手写 |
Downloader Middlewares(下载中间件) | 可以自定义的下载扩展,比如设置代理 | 一般不用手写 |
Spider Middlewares(中间件) | 可以自定义requests请求和进行response过滤 | 一般不用手写 |
1 引擎(engine) scrapy已经实现
scrapy的核心, 所有模块的衔接, 数据流程梳理2 调度器(scheduler) scrapy已经实现
本质上这东西可以看成是一个队列,里面存放着一堆我们即将要发送的请求,可以看成是一个url的容器
它决定了下一步要去爬取哪一个url,通常我们在这里可以对url进行去重操作。3 下载器(downloader) scrapy已经实现
它的本质就是用来发动请求的一个模块,小白们完全可以把它理解成是一个requests.get()的功能,
只不过这货返回的是一个response对象.4 爬虫(spider) 需要手写
这是我们要写的第一个部分的内容, 负责解析下载器返回的response对象,从中提取到我们需要的数据5 管道(Item pipeline)
这是我们要写的第二个部分的内容, 主要负责数据的存储和各种持久化操作6 下载中间件(downloader Middlewares) 一般不用手写
可以自定义的下载扩展 比如设置代理 处理引擎与下载器之间的请求与响应(用的比较多)7 爬虫中间件(Spider Middlewares) 一般不用手写
可以自定义requests请求和进行response过滤(处理爬虫程序的响应和输出结果以及新的请求)
三:Scrapy入门与总结
1.Scrapy入门
前提:路径切换 cd copy path 复制绝对路径 1. 创建scrapy项目
scrapy startproject mySpider
scrapy startproject(固定的)
mySpider(不固定的 需要创建的项目的名字)2. 进入项目里面:cd mySpider3. 创建爬虫程序
scrapy genspider example example.comscrapy genspider:固定的
example:爬虫程序的名字(不固定的)
example.com:可以允许爬取的范围(不固定的) 是根据你的目标url来指定的 其实很重要 后面是可以修改的目标url:https://www.baidu.com/scrapy genspider bd baidu.com4. 执行爬虫程序
scrapy crawl bd
scrapy crawl:固定的
db:执行的爬虫程序的名字可以通过start.py文件执行爬虫项目:
from scrapy import cmdline
cmdline.execute("scrapy crawl bd".split())2.Scrapy文件说明
baidu.py爬虫文件 # 爬虫程序的名字name = 'bd'# 可以爬取的范围# 有可能我们在实际进行爬取的时候 第一页可能是xxx.com 第三页可能就变成了xxx.cn # 或者xxx.yy 那么可能就会爬取不到数据# 所以我们需要对allowed_domains进行一个列表的添加allowed_domains = ['baidu.com']# 起始url地址 会根据我们的allowed_domains对网页前缀进行一定的补全 # 但有时候补全的url不对 所以我们也要去对他进行修改start_urls = ['https://www.baidu.com/']# 专门用于解析数据的def parse(self, response): items.py 数据封装的
middlewares.py 中间件(爬虫中间件和下载中间件)
pipelines.py 管道(保存数据的)settings.py Scrapy的配置项# 1 自动生成的配置,无需关注,不用修改
BOT_NAME = 'mySpider'
SPIDER_MODULES = ['mySpider.spiders']
NEWSPIDER_MODULE = 'mySpider.spiders'# 2 取消日志
LOG_LEVEL = 'WARNING'# 3 设置UA,但不常用,一般都是在MiddleWare中添加
USER_AGENT = 'mySpider (+http://www.yourdomain.com)'# 4 遵循robots.txt中的爬虫规则,很多人喜欢False,当然我也喜欢....
ROBOTSTXT_OBEY = True# 5 对网站并发请求总数,默认16
CONCURRENT_REQUESTS = 32# 6 相同网站两个请求之间的间隔时间,默认是0s。相当于time.sleep()
DOWNLOAD_DELAY = 3# 7 禁用cookie,默认是True,启用
COOKIES_ENABLED = False# 8 默认的请求头设置
DEFAULT_REQUEST_HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',
}# 9 配置启用爬虫中间件,Key是class,Value是优先级
SPIDER_MIDDLEWARES = {'mySpider.middlewares.MyspiderSpiderMiddleware': 543,
}# 10 配置启用Downloader MiddleWares下载中间件
DOWNLOADER_MIDDLEWARES = {'mySpider.middlewares.MyspiderDownloaderMiddleware': 543,
}# 11 开启管道 配置启用Pipeline用来持久化数据
ITEM_PIPELINES = {'mySpider.pipelines.MyspiderPipeline': 300,
}
settings配置项更多参考: https://www.cnblogs.com/seven0007/p/scrapy_setting.html
3.Scrapy总结
scrapy其实就是把我们平时写的爬虫进行了四分五裂式的改造. 对每个功能进行了单独的封装, 并且, 各个模块之间互相的不做依赖. 一切都由引擎进行调配. 这种思想希望你能知道–解耦. 让模块与模块之间的关联性更加的松散. 这样我们如果希望替换某一模块的时候会非常的容易. 对其他模块也不会产生任何的影响
相关文章:
十二:爬虫-Scrapy框架(上)
一:Scrapy介绍 1.Scrapy是什么? Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架(异步爬虫框架) 通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片 Scrapy使用了Twisted异步网…...
BUUCTF Reverse/[2019红帽杯]Snake
BUUCTF Reverse/[2019红帽杯]Snake 下载解压缩后得到可执行文件,而且有一个unity的应用程序,应该是用unity编写的游戏 打开是一个贪吃蛇游戏 用.NET Reflector打开Assembly-CSharp.dll。(unity在打包后,会将所有的代码打进一个Ass…...

概率论相关题型
文章目录 概率论的基本概念放杯子问题条件概率与重要公式的结合独立的运用 随机变量以及分布离散随机变量的分布函数特点连续随机变量的分布函数在某一点的值为0正态分布标准化随机变量函数的分布 多维随机变量以及分布条件概率max 与 min 函数的相关计算二维随机变量二维随机变…...

C#中的Attribute详解(上)
C#中的Attribute详解(上) 一、Attribute是什么二、Attribute的作用三、Attribute与注释的区别四、系统Attribute范例1、如果不使用Attribute,为了区分这四类静态方法,我们只能通过注释来说明,但这样做会给系统带来很多…...

天津医科大学临床医学院专升本药学专业有机化学考试大纲
天津医科大学临床医学院高职升本科专业课考试大纲药学专业《有机化学》科目考试大纲 一、考试基本要求 本考试大纲主要要求考生对《有机化学》基本概念有较深入的了解,能够系统地掌握各类化合物的命名、结构特点及立体异构、主要性质、反应、来源和合成制备方法等…...
电脑开机自动断电,简单4招,快速解决!
“不知道我的电脑最近是怎么回事,每次一开机就会出现自动断电的情况,有什么方法可以解决吗?” 在使用电脑时,由于电源供应不稳定或过热,以及各种硬件问题,可能会导致电脑开机自动断电。遇到这种情况&#x…...
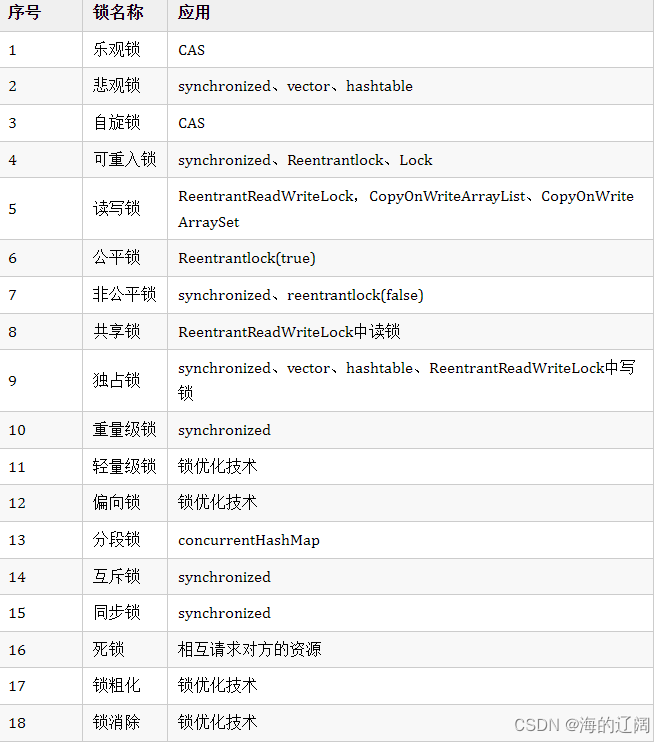
线程基础知识(三)
前言 之前两篇文章介绍了线程的基本概念和锁的基本知识,本文主要是学习同步机制,包括使用synchronized关键字、ReentrantLock等,了解锁的种类,死锁、竞争条件等并发编程中常见的问题。 一、关键字synchronized synchronied关键…...

elasticsearch系列七:聚合查询
概述 今天咱们来看下es中的聚合查询,在es中聚合查询分为三大类bucket、metrics、pipeline,每一大类下又有十几种小类,咱们各举例集中,有兴许的同学可以参考官网:https://www.elastic.co/guide/en/elasticsearch/refere…...

SQL面试题挑战11:访问会话切割
目录 问题:SQL解答: 问题: 如下为某电商公司用户访问网站的数据,包括用户id和访问时间两个字段。现有如下规则:如果某个用户的连续的访问记录时间间隔小于60秒,则属于同一个会话,现在需要计算每…...
)
2023“楚怡杯”湖南省赛“信息安全管理与评估“--应急响应(高职组)
2023“楚怡杯”湖南省“信息安全管理与评估”(高职组)任务书 2023“楚怡杯”湖南省“信息安全管理与评估”(高职组)任务书第一阶段竞赛项目试题第二阶段竞赛项目试题网络安全事件响应:需要环境私聊博主:2023“楚怡杯”湖南省“信息安全管理与评估”(高职组)任务书 第一…...

【Python百宝箱】Python引领制造变革:CAM技术全景解析与实战指南
Python 驭技术潮流:探索计算机辅助制造的全方位工具库 前言 在当今制造业的快速发展中,计算机辅助制造(Computer-Aided Manufacturing,CAM)技术扮演着至关重要的角色。为了提高制造效率、优化工艺流程以及实现数字化…...

【新版Hi3559AV100 旗舰8K30 AI摄像机芯片】
新版Hi3559AV100 旗舰8K30 AI摄像机芯片 一、总体介绍 Hi3559AV100是专业的8K Ultra-HD Camera SOC,它提供了8K30/4K120广播级图像质量的数字视频录制,支持8路Sensor输入,支持H.265编码输出或影视级的RAW数据输出,并集成高性能ISP…...
)
小样本学习idea(不断更新)
在此整理并记录自己的思考过程,其中不乏有一些尚未成熟或者尚未实现的idea,也有一些idea实现之后没有效果或者正在实现,当然也有部分idea已写成论文正在投稿,都是自己的一些碎碎念念的思考,欢迎交流。 研一上学期 9.…...
表情包搜索网站
一个非常不错的表情包搜索网站,输入关键词即可得到所有相关的表情,还可以选择套图下载,自制表情,非常给力666 可以点击下载,会新建窗口打开图片,鼠标右键“图片另存为”,下载文件名手动补充“…...
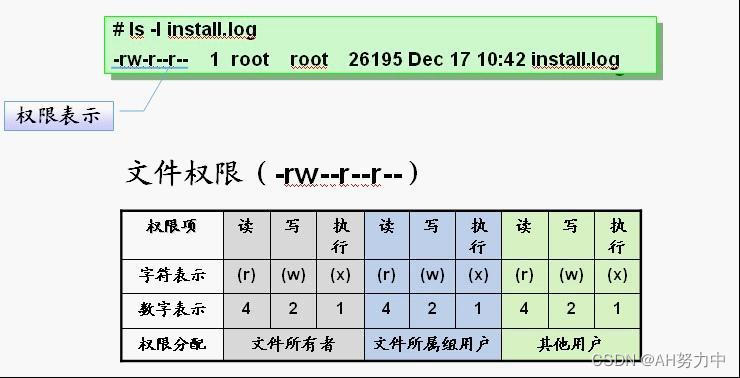
Linux账号和权限管理
目录 一、用户账号和组账号概述 1、用户账号类型 2、组账号 1.基本组(私有组) 2.附加组(公共组) 3、ID 1.UID 2.GID 4、用户和账号管理 1.文件位置 2.useradd-----创建用户 3.userdel——删除用户账号 4.usermod---修…...
)
Qt/QML编程学习之心得:QML和C++的相互调用(十五)
Qt下的QML说到底是类似于JavaScript的一种解释性语言,习惯了VC的MVC(Veiw+Control)的模式,那种界面视图任何事件都是和C++的cpp中处理函数一一对应,在类中也有明确的说明的。一下子玩Qt会觉得哪里对不上,比如使用QML这种节脚本语言贴了图做了layout布局,那么一个按钮的o…...
月入10.5K,专科小伙转行网优:据说每个领域都有一个“显眼包”
网络热词流行的今天,显眼包一词又上热搜。除了熟知的内娱显眼包外,其实各行业也都有自己的“显眼包”。 显眼包又叫“现眼包”看似丢人现眼,实则是个“褒义词”,他们勇敢自信,积极乐观,敢于展示自己&#x…...

Python自动化测试:选择最佳的自动化测试框架
在开始学习python自动化测试之前,先了解目前市场上的自动化测试框架有哪些? 随着技术的不断迭代更新,优胜劣汰也同样发展下来。从一开始工具型自动化,到现在的框架型;从一开始的能用,到现在的不仅能用&…...
Ubuntu16.04 安装Anaconda
步骤 1: 去官网下载安装包,链接如下: https://repo.anaconda.com/archive/ 找到对应版本下载至本地电脑,并上传至服务器。 步骤2: 通过命令解压 sh Anaconda3-2023.03-0-Linux-x86_64.sh 一路选择yes或则回车,直到安装成功出现下面画面&…...
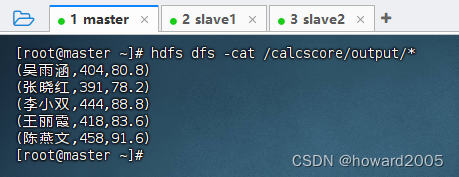
MR实战:统计总分与平均分
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据1、在虚拟机上创建文本文件2、上传文件到HDFS指定目录 (二)实现步骤1、创建Maven项目2、添加相关依赖3、创建日志属性文件4、创建成绩映射器类5、创建成绩驱动器类6、启…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...