【C++】适配器模式 -- stack/queue/dqueue
一、适配器模式
设计模式
设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结;Java 语言非常关注设计模式,而 C++ 并没有太关注,但是一些常见的设计模式我们还是要学习。
迭代器模式
其实我们在前面学习 string、vector 和 list 时就已经接触过设计模式了 – 迭代器就是一种设计模式;迭代器模式是封装后提供统一的接口 iterator,在不暴露底层实现细节的情况下,使得上层能够以相同的方式来访问不同的容器。
适配器模式
适配器模式则是将一个类的接口转换成客户希望的另外一个接口,即根据已有的东西转换出我们想要的东西。
二、stack
1、stack 的介绍和使用
stack 的介绍
和我们以前学的容器不同,为了不破坏栈 LIFO 的特性,stack 不提供迭代器,所以 stack 不是迭代器模式,而是一种容器适配器:
如图,stack 使用 dqueue 容器作为默认的适配容器,关于 dqueue 的内容,我们放在文章最后面讲。
stack 常用接口的使用
stack 的接口较少,同时其接口的使用方法也十分简单,这里我就不再一一演示,如果对某些接口有疑问的同学,还是和以前一样,到 cplusplus.com 上面查看使用细节。
| -函数说明 | -接口说明 |
|---|---|
| stack() | 构造空的栈 |
| empty() | 检测stack是否为空 |
| size() | 返回stack中元素的个数 |
| top() | 返回栈顶元素的引用 |
| push() | 栈顶入栈 |
| pop() | 栈顶出栈 |
2、stack 的模拟实现
在了解了适配器模式之后,我们就可以将适配器作为类的第二个模板参数,然后通过传递不同的适配容器来实现栈了:
//stack.h
template<class T, class Container>
class stack {//...
};//test.cpp
void test_stack() {stack<int, std::vector<int>> st1;stack<int, std::list<int>> st2;
}
如上,vector 和 list 都可以作为 stack 的适配容器,我们可以通过给定不同的第二个模板参数来使用不同的容器适配 stack;
但是出于随机抽取和缓存命中的考虑,vector 显然更适合作为 stack 的适配容器,那么我们可以还可以将 vector 设置为 stack 的默认适配容器,这样,我们以后定义栈对象时就不用显式指定 vector 了:
//stack.h
template<class T, class Container = std::vector<T>>
class stack {//...
};//test.cpp
void test_stack() {stack<int> st1; //默认使用vector做适配容器stack<int, std::list<int>> st2; //使用其他容器做适配容器需要显式指定
}
有了适配容器之后,我们就可以通过调用适配容器的接口来实现 stack 的接口了,这样,stack 的模拟实现将会变得非常简单。
stack.h:
#pragma once#include <iostream>
#include <vector>
#include <list>namespace thj {template<class T, class Container = std::vector<T>>class stack {public://构造和析构不用写,默认生成的构造和析构对于自定义类型会调用它们的构造和析构函数bool empty() const {return _Con.empty();}size_t size() const {return _Con.size();}T& top() {return _Con.back(); //数组尾部作为栈的栈顶}const T& top() const {return _Con.back();}void push(const T& val) {_Con.push_back(val); //在数组尾部插入数据}void pop() {_Con.pop_back();}private:Container _Con;};
}
test.h:
void test_stack() {//stack<int, std::vector<int>> st1;//stack<int, std::list<int>> st2;//stack<int> st1; //默认使用vector做适配容器//stack<int, std::list<int>> st2; //使用其他容器做适配容器需要显式指定stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);st.push(5);cout << st.size() << endl;while (!st.empty()) {cout << st.top() << " ";st.pop();}cout << endl;
}
3、stack 的经典 OJ 题
力扣 155.最小栈
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
实现 MinStack 类:
- MinStack() 初始化堆栈对象。
- void push(int val) 将元素val推入堆栈。
- void pop() 删除堆栈顶部的元素。
- int top() 获取堆栈顶部的元素
- int getMin() 获取堆栈中的最小元素。
示例 :
输入:
[“MinStack”,“push”,“push”,“push”,“getMin”,“pop”,“top”,“getMin”]
[[],[-2],[0],[-3],[],[],[],[]]
输出:
[null,null,null,null,-3,null,0,-2]
思路1
可能有的同学第一时间想到的就是使用一个 min 变量来记录最小值,然后每次插入时比较更新这个最小值,但是这样其实是不行的,比如我们先插入 [4, 2, 7, 2, 1, 6],此时 min = 1,现在我们 pop 掉两个元素,栈的数据变成 [4, 2, 7, 2],最小值为 2,而我们的 min 显然还是原来的 1。
思路2
思路2就是使用一个专门的栈 minST 来记录最小值,当插入的元素小于 minST 栈顶元素时就将该元素插入到 minST 中,如果该元素大于 或等于 minST 栈顶元素就向 minST 中插入一个与栈顶大小相同的值,此时最小值就是 minST 栈顶的元素,如下:
st: [4, 2, 7, 2, 1, 6] minST: [4, 2, 2, 2, 1, 1] min = 1//pop两次
st: [4, 2, 7, 2] minST: [4, 2, 2, 2] min = 2//再pop三次
st: [4] minST: [4] min = 4
思路2优化
思路2虽然可行,但是其空间复杂度为O(N) – 需要一个同等大小的栈来存放最小值,我们可以对其进行优化 – 不必每次都向 minST 中插入元素,只有当插入的元素 小于或等于 minST 栈顶元素时才插入,pop 数据时也只有当 pop 的值和 minST 栈顶元素相同时才pop,如下:
//7和6插入时minST不变
st: [4, 2, 7, 2, 1, 6] minST: [4, 2, 2, 1] min = 1 //pop两次
//6与minST栈顶不相等,minST不动,1相等,pop minST栈顶元素
st: [4, 2, 7, 2] minST: [4, 2, 2] min = 2 //再pop三次
//2和2与minST栈顶相等,minST pop,7不相等,minST不动
st: [4] minST: [4] min = 4
特别注意:当插入的元素与 minST 栈顶元素相等时也需要插入,这是为了避免后续插入的的元素中有等于当前 minST 栈顶的元素,这样 pop 该元素时会导致 minST 栈顶元素也被 pop 掉,这样就找不到 min 了:
//当前状态
st: [4, 2, 5, 3, 2, 7] minST: [4, 2] min = 2//pop两次
//由于2和minST栈顶元素相同,所以minST中2被删除
st: [4, 2, 5, 3] minST: [4] min = 4 //错误
代码实现:
class MinStack {
public:MinStack() { //可以为空,初始化列表会走自定义类型的默认构造}void push(int val) { //如果插入的元素小于等于最小元素就插入_minST_st.push(val);if(_minST.empty() || val <= _minST.top()) _minST.push(val);}void pop() { //如果删除的元素等于_minST.top()就删除int Top = _st.top();_st.pop();if(Top == _minST.top()) _minST.pop(); }int top() {return _st.top();}int getMin() {return _minST.top();}private:stack<int> _st;stack<int> _minST;
};
牛客 JZ31.栈的压入、弹出序列
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。
示例
输入:
[1,2,3,4,5],[4,5,3,2,1]返回值:
true
思路
这道题我们模拟出栈顺序即可,将 pushV 中的元素入栈,入栈时和 popV 中的元素比较,若相同,则说明当前元素在此处出栈;当循环结束后,如果 pushV 中入栈的元素全部被 pop 或者 popV 走到了结尾,则说明出栈顺序是正确的,反之错误;需要注意的是,由于出栈可能是多个元素连续出栈,所以我们需要写成循环。
代码实现:
class Solution {
public:bool IsPopOrder(vector<int> pushV,vector<int> popV) {stack<int> st;int popi = 0;for(auto e : pushV) {st.push(e);while(!st.empty() && st.top() == popV[popi]) { //这里需要写成循环,因为可能连续出栈popi++;st.pop();}}return st.empty();}
};
150. 逆波兰表达式求值 - 力扣(LeetCode)
给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。
请你计算该表达式。返回一个表示表达式值的整数。
注意:
- 有效的算符为 ‘+’、‘-’、‘*’ 和 ‘/’ 。
- 每个操作数(运算对象)都可以是一个整数或者另一个表达式。
- 两个整数之间的除法总是 向零截断 。
- 表达式中不含除零运算。
- 输入是一个根据逆波兰表示法表示的算术表达式。
- 答案及所有中间计算结果可以用 32 位 整数表示。
示例 :
输入:tokens = ["2","1","+","3","*"] 输出:9 解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9输入:tokens = ["4","13","5","/","+"] 输出:6 解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
思路
要解决这道题,我们首先要明白计算机对逆波兰表达式 (后缀表达式) 是计算方法 – 用栈来存储数据,从左到右遍历表达式,遇到数字直接入栈,遇到运算符先取出栈顶元素和下一个栈顶元素,分别作为右操作数和左操作数与运算符进行运算,运算结果放入栈中;然后再继续往后遍历,直到将表达式遍历完。
现在我们只需要模拟这个计算过程即可,完整代码如下:
class Solution {
public:int evalRPN(vector<string>& tokens) {stack<int> st;for(auto& str : tokens) {if(str == "+" || str == "-" || str == "*" || str == "/") { //运算符取两个栈顶元素运算后入栈int right = st.top(); //右操作数st.pop();int left = st.top(); //左操作数st.pop();switch(str[0]) {case '+':st.push(left + right);break;case '-':st.push(left - right);break;case '*':st.push(left * right);break;case '/':st.push(left / right);break;default:break;}} else { //数字直接入栈st.push(stoi(str));}}return st.top();}
};
拓展知识 – 中缀表达式转后缀表达式
我们日常生活中见到的都是中缀表达式,这是因为我们从小接触到的就是中缀表达式,对其十分熟悉,然而对于计算机来说,计算机更容易计算后缀表达式,所以有的计算机在计算时会先将中缀表达式转为后缀表达式 (逆波兰表达式),再根据后缀表达式求值。
上面我们已经模拟了后缀表达式求值的过程,那么中缀表达式应该如何转化为后缀表达式呢?转换规则如下:
- 遇到操作数直接输出;
- 使用栈来存储操作符,遇到操作符如果栈为空则直接入栈;
- 如果栈不为空,则与栈顶操作符进行比较,如果当前操作符优先级高于栈顶操作符,则入栈;如果低于或等于,则栈顶运算符输出,当前运算符入栈。
我们更好理解我们举例说明:
中缀表达式:1 + 2 * 3 / 4 - 5//第一步:遇到操作数1,直接输出
st: [] 后缀表达式:1//第二步:遇到操作符,且栈为空,直接入栈
st: [+] 后缀表达式:1//第三步,2输出;第四步,操作符*优先级大于+,入栈
st: [+ *] 后缀表达式:1 2 //第五步,3输出,第六步,操作符/优先级等于*,栈顶运算符*输出,当前运算符/入栈
st: [+ /] 后缀表达式:1 2 3 *//第七步,4输出;第八步,操作符-优先级小于/,栈顶运算符/输出,当前运算符-入栈
st: [+ -] 后缀表达式:1 2 3 * 4 ///第九步,此时栈中有两个运算符,且栈顶运算符-和运算符+优先级相等,所以+输出
st: [-] 后缀表达式:1 2 3 * 4 / + //第十步,5输出;第十一步,表达式遍历完成,此时栈中还剩一个-,输出
st: [] 后缀表达式:1 2 3 * 4 / + 5 -
所以,中缀表达式 [1 + 2 * 3 / 4 - 5] 转为后缀表达式为 [1 2 3 * 4 / + 5 -]
注:我们上面提到的中缀转后缀是不包含括号的情况,如果出现括号还要进行特殊处理。
232. 用栈实现队列 - 力扣(LeetCode)
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x)将元素 x 推到队列的末尾- int pop() 从队列的开头移除并返回元素
- int peek() 返回队列开头的元素
- boolean empty() 如果队列为空,返回 true ;否则,返回 false
示例 :
输入:
[“MyQueue”, “push”, “push”, “peek”, “pop”, “empty”]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 1, 1, false]
思路
由于栈只能在头部插入和删除数据,而队列是在尾部插入数据,在头部删除数据,所以我们可以使用两个栈,一个专门用来入数据,一个专门用来出数据:
pushST:专门用来入数据,当有元素入队列时直接插入 pushST 中;
popST:专门用来出数据,当数据出队列时,检查 popST 是否为空,如果为空,将 pushST 中的数据全部取出插入到 popST 中 – 因为栈是后入先出的,所以当我们将 pushST 中的数据取出插入到 popST 后,原本位于栈底的数据就会位于栈顶,此时 popST 的出栈顺序就和队列的出队顺序相同了,如图所示:

代码实现如下:
class MyQueue {
public:MyQueue() { //此处不用写,因为成员变量会自动走初始化列表,自定义类型会在此处调用默认构造}void move() { //检查popST是否为空,是就将pushST中的元素全部转移到其中if(_popST.empty()) {while(!_pushST.empty()) {_popST.push(_pushST.top());_pushST.pop();}}}void push(int x) { //直接插入到pushST中_pushST.push(x);}int pop() {move(); //pop之前先检查是否需要移动元素到popSTint Top = _popST.top();_popST.pop();return Top;}int peek() {move();return _popST.top();}bool empty() {move();return _popST.empty();}private:stack<int> _pushST;stack<int> _popST;
};
这里有几个需要注意的地方:
1、在类和对象部分我们学习了类的六大默认成员函数以及初始化列表,知道了如果我们不写构造函数编译器会自动生成一个无参的默认构造函数,它对于自定义类型会去调用自定义类型的默认构造;
2、同时,类成员变量真正的初始化工作是在初始化列表完成的,所以不管我们是否显示的在初始化列表处对成员变量进行初始化工作,成员变量都会在初始化列表进行初始化工作,而自定义类型会调用自身的默认构造完成初始化;
3、所以,题目给出的代码中 MyQueue() 即默认构造接口我们可以直接删除,此时 MyQueue 会根据自动生成的默认构造函数完成对 pushST 和 popST 的初始化;我们也可以不管它,因为即使我们不在初始化列表显式的对 pushST 和 popST 进行初始化,它们也会在初始化列表处调用自身的默认构造完成初始化工作。
4、最后,由于 pop、peek、empty 接口都需要在最开始判断 popST 是否为空,如果为空就要将 pushST 中的数据转移到 popST 中来,为了避免代码冗余,我们可以将这一部分功能单独写成一个函数供其他函数调用。
三、queue
1、queue 的介绍和使用
queue 的介绍
和 stack 一样,queue 也是一种容器适配器,也不提供迭代器:
可以看到,queue 也是使用 deque 作为默认适配容器,和之前一样,deque 我们放在最后面讲。
queue 常用接口的使用
queue 的接口较少,同时其接口的使用方法也十分简单,这里我就不再一一演示,如果对某些接口有疑问的同学,还是和以前一样,到 cplusplus.com 上面查看使用细节。
| -函数声明 | -接口说明 |
|---|---|
| queue() | 构造空的队列 |
| empty() | 检测队列是否为空 |
| size() | 返回队列中有效元素的个数 |
| front() | 返回队头元素的引用 |
| back() | 返回队尾元素的引用 |
| push() | 在队尾将元素val入队列 |
| pop() | 将队头元素出队列 |
2、queue 的模拟实现
和 stack 一样,vector 和 list 都可以作为 queue 的适配容器,但是由于 queue 需要大量在头部删除数据,所以 list 更适合作为 queue 的默认适配容器,那么 queue 模拟实现的代码如下:
queue.h:
#pragma once#include <iostream>
#include <vector>
#include <list>namespace thj {template<class T, class Container = std::list<T>>class queue {public://构造和析构不用写,默认生成的构造和析构对于自定义类型会调用它们的构造和析构函数bool empty() const {return _Con.empty();}size_t size() const {return _Con.size();}T& front() {return _Con.front(); //第一个节点为队头}const T& front() const {return _Con.front();}T& back() {return _Con.back(); //最后一个节点为队尾}const T& back() const {return _Con.back(); //最后一个节点为队尾}void push(const T& val) {_Con.push_back(val); //在链表尾部插入节点}void pop() {_Con.pop_front(); //删除第一个节点}private:Container _Con;};
}
test.cpp:
void test_queue() {queue<int> q; //默认使用vector做适配容器q.push(1);q.push(2);q.push(3);q.push(4);q.push(5);cout << q.size() << endl;while (!q.empty()) {cout << q.front() << " ";q.pop();}cout << endl;
}
需要注意的是,当我们使用 vector 作为 queue 的适配容器时,编译会报错,这是由于 vector 头插头删效率太低,所以并没有专门提供头插和头删的函数,而是通过 insert 和 erase 来完成,而我们实现的 queue 中使用了 pop_front 函数: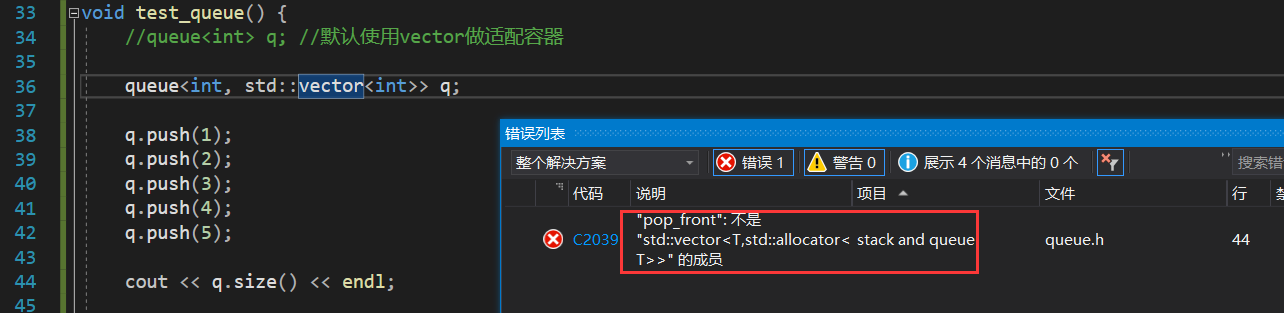
不过这种情况出现并不意味着我们实现的 queue 不行,其实报错反而提醒了 queue 的使用者 – vector 不适合作为 queue 的适配容器,应该更换一个更合适的。
3、queue 经典 OJ 题
225. 用队列实现栈 - 力扣(LeetCode)
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
实现 MyStack 类:
- void push(int x) 将元素 x 压入栈顶。
- int pop() 移除并返回栈顶元素。
- int top() 返回栈顶元素。
- boolean empty() 如果栈是空的,返回 true ;否则,返回 false 。
示例:
输入:
[“MyStack”, “push”, “push”, “top”, “pop”, “empty”]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 2, 2, false]
思路
这道题比上面 用栈实现队列 要复杂一些,用栈实现队列思路很简单,两个栈,一个专门用来入,一个专门用来出,用来出的出完了就把用来入的里面的数据转移过来即可;这个虽然也是两个队列,但它们之间的关系不仅仅是一个出、一个入那么简单:
1、入数据:定义两个队列 q1 和 q2,最开始入栈时随便将数据插入哪个队列,第二次及以后插入时把数据插入到非空队列中;
2、出数据:出栈就比较复杂了,由于队列是先入先出而栈是后入先出的,所以队尾的数据就是栈顶的数据;而出栈时我们需要将队尾前面的元素全部挪到另一个为空的队列中,然后删除队列中剩余的那个数据,即队尾数据,这样才完成了出栈 – 删除后此队列就为空,而另一个队列就不为空了,那么下次再出栈时就可以将另一个不为空队列中除队尾外所有数据挪动到此空队列中,再删除那个队列中的数据;
3、注意:将 q1 中的数据挪动 q2 中的数据时数据的前后顺序不会改变,即入 q1 的数据顺序为 1 2 3 4 5,那么将数据取出来插入到 q2 后,q2 中数据的顺序仍是 1 2 3 4 5,这是因为队列的入队顺序和出队顺序是一致的;
4、总结:不进行出栈操作时,始终有一个队列是空的,入栈直接插入到非空队列中,出栈则需要先将非空队列中除队尾以外的数据全部挪动的空队列中,再删除非空队列中剩余的那个数据。
代码实现
class MyStack {
public:MyStack() { //自动走初始化列表,调用其默认构造}void push(int x) { //向非空队列中pushif(!_q1.empty()) _q1.push(x);else _q2.push(x);}int pop() { //相当于pop非空队列队尾的元素int Top = 0; //用于记录空队列队尾的元素if(_q1.empty()) {while(_q2.size() != 1) { //注意这里是元素个数不为1,而不是队头元素不等于队尾元素int Top = _q2.front();_q1.push(Top);_q2.pop();}Top = _q2.back(); //其实此时q2中就只有一个元素了_q2.pop();} else if(_q2.empty()) {while(_q1.size() != 1) { int Top = _q1.front();_q2.push(Top);_q1.pop();}Top = _q1.back();_q1.pop();}return Top;}int top() { //非空队列的队尾元素为栈顶元素int Top = 0;if(!_q1.empty()) Top = _q1.back();else if(!_q2.empty()) Top = _q2.back();return Top;}bool empty() {return _q1.empty() && _q2.empty();}private:queue<int> _q1;queue<int> _q2;
};
注意事项:
和用栈实现队列一样,构造函数不提供编译器自动生成,成员变量不显式进行初始化也会走初始化列表进行初始化。
四、deque
1、deque 的原理介绍
deque (双端队列):是一种双开口的 “连续” 空间的数据结构,双开口的含义是 deque 可以在头尾两端进行插入和删除操作,且时间复杂度为O(1);与vector比较,头插效率高,不需要搬移元素,与 list 比较,空间利用率比较高,“随机访问” 效率较高。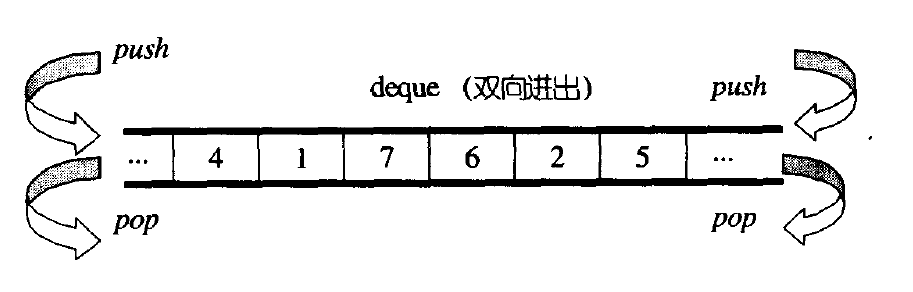
2、deque 的底层结构
deque 并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际 deque 类似于一个动态的二维数组,其结构示意图如下: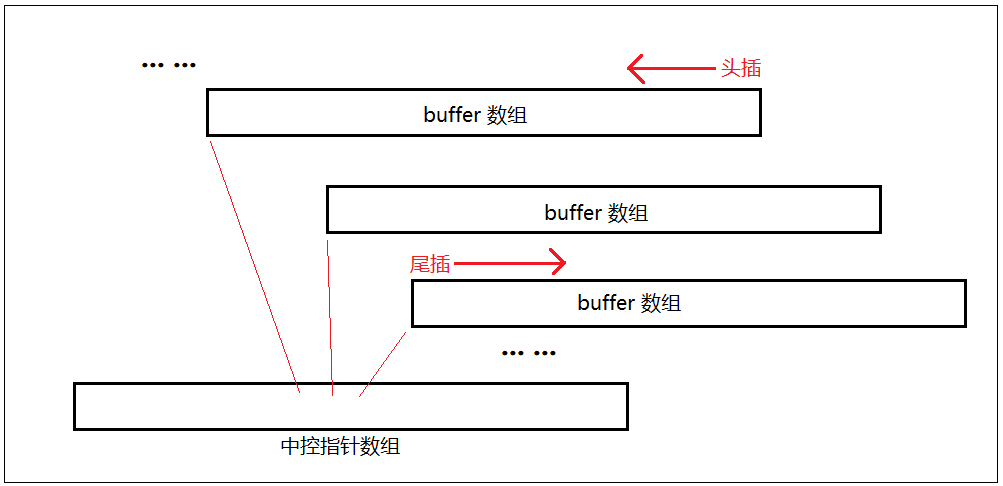
由上图我们可以知道 deque 的底层结构:
- deque 具有多个 buffer 数组,每个buffer数组可以存储 n 个数据 (n 一般为10),还具有一个用于管理 buffer 数组的中控指针数组,数组中的每个元素都指向一个 buffer 数组;
- 中控指针数组的使用:让数组最中间的元素指向第一个 buffer,当第一个buffer 数组满开辟第二个 buffer 数组时,让指针数组的后一个位置或者前一个位置指向新开辟的 buffer 数组 – 因为头插导致新 buffer 数组开辟就让前一个位置指向新 buffer 数组,尾插导致就让后一个位置指向;
- deque 的扩容:当中控指针数组满后扩容,让中控指针数组的容量变为原来的二倍,然后将原中控数组里面的数据 (即各个buffer数组的地址) 拷贝到新的中控指针数组中;
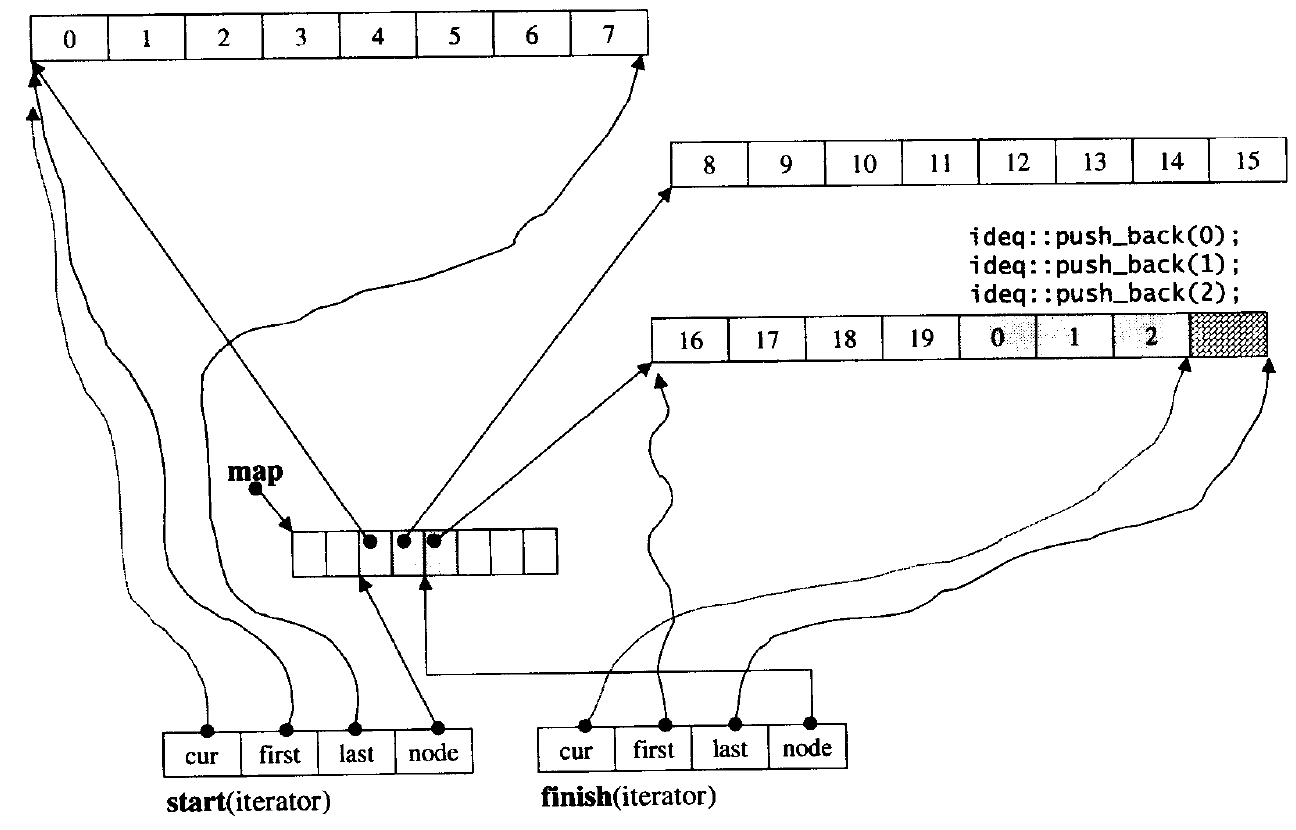
3、deque 的迭代器设计
为了维护 deque “整体连续” 以及随机访问的假象,deque 的迭代器设计非常复杂,如图: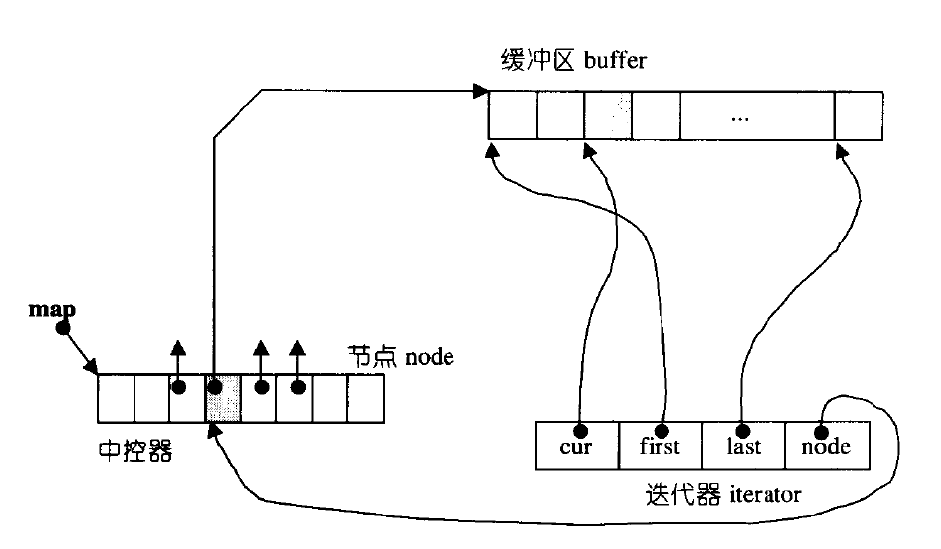
4、deque 的优缺点
根据 deque 的设计结构,我们可以知道其优点:
- 具有 vector 的优点 – 支持随机访问、缓存命中率较高、尾部插入删除数据效率高;
- 同时具有 list 的优点 – 空间浪费少、头部插入插入数据效率高;
但同时 deque 也存在一些缺点:
- deque 的随机访问效率较低 – 需要先通过中控数据找到对应的buffer数组,再找到具体的位置 (假设偏移量为 i,需先 i/10 得到位于第几个buffer数组,再 i%10 得到 buffer 数组中的具体位置),即 deque 随机访问时一次跳过一个buffer数组,需要跳多次才能准确定位,其效率比 list 高了不少,但比 vector 也低了不少;
- deque 在中部插入删除数据的效率是比较低的 – 需要挪动数据,但不一定后续 buffe 数组中的数据全部挪动,可以控制只挪一部分,即中间插入删除数据的效率高于 vector,但是低于 list。
基于 deque 的优缺点我们可以发现,虽然 deque 综合了 vector 和 list 的优缺点,看似很完美,但是它单方面的性能是不如 vector 或者 list 的,也就是说,deque 有点东西,但不多,因此 deque 在实际应用中使用的非常少;
不过不可否认的是 deque 确实很适合作为 stack 和 list 的默认适配容器,毕竟它对于 stack 和 list 的通用的,这也是 STL 中选择 deque 作为 stack 和 queue 默认适配容器的原因。
deque 特别适合需要大量进行头插和尾部数据的插入删除、偶尔随机访问、偶尔中部插入删除的场景;不太适合需要大量进行随机访问与中部数据插入删除的场景,特别是排序。
相关文章:
【C++】适配器模式 -- stack/queue/dqueue
一、适配器模式 设计模式 设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结;Java 语言非常关注设计模式,而 C 并没有太关注,但是一些常见的设计模式我们还是要学习。 迭代器模式 其实我们在前面学习 strin…...

sql server 分页查询
sql server 分页查询[toc]前言SQL server 2012版本。下面都用pageIndex表示页数,pageSize表示一页包含的记录。并且下面涉及到具体例子的,设定查询第2页,每页含10条记录。首先说一下SQL server的分页与MySQL的分页的不同,mysql的分…...

RV1126新增驱动IMX415 SENSOR,实现v4l2抓图
RV1126新增驱动IMX415 SENSOR,实现v4l2抓图。1:内核dts修改&csi_dphy0 {status "okay";ports {#address-cells <1>;#size-cells <0>;port0 {reg <0>;#address-cells <1>;#size-cells <0>;mipi_in_uca…...
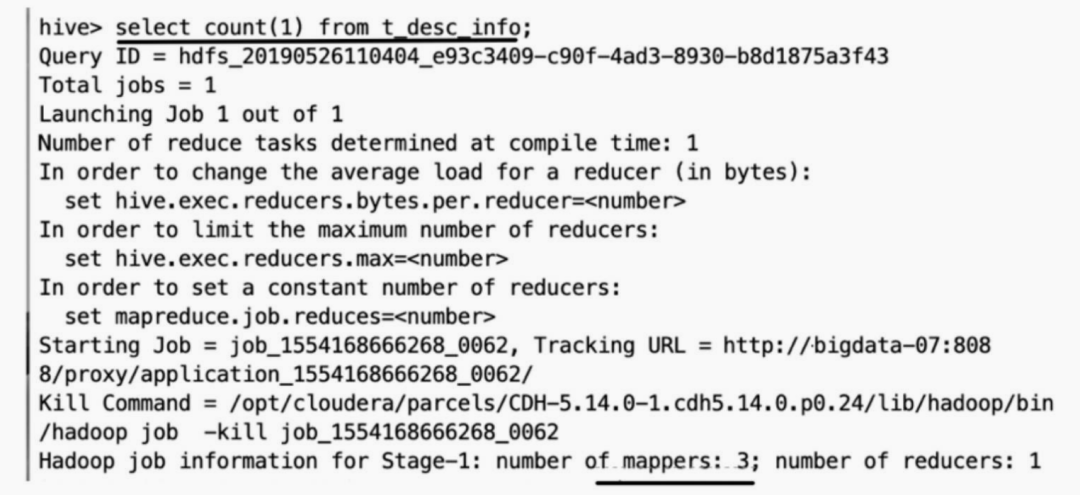
Hive 数据倾斜
数据倾斜,即单个节点任务所处理的数据量远大于同类型任务所处理的数据量,导致该节点成为整个作业的瓶颈,这是分布式系统不可能避免的问题。从本质来说,导致数据倾斜有两种原因,一是任务读取大文件,二是任务…...

2月刚上岸字节跳动测试岗面经
这时候发应该还不算太晚,金三银四找工作的小伙伴需要的可以看看。 一、测试工程师的工作是什么? 测试工程师简单点说就是找bug,然后反馈给开发人员,不要小看这个工作。 首先很明显的bug开发人员有时候自己就能找到,测…...
图解KMP算法
子串的定位操作通常称作串的模式匹配。你可以理解为在一篇英语文章中查找某个单词是否存在,或者说在一个主串中寻找某子串是否存在。朴素的模式匹配算法假设我们要从下面的主串S "goodgoogle" 中,找到T "google" 这个子串的位置。…...
Java Map和Set
目录1. 二叉排序树(二叉搜索树)1.1 二叉搜索树的查找1.2 二叉搜索树的插入1.3 二叉搜索树的删除(7种情况)1.4 二叉搜索树和TreeMap、TreeSet的关系2. Map和Set的区别与联系2.1 从接口框架的角度分析2.2 从存储的模型角度分析【2种模型】3. 关于Map3.1 Ma…...

【C/C++ 数据结构】-八大排序之 冒泡排序快速排序
作者:学Java的冬瓜 博客主页:☀冬瓜的主页🌙 专栏:【C/C数据结构与算法】 分享:那我便像你一样,永远躲在水面之下,面具之后! ——《画江湖之不良人》 主要内容:八大排序选…...

苹果ipa软件下载网站和软件的汇总
随着时间的流逝,做苹果版软件安装包下载网站和软件的渐渐多了起来。 当然,已经关站、停运、下架、倒闭的苹果软件下载网站和软件我就不说了,也不必多说那些关站停运下架倒闭的网站和软件了。 下面我统计介绍的就是苹果软件安装包下载网站和软…...
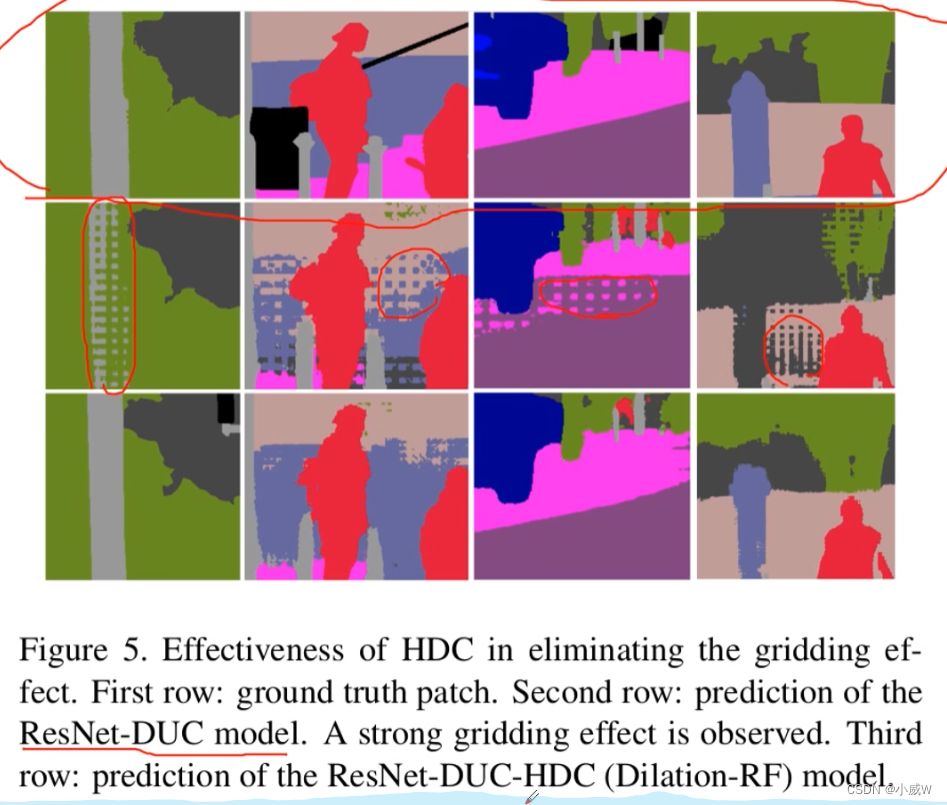
深度学习-【语义分割】学习笔记4 膨胀卷积(Dilated convolution)
文章目录膨胀卷积为什么需要膨胀卷积gridding effect连续使用三次膨胀卷积——1连续使用三次膨胀卷积——2连续使用三次膨胀卷积——3Understanding Convolution for Semantic Segmentation膨胀卷积 膨胀卷积,又叫空洞卷积。 左边是普通卷积,右边是膨胀…...

【10】SCI易中期刊推荐——工程技术-计算机:人工智能(中科院2区)
🚀🚀🚀NEW!!!SCI易中期刊推荐栏目来啦 ~ 📚🍀 SCI即《科学引文索引》(Science Citation Index, SCI),是1961年由美国科学信息研究所(Institute for Scientific Information, ISI)创办的文献检索工具,创始人是美国著名情报专家尤金加菲尔德(Eugene Garfield…...
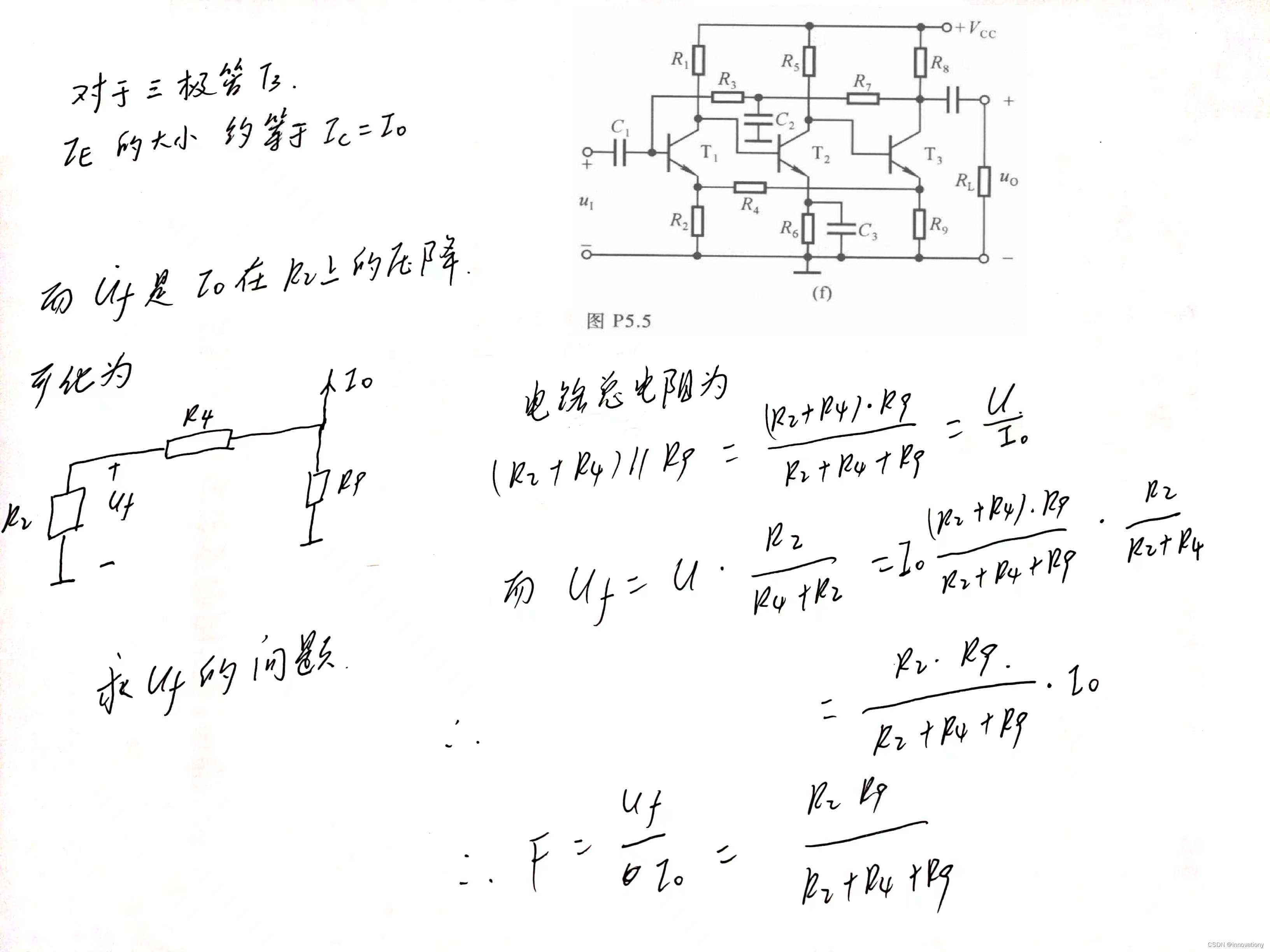
模电计算反馈系数,有时候转化为计算电阻分压的问题
模电计算反馈系数,有时候转化为计算电阻分压的问题 如果是电压反馈,F的除数是Uo 如果是电流反馈,F的除数是Io 串联反馈,F的分子是Uf 并联反馈,F的分子是If 点个赞呗,大家一起加油学习!...

专治Java底子差,不要再认为泛型就是一对尖括号了
文章目录一、泛型1.1 泛型概述1.2 集合泛型的使用1.2.1 未使用泛型1.2.2 使用泛型1.3 泛型类1.3.1 泛型类的使用1.2.2 泛型类的继承1.4 泛型方法1.5 泛型通配符1.5.1 通配符的使用1)参数列表带有泛型2)泛型通配符1.5.2 泛型上下边界1.6 泛型的擦除1.6.1 …...
PayPal轮询收款的那些事儿
想必做跨境电商独立站的小伙伴,对于PayPal是再熟悉不过了,PayPal是一个跨国际贸易的支付平台,对于做独立站的朋友来说跨境收款绝大部分都是依赖PayPal以及Stripe条纹了。简单来说PayPal跟国内的支付宝有点类似,但是PayPal它是跨国…...
【Linux】项目自动化构建工具——make/Makefile
目录 1.make与Makefile的关系 Makefile make 项目清理 clean .PHONY 当我们编写一个较大的软件项目时,通常需要将多个源文件编译成可执行程序或库文件。为了简化这个过程,我们可以使用 make 工具和 Makefile 文件。Makefile 文件可以帮助我们自动…...

成本降低90%,OpenAI正式开放ChαtGΡΤ
今天凌晨,OpenAI官方发布ChαtGΡΤ和Whisper的接囗,开发人员现在可以通过API使用最新的文本生成和语音转文本功能。OpenAI称:通过一系列系统级优化,自去年12月以来,ChαtGΡΤ的成本降低了90%;现在OpenAI用…...

hls.js如何播放m3u8文件(实例)?
HLS(HTTP Live Streaming)是一种视频流传输协议,是苹果推出的适用于iOS与macOS平台的流媒体传输协议。它将视频分割成若干个小段,每个小段大小一般为2~10秒不等,并通过HTTP协议进行传输。通过在每个小段之间插入若干秒…...

大数据平台建设方法论集合
文章目录从0到1建设大数据解决方案大数据集群的方法论数据集成方法论机器学习算法平台方法论BI建设的方法论云原生大数据的方法论低代码数据中台的方法论大数据SRE运维方法论批流一体化建设的方法论数据治理的方法论湖仓一体化建设的方法论数据分析挖掘方法论数字化转型方法论数…...
25- 卷积神经网络(CNN)原理 (TensorFlow系列) (深度学习)
知识要点 卷积神经网络的几个主要结构: 卷积层(Convolutions): Valid :不填充,也就是最终大小为卷积后的大小. Same:输出大小与原图大小一致,那么N 变成了N2P. padding-零填充. 池化层(Subsampli…...

把数组里面数值排成最小的数
问题描述:输入一个正整数数组,将它们连接起来排成一个数,输出能排出的所有数字中最小的一个。例如输入数组{12, 567},则输出这两个能排成的最小数字12567。请给出解决问题的算法,并证明该算法。 思路:先将…...
)
Allegro PCB设计必备:3分钟搞定带钻孔数据的DXF文件导出(附常见错误排查)
Allegro PCB设计实战:高效导出带钻孔数据的DXF文件全攻略 在PCB设计领域,Allegro作为行业标杆工具,其文件输出质量直接关系到生产制造的准确性。特别是当设计需要与其他CAD系统协作或提交给PCB制造商时,DXF文件的完整性至关重要。…...

深度学习驱动的光谱超分辨率:技术演进与应用前景
1. 光谱超分辨率技术的前世今生 我第一次接触光谱超分辨率技术是在2015年,当时还在用传统的线性插值方法处理遥感图像。记得有次为了获取一片农田的高光谱数据,团队不得不动用昂贵的机载传感器,结果因为天气原因导致数据质量极差。正是这次经…...

Benchmark.js 配置选项终极指南:如何优化你的 JavaScript 性能测试环境
Benchmark.js 配置选项终极指南:如何优化你的 JavaScript 性能测试环境 【免费下载链接】benchmark.js A benchmarking library. As used on jsPerf.com. 项目地址: https://gitcode.com/gh_mirrors/be/benchmark.js Benchmark.js 是一款专业的 JavaScript 性…...

Qwen3.5-9B自动化:GitHub Actions触发模型推理+PR评论生成
Qwen3.5-9B自动化:GitHub Actions触发模型推理PR评论生成 1. 项目概述 Qwen3.5-9B是一个拥有90亿参数的开源大语言模型,具备强大的逻辑推理、代码生成和多轮对话能力。最新版本还支持多模态理解(图文输入)和长达128K tokens的上…...
)
【office2pdf】PPTX 字体解析与文本样式继承(PPTX_FONT_RESOLUTION.md)
摘要 本文档记录了 PPTX 保真度问题,该问题最初看起来像是布局错误, 但实际上是由不完整的字体和文本样式解析引起的。 可见的症状是多个幻灯片上的文本块,尤其是幻灯片 4 的"SKILLS"区域, 与 PowerPoint 不匹配&#x…...

OFA视觉问答模型惊艳效果:复杂背景中主物体识别与属性描述能力
OFA视觉问答模型惊艳效果:复杂背景中主物体识别与属性描述能力 1. 模型效果惊艳展示 OFA视觉问答模型在复杂场景中的表现令人印象深刻。这个模型能够准确识别图片中的主要物体,并详细描述其属性特征,就像有一个专业的图像分析师在为你解读图…...

警惕!新型U盘蠕虫伪装文档传播:实测火绒5.0查杀+防御全攻略
深度解析U盘蠕虫病毒:从防御到查杀的全面安全指南 1. 新型U盘蠕虫病毒的运作机制剖析 U盘蠕虫病毒近年来呈现出越来越复杂的传播方式和技术手段。这类病毒通常利用Windows系统的自动播放功能(AutoRun.inf)或注册表劫持技术进行传播࿰…...

Qwen3-ASR-1.7B快速上手:3分钟完成CSDN GPU实例Web界面识别体验
Qwen3-ASR-1.7B快速上手:3分钟完成CSDN GPU实例Web界面识别体验 想体验语音转文字的神奇效果?Qwen3-ASR-1.7B让你在3分钟内就能通过网页界面完成高质量语音识别,无需任何技术背景。 1. 什么是Qwen3-ASR-1.7B? Qwen3-ASR-1.7B是阿…...
)
野火挑战者开发板实战:用STM32CubeMX从零配置GPIO、UART和ADC(附完整代码)
野火挑战者开发板实战:从零构建环境监测系统 刚拿到野火挑战者开发板时,面对密密麻麻的引脚和复杂的配置选项,很多初学者会感到无从下手。本文将带你用STM32CubeMX图形化工具,快速配置GPIO、UART和ADC这三个最常用的外设ÿ…...

从Stable Diffusion到多模态大模型:图文交错数据如何让AI学会‘边想边画’?
图文交错数据:多模态大模型实现"边想边画"的关键突破 当Stable Diffusion以惊艳的画质震惊世界时,人们很快发现它存在一个根本局限——这个能画出精美图像的模型,却无法理解自己笔下的内容。与此同时,擅长理解图像的多模…...