NLP项目之语种识别
目录
- 1. 代码及解读
- 2. 知识点
- n-grams
- 仅保留最常见的1000个n-grams。意思是n=1000 ?
1. 代码及解读
in_f = open('data.csv')
lines = in_f.readlines()
in_f.close()
dataset = [(line.strip()[:-3], line.strip()[-2:]) for line in lines]
print(dataset[:5])
[('1 december wereld aids dag voorlichting in zuidafrika over bieten taboes en optimisme','nl'),('1 mill贸n de afectados ante las inundaciones en sri lanka unicef est谩 distribuyendo ayuda de emergencia srilanka','es'),('1 mill贸n de fans en facebook antes del 14 de febrero y paty miki dani y berta se tiran en paraca铆das qu茅 har铆as t煤 porunmillondefans','es'),('1 satellite galileo sottoposto ai test presso lesaestec nl galileo navigation space in inglese','it'),('10 der welt sind bei', 'de')]
from sklearn.model_selection import train_test_split
x, y = zip(*dataset)
# 划分训练集、测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1)
# 训练集样本数
len(x_train) # 6799
import redef remove_noise(document):noise_pattern = re.compile("|".join(["http\S+", "\@\w+", "\#\w+"]))clean_text = re.sub(noise_pattern, "", document)return clean_text.strip()remove_noise("Trump images are now more popular than cat gifs. @trump #trends http://www.trumptrends.html")
# 'Trump images are now more popular than cat gifs.'
from sklearn.feature_extraction.text import CountVectorizer
# from sklearn.feature_extraction.text import TfidfVectorizervec = CountVectorizer(lowercase=True, # 英文文本全小写analyzer='char_wb', # 逐个字母解析ngram_range=(1,3), # 1=出现的字母以及每个字母出现的次数,2=出现的连续2个字母,和连续2个字母出现的频次# trump images are now... => 1gram = t,r,u,m,p... 2gram = tr,ru,um,mp...max_features=1000, # keep the most common 1000 ngramspreprocessor=remove_noise
)
# vec = TfidfVectorizer(lowercase=True, decode_error='ignore', preprocessor=remove_noise)
vec.fit(x_train)def get_features(x):vec.transform(x)
这段代码的目的是使用CountVectorizer类从sklearn.feature_extraction.text模块来转换文本数据为数值向量,这是在文本挖掘和自然语言处理中常见的第一步。向量化是将文本数据转换成数值数据,以便机器学习模型可以处理。以下是代码详细的步骤解释:
-
导入
CountVectorizer:from sklearn.feature_extraction.text import CountVectorizer这一步导入了
CountVectorizer类,它可以将文本集合转换成词频矩阵。 -
设置
CountVectorizer的参数:vec = CountVectorizer(lowercase=True, # 将文本转换为小写,这有助于统一不同大小写的相同单词analyzer='char_wb', # 以字符为单位进行分析,'char_wb'表示在单词边界内分析字符,这有助于捕获字符在单词内部的位置信息ngram_range=(1,3), # 设置n-gram的范围,从1到3,这意味着它会考虑单独的字符、两个连续字符、三个连续字符的组合max_features=1000, # 只保留最常见的1000个n-grams,这有助于降低模型复杂度和避免过拟合preprocessor=remove_noise # 使用`remove_noise`函数作为预处理器,它会在向量化前清理文本数据 )这里设置了
CountVectorizer的几个关键参数,包括:- 文本小写化。
- 字符分析器,会考虑字符在单词边界内的n-gram。
- n-gram的范围设置为1到3。
- 仅保留最常见的1000个n-grams。
- 使用预先定义的
remove_noise函数来清理文本数据。
-
训练
CountVectorizer:vec.fit(x_train)这一步是在训练集
x_train上“训练”CountVectorizer,即建立一个词汇表,并计算n-gram的频率。 -
定义一个获取特征的函数:
def get_features(x):vec.transform(x)这个
get_features函数用于将新的文本数据x转换为先前fit方法计算得到的词汇表对应的向量。这里的transform调用会将文本转换成稀疏的数值向量,这些向量的每一维代表一个n-gram的频率。
代码中注释掉的部分是TfidfVectorizer的导入和设置,这表明原作者可能在选择使用基本的词频方法(即CountVectorizer)与使用词频-逆文档频率(TF-IDF)方法(即TfidfVectorizer)之间进行权衡。TfidfVectorizer通常用于当词的重要性不能仅由频率决定时,它考虑了词在整个数据集中的分布。
2. 知识点
n-grams
当然,让我们通过一个简单的例子来理解n-grams。
假设我们有这样一个句子:
"I love to eat apples"
在这个句子中,我们可以生成不同的n-grams:
-
1-grams (或 unigrams):
- “I”
- “love”
- “to”
- “eat”
- “apples”
Unigrams是句子中的单个单词。
-
2-grams (或 bigrams):
- “I love”
- “love to”
- “to eat”
- “eat apples”
Bigrams是句子中相邻的两个单词对。
-
3-grams (或 trigrams):
- “I love to”
- “love to eat”
- “to eat apples”
Trigrams是句子中相邻的三个单词对。
每当n增加,n-gram就会包含更多的单词。通常,随着n的增加,n-gram能提供更多的上下文信息,但同时它们的出现频率可能会下降,因为更长的词序列在文本中准确出现的次数通常会更少。
在自然语言处理中,n-grams用于建立语言模型,这些模型可以预测下一个单词(在n-1个单词的上下文中),或者用于特征工程,比如在文本分类任务中。不过,要注意,随着n的增加,可能会遇到“维度灾难”,因为可能的n-gram组合的数量会呈指数增长。
仅保留最常见的1000个n-grams。意思是n=1000 ?
不是的。在这个上下文中,“保留最常见的1000个n-grams”并不意味着n=1000。这里的n指的是n-gram中的n,即组成n-gram的单词数量。比如,n=1时是unigrams(单词),n=2时是bigrams(两个单词的组合),n=3时是trigrams(三个单词的组合),以此类推。
“保留最常见的1000个n-grams”是指在对文本进行n-gram分析之后,只保留出现频率最高的1000个n-gram组合。这些n-grams可以是任何长度的(在指定的ngram_range内),而不是指n-gram的长度为1000个单词。例如,如果ngram_range设置为(1,3),那么这1000个n-grams可以包含unigrams、bigrams、trigrams的任意组合,具体取决于它们在文本中出现的频率。
这样做的目的是为了减少特征的数量,这有助于提高模型训练的效率和可能的泛化能力,同时也减少了由于过于稀有的n-grams可能导致的过拟合问题。
相关文章:

NLP项目之语种识别
目录 1. 代码及解读2. 知识点n-grams仅保留最常见的1000个n-grams。意思是n1000 ? 1. 代码及解读 in_f open(data.csv) lines in_f.readlines() in_f.close() dataset [(line.strip()[:-3], line.strip()[-2:]) for line in lines] print(dataset[:5])[(1 december wereld…...
)
Linux lpr命令教程:如何使用lpr命令打印文件(附案例详解和注意事项)
Linux lpr命令介绍 lpr命令在Unix-like操作系统中用于提交打印任务。如果在命令行中指定了文件名,那么这些文件将被发送到指定的打印机(如果没有指定目的地,则发送到默认目的地)。如果命令行中没有列出文件,lpr将从标…...

浅谈C语言inline关键字
对于C开发者来说,inline是个再熟悉不过的关键字,因为默认的成员函数都是inline,也是常规高校教材中宣扬C的“优势”之一。 但是C语言其实也是支持inline关键字的,而且是很早期的gcc就支持了该关键字。在Linux0.12版本内核代码中也…...
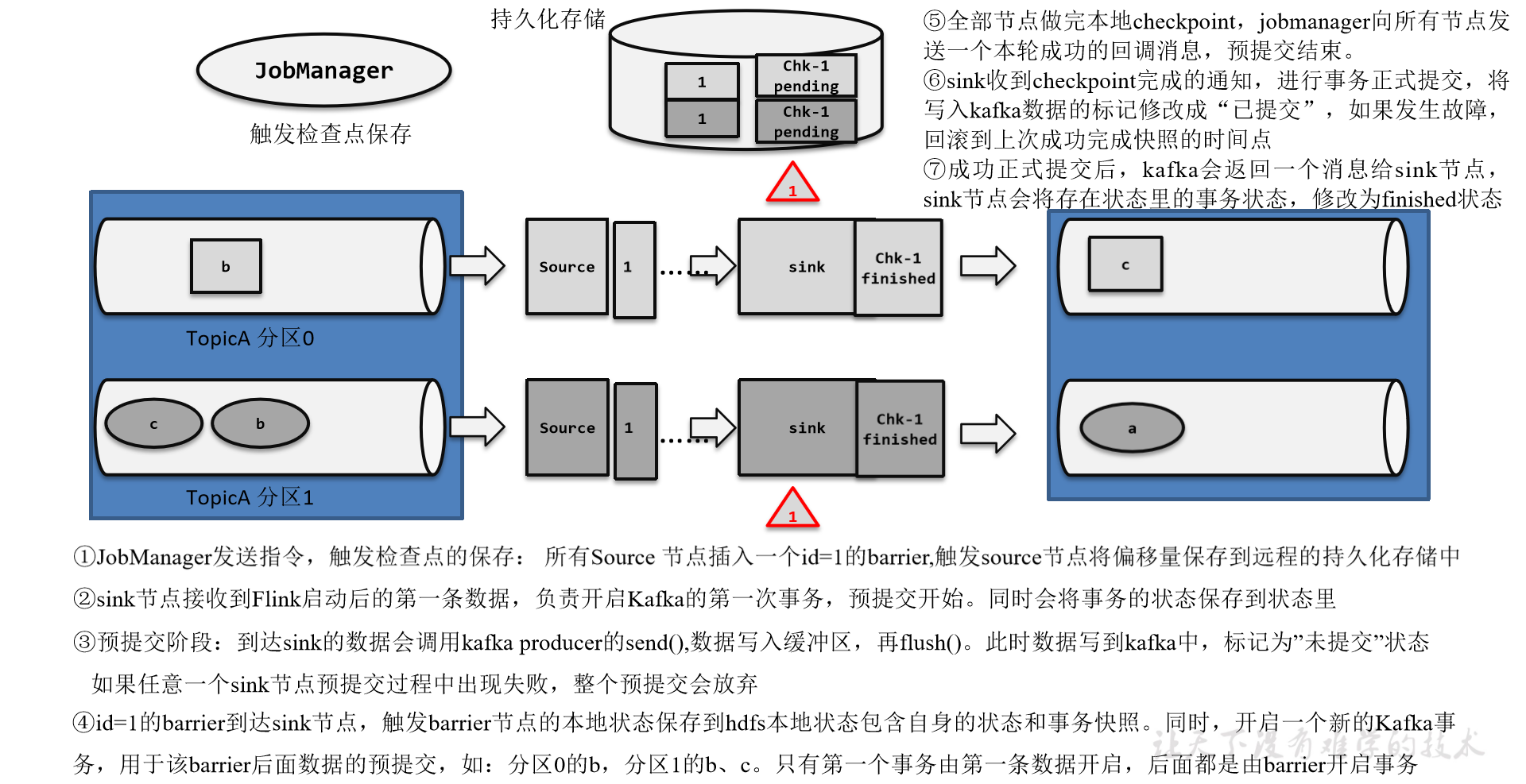
Flink1.17实战教程(第六篇:容错机制)
系列文章目录 Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…...
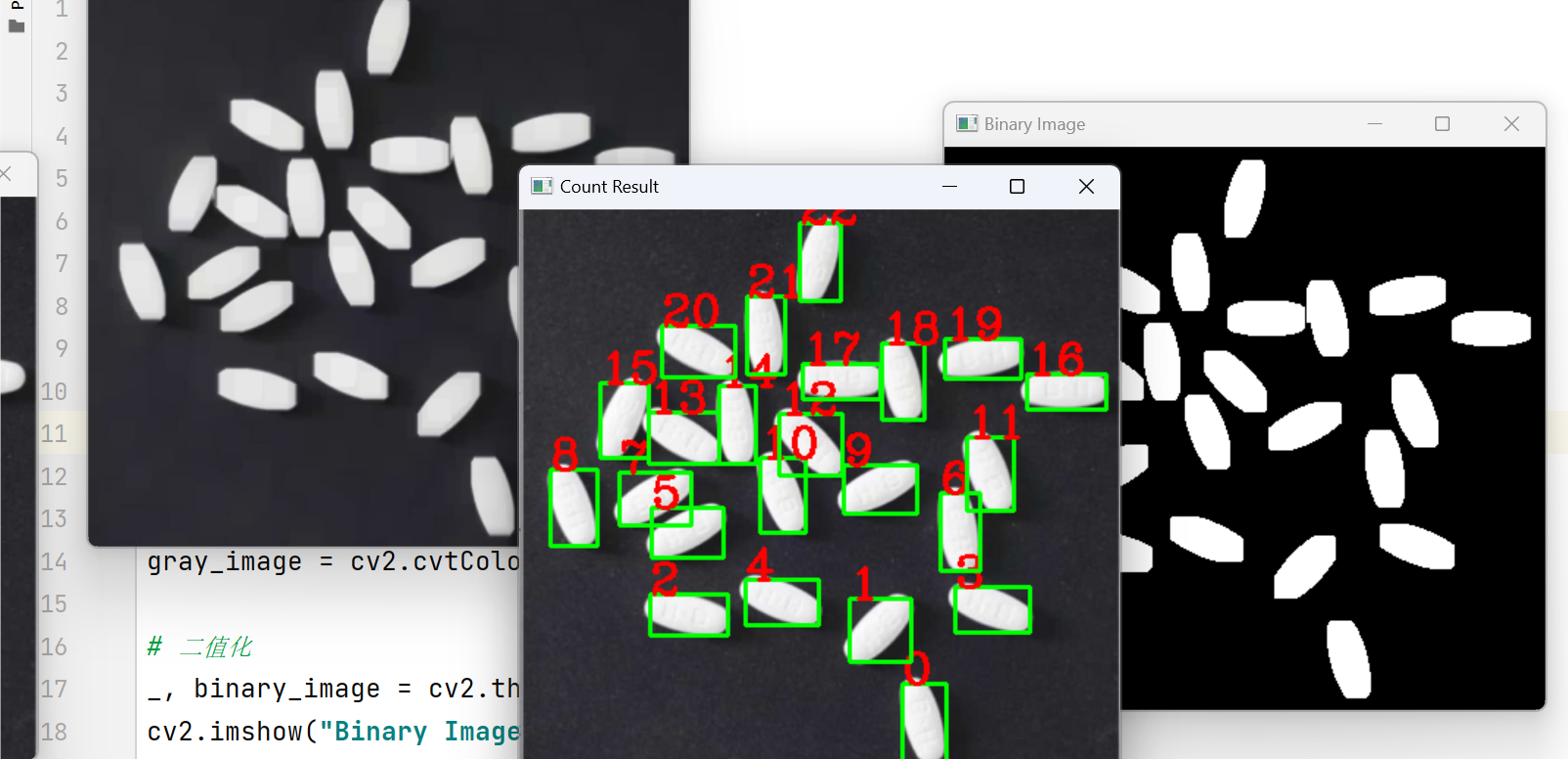
OpenCV实战 -- 维生素药片的检测记数
文章目录 检测记数原图经过操作开始进行消除粘连性--形态学变换总结实现方法1. 读取图片:2. 形态学处理:3. 二值化:4. 提取轮廓:5. 轮廓筛选和计数: 分水岭算法:逐行解释在基于距离变换的分水岭算法中&…...

【AI】注意力机制与深度学习模型
目录 一、注意力机制 二、了解发展历程 2.1 早期萌芽: 2.2 真正意义的注意力机制: 2.3 2015 年及以后: 2.4 自注意力与 Transformer: 2.5 BERT 与预训练模型: 三、基本框架 1. 打分函数(Score Fun…...
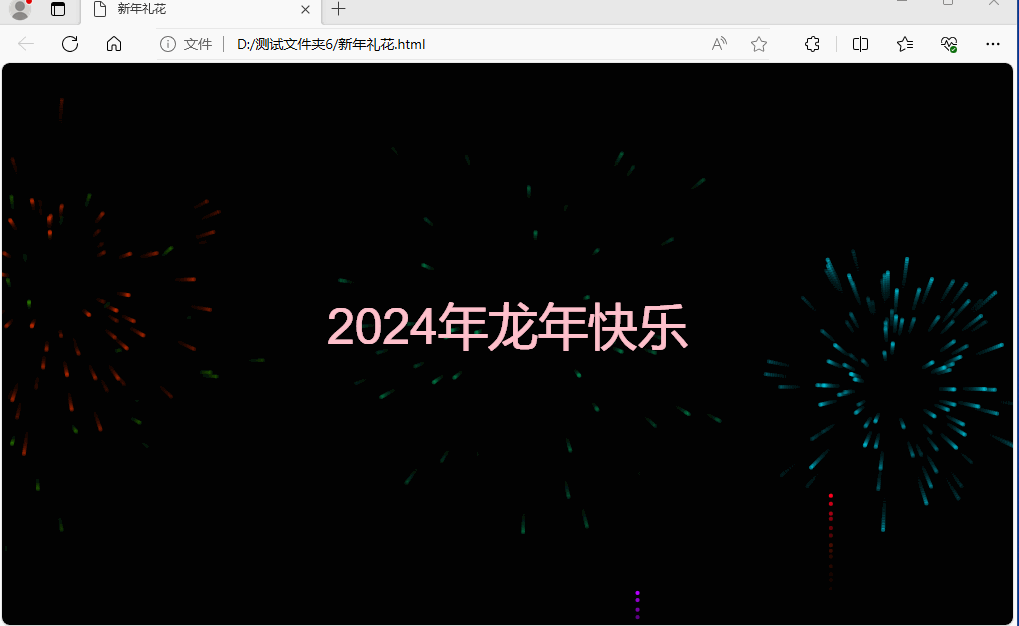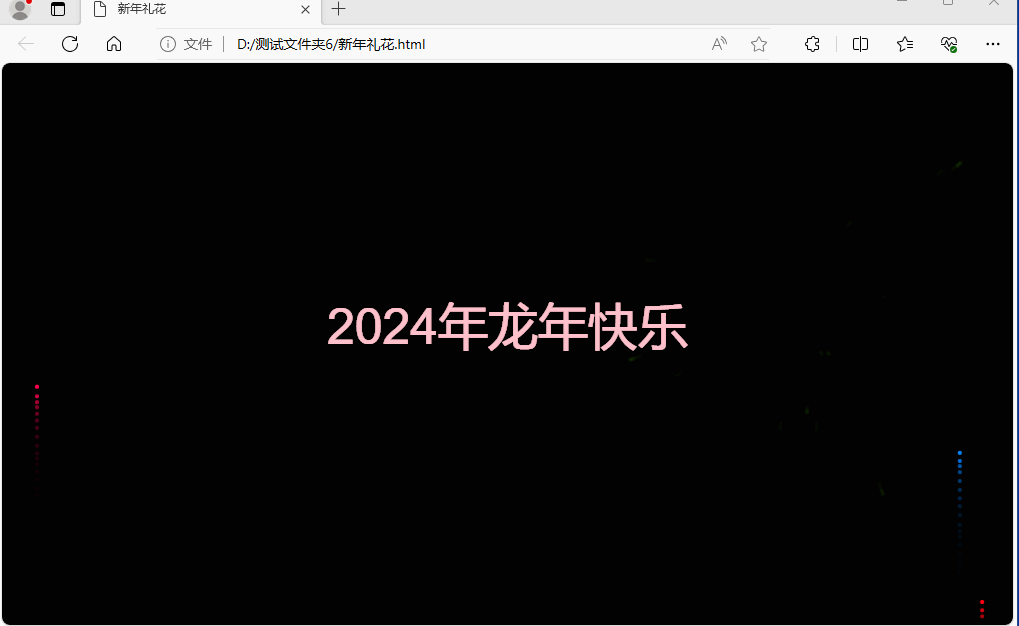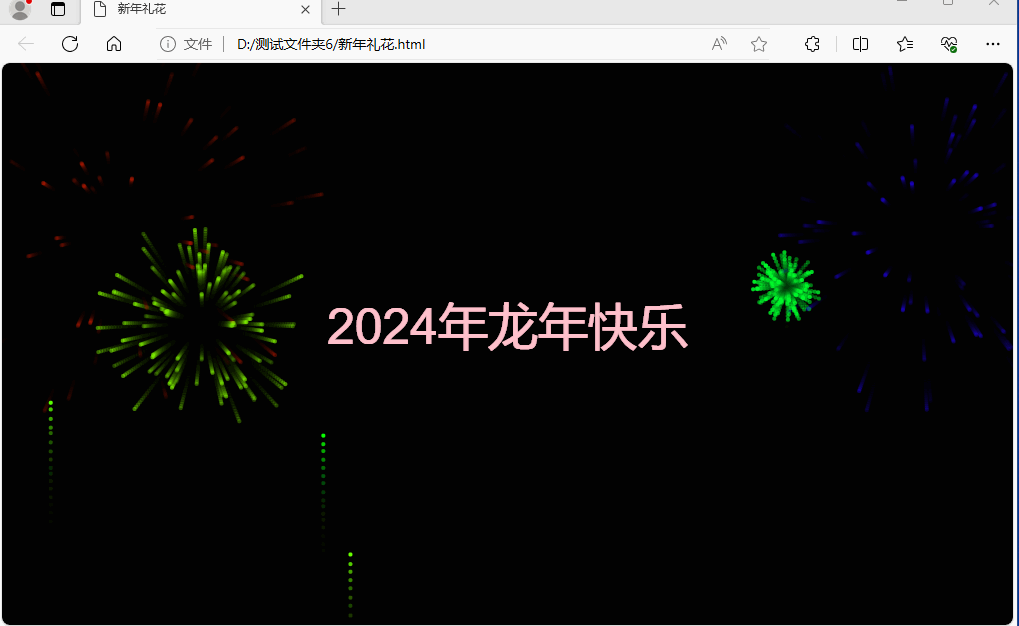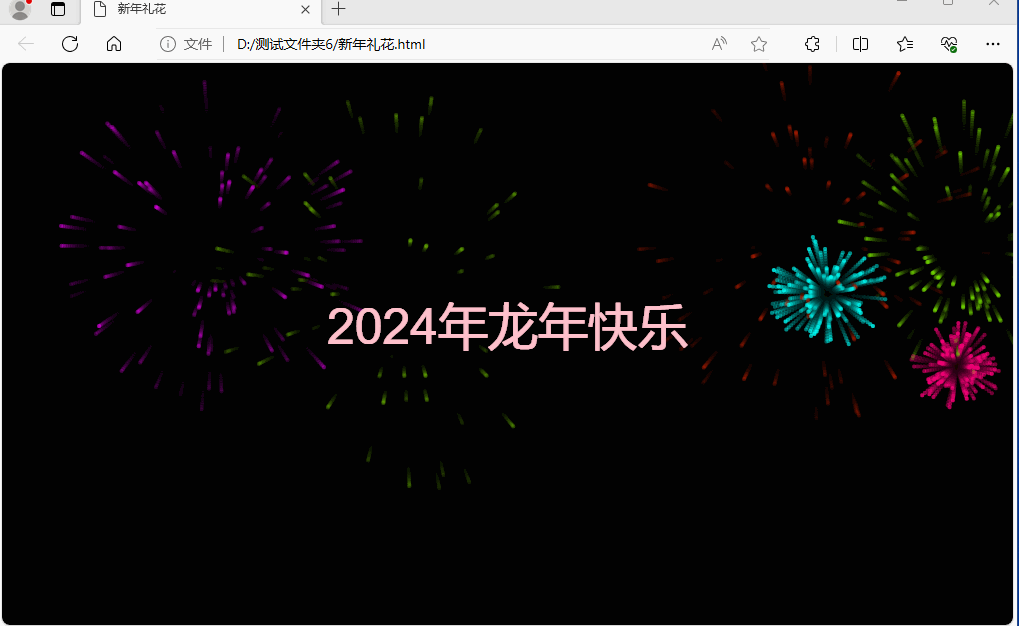
HTML5和JS实现新年礼花效果
HTML5和JS实现新年礼花效果 2023兔年再见,2024龙年来临了! 祝愿读者朋友们在2024年里,身体健康,心灵愉悦,梦想成真。 下面是用HTML5和JS实现新年礼花效果: 源码如下: <!DOCTYPE html>…...
【owt-server】一些构建项目梳理
【owt-server】清理日志:owt、srs、ffmpeg 【owt】p2p client mfc 工程梳理【m98】webrtc vs2017构建带符号的debug库【OWT】梳理构建的webrtc和owt mfc工程 m79的mfc客户端及owt-client...

Linux shell编程学习笔记38:history命令
目录 0 前言 1 history命令的功能、格式和退出状态1.1 history命令的功能1.2 history命令的格式1.3退出状态2 命令应用实例2.1 history:显示命令历史列表2.2 history -a:将当前会话的命令行历史追加到历史文件~/.bash_history中2.3 history -c…...
elasticsearch安装教程(超详细)
1.1 创建网络(单点部署) 因为我们还需要部署 kibana 容器,因此需要让 es 和 kibana 容器互联,所有先创建一个网络: docker network create es-net 1.2.加载镜像 采用的版本为 7.12.1 的 elasticsearch;…...
arkts中@Watch监听的使用
概述 Watch用于监听状态变量的变化,当状态变量变化时,Watch的回调方法将被调用。Watch在ArkUI框架内部判断数值有无更新使用的是严格相等(),遵循严格相等规范。当在严格相等为false的情况下,就会触发Watch的…...
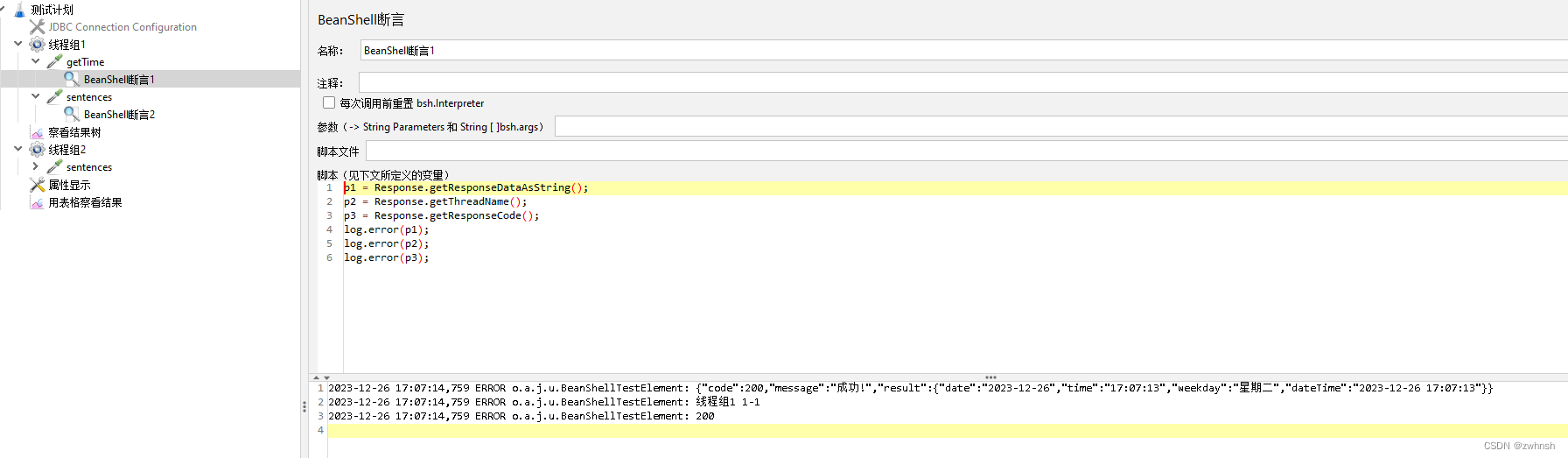
【Jmeter】Jmeter基础9-BeanShell介绍
3、BeanShell BeanShell是一种完全符合Java语法规范的脚本语言,并且又拥有自己的一些语法和方法。 3.1、Jmeter中使用的BeanShell 在Jmeter中,除了配置元件,其他类型的元件中都有BeanShell。BeanShell 是一种完全符合Java语法规范的脚本语言,并且又拥…...
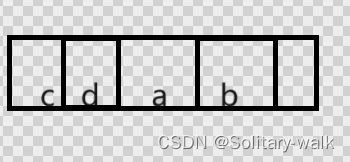
详解数组的轮转
𝙉𝙞𝙘𝙚!!👏🏻‧✧̣̥̇‧✦👏🏻‧✧̣̥̇‧✦ 👏🏻‧✧̣̥̇:Solitary-walk ⸝⋆ ━━━┓ - 个性标签 - :来于“云”的“羽球人”。…...

html 表格 笔记
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>第二个页面</title><meta name"language" content"cn"> </head> <body><h2 sytle"width:500px;…...
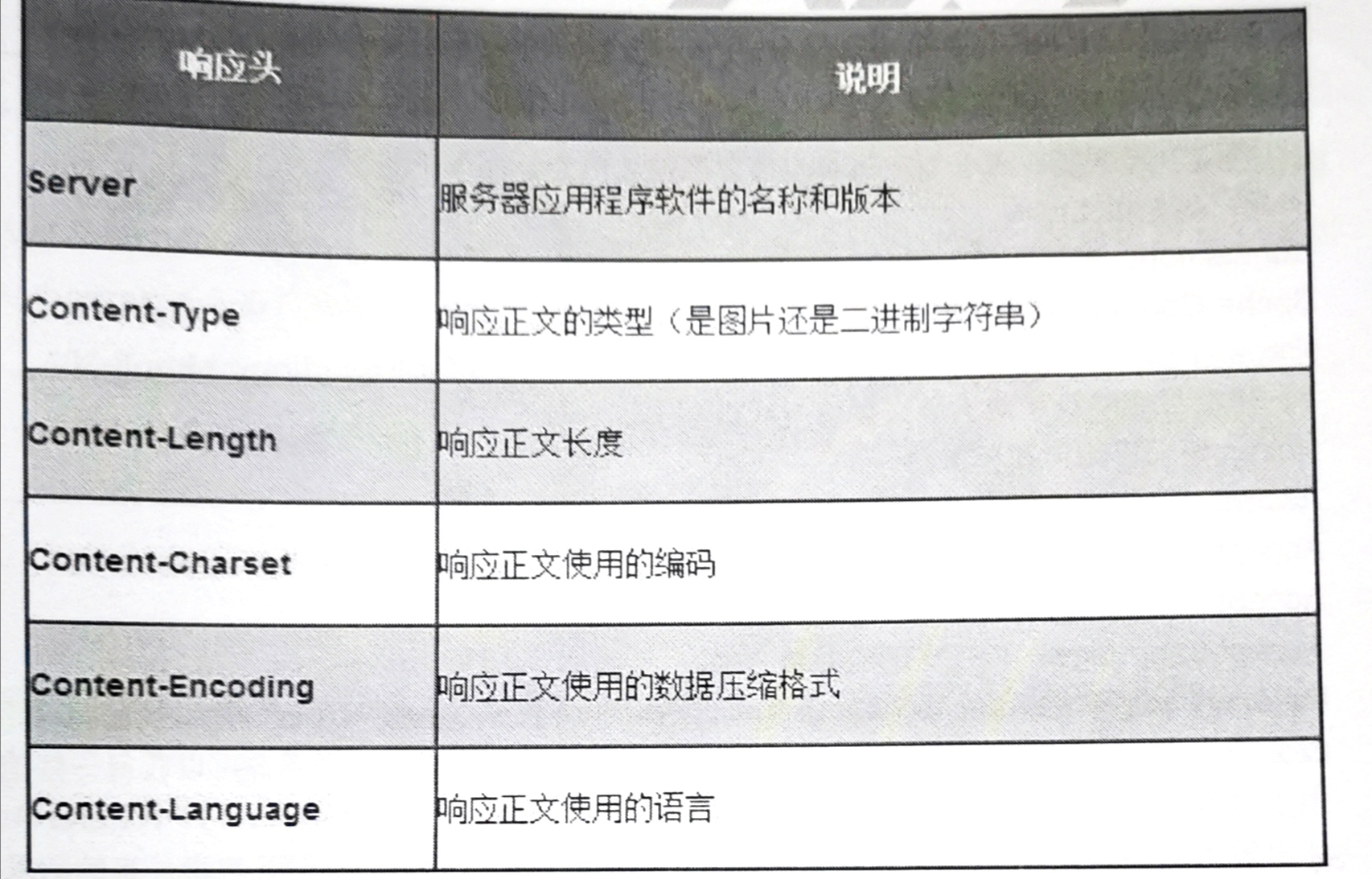
计算机网络【HTTP 面试题】
HTTP的请求报文结构和响应报文结构 HTTP请求报文主要由请求行、请求头、空行、请求正文(Get请求没有请求正文)4部分组成。 1、请求行 由三部分组成,分别为:请求方法、URL以及协议版本,之间由空格分隔;请…...

linux基于用户身份对资源访问进行控制的解析及过程
linux中用户分为三类 1.超级用户(root) 拥有至高无上的权限 2.普通用户 人为创建、权限小,权限受到控制 3.程序用户 运行程序的用户,不是给人使用的,给程序使用的,一般不给登录! 组账…...
手动创建idea SpringBoot 项目
步骤一: 步骤二: 选择Spring initializer -> Project SDK 选择自己的JDK版本 ->Next 步骤三: Maven POM ->Next 步骤四: 根据JDK版本选择Spring Boot版本 11版本及以上JDK建议选用3.2版本,JDK为11版本…...

【Go语言入门:Go语言的数据结构】
文章目录 3.Go语言的数据结构:3.1. 指针3.2. struct(结构体)3.3. Map(映射,哈希) 3.Go语言的数据结构: 简介: 在Go语言中,数据结构体可以分为四种类型:基础类型、聚合类型、引用类型…...

QT designer的ui文件转py文件之后,实现pycharm中运行以方便修改逻辑,即添加实时模板框架
为PyCharm中的实时模板,你需要遵循以下步骤: 打开PyCharm的设置: 选择 File > Settings(在macOS上是 PyCharm > Preferences)。 导航到实时模板: 在设置中找到 Editor > Live Templates。 添加新的模板组 (可选): 为了…...

什么是负载均衡?
负载均衡是指在计算机网络领域中,将客户端请求分配到多台服务器上以实现带宽资源共享、优化资源利用率和提高系统性能的技术。负载均衡可以帮助小云有效解决单个服务器容量不足或性能瓶颈的问题,小云通过平衡流量负载,使得多台服务器能够共同…...

Redis 内存淘汰与过期策略
引言Redis 作为内存数据库,内存资源有限,必须妥善处理内存占用问题。本文梳理两种核心机制:淘汰策略决定内存达到上限时如何移除数据,涵盖 noeviction、LRU、LFU 等多种算法及其实现细节;过期策略(惰性删除…...

做对这三步,拥有一个聪明的智能问数与分析Agent
这两年,智能问数与分析,几乎已经成了 ToB Agent 里最容易出圈的“爆款场景”。原因不难理解。相比很多还停留在演示层、流程层的 AI 应用,智能问数更接近企业管理者最直接的需求:我有问题,系统能不能立刻给我答案&…...

OFA图像描述系统实战:快速搭建图片转文字工具,避免常见权限错误
OFA图像描述系统实战:快速搭建图片转文字工具,避免常见权限错误 1. 项目介绍:让图片自己“说话”的智能工具 你有没有遇到过这样的场景?手头有一堆产品图片,需要为每张图配上文字描述,手动编写不仅耗时耗…...
Elsevier Tracker:学术审稿状态自动化追踪解决方案
Elsevier Tracker:学术审稿状态自动化追踪解决方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker Elsevier Tracker是一款开源Chrome插件,专为学术研究者设计,提供Elsevier期刊审…...

LoRa土壤监测与灌溉控制系统方案
当前农业生产中,土壤水分、温度等环境参数是影响作物生长的核心因素,传统种植模式依赖人工经验判断灌溉时机与用量,存在诸多局限。随着智慧农业、精准农业的快速发展,物联网技术在农业灌溉领域的应用日益广泛,LoRa作为…...

手把手教你理解半导体中的电阻优化:polycide与salicide的实战应用
半导体工艺中的电阻优化艺术:深入解析polycide与salicide技术 在28nm以下先进制程中,金属硅化物技术已成为决定芯片性能的关键因素。当我们翻开任何一款现代处理器的版图,polycide和salicide这两种看似相似的工艺,实际上在晶体管的…...
】-电阻那些事儿)
【硬件小达人-基础篇(1)】-电阻那些事儿
文章目录什么是电阻电阻的功率一定要降额使用电阻的额定电压和精度额定电压精度PCB设计中,电阻的作用1.限流电阻保护敏感元件常用经验2.分压电阻电压反馈ADC采集电路一些经验3.分流电阻4.上拉电阻/下拉电阻什么是上下拉作用一、 防止引脚悬空,消除外部干…...
] 靶点技术深度解析:分子机制、抗体药物开发与未来趋势)
[CD326(EpCAM)] 靶点技术深度解析:分子机制、抗体药物开发与未来趋势
在生物制药与细胞生物学研究领域,靶点的选择与机制解析是药物研发的基石。CD326(EpCAM,上皮细胞黏附分子) 作为一种广泛表达于上皮细胞表面的I型跨膜糖蛋白,不仅是上皮组织稳态维持的关键因子,更是当前抗体…...
)
自学渗透测试第八天(网络安全法、伦理规范与工具链联动)
3.2 网络安全法、伦理规范与工具链联动(第8天)核心目标树立法律与道德意识:深入理解《网络安全法》等相关法规的核心要求,明确渗透测试的法律边界和职业伦理,建立红线意识。掌握标准测试流程:将前7天所学的…...

Cursor Free VIP:彻底解决AI编程助手使用限制的智能解决方案
Cursor Free VIP:彻底解决AI编程助手使用限制的智能解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...