【langchain】入门初探实战笔记(Chain, Retrieve, Memory, Agent)
1. 简介
1.1 大语言模型技术栈
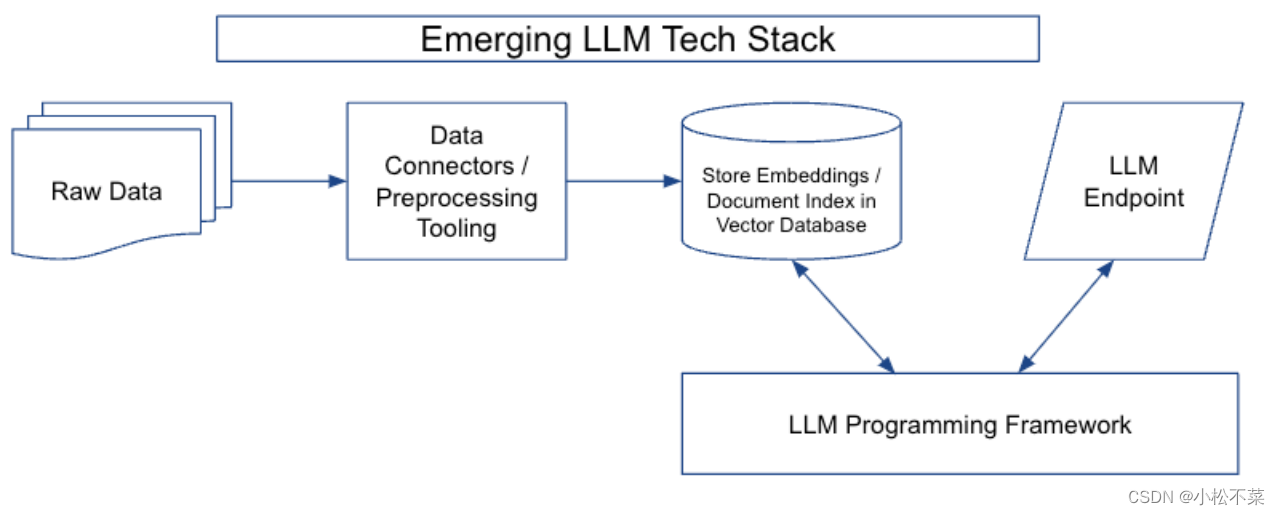
大语言模型技术栈由四个主要部分组成:
- 数据预处理流程(data preprocessing pipeline)
- 嵌入端点(embeddings endpoint )+向量存储(vector store)
- LLM 终端(LLM endpoints)
- LLM 编程框架(LLM programming framework)
1.2 Langchain的简介和部署
LangChain 就是一个 LLM 编程框架,你想开发一个基于 LLM 应用,需要什么组件它都有,直接使用就行;甚至针对常规的应用流程,它利用链(LangChain中Chain的由来)这个概念已经内置标准化方案了。
安装langchain包
pip install langchain
调用openai接口
pip install openai
在代码里调用需要设置openai的api key,有两种方法,一种是在bashrc的文件中配置,另一种直接在调用的函数里设置openai的key值配置
openai的key可以通过https://platform.openai.com/api-keys 官网的连接获取
2. 大模型交互
openai接口代码调用示例
# openai_api_key = "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"
# Importing modules
from langchain.llms import OpenAI
# Here we are using text-ada-001 but you can change it
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParseroutput_parser = StrOutputParser()
prompt = ChatPromptTemplate.from_messages([("system", "You are world class technical documentation writer."),("user", "{input}")
])
llm = ChatOpenAI(openai_api_key = "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")
# chain = prompt | llm
# print("prompt:", prompt)
# print("chain:", chain)
chain = prompt | llm | output_parser
res = chain.invoke("how can langsmith help with testing?")
print(res)
输出
content="Langsmith can help with testing in several ways:\n\n1. Test Automation: Langsmith can generate automated test scripts that cover various test scenarios and execute them repeatedly. This helps in reducing manual effort and time required for testing.\n\n2. Test Data Generation: Langsmith can generate test data that covers a wide range of input values and boundary conditions. This helps in testing the robustness and reliability of the system.\n\n3. Test Case Generation: Langsmith can generate test cases based on the specifications or requirements provided. These test cases can cover various combinations of inputs and expected outputs, ensuring comprehensive testing.\n\n4. Regression Testing: Langsmith can automate the execution of regression tests, which are performed to ensure that existing functionality is not impacted by any new changes or updates.\n\n5. Performance Testing: Langsmith can generate test scripts to simulate high loads and stress on the system, enabling performance testing and identifying potential bottlenecks or performance issues.\n\n6. Security Testing: Langsmith can help in identifying security vulnerabilities by generating test cases that simulate different attack scenarios, such as SQL injection or cross-site scripting.\n\nOverall, Langsmith's capabilities in generating automated test scripts, test data, test cases, and supporting various types of testing can significantly improve the efficiency and effectiveness of the testing process.”
3. Chain
3.1 LLM Chain
最基本的链为 LLMChain,由 PromptTemplate、LLM 和 OutputParser 组成。LLM 的输出一般为文本,OutputParser 用于让 LLM 结构化输出并进行结果解析,方便后续的调用。

from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
# from azure_chat_llm import llm
from langchain.chat_models import ChatOpenAI#output parser
keyword_schema = ResponseSchema(name="keyword", description="评论的关键词列表")
emotion_schema = ResponseSchema(name="emotion", description="评论的情绪,正向为1,中性为0,负向为-1")
response_schemas = [keyword_schema, emotion_schema]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()#prompt template
prompt_template_txt = '''
作为资深客服,请针对 >>> 和 <<< 中间的文本识别其中的关键词,以及包含的情绪是正向、负向还是中性。
>>> {text} <<<
RESPONSE:
{format_instructions}
'''prompt = PromptTemplate(template=prompt_template_txt, input_variables=["text"],partial_variables={"format_instructions": format_instructions})
llm = ChatOpenAI(openai_api_key = "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")
#llmchain
llm_chain = LLMChain(prompt=prompt, llm=llm)
comment = "京东物流没的说,速度态度都是杠杠滴!这款路由器颜值贼高,怎么说呢,就是泰裤辣!这线条,这质感,这速度,嘎嘎快!以后妈妈再也不用担心家里的网速了!"
result = llm_chain.run(comment)
data = output_parser.parse(result)
print(f"type={type(data)}, keyword={data['keyword']}, emotion={data['emotion']}")

3.2 Sequential Chain
SequentialChains 是按预定义顺序执行的链。SimpleSequentialChain 为顺序链的最简单形式,其中每个步骤都有一个单一的输入 / 输出,一个步骤的输出是下一个步骤的输入。SequentialChain 为顺序链更通用的形式,允许多个输入 / 输出。
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains import SimpleSequentialChain
from langchain.chat_models import ChatOpenAIllm = ChatOpenAI(openai_api_key = "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")
first_prompt = PromptTemplate.from_template("翻译下面的内容到中文:""\n\n{content}"
)
# chain 1: 输入:Review 输出: 英文的 Review
chain_trans = LLMChain(llm=llm, prompt=first_prompt, output_key="content_zh")second_prompt = PromptTemplate.from_template("一句话总结下面的内容:""\n\n{content_zh}"
)chain_summary = LLMChain(llm=llm, prompt=second_prompt)
overall_simple_chain = SimpleSequentialChain(chains=[chain_trans, chain_summary],verbose=True)
content = '''In a blog post authored back in 2011, Marc Andreessen warned that, “Software is eating the world.” Over a decade later, we are witnessing the emergence of a new type of technology that’s consuming the world with even greater voracity: generative artificial intelligence (AI). This innovative AI includes a unique class of large language models (LLM), derived from a decade of groundbreaking research, that are capable of out-performing humans at certain tasks. And you don’t have to have a PhD in machine learning to build with LLMs—developers are already building software with LLMs with basic HTTP requests and natural language prompts.
In this article, we’ll tell the story of GitHub’s work with LLMs to help other developers learn how to best make use of this technology. This post consists of two main sections: the first will describe at a high level how LLMs function and how to build LLM-based applications. The second will dig into an important example of an LLM-based application: GitHub Copilot code completions.
Others have done an impressive job of cataloging our work from the outside. Now, we’re excited to share some of the thought processes that have led to the ongoing success of GitHub Copilot.
'''
result = overall_simple_chain.run(content)
print(f'result={result}')

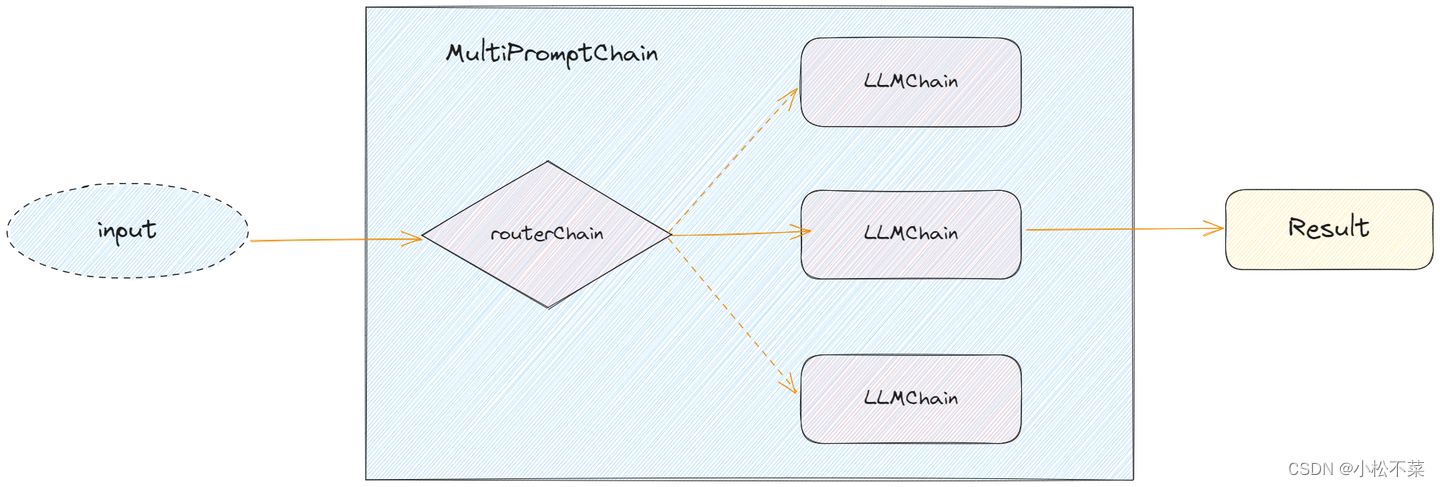
3.3 RouterChain
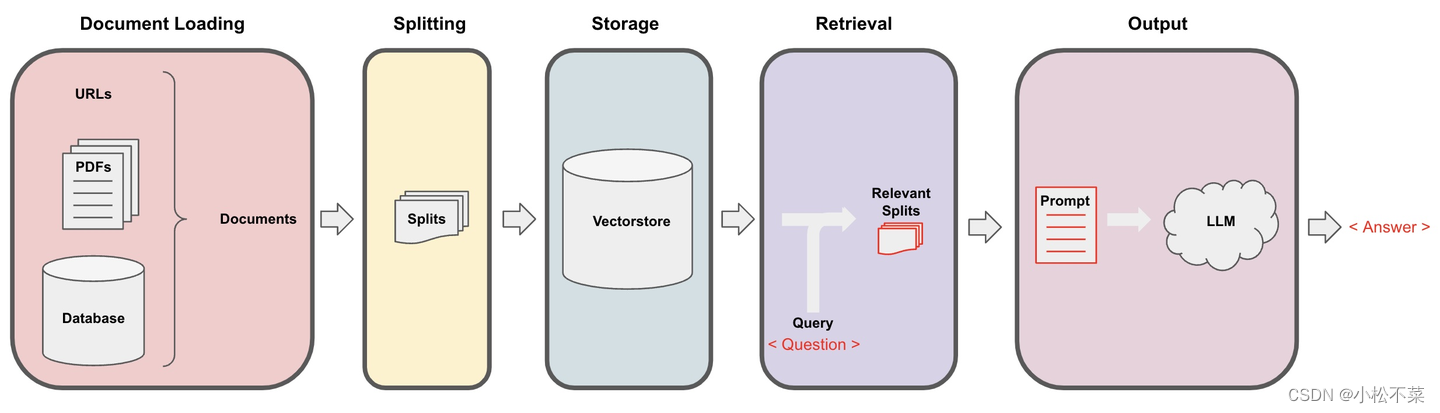
4. 外部文档检索
索引和外部数据进行集成,用于从外部数据获取答案。
- 通过 Document Loaders 加载各种不同类型的数据源,
LangChain 通过 Loader 加载外部的文档,转化为标准的 Document 类型。Document 类型主要包含两个属性:page_content 包含该文档的内容。meta_data 为文档相关的描述性数据,类似文档所在的路径等。
- 通过 Text Splitters 进行文本语义分割
LLM 一般都会限制上下文窗口的大小,有 4k、16k、32k 等。针对大文本就需要进行文本分割,常用的文本分割器为 RecursiveCharacterTextSplitter,可以通过 separators 指定分隔符。其先通过第一个分隔符进行分割,不满足大小的情况下迭代分割。
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 通过 Vectorstore 进行非结构化数据的向量存储
通过 Text Embedding models,将文本转为向量,可以进行语义搜索,在向量空间中找到最相似的文本片段。目前支持常用的向量存储有 Faiss、Chroma 等。
- 通过 Retriever 进行文档数据检索
Retriever 接口用于根据非结构化的查询获取文档,一般情况下是文档存储在向量数据库中。可以调用 get_relevant_documents 方法来检索与查询相关的文档。
from langchain import FAISS
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter#通过 Document Loaders 加载各种不同类型的数据源
#LangChain 通过 Loader 加载外部的文档,转化为标准的 Document 类型。
# Document 类型主要包含两个属性:page_content 包含该文档的内容。meta_data 为文档相关的描述性数据,类似文档所在的路径等。
loader = WebBaseLoader("https://in.m.jd.com/help/app/register_info.html")
data = loader.load()#针对大文本就需要进行文本分割,常用的文本分割器为 RecursiveCharacterTextSplitter,可以通过 separators 指定分隔符。
# 其先通过第一个分隔符进行分割,不满足大小的情况下迭代分割。
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(model_name="gpt-3.5-turbo",allowed_special="all",separators=["\n\n", "\n", "。", ","],chunk_size=800,chunk_overlap=0
)
docs = text_splitter.split_documents(data)
#通过cache_folder设置自己的本地模型路径
#embeddings = HuggingFaceEmbeddings(model_name="text2vec-base-chinese", cache_folder="models")#通过 Text Embedding models,将文本转为向量,可以进行语义搜索,在向量空间中找到最相似的文本片段。
# 目前支持常用的向量存储有 Faiss、Chroma 等。
embeddings = HuggingFaceEmbeddings()vectorstore = FAISS.from_documents(docs, embeddings)#Retriever 接口用于根据非结构化的查询获取文档,一般情况下是文档存储在向量数据库中。
# 可以调用 get_relevant_documents 方法来检索与查询相关的文档。
result = vectorstore.as_retriever().get_relevant_documents("用户注册资格")
print(result)
print(len(result))

5. 外部文档交互
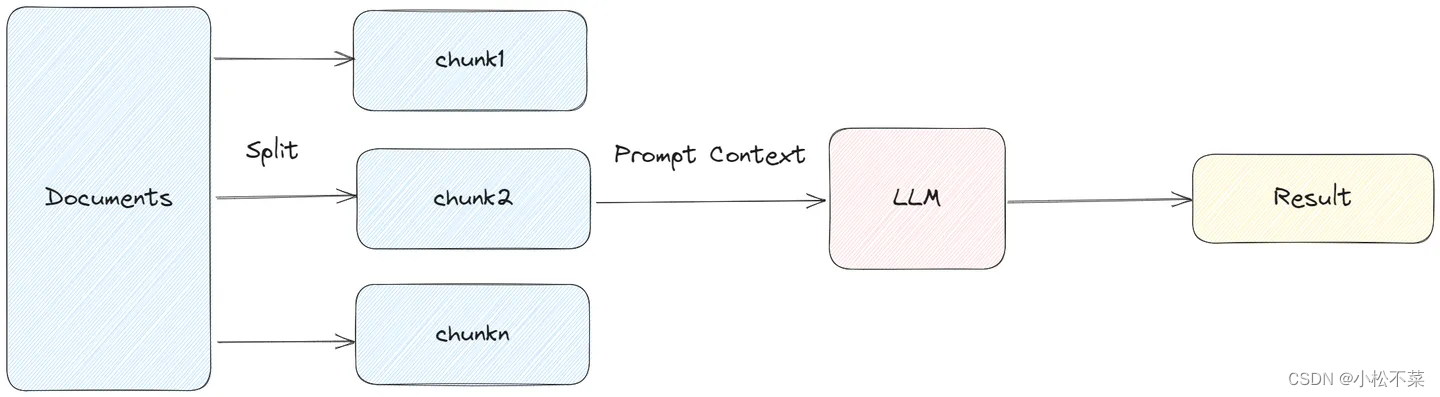
5.1 Stuff
StuffDocumentsChain 这种链最简单直接,是将所有获取到的文档作为 context 放入到 Prompt 中,传递到 LLM 获取答案
这种方式可以完整的保留上下文,调用 LLM 的次数也比较少,建议能使用 stuff 的就使用这种方式。其适合文档拆分的比较小,一次获取文档比较少的场景,不然容易超过 token 的限制。
5.2 Refine
RefineDocumentsChain 是通过迭代更新的方式获取答案。先处理第一个文档,作为 context 传递给 llm,获取中间结果 intermediate answer。然后将第一个文档的中间结果以及第二个文档发给 llm 进行处理,后续的文档类似处理。
Refine 这种方式能部分保留上下文,以及 token 的使用能控制在一定范围。
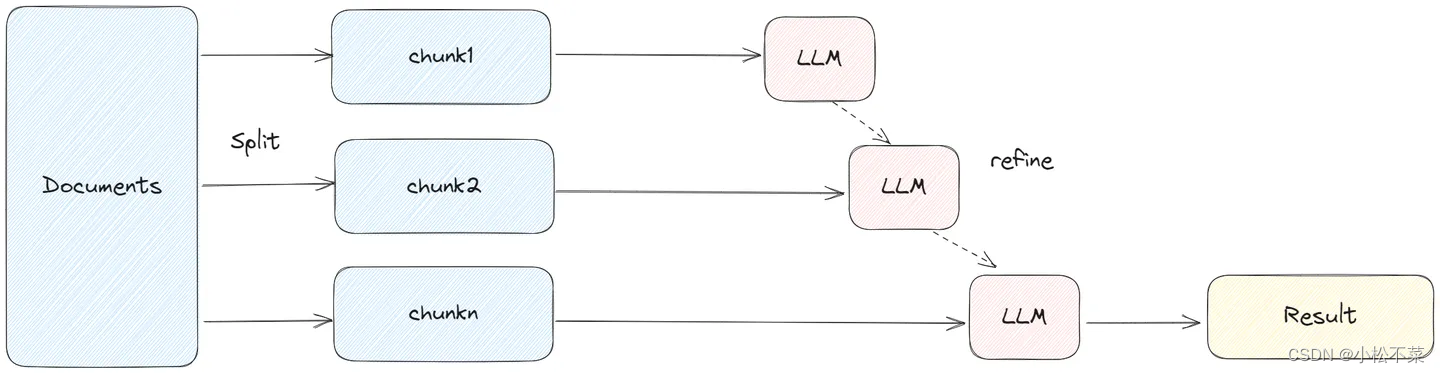
5.3 MapReduce
MapReduceDocumentsChain 先通过 LLM 对每个 document 进行处理,然后将所有文档的答案在通过 LLM 进行合并处理,得到最终的结果。
MapReduce 的方式将每个 document 单独处理,可以并发进行调用。但是每个文档之间缺少上下文。
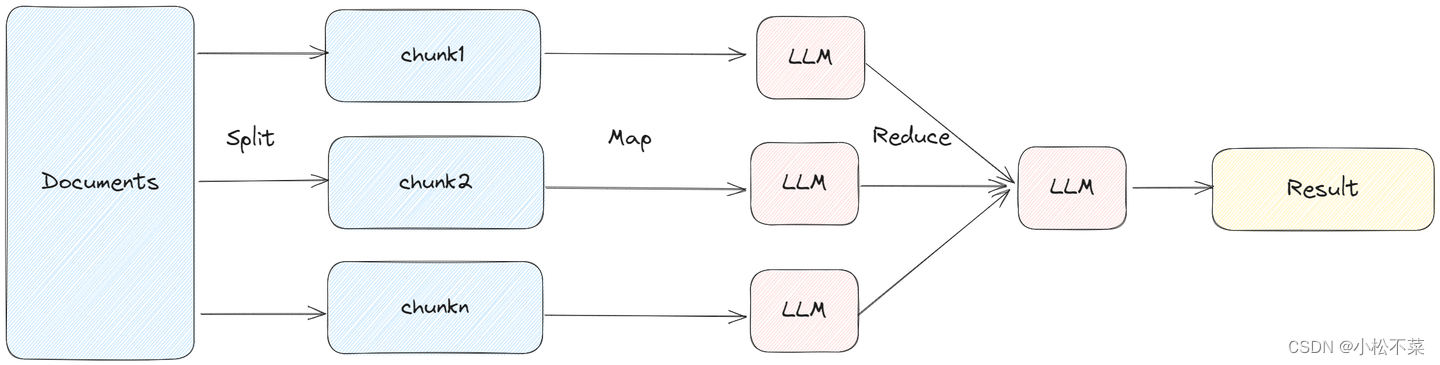
5.4 MapRerank
MapRerankDocumentsChain 和 MapReduceDocumentsChain 类似,先通过 LLM 对每个 document 进行处理,每个答案都会返回一个 score,最后选择 score 最高的答案。
MapRerank 和 MapReduce 类似,会大批量的调用 LLM,每个 document 之间是独立处理
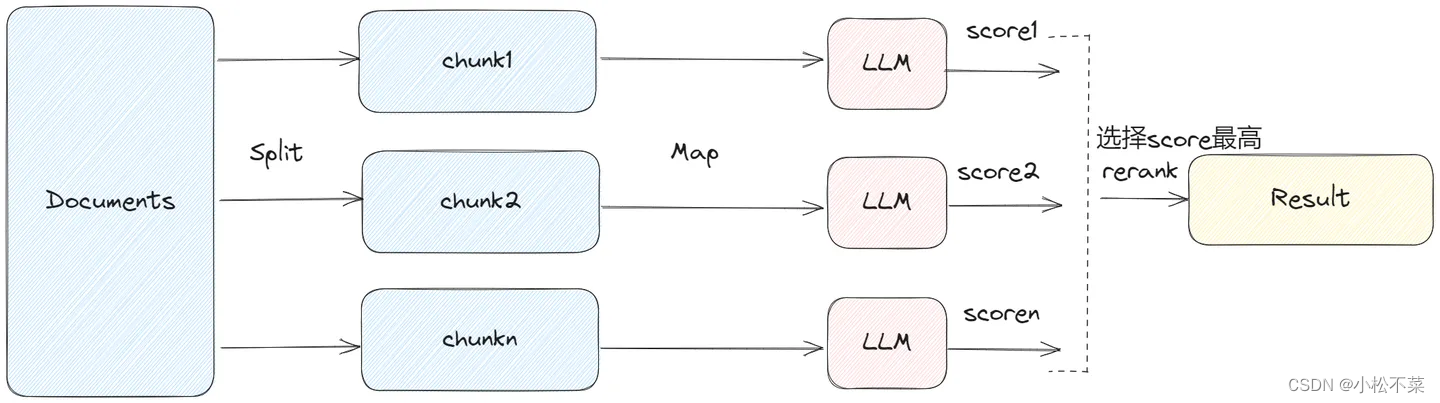
6. Memory
正常情况下 Chain 无状态的,每次交互都是独立的,无法知道之前历史交互的信息。LangChain 使用 Memory 组件保存和管理历史消息,这样可以跨多轮进行对话,在当前会话中保留历史会话的上下文。Memory 组件支持多种存储介质,可以与 Monogo、Redis、SQLite 等进行集成,以及简单直接形式就是 Buffer Memory。常用的 Buffer Memory 有:
- ConversationSummaryMemory :以摘要的信息保存记录
- ConversationBufferWindowMemory:以原始形式保存最新的 n 条记录
- ConversationBufferMemory:以原始形式保存所有记录
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemoryfrom langchain.chat_models import ChatOpenAIllm = ChatOpenAI(openai_api_key = "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")memory = ConversationBufferMemory()
conversation = ConversationChain(llm=llm, memory=memory, verbose=True)
print(conversation.prompt)
print(conversation.predict(input="我的姓名是tiger"))
print(conversation.predict(input="1+1=?"))
print(conversation.predict(input="我的姓名是什么"))

7. Agents
传统使用 LLM,需要给定 Prompt 一步一步的达成目标,通过 Agent 是给定目标,其会自动规划并达到目标。
目前这个领域特别活跃,诞生了类似 AutoGPT、BabyAGI、AgentGPT 等一堆优秀的项目。
目前的大模型一般都存在知识过时、逻辑计算能力低等问题,通过 Agent 访问工具,可以去解决这些问题。
- Agent:代理,负责调用 LLM 以及决定下一步的 Action。其中 LLM 的 prompt 必须包含 agent_scratchpad 变量,记录执行的中间过程
- Tools:工具,Agent 可以调用的方法。LangChain 已有很多内置的工具,也可以自定义工具。注意 Tools 的 description 属性,LLM 会通过描述决定是否使用该工具。
- ToolKits:工具集,为特定目的的工具集合。类似 Office365、Gmail 工具集等
- Agent Executor:Agent 执行器,负责进行实际的执行。
from langchain.agents import load_tools, initialize_agent, tool
from langchain.agents.agent_types import AgentType
from datetime import date
from langchain.chat_models import ChatOpenAIllm = ChatOpenAI(openai_api_key = "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")#有多种方式可以自定义 Tool,最简单的方式是通过 @tool 装饰器,将一个函数转为 Tool。
# 注意函数必须得有 docString,其为 Tool 的描述。
@tool
def time(text: str) -> str:"""返回今天的日期。"""return str(date.today())tools = load_tools(['llm-math'], llm=llm)
tools.append(time)
#一般通过 initialize_agent 函数进行 Agent 的初始化,除了 llm、tools 等参数,还需要指定 AgentType。
#该 Agent 为一个 zero-shot-react-description 类型的 Agent,其中 zero-shot 表明只考虑当前的操作,不会记录以及参考之前的操作。react 表明通过 ReAct 框架进行推理,description 表明通过工具的 description 进行是否使用的决策。
agent_math = initialize_agent(agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,tools=tools,llm=llm,verbose=True)
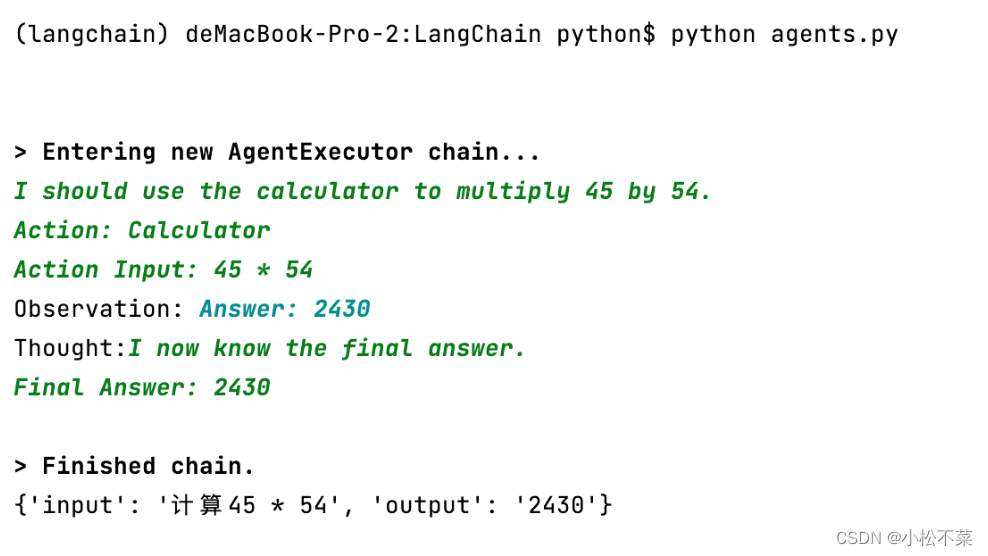
print(agent_math("计算45 * 54"))
print(agent_math("今天是哪天?"))
#可以通过 agent.agent.llm_chain.prompt.template 方法,获取其推理决策所使用的模板。
print(agent_math.agent.llm_chain.prompt.template)
参考文献
【知乎】langchain到底该怎么使用,大家在项目中实践有成功的案例吗?https://www.zhihu.com/question/609483833/answer/3146379316?utm_psn=1725522909580394496
【知乎】小白入门大模型:LangChain https://zhuanlan.zhihu.com/p/656646499
相关文章:
【langchain】入门初探实战笔记(Chain, Retrieve, Memory, Agent)
1. 简介 1.1 大语言模型技术栈 大语言模型技术栈由四个主要部分组成: 数据预处理流程(data preprocessing pipeline)嵌入端点(embeddings endpoint )向量存储(vector store)LLM 终端ÿ…...

《数据结构、算法与应用C++语言描述》- 平衡搜索树 -全网唯一完整详细实现插入和删除操作的模板类
平衡搜索树 完整可编译运行代码见:Github::Data-Structures-Algorithms-and-Applications/_34Balanced search tree 概述 本章会讲AVL、红-黑树、分裂树、B-树。 平衡搜索树的应用? AVL 和红-黑树和分裂树适合内部存储的应用。 B-树适合外部存储的…...

网络路由跟踪工具
随着企业网络需求的增长,组织发现监控和管理其网络基础设施变得越来越困难。网络管理员正在转向其他工具和资源,这些工具和资源可以使他们的工作更轻松一些,尤其是在故障排除方面。 目前,网络管理员主要使用简单、免费提供的实用…...

设计模式 七大原则
1.单一职责原则 单一职责原则(SRP:Single responsibility principle)又称单一功能原则 核心:解耦和增强内聚性(高内聚,低耦合)。 描述: 类被修改的几率很大,因此应该专注…...

(1)(1.13) SiK无线电高级配置(一)
文章目录 前言 1 监控链接质量 2 诊断范围问题 3 MAVLink协议说明 前言 本文提供 SiK 遥测无线电(SiK Telemetry Radio)的高级配置信息。它面向"高级用户"和希望更好地了解无线电如何运行的用户。 !Tip 大多数用户只需要 SiK Radio v2 中提供的基本…...
drf知识--10
接口文档 # 后端把接口写好后: 登录接口:/api/v1/login ---> post---name pwd 注册接口 查询所有图书带过滤接口 # 前后端需要做对接,对接第一个东西就是这个接口文档,前端照着接口文档开发 公司3个人ÿ…...

探索 Vue 实例方法的魅力:提升 Vue 开发技能(下)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...
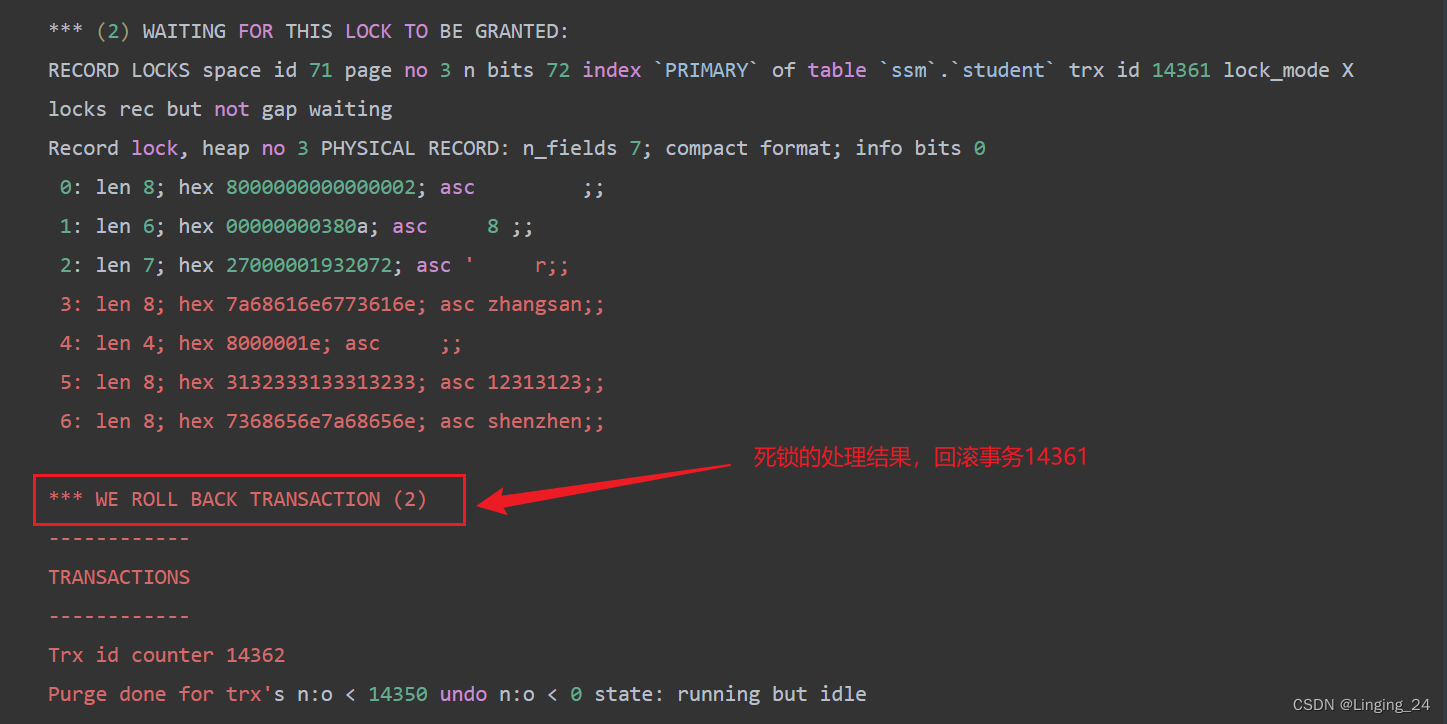
mysql死锁排查
查看正在进行中的事务 SELECT * FROM information_schema.INNODB_TRX;字段解释trx_id唯一事务id号,只读事务和非锁事务是不会创建id的trx_state事务的执行状态,值一般分为:RUNNING, LOCK WAIT, ROLLING BACK, and COMMITTING.trx_started事务…...
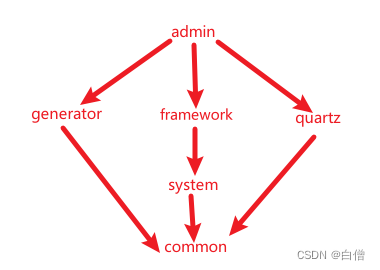
若依项目(ruoy-vue)多模块依赖情况简要分析
主pom文件关键点分析 properties标签声明变量信息:版本号、编码类型、java版本spring-boot依赖形式:spring-boot-dependencies、pom、importdependencies中添加本项目内部模块,同时在modules中声明模块packaging打包选择pom设置打包maven-co…...

【普中开发板】基于51单片机的篮球计分器液晶LCD1602显示( proteus仿真+程序+设计报告+讲解视频)
基于普中开发板51单片机的篮球计分器液晶LCD1602显示 1.主要功能:讲解视频:2.仿真3. 程序代码4. 设计报告5. 设计资料内容清单&&下载链接资料下载链接(可点击): 基于51单片机的篮球计分器液晶LCD1602显示 ( pr…...

按照层次遍历结果打印完全二叉树
按照层次遍历结果打印完全二叉树 按照推论结果: l 层首个节点位置 2h-l - 1l 层节点间距:2h-l1 - 1 编码实现 public static<E> void print(BinaryTree<E> tree) {List<List<Node<E>>> levelNodeList levelOrderTraver…...

基于SpringBoot的药店管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于SpringBoot的药店管理系统,java项目…...
Java 泛型深入解析
Java 中的泛型是一种强大的编程特性,允许我们编写更加通用和类型安全的代码。本篇博客将深入探讨 Java 泛型的各个方面,包括泛型类、泛型方法、泛型接口以及泛型通配符。 1. 泛型类 首先,让我们看一个简单的泛型类的例子。在下面的代码中&a…...

Apache Doris (六十): Doris - 物化视图
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你学编程的个人空间-豹哥教你学编程个人主页-哔哩哔哩视频 目录...

【javaweb】tomcat9.0中的HttpServlet
2023年12月28日,周四晚上 目录 什么是HttpServlet tomcat中的HttpServlet由谁产生 什么是HttpServlet 在Tomcat中,HttpServlet 是 Java Servlet API 中的一个抽象类,用于简化基于HTTP协议的Servlet的开发。HttpServlet 扩展了 GenericServ…...
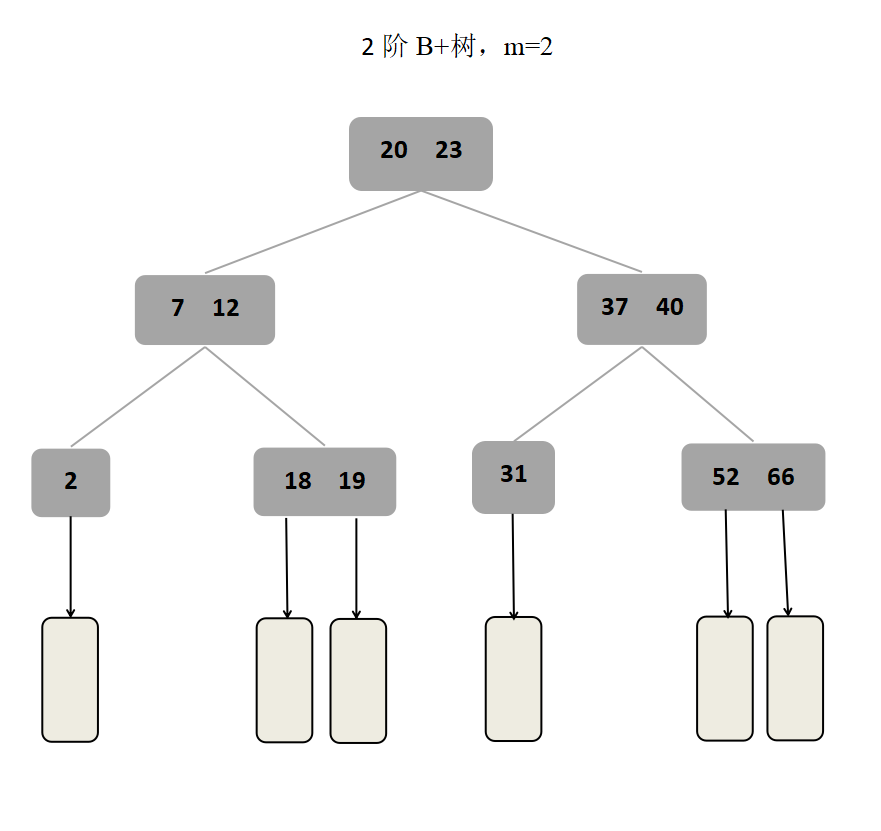
数据结构学习笔记——查找算法中的树形查找(B树、B+树)
目录 前言一、B树(一)B树的概念(二)B树的性质(三)B树的高度(四)B树的查找(五)B树的插入(六)B树的删除 二、B树(一…...
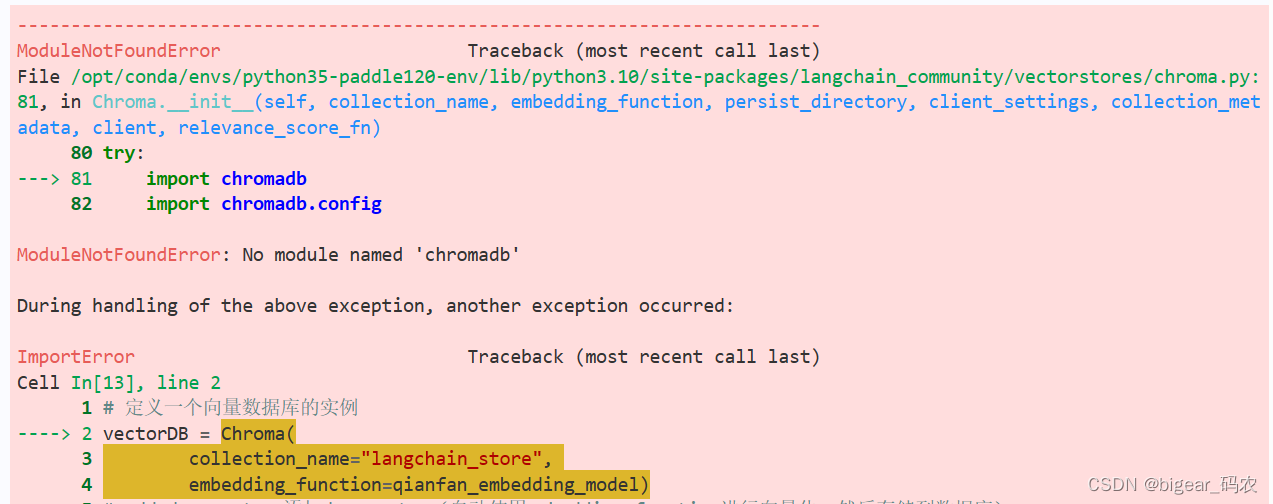
python包chromadb安装失败总结
1,背景: 最近在学习langchain的课程,里面创建自己的知识库的Retrieval模块中,需要用到向量数据库。 所以按照官方的教程(vectorstores),准备使用chroma的向量数据库。图片来源 2,问…...

机器学习(四) -- 模型评估(2)
系列文章目录 机器学习(一) -- 概述 机器学习(二) -- 数据预处理(1-3) 机器学习(三) -- 特征工程(1-2) 机器学习(四) -- 模型评估…...

泊松分布与二项分布的可加性
泊松分布与二项分布的可加性 泊松分布的可加性 例 : 设 X , Y X,Y X,Y 相互独立 , X ∼ P ( λ 1 ) X\sim P(\lambda_1) X∼P(λ1) , Y ∼ P ( λ 2 ) Y\sim P(\lambda_2) Y∼P(λ2) , 求证 Z X Y ZXY ZXY 服从参数为 λ 1 λ 2 \lambda_1 \lambda_2 λ1λ2 …...

【PostgreSQL】约束-排他约束
【PostgreSQL】约束链接 检查 唯一 主键 外键 排他 排他约束 排他约束是一种数据库约束,用于确保某一列或多个列中的值在每一条记录中都是唯一的。这意味着任何两条记录都不能具有相同的值。 排他约束可以在数据库中创建唯一索引或唯一约束来实现。当尝试插入或更…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...

Python Einops库:深度学习中的张量操作革命
Einops(爱因斯坦操作库)就像给张量操作戴上了一副"语义眼镜"——让你用人类能理解的方式告诉计算机如何操作多维数组。这个基于爱因斯坦求和约定的库,用类似自然语言的表达式替代了晦涩的API调用,彻底改变了深度学习工程…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

深入理解Optional:处理空指针异常
1. 使用Optional处理可能为空的集合 在Java开发中,集合判空是一个常见但容易出错的场景。传统方式虽然可行,但存在一些潜在问题: // 传统判空方式 if (!CollectionUtils.isEmpty(userInfoList)) {for (UserInfo userInfo : userInfoList) {…...