Kafka(六)消费者
目录
- Kafka消费者
- 1 配置消费者
- bootstrap.servers
- group.id
- key.deserializer
- value.deserializer
- group.instance.id
- fetch.min.bytes=1
- fetch.max.wait.ms
- fetch.max.bytes=57671680 (55 mebibytes)
- max.poll.record=500
- max.partition.fetch.bytes
- session.timeout.ms=45000 (45 seconds)
- heartbeat.interval.ms=3000 (3 seconds)
- max.poll.interval.ms=300000 (5 minutes)
- default.api.timeout.ms=60000 (1 minute)
- request.timeout.ms=40000 (40 seconds)
- auto.offset.reset=latest
- enable.auto.commit=true
- auto.commit.interval.ms=5000 (5 seconds)
- partition.assignment.strategy=class org.apache.kafka.clients.consumer.RangeAssignor,class org.apache.kafka.clients.consumer.CooperativeStickyAssignor
- client.id
- client.rack
- receive.buffer.bytes=65536 (64 KB)
- send.buffer.bytes=131072 (128 KB)
- offsets.retention.minutes=10080(7 days)
- 2 分区再均衡
- 2.1 再均衡发生的场景
- 2.2 再均衡的分类
- 2.3 分区分配过程
- 3 固定群组成员
- 4 创建消费者
- 5 轮询
- 5.1 线程安全
- 6 提交和偏移量
- 6.1 自动提交
- 6.2 手动同步提交
- 6.3 异步提交
- 6.4 同步和异步组合提交
- 6.5 提交特定的偏移量
- 7 再均衡监听器
- 8 从特定偏移量位置读取记录
- 9 消费者程序如何退出
- 10 反序列化器
- 10.1 自定义反序列化器
- 10.2 Avro反序列化器
- 11 独立消费者
Kafka消费者
Kafka消费者是指使用Apache Kafka消息系统的客户端应用程序,用于从Kafka集群中读取消息并进行处理。Kafka消费者可以订阅一个或多个主题,并实时地从主题中消费新的消息。消费者可以以不同的方式处理消息,例如将其存储到数据库中、进行实时分析或者将其传递给其他系统。
Kafka消费者通常是分布式的,可以部署在多个节点上以实现高可用性和扩展性。消费者使用Kafka提供的消费者API来管理消息的订阅和消费,以及处理消息的偏移量(offset)等问题。
Kafka消费者的设计使得它们能够处理高吞吐量和大规模的消息流,同时保持低延迟和高可靠性。这使得Kafka成为许多大型互联网公司和数据密集型应用程序的首选消息系统。
应用程序使用KafkaConsumer向Kafka订阅主图,并从订阅的主题中接收消息。Kafka的消费者从属于消费者群组,一个群组里的消费者订阅的是同一个主题,每个消费者负责读取这个主题的部分消息。

I will add comments for this diagram later …
1 配置消费者
bootstrap.servers
这个参数是常用的KafkaProducer和KafkaConsumer用来连接Kafka集群的入口参数,这个参数对应的值通常是Kafka集群中部分broker的地址,比如:host1:9092,host2:9092,不同的broker地址之间用逗号隔开。
group.id
消费者所属的群组id。非必须,如果未指定,则消费者不属于任何一个群组。
key.deserializer
键的反序列化器,需实现接口org.apache.kafka.common.serialization.Deserializer。
value.deserializer
值的反序列化器,需实现接口org.apache.kafka.common.serialization.Deserializer。
group.instance.id
由最终用户提供的消费者实例的唯一标识符。只允许使用非空字符串。如果设置了,使用者将被视为静态成员,这意味着在使用者组中任何时候都只允许有一个具有此ID的实例。这可以与更大的会话超时结合使用,以避免由于暂时不可用(例如进程重新启动)而导致的组重新平衡。如果未设置,则消费者将作为动态成员加入组,这是传统行为。
fetch.min.bytes=1
服务器应为获取请求返回的最小数据量。如果可用数据不足,则请求将在回答请求之前等待积累那么多数据。1字节的默认设置意味着,只要有那么多字节的数据可用,或者提取请求在等待数据到达时超时,就会立即响应提取请求。将其设置为更大的值将导致服务器等待更大量的数据积累,这可以以一些额外的延迟为代价稍微提高服务器吞吐量。
fetch.max.wait.ms
如果没有足够的数据立即满足fetch.min.bytes给出的要求,则服务器在回答提取请求之前将等待的最长时间。
fetch.max.bytes=57671680 (55 mebibytes)
为每一个请求返回的最大字节数。必须至少为1024。
max.poll.record=500
在对poll()的单个调用中返回的最大记录数。请注意,max.poll.records不会影响底层的获取行为。使用者将缓存每个提取请求中的记录,并从每次轮询中递增地返回这些记录。
max.partition.fetch.bytes
服务器将返回的每个分区的最大数据量。记录由消费者分批提取。如果提取的第一个非空分区中的第一个记录批次大于此限制,则仍将返回该批,以确保使用者能够进行处理。代理接受的最大记录批处理大小是通过message.max.bytes(代理配置)或max.message.bytes(主题配置)定义的。有关限制使用者请求大小的信息,请参阅fetch.max.bytes。
session.timeout.ms=45000 (45 seconds)
使用Kafka的组管理功能时用于检测客户端故障的超时。客户端向代理发送周期性心跳以指示其活跃度。如果代理在此会话超时到期之前没有接收到检测信号,则协调器将从组中删除此客户端并启动重新平衡。请注意,该值必须在代理配置中由group.min.session.timeout.ms和group.max.session.timeout.ms配置的允许范围内。
heartbeat.interval.ms=3000 (3 seconds)
当使用Kafka的组管理功能时,消费者协调员的心跳检测之间的预期时间。心跳用于确保消费者的会话保持活动状态,并在新消费者加入或离开该组时促进重新平衡。该值必须设置为低于session.timeout.ms,但通常应设置为不高于该值的1/3。它可以调整得更低,以控制正常再平衡的预期时间。
max.poll.interval.ms=300000 (5 minutes)
使用使用者组管理时调用poll()之间的最大延迟。这为消费者在获取更多记录之前可以空闲的时间设置了上限。如果在该超时到期之前未调用poll(),则认为使用者失败,并且组将重新平衡,以便将分区重新分配给另一个成员。对于使用非null group.instance.id的使用者,如果达到此超时,则不会立即重新分配分区。相反,使用者将停止发送检测信号,并且在session.timeout.ms到期后将重新分配分区。这反映了已关闭的静态使用者的行为。
因为心跳检测是由消费者的后台线程发送的,有可能消费者主线程发生死锁,但是心跳线程可能正常运行,这样分区的消息永远不能被消费,所以引入了这个超时。
default.api.timeout.ms=60000 (1 minute)
指定客户端API的超时(以毫秒为单位)。此配置用作所有未指定超时参数的客户端API的默认超时。poll()属于显式指定了超时时间。
request.timeout.ms=40000 (40 seconds)
配置控制客户端等待请求响应的最长时间。如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者在重试次数用完时使请求失败。不建议配置小于默认时间,这样会进一步增加broker的负载。
auto.offset.reset=latest
当Kafka中没有初始偏移量时,或者如果服务器上不再存在当前偏移量(例如,因为该数据已被删除),该怎么办
- earlist:自动将偏移重置为最早偏移
- latest:自动将偏移重置为最新偏移
- none:如果没有为消费者的组找到以前的偏移量,则向消费者抛出异常
- 其他任何配置:向消费者抛出异常。
请注意,将此配置设置为latest时更改分区编号可能会导致消息传递丢失,因为生产者可能会在消费者重置其偏移量之前开始向新添加的分区发送消息(即,还不存在初始偏移量)。
enable.auto.commit=true
如果为true,则消费者的偏移将定期在后台提交。
auto.commit.interval.ms=5000 (5 seconds)
如果enable.auto.commit设置为true,则消费者偏移自动提交到Kafka的频率(以毫秒为单位)。
partition.assignment.strategy=class org.apache.kafka.clients.consumer.RangeAssignor,class org.apache.kafka.clients.consumer.CooperativeStickyAssignor
支持的分区分配策略的类名或类列表,按首选项排序,当使用组管理时,客户端将使用这些策略在消费者实例之间分配分区所有权。可用选项包括:
- 区间:
org.apache.kafka.clients.comer.RangeAssignor:基于主题分配,将同一个主题的若干个连续分区分给同一个消费者。 - 轮询
org.apache.kafka.clients.consumer.RoundRobinAssignor:在所有订阅主题之间以依次循环方式将分区分配给消费者。 - 粘性
org.apache.kafka.clients.csumer.StickyAssigner:保证最大限度地平衡分配,同时再均衡时保留尽可能多的现有分区分配。 - 协作粘性
org.apache.kafka.clients.csumer.CooperativeStickyAssigner:遵循相同的StickyAassigner逻辑,但允许协作再均衡。
默认的分配器是[RangeAssignor,CooperativeStickyAssignor],默认情况下它将使用RangeAssignor,但允许升级到CooperativeStickeyAssigner,只需一次滚动反弹(single rolling bounce)即可从列表中删除RangeAssigner。
通过实现org.apache.kafka.clients.csumer.ConsumerPartitionAssignor接口,可以插入自定义分配策略。
client.id
发出请求时要传递给服务器的id字符串。这样做的目的是通过允许在服务器端请求日志中包含逻辑应用程序名称,能够跟踪ip/端口以外的请求源。
client.rack
此客户端的机架标识符。这可以是指示该客户端物理位置的任何字符串值。它对应于broker配置“broker.rack”。
receive.buffer.bytes=65536 (64 KB)
读取数据时要使用的TCP接收缓冲区(SO_RCVBUF)的大小。如果该值为-1,则将使用操作系统默认值。
send.buffer.bytes=131072 (128 KB)
发送数据时要使用的TCP发送缓冲区(SO_SNDBUF)的大小。如果该值为-1,则将使用操作系统默认值。
offsets.retention.minutes=10080(7 days)
群组提交的没一个分区的最后一个偏移量的保留期限。当
- 消费者组失去所有消费者(即变为空)后,该保留期已经过期,特定分区的已提交偏移将被删除;
- 自上次为分区提交偏移量以来,该保留期已经过去,并且该组不再订阅相应的主题。对于独立使用者(使用手动分配),偏移量将在上次提交后经过此保留期后过期。请注意,当通过删除组请求删除组时,其提交的偏移量也将被删除,而无需额外的保留期;此外,当通过删除主题请求删除主题时,在传播元数据更新时,该主题的任何组的已提交偏移也将被删除,而不会有额外的保留期。
2 分区再均衡
分区从一个消费者转移到另一个消费者的行为称为再均衡。
2.1 再均衡发生的场景
在以下情况会发生再均衡:
- 新的消费者加如群组,它开始读取原本由其他消费者读取的分区
- 消费者被关闭或崩溃,离开群组,原先由它读取的分区将由群组的其它消费者读取
- 主题添加了新的分区,将会导致重新分配分区。
2.2 再均衡的分类
再均衡分为两种类型:
- 主动再均衡
所有消费者停止读取消息,重新加入消费者群组,并重新分配得到分区。 - 协调再均衡(增量再均衡)
通常是指将一个消费者的分区重新分配给另一个消费者。这种增量的方式可能需要几轮迭代,才能达到稳定状态。
2.3 分区分配过程

- 群组的第一个消费者向群组协调器发送加入群组的请求,发生在第一次轮询中
- 协调器将此消费者指定为群组领袖,并发送群组成员列表
- 新的消费者请求加如群组
- 通知群组领袖更新群组成员并重新分配分区
- 分配分区并将结果告知协调器
- 通知群组其他成员分区分配结果
3 固定群组成员
可以给消费者分配一个唯一group.instance.id,使其成为群组固定成员。这样在消费者关闭时,暂时不会退出群组,保留其分区,也就是不会进行分区再均衡,直到超过session.timeout.ms规定的超时时间,才会进行再均衡。期间分区消息暂时不会被读取。
4 创建消费者
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "test-group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Arrays.asList("topic1", "topic2"));
5 轮询
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));// 处理拉取到的消息records.forEach(record -> System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()));}
5.1 线程安全
我们既不能在同一个线程中运行多个同属于一个群组的消费者,也不能保证多个线程能够安全地共享一个消费者。所以一个消费者使用一个线程。做好是使用线程池启动多个线程。
6 提交和偏移量
把更新分区当前读取位置的操作叫做偏移量提交。消费者会向一个叫做__consumer_offset的主题发送消息,消息里包含每个分区的偏移量。一旦发生分区再均衡,消费者需要读取之前的偏移量,来继续之前的读取。
如果处理过的偏移量没有及时提交,就可能造成消息重复处理或丢失。
如果使用自动提交或者不指定提交的偏移量,默认会提交poll()返回的最有一个位置+1的偏移量。
6.1 自动提交
自动提交实在poll()方法中实现的。如果在两次提交之间隔之间,默认5秒,消费者崩溃,那么就有可能重复处理这期间的消息
6.2 手动同步提交
加规enable.auto.commit设置为false,然后调用KafkaConsumer.commitSync()同步提交poll()返回的最新偏移量。
public void commitOffset() {KafkaConsumer<String, String> consumer = create();consumer.subscribe(Arrays.asList("topic1", "topic2"));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}try {consumer.commitSync();} catch (CommitFailedException | WakeupException e) {logger.error("Commit failed.", e);}}}
6.3 异步提交
只管提交请求,不等待broker做出响应。异步提交的缺点时不会自动进行重试,为避免小的偏移量覆盖大的偏移量。
public void commitOffsetAsync() {KafkaConsumer<String, String> consumer = create();consumer.subscribe(Arrays.asList("topic1", "topic2"));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {if (null != exception) {logger.error("Commit failed for offsets {}", offsets, exception);}}});}}
6.4 同步和异步组合提交
public void commitOffsetAsyncAndSync() {KafkaConsumer<String, String> consumer = create();consumer.subscribe(Arrays.asList("topic1", "topic2"));try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}consumer.commitAsync();}} catch (WakeupException e) {logger.error("Unexpected error", e);consumer.commitSync();} finally {consumer.close();}}
6.5 提交特定的偏移量
如果poll()返回了大批数据,为了避免再均衡引起的消息重复,可以在批次处理的过程中提交指定的偏移量
public void commitSpecificOffset() {KafkaConsumer<String, String> consumer = create();consumer.subscribe(Arrays.asList("topic1", "topic2"));try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}// 手动提交偏移量for (TopicPartition partition : records.partitions()) {long offset = records.records(partition).get(records.records(partition).size() - 1).offset();consumer.commitSync(Collections.singletonMap(partition, new org.apache.kafka.clients.consumer.OffsetAndMetadata(offset + 1)));}}} catch (WakeupException e) {// Ignore for shutdown} finally {consumer.close();}}
7 再均衡监听器
通过再均衡监听器,可以在消费者分配到新分区或就分区被移除是执行一些代码逻辑。
package com.qupeng.demo.kafka.kafkaapache.consumer;import org.apache.kafka.clients.consumer.ConsumerRebalanceListener;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;import java.util.Collection;public class MyRebalanceListener implements ConsumerRebalanceListener {KafkaConsumer kafkaConsumer;public MyRebalanceListener(KafkaConsumer kafkaConsumer) {this.kafkaConsumer = kafkaConsumer;}// 消费者放弃对分区的所有权时调用@Overridepublic void onPartitionsRevoked(Collection<TopicPartition> partitions) {}// 重新分配分区,消费者开始读取消息之前调用@Overridepublic void onPartitionsAssigned(Collection<TopicPartition> partitions) {}// 使用协作再均衡算法,并且之前不是通过再均衡获得的分区被重新分配给其他消费者时调用@Overridepublic void onPartitionsLost(Collection<TopicPartition> partitions) {ConsumerRebalanceListener.super.onPartitionsLost(partitions);}
}public void commitInRebalance() {KafkaConsumer<String, String> consumer = create();Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();try {consumer.subscribe(Arrays.asList("topic1", "topic2"), new MyRebalanceListener(consumer));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());currentOffsets.put(new TopicPartition(record.topic(), record.partition()),new OffsetAndMetadata(record.offset() + 1, null));}consumer.commitAsync(currentOffsets, null);}} catch (WakeupException e) {logger.error("Unexpected error", e);} finally {try {consumer.commitSync(currentOffsets);} catch (Exception e) {throw new RuntimeException(e);} finally {consumer.close();}}}
8 从特定偏移量位置读取记录
查找偏移量的用途:
- 对于时间敏感的应用程序在处理速度滞后的情况先可以向前跳过几条消息
public void seekOffsetByTime() {KafkaConsumer<String, String> consumer = create();Long oneHourEarlier = Instant.now().atZone(ZoneId.systemDefault()).minusHours(1).toEpochSecond();Map<TopicPartition, Long> partitionLongMap = consumer.assignment().stream().collect(Collectors.toMap(tp -> tp, tp ->oneHourEarlier));Map<TopicPartition, OffsetAndTimestamp> offsetMap = consumer.offsetsForTimes(partitionLongMap);for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : offsetMap.entrySet()) {consumer.seek(entry.getKey(), entry.getValue().offset());}try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}}} finally {consumer.close();}}
- 消费者的数据丢失了,可以重置偏移量,回到某个位置进行数据恢复
public void seekSpecificOffset() {KafkaConsumer<String, String> consumer = create();// Assign a specific partition and offsetTopicPartition partition = new TopicPartition("your-topic", 0);consumer.assign(Collections.singleton(partition));consumer.seek(partition, 100);try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}}} finally {consumer.close();}}
9 消费者程序如何退出
关闭一个消费者,有两种办法:
- 如果要立刻关闭消费之,可以在另一个线程中调用consumer.close(),它是consumer中唯一一个线程安全的方法。
- 如果轮询等待时间足够短,或者不介意多等待一段退出时间,可是在另一个线程中修改轮询标记的方法退出轮询。
private AtomicBoolean exitFlag = new AtomicBoolean(false);public void consumeAndExit() {KafkaConsumer<String, String> consumer = create();addShutdownHook(consumer, Thread.currentThread());consumer.subscribe(Arrays.asList("topic1", "topic2"));try {while (!exitFlag.get()) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10000));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}consumer.commitAsync();}consumer.close();} catch (WakeupException e) {consumer.commitSync();} finally {consumer.close();}}public void setExitFlag() {Runtime.getRuntime().addShutdownHook(new Thread() {@Overridepublic void run() {exitFlag.compareAndSet(false, true);}});}public void addShutdownHook(Consumer consumer, Thread mainThread) {Runtime.getRuntime().addShutdownHook(new Thread() {@Overridepublic void run() {consumer.wakeup();try {mainThread.join();} catch (InterruptedException e) {logger.error("", e);}}});}
在Java程序中可以通过添加关闭钩子,实现在程序退出时关闭资源、平滑退出的功能。
使用Runtime.addShutdownHook(Thread hook)方法,可以注册一个JVM关闭的钩子,这个钩子可以在以下几种场景被调用:
- 程序正常退出
- 使用System.exit()
- 终端使用Ctrl+C触发的中断
- 系统关闭
- 使用Kill pid命令干掉进程
10 反序列化器
消费者使用反序列化器把字节数组转换为Java对象。反序列化器和序列化器必须匹配,不然会出错。
10.1 自定义反序列化器
package com.qupeng.demo.kafka.kafkaapache.consumer;import com.qupeng.demo.kafka.kafkaapache.producer.Product;
import org.apache.kafka.common.serialization.Deserializer;import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;public class CustomizedDeserializer implements Deserializer<Product> {@Overridepublic Product deserialize(String topic, byte[] data) {ByteBuffer byteBuffer = ByteBuffer.wrap(data);int id = byteBuffer.getInt();int nameSize = byteBuffer.getInt();byte[] nameBytes = new byte[nameSize];byteBuffer.get(nameBytes);String name = new String(nameBytes, StandardCharsets.UTF_8);return new Product(id, name);}
}10.2 Avro反序列化器
package com.qupeng.demo.kafka.kafkaapache.consumer;import com.qupeng.demo.kafka.kafkaapache.producer.Product;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;public class AvroConsumer {public KafkaConsumer create() {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "test-group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "io.confluent.kafka.serializers.KafkaAvroDeserializer");props.put("schema.registry.url", "localhost:8081");return new KafkaConsumer<>(props);}public void consume() {KafkaConsumer<String, Product> consumer = create();consumer.subscribe(Arrays.asList("topic1", "topic2"));while (true) {ConsumerRecords<String, Product> records = consumer.poll(Duration.ofMillis(100));// 处理拉取到的消息records.forEach(record -> System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value().getName()));}}
}11 独立消费者
需要一个消费者读取主题的所有分区或某个分区时,只需要把主题或分区分配给这个消费者,就不需要消费者群组和再均衡了。
package com.qupeng.demo.kafka.kafkaapache.consumer;import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.TopicPartition;import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;public class IndependentConsumer {public KafkaConsumer create() {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "test-group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");return new KafkaConsumer<>(props);}public void consume() {KafkaConsumer<String, String> consumer = create();List<PartitionInfo> partitionInfos = consumer.partitionsFor("Topic");if (null != partitionInfos) {List<TopicPartition> topicPartitions = new ArrayList<>();for (PartitionInfo partitionInfo : partitionInfos) {topicPartitions.add(new TopicPartition(partitionInfo.topic(), partitionInfo.partition()));}consumer.assign(topicPartitions);while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));records.forEach(record -> System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()));consumer.commitSync();}}}
}注意独立消费者在增加了新的分区之后,并不会收到通知,需要通过API重新获取分区列表。
相关文章:
Kafka(六)消费者
目录 Kafka消费者1 配置消费者bootstrap.serversgroup.idkey.deserializervalue.deserializergroup.instance.idfetch.min.bytes1fetch.max.wait.msfetch.max.bytes57671680 (55 mebibytes)max.poll.record500max.partition.fetch.bytessession.timeout.ms45000 (45 seconds)he…...

RK3399平台入门到精通系列讲解(实验篇)共享工作队列的使用
🚀返回总目录 文章目录 一、工作队列相关接口函数1.1、初始化函数1.2、调度/取消调度工作队列函数二、信号驱动 IO 实验源码2.1、Makefile2.2、驱动部分代码工作队列是实现中断下半部分的机制之一,是一种用于管理任务的数据结构或机制。它通常用于多线程,多进程或分布式系统…...

STM32 基于 MPU6050 的飞行器姿态控制设计与实现
基于STM32的MPU6050姿态控制设计是无人机、飞行器等飞行器件开发中的核心技术之一。在本文中,我们将介绍如何利用STM32和MPU6050实现飞行器的姿态控制,并提供相应的代码示例。 1. 硬件连接及库配置 首先,我们需要将MPU6050连接到STM32微控制…...
大数据平台Bug Bash大扫除最佳实践
一、背景 随着越来越多的"新人"在日常工作以及大促备战中担当大任,我们发现仅了解自身系统业务已不能满足日常系统开发运维需求。为此,大数据平台部门组织了一次Bug Bash活动,既能提升自己对兄弟产品的理解和使用,又能…...

JavaScript 中的数组过滤
在构建动态和交互式程序时,您可能需要添加一些交互式功能。例如,用户单击按钮以筛选一长串项目。 您可能还需要处理大量数据,以仅返回与指定条件匹配的项目。 在本文中,您将学习如何使用两种主要方法在 JavaScript 中过滤数组。…...
)
随机森林(Random Forest)
随机森林(Random Forest)是一种集成学习方法,通过组合多个决策树来提高模型的性能和鲁棒性。随机森林在每个决策树的训练过程中引入了随机性,包括对样本和特征的随机选择,以提高模型的泛化能力。以下是随机森林的基本原…...
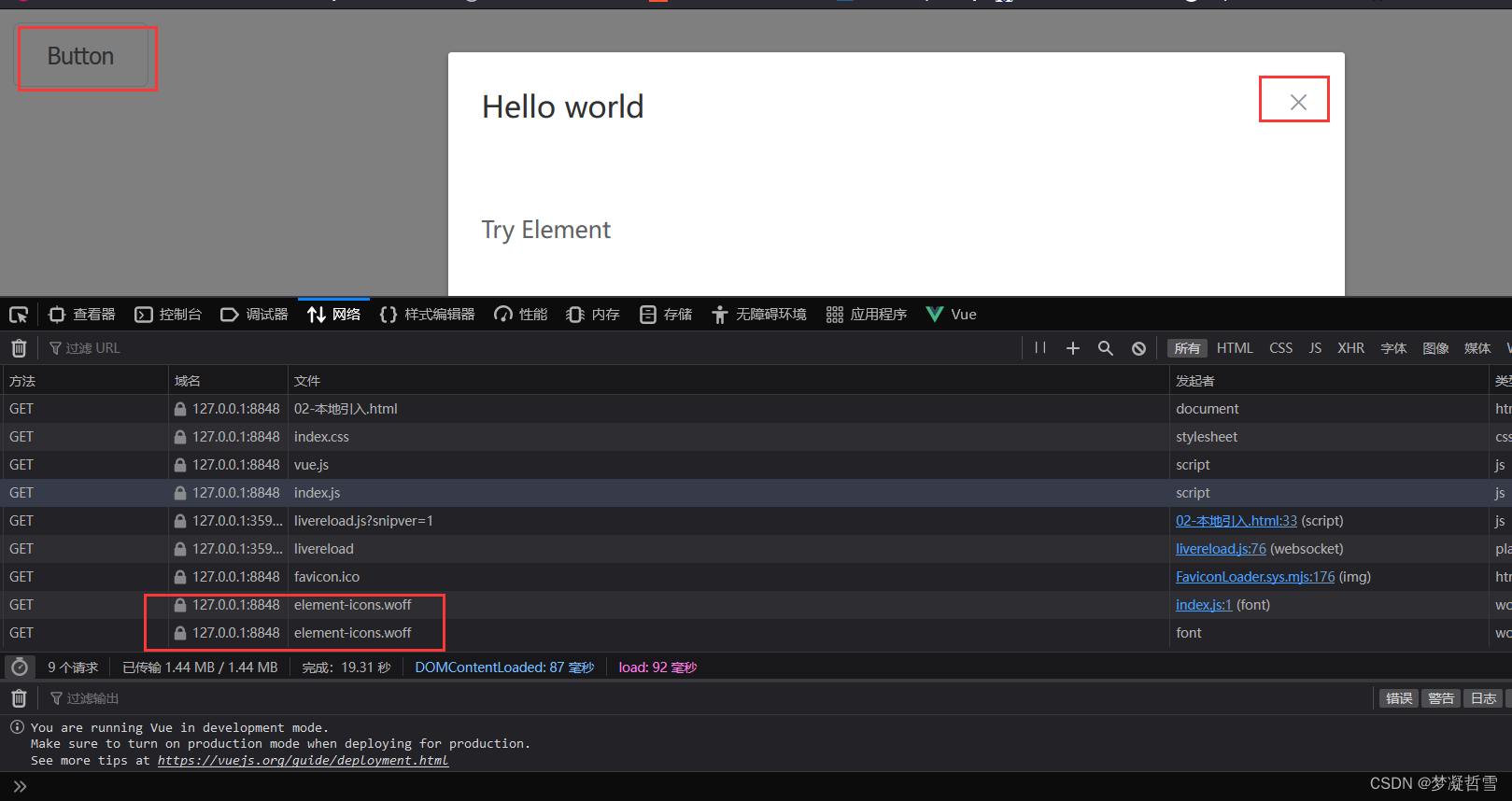
本地引入Element UI后导致图标显示异常
引入方式 npm 安装 推荐使用 npm 的方式安装,它能更好地和 webpack 打包工具配合使用。 npm i element-ui -SCDN 目前可以通过 unpkg.com/element-ui 获取到最新版本的资源,在页面上引入 js 和 css 文件即可开始使用。 <!-- 引入样式 --> <…...
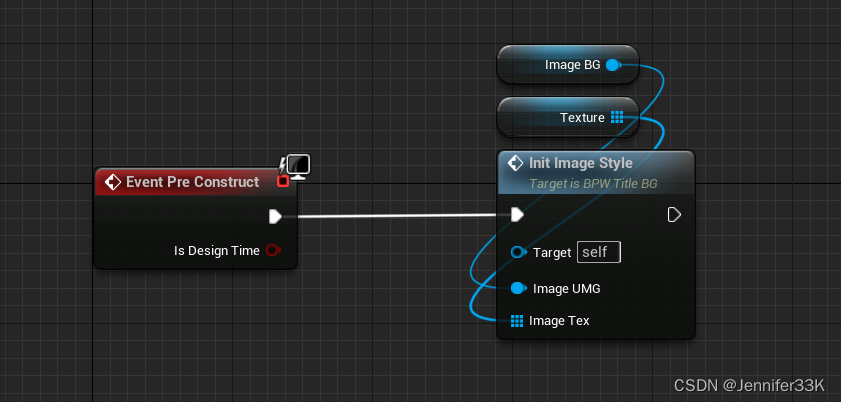
UE5.1_UMG序列帧动画制作
UE5.1_UMG序列帧动画制作 UMG序列帧动画制作相对比较简单,不像视频帧需要创建媒体播放器那么复杂,以下简要说明: 1. 事件函数 2. 准备序列帧装入数组 3. 构造调用事件函数 4. 预览 序列帧UMG0105 5. 完成!按需配置即可。...

总结HarmonyOS的技术特点
HarmonyOS是华为自主研发的面向全场景的分布式操作系统。它的技术特点主要体现在以下几个方面: 分布式架构:HarmonyOS采用了分布式架构设计,通过组件化和小型化等方法,支持多种终端设备按需弹性部署,能够适配不同类别的…...

从0到1入门C++编程——04 类和对象之封装、构造函数、析构函数、this指针、友元
文章目录 一、封装二、项目文件拆分三、构造函数和析构函数1.构造函数的分类及调用2.拷贝函数调用时机3.构造函数调用规则4.深拷贝与浅拷贝5.初始化列表6.类对象作为类成员7.静态成员 四、C对象模型和this指针1.类的对象大小计算2.this指针3.空指针访问成员函数4.const修饰成员…...

Robot Operating System 2: Design, Architecture, and Uses In The Wild
Robot Operating System 2: Design, Architecture, and Uses In The Wild (机器人操作系统 2:设计、架构和实际应用) 摘要:随着机器人在广泛的商业用例中的部署,机器人革命的下一章正在顺利进行。即使在无数的应用程序和环境中,也…...

TinyEngine 服务端正式开源啦!!!
背景介绍 TinyEngine 低代码引擎介绍 随着企业对于低代码开发平台的需求日益增长,急需一个通用的解决方案来满足各种低代码平台的开发需求。正是在这种情况下,低代码引擎应运而生。它是一种通用的开发框架,通过对低代码平台系统常用的功能进…...

网页设计与制作web前端设计html+css+js成品。电脑网站制作代开发。vscodeDrea 【企业公司宣传网站(HTML静态网页项目实战)附源码】
网页设计与制作web前端设计htmlcssjs成品。电脑网站制作代开发。vscodeDrea 【企业公司宣传网站(HTML静态网页项目实战)附源码】 https://www.bilibili.com/video/BV1Hp4y1o7RY/?share_sourcecopy_web&vd_sourced43766e8ddfffd1f1a1165a3e72d7605...

Avalonia学习(二十)-登录界面演示
今天开始继续Avalonia练习。 本节:演示实现登录界面 在网上看见一个博客,展示Avalonia实现,仿照GGTalk,我实现了一下,感觉是可以的。将测试的数据代码效果写下来。主要是样式使用,图片加载方式。 只有前…...

Spring依赖注入的魔法:深入DI的实现原理【beans 五】
欢迎来到我的博客,代码的世界里,每一行都是一个故事 Spring依赖注入的魔法:深入DI的实现原理【beans 五】 前言DI的基本概念基本概念:为什么使用依赖注入: 构造器注入构造器注入的基本概念:示例:…...
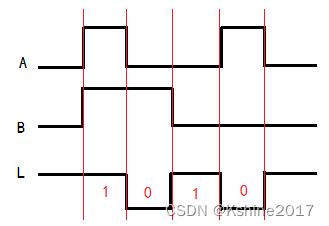
【学习笔记】1、数字逻辑概论
1.1 数字信号 数字信号,在时间和数值上均是离散的。数字信号的表达方式:二值数字逻辑和逻辑电平描述的数字波形。 (1) 数字波形的两种类型 数值信号又称为“二值信号”。数字波形又称为“二值位形图”。 什么是一拍 一定的时…...

设置代理IP地址对网络有什么影响?爬虫代理IP主要有哪些作用?
在互联网的广泛应用下,代理IP地址成为了一种常见的网络技术。代理IP地址可以改变用户的上网行为,进而影响网络访问的速度和安全性。本篇文章将探讨设置代理IP地址对网络的影响,以及爬虫代理IP的主要作用。 首先,让我们来了解一下代…...

聊聊jvm的mapped buffer的统计
序 本文主要研究一下jvm的mapped buffer的统计 示例 private void writeDirectBuffer() {// 分配一个256MB的直接缓冲区ByteBuffer buffer ByteBuffer.allocateDirect(256 * 1024 * 1024);// 填充数据Random random new Random();while (buffer.remaining() > 4) {buff…...

matrix-breakout-2-morpheus 靶场 练习思路
arp-scan -l 获取目标机器的IP nmap -sV -A IP 查看目标机器开放的端口 gobuster dir -u http://192.168.29.130 -x php,txt,jsp,asp -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt 爆破目标机器的文件目录,找到可以访问的文件路径 http://192.168…...

【Flutter 开发实战】Dart 基础篇:从了解背景开始
想要学会用 Flutter 开发 App,就不可避免的要学习另一门很有意思的编程语言 —— Dart。很多小伙伴可能在学习 Flutter 之前可能都没听说过这门编程语言,我也是一样,还以为 Dart 是为了 Flutter 而诞生的;然而,当我们去…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...

DAY 26 函数专题1
函数定义与参数知识点回顾:1. 函数的定义2. 变量作用域:局部变量和全局变量3. 函数的参数类型:位置参数、默认参数、不定参数4. 传递参数的手段:关键词参数5 题目1:计算圆的面积 任务: 编写一…...
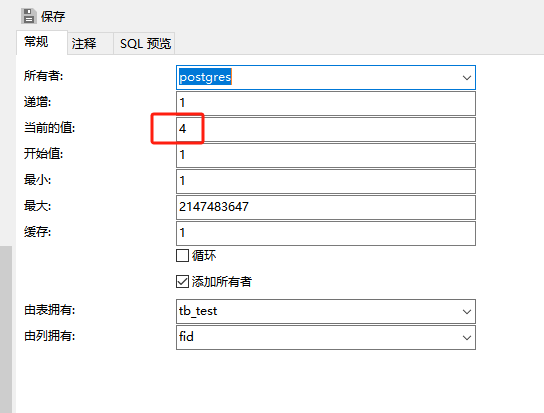
pgsql:还原数据库后出现重复序列导致“more than one owned sequence found“报错问题的解决
问题: pgsql数据库通过备份数据库文件进行还原时,如果表中有自增序列,还原后可能会出现重复的序列,此时若向表中插入新行时会出现“more than one owned sequence found”的报错提示。 点击菜单“其它”-》“序列”,…...