Python综合数据分析_RFM用户分层模型
文章目录
- 1.数据加载
- 2.查看数据情况
- 3.数据合并及填充
- 4.查看特征字段之间相关性
- 5.聚合操作
- 6.时间维度上看销售额
- 7.计算用户RFM
- 8.数据保存存储
- (1).to_csv
- (1).to_pickle
1.数据加载
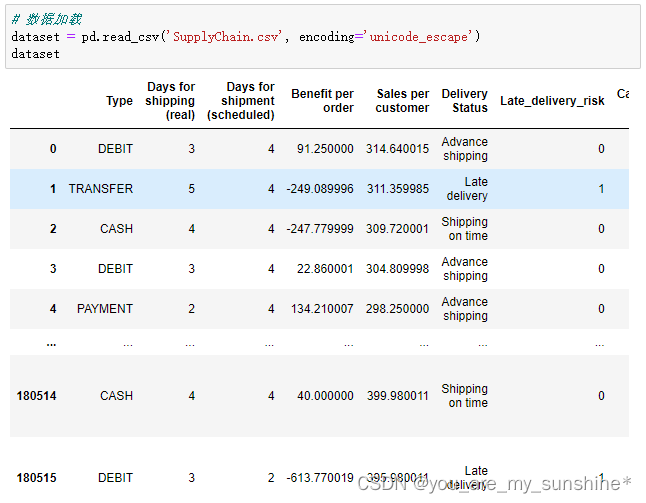
import pandas as pd
dataset = pd.read_csv('SupplyChain.csv', encoding='unicode_escape')
dataset
2.查看数据情况
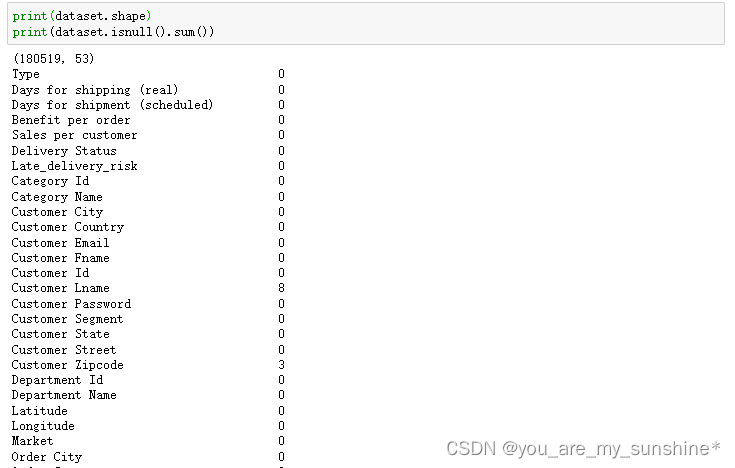
print(dataset.shape)
print(dataset.isnull().sum())

3.数据合并及填充
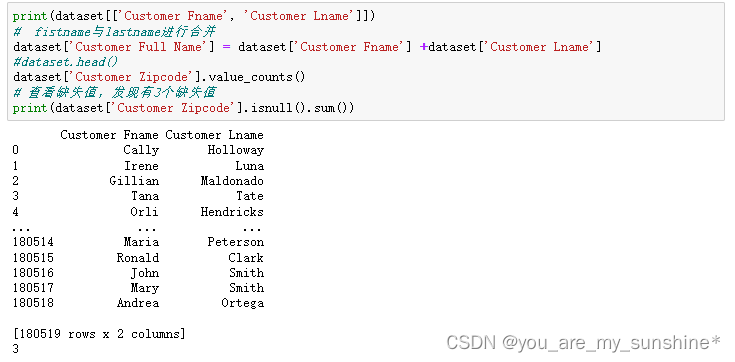
print(dataset[['Customer Fname', 'Customer Lname']])
# fistname与lastname进行合并
dataset['Customer Full Name'] = dataset['Customer Fname'] +dataset['Customer Lname']
#dataset.head()
dataset['Customer Zipcode'].value_counts()
# 查看缺失值,发现有3个缺失值
print(dataset['Customer Zipcode'].isnull().sum())
dataset['Customer Zipcode'] = dataset['Customer Zipcode'].fillna(0)
dataset.head()

4.查看特征字段之间相关性
import matplotlib.pyplot as plt
import seaborn as sns
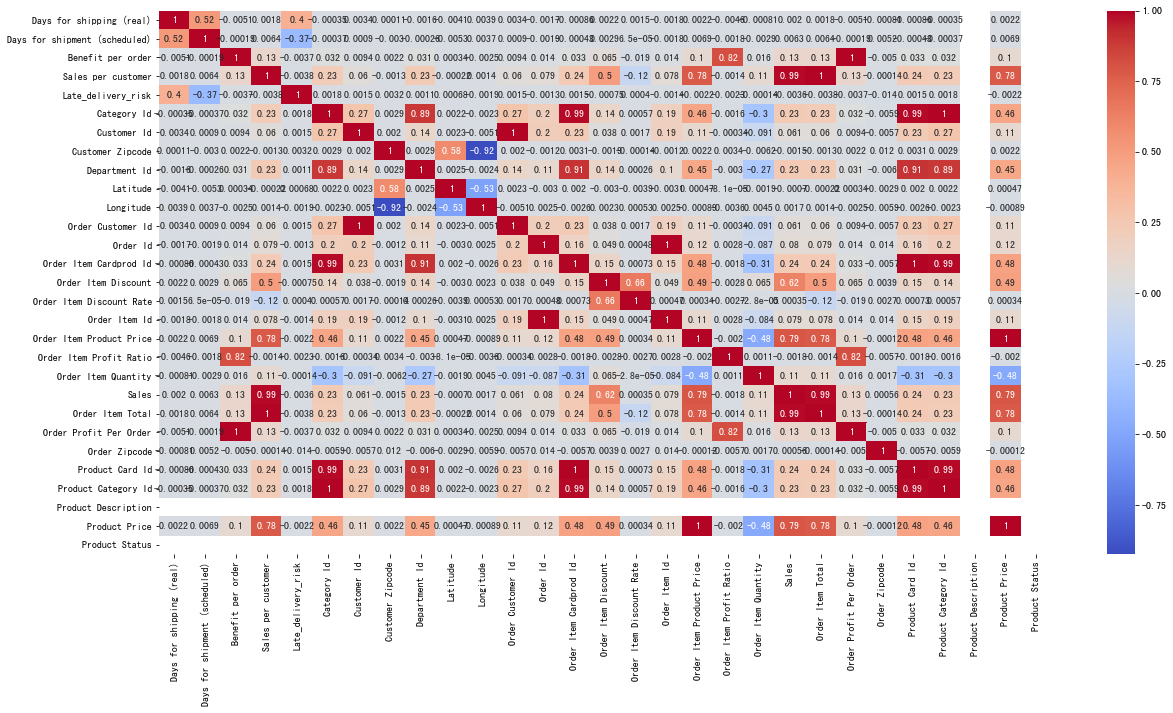
# 特征字段之间相关性 热力图
data = dataset
plt.figure(figsize=(20,10))
# annot=True 显示具体数字
sns.heatmap(data.corr(), annot=True, cmap='coolwarm')
# 结论:可以观察到Product Price和Sales,Order Item Total有很高的相关性
5.聚合操作
# 基于Market进行聚合
market = data.groupby('Market')
# 基于Region进行聚合
region = data.groupby('Order Region')
plt.figure(1)
market['Sales per customer'].sum().sort_values(ascending=False).plot.bar(figsize=(12,6), title='Sales in different markets')
plt.figure(2)
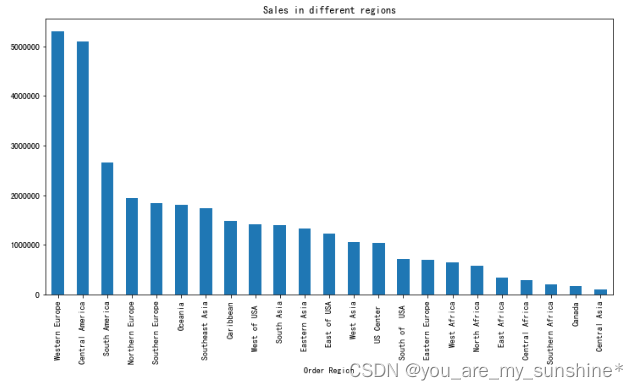
region['Sales per customer'].sum().sort_values(ascending=False).plot.bar(figsize=(12,6), title='Sales in different regions')
plt.show()

# 基于Category Name进行聚类
cat = data.groupby('Category Name')
plt.figure(1)
# 不同类别的 总销售额
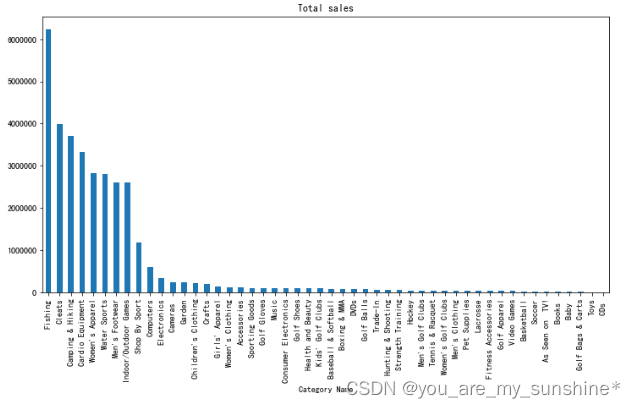
cat['Sales per customer'].sum().sort_values(ascending=False).plot.bar(figsize=(12,6), title='Total sales')
plt.figure(2)
# 不同类别的 平均销售额
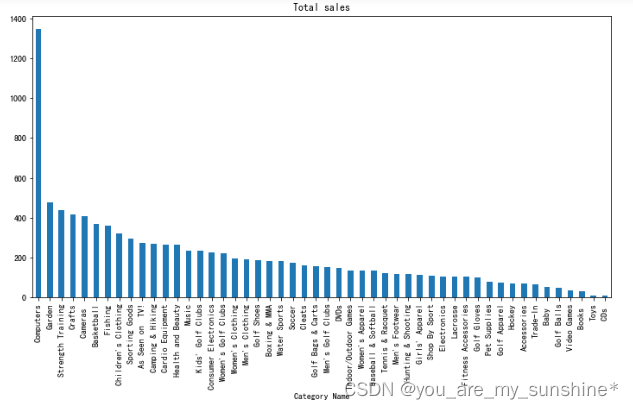
cat['Sales per customer'].mean().sort_values(ascending=False).plot.bar(figsize=(12,6), title='Total sales')
plt.show()
6.时间维度上看销售额
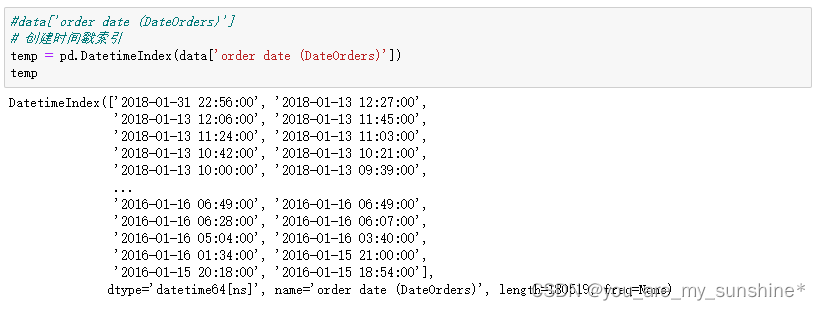
#data['order date (DateOrders)']
# 创建时间戳索引
temp = pd.DatetimeIndex(data['order date (DateOrders)'])
temp
# 取order date (DateOrders)字段中的year, month, weekday, hour, month_year
data['order_year'] = temp.year
data['order_month'] = temp.month
data['order_week_day'] = temp.weekday
data['order_hour'] = temp.hour
data['order_month_year'] = temp.to_period('M')
data.head()

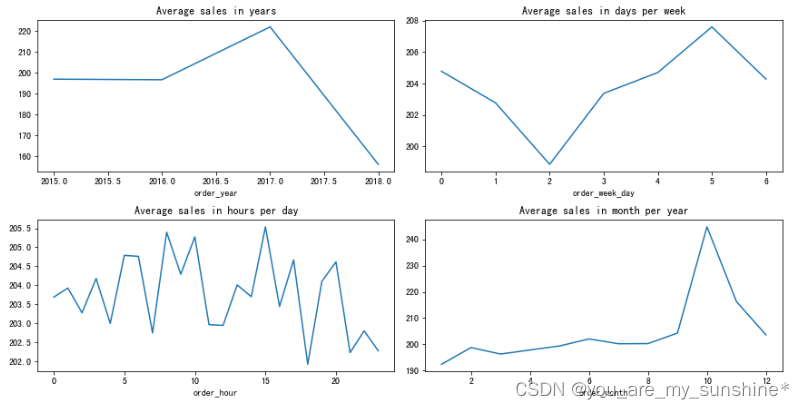
# 对销售额进行探索,按照不同时间维度 年,星期,小时,月
plt.figure(figsize=(10, 12))
plt.subplot(4, 2, 1)
df_year = data.groupby('order_year')
df_year['Sales'].mean().plot(figsize=(12, 12), title='Average sales in years')
plt.subplot(4, 2, 2)
df_day = data.groupby('order_week_day')
df_day['Sales'].mean().plot(figsize=(12, 12), title='Average sales in days per week')
plt.subplot(4, 2, 3)
df_hour = data.groupby('order_hour')
df_hour['Sales'].mean().plot(figsize=(12, 12), title='Average sales in hours per day')
plt.subplot(4, 2, 4)
df_month = data.groupby('order_month')
df_month['Sales'].mean().plot(figsize=(12, 12), title='Average sales in month per year')
plt.tight_layout()
plt.show()
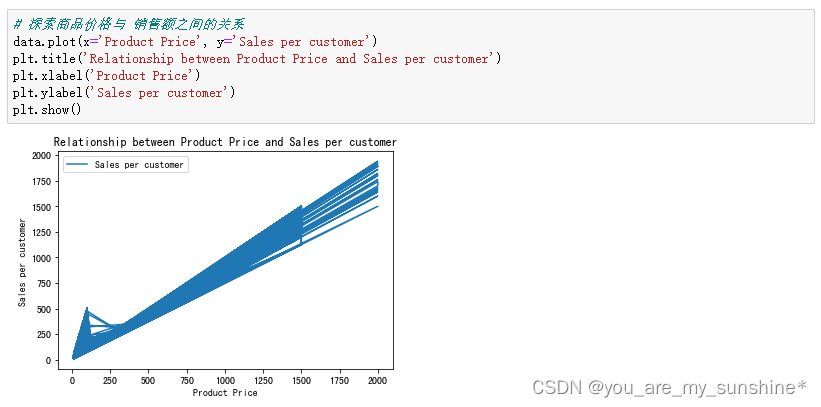
# 探索商品价格与 销售额之间的关系
data.plot(x='Product Price', y='Sales per customer')
plt.title('Relationship between Product Price and Sales per customer')
plt.xlabel('Product Price')
plt.ylabel('Sales per customer')
plt.show()
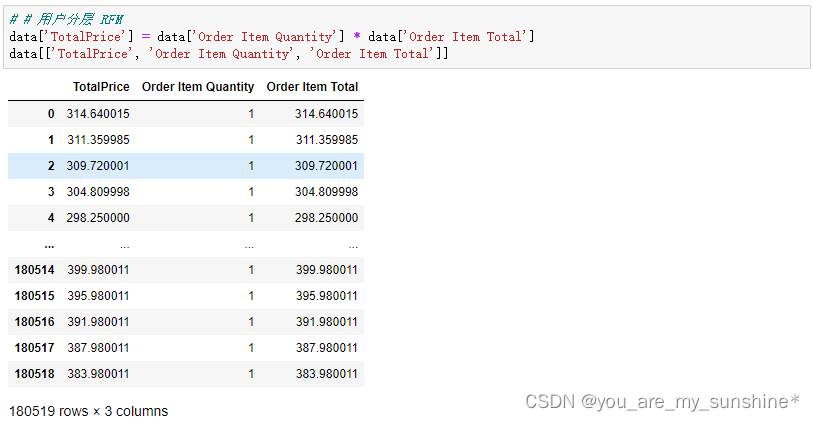
7.计算用户RFM
# # 用户分层 RFM
data['TotalPrice'] = data['Order Item Quantity'] * data['Order Item Total']
data[['TotalPrice', 'Order Item Quantity', 'Order Item Total']]
# 时间类型转换
data['order date (DateOrders)'] = pd.to_datetime(data['order date (DateOrders)'])
# 统计最后一笔订单的时间
data['order date (DateOrders)'].max()

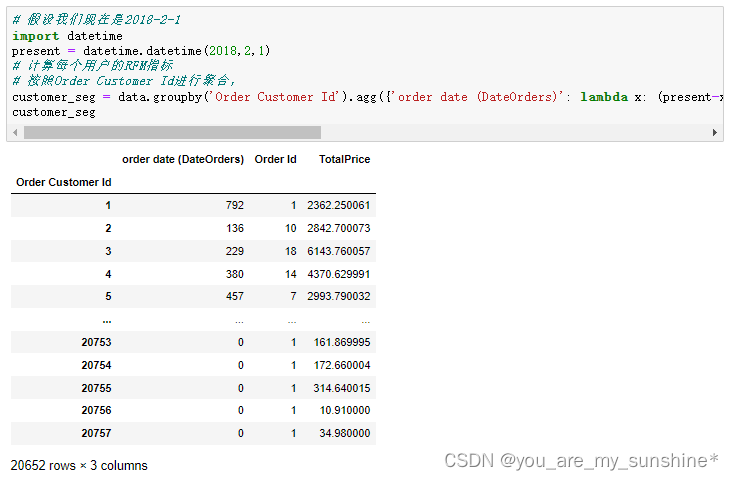
# 假设我们现在是2018-2-1
import datetime
present = datetime.datetime(2018,2,1)
# 计算每个用户的RFM指标
# 按照Order Customer Id进行聚合,
customer_seg = data.groupby('Order Customer Id').agg({'order date (DateOrders)': lambda x: (present-x.max()).days, 'Order Id': lambda x:len(x), 'TotalPrice': lambda x: x.sum()})
customer_seg
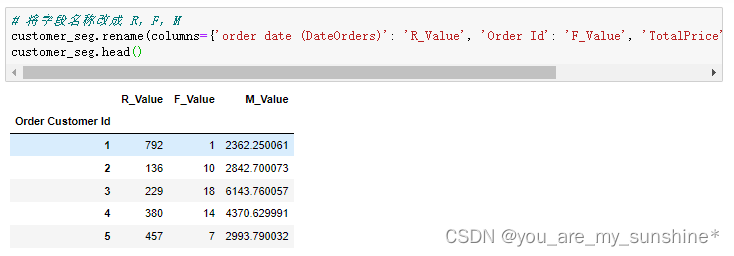
# 将字段名称改成 R,F,M
customer_seg.rename(columns={'order date (DateOrders)': 'R_Value', 'Order Id': 'F_Value', 'TotalPrice': 'M_Value'}, inplace=True)
customer_seg.head()
# 将RFM数据划分为4个尺度
quantiles = customer_seg.quantile(q=[0.25, 0.5, 0.75])
quantiles = quantiles.to_dict()
quantiles

# R_Value越小越好 => R_Score就越大
def R_Score(a, b, c):if a <= c[b][0.25]:return 4elif a <= c[b][0.50]:return 3elif a <= c[b][0.75]:return 2else:return 1# F_Value, M_Value越大越好
def FM_Score(a, b, c):if a <= c[b][0.25]:return 1elif a <= c[b][0.50]:return 2elif a <= c[b][0.75]:return 3else:return 4
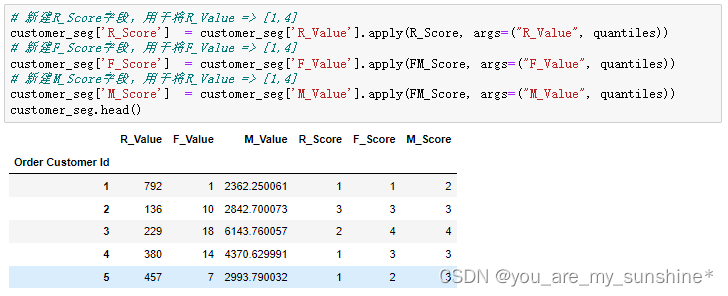
# 新建R_Score字段,用于将R_Value => [1,4]
customer_seg['R_Score'] = customer_seg['R_Value'].apply(R_Score, args=("R_Value", quantiles))
# 新建F_Score字段,用于将F_Value => [1,4]
customer_seg['F_Score'] = customer_seg['F_Value'].apply(FM_Score, args=("F_Value", quantiles))
# 新建M_Score字段,用于将R_Value => [1,4]
customer_seg['M_Score'] = customer_seg['M_Value'].apply(FM_Score, args=("M_Value", quantiles))
customer_seg.head()
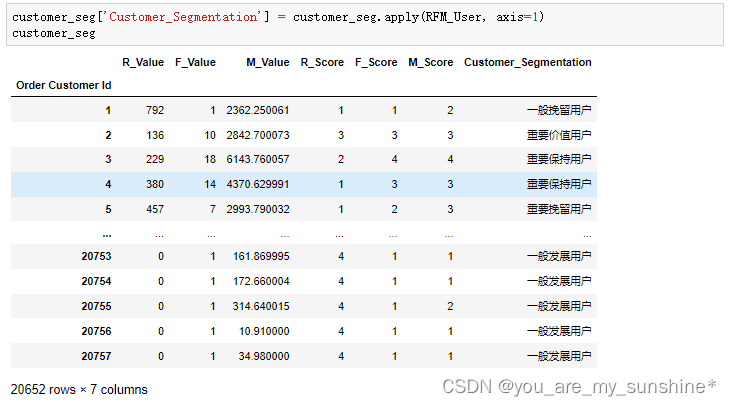
# 计算RFM用户分层
def RFM_User(df):if df['M_Score'] > 2 and df['F_Score'] > 2 and df['R_Score'] > 2:return '重要价值用户'if df['M_Score'] > 2 and df['F_Score'] <= 2 and df['R_Score'] > 2:return '重要发展用户'if df['M_Score'] > 2 and df['F_Score'] > 2 and df['R_Score'] <= 2:return '重要保持用户'if df['M_Score'] > 2 and df['F_Score'] <= 2 and df['R_Score'] <= 2:return '重要挽留用户'if df['M_Score'] <= 2 and df['F_Score'] > 2 and df['R_Score'] > 2:return '一般价值用户'if df['M_Score'] <= 2 and df['F_Score'] <= 2 and df['R_Score'] > 2:return '一般发展用户'if df['M_Score'] <= 2 and df['F_Score'] > 2 and df['R_Score'] <= 2:return '一般保持用户'if df['M_Score'] <= 2 and df['F_Score'] <= 2 and df['R_Score'] <= 2:return '一般挽留用户'customer_seg['Customer_Segmentation'] = customer_seg.apply(RFM_User, axis=1)
customer_seg
8.数据保存存储
(1).to_csv
customer_seg.to_csv('supply_chain_rfm_result.csv', index=False)
(1).to_pickle
# 数据预处理后,将处理后的数据进行保存
data.to_pickle('data.pkl')
参考资料:开课吧
相关文章:
Python综合数据分析_RFM用户分层模型
文章目录 1.数据加载2.查看数据情况3.数据合并及填充4.查看特征字段之间相关性5.聚合操作6.时间维度上看销售额7.计算用户RFM8.数据保存存储(1).to_csv(1).to_pickle 1.数据加载 import pandas as pd dataset pd.read_csv(SupplyChain.csv, encodingunicode_escape) dataset2…...
【C++进阶04】STL中map、set、multimap、multiset的介绍及使用
一、关联式容器 vector/list/deque… 这些容器统称为序列式容器 因为其底层为线性序列的数据结构 里面存储的是元素本身 map/set… 这些容器统称为关联式容器 关联式容器也是用来存储数据的 与序列式容器不同的是 其里面存储的是<key, value>结构的键值对 在数据检索时…...

在 Linux 中开启 Flask 项目持续运行
在 Linux 中开启 Flask 项目持续运行 在部署 Flask 项目时,情况往往并不是那么理想。默认情况下,关闭 SSH 终端后,Flask 服务就停止了。这时,您需要找到一种方法在 Linux 服务器上实现持续运行 Flask 项目,并在服务器…...

考研个人经验总结【心理向】
客官你好 首先,不管你是以何种原因来到这篇博客,以下内容或多或少可能带给你一些启发。如果你还是大二or大三学生,有考研的打算,不妨提前了解一些考研必备的心理战术,有时候并不是你知识学得不好,而是思维…...
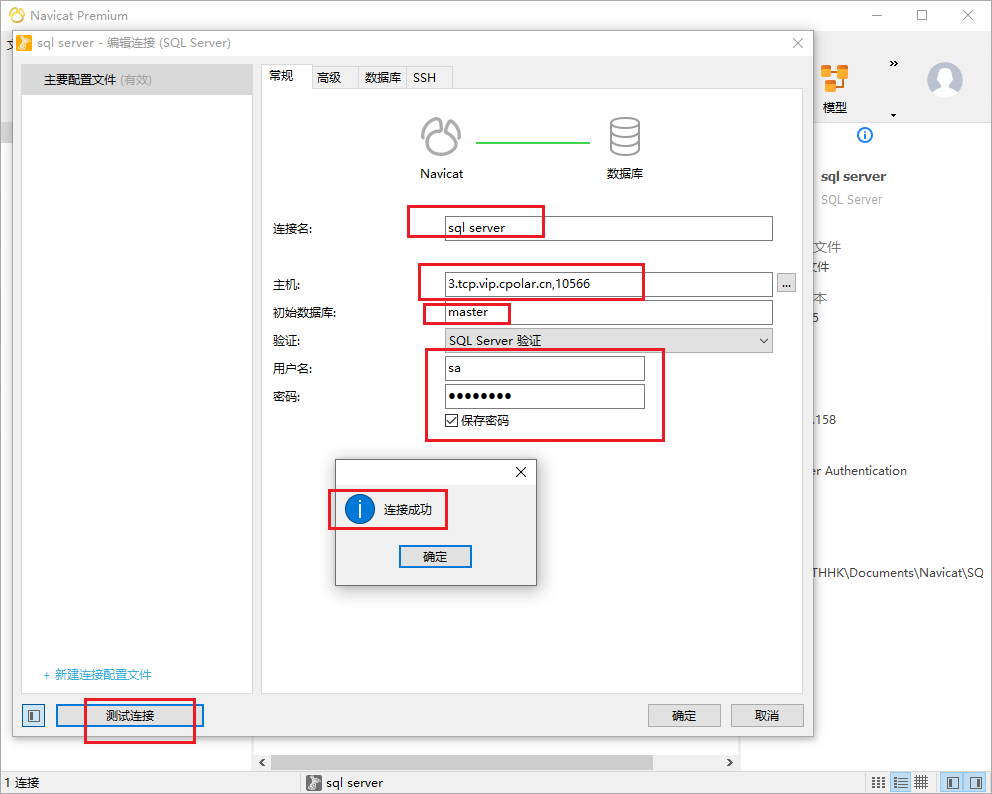
如何在CentOS安装SQL Server数据库并通过内网穿透工具实现公网访问
文章目录 前言1. 安装sql server2. 局域网测试连接3. 安装cpolar内网穿透4. 将sqlserver映射到公网5. 公网远程连接6.固定连接公网地址7.使用固定公网地址连接 前言 简单几步实现在Linux centos环境下安装部署sql server数据库,并结合cpolar内网穿透工具࿰…...

jupyter内核错误
1、在dos窗口输入以下命令激活环境:anaconda activate 【py环境名,比如py37】(目的是新家你一个虚拟环境) 2、在虚拟环境py37下安装jupyter notebook,命令:pip install jupyter notebook 3、安装ipykerne…...
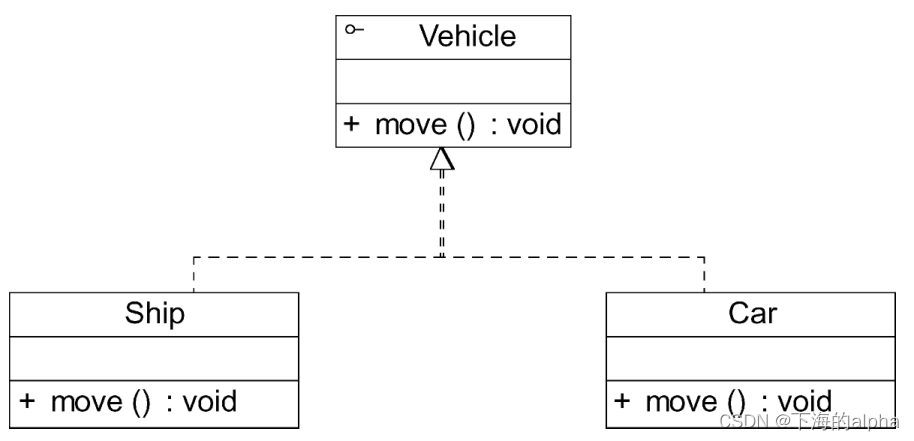
设计模式的艺术P1基础—2.3 类之间的关系
设计模式的艺术P1基础—2.3 类之间的关系 在软件系统中,类并不是孤立存在的,类与类之间存在各种关系。对于不同类型的关系,UML提供了不同的表示方式 1.关联关系 关联(Association)关系是类与类之间最常用…...

工业无人机行业研究:预计2025年将达到108.2亿美元
近年来,在技术进步和各行各业对无人驾驶飞行器 (UAV) 不断增长的需求的推动下,工业无人机市场一直在快速增长。该市场有望在未来几年继续其增长轨迹,许多关键趋势和因素推动其发展。 在全球范围内,工业无人机市场预计到 2025 年将…...

PCA主成分分析算法
在数据分析中,如果特征太多,或者特征之间的相关性太高,通常可以用PCA来进行降维。比如通过对原有10个特征的线性组合, 我们找出3个主成分,就足以解释绝大多数的方差,该算法在高维数据集中被广泛应用。 算法(…...
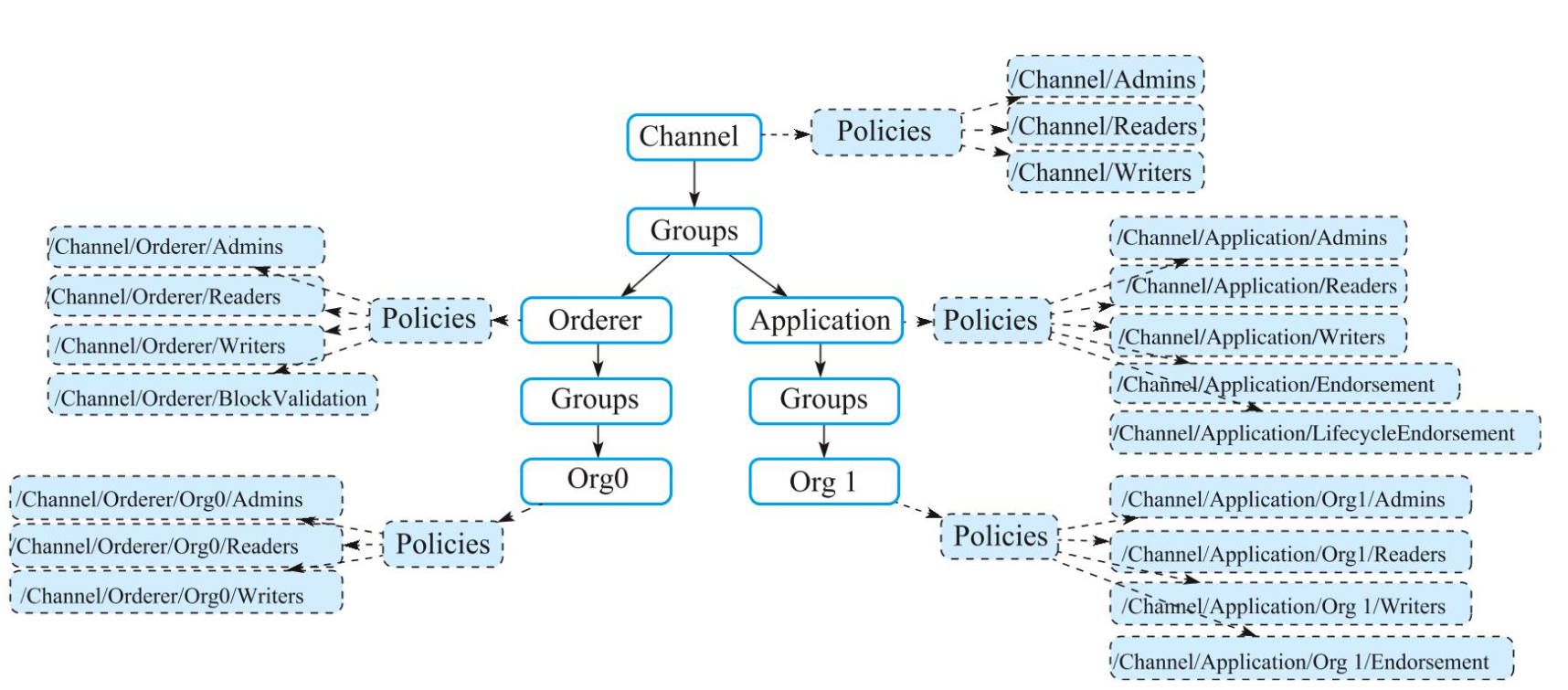
Hyperledger Fabric 权限策略和访问控制
访问控制是区块链网络十分重要的功能,负责控制某个身份在某个场景下是否允许采取某个操作(如读写某个资源)。 常见的访问控制模型包括强制访问控制(Mandatory Access Control)、自主访问控制(Discretionar…...

Day28 回溯算法part04 93. 复原IP地址 78. 子集 90. 子集 II
回溯算法part04 93. 复原IP地址 78. 子集 90. 子集 II 93. 复原 IP 地址 class Solution { private:vector<string> result;bool isValid(string& s,int start,int end){if (start > end) return false;if (s[start] 0 && start ! end) { // 0开头的数…...

Linux系统常用的安全优化
环境:CentOS7.9 1、禁用SELinux SELinux是美国国家安全局对于强制访问控制的实现 1)永久禁用SELinux vim /etc/selinux/config SELINUXdisabled #必须重启系统才能生效2)临时禁用SELInux getenforce #查看SELInux当前状态 setenforce 0 #数字…...
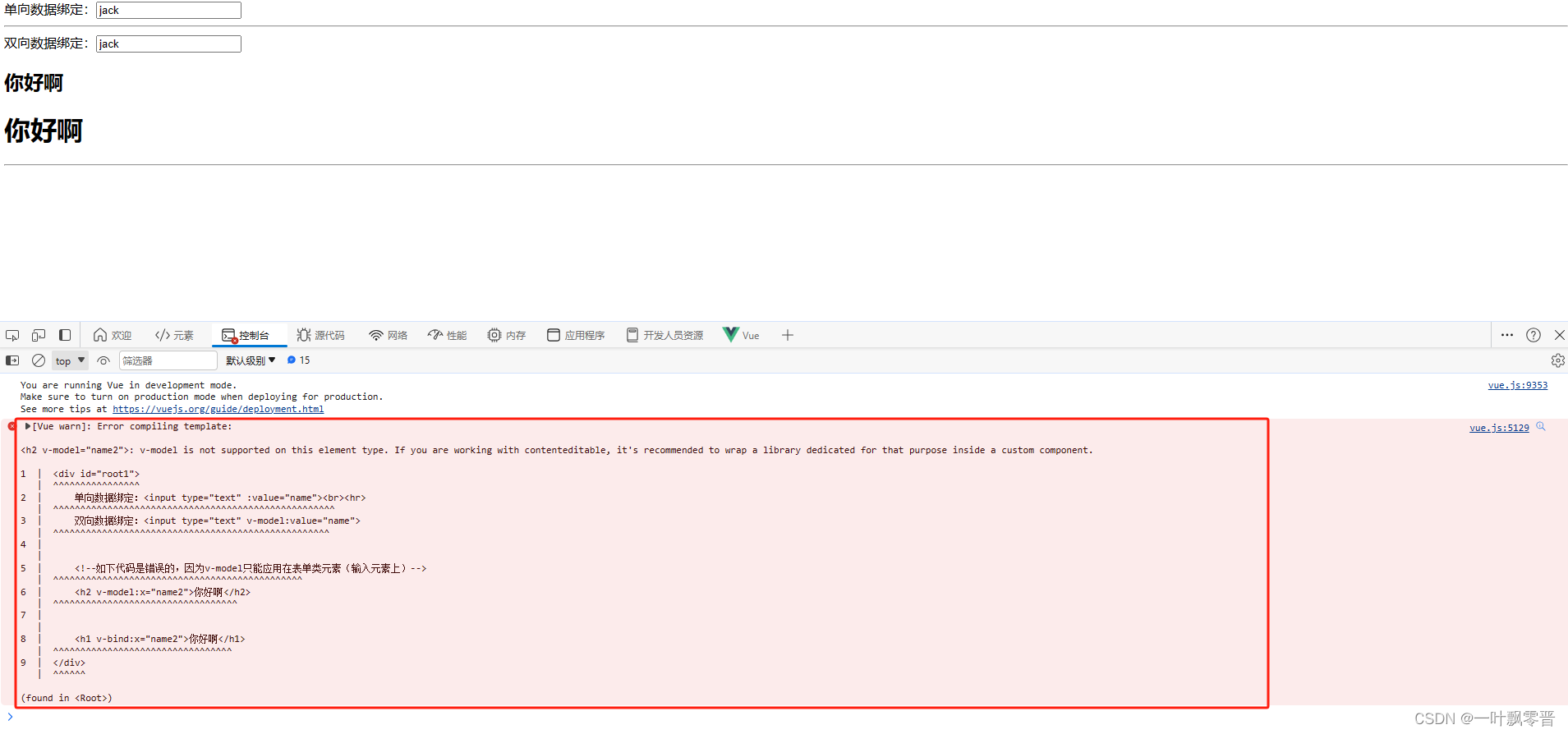
Vue-4、单向数据绑定与双向数据绑定
1、单向数据绑定 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>数据绑定</title><!--引入vue--><script type"text/javascript" src"https://cdn.jsdelivr.net/npm/…...

【Flutter 开发实战】Dart 基础篇:常用运算符
在Dart中,运算符是编写任何程序的基本构建块之一。本文将详细介绍Dart中常用的运算符,以帮助初学者更好地理解和运用这些概念。 1. 算术运算符 算术运算符用于执行基本的数学运算。Dart支持常见的加、减、乘、除、整除以及取余运算。常见的算数运算符如…...

C++:ifstream通过getline读取文件会忽略最后一行空行
getline是读取文件的常用函数,虽然使用简单,但是有一个较容易被忽视的问题,就是文件最后一行空行会被忽略。 #include <iostream> #include <fstream> #include <string> using namespace std;void readWholeFileWithGetline(string fileName) {string t…...

力扣123. 买卖股票的最佳时机 III
动态规划 思路: 最多可以完成两笔交易,因此任意一天结束后,会处于5种状态: 未进行任何操作;只进行了一次买操作;进行了一次买操作和一次卖操作;再完成了一次交易之后,进行了一次买操…...

Vue3:vue-cli项目创建
一、node.js检测或安装: node -v node.js官方 二、vue-cli安装: npm install -g vue/cli # OR yarn global add vue/cli/*如果安装的时候报错,可以尝试一下方法 删除C:\Users**\AppData\Roaming下的npm和npm-cache文件夹 删除项目下的node…...

C# .Net学习笔记—— 异步和多线程(Task)
一、概念 Task是DotNet3.0之后所推出的一种新的使用多线程的方式,它是基于ThreadPool线程进行封装的。 二、使用多线程的时机 任务能够并发运行的时候,提升速度;优化体验 三、基本使用方法 private void button5_Click(object sender, Ev…...
Python从入门到网络爬虫(读写Excel详解)
前言 Python操作Excel的模块有很多,并且各有优劣,不同模块支持的操作和文件类型也有不同。最常用的Excel处理库有xlrd、xlwt、xlutils、xlwings、openpyxl、pandas,下面是各个模块的支持情况: 工具名称.xls.xlsx获取文件内容写入…...
Mysql之子查询、连接查询(内外)以及分页查询
目录 一.案例(接上篇博客) 09)查询学过「张三」老师授课的同学的信息 10)查询没有学全所有课程的同学的信息 11)查询没学过"张三"老师讲授的任一门课程的学生姓名 12)查询两门及其以上不及格课程…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...