大创项目推荐 深度学习图像修复算法 - opencv python 机器视觉
文章目录
- 0 前言
- 2 什么是图像内容填充修复
- 3 原理分析
- 3.1 第一步:将图像理解为一个概率分布的样本
- 3.2 补全图像
- 3.3 快速生成假图像
- 3.4 生成对抗网络(Generative Adversarial Net, GAN) 的架构
- 3.5 使用G(z)生成伪图像
- 4 在Tensorflow上构建DCGANs
- 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 深度学图像修复算法
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 什么是图像内容填充修复
内容识别填充(译注: Content-aware fill ,是 photoshop
的一个功能)是一个强大的工具,设计师和摄影师可以用它来填充图片中不想要的部分或者缺失的部分。在填充图片的缺失或损坏的部分时,图像补全和修复是两种密切相关的技术。有很多方法可以实现内容识别填充,图像补全和修复。
- 首先我们将图像理解为一个概率分布的样本。
- 基于这种理解,学*如何生成伪图片。
- 然后我们找到最适合填充回去的伪图片。

自动删除不需要的部分(海滩上的人)

最经典的人脸补充
补充前:

补充后:

3 原理分析
3.1 第一步:将图像理解为一个概率分布的样本
你是怎样补全缺失信息的呢?
在上面的例子中,想象你正在构造一个可以填充缺失部分的系统。你会怎么做呢?你觉得人类大脑是怎么做的呢?你使用了什么样的信息呢?
在博文中,我们会关注两种信息:
语境信息:你可以通过周围的像素来推测缺失像素的信息。
感知信息:你会用“正常”的部分来填充,比如你在现实生活中或其它图片上看到的样子。
两者都很重要。没有语境信息,你怎么知道填充哪一个进去?没有感知信息,通过同样的上下文可以生成无数种可能。有些机器学*系统看起来“正常”的图片,人类看起来可能不太正常。
如果有一种确切的、直观的算法,可以捕获前文图像补全步骤介绍中提到的两种属性,那就再好不过了。对于特定的情况,构造这样的算法是可行的。但是没有一般的方法。目前最好的解决方案是通过统计和机器学习来得到一个类似的技术。
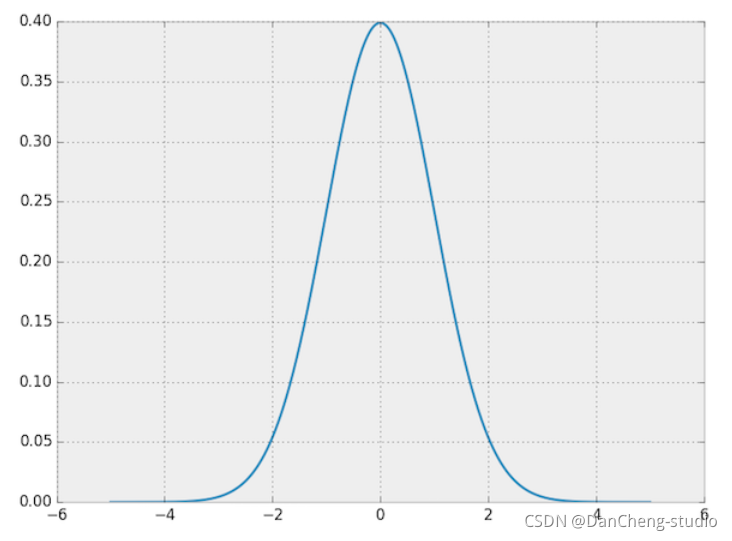
从这个分布中采样,就可以得到一些数据。需要搞清楚的是PDF和样本之间的联系。
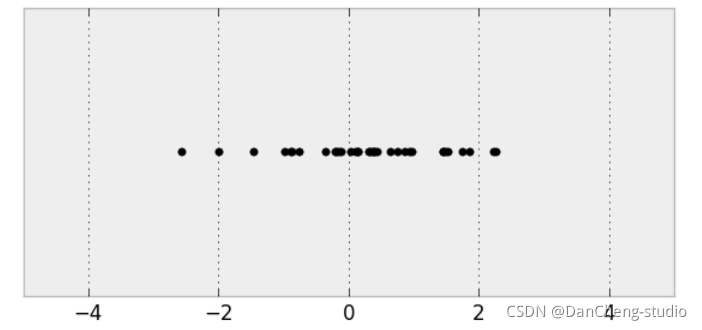
从正态分布中的采样
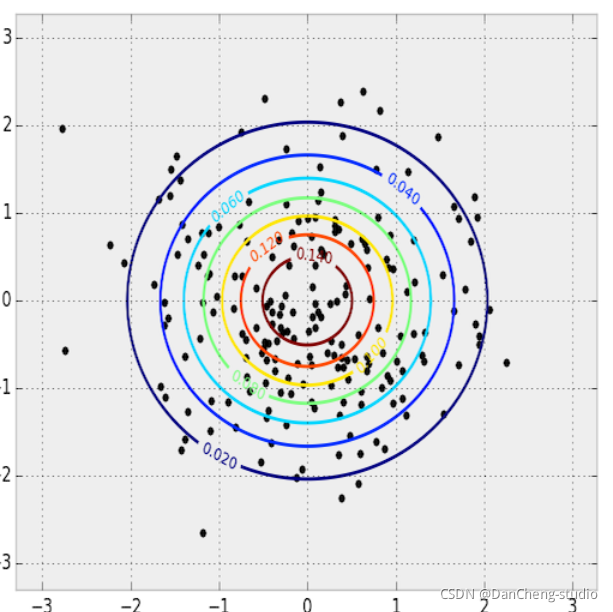
2维图像的PDF和采样。 PDF 用等高线图表示,样本点画在上面。
3.2 补全图像
首先考虑多变量正态分布, 以求得到一些启发。给定 x=1 , 那么 y 最可能的值是什么?我们可以固定x的值,然后找到使PDF最大的 y。
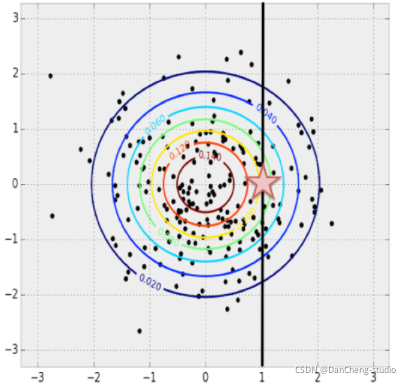
在多维正态分布中,给定x,得到最大可能的y
这个概念可以很自然地推广到图像概率分布。我们已知一些值,希望补全缺失值。这可以简单理解成一个最大化问题。我们搜索所有可能的缺失值,用于补全的图像就是可能性最大的值。
从正态分布的样本来看,只通过样本,我们就可以得出PDF。只需挑选你喜欢的 统计模型, 然后拟合数据即可。
然而,我们实际上并没有使用这种方法。对于简单分布来说,PDF很容易得出来。但是对于更复杂的图像分布来说,就十分困难,难以处理。之所以复杂,一部分原因是复杂的条件依赖:一个像素的值依赖于图像中其它像素的值。另外,最大化一个一般的PDF是一个非常困难和棘手的非凸优化问题。
3.3 快速生成假图像
在未知概率分布情况下,学习生成新样本
除了学 如何计算PDF之外,统计学中另一个成熟的想法是学 怎样用 生成模型
生成新的(随机)样本。生成模型一般很难训练和处理,但是后来深度学*社区在这个领域有了一个惊人的突破。Yann LeCun 在这篇 Quora
回答中对如何进行生成模型的训练进行了一番精彩的论述,并将它称为机器学习领域10年来最有意思的想法。
3.4 生成对抗网络(Generative Adversarial Net, GAN) 的架构
使用微步长卷积,对图像进行上采样
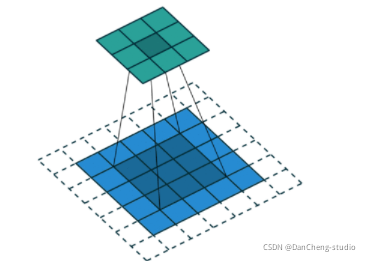
现在我们有了微步长卷积结构,可以得到G(z)的表达,以一个向量z∼pz 作为输入,输出一张 64x64x3 的RGB图像。
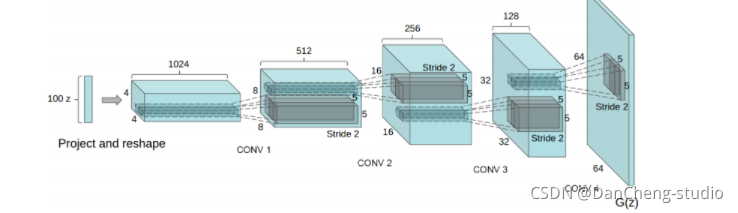
3.5 使用G(z)生成伪图像
基于DCGAN的人脸代数运算 DCGAN论文 。

4 在Tensorflow上构建DCGANs
部分代码:
def generator(self, z):self.z_, self.h0_w, self.h0_b = linear(z, self.gf_dim*8*4*4, 'g_h0_lin', with_w=True)self.h0 = tf.reshape(self.z_, [-1, 4, 4, self.gf_dim * 8])h0 = tf.nn.relu(self.g_bn0(self.h0))self.h1, self.h1_w, self.h1_b = conv2d_transpose(h0,[self.batch_size, 8, 8, self.gf_dim*4], name='g_h1', with_w=True)h1 = tf.nn.relu(self.g_bn1(self.h1))h2, self.h2_w, self.h2_b = conv2d_transpose(h1,[self.batch_size, 16, 16, self.gf_dim*2], name='g_h2', with_w=True)h2 = tf.nn.relu(self.g_bn2(h2))h3, self.h3_w, self.h3_b = conv2d_transpose(h2,[self.batch_size, 32, 32, self.gf_dim*1], name='g_h3', with_w=True)h3 = tf.nn.relu(self.g_bn3(h3))h4, self.h4_w, self.h4_b = conv2d_transpose(h3,[self.batch_size, 64, 64, 3], name='g_h4', with_w=True)return tf.nn.tanh(h4)def discriminator(self, image, reuse=False):if reuse:tf.get_variable_scope().reuse_variables()h0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2, name='d_h1_conv')))h2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4, name='d_h2_conv')))h3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8, name='d_h3_conv')))h4 = linear(tf.reshape(h3, [-1, 8192]), 1, 'd_h3_lin')return tf.nn.sigmoid(h4), h4
当我们初始化这个类的时候,将要用到这两个函数来构建模型。我们需要两个判别器,它们共享(复用)参数。一个用于来自数据分布的小批图像,另一个用于生成器生成的小批图像。
self.G = self.generator(self.z)
self.D, self.D_logits = self.discriminator(self.images)
self.D_, self.D_logits_ = self.discriminator(self.G, reuse=True)
接下来,我们定义损失函数。这里我们不用求和,而是用D的预测值和真实值之间的交叉熵(cross
entropy),因为它更好用。判别器希望对所有“真”数据的预测都是1,对所有生成器生成的“伪”数据的预测都是0。生成器希望判别器对两者的预测都是1 。
self.d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits,tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,tf.zeros_like(self.D_)))
self.g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,tf.ones_like(self.D_)))
self.d_loss = self.d_loss_real + self.d_loss_fake
下面我们遍历数据。每一次迭代,我们采样一个小批数据,然后使用优化器来更新网络。有趣的是,如果G只更新一次,鉴别器的损失不会变成0。另外,我认为最后调用
d_loss_fake 和 d_loss_real 进行了一些不必要的计算, 因为这些值在 d_optim 和 g_optim 中已经计算过了。
作为Tensorflow 的一个联系,你可以试着优化这一部分,并发送PR到原始的repo。
for epoch in xrange(config.epoch):...for idx in xrange(0, batch_idxs):batch_images = ...batch_z = np.random.uniform(-1, 1, [config.batch_size, self.z_dim]) \.astype(np.float32)# Update D network_, summary_str = self.sess.run([d_optim, self.d_sum],feed_dict={ self.images: batch_images, self.z: batch_z })# Update G network_, summary_str = self.sess.run([g_optim, self.g_sum],feed_dict={ self.z: batch_z })# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)_, summary_str = self.sess.run([g_optim, self.g_sum],feed_dict={ self.z: batch_z })errD_fake = self.d_loss_fake.eval({self.z: batch_z})errD_real = self.d_loss_real.eval({self.images: batch_images})errG = self.g_loss.eval({self.z: batch_z})最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
大创项目推荐 深度学习图像修复算法 - opencv python 机器视觉
文章目录 0 前言2 什么是图像内容填充修复3 原理分析3.1 第一步:将图像理解为一个概率分布的样本3.2 补全图像 3.3 快速生成假图像3.4 生成对抗网络(Generative Adversarial Net, GAN) 的架构3.5 使用G(z)生成伪图像 4 在Tensorflow上构建DCGANs最后 0 前言 &#…...

嵌入式系统复习--基于ARM的嵌入式程序设计
文章目录 上一篇编译环境ADS编译环境下的伪操作GNU编译环境下的伪操作ARM汇编语言的伪指令 汇编语言程序设计相关运算操作符汇编语言格式汇编语言程序重点C语言的一些技巧 下一篇 上一篇 嵌入式系统复习–Thumb指令集 编译环境 ADS/SDT IDE开发环境:它由ARM公司开…...

【C++入门到精通】异常 | 异常的使用 | 自定义异常体系 [ C++入门 ]
阅读导航 引言一、C异常的概念二、异常的使用1. 异常的抛出和捕获(1)throw(2)try-catch(3)catch(. . .)(4)异常的抛出和匹配原则(5)在函数调用链中异常栈展开…...
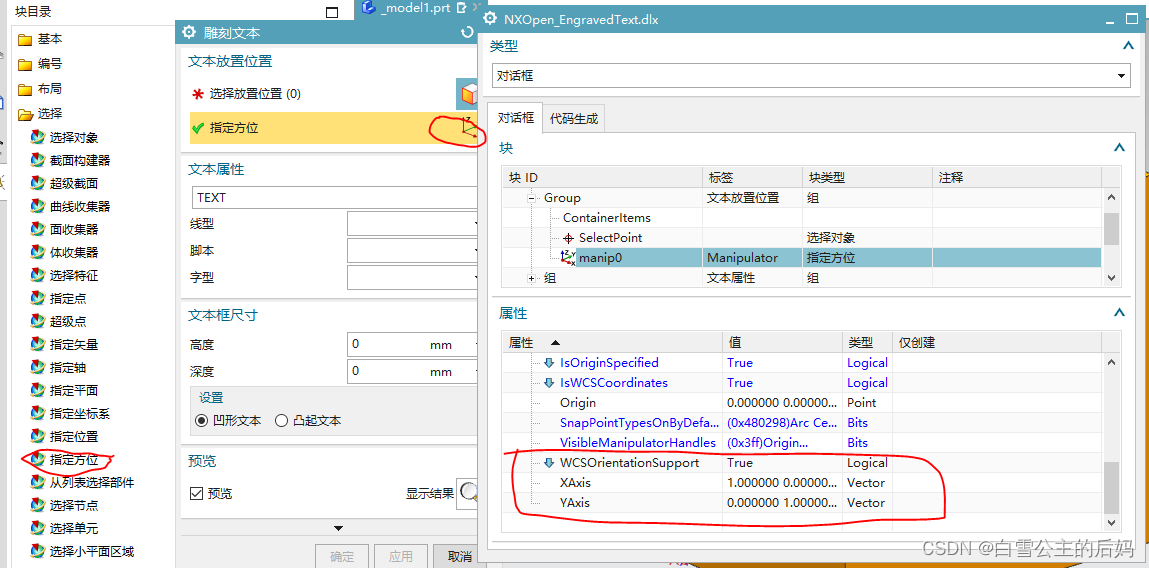
NX二次开发 Block UI 指定方位控件的应用
一、概述 NX二次开发中一般都是多个控件的组合,这里我首先对指定方位控件进行说明并结合选择对象控件,具体如下图所示。 二、实现功能获取方位其在选择面上原点的目标 2.1 在initialize_cb()函数中进行初始化,实现对象选择过滤面 //过滤平…...

2024年【R2移动式压力容器充装】模拟考试及R2移动式压力容器充装实操考试视频
题库来源:安全生产模拟考试一点通公众号小程序 2024年【R2移动式压力容器充装】模拟考试及R2移动式压力容器充装实操考试视频,包含R2移动式压力容器充装模拟考试答案和解析及R2移动式压力容器充装实操考试视频练习。安全生产模拟考试一点通结合国家R2移…...
)
数仓工具—Hive进阶之StorageHandler(23)
Storage Handler 引入Storage Handler,Hive用户使用SQL的方式读写外部数据源, 例如ElasticSearch、 Kafka、HBase等数据源的查询对非专业开发是有一定门槛的,借助Storage Handler,他们有了一种方便快捷的手段查询数据,Storage Handler作为Hive的存储插件,我们需要的时候直…...

科技创新创业
科技创新创业是一个涉及多个方面的过程,主要包括以下几个方面: 创意产生:创业的起始点通常是一个新的创意或想法,这可能是一个新的产品、服务或技术的概念。这个创意需要独特且具有商业潜力。市场调研:一旦有了创意&a…...

高校电力能耗监测精细化管理系统,提升能源利用效率的利器
电力是高校不可离开的重要能源,为学校相关管理人员提供在线用能查询统计等服务。通过对学校照明用电、空调用电等数据的采集、监控、分析,为学校电能管理制定合理的能源政策提供参考。同时,也可以培养学生的节能意识,学校后勤电力…...

Java_Swing程序设计
swing组件允许编程人员在跨平台时指定统一的外观和风格。 Swing组件通常被称为轻量级组件, JFrame在程序中的语法格式: JFrame jfnew JFrame(title); Container containerjf.getContentPane(); jf:JFrame类的对象 container:Container类的对象。 J…...

ZeroBind:DTI零样本预测器
现有的药物-靶点相互作用(DTI)预测方法通常无法很好地推广到新的(unseen)蛋白质和药物。 在这项研究中,作者提出了一种具有子图匹配功能的蛋白质特异性元学习框架 ZeroBind,用于根据其结构预测蛋白质-药物相…...

Win10子系统Ubuntu实战(一)
在 Windows 10 中安装 Ubuntu 子系统(Windows Subsystem for Linux,简称 WSL)有几个主要的用途和好处:Linux 环境的支持、跨平台开发、命令行工具、测试和验证、教育用途。总体而言,WSL 提供了一种将 Windows 和 Linux…...
 质量刚体的在坐标系下运动)
[足式机器人]Part3 机构运动学与动力学分析与建模 Ch00-2(3) 质量刚体的在坐标系下运动
本文仅供学习使用,总结很多本现有讲述运动学或动力学书籍后的总结,从矢量的角度进行分析,方法比较传统,但更易理解,并且现有的看似抽象方法,两者本质上并无不同。 2024年底本人学位论文发表后方可摘抄 若有…...

云计算历年题整理
目录 第一大题 第一大题HA计算 给出计算连接到EC2节点的EBS的高可用性(HA)的数学公式,如场景中所述;计算EC2节点上的EBS的高可用性(HA);场景中80%的AWS EC2节点用于并行处理,总共有100个虚拟中央处理单元(vCPUs)用于处理数据&a…...

2401vim,vim重要修改更新大全
原文 2023 更好的UTF-16支持 添加strutf16len()和utf16idx(),并在byteidx(),byteidxcomp()和charidx()中添加utf16标志,在内置.txt文档中. 添加crypymethod xchacha20v2 与xchacha20基本相同,但更能抵御libsodium的变化. 2022 添加"smoothscroll" 用鼠标滚动…...

安卓多用户管理之Userinfo
目录 前言Userinfo----用户信息1.1 属性1.2 构造器1.3 信息的判断及获取方法1.3.1 获取默认用户类型1.3.2 基础信息判断 1.4 序列化部分 总结 前言 UserManagerService内部类UserData中有一个Userinfo类型的info参数,在UserData中并未有所体现,但在后续…...

JavaScript-流程控制-笔记
1.流程语句的分类 顺序结构 分支结构 循环结构 2.if语句 1)if结构 if( 条件 ){ // 条件成立执行的代码 } 2)if else 结构 if( 条件 ){ // 条件成立执行的代码 }else{ // 条件不成…...

springboot + vue3实现增删改查分页操作
springboot vue3实现增删改查分页操作 环境最终实现效果实现功能主要框架代码实现数据库后端前端 注意事项 环境 jdk17 vue3 最终实现效果 实现功能 添加用户,禁用,启用,删除,编辑,分页查询 主要框架 后端 spri…...

leetcode01-重复的子字符串
题目链接:459. 重复的子字符串 - 力扣(LeetCode) 一般思路: 如果存在k是S的字串,记k的长度为s,S的长度为n,则一定有n是s的倍数,且满足对于j∈[s,n],一定存在s[j]s[j-s]; …...

目标检测数据集 - 夜间行人检测数据集下载「包含VOC、COCO、YOLO三种格式」
数据集介绍:夜间、低光行人检测数据集,真实场景高质量图片数据,涉及场景丰富,比如夜间街景行人、夜间道路行人、夜间遮挡行人、夜间严重遮挡行人数据;适用实际项目应用:公共场所监控场景下夜间行人检测项目…...
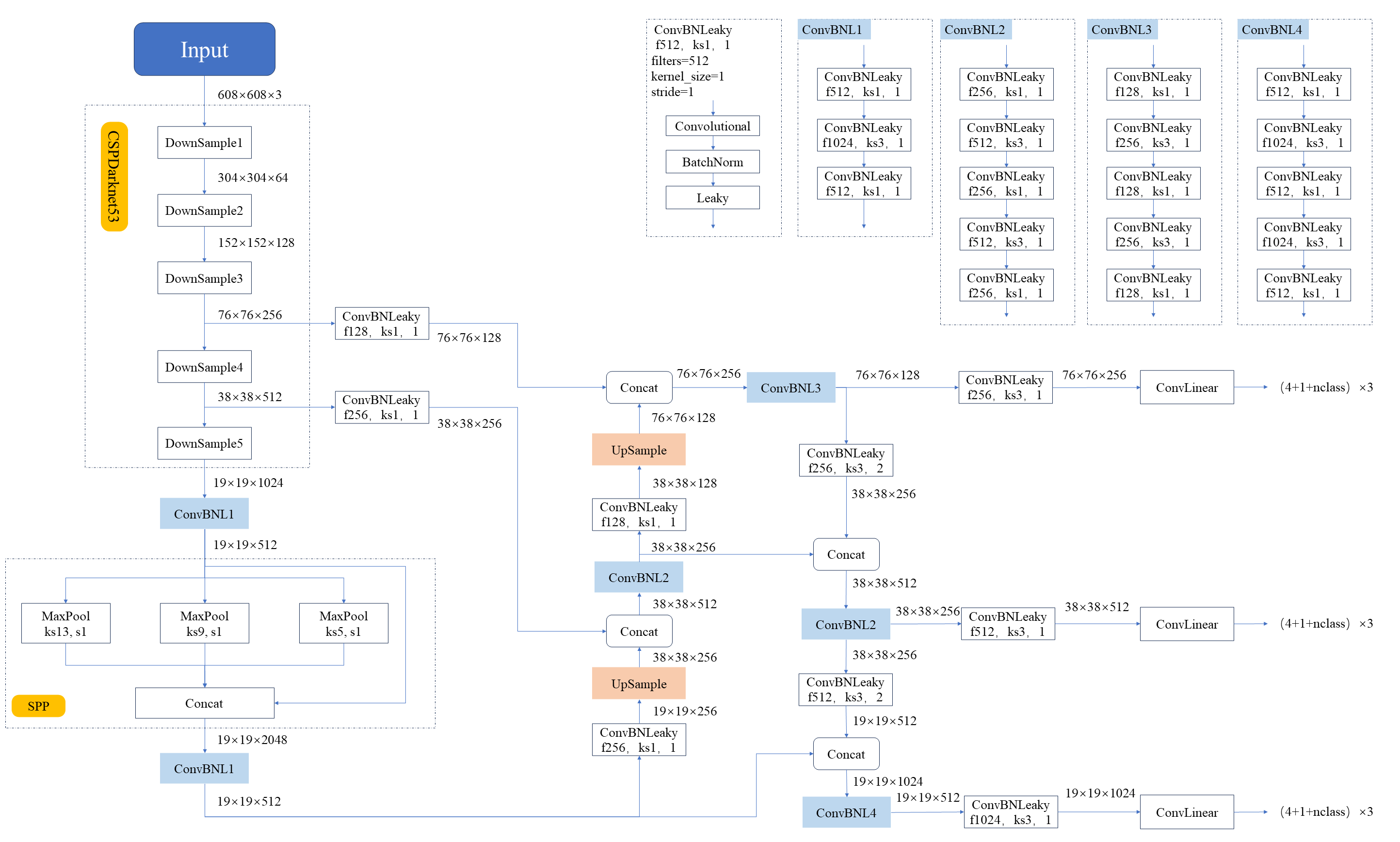
【YOLO系列】 YOLOv4思想详解
前言 以下内容仅为个人在学习人工智能中所记录的笔记,先将目标识别算法yolo系列的整理出来分享给大家,供大家学习参考。 本文未对论文逐句逐段翻译,而是阅读全文后,总结出的YOLO V4论文的思路与实现路径。 若文中内容有误…...

2026年怎么搭建OpenClaw?阿里云及Coding Plan配置详细步骤
2026年怎么搭建OpenClaw?阿里云及Coding Plan配置详细步骤。OpenClaw作为阿里云生态下新一代的开源AI自动化代理平台,曾用名Moltbot/Clawdbot,凭借“自然语言交互自动化任务执行大模型智能决策”的核心能力,正在重构个人与企业的工…...
实战:利用MBIST BAP接口,在用户模式下快速完成内存健康诊断)
芯片自检(In-System Test)实战:利用MBIST BAP接口,在用户模式下快速完成内存健康诊断
芯片内存健康诊断实战:基于MBIST BAP接口的低延迟自检方案 在汽车电子和工业控制领域,系统运行时的内存可靠性直接关系到功能安全。想象一下,当一辆高速行驶的电动汽车突然遭遇内存位翻转错误,或者一台工业机器人因存储单元失效而…...

ClawDen:基于Node.js的配置驱动网页自动化与数据抓取框架实战
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫 ClawDen。乍一看这个名字,可能有点摸不着头脑,但如果你对自动化测试、网页数据抓取或者RPA(机器人流程自动化)感兴趣,那这个项目绝对值得你花时…...

基于Godot与C#的开源进化模拟游戏Thrive开发全解析
1. 项目概述:一个基于科学的进化模拟游戏 如果你对生命如何从单细胞演化到复杂多细胞生物体的过程感到好奇,或者你一直想亲手“设计”一个属于自己的生态系统,那么 Thrive 这款游戏可能就是你一直在寻找的答案。作为一名长期关注模拟与策略游…...

长芯微LMD9245完全P2P替代AD9245,14位、20/40/65/80MSPS模数转换器ADC
描述长芯微LMD9245是一款单芯片、14位、20 MSPS/40 MSPS/65 MSPS/80 MSPS模数转换器(ADC),采用3 V单电源供电,内置一个高性能采样保持放大器(SHA)和基准电压源。它采用多级差分流水线架构,内置输…...

扩散模型在图像编辑中的应用与优化实践
1. 扩散模型与图像编辑的技术融合去年我在处理一批商业摄影素材时,客户突然要求将照片中的阴天背景替换成阳光明媚的沙滩场景。传统Photoshop处理需要数小时精细修图,而使用扩散模型技术,我在15分钟内就输出了自然逼真的合成效果。这种技术革…...

终于不用手搓两级缓存了!C#.NET HybridCache 详解:L1 L2、标签失效与防击穿实战
简介 很多项目一开始做缓存,通常都是这么写的: 先查 IMemoryCache -> 没有再查 Redis -> 还没有就查数据库 -> 再把结果写回两层缓存刚开始看起来没什么问题。 但只要项目一复杂,这套逻辑很快就会变得又长又散: 每个地方…...

3步解锁老旧Mac新生命:OpenCore Legacy Patcher硬件适配全指南
3步解锁老旧Mac新生命:OpenCore Legacy Patcher硬件适配全指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能依然强劲但被苹…...

R-KV分布式键值存储:基于Raft与Multi-Raft的架构设计与工程实践
1. 项目概述与核心价值最近在分布式存储和缓存领域,一个名为R-KV的项目引起了我的注意。这个项目由 Zefan-Cai 发起,定位为一个“基于 Raft 共识算法的分布式键值存储系统”。听起来是不是有点耳熟?没错,它瞄准的是类似 etcd、TiK…...

Human-MCP:基于MCP协议的人机协作框架,让AI助手安全调用人类执行操作
1. 项目概述:当AI助手学会“动手”最近在折腾AI Agent和工具调用时,发现了一个让我眼前一亮的项目:mrgoonie/human-mcp。简单来说,这是一个“人机协作协议”(Human-MCP)的实现,它能让像Claude、…...