简单易懂的PyTorch激活函数大全详解
目录
torch.nn子模块Non-linear Activations
nn.ELU
主要特点与注意事项
使用方法与技巧
示例代码
图示
nn.Hardshrink
Hardshrink函数定义
参数
形状
示例代码
图示
nn.Hardsigmoid
Hardsigmoid函数定义
参数
形状
示例代码
图示
nn.Hardtanh
HardTanh函数定义
参数
形状
示例代码
图示
nn.Hardswish
Hardswish函数定义
参数
形状
示例代码
图示
nn.LeakyReLU
LeakyReLU函数定义
参数
形状
示例代码
图示
nn.LogSigmoid
LogSigmoid函数定义
形状
示例代码
图示
nn.MultiheadAttention
多头注意力的定义
参数
示例
nn.PReLU
PReLU函数定义
参数
形状
变量
示例
图示
nn.ReLU
ReLU函数定义
参数
形状
示例
图示
nn.ReLU6
ReLU6函数定义
参数
形状
示例
图示
nn.RReLU
RReLU函数定义
参数
形状
示例
图示
nn.SELU
SELU函数定义
参数
形状
示例
图示
nn.CELU
CELU函数定义
参数
形状
示例
图示
nn.GELU
GELU函数定义
参数
形状
示例
图示
nn.Sigmoid
Sigmoid函数定义
形状
示例
图示
nn.SiLU
SiLU函数定义
形状
示例
图示
nn.Mish
Mish函数定义
形状
示例
图示
nn.Softplus
Softplus函数定义
参数
形状
示例
图示
nn.Softshrink
Softshrink函数定义
参数
形状
示例
图示
nn.Softsign
Softsign函数定义
形状
示例
图示
nn.Tanh
Tanh函数定义
形状
示例
图示
nn.Tanhshrink
Tanhshrink函数定义
形状
示例
图示
nn.Threshold
Threshold函数定义
参数
形状
示例
nn.GLU
GLU函数定义
参数
形状
示例
总结
torch.nn子模块Non-linear Activations
nn.ELU
PyTorch中的torch.nn.ELU函数是一个神经网络层,用于应用指数线性单元(Exponential Linear Unit, ELU)激活函数。这个函数首次由Clevert等人在论文《Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)》中提出。ELU激活函数旨在解决传统ReLU激活函数中的某些问题,比如不活跃的神经元问题。
主要特点与注意事项
-
定义:当输入
x大于0时,ELU函数输出值为x本身;当x小于或等于0时,输出为α * (exp(x) - 1)。这里的α是ELU函数的一个参数,通常默认为1.0。 -
参数:
alpha:控制负输入值的饱和度。默认为1.0。inplace:若设置为True,将会直接在输入数据上进行操作,从而减少内存占用。但这可能会对原始数据产生不可预知的影响。默认为False。
-
形状:
- 输入:任意形状。
- 输出:与输入形状相同。
-
使用场景:适用于需要激活函数的神经网络层,特别是在深度学习模型中,以增加非线性。
-
注意事项:
- 使用
inplace=True时需谨慎,因为这可能会改变原始数据。 - 在某些情况下,ELU可能比ReLU激活函数更难优化,因为它的输出对负输入值是非零的。
- 使用
使用方法与技巧
- 初始化:在定义神经网络模型时,通过
nn.ELU()来创建ELU层。 - 配置参数:根据需要调整
alpha值以控制负输入值的饱和度。
示例代码
下面是一个使用torch.nn.ELU的简单例子,展示了如何在PyTorch模型中实现和使用ELU激活函数:
import torch
import torch.nn as nn# 创建一个ELU激活函数层
elu = nn.ELU(alpha=1.0, inplace=False)# 创建一个随机输入数据
input_data = torch.randn(2)# 应用ELU激活函数
output = elu(input_data)print("Input:", input_data)
print("Output:", output)
在这个例子中,我们首先导入了必要的PyTorch库,然后创建了一个ELU激活函数层,并对一个随机生成的输入数据进行了处理。最后,我们打印出输入和经过ELU激活函数处理后的输出。这个示例是在PyTorch框架下使用ELU激活函数的基本方式。
图示

这个图是一个二维平面图,显示了ELU(Exponential Linear Unit)激活函数的图形表示。图的X轴表示输入值,Y轴表示ELU函数的输出值。在X轴的正半轴上,即输入值大于0时,ELU函数的输出与输入值相同,因此图形呈现出一条穿过原点的直线,斜率为1。在X轴的负半轴上,即输入值小于或等于0时,ELU函数的输出变为一个渐进的曲线,这部分曲线逐渐接近但不会触及Y轴下方的水平线,这条水平线对应于α * (exp(x) - 1)当x接近负无穷大时的极限值。
图形的标题是“ELU(alpha=1.0)”,指出了这个图是在α值设定为1.0的情况下绘制的。整个图表背景是网格线,有助于观察和估计函数在特定输入值下的输出值。图形的曲线以蓝色显示,整体上呈现出ELU激活函数典型的非线性特性,即在正值区域保持线性,在负值区域提供平滑的非线性过渡。
nn.Hardshrink
PyTorch的torch.nn.Hardshrink函数是一个神经网络层,用来应用硬收缩(Hardshrink)函数。这个函数是一个阈值激活函数,通常用在神经网络的正则化过程中,可以在训练过程中帮助减少微小的权重,促进模型的简化和稀疏性。
Hardshrink函数定义
Hardshrink函数的行为如下:
- 当输入
x大于阈值λ时,输出等于输入x。 - 当输入
x小于负的阈值-λ时,输出也等于输入x。 - 在其他情况下,输出为0。
这意味着Hardshrink函数会将所有绝对值小于λ的输入“收缩”为0,而保持其他输入不变。这可以被看作是一种过滤噪声或非重要特征的方式。
参数
lambd(浮点数):用于Hardshrink公式的λ值,默认为0.5。这个值决定了何时激活一个神经元,何时将其输出设置为0。
形状
- 输入:任意形状的张量。
- 输出:与输入相同形状的张量。
示例代码
以下是如何使用torch.nn.Hardshrink的一个例子:
import torch
import torch.nn as nn# 创建Hardshrink层,设置λ=0.5
hardshrink = nn.Hardshrink(lambd=0.5)# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 通过Hardshrink层处理输入
output_tensor = hardshrink(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
这段代码首先导入了PyTorch和它的神经网络模块。然后创建了一个Hardshrink层,其λ值默认为0.5。接着,生成了一个包含两个随机数的张量作为输入,并通过Hardshrink层处理。最后,输出了原始输入张量和处理后的输出张量,可以观察到绝对值小于0.5的输入值被置为0。
图示
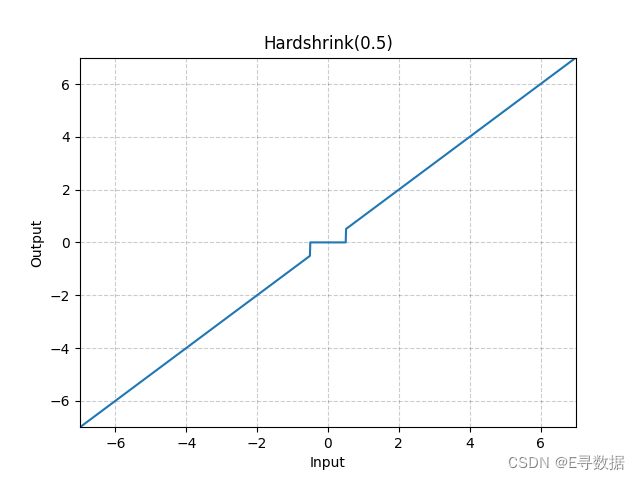
上传的图形是一个二维坐标系上的图示,展现了Hardshrink函数的特性。图中X轴表示输入值,Y轴表示经过Hardshrink函数处理后的输出值。
从图中可以看出,Hardshrink函数对于绝对值大于0.5的输入,直接输出该输入值,这部分曲线与45度角直线一致,穿过第一和第三象限。对于绝对值小于0.5的输入,输出值为0,这在图中表现为X轴上-0.5到0.5之间的一段水平线。图形的标题“Hardshrink(0.5)”表示λ值为0.5。
总的来说,Hardshrink函数在λ的阈值范围内将输入“硬性切断”为0,而在阈值外保持输入不变。这种特性使得Hardshrink函数在去除小幅度信号或实现稀疏表示方面非常有用。
nn.Hardsigmoid
torch.nn.Hardsigmoid是PyTorch神经网络模块中的一个激活函数,用于逐元素(element-wise)应用Hardsigmoid函数。Hardsigmoid函数是Sigmoid激活函数的一个分段线性近似,通常计算更快,且在硬件上更易于实现。
Hardsigmoid函数定义
Hardsigmoid函数定义如下:
- 当输入
x小于或等于-3时,输出为0。 - 当输入
x大于或等于+3时,输出为1。 - 在其他情况下,输出为
x/6 + 1/2。
这个定义使得Hardsigmoid函数在输入值远离0点时产生饱和效应,即当输入值超出某个范围时,输出值会被限制在0和1之间。在中间区域,输出值随输入值线性变化。
参数
inplace(布尔值):可以选择是否就地(in-place)进行操作。默认为False。当设置为True时,操作会直接在输入数据上进行,从而减少内存消耗。但是,这可能会对原始数据造成破坏。
形状
- 输入:任意维度的张量。
- 输出:与输入同形状的张量。
示例代码
以下是如何使用torch.nn.Hardsigmoid的一个例子:
import torch
import torch.nn as nn# 创建Hardsigmoid激活函数层
hardsigmoid = nn.Hardsigmoid()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 通过Hardsigmoid层处理输入
output_tensor = hardsigmoid(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,首先导入了必要的PyTorch库和神经网络模块。然后实例化了一个Hardsigmoid激活函数层。创建了一个含有两个随机数值的张量作为输入,并通过Hardsigmoid激活函数层进行处理。最后,打印了输入张量和输出张量,可以看到输入值在不同范围内如何被转换成输出值。
图示
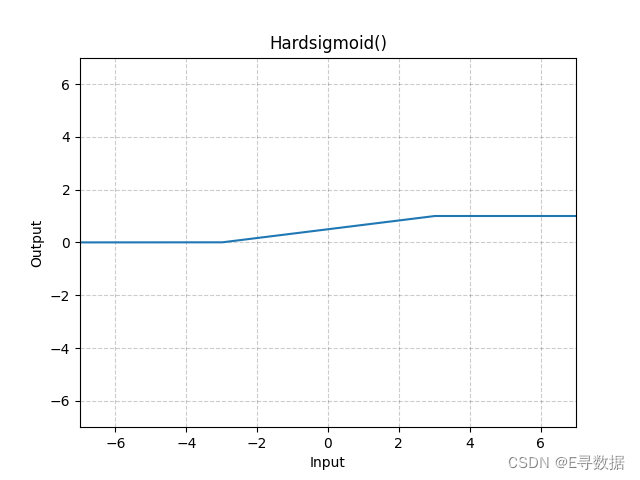
这张图展示了Hardsigmoid激活函数的图形。X轴代表输入值,Y轴代表Hardsigmoid函数处理后的输出值。
从图形可以看出以下几点:
- 当输入值小于-3时(X轴的-3左侧),输出值保持为0,这对应于Hardsigmoid函数定义中的下限饱和区域。
- 当输入值大于+3时(X轴的+3右侧),输出值保持为1,这是Hardsigmoid函数定义中的上限饱和区域。
- 在输入值介于-3到+3之间时,输出值是输入值的线性函数,具体是
x/6 + 1/2。这导致了图中从X轴-3到+3的斜率变化,输出值从0平滑过渡到1。
整体而言,图形显示了Hardsigmoid函数作为一种分段线性函数的特征,与传统Sigmoid函数相比,它在计算上更简单,易于优化。图形的标题“Hardsigmoid()”表明这是一个不带参数的Hardsigmoid函数标准图形。
nn.Hardtanh
torch.nn.Hardtanh是PyTorch中的一个神经网络模块,它提供了HardTanh激活函数的实现。HardTanh是Tanh(双曲正切)激活函数的分段线性版本,经常用于神经网络中以增加非线性,同时保持计算的高效性。
HardTanh函数定义
HardTanh函数的行为如下:
- 当输入
x大于max_val时,输出为max_val。 - 当输入
x小于min_val时,输出为min_val。 - 在其他情况下,输出为输入
x本身。
这个函数通过限制输出值在一个指定的范围内,为输入值提供了硬饱和。
参数
min_val(浮点数):线性区域范围的最小值,默认为-1。max_val(浮点数):线性区域范围的最大值,默认为1。inplace(布尔值):可以选择是否就地(in-place)进行操作,这会直接在输入数据上修改,减少内存占用,但会破坏原数据。默认为False。
min_value和max_value是过时的关键字参数,现在应使用min_val和max_val。
形状
- 输入:可以是任意维度的张量。
- 输出:与输入相同形状的张量。
示例代码
下面是使用torch.nn.Hardtanh的一个示例:
import torch
import torch.nn as nn# 创建Hardtanh激活函数层,指定最小值和最大值
hardtanh = nn.Hardtanh(min_val=-2, max_val=2)# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用Hardtanh激活函数
output_tensor = hardtanh(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,我们首先导入了必要的库,然后创建了一个Hardtanh激活函数层,其中min_val设置为-2,max_val设置为2。接下来,生成了一个随机张量作为输入,并通过Hardtanh层处理。最后,打印出输入和输出张量,可以观察到输入值在[-2, 2]的范围内是线性的,在这个范围外则被裁剪到-2或2。
图示
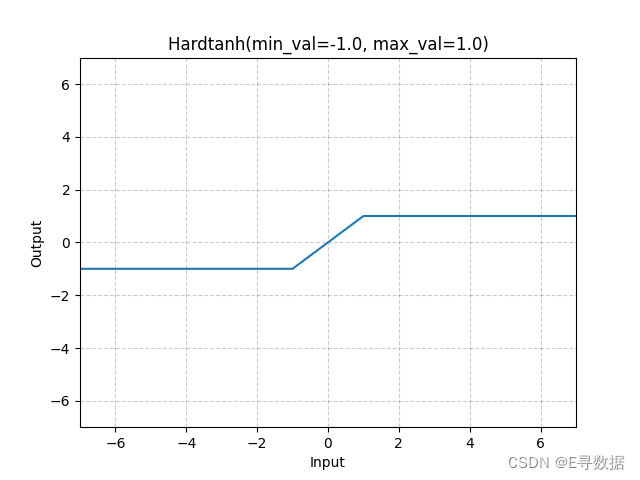
这张图展示了Hardtanh激活函数的图形。X轴代表输入值,Y轴代表Hardtanh函数处理后的输出值。
从图中可以看出:
- 当输入值小于-1时,输出值保持在-1,这部分是图中的水平线段,位于X轴左侧。
- 当输入值大于1时,输出值保持在1,这部分是图中的另一个水平线段,位于X轴右侧。
- 在输入值介于-1到1之间时,输出值与输入值相同,这部分是图中的斜线段,穿过原点。
图表的标题“Hardtanh(min_val=-1.0, max_val=1.0)”表明了这个函数的两个参数min_val和max_val分别被设置为-1.0和1.0。总体上,Hardtanh函数提供了一个输出值在[-1, 1]范围内的有界线性区域,并且在这个区间之外将输入值限制在这个范围的上下限值。这样的特性使Hardtanh函数在深度学习中被用来避免梯度爆炸并加速训练。
nn.Hardswish
torch.nn.Hardswish是PyTorch神经网络模块中的一个激活函数,它提供了Hardswish函数的实现。Hardswish是在Google的论文《Searching for MobileNetV3》中提出的,被设计用于更高效的深度学习模型,尤其是在移动和边缘设备上。
Hardswish函数定义
Hardswish函数的行为如下:
- 当输入
x小于或等于-3时,输出为0。 - 当输入
x大于或等于+3时,输出为x。 - 在其他情况下,输出为
x * (x + 3) / 6。
这个函数提供了一个平滑的非线性激活函数,与ReLU类似,但是在接近0的区域内提供了一些梯度,从而避免了ReLU的一些潜在问题。
参数
inplace(布尔值):可以选择是否就地(in-place)进行操作。默认为False。当设置为True时,操作会直接在输入数据上进行,从而减少内存消耗,但会破坏原数据。
形状
- 输入:任意维度的张量。
- 输出:与输入同形状的张量。
示例代码
以下是使用torch.nn.Hardswish的一个示例:
import torch
import torch.nn as nn# 创建Hardswish激活函数层
hardswish = nn.Hardswish()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用Hardswish激活函数
output_tensor = hardswish(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在这段代码中,我们导入了PyTorch及其神经网络模块,然后创建了一个Hardswish激活函数层。接着,我们创建了一个随机数值的张量作为输入,通过Hardswish激活函数层进行处理。最后,打印出了输入和经过激活函数处理后的输出张量,从中可以观察到输入值在不同区间内的变化。
图示
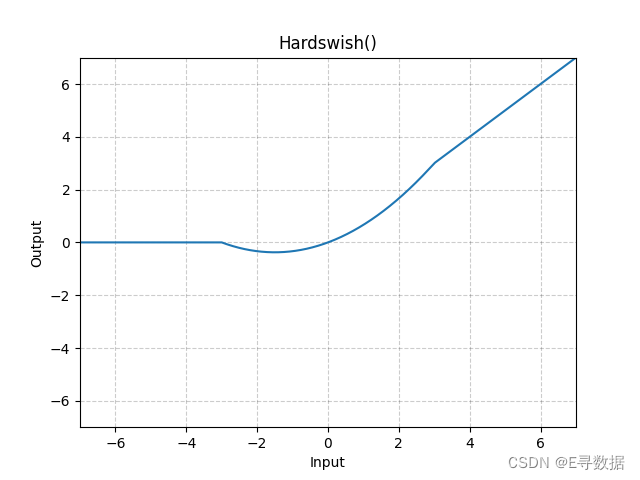
这张图展示了Hardswish激活函数的曲线。X轴代表输入值,而Y轴代表Hardswish函数处理后的输出值。
从图中可以看出:
- 当输入值小于或等于-3时(X轴左侧的部分),输出保持为0,这对应Hardswish函数中的第一个条件。
- 当输入值介于-3和+3之间时,输出是输入值的一个缩放版,并且向上平移,这符合Hardswish函数的第三个条件,即
x * (x + 3) / 6,导致曲线在这个区间内平滑地从0过渡到正值。 - 当输入值大于或等于+3时(X轴右侧的部分),输出值与输入值相等,这对应Hardswish函数中的第二个条件。
总的来说,图形显示了Hardswish函数提供的平滑非线性激活,它在负值区域开始为0,然后随着输入值增加而渐进地增加,直到输入值大于+3时,输出值直接等于输入值,这种特性使得Hardswish激活函数在某些场合比标准的ReLU函数更受欢迎。图表的标题“Hardswish()”表明这是标准的Hardswish激活函数,没有自定义参数。
nn.LeakyReLU
torch.nn.LeakyReLU 是 PyTorch 神经网络模块中的一个激活函数,用于在神经网络中逐元素应用LeakyReLU函数。LeakyReLU是ReLU(修正线性单元)激活函数的变种,其目的是解决ReLU激活函数在训练期间神经元“死亡”(输出始终为零)的问题。
LeakyReLU函数定义
LeakyReLU函数的行为如下:
- 当输入
x大于或等于0时,输出为x。 - 当输入
x小于0时,输出为x乘以一个小的正斜率(negative_slope)。
形式上,函数可以表示为:
LeakyReLU(x) = max(0, x) + negative_slope * min(0, x)
或者等价的分段函数形式:
LeakyReLU(x) = { x if x >= 0, negative_slope * x otherwise }
参数
negative_slope(浮点数):控制负斜率的角度,用于输入值为负时。默认值为0.01。inplace(布尔值):可选地进行就地操作。默认值为False。
形状
- 输入:任意形状的张量。
- 输出:与输入相同形状的张量。
示例代码
下面是使用torch.nn.LeakyReLU的一个示例:
import torch
import torch.nn as nn# 创建LeakyReLU激活函数层,设置negative_slope参数
leaky_relu = nn.LeakyReLU(negative_slope=0.1)# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用LeakyReLU激活函数
output_tensor = leaky_relu(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,我们首先导入了必要的库,然后创建了一个LeakyReLU激活函数层,其中negative_slope参数设置为0.1。这表示对于输入值小于0的元素,它们的输出将会被该系数缩小,而不是直接设置为0。接下来,我们创建了一个随机数值的张量作为输入,并通过LeakyReLU层处理。最后,打印出了输入和输出张量,可以观察到负输入值经过处理后被缩小了,而正输入值保持不变。
图示
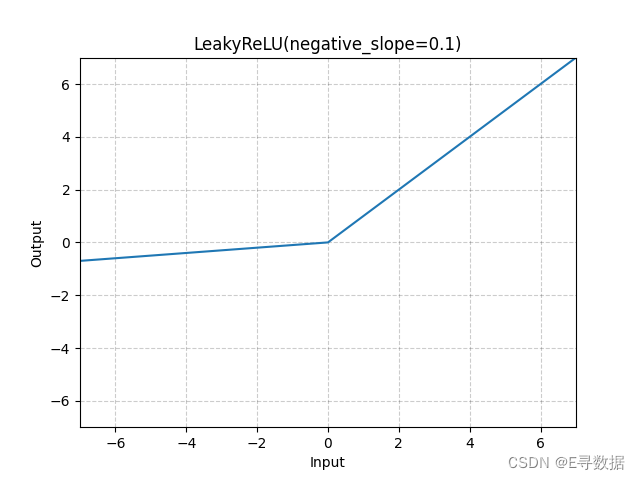
这张图展示了LeakyReLU激活函数的图形,其中负斜率(negative_slope)参数设置为0.1。X轴代表输入值,Y轴代表LeakyReLU函数处理后的输出值。
图中显示了LeakyReLU函数的两个主要特点:
- 对于所有大于0的输入值(X轴的正值部分),输出与输入相同,这部分的函数图形是一条通过原点的斜率为1的直线。
- 对于小于0的输入值(X轴的负值部分),输出是输入值的0.1倍,这部分的函数图形是一条更平缓的线,斜率为0.1。
图形上方的标题“LeakyReLU(negative_slope=0.1)”指出了使用的激活函数及其参数。总体上,LeakyReLU通过为负输入值提供一个小的非零斜率,避免了ReLU函数中的神经元死亡问题,允许梯度在负区域传播,有助于保持神经网络的活性。
nn.LogSigmoid
torch.nn.LogSigmoid 是 PyTorch 神经网络模块中提供的一个激活函数。它对输入张量逐元素应用LogSigmoid激活函数。LogSigmoid函数是Sigmoid激活函数的对数版本,它能够将输入值映射到一个平滑的梯度,有利于防止梯度消失的问题,特别是在训练深度神经网络时。
LogSigmoid函数定义
LogSigmoid函数定义如下:
LogSigmoid(x) = log(1 / (1 + exp(-x)))
这个函数实际上是计算Sigmoid函数的输出的对数。由于对数函数在0到1范围内是单调的,因此LogSigmoid能够保留Sigmoid函数将输入挤压到(0, 1)区间的性质,同时在梯度下降过程中提供更平滑的梯度。
形状
- 输入:可以是任意维度的张量。
- 输出:与输入相同形状的张量。
示例代码
以下是如何使用torch.nn.LogSigmoid的一个示例:
import torch
import torch.nn as nn# 创建LogSigmoid激活函数层
log_sigmoid = nn.LogSigmoid()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用LogSigmoid激活函数
output_tensor = log_sigmoid(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,首先导入了PyTorch及其神经网络模块,然后创建了一个LogSigmoid激活函数层。接着,我们创建了一个随机数值的张量作为输入,并通过LogSigmoid层处理。最后,打印出了输入和输出张量,展示了LogSigmoid激活函数将输入映射到对数空间后的结果。
图示
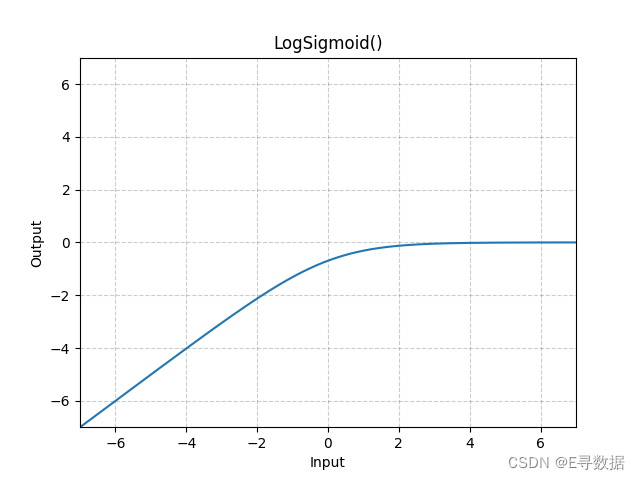
这张图展示了LogSigmoid激活函数的图形。X轴代表输入值,而Y轴代表LogSigmoid函数处理后的输出值。
从图中可以看出:
- 当输入值非常负时(X轴的左侧部分),LogSigmoid的输出接近于0,但是输出是负无穷大,因为log函数在0附近趋于负无穷。
- 当输入值增加接近0时,输出值开始上升。
- 当输入值正且继续增大时(X轴的右侧部分),LogSigmoid的输出增加速度减慢,并且开始趋于平稳。这是因为随着Sigmoid函数输出接近1时,其对数将接近0。
总体上,LogSigmoid函数提供了一个在负无穷到0的平滑过渡,这有助于梯度下降算法稳定地更新权重,特别是在梯度值较小的情况下。图形上方的标题“LogSigmoid()”表明这是标准的LogSigmoid激活函数,没有自定义参数。
nn.MultiheadAttention
torch.nn.MultiheadAttention 是 PyTorch 中实现的多头注意力(Multi-Head Attention)机制,这种机制首次在论文 "Attention Is All You Need" 中被提出。多头注意力是一种机制,它允许模型在不同的表示子空间中联合注意(即同时处理)信息,这是现代 Transformer 架构的核心组件之一。
多头注意力的定义
多头注意力的定义是:
- 对于给定的查询(Q)、键(K)和值(V),将它们与不同的权重矩阵
相乘,得到不同头的表示。
- 每个头计算出的注意力
。
- 所有头计算的注意力通过拼接(Concat)后,再乘以输出权重矩阵
得到最终的输出。
参数
embed_dim:模型的总维度。num_heads:并行注意力头的数量。注意,embed_dim将在num_heads之间分割(即每个头的维度将是embed_dim // num_heads)。dropout:在 attn_output_weights 上应用的 Dropout 概率。默认为 0.0(无dropout)。bias:如果指定,会添加到输入/输出投影层的偏置。默认为 True。add_bias_kv:如果指定,在dim=0上为键和值序列添加偏置。默认为 False。add_zero_attn:如果指定,在dim=1上为键和值序列添加一批零。默认为 False。kdim:键的特征总数。默认为 None(使用 kdim=embed_dim)。vdim:值的特征总数。默认为 None(使用 vdim=embed_dim)。batch_first:如果为 True,则输入和输出张量的格式为(批次,序列,特征)。默认为 False(序列,批次,特征)。
示例
import torch
import torch.nn as nn# 初始化多头注意力层
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)# 随机生成query, key, value张量
query = torch.randn(seq_length, batch_size, embed_dim)
key = torch.randn(seq_length, batch_size, embed_dim)
value = torch.randn(seq_length, batch_size, embed_dim)# 应用多头注意力层
attn_output, attn_output_weights = multihead_attn(query, key, value)
在上面的示例中,query、key和value张量需要具有合适的形状,以便与多头注意力层的参数相匹配。attn_output 是注意力操作的输出,attn_output_weights 是注意力权重。
当使用多头注意力层时,可以通过设置不同的参数来控制模型的行为,例如调整注意力头的数量或改变dropout率以防止过拟合。该层通常用于自注意力场景,即 query、key 和 value 是同一个张量的情况,这是 Transformer 架构中的常见用法。此外,根据输入和训练/推理模式的不同,该层可以使用优化的 scaled_dot_product_attention() 实现,以加速推理过程。
nn.PReLU
torch.nn.PReLU 是 PyTorch 中实现的参数化修正线性单元(Parametric Rectified Linear Unit,PReLU)激活函数。PReLU 是 ReLU 激活函数的一种推广,允许负输入值时的斜率也能够通过学习得到,而不是被设为固定的0。
PReLU函数定义
PReLU函数定义如下:
- 当输入
x大于等于 0 时,输出为x。 - 当输入
x小于 0 时,输出为a * x。
其中 a 是可学习的参数。
参数
num_parameters(int):要学习的a的数量。尽管它接受一个整数作为输入,但只有两个值是合法的:1,或输入通道的数量。默认值为 1。init(float):a的初始值。默认值为 0.25。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
变量
weight(Tensor):可学习的权重,形状为(num_parameters)。
示例
import torch
import torch.nn as nn# 初始化PReLU层
m = nn.PReLU()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用PReLU激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述示例代码中,m 是一个 PReLU 激活函数层,其中 a 的数量为默认值 1,初始值为 0.25。然后创建了一个随机数值的张量 input_tensor 作为输入,并通过 PReLU 层进行处理。由于 a 是可学习的,所以在训练过程中,网络可以调整这个参数,以改进模型对数据的拟合能力。
注意,在学习 a 时不应该使用权重衰减(weight decay),因为这可能会影响学习性能。通常,当输入张量的维度小于 2 时,不存在通道维度,这种情况下通道数为 1。在具有更多维度的输入上使用 PReLU,num_parameters 可以设置为通道数,允许每个通道有其自己的 a 值。
图示
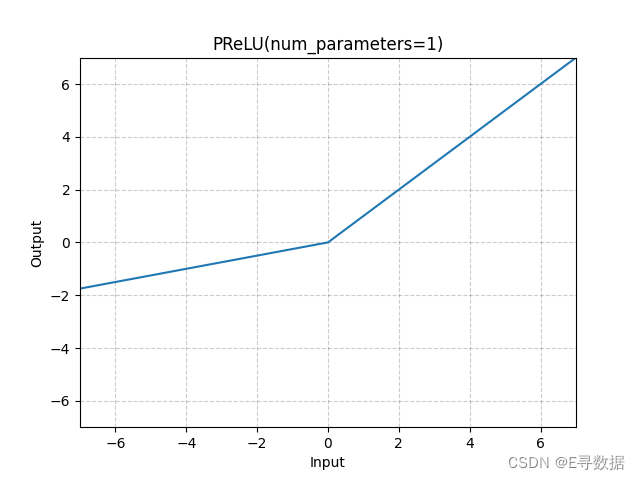
这张图展示了Parametric Rectified Linear Unit(PReLU)激活函数的图形,其中可学习参数的数量(num_parameters)被设置为1。X轴代表输入值,Y轴代表PReLU函数处理后的输出值。
从图中可以观察到以下特点:
- 当输入值大于或等于0时(X轴的正值部分),输出值与输入值相同,即函数图形是一条通过原点的斜率为1的直线。
- 当输入值小于0时(X轴的负值部分),输出值是输入值的线性函数,具有一个比1小的正斜率。这个斜率是可学习参数
a的值,由于这里num_parameters=1,所有通道共享同一个a参数。
图形的标题“PReLU(num_parameters=1)”表明这是一个使用单一可学习参数 a 的PReLU函数。这种激活函数允许负输入值时有一个非零的梯度,这可以帮助在训练深度神经网络时防止激活单元“死亡”。
nn.ReLU
torch.nn.ReLU 是 PyTorch 神经网络模块中的一个激活函数,它逐元素地应用修正线性单元(Rectified Linear Unit,ReLU)函数。
ReLU函数定义
ReLU函数定义如下:
ReLU(x) = max(0, x)
- 当输入
x大于或等于 0 时,输出为x。 - 当输入
x小于 0 时,输出为 0。
参数
inplace(bool):可选参数,如果设为 True,则会直接在输入上进行修改,而不是创建新的输出张量。默认为 False。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化ReLU激活函数层
m = nn.ReLU()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用ReLU激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
ReLU 是神经网络中最常用的激活函数之一,因为它简单且计算效率高。ReLU 的主要优点是它能够解决梯度消失问题(在正区域),并且加速神经网络的收敛速度。
此外,ReLU的另一种变体是CReLU(Concatenated ReLU),它在原始ReLU的基础上,将输入的正部分和输入的负部分的相反数(通过ReLU后)拼接在一起。这种激活函数可以提供更丰富的特征表示,因为它同时保留了输入的正激活和负激活信息。在CReLU的实现中,通常需要对输入的负值部分也使用ReLU函数,然后将正部分的输出和负部分的输出拼接起来。在PyTorch中,这可以通过以下示例代码实现:
import torch
import torch.nn as nn# 初始化ReLU激活函数层
m = nn.ReLU()# 创建一个随机张量作为输入并增加一个维度
input_tensor = torch.randn(2).unsqueeze(0)# 应用CReLU激活函数
output_tensor = torch.cat((m(input_tensor), m(-input_tensor)), dim=1)print("Input:", input_tensor)
print("Output:", output_tensor)
在这段代码中,输入张量 input_tensor 通过 unsqueeze(0) 在第0维增加了一个维度,使其形状变为(1, 2),然后分别对原输入和其相反数应用ReLU,最后在第1维将两者的输出拼接起来,产生ReLU的输出。
图示
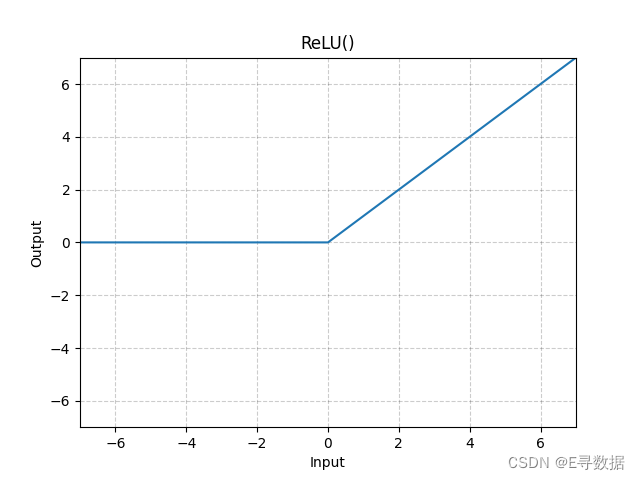
这张图展示了ReLU(Rectified Linear Unit)激活函数的图形。X轴代表输入值,Y轴代表ReLU函数处理后的输出值。
从图中可以观察到以下特点:
- 当输入值小于0时(X轴的负值部分),ReLU函数的输出为0,这部分的函数图形是一条位于X轴上的水平线。
- 当输入值大于或等于0时(X轴的正值部分),ReLU函数的输出与输入相同,这部分的函数图形是一条斜率为1的直线,即函数图形是一个45度角的直线。
图形上方的标题“ReLU()”表明这是标准的ReLU激活函数,没有自定义参数。ReLU激活函数因其简单性和效率而被广泛用于神经网络模型中,特别是在隐藏层中。它的主要优点是计算简单并且能够缓解梯度消失问题。
nn.ReLU6
torch.nn.ReLU6 是 PyTorch 中的一个激活函数,它逐元素地应用ReLU6函数。ReLU6是标准ReLU函数的一个变体,它限制了输出的最大值为6。这种激活函数在移动网络中比较流行,如MobileNet架构,因为它能够在不显著增加计算负担的情况下,减少模型的大小和提高运行速度。
ReLU6函数定义
ReLU6函数定义如下:
ReLU6(x) = min(max(0, x), 6)
- 当输入
x大于或等于 0 且小于或等于 6 时,输出为x。 - 当输入
x小于 0 时,输出为 0。 - 当输入
x大于 6 时,输出为 6。
参数
inplace(bool):如果设置为 True,则会直接在输入上进行修改,而不是额外创建一个输出张量。默认为 False。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化ReLU6激活函数层
m = nn.ReLU6()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用ReLU6激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述示例代码中,通过 nn.ReLU6() 创建了一个 ReLU6 激活函数层,然后生成了一个包含两个随机数的张量作为输入,并应用了 ReLU6 激活函数。ReLU6 函数将输入张量中所有小于0的值置为0,并将所有大于6的值置为6,输出张量将具有与输入相同的形状。
图示
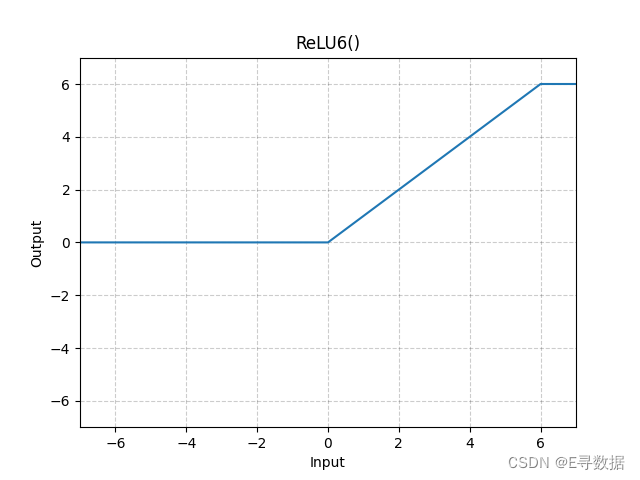
这张图展示了ReLU6激活函数的图形。X轴代表输入值,Y轴代表ReLU6函数处理后的输出值。
从图中可以看出ReLU6函数的特点:
- 当输入值小于0时(X轴的负值部分),输出值保持为0。
- 当输入值在0和6之间时,输出值与输入值相同,即在这个区间内,函数图形是一条斜率为1的直线。
- 当输入值大于6时,输出值保持为6,这部分是图中的水平线段,位于Y轴的6处。
图形上方的标题“ReLU6()”指明这是ReLU6激活函数的标准形式。ReLU6函数是ReLU函数的一个变体,它不仅将所有负输入截断为0,还将所有超过6的输入值截断为6,这有助于在某些情况下减少模型的过拟合。
nn.RReLU
torch.nn.RReLU 是 PyTorch 神经网络模块中的一个激活函数,它逐元素地应用随机泄露的整流线性单元(Randomized Leaky Rectified Linear Unit,RReLU)函数。RReLU 是 LeakyReLU 的一个随机变种,其负斜率 a 不是固定的,而是在训练期间从一个均匀分布中随机采样的。在测试时,a 是固定的,通常是 lower 和 upper 边界的平均值。
RReLU函数定义
RReLU函数的行为如下:
- 当输入
x大于或等于 0 时,输出为x。 - 当输入
x小于 0 时,输出为a * x,其中a是从均匀分布U(lower, upper)中随机采样的。
在训练期间,a 的值是随机的,帮助模型增加鲁棒性。在评估期间(例如,模型被设置为 .eval()),a 的值是固定的,等于 (lower + upper) / 2。
参数
lower(float):均匀分布的下界。默认为 1/8。upper(float):均匀分布的上界。默认为 1/3。inplace(bool):可以选择是否就地操作。默认为 False。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化RReLU激活函数层,指定lower和upper
m = nn.RReLU(0.1, 0.3)# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用RReLU激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个 RReLU 激活函数层,其中 lower 和 upper 分别被设置为 0.1 和 0.3。然后创建了一个随机数值的张量 input_tensor 作为输入,并通过 RReLU 层进行处理。在训练过程中,每个负输入的 a 值将从 [0.1, 0.3] 的均匀分布中随机采样。而在模型评估时,这些值将被固定为两者的平均值,即 0.2。
图示
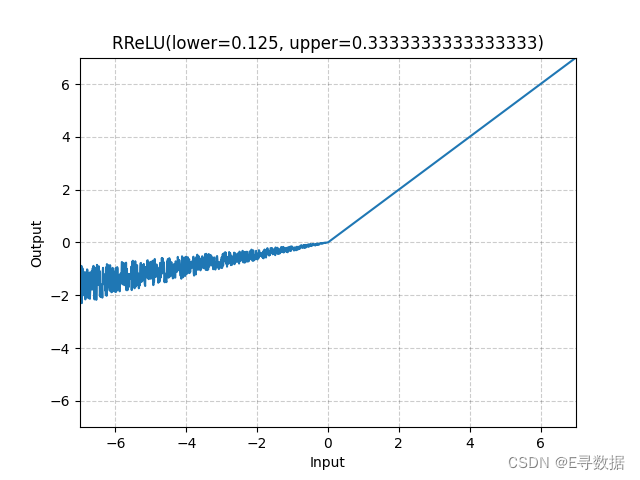
这张图展示了RReLU(Randomized Leaky Rectified Linear Unit)激活函数的图形。X轴代表输入值,Y轴代表RReLU函数处理后的输出值。
图中可以看出RReLU函数的主要特点:
- 当输入值大于或等于0时(X轴的正值部分),输出值与输入值相同,这部分的函数图形是一条斜率为1的直线。
- 当输入值小于0时(X轴的负值部分),输出值为输入值乘以一个小的正斜率。这个斜率在训练期间是从一个由
lower和upper参数定义的均匀分布中随机采样的,因此在图中呈现出许多不同斜率的线段。这些斜率的变化导致负输入部分的图形呈现出一种随机的、有噪声的外观。
图形上方的标题“RReLU(lower=0.125, upper=0.3333333333333333)”指明了定义RReLU行为的参数。在此示例中,lower参数为0.125,upper参数大约为0.333,这表明在训练期间对于每个负输入值,其斜率是在这两个值之间随机选取的。
总体而言,这种图形展示了RReLU函数在负输入值时可以增加模型的鲁棒性,因为它通过引入随机性来防止模型过于依赖于任何特定的激活路径。在评估或测试模式下,RReLU的行为类似于LeakyReLU,但斜率是lower和upper的平均值。
nn.SELU
torch.nn.SELU 是 PyTorch 神经网络模块中实现的激活函数,它逐元素地应用缩放指数线性单元(Scaled Exponential Linear Unit,SELU)。SELU 激活函数在论文 "Self-Normalizing Neural Networks" 中被提出,旨在通过激活函数自身的属性使神经网络的输出在训练过程中自我归一化,这有助于改善深层网络的训练过程。
SELU函数定义
SELU函数定义如下:
SELU(x) = scale * (max(0, x) + min(0, α * (exp(x) - 1)))
其中 α 和 scale 是预定义的常数,α ≈ 1.6732632423543772848170429916717 和 scale ≈ 1.0507009873554804934193349852946。
SELU函数的特点是在输入值为正时,它表现得像一个线性函数(带有scale缩放),而在输入值为负时,它是一个接近0的指数函数(也带有scale缩放和α偏移)。
参数
inplace(bool,可选):可以选择是否就地进行操作。默认为 False。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化SELU激活函数层
m = nn.SELU()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用SELU激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个 SELU 激活函数层,然后生成了一个包含两个随机数的张量 input_tensor 作为输入,并通过 SELU 层进行处理。SELU 激活函数会自动调整输入张量的值,使得经过训练的深度神经网络层的输出尽可能自我归一化,从而增强训练的稳定性。
在使用基于He初始化(也称为Kaiming初始化)方法时,如果目标是获得自归一化的网络属性,建议在 torch.nn.init 中将nonlinearity参数设置为 'linear' 而不是 'selu'。这是因为He初始化假定激活函数在负值时为0,而SELU在负值时不为0。
图示
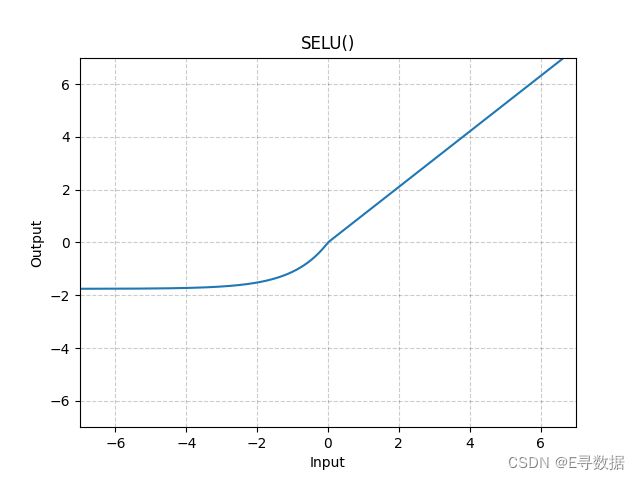
这张图展示了SELU(Scaled Exponential Linear Unit)激活函数的图形。X轴代表输入值,Y轴代表SELU函数处理后的输出值。
从图中可以看出SELU函数的特点:
- 当输入值大于或等于0时(X轴的正值部分),输出值与输入值相同,但经过一个固定的
scale因子放大,这部分的函数图形是一条斜率略大于1的直线。 - 当输入值小于0时(X轴的负值部分),输出值是负值部分的指数函数经过放大和偏移,其增长速度随着输入值的减小而减慢,趋向于一个负的饱和值。
图形上方的标题“SELU()”表明这是标准的SELU激活函数,没有自定义参数。SELU激活函数通过其自身的属性有助于神经网络层的输出自我归一化,这通常有助于改善深层网络的训练稳定性。在实际应用中,SELU激活函数可能有助于减少需要批量归一化的层数。
nn.CELU
torch.nn.CELU 是 PyTorch 神经网络模块中的一个激活函数,它逐元素地应用连续可微的指数线性单元(Continuously Differentiable Exponential Linear Unit,CELU)。CELU 是 ELU(Exponential Linear Unit)的一个变种,设计成在负值部分具有连续的梯度,这可以改善梯度下降的性能。
CELU函数定义
CELU函数定义如下:
CELU(x) = max(0, x) + min(0, α * (exp(x / α) - 1))
其中 α 是 CELU 函数的一个参数,它决定了激活函数在负值区域的饱和点。
参数
alpha(float):CELU公式中的α值。默认为 1.0。inplace(bool):可选参数,如果设为 True,则会直接在输入上进行修改,而不是创建新的输出张量。默认为 False。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化CELU激活函数层,指定alpha参数
m = nn.CELU(alpha=1.0)# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用CELU激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个 CELU 激活函数层,其中 alpha 参数被设置为默认值 1.0。然后创建了一个随机数值的张量 input_tensor 作为输入,并通过 CELU 层进行处理。CELU 函数将输入张量中所有大于0的值保持不变,并将所有小于0的值转换为 α * (exp(x / α) - 1),输出张量将具有与输入相同的形状。
图示
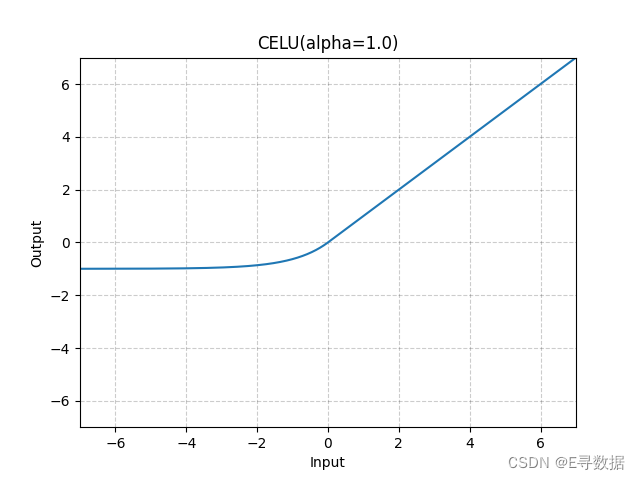
这张图展示了CELU(Continuously Differentiable Exponential Linear Unit)激活函数的图形,其中参数 alpha 被设置为1.0。X轴代表输入值,Y轴代表CELU函数处理后的输出值。
从图中可以观察到CELU函数的主要特点:
- 当输入值大于或等于0时(X轴的正值部分),输出值与输入值相同,这部分的函数图形是一条斜率为1的直线。
- 当输入值小于0时(X轴的负值部分),输出值是输入值经过一个指数函数变换后的结果。这部分的曲线表现出平滑过渡,随着输入值的减小而逐渐饱和,接近于
α * (exp(x / α) - 1)的值,由于alpha设置为1,这个表达式简化为(exp(x) - 1)。
图形上方的标题“CELU(alpha=1.0)”指明了使用的激活函数及其参数。CELU激活函数在负输入值时提供了平滑的非线性转换,这有助于改善神经网络在负值输入时的学习特性。与ELU类似,CELU旨在提供ReLU的一些优点,如减轻梯度消失问题,同时在负数区域提供更强的梯度信息。
nn.GELU
torch.nn.GELU 是 PyTorch 神经网络模块中的一个激活函数,它逐元素地应用高斯误差线性单元(Gaussian Error Linear Unit,GELU)函数。GELU 是一种基于高斯分布的非线性激活函数,被广泛用于最新的深度学习模型中,例如BERT语言模型。
GELU函数定义
GELU函数定义如下:
GELU(x) = x * Φ(x)
其中 Φ(x) 是高斯分布的累积分布函数(CDF)。
参数
approximate(str,可选):GELU近似算法的类型:'none' | 'tanh'。默认为 'none'。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化GELU激活函数层
m = nn.GELU()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用GELU激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个 GELU 激活函数层,然后生成了一个包含两个随机数的张量 input_tensor 作为输入,并通过 GELU 层进行处理。GELU 函数提供了一种平滑的非线性转换,它在输入的正负区域都提供了有用的梯度,且特别适合自然语言处理等任务。
如果使用 'tanh' 近似,GELU函数可以用以下公式表示:
GELU(x) ≈ 0.5 * x * (1 + tanh(sqrt(2/π) * (x + 0.044715 * x^3)))
这是一种近似计算,能够提高计算效率。
图示
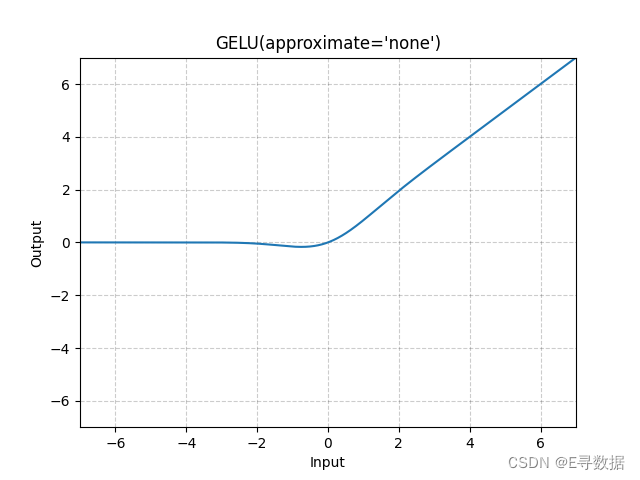
这张图展示了GELU(Gaussian Error Linear Unit)激活函数的图形,其中approximate参数被设置为'none',意味着这里使用的是GELU的精确形式而不是近似形式。X轴代表输入值,Y轴代表GELU函数处理后的输出值。
从图中可以观察到GELU函数的主要特点:
- 在输入值小于0的区域(X轴左侧),GELU函数提供了平滑的非线性转换,使输出值逐渐接近0,而非突然跳跃到0。
- 随着输入值从负向正增加,输出值开始增加,并在接近0的位置提供了平滑的曲线过渡。
- 在输入值大于0的区域(X轴右侧),输出值随输入值的增加而线性增加,但由于GELU的特性,增长速度略微低于输入值本身的增长速度。
图形上方的标题“GELU(approximate='none')”表明这是标准的GELU激活函数。GELU激活函数因其平滑的性质而在深度学习模型中受到青睐,尤其是在处理自然语言处理任务时。它能够在输入数据的正负区间内都提供有意义的梯度,从而有助于训练过程中的梯度传播。
nn.Sigmoid
torch.nn.Sigmoid 是 PyTorch 中的一个激活函数层,它逐元素地应用Sigmoid函数。Sigmoid函数是一个经典的激活函数,它将任意实数值映射到(0, 1)区间,常用于二分类问题的输出层。
Sigmoid函数定义
Sigmoid函数的数学表达式为:
Sigmoid(x) = σ(x) = 1 / (1 + exp(-x))
这个函数的输出值始终在0和1之间。
形状
- 输入:可以是任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化Sigmoid激活函数层
m = nn.Sigmoid()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用Sigmoid激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述示例中,m 是一个 Sigmoid 激活函数层。通过 nn.Sigmoid() 创建该层后,生成一个随机数值的张量 input_tensor 作为输入,并通过 Sigmoid 层进行处理。Sigmoid 函数将输入张量中的每个元素映射到(0, 1)区间,输出张量将具有与输入相同的形状。
Sigmoid函数在深度学习早期非常流行,但在现代深度学习模型中由于其一些缺点(如梯度消失问题)而逐渐被其他激活函数(如ReLU及其变种)所取代。尽管如此,它仍然在某些特定场合下(如输出层需要概率输出时)被使用。
图示
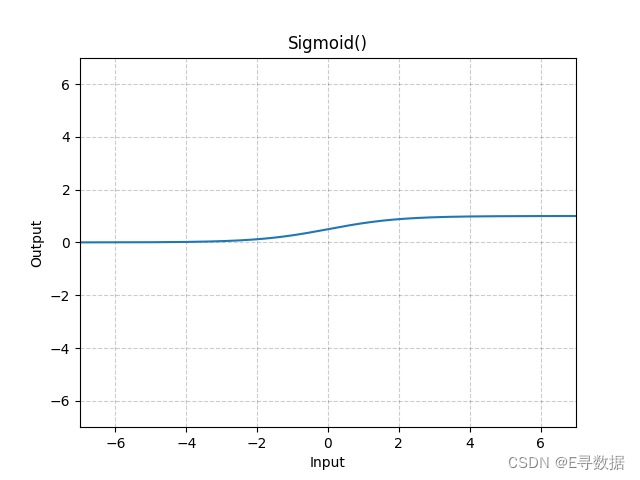
这张图展示了Sigmoid激活函数的图形。X轴代表输入值,Y轴代表Sigmoid函数处理后的输出值。
从图中可以观察到Sigmoid函数的特点:
- 当输入值远小于0时(X轴左侧),Sigmoid函数的输出接近于0。
- 当输入值远大于0时(X轴右侧),Sigmoid函数的输出接近于1。
- 在输入值接近0时(X轴中间部分),Sigmoid函数的输出从0平滑过渡到1,其中输出值0.5对应于输入值0。
图形上方的标题“Sigmoid()”表明这是标准的Sigmoid激活函数。Sigmoid激活函数因其S形曲线(Sigmoid曲线)而得名,它是最早用于神经网络的激活函数之一,特别是在二分类问题中,用于将输出映射到概率。
nn.SiLU
torch.nn.SiLU 是 PyTorch 神经网络模块中实现的一个激活函数,逐元素地应用Sigmoid Linear Unit(SiLU),也被称为swish函数。SiLU函数是一个平滑的非单调激活函数,它将Sigmoid函数与输入相乘,提供了ReLU函数的非饱和性质,并改善了训练过程。
SiLU函数定义
SiLU函数定义如下:
silu(x) = x * σ(x)
其中 σ(x) 是逻辑Sigmoid函数。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化SiLU激活函数层
m = nn.SiLU()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用SiLU激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个 SiLU 激活函数层。通过 nn.SiLU() 创建该层后,生成一个随机数值的张量 input_tensor 作为输入,并通过 SiLU 层进行处理。SiLU 函数将输入张量中的每个元素乘以Sigmoid函数的结果,输出张量将具有与输入相同的形状。
SiLU激活函数的一个特点是在输入值较大时它近似于线性,而在输入值较小时它接近于0,这个特性使得它可以自适应地调节激活门限。在一些最新的深度学习模型中,SiLU显示出了优于ReLU的性能。
图示
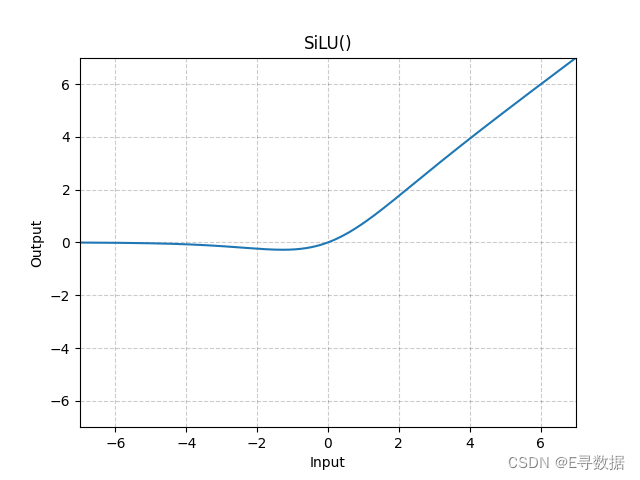
这张图展示了SiLU(Sigmoid Linear Unit)激活函数的图形。X轴代表输入值,Y轴代表SiLU函数处理后的输出值。
从图中可以观察到SiLU函数的主要特点:
- 在输入值小于0的区域(X轴左侧),SiLU函数提供了平滑的非线性转换,使输出值逐渐接近0,但不是突然跳跃到0。
- 在输入值为0附近,SiLU函数的输出从0平滑地上升,提供了一个非线性的过渡区域。
- 在输入值大于0的区域(X轴右侧),SiLU函数的输出开始类似线性增加,但由于Sigmoid函数的作用,输出值的增加速度略低于输入值的增加速度。
图形上方的标题“SiLU()”表明这是标准的SiLU激活函数。SiLU激活函数有助于在正区域内保持激活的同时,在负区域内引入非线性,它结合了ReLU的正区域属性与Sigmoid函数的平滑非线性特性。
nn.Mish
torch.nn.Mish 是 PyTorch 中的一个激活函数,它按元素应用Mish函数。Mish是一种相对较新的激活函数,它结合了TanH和Softplus函数的特点,以提供一种自我正则化的非单调激活函数。它被发现在多个任务中优于ReLU及其变体,如LeakyReLU和ELU。
Mish函数定义
Mish函数定义如下:
Mish(x) = x * Tanh(Softplus(x))
其中 Softplus(x) 是一个平滑的ReLU变体,定义为 log(1 + exp(x))。因此,Mish函数结合了Softplus提供的平滑阈值和TanH提供的非线性挤压效应。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化Mish激活函数层
m = nn.Mish()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用Mish激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个 Mish 激活函数层。通过 nn.Mish() 创建该层后,生成一个随机数值的张量 input_tensor 作为输入,并通过 Mish 层进行处理。Mish 函数将输入张量中的每个元素经过Softplus和TanH处理后乘以原始输入,输出张量将具有与输入相同的形状。
Mish函数由于其平滑性和自我正则化的特性,尤其在深度学习模型的训练中表现出色,有助于改善梯度流动并减少训练过程中的梯度消失问题。
图示
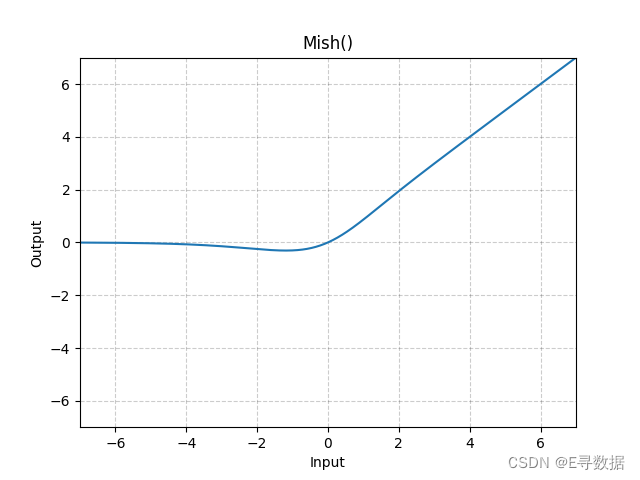
这张图展示了Mish激活函数的图形。X轴代表输入值,Y轴代表Mish函数处理后的输出值。
从图中可以观察到Mish函数的主要特点:
- 当输入值小于0时(X轴左侧),Mish函数提供平滑的非线性转换,使输出值逐渐接近0。由于Softplus函数的特性,输出值在负无穷时趋于0,而不是直接跳跃到0。
- 当输入值为0附近时,Mish函数的输出从0平滑地上升。
- 当输入值大于0时(X轴右侧),Mish函数的输出与输入值的增加而增加,但由于Tanh函数的作用,增加速度稍微慢于线性。
图形上方的标题“Mish()”表明这是标准的Mish激活函数。Mish激活函数是一种自我正则化的激活函数,它在正区域内近似线性,在负区域内提供非线性响应。Mish因其在训练深度网络时改善梯度流和减少梯度消失问题的能力而受到关注。
nn.Softplus
torch.nn.Softplus 是 PyTorch 中的一个激活函数,它按元素应用Softplus函数。Softplus函数是ReLU函数的平滑近似,可以用来确保机器输出始终为正值。
Softplus函数定义
Softplus函数定义如下:
Softplus(x) = (1 / β) * log(1 + exp(β * x))
其中 β 是函数的一个参数,它决定了函数近似ReLU的弯曲程度。当 β 的值越大,Softplus函数越接近ReLU函数。然而,为了数值稳定性,当输入乘以 β 大于 threshold 时,Softplus函数会转换为线性函数。
参数
beta(int):Softplus公式中的β值。默认值为 1。threshold(int):当输入乘以β超过这个阈值时,函数将变为线性。默认值为 20。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化Softplus激活函数层
m = nn.Softplus()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用Softplus激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个 Softplus 激活函数层。通过 nn.Softplus() 创建该层后,生成一个随机数值的张量 input_tensor 作为输入,并通过 Softplus 层进行处理。Softplus 函数将输入张量中的每个元素通过Softplus函数转换,使得输出张量的所有值都为正,且具有与输入相同的形状。
Softplus函数因其平滑性而在深度学习模型中得到了应用,尤其是在需要正输出的情况下,例如在模型中预测价格或概率时。
图示
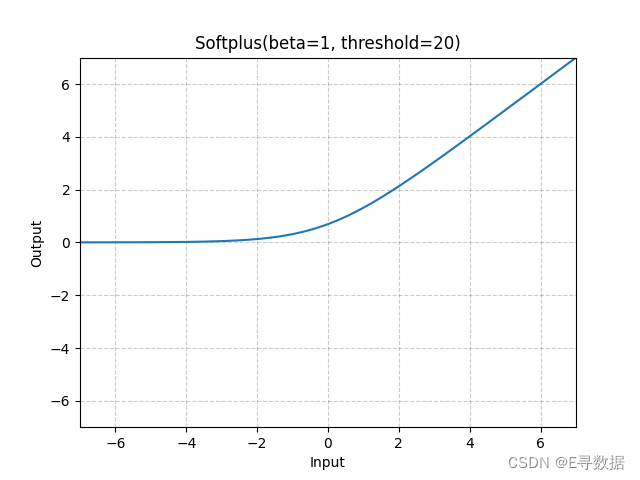
这张图展示了Softplus激活函数的图形,其中参数 beta 被设置为1,threshold 被设置为20。X轴代表输入值,Y轴代表Softplus函数处理后的输出值。
从图中可以看出Softplus函数的主要特点:
- 在输入值为负的区域(X轴左侧),Softplus函数的输出平滑且逐渐接近0。这表明对于负输入,激活函数输出一个接近于0的正值,而不是0,这有助于保持梯度流动。
- 在输入值为正的区域(X轴右侧),Softplus函数输出值随输入值的增加而增加,且增长速度逐渐接近线性。
- 函数图形整体呈现为平滑的曲线,逐渐从左侧的饱和区转变为右侧的线性区。由于
threshold被设置为20,所以在此输入范围内,我们不会看到函数转为线性的行为,该线性行为仅在更高的输入值(乘以beta超过threshold)时发生。
图形上方的标题“Softplus(beta=1, threshold=20)”明确了激活函数的参数设置。Softplus函数是ReLU函数的平滑版本,常被用于输出层以确保预测值始终为正,或在隐藏层中作为ReLU的替代,以提供更丰富的梯度信息。
nn.Softshrink
torch.nn.Softshrink 是 PyTorch 中的一个激活函数,按元素应用软缩减函数(Softshrinkage function)。
Softshrink函数定义
Softshrink函数定义如下:
SoftShrinkage(x) = { x - λ, if x > λ; x + λ, if x < -λ; 0, otherwise }
其中 λ(lambda)是软缩减公式中的参数,必须大于等于零。
参数
lambd(float):Softshrink公式中的λ值。默认为 0.5。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化Softshrink激活函数层
m = nn.Softshrink()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用Softshrink激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个Softshrink激活函数层,其中 λ 参数被设置为默认值0.5。然后创建了一个随机数值的张量 input_tensor 作为输入,并通过Softshrink层进行处理。Softshrink函数会将输入张量中所有绝对值大于 λ 的元素向零缩减 λ 的值,而将绝对值小于 λ 的元素置为0,从而得到输出张量。这种激活函数可以增加数据的稀疏性,有助于某些类型的模型,比如压缩感知和去噪任务。
图示
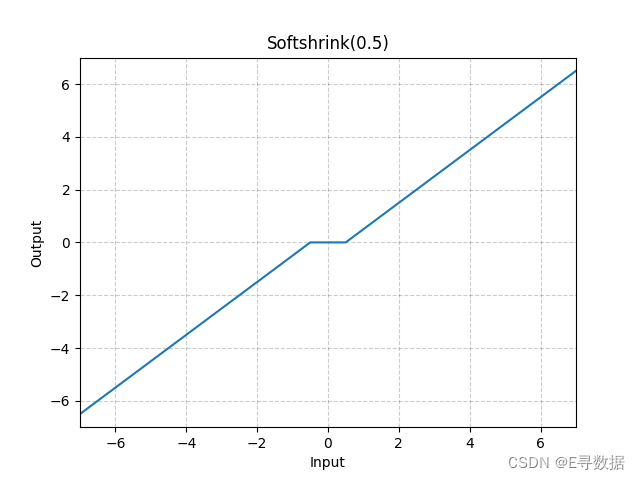
图片展示了Softshrink激活函数的图像,其中λ(lambda)值设置为0.5。图中的X轴表示输入值,Y轴表示Softshrink函数处理后的输出值。
从图中可以看出Softshrink函数的特点:
- 当输入值大于λ时(在这个例子中是0.5),输出值为输入值减去λ。
- 当输入值小于负λ时(在这个例子中是-0.5),输出值为输入值加上λ。
- 当输入值在-λ和λ之间时,输出值为0。
这种激活函数通常用于稀疏编码应用中,因为它可以抑制较小的值,仅保留较大的激活值,从而产生稀疏的激活模式。在图像的中心区域,我们可以看到一个“死区”,其中输入值没有任何输出。
nn.Softsign
torch.nn.Softsign 是 PyTorch 神经网络模块中的一个激活函数,它按元素应用Softsign函数。
Softsign函数定义
Softsign函数定义如下:
SoftSign(x) = x / (1 + |x|)
这个函数类似于tanh函数,它将输入值映射到(-1, 1)的范围内。不同于tanh的是,Softsign在输入值很大时,其曲线的接近饱和区的速度更慢,这使得它在输入值很大时不那么敏感。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化Softsign激活函数层
m = nn.Softsign()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用Softsign激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个Softsign激活函数层。通过 nn.Softsign() 创建该层后,生成一个随机数值的张量 input_tensor 作为输入,并通过Softsign层进行处理。Softsign 函数将输入张量中的每个元素转换成一个在(-1, 1)范围内的值,输出张量将具有与输入相同的形状。
Softsign函数提供了一种替代tanh和Sigmoid函数的方式,特别是在需要避免梯度消失问题时。由于其性质更为平滑,它在某些情况下可能比tanh函数表现得更好。
图示
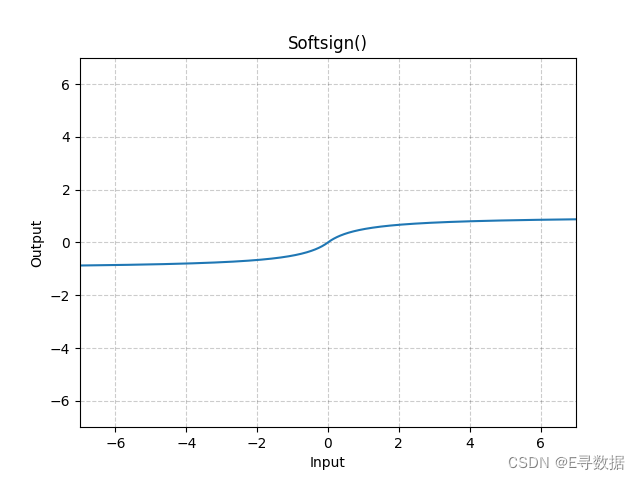
这张图展示了Softsign激活函数的图形。X轴代表输入值,Y轴代表Softsign函数处理后的输出值。
从图中可以看出Softsign函数的特点:
- 当输入值增加时,输出值趋于1,但是接近饱和的速度比Sigmoid和tanh函数要慢。
- 当输入值减少时,输出值趋于-1,同样地,接近饱和的速度也比Sigmoid和tanh函数要慢。
- 在输入值为0附近,Softsign函数提供了一个平滑的非线性过渡。
Softsign函数因其简单且平滑的性质,在某些情况下可能是一个比Sigmoid或tanh更好的选择,尤其是在需要避免梯度消失问题时。图形上方的标题“Softsign()”表明这是标准的Softsign激活函数。
nn.Tanh
torch.nn.Tanh 是 PyTorch 中的一个激活函数,它按元素应用双曲正切(Hyperbolic Tangent,Tanh)函数。
Tanh函数定义
Tanh函数定义如下:
Tanh(x) = tanh(x) = (exp(x) - exp(-x)) / (exp(x) + exp(-x))
Tanh函数将输入值映射到(-1, 1)的范围内,这使得它在许多情况下都是一个很好的选择,特别是当你想要输出值包含负值并且有界时。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化Tanh激活函数层
m = nn.Tanh()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用Tanh激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个Tanh激活函数层。通过 nn.Tanh() 创建该层后,生成一个随机数值的张量 input_tensor 作为输入,并通过Tanh层进行处理。Tanh函数将输入张量中的每个元素映射到(-1, 1)的范围内,输出张量将具有与输入相同的形状。
Tanh因其输出范围和平滑的梯度曲线而在深度学习模型中得到了广泛的应用,尤其是在早期的神经网络和循环神经网络中。然而,由于可能发生的梯度消失问题,现代深度学习实践中常常使用ReLU及其变种作为激活函数。
图示
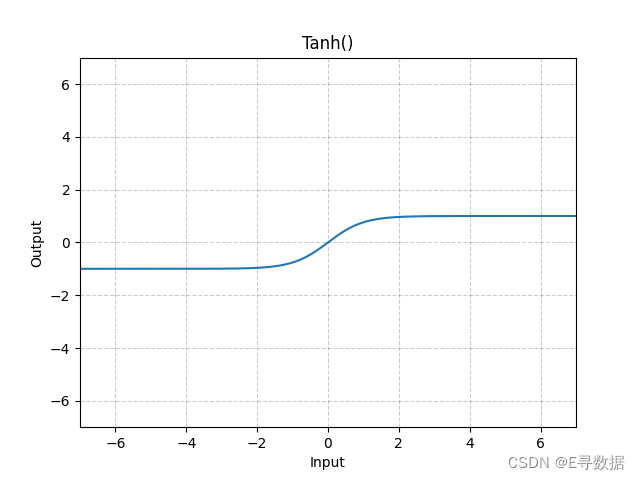
这张图展示了Tanh(双曲正切)激活函数的图形。X轴代表输入值,Y轴代表Tanh函数处理后的输出值。
从图中可以观察到Tanh函数的主要特点:
- 当输入值小于0时(X轴左侧),Tanh函数的输出值逐渐接近-1。
- 当输入值大于0时(X轴右侧),Tanh函数的输出值逐渐接近1。
- 在输入值为0时,Tanh函数的输出值为0,表现为一个S形的曲线(即Sigmoid曲线),它是Sigmoid函数的缩放和平移版本。
图形上方的标题“Tanh()”表明这是标准的Tanh激活函数。Tanh激活函数因其输出范围在(-1, 1)之间并且在输入值为0时具有最大的导数(即最陡峭的斜率)而被广泛用于神经网络中。这种性质使得Tanh函数在处理以0为中心的数据时特别有用,因为它可以帮助模型学习到负相关性。然而,对于深层网络,Tanh函数可能会导致梯度消失的问题,这是因为当输入值的绝对值变得很大时,梯度会接近于0。
nn.Tanhshrink
torch.nn.Tanhshrink 是 PyTorch 中的一个激活函数,它按元素应用Tanhshrink函数。
Tanhshrink函数定义
Tanhshrink函数定义如下:
Tanhshrink(x) = x - tanh(x)
这个函数计算输入值与其双曲正切值的差。当输入值较小(接近0)时,双曲正切函数的输出接近于输入值,因此Tanhshrink的结果接近于0。当输入值的绝对值增加时,双曲正切函数趋向于1或-1,因此Tanhshrink的输出将趋向于输入值减去1或加上1。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化Tanhshrink激活函数层
m = nn.Tanhshrink()# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用Tanhshrink激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个Tanhshrink激活函数层。通过 nn.Tanhshrink() 创建该层后,生成一个随机数值的张量 input_tensor 作为输入,并通过Tanhshrink层进行处理。Tanhshrink函数会对输入张量中的每个元素进行操作,输出张量将具有与输入相同的形状。
Tanhshrink激活函数在深度学习中不如其他函数(如ReLU或其变种)常见,但它可以在特定情况下提供有用的性质,特别是在需要减少输入值影响的情况下。
图示
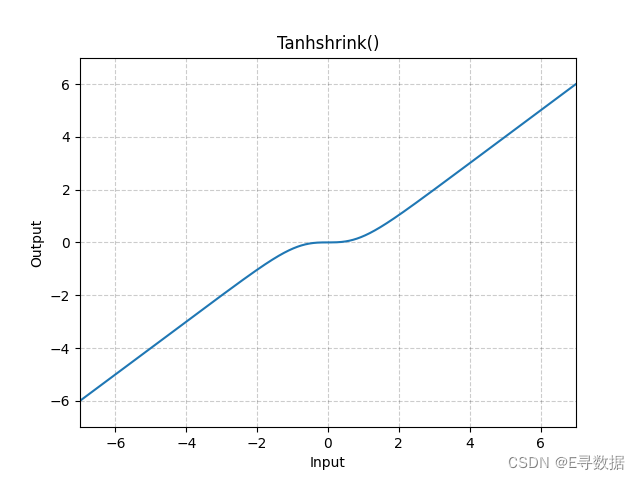
这张图展示了Tanhshrink激活函数的图形。X轴代表输入值,Y轴代表Tanhshrink函数处理后的输出值。
从图中可以观察到Tanhshrink函数的主要特点:
- 在输入值为0时,Tanhshrink函数的输出也为0,因为此时
tanh(0) = 0。 - 当输入值为正或负时,Tanhshrink函数的输出是输入值与其双曲正切值(tanh(x))的差。由于tanh(x)在x为正时小于x且为x为负时大于x,Tanhshrink函数的曲线在0附近有一个平滑的非线性过渡,然后逐渐趋向于线性。
- 当输入值的绝对值变得很大时,双曲正切函数的输出接近于1或-1,因此Tanhshrink函数的输出将趋向于输入值本身,因为
x - tanh(x)将接近于x - 1或x + 1。
总体而言,Tanhshrink激活函数在输入值较小的时候提供了一种平滑的非线性转换,而在输入值较大的时候则提供了近似线性的行为。这种性质使得Tanhshrink在特定的深度学习模型中可能会有其应用场景,尤其是在希望减少极端值影响时。
nn.Threshold
torch.nn.Threshold 是 PyTorch 中的一个激活函数,按元素对输入张量应用阈值操作。
Threshold函数定义
Threshold函数定义如下:
y = { x, if x > threshold; value, otherwise }
这意味着如果输入元素大于阈值(threshold),则输出该元素;否则输出指定的值(value)。
参数
threshold(float):要在其上应用阈值的值。value(float):替换小于阈值元素的值。inplace(bool):可选参数,如果设置为True,则会在原地修改输入张量。默认为False。
形状
- 输入:任意维度的张量。
- 输出:与输入相同形状的张量。
示例
import torch
import torch.nn as nn# 初始化Threshold激活函数层,设定阈值和替换值
m = nn.Threshold(0.1, 20)# 创建一个随机张量作为输入
input_tensor = torch.randn(2)# 应用Threshold激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个Threshold激活函数层,其中阈值设为0.1,替换值设为20。通过 nn.Threshold() 创建该层后,生成一个随机数值的张量 input_tensor 作为输入,并通过Threshold层进行处理。Threshold函数将输入张量中所有小于或等于0.1的元素替换为20,输出张量将具有与输入相同的形状。
Threshold函数在处理一些特定的机器学习问题时很有用,特别是在需要对异常值或不重要的值进行过滤时。它可以用作数据预处理的一部分,或者在神经网络中作为一个激活函数来增加稀疏性。
nn.GLU
torch.nn.GLU 是 PyTorch 中的一个模块,它应用门控线性单元(Gated Linear Unit)函数。GLU 是一种利用输入数据的一部分来决定另一部分如何通过网络的激活函数。
GLU函数定义
GLU函数的操作可以定义为:
GLU(a, b) = a ⊗ σ(b)
其中 a 是输入张量的前一半,b 是输入张量的后一半,σ 是Sigmoid激活函数,⊗ 表示逐元素乘法。
参数
dim(int):用于在该维度上分割输入张量的维数。默认为 -1,表示最后一个维度。
形状
- 输入:形状为
(∗1, N, ∗2)的张量,其中*表示任意数量的额外维度。 - 输出:形状为
(∗1, M, ∗2)的张量,其中M = N / 2。
示例
import torch
import torch.nn as nn# 初始化GLU激活函数层
m = nn.GLU()# 创建一个随机张量作为输入
input_tensor = torch.randn(4, 2)# 应用GLU激活函数
output_tensor = m(input_tensor)print("Input:", input_tensor)
print("Output:", output_tensor)
在上述代码中,m 是一个GLU激活函数层。通过 nn.GLU() 创建该层后,生成一个形状为(4, 2)的张量 input_tensor 作为输入,并通过GLU层进行处理。GLU函数将输入张量分为两半,第一半与第二半的Sigmoid激活的逐元素乘积作为输出,输出张量的维度将是输入张量的一半。
GLU激活函数在某些深度学习模型中表现出了优异的性能,尤其是在自然语言处理和序列数据建模中,因为它可以增加模型的非线性并允许网络学习更复杂的表示。
总结
本文综合概述了PyTorch框架中一系列关键的激活函数,从经典的ReLU到前沿的GELU和Mish,探讨了它们的数学定义、特点及实际应用。通过各函数对输入数据的不同处理方式,文章揭示了如何通过激活函数为神经网络模型注入非线性动力,以及它们在深度学习中的核心作用。从Sigmoid的平滑概率转换到GLU的复杂数据门控,这些激活函数是构建高效、稳健机器学习模型的基石,同时它们的多样性和特定应用场景为深度学习的进步提供了广阔空间。
相关文章:
简单易懂的PyTorch激活函数大全详解
目录 torch.nn子模块Non-linear Activations nn.ELU 主要特点与注意事项 使用方法与技巧 示例代码 图示 nn.Hardshrink Hardshrink函数定义 参数 形状 示例代码 图示 nn.Hardsigmoid Hardsigmoid函数定义 参数 形状 示例代码 图示 nn.Hardtanh HardTanh函数…...

x-cmd pkg | pdfcpu - 强大的 PDF 处理工具
目录 简介首次用户多功能支持性能表现安全的加密处理进一步阅读 简介 pdfcpu 是一个用 Go 编写的 PDF 处理库。同时它也提供 API 和 CLI。pdfcpu 提供了丰富的 PDF 操作功能,用户还能自己编写配置文件,用来管理和使用各种自定义字体并存储有效的默认配置…...
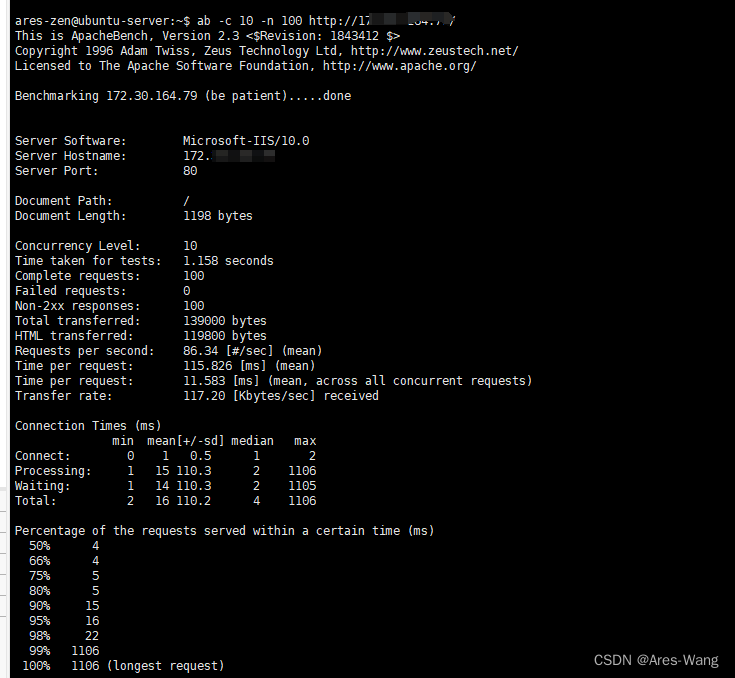
linux 压力测试 AB ApacheBench
ab的简介 ab是apachebench命令的缩写。 ab是apache自带的压力测试工具。ab非常实用,它不仅可以对apache服务器进行网站访问压力测试,也可以对或其它类型的服务器进行压力测试。比如nginx、tomcat、IIS等 ab的原理 ab的原理:ab命令会创建多…...

【云计算】云存储是什么意思?与本地存储有什么区别?
云计算环境下,衍生了云存储、云安全、云资源、云管理、云支出等等概念。今天我们就来了解下什么是云存储?云存储与本地存储有什么区别? 云存储是什么意思? 云存储是一种新型的数据管理方式,它通过网络将大量不同类型、…...
月入7K,19岁少年转行网优,他凭什么打破低学历魔咒?
专科未毕业、19岁,毫无专业技能,被匆匆赶进就业市场你会遇到什么? 毫无疑问,铺天盖地的拒绝和不合适,甚至有些公司连投递的资格都没有,这可能是所有低学历者求职过程中会遇到的“魔咒”。低学历似乎与低薪资…...
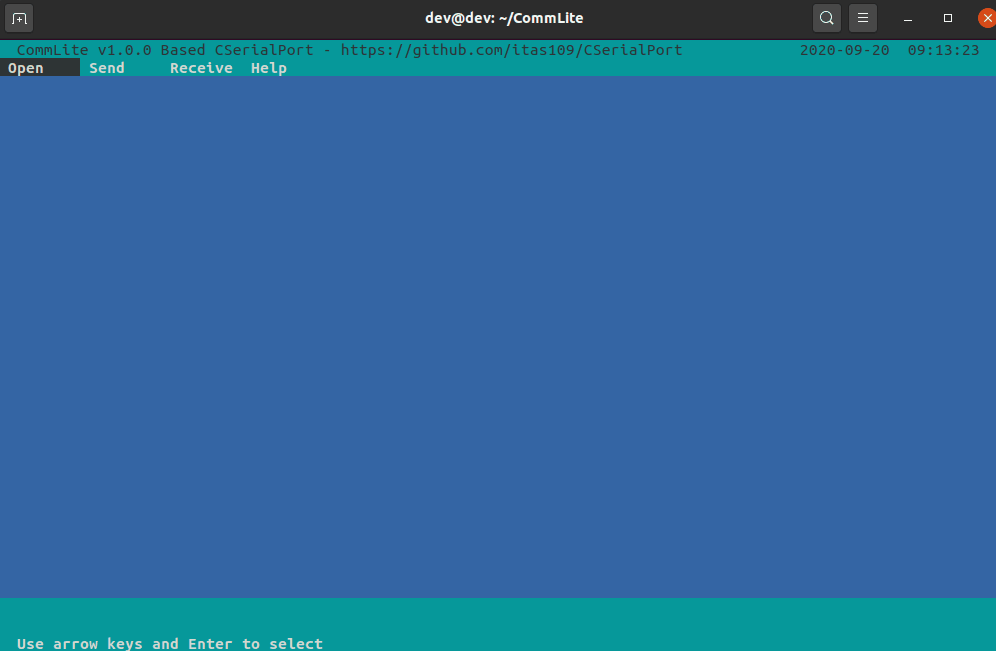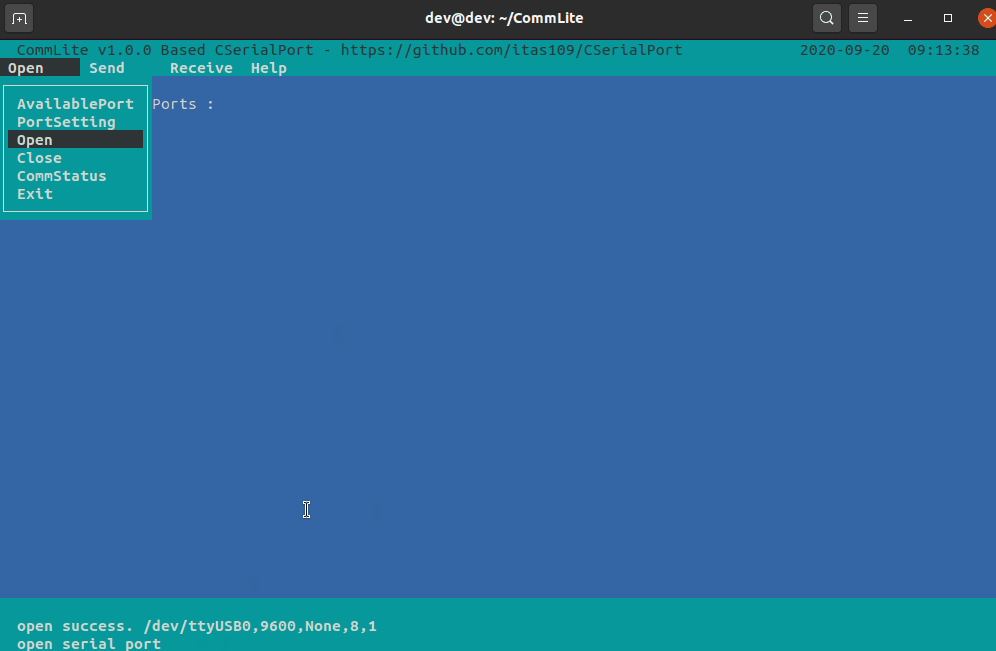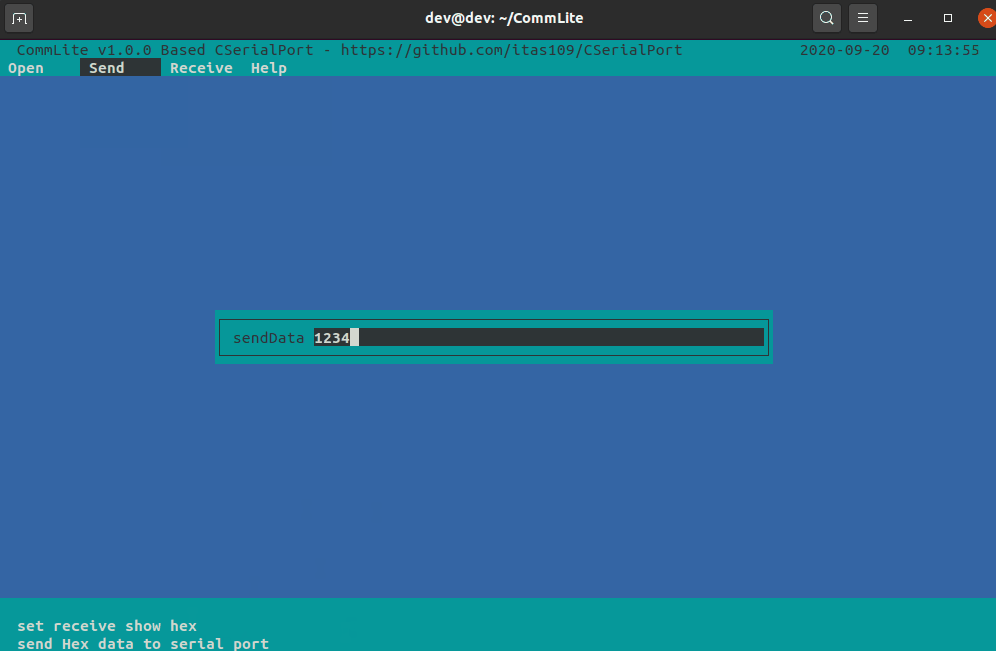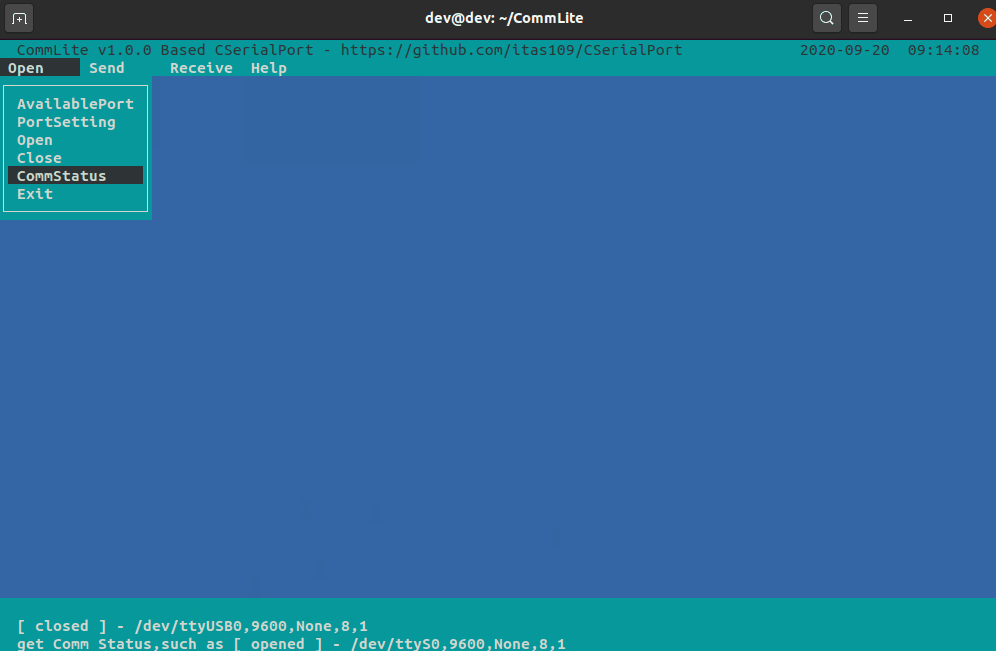
【C/C++】轻量级跨平台 开源串口库 CSerialPort
文章目录 1、简介2、支持的平台3、已经支持的功能4、Linux下使用5、使用vcpkg安装CSerialPort6、交叉编译7、效果图8、基于CSerialPort的应用8.1、CommMaster通信大师8.2、CommLite串口调试器 1、简介 Qt 的QSerialPort 已经是跨平台的解决方案,但Qt开发后端需要 Q…...

大创项目推荐 深度学习图像修复算法 - opencv python 机器视觉
文章目录 0 前言2 什么是图像内容填充修复3 原理分析3.1 第一步:将图像理解为一个概率分布的样本3.2 补全图像 3.3 快速生成假图像3.4 生成对抗网络(Generative Adversarial Net, GAN) 的架构3.5 使用G(z)生成伪图像 4 在Tensorflow上构建DCGANs最后 0 前言 &#…...

嵌入式系统复习--基于ARM的嵌入式程序设计
文章目录 上一篇编译环境ADS编译环境下的伪操作GNU编译环境下的伪操作ARM汇编语言的伪指令 汇编语言程序设计相关运算操作符汇编语言格式汇编语言程序重点C语言的一些技巧 下一篇 上一篇 嵌入式系统复习–Thumb指令集 编译环境 ADS/SDT IDE开发环境:它由ARM公司开…...

【C++入门到精通】异常 | 异常的使用 | 自定义异常体系 [ C++入门 ]
阅读导航 引言一、C异常的概念二、异常的使用1. 异常的抛出和捕获(1)throw(2)try-catch(3)catch(. . .)(4)异常的抛出和匹配原则(5)在函数调用链中异常栈展开…...
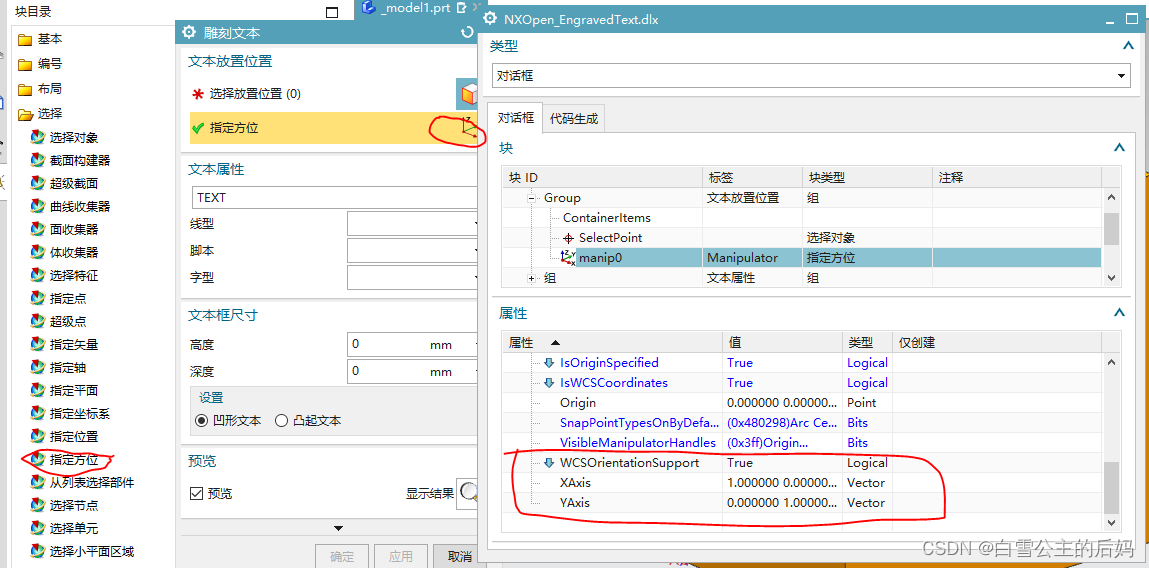
NX二次开发 Block UI 指定方位控件的应用
一、概述 NX二次开发中一般都是多个控件的组合,这里我首先对指定方位控件进行说明并结合选择对象控件,具体如下图所示。 二、实现功能获取方位其在选择面上原点的目标 2.1 在initialize_cb()函数中进行初始化,实现对象选择过滤面 //过滤平…...

2024年【R2移动式压力容器充装】模拟考试及R2移动式压力容器充装实操考试视频
题库来源:安全生产模拟考试一点通公众号小程序 2024年【R2移动式压力容器充装】模拟考试及R2移动式压力容器充装实操考试视频,包含R2移动式压力容器充装模拟考试答案和解析及R2移动式压力容器充装实操考试视频练习。安全生产模拟考试一点通结合国家R2移…...
)
数仓工具—Hive进阶之StorageHandler(23)
Storage Handler 引入Storage Handler,Hive用户使用SQL的方式读写外部数据源, 例如ElasticSearch、 Kafka、HBase等数据源的查询对非专业开发是有一定门槛的,借助Storage Handler,他们有了一种方便快捷的手段查询数据,Storage Handler作为Hive的存储插件,我们需要的时候直…...

科技创新创业
科技创新创业是一个涉及多个方面的过程,主要包括以下几个方面: 创意产生:创业的起始点通常是一个新的创意或想法,这可能是一个新的产品、服务或技术的概念。这个创意需要独特且具有商业潜力。市场调研:一旦有了创意&a…...

高校电力能耗监测精细化管理系统,提升能源利用效率的利器
电力是高校不可离开的重要能源,为学校相关管理人员提供在线用能查询统计等服务。通过对学校照明用电、空调用电等数据的采集、监控、分析,为学校电能管理制定合理的能源政策提供参考。同时,也可以培养学生的节能意识,学校后勤电力…...

Java_Swing程序设计
swing组件允许编程人员在跨平台时指定统一的外观和风格。 Swing组件通常被称为轻量级组件, JFrame在程序中的语法格式: JFrame jfnew JFrame(title); Container containerjf.getContentPane(); jf:JFrame类的对象 container:Container类的对象。 J…...

ZeroBind:DTI零样本预测器
现有的药物-靶点相互作用(DTI)预测方法通常无法很好地推广到新的(unseen)蛋白质和药物。 在这项研究中,作者提出了一种具有子图匹配功能的蛋白质特异性元学习框架 ZeroBind,用于根据其结构预测蛋白质-药物相…...

Win10子系统Ubuntu实战(一)
在 Windows 10 中安装 Ubuntu 子系统(Windows Subsystem for Linux,简称 WSL)有几个主要的用途和好处:Linux 环境的支持、跨平台开发、命令行工具、测试和验证、教育用途。总体而言,WSL 提供了一种将 Windows 和 Linux…...
 质量刚体的在坐标系下运动)
[足式机器人]Part3 机构运动学与动力学分析与建模 Ch00-2(3) 质量刚体的在坐标系下运动
本文仅供学习使用,总结很多本现有讲述运动学或动力学书籍后的总结,从矢量的角度进行分析,方法比较传统,但更易理解,并且现有的看似抽象方法,两者本质上并无不同。 2024年底本人学位论文发表后方可摘抄 若有…...

云计算历年题整理
目录 第一大题 第一大题HA计算 给出计算连接到EC2节点的EBS的高可用性(HA)的数学公式,如场景中所述;计算EC2节点上的EBS的高可用性(HA);场景中80%的AWS EC2节点用于并行处理,总共有100个虚拟中央处理单元(vCPUs)用于处理数据&a…...

2401vim,vim重要修改更新大全
原文 2023 更好的UTF-16支持 添加strutf16len()和utf16idx(),并在byteidx(),byteidxcomp()和charidx()中添加utf16标志,在内置.txt文档中. 添加crypymethod xchacha20v2 与xchacha20基本相同,但更能抵御libsodium的变化. 2022 添加"smoothscroll" 用鼠标滚动…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...

Unity中的transform.up
2025年6月8日,周日下午 在Unity中,transform.up是Transform组件的一个属性,表示游戏对象在世界空间中的“上”方向(Y轴正方向),且会随对象旋转动态变化。以下是关键点解析: 基本定义 transfor…...

字符串哈希+KMP
P10468 兔子与兔子 #include<bits/stdc.h> using namespace std; typedef unsigned long long ull; const int N 1000010; ull a[N], pw[N]; int n; ull gethash(int l, int r){return a[r] - a[l - 1] * pw[r - l 1]; } signed main(){ios::sync_with_stdio(false), …...