机器学习系列--R语言随机森林进行生存分析(2)
随机森林(Breiman 2001a)(RF)是一种非参数统计方法,需要没有关于响应的协变关系的分布假设。RF是一种强大的、非线性的技术,通过拟合一组树来稳定预测精度模型估计。随机生存森林(RSF)(Ishwaran和Kogalur,2007;Ishwaraan,Kogalur、Blackstone和Lauer(2008)是Breimans射频技术的延伸从而降低了对时间到事件数据的有效非参数分析。
接着文章《机器学习系列–R语言随机森林进行生存分析(1)》, 咱们继续分析
上一节,咱们已经介绍了通过VIMP来绘制变量的重要性。
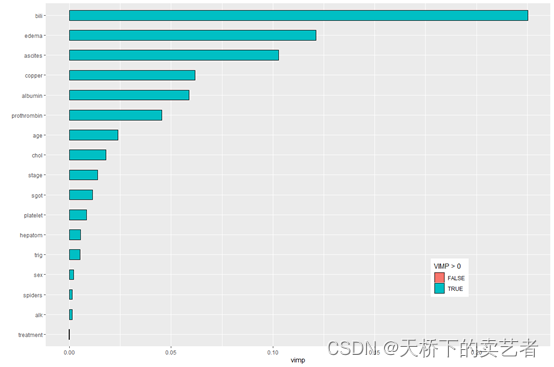
在 VIMP 中,预后风险因素是通过在其他数据设置下测试森林预测来确定的,根据对森林预测能力的影响对最重要的变量进行排序。
randomForestSRC包中还有另一种方法是就是利用对森林构建的检验来对变量进行排序,就是最小森度。最小深度(Ishwaran 等人,2010 年;Ishwaran、Kogalur、Chen 和
Minn 2011)假定,对预测影响大的变量是那些最频繁地分割离根节点最近的节点的变量,它们在根节点上分割了最大的群体样本。在每棵树中,节点级别根据其与树根的相对距离进行编号(树根为 0)。最小深度是通过对森林中所有树的每个变量的第一次分割深度取平均值来衡量重要的风险因素。
该指标的假设是,较小的最小深度值表明该变量分离了大组观测值,因此对森林预测的影响较大。
一般来说,要根据 VIMP 选择变量,我们要检查 VIMP 值,寻找 VIMP 测量值差异较大的排序点。但是最小深度是森林构建的定量属性,Ishwaran 等人(2010 年)还推导出了变量影响证据的分析阈值。规则使用最小深度分布的平均值,将最小深度低于该阈值的变量归类为森林预测中的重要变量。
varsel_pbc <- var.select(rfsrc_pbc)
topvars <- varsel_pbc$topvars
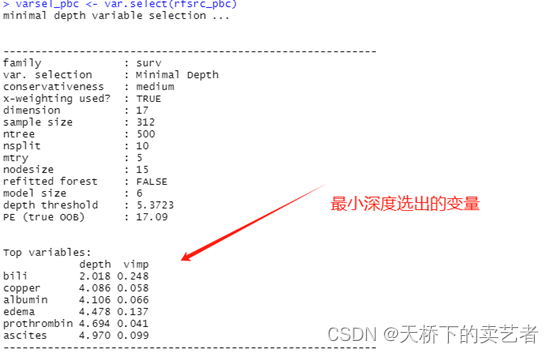
gg_md <- gg_minimal_depth(varsel_pbc, lbls = st.labs)
print(gg_md)

综合上面两图,咱们可以得到,最小深度阈值(depth threshold)为5.2757,共筛选了15个变量,第一个进行分裂的变量就是bili,在深度2.144就开始分裂了,接着就是albumin和copper。
绘制深度节点和变量图
plot(gg_md)
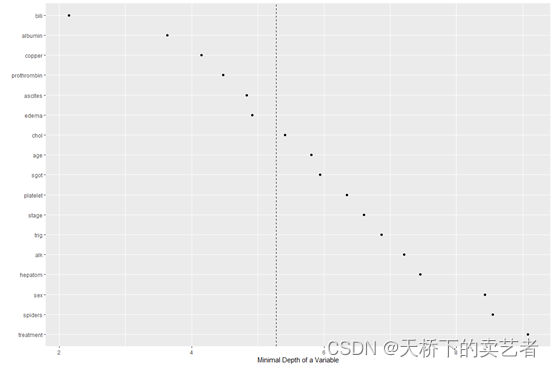
从上图可以看出虚线就是最小深度,越往右深度越大,其中较小的最小深度值表示较高的重要性,较大的值表示重要性较低。
由于我们现在有两个指标来判定,那选哪个好呢?我们可以使用gg_minimal_vimp函数来进行综合比较,
plot(gg_minimal_vimp(gg_md)) +theme(legend.position=c(0.8, 0.2))
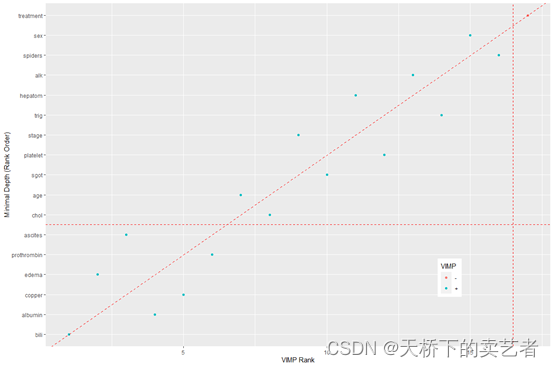
这个图形是这个包中的一个核心图形,我要好好解释一下。因为这张图使用两个方法,vimp和最小深度法。这条斜着的虚线是这两种方法的分界点,蓝色的点代表vimp大于0的,红色的点代表vimp小于0。红色斜着的虚线上的点,代表这个变量在两种分类方法排名相同,高于红色虚线上的点,代表它的vimp的排名更加高,低于红色虚线上的点,表明它的最小深度排名更高。
看它生成的表格也可以看出来
out2<-gg_minimal_vimp(gg_md)
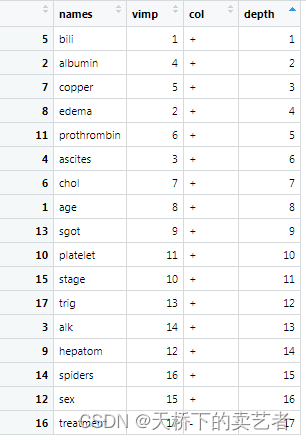
我们可以看到两种方法有些排名是一样的,有些是不一样的。如果我们根据阈值5.2757进行筛选,那么最终可以选出"bili" ,“albumin” ,“copper” ,“prothrombin” ,"edema"这5个变量,有些文章介绍有临床意义的变量也是可以选进来的。
接下来绘制部分依赖图(PDP),假设咱们想了解"bili"这个变量,对1年和3年生存结局的影响(也就是依赖性),咱们先生成这个结局治疗的数据
gg_v <-gg_variable(rfsrc_pbc, time = c(1, 3),time.labels = c("1 Year", "3 Years"))
进行绘图,注意形状散点代表的意义不一样
plot(gg_v, xvar = "bili", alpha = 0.4) + #, se=FALSElabs(y = "Survival", x = "bili") +theme(legend.position = "none") +scale_color_manual(values = c("red", "blue"), labels = c("1 Year", "3 Years")) +coord_cartesian(ylim = c(-0.01, 1.01))+xlab("Serum Bilirubin")
ggRandomForests包的绘图函数画起来不咱们美观,我们可以根据结局数据自己来画
ggplot(gg_v) + geom_point(aes_string(x = "bili", y = "yhat", color = "event", shape = "event"))+geom_smooth(aes_string(x = "bili", y = "yhat", color = "time",fill="time"))+theme_classic()+xlab("bili")+ylab("yhat")

当然咱们也可以分面
ggplot(gg_v) + geom_point(aes_string(x = "bili", y = "yhat", color = "event", shape = "event"))+geom_smooth(aes_string(x = "bili", y = "yhat", color = "time",fill="time"))+facet_wrap(~time,ncol = 1)
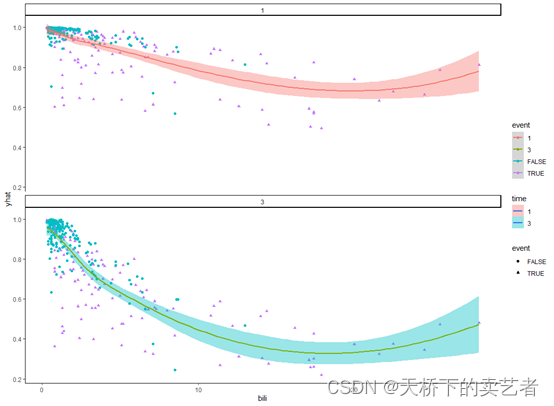
上图表明胆红素超过20后,随着胆红素增加存活率上升。
部分依赖图(Partial Dependence Plot)显示了一个或两个特征对机器学习模型的预测结果的边际效应,由于机器学习算法非参数的特性使得部份依赖图可以揭示线性以及非线性特征,容易理解并且有较高的解释力。但是对于生存数据,我们还要考虑时间的影响,
咱们可以使用parallel包的mclapply函数,结合plot.variable函数来处理时间数据,我们先定义要观察的变量和3个时间节点(1年,3年和5年)
xvar <- c("bili", "albumin", "copper", "prothrombin", "age", "edema")
time_index <- c(which(rfsrc_pbc$time.interest > 1)[1]-1,which(rfsrc_pbc$time.interest > 3)[1]-1,which(rfsrc_pbc$time.interest > 5)[1]-1)
time_index装有3个时间点数据,下面导入包来分析mclapply函数类似于平时咱们的lapply函数,就是对多个时间点使用plot.variable函数来跑循环
library(parallel)
partial_pbc <- mclapply(rfsrc_pbc$time.interest[time_index],function(tm){plot.variable(rfsrc_pbc, surv.type = "surv",time = tm, xvar.names = xvar,partial = TRUE ,show.plots = FALSE)})
时间点的预测值存在partial_pbc列表里面,3个数据代表3年

咱们把数据提取出来,咱们这里只提取1年和3年
gg_dta <- mclapply(partial_pbc, gg_partial)
pbc_ggpart <- combine.gg_partial(gg_dta[[1]], gg_dta[[2]],lbls = c("1 Year", "3 Years"))
提取数据后就可以绘图了,先绘制一个箱线图
ggplot(pbc_ggpart[["edema"]], aes(y=yhat, x=edema, col=group))+geom_boxplot(notch = TRUE,outlier.shape = NA) + # panel=TRUE,labs(x = "Edema", y = "Survival (%)", color="Time", shape="Time") +theme_classic()
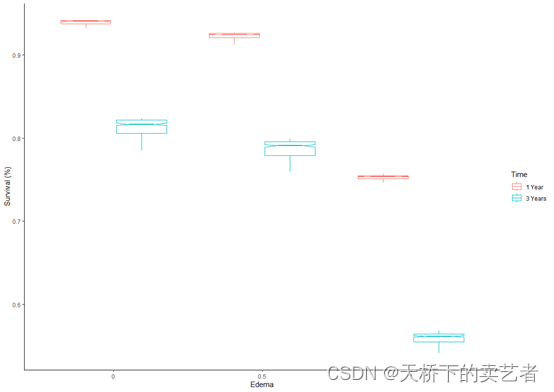
绘制时间依赖图(文章是这么叫的)
ggplot(pbc_ggpart[["bili"]], aes(y=yhat, x=bili, col=group))+geom_smooth() + # panel=TRUE,labs(x = "bili", y = "Survival (%)", color="Time", shape="Time") +theme(legend.position = c(0.1, 0.2))+theme_classic()
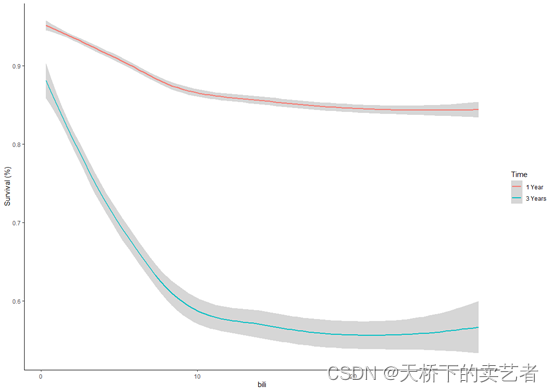
咱们可以看到和部分依赖图还是有点区别的,结论也不一样了。咱们也可以按我上面的方法从pbc_ggpart提取数据来自己绘制,有兴趣的可以试一下,这样更加灵活,更加好看。
接下来咱们来做下亚组的依赖关系,也就是亚组分析,亚组关系需要按年提取,咱们提取第一年的数据
ggvar<- gg_variable(rfsrc_pbc, time = 1)
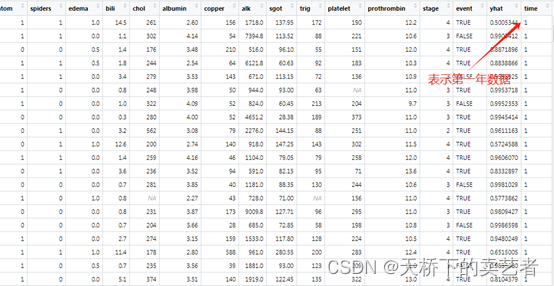
咱们把edema改成分组的显示
ggvar$edema <- paste("edema = ", ggvar$edema, sep = "")
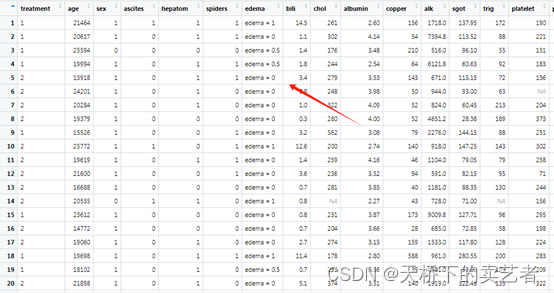
绘制亚组关系图,表明了每个亚组对生存结局的影响
ggplot(ggvar) + geom_point(aes_string(x = "bili", y = "yhat", color = "event", shape = "event"))+geom_smooth(aes_string(x = "bili", y = "yhat"))+facet_wrap(~edema)
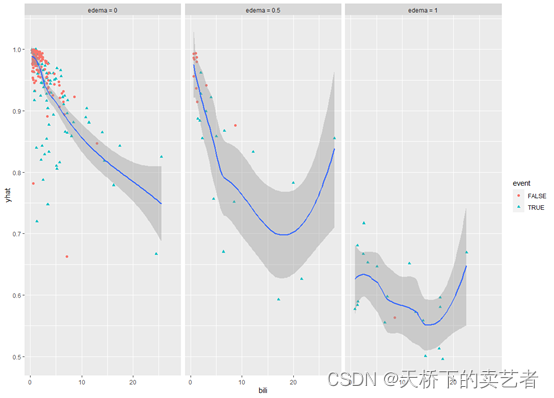
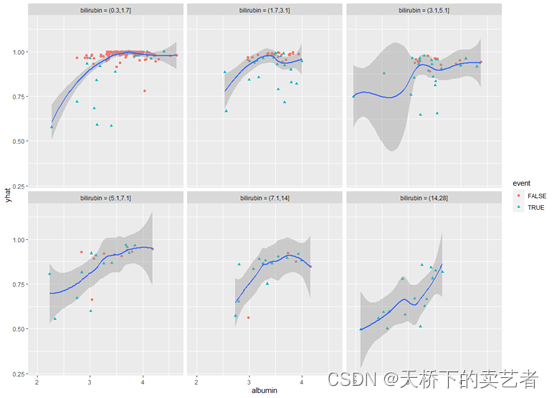
咱们也可以对连续变量进行分组后在绘制
bili_cts <-quantile_pts(ggvar$bili, groups = 6, intervals = TRUE)
bili_cts[1] <- bili_cts[1] - 1.e-7 #我们需要移动最小值,以便包含该观察结果
##创建条件组并添加到gg_variable对象
bili_grp <- cut(ggvar$bili, breaks = bili_cts)
ggvar$bili_grp <- bili_grp
levels(ggvar$bili_grp) <- paste("bilirubin =", levels(bili_grp)) #调整面的命名
绘图
ggplot(ggvar) + geom_point(aes_string(x = "albumin", y = "yhat", color = "event", shape = "event"))+geom_smooth(aes_string(x = "albumin", y = "yhat"))+facet_wrap(~bili_grp)
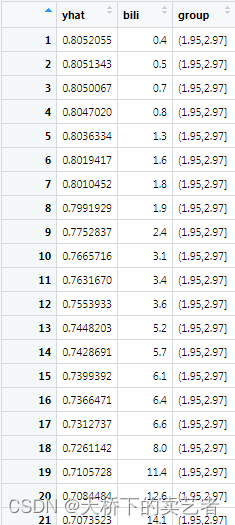
也可以使用gg_partial_coplot来绘制亚组的图,前面步骤是一样的,先生成分组变量
albumin_cts <-quantile_pts(ggvar$albumin, groups = 6, intervals = TRUE)
albumin_cts[1] <- albumin_cts[1] - 0.01 #我们需要移动最小值,以便包含该观察结果
##创建条件组并添加到gg_variable对象
albumin_grp <- cut(ggvar$albumin, breaks = albumin_cts)
ggvar$albumin_grp <- albumin_grp
使用g_partial_coplot生成绘图数据
coplotpbc <- gg_partial_coplot(rfsrc_pbc, xvar = "bili",groups = ggvar$albumin_grp,surv_type = "surv",time = rfsrc_pbc$time.interest[time_index[1]],show.plots = FALSE)
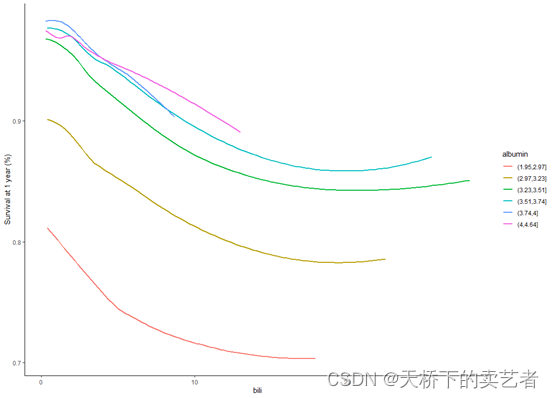
绘图
ggplot(coplotpbc, aes(x=bili, y=yhat, col=group, shape=group)) +geom_smooth(se = FALSE) +labs(x = "bili", y = "Survival at 1 year (%)",color = "albumin", shape = "albumin")+theme_classic()
除此之外还可以做决策曲线和roc曲线,这里就不弄了,我的既往文章都有。这两章内容比较多,代码我自己跑是没问题,但是怕有时候贴出来有时候会少贴一段,我把这两章代码进行了打包,公众号回复:随机森林生存分析代码,可以获得,回复要一模一样才行。
相关文章:
机器学习系列--R语言随机森林进行生存分析(2)
随机森林(Breiman 2001a)(RF)是一种非参数统计方法,需要没有关于响应的协变关系的分布假设。RF是一种强大的、非线性的技术,通过拟合一组树来稳定预测精度模型估计。随机生存森林(RSF࿰…...

Flutter GetX 之 状态管理
上一篇文章为大家介绍了 GetX的 路由管理,让大家对GetX有了初步了解,今天为大家介绍一下GetX的 状态管理。 StatelessWidget 和 StatefulWidget 介绍 在介绍之前,先简单介绍一下 Flutter 页面的 StatelessWidget 和 StatefulWidget ,其实Flutter的本质是万物都是Widget,…...

e2studio开发磁力计LIS2MDL(1)----轮询获取磁力计数据
e2studio开发磁力计LIS2MDL.1--轮询获取磁力计数据 概述视频教学样品申请源码下载速率新建工程工程模板保存工程路径芯片配置工程模板选择时钟设置UART配置UART属性配置设置e2studio堆栈e2studio的重定向printf设置R_SCI_UART_Open()函数原型回调函数user_uart_callback ()prin…...

C++ 字符串大小写转换,替换,文件保存 方法封装
此示例程序方法已经封装好使用std::islower()函数可以检查一个字符是否是小写字母,使用std::isupper()函数可以检查一个字符是否是大写字母。 如果传入的字母是小写字母,则使用std::toupper()函数将其转换为大写字母,并输出转换后的结果。 如果输入的字母是大写字母,则使…...

计算机基础面试题 |19.精选计算机基础面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

mysql 添加用户并分配select权限
1.root用户先登录或者在可执行界面 1.1 选择mysql 点击mysql 或者在命令行 use mysql 1.2创建用户 CREATE USER username% IDENTIFIED BY password; 备注1:%替换为可访问数据库的ip,例如“127.0.0.1”“192.168.1.1”,使用“%”表示不限制…...

重新认识canvas,掌握必要的联结密码
查看专栏目录 canvas示例教程100专栏,提供canvas的基础知识,高级动画,相关应用扩展等信息。canvas作为html的一部分,是图像图标地图可视化的一个重要的基础,学好了canvas,在其他的一些应用上将会起到非常重…...
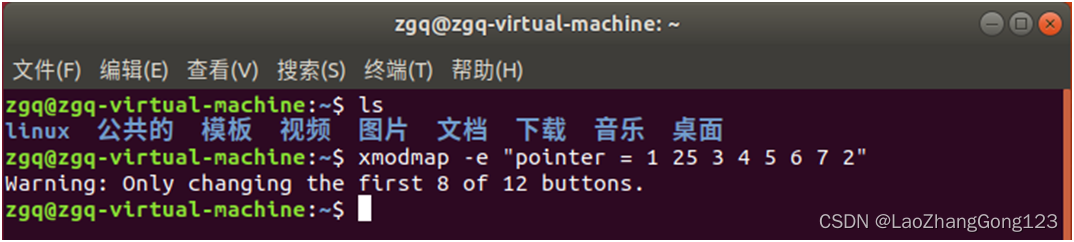
Linux第21步_取消鼠标中键的复制粘贴功能
在ubuntu18.04操作系统中,选中文本后,若按下鼠标中键,就可以执行复制粘贴,相当于 CtrlshiftC 后又按了 CtrlshiftV。在Linux系统中,基本上都是这么配置的。在windows系统中,我们习惯用Ctrl-C复制࿰…...
数学建模-Matlab R2022a安装步骤
软件介绍 MATLAB是一款商业数学软件,用于算法开发、数据可视化、数据分析以及数值计算的高级技术计算语言和交互式环境,主要包括MATLAB和Simulink两大部分,可以进行矩阵运算、绘制函数和数据、实现算法、创建用户界面、连接其他编程语言的程…...

【AI】Pytorch 系列:学习率设置
a. 有序调整:等间隔调整(Step),按需调整学习率(MultiStep),指数衰减调整(Exponential)和 余弦退火CosineAnnealing。 b. 自适应调整:自适应调整学习率 ReduceLROnPlateau。 c. 自定义调整:自定义调整学习率 LambdaLR。 #得到当前学习率 lr = next(iter(optimizer.param_gr…...

LeetCode第107题 - 二叉树的层序遍历 II
题目 解答 class Solution {List<List<Integer>> nodeLevels new LinkedList<>();public List<List<Integer>> levelOrderBottom(TreeNode root) {levelOrder(root, 0);List<List<Integer>> nodeLevels2 new LinkedList<>…...

java 常⽤的线程池模式FixedThreadPool
java 常⽤的线程池模式FixedThreadPool 线程池中的线程数量是固定的。 当提交一个新任务时,如果线程池中的线程都在运行,新任务就会被放入任务队列中等待执行。 如果线程池中的所有线程都在运行,且任务队列已满,那么线程池会创建新…...

双机调度算法
假设当前有两个处理机A、B,以及n个待处理的任务。第i个任务在处理处理机A上处理需要的时间为ai,在处理机B上处理的时间为bi,两个处理机可以并行处理任务,但单个处理机不能同时执行任务。要求给定n个任务及各个任务对应的ai 、bi&a…...

精进单元测试技能——Pytest断言的艺术
本篇文章主要是阐述Pytest在断言方面的应用。让大家能够了解和掌握Pytest针对断言设计了多种功能以适应在不同测试场景上使用。 了解断言的基础 在Pytest中,断言是通过 assert 语句来实现的。简单的断言通常用于验证预期值和实际值是否相等,例如…...

探索人工智能:深度学习、人工智能安全和人工智能
深度学习是人工智能的一种重要技术,它模拟了人类大脑神经网络的工作原理,通过建立多层次的神经元网络来实现对数据的分析和处理。这种技术的引入使得人工智能的发展进入到了一个新的阶段。 现如今,深度学习在各个领域都有着广泛的应用。例如…...
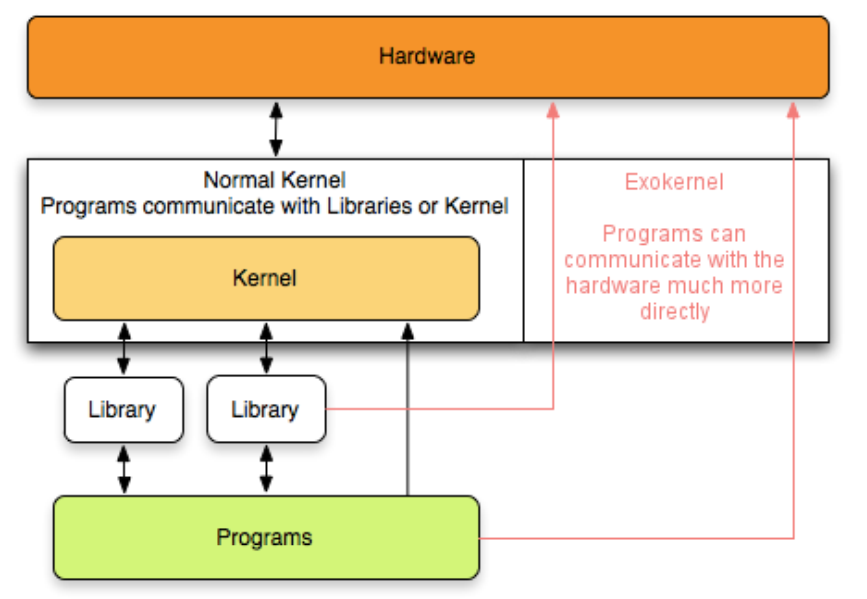
CHS_02.1.4+操作系统体系结构 二
CHS_02.1.4操作系统体系结构 二 操作系统的结构 上篇文章我们只介绍过宏内核 也就是大内核以及微内核分层结构的操作系统模块化是一种很经典的程序设计思想宏内核和微内核外核 操作系统的结构 上篇文章我们只介绍过宏内核 也就是大内核以及微内核 今年大纲又增加了分层结构 模块…...
【python可视化大屏】使用python实现可拖拽数据可视化大屏
介绍: 我在前几期分享了关于爬取weibo评论的爬虫,同时也分享了如何去进行数据可视化的操作。但是之前的可视化都是单独的,没有办法在一个界面上展示的。这样一来呢,大家在看的时候其实是很不方便的,就是没有办法一目了…...
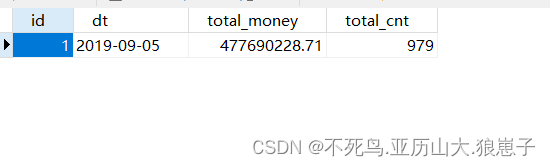
FineBI实战项目一(4):指标分析之每日订单总额/总笔数
1 明确数据分析目标 统计每天的订单总金额及订单总笔数 2 创建用于保存数据分析结果的表 use finebi_shop_bi;create table app_order_total(id int primary key auto_increment,dt date,total_money double,total_cnt int ); 3 编写SQL语句进行数据分析 selectsubstring(c…...

如何确定CUDA对应的pytorch版本?
参考:此链接...
分布式锁3: zk实现分布式锁5 使用中间件curator
一 curator的说明 1.1 curator的说明 curator是netflix公司开源的一个zk客户端。对Zookeeper提供的原生客户端进行封装,简化了Zookeeper客户端的开发量。Curator解决了很多zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册wathcer和Node…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...
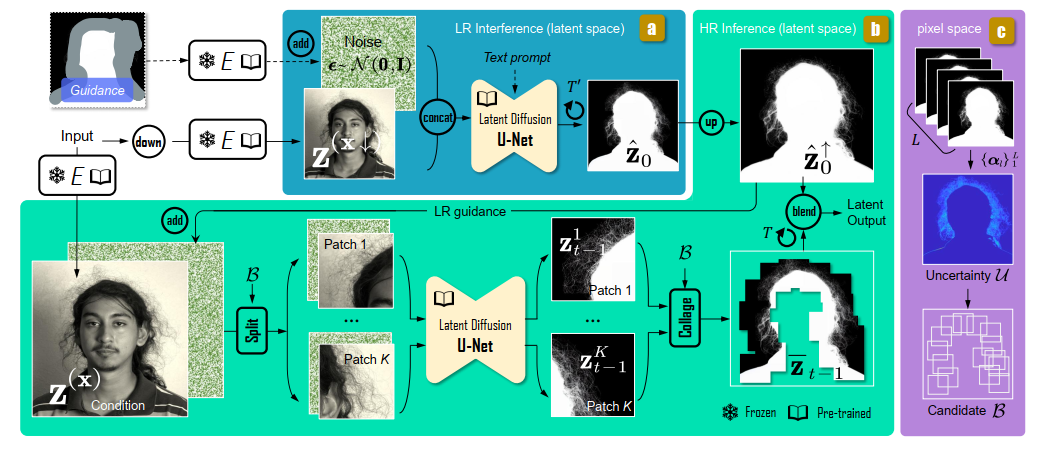
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...