Hive之set参数大全-3
D
是否启用本地任务调试模式
hive.debug.localtask 是 Apache Hive 中的一个配置参数,用于控制是否启用本地任务调试模式。在调试模式下,Hive 将尝试在本地模式下运行一些任务,以便更容易调试和分析问题。
具体来说,当 hive.debug.localtask 被设置为 true 时,Hive 在执行查询时会尽量在本地运行一些任务,而不是分布式运行在集群上。这使得开发人员可以更轻松地调试和观察任务的执行过程,以便更好地理解任务的行为。
示例:
-- 设置 hive.debug.localtask 为 true
SET hive.debug.localtask=true;-- 执行查询
SELECT * FROM your_table;
请注意,将 hive.debug.localtask 设置为 true 仅影响查询期间的一些任务,而不是整个查询过程。这对于部分调试和性能分析是有用的。
在生产环境中,应该将 hive.debug.localtask 设置为 false,以确保查询正常运行在分布式环境中,以获得更准确的性能和行为分析。在调试结束后,记得将该参数设置为默认值或者 false 以避免影响正常的生产查询。
指定在创建表时使用的默认文件格式
hive.default.fileformat 是 Hive 中的一个配置参数,用于指定在创建表时使用的默认文件格式。文件格式指定了 Hive 表中数据的存储方式,例如文本文件 (TEXTFILE)、Parquet 文件 (PARQUET)、ORC 文件 (ORC) 等。
当创建表时,如果没有显式指定文件格式,Hive 将使用 hive.default.fileformat 参数中设置的默认文件格式。
以下是一个示例:
-- 设置默认文件格式为 ORC
SET hive.default.fileformat=ORC;-- 创建表时未指定文件格式,将使用默认值
CREATE TABLE example_table (id INT,name STRING
);
在上述示例中,如果在创建表时没有指定文件格式,表 example_table 将使用默认文件格式 ORC。
常见的文件格式包括:
TEXTFILE: 文本文件格式。SEQUENCEFILE: Hadoop 序列文件格式。ORC: 优化的行列存储格式。PARQUET: Apache Parquet 列式存储格式。
你可以根据你的需求和使用场景设置 hive.default.fileformat 参数,确保默认的文件格式符合你的存储和查询需求。
指定在创建表时使用的默认 RCFile(Record Columnar File)的序列化/反序列化(SerDe)类
hive.default.rcfile.serde 是 Hive 中的一个配置参数,用于指定在创建表时使用的默认 RCFile(Record Columnar File)的序列化/反序列化(SerDe)类。RCFile 是一种列式存储文件格式,用于提高查询性能。
这个参数指定了 RCFile 表的默认 SerDe 类。SerDe 是 Hive 中用于解析数据格式的一种机制,它定义了如何将数据序列化为二进制格式以及如何反序列化。不同的数据格式和存储格式可能需要不同的 SerDe 类。
以下是一个示例:
-- 设置默认的 RCFile SerDe 类
SET hive.default.rcfile.serde=org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe;-- 创建 RCFile 表时未指定 SerDe 类,将使用默认值
CREATE TABLE example_rcfile_table (id INT,name STRING
) STORED AS RCFILE;
在上述示例中,如果在创建 RCFile 表时没有显式指定 SerDe 类,表 example_rcfile_table 将使用默认的 RCFile SerDe 类 org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe。
请注意,确保设置的 SerDe 类是有效的、存在的,并且适用于你的使用场景。根据你的 Hive 版本和需求,可能有其他可用的 SerDe 类。
指定在创建表时使用的默认序列化/反序列化 (SerDe) 类
在 Apache Hive 中,hive.default.serde 是一个配置参数,用于指定在创建表时使用的默认序列化/反序列化 (SerDe) 类。SerDe 是 Hive 中用于解析数据格式的一种机制,它定义了如何将数据序列化为二进制格式以及如何反序列化。
以下是一个示例:
-- 设置默认的 SerDe 类
SET hive.default.serde=org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe;-- 创建表时未指定 SerDe 类,将使用默认值
CREATE TABLE example_table (id INT,name STRING
);
在上述示例中,如果在创建表时没有显式指定 SerDe 类,表 example_table 将使用默认的 SerDe 类 org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe。
这个参数对于确保创建的表与默认 SerDe 类的数据格式一致是很有用的。根据你的 Hive 版本和需求,可能有其他可用的 SerDe 类,例如 org.apache.hadoop.hive.serde2.avro.AvroSerDe、org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe 等。
请确保设置的 SerDe 类是有效的、存在的,并且适用于你的使用场景。根据你的 Hive 版本和需求,可能有其他可用的 SerDe 类。
控制生成的 SQL 查询中 IN 子句的最大元素数量
hive.direct.sql.max.elements.in.clause 是 Hive 中的一个配置参数,用于控制生成的 SQL 查询中 IN 子句的最大元素数量。IN 子句通常用于在 SQL 查询中指定一个值列表,例如 WHERE column_name IN (value1, value2, ...)。
具体而言,hive.direct.sql.max.elements.in.clause 参数指定了在执行某些查询时,Hive 将生成的 IN 子句中允许的最大元素数量。如果查询中包含的元素数量超过了这个限制,Hive 可能会生成多个 IN 子句来处理。
示例:
-- 设置 hive.direct.sql.max.elements.in.clause 为 1000
SET hive.direct.sql.max.elements.in.clause=1000;
在上述示例中,将 hive.direct.sql.max.elements.in.clause 设置为 1000,表示在生成的 SQL 查询中,IN 子句中允许的最大元素数量为 1000。
这个参数的值应该根据你的数据和查询模式进行调整。如果查询中的元素数量经常超过默认值,你可能需要增加这个限制,以避免查询失败或性能下降。但要注意,增加这个值也会增加查询的内存消耗。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
是否禁用不安全的外部表(external table)操作
hive.disable.unsafe.external.table.operations 是 Hive 中的一个配置参数,用于控制是否禁用不安全的外部表(external table)操作。外部表是 Hive 中的一种表类型,它们的数据存储在外部文件系统中,而不是 Hive 管理的内部文件系统中。
当设置 hive.disable.unsafe.external.table.operations 为 true 时,将禁用某些不安全的外部表操作,以防止误操作导致数据的丢失。例如,禁用删除外部表数据的操作。
以下是一个示例:
-- 设置 hive.disable.unsafe.external.table.operations 为 true
SET hive.disable.unsafe.external.table.operations=true;
在上述示例中,将 hive.disable.unsafe.external.table.operations 设置为 true,以禁用不安全的外部表操作。
请注意,启用此参数可能会限制一些表维护的自由度,因此在使用之前请确保了解其潜在影响,并根据具体情况进行设置。这个参数通常用于提高数据安全性,尤其是在共享和多用户环境中。
是否将分区列(Partition Columns)单独列出
在 Apache Hive 中,hive.display.partition.cols.separately 是一个配置参数,用于控制在显示表的元数据时是否将分区列(Partition Columns)单独列出。分区列是表中用于分区的列,其值决定了数据存储在表中的哪个分区。
如果设置 hive.display.partition.cols.separately 为 true,则在显示表的元数据时,分区列将会单独列出,而不与非分区列混在一起。
以下是一个示例:
-- 设置 hive.display.partition.cols.separately 为 true
SET hive.display.partition.cols.separately=true;
在上述示例中,将 hive.display.partition.cols.separately 设置为 true,以在显示表的元数据时单独列出分区列。
这个参数的设置影响的主要是在 Hive 命令行界面或其他管理工具中执行 DESCRIBE FORMATTED table_name 等命令时的输出。设置为 true 可以使分区列更容易识别和理解。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
控制在执行分布式拷贝(DistCp)操作时是否使用特权身份(privileged doAs)
在 Hive 中,hive.distcp.privileged.doAs 是一个配置参数,用于控制在执行分布式拷贝(DistCp)操作时是否使用特权身份(privileged doAs)。
DistCp 是用于在 Hadoop 群集之间复制大量数据的工具。hive.distcp.privileged.doAs 参数的作用是为 DistCp 操作提供特权身份,以便拥有执行 DistCp 操作所需的访问权限。
以下是一个示例:
-- 设置 hive.distcp.privileged.doAs 为 true
SET hive.distcp.privileged.doAs=true;
在上述示例中,将 hive.distcp.privileged.doAs 设置为 true,以启用特权身份执行 DistCp 操作。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。此外,使用特权身份需要确保拥有足够的权限,以避免潜在的安全问题。
是否启用驱动程序(driver)的并行编译
hive.driver.parallel.compilation 是 Hive 中的一个配置参数,用于控制是否启用驱动程序(driver)的并行编译。
当设置 hive.driver.parallel.compilation 为 true 时,Hive 驱动程序将尝试并行编译多个查询。这可以提高查询性能,尤其是在执行多个独立查询时。
以下是一个示例:
-- 设置 hive.driver.parallel.compilation 为 true
SET hive.driver.parallel.compilation=true;
在上述示例中,将 hive.driver.parallel.compilation 设置为 true,以启用并行编译。
请注意,启用并行编译可能会增加系统资源的使用,因为每个查询都需要额外的资源。在决定是否启用此选项时,应考虑系统的可用资源和查询的特性。这个参数的默认值通常是 false。
具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
配置 Apache Druid 存储和查询的一个参数
hive.druid.bitmap.type 是 Hive 中用于配置 Apache Druid 存储和查询的一个参数。Druid 是一个实时数据存储和分析引擎,用于处理大规模的实时事件数据。
hive.druid.bitmap.type 参数用于指定 Druid 存储中使用的 Bitmap 索引的类型。Bitmap 索引是一种用于高效存储和查询集合数据的索引结构,通常用于 Druid 中的维度列。
以下是一个示例:
-- 设置 hive.druid.bitmap.type 为 Roaring
SET hive.druid.bitmap.type=Roaring;
在上述示例中,将 hive.druid.bitmap.type 设置为 Roaring,指定了在 Druid 存储中使用 Roaring Bitmap 索引。
具体的 Bitmap 索引类型可能包括 Roaring、Concise 等,这些类型的选择可能取决于你的数据特性和查询模式。Roaring Bitmap 通常用于处理高基数(cardinality)的列,而 Concise Bitmap 可能更适用于低基数的列。
请注意,具体的配置参数和其行为可能会根据 Hive 版本和 Druid 插件版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
配置 Apache Druid 存储和查询的一个参数
hive.druid.coordinator.address.default 是 Hive 中用于配置 Apache Druid 存储和查询的一个参数。Druid 是一个实时数据存储和分析引擎,用于处理大规模的实时事件数据。
hive.druid.coordinator.address.default 参数用于指定 Druid 存储中的协调节点(coordinator)的地址。协调节点在 Druid 集群中负责管理数据分片的分配、数据的加载和移除等任务。
以下是一个示例:
-- 设置 hive.druid.coordinator.address.default 为 http://druid-coordinator:8081
SET hive.druid.coordinator.address.default=http://druid-coordinator:8081;
在上述示例中,将 hive.druid.coordinator.address.default 设置为 http://druid-coordinator:8081,指定了 Druid 集群中的协调节点的地址。
请注意,具体的配置参数和其行为可能会根据 Hive 版本和 Druid 插件版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
配置 Apache Druid 存储和查询的一个参数
hive.druid.http.read.timeout 是 Hive 中用于配置 Apache Druid 存储和查询的一个参数。Druid 是一个实时数据存储和分析引擎,用于处理大规模的实时事件数据。
hive.druid.http.read.timeout 参数用于指定 Druid 存储中的 HTTP 请求的读取超时时间。读取超时时间是指在发出 HTTP 请求后,等待从服务器读取响应的最大时间。
以下是一个示例:
-- 设置 hive.druid.http.read.timeout 为 30000 毫秒(30秒)
SET hive.druid.http.read.timeout=30000;
在上述示例中,将 hive.druid.http.read.timeout 设置为 30000,表示 Druid 存储中的 HTTP 请求的读取超时时间为 30 秒。
请注意,具体的配置参数和其行为可能会根据 Hive 版本和 Druid 插件版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。此外,读取超时时间的设置应该根据你的网络状况和查询性能的需求进行调整。
配置 Apache Druid 存储和查询的一个参数
hive.druid.indexer.memory.rownum.max 是 Hive 中用于配置 Apache Druid 存储和查询的一个参数。Druid 是一个实时数据存储和分析引擎,用于处理大规模的实时事件数据。
hive.druid.indexer.memory.rownum.max 参数用于指定 Druid 索引任务中,内存中存储的最大行数。这个参数影响到在 Druid 中执行的索引任务的内存使用。
以下是一个示例:
-- 设置 hive.druid.indexer.memory.rownum.max 为 50000
SET hive.druid.indexer.memory.rownum.max=50000;
在上述示例中,将 hive.druid.indexer.memory.rownum.max 设置为 50000,表示 Druid 索引任务中内存中存储的最大行数为 50000。
请注意,具体的配置参数和其行为可能会根据 Hive 版本和 Druid 插件版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。这个参数的设置应该根据你的索引任务和硬件资源进行调整,以达到性能和资源利用的平衡。
配置 Apache Druid 存储和查询的参数
在 Hive 中,hive.druid.indexer.partition.size.max 是用于配置 Apache Druid 存储和查询的参数之一。Druid 是一个实时数据存储和分析引擎,用于处理大规模的实时事件数据。
hive.druid.indexer.partition.size.max 参数用于指定 Druid 索引任务中每个分区的最大大小。这个参数影响到在 Druid 中执行的索引任务的数据切分和分区。
以下是一个示例:
-- 设置 hive.druid.indexer.partition.size.max 为 500000000(500MB)
SET hive.druid.indexer.partition.size.max=500000000;
在上述示例中,将 hive.druid.indexer.partition.size.max 设置为 500000000,表示 Druid 索引任务中每个分区的最大大小为 500MB。
请注意,具体的配置参数和其行为可能会根据 Hive 版本和 Druid 插件版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。这个参数的设置应该根据你的索引任务、硬件资源以及数据特性进行调整,以达到最佳性能。
配置 Apache Druid 存储和查询的参数之一
hive.druid.indexer.segments.granularity 是 Hive 中用于配置 Apache Druid 存储和查询的参数之一。Druid 是一个实时数据存储和分析引擎,用于处理大规模的实时事件数据。
hive.druid.indexer.segments.granularity 参数用于指定 Druid 索引任务中生成的数据段(segments)的时间粒度。数据段是 Druid 存储的基本单元,精细的时间粒度可以影响查询性能和存储效率。
以下是一个示例:
-- 设置 hive.druid.indexer.segments.granularity 为 DAY
SET hive.druid.indexer.segments.granularity=DAY;
在上述示例中,将 hive.druid.indexer.segments.granularity 设置为 DAY,表示 Druid 索引任务中生成的数据段的时间粒度为一天。
其他可能的值包括 HOUR, FIFTEEN_MINUTE, THIRTY_MINUTE 等,用于指定不同的时间粒度。
请注意,具体的配置参数和其行为可能会根据 Hive 版本和 Druid 插件版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。选择合适的时间粒度通常取决于你的数据模型和查询需求。
配置 Apache Druid 存储和查询的参数之一
hive.druid.metadata.base 是 Hive 中用于配置 Apache Druid 存储和查询的参数之一。Druid 是一个实时数据存储和分析引擎,用于处理大规模的实时事件数据。
hive.druid.metadata.base 参数用于指定 Druid 中元数据(metadata)的基础路径。元数据是 Druid 集群用于存储有关数据段、查询等信息的关键组件。
以下是一个示例:
-- 设置 hive.druid.metadata.base 为 /druid/metadata
SET hive.druid.metadata.base=/druid/metadata;
在上述示例中,将 hive.druid.metadata.base 设置为 /druid/metadata,表示 Druid 中元数据的基础路径为 /druid/metadata。
请注意,具体的配置参数和其行为可能会根据 Hive 版本和 Druid 插件版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。这个参数的设置通常应与 Druid 集群中的元数据存储配置相匹配。
配置 Apache Druid 存储和查询的参数之一
hive.druid.metadata.db.type 是 Hive 中用于配置 Apache Druid 存储和查询的参数之一。Druid 是一个实时数据存储和分析引擎,用于处理大规模的实时事件数据。
hive.druid.metadata.db.type 参数用于指定 Druid 中元数据(metadata)存储所使用的数据库类型。元数据是 Druid 集群用于存储有关数据段、查询等信息的关键组件。
以下是一个示例:
-- 设置 hive.druid.metadata.db.type 为 mysql
SET hive.druid.metadata.db.type=mysql;
在上述示例中,将 hive.druid.metadata.db.type 设置为 mysql,表示 Druid 中元数据存储所使用的数据库类型为 MySQL。
其他可能的数据库类型包括 postgresql、h2 等,具体的配置参数和其行为可能会根据 Hive 版本和 Druid 插件版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。此外,你需要确保 Druid 集群和 Hive 配置的数据库类型一致,以便元数据的正确存储和访问。
配置 Apache Druid 存储和查询的参数之一
hive.druid.overlord.address.default 是 Hive 中用于配置 Apache Druid 存储和查询的参数之一。Druid 是一个实时数据存储和分析引擎,用于处理大规模的实时事件数据。
hive.druid.overlord.address.default 参数用于指定 Druid 集群中的 Overlord 节点的地址。Overlord 负责协调和调度 Druid 集群中的任务,包括索引任务、数据加载等。
以下是一个示例:
-- 设置 hive.druid.overlord.address.default 为 http://druid-overlord:8090
SET hive.druid.overlord.address.default=http://druid-overlord:8090;
在上述示例中,将 hive.druid.overlord.address.default 设置为 http://druid-overlord:8090,表示 Druid 集群中的 Overlord 节点的地址为 http://druid-overlord:8090。
请注意,具体的配置参数和其行为可能会根据 Hive 版本和 Druid 插件版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。这个参数的设置应该根据你的 Druid 集群配置和网络环境进行调整。
配置 Apache Druid 存储和查询的参数之一
hive.druid.select.threshold 是 Hive 中用于配置 Apache Druid 存储和查询的参数之一。Druid 是一个实时数据存储和分析引擎,用于处理大规模的实时事件数据。
hive.druid.select.threshold 参数用于指定 Hive 查询中选择使用 Druid 进行查询的阈值。当 Hive 查询的代价低于此阈值时,将选择使用 Druid 进行查询。
以下是一个示例:
-- 设置 hive.druid.select.threshold 为 1000000
SET hive.druid.select.threshold=1000000;
在上述示例中,将 hive.druid.select.threshold 设置为 1000000,表示当 Hive 查询的代价低于 1000000 时,将选择使用 Druid 进行查询。
这个参数的设置可以根据查询的性质和数据的规模进行调整,以获得最佳的查询性能。具体的配置参数和其行为可能会根据 Hive 版本和 Druid 插件版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
配置 Apache Druid 存储和查询的参数之一
hive.druid.working.directory 是 Hive 中用于配置 Apache Druid 存储和查询的参数之一。Druid 是一个实时数据存储和分析引擎,用于处理大规模的实时事件数据。
hive.druid.working.directory 参数用于指定 Druid 索引任务等工作时的工作目录。这个目录用于存储索引任务生成的临时文件和中间结果。
以下是一个示例:
-- 设置 hive.druid.working.directory 为 /druid/working
SET hive.druid.working.directory=/druid/working;
在上述示例中,将 hive.druid.working.directory 设置为 /druid/working,表示 Druid 索引任务等工作时使用的工作目录为 /druid/working。
请注意,具体的配置参数和其行为可能会根据 Hive 版本和 Druid 插件版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。这个参数的设置通常应该与 Druid 集群中的工作节点配置相匹配。
E
是否强制启用桶映射连接(Bucket Map Join)
hive.enforce.bucketmapjoin 是 Hive 的一个配置参数,用于控制是否强制启用桶映射连接(Bucket Map Join)。
当设置 hive.enforce.bucketmapjoin 为 true 时,Hive 将尝试使用桶映射连接来优化某些查询。桶映射连接是一种在执行连接操作时利用桶排序的优化技术,以提高查询性能的方法。
以下是一个示例:
-- 设置 hive.enforce.bucketmapjoin 为 true
SET hive.enforce.bucketmapjoin=true;
在上述示例中,将 hive.enforce.bucketmapjoin 设置为 true,以启用桶映射连接的优化。
请注意,启用桶映射连接可能会在某些情况下提高查询性能,但并不适用于所有查询。在具体的查询场景中,优化的效果可能因数据分布和查询条件而有所不同。因此,在启用此选项之前,建议测试查询性能,并根据实际情况进行调整。
是否强制启用排序合并桶映射连接(Sort-Merge Bucket Map Join)
hive.enforce.sortmergebucketmapjoin 是 Hive 的一个配置参数,用于控制是否强制启用排序合并桶映射连接(Sort-Merge Bucket Map Join)。
当设置 hive.enforce.sortmergebucketmapjoin 为 true 时,Hive 将尝试使用排序合并桶映射连接来优化某些查询。排序合并桶映射连接是一种在执行连接操作时结合了排序和合并的优化技术,以提高查询性能的方法。
以下是一个示例:
-- 设置 hive.enforce.sortmergebucketmapjoin 为 true
SET hive.enforce.sortmergebucketmapjoin=true;
在上述示例中,将 hive.enforce.sortmergebucketmapjoin 设置为 true,以启用排序合并桶映射连接的优化。
请注意,启用排序合并桶映射连接可能会在某些情况下提高查询性能,但并不适用于所有查询。在具体的查询场景中,优化的效果可能因数据分布和查询条件而有所不同。因此,在启用此选项之前,建议测试查询性能,并根据实际情况进行调整。
控制当查询结果为空时是否报错
hive.error.on.empty.partition 是 Hive 中的一个配置参数,用于控制在查询时是否报错当分区为空。当设置为 true 时,如果查询涉及到的分区没有数据,Hive 会报错。当设置为 false 时,如果分区为空,Hive 不会报错,而是返回空结果。
以下是一个示例:
-- 设置 hive.error.on.empty.partition 为 true
SET hive.error.on.empty.partition=true;
在上述示例中,将 hive.error.on.empty.partition 设置为 true,表示在查询时,如果分区为空,将会报错。
-- 设置 hive.error.on.empty.partition 为 false
SET hive.error.on.empty.partition=false;
在上述示例中,将 hive.error.on.empty.partition 设置为 false,表示在查询时,如果分区为空,不会报错,而是返回空结果。
这个参数的选择通常取决于你对于查询结果的期望和处理方式。如果分区为空时你希望得到一个空结果而不是报错,可以将其设置为 false。如果你希望在查询中处理非空分区,可以将其设置为 true 以便及时发现潜在的问题。
是否检查查询计划中是否存在跨产品(cross product)的情况
在 Hive 中,hive.exec.check.crossproducts 是一个配置参数,用于控制是否检查查询计划中是否存在跨产品(cross product)的情况。跨产品是指在连接操作中没有指定关联条件,导致结果集是两个表的笛卡尔积。
以下是一个示例:
-- 设置 hive.exec.check.crossproducts 为 true
SET hive.exec.check.crossproducts=true;
在上述示例中,将 hive.exec.check.crossproducts 设置为 true,表示启用查询计划中是否存在跨产品的检查。
-- 设置 hive.exec.check.crossproducts 为 false
SET hive.exec.check.crossproducts=false;
在上述示例中,将 hive.exec.check.crossproducts 设置为 false,表示禁用查询计划中是否存在跨产品的检查。
启用这个选项可以帮助发现潜在的错误或性能问题,但在某些情况下,一些查询可能确实需要跨产品。因此,在设置此选项之前,请确保了解查询的性质和业务需求,并谨慎使用。
控制在执行 MapReduce 中间阶段时是否对数据进行压缩
hive.exec.compress.intermediate 是 Hive 的一个配置参数,用于控制在执行 MapReduce 中间阶段时是否对数据进行压缩。
以下是一个示例:
-- 设置 hive.exec.compress.intermediate 为 true
SET hive.exec.compress.intermediate=true;
在上述示例中,将 hive.exec.compress.intermediate 设置为 true,表示在执行 MapReduce 中间阶段时启用数据压缩。
-- 设置 hive.exec.compress.intermediate 为 false
SET hive.exec.compress.intermediate=false;
在上述示例中,将 hive.exec.compress.intermediate 设置为 false,表示在执行 MapReduce 中间阶段时禁用数据压缩。
启用数据压缩可以减少数据在存储和传输过程中的空间和网络开销,但会增加 CPU 开销。选择是否启用压缩通常取决于集群的配置和性能需求。在大多数情况下,启用压缩是一个有效的性能优化手段。
控制在执行 MapReduce 输出阶段时是否对结果数据进行压缩
hive.exec.compress.output 是 Hive 的一个配置参数,用于控制在执行 MapReduce 输出阶段时是否对结果数据进行压缩。
以下是一个示例:
-- 设置 hive.exec.compress.output 为 true
SET hive.exec.compress.output=true;
在上述示例中,将 hive.exec.compress.output 设置为 true,表示在执行 MapReduce 输出阶段时启用数据压缩。
-- 设置 hive.exec.compress.output 为 false
SET hive.exec.compress.output=false;
在上述示例中,将 hive.exec.compress.output 设置为 false,表示在执行 MapReduce 输出阶段时禁用数据压缩。
启用数据压缩可以减少数据在存储和传输过程中的空间和网络开销,但会增加 CPU 开销。选择是否启用压缩通常取决于集群的配置和性能需求。在大多数情况下,启用压缩是一个有效的性能优化手段。
控制在执行复制文件操作时的最大文件数量
hive.exec.copyfile.maxnumfiles 是 Hive 的一个配置参数,用于控制在执行复制文件操作时的最大文件数量。
以下是一个示例:
-- 设置 hive.exec.copyfile.maxnumfiles 为 1000
SET hive.exec.copyfile.maxnumfiles=1000;
在上述示例中,将 hive.exec.copyfile.maxnumfiles 设置为 1000,表示在执行复制文件操作时允许的最大文件数量为 1000。
这个参数通常用于限制一次性复制文件操作中的文件数量,以防止过多的文件同时被复制,导致系统资源占用过高。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
控制在执行复制文件操作时的最大文件大小
在 Hive 中,hive.exec.copyfile.maxsize 是一个配置参数,用于控制在执行复制文件操作时的最大文件大小。
以下是一个示例:
-- 设置 hive.exec.copyfile.maxsize 为 1024
SET hive.exec.copyfile.maxsize=1024;
在上述示例中,将 hive.exec.copyfile.maxsize 设置为 1024,表示在执行复制文件操作时允许的最大文件大小为 1024 MB。
这个参数通常用于限制一次性复制文件操作中单个文件的大小,以防止复制过大的文件,导致系统资源占用过高。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
控制在执行 MapReduce 作业时定期拉取计数器(counters)的间隔时间
hive.exec.counters.pull.interval 是 Hive 的一个配置参数,用于控制在执行 MapReduce 作业时定期拉取计数器(counters)的间隔时间。
以下是一个示例:
-- 设置 hive.exec.counters.pull.interval 为 1000(毫秒)
SET hive.exec.counters.pull.interval=1000;
在上述示例中,将 hive.exec.counters.pull.interval 设置为 1000 毫秒,表示每隔 1 秒将拉取一次作业的计数器。
计数器是用于跟踪作业执行过程中各种指标的机制,包括任务的输入记录数、输出记录数、执行时间等。设置拉取计数器的间隔时间可以影响计数器的实时性和对作业执行过程的监控。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
指定在没有指定分区列值的情况下,Hive 使用的默认分区名称
hive.exec.default.partition.name 是 Hive 的一个配置参数,用于指定在没有指定分区列值的情况下,Hive 使用的默认分区名称。
以下是一个示例:
-- 设置 hive.exec.default.partition.name 为 default_partition
SET hive.exec.default.partition.name=default_partition;
在上述示例中,将 hive.exec.default.partition.name 设置为 default_partition,表示当执行操作时没有指定分区列值时,将使用这个默认的分区名称。
这个参数的作用是在没有显式提供分区列值的情况下,确保数据能够被正确存储到某个分区中。例如,如果你执行了以下操作:
INSERT INTO TABLE my_table VALUES (1, 'value1');
如果没有提供分区列的值,Hive 将使用默认的分区名称。上述配置的话,相当于插入到了 default_partition 这个分区。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
控制在执行 DROP 操作时是否忽略不存在的对象(表、分区等)而不抛出错误
hive.exec.drop.ignorenonexistent 是 Hive 的一个配置参数,用于控制在执行 DROP 操作时是否忽略不存在的对象(表、分区等)而不抛出错误。
以下是一个示例:
-- 设置 hive.exec.drop.ignorenonexistent 为 true
SET hive.exec.drop.ignorenonexistent=true;
在上述示例中,将 hive.exec.drop.ignorenonexistent 设置为 true,表示在执行 DROP 操作时,如果对象不存在,将忽略该错误而不抛出异常。
-- 设置 hive.exec.drop.ignorenonexistent 为 false
SET hive.exec.drop.ignorenonexistent=false;
在上述示例中,将 hive.exec.drop.ignorenonexistent 设置为 false,表示在执行 DROP 操作时,如果对象不存在,将抛出异常。
这个参数的设置可以根据实际需求来确定。如果你希望在执行 DROP 操作时无论对象是否存在都不抛出异常,可以将其设置为 true。如果你希望在对象不存在时抛出异常,可以将其设置为 false。
是否启用动态分区插入
hive.exec.dynamic.partition 是 Hive 的一个配置参数,用于控制是否启用动态分区插入。
动态分区插入是指在向分区表插入数据时,根据数据中的字段值动态创建新的分区。这种机制允许用户不必在插入数据之前提前创建分区,而是在插入数据的同时创建分区。
以下是一个示例:
-- 设置 hive.exec.dynamic.partition 为 true
SET hive.exec.dynamic.partition=true;
在上述示例中,将 hive.exec.dynamic.partition 设置为 true,表示启用动态分区插入。
-- 设置 hive.exec.dynamic.partition 为 false
SET hive.exec.dynamic.partition=false;
在上述示例中,将 hive.exec.dynamic.partition 设置为 false,表示禁用动态分区插入。
启用动态分区插入可以简化操作,但需要注意潜在的性能和安全性问题。具体的使用取决于你的业务需求和安全策略。在一些情况下,动态分区插入可能会造成性能问题,因此建议谨慎使用,并根据实际情况进行性能测试。
指定动态分区模式
hive.exec.dynamic.partition.mode 是 Hive 的一个配置参数,用于指定动态分区模式。
动态分区模式决定了在动态分区插入时,Hive 如何处理插入数据中的分区字段。该参数有三个可能的取值:
-
strict:表示在插入数据时,所有分区字段都必须出现在插入语句的末尾,并且必须按照分区字段的顺序出现。这是默认的模式。SET hive.exec.dynamic.partition.mode=strict; -
nonstrict:表示在插入数据时,可以在插入语句中的任何位置包含分区字段,但至少需要提供一个分区字段。SET hive.exec.dynamic.partition.mode=nonstrict; -
strictall:表示在插入数据时,必须包含所有分区字段,且按照分区字段的顺序出现。SET hive.exec.dynamic.partition.mode=strictall;
这个参数影响到动态分区插入时的语法约束。例如,如果使用 strict 模式,插入语句必须按照分区字段的顺序提供,并且所有分区字段必须出现在插入语句的末尾。
在选择模式时,建议根据你的数据插入场景和需求来决定。如果希望更加灵活,可以选择 nonstrict 模式。如果需要更严格的控制,可以选择 strict 或 strictall 模式。
控制在执行插入操作时是否推断桶和排序列信息
hive.exec.infer.bucket.sort 是 Hive 的一个配置参数,用于控制在执行插入操作时是否推断桶和排序列信息。
当设置为 true 时,Hive 会尝试根据插入数据的字段信息来推断桶和排序列。这可以简化插入操作,因为用户不需要显式指定桶和排序列。
以下是一个示例:
-- 设置 hive.exec.infer.bucket.sort 为 true
SET hive.exec.infer.bucket.sort=true;
在上述示例中,将 hive.exec.infer.bucket.sort 设置为 true,表示启用推断桶和排序列。
-- 设置 hive.exec.infer.bucket.sort 为 false
SET hive.exec.infer.bucket.sort=false;
在上述示例中,将 hive.exec.infer.bucket.sort 设置为 false,表示禁用推断桶和排序列。
在某些场景下,推断桶和排序列可以简化操作,但也可能因为数据不符合期望而导致错误。因此,在设置此选项时,建议根据具体的业务需求和数据特点来进行考虑,并进行相应的测试。
控制推断桶的数量是否取 2 的幂次方
在 Hive 中,hive.exec.infer.bucket.sort.num.buckets.power.two 是一个配置参数,用于控制推断桶的数量是否取 2 的幂次方。
当设置为 true 时,Hive 会将推断的桶的数量限制为 2 的幂次方。这样做的目的是为了更好地利用桶映射连接(Bucket Map Join)等优化。
以下是一个示例:
-- 设置 hive.exec.infer.bucket.sort.num.buckets.power.two 为 true
SET hive.exec.infer.bucket.sort.num.buckets.power.two=true;
在上述示例中,将 hive.exec.infer.bucket.sort.num.buckets.power.two 设置为 true,表示启用将推断的桶的数量限制为 2 的幂次方。
-- 设置 hive.exec.infer.bucket.sort.num.buckets.power.two 为 false
SET hive.exec.infer.bucket.sort.num.buckets.power.two=false;
在上述示例中,将 hive.exec.infer.bucket.sort.num.buckets.power.two 设置为 false,表示不对推断的桶数量进行幂次方的限制。
这个参数的设置影响到推断桶的优化策略,具体是否启用,需要根据查询性能和数据特征进行测试和调整。
控制执行 Hive 查询时获取输入表或分区列表的最大线程数
hive.exec.input.listing.max.threads 是 Hive 的一个配置参数,用于控制执行 Hive 查询时获取输入表或分区列表的最大线程数。
以下是一个示例:
-- 设置 hive.exec.input.listing.max.threads 为 10
SET hive.exec.input.listing.max.threads=10;
在上述示例中,将 hive.exec.input.listing.max.threads 设置为 10,表示最大允许使用 10 个线程获取输入表或分区列表。
这个参数的目的是在查询中提高并行度,以便更快地获取输入表或分区的信息。然而,设置过高的线程数可能导致资源消耗过大,因此需要根据集群的配置和性能需求来进行调整。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
控制在作业调试模式下是否捕获堆栈跟踪信息
hive.exec.job.debug.capture.stacktraces 是 Hive 的一个配置参数,用于控制在作业调试模式下是否捕获堆栈跟踪信息。
以下是一个示例:
-- 设置 hive.exec.job.debug.capture.stacktraces 为 true
SET hive.exec.job.debug.capture.stacktraces=true;
在上述示例中,将 hive.exec.job.debug.capture.stacktraces 设置为 true,表示在作业调试模式下捕获堆栈跟踪信息。
-- 设置 hive.exec.job.debug.capture.stacktraces 为 false
SET hive.exec.job.debug.capture.stacktraces=false;
在上述示例中,将 hive.exec.job.debug.capture.stacktraces 设置为 false,表示在作业调试模式下不捕获堆栈跟踪信息。
作业调试模式允许用户在 Hive 作业运行过程中暂停和检查作业的状态。捕获堆栈跟踪信息可以帮助进行问题诊断和调试。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
设置作业调试模式的超时时间
hive.exec.job.debug.timeout 是 Hive 的一个配置参数,用于设置作业调试模式的超时时间。作业调试模式允许用户在 Hive 作业运行过程中暂停和检查作业的状态。
以下是一个示例:
-- 设置 hive.exec.job.debug.timeout 为 600000(毫秒)
SET hive.exec.job.debug.timeout=600000;
在上述示例中,将 hive.exec.job.debug.timeout 设置为 600000 毫秒,表示作业调试模式的超时时间为 600 秒。
这个参数指定了允许作业调试模式运行的最大时间。如果在指定的时间内没有完成调试,作业调试模式可能会被自动终止。超时时间的设置取决于用户的需求和实际情况。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
指定在本地文件系统上存储中间数据的临时目录
hive.exec.local.scratchdir 是 Hive 的一个配置参数,用于指定在本地文件系统上存储中间数据的临时目录。
以下是一个示例:
-- 设置 hive.exec.local.scratchdir 为 /tmp/hive-scratch
SET hive.exec.local.scratchdir=/tmp/hive-scratch;
在上述示例中,将 hive.exec.local.scratchdir 设置为 /tmp/hive-scratch,表示指定在本地文件系统上存储中间数据的临时目录为 /tmp/hive-scratch。
Hive 在执行 MapReduce 任务时,可能需要在本地文件系统上存储一些临时中间数据。hive.exec.local.scratchdir 参数用于配置这个临时目录的路径。这对于避免对分布式文件系统的过度负载是有益的。
请确保指定的目录对 Hive 运行的用户是可写的,并且有足够的空间来存储临时数据。
设置在执行查询时,Hive 允许创建的最大文件数量
hive.exec.max.created.files 是 Hive 的一个配置参数,用于设置在执行查询时,Hive 允许创建的最大文件数量。
以下是一个示例:
-- 设置 hive.exec.max.created.files 为 1000
SET hive.exec.max.created.files=1000;
在上述示例中,将 hive.exec.max.created.files 设置为 1000,表示在执行查询时,Hive 允许创建的最大文件数量为 1000。
这个参数的设置影响到查询执行过程中输出文件的数量。限制文件数量可以帮助控制查询的性能和资源消耗。请根据具体的集群配置和查询需求来调整这个参数。
控制动态分区插入时允许创建的最大分区数量
hive.exec.max.dynamic.partitions 是 Hive 的一个配置参数,用于控制动态分区插入时允许创建的最大分区数量。
以下是一个示例:
-- 设置 hive.exec.max.dynamic.partitions 为 100
SET hive.exec.max.dynamic.partitions=100;
在上述示例中,将 hive.exec.max.dynamic.partitions 设置为 100,表示在动态分区插入时允许创建的最大分区数量为 100。
动态分区插入是指根据插入数据的字段值动态创建新的分区。这个参数可以帮助限制在一次插入操作中创建的分区数量,防止创建过多的分区,从而控制系统资源的使用。
请根据实际需求和集群配置来调整这个参数。在大规模数据插入时,合理设置此参数可以避免潜在的性能问题。
控制动态分区插入时每个节点(Node)上允许创建的最大分区数量
hive.exec.max.dynamic.partitions.pernode 是 Hive 的一个配置参数,用于控制动态分区插入时每个节点(Node)上允许创建的最大分区数量。
以下是一个示例:
-- 设置 hive.exec.max.dynamic.partitions.pernode 为 50
SET hive.exec.max.dynamic.partitions.pernode=50;
在上述示例中,将 hive.exec.max.dynamic.partitions.pernode 设置为 50,表示在动态分区插入时每个节点上允许创建的最大分区数量为 50。
动态分区插入是指根据插入数据的字段值动态创建新的分区。这个参数可以帮助限制每个节点上一次插入操作中创建的分区数量,防止某个节点上创建过多的分区,从而控制系统资源的使用。
请根据实际需求和集群配置来调整这个参数。在大规模数据插入时,合理设置此参数可以避免潜在的性能问题。
是否自动选择本地模式执行
hive.exec.mode.local.auto 是 Hive 的一个配置参数,用于控制是否自动选择本地模式执行。
本地模式执行是指在本地机器上执行查询而不涉及分布式计算,主要用于小型数据集的测试和调试。当 hive.exec.mode.local.auto 设置为 true 时,Hive 会根据查询的复杂度和数据规模自动选择是否使用本地模式执行。
以下是一个示例:
-- 设置 hive.exec.mode.local.auto 为 true
SET hive.exec.mode.local.auto=true;
在上述示例中,将 hive.exec.mode.local.auto 设置为 true,表示启用自动选择本地模式执行。
-- 设置 hive.exec.mode.local.auto 为 false
SET hive.exec.mode.local.auto=false;
在上述示例中,将 hive.exec.mode.local.auto 设置为 false,表示禁用自动选择本地模式执行,强制使用分布式模式。
根据实际需求和查询的性质,你可以选择启用或禁用自动选择本地模式执行。在测试和调试阶段,使用本地模式可能更加方便,但在生产环境中,通常会使用分布式模式以处理大规模数据。
控制自动选择本地模式执行时,允许的最大输入文件数量
hive.exec.mode.local.auto.input.files.max 是 Hive 的一个配置参数,用于控制自动选择本地模式执行时,允许的最大输入文件数量。
在自动选择本地模式执行时,Hive 会考虑查询的复杂度和数据规模,并决定是否使用本地模式。hive.exec.mode.local.auto.input.files.max 参数用于限制在自动选择本地模式执行时,可以处理的最大输入文件数量。
以下是一个示例:
-- 设置 hive.exec.mode.local.auto.input.files.max 为 100
SET hive.exec.mode.local.auto.input.files.max=100;
在上述示例中,将 hive.exec.mode.local.auto.input.files.max 设置为 100,表示在自动选择本地模式执行时,最大允许处理的输入文件数量为 100。
这个参数的设置可以帮助控制在本地模式下处理的数据规模,防止由于数据量过大导致本地计算资源不足。请根据实际需求和查询的性质来调整这个参数。
控制在自动选择本地模式执行时,允许的最大输入数据量
hive.exec.mode.local.auto.inputbytes.max 是 Hive 的一个配置参数,用于控制在自动选择本地模式执行时,允许的最大输入数据量。
在自动选择本地模式执行时,Hive 会考虑查询的复杂度和数据规模,并决定是否使用本地模式。hive.exec.mode.local.auto.inputbytes.max 参数用于限制在自动选择本地模式执行时,可以处理的最大输入数据量。
以下是一个示例:
-- 设置 hive.exec.mode.local.auto.inputbytes.max 为 1GB
SET hive.exec.mode.local.auto.inputbytes.max=1073741824;
在上述示例中,将 hive.exec.mode.local.auto.inputbytes.max 设置为 1073741824 字节,表示在自动选择本地模式执行时,最大允许处理的输入数据量为 1GB。
这个参数的设置可以帮助控制在本地模式下处理的数据规模,防止由于数据量过大导致本地计算资源不足。请根据实际需求和查询的性质来调整这个参数。
控制 ORC 文件中列的基数(base)与增量(delta)之间的比率
hive.exec.orc.base.delta.ratio 是 Hive 的一个配置参数,用于控制 ORC 文件中列的基数(base)与增量(delta)之间的比率。
以下是一个示例:
-- 设置 hive.exec.orc.base.delta.ratio 为 0.9
SET hive.exec.orc.base.delta.ratio=0.9;
在上述示例中,将 hive.exec.orc.base.delta.ratio 设置为 0.9,表示 ORC 文件中列的基数与增量之间的比率为 0.9。
这个参数的设置影响到 ORC 文件的压缩和存储策略。ORC 文件中的列可以被划分为基数(base)和增量(delta),其中基数通常是比较大的非重复值,而增量是相对较小的重复值。通过调整 hive.exec.orc.base.delta.ratio 参数,可以在基数和增量之间取得平衡,以达到更好的压缩效果。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
启用或禁用 ORC 文件格式的增量流式写入优化
hive.exec.orc.delta.streaming.optimizations.enabled 是 Hive 的一个配置参数,用于启用或禁用 ORC 文件格式的增量流式写入优化。
以下是一个示例:
-- 启用 ORC 文件增量流式写入优化
SET hive.exec.orc.delta.streaming.optimizations.enabled=true;
在上述示例中,将 hive.exec.orc.delta.streaming.optimizations.enabled 设置为 true,表示启用 ORC 文件的增量流式写入优化。
-- 禁用 ORC 文件增量流式写入优化
SET hive.exec.orc.delta.streaming.optimizations.enabled=false;
在上述示例中,将 hive.exec.orc.delta.streaming.optimizations.enabled 设置为 false,表示禁用 ORC 文件的增量流式写入优化。
这个参数的设置影响到 ORC 文件的增量流式写入性能。增量流式写入是一种优化技术,用于在已有的 ORC 文件中追加数据而无需重新写入整个文件。启用这个优化可以提高增量写入的效率,特别是在流式数据追加的场景下。
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
指定 ORC 文件的切分策略
hive.exec.orc.split.strategy 是 Hive 的一个配置参数,用于指定 ORC 文件的切分策略。
以下是一个示例:
-- 设置 hive.exec.orc.split.strategy 为 EAGER
SET hive.exec.orc.split.strategy=EAGER;
在上述示例中,将 hive.exec.orc.split.strategy 设置为 EAGER,表示使用 EAGER 切分策略。
hive.exec.orc.split.strategy 支持的值包括:
EAGER:表示采用更为主动的切分策略,以提高并行度。LAZY:表示采用更为懒惰的切分策略,以减少切分时的计算成本。
选择合适的切分策略可以根据查询的性质和集群配置来进行调整。EAGER 策略可能会导致更多的并行度,但可能会增加切分时的计算成本。LAZY 策略则相反,可能降低并行度但减少计算成本。需要根据实际情况进行测试和权衡,选择适合的切分策略。
指定在执行任务时是否启用并行执行
hive.exec.parallel 是 Hive 的一个配置参数,用于指定在执行任务时是否启用并行执行。
以下是一个示例:
-- 设置 hive.exec.parallel 为 true
SET hive.exec.parallel=true;
在上述示例中,将 hive.exec.parallel 设置为 true,表示启用并行执行。
-- 设置 hive.exec.parallel 为 false
SET hive.exec.parallel=false;
在上述示例中,将 hive.exec.parallel 设置为 false,表示禁用并行执行。
启用并行执行允许 Hive 在执行查询时同时处理多个任务,从而提高查询性能。然而,在某些情况下,禁用并行执行可能有助于避免资源竞争和提高查询的稳定性。
请根据实际查询的性质和集群配置来选择是否启用并行执行,并进行性能测试以确定最佳设置。
指定在执行任务时的并行线程数
hive.exec.parallel.thread.number 是 Hive 的一个配置参数,用于指定在执行任务时的并行线程数。
以下是一个示例:
-- 设置 hive.exec.parallel.thread.number 为 10
SET hive.exec.parallel.thread.number=10;
在上述示例中,将 hive.exec.parallel.thread.number 设置为 10,表示在执行任务时使用的并行线程数为 10。
启用并行执行允许 Hive 在执行查询时同时处理多个任务,而 hive.exec.parallel.thread.number 则控制并行执行时使用的线程数量。这可以在一定程度上影响查询性能和资源利用率。
请根据实际查询的性质、数据规模和集群配置来选择合适的并行线程数,并进行性能测试以确定最佳设置。过高的线程数可能导致资源竞争和性能下降,因此需要谨慎选择适当的数值。
启用或禁用性能日志记录
hive.exec.perf.logger 是 Hive 的一个配置参数,用于启用或禁用性能日志记录。
以下是一个示例:
-- 启用性能日志记录
SET hive.exec.perf.logger=true;
在上述示例中,将 hive.exec.perf.logger 设置为 true,表示启用性能日志记录。
-- 禁用性能日志记录
SET hive.exec.perf.logger=false;
在上述示例中,将 hive.exec.perf.logger 设置为 false,表示禁用性能日志记录。
性能日志记录可以用于收集和分析 Hive 作业的性能指标,包括任务执行时间、资源利用率等。启用性能日志记录可以帮助进行性能调优和问题排查。
请注意,具体的性能日志记录内容和格式可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
指定是否使用显式的表头(Header)信息来标识 RCFile 中列的名称
hive.exec.rcfile.use.explicit.header 是 Hive 的一个配置参数,用于指定是否使用显式的表头(Header)信息来标识 RCFile 中列的名称。
以下是一个示例:
-- 设置 hive.exec.rcfile.use.explicit.header 为 true
SET hive.exec.rcfile.use.explicit.header=true;
在上述示例中,将 hive.exec.rcfile.use.explicit.header 设置为 true,表示使用显式的表头信息。
-- 设置 hive.exec.rcfile.use.explicit.header 为 false
SET hive.exec.rcfile.use.explicit.header=false;
在上述示例中,将 hive.exec.rcfile.use.explicit.header 设置为 false,表示不使用显式的表头信息。
RCFile 是 Hive 中一种列式存储格式,可以用于优化查询性能。当 hive.exec.rcfile.use.explicit.header 设置为 true 时,RCFile 中的第一行数据会被视为列名,用于标识每列的名称。设置为 false 则表示不使用显式的表头信息,列的名称由表的元数据(metadata)中的列信息确定。
选择是否使用显式的表头信息取决于你的数据和查询需求。如果你的数据文件包含列名信息,并且你希望使用这些列名作为表头信息,可以设置为 true。如果不需要或者数据文件中不包含列名信息,可以设置为 false。
控制是否使用同步缓存(sync cache)来提高 RCFile 的写入性能
hive.exec.rcfile.use.sync.cache 是 Hive 的一个配置参数,用于控制是否使用同步缓存(sync cache)来提高 RCFile 的写入性能。
以下是一个示例:
-- 启用同步缓存
SET hive.exec.rcfile.use.sync.cache=true;
在上述示例中,将 hive.exec.rcfile.use.sync.cache 设置为 true,表示启用同步缓存。
-- 禁用同步缓存
SET hive.exec.rcfile.use.sync.cache=false;
在上述示例中,将 hive.exec.rcfile.use.sync.cache 设置为 false,表示禁用同步缓存。
RCFile 是 Hive 中一种列式存储格式,同步缓存是一种优化技术,可以提高写入性能。启用同步缓存可以减少磁盘 I/O 操作,提高数据写入的效率。但需要注意的是,同步缓存可能会增加内存的使用量。
根据实际的数据规模和查询需求,可以根据性能测试结果来决定是否启用同步缓存。在某些情况下,启用同步缓存可能对写入性能产生积极的影响。
指定每个 reducer 处理的输入数据大小
hive.exec.reducers.bytes.per.reducer 是 Hive 的一个配置参数,用于指定每个 reducer 处理的输入数据大小。
以下是一个示例:
-- 设置 hive.exec.reducers.bytes.per.reducer 为 1000000000
SET hive.exec.reducers.bytes.per.reducer=1000000000;
在上述示例中,将 hive.exec.reducers.bytes.per.reducer 设置为 1000000000,表示每个 reducer 处理的输入数据大小为 1GB。
这个参数的目的是控制 MapReduce 作业中每个 reducer 处理的数据量,从而影响 reducer 的数量。较小的值会导致更多的 reducer,而较大的值会导致较少的 reducer。通过调整这个参数,可以对作业的性能进行微调。
请注意,具体的最佳值取决于数据规模、计算资源和集群配置等因素。建议在实际应用中进行性能测试,并根据测试结果调整这个参数的值。
设置在执行 MapReduce 作业时的最大 reducer 数量
hive.exec.reducers.max 是 Hive 的一个配置参数,用于设置在执行 MapReduce 作业时的最大 reducer 数量。
以下是一个示例:
-- 设置 hive.exec.reducers.max 为 1000
SET hive.exec.reducers.max=1000;
在上述示例中,将 hive.exec.reducers.max 设置为 1000,表示在执行 MapReduce 作业时最多使用 1000 个 reducer。
这个参数的设置影响到作业的并行度,即同时运行的 reducer 的数量。通过增加 reducer 的数量,可以提高作业的并行性,从而加快查询的执行速度。但是,需要注意在集群中合理配置 reducer 的数量,以避免资源竞争和性能下降。
在实际应用中,最佳的 hive.exec.reducers.max 值取决于数据规模、集群配置和查询性质等因素。建议进行性能测试,并根据测试结果调整这个参数的值。
读取表数据时的偏移量
hive.exec.rowoffset 是 Hive 的一个配置参数,用于设置在读取表数据时的偏移量。
以下是一个示例:
-- 设置 hive.exec.rowoffset 为 100
SET hive.exec.rowoffset=100;
在上述示例中,将 hive.exec.rowoffset 设置为 100,表示在读取表数据时从第 101 行开始读取。
这个参数的设置允许你指定一个偏移量,从而在读取表数据时跳过指定数量的行。这可以用于从指定位置开始读取数据,而不必读取整个表。这在处理大型表时可能是有用的,可以减少读取的数据量,提高查询性能。
请注意,在使用 hive.exec.rowoffset 时要确保指定的偏移量值是有效的,不超过表的总行数。如果超过了表的总行数,将导致查询返回空结果。
指定在表模式演进(schema evolution)时的处理策略
hive.exec.schema.evolution 是 Hive 的一个配置参数,用于指定在表模式演进(schema evolution)时的处理策略。
以下是一个示例:
-- 设置 hive.exec.schema.evolution 为 true
SET hive.exec.schema.evolution=true;
在上述示例中,将 hive.exec.schema.evolution 设置为 true,表示启用表模式演进。
-- 设置 hive.exec.schema.evolution 为 false
SET hive.exec.schema.evolution=false;
在上述示例中,将 hive.exec.schema.evolution 设置为 false,表示禁用表模式演进。
表模式演进是指在表的架构发生变化时(例如,添加或删除列),Hive 是否能够处理旧版本数据的查询。启用表模式演进允许查询在表模式变更后仍然能够成功执行,而禁用表模式演进则要求查询与表的最新模式完全匹配。
选择是否启用表模式演进取决于你的数据演进需求和查询的灵活性。如果你需要能够处理表模式变更后的查询,可以启用表模式演进。如果要求查询与表的最新模式完全匹配,可以禁用表模式演进。
指定在分布式计算中存储临时数据的目录
hive.exec.scratchdir 是 Hive 的一个配置参数,用于指定在分布式计算中存储临时数据的目录。
以下是一个示例:
-- 设置 hive.exec.scratchdir 为 /tmp/hive-scratch
SET hive.exec.scratchdir=/tmp/hive-scratch;
在上述示例中,将 hive.exec.scratchdir 设置为 /tmp/hive-scratch,表示指定分布式计算中存储临时数据的目录为 /tmp/hive-scratch。
Hive 在执行 MapReduce 任务时,可能需要在分布式文件系统上存储一些临时中间数据。hive.exec.scratchdir 参数用于配置这个临时目录的路径。这对于避免对分布式文件系统的过度负载是有益的。
请确保指定的目录对 Hive 运行的用户是可写的,并且有足够的空间来存储临时数据。
指定是否允许脚本运行时对部分数据进行消费
hive.exec.script.allow.partial.consumption 是 Hive 的一个配置参数,用于指定是否允许脚本运行时对部分数据进行消费。
以下是一个示例:
-- 设置 hive.exec.script.allow.partial.consumption 为 true
SET hive.exec.script.allow.partial.consumption=true;
在上述示例中,将 hive.exec.script.allow.partial.consumption 设置为 true,表示允许脚本在运行时对部分数据进行消费。
-- 设置 hive.exec.script.allow.partial.consumption 为 false
SET hive.exec.script.allow.partial.consumption=false;
在上述示例中,将 hive.exec.script.allow.partial.consumption 设置为 false,表示禁止脚本在运行时对部分数据进行消费,要求脚本必须完全消费输入数据。
当设置为 true 时,Hive 允许 MapReduce 脚本在运行时只消费部分输入数据,而不是要求脚本必须完全消费所有输入数据。这在某些情况下可能提高脚本的执行效率。然而,设置为 false 时,要求脚本必须完全消费所有输入数据,以确保正确的处理。
选择合适的设置取决于脚本的性质和需求,以及是否允许脚本在运行时只处理部分数据。
设置脚本执行时的最大错误输出大小
hive.exec.script.maxerrsize 是 Hive 的一个配置参数,用于设置脚本执行时的最大错误输出大小。
以下是一个示例:
-- 设置 hive.exec.script.maxerrsize 为 1000000
SET hive.exec.script.maxerrsize=1000000;
在上述示例中,将 hive.exec.script.maxerrsize 设置为 1000000,表示脚本执行时的最大错误输出大小为 1,000,000 字节(约1MB)。
这个参数控制了脚本执行时标准错误输出(stderr)的最大大小。如果脚本的错误输出超过了这个大小,Hive 将截断错误输出并将其记录在作业日志中,以防止过大的错误输出影响系统性能。
可以根据实际脚本的输出情况和集群配置来调整这个参数的值。过大的错误输出可能会占用过多的资源,因此需要合理设置以平衡错误信息的记录和系统性能。
指定是否信任用户提供的 MapReduce 脚本
hive.exec.script.trust 是 Hive 的一个配置参数,用于指定是否信任用户提供的 MapReduce 脚本。
以下是一个示例:
-- 设置 hive.exec.script.trust 为 true
SET hive.exec.script.trust=true;
在上述示例中,将 hive.exec.script.trust 设置为 true,表示信任用户提供的 MapReduce 脚本。
-- 设置 hive.exec.script.trust 为 false
SET hive.exec.script.trust=false;
在上述示例中,将 hive.exec.script.trust 设置为 false,表示不信任用户提供的 MapReduce 脚本。
如果设置为 true,Hive 将信任用户提供的 MapReduce 脚本,并允许执行。这意味着用户可以使用任意的脚本,包括可能包含有害代码的脚本。因此,在启用这个选项时需要谨慎,确保只有可信任的用户能够提交脚本。
如果设置为 false,Hive 将不信任用户提供的 MapReduce 脚本,不允许执行。这是一个更为安全的设置,特别是在共享环境中,以避免潜在的安全风险。
指定是否在作业失败时显示详细的调试信息
hive.exec.show.job.failure.debug.info 是 Hive 的一个配置参数,用于指定是否在作业失败时显示详细的调试信息。
以下是一个示例:
-- 设置 hive.exec.show.job.failure.debug.info 为 true
SET hive.exec.show.job.failure.debug.info=true;
在上述示例中,将 hive.exec.show.job.failure.debug.info 设置为 true,表示在作业失败时显示详细的调试信息。
-- 设置 hive.exec.show.job.failure.debug.info 为 false
SET hive.exec.show.job.failure.debug.info=false;
在上述示例中,将 hive.exec.show.job.failure.debug.info 设置为 false,表示在作业失败时不显示详细的调试信息。
当作业执行失败时,启用 hive.exec.show.job.failure.debug.info 可以提供有关失败的更详细的调试信息,包括堆栈跟踪等。这对于诊断和解决作业执行问题非常有帮助。
请注意,启用详细的调试信息可能包含敏感信息,因此在生产环境中可能需要谨慎使用。在调试和开发阶段,启用此选项可以更轻松地定位和解决问题。
指定 Hive 作业的暂存目录,该目录用于存放 MapReduce 作业的输出数据和其他临时文件
hive.exec.stagingdir 是 Hive 的一个配置参数,用于指定 Hive 作业的暂存目录,该目录用于存放 MapReduce 作业的输出数据和其他临时文件。
以下是一个示例:
-- 设置 hive.exec.stagingdir 为 /user/hive/staging
SET hive.exec.stagingdir=/user/hive/staging;
在上述示例中,将 hive.exec.stagingdir 设置为 /user/hive/staging,表示指定 Hive 作业的暂存目录为 /user/hive/staging。
Hive 作业在执行期间会生成一些中间结果和临时文件,这些文件通常存储在作业的暂存目录中。通过配置 hive.exec.stagingdir 参数,你可以指定一个适当的目录来存放这些文件。这有助于组织和管理作业的中间数据,同时避免在默认目录中产生大量的临时文件。
请确保指定的目录对 Hive 运行的用户是可写的,并且有足够的空间来存储作业的暂存数据。
指定是否通过子进程本地提交任务
hive.exec.submit.local.task.via.child 是 Hive 的一个配置参数,用于指定是否通过子进程本地提交任务。
以下是一个示例:
-- 设置 hive.exec.submit.local.task.via.child 为 true
SET hive.exec.submit.local.task.via.child=true;
在上述示例中,将 hive.exec.submit.local.task.via.child 设置为 true,表示通过子进程本地提交任务。
-- 设置 hive.exec.submit.local.task.via.child 为 false
SET hive.exec.submit.local.task.via.child=false;
在上述示例中,将 hive.exec.submit.local.task.via.child 设置为 false,表示不通过子进程本地提交任务。
当设置为 true 时,Hive 将通过子进程的方式本地提交任务。这种方式可以降低任务启动的开销,尤其在启动任务时存在较多的开销的情况下。但需要注意,这可能会引入一些局限性和安全性问题,因此在安全环境中要慎重使用。
当设置为 false 时,Hive 将采用默认的方式提交任务。
在选择是否启用 hive.exec.submit.local.task.via.child 时,需要考虑作业的性质和集群配置,确保选择的方式符合实际需求和安全要求。
指定是否通过子进程提交任务
hive.exec.submitviachild 是 Hive 的一个配置参数,用于指定是否通过子进程提交任务。
以下是一个示例:
-- 设置 hive.exec.submitviachild 为 true
SET hive.exec.submitviachild=true;
在上述示例中,将 hive.exec.submitviachild 设置为 true,表示通过子进程提交任务。
-- 设置 hive.exec.submitviachild 为 false
SET hive.exec.submitviachild=false;
在上述示例中,将 hive.exec.submitviachild 设置为 false,表示不通过子进程提交任务。
当设置为 true 时,Hive 将通过子进程的方式提交任务。这种方式可以降低任务启动的开销,尤其在启动任务时存在较多的开销的情况下。但需要注意,这可能会引入一些局限性和安全性问题,因此在安全环境中要慎重使用。
当设置为 false 时,Hive 将采用默认的方式提交任务。
在选择是否启用 hive.exec.submitviachild 时,需要考虑作业的性质和集群配置,确保选择的方式符合实际需求和安全要求。
指定调试日志的超时时间
hive.exec.tasklog.debug.timeout 是 Hive 的一个配置参数,用于指定调试日志的超时时间。
以下是一个示例:
-- 设置 hive.exec.tasklog.debug.timeout 为 300000
SET hive.exec.tasklog.debug.timeout=300000;
在上述示例中,将 hive.exec.tasklog.debug.timeout 设置为 300000,表示调试日志的超时时间为 300,000 毫秒(即 5 分钟)。
该参数用于控制在调试模式下,作业的调试日志输出的超时时间。在调试模式下,Hive 可能会将作业的调试日志保存一段时间以供查看,而 hive.exec.tasklog.debug.timeout 就是用于指定这段时间的长度。
请注意,这个参数的单位是毫秒,因此在设置时需要根据实际需求和超时时间单位进行适当的调整。
指定在创建临时表时使用的存储格式
hive.exec.temporary.table.storage 是 Hive 的一个配置参数,用于指定在创建临时表时使用的存储格式。
以下是一个示例:
-- 设置 hive.exec.temporary.table.storage 为 ORC
SET hive.exec.temporary.table.storage=ORC;
在上述示例中,将 hive.exec.temporary.table.storage 设置为 ORC,表示在创建临时表时使用 ORC 存储格式。
临时表是在查询执行期间临时创建的表,通常用于存储中间结果或者在查询中使用。通过配置 hive.exec.temporary.table.storage 参数,可以指定临时表的存储格式,例如 ORC、Parquet 等。
这个配置参数的设置可以根据实际需求和性能考虑来进行选择。使用列式存储格式(如 ORC、Parquet)可能会提高查询性能,但也可能会增加存储开销。需要根据实际情况进行权衡和调整。
指定 Hive 查询执行时使用的执行引擎
hive.execution.engine 是 Hive 的一个配置参数,用于指定 Hive 查询执行时使用的执行引擎。
以下是一个示例:
-- 设置 hive.execution.engine 为 tez
SET hive.execution.engine=tez;
在上述示例中,将 hive.execution.engine 设置为 tez,表示使用 Tez 作为 Hive 查询执行的执行引擎。
-- 设置 hive.execution.engine 为 mr
SET hive.execution.engine=mr;
在上述示例中,将 hive.execution.engine 设置为 mr,表示使用 MapReduce 作为 Hive 查询执行的执行引擎。
Hive 提供了多种执行引擎,其中常见的有 MapReduce 和 Tez。选择执行引擎可以根据集群配置、性能需求和查询特性进行优化。Tez 通常比 MapReduce 更高效,尤其在处理复杂的查询时。
其他可能的取值还包括 spark(Spark 执行引擎)等,具体取决于 Hive 的版本和配置。在选择执行引擎时,建议参考 Hive 的官方文档以获取最新和详细的信息。
指定 Hive 查询执行的模式
hive.execution.mode 是 Hive 的一个配置参数,用于指定 Hive 查询执行的模式。
以下是一个示例:
-- 设置 hive.execution.mode 为 container
SET hive.execution.mode=container;
在上述示例中,将 hive.execution.mode 设置为 container,表示使用容器执行模式。
-- 设置 hive.execution.mode 为 local
SET hive.execution.mode=local;
在上述示例中,将 hive.execution.mode 设置为 local,表示使用本地执行模式。
Hive 提供了多种执行模式,其中常见的包括:
container模式:将任务提交到集群中运行,适用于大规模数据处理。local模式:在本地机器上执行查询,适用于小规模数据或者测试。
选择执行模式可以根据查询的性质、数据规模和集群配置来进行优化。在大规模集群上运行大数据查询时,通常使用 container 模式以充分利用分布式计算资源。在小规模环境或者进行开发测试时,可以使用 local 模式以减少资源占用和简化调试过程。
在实际应用中,可以根据需求灵活配置 hive.execution.mode 参数。
指定在导入和导出数据时是否严格遵循复制表的策略
hive.exim.strict.repl.tables 是 Hive 的一个配置参数,用于指定在导入和导出数据时是否严格遵循复制表的策略。
以下是一个示例:
-- 设置 hive.exim.strict.repl.tables 为 true
SET hive.exim.strict.repl.tables=true;
在上述示例中,将 hive.exim.strict.repl.tables 设置为 true,表示在导入和导出数据时严格遵循复制表的策略。
-- 设置 hive.exim.strict.repl.tables 为 false
SET hive.exim.strict.repl.tables=false;
在上述示例中,将 hive.exim.strict.repl.tables 设置为 false,表示在导入和导出数据时不严格遵循复制表的策略。
复制表策略通常用于 Hive 复制表的元数据和数据。当设置为 true 时,hive.exim.strict.repl.tables 将检查表的属性、分区、存储格式等,确保目标表和源表的属性完全匹配。如果属性不匹配,将抛出异常,导入或导出将失败。当设置为 false 时,导入和导出将忽略表的属性差异,仅复制数据。
在选择是否启用 hive.exim.strict.repl.tables 时,需要考虑表的复制需求和复制的准确性要求。启用严格模式可以确保表的完整性,但在某些情况下可能会导致复制失败。如果对完整性要求不高,可以选择禁用严格模式以忽略表的属性差异。
指定是否启用导入和导出的测试模式
hive.exim.test.mode 是 Hive 的一个配置参数,用于指定是否启用导入和导出的测试模式。
以下是一个示例:
-- 设置 hive.exim.test.mode 为 true
SET hive.exim.test.mode=true;
在上述示例中,将 hive.exim.test.mode 设置为 true,表示启用导入和导出的测试模式。
-- 设置 hive.exim.test.mode 为 false
SET hive.exim.test.mode=false;
在上述示例中,将 hive.exim.test.mode 设置为 false,表示禁用导入和导出的测试模式。
启用测试模式时,Hive 将在导入和导出操作中进行模拟,而不会实际执行数据的写入或读取。这对于在不影响实际数据的情况下测试导入和导出的操作逻辑非常有用。
在生产环境中,通常将 hive.exim.test.mode 设置为 false,以确保导入和导出的操作能够正确地读写实际数据。在测试环境或进行调试时,可以将其设置为 true 以执行测试操作。
指定在导入和导出数据时允许的 URI 协议白名单
hive.exim.uri.scheme.whitelist 是 Hive 的一个配置参数,用于指定在导入和导出数据时允许的 URI 协议白名单。
以下是一个示例:
-- 设置 hive.exim.uri.scheme.whitelist 为 hdfs,s3
SET hive.exim.uri.scheme.whitelist=hdfs,s3;
在上述示例中,将 hive.exim.uri.scheme.whitelist 设置为 hdfs,s3,表示允许使用 HDFS 和 S3 协议进行导入和导出操作。
这个参数主要用于限制导入和导出操作中使用的 URI 协议。通过配置白名单,可以防止使用不受信任的协议,提高系统的安全性。
具体可使用的 URI 协议取决于 Hive 的版本和配置。在实际应用中,可以根据需求和安全性考虑来配置白名单。如果不需要限制 URI 协议,可以将该参数设置为空或不配置。
指定在执行计划解释(explain)时是否附加任务类型信息
hive.explain.dependency.append.tasktype 是 Hive 的一个配置参数,用于指定在执行计划解释(explain)时是否附加任务类型信息。
以下是一个示例:
-- 设置 hive.explain.dependency.append.tasktype 为 true
SET hive.explain.dependency.append.tasktype=true;
在上述示例中,将 hive.explain.dependency.append.tasktype 设置为 true,表示在执行计划解释时附加任务类型信息。
-- 设置 hive.explain.dependency.append.tasktype 为 false
SET hive.explain.dependency.append.tasktype=false;
在上述示例中,将 hive.explain.dependency.append.tasktype 设置为 false,表示在执行计划解释时不附加任务类型信息。
在 Hive 中,执行计划解释是通过使用 EXPLAIN 命令来查看查询执行计划的过程。通过配置 hive.explain.dependency.append.tasktype 参数,可以选择是否在解释输出中包含任务类型信息。
当设置为 true 时,任务类型信息将被附加到解释输出中,以提供更多关于执行计划的细节。当设置为 false 时,解释输出将不包含任务类型信息,可能更加简洁。
选择是否启用 hive.explain.dependency.append.tasktype 取决于用户对执行计划细节的需求。在进行性能调优或详细分析查询计划时,启用任务类型信息可能会更有帮助。
指定在执行计划解释(explain)时是否包含用户信息
hive.explain.user 是 Hive 的一个配置参数,用于指定在执行计划解释(explain)时是否包含用户信息。
以下是一个示例:
-- 设置 hive.explain.user 为 true
SET hive.explain.user=true;
在上述示例中,将 hive.explain.user 设置为 true,表示在执行计划解释时包含用户信息。
-- 设置 hive.explain.user 为 false
SET hive.explain.user=false;
在上述示例中,将 hive.explain.user 设置为 false,表示在执行计划解释时不包含用户信息。
在 Hive 中,执行计划解释是通过使用 EXPLAIN 命令来查看查询执行计划的过程。通过配置 hive.explain.user 参数,可以选择是否在解释输出中包含用户信息。
当设置为 true 时,用户信息将被包含在解释输出中,以显示执行计划的创建者。当设置为 false 时,解释输出将不包含用户信息。
选择是否启用 hive.explain.user 取决于用户对执行计划细节的需求。在多用户环境中,了解执行计划的创建者可能有助于跟踪和调试查询。
相关文章:

Hive之set参数大全-3
D 是否启用本地任务调试模式 hive.debug.localtask 是 Apache Hive 中的一个配置参数,用于控制是否启用本地任务调试模式。在调试模式下,Hive 将尝试在本地模式下运行一些任务,以便更容易调试和分析问题。 具体来说,当 hive.de…...
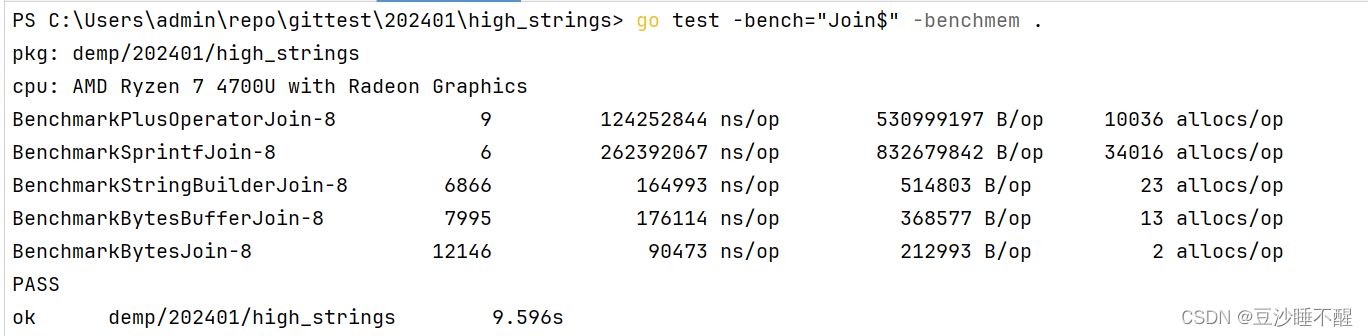
Golang拼接字符串性能对比
g o l a n g golang golang的 s t r i n g string string类型是不可修改的,对于拼接字符串来说,本质上还是创建一个新的对象将数据放进去。主要有以下几种拼接方式 拼接方式介绍 1.使用 s t r i n g string string自带的运算符 ans ans s2. 使用…...

【问题解决】web页面html锚点定位后内容被遮挡问题解决【暗锚】
正常的锚点跳转 a标签的href填写目标元素的id即可 <a href"#my_target">to div1</a> <div id"my_target">div1</div> 内容被顶栏遮挡示例 但是当id所在元素被嵌套多层flex和relative布局之后,跳转后部分内容会被遮挡…...

easyui datagrid无数据时显示无数据
这里写自定义目录标题 需求解决办法 需求 使用datagrid显示记录时,结果查询记录数为0,此时需要显示无数据。 示例代码 <table id"dg"></table>$(#dg).datagrid({url:datagrid_data.json,columns:[[{field:code,title:Code,widt…...

动态规划python简单例子-斐波那契数列
def fibonacci(n):dp [0, 1] [0] * (n - 1) # 初始化动态规划数组for i in range(2, n 1):dp[i] dp[i - 1] dp[i - 2] # 计算斐波那契数列的第 i 项print(dp)return dp[n] # 返回斐波那契数列的第 n 项# 示例用法 n 10 # 计算斐波那契数列的第 10 项 result fibonac…...
免 费 搭 建 多模式商城:b2b2c、o2o、直播带货一网打尽
鸿鹄云商 b2b2c产品概述 【b2b2c平台】,以传统电商行业为基石,鸿鹄云商支持“商家入驻平台自营”多运营模式,积极打造“全新市场,全新 模式”企业级b2b2c电商平台,致力干助力各行/互联网创业腾飞并获取更多的收益。从消…...

Python AttributeError: ‘NoneType‘ object has no attribute ‘shape‘如何解决
Python AttributeError: ‘NoneType‘ object has no attribute ‘shape‘ 运行出现上述错误,这个错误表示某个图像对象为 NoneType ,没有 shape 属性。通常情况下,这是因为 OpenCV 没有能够正确地加载图像,导致无法访问图像数据。…...
vue3自定义确认密码匹配验证规则
// 自定义确认密码匹配验证规则 const matchPassword (rules:any, value:any, callback:any) > {if (value ! addData.payPwd) {callback(new Error(两次密码输入不一致!))} else {callback()} }const rules reactive({payPwd: [{ required: true, message: &q…...

岗位所处定位,岗位职责
电子产品所需岗位:pcb设计电路板,fpga,嵌入式,应用层(前后端,移动端)。 PCB 岗位职责:1.负责器件.工程或者项目与技术验证类的PCB板设计工作;2.协助项目中部分模块的PCB(…...

2024阿里云服务器配置推荐方案
阿里云服务器配置怎么选择合适?CPU内存、公网带宽和ECS实例规格怎么选择合适?阿里云服务器网aliyunfuwuqi.com建议根据实际使用场景选择,例如企业网站后台、自建数据库、企业OA、ERP等办公系统、线下IDC直接映射、高性能计算和大游戏并发&…...

OceanBase原生分布式数据库
1.历史背景 在Java Web项目中,常常使用免费开源的MySQL数据库存储业务数据,按业界经验MySQL单库超过多大数据体量,或单表超过几百万条数据后就会出现查询变慢的情况,单实例数据库只能扩展物理资源(CPU、内存),来提升查…...

首次使用go-admin
go-admin 1.1 拉取 拉去后端代码 git clone https://github.com/go-admin-team/go-admin.git拉取前端代码 git clone gitgithub.com:go-admin-team/go-admin-ui.git 1.2 编译 cd ./go-admingo mod tidygo build1.3 配置文件的修改 这里可以可以根据自己的需要进行自定义两…...
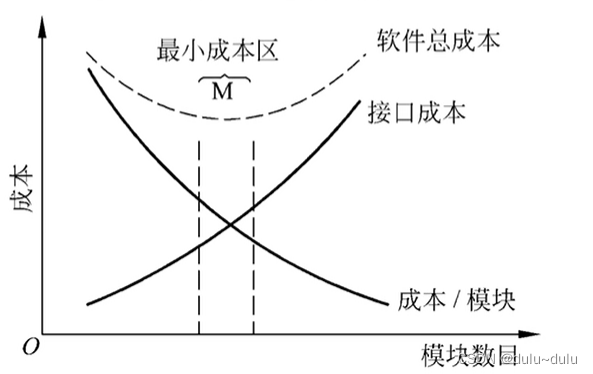
软件工程概论---内聚性和耦合性
目录 一.耦合性 1.内容耦合 2.公共耦合 4.控制耦合 5.标记耦合(特征耦合) 6.数据耦合 7.非直接耦合 二.内聚性 1.偶然内聚 2.逻辑内聚 3.时间内聚 4.过程内聚 5.通信内聚 6.顺序内聚 7.功能内聚 一.耦合性 耦合性是指软件结构中模块相互…...

纯血鸿蒙「扩圈」100天,酝酿已久的突围
坦白讲,去年参加华为开发者大会看到HarmonyOS NEXT(仅运行鸿蒙原生应用,所以也称作「纯血鸿蒙」)的时候,小雷也没料想到鸿蒙原生应用生态的发展速度会如此之快。 9月25日,华为正式对外宣布启动HarmonyOS NE…...
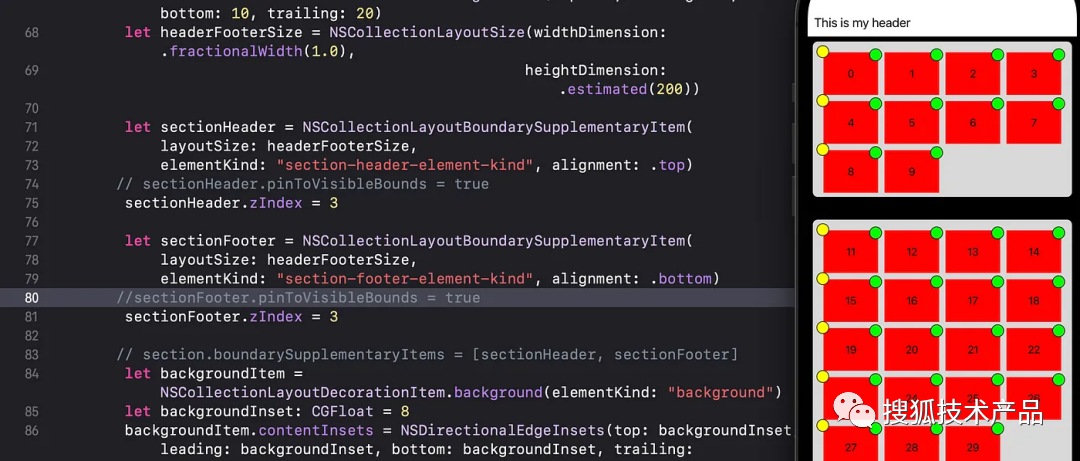
UICollection Compositional Layout全详解
本文字数:8325字 预计阅读时间:45分钟 01 Collection View Layout全详解 UICollectionView在iOS中是构建复杂布局的强大工具。iOS13中引入的 UICollectionViewCompositionalLayout为创建自定义布局提供了全新的可能性。本文将深入探讨Compositional Lay…...

单例模式的模板
参考了网上的一些单例模式,自己也写一个模板。 要点: 线程安全性单例对象的唯一性 #include <mutex> //在模板类 Singleton 中,可以定义单例模式的实现细节 template <typename T> class Singleton { public://通过删除拷贝构造…...

C#基础-空处理
在c#中,值对象是没有办法赋值为null的。比如说,你想要定义一个布尔值,你的赋值数据要么得是true、要么就得是false,默认情况下我们永远没可能给这个布尔赋值为null,即使只是对这个变量进行声明而不初始化数据ÿ…...

测试平台开发vue组件化重构前端代码
基于 springbootvue 的测试平台开发 继续更新(人在魔都 T_T)。 这期其实并不是一个详细的开发过程记录,主要还是针对本次前端重构来聊聊几个关注点。 目前重构的总进度在80%,重构完的页面没什么变化,再回顾一下。 一…...

龍运当头--html做一个中国火龙祝大家龙年大吉
🐉效果展示 🐉HTML展示 <body> <!-- partial:index.partial.html --> <svg><defs><g id=...
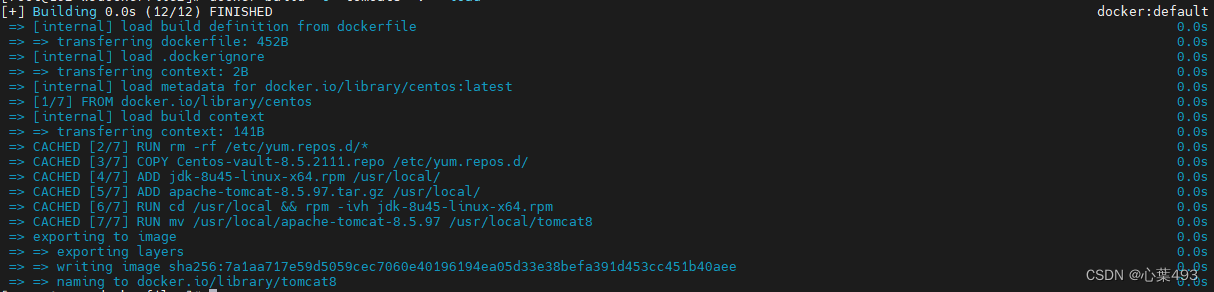
Dockerfile语法和简单镜像构建
Dockerfile是一个用于定义Docker镜像的文本文件,包含了一系列的指令和参数,用于指示Docker在构建镜像时应该执行哪些操作,例如基于哪个基础镜像、复制哪些文件到镜像中、运行哪些命令等。 Dockerfile文件的内容主要有几个部分组成,…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...
:电商转化率优化与网站性能的底层逻辑)
精益数据分析(98/126):电商转化率优化与网站性能的底层逻辑
精益数据分析(98/126):电商转化率优化与网站性能的底层逻辑 在电子商务领域,转化率与网站性能是决定商业成败的核心指标。今天,我们将深入解析不同类型电商平台的转化率基准,探讨页面加载速度对用户行为的…...
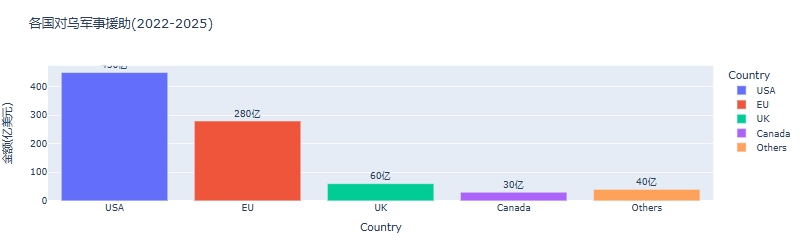
python可视化:俄乌战争时间线关键节点与深层原因
俄乌战争时间线可视化分析:关键节点与深层原因 俄乌战争是21世纪欧洲最具影响力的地缘政治冲突之一,自2022年2月爆发以来已持续超过3年。 本文将通过Python可视化工具,系统分析这场战争的时间线、关键节点及其背后的深层原因,全面…...