【数据库原理】(10)数据定义功能
SQL 数据定义功能包括定义模式、定义表、定义索引和定义视图,其语句如表所示。

一.创建、删除模式
1.创建模式 (Create Schema)
用途:创建模式是为了在数据库中定义一个新的命名空间,它可以包含多个数据库对象。
语法:
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>;
只有获得了授权的用户才能创建模式。
示例:
用户 Li 定义一个数据库模式“教学管理”EM:
CREATE SCHEMA "EM" AUTHORIZATION Li;
如果没有指定模式名,那么模式名隐含为用户名,请看下面的例子:
用户 Li 定义一个数据库模式“Li”
CREATE SCHEMA AUTHORIZATION Li;
2.删除模式 (Drop Schema)
用途:删除一个现有的模式以及其包含的所有数据库对象。
语法:
DROP SCHEMA <模式名> <CASCADE|RESTRICT>
其中 CASCADE 和 RESTRICT 必选其一。
选项:
CASCADE:(级联)删除模式及其包含的所有对象。RESTRICT:(限制)仅当模式中没有关联对象时,才能删除模式。
示例:
- 删除模式 “EM” 及其所有对象:
DROP SCHEMA "EM" CASCADE;
注意事项
- 权限:只有具有相应权限的用户才能创建或删除模式。
- 影响:删除模式可能会影响到依赖于该模式中对象的其他数据库组件。
- 数据库系统差异:不同的数据库系统对模式的支持可能会有所差异,尤其是在命名约定和权限管理方面。
二.创建、删除、修改基本表
**1.创建基本表
目的:在数据库中定义一个新表,包括列名、数据类型及可能的完整性约束条件。
格式:
CREATE TABLE <基本表名>(<列名 1><数据类型> [列名 1的列级完整性约束条件][,<列名 2><数据类型> [列名 2 的列级完整性约束条件]...,<列名 n> <数据类型>[列名 n 的列级完整性约束条件]][,<表级完整性约束条件 1 >[,<表级完整性约束条件 2>]...[,<表级完整性约束条件 m>]]
- 表名:要定义的新表的名称。
- 列:由列名、数据类型和可选的列级完整性约束组成。
- 完整性约束:保证数据的准确性和可靠性,如主键、外键等。
示例
创建课程表 C
- 包含课程编号、名称、学分和前导课程编号。
- 课程编号为主键,不允许为空且唯一;课程名称唯一。
CREATE TABLE C( Cno CHAR(3) NOT NULL UNIQUE,/* 列级完整性约束条件,Cno 不空且唯一 */Cname CHAR(20) UNIQUE,/* 列级完整性约束条件,Cname 唯一*/Cpno CHAR(3),Ccredit INT);
系统执行上面的 CREATE TABLE 语句后,就在数据库中建立了一个新的空的“课程表”C,并将有关“课程表”的定义及有关约束条件存放在数据字典中。
定义表的各个属性时需要指明其数据类型及长度。
建立一个“课程表”C 的同时先行课是自身的外码。
CREATE TABLE C( Cno CHAR(3) PRIMARY KEY, /* 表级完整性约束条件 */Cname CHAR(20) UNIQUE, /*表级完整性约束条件 */Cpno CHAR(3),/*先行棵*/Ccredit INT,FOREIGN KEY (Cpno) REFERENCES C(Cno) /* 表级完整性约束条件 */
);
创建学生表 S
- 包含学号、性别、年龄和班级。
- 学号为主键。
CREATE TABLE S(Sno CHAR(10) PRIMARY KEY,/*列级完整性约束条件,Sno 是主码 */Ssex CHAR(1),Sage INT,Sclass CHAR(6)
);
创建选修表 SC
- 包含学号、课程编号和成绩。
- 学号和课程编号联合主键,分别引用学生表和课程表。
CREATE TABLE SC(Sno CHAR(10),Cno CHAR(3),Grade INT,PRIMARY KEY(Sno,Cno),FOREIGN KEY(Sno) REFERENCES S(Sno),/* 表级完整性约束条件 */FOREIGN KEY(Cno) REFERENCES C(Cno)/* 表级完整性约束条件 */
)
2.修改基本表
目的:
对已存在的表结构进行调整,包括增加列、修改列定义或删除完整性约束。
ALTER TABLE <表名>[ ADD<新列名><数据类型>[完整性约束]]DROP <完整性约束名>][ MODIFY <列名><数据类型>];
- 表名:指定需要修改的表。
- ADD:用于增加新列或完整性约束。
- DROP:用于删除指定的完整性约束。
- MODIFY:用于修改列的数据类型。
示例
向表 C 增加列
- 增加名为
Ctype的列,数据类型为定长字符串。
ALTER TABLE C ADD Ctype CHAR(16);
删除列级完整性约束
- 删除课程名称
Cname的唯一性约束。
ALTER TABLE C DROP UNIOUE Cname;
修改列的数据类型
- 将选修表 SC 中的
Grade列的数据类型改为浮点型。
ALTER TABLE SC MODIFY Grade FLOAT(4);
3.删除基本表
目的:从数据库中完全移除一个表及其数据。
删除表的一般格式
DROP TABLE <表名>[<CASCADE|RESTRICT>];
- 表名:指定要删除的表。
- CASCADE:删除表及其相关的所有依赖对象(如视图、触发器等),谨慎使用。
- RESTRICT:缺省情况是 RESTRICT,仅在没有任何依赖关系时允许删除表。
示例:
删除名为 C 的表:
DROP TABLE C;
注意事项
- 使用 CASCADE 选项时需格外小心,因为它会删除所有依赖于该表的数据库对象,可能导致数据丢失或完整性问题。
- RESTRICT 选项确保在表有任何外部依赖(如外键引用、视图或存储过程)时阻止删除操作,以保持数据库的完整性。
- 不同的数据库系统对 CASCADE 和 RESTRICT 的实现可能略有差异,因此在使用时应参考特定数据库系统的文档。
三.创建、删除、修改索引
建立索引是加快表的查询速度的有效手段。索引就像书的目录一样。可以直接定位到要查找的内容。SQL语言支持用户根据应用环境的需要,在基本表上建立一个或多个索引,以提供多种存取路径,加快查找速度。
1.建立索引(Create Index)
目的:为数据库表的一个或多个列创建索引,以加速查询操作。
格式:
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名>(<列名 1> [<次序>][,<列名 2>[<次序>]]... );
其中,<表名>指定要建索引的基本表的名字。索引可以建在该表的一列或多列上,各列名之间用逗号分隔。每个<列名>后面还可以用<次序>指定索引值的排列次序,包括ASC(升序)或 DESC(降序),默认值为 ASC。
UNIQUE 为唯一性索引,表示此索引的每一个索引值只对应唯一的数据记录。
CLUSTER 为聚簇索引,指索引项的顺序与表中记录的物理顺序一致的索引组织。
例如CREATE CLUSTER INDEX Cname ON C(Cname); 将会在表 C的Cname 列建一个聚簇索引,而且表中的记录将按照 Cname 值的升序存放。
示例
为课程表 C 按课程号升序建立唯一性索引。
CREATE UNIOUE INDEX idxCno ON C(Cno);
为学生表 S 按学号升序建立聚簇索引
CREATE CLUSTER INDEX CidxSno ON S(Sno);
创建一个复合索引,以加快基于这些字段的查询速度。我们将使用 UNIQUE 和 CLUSTER 关键字,并指定列的排序次序。
CREATE UNIQUE CLUSTER INDEX idxOrders ON Orders(OrderID ASC, CustomerID DESC, OrderDate ASC);
这条 SQL 语句执行以下操作:
- CREATE INDEX: 创建一个新索引。
- UNIQUE: 确保索引列的组合值在表中是唯一的。
- CLUSTER: 索引的顺序将决定表中数据的物理存储顺序。
- idxOrders: 为新索引指定的名称。
- ON Orders: 指定索引将创建在
Orders表上。 - OrderID ASC, CustomerID DESC, OrderDate ASC: 索引包含三列,其中
OrderID按升序排列,CustomerID按降序排列,而OrderDate按升序排列。
2.删除索引 (Drop Index)
目的:删除已存在的索引。
格式:
DROP INDEX <索引名>;
示例:
- 删除课程表 C 的 idxCno 索引:
DROP INDEX idxCno;
删除索引时,系统会同时从数据字典中删去有关该索引的描述。
注意事项
- 聚簇索引:因为聚簇索引影响数据的物理存储顺序,所以在经常更新的列上创建聚簇索引可能会影响性能。
- 索引维护:创建和删除索引时,数据库会自动更新数据字典中的相关信息。
- 索引选择:选择在哪些列上创建索引需要谨慎考虑,以平衡查询速度和更新成本。
相关文章:
【数据库原理】(10)数据定义功能
SQL 数据定义功能包括定义模式、定义表、定义索引和定义视图,其语句如表所示。 一.创建、删除模式 1.创建模式 (Create Schema) 用途:创建模式是为了在数据库中定义一个新的命名空间,它可以包含多个数据库对象。 语法: CREATE SCHEMA &…...
: The TLS connection was non-properly terminated.)
GnuTLS recv error (-110): The TLS connection was non-properly terminated.
bug 解决方案:参考 GnuTLS recv error (-110): The TLS connection was non-properly terminated. 解决方案: apt-get install gnutls-bin git config --global http.sslVerify false git config --global http.postBuffer 1048576000参考...

hive sql 和 spark sql的区别
Hive SQL 和 Spark SQL 都是用于在大数据环境中处理结构化数据的工具,但它们有一些关键的区别: 底层计算引擎: Hive SQL:Hive 是建立在 Hadoop 生态系统之上的,使用 MapReduce 作为底层计算引擎。因此,它的…...

SparkStreaming基础解析(四)
1、 Spark Streaming概述 1.1 Spark Streaming是什么 Spark Streaming用于流式数据的处理。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、…...
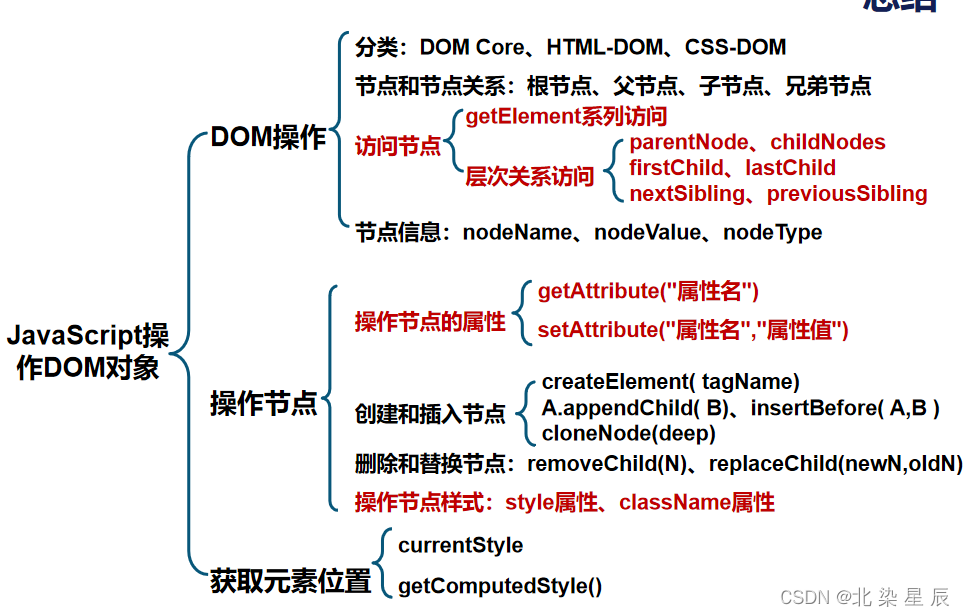
HTML---JavaScript操作DOM对象
目录 文章目录 本章目标 一.DOM对象概念 二.节点访问方法 常用方法: 层次关系访问节点 三.节点信息 四.节点的操作方法 操作节点的属性 创建节点 删除替换节点 五.节点操作样式 style属性 class-name属性 六.获取元素位置 总结 本章目标 了解DOM的分类和节点间的…...
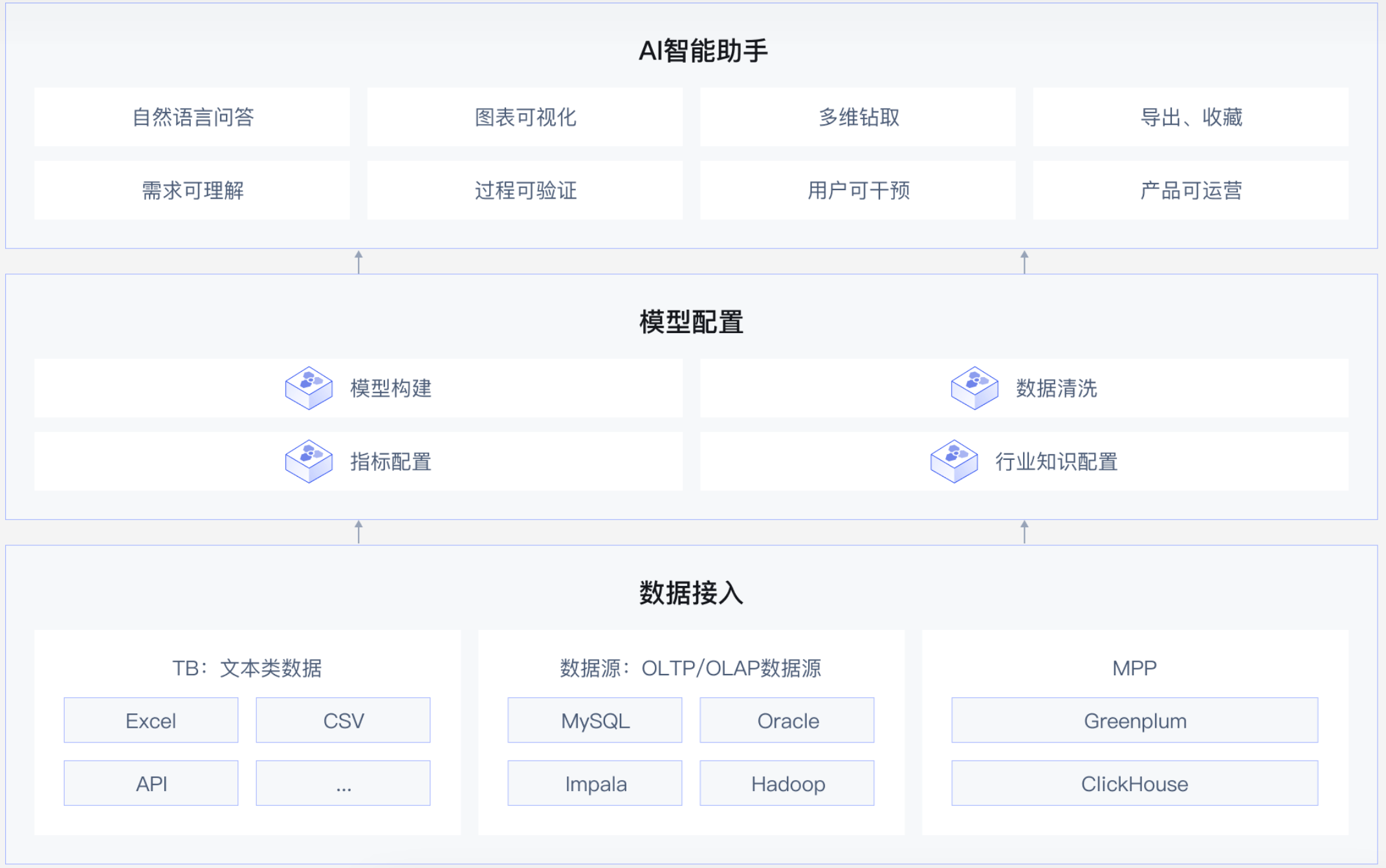
ChatGPT扩展系列之网易数帆ChatBI
在当今数字化快速发展的时代,数据已经成为业务经营与管理决策的核心驱要素。无论是跨国大企业还是新兴创业公司,正确、迅速地洞察数据已经变得至关重要。然而,传统的BI工具往往对用户有一定的技术门槛,需要熟练的操作技能和复杂的查询语句,这使得大部分的企业员工难以深入…...
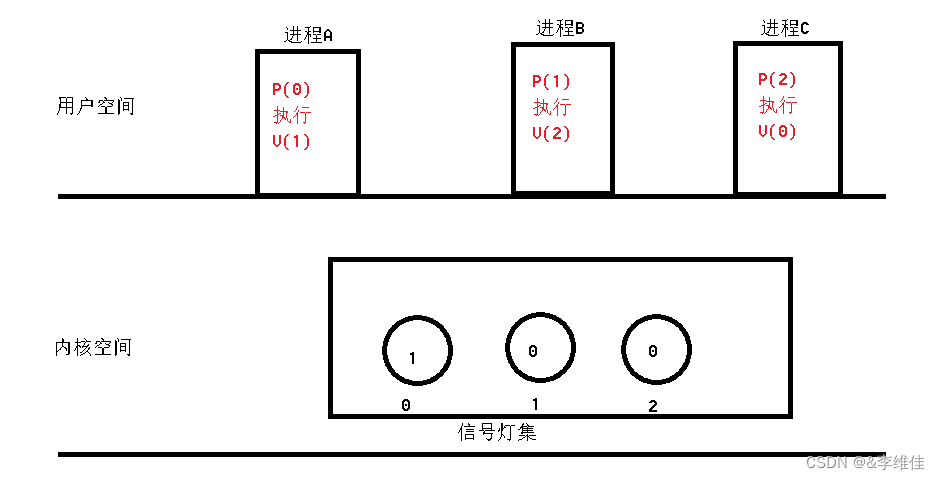
1.10号io网络
信号量(信号灯集) 1> 信号灯集主要完成进程间同步工作,将多个信号灯,放在一个信号灯集中,每个信号灯控制一个进程 2> 每个灯维护了一个value值,当value值等于0时,申请该资源的进程处于阻…...
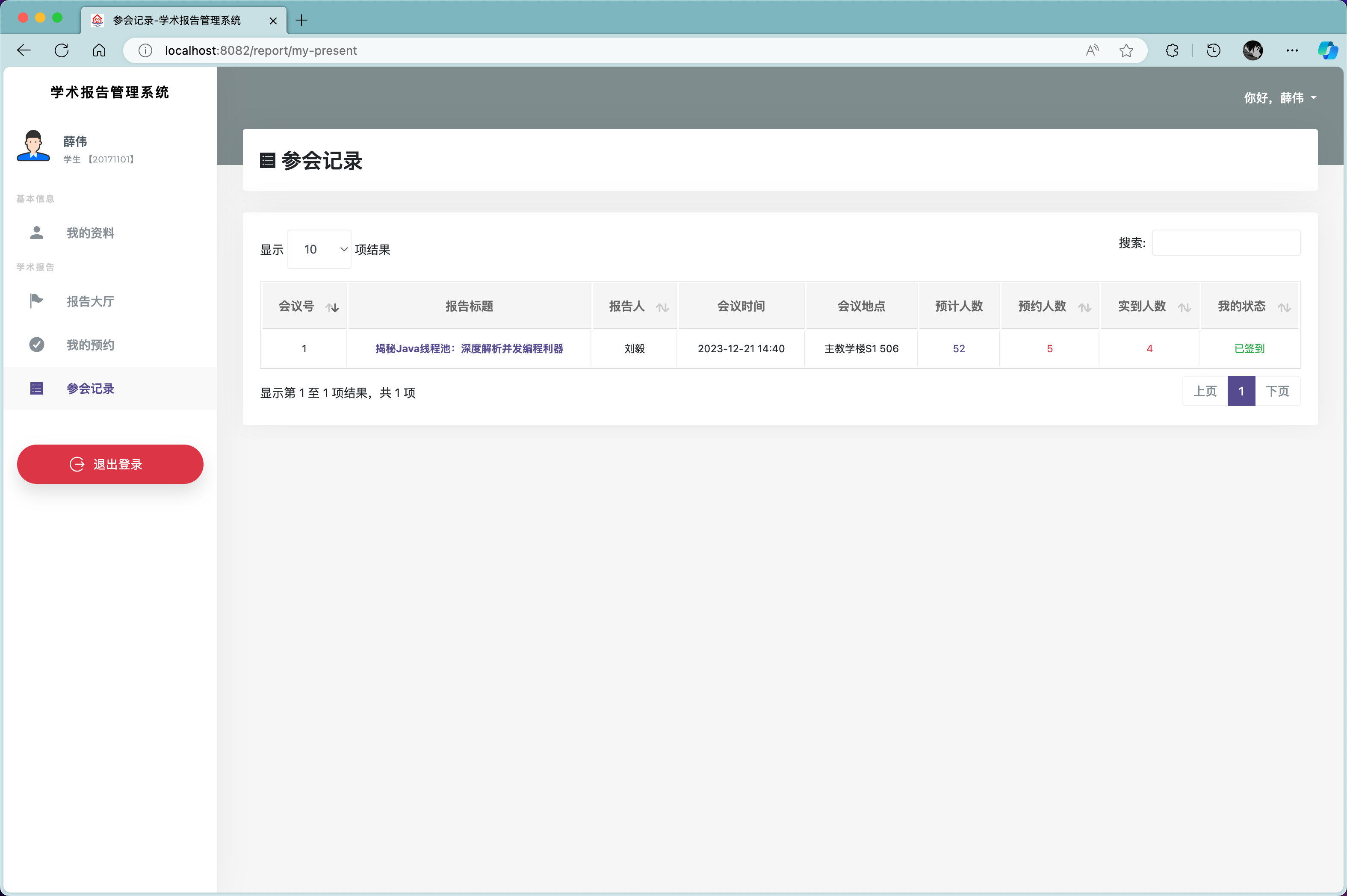
基于JAVA+SpringBoot的高校学术报告系统
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 智慧高校学术报告系统…...

单机部署Rancher
上次已经安装完毕了k8s了,但是想要界面化的管理,离不开界面工具,首推就是rancher,本文介绍安装rancher的安装,也可以将之前安装的k8s管理起来。 已经安装完毕docker和docker-ce的可以直接从第三部分开始。 一、基础准…...
linux 命令
ps: 命令用来查看系统上的进程信息。 查看内存 cat /proc/进程id/maps...

MySQL数据库进阶|SQL优化|开发手册
系列专栏:MySQL数据库进阶 前言 在看此篇前,建议先阅读MySQL索引,对索引有个基本了解:MySQL数据库进阶-索引-CSDN博客 在进行SQL优化前,我们必须先了解SQL查询的性能分析,为什么这条SQL慢,慢在…...

一文了解Git(所有命令)附带图片
我是南城余!阿里云开发者平台专家博士证书获得者! 欢迎关注我的博客!一同成长! 一名从事运维开发的worker,记录分享学习。 专注于AI,运维开发,windows Linux 系统领域的分享! 其他…...
Hex2Bin转换软件、Bootloader 、OTA加密升级 、STM32程序加密、其他MCU同样适用
说明:这个工具可以将 Hex 文件 转换为 Bin 格式文件,软件是按自己开发 STM32 OAT 功能需求开发的一款辅助 上位机软件。 文中的介绍时 bootloader boot 文档在补充完善中... 有兴趣的朋友可留言探讨。 1. 软件功能: 1.生成 bin&#x…...

Hadoop之mapreduce参数大全-6
126.指定 Map 任务运行的节点标签表达式 mapreduce.map.node-label-expression 是 Hadoop MapReduce 框架中的一个配置属性,用于指定 Map 任务运行的节点标签表达式。节点标签是在 Hadoop 集群中为节点分配的用户定义的标签,可用于将 Map 任务限制在特定…...
前端路由时的hash模式和history模式的区别及详细介绍)
Vue开发中,在实现单页面应用(SPA)前端路由时的hash模式和history模式的区别及详细介绍
文章目录 一、前言二、hash模式hashchange 事件: 三、history模式方法:1、history.go():2、history.back():3、history.forward():4、History.replaceState()5、History.pushState()popState 事件 四、nginx配置五、原…...
功能强大的免费SSL证书
一、数据加密的重要性 免费SSL证书的核心作用在于对网站的数据传输进行加密处理。当一个网站部署了SSL证书后,它能够将HTTP协议升级至HTTPS,这意味着所有在客户端(如浏览器)与服务器之间传输的信息都将被高强度的加密算法所保护。…...

在Vue中使用Web Worker详细教程
1.什么是Web Worker? Web Worker 是2008年h5提供的新功能,每一个新功能都是为了解决原有技术的的痛点,那么这个痛点是什么呢? 1.1 JavaScript的单线程 JavaScript 为什么要设计成单线程? 这与js的工作内容有关:js只…...
)
四、C#高级特性(动态类型与Expando类)
在C#中,动态类型和ExpandoObject类是两个与运行时类型系统相关的特性,它们提供了更灵活的数据处理能力。 动态类型 动态类型是一种特殊的类型,允许你在运行时解析和操作对象的成员,而不需要在编译时知道这些成员的细节。使用动态…...

贪心算法的“左最优“与“右最优“及其对应的堆处理和预处理方法
1 答疑 1.1 什么是贪心算法的"左最优"与"右最优" "左最优"和"右最优"是贪心算法中的两种策略: 左最优 (Leftmost Greedy): 在每一步选择中,总是选择最左边(最早出现的)可行的选项。 右…...

【Docker】容器的相关命令
上一篇:创建,查看,进入容器 https://blog.csdn.net/m0_67930426/article/details/135430093?spm1001.2014.3001.5502 目录 1. 关闭容器 2.启动容器 3.删除容器 4.查看容器的信息 查看容器 1. 关闭容器 从图上来看,容器 aa…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...