Hadoop之mapreduce参数大全-6
126.指定 Map 任务运行的节点标签表达式
mapreduce.map.node-label-expression 是 Hadoop MapReduce 框架中的一个配置属性,用于指定 Map 任务运行的节点标签表达式。节点标签是在 Hadoop 集群中为节点分配的用户定义的标签,可用于将 Map 任务限制在特定类型的节点上运行。
在 Hadoop MapReduce 配置文件中,可以通过以下方式设置 mapreduce.map.node-label.expression:
<property><name>mapreduce.map.node-label.expression</name><value>high-memory</value> <!-- 设置 Map 任务运行的节点标签表达式为 "high-memory" -->
</property>
上述配置中,mapreduce.map.node-label.expression 的值为 high-memory,表示该作业的 Map 任务将只在具有 “high-memory” 标签的节点上运行。
通过设置这个配置属性,可以在 Hadoop 集群中利用节点标签功能,将 Map 任务限制在特定类型的节点上运行,以满足 Map 任务对硬件或软件环境的特定需求。这对于需要更多内存资源的 Map 任务很有用。
请注意,要使用节点标签功能,Hadoop 集群需要启用节点标签,并且相应的节点需要被分配标签。确保配置的节点标签表达式与集群中实际的节点标签匹配,以确保 Map 任务在正确的节点上运行。
127.指定 Reduce 任务运行的节点标签表达式
mapreduce.reduce.node-label-expression 是 Hadoop MapReduce 框架中的一个配置属性,用于指定 Reduce 任务运行的节点标签表达式。节点标签是在 Hadoop 集群中为节点分配的用户定义的标签,可用于将 Reduce 任务限制在特定类型的节点上运行。
在 Hadoop MapReduce 配置文件中,可以通过以下方式设置 mapreduce.reduce.node-label.expression:
<property><name>mapreduce.reduce.node-label.expression</name><value>gpu</value> <!-- 设置 Reduce 任务运行的节点标签表达式为 "gpu" -->
</property>
上述配置中,mapreduce.reduce.node-label.expression 的值为 gpu,表示该作业的 Reduce 任务将只在具有 “gpu” 标签的节点上运行。
通过设置这个配置属性,可以在 Hadoop 集群中利用节点标签功能,将 Reduce 任务限制在特定类型的节点上运行,以满足 Reduce 任务对硬件或软件环境的特定需求。这对于需要 GPU 加速的 Reduce 任务很有用。
请注意,要使用节点标签功能,Hadoop 集群需要启用节点标签,并且相应的节点需要被分配标签。确保配置的节点标签表达式与集群中实际的节点标签匹配,以确保 Reduce 任务在正确的节点上运行。
128.指定作业计数器的数量上限
mapreduce.job.counters.limit 是 Hadoop MapReduce 框架中的一个配置属性,用于指定作业计数器的数量上限。计数器用于记录作业的各种统计信息,例如任务的执行次数、记录的读写次数等。mapreduce.job.counters.limit 允许用户设置作业计数器的数量上限,以防止计数器过多导致内存占用过大。
在 Hadoop MapReduce 配置文件中,可以通过以下方式设置 mapreduce.job.counters.limit:
<property><name>mapreduce.job.counters.limit</name><value>120</value> <!-- 设置作业计数器的数量上限为 120 -->
</property>
上述配置中,mapreduce.job.counters.limit 的值为 120,表示作业的计数器数量上限为 120。
通过设置这个属性,可以限制作业生成的计数器的数量,以避免在大规模作业中产生大量的计数器,导致内存占用过大。请注意,适当设置计数器的数量上限有助于平衡监控和系统资源的使用。
在实际应用中,根据作业的复杂性和需求,可以根据需要调整计数器的数量上限。
129.指定作业运行的 MapReduce 框架的名称
mapreduce.framework.name 是 Hadoop MapReduce 框架中的一个配置属性,用于指定作业运行的 MapReduce 框架的名称。该属性可以用来选择使用经典的MapReduce框架(Classic MapReduce)还是使用新的MapReduce框架(YARN MapReduce)。
在 Hadoop MapReduce 配置文件中,可以通过以下方式设置 mapreduce.framework.name:
<property><name>mapreduce.framework.name</name><value>yarn</value> <!-- 设置作业运行的 MapReduce 框架为 YARN MapReduce -->
</property>
上述配置中,mapreduce.framework.name 的值为 yarn,表示作业将使用 YARN MapReduce 框架。
另一种常见的设置是使用 local,表示作业将在本地模式下运行,而不使用分布式集群:
<property><name>mapreduce.framework.name</name><value>local</value> <!-- 设置作业运行的 MapReduce 框架为本地模式 -->
</property>
这样的设置可以方便在开发和调试阶段在本地环境中运行作业。
请注意,具体可用的值可能会依赖于 Hadoop 版本和配置。确保根据实际情况设置正确的框架名称。
130.指定MapReduce应用程序的staging目录
yarn.app.mapreduce.am.staging-dir 是 Apache Hadoop YARN 中的一个配置属性,用于指定MapReduce应用程序的staging目录,该目录用于存储应用程序的资源文件和其他必需的文件。
在YARN中,每个MapReduce应用程序都需要一个staging目录,该目录用于存储应用程序所需的资源和文件。这个目录通常是在HDFS上的一个特定路径。配置yarn.app.mapreduce.am.staging-dir可以指定这个目录的路径。
以下是一个示例:
<property><name>yarn.app.mapreduce.am.staging-dir</name><value>/user/mapred/staging</value>
</property>
上述配置中,yarn.app.mapreduce.am.staging-dir 的值为 /user/mapred/staging,表示MapReduce应用程序的staging目录将位于HDFS上的/user/mapred/staging路径。
在实际配置中,你可以根据你的集群和部署需求修改这个配置项的值。确保该路径在HDFS上对应的目录是可访问和可写的,并且适当设置相关的权限。
131.指定MapReduce应用程序的ApplicationMaster(AM)的最大尝试次数
mapreduce.am.max-attempts 是Apache Hadoop MapReduce中的一个配置属性,用于指定MapReduce应用程序的ApplicationMaster(AM)的最大尝试次数。
在MapReduce中,ApplicationMaster是负责协调和管理MapReduce作业执行的组件。如果ApplicationMaster失败(例如由于崩溃或其他原因),YARN ResourceManager将尝试重新启动ApplicationMaster,mapreduce.am.max-attempts 就是指定了最大的尝试次数。
以下是一个示例配置:
<property><name>mapreduce.am.max-attempts</name><value>2</value>
</property>
上述配置中,mapreduce.am.max-attempts 的值为 2,表示如果ApplicationMaster失败,将最多尝试两次重新启动。
你可以根据你的需求调整这个配置项的值。请注意,较小的尝试次数可能导致在应用程序启动期间更快地放弃,但可能会增加由于故障而导致的作业失败的风险。反之,较大的尝试次数允许更多的尝试,但可能会导致更长的等待时间。
确保在调整这个配置项时考虑到你集群的性能和可用性需求。
132.指定在MapReduce作业完成时发送通知的URL
mapreduce.job.end-notification.url 是Apache Hadoop MapReduce中的一个配置属性,用于指定在MapReduce作业完成时发送通知的URL。
当MapReduce作业完成时,可以配置这个属性,使得系统在作业完成时向指定的URL发送通知。这通常用于通知外部系统或服务有关作业的状态或结果。
以下是一个示例配置:
<property><name>mapreduce.job.end-notification.url</name><value>http://example.com/notify</value>
</property>
上述配置中,mapreduce.job.end-notification.url 的值为 http://example.com/notify,表示当作业完成时,系统将向该URL发送通知。
你可以将这个URL设置为接收HTTP POST请求的端点,以便在作业完成时接收通知。确保通知的目标系统能够处理这些通知并采取适当的操作。
请注意,通知的确切内容和格式可能取决于你的应用程序或系统的要求,因此你可能需要进一步配置或定制通知的内容和处理逻辑。
133.指定在发送作业完成通知时的重试次数
mapreduce.job.end-notification.retry.attempts 是 Apache Hadoop MapReduce 中的一个配置属性,用于指定在发送作业完成通知时的重试次数。
当作业完成时,MapReduce 可以通过 mapreduce.job.end-notification.url 指定的 URL 发送通知。如果通知发送失败,可以通过配置 mapreduce.job.end-notification.retry.attempts 来指定重试的次数。
以下是一个示例配置:
<property><name>mapreduce.job.end-notification.retry.attempts</name><value>3</value>
</property>
上述配置中,mapreduce.job.end-notification.retry.attempts 的值为 3,表示在发送作业完成通知时,最多重试 3 次。
这个配置项的目的是在通知发送失败时提供一定的重试机制,以增加通知的可靠性。请注意,在设置重试次数时,应考虑到通知接收方是否支持重复通知,以避免不必要的重复操作。
确保根据你的需求和通知接收方的特性来调整这个配置项。
134.指定在发送作业完成通知时的重试间隔
mapreduce.job.end-notification.retry.interval 是 Apache Hadoop MapReduce 中的一个配置属性,用于指定在发送作业完成通知时的重试间隔。
当作业完成时,MapReduce 可以通过 mapreduce.job.end-notification.url 指定的 URL 发送通知。如果通知发送失败,可以通过配置 mapreduce.job.end-notification.retry.interval 来指定重试的时间间隔。
以下是一个示例配置:
<property><name>mapreduce.job.end-notification.retry.interval</name><value>30000</value>
</property>
上述配置中,mapreduce.job.end-notification.retry.interval 的值为 30000 毫秒,表示在发送作业完成通知时,重试之间的时间间隔为 30 秒。
这个配置项的目的是定义重试的时间间隔,以便控制在通知发送失败后多久进行下一次重试。请确保根据你的需求和通知接收方的特性来调整这个配置项。
注意:较短的重试间隔可能会导致频繁的重试,对通知接收方和网络负载造成额外的压力。因此,需要根据实际情况谨慎调整这个值。
135.指定发送作业完成通知的最大重试次数
mapreduce.job.end-notification.max.attempts 是 Apache Hadoop MapReduce 中的一个配置属性,用于指定发送作业完成通知的最大重试次数。
当作业完成时,MapReduce 可以通过 mapreduce.job.end-notification.url 指定的 URL 发送通知。如果通知发送失败,可以通过配置 mapreduce.job.end-notification.max.attempts 来指定最大的重试次数。
以下是一个示例配置:
<property><name>mapreduce.job.end-notification.max.attempts</name><value>5</value>
</property>
上述配置中,mapreduce.job.end-notification.max.attempts 的值为 5,表示在发送作业完成通知时,最多进行 5 次重试。
这个配置项的目的是定义最大的重试次数,以便在达到此次数后放弃通知的发送。请确保根据你的需求和通知接收方的特性来调整这个配置项。
需要注意的是,较大的最大重试次数可能导致重试过程较长,而较小的值可能会影响通知的可靠性。因此,需要根据实际情况谨慎调整这个值。
136.指定用于作业(Job)的Log4j配置文件
mapreduce.job.log4j-properties-file 是 Apache Hadoop MapReduce 中的一个配置属性,用于指定用于作业(Job)的Log4j配置文件。
Log4j是Java中用于记录日志的一个流行框架,Hadoop MapReduce使用Log4j来配置和管理作业的日志输出。
通过配置 mapreduce.job.log4j-properties-file,可以指定作业使用的Log4j配置文件的路径。例如:
<property><name>mapreduce.job.log4j-properties-file</name><value>/path/to/your/log4j.properties</value>
</property>
上述配置中,/path/to/your/log4j.properties 是Log4j配置文件的路径。
这个配置项的目的是允许用户自定义作业的日志输出配置。Log4j配置文件包含有关日志输出的详细信息,例如输出格式、输出级别和输出位置等。
确保配置文件的路径正确,并包含所需的Log4j配置信息。通过自定义Log4j配置文件,你可以更灵活地控制作业的日志输出。
137.指定发送作业完成通知时的最大重试间隔
mapreduce.job.end-notification.max.retry.interval 是 Apache Hadoop MapReduce 中的一个配置属性,用于指定发送作业完成通知时的最大重试间隔。
当作业完成时,MapReduce 可以通过 mapreduce.job.end-notification.url 指定的 URL 发送通知。如果通知发送失败,可以通过配置 mapreduce.job.end-notification.max.retry.interval 来指定最大的重试间隔。
以下是一个示例配置:
<property><name>mapreduce.job.end-notification.max.retry.interval</name><value>5000</value><final>true</final><description>The maximum amount of time (in milliseconds) to wait beforeretrying job end notification. Cluster administrators can set this tolimit how long the Application Master waits before exiting. Must be markedas final to prevent users from overriding this.</description>
</property>
上述配置中,mapreduce.job.end-notification.max.retry.interval 的值为 600000 毫秒,表示在发送作业完成通知时,最大的重试间隔为 600 秒(10分钟)。
这个配置项的目的是定义在通知发送失败时,重试之间的最大时间间隔。请确保根据你的需求和通知接收方的特性来调整这个配置项。
如果设置了 mapreduce.job.end-notification.retry.interval(重试间隔),而没有设置 mapreduce.job.end-notification.max.retry.interval,则默认情况下,重试间隔不会受到最大重试间隔的限制。
138.指定MapReduce应用程序的ApplicationMaster(AM)启动时的环境变量
yarn.app.mapreduce.am.env 是 Apache Hadoop YARN 中的一个配置属性,用于指定MapReduce应用程序的ApplicationMaster(AM)启动时的环境变量。
ApplicationMaster是MapReduce作业的主要组件,负责协调和管理作业的执行。通过配置 yarn.app.mapreduce.am.env,可以向ApplicationMaster的启动环境中添加自定义的环境变量。
以下是一个示例配置:
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/path/to/mapred_home</value>
</property>
上述配置中,yarn.app.mapreduce.am.env 的值为 HADOOP_MAPRED_HOME=/path/to/mapred_home,表示在启动ApplicationMaster时,会设置一个名为 HADOOP_MAPRED_HOME 的环境变量,其值为 /path/to/mapred_home。
通过这种方式,你可以向ApplicationMaster的运行环境中引入自定义的环境变量,以满足作业运行时的特定需求。根据实际情况,你可以添加多个环境变量,用逗号或空格分隔它们。
请确保配置的环境变量对作业的正确运行至关重要,并仔细测试配置更改以确保其有效性。
139.指定对于指定用户的MapReduce应用程序的ApplicationMaster(AM)启动时的环境变量
yarn.app.mapreduce.am.admin.user.env 是 Apache Hadoop YARN 中的一个配置属性,用于指定对于指定用户的MapReduce应用程序的ApplicationMaster(AM)启动时的环境变量。
ApplicationMaster是MapReduce作业的主要组件,负责协调和管理作业的执行。通过配置 yarn.app.mapreduce.am.admin.user.env,可以为指定的用户(或一组用户)的作业设置额外的环境变量。
以下是一个示例配置:
<property><name>yarn.app.mapreduce.am.admin.user.env</name><value>user1=VAR1=value1,VAR2=value2;user2=VAR3=value3</value>
</property>
上述配置中,yarn.app.mapreduce.am.admin.user.env 的值为 user1=VAR1=value1,VAR2=value2;user2=VAR3=value3,表示对于 user1 的作业,将添加环境变量 VAR1=value1 和 VAR2=value2;对于 user2 的作业,将添加环境变量 VAR3=value3。
通过这种方式,你可以根据不同用户的需求为其作业设置不同的环境变量。环境变量的设置格式是 键=值,多个环境变量之间用逗号或分号分隔。
请确保配置的环境变量对于指定用户的作业是正确和安全的。配置变更后,建议进行充分测试以确保其有效性。
140.设置MapReduce Application Master的Java虚拟机(JVM)启动参数
yarn.app.mapreduce.am.command-opts是Apache Hadoop YARN中一个与MapReduce应用程序(Application Master)有关的配置属性。在YARN中,Application Master是负责协调和管理应用程序执行的组件。yarn.app.mapreduce.am.command-opts配置属性允许你设置MapReduce Application Master的Java虚拟机(JVM)启动参数。
以下是对该配置属性的解释:
-
属性名称:
yarn.app.mapreduce.am.command-opts -
描述: 该属性用于指定MapReduce Application Master的Java虚拟机启动参数。这包括任何你希望传递给Application Master的额外的JVM选项,如堆大小、垃圾回收器设置等。
-
示例: 如果你希望为MapReduce Application Master设置最大堆大小为2GB,可以将该属性设置如下:
xmlCopy code<property><name>yarn.app.mapreduce.am.command-opts</name><value>-Xmx2g</value> </property>上述配置将为Application Master分配最大2GB的堆内存。
这个配置属性是在yarn-site.xml文件中配置的,该文件通常位于Hadoop配置目录中。修改这个配置可能需要重启与YARN相关的服务以使更改生效。请注意,确保仔细调整这些参数以满足你特定应用程序的性能和资源需求。
141.设置MapReduce Application Master 的 Java 虚拟机(JVM)的启动参数,但是专门用于管理员命令的执行
在Apache Hadoop YARN中,yarn.app.mapreduce.am.admin-command-opts是与MapReduce应用程序(Application Master)有关的另一个配置属性。与之前提到的 yarn.app.mapreduce.am.command-opts 相似,yarn.app.mapreduce.am.admin-command-opts 允许你设置MapReduce Application Master 的 Java 虚拟机(JVM)的启动参数,但是专门用于管理员命令的执行。
以下是对这个配置属性的解释:
-
属性名称:
yarn.app.mapreduce.am.admin-command-opts -
描述: 该属性用于指定 MapReduce Application Master 在执行管理员命令时的 Java 虚拟机启动参数。管理员命令通常用于执行管理任务,如维护、诊断或与应用程序的交互。
-
示例: 如果你希望为 MapReduce Application Master 在执行管理员命令时设置最大堆大小为1GB,可以将该属性设置如下:
<property><name>yarn.app.mapreduce.am.admin-command-opts</name><value>-Xmx1g</value> </property>上述配置将为执行管理员命令的 Application Master 分配最大1GB的堆内存。
这个配置属性同样是在 yarn-site.xml 文件中配置的,通常位于 Hadoop 配置目录中。类似于其他 YARN 配置属性,更改这个属性可能需要重启与 YARN 相关的服务。确保了解应用程序的特定要求,并根据需要进行调整。
142.设置任务监听器(task listener)线程的数量
yarn.app.mapreduce.am.job.task.listener.thread-count 是一个 Apache Hadoop YARN 中 MapReduce Application Master(AM)的配置属性。该属性用于设置任务监听器(task listener)线程的数量。
以下是对该配置属性的解释:
-
属性名称:
yarn.app.mapreduce.am.job.task.listener.thread-count -
描述: 该属性指定了 MapReduce Application Master 用于任务监听器的线程数量。任务监听器是用于处理任务事件的组件,例如任务的启动、完成等。
-
默认值: 该属性通常有一个默认值,如果未显式设置,则使用默认值。
-
示例: 如果你希望为任务监听器配置 5 个线程,可以将该属性设置如下:
<property><name>yarn.app.mapreduce.am.job.task.listener.thread-count</name><value>5</value> </property>上述配置将为任务监听器分配 5 个线程。
这个配置属性通常是在 mapred-site.xml 文件中配置的,该文件位于 Hadoop 的配置目录中。在调整这个属性时,请考虑集群的规模、任务的特性和资源的可用性。更改这个属性可能需要重启与 MapReduce 和 YARN 相关的服务。
143.配置 AM 用于与客户端通信的端口范围
yarn.app.mapreduce.am.job.client.port-range 是 Apache Hadoop YARN 中 MapReduce Application Master(AM)的配置属性之一。该属性用于配置 AM 用于与客户端通信的端口范围。
以下是对该配置属性的解释:
-
属性名称:
yarn.app.mapreduce.am.job.client.port-range -
描述: 该属性指定了 MapReduce Application Master 用于与客户端通信的端口范围。AM 通常需要与客户端进行通信,以接收来自客户端的命令或状态更新。
-
默认值: 该属性通常有一个默认值,如果未显式设置,则使用默认值。
-
示例: 如果你希望为 AM 配置客户端通信端口范围为 10000 到 11000,可以将该属性设置如下:
<property><name>yarn.app.mapreduce.am.job.client.port-range</name><value>10000-11000</value> </property>上述配置将指定端口范围为 10000 到 11000。
这个配置属性通常是在 mapred-site.xml 文件中配置的,该文件位于 Hadoop 的配置目录中。调整端口范围时,请确保不与其他服务或应用程序使用的端口发生冲突。更改这个属性可能需要重启与 MapReduce 和 YARN 相关的服务。
144.配置 AM 的 Web 应用程序(WebApp)使用的端口范围
yarn.app.mapreduce.am.webapp.port-range 是 Apache Hadoop YARN 中 MapReduce Application Master(AM)的配置属性之一。该属性用于配置 AM 的 Web 应用程序(WebApp)使用的端口范围。
以下是对该配置属性的解释:
-
属性名称:
yarn.app.mapreduce.am.webapp.port-range -
描述: 该属性指定了 MapReduce Application Master 的 Web 应用程序(WebApp)使用的端口范围。WebApp 通常用于提供 AM 相关的 Web 界面,允许用户监视和管理 MapReduce 任务。
-
默认值: 该属性通常有一个默认值,如果未显式设置,则使用默认值。
-
示例: 如果你希望为 AM 的 WebApp 配置端口范围为 15000 到 16000,可以将该属性设置如下:
<property><name>yarn.app.mapreduce.am.webapp.port-range</name><value>15000-16000</value> </property>上述配置将指定 WebApp 使用的端口范围为 15000 到 16000。
这个配置属性通常是在 mapred-site.xml 文件中配置的,该文件位于 Hadoop 的配置目录中。确保所配置的端口范围不会与其他服务或应用程序使用的端口冲突。更改这个属性可能需要重启与 MapReduce 和 YARN 相关的服务。
145.设置任务提交器(committer)取消的超时时间
yarn.app.mapreduce.am.job.committer.cancel-timeout 是 Apache Hadoop YARN 中 MapReduce Application Master(AM)的一个配置属性。该属性用于设置任务提交器(committer)取消的超时时间。
以下是对该配置属性的解释:
-
属性名称:
yarn.app.mapreduce.am.job.committer.cancel-timeout -
描述: 该属性指定了任务提交器取消的超时时间。任务提交器负责提交 MapReduce 任务的输出,当任务被取消时,可能需要取消提交的操作。此配置属性定义了超时时间,即在超过该时间后,即使提交器尚未完成,也将取消提交操作。
-
默认值: 该属性通常有一个默认值,如果未显式设置,则使用默认值。
-
示例: 如果你希望为任务提交器设置取消超时时间为 600 秒,可以将该属性设置如下:
<property><name>yarn.app.mapreduce.am.job.committer.cancel-timeout</name><value>600000</value> </property>上述配置将取消超时时间设置为 600 秒。
这个配置属性通常是在 mapred-site.xml 文件中配置的,该文件位于 Hadoop 的配置目录中。确保理解任务提交器的行为,以及设置适当的取消超时时间,以平衡任务取消的迅速性和提交器完成的可能性。更改这个属性可能需要重启与 MapReduce 和 YARN 相关的服务。
146.设置任务提交器(committer)的提交窗口(commit window)
yarn.app.mapreduce.am.job.committer.commit-window 是 Apache Hadoop YARN 中 MapReduce Application Master(AM)的配置属性之一。该属性用于设置任务提交器(committer)的提交窗口(commit window)。
以下是对该配置属性的解释:
-
属性名称:
yarn.app.mapreduce.am.job.committer.commit-window -
描述: 该属性指定了任务提交器的提交窗口,即在任务成功完成后,提交器等待的时间窗口,在此窗口内提交器将尝试提交输出。提交窗口的设置可以影响任务的最终提交的时间。
-
默认值: 该属性通常有一个默认值,如果未显式设置,则使用默认值。
-
示例: 如果你希望为任务提交器设置提交窗口为 300 秒,可以将该属性设置如下:
<property><name>yarn.app.mapreduce.am.job.committer.commit-window</name><value>300000</value> </property>上述配置将提交窗口设置为 300 秒。
这个配置属性通常是在 mapred-site.xml 文件中配置的,该文件位于 Hadoop 的配置目录中。了解提交窗口的概念并配置适当的数值,以满足任务提交的时间要求。更改这个属性可能需要重启与 MapReduce 和 YARN 相关的服务。
147.指定文件输出提交器(FileOutputCommitter)的算法版本
mapreduce.fileoutputcommitter.algorithm.version 是 Hadoop MapReduce 中的一个配置属性,用于指定文件输出提交器(FileOutputCommitter)的算法版本。FileOutputCommitter 负责在 MapReduce 任务成功完成时将输出提交到最终目的地(通常是 Hadoop 分布式文件系统 HDFS)。
以下是对该配置属性的解释:
-
属性名称:
mapreduce.fileoutputcommitter.algorithm.version -
描述: 该属性指定了 FileOutputCommitter 使用的算法版本。不同的算法版本可能影响输出提交的性能和行为。此属性通常用于允许在不同的 Hadoop 版本之间选择不同的算法版本。
-
默认值: 该属性通常有一个默认值,如果未显式设置,则使用默认值。
-
示例: 如果你希望明确指定 FileOutputCommitter 使用的算法版本为 2,可以将该属性设置如下:
<property><name>mapreduce.fileoutputcommitter.algorithm.version</name><value>2</value> </property>上述配置将指定算法版本为 2。
这个配置属性通常是在 mapred-site.xml 文件中配置的,该文件位于 Hadoop 的配置目录中。确保了解所选择的算法版本的特性,并根据实际需求进行配置。更改这个属性可能需要重启与 MapReduce 和 Hadoop 相关的服务。
148.指定在任务成功完成后是否执行文件输出提交器(FileOutputCommitter)的任务清理操作
mapreduce.fileoutputcommitter.task.cleanup.enabled 是 Hadoop MapReduce 中的一个配置属性,用于指定在任务成功完成后是否执行文件输出提交器(FileOutputCommitter)的任务清理操作。
以下是对该配置属性的解释:
-
属性名称:
mapreduce.fileoutputcommitter.task.cleanup.enabled -
描述: 该属性用于控制在任务成功完成后是否执行任务清理操作。任务清理操作通常包括删除临时输出目录等。
-
默认值: 默认情况下,此属性的值通常是
false,即任务清理操作被禁用。 -
示例: 如果你希望在任务成功完成后执行任务清理操作,可以将该属性设置为
true:<property><name>mapreduce.fileoutputcommitter.task.cleanup.enabled</name><value>true</value> </property>上述配置将启用任务清理操作。
这个配置属性通常是在 mapred-site.xml 文件中配置的,该文件位于 Hadoop 的配置目录中。启用任务清理操作可能会带来一些性能开销,但可以确保在任务成功完成后进行相关的清理操作。更改这个属性可能需要重启与 MapReduce 和 Hadoop 相关的服务。
149.设置 AM 向资源管理器(ResourceManager)发送调度心跳的时间间隔
yarn.app.mapreduce.am.scheduler.heartbeat.interval-ms 是 Apache Hadoop YARN 中 MapReduce Application Master(AM)的一个配置属性。该属性用于设置 AM 向资源管理器(ResourceManager)发送调度心跳的时间间隔。
以下是对该配置属性的解释:
-
属性名称:
yarn.app.mapreduce.am.scheduler.heartbeat.interval-ms -
描述: 该属性指定了 MapReduce Application Master 向 ResourceManager 发送调度心跳的时间间隔(以毫秒为单位)。调度心跳是 AM 用来通知 ResourceManager 关于任务的资源需求和状态的机制。
-
默认值: 该属性通常有一个默认值,如果未显式设置,则使用默认值。
-
示例: 如果你希望设置调度心跳的时间间隔为 5 秒,可以将该属性设置如下:
<property><name>yarn.app.mapreduce.am.scheduler.heartbeat.interval-ms</name><value>5000</value> </property>上述配置将调度心跳的时间间隔设置为 5000 毫秒(即 5 秒)。
这个配置属性通常是在 mapred-site.xml 文件中配置的,该文件位于 Hadoop 的配置目录中。调整这个属性可能会影响 MapReduce 任务对资源的请求和 ResourceManager 对 AM 的资源分配的响应速度。确保根据你的集群规模和性能要求来调整这个值。更改这个属性可能需要重启与 MapReduce 和 YARN 相关的服务。
150.设置客户端与 AM 之间的IPC(Inter-Process Communication)连接的最大重试次数
yarn.app.mapreduce.client-am.ipc.max-retries 是 Apache Hadoop YARN 中 MapReduce Application Master(AM)的一个配置属性。该属性用于设置客户端与 AM 之间的IPC(Inter-Process Communication)连接的最大重试次数。
以下是对该配置属性的解释:
-
属性名称:
yarn.app.mapreduce.client-am.ipc.max-retries -
描述: 该属性指定了客户端与 MapReduce Application Master 之间的IPC连接的最大重试次数。IPC连接用于客户端与 AM 进行通信,例如提交任务、获取任务状态等。
-
默认值: 该属性通常有一个默认值,如果未显式设置,则使用默认值。
-
示例: 如果你希望设置客户端与 AM 之间的IPC连接的最大重试次数为 3 次,可以将该属性设置如下:
<property><name>yarn.app.mapreduce.client-am.ipc.max-retries</name><value>3</value> </property>上述配置将最大重试次数设置为 3。
这个配置属性通常是在 mapred-site.xml 文件中配置的,该文件位于 Hadoop 的配置目录中。调整这个属性可能对客户端与 AM 之间的通信可靠性产生影响。确保根据你的需求和网络条件来调整这个值。更改这个属性可能需要重启与 MapReduce 和 YARN 相关的服务。
相关文章:

Hadoop之mapreduce参数大全-6
126.指定 Map 任务运行的节点标签表达式 mapreduce.map.node-label-expression 是 Hadoop MapReduce 框架中的一个配置属性,用于指定 Map 任务运行的节点标签表达式。节点标签是在 Hadoop 集群中为节点分配的用户定义的标签,可用于将 Map 任务限制在特定…...
前端路由时的hash模式和history模式的区别及详细介绍)
Vue开发中,在实现单页面应用(SPA)前端路由时的hash模式和history模式的区别及详细介绍
文章目录 一、前言二、hash模式hashchange 事件: 三、history模式方法:1、history.go():2、history.back():3、history.forward():4、History.replaceState()5、History.pushState()popState 事件 四、nginx配置五、原…...
功能强大的免费SSL证书
一、数据加密的重要性 免费SSL证书的核心作用在于对网站的数据传输进行加密处理。当一个网站部署了SSL证书后,它能够将HTTP协议升级至HTTPS,这意味着所有在客户端(如浏览器)与服务器之间传输的信息都将被高强度的加密算法所保护。…...

在Vue中使用Web Worker详细教程
1.什么是Web Worker? Web Worker 是2008年h5提供的新功能,每一个新功能都是为了解决原有技术的的痛点,那么这个痛点是什么呢? 1.1 JavaScript的单线程 JavaScript 为什么要设计成单线程? 这与js的工作内容有关:js只…...
)
四、C#高级特性(动态类型与Expando类)
在C#中,动态类型和ExpandoObject类是两个与运行时类型系统相关的特性,它们提供了更灵活的数据处理能力。 动态类型 动态类型是一种特殊的类型,允许你在运行时解析和操作对象的成员,而不需要在编译时知道这些成员的细节。使用动态…...

贪心算法的“左最优“与“右最优“及其对应的堆处理和预处理方法
1 答疑 1.1 什么是贪心算法的"左最优"与"右最优" "左最优"和"右最优"是贪心算法中的两种策略: 左最优 (Leftmost Greedy): 在每一步选择中,总是选择最左边(最早出现的)可行的选项。 右…...

【Docker】容器的相关命令
上一篇:创建,查看,进入容器 https://blog.csdn.net/m0_67930426/article/details/135430093?spm1001.2014.3001.5502 目录 1. 关闭容器 2.启动容器 3.删除容器 4.查看容器的信息 查看容器 1. 关闭容器 从图上来看,容器 aa…...

Android BUG 之 Error: Activity class {} does not exist
项目场景: 更换包名,运行报错 问题描述 原因分析: 在替换包名的时候要确认,配置文件跟build中的保持一致,在更换后还要将旧包的缓存数据清理掉 解决方案: 1 替换后删除 app 下的build 文件夹 2 Rebuild Pr…...
听劝,年度规划有它真的很必要!
2024年的时间进度条已走过一周,完成全年的1/52。 新年的flag悄然立下:愿逆风如解意,税后八个亿。 在不确定的世界中,发财暴富终归是确定的目标。 相比2023年的卷,年底的即兴生活正在悄悄上演,上一秒还在…...

leetcode滑动窗口问题总结 Python
目录 一、理论 二、例题 1. 最长无重复字符串 2. 长度最小的子数组 3. 字符串的排列 4. 最小覆盖子串 5. 滑动窗口最大值 一、理论 滑动窗口是一类比较重要的解题思路,一般来说我们面对的都是非定长窗口,所以一般需要定义两个指针 left 和 right&…...
秒变办公达人,只因用了这5款在线协同文档app!
在日常工作中,我们不可避免地需要处理各种文档,有时你可能会为如何高效地管理这些文档而感到烦恼,或是不知道如何挑选合适的在线文档工具? 不用担心!在这篇文章中,我们将介绍5个好用的在线文档工具App&…...

镜头选型和计算
3.5 补充知识 一、单像元分辨率(单像素精度) 单像素精度是表示视觉系统综合精度的指标,表示一个像元对应检测目标的实际物理尺寸,是客户重点关注的 视觉系统参数; 计算公式1:单像素精度视野范围FOV/相机分辨…...
2024--Django平台开发-Django知识点(四)
1.知识回顾 创建项目:新项目、别人项目、新版版、老版本 项目目录(v1.0版本) 路由系统 常见路由编写加粗样式 /index/ 函数 /index/<str:v1> 函数 re_path(ryy/(\d{4})-(\d{2})-(\d{2})/, views.yy), re_path(ryy/(?…...

可狱可囚的爬虫系列课程 09:通过 API 接口抓取数据
前面已经讲解过 Requests 结合 BeautifulSoup4 库抓取数据,这种方式在抓取数据时还是比较方便快捷的,但是这并不意味着所有的网站都适合这种方式,并且这也不是抓取数据的最快方式,今天我们来讲一种更快速的获取数据的方式…...

2. Spring Boot 自动配置 Mybatis 流程
1. Spring Boot 自动配置 Mybatis 自动配置过程中做了3个主要bean的创建及很重要的一些事情。 sqlSessionFactory、sqlSessionTemplate、MapperScannerConfigurer 等配置bean的创建。sqlSessionFactory:解析 xml配置文件,并将MappedStatement放入到Has…...
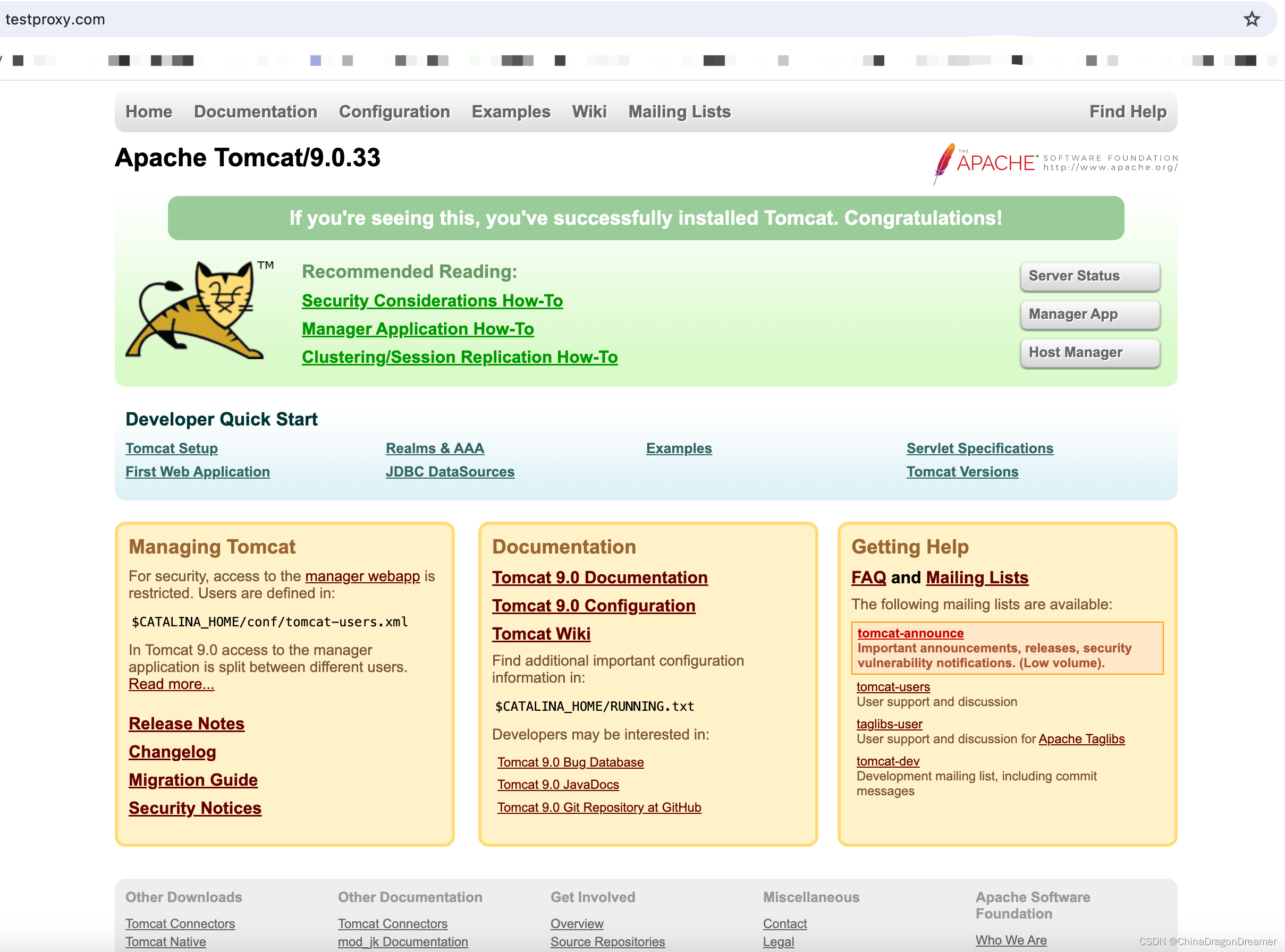
Nginx配置反向代理实例一
Mac 安装Nginx教程 提醒一下:下面实例讲解是在Mac系统演示的; 反向代理实例一实现的效果 在浏览器地址栏输入www.testproxy.com, 跳转到系统Tomcat主页面。 第一步:在系统的 hosts 文件进行ip和域名对应关系的配置。 Mac 系统修改Hosts文…...

训练自己的GPT2
训练自己的GPT2 1.预训练与微调2.准备工作2.在自己的数据上进行微调 1.预训练与微调 所谓的预训练,就是在海量的通用数据上训练大模型。比如,我把全世界所有的网页上的文本内容都整理出来,把全人类所有的书籍、论文都整理出来,然…...
etcd储存安装
目录 etcd介绍: etcd工作原理 选举 复制日志 安全性 etcd工作场景 服务发现 etcd基本术语 etcd安装(centos) 设置:etcd后台运行 etcd 是云原生架构中重要的基础组件,由 CNCF 孵化托管。etcd 在微服务和 Kubernates 集群中不仅可以作为服务注册…...

如何彻底卸载Microsoft Edge浏览器
一、引语 随着微软推出全新的Edge浏览器,许多用户可能想要尝试或完全切换到其他浏览器。在这篇文章中,我们将向您介绍如何彻底卸载Microsoft Edge浏览器,以确保您的系统干净整洁。 二、通过系统设置卸载 1、首先,右键单击桌面上…...
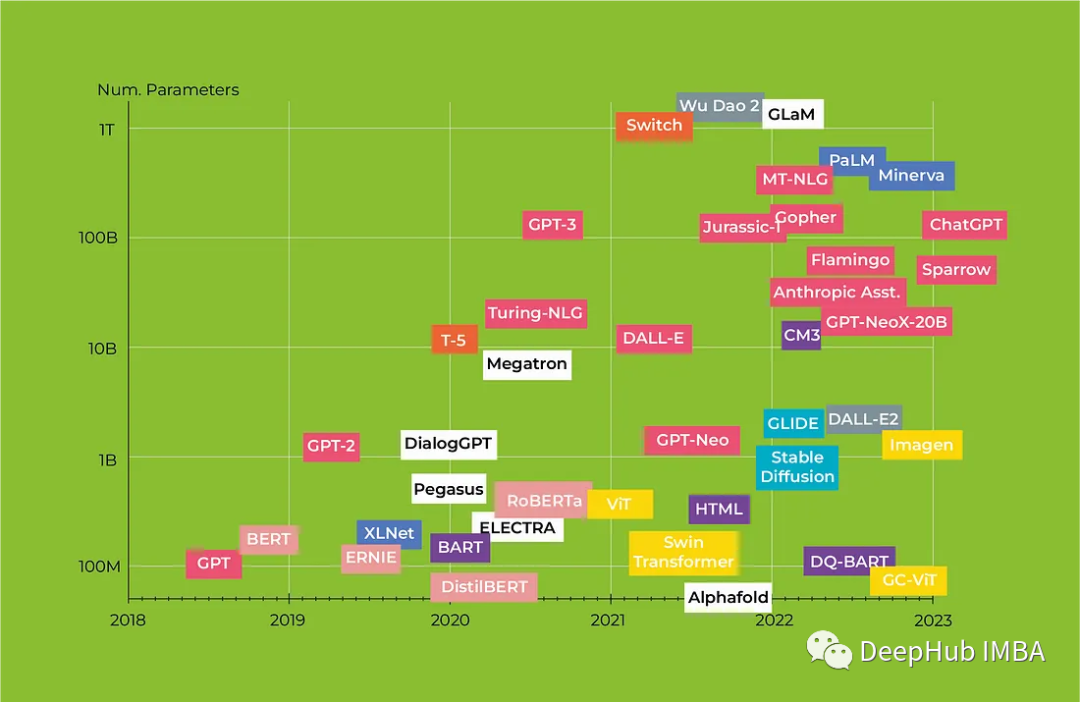
Transformers 2023年度回顾 :从BERT到GPT4
人工智能已成为近年来最受关注的话题之一,由于神经网络的发展,曾经被认为纯粹是科幻小说中的服务现在正在成为现实。从对话代理到媒体内容生成,人工智能正在改变我们与技术互动的方式。特别是机器学习 (ML) 模型在自然语言处理 (NLP) 领域取得…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...