redis数据结构的适用场景分析
1、String 类型的内存空间消耗问题,以及选择节省内存开销的数据类型的解决方案。
为什么 String 类型内存开销大?
图片 ID 和图片存储对象 ID 都是 10 位数,我们可以用两个 8 字节的 Long 类型表示这两个 ID。因为 8 字节的 Long 类型最大可以表示 2 的 64 次方的数值,所以肯定可以表示 10 位数。但是,为什么 String 类型却用了 64 字节呢?
除了记录实际数据,String 类型还需要额外的内存空间记录数据长度、空间使用等信息,这些信息也叫作元数据。当实际保存的数据较小时,元数据的空间开销就显得比较大了,有点“喧宾夺主”的意思。
当你保存 64 位有符号整数时,String 类型会把它保存为一个 8 字节的 Long 类型整数,这种保存方式通常也叫作 int 编码方式。
但是,当你保存的数据中包含字符时,String 类型就会用简单动态字符串(Simple Dynamic String,SDS)结构体来保存,如下图所示:
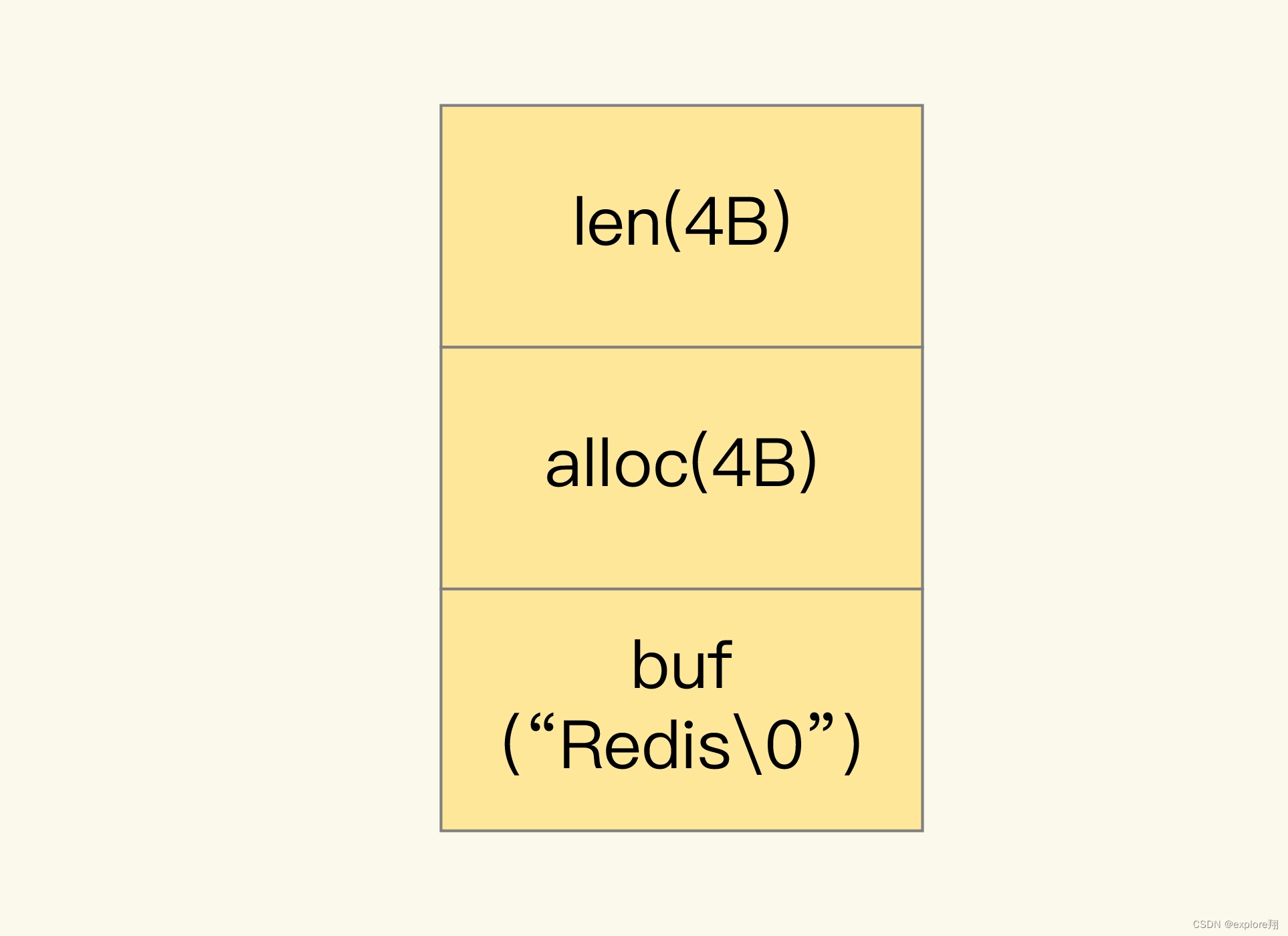
可以看到,在 SDS 中,buf 保存实际数据,而 len 和 alloc 本身其实是 SDS 结构体的额外开销。
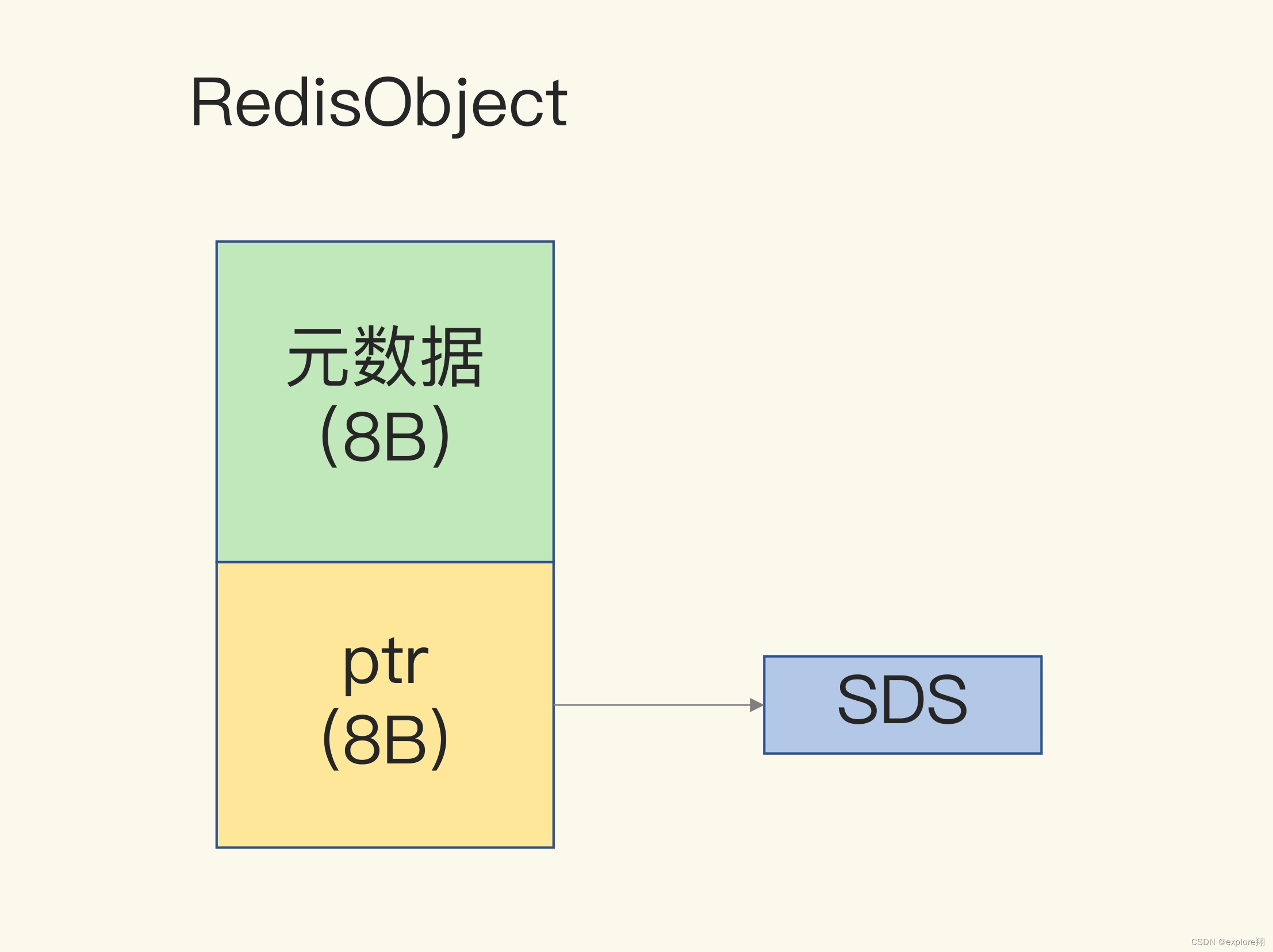
另外,对于 String 类型来说,除了 SDS 的额外开销,还有一个来自于 RedisObject 结构体的开销。因为 Redis 的数据类型有很多,而且,不同数据类型都有些相同的元数据要记录(比如最后一次访问的时间、被引用的次数等),所以,Redis 会用一个 RedisObject 结构体来统一记录这些元数据,同时指向实际数据。
一个 RedisObject 包含了 8 字节的元数据和一个 8 字节指针,这个指针再进一步指向具体数据类型的实际数据所在,例如指向 String 类型的 SDS 结构所在的内存地址,可以看一下下面的示意图。关于 RedisObject 的具体结构细节,我会在后面的课程中详细介绍,现在你只要了解它的基本结构和元数据开销就行了。
为了节省内存空间,Redis 还对 Long 类型整数和 SDS 的内存布局做了专门的设计。
一方面,当保存的是 Long 类型整数时,RedisObject 中的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了,节省了指针的空间开销。
另一方面,当保存的是字符串数据,并且字符串小于等于 44 字节时,RedisObject 中的元数据、指针和 SDS 是一块连续的内存区域,这样就可以避免内存碎片。这种布局方式也被称为 embstr 编码方式。
当然,当字符串大于 44 字节时,SDS 的数据量就开始变多了,Redis 就不再把 SDS 和 RedisObject 布局在一起了,而是会给 SDS 分配独立的空间,并用指针指向 SDS 结构。这种布局方式被称为 raw 编码模式。
因为 10 位数的图片 ID 和图片存储对象 ID 是 Long 类型整数,所以可以直接用 int 编码的 RedisObject 保存。每个 int 编码的 RedisObject 元数据部分占 8 字节,指针部分被直接赋值为 8 字节的整数了。此时,每个 ID 会使用 16 字节,加起来一共是 32 字节。但是,另外的 32 字节去哪儿了呢?
Redis 会使用一个全局哈希表保存所有键值对,哈希表的每一项是一个 dictEntry 的结构体,用来指向一个键值对。dictEntry 结构中有三个 8 字节的指针,分别指向 key、value 以及下一个 dictEntry,三个指针共 24 字节,如下图所示:
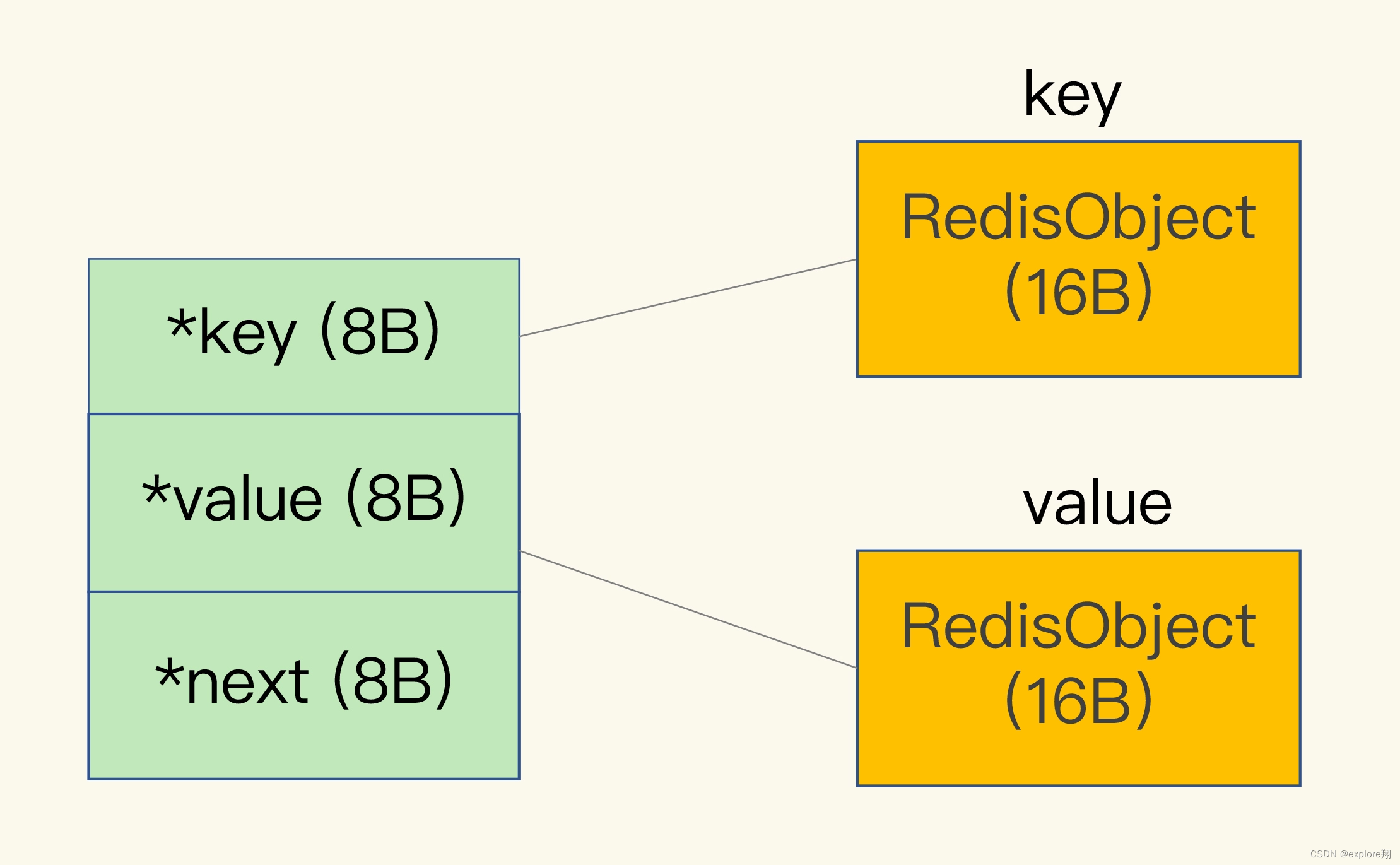
但是,这三个指针只有 24 字节,为什么会占用了 32 字节呢?这就要提到 Redis 使用的内存分配库 jemalloc 了。
jemalloc 在分配内存时,会根据我们申请的字节数 N,找一个比 N 大,但是最接近 N 的 2 的幂次数作为分配的空间,这样可以减少频繁分配的次数。所以,在我们刚刚说的场景里,dictEntry 结构就占用了 32 字节。
用什么数据结构可以节省内存?
Redis 有一种底层数据结构,叫压缩列表(ziplist),这是一种非常节省内存的结构。我们先回顾下压缩列表的构成。表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量,以及列表中的 entry 个数。压缩列表尾还有一个 zlend,表示列表结束。
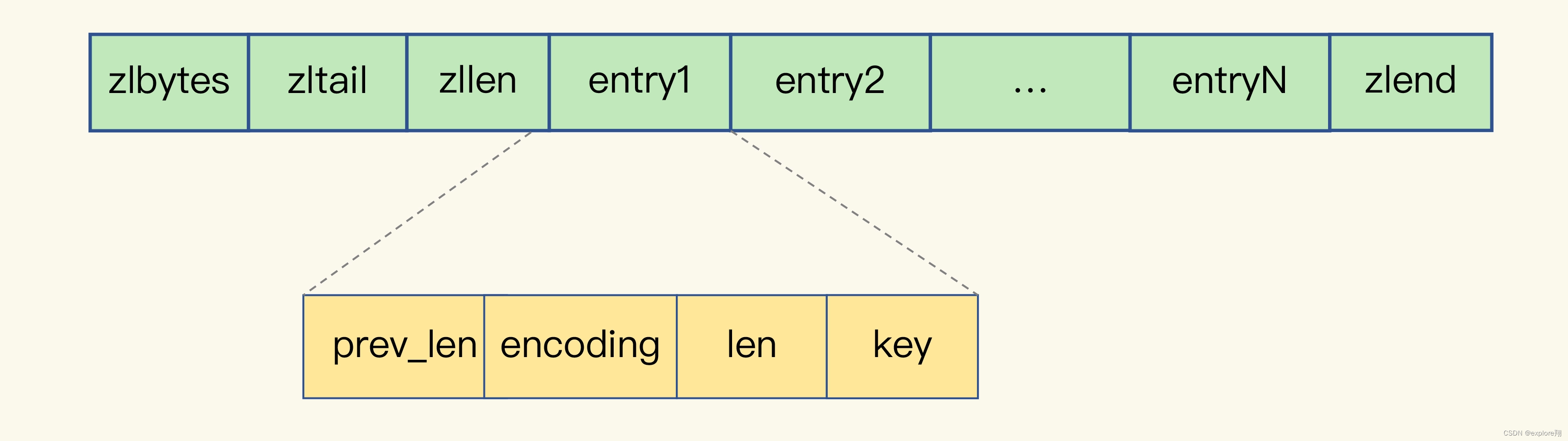
压缩列表之所以能节省内存,就在于它是用一系列连续的 entry 保存数据。每个 entry 的元数据包括下面几部分。这些 entry 会挨个儿放置在内存中,不需要再用额外的指针进行连接,这样就可以节省指针所占用的空间。
Redis 基于压缩列表实现了 List、Hash 和 Sorted Set 这样的集合类型,这样做的最大好处就是节省了 dictEntry 的开销。当你用 String 类型时,一个键值对就有一个 dictEntry,要用 32 字节空间。但采用集合类型时,一个 key 就对应一个集合的数据,能保存的数据多了很多,但也只用了一个 dictEntry,这样就节省了内存。
如何用集合类型保存单值的键值对?
在保存单值的键值对时,可以采用基于 Hash 类型的二级编码方法。这里说的二级编码,就是把一个单值的数据拆分成两部分,前一部分作为 Hash 集合的 key,后一部分作为 Hash 集合的 value,这样一来,我们就可以把单值数据保存到 Hash 集合中了。
以图片 ID 1101000060 和图片存储对象 ID 3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。按照这种设计方法,我在 Redis 中插入了一组图片 ID 及其存储对象 ID 的记录,并且用 info 命令查看了内存开销,我发现,增加一条记录后,内存占用只增加了 16 字
(实测老师的例子,**长度7位数,共100万条数据。使用string占用70mb,使用hash ziplist只占用9mb。**效果非常明显。redis版本6.0.6)
2 有一亿个keys要统计,应该用哪种集合?
在 Web 和移动应用的业务场景中,我们经常需要保存这样一种信息:一个 key 对应了一个数据集合
手机 App 中的每天的用户登录信息:一天对应一系列用户 ID 一个网页对应一系列的访问点击。在这些场景中,除了记录信息,我们往往还需要对集合中的数据进行统计,例如:
在移动应用中,需要统计每天的新增用户数和第二天的留存用户数;
在电商网站的商品评论中,需要统计评论列表中的最新评论
通常情况下,我们面临的用户数量以及访问量都是巨大的,比如百万、千万级别的用户数量,或者千万级别、甚至亿级别的访问信息。所以,我们必须要选择能够非常高效地统计大量数据(例如亿级)的集合类型。
要想选择合适的集合,我们就得了解常用的集合统计模式。介绍集合类型常见的四种统计模式,包括聚合统计、排序统计、二值状态统计和基数统计。以刚刚提到的这四个场景为例,来聊聊在这些统计模式下,什么集合类型能够更快速地完成统计,而且还节省内存空间。
聚合统计
所谓的聚合统计,就是指统计多个集合元素的聚合结果,包括:统计多个集合的共有元素(交集统计);把两个集合相比,统计其中一个集合独有的元素(差集统计);统计多个集合的所有元素(并集统计)。在刚才提到的场景中,统计手机 App 每天的新增用户数和第二天的留存用户数,正好对应了聚合统计。
要完成这个统计任务,我们可以用一个集合记录所有登录过 App 的用户 ID,同时,用另一个集合记录每一天登录过 App 的用户 ID。然后,再对这两个集合做聚合统计。
执行 SDIFFSTORE 命令计算累计用户 Set 和 user🆔20200804 Set 的差集,结果保存在 key 为 user:new 的 Set 中,如下所示:
SDIFFSTORE user:new user🆔20200804 user:id
可以看到,这个差集中的用户 ID 在 user🆔20200804 的 Set 中存在,但是不在累计用户 Set 中。所以,user:new 这个 Set 中记录的就是 8 月 4 日的新增用户。
当要计算 8 月 4 日的留存用户时,我们只需要再计算 user🆔20200803 和 user🆔20200804 两个 Set 的交集,就可以得到同时在这两个集合中的用户 ID 了,这些就是在 8 月 3 日登录,并且在 8 月 4 日留存的用户。执行的命令如下:
SINTERSTORE user🆔rem user🆔20200803 user🆔20200804
Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。所以,我给你分享一个小建议:你可以从主从集群中选择一个从库,让它专门负责聚合计算,或者是把数据读取到客户端,在客户端来完成聚合统计,这样就可以规避阻塞主库实例和其他从库实例的风险了。
排序统计
这就要求集合类型能对元素保序,也就是说,集合中的元素可以按序排列,这种对元素保序的集合类型叫作有序集合。
在 Redis 常用的 4 个集合类型中(List、Hash、Set、Sorted Set),List 和 Sorted Set 就属于有序集合。List 是按照元素进入 List 的顺序进行排序的,而 Sorted Set 可以根据元素的权重来排序,我们可以自己来决定每个元素的权重值。
比如说,我们可以根据元素插入 Sorted Set 的时间确定权重值,先插入的元素权重小,后插入的元素权重大。看起来好像都可以满足需求,我们该怎么选择呢?
我先说说用 List 的情况。每个商品对应一个 List,这个 List 包含了对这个商品的所有评论,而且会按照评论时间保存这些评论,每来一个新评论,就用 LPUSH 命令把它插入 List 的队头。在只有一页评论的时候,我们可以很清晰地看到最新的评论,但是,在实际应用中,网站一般会分页显示最新的评论列表,一旦涉及到分页操作,List 就可能会出现问题了。 List 是通过元素在 List 中的位置来排序的,当有一个新元素插入时,原先的元素在 List 中的位置都后移了一位,比如说原来在第 1 位的元素现在排在了第 2 位。
和 List 相比,Sorted Set 就不存在这个问题,因为它是根据元素的实际权重来排序和获取数据的。我们可以按评论时间的先后给每条评论设置一个权重值,然后再把评论保存到 Sorted Set 中。
Sorted Set 的 ZRANGEBYSCORE 命令就可以按权重排序后返回元素。这样的话,即使集合中的元素频繁更新,Sorted Set 也能通过 ZRANGEBYSCORE 命令准确地获取到按序排列的数据。
设越新的评论权重越大,目前最新评论的权重是 N,我们执行下面的命令时,就可以获得最新的 10 条评论:
ZRANGEBYSCORE comments N-9 N
所以,在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议你优先考虑使用 Sorted Set。
二值状态统计
现在,我们再来分析下第三个场景:二值状态统计。这里的二值状态就是指集合元素的取值就只有 0 和 1 两种。在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态,
在签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一个月(假设是 31 天)的签到情况用 31 个 bit 位就可以,而一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。这个时候,我们就可以选择 Bitmap。
SETBIT GETBIT BITCOUNT。注意是从0开始的,所以SETBIT uid:sign:3000:202008 2 1 是设置8月3号已经签到。
在统计 1 亿个用户连续 10 天的签到情况时,你可以把每天的日期作为 key,每个 key 对应一个 1 亿位的 Bitmap,每一个 bit 对应一个用户当天的签到情况。接下来,我们对 10 个 Bitmap 做“与”操作,得到的结果也是一个 Bitmap。最后,我们可以用 BITCOUNT 统计下 Bitmap 中的 1 的个数,这就是连续签到 10 天的用户总数了。
不过,在实际应用时,最好对 Bitmap 设置过期时间,让 Redis 自动删除不再需要的签到记录,以节省内存开销
基数统计
最后,我们再来看一个统计场景:基数统计。基数统计就是指统计一个集合中不重复的元素个数。对应到我们刚才介绍的场景中,就是统计网页的 UV。网页 UV 的统计有个独特的地方,就是需要去重,一个用户一天内的多次访问只能算作一次。在 Redis 的集合类型中,Set 类型默认支持去重,所以看到有去重需求时,我们可能第一时间就会想到用 Set 类型。当你需要统计 UV 时,可以直接用 SCARD 命令,这个命令会返回一个集合中的元素个数。
但是,如果 page1 非常火爆,UV 达到了千万,这个时候,一个 Set 就要记录千万个用户 ID。对于一个搞大促的电商网站而言,这样的页面可能有成千上万个,如果每个页面都用这样的一个 Set,就会消耗很大的内存空间。
这时候,就要用到 Redis 提供的 HyperLogLog 了。HyperLogLog 是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。不过,有一点需要你注意一下,HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。
面向 LBS 应用的 GEO 数据类型
一辆车(或一个用户)对应一组经纬度,并且随着车(或用户)的位置移动,相应的经纬度也会变化。这种数据记录模式属于一个 key(例如车 ID)对应一个 value(一组经纬度)
当有很多车辆信息要保存时,就需要有一个集合来保存一系列的 key 和 value。Hash 集合类型可以快速存取一系列的 key 和 value,正好可以用来记录一系列车辆 ID 和经纬度的对应关系,所以,我们可以把不同车辆的 ID 和它们对应的经纬度信息存在 Hash 集合中。同时,Hash 类型的 HSET 操作命令,会根据 key 来设置相应的 value 值,所以,我们可以用它来快速地更新车辆变化的经纬度信息。到这里,Hash 类型看起来是一个不错的选择。
但问题是,对于一个 LBS 应用来说,除了记录经纬度信息,还需要根据用户的经纬度信息在车辆的 Hash 集合中进行范围查询。一旦涉及到范围查询,就意味着集合中的元素需要有序,但 Hash 类型的元素是无序的,显然不能满足我们的要求。
Sorted Set 类型也支持一个 key 对应一个 value 的记录模式,其中,key 就是 Sorted Set 中的元素,而 value 则是元素的权重分数。更重要的是,Sorted Set 可以根据元素的权重分数排序,支持范围查询。这就能满足 LBS 服务中查找相邻位置的需求了。实际上,**GEO 类型的底层数据结构就是用 Sorted Set 来实现的。**这时问题来了,Sorted Set 元素的权重分数是一个浮点数(float 类型),而一组经纬度包含的是经度和纬度两个值,是没法直接保存为一个浮点数的,那具体该怎么进行保存呢?
这就要用到 GEO 类型中的 GeoHash 编码了。
如何定义新的数据类型
首先,我们需要了解 Redis 的基本对象结构 RedisObject,因为 Redis 键值对中的每一个值都是用 RedisObject 保存的。
RedisObject 的内部组成包括了 type,、encoding,、lru 和 refcount 4 个元数据,以及 1 个*ptr指针。
首先,我们需要为新数据类型定义好它的底层结构、type 和 encoding 属性值,然后再实现新数据类型的创建、释放函数和基本命令。
如何在Redis中保存时间序列数据?
在实际应用中,时间序列数据通常是持续高并发写入的,例如,需要连续记录数万个设备的实时状态值。同时,时间序列数据的写入主要就是插入新数据,而不是更新一个已存在的数据,也就是说,一个时间序列数据被记录后通常就不会变了,因为它就代表了一个设备在某个时刻的状态值。
所以,这种数据的写入特点很简单,就是插入数据快,这就要求我们选择的数据类型,在进行数据插入时,复杂度要低,尽量不要阻塞。看到这儿,你可能第一时间会想到用 Redis 的 String、Hash 类型来保存,因为它们的插入复杂度都是 O(1),是个不错的选择。但是,String 类型在记录小数据时(例如刚才例子中的设备温度值),元数据的内存开销比较大,不太适合保存大量数据。
基于 Hash 和 Sorted Set 保存时间序列数据
关于 Hash 类型,我们都知道,它有一个特点是,可以实现对单键的快速查询。这就满足了时间序列数据的单键查询需求。我们可以把时间戳作为 Hash 集合的 key,把记录的设备状态值作为 Hash 集合的 value。当我们想要查询某个时间点或者是多个时间点上的温度数据时,直接使用 HGET 命令或者 HMGET 命令,就可以分别获得 Hash 集合中的一个 key 和多个 key 的 value 值了。
但是,Hash 类型有个短板:它并不支持对数据进行范围查询。
为了能同时支持按时间戳范围的查询,可以用 Sorted Set 来保存时间序列数据,因为它能够根据元素的权重分数来排序。我们可以把时间戳作为 Sorted Set 集合的元素分数,把时间点上记录的数据作为元素本身。
如何保证写入 Hash 和 Sorted Set 是一个原子性的操作呢?
所谓“原子性的操作”,就是指我们执行多个写命令操作时(例如用 HSET 命令和 ZADD 命令分别把数据写入 Hash 和 Sorted Set),这些命令操作要么全部完成,要么都不完成。这里就涉及到了 Redis 用来实现简单的事务的 MULTI 和 EXEC 命令。当多个命令及其参数本身无误时,MULTI 和 EXEC 命令可以保证执行这些命令时的原子性(相当于mysql事务的begin commit)
接下来,我们需要继续解决第三个问题:如何对时间序列数据进行聚合计算?
因为 Sorted Set 只支持范围查询,无法直接进行聚合计算,所以,我们只能先把时间范围内的数据取回到客户端,然后在客户端自行完成聚合计算。为了避免客户端和 Redis 实例间频繁的大量数据传输,我们可以使用 RedisTimeSeries 来保存时间序列数据
所以,如果我们只需要进行单个时间点查询或是对某个时间范围查询的话,适合使用 Hash 和 Sorted Set 的组合,它们都是 Redis 的内在数据结构,性能好,稳定性高。但是,如果我们需要进行大量的聚合计算,同时网络带宽条件不是太好时,Hash 和 Sorted Set 的组合就不太适合了。此时,使用 RedisTimeSeries 就更加合适一些。
消息队列的考验:Redis有哪些解决方案?
现在的互联网应用基本上都是采用分布式系统架构进行设计的,而很多分布式系统必备的一个基础软件就是消息队列。
消息队列的消息存取需求
不过,消息队列在存取消息时,必须要满足三个需求,分别是消息保序、处理重复的消息(消费者从消息队列读取消息时,有时会因为网络堵塞而出现消息重传的情况。此时,消费者可能会收到多条重复的消息。)和保证消息可靠性(当消费者重启后,可以重新读取消息再次进行处理,否则,就会出现消息漏处理的问题了。)。
基于 List 的消息队列解决方案
List 本身就是按先进先出的顺序对数据进行存取的,所以,如果使用 List 作为消息队列保存消息的话,就已经能满足消息保序的需求了。
,如果消费者想要及时处理消息,就需要在程序中不停地调用 RPOP 命令(比如使用一个 while(1) 循环)。如果有新消息写入,RPOP 命令就会返回结果,否则,RPOP 命令返回空值,再继续循环。为了解决这个问题,Redis 提供了 BRPOP 命令。BRPOP 命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据。
消息保序的问题解决了,接下来,我们还需要考虑解决重复消息处理的问题,这里其实有一个要求:消费者程序本身能对重复消息进行判断。
一方面,消息队列要能给每一个消息提供全局唯一的 ID 号;另一方面,消费者程序要把已经处理过的消息的 ID 号记录下来。
当消费者程序从 List 中读取一条消息后,List 就不会再留存这条消息了。所以,如果消费者程序在处理消息的过程出现了故障或宕机,就会导致消息没有处理完成,那么,消费者程序再次启动后,就没法再次从 List 中读取消息了。
为了留存消息,List 类型提供了 BRPOPLPUSH 命令,这个命令的作用是让消费者程序从一个 List 中读取消息,同时,Redis 会把这个消息再插入到另一个 List(可以叫作备份 List)留存。这样一来,如果消费者程序读了消息但没能正常处理,等它重启后,就可以从备份 List 中重新读取消息并进行处理了。
这就要说到 Redis 从 5.0 版本开始提供的 Streams 数据类型了。和 List 相比,Streams 同样能够满足消息队列的三大需求。而且,它还支持消费组形式的消息读取。
其实,关于 Redis 是否适合做消息队列,业界一直是有争论的。很多人认为,要使用消息队列,就应该采用 Kafka、RabbitMQ 这些专门面向消息队列场景的软件,而 Redis 更加适合做缓存。
我的看法是:Redis 是一个非常轻量级的键值数据库,部署一个 Redis 实例就是启动一个进程,部署 Redis 集群,也就是部署多个 Redis 实例。而 Kafka、RabbitMQ 部署时,涉及额外的组件,例如 Kafka 的运行就需要再部署 ZooKeeper。相比 Redis 来说,Kafka 和 RabbitMQ 一般被认为是重量级的消息队列。
相关文章:
redis数据结构的适用场景分析
1、String 类型的内存空间消耗问题,以及选择节省内存开销的数据类型的解决方案。 为什么 String 类型内存开销大? 图片 ID 和图片存储对象 ID 都是 10 位数,我们可以用两个 8 字节的 Long 类型表示这两个 ID。因为 8 字节的 Long 类型最大可以…...

同步、异步、全双工、半双工的区别
1、通讯 1.1 并行通讯 定义:一条信息的各位数据被同时传送的通讯方式称为并行通讯; 特点: 各个数据位同时发送,传送速度快、效率高,但有多少数据位就需要多少根数据线,因此传送成本高,并且只…...

ClickHouse 与 Amazon S3 结合?一起来探索其中奥秘
目录ClickHouse 简介ClickHouse 与对象存储ClickHouse 与 S3 结合的三种方法示例参考架构小结参考资料ClickHouse 简介ClickHouse 是一种快速的、开源的、用于联机分析(OLAP)的列式数据库管理系统(DBMS),由俄罗斯的Yan…...
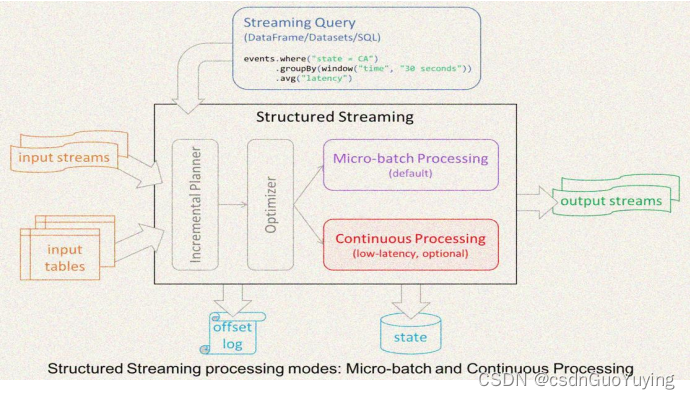
【Spark分布式内存计算框架——Structured Streaming】1. Structured Streaming 概述
前言 Apache Spark在2016年的时候启动了Structured Streaming项目,一个基于Spark SQL的全新流计算引擎Structured Streaming,让用户像编写批处理程序一样简单地编写高性能的流处理程序。 Structured Streaming并不是对Spark Streaming的简单改进…...
【Windows】【Linux】---- Java证书导入
问题: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target 无法找到请求目标的有效证书路径 一、Windows—java证书导入 1、下载证书到本地(以下…...

【Linux学习】菜鸟入门——gcc与g++简要使用
一、gcc/g gcc/g是编译器,gcc是GCC(GUN Compiler Collection,GUN编译器集合)中的C编译器;g是GCC中的C编译器。使用g编译文件时会自动链接STL标准库,而gcc不会自动链接STL标准库。下面简单介绍一下Linux环境下(Windows差…...

Cadence Allegro 导出Bill of Material Report详解
⏪《上一篇》 🏡《总目录》 ⏩《下一篇》 目录 1,概述2,Assigned Functions Report作用3,Assigned Functions Report示例4,Assigned Functions Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频...
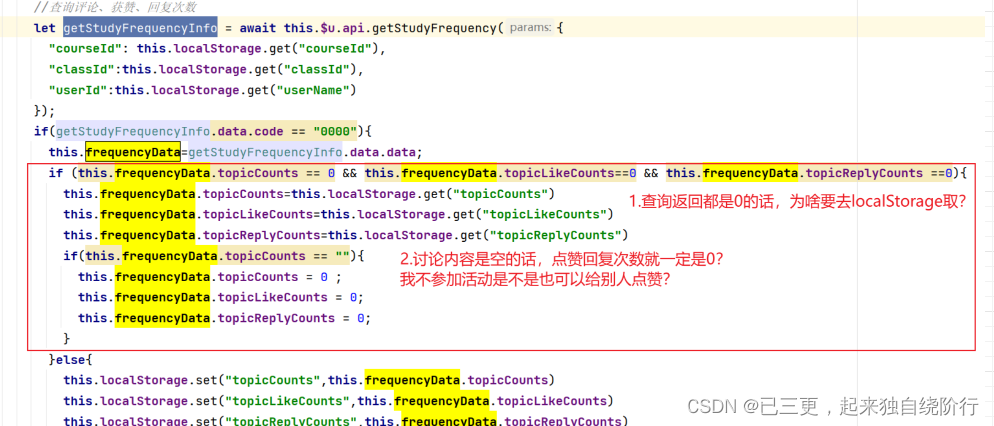
localStorage线上问题的思考
一、背景: localStorage作为HTML5 Web Storage的API之一,使用标准的键值对(Key-Value,简称KV)数据类型主要作用是本地存储。本地存储是指将数据按照键值对的方式保存在客户端计算机中,直到用户或者脚本主动清除数据&a…...

什么是DNS域名解析
什么是DNS域名解析?因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,得到该主机名对应的IP地址的过程叫做域名解析。正向解析:…...

Cadence Allegro 导出Assigned Functions Report详解
⏪《上一篇》 🏡《总目录》 ⏩《下一篇》 目录 1,概述2,Assigned Functions Report作用3,Assigned Functions Report示例4,Assigned Functions Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频...

Python中Opencv和PIL.Image读取图片的差异对比
近日,在进行深度学习进行推理的时候,发现不管怎么样都得不出正确的结果,再仔细和正确的代码进行对比了后发现原来是Python中不同的库读取的图片数组是有差异的。 image np.array(Image.open(image_file).convert(RGB)) image cv2.imread(…...
win10 WSL2 使用Ubuntu配置与安装教程
Win10 22H2ubuntu 22.04ROS2 文章目录一、什么是WSL2二、Win10 系统配置2.1 更新Windows版本2.2 Win10系统启用两个功能2.3 Win10开启BIOS/CPU开启虚拟化(VT)(很关键)2.4 下载并安装wsl_update_x64.msi2.5 PowerShell安装组件三、PowerShell安装Ubuntu3.…...
)
LeetCode每日一题(28. Find the Index of the First Occurrence in a String)
Given two strings needle and haystack, return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack. Example 1: Input: haystack “sadbutsad”, needle “sad” Output: 0 Explanation: “sad” occurs at index 0 and…...
Android 圆弧形 SeekBar
效果预览package com.gcssloop.widget;import android.annotation.SuppressLint;import android.content.Context;import android.content.res.TypedArray;import android.graphics.Canvas;import android.graphics.Color;import android.graphics.Matrix;import android.graph…...
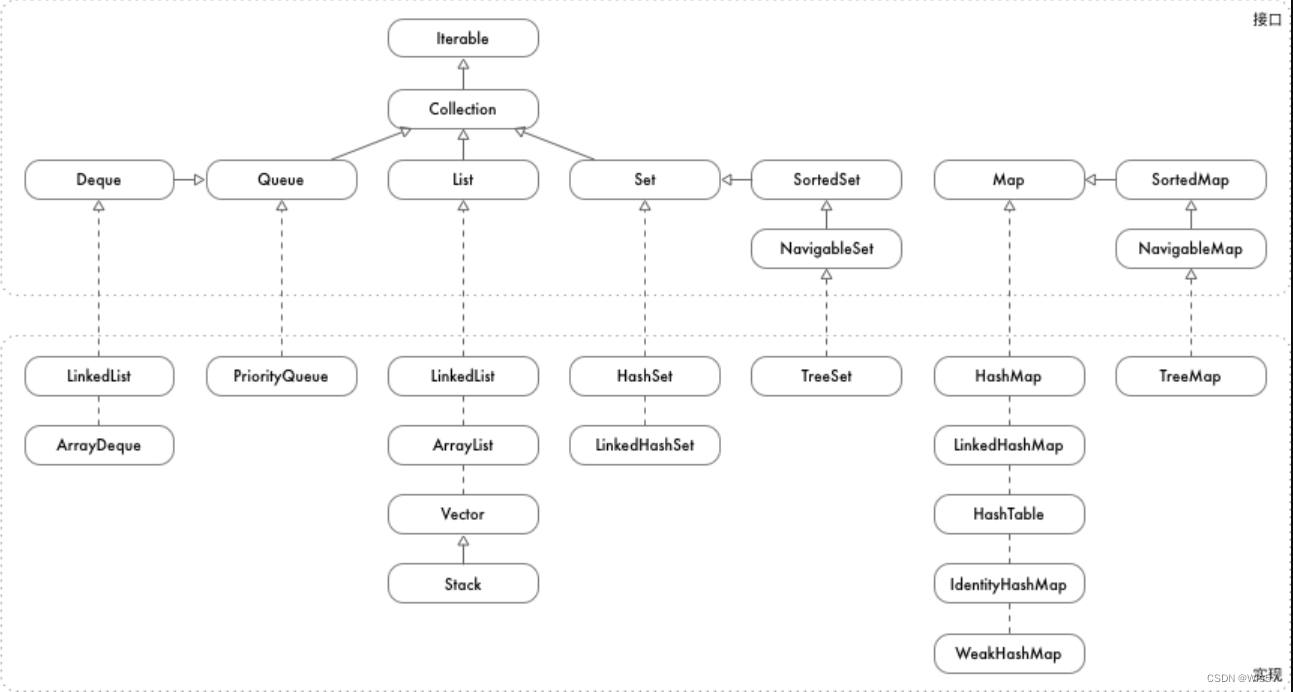
java 字典
java 字典 数据结构总览 Map Map 描述的是一种映射关系,一个 key 对应一个 value,可以添加,删除,修改和获取 key/value,util 提供了多种 Map HashMap: hash 表实现的 map,插入删除查找性能都是 O(1)&…...
【企业服务器LNMP环境搭建】mysql安装
MySQL安装步骤: 1、相关说明 1.1、编译参数的说明 -DCMAKE_INSTALL_PREFIX安装到的软件目录-DMYSQL_DATADIR数据文件存储的路径-DSYSCONFDIR配置文件路径 (my.cnf)-DENABLED_LOCAL_INFILE1使用localmysql客户端的配置-DWITH_PARTITION_STORAGE_ENGINE使mysql支持…...
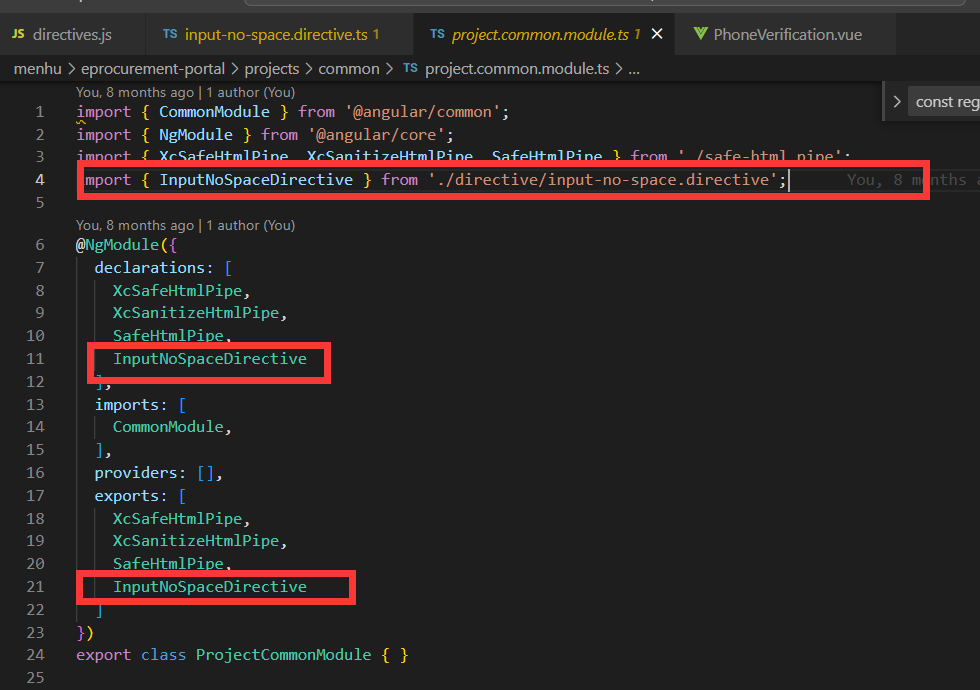
vue自定义指令以及angular自定义指令(以禁止输入空格为例)
哈喽,小伙伴们,大家好啊,最近要实现一个vue自定义指令,就是让input输入框禁止输入空格建立一个directives的指令文件,里面专门用来建立各个指令的官方文档:自定义指令 | Vue.js (vuejs.org)我们都知道vue中…...

异常 复习
异常复习 异常(广义):泛指程序中一切不正常的情况 错误:例如内存不够用,程序是无法解决的 异常(狭义):程序在运行中出现问题,但是可以通过异常处理机制处理,程序可以继续向后执行 异常体系 Throwable类有两个直接子类:Excepti…...
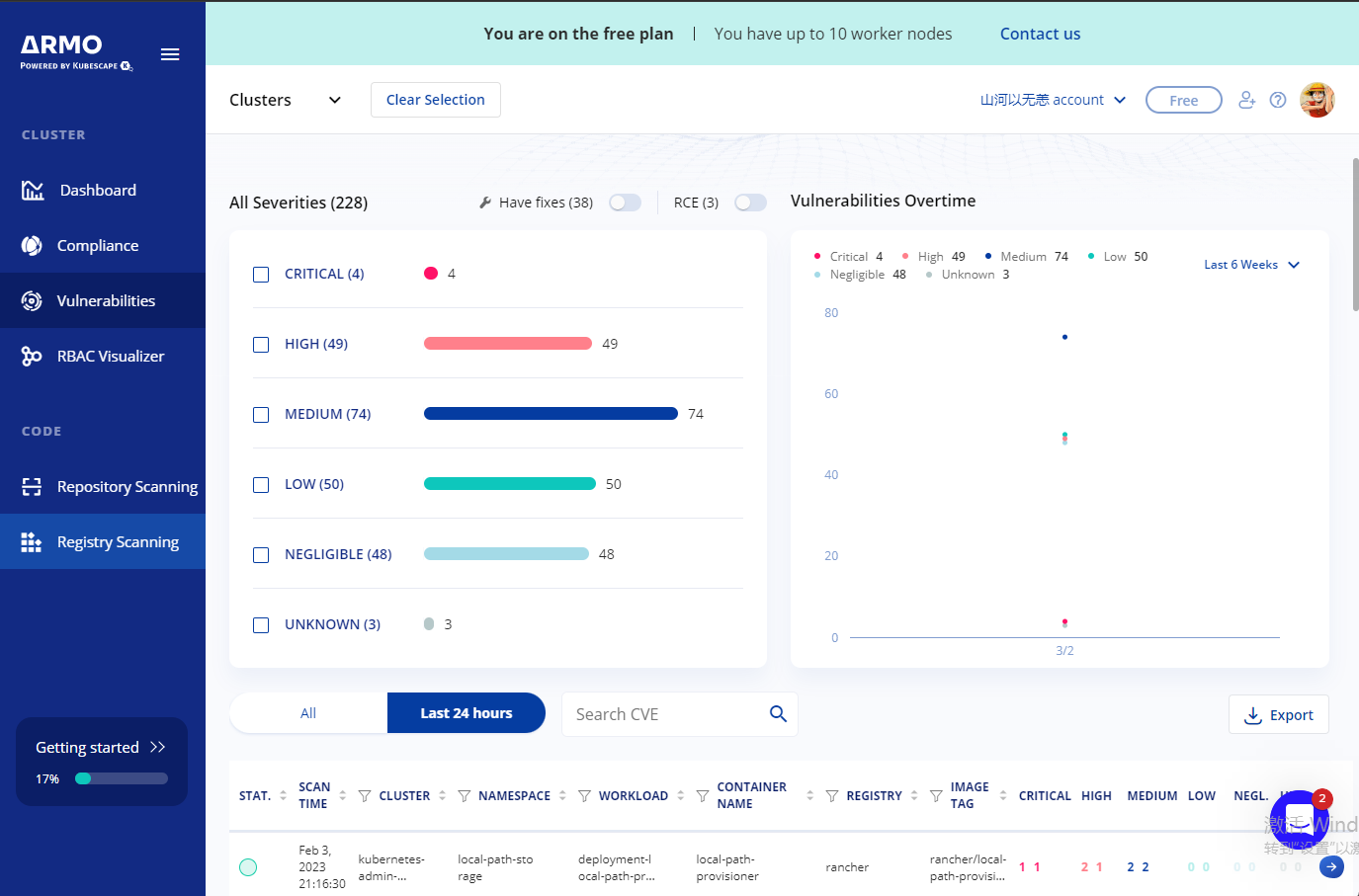
K8s:开源安全平台 kubescape 实现 Pod 的安全合规检查/镜像漏洞扫描
写在前面 生产环境中的 k8s 集群安全不可忽略,即使是内网环境容器化的应用部署虽然本质上没有变化,始终是机器上的一个进程但是提高了安全问题的处理的复杂性分享一个开源的 k8s 集群安全合规检查/漏洞扫描 工具 kubescape博文内容涉及: kube…...

C#中,FTP同步或异步读取大量文件
一次快速读取上万个文件中的内容 在C#中,可以使用FTP客户端类(如FtpWebRequest)来连接FTP服务器并进行文件操作。一次快速读取上万个文件中的内容,可以采用多线程的方式并发读取文件。 以下是一个示例代码,用于读取FT…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...
)
Frida无Root Hook PC微信小程序源码(Electron+Chromium)
1. 这不是“破解”,而是一次对微信小程序运行机制的逆向观察 你有没有试过,在PC版微信里点开一个小程序,想看看它背后是怎么写的?比如某个电商小程序的优惠券逻辑、某个工具类小程序的数据渲染方式,甚至只是单纯好奇—…...

第2章 谁在危险中——被AI替代的五类程序员
第2章 谁在危险中——被AI替代的五类程序员 核心问题:哪些程序员最容易被AI替代?背后的原因是什么? 2.1 问题定义:一场正在发生的结构性塌陷 2.1.1 数据不会说谎 2026年1月12日,Ravio发布了一份让整个科技圈沉默的报告:过去一年,初级开发者岗位招聘量暴跌73%。 不是…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...