FlinkAPI开发之窗口(Window)
案例用到的测试数据请参考文章:
Flink自定义Source模拟数据流
原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048
窗口的概念
Flink是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。

注意:Flink中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。另外,这里我们认为到达窗口结束时间时,窗口就触发计算并关闭,事实上“触发计算”和“窗口关闭”两个行为也可以分开,这部分内容我们会在后面详述。
窗口的分类
我们在上一节举的例子,其实是最为简单的一种时间窗口。在Flink中,窗口的应用非常灵活,我们可以使用各种不同类型的窗口来实现需求。接下来我们就从不同的角度,对Flink中内置的窗口做一个分类说明。
按照驱动类型分类
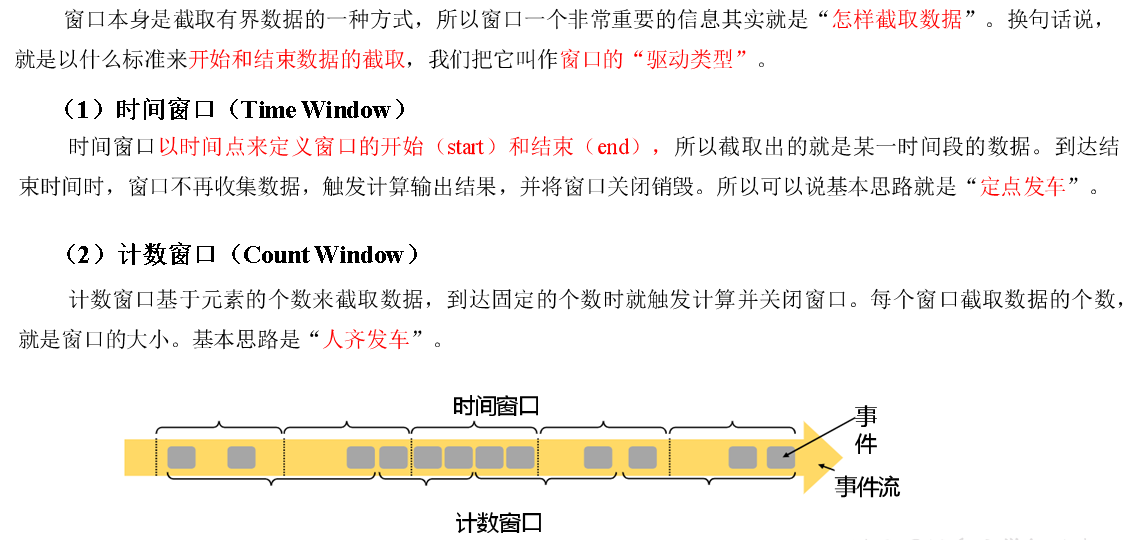
按照窗口分配数据的规则分类
根据分配数据的规则,窗口的具体实现可以分为4类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)。
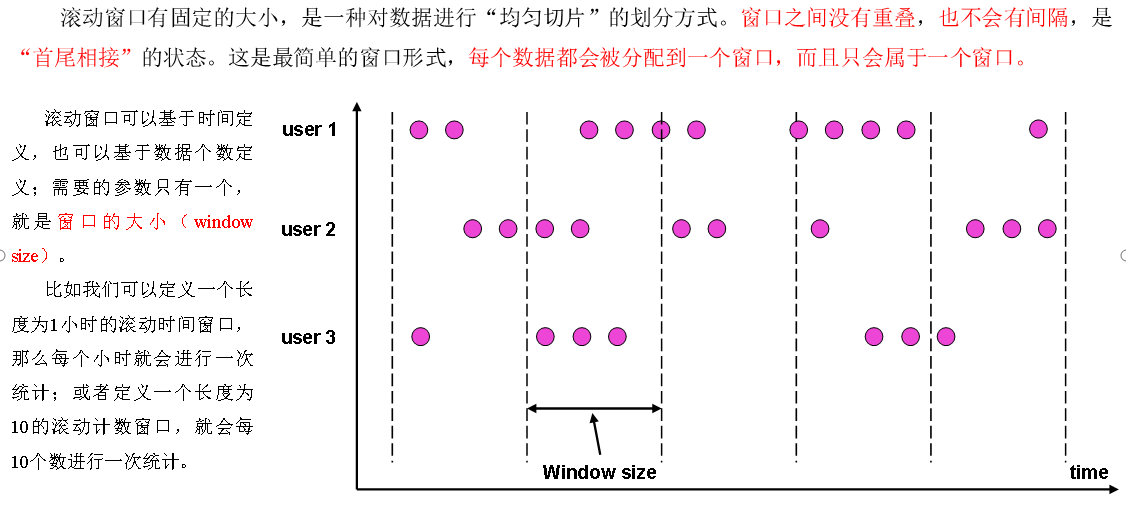
滚动窗口
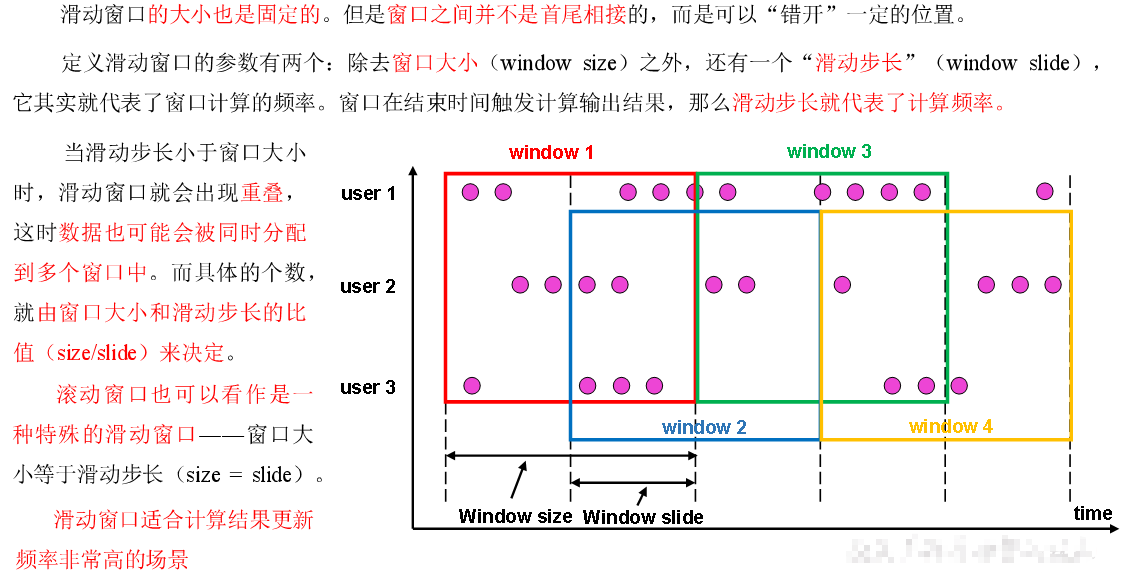
滑动窗口
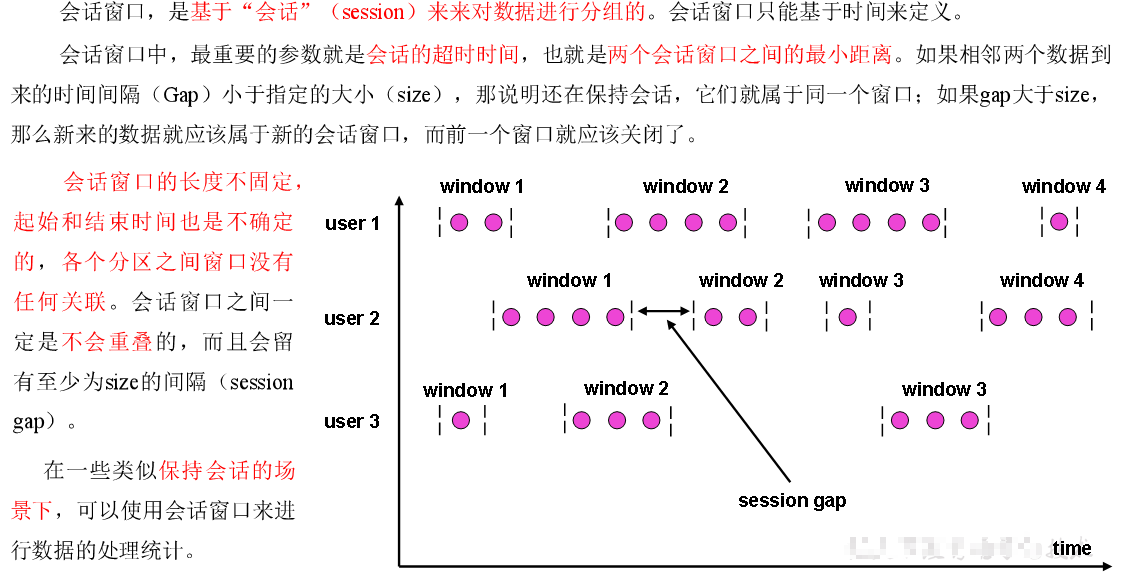
会话窗口
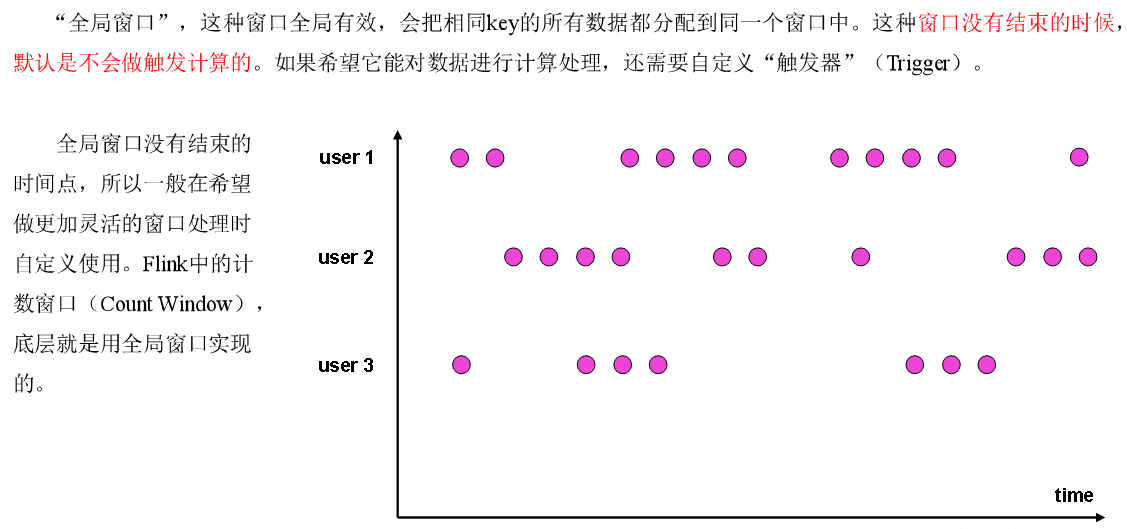
全局窗口
窗口API概览
按键分区(Keyed)和非按键分区(Non-Keyed)
在定义窗口操作之前,首先需要确定,到底是基于按键分区(Keyed)的数据流KeyedStream来开窗,还是直接在没有按键分区的DataStream上开窗。也就是说,在调用窗口算子之前,是否有keyBy操作。
按键分区窗口(Keyed Windows)
经过按键分区keyBy操作后,数据流会按照key被分为多条逻辑流(logical streams),这就是KeyedStream。基于KeyedStream进行窗口操作时,窗口计算会在多个并行子任务上同时执行。相同key的数据会被发送到同一个并行子任务,而窗口操作会基于每个key进行单独的处理。所以可以认为,每个key上都定义了一组窗口,各自独立地进行统计计算。
在代码实现上,我们需要先对DataStream调用.keyBy()进行按键分区,然后再调用.window()定义窗口。
stream.keyBy(...).window(...)
非按键分区(Non-Keyed Windows)
如果没有进行keyBy,那么原始的DataStream就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了1。
在代码中,直接基于DataStream调用.windowAll()定义窗口。
stream.windowAll(...)
注意:对于非按键分区的窗口操作,手动调大窗口算子的并行度也是无效的,windowAll本身就是一个非并行的操作。
代码中窗口API的调用
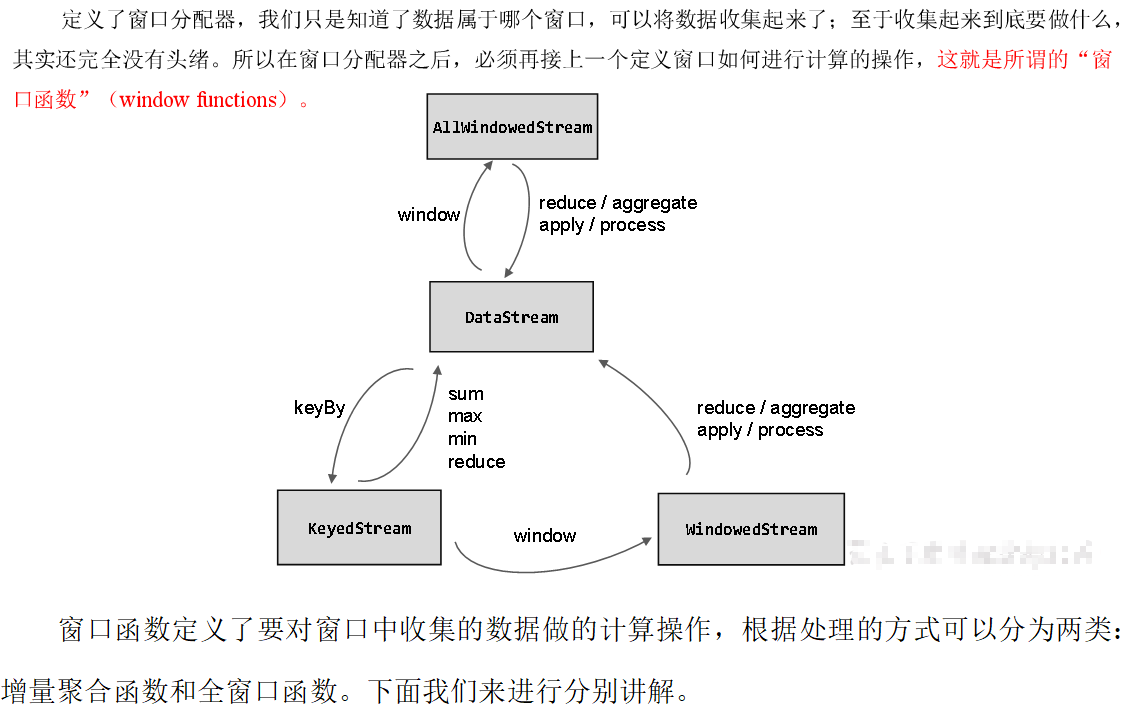
窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)。
stream.keyBy(<key selector>).window(<window assigner>).aggregate(<window function>)
其中.window()方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的.aggregate()方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。窗口分配器有各种形式,而窗口函数的调用方法也不只.aggregate()一种
窗口分配器
定义窗口分配器(Window Assigners)是构建窗口算子的第一步,它的作用就是定义数据应该被“分配”到哪个窗口。所以可以说,窗口分配器其实就是在指定窗口的类型。
窗口分配器最通用的定义方式,就是调用.window()方法。这个方法需要传入一个WindowAssigner作为参数,返回WindowedStream。如果是非按键分区窗口,那么直接调用.windowAll()方法,同样传入一个WindowAssigner,返回的是AllWindowedStream。
窗口按照驱动类型可以分成时间窗口和计数窗口,而按照具体的分配规则,又有滚动窗口、滑动窗口、会话窗口、全局窗口四种。除去需要自定义的全局窗口外,其他常用的类型Flink中都给出了内置的分配器实现,我们可以方便地调用实现各种需求。
时间窗口
时间窗口是最常用的窗口类型,又可以细分为滚动、滑动和会话三种。
滚动处理时间窗口
窗口分配器由类TumblingProcessingTimeWindows提供,需要调用它的静态方法.of()。
stream.keyBy(...).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).aggregate(...)
这里.of()方法需要传入一个Time类型的参数size,表示滚动窗口的大小,我们这里创建了一个长度为5秒的滚动窗口。
另外,.of()还有一个重载方法,可以传入两个Time类型的参数:size和offset。第一个参数当然还是窗口大小,第二个参数则表示窗口起始点的偏移量。
滑动处理时间窗口
窗口分配器由类SlidingProcessingTimeWindows提供,同样需要调用它的静态方法.of()。
stream.keyBy(...).window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5))).aggregate(...)
这里.of()方法需要传入两个Time类型的参数:size和slide,前者表示滑动窗口的大小,后者表示滑动窗口的滑动步长。我们这里创建了一个长度为10秒、滑动步长为5秒的滑动窗口。
滑动窗口同样可以追加第三个参数,用于指定窗口起始点的偏移量,用法与滚动窗口完全一致。
处理时间会话窗口
窗口分配器由类ProcessingTimeSessionWindows提供,需要调用它的静态方法.withGap()或者.withDynamicGap()。
stream.keyBy(...).window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))).aggregate(...)
这里.withGap()方法需要传入一个Time类型的参数size,表示会话的超时时间,也就是最小间隔session gap。我们这里创建了静态会话超时时间为10秒的会话窗口。
另外,还可以调用withDynamicGap()方法定义session gap的动态提取逻辑。
滚动事件时间窗口
窗口分配器由类TumblingEventTimeWindows提供,用法与滚动处理事件窗口完全一致。
stream.keyBy(...).window(TumblingEventTimeWindows.of(Time.seconds(5))).aggregate(...)
滑动事件时间窗口
窗口分配器由类SlidingEventTimeWindows提供,用法与滑动处理事件窗口完全一致。
stream.keyBy(...).window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5))).aggregate(...)
事件时间会话窗口
窗口分配器由类EventTimeSessionWindows提供,用法与处理事件会话窗口完全一致。
stream.keyBy(...).window(EventTimeSessionWindows.withGap(Time.seconds(10))).aggregate(...)
计数窗口
计数窗口概念非常简单,本身底层是基于全局窗口(Global Window)实现的。Flink为我们提供了非常方便的接口:直接调用.countWindow()方法。根据分配规则的不同,又可以分为滚动计数窗口和滑动计数窗口两类,下面我们就来看它们的具体实现。
滚动计数窗口
滚动计数窗口只需要传入一个长整型的参数size,表示窗口的大小。
stream.keyBy(...).countWindow(10)
我们定义了一个长度为10的滚动计数窗口,当窗口中元素数量达到10的时候,就会触发计算执行并关闭窗口。
滑动计数窗口
与滚动计数窗口类似,不过需要在.countWindow()调用时传入两个参数:size和slide,前者表示窗口大小,后者表示滑动步长。
stream.keyBy(...).countWindow(10,3)
我们定义了一个长度为10、滑动步长为3的滑动计数窗口。每个窗口统计10个数据,每隔3个数据就统计输出一次结果。
全局窗口
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调用.window(),分配器由GlobalWindows类提供。
stream.keyBy(...).window(GlobalWindows.create());
需要注意使用全局窗口,必须自行定义触发器才能实现窗口计算,否则起不到任何作用。
窗口函数
增量聚合函数(ReduceFunction / AggregateFunction)
窗口将数据收集起来,最基本的处理操作当然就是进行聚合。我们可以每来一个数据就在之前结果上聚合一次,这就是“增量聚合”。
典型的增量聚合函数有两个:ReduceFunction和AggregateFunction。
归约函数(ReduceFunction)
代码示例:
package com.zxl.Windows;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;public class WindowAggregateAndProcessDemo {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/9 根据商品ID分区KeyedStream<Orders, Integer> keyedStream = ordersDataStreamSource.keyBy(orders -> orders.getProduct_id());// TODO: 2024/1/9 设置滚动事件时间窗口WindowedStream<Orders, Integer, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));// TODO: 2024/1/9 调用聚合函数DataStream<Orders> reduce = windowedStream.reduce(new ReduceFunction<Orders>() {@Overridepublic Orders reduce(Orders orders, Orders t1) throws Exception {Orders orders1 = new Orders(t1.getOrder_id(), t1.getUser_id(), t1.getOrder_date(), orders.getOrder_amount() + t1.getOrder_amount(), t1.getProduct_id(), t1.getOrder_num());return orders1;}});ordersDataStreamSource.print("订单数据");reduce.print("聚合后的数据");environment.execute();}
}


聚合函数(AggregateFunction)
ReduceFunction可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。
Flink Window API中的aggregate就突破了这个限制,可以定义更加灵活的窗口聚合操作。这个方法需要传入一个AggregateFunction的实现类作为参数。
AggregateFunction可以看作是ReduceFunction的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。输入类型IN就是输入流中元素的数据类型;累加器类型ACC则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类型了。
接口中有四个方法:
createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
add():将输入的元素添加到累加器中。
getResult():从累加器中提取聚合的输出结果。
merge():合并两个累加器,并将合并后的状态作为一个累加器返回。
所以可以看到,AggregateFunction的工作原理是:首先调用createAccumulator()为任务初始化一个状态(累加器);而后每来一个数据就调用一次add()方法,对数据进行聚合,得到的结果保存在状态中;等到了窗口需要输出时,再调用getResult()方法得到计算结果。很明显,与ReduceFunction相同,AggregateFunction也是增量式的聚合;而由于输入、中间状态、输出的类型可以不同,使得应用更加灵活方便。
代码实现如下:
package com.zxl.Windows;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import scala.Tuple2;public class WindowAggregateDemo {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/9 根据商品ID分区KeyedStream<Orders, Integer> keyedStream = ordersDataStreamSource.keyBy(orders -> orders.getProduct_id());// TODO: 2024/1/9 设置滚动事件时间窗口WindowedStream<Orders, Integer, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));// TODO: 2024/1/9 调用聚合函数 输入类型(IN)、累加器类型(ACC)和输出类型(OUT)DataStream<Tuple2<String,Integer>> aggregate = windowedStream.aggregate(new AggregateFunction<Orders, Integer, Tuple2<String,Integer>>() {@Overridepublic Integer createAccumulator() {return 0;}@Overridepublic Integer add(Orders orders, Integer integer) {return orders.getOrder_amount() + integer;}@Overridepublic Tuple2 getResult(Integer integer) {return new Tuple2("总销售额为", integer);}@Overridepublic Integer merge(Integer integer, Integer acc1) {return integer + acc1;}});ordersDataStreamSource.print("订单数据");aggregate.print("累加结果");environment.execute();}
}

另外,Flink也为窗口的聚合提供了一系列预定义的简单聚合方法,可以直接基于WindowedStream调用。主要包括.sum()/max()/maxBy()/min()/minBy(),与KeyedStream的简单聚合非常相似。它们的底层,其实都是通过AggregateFunction来实现的。
全窗口函数(full window functions)
有些场景下,我们要做的计算必须基于全部的数据才有效,这时做增量聚合就没什么意义了;另外,输出的结果有可能要包含上下文中的一些信息(比如窗口的起始时间),这是增量聚合函数做不到的。
所以,我们还需要有更丰富的窗口计算方式。窗口操作中的另一大类就是全窗口函数。与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
在Flink中,全窗口函数也有两种:WindowFunction和ProcessWindowFunction。
窗口函数(WindowFunction)
WindowFunction字面上就是“窗口函数”,它其实是老版本的通用窗口函数接口。我们可以基于WindowedStream调用.apply()方法,传入一个WindowFunction的实现类。
stream.keyBy(<key selector>).window(<window assigner>).apply(new MyWindowFunction());
这个类中可以获取到包含窗口所有数据的可迭代集合(Iterable),还可以拿到窗口(Window)本身的信息。
不过WindowFunction能提供的上下文信息较少,也没有更高级的功能。事实上,它的作用可以被ProcessWindowFunction全覆盖,所以之后可能会逐渐弃用。
处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction是Window API中最底层的通用窗口函数接口。之所以说它“最底层”,是因为除了可以拿到窗口中的所有数据之外,ProcessWindowFunction还可以获取到一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得ProcessWindowFunction更加灵活、功能更加丰富,其实就是一个增强版的WindowFunction。
事实上,ProcessWindowFunction是Flink底层API——处理函数(process function)中的一员。
package com.zxl.Windows;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
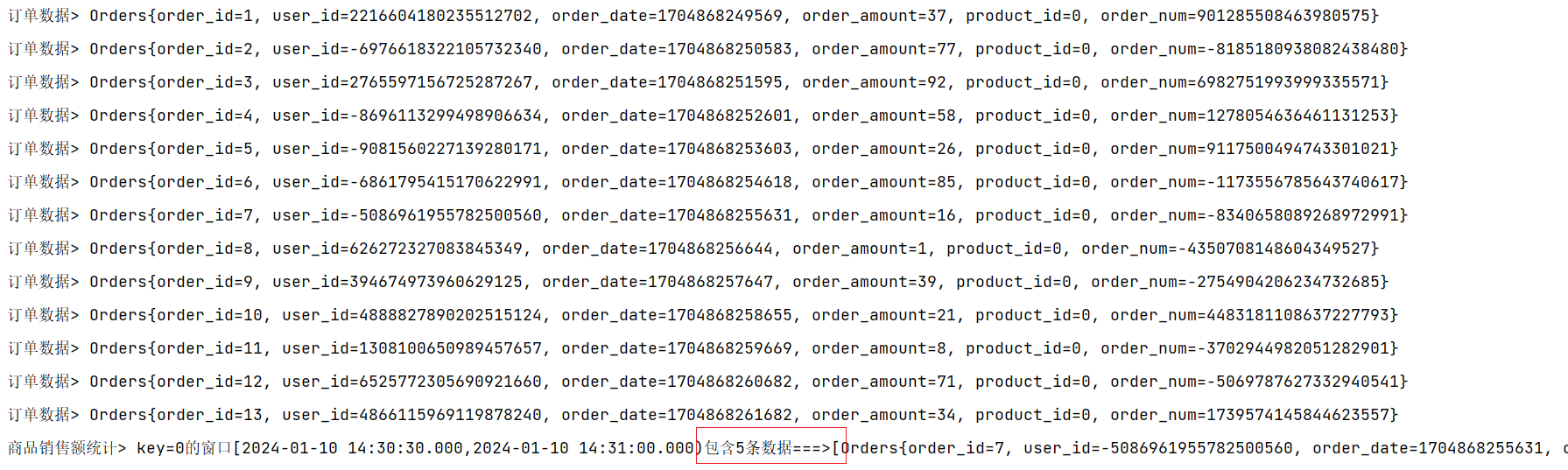
import org.apache.flink.util.Collector;public class WindowAggregateDemo {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/9 根据商品ID分区KeyedStream<Orders, Integer> keyedStream = ordersDataStreamSource.keyBy(orders -> orders.getProduct_id());// TODO: 2024/1/9 设置滚动事件时间窗口WindowedStream<Orders, Integer, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));// TODO: 2024/1/9 调用聚合函数DataStream<Object> process = windowedStream.process(new ProcessWindowFunction<Orders, Object, Integer, TimeWindow>() {// TODO: 2024/1/9 参数说明:分组key值,窗口计时器,按照key分组后的数据,收集器 @Overridepublic void process(Integer integer, ProcessWindowFunction<Orders, Object, Integer, TimeWindow>.Context context, Iterable<Orders> elements, Collector<Object> collector) throws Exception {// TODO: 2024/1/9 窗口内同一个key包含的数据条数 long count = elements.spliterator().estimateSize();// TODO: 2024/1/9 窗口的开始时间 long windowStartTs = context.window().getStart();// TODO: 2024/1/9 窗口的结束时间 long windowEndTs = context.window().getEnd();String windowStart = DateFormatUtils.format(windowStartTs, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(windowEndTs, "yyyy-MM-dd HH:mm:ss.SSS");// TODO: 2024/1/9 输出收集器 collector.collect("key=" + integer + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());}});process.print();environment.execute();}
}
运行结果:
key=1的窗口[2024-01-09 13:50:50.000,2024-01-09 13:50:55.000)包含1条数据===>[Orders{order_id=1, user_id=2121915138602483235, order_date=1704779453159, order_amount=98, product_id=1, order_num=-2382721988645133419}]
key=0的窗口[2024-01-09 13:50:50.000,2024-01-09 13:50:55.000)包含1条数据===>[Orders{order_id=2, user_id=2482049739997888089, order_date=1704779454164, order_amount=30, product_id=0, order_num=2841964982779121029}]
key=0的窗口[2024-01-09 13:50:55.000,2024-01-09 13:51:00.000)包含1条数据===>[Orders{order_id=3, user_id=1566873382166007709, order_date=1704779455179, order_amount=93, product_id=0, order_num=-2599995117944339091}]
key=2的窗口[2024-01-09 13:50:55.000,2024-01-09 13:51:00.000)包含2条数据===>[Orders{order_id=5, user_id=2939156557521059655, order_date=1704779457190, order_amount=53, product_id=2, order_num=7558610452657634753}, Orders{order_id=7, user_id=3207606619087344211, order_date=1704779459207, order_amount=68, product_id=2, order_num=2916017858049892473}]
key=1的窗口[2024-01-09 13:50:55.000,2024-01-09 13:51:00.000)包含2条数据===>[Orders{order_id=4, user_id=-2913400211728912094, order_date=1704779456181, order_amount=53, product_id=1, order_num=-8211762615419411134}, Orders{order_id=6, user_id=-4625564783991851952, order_date=1704779458198, order_amount=38, product_id=1, order_num=-9192672975024206743}]
key=2的窗口[2024-01-09 13:51:00.000,2024-01-09 13:51:05.000)包含3条数据===>[Orders{order_id=8, user_id=-7783175175017253666, order_date=1704779460220, order_amount=30, product_id=2, order_num=2014420473146031881}, Orders{order_id=11, user_id=3996488467291302343, order_date=1704779463255, order_amount=64, product_id=2, order_num=4251423100237069659}, Orders{order_id=12, user_id=-4442107151361004758, order_date=1704779464261, order_amount=47, product_id=2, order_num=-8911659840331004860}]
key=1的窗口[2024-01-09 13:51:00.000,2024-01-09 13:51:05.000)包含1条数据===>[Orders{order_id=10, user_id=-5659886496986843749, order_date=1704779462243, order_amount=69, product_id=1, order_num=6495063122490543901}]
key=0的窗口[2024-01-09 13:51:00.000,2024-01-09 13:51:05.000)包含1条数据===>[Orders{order_id=9, user_id=3106531123134616644, order_date=1704779461234, order_amount=56, product_id=0, order_num=-7056086034933246593}]
key=0的窗口[2024-01-09 13:51:05.000,2024-01-09 13:51:10.000)包含1条数据===>[Orders{order_id=13, user_id=3095515769034599633, order_date=1704779465271, order_amount=5, product_id=0, order_num=-2769186321280716014}]
key=2的窗口[2024-01-09 13:51:05.000,2024-01-09 13:51:10.000)包含1条数据===>[Orders{order_id=17, user_id=-4750354619891992805, order_date=1704779469301, order_amount=81, product_id=2, order_num=4522156848590983285}]
也可以这样写:
// TODO: 2024/1/9 调用聚合函数DataStream<Object> process = windowedStream.process(new ProcessWindowFunction<Orders, Object, Integer, TimeWindow>() {@Overridepublic void process(Integer integer, ProcessWindowFunction<Orders, Object, Integer, TimeWindow>.Context context, Iterable<Orders> elements, Collector<Object> collector) throws Exception {Integer sum=0;for (Orders element : elements) {sum=sum+element.getOrder_amount();}collector.collect("商品ID为"+integer+"的总销售额为"+sum);}});ordersDataStreamSource.print("订单数据");process.print("商品销售额统计");
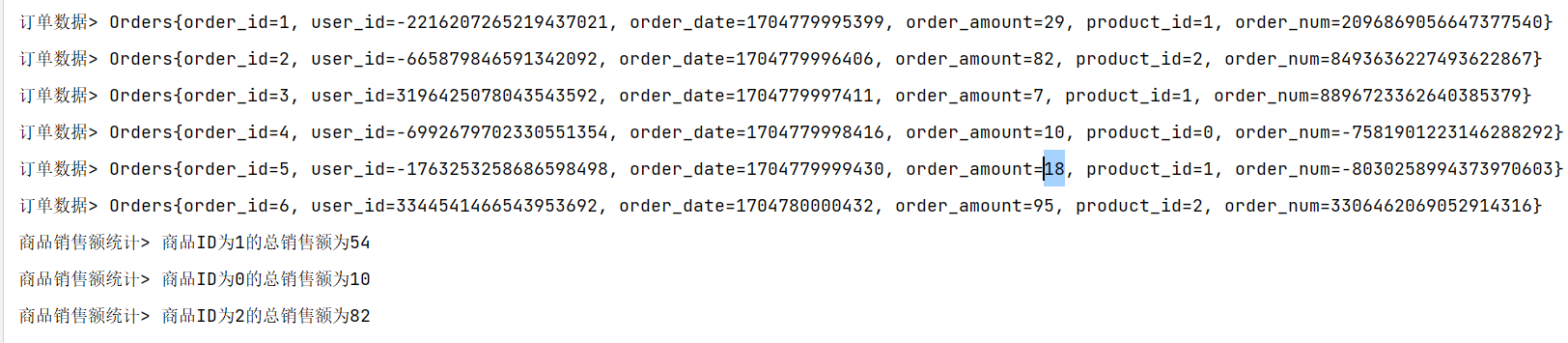
增量聚合和全窗口函数的结合使用
在实际应用中,我们往往希望兼具这两者的优点,把它们结合在一起使用。Flink的Window API就给我们实现了这样的用法。
我们之前在调用WindowedStream的.reduce()和.aggregate()方法时,只是简单地直接传入了一个ReduceFunction或AggregateFunction进行增量聚合。除此之外,其实还可以传入第二个参数:一个全窗口函数,可以是WindowFunction或者ProcessWindowFunction。
// ReduceFunction与WindowFunction结合
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction,WindowFunction<T,R,K,W> function) // ReduceFunction与ProcessWindowFunction结合
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction,ProcessWindowFunction<T,R,K,W> function)
// AggregateFunction与WindowFunction结合
public <ACC,V,R> SingleOutputStreamOperator<R> aggregate(AggregateFunction<T,ACC,V> aggFunction,WindowFunction<V,R,K,W> windowFunction)// AggregateFunction与ProcessWindowFunction结合
public <ACC,V,R> SingleOutputStreamOperator<R> aggregate(AggregateFunction<T,ACC,V> aggFunction,ProcessWindowFunction<V,R,K,W> windowFunction)
这样调用的处理机制是:基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输出结果。需要注意的是,这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当作了Iterable类型的输入。
具体实现代码如下:
package com.zxl.Windows;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;public class WindowAggregateDemo {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/9 根据商品ID分区KeyedStream<Orders, Integer> keyedStream = ordersDataStreamSource.keyBy(orders -> orders.getProduct_id());// TODO: 2024/1/9 设置滚动事件时间窗口WindowedStream<Orders, Integer, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));// TODO: 2024/1/9 调用增量聚合和全量聚合DataStream<Object> outputStreamOperator = windowedStream.aggregate(// TODO: 2024/1/9 增量聚合new AggregateFunction<Orders, Integer, Integer>() {@Overridepublic Integer createAccumulator() {return 0;}@Overridepublic Integer add(Orders orders, Integer o) {return orders.getOrder_amount() + o;}@Overridepublic Integer getResult(Integer o) {return o;}@Overridepublic Integer merge(Integer o, Integer acc1) {return o + acc1;}},// TODO: 2024/1/9 全量聚合new ProcessWindowFunction<Integer, Object, Integer, TimeWindow>() {// TODO: 2024/1/9 参数说明:分组key值,窗口计时器,按照key分组后的数据,收集器@Overridepublic void process(Integer integer, ProcessWindowFunction<Integer, Object, Integer, TimeWindow>.Context context, Iterable<Integer> elements, Collector<Object> collector) throws Exception {// TODO: 2024/1/9 窗口内同一个key包含的数据条数long count = elements.spliterator().estimateSize();// TODO: 2024/1/9 窗口的开始时间long windowStartTs = context.window().getStart();// TODO: 2024/1/9 窗口的结束时间long windowEndTs = context.window().getEnd();String windowStart = DateFormatUtils.format(windowStartTs, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(windowEndTs, "yyyy-MM-dd HH:mm:ss.SSS");// TODO: 2024/1/9 输出收集器collector.collect("key=" + integer + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());}});ordersDataStreamSource.print("聚合前的数据");outputStreamOperator.print("分组聚合后的数据");environment.execute();}
}
可以看到结果是统计的值,而不是归并后的数据。

其他API
对于一个窗口算子而言,窗口分配器和窗口函数是必不可少的。除此之外,Flink还提供了其他一些可选的API,让我们可以更加灵活地控制窗口行为。
触发器(Trigger)
触发器主要是用来控制窗口什么时候触发计算。所谓的“触发计算”,本质上就是执行窗口函数,所以可以认为是计算得到结果并输出的过程。
基于WindowedStream调用.trigger()方法,就可以传入一个自定义的窗口触发器(Trigger)。
stream.keyBy(...).window(...).trigger(new Trigger())
触发器抽象类具有四种抽象方法,这些方法允许触发器对不同事件做出反应:
onElement:在窗口中每进入一条数据的时候调用一次
onProcessingTime:根据窗口中最新的ProcessingTime判断是否满足定时器的条件,如果满足,将触发ProcessingTime定时器,并执行定时器的回调函数,即执行onProcessingTime方法里的逻辑
onEventTime:根据窗口中最新的EventTim判断是否满足定时器的条件,如果满足,将触发EventTime定时器,并执行定时器的回调函数,即onEventTime方法里的逻辑
clear:在窗口清除的时候调用
前三个方法返回TriggerResult枚举类型,其包含四个枚举值:
CONTINUE:表示对窗口不执行任何操作。即不触发窗口计算,也不删除元素。
FIRE:触发窗口计算,但是保留窗口元素
PURGE:不触发窗口计算,丢弃窗口,并且删除窗口的元素。
FIRE_AND_PURGE:触发窗口计算,输出结果,然后将窗口中的数据和窗口进行清除。
创建触发器
package com.zxl.Functions;import com.zxl.bean.Orders;
import org.apache.flink.streaming.api.windowing.triggers.Trigger;
import org.apache.flink.streaming.api.windowing.triggers.TriggerResult;
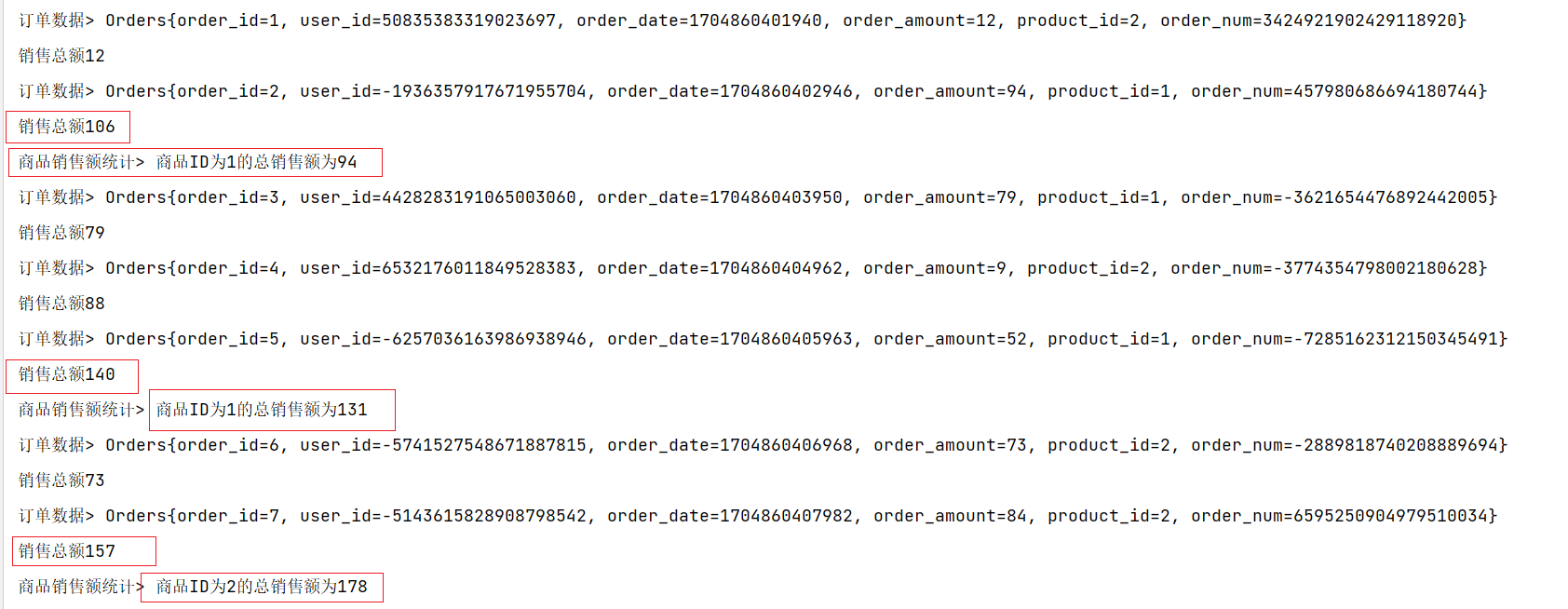
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;public class TriggerDemo extends Trigger<Orders, TimeWindow> {// TODO: 2024/1/10 定义销售总额为0;Integer sum = 0;@Overridepublic TriggerResult onElement(Orders orders, long l, TimeWindow window, TriggerContext ctx) throws Exception {// TODO: 2024/1/10 累加销售额,超过100元触发计算sum += orders.getOrder_amount();System.out.println("销售总额" + sum);if (sum >= 100) {sum = 0;return TriggerResult.FIRE_AND_PURGE;} else {ctx.registerProcessingTimeTimer(window.maxTimestamp());return TriggerResult.CONTINUE;}}@Overridepublic TriggerResult onProcessingTime(long l, TimeWindow timeWindow, TriggerContext triggerContext) throws Exception {return TriggerResult.FIRE;}@Overridepublic TriggerResult onEventTime(long l, TimeWindow timeWindow, TriggerContext triggerContext) throws Exception {return TriggerResult.CONTINUE;}@Overridepublic void clear(TimeWindow window, TriggerContext ctx) throws Exception {ctx.deleteProcessingTimeTimer(window.maxTimestamp());}
}
package com.zxl.Windows;import com.zxl.Functions.TriggerDemo;
import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;public class WindowsTriggerDemo {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/9 根据商品ID分区KeyedStream<Orders, Integer> keyedStream = ordersDataStreamSource.keyBy(Orders::getProduct_id);// TODO: 2024/1/9 设置滚动事件时间窗口WindowedStream<Orders, Integer, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));WindowedStream<Orders, Integer, TimeWindow> trigger = windowedStream.trigger(new TriggerDemo());DataStream<Object> process = trigger.process(new ProcessWindowFunction<Orders, Object, Integer, TimeWindow>() {@Overridepublic void process(Integer integer, ProcessWindowFunction<Orders, Object, Integer, TimeWindow>.Context context, Iterable<Orders> elements, Collector<Object> collector) throws Exception {Integer sum=0;for (Orders element : elements) {sum=sum+element.getOrder_amount();}collector.collect("商品ID为"+integer+"的总销售额为"+sum);}});ordersDataStreamSource.print("订单数据");process.print("商品销售额统计");environment.execute();}
}
销售额满100触发计算
移除器(Evictor)
移除器主要用来定义移除某些数据的逻辑。基于WindowedStream调用.evictor()方法,就可以传入一个自定义的移除器(Evictor)。Evictor是一个接口,不同的窗口类型都有各自预实现的移除器。
stream.keyBy(...).window(...).evictor(new MyEvictor())
Flink 内置有三个 evictor:
CountEvictor: 仅记录用户指定数量的元素,一旦窗口中的元素超过这个数量,多余的元素会从窗口缓存的开头移除;
DeltaEvictor: 接收 DeltaFunction 和 threshold 参数,计算最后一个元素与窗口缓存中所有元素的差值, 并移除差值大于或等于 threshold 的元素。
TimeEvictor: 接收 interval 参数,以毫秒表示。 它会找到窗口中元素的最大 timestamp max_ts 并移除比 max_ts - interval 小的所有元素。
CountEvictor
CountEvictor 用于在窗口中保留用户指定数量的元素。如果窗口中的元素超过用户指定的阈值,会从窗口头部开始删除剩余元素。
package com.zxl.Windows;import com.zxl.Functions.EvictorDemo; import com.zxl.Functions.TriggerDemo; import com.zxl.bean.Orders; import com.zxl.datas.OrdersData; import org.apache.commons.lang3.time.DateFormatUtils; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.WindowedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.evictors.CountEvictor; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector;public class WindowsEvictorDemo {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/9 根据商品ID分区KeyedStream<Orders, Integer> keyedStream = ordersDataStreamSource.keyBy(Orders::getProduct_id);// TODO: 2024/1/9 设置滚动事件时间窗口WindowedStream<Orders, Integer, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));WindowedStream<Orders, Integer, TimeWindow> trigger = windowedStream.evictor(CountEvictor.of(2));DataStream<Object> process = trigger.process(new ProcessWindowFunction<Orders, Object, Integer, TimeWindow>() {@Overridepublic void process(Integer integer, ProcessWindowFunction<Orders, Object, Integer, TimeWindow>.Context context, Iterable<Orders> elements, Collector<Object> collector) throws Exception {// TODO: 2024/1/9 窗口内同一个key包含的数据条数long count = elements.spliterator().estimateSize();// TODO: 2024/1/9 窗口的开始时间long windowStartTs = context.window().getStart();// TODO: 2024/1/9 窗口的结束时间long windowEndTs = context.window().getEnd();String windowStart = DateFormatUtils.format(windowStartTs, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(windowEndTs, "yyyy-MM-dd HH:mm:ss.SSS");// TODO: 2024/1/9 输出收集器collector.collect("key=" + integer + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());}});ordersDataStreamSource.print("订单数据");process.print("商品销售额统计");environment.execute();} }
运行结果可以看到剔除了每个key的值只保留最后面的2个元素
订单数据> Orders{order_id=1, user_id=-1718527784045868614, order_date=1704863683145, order_amount=48, product_id=0, order_num=-6369094025414748042}
订单数据> Orders{order_id=2, user_id=1893667416148355553, order_date=1704863684155, order_amount=66, product_id=1, order_num=7668054511610210829}
订单数据> Orders{order_id=3, user_id=6270758312821279307, order_date=1704863685156, order_amount=24, product_id=1, order_num=-738706605235934490}
订单数据> Orders{order_id=4, user_id=-4650292127676605788, order_date=1704863686170, order_amount=52, product_id=2, order_num=4416123283706746554}
订单数据> Orders{order_id=5, user_id=8377505245371224820, order_date=1704863687184, order_amount=20, product_id=1, order_num=9054812173240955137}
订单数据> Orders{order_id=6, user_id=-1804262787948928277, order_date=1704863688195, order_amount=39, product_id=2, order_num=6974915230885280524}
订单数据> Orders{order_id=7, user_id=2755727732632294824, order_date=1704863689209, order_amount=29, product_id=1, order_num=5422281260531357789}
订单数据> Orders{order_id=8, user_id=-2106336677386318216, order_date=1704863690209, order_amount=2, product_id=2, order_num=-5138638189645891765}
商品销售额统计> key=0的窗口[2024-01-10 13:14:40.000,2024-01-10 13:14:50.000)包含1条数据===>[Orders{order_id=1, user_id=-1718527784045868614, order_date=1704863683145, order_amount=48, product_id=0, order_num=-6369094025414748042}]
商品销售额统计> key=2的窗口[2024-01-10 13:14:40.000,2024-01-10 13:14:50.000)包含2条数据===>[Orders{order_id=4, user_id=-4650292127676605788, order_date=1704863686170, order_amount=52, product_id=2, order_num=4416123283706746554}, Orders{order_id=6, user_id=-1804262787948928277, order_date=1704863688195, order_amount=39, product_id=2, order_num=6974915230885280524}]
商品销售额统计> key=1的窗口[2024-01-10 13:14:40.000,2024-01-10 13:14:50.000)包含2条数据===>[Orders{order_id=5, user_id=8377505245371224820, order_date=1704863687184, order_amount=20, product_id=1, order_num=9054812173240955137}, Orders{order_id=7, user_id=2755727732632294824, order_date=1704863689209, order_amount=29, product_id=1, order_num=5422281260531357789}]
订单数据> Orders{order_id=9, user_id=1263718349205479033, order_date=1704863691215, order_amount=28, product_id=2, order_num=5580559753146164066}
DeltaEvictor
根据用户自定的 DeltaFunction 函数来计算窗口中最后一个元素与其余每个元素之间的差值,如果差值大于等于用户指定的阈值就会删除该元素。
package com.zxl.Windows;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.functions.windowing.delta.DeltaFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.evictors.DeltaEvictor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;public class WindowsEvictorDemo {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/9 根据商品ID分区KeyedStream<Orders, Integer> keyedStream = ordersDataStreamSource.keyBy(Orders::getProduct_id);// TODO: 2024/1/9 设置滚动事件时间窗口WindowedStream<Orders, Integer, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));WindowedStream<Orders, Integer, TimeWindow> trigger = windowedStream.evictor(DeltaEvictor.of(20, new DeltaFunction<Orders>() {@Overridepublic double getDelta(Orders orders, Orders data1) {return orders.getOrder_amount()-data1.getOrder_amount();}}));DataStream<Object> process = trigger.process(new ProcessWindowFunction<Orders, Object, Integer, TimeWindow>() {@Overridepublic void process(Integer integer, ProcessWindowFunction<Orders, Object, Integer, TimeWindow>.Context context, Iterable<Orders> elements, Collector<Object> collector) throws Exception {// TODO: 2024/1/9 窗口内同一个key包含的数据条数long count = elements.spliterator().estimateSize();// TODO: 2024/1/9 窗口的开始时间long windowStartTs = context.window().getStart();// TODO: 2024/1/9 窗口的结束时间long windowEndTs = context.window().getEnd();String windowStart = DateFormatUtils.format(windowStartTs, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(windowEndTs, "yyyy-MM-dd HH:mm:ss.SSS");// TODO: 2024/1/9 输出收集器collector.collect("key=" + integer + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());}});ordersDataStreamSource.print("订单数据");process.print("商品销售额统计");environment.execute();}
}
运行结果可以看出key=0的窗口只保留了销售额为74和61两个数据其他剔除。
订单数据> Orders{order_id=1, user_id=539439441883936825, order_date=1704865045455, order_amount=74, product_id=0, order_num=3206652734135370050}
订单数据> Orders{order_id=2, user_id=49231723398277166, order_date=1704865046465, order_amount=93, product_id=0, order_num=3160015635782687185}
订单数据> Orders{order_id=3, user_id=4323217335297892028, order_date=1704865047479, order_amount=86, product_id=0, order_num=-2693168188390272462}
订单数据> Orders{order_id=4, user_id=9114737657305455261, order_date=1704865048479, order_amount=61, product_id=0, order_num=6661679659763746532}
订单数据> Orders{order_id=5, user_id=-6666866686774977356, order_date=1704865049488, order_amount=87, product_id=1, order_num=-1684352545863963613}
订单数据> Orders{order_id=6, user_id=436130461891163880, order_date=1704865050500, order_amount=12, product_id=1, order_num=-4339619073044213208}
商品销售额统计> key=0的窗口[2024-01-10 13:37:20.000,2024-01-10 13:37:30.000)包含2条数据===>[Orders{order_id=1, user_id=539439441883936825, order_date=1704865045455, order_amount=74, product_id=0, order_num=3206652734135370050}, Orders{order_id=4, user_id=9114737657305455261, order_date=1704865048479, order_amount=61, product_id=0, order_num=6661679659763746532}]
商品销售额统计> key=1的窗口[2024-01-10 13:37:20.000,2024-01-10 13:37:30.000)包含1条数据===>[Orders{order_id=5, user_id=-6666866686774977356, order_date=1704865049488, order_amount=87, product_id=1, order_num=-1684352545863963613}]
订单数据> Orders{order_id=7, user_id=-555269566023654623, order_date=1704865051511, order_amount=80, product_id=2, order_num=-4610465301102922149}
TimeEvictor
以毫秒为单位的时间间隔 windowSize 作为参数,在窗口所有元素中找到最大时间戳 max_ts 并删除所有时间戳小于 max_ts - windowSize 的元素。我们可以理解为只保留最新 windowSize 毫秒内的元素。
package com.zxl.Windows;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.evictors.TimeEvictor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;import java.time.Duration;public class WindowsEvictorDemo {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/7 配置订单数据水位线DataStream<Orders> ordersWater = ordersDataStreamSource.assignTimestampsAndWatermarks(WatermarkStrategy// TODO: 2024/1/7 指定watermark生成:升序的watermark,没有等待时间.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(0)).withTimestampAssigner(new SerializableTimestampAssigner<Orders>() {@Overridepublic long extractTimestamp(Orders orders, long l) {return orders.getOrder_date();}}));// TODO: 2024/1/9 根据商品ID分区KeyedStream<Orders, Integer> keyedStream = ordersWater.keyBy(Orders::getProduct_id);// TODO: 2024/1/9 设置滚动事件时间窗口WindowedStream<Orders, Integer, TimeWindow> windowedStream = keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(30)));WindowedStream<Orders, Integer, TimeWindow> evictor = windowedStream.evictor(TimeEvictor.of(Time.seconds(5)));DataStream<Object> process = evictor.process(new ProcessWindowFunction<Orders, Object, Integer, TimeWindow>() {@Overridepublic void process(Integer integer, ProcessWindowFunction<Orders, Object, Integer, TimeWindow>.Context context, Iterable<Orders> elements, Collector<Object> collector) throws Exception {// TODO: 2024/1/9 窗口内同一个key包含的数据条数long count = elements.spliterator().estimateSize();// TODO: 2024/1/9 窗口的开始时间long windowStartTs = context.window().getStart();// TODO: 2024/1/9 窗口的结束时间long windowEndTs = context.window().getEnd();String windowStart = DateFormatUtils.format(windowStartTs, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(windowEndTs, "yyyy-MM-dd HH:mm:ss.SSS");// TODO: 2024/1/9 输出收集器collector.collect("key=" + integer + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());}});ordersDataStreamSource.print("订单数据");process.print("商品销售额统计");environment.execute();}
}
相关文章:
FlinkAPI开发之窗口(Window)
案例用到的测试数据请参考文章: Flink自定义Source模拟数据流 原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048 窗口的概念 Flink是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。…...
【Unity】Joystick Pack摇杆插件实现锁四向操作
Joystick Pack 简介:一款Unity摇杆插件,非常轻量化 摇杆移动类型:圆形、横向、竖向 摇杆类型: Joystick描述Fixed固定位置Floating浮动操纵杆从用户触碰的地方开始,一直固定到触碰被释放。Dynamic动态操纵…...

29 旋转工具箱
效果演示 实现了一个菜单按钮的动画效果,当鼠标悬停在菜单按钮上时,菜单按钮会旋转315度,菜单按钮旋转的同时,菜单按钮旋转的8个小圆圈也会依次旋转360度,并且每个小圆圈的旋转方向和菜单按钮的旋转方向相反࿰…...
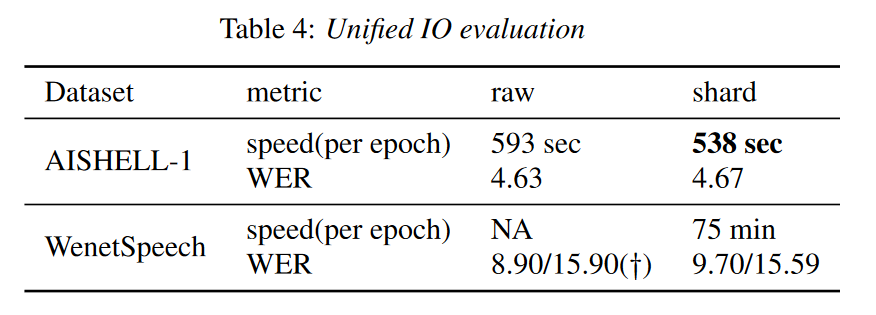
WeNet2.0:提高端到端ASR的生产力
摘要 最近,我们提供了 WeNet [1],这是一个面向生产(工业生产环境需求)的端到端语音识别工具包,在单个模型中,它引入了统一的两次two-pass (U2) 框架和内置运行时(built-in runtime)…...
)
第九部分 使用函数 (四)
目录 一、foreach 函数 二、if 函数 三、call 函数 一、foreach 函数 foreach 函数和别的函数非常的不一样。因为这个函数是用来做循环用的,Makefile 中的 foreach 函数几乎是仿照于 Unix 标准 Shell(/bin/sh)中的 for 语句,或…...
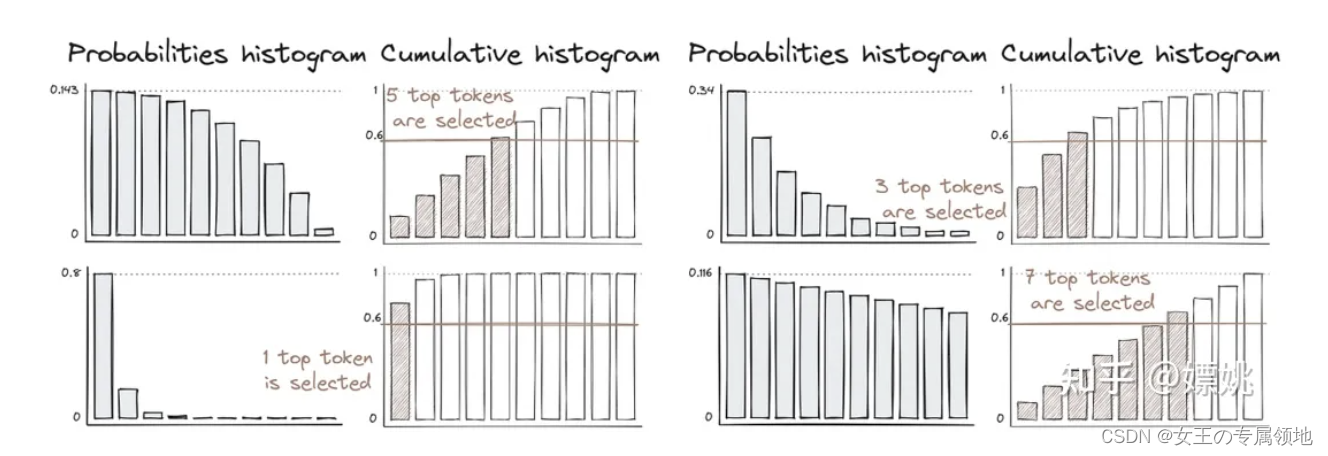
一文读懂「Prompt Engineering」提示词工程
在了解提示过程之前,先了解一下什么是提示prompt,见最后附录部分 一、什么是Prompt Engingering? 提示工程(Prompt Engingering),也被称为上下文提示(In-Context Prompting)&#x…...

微信小程序(一)简单的结构及样式演示
注释很详细,直接上代码 涉及内容: view和text标签的使用类的使用flex布局水平方向上均匀分布子元素垂直居中对齐子元素字体大小文字颜色底部边框的宽和颜色 源码: index.wxml <view class"navs"><text class"active…...

【设计模式】外观模式
前言 1. 单例模式(Singleton Pattern):保证一个类只有一个实例,并提供一个全局的访问点。 2. 工厂模式(Factory Pattern):定义一个创建对象的接口,但由子类决定要实例化的类是哪一…...
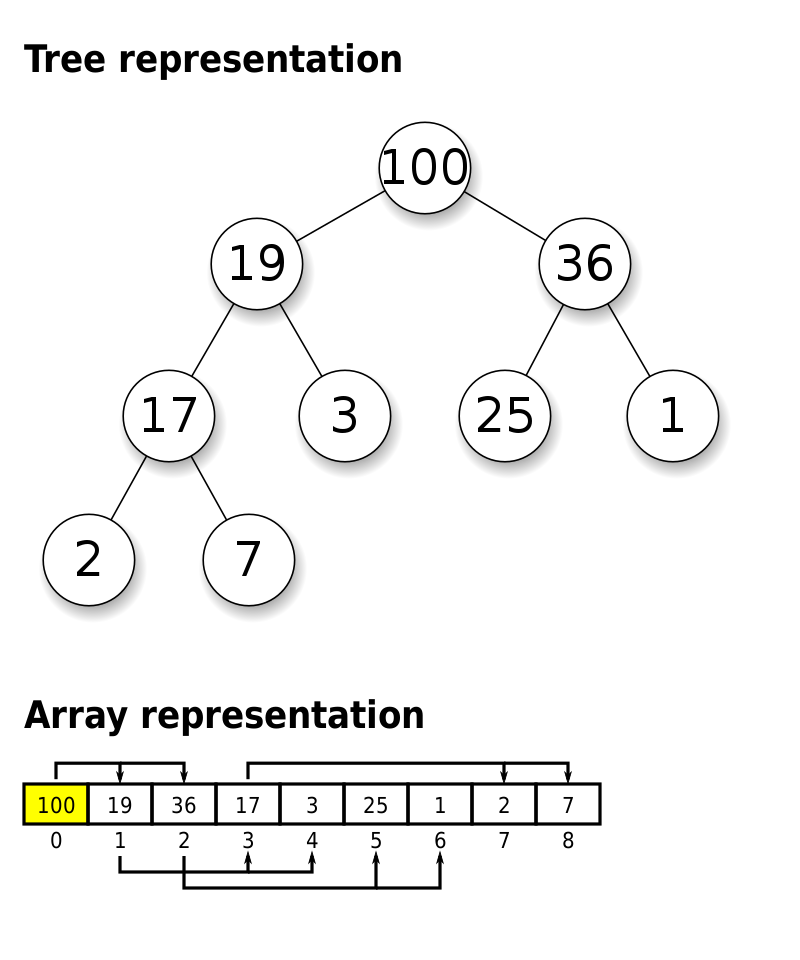
优先级队列(Priority Queue)
文章目录 优先级队列(Priority Queue)实现方式基于数组实现基于堆实现方法实现offer(E value)poll()peek()isEmpty()isFull() 优先级队列的实现细节 优先级队列(Priority Queue) 优先级队列是一种特殊的队列,其中的元素…...
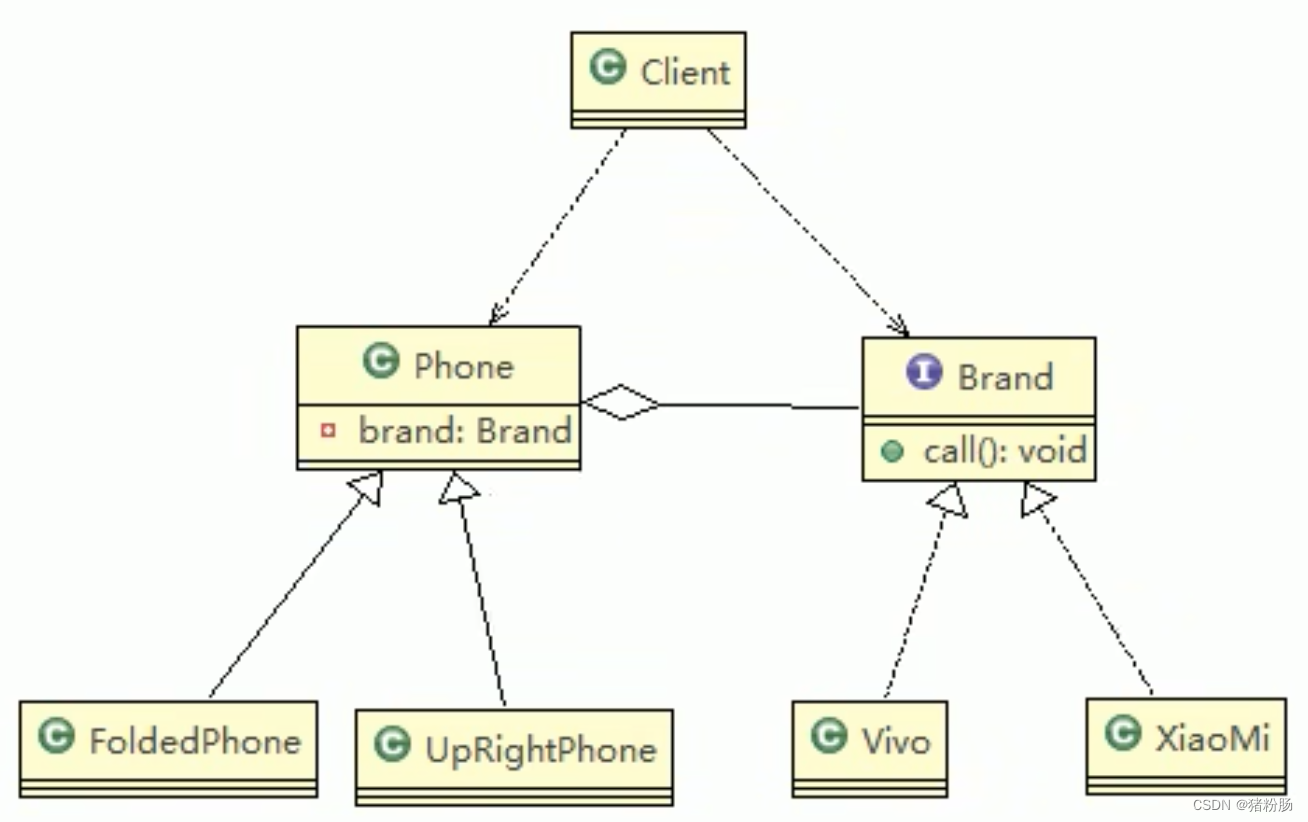
12-桥接模式(Bridge)
意图 将抽象部分与它的实现部分分离,使他们可以独立地变化 个人理解 一句话概括就是只要是在抽象类中聚合了某个接口或者抽象类,就是使用了桥接模式。 抽象类A中聚合了抽象类B(或者接口B),A的子类的方法中在相同的场…...

Zookeeper+Kafka概述
一 Zookeeper 1.1 Zookeeper定义 Zookeeper是一个开源的、分布式的,为分布式框架提供协调服务的Apache项目。 1.2 Zookeeper特点 Zookeeper:一个领导者(leader),多个跟随者(Follower)组成的…...
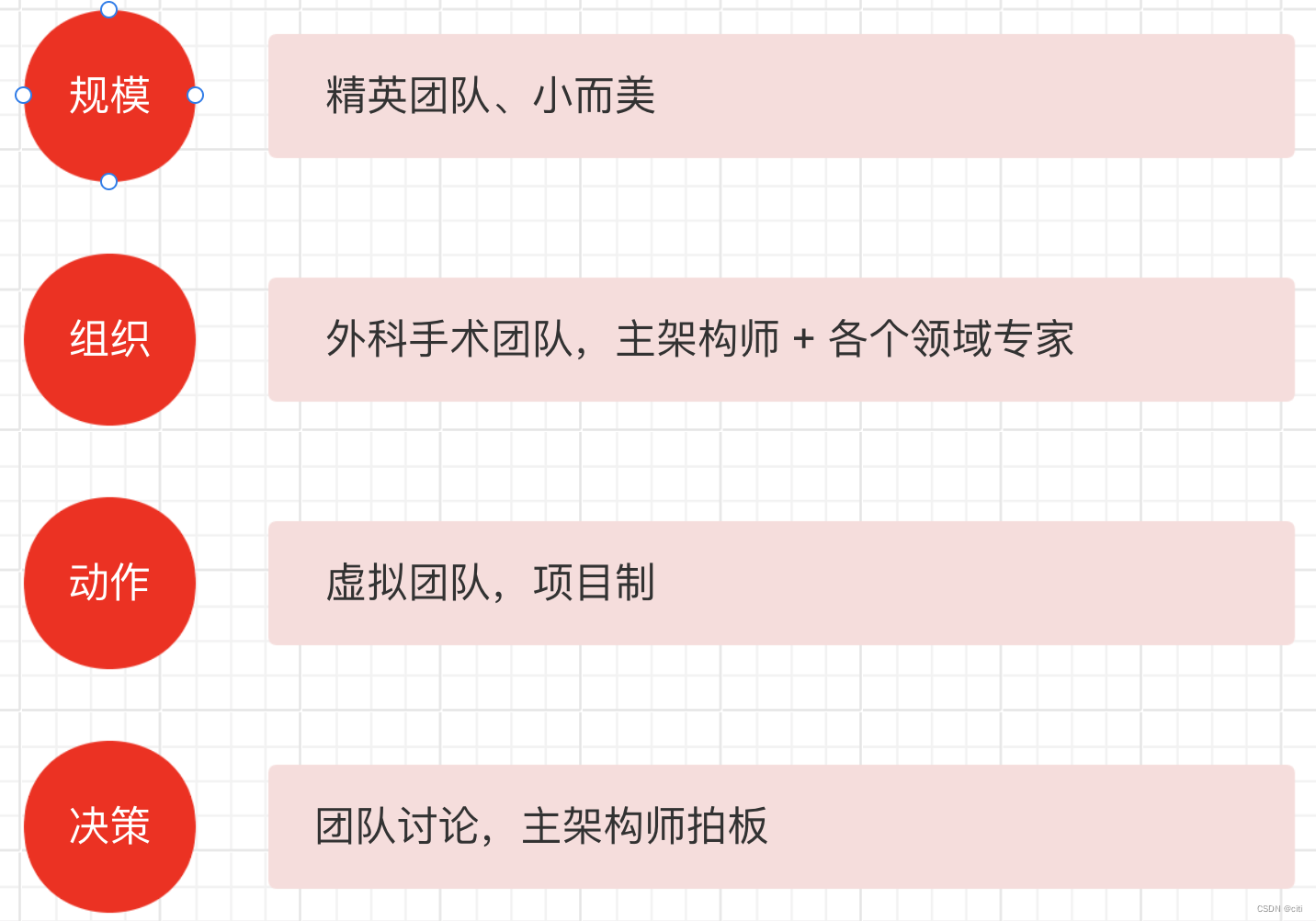
架构师 - 架构师是做什么的 - 学习总结
架构师核心定义 架构师是什么 架构师是业务和技术之间的桥梁 架构师的核心职责是消除不确定性、和降低复杂性 架构设计环 架构师的三个核心能力 架构师的三个关键思维 架构师主要职责 架构设计 Vs 方案设计 架构设计前期 主要任务 澄清不确定性 明确利益干系人的诉求消除冲…...
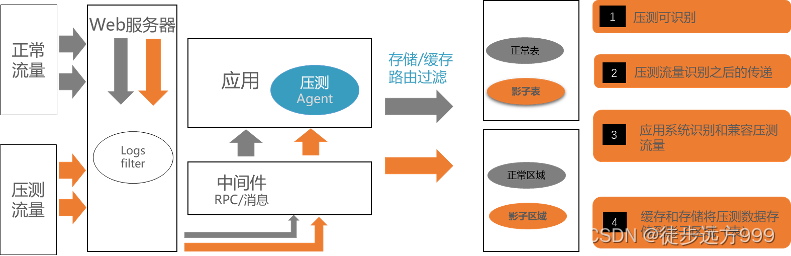
全链路压测方案(一)—方案调研
一、概述 在业务系统中,保证系统稳定至关重要,直接影响线上业务稳定和性能。测试工作作为保证生产质量的最后一关,扮演者重要的角色。全链路压测是一种重要的测试工具和手段。可以解决系统中多环节多节点无法全流程打满流量的痛点问题&a…...

c++关键字const
C中的const是一种常量修饰符。在变量、函数参数和成员函数中使用const可以限制其对数据的修改。 const修饰的数据在定义时必须进行初始化,且不能被修改,因此使用const可以提高代码的安全性和可读性。在C中,const修饰的成员函数表示该函数保证…...
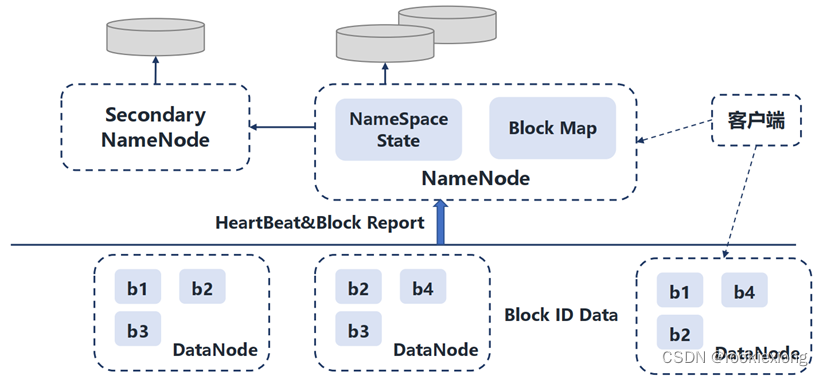
分布式计算平台 Hadoop 简介
Hadoop简介 Hadoop是一种分析和处理大数据的软件平台,是一个用Java语言实现的Apache的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算。其主要采用MapReduce分布式计算框架,包括根据GFS原理开发的分布式文件系统HDFS、…...

系统学习Python——警告信息的控制模块warnings:常见函数-[warnings.warn]
分类目录:《系统学习Python》总目录 warnings.warn(message, categoryNone, stacklevel1, sourceNone, \*, skip_file_prefixesNone)常备用于引发警告、忽略或者触发异常。 如果给出category参数,则必须是警告类别类 ;默认为UserWarning。 或…...

监听键盘事件vue3封装hooks
监听页面键盘事件,执行对应方法 使用第三方API:vueuse 我封装的: 1. useKeyboardEvent.ts import { useMagicKeys } from vueuse/coreexport function enterKey(f: Function) {const { enter } useMagicKeys()watch(enter, v > {if (…...

Java Stream简化代码
使用原始流以获得更好的性能 使用 int、long 和 double 等基本类型时,请使用IntStream、LongStream 和 DoubleStream 等基本流,而不是 Integer、Long 和 Double 等装箱类型流。原始流可以通过避免装箱和拆箱的成本来提供更好的性能。 var array new i…...
py爬虫入门笔记(request.get的使用)
文章目录 Day11. 了解浏览器开发者工具2. Get请求http://baidu.com3. Post请求https://fanyi.baidu.com/sug4. 肯德基小作业 Day21. 正则表达式2. 使用re模块3. 爬取豆瓣电影Top250的第一页4. 爬取豆瓣电影Top250所有的250部电影信息 Day31. xpath的使用2. 认识下载照片线程池的…...

openssl3.2 - 官方demo学习 - encode - rsa_encode.c
文章目录 openssl3.2 - 官方demo学习 - encode - rsa_encode.c概述笔记END openssl3.2 - 官方demo学习 - encode - rsa_encode.c 概述 命令行参数 server_priv_key.pem client_priv_key.pem 这2个证书是前面certs目录里面做的 官方这个程序有bug, 给出2个证书, 还要从屏幕上输…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

Modbus RTU与Modbus TCP详解指南
目录 1. Modbus协议基础 1.1 什么是Modbus? 1.2 Modbus协议历史 1.3 Modbus协议族 1.4 Modbus通信模型 🎭 主从架构 🔄 请求响应模式 2. Modbus RTU详解 2.1 RTU是什么? 2.2 RTU物理层 🔌 连接方式 ⚡ 通信参数 2.3 RTU数据帧格式 📦 帧结构详解 🔍…...

全面解析数据库:从基础概念到前沿应用
在数字化时代,数据已成为企业和社会发展的核心资产,而数据库作为存储、管理和处理数据的关键工具,在各个领域发挥着举足轻重的作用。从电商平台的商品信息管理,到社交网络的用户数据存储,再到金融行业的交易记录处理&a…...