语境化语言表示模型-ELMO、BERT、GPT、XLnet
一.语境化语言表示模型介绍
语境化语言表示模型(Contextualized Language Representation Models)是一类在自然语言处理领域中取得显著成功的模型,其主要特点是能够根据上下文动态地学习词汇和短语的表示。这些模型利用了上下文信息,使得同一词汇在不同语境中可以有不同的表示。以下是一些著名的语境化语言表示模型:
-
ELMo(Embeddings from Language Models): ELMo是一种基于LSTM(长短时记忆网络)的双向语言模型,通过在训练时考虑双向上下文信息,为每个词生成一个上下文相关的词向量。ELMo的词向量是通过将前向LSTM和后向LSTM的隐藏状态进行线性组合而得到的。
-
BERT(Bidirectional Encoder Representations from Transformers): BERT是一种基于Transformer架构的预训练模型,通过使用大规模的语言模型预训练来学习上下文相关的词表示。BERT考虑了一个词在句子中的左右上下文,并通过遮蔽掉一些词汇,训练模型来预测这些被遮蔽的词汇。
-
GPT(Generative Pre-trained Transformer): GPT是一系列基于Transformer的预训练模型,与BERT不同,GPT使用了单向的语言模型,即只考虑前面的上下文。GPT系列的模型通过自回归生成方式,逐个预测下一个词。
这些语境化语言表示模型在自然语言处理的多个任务中取得了显著的性能提升,包括文本分类、命名实体识别、情感分析、问答系统等。由于它们能够充分考虑上下文信息,更好地捕捉语义和语法结构,因此在处理复杂的自然语言任务时表现优异。
这些模型通常是在大规模语料库上进行预训练,然后在特定任务上进行微调。这使得它们能够在各种不同领域和任务中取得良好的泛化性能。
二.语境化语言表示模型-ELMO
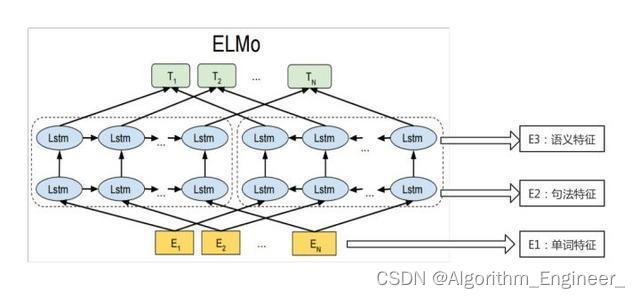
ELMo(Embeddings from Language Models)是一种语境化语言表示模型,由斯坦福大学的研究团队于2018年提出。ELMo旨在通过使用深度双向LSTM(长短时记忆网络)来生成上下文相关的词向量,从而改进传统的静态词向量表示。
ELMo的主要特点包括:
双向上下文建模: ELMo通过使用双向LSTM模型,考虑了一个词在句子中的左右上下文信息。这使得生成的词向量能够更好地捕捉词汇在不同上下文中的含义。层次化表示: ELMo的表示不是简单地从模型的最后一层获取,而是将多个LSTM层的隐藏状态进行线性组合,从而形成多层的语言表示。每一层都对应于不同抽象级别的语言表示,这种层次化的表示可以更好地适应不同任务。预训练和微调: ELMo首先在大规模的语言模型预训练阶段进行学习,然后在特定任务上进行微调。预训练过程使得模型能够学习通用的语言表示,而微调过程则使得模型能够适应特定领域或任务的上下文。
ELMo的词向量表示是通过以下方式计算的:
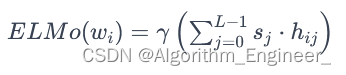
其中,wi是第 i 个词汇,L是LSTM层数,hij 是第 j 层LSTM在第i个词汇上的隐藏状态,sj是模型学到的权重系数,γ是缩放系数。
ELMo的提出带来了对传统静态词向量的一些重要改进,主要体现在以下几个方面:
-
上下文相关性: ELMo生成的词向量是上下文相关的,能够捕捉每个词在不同上下文中的含义。这使得模型更加灵活,能够适应不同语境和任务的要求。
-
多层表示: ELMo采用了多层的双向LSTM,生成了多个层次的语言表示。每个层次对应不同抽象级别的语义信息,使得模型能够在更细粒度和更高层次上理解文本。
-
预训练和微调: ELMo首先在大规模语料上进行预训练,学习通用的语言表示,然后在特定任务上进行微调,适应特定领域或任务的上下文。这种两阶段的训练使得模型更具泛化性。
-
多任务学习: 由于ELMo的语言表示是通过多层双向LSTM的线性组合得到的,每一层都可以用于不同任务。这种多任务学习的特性使得模型能够在一个模型中同时适应多个任务。
ELMo在这些任务中的应用表现:
-
情感分析: 在情感分析任务中,理解文本中的情感极性对于判断文本的情感态度非常重要。ELMo能够捕捉词汇在句子中的不同语境,从而更好地理解和表示情感相关的信息,提高了情感分析模型的性能。
-
问答系统: 在问答系统中,理解问题和文本的语境是关键。ELMo生成的上下文相关的词向量可以更好地捕捉问题和答案之间的关系,使得问答系统更具智能性和准确性。
-
文本分类: 在文本分类任务中,ELMo的上下文相关性使得模型能够更好地理解文本中的语义信息。这对于区分不同类别的文本非常有帮助,提高了文本分类模型的准确性。
-
命名实体识别: 在命名实体识别任务中,ELMo的上下文相关的词向量有助于更好地理解文本中实体的边界和语境,提高了命名实体识别模型的精度。
总的来说,ELMo的应用范围广泛,其上下文相关的词向量表示在多个任务中都展现了显著的优势,使得模型能够更好地理解语言的复杂性和多义性。然而,也需要注意到后续出现的一些更先进的语境化表示模型(如BERT和GPT等)在某些任务上取得了更好的性能。
三.语境化语言表示模型-BERT向量
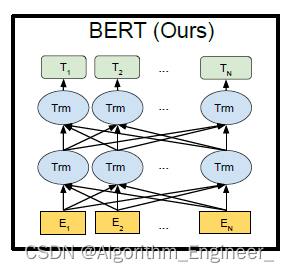
BERT(Bidirectional Encoder Representations from Transformers)模型是一种语境化语言表示模型,通过预训练来生成上下文相关的词向量。在BERT中,词向量通常被称为BERT向量。BERT向量的生成过程包括两个阶段:预训练和微调。
预训练阶段: 在预训练阶段,BERT模型通过大规模的无标签语料库进行训练。在这个阶段,BERT使用了两个任务来学习上下文相关的词向量:掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)任务。
通过在输入文本中随机掩盖一些词汇,BERT模型被训练来预测被掩盖的词汇。同时,BERT模型还通过判断两个句子是否是原文中的连续句子来学习句子级别的关系。这个阶段的输出是每个位置上的上下文相关的词向量。
微调阶段: 在微调阶段,BERT模型根据具体的下游任务(如文本分类、命名实体识别等)的标签信息,使用带标签的数据对模型进行微调。在微调阶段,模型的参数会根据任务的特定目标进行调整,以适应特定任务的要求。微调可以在相对较小的标注数据集上进行,因为BERT已经在大规模的无标签数据上进行了预训练。
BERT向量的特点包括:
上下文相关性: 由于BERT是基于双向Transformer结构进行训练的,生成的词向量能够捕捉每个词在其上下文中的语义信息。
多层次表示: BERT模型包含多个Transformer层,每个层次都提供了一个不同抽象级别的表示。因此,BERT向量是一个多层次的表示,可以在不同任务中灵活应用。
预训练和微调: BERT向量在预训练阶段学习通用的语言表示,而在微调阶段可以根据具体任务的需求进行进一步优化。
BERT向量在自然语言处理的各个任务中都表现出色,取得了许多领域的最新性能。由于BERT的成功,许多后续的语境化语言表示模型(如GPT、RoBERTa等)也在此基础上进行了发展和改进。

四.语境化语言表示模型-GPT
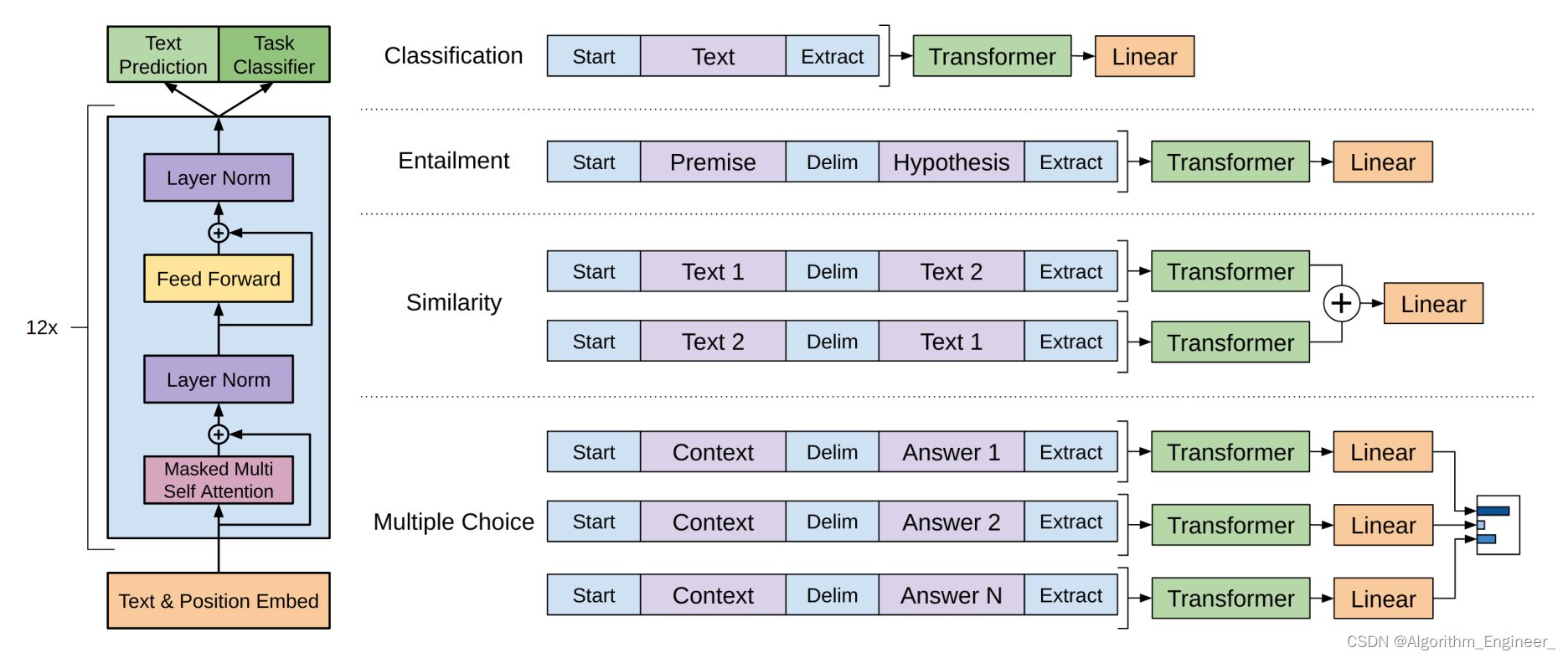
GPT(Generative Pre-trained Transformer)是一种语境化语言表示模型,属于Transformer架构的一部分。与BERT不同,GPT是通过自回归方式进行训练的,即模型在生成文本时依次预测下一个词汇。以下是GPT的一些关键特点:
Transformer架构: GPT采用了Transformer架构,这种架构在处理序列数据时非常强大。Transformer使用注意力机制来捕捉输入序列中不同位置的关系,使得模型能够在长距离上捕捉依赖关系。自回归训练: GPT采用自回归的方式进行训练。在训练过程中,模型通过最大化下一个词的条件概率来预测整个序列。这种方法使得GPT生成的语言表示更加连贯,适用于生成任务。层次化表示: GPT模型通常包含多个Transformer层,每一层都提供了一个不同层次的语言表示。这种层次化的表示使得GPT能够理解文本的不同抽象级别的语义信息。无监督预训练: 在预训练阶段,GPT通过大规模的无标签语料库进行自监督学习,学习通用的语言表示。预训练完成后,模型可以在各种下游任务上进行微调,以适应具体的应用。生成任务应用: GPT最初设计用于生成任务,如文本生成、对话生成等。由于采用了自回归训练方式,GPT在生成连贯且富有语义的文本方面表现出色。OpenAI的GPT系列: GPT的发展成为了一系列模型,包括GPT-2和GPT-3。这些模型在参数规模、性能和能力方面逐渐提升,GPT-3更是达到了数万亿个参数的规模。
GPT在多个自然语言处理任务中都取得了显著的成功,包括文本生成、对话系统、文本摘要等。然而,与BERT等其他模型相比,GPT的无监督训练方式也带来了一些挑战,例如对大规模数据和计算资源的需求。
五.语境化语言表示模型-XLNet
XLNet(eXtreme Learning Machine Network)是一种语境化语言表示模型,由谷歌AI团队于2019年提出。它结合了Transformer的架构和自回归(autoregressive)以及自编码(autoencoding)等训练目标,以提高对上下文的建模能力。以下是一些关键特点:
Transformer架构: XLNet采用Transformer的结构,包括自注意力机制。这使得模型能够有效捕捉文本中的长距离依赖关系。自回归和自编码: XLNet结合了自回归和自编码两种训练目标。自回归部分通过最大化给定上下文条件下下一个词的概率,类似于GPT。自编码部分则通过最大化一个被随机掩码的词预测所有其他词的概率,类似于BERT。Permutation Language Modeling(PLM): XLNet引入了Permutation Language Modeling任务,即对输入序列中的一些词的排列进行预测。这使得模型能够更好地理解词汇之间的全局关系。两个流的架构: XLNet通过两个流的架构实现了自回归和自编码目标的融合。一个流负责从左到右的自回归目标,另一个流负责从右到左的自编码目标。这种设计使得模型更加全面地捕捉上下文信息。超长序列: 由于采用了自回归的方式,XLNet相对于BERT等模型更容易处理长文本,因为它不需要将整个上下文序列压缩到一个固定长度。
XLNet在多个自然语言处理任务上表现出色,包括文本分类、问答系统、命名实体识别等。它的训练过程和细节相对复杂,需要大规模的数据和计算资源。以下是一个简化的伪代码示例,用于理解XLNet的基本训练流程:
import torch
from torch.optim import Adam
from transformers import XLNetTokenizer, XLNetForSequenceClassification# 使用预训练的XLNet模型和tokenizer
model = XLNetForSequenceClassification.from_pretrained('xlnet-base-cased')
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')# 数据准备
text_data = ["Your text data here...", "Another sentence...", ...]
labels = [0, 1, ...] # 根据任务的不同,labels会有所变化tokenized_data = tokenizer(text_data, return_tensors='pt', padding=True, truncation=True)
labels = torch.tensor(labels)# 模型和优化器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
optimizer = Adam(model.parameters(), lr=2e-5)# 训练过程
num_epochs = 3for epoch in range(num_epochs):model.train()optimizer.zero_grad()# 前向传播outputs = model(**tokenized_data, labels=labels)loss = outputs.loss# 反向传播和优化loss.backward()optimizer.step()print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {loss.item()}")# 保存训练好的模型
model.save_pretrained('path/to/save/model')
tokenizer.save_pretrained('path/to/save/tokenizer')这里的代码是基于Hugging Face的transformers库,该库提供了方便的接口用于使用和微调预训练的XLNet模型。在实际应用中,你可能需要根据任务的不同对模型进行微调,调整模型的超参数,并根据实际情况对数据进行更详细的处理。
相关文章:
语境化语言表示模型-ELMO、BERT、GPT、XLnet
一.语境化语言表示模型介绍 语境化语言表示模型(Contextualized Language Representation Models)是一类在自然语言处理领域中取得显著成功的模型,其主要特点是能够根据上下文动态地学习词汇和短语的表示。这些模型利用了上下文信息…...

和MATLAB相关的设置断点的快捷键
一个朋友在修改错误的时候,有个操作震惊到我了。 他把迭代次数从1000减小到100,就可以快速仿真完。 废话不多说,直接上快捷键。 F12:设置或者清楚断点。 F5:运行 F10和F11都是步进,但是两者有区别。 …...
实人认证(人像三要素)API:加强用户身份验证
前言 在当今数字化时代,随着互联网应用的广泛普及,用户身份验证的重要性日益凸显。实人认证(人像三要素)API作为一种新型的身份验证方式,凭借其高效、安全和便捷的特性,正在成为加强用户身份验证的强大工具…...

美易官方:一路火到2024!英伟达还在创造历史
一路火到2024!英伟达还在创造历史:两周来市值增逾千亿美元 自今年8月以来,英伟达的股价一直处于快速上涨的轨道上。最近两周,英伟达的市值更是增加了超过1000亿美元,这主要得益于其数据中心业务的持续强劲表现和游戏业…...

6个免费/商用图片素材网站
推荐6个免费可商用图片素材网站,收藏走一波~ 1、菜鸟图库 https://www.sucai999.com/pic.html?vNTYwNDUx 我推荐过很多次的设计素材网站,除了设计类素材,还有很多自媒体可以用到的高清图片、背景图、插画、视频、音频素材等等。网站提供的图…...
Java使用IText生产PDF时,中文标点符号出现在行首的问题处理
Java使用IText生成PDF时,中文标点符号出现在行首的问题处理 使用itext 5进行html转成pdf时,标点符号出现在某一行的开头 但这种情况下显然不符合中文书写的规则,主要问题出在itext中的DefaultSplitCharacter类,该方法主要用来判断…...

npx和npm有什么区别,包管理器yarn的使用方法,node的版本管理工具nvm使用方法
文章目录 一、npx介绍及使用1、npx 是什么2、npx 会把远端的包下载到本地吗?3、npx 执行完成之后, 下载的包是否会被删除?4、npx和npm的区别 二、yarn介绍及使用1、Yarn是什么?2、Yarn的常见场景:3、Yarn常用命令 三、nvm介绍及使…...
【网络技术】【Kali Linux】Wireshark嗅探(九)安全HTTP协议(HTTPS协议)
一、实验目的 本次实验是基于之前的实验:Wireshark嗅探(七)(HTTP协议)进行的。本次实验使用Wireshark流量分析工具进行网络嗅探,旨在初步了解安全的HTTP协议(HTTPS协议)的工作原理。…...

POI-tl 知识整理:整理3 -> 动态生成表格
1 表格行循环 (1)需要渲染的表格的模板 说明:{{goods}} 是个标准的标签,将 {{goods}} 置于循环行的上一行,循环行设置要循环的标签和内容,注意此时的标签应该使用 [] ,以此来区别poi-tl的默认标…...

chatgpt和文心一言哪个更好用
ChatGPT和文心一言都是近年来备受关注的人工智能语言模型。它们在智能回复、语言准确性、知识库丰富度等方面都有着较高的表现。然而,它们各自也有自己的特点和优势。在本文中,我们将从这几个方面对这两个模型进行比较,以帮助您更好地了解它们…...

移动端开发进阶之蓝牙通讯(一)
移动端开发进阶之蓝牙通讯(一) 移动端进阶之蓝牙通讯需要综合考虑蓝牙版本选择、协议栈使用、服务匹配、设备连接、安全性和硬件支持等方面。 一、蓝牙版本选择 根据实际需求和应用场景选择合适的蓝牙版本; 1.0,1M/s。 2.0EDR…...
一个完整的流程表单流转
1.写在前面 一个完整的流程表单审批(起表单-->各环节审批-->回退-->重新审批-->完成),前端由Vue2jsElement UI升级为Vue3tsElement Plus,后端流程框架使用Flowable,项目参考了ruoyi-vue-pro(https://gite…...

2024杭州国际智慧城市,人工智能,安防展览会(杭州智博会)
在智能化浪潮的冲击下,我们的生活与环境正在经历一场深刻的变革。这是一场前所未有的技术革命,它以前所未有的速度和广度,改变着我们的生活方式、工作方式、思维方式和社会结构。在这场变革中,有的人选择激流勇进,拥抱…...

编程笔记 html5cssjs 031 HTML视频
编程笔记 html5&css&js 031 HTML视频 一、<video>: 视频元素二、属性三、事件四、嵌入视频页面五、练习小结 视频应用广泛,当前的互联网应用中,视频越来越重要,比如抖音、快手、腾讯视频等应用。 一、<video>: 视频元素 …...

SpringBoot外部配置文件
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: 循序渐进学SpringBoot ✨特色专栏: MySQL学习 🥭本文内容:SpringBoot外部配置文件 📚个人知识库: Leo知识库,欢迎大家访问 1.前言☕…...

99个Python脚本实用实例
题目:有四个数字:1、2、3、4,能组成多少个互不相同且无重复数字的三位数?各是多少? #!/usr/bin/python# -*- coding: UTF-8 -*-for i in range(1,5): for j in range(1,5): for k in range(1,5): …...

HarmonyOS 工程目录介绍
工程目录 AppScope:存放应用全局所需要的资源文件 base element:文件夹主要存放公共的字符串、布局文件等资源media:存放全局公共的多媒体资源文件app.json5:应用的全局的配置文件,用于存放应用公共的配置信息 {"…...
门店管理系统驱动智慧零售升级
在当今数字化经济的大潮中,实体门店正在经历一场由内而外的深度变革。门店管理系统以其高效、便捷和全面的功能特性,为实体店提供了高效的运营解决方案。 门店管理系统拜托了传统零售业对本地化软件的依赖,它将复杂的信息技术转化为易于获取…...

Iterator迭代器操作集合元素时,不能用集合删除元素
在使用Iterator迭代器对集合中的元素进行迭代时,如果调用了集合对象的remove()方法删除元素或者调用add()方法添加元素之后,继续使用迭代器遍历元素,会出现异常(java.util.ConcurrentModificationException)。 import java.util.ArrayList; …...
Spring Boot是什么-特点介绍
什么是SpringBoot Spring Boot是由Pivotal团队提供的全新框架,其中“Boot”的意思就是“引导”,Spring Boot 并不是对 Spring 功能上的增强,而是提供了一种快速开发 Spring应用的方式。 Spring Boot 特点 嵌入的 Tomcat,无需部署…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...