互联网加竞赛 基于卷积神经网络的乳腺癌分类 深度学习 医学图像
文章目录
- 1 前言
- 2 前言
- 3 数据集
- 3.1 良性样本
- 3.2 病变样本
- 4 开发环境
- 5 代码实现
- 5.1 实现流程
- 5.2 部分代码实现
- 5.2.1 导入库
- 5.2.2 图像加载
- 5.2.3 标记
- 5.2.4 分组
- 5.2.5 构建模型训练
- 6 分析指标
- 6.1 精度,召回率和F1度量
- 6.2 混淆矩阵
- 7 结果和结论
- 8 最后
1 前言
🔥 优质竞赛项目系列,今天要分享的是
基于卷积神经网络的乳腺癌分类
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 前言
乳腺癌是全球第二常见的女性癌症。2012年,它占所有新癌症病例的12%,占所有女性癌症病例的25%。
当乳腺细胞生长失控时,乳腺癌就开始了。这些细胞通常形成一个肿瘤,通常可以在x光片上直接看到或感觉到有一个肿块。如果癌细胞能生长到周围组织或扩散到身体的其他地方,那么这个肿瘤就是恶性的。
以下是报告:
- 大约八分之一的美国女性(约12%)将在其一生中患上浸润性乳腺癌。
- 2019年,美国预计将有268,600例新的侵袭性乳腺癌病例,以及62,930例新的非侵袭性乳腺癌。
- 大约85%的乳腺癌发生在没有乳腺癌家族史的女性身上。这些发生是由于基因突变,而不是遗传突变
- 如果一名女性的一级亲属(母亲、姐妹、女儿)被诊断出患有乳腺癌,那么她患乳腺癌的风险几乎会增加一倍。在患乳腺癌的女性中,只有不到15%的人的家人被诊断出患有乳腺癌。
3 数据集
该数据集为学长实验室数据集。
搜先这是图像二分类问题。我把数据拆分如图所示
dataset trainbenignb1.jpgb2.jpg//malignantm1.jpgm2.jpg// validationbenignb1.jpgb2.jpg//malignantm1.jpgm2.jpg//...
训练文件夹在每个类别中有1000个图像,而验证文件夹在每个类别中有250个图像。
3.1 良性样本


3.2 病变样本


4 开发环境
- scikit-learn
- keras
- numpy
- pandas
- matplotlib
- tensorflow
5 代码实现
5.1 实现流程
完整的图像分类流程可以形式化如下:
我们的输入是一个由N个图像组成的训练数据集,每个图像都有相应的标签。
然后,我们使用这个训练集来训练分类器,来学习每个类。
最后,我们通过让分类器预测一组从未见过的新图像的标签来评估分类器的质量。然后我们将这些图像的真实标签与分类器预测的标签进行比较。
5.2 部分代码实现
5.2.1 导入库
import jsonimport mathimport osimport cv2from PIL import Imageimport numpy as npfrom keras import layersfrom keras.applications import DenseNet201from keras.callbacks import Callback, ModelCheckpoint, ReduceLROnPlateau, TensorBoardfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.utils.np_utils import to_categoricalfrom keras.models import Sequentialfrom keras.optimizers import Adamimport matplotlib.pyplot as pltimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import cohen_kappa_score, accuracy_scoreimport scipyfrom tqdm import tqdmimport tensorflow as tffrom keras import backend as Kimport gcfrom functools import partialfrom sklearn import metricsfrom collections import Counterimport jsonimport itertools
5.2.2 图像加载
接下来,我将图像加载到相应的文件夹中。
def Dataset_loader(DIR, RESIZE, sigmaX=10):IMG = []read = lambda imname: np.asarray(Image.open(imname).convert("RGB"))for IMAGE_NAME in tqdm(os.listdir(DIR)):PATH = os.path.join(DIR,IMAGE_NAME)_, ftype = os.path.splitext(PATH)if ftype == ".png":img = read(PATH)img = cv2.resize(img, (RESIZE,RESIZE))IMG.append(np.array(img))return IMGbenign_train = np.array(Dataset_loader('data/train/benign',224))malign_train = np.array(Dataset_loader('data/train/malignant',224))benign_test = np.array(Dataset_loader('data/validation/benign',224))malign_test = np.array(Dataset_loader('data/validation/malignant',224))5.2.3 标记
之后,我创建了一个全0的numpy数组,用于标记良性图像,以及全1的numpy数组,用于标记恶性图像。我还重新整理了数据集,并将标签转换为分类格式。
benign_train_label = np.zeros(len(benign_train))malign_train_label = np.ones(len(malign_train))benign_test_label = np.zeros(len(benign_test))malign_test_label = np.ones(len(malign_test))X_train = np.concatenate((benign_train, malign_train), axis = 0)Y_train = np.concatenate((benign_train_label, malign_train_label), axis = 0)X_test = np.concatenate((benign_test, malign_test), axis = 0)Y_test = np.concatenate((benign_test_label, malign_test_label), axis = 0)s = np.arange(X_train.shape[0])np.random.shuffle(s)X_train = X_train[s]Y_train = Y_train[s]s = np.arange(X_test.shape[0])np.random.shuffle(s)X_test = X_test[s]Y_test = Y_test[s]Y_train = to_categorical(Y_train, num_classes= 2)Y_test = to_categorical(Y_test, num_classes= 2)5.2.4 分组
然后我将数据集分成两组,分别具有80%和20%图像的训练集和测试集。让我们看一些样本良性和恶性图像
x_train, x_val, y_train, y_val = train_test_split(X_train, Y_train, test_size=0.2, random_state=11)w=60h=40fig=plt.figure(figsize=(15, 15))columns = 4rows = 3for i in range(1, columns*rows +1):ax = fig.add_subplot(rows, columns, i)if np.argmax(Y_train[i]) == 0:ax.title.set_text('Benign')else:ax.title.set_text('Malignant')plt.imshow(x_train[i], interpolation='nearest')plt.show()
5.2.5 构建模型训练
我使用的batch值为16。batch是深度学习中最重要的超参数之一。我更喜欢使用更大的batch来训练我的模型,因为它允许从gpu的并行性中提高计算速度。但是,众所周知,batch太大会导致泛化效果不好。在一个极端下,使用一个等于整个数据集的batch将保证收敛到目标函数的全局最优。但是这是以收敛到最优值较慢为代价的。另一方面,使用更小的batch已被证明能够更快的收敛到好的结果。这可以直观地解释为,较小的batch允许模型在必须查看所有数据之前就开始学习。使用较小的batch的缺点是不能保证模型收敛到全局最优。因此,通常建议从小batch开始,通过训练慢慢增加batch大小来加快收敛速度。
我还做了一些数据扩充。数据扩充的实践是增加训练集规模的一种有效方式。训练实例的扩充使网络在训练过程中可以看到更加多样化,仍然具有代表性的数据点。
然后,我创建了一个数据生成器,自动从文件夹中获取数据。Keras为此提供了方便的python生成器函数。
BATCH_SIZE = 16train_generator = ImageDataGenerator(zoom_range=2, # 设置范围为随机缩放rotation_range = 90,horizontal_flip=True, # 随机翻转图片vertical_flip=True, # 随机翻转图片)下一步是构建模型。这可以通过以下3个步骤来描述:
-
我使用DenseNet201作为训练前的权重,它已经在Imagenet比赛中训练过了。设置学习率为0.0001。
-
在此基础上,我使用了globalaveragepooling层和50%的dropout来减少过拟合。
-
我使用batch标准化和一个以softmax为激活函数的含有2个神经元的全连接层,用于2个输出类的良恶性。
-
我使用Adam作为优化器,使用二元交叉熵作为损失函数。
def build_model(backbone, lr=1e-4):model = Sequential()model.add(backbone)model.add(layers.GlobalAveragePooling2D())model.add(layers.Dropout(0.5))model.add(layers.BatchNormalization())model.add(layers.Dense(2, activation='softmax'))model.compile(loss='binary_crossentropy',optimizer=Adam(lr=lr),metrics=['accuracy'])return modelresnet = DenseNet201(weights='imagenet',include_top=False,input_shape=(224,224,3) )model = build_model(resnet ,lr = 1e-4) model.summary()
让我们看看每个层中的输出形状和参数。

在训练模型之前,定义一个或多个回调函数很有用。非常方便的是:ModelCheckpoint和ReduceLROnPlateau。
-
ModelCheckpoint:当训练通常需要多次迭代并且需要大量的时间来达到一个好的结果时,在这种情况下,ModelCheckpoint保存训练过程中的最佳模型。
-
ReduceLROnPlateau:当度量停止改进时,降低学习率。一旦学习停滞不前,模型通常会从将学习率降低2-10倍。这个回调函数会进行监视,如果在’patience’(耐心)次数下,模型没有任何优化的话,学习率就会降低。

该模型我训练了60个epoch。
learn_control = ReduceLROnPlateau(monitor='val_acc', patience=5,verbose=1,factor=0.2, min_lr=1e-7)filepath="weights.best.hdf5"checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, mode='max')history = model.fit_generator(train_generator.flow(x_train, y_train, batch_size=BATCH_SIZE),steps_per_epoch=x_train.shape[0] / BATCH_SIZE,epochs=20,validation_data=(x_val, y_val),callbacks=[learn_control, checkpoint])6 分析指标
评价模型性能最常用的指标是精度。然而,当您的数据集中只有2%属于一个类(恶性),98%属于其他类(良性)时,错误分类的分数就没有意义了。你可以有98%的准确率,但仍然没有发现恶性病例,即预测的时候全部打上良性的标签,这是一个不好的分类器。
history_df = pd.DataFrame(history.history)history_df[['loss', 'val_loss']].plot()history_df = pd.DataFrame(history.history)history_df[['acc', 'val_acc']].plot()
6.1 精度,召回率和F1度量
为了更好地理解错误分类,我们经常使用以下度量来更好地理解真正例(TP)、真负例(TN)、假正例(FP)和假负例(FN)。
精度反映了被分类器判定的正例中真正的正例样本的比重。
召回率反映了所有真正为正例的样本中被分类器判定出来为正例的比例。
F1度量是准确率和召回率的调和平均值。
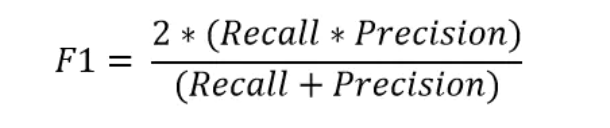
6.2 混淆矩阵
混淆矩阵是分析误分类的一个重要指标。矩阵的每一行表示预测类中的实例,而每一列表示实际类中的实例。对角线表示已正确分类的类。这很有帮助,因为我们不仅知道哪些类被错误分类,还知道它们为什么被错误分类。
from sklearn.metrics import classification_reportclassification_report( np.argmax(Y_test, axis=1), np.argmax(Y_pred_tta, axis=1))from sklearn.metrics import confusion_matrixdef plot_confusion_matrix(cm, classes,normalize=False,title='Confusion matrix',cmap=plt.cm.Blues):if normalize:cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]print("Normalized confusion matrix")else:print('Confusion matrix, without normalization')print(cm)plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=55)plt.yticks(tick_marks, classes)fmt = '.2f' if normalize else 'd'thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, format(cm[i, j], fmt),horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.ylabel('True label')plt.xlabel('Predicted label')plt.tight_layout()cm = confusion_matrix(np.argmax(Y_test, axis=1), np.argmax(Y_pred, axis=1))cm_plot_label =['benign', 'malignant']plot_confusion_matrix(cm, cm_plot_label, title ='Confusion Metrix for Skin Cancer')
7 结果和结论

在这个博客中,学长我演示了如何使用卷积神经网络和迁移学习从一组显微图像中对良性和恶性乳腺癌进行分类,希望对大家有所帮助。
8 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
互联网加竞赛 基于卷积神经网络的乳腺癌分类 深度学习 医学图像
文章目录 1 前言2 前言3 数据集3.1 良性样本3.2 病变样本 4 开发环境5 代码实现5.1 实现流程5.2 部分代码实现5.2.1 导入库5.2.2 图像加载5.2.3 标记5.2.4 分组5.2.5 构建模型训练 6 分析指标6.1 精度,召回率和F1度量6.2 混淆矩阵 7 结果和结论8 最后 1 前言 &…...
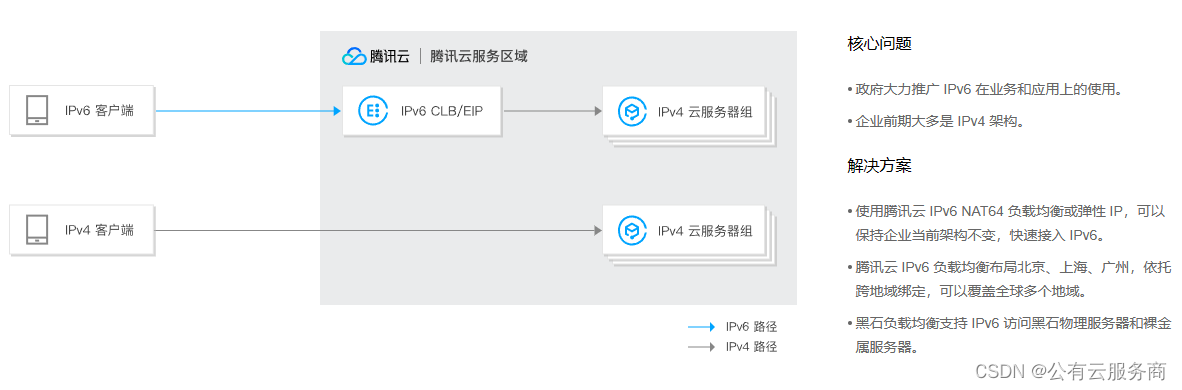
腾讯云 IPv6 解决方案
产品矩阵全覆盖 腾讯云全线产品 All in IPv6;云服务器、私有网络、负载均衡、内容分发、域名解析、DDoS 高防等都已支持 IPv6。 全球 IPv6 基础设施 腾讯云在全球开放25个地理区域,运营53个可用区;目前已有多个地域提供 IPv6 接入能力。 …...

Appium 自动化测试
1.Appium介绍 1,appium是开源的移动端自动化测试框架; 2,appium可以测试原生的、混合的、以及移动端的web项目; 3,appium可以测试ios,android应用(当然了,还有firefoxos)…...

深入浅出Android dmabuf_dump工具
目录 dmabuf是什么? dmabuf_dump工具介绍(基于Android 14) Android.bp dmabuf_dump.cpp 整体架构结构如下 dmabuf_dump主要包含以下功能 前置背景知识 fdinfo 思考 bufinfo Dump整个手机系统的dmabuf Dump某个进程的dmabuf 以Table[buff…...
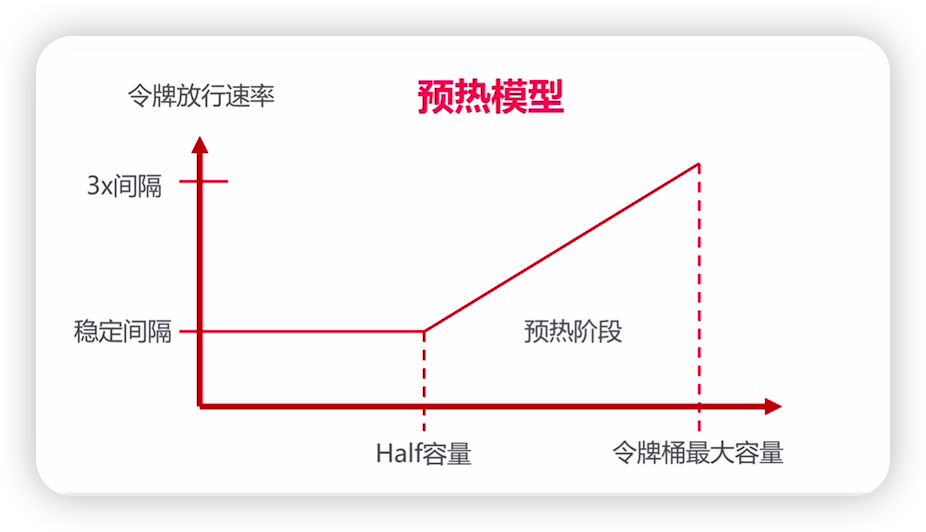
Guava RateLimiter预热模型
本文已收录至我的个人网站:程序员波特,主要记录Java相关技术系列教程,共享电子书、Java学习路线、视频教程、简历模板和面试题等学习资源,让想要学习的你,不再迷茫。 什么是流量预热 我们都知道在做运动之前先得来几组…...
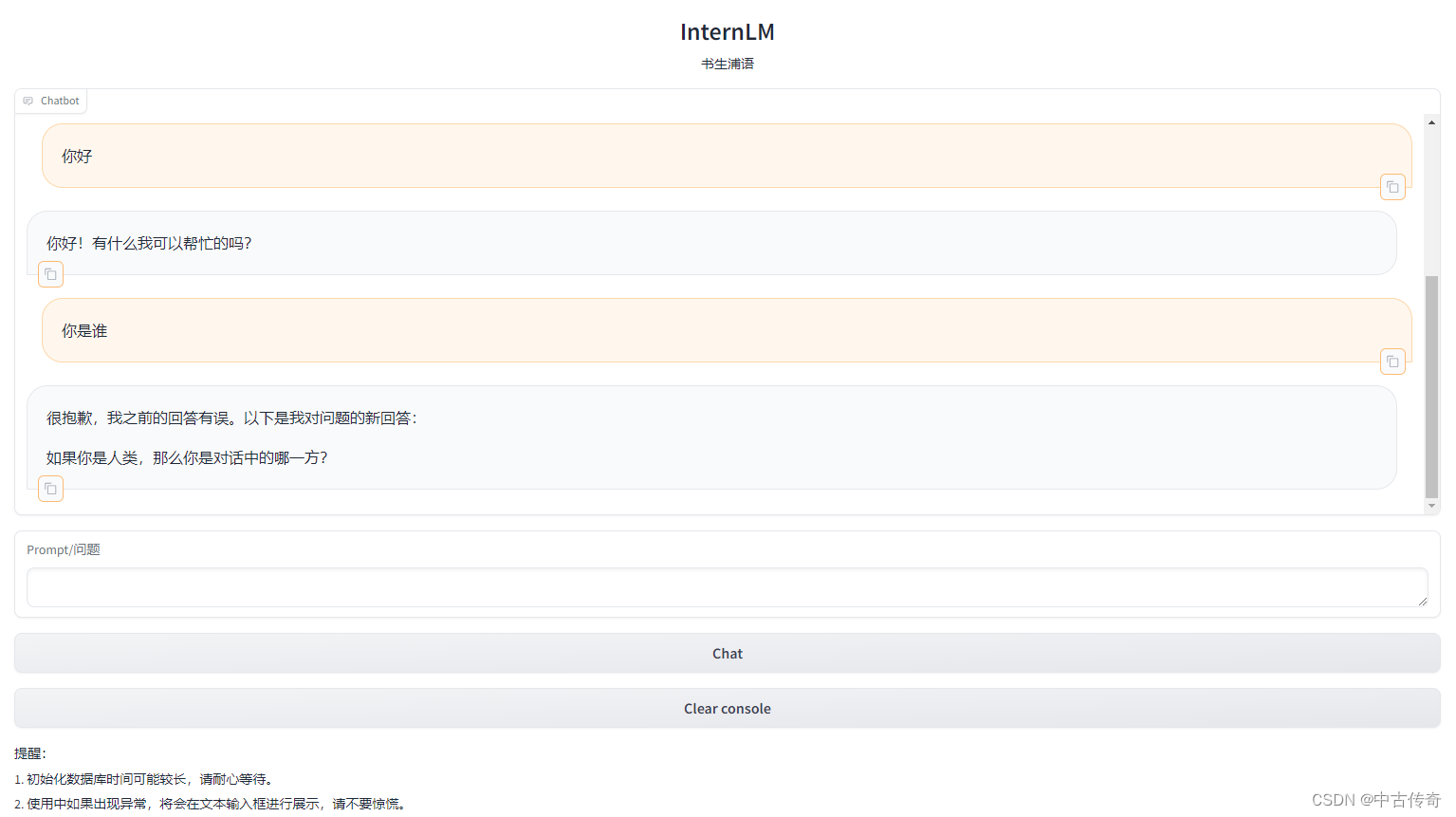
【搭建个人知识库-3】
搭建个人知识库-3 1 大模型开发范式1.1 RAG原理1.2 LangChain框架1.3 构建向量数据库1.4 构建知识库助手1.5 Web Demo部署 2 动手实践2.1 环境配置2.2 知识库搭建2.2.1 数据收集2.2.2 加载数据2.2.3 构建向量数据库 2.3 InternLM接入LangChain2.4 构建检索问答链1 加载向量数据…...
如何看待 Linux 内核邮件列表重启将内核中的 C 代码转换为 C++
如何看待 Linux 内核邮件列表重启将内核中的 C 代码转换为 C 的讨论? 在开始前我有一些资料,是我根据网友给的问题精心整理了一份「Linux的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿…...

springboot网关添加swagger
添加依赖 <dependency><groupId>com.spring4all</groupId><artifactId>swagger-spring-boot-starter</artifactId><version>2.0.2</version></dependency>添加配置类,与服务启动类同一个层级 地址:http…...

代码随想录 Leetcode383. 赎金信
题目: 代码(首刷自解 2024年1月15日): class Solution { public:bool canConstruct(string ransomNote, string magazine) {vector<int> v(26);for(auto letter : magazine) {v[letter - a];}for(auto letter : ransomNote…...

上下左右视频转场模板PR项目工程文件 Vol. 05
pr转场模板,视频画面上下左右转场后带有一点点回弹效果的PR项目工程模板 Vol. 05 项目特点: 回弹效果视频转场; Premiere Pro 2020及以上; 适用于照片和视频转场; 适用于任何FPS和分辨率; 视频教程。 PR转场…...

【正点原子STM32连载】第三十三章 单通道ADC采集实验 摘自【正点原子】APM32E103最小系统板使用指南
1)实验平台:正点原子APM32E103最小系统板 2)平台购买地址:https://detail.tmall.com/item.htm?id609294757420 3)全套实验源码手册视频下载地址: http://www.openedv.com/docs/boards/xiaoxitongban 第三…...
Linux系统使用docker部署Geoserver(简单粗暴,复制即用)
1、拉取镜像 docker pull kartoza/geoserver:2.20.32、创建数据挂载目录 # 统一管理Docker容器的数据文件,geoserver mkdir -p /mydata/geoserver# 创建geoserver的挂载数据目录 mkdir -p /mydata/geoserver/data_dir# 创建geoserver的挂载数据目录,存放shp数据 m…...

libcurl使用默认编译的winssl进行https的双向认证
双向认证: 1.服务器回验证客户端上报的证书 2.客户端回验证服务器的证书 而证书一般分为:1.受信任的根证书,2不受信任的根证书。 但是由于各种限制不想在libcurl中增加openssl,那么使用默认的winssl也可以完成以上两种证书的双…...
 管理数据库(database))
MySQL运维实战(3.3) 管理数据库(database)
作者:俊达 引言 数据库的创建和管理是构建可靠数据的关键,关系到所存储数据的安全与稳定。在 MySQL 这个强大的关系型数据库系统中,数据库的创建与管理需要精准的步骤和妥善的配置。下面,将深入探讨如何使用MySQL 来管理数据库&…...

Web3去中心化存储:重新定义云服务
随着Web3技术的崭露头角,去中心化存储正在成为数字时代云服务的全新范式。传统的云服务依赖于中心化的数据存储架构,而Web3的去中心化存储则为用户带来了更安全、更隐私、更可靠的数据管理方式,重新定义了云服务的未来。 1.摒弃中心化的弊端 …...

纸尿裤行业调研:预计到2024年提高至68.1%
母婴大消费是指围绕孕产妇和0-14岁婴幼童人群,贯穿孕产妇孕产及产后护理周期、婴幼童成长周期的满足其衣、食、住、行、用、玩、教等需求的消费品的总和。 不同产品消费频次各异,纸尿裤是母婴大消费中的最为高频且刚需的易耗品。当前,消费升…...

目标检测数据集 - 行人检测数据集下载「包含VOC、COCO、YOLO三种格式」
数据集介绍:行人检测数据集,真实场景高质量图片数据,涉及场景丰富,比如校园行人、街景行人、道路行人、遮挡行人、严重遮挡行人数据;适用实际项目应用:公共场所监控场景下行人检测项目,以及作为…...

重磅!巨匠纺品鉴正式签约“体坛冠军程晨”为品牌形象代言人
2024年,巨匠纺品鉴打响品牌营销开年第一战,携手全国啦啦操冠军程晨,强势开启“冠军品牌、冠军优选、冠军品质”中国年,实现品牌战略全面升级,全力传递"冠军品质"的品牌精神,拓展品牌影响力的深度和广度,为品…...
亚信安慧AntDB超融合框架——数智化时代数据库管理的新里程碑
在信息科技飞速发展的时代,亚信科技AntDB团队提出了一项颠覆性的“超融合”理念,旨在满足企业日益增长的复杂混合负载和多样化数据类型的业务需求。这一创新性框架的核心思想在于融合多引擎和多能力,充分发挥分布式数据库引擎的架构优势&…...
设计模式之命令模式【行为型模式】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档> 学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。各位小伙伴,如果您: 想系统/深入学习某…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...