06-枚举和模式匹配
上一篇:05-使用结构体构建相关数据
在本章中,我们将介绍枚举。枚举允许你通过枚举其可能的变体来定义一种类型。首先,我们将定义并使用一个枚举,以展示枚举如何与数据一起编码意义。接下来,我们将探索一个特别有用的枚举,名为 Option ,它表示一个值可以是 "有 "或 "无"。然后,我们将了解 match 表达式中的模式匹配如何使我们能够轻松地针对枚举的不同值运行不同的代码。最后,我们将介绍 if let 结构是如何在代码中处理枚举的另一个方便简洁的方式。
1. 定义枚举
结构体提供了一种将相关字段和数据组合在一起的方法,如 Rectangle 及其 width 和 height ,而枚举则提供了一种表示某个值是一组可能值之一的方法。例如,我们可能想说 Rectangle 是一组可能的形状之一,其中还包括 Circle 和 Triangle 。为此,Rust 允许我们将这些可能性编码为一个枚举。
让我们来看看我们可能想在代码中表达的一种情况,看看为什么在这种情况下枚举是有用的,而且比结构体更合适。假设我们需要处理 IP 地址。目前,IP 地址使用两种主要标准:第四版和第六版。由于我们的程序只会遇到这两种可能的 IP 地址,因此我们可以枚举所有可能的变体,这就是枚举名称的由来。
任何 IP 地址都可以是版本 4 或版本 6 地址,但不能同时是这两种。IP 地址的这一特性使得枚举数据结构非常适合,因为枚举值只能是其变体之一。从根本上说,版本 4 和版本 6 地址都是 IP 地址,因此在代码处理适用于任何类型 IP 地址的情况时,应将它们视为同一类型。
我们可以通过定义 IpAddrKind 枚举并列出 IP 地址的可能类型( V4 和 V6 )来用代码表达这一概念。这些就是枚举的变体:
enum IpAddrKind {V4,V6,
}
IpAddrKind 现在是一种自定义数据类型,我们可以在代码的其他地方使用它。
1.1 枚举值
我们可以像这样为 IpAddrKind 的两个变体分别创建实例:
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
请注意,枚举的变体是在其标识符下命名的,我们使用双冒号分隔两者。这样做很有用,因为现在 IpAddrKind::V4 和 IpAddrKind::V6 的值都属于同一类型: IpAddrKind 。例如,我们可以定义一个接收任意 IpAddrKind 的函数:
我们可以用任意一个变量来调用这个函数:
route(IpAddrKind::V4);
route(IpAddrKind::V6);
使用枚举还有更多优势。再想想我们的 IP 地址类型,目前我们还没有存储实际 IP 地址数据的方法;我们只知道它是什么类型。鉴于您了解了结构体,您可能会想使用结构体来解决这个问题,如下所示:
enum IpAddrKind {V4,V6,
}struct IpAddr {kind: IpAddrKind,address: String,
}let home = IpAddr {kind: IpAddrKind::V4,address: String::from("127.0.0.1"),
};let loopback = IpAddr {kind: IpAddrKind::V6,address: String::from("::1"),
};
在这里,我们定义了一个结构 IpAddr ,它有两个字段:一个是 IpAddrKind 类型的 kind 字段(我们之前定义的枚举),另一个是 String 类型的 address 字段。这个结构体有两个实例。第一个实例是 home ,其值为 IpAddrKind::V4 , kind ,相关地址数据为 127.0.0.1 。第二个实例是 loopback 。它的 kind 值是 IpAddrKind 的另一个变体,即 V6 ,并关联了地址 ::1 。我们使用结构体将 kind 和 address 的值捆绑在一起,因此现在变体与值相关联。
不过,使用枚举来表示相同的概念更为简洁:我们可以将数据直接放入每个枚举变体中,而不是将枚举放在结构体中。 IpAddr 枚举的新定义指出, V4 和 V6 变量都有相关的 String 值:
enum IpAddr {V4(String),V6(String),
}let home = IpAddr::V4(String::from("127.0.0.1"));let loopback = IpAddr::V6(String::from("::1"));
我们直接为枚举的每个变量附加数据,因此不需要额外的结构体。在这里,我们还可以更容易地了解枚举的另一个工作细节:我们定义的每个枚举变量的名称都会成为一个函数,用来构造枚举的实例。也就是说, IpAddr::V4() 是一个函数调用,它接收 String 参数并返回 IpAddr 类型的实例。在定义枚举时,我们自动获得了这个构造函数。
使用枚举而不是结构体还有另一个好处:每个变量可以有不同类型和数量的相关数据。四个版本的 IP 地址总是有四个数值部分,数值范围在 0 到 255 之间。如果我们想将 V4 地址存储为四个 u8 值,但又想将 V6 地址表示为一个 String 值,那么我们就无法使用结构体。枚举可以轻松处理这种情况:
enum IpAddr {V4(u8, u8, u8, u8),V6(String),
}let home = IpAddr::V4(127, 0, 0, 1);let loopback = IpAddr::V6(String::from("::1"));
我们已经展示了几种不同的方法来定义数据结构,以存储第四版和第六版 IP 地址。然而,事实证明,存储 IP 地址并对其类型进行编码的需求非常普遍,标准库中也有我们可以使用的定义!让我们来看看标准库是如何定义 IpAddr 的:它拥有与我们定义和使用的完全相同的枚举和变体,但它将地址数据以两个不同结构体的形式嵌入到变体中,每个变体的定义都不同:
struct Ipv4Addr {// --snip--
}struct Ipv6Addr {// --snip--
}enum IpAddr {V4(Ipv4Addr),V6(Ipv6Addr),
}
这段代码说明,你可以在枚举变量中放入任何类型的数据:例如字符串、数字类型或结构体。甚至还可以包含另一个枚举!另外,标准库中的类型通常不会比你想出的复杂多少。
请注意,即使标准库包含 IpAddr 的定义,我们仍然可以创建并使用自己的定义,而不会发生冲突,因为我们没有将标准库的定义引入我们的作用域。(即命名空间)
下面的枚举示例,变体中嵌入了多种类型。
enum Message {Quit,Move { x: i32, y: i32 },Write(String),ChangeColor(i32, i32, i32),
}
该枚举有四个不同类型的变量:
①. Quit 完全没有相关数据;
②. Move 具有命名字段,就像结构体一样;
③. Write 包括一个 String;
④. ChangeColor 包括三个 i32类型的参数;
定义枚举的变体类似于定义不同类型的结构体定义,只是枚举不使用 struct 关键字,而且所有变体都集中在 Message 类型下。下面的结构体可以保存与前面的枚举变体相同的数据:
struct QuitMessage; // unit struct
struct MoveMessage {x: i32,y: i32,
}
struct WriteMessage(String); // tuple struct
struct ChangeColorMessage(i32, i32, i32); // tuple struct
但是,如果我们使用不同的结构体(每个结构体都有自己的类型),我们就不能像使用清Message 枚举(它是一个单一类型)那样,轻松定义一个函数来接收这些类型的任何信息。
枚举和结构体之间还有一个相似之处:正如我们可以使用 impl 在结构体上定义方法一样,我们也可以在枚举上定义方法。下面是一个名为 call 的方法,我们可以在 Message 枚举上定义这个方法:
impl Message {fn call(&self) {// method body would be defined here}
}let m = Message::Write(String::from("hello"));
m.call();
方法的主体将使用 self 来获取我们调用方法的值。在本例中,我们创建了一个变量 m ,其值为 Message::Write(String::from("hello")) ,当 m.call() 运行时, self 将出现在 call 方法的主体中。
让我们来看看标准库中另一个非常常见和有用的枚举: Option
1.2 Option 枚举及其与空值相比的优势
本节将对 Option 进行案例研究,这是标准库定义的另一个枚举。 Option 类型编码了一种非常常见的情况,即一个值可能是什么,也可能什么都不是。
例如,如果您请求非空列表中的第一个项目,您将得到一个值。如果请求空列表中的第一项,则什么也得不到。用类型系统来表达这一概念意味着编译器可以检查您是否处理了所有应该处理的情况;这一功能可以防止其他编程语言中极为常见的 bug。
编程语言的设计通常会考虑包含哪些功能,但排除哪些功能也很重要。Rust 没有许多其他语言所具有的 null 功能。Null 是一个表示没有值的值。在有 null 的语言中,变量总是处于两种状态之一:null 或 not-null。
在 2009 年的演讲 "null,十亿美元的错误 "的演讲中,null 的发明者托尼-霍尔(Tony Hoare)这样说道:
我称它为我的 "十亿美元错误"。当时,我正在为面向对象语言中的引用设计第一个全面的类型系统。我的目标是确保所有引用的使用都绝对安全,并由编译器自动进行检查。但是,我无法抵制加入空引用的诱惑,因为这太容易实现了。这导致了无数的错误、漏洞和系统崩溃,在过去的四十年里,这些错误和漏洞可能造成了数十亿美元的损失。
空值的问题在于,如果试图将空值用作非空值,就会出现某种错误。由于 null 或 not-null 属性普遍存在,因此极易出现这种错误。
不过,null 所要表达的概念仍然很有用:空值是指由于某种原因当前无效或不存在的值。
问题其实不在于概念,而在于特定的实现。因此,Rust 没有空值,但有一个枚举可以编码值存在或不存在的概念。这个枚举就是 Option<T> ,标准库对它的定义如下:
enum Option<T> {None,Some(T),
}
Option<T> 枚举非常有用,甚至已包含在前奏中;您无需明确将其纳入作用域。其变体也包含在前奏中:您可以直接使用 Some 和 None ,而无需 Option:: 前缀。 Option<T> 枚举仍然只是一个普通的枚举,而 Some(T) 和 None 仍然是 Option<T> 类型的变体。
<T> 语法是我们尚未讨论过的 Rust 特性。它是一个泛型类型参数,现在你只需知道 <T> 意味着 Option 枚举的 Some 变体可以容纳一个任意类型的数据,而每一个用来代替 T 的具体类型都会使 Option<T> 整体类型成为一个不同的类型。下面是一些使用 Option 值来保存数字类型和字符串类型的示例:
let some_number = Some(5);
let some_char = Some('e');let absent_number: Option<i32> = None;
some_number 的类型是 Option<i32> 。 some_char 的类型是 Option<char> ,这是一种不同的类型。Rust 可以推断出这些类型,因为我们在 Some 变体中指定了一个值。对于 absent_number ,Rust 要求我们注解整个 Option 的类型:编译器无法仅通过查看 None 值来推断相应的 Some 变体将持有的类型。在这里,我们告诉 Rust,我们的意思是 absent_number 属于 Option<i32> 类型。
当我们有一个 Some 值时,我们知道有一个值存在,并且该值被保存在 Some 中。当我们有一个 None 值时,从某种意义上说,它的含义与 null 相同:我们没有一个有效的值。那么,为什么 Option<T> 会比 null 好呢?
简而言之,由于 Option<T> 和 T (其中 T 可以是任何类型)是不同的类型,编译器不会让我们把 Option<T> 值当作有效值来使用。例如,这段代码无法编译,因为它试图将 i8 添加到 Option<i8> 中:
let x: i8 = 5;
let y: Option<i8> = Some(5);let sum = x + y;
如果我们运行这段代码,就会得到这样一条错误信息:
cargo.exe buildCompiling enum_type v0.1.0 (D:\rustProj\enum_type)
error[E0277]: cannot add `Option<i8>` to `i8`--> src\main.rs:4:17|
4 | let sum = x + y;| ^ no implementation for `i8 + Option<i8>`|= help: the trait `Add<Option<i8>>` is not implemented for `i8`= help: the following other types implement trait `Add<Rhs>`:<i8 as Add><i8 as Add<&i8>><&'a i8 as Add<i8>><&i8 as Add<&i8>>For more information about this error, try `rustc --explain E0277`.
error: could not compile `enum_type` (bin "enum_type") due to previous error强烈!实际上,这条错误信息意味着 Rust 不理解如何添加 i8 和 Option<i8> ,因为它们是不同的类型。在 Rust 中,当我们有一个像 i8 这样类型的值时,编译器会确保我们始终有一个有效的值。在使用该值之前,我们无需检查其是否为空,就可以放心地继续编译。只有当我们有一个 Option<i8> (或其他任何类型的值)时,我们才需要担心可能没有值,编译器会确保我们在使用该值前处理这种情况。
换句话说,在对 Option<T> 执行 T 操作之前,必须先将转换为 T 。一般来说,这有助于解决 null 最常见的问题之一:假设某个东西不是 null,而实际上它是 null。
消除错误假定非空值的风险,可以让您对自己的代码更有信心。为了获得可能为空的值,您必须显式地选择将该值的类型设为 Option<T> 。然后,在使用该值时,必须明确处理该值为空的情况。只要值的类型不是 Option<T> ,就可以放心地认为该值不是空值。这是 Rust 故意的设计决策,目的是限制 null 的普遍存在,并提高 Rust 代码的安全性。
那么,当您有一个 Option<T> 类型的值时,如何从 Some 变体中获取 T 值,以便使用该值呢? Option<T> 枚举拥有大量在各种情况下都非常有用的方法;您可以在其文档中查看这些方法。熟悉 Option<T> 上的方法将对你的 Rust 之旅大有裨益。
一般来说,要使用 Option<T> 值,需要有代码来处理每个变量。您希望某些代码只在有 Some(T) 值的情况下运行,而这些代码可以使用内部的 T 。而另一些代码只有在有 None 值时才运行,且该代码没有可用的 T 值。 match 表达式是一种控制流结构,当与枚举一起使用时,它就能做到这一点:它将根据枚举的变体运行不同的代码,而这些代码可以使用匹配值内部的数据。
2. match 控制流结构
Rust 有一个非常强大的控制流结构,叫做 match ,它允许你将一个值与一系列模式进行比较,然后根据哪种模式匹配来执行代码。模式可以由字面值、变量名、通配符和许多其他内容组成;match 的威力来自于模式的表现力,以及编译器确认所有可能的情况都已得到处理这一事实。
可以把 match 表达式想象成一台硬币分拣机:硬币在轨道上滑动,轨道上有大小不一的孔,每枚硬币都从它遇到的第一个适合的孔中滑落。同样,数值会穿过 match 中的每个图案,在数值 "适合 "的第一个图案处,数值会落入相关的代码块中,以便在执行过程中使用。
说到硬币,让我们以 match 为例!我们可以编写一个函数,接收一枚未知的美制硬币,然后以类似于点钞机的方式确定它是哪一枚硬币,并返回其价值(以美分为单位),如下面代码所示:
enum Coin {Penny,Nickel,Dime,Quarter,
}fn value_in_cents(coin: Coin) -> u8 {match coin {Coin::Penny => 1,Coin::Nickel => 5,Coin::Dime => 10,Coin::Quarter => 25,}
}
让我们分解一下 value_in_cents 函数中的 match 。首先,我们列出 match 关键字,然后是一个表达式,在本例中是值 coin 。这似乎与 if 中使用的条件表达式非常相似,但有一个很大的区别:在 if 中,条件需要求值为布尔值,但这里可以是任何类型。本例中 coin 的类型是我们在第一行定义的 Coin 枚举。
接下来是 match arm。arm由两部分组成:一个模式和一些代码。第一个arm的模式是 Coin::Penny ,然后是 => 运算符,它将模式和要运行的代码分开。这里的代码就是 1 。每个分支之间用逗号隔开。
match 表达式执行时,会依次将结果值与每个arm的模式进行比较。如果某个模式与数值匹配,则执行与该模式相关的代码。如果该模式与数值不匹配,则继续执行下一个arm,就像硬币排序机一样。我们可以根据需要设置多个臂:在上述代码中,我们的 match 有三个arm。
与每个arm相关的代码都是一个表达式,匹配arm中表达式的结果值就是整个 match 表达式返回的值。
如果匹配arm代码很短,我们通常不使用大括号,就像上述代码中那样,每个匹配arm只返回一个值。如果要在一个匹配arm中运行多行代码,则必须使用大括号,而且匹配臂后面的逗号是可选的。例如,下面的代码在每次调用 Coin::Penny 方法时都会打印 "Lucky Jiao" ,但仍会返回代码块的最后一个值 10 :
fn value_in_cents(coin: Coin) -> u8 {match coin {Coin::Penny => {println!("Lucky penny!");1}Coin::Nickel => 5,Coin::Dime => 10,Coin::Quarter => 25,}
}
2.1 绑定值的模式
匹配arm的另一个有用特性是,它们可以绑定到与模式匹配的值的部分。这就是我们从枚举变体中提取值的方法。
举个例子,让我们改变其中一个枚举变量,在它内部保存数据。从 1999 年到 2008 年,美国铸造了 50 个州一面图案各不相同的 25 分硬币。其他硬币都没有州的图案,因此只有 25 美分硬币有这种额外的价值。我们可以通过修改 Quarter 变量将 UsState 值存储到 enum 中,从而将此信息添加到 中,具体做法如下:
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {Alabama,Alaska,// --snip--
}enum Coin {Penny,Nickel,Dime,Quarter(UsState),
}
假设一位朋友正在努力收集 50 个州的硬币。当我们按照硬币种类对零钱进行分类时,我们也会喊出与每个25美分硬币相关的州名,这样,如果我们的朋友没有这个硬币,他们就可以将其添加到自己的收藏中。
在这段代码的匹配表达式中,我们在模式中添加了一个名为 state 的变量,用于匹配变体 Coin::Quarter 的值。当 Coin::Quarter 匹配时, state 变量将绑定到该quarter的状态值。然后,我们就可以在该arm的代码中使用 state ,就像这样:
fn value_in_cents(coin: Coin) -> u8 {match coin {Coin::Penny => 1,Coin::Nickel => 5,Coin::Dime => 10,Coin::Quarter(state) => {println!("State quarter from {:?}!", state);25}}
}
如果我们调用 value_in_cents(Coin::Quarter(UsState::Alaska)) , coin 就是 Coin::Quarter(UsState::Alaska) 。当我们将该值与每个匹配臂进行比较时,在到达 Coin::Quarter(state) 之前,没有一个匹配arm是匹配的。此时, state 的绑定值将是 UsState::Alaska 。然后,我们就可以在 println! 表达式中使用该绑定,从而从 Coin 枚举变体中获得 Quarter 的内部状态值。
如果我们调用 value_in_cents(Coin::Quarter(UsState::Alaska)) , coin 就是 Coin::Quarter(UsState::Alaska) 。当我们将该值与每个匹配臂进行比较时,在到达 Coin::Quarter(state) 之前,没有一个匹配臂是匹配的。此时, state 的绑定值将是 UsState::Alaska 。然后,我们就可以在 println! 表达式中使用该绑定,从而从 Coin 枚举变体中获得 Quarter 的内部状态值。
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {Alabama,Alaska,// --snip--
}enum Coin {Penny,Nickel,Dime,Quarter(UsState),
}fn main() {let money = Coin::Quarter(UsState::Alaska);value_in_cents(money);
}fn value_in_cents(coin: Coin) -> u8 {match coin {Coin::Penny => 1,Coin::Nickel => 5,Coin::Dime => 10,Coin::Quarter(state) => {println!("State quarter from {:?}!", state);25}}
}
运行结果为:
cargo.exe runCompiling match_flow v0.1.0 (D:\rustProj\match_flow)Finished dev [unoptimized + debuginfo] target(s) in 0.66sRunning `target\debug\match_flow.exe`
State quarter from Alaska!2.2 Matching with Option<T> 与 Option<T>
在上一节中,我们希望在使用 Option<T> 时从 Some 的情况下获取 T 的内部值;我们也可以使用 match 来处理 Option<T> ,就像处理 Coin 枚举一样!我们不比较硬币,而是比较 Option<T> 的变体,但 match 表达式的工作方式保持不变。
比方说,我们要编写一个函数,接收 Option<i32> ,如果里面有一个值,就在该值上加 1。如果里面没有值,函数应该返回 None ,而不试图执行任何操作。
由于使用了 match ,该函数的编写非常简单,与下面代码类似。
fn plus_one(x: Option<i32>) -> Option<i32> {match x {None => None,Some(i) => Some(i + 1),}
}let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
让我们详细研究一下 plus_one 的第一次执行。当我们调用 plus_one(five) 时, plus_one 主体中的变量 x 的值为 Some(5) 。然后,我们将其与每个匹配arm进行比较:
None => None,
Some(5) 值与模式 None 不匹配,因此我们继续下一个arm:
Some(i) => Some(i + 1),Some(5) 与 Some(i) 匹配吗?匹配!我们有相同的变体。 i 与 Some 中的值绑定,因此 i 的值为 5 。然后执行匹配arm中的代码,在 i 的值上加 1,并创建一个新的 Some 值,其中包含我们的总 6 。
现在我们来看看plus_one 的第二次调用,其中 x 就是 None 。我们输入 match 并与第一arm进行比较:
None => None,匹配!没有值可添加,因此程序停止,并返回 => 右侧的 None 值。由于第一个arm匹配,因此不再比较其他arm。
在很多情况下,将 match 与枚举结合起来是非常有用的。在 Rust 代码中,你会经常看到这种模式: match 对应一个枚举,将一个变量与枚举中的数据绑定,然后根据枚举执行代码。一开始有点麻烦,但一旦习惯了,你就会希望在所有语言中都能使用它。它一直是用户的最爱。
2.3 匹配详尽
我们还需要讨论 match 的另一个方面:arm的模式必须涵盖所有可能性。请看我们这个版本的 plus_one 函数,它有一个错误,无法编译:
fn main() {let five = Some(5);let six = plus_one(five);let none = plus_one(None);
}fn plus_one(x: Option<i32>) -> Option<i32> {match x {Some(i) => Some(i + 1),}
}我们没有处理 None 的情况,因此这段代码会导致错误。幸运的是,Rust 知道如何捕获这个错误。如果我们尝试编译这段代码,就会出现这个错误:
cargo.exe runCompiling match_flow v0.1.0 (D:\rustProj\match_flow)
error[E0004]: non-exhaustive patterns: `None` not covered--> src\main.rs:5:11|
5 | match x {| ^ pattern `None` not covered|
note: `Option<i32>` defined here--> /rustc/82e1608dfa6e0b5569232559e3d385fea5a93112\library\core\src\option.rs:569:1::: /rustc/82e1608dfa6e0b5569232559e3d385fea5a93112\library\core\src\option.rs:573:5|= note: not covered= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown|
6 ~ Some(i) => Some(i + 1),
7 ~ None => todo!(),|For more information about this error, try `rustc --explain E0004`.
error: could not compile `match_flow` (bin "match_flow") due to previous errorRust 知道我们没有涵盖所有可能的情况,甚至知道我们忘记了哪种模式!Rust 中的匹配是穷举性的:我们必须穷举每一种可能,代码才能有效。特别是在 Option<T> 的情况下,当 Rust 防止我们忘记显式处理 None 的情况时,它保护了我们,使我们不会在可能有 null 的情况下假设我们有一个值,从而使前面讨论的价值十亿美元的错误不可能发生。
2.4 万能模式和 “_”占位符
使用枚举,我们还可以对一些特定值采取特殊操作,而对所有其他值采取默认操作。试想一下,我们在实现一个游戏时,如果掷骰子掷出 3,玩家不会移动,但会得到一顶新的花式帽子。如果掷出的骰子是 7,玩家就会失去一顶华丽的帽子。对于所有其他数值,玩家都会在游戏板上移动相应数量的空间。下面是实现该逻辑的 match ,其中掷骰子的结果是硬编码,而不是随机值,所有其他逻辑都由没有主体的函数表示,因为实际实现这些函数不在本例的范围之内:
let dice_roll = 9;
match dice_roll {3 => add_fancy_hat(),7 => remove_fancy_hat(),other => move_player(other),
}fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn move_player(num_spaces: u8) {}
对于前两个arm,模式是字面值 3 和 7 。对于涵盖所有其他可能值的最后一个arm,模式是我们选择命名为 other 的变量。 other分支运行代码通过将变量传递给 move_player 函数来使用该变量。
即使我们没有列出 u8 可能具有的所有值,这段代码也能编译成功,因为最后一个模式将匹配所有未具体列出的值。这种包罗万象的模式符合 match 必须详尽无遗的要求。需要注意的是,我们必须把 "catch-all" arm 放在最后,因为模式是按顺序评估的。如果我们把 "全包 " arm放在前面,其他arm就不会运行,所以如果我们在 "全包 "arm之后添加arm,Rust 就会发出警告!
Rust 还有一种模式,当我们需要一个 catch-all,但又不想使用 catch-all 模式中的值时,可以使用: _ 是一种特殊的模式,它可以匹配任何值,但不会绑定到该值。这告诉 Rust 我们不会使用该值,因此 Rust 不会警告我们存在未使用的变量。
让我们改变一下游戏规则:现在,如果掷出的不是 3 或 7,就必须再掷一次。我们不再需要使用万能值,因此可以修改代码,使用 _ 代替名为 other 的变量:
fn main() {let dice_roll = 9;match dice_roll {3 => add_fancy_hat(),7 => remove_fancy_hat(),_ => reroll(),}
}fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn reroll() {}
这个例子也符合穷举要求,因为我们明确忽略了最后一arm中的所有其他值;我们没有遗忘任何东西。
最后,我们再改变一次游戏规则,如果掷出的不是 3 或 7,则在你的回合中不会发生任何其他事情。我们可以通过使用单位值(我们在 "元组类型 "一节中提到的空元组类型)作为 “_”的arm 分支代码来表达这一点:
fn main() {let dice_roll = 9;match dice_roll {3 => add_fancy_hat(),7 => remove_fancy_hat(),_ => (),}
}fn add_fancy_hat() {}
fn remove_fancy_hat() {}
在这里,我们明确地告诉 Rust,我们不会使用任何不符合先前臂中模式的其他值,而且我们不想在这种情况下运行任何代码。
3. if let简明控制流
if let 语法使您可以将 if 和 let 结合起来,以一种不那么冗长的方式来处理只匹配一种模式而忽略其他模式的值。请看如下代码示例,它与 config_max 变量中的 Option<u8> 值匹配,但只想在该值是 Some 变体时执行代码。
let config_max = Some(3u8);
match config_max {Some(max) => println!("The maximum is configured to be {}", max),_ => (),
}
如果值是 Some ,我们就将该值绑定到模式中的变量 max ,打印出 Some 变量中的值。我们不想对 None 的值做任何处理。为了满足 match 表达式的要求,我们必须在只处理一个变量后添加 _ => () ,而这是令人讨厌的模板代码。
相反,我们可以使用 if let 以更简短的方式编写。以下代码的行为与上述中的 match 相同:
let config_max = Some(3u8);
if let Some(max) = config_max {println!("The maximum is configured to be {}", max);
}
语法 if let 包含一个模式和一个表达式,以等号分隔。它的工作方式与 match 相同,其中表达式提供给 match ,而模式则是其第一arm。在本例中,模式是 Some(max) ,而 max 与 Some 中的值绑定。然后,我们可以在 if let 块的主体中使用 max ,方法与在相应的 match arm 中使用 max 相同。如果值与模式不匹配,就不会运行 if let 代码块中的代码。
使用 if let 意味着更少的键入、更少的缩进和更少的模板代码。但是,您将失去 match 所提供的详尽检查功能。在 match 和 if let 之间做出选择,取决于您在特定情况下要做什么,以及在失去详尽检查的情况下,获得简洁性是否是一个适当的权衡。
换句话说,你可以把 if let 看作是 match 的语法糖,当值与一种模式匹配时,它就会运行代码,然后忽略所有其他值。
我们可以在 if let 中包含 else 。与 else 对应的代码块与 match 表达式中与 _ 对应的代码块相同,后者等同于 if let 和 else 。回顾Coin 枚举定义,其中 Quarter 变体还包含一个 UsState 值。如果我们想计算所看到的所有非四角硬币,同时公布四角硬币的状态,我们可以使用 match 表达式,如下所示:
let mut count = 0;
match coin {Coin::Quarter(state) => println!("State quarter from {:?}!", state),_ => count += 1,
}
或者,我们可以使用 if let 和 else 表达式,就像这样:
let mut count = 0;
if let Coin::Quarter(state) = coin {println!("State quarter from {:?}!", state);
} else {count += 1;
}
如果程序中的逻辑过于冗长,无法使用 match 来表达,请记住 if let 也在 Rust 工具箱中。
下一篇: 07-用软件包、cratres和模块管理项:
相关文章:

06-枚举和模式匹配
上一篇:05-使用结构体构建相关数据 在本章中,我们将介绍枚举。枚举允许你通过枚举其可能的变体来定义一种类型。首先,我们将定义并使用一个枚举,以展示枚举如何与数据一起编码意义。接下来,我们将探索一个特别有用的枚…...

【C/C++】C/C++编程——C++ 开发环境搭建
C的开发环境种类繁多,以下是一些常见的C 集成开发环境: AppCode :构建与JetBrains’ IntelliJ IDEA 平台上的用于Objective-C,C,C,Java和Java开发的集成开发环境CLion:来自JetBrains的跨平台的C/C的集成开…...

Go 接口
接口概览 接口大概理解 接口类型是队其他类型行为的概括与抽象 接口类型中,包含函数声明,但没有数据变量接口的作用通过使用接口,可以写出更加灵活和通用的函数,这些函数不用绑定在一个特定的类型实现上Go 接口特征 很多面向对象…...
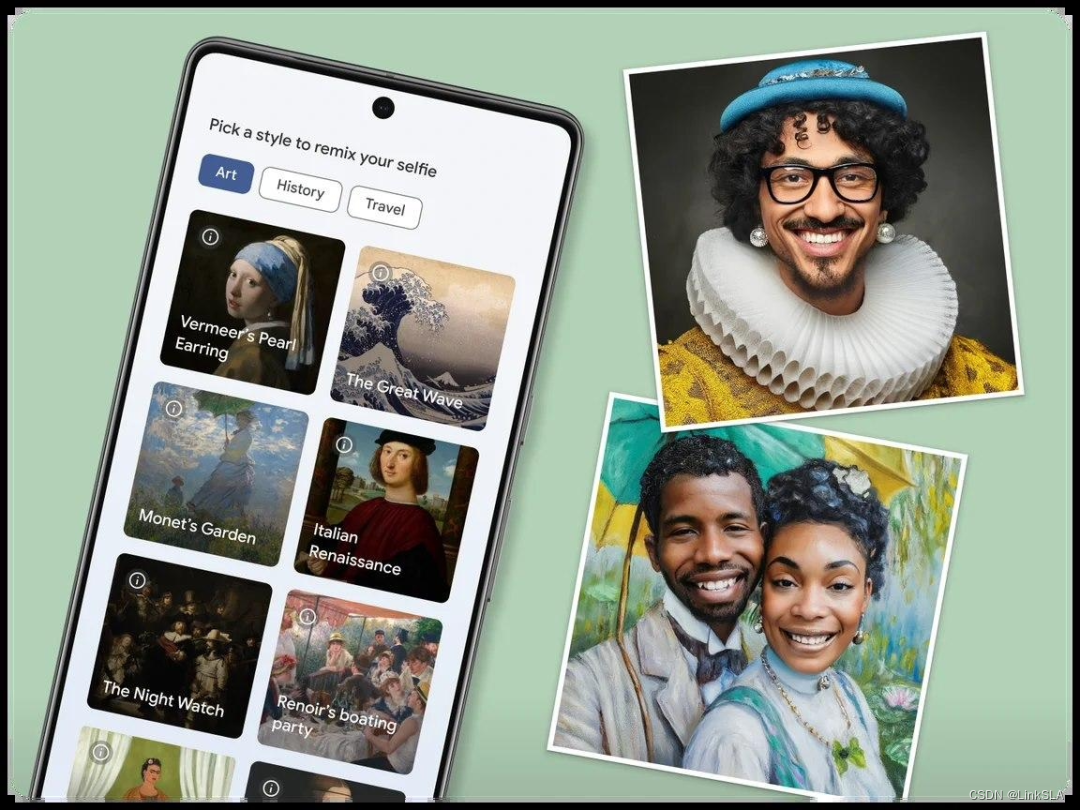
用 AI 将自拍照 P 进不同艺术作品,谷歌发布「艺术自拍 2」
1 月 24 日消息,谷歌旗下「艺术与文化」应用今日宣布,2018 年推出的「艺术自拍」功能在时隔近六年后,借助生成式 AI 的力量回归。官方表示,「艺术自拍 2」将再次使用户与艺术面对面,重新探访世界各地的艺术、历史和文化…...
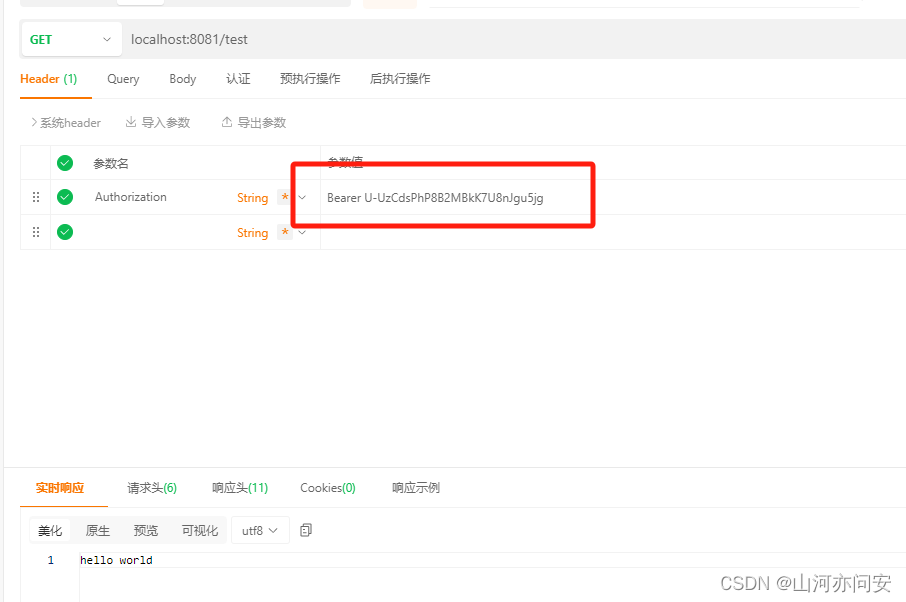
SpringSecurity+OAuth2.0 搭建认证中心和资源服务中心
目录 1. OAuth2.0 简介 2. 代码搭建 2.1 认证中心(8080端口) 2.2 资源服务中心(8081端口) 3. 测试结果 1. OAuth2.0 简介 OAuth 2.0(开放授权 2.0)是一个开放标准,用于授权第三方应用程序…...

c# 策略模式
在 C# 中,策略模式是一种行为型设计模式,它定义了一系列算法,并将每个算法封装到具有公共接口的独立类中,使得它们可以互相替换。这样可以使得算法的选择独立于算法的使用者,从而提高了灵活性和可维护性。 以下是策略…...

消息队列RabbitMQ.03.死信交换机的讲解与使用
目录 一、死信队列(延迟队列) 概念讲解 二、确认消息(局部方法处理消息) 三、代码实战 1.编写生产者代码,配置消息、直连交换机、路由键 1.1代码解析: 2.配置消费者接受类接受直连交换机的路由键 2.1. String msgÿ…...
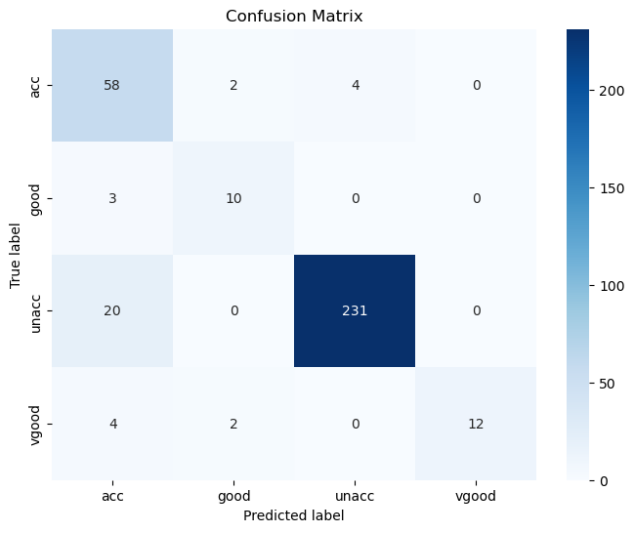
人工智能原理实验4(2)——贝叶斯、决策求解汽车评估数据集
🧡🧡实验内容🧡🧡 汽车数据集 车子具有 buying,maint,doors,persons,lug_boot and safety六种属性,而车子的好坏分为uncc,ucc,good and vgood四种。 🧡🧡贝叶斯求解🧡🧡…...

算力网络:未来计算资源的驱动力
文章目录 前言一、算力网络的基本概况(一)算力网络的基本概念(二)算力网络研究进展二、运营商的算力网络架构(一)算力网络基础设施构成(二)算力网络编排管理(三)能力开放三、算力网络的优势(一)弹性计算(二)降低成本(三)去中心化四、算力网络的应用场景(一)人…...

java动态导入excel按照表头生成数据库表
1、创建接口接收文件 //controller层 PostMapping("/importExcel1")public void importExcel1(HttpServletRequest request, MultipartFile file) {try {waterMeterService.importExcel1(request,file);} catch (Exception e) {throw new RuntimeException(e);}}//se…...

Java 集合List相关面试题
📕作者简介: 过去日记,致力于Java、GoLang,Rust等多种编程语言,热爱技术,喜欢游戏的博主。 📗本文收录于java面试题系列,大家有兴趣的可以看一看 📘相关专栏Rust初阶教程、go语言基…...
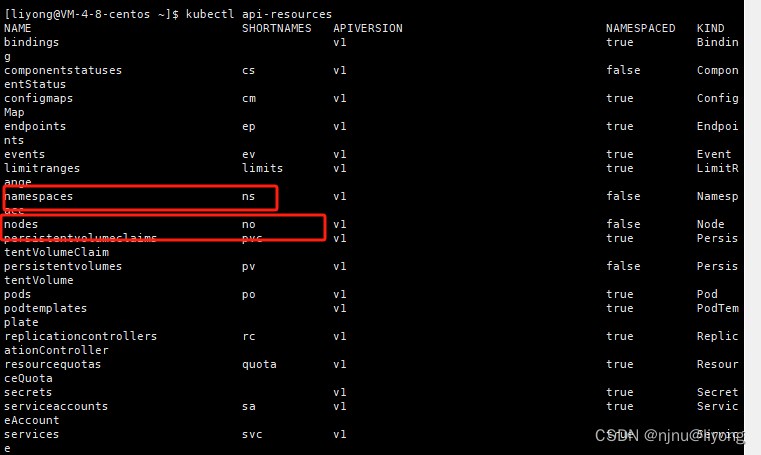
k8s-基础知识(Pod,Deployment,ReplicaSet)
k8s职责 自动化容器部署和复制随时扩展或收缩容器容器分组group,并且提供容器间的负载均衡实时监控,即时故障发现,自动替换 k8s概念及架构 pod pod是容器的容器,可以包含多个container pod是k8s最小可部署单元,容器…...

matlab查看源代码
matlab函数源代码-查看 CtrlD 最简单方便的一种方法,鼠标划中函数名,按CTRLD即可打开函数的m文件...

【数据库学习】PostgreSQL优化
1,思路 2,执行计划 explain sql语句; #查看执行计划。也可以使用navicat的解释功能查看。结果说明: QUERY PLAN Index Scan using tenk1_unique1 on tenk1 (cost0.00..10.01 rows1 width244) --Index 使用索引 --cost&#x…...

微信小程序分页加载功能,结合后端实现上拉底部加载下一页数据,数据加载中和暂无数据提示
🤵 作者:coderYYY 🧑 个人简介:前端程序媛,目前主攻web前端,后端辅助,其他技术知识也会偶尔分享🍀欢迎和我一起交流!🚀(评论和私信一般会回&#…...

idea 打包跳过测试
IDEA操作 点击蓝色的小球 手动命令 mvn clean package -Dmaven.test.skiptrue...

python sqlite3 线程池封装
1. 封装 sqlite3 1.1. 依赖包引入 # -*- coding: utf-8 -*- #import os import sys import datetime import loggingimport sqlite31.2. 封装类 class SqliteTool(object):#def __init__(self, host, port, user, password, database):def __init__(self, host, database):s…...

亚马逊运营:如何通过自养号测评有效防关联,避免砍单
店铺安全对于跨境电商卖家至关重要,它是我们业务稳定运营的基础。一旦店铺遭到亚马逊的封禁,往往意味着巨大的损失。因此,合规运营已经成为了卖家们的共识。然而,许多卖家可能会因为一些看似微小的失误,导致店铺被关联…...

winfrom图像加速渲染时图像不显示
winform中加入这段代码,即使不调用也会起作用;当图像不显示时,可以注释掉这段代码...

Redash 默认key漏洞(CVE-2021-41192)复现
Redash是以色列Redash公司的一套数据整合分析解决方案。该产品支持数据整合、数据可视化、查询编辑和数据共享等。 Redash 10.0.0及之前版本存在安全漏洞,攻击者可利用该漏洞来使用已知的默认值伪造会话。 1.漏洞级别 中危 2.漏洞搜索 fofa "redash"…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...