PyTorch的衍生资源
PyTorch作为深度学习领域的一个重要框架,自2016年首次发布以来经历了显著的发展。以下是PyTorch发展过程中的几个关键里程碑事件:
-
2016年:
- PyTorch于2016年首次发布,作为一个基于动态计算图的开源机器学习库,它提供了自动微分功能,并强调代码可读性和灵活性。
-
2017年:
- 发布了PyTorch 0.2版本,引入了许多新特性,如对Windows操作系统的支持、多GPU训练等。
- 这一年,PyTorch在学术界和工业界逐渐流行起来,吸引了众多研究人员和开发者使用。
-
2018年:
- PyTorch 1.0发布,带来了一系列重大更新,包括与Caffe2的集成,使得模型可以无缝部署到生产环境,同时提供ONNX(Open Neural Network Exchange)支持,方便模型跨平台和框架转换。
- Facebook宣布将PyTorch作为其主要研究框架,并承诺投入更多资源进行开发和维护。
-
2019年:
- PyTorch Lightning项目的推出,旨在简化PyTorch中训练神经网络的过程,特别是对于那些需要实现复杂训练循环的研究人员来说。
- 更多官方预训练模型库出现,如Transformers和TorchVision等,促进了NLP和计算机视觉领域的研究。
-
2020年:
- PyTorch Mobile和PyTorch.js发布,允许模型在移动设备和浏览器上运行。
- PyTorch Profiler工具增强,帮助用户更好地分析和优化模型性能。
-
2021年及以后:
- PyTorch持续扩展其生态系统,包含更多的子库和服务,如TorchText(用于处理文本数据)、TorchAudio(用于音频处理)、TorchServe(用于模型服务部署)等。
- 对分布式训练、混合精度训练等高级特性的改进和支持。
- 开始支持更多的硬件后端,例如AMD ROCm和Intel oneAPI等。
这些里程碑事件推动了PyTorch从一个新兴框架成长为业界广泛认可的标准工具之一,为深度学习和机器学习研究与应用开发提供了强大支持。随着技术的不断发展,PyTorch还将继续创新和完善其功能,以满足日益增长的AI需求。
PyTorch作为一个广泛使用的开源深度学习框架,支持调用许多外部库资源以扩展其功能,拥有丰富的生态系统和众多衍生资源。这些衍生资源极大地扩展了PyTorch的功能性,并帮助用户更高效地进行各种机器学习和深度学习任务的研究与开发工作。
1. 外部库资源
一些在GitHub上获星较多的PyTorch相关项目可能包括但不限于:Fairseq(用于序列到序列学习和Transformer模型)、Detectron2(Facebook AI的物体检测库)、Transformers(Hugging Face的预训练模型库,支持多种NLP任务)、Pyro(概率编程库)、Lightning(简化PyTorch模型训练流程)等。
以下是一些与PyTorch兼容并被广泛使用的外部库:
-
Hugging Face Transformers:提供了大量的预训练Transformer模型(如BERT、GPT-2、GPT-3等)及其配套的分词器,用于自然语言处理任务。
-
torchtext:为PyTorch提供了一系列工具和数据集,简化了NLP任务的数据加载、预处理以及文本生成等任务。
-
torchvision:包含图像处理相关的数据集(如CIFAR10、MNIST)、数据加载器和预训练模型(如ResNet、AlexNet等),适用于计算机视觉任务。
-
torchaudio:针对音频处理提供了多种工具和预训练模型,帮助用户处理音频数据和进行语音识别、声纹识别等相关任务。
-
detectron2:Facebook AI Research (FAIR) 开发的用于物体检测、语义分割和其他视觉任务的库,基于PyTorch构建。
-
pytorch-lightning:一个高级接口,旨在简化模型开发、训练和调试流程,并且能轻松地在多个GPU上运行和监控训练过程。
-
apex:NVIDIA提供的一个库,包含混合精度训练、动态损失缩放以及其他优化技术,用于加速PyTorch中的深度学习训练。
-
einops:提供了一种统一的操作符来实现张量的重塑、批处理操作以及逐元素运算,使得代码更具有可读性和可复用性。
-
tensorboardX:对接TensorBoard,可以可视化PyTorch模型的训练进度、损失曲线、权重分布等信息。
-
hydra-core:一个用于配置管理和命令行参数解析的库,有助于组织和管理复杂的实验设置。
-
pytorch-metric-learning:用于度量学习(Metric Learning)任务,如生成深度学习模型中的嵌入空间,并在该空间中实现样本之间的相似性度量。
-
** ignite**:PyTorch的一个高性能机器学习和深度学习训练库,提供了一套简洁易用的API来构建复杂的训练循环、评估程序以及可视化工具。
-
gpytorch:基于PyTorch构建的高斯过程(Gaussian Processes)库,常用于贝叶斯优化、不确定性建模和其他回归/分类问题。
-
pyro:开源的概率编程库,可以与PyTorch结合使用,支持贝叶斯统计推断和深度概率编程。
-
optuna 或 nevergrad:这两个是超参数优化库,可与PyTorch配合使用,自动调整模型的超参数以达到最佳性能。
-
pytorch-forecasting:时间序列预测库,针对各种时间序列数据集提供了预处理、模型训练和评估的功能。
-
lightning-bolts:作为PyTorch Lightning生态的一部分,包含大量预先实现的模块、损失函数和数据集,便于快速开发新的实验。
-
albumentations:图像增强库,可用于对训练图像进行各种变换,提高模型的泛化能力,尤其在计算机视觉领域。
-
deepspeed:提供了优化器、混合精度训练等功能,能够加速大规模模型的训练,尤其是对于大模型如GPT-3等。
-
torchmetrics:由PyTorch Lightning团队开发,为PyTorch项目提供了广泛的评估指标集合,方便地追踪和报告模型性能。
这些库通过提供丰富的模块、工具和API,极大地增强了PyTorch的功能性、易用性和效率。
2. Hugging Face社区
Hugging Face社区是围绕自然语言处理(NLP)和机器学习技术构建的一个活跃且开放的开发者、研究者以及爱好者平台。该社区以其同名开源项目“Hugging Face”而知名,特别是transformers库,这个库已经成为预训练模型在NLP领域应用的事实标准之一。
2.1 社区特点:
-
模型与数据集共享:Hugging Face Model Hub:提供了一个集中存储和分享预训练模型的地方,用户可以在这里找到各种基于Transformer架构和其他NLP模型,涵盖BERT、GPT、T5等系列,并且支持多种任务类型。
-
开源文化:社区鼓励并支持开源贡献,成员可以上传自己的模型、数据集和代码实现,共同推动NLP的发展。
-
交流讨论:社区论坛(Forum)上,成员们可以提问、分享经验、解决问题,涵盖了从初学者入门到高级实践的各种话题。
-
资源丰富:提供了大量的教程、博客文章、示例代码和文档,帮助新手快速上手和老手深入探索。
-
合作与竞赛:举办各类挑战赛、研讨会等活动,促进学术界与工业界的交流合作,推动NLP前沿技术的应用与创新。
-
工具与服务:除了
transformers库之外,社区还提供了其他有用的工具,如datasets库(用于管理大规模数据集)、Tokenizers库(用于文本预处理)和Gradio库(用于交互式演示模型效果)等。
总之,Hugging Face社区是一个包容性强、互动频繁、资源丰富的平台,在这里,全球的研究者和开发者共同努力,推进了自然语言处理技术的进步和应用普及。
2.2 社区资源:
Hugging Face社区开发和维护的库主要包括以下几个:
-
transformers库:这是Hugging Face最为知名的库,提供了大量预训练模型的支持,包括但不限于BERT、GPT-2/3、RoBERTa、T5、DistilBERT等。这些模型基于Transformer架构,覆盖了多种NLP任务,如文本分类、问答系统、文本生成、命名实体识别等。通过
transformers库,用户可以轻松加载预训练模型并进行微调以适应特定任务。 -
datasets库:该库用于简化大规模数据集的管理和处理流程,包含了许多流行的自然语言处理和计算机视觉领域的数据集,并支持自定义数据集。它提供了一致且高效的API来加载、预处理和操作数据集,方便研究人员快速构建机器学习和深度学习应用。
-
Tokenizers库:一个高性能的分词器库,支持多种分词算法(如Byte-Pair Encoding, WordPiece等),并且与
transformers库中的模型紧密集成。用户可以使用此库对文本进行高效编码和解码,以及词汇表管理。 -
Gradio库:Gradio是一个开源库,用于快速创建和分享机器学习模型的交互式演示界面。用户可以使用几行代码就构建出可视化应用程序,使得非技术用户也能上传输入并实时查看模型预测结果。
-
Spaces:Hugging Face Spaces是社区成员展示项目、模型和教程的一个平台,允许用户创建交互式的网页来共享他们的研究成果和实践经验。
-
Model Hub:虽然不是一个库,但Hugging Face Model Hub是一个重要的资源中心,它作为一个在线存储库,收集了大量的预训练模型和数据集,供开发者和研究者下载、分享和复用。
-
Inference API 和 Model Serving:Hugging Face还提供了API服务,使得用户可以直接在云端部署和调用预训练模型进行推理,无需本地部署模型。
以上每个库都有详细的文档说明和示例代码,为NLP和AI领域的研究者及开发者提供了极大的便利。此外,Hugging Face社区还在持续开发和维护其他相关的工具和服务,以满足日益增长的AI研究和开发需求。这些工具使得整个NLP生态系统变得更加丰富和完善,促进了AI技术在各个领域的普及和应用。
2.3 Transformers库详细介绍:
Hugging Face Transformers库是一个广泛使用的Python库,它集成了大量的预训练模型,涵盖了自然语言处理(NLP)领域的多种任务和架构。随着时间的推移,该库中包含的模型数量不断增加,Transformers库已经整合了包括但不限于以下预训练模型:
-
BERT 及其变体:BERT, BERT-Base, BERT-Large, DistilBERT, ALBERT, RoBERTa, SpanBERT等。
-
GPT系列:GPT, GPT-2, GPT-3(虽然GPT-3不直接提供完整模型,但支持通过API使用),以及相关的开源实现如GPT-NeoX、GPT-J等。
-
Transformer-XL 和 XLNet,分别用于处理长文本序列和引入顺序感知自回归机制。
-
T5 文本到文本转换模型及各种规模版本。
-
MT5 是多语言版的T5,用于处理多种语言的任务。
-
Electra 采用了生成对抗网络思路进行预训练。
-
Reformer 和 Longformer 针对长文档优化的模型,减少内存消耗并提高效率。
-
BERTweet 专门针对推文数据训练的BERT模型。
-
XLM-RoBERTa (XLM-R) 是一个大规模的多语言预训练模型。
-
DeBERTa 和 DeBERTa-v2 对BERT进行了改进,增强了模型的表达能力。
-
BigBird 是Google提出的可以处理更长上下文的稀疏注意力Transformer模型。
-
ConvBERT 结合了卷积神经网络和Transformer的优点。
此外,库中还包括大量针对特定任务或语言定制的预训练模型,例如语音相关的Wav2Vec2、Speech2Text,以及其他公司和研究团队发布的各种预训练模型。随着NLP领域的发展和社区贡献,Transformers库中的模型种类会持续增长和更新。要获取最新最全的模型列表,建议直接访问Hugging Face Model Hub查看。
2.4 Transformers库预训练模型的调用:
在Hugging Face Transformers库中,调用预训练模型进行预测和微调通常涉及以下步骤:
载入预训练模型
Python
1 from transformers import AutoModel, AutoTokenizer
2
3 # 指定模型名称或路径
4 model_name = "bert-base-uncased" # 例如使用BERT的预训练模型
5
6 # 加载模型与对应的tokenizer
7 tokenizer = AutoTokenizer.from_pretrained(model_name)
8 model = AutoModel.from_pretrained(model_name)Hugging Face Transformers库中的model_name可以是众多预训练模型的名称,这些模型涵盖了多种架构和任务。以下是一些流行和广泛使用的预训练模型示例:
-
BERT 系列:
bert-base-uncasedbert-large-casedbert-base-multilingual-cased
-
GPT 系列:
gpt2gpt-neogpt-jgpt3(通过API访问)
-
GPT-3衍生模型 (如在Transformers库中可用的小型化版本):
gpt3-smallgpt3-mediumgpt3-large
-
RoBERTa 系列:
roberta-baseroberta-large
-
DistilBERT:
distilbert-base-uncased
-
ALBERT:
albert-base-v2albert-large-v2
-
T5:
t5-smallt5-baset5-large
-
XLM-RoBERTa:
xlm-roberta-basexlm-roberta-large
-
Electra:
electra-base-discriminatorelectra-large-generator
以及更多来自不同研究机构和个人贡献者上传到Hugging Face Model Hub上的模型。最新或所有可用模型列表,请查阅模型库以获取最准确和最新的信息。
预测(快速推理)
可以使用pipeline API来简化预测过程,比如文本分类任务:
Python
1 from transformers import pipeline
2
3 # 创建一个文本分类pipeline
4 classifier = pipeline("text-classification", model=model_name)
5
6 # 进行预测
7 prediction = classifier("This is an example text to classify.")
8 print(prediction)对于更复杂的任务,如生成、问答等,也有相应的pipeline。
自定义预测(手动处理输入)
如果你需要对模型的输入输出有更多控制,可以手动编码和解码:
Python
1# 对文本进行编码
2inputs = tokenizer("Hello, world!", return_tensors="pt")
3
4# 获取模型预测
5outputs = model(**inputs)
6
7# 根据模型类型处理输出,例如对于Bert模型提取[CLS]标记的隐藏状态用于分类任务
8last_hidden_state = outputs.last_hidden_state[:, 0]
9
10# 对于生成任务,如GPT-2,则需使用模型的生成方法
11generated_text = model.generate(inputs["input_ids"], max_length=100, num_return_sequences=1, no_repeat_ngram_size=2, do_sample=True)
12decoded_text = tokenizer.decode(generated_text[0], skip_special_tokens=True)微调模型
微调通常包括数据预处理、构建DataLoader、设置训练参数,并调用Trainer类:
Python
1from transformers import Trainer, TrainingArguments
2
3# 定义训练参数
4training_args = TrainingArguments(
5 output_dir='./results',
6 num_train_epochs=3,
7 per_device_train_batch_size=8,
8 logging_dir='./logs',
9 evaluation_strategy="epoch",
10)
11
12# 定义微调函数
13def compute_metrics(eval_pred):
14 predictions, labels = eval_pred
15 # 根据具体任务计算指标,例如准确率
16 accuracy = (predictions.argmax(axis=-1) == labels).float().mean()
17 return {"accuracy": accuracy}
18
19# 训练集、验证集准备
20train_dataset = ... # 使用datasets库加载或自定义数据集
21eval_dataset = ...
22
23# 初始化Trainer
24trainer = Trainer(
25 model=model,
26 args=training_args,
27 train_dataset=train_dataset,
28 eval_dataset=eval_dataset,
29 compute_metrics=compute_metrics,
30)
31
32# 开始微调
33trainer.train()请注意,以上代码仅为示例,并且实际使用时需要根据特定任务需求进行调整。同时,请确保已安装最新版本的Transformers库并查阅官方文档以获取最新API指南。
3. Torchaudio
3.1 Torchaudio的发展历程
Torchaudio的发展历程与PyTorch深度学习框架紧密相关。以下是Torchaudio从创建到发展的大致过程:
-
起源:Torchaudio最初作为PyTorch社区的一个扩展项目,旨在为音频处理提供一套完整的工具集和API接口,使得音频数据能够方便地被整合到基于PyTorch的机器学习和深度学习应用中。
-
发布:它在PyTorch发展过程中逐步成熟,并于2019年正式成为PyTorch官方支持的一部分,作为一个专门用于音频处理的子库对外发布。
-
功能完善:随着时间的推移,Torchaudio的功能不断完善,增加了对多种音频文件格式的支持、提供了丰富的音频信号处理函数以及音频特征提取工具(如Mel频谱图、MFCC等)。同时,Torchaudio也优化了GPU加速能力,确保音频处理操作可以高效地在CUDA设备上运行。
-
社区贡献:由于其开源属性,Torchaudio得到了来自全球开发者和研究者的广泛支持和贡献,不断有新的功能和优化添加进来,例如更先进的音频处理算法、更好的集成示例代码以及与更多音频数据集的兼容性。
-
持续更新与维护:目前,Torchaudio仍然在积极开发和维护中,随着音频领域技术的发展和PyTorch框架本身的升级,Torchaudio也在不断适应并满足用户在音频分析、语音识别、音乐生成等任务上的需求。
总之,Torchaudio自诞生以来,始终紧跟AI和深度学习技术的步伐,通过集成进PyTorch生态系统,极大地推动了音频相关的机器学习研究和应用开发。
3.2 Milestones
Torchaudio库发展中的几个关键里程碑事件:
-
发布与初步建设(2019年初):
- Torchaudio作为PyTorch的一部分,在2019年初正式发布,旨在简化音频处理和分析任务,并且能够轻松与PyTorch深度学习框架集成。
-
核心功能实现(2019-2020年):
- 提供了加载和保存多种音频文件格式的功能,包括WAV、MP3等。
- 实现了一系列音频信号处理操作,如重采样、归一化、分帧、窗口函数应用、STFT转换、梅尔频谱图生成等。
- 集成了用于特征提取的常见方法,例如MFCC(梅尔频率倒谱系数)计算。
-
模型支持扩展(2020-至今):
- 随着研究的发展,Torchaudio开始支持更多预训练音频模型,比如Facebook AI Research (FAIR) 开发的Wave2Vec 2.0模型及其变体,这些模型可以直接在Torchaudio中加载和使用,进行语音识别或其它下游任务。
-
性能优化与API改进(持续更新):
- 不断对内部代码进行优化,提高音频处理速度,特别是在GPU上的并行计算能力。
- 根据用户反馈和社区需求,Torchaudio不断完善其API设计,使其更加易用且灵活。
-
社区贡献与生态建设(持续增长):
- 社区贡献者积极提供新的功能和示例代码,使得Torchaudio成为一个活跃的开源项目,不仅局限于音频数据预处理,也逐渐覆盖到整个音频处理流水线,从数据准备到模型训练及评估。
请参考官方文档和GitHub仓库以获取Torchaudio最新、最准确的里程碑事件和发展情况。
3.3 Torchaudio内部构成
Torchaudio是PyTorch库的一个子模块,专注于音频处理和分析,为音频信号处理和音频相关的深度学习任务提供了丰富的工具集。它不仅包含了一系列用于加载、预处理和转换音频数据的函数和类,而且还支持开发人员构建复杂的音频处理管道,并将这些操作无缝集成到基于PyTorch的神经网络模型中。虽然没有详尽的内部实现细节,但可以概述Torchaudio主要包含以下几个核心部分:
-
音频I/O:
torchaudio.load():用于从文件中加载音频数据,返回一个张量(Tensor)代表音频信号,并提供采样率等元数据。torchaudio.save():将张量形式的音频数据保存为指定格式的音频文件。
-
数据转换与处理:
torchaudio.transforms:一系列预定义的变换函数,包括但不限于重采样、归一化、分帧窗口、Mel频谱转换、MFCC计算等。
-
实用功能:
- 音频信号基本操作:如混音、增益控制、裁剪、声道混合等。
- 特征提取:提供多种音频特征计算方法,如梅尔频率倒谱系数(MFCC)、梅尔谱图、功率谱密度估计等。
-
实用工具:
torchaudio.functional:包含一些高级的音频信号处理函数,如将幅度谱或功率谱转换为对数尺度(分贝dB)。 -
深度学习友好接口:
将音频数据适配于深度学习模型输入,通过上述转换生成适合神经网络训练的特征表示。 -
集成模型与示例:
提供了一些预训练模型或相关应用的代码示例,帮助用户快速入门音频领域的深度学习项目。 -
后端支持:
内部可能依赖于不同的音频处理后端,例如在某些情况下使用librosa等第三方库进行高效处理。
总之,Torchaudio的设计目的是简化音频数据的加载和预处理流程,使音频信号能够方便地与PyTorch的神经网络模型相结合,从而便于研究人员和开发者在音频领域开展深度学习研究和应用开发。
3.4 Torchaudio的使用实例
利用Torchaudio实现语音识别任务:虽然Torchaudio本身不提供完整的端到端的语音识别系统实现,但它可以作为构建此类系统的基石。以下是一个大致步骤来说明如何利用Torchaudio和其他相关组件(如Wav2Vec 2.0或其他语音识别模型)实现一个简单的语音识别流程:
数据加载:使用Torchaudio加载音频文件,将其转换为Tensor格式。
Python
1import torchaudio
2waveform, sample_rate = torchaudio.load("path_to_your_audio_file.wav")预处理:对音频信号进行必要的预处理,如归一化、分帧、加窗、提取MFCC特征等。
Python
1transforms = torchaudio.transforms.MFCC(sample_rate=sample_rate)
2mfcc_features = transforms(waveform)使用预训练模型:利用已经预训练好的语音识别模型,比如Facebook AI的Wav2Vec 2.0模型。这些模型通常在大型无标签或带标签的数据集上预先训练,然后可以微调以适应特定语言的语音识别任务。
Python
1# 假设你已经有了一个名为wav2vec_model的预训练模型
2encoded_audio = wav2vec_model.encode(waveform)解码与预测文本:将编码后的音频特征传递给解码器,例如CTC解码器或其他序列转导模型,以生成文本预测。
Python
1# 假设你有一个名为decoder的CTC解码器
2predicted_transcription = decoder.decode(encoded_audio)微调和训练:如果你需要针对特定领域的语音数据进行微调,那么需要准备对应的带标签数据,并通过反向传播和优化算法更新模型参数。
后处理:对预测出的原始文本进行后处理,如删除重复字符、空格修正等。
要实现上述步骤,请确保安装了torchaudio库以及相关的语音识别模型包,如fairseq(用于Wav2Vec 2.0)。具体代码可能会根据所选模型的不同而有所差异。同时,对于实际项目,还需要考虑语音活动检测(VAD)、噪音抑制、回声消除等额外步骤以提升识别性能。
4. Torchvision
4.1 Milestones
Torchvision库发展中的几个关键里程碑事件:
-
发布与初步建设(2016-2017年):
- 2016年随着PyTorch项目一同发布,初始版本提供了基本的图像处理工具、数据加载器以及经典计算机视觉模型架构如AlexNet、VGG、ResNet等。
- 支持了COCO和ImageNet等标准计算机视觉数据集的加载。
-
功能扩展与优化(2018-2020年):
- 添加对更多深度学习模型的支持,例如DenseNet、Inception系列等。
- 引入更多的数据增强变换方法以提高模型泛化能力。
- 不断改进API设计和性能优化,尤其是在GPU上的加速处理。
-
预训练模型库的丰富与发展(2019-至今):
- 提供了大量预训练模型的权重下载,使得用户可以直接基于预训练模型进行迁移学习。
- 随着新的研究进展,及时将EfficientNets、Vision Transformer (ViT)、Swin Transformer等新型模型集成到库中。
-
多模态支持的探索(2021-至今):
- 随着研究领域的发展,可能开始探索对视频处理、音频处理或跨模态任务的支持。
请注意,以上内容根据历史趋势推测,具体的里程碑事件需要查阅官方文档或者相关资料以获取准确信息。由于技术更新迅速,请参考最新官方发布的更新日志以了解Torchvision最新的里程碑事件和发展情况。
4.2 核心功能
Torchvision是PyTorch生态系统中的一个重要组成部分,主要用于计算机视觉任务。这个库提供了以下核心功能:
-
数据集加载:
内置了多个标准图像数据集,如CIFAR10、CIFAR100、MNIST、Fashion-MNIST、ImageNet等,用户可以直接通过API方便地加载这些数据集进行训练和测试。 -
数据预处理与变换:
提供了一系列用于图像预处理的工具,包括图片裁剪、旋转、翻转、归一化、色彩空间转换(RGB到BGR或灰度图)等。支持构建自定义的数据增强操作,如随机改变亮度、对比度、饱和度等以提高模型泛化能力。 -
模型架构:
包含多种预训练的卷积神经网络模型,如AlexNet、VGG、ResNet、DenseNet、Inception、SqueezeNet等,以及它们在ImageNet上的预训练权重,用户可以直接加载并用于迁移学习或者作为基础模型进行微调。 -
实用工具:
提供了一些常用的计算机视觉相关的辅助函数,例如读取和显示图像、视频等多媒体数据,以及将模型导出为ONNX格式等。 -
推理与可视化支持:
可以帮助用户轻松实现模型预测,并提供了一些可视化功能,如绘制混淆矩阵、显示图像和其对应的预测结果等。
通过torchvision,研究人员和开发者可以更加高效地完成从数据准备到模型训练和评估的整个流程,极大地提高了计算机视觉项目开发的速度和便利性。
5. Torchtext
torchtext是PyTorch的一个库,专门针对自然语言处理(NLP)任务提供数据集加载、预处理和高效的数据迭代器。其设计目标在于简化从原始文本到模型训练输入格式的转换过程,使得研究者和开发者能够更专注于构建和训练深度学习模型。
主要特性:
-
数据集支持:
内置了多个标准NLP数据集,例如AG_NEWS、SST-2等。支持自定义数据集,并提供了统一的数据接口用于加载多种文件格式(如TSV、CSV、JSON等)。 -
Field API:
Field对象用于定义数据列的特征,包括词汇表大小、是否进行词干提取或小写转换、填充策略等。用户可以根据需要创建不同类型的Field,比如对文本使用TextField,对标签使用LabelField。 -
Dataset与Iterator:
TabularDataset和SequenceDataset等类用来表示整个数据集,可以将预处理后的数据存储为可迭代对象。BucketIterator和BatchIterator能够根据数据长度进行动态分批,以优化计算效率。 -
Pipeline自动化:
提供了从文本读取、Tokenization、词汇表构建到数据批量化的一站式解决方案。 -
实用工具:
包含一些实用函数和类,如文本分词、词汇表构建和管理、文本标准化处理等。 -
兼容性:
与PyTorch深度学习框架紧密集成,输出可以直接作为深度学习模型的输入。
通过使用torchtext,用户可以快速地准备并组织NLP任务的数据集,使其适应各种基于Transformer或其他架构的深度学习模型,从而极大地提高了开发效率和代码的可维护性。同时,它也支持大规模数据集的高效处理和分布式训练场景。
相关文章:

PyTorch的衍生资源
PyTorch作为深度学习领域的一个重要框架,自2016年首次发布以来经历了显著的发展。以下是PyTorch发展过程中的几个关键里程碑事件: 2016年: PyTorch于2016年首次发布,作为一个基于动态计算图的开源机器学习库,它提供了自…...

开源项目Git Commit规范与ChangeLog
一,conventional commit(约定式提交) Conventional Commits 是一种用于给提交信息增加人机可读含义的规范。它提供了一组用于创建清晰的提交历史的简单规则。 1.1 作用 自动化生成 CHANGELOG基于提交类型,自动决定语义化的版本变更向项目相关合作开发…...

【原理图PCB专题】OrCAD Capture CIS关闭开始界面
17.4版本 在打开OrCAD Capture CIS时会发现打开Start Page页面,那么如何将他关闭再也不看这个界面呢? 在窗口中输入SetOptionBool EnableStartPage 0 回车 重启软件后就再也不会弹出Start Page页面 如果没有发现Command Window那么将菜单栏view->C…...

【Linux】Ubuntu的gnome切换KDE Plasma
文章目录 安装KDE Plasma桌面环境添加软件源并更新apt安装kubuntu-desktop(作者没有成功)aptitude安装kubuntu-desktop多次aptitude install(特别重要特别重要)其他kde软件包 卸载gnome桌面 Ubuntu自带的桌面环境是gnomeÿ…...

Docker(九)Docker Buildx
作者主页: 正函数的个人主页 文章收录专栏: Docker 欢迎大家点赞 👍 收藏 ⭐ 加关注哦! Docker Buildx Docker Buildx 是一个 docker CLI 插件,其扩展了 docker 命令,支持 [Moby BuildKit] 提供的功能。提…...
Flink问题解决及性能调优-【Flink不同并行度引起sink2es报错问题】
最近需求,仅想提高sink2es的qps,所以仅调节了sink2es的并行度,但在调节不同算子并行度时遇到一些问题,找出问题的根本原因解决问题,并分析整理。 实例代码 --SET table.exec.state.ttl86400s; --24 hour,默认: 0 ms …...

瑞_数据结构与算法_二叉搜索树
文章目录 1 什么是二叉搜索树1.1 二叉搜索树的特征1.2 前驱后继 2 二叉搜索树的Java实现2.1 定义二叉搜索树节点类BSTNode泛型key改进 2.2 实现查找方法get(int key)递归实现非递归实现 ★非递归实现 泛型key版本 2.3 实现查找最小方法min()递归实现非递归实现 ★ 2.4 实现查找…...

Linux 命令行访问名字中包含空格的文件或文件夹
Linux 命令行访问名字中包含空格的文件或文件夹 References 在 Windows 下命名文件或文件夹名有空格是可以的,甚至在 Windows 和 Ubuntu 虚拟机共享的文件中也可以这么做,但是在 Ubuntu 中空格要用下划线代替,养成好习惯。Linux 会把空格当成…...

Dart/Flutter工具模块:the_utils
Flutter笔记 Dart/Flutter工具模块:the_utils 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/detail…...
矩阵号:日入100+,八大提示词(Prompt)使用技巧
最近在搞头条矩阵,发现自己的指令写的太烂了,一个指令将会决定你的写作质量。 收益比较拉垮,50个号收益好的,也就这么几个号。 于是我扒了一些提示词的操作技巧,分享一下自己的学习心得。 先说理论知识,实…...

爬虫工作量由小到大的思维转变---<第三十九章 Scrapy-redis 常用的那个RetryMiddleware>
前言: 为什么要讲这个RetryMiddleware呢?因为他很重要~ 至少在你装配代理ip或者一切关于重试的时候需要用到!----最关键的是:大部分的教学视频里面,没有提及这个!!!! 正文: 源代码分析 这个RetryMiddleware是来自: from scrapy.downloadermiddlewares.retry import Retry…...

【MongoDB】mongodb安装及启动踩坑点
mongodb的安装,基本上参考文章[1]。 但是在过程中,有一些踩坑点。 1,高版本mongodb不自带mongo脚本 在文章1中,作者在解压后,直接使用了mongo脚本,而我下载的mongodb版本要更高,在解压后&…...

动态规划——采矿的小奇【集训笔记】
题目描述 假期小奇去采矿场体验生活,工头为每个员工发放了一个最多能装 M 公斤的背包,经过一天的辛苦小奇开采出了 n 块矿石,它们的重量分别是W1,W2,...,Wn,经过预估它们的价值分别为C1,C2,...,Cn,那么请你…...
wpf控件Expander集合下的像素滚动
项目场景:Expander集合滚动 如下图,有一个Expander集合,且设置 ScrollViewer.VerticalScrollBarVisibility "Auto" 每个Expaner下包含有若干元素,当打开Expader(即IsExpanded "true")时&#…...

docker 基础手册
文章目录 docker 基础手册docker 容器技术镜像与容器容器与虚拟机docker 引擎docker 架构docker 底层技术docker 二进制安装docker 镜像加速docker 相关链接docker 生态 docker 基础手册 docker 容器技术 开源的容器项目,使用 Go 语言开发原意“码头工人”&#x…...
记一次SPI机制导致的BUG定位【不支持:http://javax.xml.XMLConstants/property/accessExternalDTD】
1、前因 今天在生产环境启用了某个功能,结果发现有个文件上传华为云OBS失败了,报错如下: Caused by: java.lang.IllegalArgumentException: 不支持:http://javax.xml.XMLConstants/property/accessExternalDTDat org.apache.xal…...
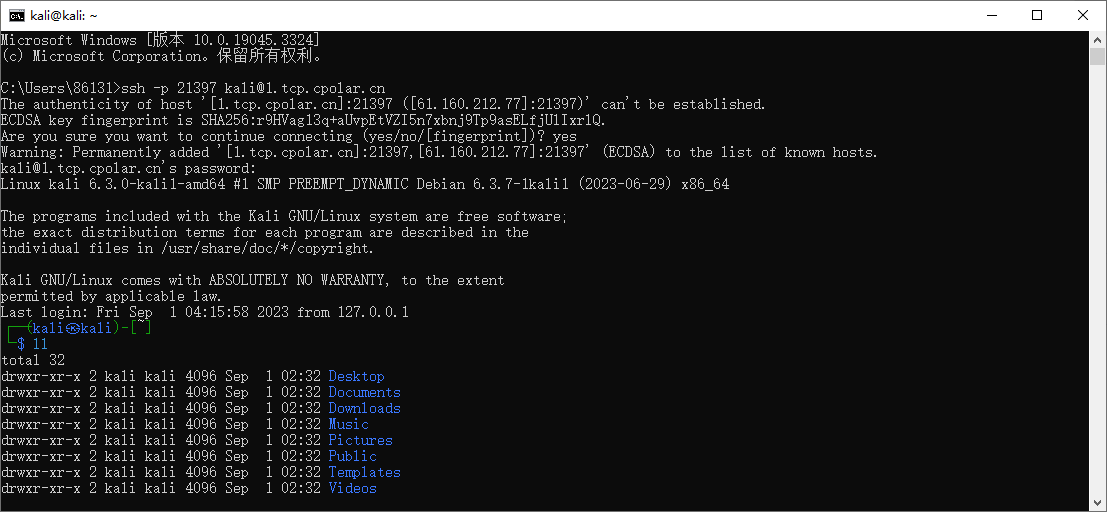
Kali如何启动SSH服务并实现无公网ip环境远程连接
文章目录 1. 启动kali ssh 服务2. kali 安装cpolar 内网穿透3. 配置kali ssh公网地址4. 远程连接5. 固定连接SSH公网地址6. SSH固定地址连接测试 简单几步通过[cpolar 内网穿透](cpolar官网-安全的内网穿透工具 | 无需公网ip | 远程访问 | 搭建网站)软件实现ssh 远程连接kali! …...
谷粒商城配置虚拟机
一、创建虚拟机 之前有在VM里面建一个ubuntu的虚拟机,准备拿来直接用,网络设置为NAT模式,查看我的虚拟机是虚拟机:192.168.248.128 主机: 192.168.2.12。可以互相ping通。 二、linux安装docker Docker docker是虚拟…...
Java中文乱码浅析及解决方案
Java中文乱码浅析及解决方案 一、GBK和UTF-8编码方式二、idea和eclipse的默认编码方式三、解码和编码方法四、代码实现编码解码 五、额外知识扩展 一、GBK和UTF-8编码方式 如果采用的是UTF-8的编码方式,那么1个英文字母 占 1个字节,1个中文占3个字节如果…...

【前端基础--3】
文字样式 1.文字颜色 color 取值方式: 英文单词 red green blue十六进制的颜色值 #000000 也可以写为#000(如aabbcc可以简写为abc)rgb三原色取值 color:rgb(220,32,215) 取值范围都在0~255之间 2.文字大小 font-size …...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...