【Spring连载】使用Spring Data访问Redis(九)----Redis流 Streams
【Spring连载】使用Spring Data访问Redis(九)----Redis流 Streams
- 一、追加Appending
- 二、消费Consuming
- 2.1 同步接收Synchronous reception
- 2.2 通过消息监听器容器进行异步接收Asynchronous reception through Message Listener Containers
- 2.2.1 命令式Imperative StreamMessageListenerContainer
- 2.2.2 反应式Reactive StreamReceiver
- 2.3 确认策略Acknowledge strategies
- 2.4 读取偏移量策略ReadOffset strategies
- 三、序列化Serialization
- 四、对象映射Object Mapping
- 4.1 简单值Simple Values
- 4.2 复杂值Complex Values
Redis Streams以抽象的方法对日志数据结构进行建模。通常,日志是仅追加(append-only)的数据结构,并且从一开始就在随机位置或通过流式传输新消息来消费。
在 Redis参考文档中了解有关Redis Streams的更多信息。
Redis Streams大致可以分为两个功能领域:
- 追加记录
- 消费记录
尽管这种模式与Pub/Sub有相似之处,但主要区别在于消息的持久性以及消息的消费方式。
Pub/Sub依赖于瞬态消息的广播(即,如果你不听,你就会错过消息),而Redis Stream使用了一种持久的、仅追加的数据类型,它会保留消息,直到流被修剪。消费方面的另一个区别是Pub/Sub注册服务器端订阅。Redis将到达的消息推送到客户端,而Redis Streams需要活动轮询(active polling)。
org.springframework.data.redis.connection 和 org.springframework.data.redis.stream包为Redis Streams提供了核心功能。
一、追加Appending
要发送记录,你可以像使用其他操作一样,使用低级(low-level)RedisConnection或高级StreamOperations。这两个实体都提供add (xAdd)方法,该方法接受记录和目标流作为参数。RedisConnection需要原始数据(字节数组),而StreamOperations允许任意对象作为记录传入,如以下示例所示:
// append message through connection
RedisConnection con = …
byte[] stream = …
ByteRecord record = StreamRecords.rawBytes(…).withStreamKey(stream);
con.xAdd(record);// append message through RedisTemplate
RedisTemplate template = …
StringRecord record = StreamRecords.string(…).withStreamKey("my-stream");
template.opsForStream().add(record);
流记录携带一个Map,键值元组,作为它们的payload。将记录附加到流中会返回可作为进一步引用的RecordId。
二、消费Consuming
在消费端,你可以消费一个或多个流。Redis Streams提供读取命令,允许从已知流的任意位置(随机访问)消费流和从流的结束消费新的流记录。
在底层,RedisConnection提供了xRead和xReadGroup方法,它们分别映射Redis命令以在消费者组中进行各自读取。请注意,可以将多个流用作参数。
Redis中的订阅命令可能会被阻塞。也就是说,在连接(connection)上调用xRead会导致当前线程在开始等待消息时阻塞。只有当读取命令超时或收到消息时,线程才会被释放。
要消费流消息,可以在应用程序代码中轮询(poll)消息,也可以通过消息监听器容器使用两个异步接收中的一个(2.2章节),命令式或反应式。每次新记录到达时,容器都会通知应用程序代码。
2.1 同步接收Synchronous reception
虽然流消费通常与异步处理相关联,但也可以同步消费消息。重载的StreamOperations.read(…)方法提供了这个功能。在同步接收期间,调用线程可能会阻塞,直到消息可用为止。属性StreamReadOptions.block指定接收者在放弃等待消息之前应该等待多长时间。
// Read message through RedisTemplate
RedisTemplate template = …List<MapRecord<K, HK, HV>> messages = template.opsForStream().read(StreamReadOptions.empty().count(2),StreamOffset.latest("my-stream"));List<MapRecord<K, HK, HV>> messages = template.opsForStream().read(Consumer.from("my-group", "my-consumer"),StreamReadOptions.empty().count(2),StreamOffset.create("my-stream", ReadOffset.lastConsumed()))
2.2 通过消息监听器容器进行异步接收Asynchronous reception through Message Listener Containers
由于其阻塞性,低级别轮询(low-level polling)没有吸引力,因为它需要为每个消费者提供连接和线程管理。为了缓解这个问题,SpringData提供了消息监听器,它完成了所有繁重的工作。如果你熟悉EJB和JMS,你应该会发现这些概念很熟悉,因为它的设计尽可能接近Spring Framework中的支持及其消息驱动的POJO(MDP)。
Spring Data提供了两种针对所用编程模型量身定制的实现:
- StreamMessageListenerContainer充当命令式编程模型的消息监听器容器。它用于消费Redis流中的记录,并驱动注入其中的StreamListener实例。
- StreamReceiver提供了消息监听器的反应式变体。它用于将Redis流中的消息作为潜在的无限流消费,并通过Flux发出流消息。
StreamMessageListenerContainer和StreamReceiver负责消息接收和分发到监听器中进行处理的所有线程。消息监听器容器/接收器是MDP和消息传递提供者之间的中介,负责注册接收消息、资源获取和释放、异常转换等。这使你作为应用程序开发人员能够编写与接收消息相关联的(可能复杂的)业务逻辑,并将Redis基础设施的公式化问题委托给框架。
这两个容器都允许更改运行时配置,以便在应用程序运行时添加或删除订阅,而无需重新启动。此外,容器使用延迟订阅方法,仅在需要时使用RedisConnection。如果所有监听器都被取消订阅,它会自动执行清理,线程就会被释放。
2.2.1 命令式Imperative StreamMessageListenerContainer
以类似于EJB世界中的消息驱动Bean (MDB)的方式,流驱动POJO (SDP)充当流消息的接收者。SDP的一个限制是它必须实现org.springframework.data.redis.stream.StreamListener接口。还请注意,当POJO在多个线程上接收消息的情况下,要确保实现是线程安全的。
class ExampleStreamListener implements StreamListener<String, MapRecord<String, String, String>> {@Overridepublic void onMessage(MapRecord<String, String, String> message) {System.out.println("MessageId: " + message.getId());System.out.println("Stream: " + message.getStream());System.out.println("Body: " + message.getValue());}
}
StreamListener代表了一个函数式接口,因此可以使用Lambda形式重写实现:
message -> {System.out.println("MessageId: " + message.getId());System.out.println("Stream: " + message.getStream());System.out.println("Body: " + message.getValue());
};
一旦你实现了StreamListener,就该创建一个消息监听器容器并注册订阅了:
RedisConnectionFactory connectionFactory = …
StreamListener<String, MapRecord<String, String, String>> streamListener = …StreamMessageListenerContainerOptions<String, MapRecord<String, String, String>> containerOptions = StreamMessageListenerContainerOptions.builder().pollTimeout(Duration.ofMillis(100)).build();StreamMessageListenerContainer<String, MapRecord<String, String, String>> container = StreamMessageListenerContainer.create(connectionFactory,containerOptions);Subscription subscription = container.receive(StreamOffset.fromStart("my-stream"), streamListener);
请参阅各种消息监听器容器的Javadoc,了解每种实现支持的特性的完整描述。
2.2.2 反应式Reactive StreamReceiver
流式数据源的反应式消费通常通过事件或消息的Flux发生。反应式接收器实现提供有StreamReceiver及其重载的receive(…)。与StreamMessageListenerContainer相比,反应式方法需要更少的基础设施资源,如线程,因为它利用了驱动程序提供的线程资源。接收流是StreamMessage的需求驱动(demand-driven)发布者:
Flux<MapRecord<String, String, String>> messages = …return messages.doOnNext(it -> {System.out.println("MessageId: " + message.getId());System.out.println("Stream: " + message.getStream());System.out.println("Body: " + message.getValue());
});
现在我们需要创建StreamReceiver并注册订阅来消费流消息:
ReactiveRedisConnectionFactory connectionFactory = …StreamReceiverOptions<String, MapRecord<String, String, String>> options = StreamReceiverOptions.builder().pollTimeout(Duration.ofMillis(100)).build();
StreamReceiver<String, MapRecord<String, String, String>> receiver = StreamReceiver.create(connectionFactory, options);Flux<MapRecord<String, String, String>> messages = receiver.receive(StreamOffset.fromStart("my-stream"));
请参阅各种消息监听器容器的Javadoc,了解每种实现支持的特性的完整描述。需求驱动的消费使用背压(backpressure)信号来激活和关闭轮询。如果需求得到满足,StreamReceiver订阅暂停轮询,直到订阅者发出进一步需求的信号。根据ReadOffset策略的不同,这可能导致消息被跳过。
2.3 确认策略Acknowledge strategies
当你通过Consumer Group读取消息时,服务器将记住给定的消息已传递并将其添加到Pending Entries List (PEL)中,它是已传递但尚未确认的消息列表。消息必须通过StreamOperations.acknowledge进行确认,才能从PEL中删除,如下面的代码段所示。
StreamMessageListenerContainer<String, MapRecord<String, String, String>> container = ...container.receive(Consumer.from("my-group", "my-consumer"), ------1StreamOffset.create("my-stream", ReadOffset.lastConsumed()),msg -> {// ...redisTemplate.opsForStream().acknowledge("my-group", msg); ------2});1. 作为my-consumer从my-group中读取。接收到的消息不被确认。
2. 确认处理后的消息。
要在接收时自动确认消息,请使用receiveAutoAck而不是receive。
2.4 读取偏移量策略ReadOffset strategies
流读取操作接受读取偏移量规范,以消费给定偏移量的消息。ReadOffset表示读取偏移量规范。Redis支持3种偏移量变体,具体取决于你是单独使用流还是在消费者组中使用流:
- ReadOffset.latest()–读取最新消息。
- ReadOffset.from(…)–在特定消息Id之后读取。
- ReadOffset.lastConsumed()–在上次消费的消息Id之后读取(仅限消费者组)。
在基于消息容器的消费上下文中,我们需要在消费消息时推进(或增加)读取偏移量。推进(advance)取决于请求的ReadOffset和消费模式(有没有消费者组)。以下表格说明了容器如何推进ReadOffset:
表1:推进ReadOffset
| Read offset | Standalone | Consumer Group |
|---|---|---|
| Latest | 读取最新消息 | 读取最新消息 |
| 特定Message Id | 使用最后看到的消息作为下一个MessageId | 使用最后看到的消息作为下一个MessageId |
| Last Consumed | 使用最后看到的消息作为下一个MessageId | 每个消费者组最后消费的消息 |
从特定的消息id和最后消费(last consumed)的消息中读取可以被认为是安全的操作,可以确保消费追加到流中的所有消息。使用最新消息进行读取可以跳过在轮询操作处于dead time状态时添加到流中的消息。轮询引入了一个dead time,在此期间消息可以在各个轮询命令之间到达。流消耗不是线性连续读取,而是分成重复的XREAD调用。
三、序列化Serialization
任何发送到流的记录都需要被序列化为二进制格式。由于流接近hash数据结构, stream key, field names 和 values使用RedisTemplate上配置的相应序列化器。
表2:流序列化
| Stream Property | 序列化器 | 描述 |
|---|---|---|
| key | keySerializer | 用于Record#getStream() |
| field | hashKeySerializer | 用于payload中map的每个key |
| value | hashValueSerializer | 用于payload中map的每个value |
请务必查看正在使用的RedisSerializers,并注意如果你决定不使用任何序列化器,则需要确保这些值已经是二进制的。
四、对象映射Object Mapping
4.1 简单值Simple Values
StreamOperations允许通过ObjectRecord将简单的值直接追加到流中,而不必将那些值放入Map结构中。然后将该值分配给一个payload字段,并可以在读回该值时提取该值。
ObjectRecord<String, String> record = StreamRecords.newRecord().in("my-stream").ofObject("my-value");redisTemplate().opsForStream().add(record); ------1List<ObjectRecord<String, String>> records = redisTemplate().opsForStream().read(String.class, StreamOffset.fromStart("my-stream"));
1. XADD my-stream * "_class" "java.lang.String" "_raw" "my-value"
ObjectRecords和所有其他记录一样,都要经过相同的序列化过程,因此也可以使用返回MapRecord的非类型化读取操作获得Record。
4.2 复杂值Complex Values
向流添加复杂值可以通过以下三种方式完成:
- 使用例如String JSON的表示转换为简单值。
- 使用合适的RedisSerializer序列化该值。
- 使用HashMapper将值转换为适合序列化的Map。
第一种变体是最直接的变体,但忽略了流结构提供的字段值功能,流中的值对其他消费者来说仍然是可读的。第二个选项与第一个选项具有相同的优点,但可能会导致非常特定的消费者限制,因为所有消费者都必须实现相同的序列化机制。HashMapper方法稍微复杂一点,它使用了stream哈希结构,但将源记录扁平化。只要选择了合适的序列化器组合,其他消费者仍然能够读取记录。
HashMappers将payload转换为具有特定类型的Map。请确保使用能够反序列化哈希的哈希键和哈希值序列化程序。
ObjectRecord<String, User> record = StreamRecords.newRecord().in("user-logon").ofObject(new User("night", "angel"));redisTemplate().opsForStream().add(record); -------1List<ObjectRecord<String, User>> records = redisTemplate().opsForStream().read(User.class, StreamOffset.fromStart("user-logon"));1. XADD user-logon * "_class" "com.example.User" "firstname" "night" "lastname" "angel"
StreamOperations默认使用ObjectHashMapper。在获得StreamOperations时,你可以提供适合你需求的HashMapper。
redisTemplate().opsForStream(new Jackson2HashMapper(true)).add(record); -----11. XADD user-logon * "firstname" "night" "@class" "com.example.User" "lastname" "angel"
StreamMessageListenerContainer可能不知道域类型上使用的任何@TypeAlias,因为这些需要通过MappingContext进行解析。确保用initialEntitySet初始化RedisMappingContext。
@Bean
RedisMappingContext redisMappingContext() {RedisMappingContext ctx = new RedisMappingContext();ctx.setInitialEntitySet(Collections.singleton(Person.class));return ctx;
}@Bean
RedisConverter redisConverter(RedisMappingContext mappingContext) {return new MappingRedisConverter(mappingContext);
}@Bean
ObjectHashMapper hashMapper(RedisConverter converter) {return new ObjectHashMapper(converter);
}@Bean
StreamMessageListenerContainer streamMessageListenerContainer(RedisConnectionFactory connectionFactory, ObjectHashMapper hashMapper) {StreamMessageListenerContainerOptions<String, ObjectRecord<String, Object>> options = StreamMessageListenerContainerOptions.builder().objectMapper(hashMapper).build();return StreamMessageListenerContainer.create(connectionFactory, options);
}
相关文章:
----Redis流 Streams)
【Spring连载】使用Spring Data访问Redis(九)----Redis流 Streams
【Spring连载】使用Spring Data访问Redis(九)----Redis流 Streams 一、追加Appending二、消费Consuming2.1 同步接收Synchronous reception2.2 通过消息监听器容器进行异步接收Asynchronous reception through Message Listener Containers2.2.1 命令式I…...

MySQL:从基础到实践(简单操作实例)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 下载前言一、MySQL是什么?二、使用步骤1.引入库2.读入数据 提交事务查询数据获取查询结果总结 下载 点击下载提取码888999 前言 在现代信息技术的世界…...
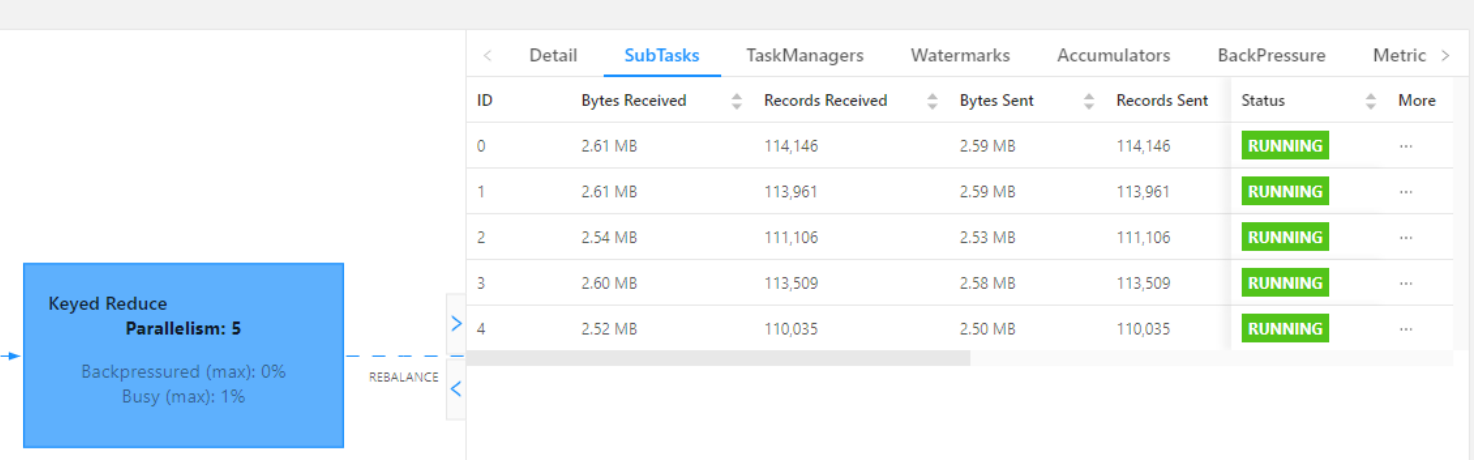
Flink流式数据倾斜
1. 流式数据倾斜 流式处理的数据倾斜和 Spark 的离线或者微批处理都是某一个 SubTask 数据过多这种数据不均匀导致的,但是因为流式处理的特性其中又有些许不同 2. 如何解决 2.1 窗口有界流倾斜 窗口操作类似Spark的微批处理,直接两阶段聚合的方式来解决…...
零基础学编程系列,从入门到精通,中文编程开发语言工具下载,编程构件容器件之控制面板构件用法
零基础学编程系列,从入门到精通,中文编程开发语言工具下载,编程构件容器件之控制面板构件用法 一、前言 编程入门视频教程链接 https://edu.csdn.net/course/detail/39036 编程工具及实例源码文件下载可以点击最下方官网卡片——软件下载…...
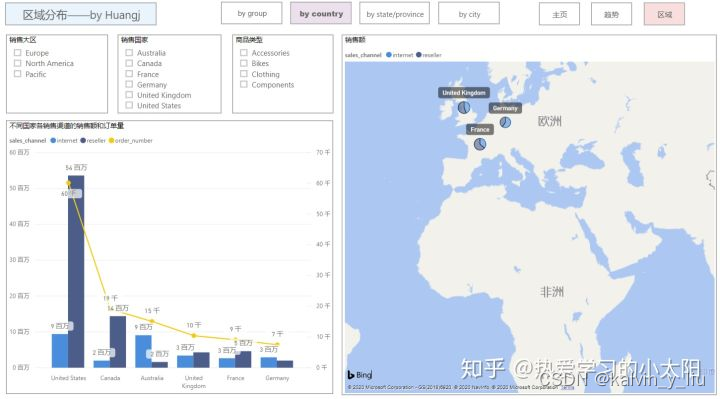
使用PowerBI 基于Adventure Works案例分析
Adventure Works案例分析 前言 数据时代来临,但一个人要顺应时代的发展是真理。 数据分析的核心要素 那数分到底是什么? 显然DT 并不等同于 IT,我们需要的不仅仅是更快的服务器、更多的数据、更好用的工具。这些都是重要的组成部分&…...

人工智能之估计量评估标准及区间估计
评估估计量的标准 无偏性:若估计量( X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn)的数学期望等于未知参数θ,即 E ( θ ^ ) = θ E(\hat\theta)=\theta E(θ^)=θ 则称 θ ^ \hat\theta θ^为θ的无偏估计量。 估计量 θ ^ \hat\theta θ^的值不一定就是…...

Ubuntu权限相关命令
文章目录 文件夹/文件带锁(图标) 解锁无密码访问文件/目录sudo usermod -aG sudo your_username其他后记 命令参考: https://www.cnblogs.com/alongdidi/p/linux_ownership_permission.html 文件夹/文件带锁(图标) 解锁 递归解锁当前路径下的所有文件夹以及文件(包括子文件)su…...

RTE2023第九届实时互联网大会:揭秘未来互联网趋势,PPT分享引领行业新思考
随着互联网的不断发展,实时互动技术正逐渐成为新时代的核心驱动力。 在这样的背景下,RTE2023第九届实时互联网大会如期而至,为业界人士提供了一个探讨实时互联网技术、交流创新理念的绝佳平台。 本文将从大会内容、PPT分享价值等方面&#…...

Hadoop-生产调优
第1章 HDFS-核心参数 1.1 NameNode内存生产配置 1)NameNode 内存计算 每个文件块大概占用 150 byte,一台服务器 128G 内存为例,能存储多少文件块呢? 128 * 1024 * 1024 * 1024 / 150byte ≈ 9.1 亿G MB KB Byte 2)…...

Elasticsearch基于分区的索引策略
分区索引,或者更常见的说法,基于分区的索引策略,是一种按照特定规则(如时间、地理位置、业务线等)将数据分散到多个不同的索引中的方法。这种做法可以提高Elasticsearch的性能和可管理性,尤其是在处理大量数…...

ASP.NET Core MVC 控制查询数据表后在视图显示
如果是手动写代码,不用VS自带的一些控件,那比较简单的方式就是把查询的数据集,逐条赋给对象模型,再加到List,最后在控制加到 ViewBag,视图循环显示ViewBag变量 控制器代码 List<Users> list new Li…...

C语言第二十弹---指针(四)
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】 指针 1、字符指针变量 2、数组指针变量 2.1、数组指针变量是什么? 2.2、数组指针变量怎么初始化 3、⼆维数组传参的本质 4、函数指针变量 4.1…...

常用排序算法(Java版本)
1 引言 常见的排序算法有八种:交换排序【冒泡排序、快速排序】、插入排序【直接插入排序、希尔排序】、选择排序【简单选择排序、堆排序】、归并排序、基数排序。 2 交换排序 所谓交换,就是序列中任意两个元素进行比较,根据比较结果来交换…...

CPP项目:Boost搜索引擎
1.项目背景 对于Boost库来说,它是没有搜索功能的,所以我们可以实现一个Boost搜索引擎来实现一个简单的搜索功能,可以更快速的实现Boost库的查找,在这里,我们实现的是站内搜索,而不是全网搜索。 2.对于搜索…...
)
【洛谷 P1616】疯狂的采药 题解(动态规划+完全背包)
疯狂的采药 题目背景 此题为纪念 LiYuxiang 而生。 题目描述 LiYuxiang 是个天资聪颖的孩子,他的梦想是成为世界上最伟大的医师。为此,他想拜附近最有威望的医师为师。医师为了判断他的资质,给他出了一个难题。医师把他带到一个到处都是草…...

L1-027 出租分数 20
下面是新浪微博上曾经很火的一张图: 一时间网上一片求救声,急问这个怎么破。其实这段代码很简单,index数组就是arr数组的下标,index[0]2 对应 arr[2]1,index[1]0 对应 arr[0]8,index[2]3 对应 arr[3]0&…...

51单片机精进之路-1点亮led灯
本例中led灯使用共阳极连接在电路中,共阳极即将led的正极接在一起,通过上拉电阻接到电源正极,通过单片机io与Led的负极相连,io输出低电平,有电流从led流过,此时led点亮,当io输出高电平时&#x…...
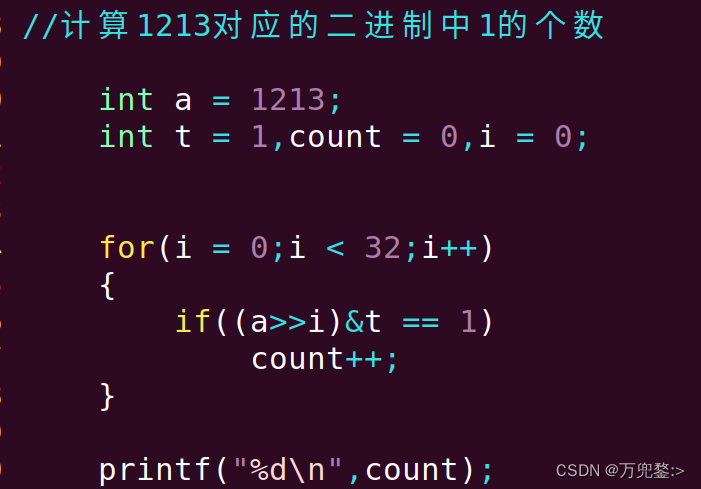
嵌入式学习Day14 C语言 --- 位运算
位运算 注意:符号位也遵循这个规则 一、按位与(&) 运算规则:一假则假 int a 0x33;a & 0x55;0011 00110101 0101 &----------0001 0001 //0x11 二、按位或(|) 运算规则:一真则真 int a 0x33;a |0x55;0011 00110101 0101 |…...
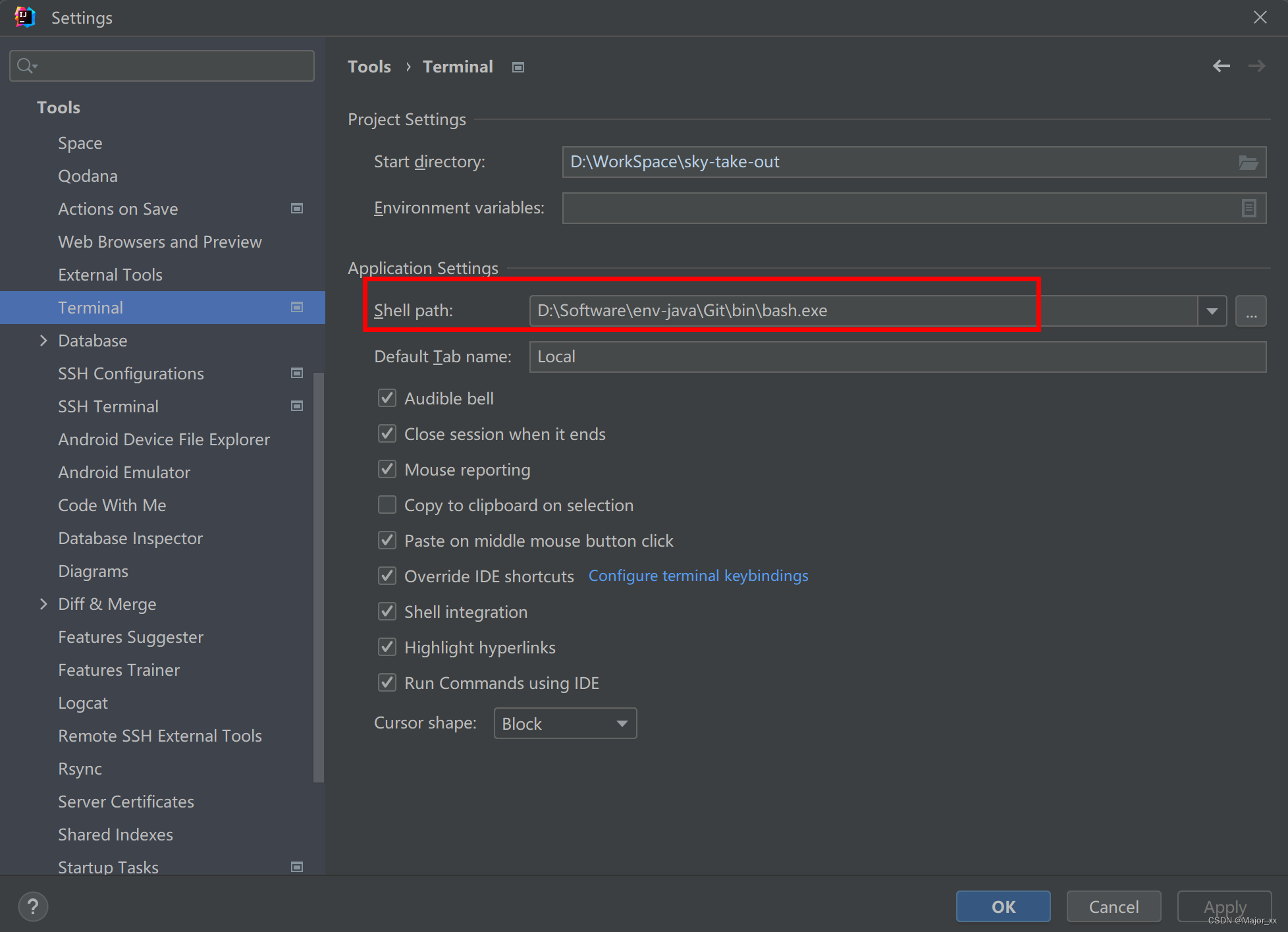
idea设置terminal为git
要在IntelliJ IDEA中设置终端为Git Bash,请按照以下步骤操作: 打开 Settings(设置)。点击 Tools(工具)选项卡。进入 Terminal(终端)界面。在 Shell Path 下选择 Browse(…...

《MySQL 简易速速上手小册》第3章:性能优化策略(2024 最新版)
文章目录 3.1 查询优化技巧3.1.1 基础知识3.1.2 重点案例3.1.3 拓展案例 3.2 索引和查询性能3.2.1 基础知识3.2.2 重点案例3.2.3 拓展案例 3.3 优化数据库结构和存储引擎3.3.1 基础知识3.3.2 重点案例3.3.3 拓展案例 3.1 查询优化技巧 让我们来聊聊如何让你的 MySQL 查询跑得像…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...