【Go】一、Go语言基本语法与常用方法容器
GO基础
Go语言是由Google于2006年开源的静态语言
1972:(C语言) — 1983(C++)—1991(python)—1995(java、PHP、js)—2005(amd双核技术 + web端新技术飞速发展)—2006 (Go)
Go语言的优势
- 开发效率高 ---- 语法简单
- 集各家语言的优势 ---- 出生时间晚,大量参考C和Python
- 执行性能高 ---- 直接编译成二进制,部署简单(Python、Java都需要各自的环境才行)
- 并发编程效率高 ---- goroutine
- 编译速度快 ---- 比C++、Java的编译速度快
Go语言的使用方向
- Web开发(Gin、beego)
- 容器虚拟化(docker、k8s、istio)
- 中间件(etcd、tidb、influxdb、nsq等)
- 区块链(以太坊、fabric)
- 微服务(go-zero、dapr、rpcx、kratos、dubbo-go、kitex)
关于包(package)
当我们创建好一个Go语言文件时,会自动创建一行代码:package xxx,这是Go语言区分于动态语言的重要标志,我们在其他包中引入这个包的内容时,我们会使用包名来调用相关内容,而动态语言如python是通过文件名来调用的。
HelloWorld
这是一个简单的HelloWorld:
package mainimport "fmt"func main() {fmt.Println("Hello World")
}
注意在这个程序中:package和函数名都必须为main,这标识了这个程序的入口
我们也可以在控制台中进行简单的操作:
go build xxx.go
./xxx.exe
go run xxx.go
上面三条语句,分别是:编译、运行编译后的exe文件、编译并运行
要注意的问题:不要在一个文件夹内使用两个及以上的main函数,这是不推荐的,我们尽量在多个文件夹中对多个入口函数的情况进行使用
关于变量的定义方法
基础变量定义:GO语言的变量定义出来之后是有一个初值的,int为0,string为’',这一点区别于C和Java
变量的基本定义方法:
func variableZeroValue() {var a intvar s stringfmt.Println(a, s)
}
注意这里的string是不会显示的,因为是一个空串
如果我们一定要打印一下的话,可以使用下面的方法:
func variableZeroValuePrintEmpty() {var a intvar s string// 下面这种格式会自动给字符串加一个双引号// 这个是%q的功效fmt.Printf("%d, %q\n", a, s)
}
赋初值的方法:
// 赋初值
func variableInitialValue() {var a, b int = 3, 4var s string = "abc"fmt.Println(a, b, s)
}
更进一步的,我们还可以省略类型
在省略类型之后,我们就可以在一行赋很多不同类型的数值
// 更进一步的,我们还可以省略类型
// 在省略类型之后,我们就可以在一行赋很多不同类型的数值
func variableInitialValueDifferent() {var a, b, c, s = 5, 6, true, "def"fmt.Println(a, b, c, s)
}
再进一步,我们可以省略var,以:=代替:来进行变量定义
// 再进一步,我们可以省略var,以:=代替:来进行变量定义
func variableShorter() {a, b, c, s := 3, 4, true, "var"fmt.Println(a, b, c, s)
}
再另外,我们也可以在方法外直接定义变量,但这种变量不叫做全局变量,其属于包内变量(后续理解)
下面是一种集中的定义方式
var (aa = 33bb = falsecc = "kiu"
)
但注意,我们在函数外定义(全局变量)语言是不能使用 := 的。
若全局变量与局部变量重名,会优先使用局部变量
常量
常量的定义可以使用const进行定义,其方法是:
func main() {const PI float32 = 3.14fmt.Println(PI)// 我们可以通过小括号的方式来批量定义常量// 如果我们定义的常量没有赋初值也没有赋数据类型的话,会默认沿用上一个常量// 第一个常量必须被定义,不能只赋类型不赋值(编译不通过)const (A = 16BC = "abc"D)fmt.Println(A, B, C, D)
}
注意常量的定义一般会将常量名全部大写,涉及到单词问题使用下划线进行分割
iota
iota是一个自增的int数,其用于在常量中进行递增的对常量进行定义,其提供了充足的便捷性
const (AA = iota + 100BBCC = "iota"DD = iota)fmt.Println(AA, BB, CC, DD)// 100 101 iota 3
我们的iota只要在定义变量,就会自动 + 1
我们可以通过给iota进行加减操作来进行业务处理
我们只需要给第一个常量赋iota,结合常量定义中的操作,我们可以不显示的在后续进行定义,其也能得到递增的效果
在必须接收某些内容,自己却不需要使用这些内容时,我们使用下划线_来进行占位,避免被迫输出该变量的场景,这个下划线就叫做匿名变量
注意:局部变量和全局变量是允许同名的,其访问优先级是:能访问到局部变量的情况先访问局部变量
另外,IF 语句中的局部变量不会因为IF块和ELSE块中都存在而允许被外部访问,其仍然属于局部变量
变量的内建类型
-
bool、string
-
(u)int(int64)、(u)int8(1字节)、(u)int16(2字节)、(u)int32(4字节,正常int)、(u)int64(8字节)、uintptr
GoLang中没有long、short等类型,其使用int + 数字的形式来定义长整型
若前面带u,就代表他是一个无符号整数、uintptr代表其长度跟随操作系统变化(32位操作系统为32位、64位操作系统为64位)
-
byte、rune
byte指的是一个8字节的数据(专门用来存放ASCII码,甚至可以直接赋一个字符给它,但注意其需要使用百分号进行格式化输出)、rune则是Go语言中的char类型,但不同于普通的char、其有32位,即4字节(UTF-8汉语有3字节,也就是说其可以对汉字进行操作),这样更方便其拓展语言
-
float32(3.4e38)、float64(1.8e308)、complex64、complex128
float也就是浮点数,complex则指的是复数(一半作为虚部、另一半作为实部)
显式类型转换
Go语言没有隐式类型转换,我们在进行参数的传递或计算时,不会有隐式的类型转换,所有的类型转换都要显式的进行,否则编译就不会通过:
func triangle() {var a, b int = 3, 4var c intc = int(math.Sqrt(float64(a * a + b * b)))
}
并且,Go语言中的类型转换中,数据类型不用加括号,但其要转换的内容必须加括号
float转int会丢掉小数部分
字符串转整数,整数转字符串
func main() {// 基础的类型转还能var t1 uint = 12var t2 = int8(t1)print(t2)// string 和 基本数据之间的类型转换// Itoa 指的是数字转字符串// Atii 指的是字符串转数字var testStr string = "12"resInt, err := strconv.Atoi(testStr)if err != nil {print("类型转换异常1151")}resStr := strconv.Itoa(resInt)print(resStr)
}
字符串转Float、字符串转8、10、16进制
// 字符串转FloattestStrToFloat := "12.5"strToFloat, err := strconv.ParseFloat(testStrToFloat, 64) // 第二个参数是编码参数,一般直接写64if err != nil {print("类型转换异常")}fmt.Println(strToFloat)// 字符串转int,一般用来进行进制转换tsetBaseConvert := "15"baseConvert10, err := strconv.ParseInt(tsetBaseConvert, 10, 64)if err != nil {print("类型转换异常")}baseConvert8, err := strconv.ParseInt(tsetBaseConvert, 8, 64)if err != nil {print("类型转换异常")}baseConvert16, err := strconv.ParseInt(tsetBaseConvert, 16, 64)if err != nil {print("类型转换异常")}fmt.Println("十进制下15:", baseConvert10)fmt.Println("八进制下15:", baseConvert8)fmt.Println("十六进制下15:", baseConvert16)
另外的,strconv.ParseBool也可以将字符串转换为bool类型,但只能传入true、false、1、0,传入其他就会触发err变量,1会被转换为true、0会被转换为false
Float等转str,FormatInt具有独特的类型转换的功效
// 第一个参数是转成string的值,第二个参数是格式化的类型,这个要看源码,一般使用f,不额外携带信息,-1也是一般性参数,必须要携带的,64是指使用64位floatStr := strconv.FormatFloat(3.1415, 'E', -1, 64)fmt.Println(floatStr)// 第一个数是转换的参数,第二个数是转为多少进制intStr := strconv.FormatInt(15, 16)fmt.Println(intStr)运算符
基本运算符都差不多,这里只列举一些值得记录的:
<< 左移运算符 扩大 >> 右移运算符,缩小
字符串
Rune
我们的字符都是由一定的编码组成的,举例:
str := "Yes你好!"
例如上面这样的字符串,是由utf8编码构成的,我们可以使用[]bytes对其进行实验
for i, ch := range byteList {fmt.Printf("(%d, %X) ", i, ch)}// 这里将字符串转为了byte,在对byte进行遍历时,每一个内容都是一个编码// (0, 59) (1, 65) (2, 73) (3, E4) (4, BD) (5, A0) (6, E5) (7, A5) (8, BD) (9, 21)fmt.Println()
如果我们直接对string进行遍历
for i, ch := range str {fmt.Printf("(%d, %X) ", i, ch)}// 而当我们直接对字符串进行遍历时,其每次会以人类直视的模式来输出字符,但其下标还是对应byte的坐标,每一个字符都是转为unicode编码形式的字符// (0, 59) (1, 65) (2, 73) (3, 4F60) (6, 597D) (9, 21)
而我们如果想要获取其真正的内容,就需要我们使用%c来接收也可以使其获取真正的内容:
如果我们想要顺序使用下标,获取人类可以识别的下标,就需要我们使用到rune
runeStr := []rune(str)for i, ch := range runeStr {fmt.Printf("(%d, %c) ", i, ch)}// (0, Y) (1, e) (2, s) (3, 你) (4, 好) (5, !)
其他字符串操作
我们如果希望对字符串进行操作,会用到许多的字符串工具类:
- Fields、Split、Join
- Contains、Index
- ToLower、ToUpper
- Trim、TrimRight、TrimLeft
// 常用字符串操作testStr := "-Galaxy-Tree- "// 是否包含var flag bool = strings.Contains(testStr, "-")fmt.Println(flag) // true// 子串出现次数var count int = strings.Count(testStr, "-")fmt.Println(count) // 2// 分隔,注意如果分隔符在第一个位置,最前面的字符也会被截为空串// 在最后一位时,也会把最后一位截成空串var strs []string = strings.Split(testStr, "-")for i := 0; i < len(strs); i++ {fmt.Println(strs[i])}fmt.Println(len(strs))// 是否以xxx为前缀,是否以xxx为后缀var preFlag bool = strings.HasPrefix(testStr, "-Ga")var sufFlag bool = strings.HasSuffix(testStr, "e-")fmt.Println(preFlag, sufFlag)// 字符串出现的位置(按照 UTF8MB3 编码编码个数排序)var indexTest int = strings.Index(testStr, "a")fmt.Println(indexTest)// 子串替换// 最后一个数字的意思是,从左向右替换几次,-1为全部替换var testReplace string = strings.Replace(testStr, "-", ",", -1)fmt.Println(testReplace)// 大小写转换(全部转换)var lowerTest string = strings.ToLower(testStr)var upperTest string = strings.ToUpper(testStr)fmt.Println(lowerTest, upperTest)// 修剪()去除字符串最前和最后的某个字符(指定)// 这种会去掉多个,如果去掉之后的字符仍然需要被去掉,那其仍然会去掉它var trimTest string = strings.Trim(testStr, " G-e")fmt.Println(trimTest)
常量、枚举的定义
使用const进行常量的定义
func testConst() {const fileName = "abc.txt"// 注意,在定义数字变量的时候,它的变量类型是不一定的,有可能是float、也有可能是int、我们在使用它时它会自动进行转换const a, b = 3, 4// 变量的批量定义const (fileName2 = "def.txt"e, f = 8, 9)
}
在Go语言中,枚举类型也是通过const进行定义的:
func enumTest() {const (sun = 1moon = 2star = 3)// 另外,我们可以利用iota这个表达式// 这个表达式可以对我们的常量进行自增const (sun1 = iotasun2sun3)fmt.Println(sun1, sun2, sun3) //0 1 2// 我们可以利用这个表达式进行一些操作const (b = 1 << (10 * iota)kbmbgb)fmt.Println(b, kb, mb, gb) //1 1024 1048576 1073741824
}
IF、SWITCH
下面是一个尝试读取文件的程序:
func main() {const filename = "abc.txt"// 该行允许试图读取一个文件,若该文件未读取到,则返回err,file为nil// 若文件读取到,则err为nil,返回一个byte[] 类型的file,该数组应该使用%s进行接收file, err := ioutil.ReadFile(filename)if err != nil {fmt.Println(err)} else {fmt.Printf("%s\n", file)}
}
另外,if可以使用类似于for一样进行先执行,再判断
func main() {const filename = "abc.txt"// 但注意,这种形式就类似于定义了一个局部变量,file、err都只能在if语句中使用if file, err := ioutil.ReadFile(filename); err != nil {fmt.Println(err)} else {fmt.Printf("%s\n", file)}
}
下面是一个Switch语句的示例,要注意的是:Switch后可以不跟任何语句,直接在CASE中进行判断:
func grade(score int) string {switch {case score < 0 || score > 100:// panic代表,中断程序并抛出异常信息,异常信息为后面的内容panic(fmt.Sprintf("Wrong Score %d", score))case score < 60:return "F"case score < 80:return "C"case score < 90:return "B"case score <= 100:return "A"default:return "?"}
}
Loop
Go语言中的循环:
同IF一样,GO语言中的循环也不需要括号,其他的基本与JAVA一致
func convertToBin(n int) string {result := ""for ; n > 0; n /= 2 {lsb := n % 2// strconv.Itoa()用来实现将int转stringresult = strconv.Itoa(lsb) + result}return result
}func main() {fmt.Println(convertToBin(13))
}Go语言中没有while,我们直接在for后面写条件就是传统意义上的while
func printFile(filename string) {file, err := os.Open(filename)if err != nil {panic(err)}scanner := bufio.NewScanner(file)for scanner.Scan() {fmt.Println(scanner.Text()) // 输出文件的一行}
}
如果我们for后面什么也不写,就是一个死循环,相当于while(true)
func forever () {for {fmt.Println("abc")}
}
我们GO语言中的并发编程就是基于GO语言中的死循环的,GO语言对于死循环有非常中意的思路,故其把死循环定义的十分优雅
time.Sleep(time * Second * 2) 使用单位 * 时间数的方式来处理时间问题,更加直观
For+ Range
我们可以使用 for 与 关键字 range 连用的方式来对容器进行遍历(这里的容器也包括字符串):
func main() {name := "GoLang Go"builder := strings.Builder{}// 注意对字符串的打印,其打印的是ASCII码for index, value := range name {builder.WriteString("数据格式:")builder.WriteString(strconv.Itoa(index))builder.WriteString(" --> ")builder.WriteString(string(rune(value)) + "\n")}fmt.Println(builder.String())
}
将ASCII 的 int 数字转为对应字符的方式:两次强转(string(rune(x)))
另外,我们这个地方操作的是这个字符串的拷贝,而不是字符串本身
同时,我们对字符串操作:[]rune(string)
函数
GO语言中的函数示例:
func eval(a, b int, op string) int {switch op {case "+":return a + bcase "-":return a - bcase "*":return a * bcase "/":return a / bdefault:panic("unsupported operation:" + op)}
}
另外,GO语言的另一个显著的特点:其函数可以定义多个返回值:
// 带鱼除法
func div(a, b int) (int, int) {return a / b, a % b
}
另外,我们可以通过给返回值命名的方式来更灵活的处理函数
// 带鱼除法
func div(a, b int) (q, r int) {q = a / br = a % breturn
}func main() {q, r := div(8, 3)fmt.Println(q, r)
}
但是,如果我们只想使用其中一个参数,就需要我们使用下划线在取值时忽略掉另一个参数:
// 带鱼除法
func div(a, b int) (q, r int) {q = a / br = a % breturn
}func main() {q, _ := div(8, 3)fmt.Println(q)
}
同时,我们可以利用Go语言中提供的多返回值机制优化四则运算中错的问题:
func eval(a, b int, op string) (int, error) {switch op {case "+":return a + b, nilcase "-":return a - b, nilcase "*":return a * b, nilcase "/":q, _ := div(a, b)return q, nildefault:return 0, fmt.Errorf("Unsupported Operation: %s ", op)}
}func main() {if result, err := eval(15, 4, "C"); err != nil {fmt.Println("Error:", err)} else {fmt.Println(result)}
}
另外,我们也可以在函数的形参中定义函数,这也被我们叫做函数式编程,在后面详细讲
对于重载等Java中的技术,在Go语言中都不存在,其存在的有一个可变形参列表:
func sumArgs(values ...int) int {sum := 0for i := range values {sum += values[i]}return sum
}// main: fmt.Println(sumArgs(1, 2, 3, 4, 5, 6, 7, 8, 9))
指针
指针指的是通过操作数据的存储地址从而进行对数据操作的工具,不同于C中的指针,Go中的指针没有运算操作,这一点大大简化了学习指针的难度。
值传递和引用传递
在此之前,我们需要理清楚值传递和引用传递的区别:
void pass_by_val(int a) {a++;}
void pass_by_ref(int& a) {a++;}
在上面的C++代码片段中,没有加&的就属于值传递,其会在空间中开辟一片新的区域用来存储一个传进来的形参a的复制,这就叫做值传递,而在下面的代码中,添加了&,这就属于引用传递,其会在传入的形参原值上进行操作
典例:交换两个元素的内容
值传递的经典例子:
func swap(a, b int) {a, b = b, a
}
这种写法不会交换任何元素,这是在元素的复制上进行操作,没有效果
下面是利用指针的写法:
func swap(a, b *int) {*a, *b = *b, *a
}
func main() {a, b := 3, 4swap(&a, &b)fmt.Println(a, b)
}
但问题就是:我们这种写法对观感来讲非常差,不利于代码维护,故我们一般不使用指针,而是将我们需要的值返回出去并让其他变量接收,进而解决值传递的问题。
通常解法:
func swap(a, b int) (int, int) {return b, a
}func main() {a, b := 3, 4a, b = swap(a, b)fmt.Println(a, b)}
数组
数组的定义方式
func main() {// 定义数组的常规方式,这样定义会给他们赋初值都是0var arr1 [5]int// 以这种方式定义的数组必须赋初值arr2 := [3]int{1, 2, 3}// 这种方式可以定义数量不确定的数组,但同时,使用[...]的话就也必须赋初值arr3 := [...]int{5, 6, 7}// 多维数组的定义方式var grid [3][4]intfmt.Println(arr1, arr2, arr3)fmt.Println(grid)
}
注意一点:[3]string和[4]string都不算是同一种类型,因为他们的数组长度不同
另外:[x]string和[]string也不是相同的数据类型,[x]string是数组,而[]string叫做切片
注意:数组是可以判断是否相等的,直接使用==来判断,如果两个数组的顺序与内容完全一致,则会输出相等
多维数组的一个小例子:
var courseInfo [3][4]string// 二维数组的初始化:courseInfo[0] = [4]string{"Java", "static", "4", "back"}
使用range进行遍历:
var courseInfo [3][4]string// 二维数组的初始化:courseInfo[0] = [4]string{"Java", "static", "4", "back"}courseInfo[1] = [4]string{"Go", "static", "12", "back"}courseInfo[2] = [4]string{"TypeScript", "nonstatic", "24", "front"}for _, rows := range courseInfo {for _, values := range rows {fmt.Print(values)}}
数组的遍历
// 遍历的方法// 最基础的遍历方法for i := 0; i < len(arr3); i++ {fmt.Println(arr3[i])}// 利用range进行遍历for index, value := range arr3 {fmt.Println(index, value)}// 若我们不想使用下标或值,我们需要使用下划线_代替(因为Go语言不支持定义未使用的变量)for _, v := range arr3 {fmt.Print(v)}
数组是值类型
我们调用函数的时候和Java中是一样的,我们的函数在对形参进行修改的时候,不会修改到传入的参数,而是会修改其传入的形参的复制,也就是说,数组的调用是值传递(Java中会直接传入数组的地址,所以看似是引用传递,但实际上是值传递,实现了引用传递的功能)。
另外:a [10]int和[11]int是不同的类型,再进行形参传递时甚至无法通过编译
如果我们需要对数组的内容进行修改,就需要使用到指针:
func printArray(arr *[3]int) {arr[0] = 100for i, v := range arr {fmt.Println(i, v)}
}printArray(&arr3)
这样使用数组其实不太方便,我们在实际使用中一般使用切片来代替数组的功能
切片(slice)
在我们以后的开发过程中,使用切片就像我们使用Java中的数组一样,我们更多使用Slice进行实际的开发
切片的定义
切片的定义:
arr := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}s1 := arr[2:6]fmt.Println(s1) // [2 3 4 5]
切片的灵活定义:
s2 := arr[:6]s3 := arr[2:]s4 := arr[:]fmt.Println(s2) // [0 1 2 3 4 5]fmt.Println(s3) //[2 3 4 5 6 7 8 9]fmt.Println(s4)//[0 1 2 3 4 5 6 7 8 9]
切片的基本原理
切片是对数组的视图,对这个视图的修改会对原数据造成修改:
func updateSlice(slice []int) {slice[0] = 100
}s5 := arr[2:6]fmt.Println(s5) //[2 3 4 5]updateSlice(s5)fmt.Println(s5) // [100 3 4 5]fmt.Println(arr) // [0 1 100 3 4 5 6 7 8 9]
另外的:我们甚至可以在slice上再slice,但我们最终操作的都是第一个slice基于的数组
Slice的扩展
我们还可以注意一个问题:Slice是可以向后自动拓展的

举例:
s6 := arr[3:5]fmt.Println(s6)s7 := s6[1:4] //[3 4]fmt.Println(s7) //[4 5 6]s8 := s6[3:4] // [6]fmt.Println(s8)
按理说s6中只有两个元素,我们不可能取出第3、4个元素,但我们却实实在在的取出来了,这是因为我们的slice会存储一个cap元素用来记录从slice的起始位置到arr的最后位置,这样我们向后延展的时候就可以取出来了,并且我们甚至可以从超出slice长度的后面开始取,但基于这种原理,我们无法向前延展。
同理,由于s[index]不属于slice切片的赋值范畴,所以我们也不能用这种方式拓展
切片的操作
我们可以使用append来向slice中添加元素,这个添加可以超过原数组的长度,并且如果没有超过长度时,会修改对应原数组对应索引位置的数据,如果超过了长度,我们的Slice就不再作为原数组的索引,而是会被系统自动映射一个新的更长的索引,这个索引会比Append以后的切片更长(其实是拥有一个扩容机制,这个扩容机制也是由0、1、2、4、8、16、32、64、128。。。这样进行扩容的,在append时发现cap长度不足时会触发扩容
s9 := arr[8:9]fmt.Println(s9) // [8]s10 := append(s9, 100)s11 := append(s10, 101)fmt.Println(s11) // [8 100 101]fmt.Println(s11[0:4]) // [8 100 101 0]
另外的,append添加元素后的新切片必须被接收
合并两个切片
// 切片可以直接定义,类似与动态数组courses1 := []string{"语文", "数学", "英语"}courses2 := []string{"政治", "历史", "地理"}courses := append(courses1, courses2[1:]...)fmt.Println(courses)
Slice如果以基础的方式被声明,其内容为nil,len=0、cap=0
直接声明Slice
以下面这种方式可以直接声明一个切片
使用make方法可以创建一个切片,并声明它的len和cap
一般使用make进行切片的创建,可以避免其在空间不足时进行扩容
所以,我们在直接定义切片时,是不能直接向其中的某个元素赋值的,我们必须使用 append 进行添加
var s12 []intfmt.Println(s12) // []s13 := make([]int, 15, 16)fmt.Println(s13) // [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]fmt.Println(len(s13)) // 15fmt.Println(cap(s13)) // 16
Slice的复制与删除
Slice的Copy操作:
s14 := []int{2, 4, 8, 10}copy(s13, s14) // s14 复制给 s13、不会改变s13的len和cap,只从前往后改变,后面的也不便// s13:[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]// s14:[2 4 8 10]fmt.Println(s13) // [2 4 8 10 0 0 0 0 0 0 0 0 0 0 0]
另外的,我们若把长的Copy给短的,短的的长度也不会改变,只会从前往后把元素复制过来
使用copy是深拷贝
使用slice = slice[:]是浅拷贝
如果我们要进行删除操作:
我们可以使用slice的切片机制以及append机制进行拼接
s15 := s14[0:2]s16 := s14[3:4]s17 := append(s15, s16...) // 这个...用来将slice中的元素全部以逗号分隔的形式取出fmt.Println(s17) // 这样就删除了第3个元素
另外的,我们可以使用s[1:]和s[:len(s)- 1]来掐头去尾
Slice 的底层原理
再进行函数的参数传递时,是值传递,不过其复制出来的是slice的指针,也就是另一个slice,但是其指向的是同一个数组。
所以我们在函数中进行调用时会改变原有的内容
但是,一旦我们使用了append方法令其发生了扩容,其就会将一个新数组进行返回,此时就不会影响原有内容
再另外,slice的扩容是按照 1、2、4、8、16、32、64、128、256、512、814.。。。。。也就是说其一开始以2的次方进行扩容,后来再对扩容的速度进行降低
Map
Map,键值对
Map的定义
Map的定义方式:有初值的定义方式
// 有初值的定义方式m := map[string]string{"name": "ccmouse","course": "golang","site": "imooc","quality": "notbad",}fmt.Println(m)
使用Make和var进行定义的方式:
m2 := make(map[string]int)fmt.Println(m2)var m3 map[string]intfmt.Println(m3)
要注意的是:使用make定义出来的map是一个空map、而使用var定义的map是nil
map的操作
Map的遍历
for k, v := range m {fmt.Println(k, v)}
同样的:我们的k,v也可以使用下划线进行省略
这里要注意的是:map底层是一个HashMap:其内部是无序的,故我们每次遍历其顺序都不同
另外:map是区分声明和初始化的,没有初始化的map无法插入数据
我们需要 var mymap = map[string]string{} 注意后面的花括号,必须加上了花括号才算是初始化完成了
,但相反的:Slice就没有这个需求,其可以直接进行添加
Map的取值:
courseName := m["name"]fmt.Println(courseName)
要注意的是:
我们就算取了一个不存在的Key值,也可以通过编译(会取到Zero Value)并返回一个空值,我们可以使用第二个返回值来判断是否取到元素
courseName, ok := m["name"]fmt.Println(courseName, ok)c, ok := m["c"]fmt.Println(c, ok)
这就自然而然的延伸出了一种防止取到空值的方法:
if courseName, ok := m["name"]; ok {fmt.Println(courseName)}
Map的值的删除:
delete(m, "name")
另外还要注意:Map是线程不安全的
例题
一个简单的判断子串问题:
func length(s string) int {lastOccurred := make(map[byte]int) // 每个byte为键、int为值start := 0maxLength := 0// 遍历字符串for i, ch := range []byte(s) {if lastI, ok := lastOccurred[ch]; ok && lastI >= start {start = lastI + 1}if i-start+1 > maxLength {maxLength = i - start + 1}lastOccurred[ch] = i}return maxLength
}func main() {fmt.Println(length("abcabcdbb"))
}
思路是:遍历每一个字符,对于每一个字符:若其在空map中不存在,则认为其在之前的位置都没有出现过,一定可以新加入进来,若其在map中不为空,则证明其在之前出现过,但我们仍然需要判断其最后是否在start的位置之前出现的,若是的话,也可以新加入进来,若不是的话,则证明这个字符串到头了,可以作为一个不重复子串了
list
list 就相当于链表
字符和字符串的处理
一个Demo:
func main() {str := "Luckin瑞幸咖啡"// 将字符串转成字节流就是这个样子(16进制数)// 每一个中文字符都是3个字节for index, value := range []byte(str) {fmt.Printf("(%d %X)", index, value)}fmt.Println()// 若转成char型呢:// 将每一个字符串联在一起,并且其下标是按照字符标注的,遇到中文会跳跃两个for index, value := range str {fmt.Printf("(%d %X)", index, value)}fmt.Println()// 同时,我们可以使用utf8的标准库进行一些操作count := utf8.RuneCountInString(str) // 求字符串字符数fmt.Printf("%d", count)bytes := []byte(str)for len(bytes) > 0 {ch, size := utf8.DecodeRune(bytes) // 可以将字节流转换成字符bytes = bytes[size:]fmt.Printf("%c ", ch) // 输出每一个字符}fmt.Println()
}
要注意的是,我们在直接使用i, v := string的时候,我们的下标是跳跃的,很容易出现乱码的情况。
我们可以使用rune进行操作。(rune会将原先的东西另开一片空间,将他们都存储在新的空间中)
// 使用rune,这样它的下标是连续的for index, ch := range []rune(str) {fmt.Printf("(%d %c)", index, ch)}fmt.Println()
%d 整数、%c 字符、%X 字节
但是我们在使用fmt.Println的时候是不允许使用百分号的形式来进行格式化输出的
以百分号进行格式化输出会提高格式化的可维护性,但其效率很低
另外的,我们可以使用fmt.Sprintf()的方式来将格式化的字符串存储在变量中
name := "曹操"age := 500stringTest := fmt.Sprintf("他的名字是%s, 他%d岁了", name, age)fmt.Println(stringTest)
高性能字符串拼接(strings.Builder)
var stringBuilder strings.BuilderstringBuilder.WriteString("他的名字是")stringBuilder.WriteString(name)stringBuilder.WriteString(", 他")stringBuilder.WriteString(strconv.Itoa(age))stringBuilder.WriteString("岁了")stringb := stringBuilder.String()fmt.Println(stringb)
使用strings.Builder的方式拼接字符串的效率远高于上面两种格式化的方式
字符串的比较
使用 == 来比较字符串的内容是否相同
比较大小是按字符依次比较ASCII码,看谁先更大。
goto语句
goto语句允许我们将程序直接跳转到某个代码块中,其后的代码无论其处在哪个阶段,代码都不再执行
这个写法是很危险的,很容易导致代码的混乱或造成代码的不确定性,极难维护
func main() {for i := 0; i < 10; i++ {print(i)if i == 5 {goto over}}over:print("程序被跳转到了这个位置")
}
相关文章:
【Go】一、Go语言基本语法与常用方法容器
GO基础 Go语言是由Google于2006年开源的静态语言 1972:(C语言) — 1983(C)—1991(python)—1995(java、PHP、js)—2005(amd双核技术 web端新技术飞速发展&…...

杨中科 ASP.NETCORE 高级14 SignalR
1、什么是websocket、SignalR 服务器向客户端发送数据 1、需求:Web聊天;站内沟通。 2、传统HTTP:只能客户端主动发送请求 3、传统方案:长轮询(Long Polling)。缺点是?(1.客户端发送请求后&…...

哪家洗地机比较好用?性能好的洗地机推荐
在众多功能中,我坚信洗地机的核心依旧是卓越的清洁能力以及易于维护的便捷性,其他的附加功能可以看作是锦上添花,那么如何找到性能好的洗地机呢?我们一起看看哪些洗地机既能确保卫生效果还能使用便利。 洗地机工作原理࿱…...

学习与非学习
学习与非学习是人类和动物行为表现中的两种基本形式,它们在认知过程和行为适应上有着根本的区别。理解这两者之间的差异对于把握认知发展、心理学以及教育学等领域的核心概念至关重要。 学习 学习是一个获取新知识、技能、态度或价值观的过程,它导致行为…...
牛客网SQL进阶127: 月总刷题数和日均刷题数
官网链接: 月总刷题数和日均刷题数_牛客题霸_牛客网现有一张题目练习记录表practice_record,示例内容如下:。题目来自【牛客题霸】https://www.nowcoder.com/practice/f6b4770f453d4163acc419e3d19e6746?tpId240 0 问题描述 基于练习记录表…...

19:Web开发模式与MVC设计模式-Java Web
目录 19.1 Java Web开发模式19.2 MVC设计模式详解19.3 MVC与其他Java Web开发模式的区别总结19.4 应用场景总结 在Java Web应用程序开发领域,有效的架构模式和设计模式对提高代码可维护性、模块化以及团队协作至关重要。本文将探讨Java Web开发中的常见模式——模型…...

Z字形变换
问题: 将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。 比如输入字符串为 "PAYPALISHIRING" 行数为 3 时,排列如下: P A H N A P L S I I G Y I R 之后,你…...
飞书上传图片
飞书上传图片 1. 概述1.1 访问凭证2. 上传图片获取image_key1. 概述 飞书开发文档上传图片: https://open.feishu.cn/document/server-docs/im-v1/image/create 上传图片接口,支持上传 JPEG、PNG、WEBP、GIF、TIFF、BMP、ICO格式图片。 在请求头上需要获取token(访问凭证) …...
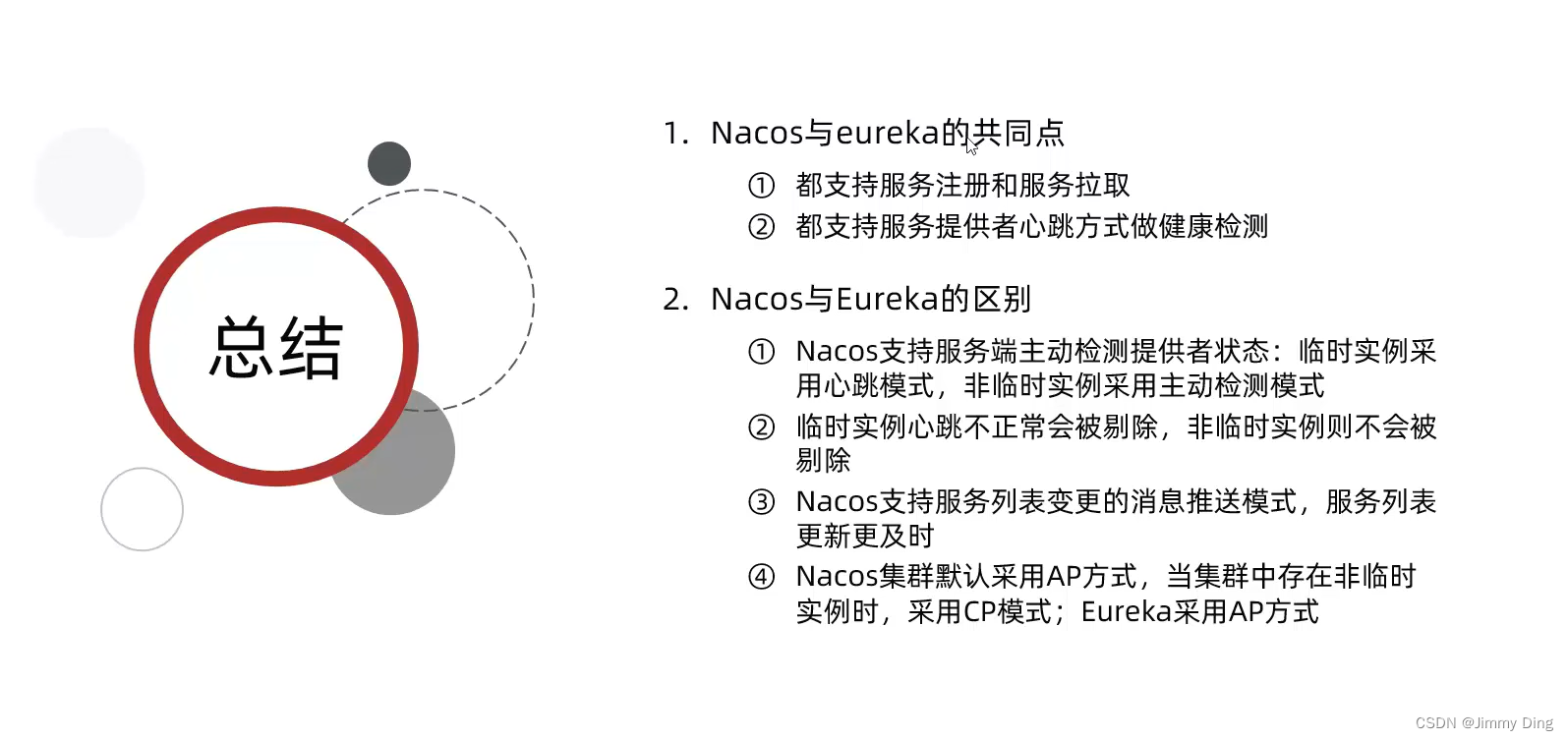
Java微服务学习Day1
文章目录 认识微服务服务拆分及远程调用服务拆分服务远程调用提供者与消费者 Eureka注册中心介绍构建EurekaServer注册user-serviceorder-service完成服务拉取 Ribbon负载均衡介绍原理策略饥饿加载 Nacos注册中心介绍配置分级存储负载均衡环境隔离nacos注册中心原理 认识微服务…...

STM32标准库驱动W25Q64模块读写字库数据+OLED0.96显示例程
STM32标准库驱动W25Q64 模块读写字库数据OLED0.96显示例程 🎬原创作者对W25Q64保存汉字字库演示: W25Q64保存汉字字库 🎞测试字体显示效果: 📑功能实现说明 利用W25Q64保存汉字字库,OLED显示汉字的时候&…...

【java】简单的Java语言控制台程序
一、用于文本文件处理的Java语言控制台程序示例 以下是一份简单的Java语言控制台程序示例,用于文本文件的处理。本例中我们将会创建一个程序,它会读取一个文本文件,显示其内容,并且对内容进行计数,然后将结果输出到控…...

【服务器数据恢复】HP EVA虚拟化磁盘阵列数据恢复原理方案
EVA存储结构&原理: EVA是虚拟化存储,在工作过程中,EVA存储中的数据会不断地迁移,再加上运行在EVA上的应用都比较繁重,磁盘负载高,很容易出现故障。EVA是通过大量磁盘的冗余空间和故障后rss冗余磁盘动态…...

08-OpenFeign-结合Sentinel,实现熔断降级
当我们在对服务远程调用时,会因为服务的请求超时、抛出异常等情况,导致调用失败。 如果短时间内,产生大量请求异常。引发上游的调用方请求积压,最终会引起整个调用链雪崩。 为此我们需要对核心的调用过程进行监控,当…...

15.实现数组的扁平化
实现方式1(递归) 普通的递归思路很容易理解,就是通过循环递归的方式,一项一项地去遍历,如果每一项还是一个数组,那么就继续往下遍历,利用递归程序的方法,来实现数组的每一项的连接: let arr […...
对话模型Demo解读(使用代码解读原理)
文章目录 前言一、数据加工二、模型搭建三、模型训练1、构建模型2、优化器与损失函数定义3、模型训练 四、模型推理五、所有Demo源码 前言 对话模型是一种人工智能技术,旨在使计算机能够像人类一样进行对话和交流。这种模型通常基于深度学习和自然语言处理技术&…...

Android 自定义BaseFragment
直接上代码: BaseFragment代码: package com.example.custom.fragment;import android.content.Context; import android.os.Bundle; import android.view.LayoutInflater; import android.view.View; import android.view.ViewGroup; import androidx…...

[C#] 如何对列表,字典等进行排序?
对列表进行排序 下面是一个基于C#的列表排序的案例: using System; using System.Collections.Generic;class Program {static void Main(string[] args){// 创建一个列表List<int> numbers new List<int>() { 5, 2, 8, 1, 10 };// 使用Sort方法对列…...

Mac 下载安装Java、maven并配置环境变量
下载Java8 下载地址:https://www.oracle.com/java/technologies/downloads/ 根据操作系统选择版本 没有oracle账号需要注册、激活登录 mac直接选择.dmg文件进行下载,下载后安装。 默认安装路径:/Library/Java/JavaVirtualMachines/jdk-1…...

【多模态】27、Vary | 通过扩充图像词汇来提升多模态模型在细粒度感知任务(OCR等)上的效果
文章目录 一、背景二、方法2.1 生成 new vision vocabulary2.1.1 new vocabulary network2.1.2 Data engine in the generating phrase2.1.3 输入的格式 2.2 扩大 vision vocabulary2.2.1 Vary-base 的结构2.2.2 Data engine2.2.3 对话格式 三、效果3.1 数据集3.2 图像细粒度感…...
【包括石头剪刀布判断程序(模拟版)】)
|Python新手小白低级教程|第二十章:函数(2)【包括石头剪刀布判断程序(模拟版)】
文章目录 前言一、复习一、函数实战之——if语句特殊系统1.判断等第分数(函数名为mark(参数num))2.石头剪刀布判断程序 二、练习总结 前言 Hello,大家好,我是你们的BoBo仔,感谢你们来阅读我的文…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

DBLP数据库是什么?
DBLP(Digital Bibliography & Library Project)Computer Science Bibliography是全球著名的计算机科学出版物的开放书目数据库。DBLP所收录的期刊和会议论文质量较高,数据库文献更新速度很快,很好地反映了国际计算机科学学术研…...