ELFK日志采 - QuickStart
文章目录
- 架构选型
- ELK
- EFLK
- Elasticsearch
- ES集群搭建
- 常用命令
- Filebeat
- 功能介绍
- 安装步骤
- Filebeat配置详解
- filebeat常用命令
- Logstash
- 功能介绍
- 安装步骤
- Input插件
- Filter插件
- Grok Filter 插件
- Mutate Filter 插件
- 常见的插件配置选项:
- Mutate Filter配置案例:
- Output插件
- Kibana
- 功能介绍
- 安装步骤
架构选型
ELK

“ELK” 是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
- Elasticsearch 是一个搜索和分析引擎。
- Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到Elasticsearch、kafka等。
- Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
一套日志采集系统需要具备以下5个功能:
- 收集 :能够采集多个来源的日志数据。
- 传输 :能够稳定的把日志数据传输到日志服务。
- 存储 :能够存储海量的日志数据。
- 查询 :能够灵活且高效的查询日志数据,并提供一定的分析能力。
- 告警 :能够提供提供告警功能,通知开发和运维等等
Elastic官网:https://www.elastic.co/cn/what-is/elk-stack
EFLK
在采集日志数据时,我们需要在服务器上安装一个 Logstash。不过 Logstash 是基于 JVM 的重量级的采集器,对系统的 CPU、内存、IO 等等资源占用非常高,这样可能影响服务器上的其它服务的运行。所以,Elastic NV 推出 Beats ,基于 Go 的轻量级采集器,对系统的 CPU、内存、IO 等等资源的占用基本可以忽略不计。因此,本文的示例就变成了 ELFK 。其中,Beats 负责采集数据,并通过网路传输给 Logstash。即整体架构:
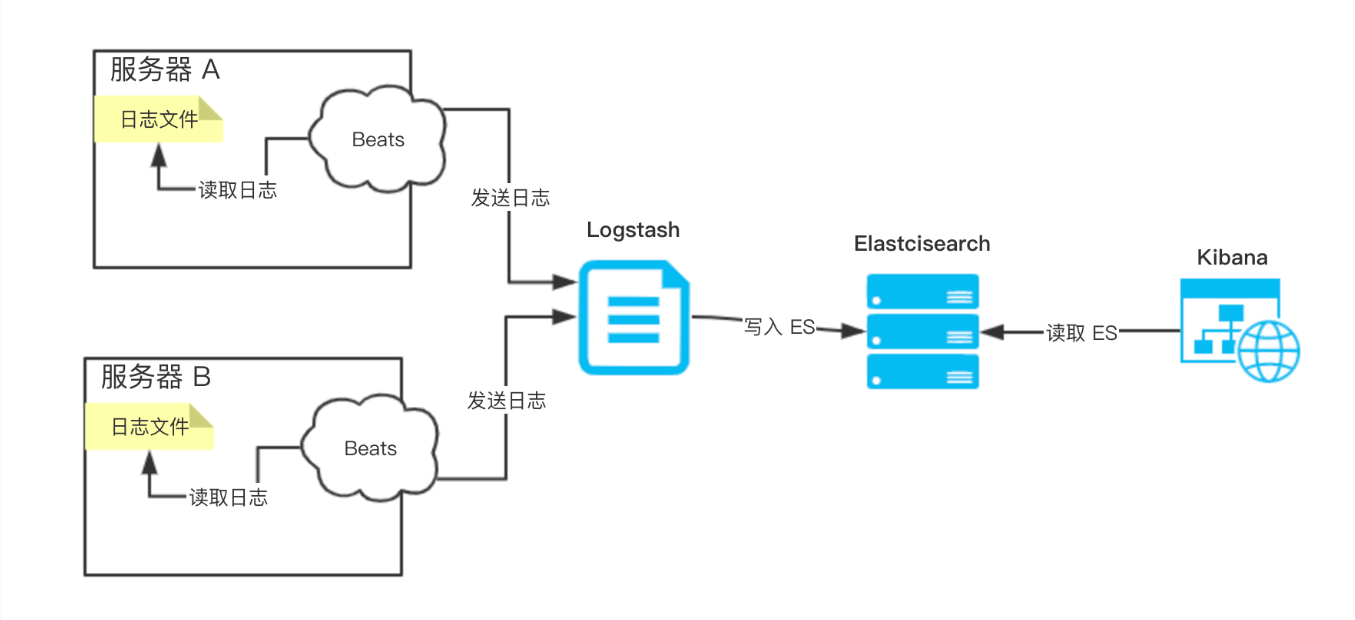
Beats 是一个全品类采集器的系列,包含多个:(使用 Filebeat,采集日志文件)
- Filebeat :轻量型日志采集器。√
- Metricbeat :轻量型指标采集器。
- Packetbeat :轻量型网络数据采集器。
- Winlogbeat :轻量型 Windows 事件日志采集器。
- Auditbeat :轻量型审计日志采集器。
- Heartbeat :面向运行状态监测的轻量型采集器。
- Functionbeat :面向云端数据的无服务器采集器。
Elasticsearch
ES集群搭建
参考:Elasticsearch7.x - 集群部署 - lihewei - 博客园 (cnblogs.com)
常用命令
启动 Elasticsearch 服务:
# 使用命令行启动 Elasticsearch 服务
elasticsearch# 或者使用 systemd(根据您的操作系统)
sudo systemctl start elasticsearch
停止 Elasticsearch 服务:
# 使用命令行停止 Elasticsearch 服务
Ctrl+C# 或者使用 systemd(根据您的操作系统)
sudo systemctl stop elasticsearch
检查 Elasticsearch 集群健康状态:
# 使用 curl 命令检查集群健康状态
curl -X GET "http://localhost:9200/_cat/health?v"
查看节点信息:
shellCopy code
# 使用 curl 命令查看节点信息
curl -X GET "http://localhost:9200/_cat/nodes?v"创建索引:
# 使用 curl 命令创建一个名为 "my_index" 的索引
curl -X PUT "http://localhost:9200/my_index"
删除索引:
# 使用 curl 命令删除名为 "my_index" 的索引
curl -X DELETE "http://localhost:9200/my_index"
索引文档:
# 使用 curl 命令索引一篇文档到 "my_index" 索引中
curl -X POST "http://localhost:9200/my_index/_doc" -d '{"field1": "value1","field2": "value2"
}'
搜索文档:
# 使用 curl 命令执行搜索查询
curl -X GET "http://localhost:9200/my_index/_search?q=field1:value1"
查看索引的映射(Mapping):
# 使用 curl 命令查看索引 "my_index" 的映射
curl -X GET "http://localhost:9200/my_index/_mapping"
查看索引的统计信息:
# 使用 curl 命令查看索引 "my_index" 的统计信息
curl -X GET "http://localhost:9200/my_index/_stats"
查看索引中的文档数量:
# 使用 curl 命令查看索引 "my_index" 中的文档数量
curl -X GET "http://localhost:9200/my_index/_count"
聚合数据:
# 使用 curl 命令执行聚合操作
curl -X POST "http://localhost:9200/my_index/_search" -d '{"size": 0,"aggs": {"avg_field2": {"avg": {"field": "field2"}}}
}'
更新文档:
# 使用 curl 命令更新文档
curl -X POST "http://localhost:9200/my_index/_update/1" -d '{"doc": {"field1": "new_value"}
}'
删除文档:
# 使用 curl 命令删除文档
curl -X DELETE "http://localhost:9200/my_index/_doc/1"
Filebeat
功能介绍
Filebeat是一个轻量型日志采集器,负责采集数据,并通过网路传输给 Logstash。
安装步骤
1)官网下载:https://www.elastic.co/cn/downloads/beats/filebeat
2)解压:tar -zxvf filebeat-7.5.1-darwin-x86_64.tar.gz
3)修改配置:
filebeat.inputs:
- type: logenabled: truepaths:- /home/crbt/logs/crbtRingSync/wrapper.logfields:log_source: vrbt-rd1-hbbjlog_topic: crbt-web-logoutput.kafka:hosts: ["10.1.61.121:9092"]topic: '%{[fields.log_topic]}'
Filebeat配置详解
filebeat.inputs配置项,设置 Filebeat 读取的日志来源。该配置项是数组类型,可以将 Nginx、MySQL、Spring Boot 每一类,作为数组中的一个元素。output.elasticsearch配置项,设置 Filebeat 直接写入数据到 Elasticsearch 中。虽然说 Filebeat5.0版本以来,也提供了 Filter 功能,但是相比 Logstash 提供的 Filter 会弱一些。所以在一般情况下,Filebeat 并不直接写入到 Elasticsearch 中output.logstash配置项,设置 Filebeat 写入数据到 Logstash 中output.kafka配置项,设置Filebeat 写入数据到 kafka 中
filebeat常用命令
# 启动filebeat
nohup ./filebeat -e &# -e 参数表示以前台模式运行 -c 指定配置文件
./filebeat -e -c /home/crbt/lihewei/filebeat-7.5.1-linux-x86_64/filebeat.yml
./filebeat -e -c filebeat.yml# 查看filebeat是否正常启动
curl http://localhost:5066/
ps -ef | grep filebeat
Logstash
功能介绍
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到喜欢的“存储库”中。通过定义了一个 Logstash 管道(Logstash Pipeline),来读取、过滤、输出数据。一个 Logstash Pipeline 包含三部分:
- 【必选】输入(Input): 数据(包含但不限于日志)往往都是以不同的形式、格式存储在不同的系统中,而 Logstash 支持从多种数据源中收集数据(File、Syslog、MySQL、消息中间件等等)
- 【可选】过滤器(Filter) :实时解析和转换数据,识别已命名的字段以构建结构,并将它们转换成通用格式。
- 【必选】输出(Output) :Elasticsearch 并非存储的唯一选择,Logstash 提供很多输出选择。
安装步骤
1)下载: https://www.elastic.co/cn/products/logstash
2)解压:unzip logstash-7.5.1.zip
3)修改配置文件
在 config 目录下,提供了 Logstash 的配置文件,其中,logstash-sample.conf 配置文件,是 Logstash 提供的 Pipeline 配置的示例
crbt@node2:/home/crbt/lihw/logstash-7.5.1/config>ll
total 40
-rw-r--r-- 1 crbt crbt 2019 Dec 17 2019 jvm.options
-rw-r--r-- 1 crbt crbt 7482 Dec 17 2019 log4j2.properties
-rw-rw-r-- 1 crbt crbt 843 Sep 15 19:07 logstash.conf
-rw-r--r-- 1 crbt crbt 342 Dec 17 2019 logstash-sample.conf
-rw-r--r-- 1 crbt crbt 8372 Sep 15 10:53 logstash.yml
-rw-r--r-- 1 crbt crbt 3146 Dec 17 2019 pipelines.yml
-rw-r--r-- 1 crbt crbt 1696 Dec 17 2019 startup.options
crbt@node2:/home/crbt/lihw/logstash-7.5.1/config>cat logstash-sample.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.#日志消息从哪里来(这里使用filebeat进行日志收集)
input {beats {port => 5044}
}#日志信息输出到哪里去(这里写入es数据库)
output {elasticsearch {hosts => ["http://10.1.61.121:9200"]index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"}
}
4)指定配置文件并启动logstash:W
# 启动logstash服务(指定自定义的配置文件logstash.conf)
./logstash -f ../config/logstash.conf# 后台启动logstash服务🚩
nohup ./logstash -f ../config/logstash.conf &Input插件
Logstash 的 input 插件用于从不同的数据源中接收数据,并将其发送到 Logstash 事件流中供进一步处理。每个 input 插件都有其特定的配置选项,以适应不同类型的数据源,修改自定义的配置文件即可生效(下面仅列举了几个常用输入方法)
-
File Input 插件:用于从本地文件读取数据。
input {file {path => "/path/to/your/logfile.log"start_position => "beginning"sincedb_path => "/dev/null"} } -
Beats Input 插件:用于接收来自 Elastic Beats 系列工具(如 Filebeat、Metricbeat)的数据。
input {beats {port => 5044} } -
Kafka Input 插件:用于从 Apache Kafka 主题中消费数据。
input {kafka {bootstrap_servers => "kafka-server:9092"topics => ["your-topic"]} }
Filter插件
Logstash 的 filter 插件用于对接收的事件进行处理、转换和丰富,以便更好地进行索引和分析。每个 filter 插件都有其特定的配置选项,以适应不同的数据处理需求。以下是一些常见的 Logstash filter 插件及其配置示例:
Grok Filter 插件
Logstash 的 Grok Filter 插件用于从非结构化的文本数据中提取结构化的字段。
filter {grok {match => { "message" => "%{COMBINEDAPACHELOG}" }}
}
Mutate Filter 插件
常见的插件配置选项:
-
add_field:添加新字段到事件中,并指定字段的名称和值。
rubyCopy code mutate {add_field => { "new_field" => "New Value" } } -
remove_field:从事件中删除指定字段。
rubyCopy code mutate {remove_field => [ "field1", "field2" ] } -
rename:重命名事件中的字段,将字段从旧名称改为新名称。
rubyCopy code mutate {rename => { "old_field" => "new_field" } } -
copy:复制字段的值到新的字段中。
rubyCopy code mutate {copy => { "source_field" => "destination_field" } } -
replace:替换字段的值为新的值。
rubyCopy code mutate {replace => { "field_to_replace" => "new_value" } } -
update:更新字段的值为新的值,类似于替换操作。
rubyCopy code mutate {update => { "field_to_update" => "new_value" } } -
convert:将字段的数据类型转换为指定的类型。
rubyCopy code mutate {convert => { "numeric_field" => "integer" } } -
gsub:使用正则表达式替换字段中的文本。
rubyCopy code mutate {gsub => [ "field_to_modify", "pattern_to_replace", "replacement_text" ] } -
uppercase/lowercase:将字段值转换为大写或小写。
rubyCopy code mutate {uppercase => [ "field_to_uppercase" ]lowercase => [ "field_to_lowercase" ] } -
strip:删除字段值两端的空格。
rubyCopy code mutate {strip => [ "field_to_strip" ] }
Mutate Filter配置案例:
用于对字段进行修改、重命名和删除。
filter {mutate {add_field => { "new_field" => "New Value" }rename => { "user" => "username" }remove_field => [ "message" ]}
}
在上面的配置中,我们使用 Mutate Filter 插件执行了以下操作:
- add_field:我们添加了一个名为 “new_field” 的新字段,并将其值设置为 “New Value”。此时事件将变为:
- rename:我们重命名了 “user” 字段为 “username”。此时事件将变为:
- remove_field:我们删除了 “message” 字段。此时事件将不再包含 “message” 字段。
#过滤前
{"message": "Log entry","user": "john_doe","status": "success","response_time_ms": 45
}#过滤后
{"username": "john_doe","status": "success","response_time_ms": 45,"new_field": "New Value"
}
Output插件
Logstash 的 output 插件用于将处理过的事件发送到各种目标,如 Elasticsearch、文件、数据库等。每个 output 插件都有其特定的配置选项,以适应不同的目标和需求。以下是一些常见的 Logstash output 插件及其配置示例:
-
Elasticsearch Output 插件:用于将事件发送到 Elasticsearch 集群。
output {elasticsearch {hosts => ["http://localhost:9200"]index => "my_index"} } -
File Output 插件:用于将事件写入本地文件。
output {file {path => "/path/to/output/file.txt"} } -
Kafka Output 插件:用于将事件发送到 Apache Kafka 主题。
rubyCopy code output {kafka {topic_id => "my_topic"bootstrap_servers => "kafka-server:9092"} }
Kibana
功能介绍
通过 Kibana,您可以对自己的 Elasticsearch 进行可视化,也可以通过插件的方式查看es
安装步骤
1)官网下载:https://www.elastic.co/cn/products/kibana
2)解压 tar -zxvf kibana-7.5.1-darwin-x86_64.tar.gz
3)修改配置,vi config/kibana.yml 命令,编辑 Kibana 配置文件
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]
kibana.index: ".kibana"
4)启动Kibana:nohup bin/kibana & 命令,后台启动 Kibana 服务。
nohup bin/kibana &nohup ./kibana &ps aux | grep kibana
5)测试:访问 http://10.1.61.122:5601/ 地址,查看 Kibana 是否启动成功
相关文章:
ELFK日志采 - QuickStart
文章目录 架构选型ELKEFLK ElasticsearchES集群搭建常用命令 Filebeat功能介绍安装步骤Filebeat配置详解filebeat常用命令 Logstash功能介绍安装步骤Input插件Filter插件Grok Filter 插件Mutate Filter 插件常见的插件配置选项:Mutate Filter配置案例: O…...
微信小程序的图片色彩分析,窃取网络图片的主色调
1、安装 Mini App Color Thief 包 包括下载包,简单使用都有,之前写了,这里就不写了 网址:微信小程序的图片色彩分析,窃取主色调,调色板-CSDN博客 2、 问题和解决方案 问题:由于我们的窃取图片的…...

Leetcode 121 买卖股票的最佳时机
题意理解: 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。 返回你可以从这笔交…...

SQL语言复习-----1
1,前言 SQL是计算机的一门基础语言,无论在开发还是数据库管理上都是非常重要,最近总结归纳了一下相关知识,记录如下。 2,归纳 SQL是结构化查询语言。 关系数据库有三级模式结构。 基本表和视图一样都是关系。 举例…...
爬虫2—用爬虫爬取壁纸(想爬多少张爬多少张)
先看效果图: 我这个是爬了三页的壁纸60张。 上代码了。 import requests import re import os from bs4 import BeautifulSoupcount0 img_path "./壁纸图片/"#指定保存地址 if not os.path.exists(img_path):os.mkdir(img_path) headers{ "User-Ag…...

学习Android的第九天
目录 Android Button 按钮 基本的按钮 StateListDrawable 范例 使用颜色值绘制圆角按钮 自制水波纹效果 Android ImageButton 图片按钮 ImageButton 不同状态下的 ImageButton Android RadioButton 单选按钮 RadioButton 获得选中的值 Android Button 按钮 在 And…...

课时21:内置变量_脚本相关
2.4.1 脚本相关 学习目标 这一节,我们从 基础知识、简单实践、小结 三个方面来学习 基础知识 脚本相关的变量解析 序号变量名解析1$0获取当前执行的shell脚本文件名2$n获取当前执行的shell脚本的第n个参数值,n1…9,当n为0时表示脚本的文…...

ubuntu22.04@laptop OpenCV Get Started: 006_annotating_images
ubuntu22.04laptop OpenCV Get Started: 006_annotating_images 1. 源由2. line/circle/rectangle/ellipse/text 应用Demo3 image_annotation3.1 C应用Demo3.2 Python应用Demo3.3 重点过程分析3.3.1 划线3.3.2 画圆3.3.3 矩形3.3.4 椭圆3.3.5 文字 4. 总结5. 参考资料 1. 源由 …...

【制作100个unity游戏之23】实现类似七日杀、森林一样的生存游戏10(附项目源码)
本节最终效果演示 文章目录 本节最终效果演示系列目录前言快捷栏绘制UI代码控制快捷列表信息 源码完结 系列目录 前言 欢迎来到【制作100个Unity游戏】系列!本系列将引导您一步步学习如何使用Unity开发各种类型的游戏。在这第23篇中,我们将探索如何制作…...
uniapp vue3怎么调用uni-popup组件的this.$refs.message.open() ?
vue2代码 <!-- 提示信息弹窗 --><uni-popup ref"message" type"message"><uni-popup-message :type"msgType" :message"messageText" :duration"2000"></uni-popup-message></uni-popup>typ…...

【深度学习:语义分割】语义分割简介
【深度学习:语义分割】语义分割简介 什么是图像分割?了解语义分割数据采集语义分割的深度学习实现全卷积网络上采样跳跃连接U-NetDeepLab多尺度物体检测金字塔场景解析网络(PSPNet) 语义分割的应用医学影像自动驾驶汽车农业图片处…...

前端开发_AJAX基本使用
AJAX概念 AJAX是异步的JavaScript和XML(Asynchronous JavaScript And XML)。 简单点说,就是使用XMLHttpRequest对象与服务器通信。 它可以使用JSON,XML,HTML和text文本等格式发送和接收数据。 AJAX最吸引人的就是它的“异步"特性&am…...
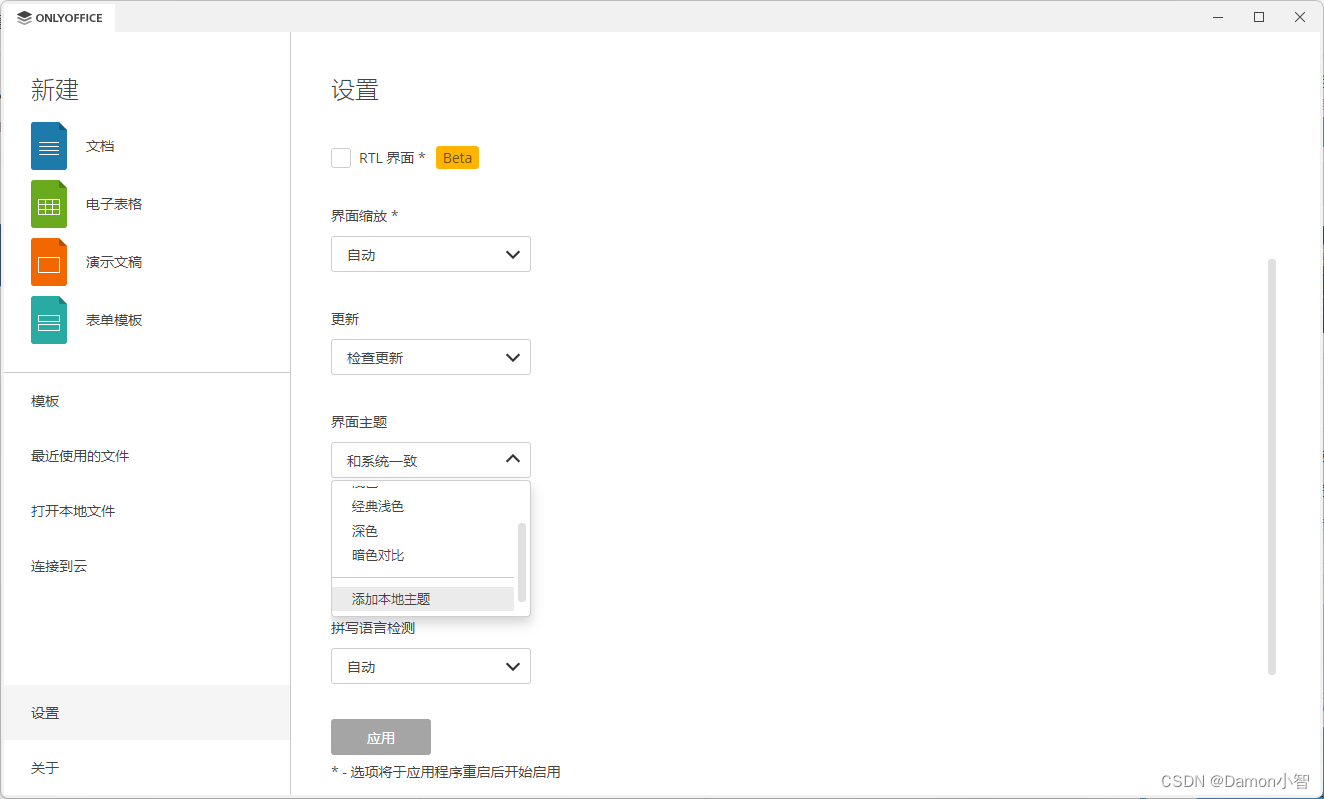
OnlyOffice-8.0版本深度测评
OnlyOffice 是一套全面的开源办公协作软件,不断演进的 OnlyOffice 8.0 版本为用户带来了一系列引人瞩目的新特性和功能改进。OnlyOffice 8.0 版本在功能丰富性、安全性和用户友好性上都有显著提升,为用户提供了更为强大、便捷和安全的文档处理和协作环境…...

【Go】一、Go语言基本语法与常用方法容器
GO基础 Go语言是由Google于2006年开源的静态语言 1972:(C语言) — 1983(C)—1991(python)—1995(java、PHP、js)—2005(amd双核技术 web端新技术飞速发展&…...

杨中科 ASP.NETCORE 高级14 SignalR
1、什么是websocket、SignalR 服务器向客户端发送数据 1、需求:Web聊天;站内沟通。 2、传统HTTP:只能客户端主动发送请求 3、传统方案:长轮询(Long Polling)。缺点是?(1.客户端发送请求后&…...

哪家洗地机比较好用?性能好的洗地机推荐
在众多功能中,我坚信洗地机的核心依旧是卓越的清洁能力以及易于维护的便捷性,其他的附加功能可以看作是锦上添花,那么如何找到性能好的洗地机呢?我们一起看看哪些洗地机既能确保卫生效果还能使用便利。 洗地机工作原理࿱…...

学习与非学习
学习与非学习是人类和动物行为表现中的两种基本形式,它们在认知过程和行为适应上有着根本的区别。理解这两者之间的差异对于把握认知发展、心理学以及教育学等领域的核心概念至关重要。 学习 学习是一个获取新知识、技能、态度或价值观的过程,它导致行为…...
牛客网SQL进阶127: 月总刷题数和日均刷题数
官网链接: 月总刷题数和日均刷题数_牛客题霸_牛客网现有一张题目练习记录表practice_record,示例内容如下:。题目来自【牛客题霸】https://www.nowcoder.com/practice/f6b4770f453d4163acc419e3d19e6746?tpId240 0 问题描述 基于练习记录表…...

19:Web开发模式与MVC设计模式-Java Web
目录 19.1 Java Web开发模式19.2 MVC设计模式详解19.3 MVC与其他Java Web开发模式的区别总结19.4 应用场景总结 在Java Web应用程序开发领域,有效的架构模式和设计模式对提高代码可维护性、模块化以及团队协作至关重要。本文将探讨Java Web开发中的常见模式——模型…...

Z字形变换
问题: 将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。 比如输入字符串为 "PAYPALISHIRING" 行数为 3 时,排列如下: P A H N A P L S I I G Y I R 之后,你…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...

消防一体化安全管控平台:构建消防“一张图”和APP统一管理
在城市的某个角落,一场突如其来的火灾打破了平静。熊熊烈火迅速蔓延,滚滚浓烟弥漫开来,周围群众的生命财产安全受到严重威胁。就在这千钧一发之际,消防救援队伍迅速行动,而豪越科技消防一体化安全管控平台构建的消防“…...