【数据结构和算法】--- 基于c语言排序算法的实现(2)
目录
- 一、交换排序
- 1.1 冒泡排序
- 1.2 快速排序
- 1.2.1 hoare法
- 1.2.2 挖坑法
- 1.2.3 前后指针法
- 1.3 快速排序优化
- 1.3.1 三数取中法选key
- 1.3.2 递归到小的子区间使用插入排序
- 1.4 快排非递归版
- 二、归并排序
- 2.1 归并排序
- 2.1.1 递归版
- 2.1.2 非递归版
一、交换排序
基本思想:所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置。交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
1.1 冒泡排序
说起冒泡排序,这也算是在我们学习编程时遇到的第一个排序算法,总体逻辑就是从待排序数组第一个一直向后遍历,遇到比自己大的就记录该值,遇到比自己小的就交换,直到到达待排序数组结尾,此时待排序数组长度--,依此逻辑每次都能将最大值移动到最后。直到待排序数组长度为0,此时数组已有序。
冒泡排序动态演示:
在实现代码时,还可以增加一个变量bool exchange = true,如果一趟遍历下来,没有任何数据进行交换,则exchange不变,代表此时数组已有序,那么便直接结束排序(if(exchange == true) break;);如果发生数据交换,则改变exchange值为false,那么排序任然继续下一趟。 代码如下:
//冒泡排序
void BubbleSort(int* a, int n)
{//排序趟数for(int i = 0; i < n - 1; ++i){bool exchange = true;//每趟需要排的元素for(int j = 0; j < n - 1 - i; ++j){//左大于右就交换if(a[j] > a[j + 1]){Swap(&a[j], &a[j + 1])exchange = false;}}if(exchange == true)break;}
}
冒泡排序的特性总结:
- 冒泡排序是一种非常容易理解的排序
- 时间复杂度:
O(N^2) - 空间复杂度:
O(1) - 稳定性: 稳定
1.2 快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
那么具体是如何实现的呢?可以参考如下过程:
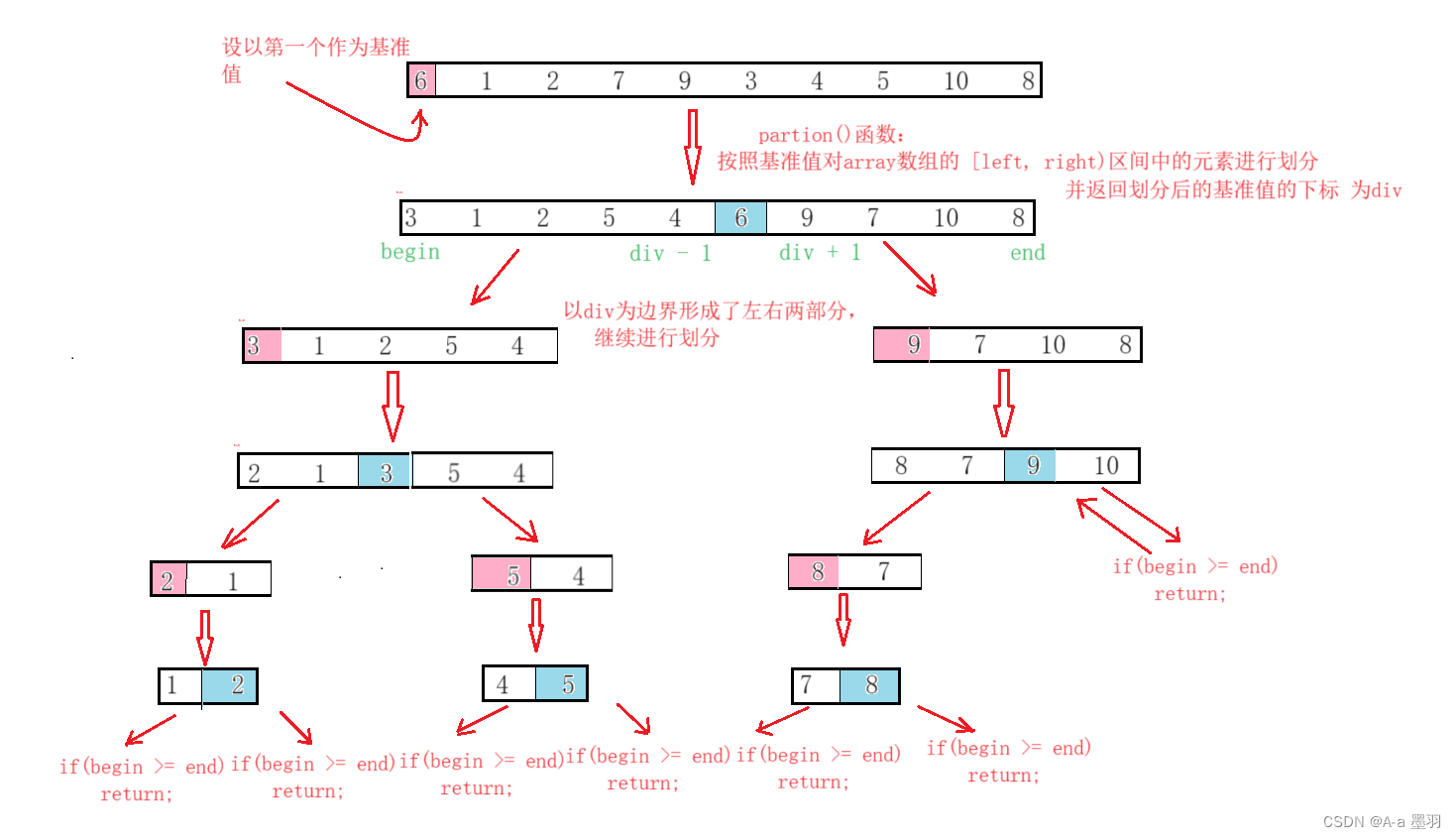
事实上整体逻辑就是二叉树的前序遍历,即先处理当前数组,取基准值,以基准值为标准划分左右两部分,然后递归基准值左部分([begin, div - 1]),最后在递归基准值右部分([div + 1, end])。 将begin >= end作为结束条件,说明当前已经递归到的部分的数据个数<= 1,return回到上层递归。
整个递归逻辑的主体部分为partion()函数,用来划分基准值左右两部分,并返回当前基准值的下标。 可以使用三种方法来实现partion()函数,即初版hoare法,挖坑法,前后指针法,后两者是对hoare法的改进,下面将逐一介绍!
递归框架:
// 假设按照升序对a数组中[bedin, end]区间中的元素进行排序
void QuickSort(int* a, int begin, int end)
{if(begin >= end)return;// 按照基准值对a数组的 [begin, end]区间中的元素进行划分int div = partion(a, begin, end);// 划分成功后以div为边界形成了左右两部分 [begin, div - 1] 和 [div + 1, end]// 递归排[begin, div - 1]QuickSort(a, begin, div - 1);// 递归排[div + 1, end]QuickSort(a, div + 1, end);
}
上述为快速排序递归实现的主框架,发现与二叉树前序遍历规则非常像,我们可以参照二叉树前序遍历(如有疑问请参考:【数据结构和算法】— 二叉树(3)–二叉树链式结构的实现(1))规则即可快速写出来,后序只需分析如何按照基准值来对区间中数据进行划分的方式即可。
将区间按照基准值划分为左右两半部分的常见方式有:
1.2.1 hoare法
hoare法 动态演示:

hoare法主要思想:定义两个变量分别对应待排序数组首元素下标int left = begin,待排序数组尾元素下标int right = end。右边先向左找小于a[keyi]的值,找到后,左边在向右找大于a[keyi]的值,然后交换两数Swap(&a[left], &a[right])。需要注意的是,在寻找过程中要保证left < right。最后直到left == right,将基准值和相遇点的值交换Swap(&a[keyi], &a[left]),并返回基准值下标return keyi。
hoare法代码:
//hoare法
int partion(int* a, int begin, int end)
{int left = begin, right = end;//设基准值为首元素,keyi记录下标int keyi = begin;while(left < right){//右向左 找小于a[keyi]的值while(left < right && a[keyi] <= a[right]--right;//左向右 找大于a[keyi]的值while(left < right && a[keyi] >= a[left]++left;//找完一次便交换,Swap(&a[left], &a[right]);}//left 和 right 相遇交换基准值和 < a[keyi] 的值(即a[left])Swap(&a[left], &a[keyi]);return left;
}相信看完上面上面代码和演示,会有这么一个问题:为什么相遇的位置比a[keyi]要小呢?
因为左边做keyi,右边right先走:
- 情况1:
right先遇到left。此时right没有找到比a[keyi]小的,一直走,直到遇到left,相遇位置是a[left],一定比a[keyi]小; - 情况2:
left先遇到right。因为是right先走,找到小于a[keyi]的元素便会停下,接着left找大,没有找到,遇到了right停下来了,相遇点是right,比a[keyi]要小。
当然如果右边做基准值,那么必须要左边left先走,才能确保相遇点都大于a[keyi]。
1.2.2 挖坑法
挖坑法 动态演示:

挖坑法主要思想:先取出基准值,并将其赋值给key ,此时这个位置就空出来了,称之为坑位,用holei来记录坑位的下标。 紧接着右边向左找小(即小于key的元素),若找到就将该元素填入坑位中a[holei] = a[end],并改变坑位为替换元素的下标holei = end,然后左边向右找大(即大于key的元素),同样填入坑位,并更新坑位。依次循环,直到左右相遇begin == end,这时将基准值填入坑中(a[holei] = key),并返回坑位return holei;。
挖坑法代码:
//挖坑法
int partion(int* a, int begin, int end)
{//基准值记录int key = a[begin];//坑位记录int holei = begin;while(begin < end){//右边找小,填左坑,更新坑位while(begin < end && a[end] >= key)--end;a[holei] = a[end];holei = end;//左边找小,填右坑,更新坑位while(begin < end && a[begin] <= key)++begin;a[holei] = a[begin];holei = begin;}//基准值填入坑位a[holei] = key;return holei;
}
1.2.3 前后指针法
前后指针法 动态演示:

前后指针法主要思想:事实上这里定义的并不是真正的指针,而是整形来模拟指针。 将初始位置定义为前指针int prev = begin;,后一个位置定义为后指针int cur = begin + 1;,并记录基准值int key = a[begin];。当后指针指向的元素大于key时,++cur;若找到了小于key的值,那么就++prev,在判断prev != cur之后,就交换前后指针对应的值(Swap(&a[prev], &a[cur]));若相等则跳过。最后在交换基准值和前指针对应的元素(Swap(&a[prev], &a[keyi])),并返回前指针对应元素下标(return prev;)。
cur遇到比key大的值,++cur;cur遇到比key小的值,Swap(&a[prev], &a[cur]),++cur,++prev。
前后指针法代码:
//前后指针法
int partion(int* a, int begin, int end)
{int prev = begin, cur = begin + 1;int keyi = begin;//注意此处 <=while(cur <= end){//将两种逻辑合二为一if(a[cur] < a[keyi] && ++prev != cur)Swap(&a[prev], &a[cur]);++cur;}Swap(&a[prev], &a[keyi]);return prev;
}
1.3 快速排序优化
1.3.1 三数取中法选key
考虑下面这种情况:当数组已经有序或者极其接近有序时,再使用递归法写快速排序,时间复杂度如何?
此时基准值如果还选择待排序数组第一个元素的话,那么每层递归便缺少基准值左部分的递归(即begin >= end),只有右部分, 这样待排序的数组只减少了一个元素,递归深度由原来的log(N)变成了N,时间复杂度也随之变成了O(N^2)。
于是乎,一般会选择三数取中法来确定基准值,这样选出来的数既不会是最大值,也不会是最小值。三数指的是:待排序数组第一个元素a[begin],待排序数组最后一个元素a[end],待排序数组中间那个数a[(begin + end) / 2];取中指:取这三个数的中位数。 取到之后与初始值交换 Swap(&a[midi], &a[begin]);,确保第一个值为中位数。实现代码如下:
//三数取中
int GetMidi(int* a, int begin, int end)
{int midi = (begin + end) / 2;//begin midi end 三个数选中位数if(a[begin] < a[midi]){if(a[midi] < a[end])return midi;else if(a[begin] > a[end])return begin;elsereturn end;}else //a[begin] >= a[midi]{if(a[midi] > a[end])return midi;else if(a[end] > a[bedin])return begin;elsereturn end;}
}int midi = GetMidi(a, begin, end);
Swap(&a[midi], &a[begin]);
1.3.2 递归到小的子区间使用插入排序
为什么说递归到小的子区间要使用插入排序呢? 根据这里写的递归的特性,可以看出整体的逻辑是一棵二叉树。说到二叉树,二叉树最后一层的节点数大约占整个二叉树的节点数的一半,这样一来时间复杂度便会升高。那么我们只需要想办法将最后两三层递归逻辑,使用其他效率高的排序给替换掉即可。 这样一来如果替换掉两层,就减少了大约75%的递归,替换三层,大约就减少了87.5%的递归。
小区间优化代码如下:
//小区间优化
void QuickSort(int* a, int begin, int end)
{if(begin >= end)return;if(end - begin + 1 <= 10){//end - begin + 1 <= 10 此逻辑大约优化了三层//插入排序InsertSort(a + begin, end - begin + 1);}else{int keyi = partion(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}
}
事实上,在如今的编译器上,此优化是微乎其微的,因为编译器已经帮助我们进行了很多优化,特别是在release版编译程序时。那么此处为什么选择直接插入排序?根据其特性,元素集合越接近有序,直接插入排序算法的时间效率越高。且此时待排序数组的元素个数较少,不适合希尔排序,且他是一种稳定的排序算法。
1.4 快排非递归版
根据递归版快排的特性,相当于二叉树的前序遍历,那么我们便可利用栈后进先出的特性,来模拟递归并实现排序,栈的实现还请参考:【数据结构和算法】— 栈。快排非递归整体逻辑大致如下:
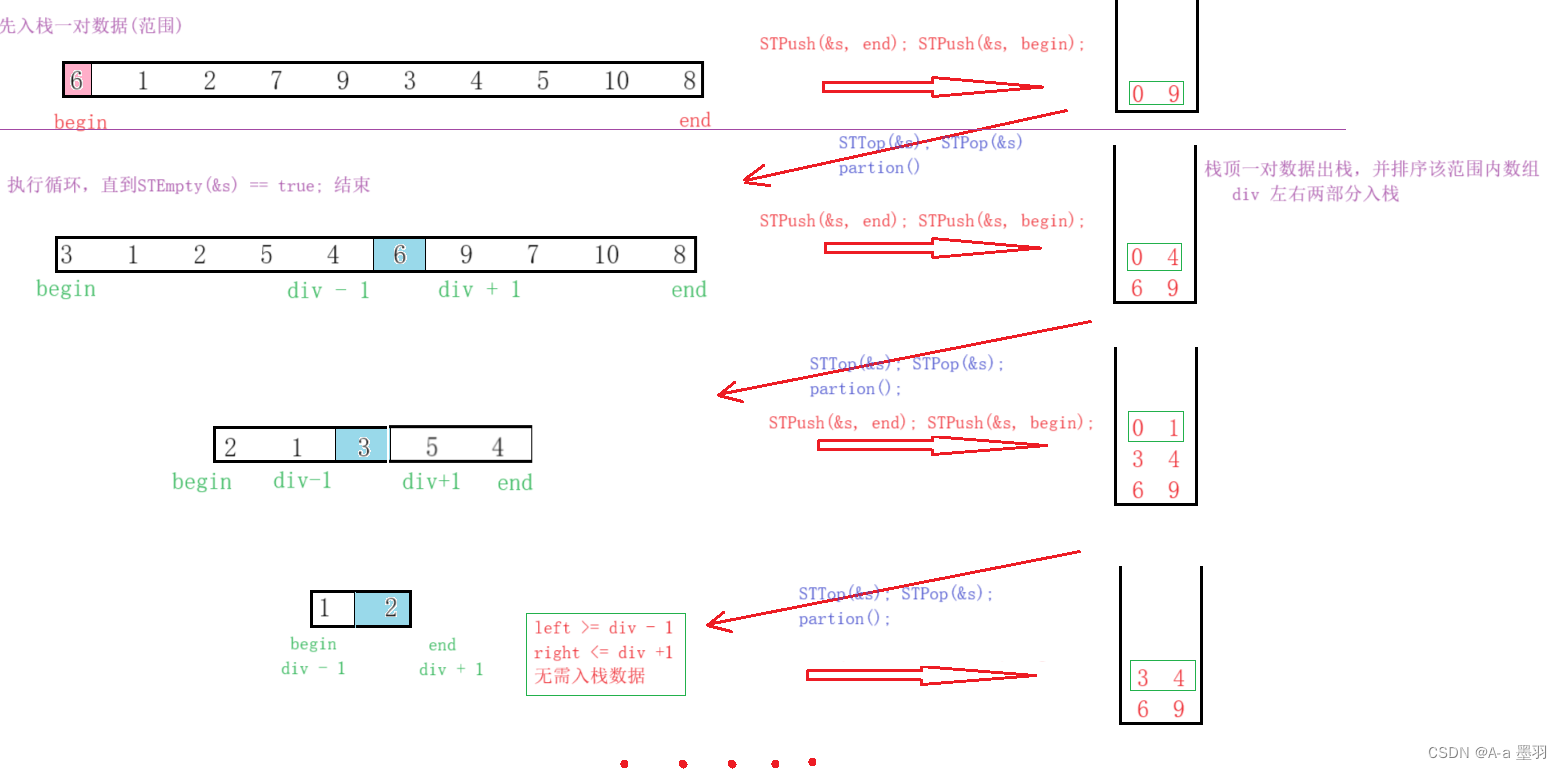
在实现时我们要先创建栈并初始化,然后进栈一对数据(整个待排序数组的下标范围), 以!STEmpty(&s)作为循环条件,当栈中无节点时,便会结束。每进栈一次,便出栈顶两元素作为此次排序的范围,然后进栈div左右两部分的范围,当然只有范围中有一个数据以上才会进栈(即left < div - 1或right > div + 1)。
//非递归,栈模拟
void QuickSortNonR(int* a, int begin, int end)
{ST s;STInit(&s);//先进栈一对数据STPush(&s, end);STPush(&s, begin);while(!STEmpty(&s)){//出栈一对数据,为此次排序范围int left = STTop(&s);STPop(&s);int right = STTop(&s);STPop(&s);int div = partion(a, begin, end);//div 右部分进栈if(right > div + 1){STPush(&s, right);STPush(&s, div + 1);}//div 左部分进栈if(left < div - 1){STPush(&s, div - 1);STPush(&s, left);}}
}
快速排序的特性总结:
-
快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序;
-
时间复杂度:
O(N*logN)

-
空间复杂度:
O(logN) -
稳定性: 不稳定
二、归并排序
2.1 归并排序
基本思想:
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 归并排序核心步骤:

归并排序 动态演示:

2.1.1 递归版
递归版的归并排序,逻辑上与二叉树的后序遍历十分相似。可先找到待排序数组的中间那个数的下标int mid = (begin + end) / 2;,将左部分[begin, mid]作为左子树,右部分[mid + 1, end]作为右子树,继续递归,直到begin >= end(即当前元素个数小于等于一个)结束并返回,当左右部分递归完便开始合并。
此处合并即为两待排序数组[begin, mid]和[mid + 1, end],向动态开辟的数组tmp中拷贝并排序。 至于合并的逻辑就十分简单,两待排序数组元素依次比较,小的拷贝进tmp,直到一方拷贝完begin1 > end1或begin2 > end2,然后直接拷贝未拷贝完的一方,最后再使用memcpy()函数将tmp中数据(此时tmp中元素已有序)拷回a中。
代码如下:
//递归版 归并排序
void _MergeSort(int* a, int begin, int end, int* tmp)
{if(begin >= end)return;int mid = (begin + end) / 2;//[begin, mid] [mid + 1, end]_MergeSort(a, begin, mid, tmp);_MergeSort(a, mid + 1, end, tmp);//归并int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin;//将两个数组合并为一个,并排为升序while(begin1 <= end1 && begin2 <= end2){if(a[begin1] < a[begin2])tmp[i++] = a[begin1++];elsetmp[i++] = a[begin2++];}//拷贝剩余数据while(begin1 <= end1)tmp[i++] = a[begin1++];while(begin2 <= end2)tmp[i++] = a[begin2++];//拷贝回原数组memcpy(a + begin, tmp + begin, sizeof(int)* (end - begin + 1));
}void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int)* n);if(tmp == NULL){perror("malloc fail");return;}_MergeSort(a, 0, n - 1, tmp);free(tmp);
}
2.1.2 非递归版
归并排序非递归版与递归相似,使用循环来模拟递归的合并逻辑。定义变量int gap来表示所需合并的两数组的长度,动态开辟长度为n的数组来存储合并后的数组,用i来控制待合并数组的初始下标for(size_t i = 0; i < n; i += 2*gap)(长度小于数组长度,一次跳过两gap)。

根据i确定好两待合并数组的首元素下标begin,尾元素下标end,然后将两个数组合并为一个,并排为升序。在确定begin和end时要注意边界条件的处理(即最后一对待排序数组下标可能超出n),大致分为以下几种情况:

当情况1时,因为只有一个待排序数组[begin1, end1],且此数组已有序所以无需进行合并排序操作,直接break即可;而情况2,是两个待排序数组,需要合并,但第二个数组可能超出了a数组的范围,所以要缩小end2(即end2 = n - 1)。
代码如下:
//递归版 归并排序
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int)* n);if(tmp == NULL){perror("malloc fail");return;}int gap = 1;while(gap < n){for(size_t i = 0; i < n; i += 2*gap){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2*gap - 1;//边界处理if(end1 >= n || begin2 >= n)break;if(end2 >= n)end2 = n - 1;//[begin1, end1] [begin2, end2] 归并int j = begin1;//将两个数组合并为一个,并排为升序while(begin1 <= end1 && begin2 <= end2){if(a[begin1] < a[begin2])tmp[j++] = a[begin1++];elsetmp[j++] = a[begin2++];}//拷贝剩余数据while(begin1 <= end1)tmp[j++] = a[begin1++];while(begin2 <= end2)tmp[j++] = a[begin2++];//拷贝回原数组memcpy(a + i, tmp + i, sizeof(int)* (end2 - i + 1));}gap *= 2;}free(tmp);
}
在非递归的归并排序中,有这么两个问题值得思考:
-
对比栈实现快排的非递归,归并排序为什么不可以使用栈?
两种排序的非递归写法,本质上与二叉树遍历极其相似。区别在于快速排序的非递归相当于二叉树的前序遍历,可以利用栈后进先出的特性来实现;而归并排序相当于二叉树的后序遍历,只能用循环来模拟实现。 -
上面代码中
memcpy()函数的拷贝操作与放在for循环外对比!
放在for循环内(即每归并一小段,就放回原数组a中),这样避免了随机值。因为当情况1时,break了,后面的数据(最后一组)并没有放到动态开辟的数组tmp中,从而导致访问到随机值(即因为拷贝操作放在for循环外,全部数据,统一拷贝,最后一对数据memcpy()时,会遇到随机值)
归并排序的特性总结:
- 归并的缺点在于需要
O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。 - 时间复杂度:
O(N*logN) - 空间复杂度:
O(N) - 稳定性: 稳定
相关文章:
【数据结构和算法】--- 基于c语言排序算法的实现(2)
目录 一、交换排序1.1 冒泡排序1.2 快速排序1.2.1 hoare法1.2.2 挖坑法1.2.3 前后指针法 1.3 快速排序优化1.3.1 三数取中法选key1.3.2 递归到小的子区间使用插入排序 1.4 快排非递归版 二、归并排序2.1 归并排序2.1.1 递归版2.1.2 非递归版 一、交换排序 基本思想:…...

ORACLE的 软 软 软 解析!
在海鲨数据库架构师精英群里,有位朋友说ORACLE 有 软软软解析. 就是把执行计划缓存在客户端里,从而避免去服务端找执行计划. 他给了个设置方法, Weblogic console->datasource->connectionPool Statement Cache Type >LRU Statement Cache Size100 CURSOR_NUMBER …...

【模板】k 短路 / [SDOI2010] 魔法猪学院
题目背景 注:对于 k k k 短路问题,A* 算法的最坏时间复杂度是 O ( n k log n ) O(nk \log n) O(nklogn) 的。虽然 A* 算法可以通过本题原版数据,但可以构造数据,使得 A* 算法在原题的数据范围内无法通过。事实上,…...

【Make编译控制 08】CMake动静态库
目录 一、编译动静态库 二、链接静态库 三、链接动态库 前情提示:【Make编译控制 07】CMake常用命令-CSDN博客 有些时候我们编写的源代码并不需要将他们编译生成可执行程序,而是生成一些静态库或动态库提供给第三方使用,所以我们需要用到…...
05 06 Verilog基础语法与应用讲解
05. 1. 位操作 计数器实验升级,设计8个LED灯以每个0.5s的速率循环闪烁(跑马灯) 1.1 方法1:使用移位操作符<<来控制led灯的循环亮灭 设计代码 Verilog中,判断操作的时候不加位宽限定是可以的,比如i…...
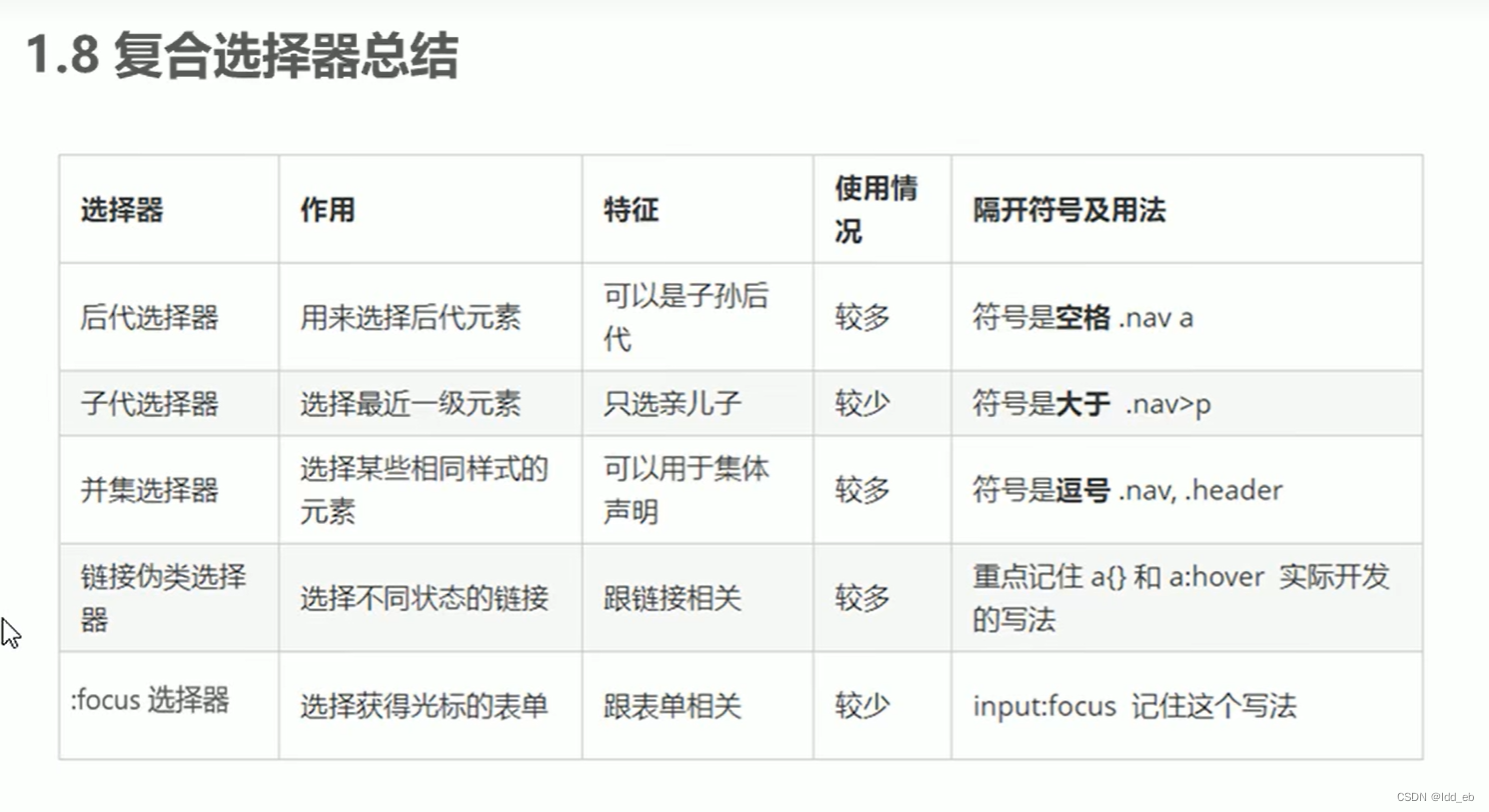
css2复合选择器
一.后代(包含)选择器(一样的标签可以用class命名以分别) 空格表示 全部后代 应用 二.子类选择器 >表示 只要子不要孙 应用 三.并集选择器 ,表示 代表和 一般竖着写 应用 四.伪类选择器(包括伪链接…...
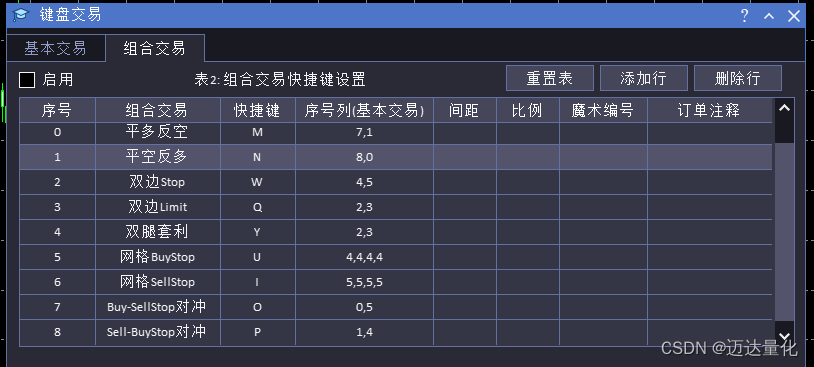
新版MQL语言程序设计:键盘快捷键交易的设计与实现
文章目录 一、什么是快捷键交易二、使用快捷键交易的好处三、键盘快捷键交易程序设计思路四、键盘快捷键交易程序具体实现1.界面设计2.键盘交易事件机制的代码实现 一、什么是快捷键交易 操盘中按快捷键交易是指在股票或期货交易中,通过使用快捷键来进行交易操作的…...

数据结构之基数排序
基数排序的思想是按组成关键字的各个数位的值进行排序,它是分配排序的一种。在该排序方法中把一个关键字 Ki看成一个 d 元组,即 K1i,K2i,,Kdi 其中,0≤ Kji<r,i1~ n,j1~d。这里的r 称为基数。若关键字是…...
区间dp 笔记
区间dp一般是先枚举区间长度,再枚举左端点,再枚举分界点,时间复杂度为 环形石子合并 将 n 堆石子绕圆形操场排放,现要将石子有序地合并成一堆。 规定每次只能选相邻的两堆合并成新的一堆,并将新的一堆的石子数记做该…...
MySQL-SQL优化
文章目录 1. SQL性能分析1.1 SQL执行频率1.2 慢查询日志1.3 profile详情1.4 explain 2. SQL优化2.1 Insert 优化2.2 Group By 优化2.3 Order By 优化2.4 Limit 优化2.5 Count() 优化2.6 Update 优化 3. 拓展3.1 请你说一下MySQL中的性能调优的方法?3.2 执行 SQL 响应…...

详细了解ref和reactive.
这几天看到好多文章标题都是类似于: 不用 ref 的 xx 个理由不用 reactive 的 xx 个理由历数 ref 的 xx 宗罪 我就很不解,到底是什么原因导致有这两批人: 抵触 ref 的人抵触 reactive 的人 看了这些文章,我可以总结出他们的想法…...
使用Linux docker方式快速安装Plik并结合内网穿透实现公网访问
文章目录 1. Docker部署Plik2. 本地访问Plik3. Linux安装Cpolar4. 配置Plik公网地址5. 远程访问Plik6. 固定Plik公网地址7. 固定地址访问Plik 本文介绍如何使用Linux docker方式快速安装Plik并且结合Cpolar内网穿透工具实现远程访问,实现随时随地在任意设备上传或者…...

Redis Centos7 安装到启动
文章目录 安装Redis启动redis查看redis状况连接redis服务端 安装Redis 1.下载scl源 yum install centos-release-scl-rh2.下载redis yum install rh-redis5-redis 3. 创建软连接 1.cd /usr/bin 2. In -s /opt/rh/rh-redis5/root/usr/bin/redis-server ./redis-server 3. …...
「数据结构」二叉搜索树1:实现BST
🎇个人主页:Ice_Sugar_7 🎇所属专栏:Java数据结构 🎇欢迎点赞收藏加关注哦! 实现BST 🍉二叉搜索树的性质🍉实现二叉搜索树🍌插入🍌查找🍌删除 &am…...

可达鸭二月月赛——基础赛第六场(周五)题解,这次四个题的题解都在这一篇文章内,满满干货,含有位运算的详细用法介绍。
姓名 王胤皓 T1 题解 T1 题面 T1 思路 样例输入就是骗人的,其实直接输出就可以了,输出 Hello 2024,注意,中间有一个空格! T1 代码 #include<bits/stdc.h> using namespace std; #define ll long long int …...
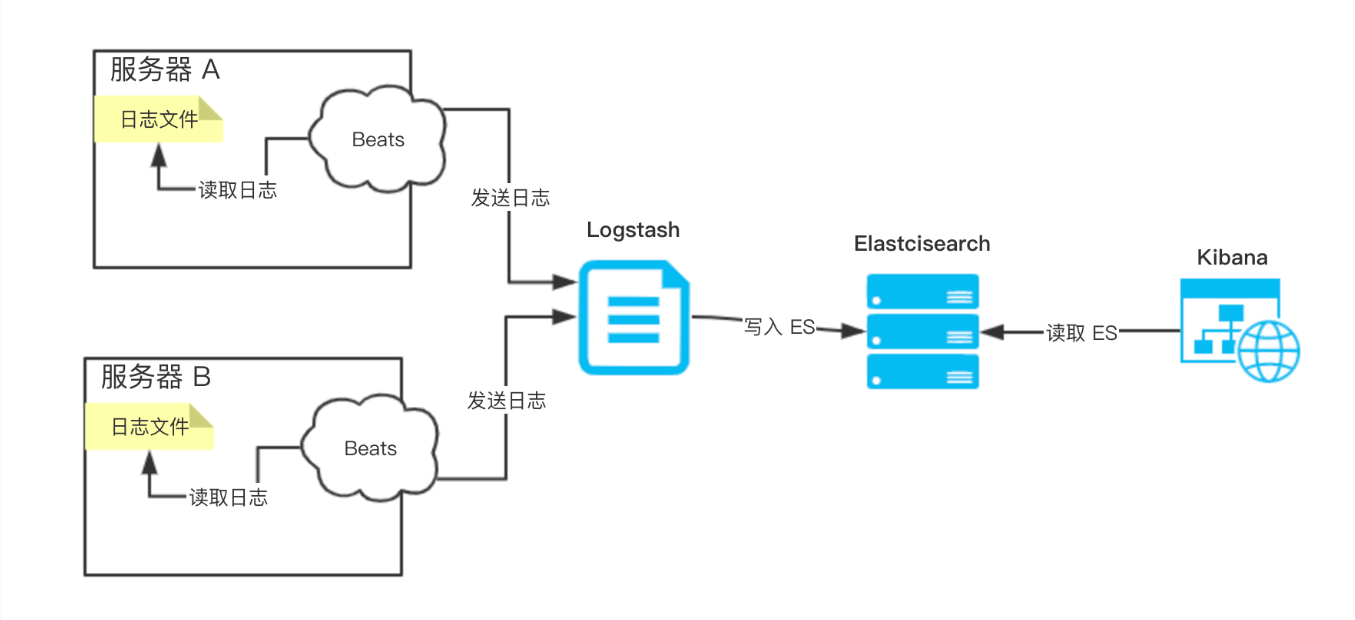
ELFK日志采 - QuickStart
文章目录 架构选型ELKEFLK ElasticsearchES集群搭建常用命令 Filebeat功能介绍安装步骤Filebeat配置详解filebeat常用命令 Logstash功能介绍安装步骤Input插件Filter插件Grok Filter 插件Mutate Filter 插件常见的插件配置选项:Mutate Filter配置案例: O…...
微信小程序的图片色彩分析,窃取网络图片的主色调
1、安装 Mini App Color Thief 包 包括下载包,简单使用都有,之前写了,这里就不写了 网址:微信小程序的图片色彩分析,窃取主色调,调色板-CSDN博客 2、 问题和解决方案 问题:由于我们的窃取图片的…...

Leetcode 121 买卖股票的最佳时机
题意理解: 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。 返回你可以从这笔交…...

SQL语言复习-----1
1,前言 SQL是计算机的一门基础语言,无论在开发还是数据库管理上都是非常重要,最近总结归纳了一下相关知识,记录如下。 2,归纳 SQL是结构化查询语言。 关系数据库有三级模式结构。 基本表和视图一样都是关系。 举例…...
爬虫2—用爬虫爬取壁纸(想爬多少张爬多少张)
先看效果图: 我这个是爬了三页的壁纸60张。 上代码了。 import requests import re import os from bs4 import BeautifulSoupcount0 img_path "./壁纸图片/"#指定保存地址 if not os.path.exists(img_path):os.mkdir(img_path) headers{ "User-Ag…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...
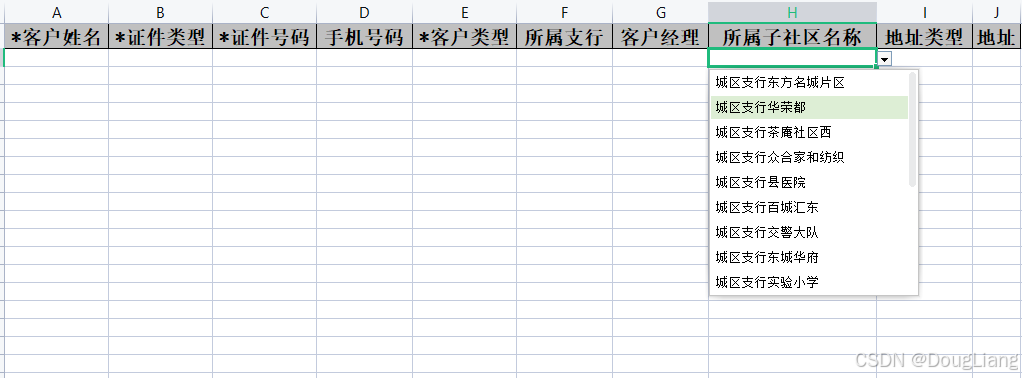
关于easyexcel动态下拉选问题处理
前些日子突然碰到一个问题,说是客户的导入文件模版想支持部分导入内容的下拉选,于是我就找了easyexcel官网寻找解决方案,并没有找到合适的方案,没办法只能自己动手并分享出来,针对Java生成Excel下拉菜单时因选项过多导…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...

python打卡第47天
昨天代码中注意力热图的部分顺移至今天 知识点回顾: 热力图 作业:对比不同卷积层热图可视化的结果 def visualize_attention_map(model, test_loader, device, class_names, num_samples3):"""可视化模型的注意力热力图,展示模…...