【论文笔记之 YIN】YIN, a fundamental frequency estimator for speech and music
本文对 Alain de Cheveigne´ 等人于 2002 年在 The Journal of the Acoustical Society of America 上发表的论文进行简单地翻译。如有表述不当之处欢迎批评指正。欢迎任何形式的转载,但请务必注明出处。
论文链接:http://audition.ens.fr/adc/pdf/2002_JASA_YIN.pdf
目录
- 1. 论文目的
- 2. 摘要
- 3. 介绍
- 4. 方法
- A. 步骤 1: 自相关方法
- B. 步骤 2: 差分函数
- C. 步骤 3: 累积均值归一化差分函数
- D. 步骤 4: 绝对阈值
- E. 步骤 5: 抛物线插值
- F. 步骤 6: 最优局部估计
- 5. 评估
- 6. 对参数的敏感度
- 7. 实现考虑
- 8. 扩展
- A. 变化的幅度
- B. 变化的 F 0 F_0 F0
- C. 加性噪声:缓慢变化的 DC
- D. 加性噪声:周期性的
- E. 加性噪声:与目标不同的频谱
- F. 加性噪声:与目标相同的频谱
- 9. 与听觉感知模型的关系
- 10. 讨论
- 11. 总结
1. 论文目的
提出一种语音和音乐场景下估计基频的方法:YIN.
2. 摘要
论文提出了一种用于估计语音和音乐基频( F 0 F_0 F0)的算法。该算法基于著名的自相关方法,并加入了一些修改,以减少错误。在语音和喉镜信号数据集上的评估显示,该算法的错误率比最佳竞争方法低 3 倍左右。由于没有对频率搜索范围的上界做限制,因此,该算法适合音调较高的声音和音乐。算法相对简单,延迟低,而且可调参数少。该算法基于一个周期信号模型,该模型可以以各种方式被扩展,以处理特定应用中出现的各种形式的非周期性。
3. 介绍
周期信号的基频( F 0 F_0 F0)是其周期的逆,而周期可以定义为:使得信号保持不变的所有时间偏移集合中的最小正整数。该定义只适用于完美的周期性信号。然而,所关注的语音或音乐信号并不具备完美的周期性,基频估计的艺术就是以有用且一致的方式来处理这类信号。
声音的主观音高 (pitch) 通常取决于它的基频,但也有例外。然而,宽泛地来说,音高和周期是一对一的关系。以至于“音高”一词通常被用来代替 F 0 F_0 F0,而且 F 0 F_0 F0 估计方法通常被称为 “音高检测算法” 或 PDA(pitch detection algorithms). 现代音高感知模型假设:音高要么来源于时域中神经模式的周期性,要么来源于耳蜗在频域中分辨出的局部谐波模式。这两个过程都会产生基频或者周期。
一些应用给出了对 F 0 F_0 F0 的不同定义。对于语音来说, F 0 F_0 F0 通常定义为声带的振动频率。声门处的周期性振动可能产生不太完美的周期性语音,because of movements of the vocal tract that filters the glottal source waveform. 然而,声门振动本身也会表现出非周期性。各种因素叠加在一起,使得获得语音信号 F 0 F_0 F0 的有用估计是相当困难的。尽管已经有很多方法被提了出来,但 F 0 F_0 F0 估计是一个持续吸引业界关注的话题。最全面的综述出自于 Hess, 由 Hess 或 Hermes 作以更新。近期的方法包括:瞬时频率法、统计学习和神经网络、听觉模型等,当然还有很多其它的方法。
F 0 F_0 F0 可被用于很多应用中,在语音识别系统中使用 F 0 F_0 F0 的尝试已经取得了一定的成功。一些音乐类的应用需要估计 F 0 F_0 F0, 比如自动乐谱转录或实时交互系统。 F 0 F_0 F0 是许多信号处理方法中很有用的特征。
本文介绍了一种比其它著名方法产生更少错误的 F 0 F_0 F0 估计方法。名称 “YIN” (来自于东方哲学的“阴”和“阳”)暗示了它所涉及的 autocorrelation 和 cancellation 之间的相互作用。
4. 方法
本章逐步介绍该方法,以深入了解该方法的有效性。首先,给出了经典的自相关算法;接着,分析了其误差机理;最后,提出了一系列的改进措施来降低错误率;出于说明目的,每一步都在一个小数据集上对错误率进行了测试。下一章提出了更全面的评估。
A. 步骤 1: 自相关方法
离散信号 x t x_t xt 的自相关函数 (ACF) 可以被定义为:
r t ( τ ) = ∑ j = t + 1 t + W x j x j + τ , \begin{align} r_t(\tau) = \sum_{j=t+1}^{t+W} x_j x_{j+\tau}, \end{align} rt(τ)=j=t+1∑t+Wxjxj+τ,
其中, r t ( τ ) r_t(\tau) rt(τ) 是在 t t t 时刻计算的滞后了 τ \tau τ 之后的自相关函数, W W W 是积分窗口的长度。图 1 给出了一个示例。在信号处理中,通常使用略微不同的定义:
r t ′ ( τ ) = ∑ j = t + 1 t + W − τ x j x j + τ . \begin{align} r_t^{'}(\tau) = \sum_{j=t+1}^{t+W-\tau} x_j x_{j+\tau}. \end{align} rt′(τ)=j=t+1∑t+W−τxjxj+τ.
这里积分窗口的长度随着 τ \tau τ 值的增加而减少,这会导致函数的包络线作为滞后的函数而减少。如果信号在区域 [ t + 1 , t + W ] \left[t+1, t+W\right] [t+1,t+W] 之外的值全是零,那么上述两个定义将给出相同的结果,否则,将给出不同的结果。除非另有说明,否则本文采用第一种定义。

对于周期信号,ACF 在周期的倍数处显示出了峰值。“自相关方法”通过在滞后范围内的穷举搜索来选择最高的非零滞后峰值(图 1 中水平箭头)。显然,如果下限太接近零,算法可能会错误地选择零滞后峰值。反过来,如果上限足够大,它可能会错误地选择更高阶的峰值。 ( 1 ) (1) (1) 中的定义很容易出现第二个问题,而 ( 2 ) (2) (2) 中的定义又很容易出现第一个问题(当窗口长度 W W W 较小时,更是如此)。
为了评估 tapered ACF 包络对错误率的影响,对 ( 1 ) (1) (1) 中计算的函数乘以 a negative ramp 来模拟 ( 2 ) (2) (2) 的结果,且令 W = τ m a x W=\tau_{max} W=τmax:
r t ′ ′ ( τ ) = { r t ( τ ) ( 1 − τ / τ m a x ) if τ ≤ τ m a x , 0 , otherwise . \begin{align} r_t^{''}(\tau) = \left\{ \begin{array}{lc} r_t(\tau)(1-\tau/\tau_{max}) & \text{if} \; \tau \leq \tau_{max}, \\ 0, & \text{otherwise}. \\ \end{array} \right. \end{align} rt′′(τ)={rt(τ)(1−τ/τmax)0,ifτ≤τmax,otherwise.
在一个小语音数据集上对错误率进行了评估(细节参见下章),并在图 2 中给出了其与 τ m a x \tau_{max} τmax 的关系。参数 τ m a x \tau_{max} τmax 允许算法以牺牲两种错误中的一种为代价,而偏向另一种,with a minimum of total error for intermediate values. 如果使用 ( 2 ) (2) (2) 而不是 ( 1 ) (1) (1) 会引入 a natural bias that can be tuned by adjusting W W W. 然而,改变窗长还会产生其它影响,and one can argue that a bias of this sort, if useful, should be applied explicitly rather than implicitly. 这是为啥使用 ( 1 ) (1) (1) 的原因之一。

自相关方法将信号与其自身的平移版本进行比较。从这个意义上讲它和 AMDF(average magnitude difference function)方法是有关联的,后者比较的是差值而不是乘积,而且它是一种更通用的测量事件之间时间间隔的时域方法。ACF 是功率谱的傅立叶变换,and can be seen as measuring the regular spacing of harmonics within that spectrum. 倒谱方法用对数幅度谱代替功率谱,因此对频谱的高频幅度部分所施加的权重变小(particularly near the first formant that often dominates the ACF.) 类似地,‘谱白化’(‘spectral whitening’)效果可以通过线性预测逆滤波(linear predictive inverse filtering)或者中心剪切(center-clipping),或者通过使用滤波器组对信号进行分解,然后在每个通道内计算 ACFs,并将幅度归一化之后的结果相加来得到。基于自相关的听觉模型是目前解释音高感知的更流行的方法之一。
尽管自相关方法(以及与此相关的其它方法)很具有吸引力,而且研究者们付出了很多努力来提升其性能,但它在许多应用中仍会产生很多错误。接下来的内容会逐步降低其错误率。表 1 的第一行给出了基于 ( 1 ) (1) (1) 的基础自相关方法所产生的 gross error rate(定义在下一章中,且是在下一章所使用的数据集的一个子集上测量的)。表 1 中的其它行是通过一系列改进所得到的结果,下一章给出了更正式的报告。

B. 步骤 2: 差分函数
首先,将信号 x t x_t xt 建模为周期为 T T T 的周期函数,可得:
x t − x t + T = 0 , ∀ t . \begin{align} x_t - x_{t+T} = 0, \quad \forall t. \end{align} xt−xt+T=0,∀t.
在一个窗口内对其取平方、求均值后也是如此:
∑ j = t + 1 t + W ( x j − x j + T ) 2 = 0. \begin{align} \sum_{j=t+1}^{t+W} (x_j - x_{j+T})^2 = 0. \end{align} j=t+1∑t+W(xj−xj+T)2=0.
反过来,可以通过计算差分函数,并搜找使得函数值为零的 τ \tau τ 值,来找到一个未知的周期:
d t ( τ ) = ∑ j = 1 W ( x j − x j + τ ) 2 , \begin{align} d_t(\tau) = \sum_{j=1}^{W}(x_j-x_{j+\tau})^2, \end{align} dt(τ)=j=1∑W(xj−xj+τ)2,
存在无数这样的值,它们都是周期的整数倍。图 3(a) 给出了在图 1(a) 的信号上计算出的差分函数。将平方和展开之后,可以使用 ACF 来描述差分函数:
d t ( τ ) = r t ( 0 ) + r t + τ ( 0 ) − 2 r t ( τ ) . \begin{align} d_t(\tau) = r_t(0) + r_{t+\tau}(0) - 2r_t(\tau). \end{align} dt(τ)=rt(0)+rt+τ(0)−2rt(τ).
前两项是能量项,如果它们是常数,那么差分函数 d t ( τ ) d_t(\tau) dt(τ) 将与 r t ( τ ) r_t(\tau) rt(τ) 呈负相关,进一步,寻找其中一个函数的最小值或寻找另一个函数的最大值将会得到相同的结果。然而,第二项能量项会随着 τ \tau τ 值的变化而变化,这意味着 r t ( τ ) r_t(\tau) rt(τ) 的最大值和 d t ( τ ) d_t(\tau) dt(τ) 的最小值不一定一一对应。实际上,错误率从无偏自相关的 10.0% 降低到了差分函数的 1.95%(见表 1)。

错误率的降幅是令人惊讶的。一个解释是根据 ( 1 ) (1) (1) 实现的 ACF 对幅度的变化相当敏感。正如 Hess 在他之前的文献中所指出的那样,如果信号幅度随着时间增加,那么 ACF 的峰值幅度会随着滞后 τ \tau τ 的增加而增加,而不会是像图 1(b) 那样保持恒定。这会使得算法趋向于选择一个更高阶的峰值,并产生一个 “too low” 的错误(幅度降低会产生相反的效果)。而差分函数不受这个特定问题的影响,as amplitude changes cause period-to-period dissimilarity to increase with lag in all cases. Hess 指出 ( 2 ) (2) (2) 对幅度变化不太敏感[ (A1) \text{(A1)} (A1) 也具有该属性]。然而,使用 d ( τ ) d(\tau) d(τ) 具有额外的吸引力,它更紧密地基于 ( 4 ) (4) (4) 中的信号模型,而且为接下来的两个减少错误的步骤铺平了道路,第一个是 “too high” 错误,第二个是 “too low” 错误。
C. 步骤 3: 累积均值归一化差分函数
在零滞后的时候,图 3(a) 所示的差分函数值为零,并且由于不完美的周期性,在周期处,其值通常不为零。除非对搜索范围设置下限,否则算法一定会选择零滞后的值,而不是周期处的值,这会导致该方法必定失败。即使设置了下限,第一共振峰( F 1 F_1 F1)处的强烈共振可能会产生一系列的二次凹陷,其中的某个可能会比周期凹陷更深。搜索范围的下限设置并不是避免该问题的满意方法,因为已知的 F 0 F_0 F0 和 F 1 F_1 F1 的范围是重叠的。
作者提出的解决方案是使用累积均值归一化差分函数( “cumulative mean normalized difference function”)代替差分函数:
d t ′ ( τ ) = { 1 , if τ = 0 , d t ( τ ) / [ ( 1 / τ ) ∑ j = 1 τ d t ( j ) ] , otherwise . \begin{align} d_t^{'}(\tau) = \left\{ \begin{array}{lc} 1, & \text{if} \; \tau = 0, \\ d_t(\tau)/[(1/\tau)\sum_{j=1}^{\tau}{d_t(j)}], & \text{otherwise}. \\ \end{array} \right. \end{align} dt′(τ)={1,dt(τ)/[(1/τ)∑j=1τdt(j)],ifτ=0,otherwise.
它与 d ( τ ) d(\tau) d(τ) 的不同之处在于它的值从 1 1 1 而不是从 0 0 0 开始,在低滞后时,其值也往往比较大,而且仅当 d ( τ ) d(\tau) d(τ) 低于平均值时,其值才会小于 1 1 1(见图 3(b) )。使用 d ′ d^{'} d′ 代替 d d d 降低了 “too high” 错误,错误率从 1.95% 降到了 1.69%。第二个好处是取消了搜索范围的频率上限,不再需要 avoid the zero-lag dip. 第三个好处是对函数进行了归一化,更方便后续的进一步优化。
D. 步骤 4: 绝对阈值
很容易出现的一种情况是,差分函数(图 3(b) )的高阶凹陷中的某个会比周期凹陷更深。如果前者正好处于搜索范围之内,将会导致次谐波错误,有时候称之为 “octave error”(该说法不严谨,因为与真正基频的比率不一定是 2 2 2 的整数次幂)。自相关方法同样也比较容易选择高阶峰值。
作者提出的解决方案是预设一个绝对阈值,and choose the smallest value of τ \tau τ that gives a minimum of d ′ d^{'} d′ deeper than that threshold. If none is found, the global minimum is chosen instead. 当阈值为 0.1 0.1 0.1 时,错误率从 1.69% 降到了 0.78%,这是 “too low” 错误降低,“too high” 错误略微增加而产生的结果。
该步骤实现了短语 “the period is the smallest positive member of a set” 中的单词 “smallest”(前述步骤实现了单词 “positive”)。预设阈值决定了进入该集合的候选列表,并且可以将其解释为 the proportion of aperiodic power tolerated within a “periodic” signal. 要看到这一点,考虑以下等式:
2 ( x t 2 + x t + T 2 ) = ( x t + x t + T ) 2 + ( x t − x t + T ) 2 . \begin{align} 2(x_t^2 + x_{t+T}^2) = (x_t + x_{t+T})^2 + (x_t - x_{t+T})^2. \end{align} 2(xt2+xt+T2)=(xt+xt+T)2+(xt−xt+T)2.
在一个窗口内对上式取均值,并且除以 4 4 4 可得:
1 / ( 2 W ) ∑ j = t + 1 t + W ( x j 2 + x j + T 2 ) = 1 / ( 4 W ) ∑ j = t + 1 t + W ( x j + x j + T ) 2 + 1 / ( 4 W ) × ∑ j = t + 1 t + W ( x j − x j + T ) 2 . \begin{align} 1/(2W) \sum_{j=t+1}^{t+W}(x_j^2 + x_{j+T}^2) \notag \\ = 1/(4W) \sum_{j=t+1}^{t+W}(x_j + x_{j+T})^2 + \notag \\ 1/(4W) \times \sum_{j=t+1}^{t+W}(x_j - x_{j+T})^2. \end{align} 1/(2W)j=t+1∑t+W(xj2+xj+T2)=1/(4W)j=t+1∑t+W(xj+xj+T)2+1/(4W)×j=t+1∑t+W(xj−xj+T)2.
等式左边近似于信号的功率,等式右边的两项将总功率进行了划分。如果是周期为 T T T 的周期信号,那么右边第二项将为零,and is unaffected by adding or subtracting periodic components at that period. 它可以被解释为信号功率的“非周期功率”成分。当 τ = T \tau=T τ=T 时, ( 8 ) (8) (8) 中的分子与非周期功率成正比,而其分母(对 d ( τ ) d(\tau) d(τ) 在 τ = [ 0 , T ] \tau=[0,T] τ=[0,T] 范围内进行了平均)大约是信号功率的两倍。因此, d ′ ( T ) d^{'}(T) d′(T) 与非周期功率/总功率的比值成正比。如果该比值低于阈值,那么候选值 T T T 也是满足上述集合要求的。后续将看到,该阈值的精确值不会严重影响错误率。
E. 步骤 5: 抛物线插值
如果信号周期是采样周期的整数倍,那么按照上述所说的步骤来执行是没什么问题的。而如果不是,那么估计出来的值将会有问题。
该问题的解决方案之一是使用抛物线插值。对每个 d ′ ( τ ) d^{'}(\tau) d′(τ) 局部极小值及其相邻的值进行抛物线拟合,and the ordinate of the interpolated minimum is used in the dip-selection process. The abscissa of the selected minimum then serves as a period estimate. 事实上,人们发现用这种方式得到的估计是有偏的。为了避免该偏差,使用原生差分函数 d ( τ ) d(\tau) d(τ) 相应的极小值的横坐标来代替。
对 d ′ ( τ ) d^{'}(\tau) d′(τ) 或 d ( τ ) d(\tau) d(τ) 进行插值比对信号进行上采样的计算复杂度更低,and accurate to the extent that d ′ ( τ ) d^{'}(\tau) d′(τ) can be modeled as a quadratic function near the dip. Simple reasoning argues that this should be the case if the signal is band-limited. 首先,回顾下 ACF 是功率谱的傅立叶变换:如果 x t x_t xt 是带限信号,那么它的 ACF 也是如此。然后,ACF 是余弦之和,which can be approximated near zero by a Taylor series with even powers. 4 4 4 次或更高次数的项主要来自于最高频率成分,如果这些分量不存在或较弱,那么函数可以由较低阶的项来准确地表示(二次项和常量)。最后,要注意的是周期峰值和零滞后峰值具有相同的形状,and the same shape (modulo a change in sign) as the period dip of d ( τ ) d(\tau) d(τ), which in turn is similar to that of d ′ ( t ) d^{'}(t) d′(t). 因此,除非信号包含强高频分量(实际中,高于采样率的四分之一),否则 parabolic interpolation of a dip is accurate. 插值对数据集中的 gross error rate 几乎没有影响( 0.77 0.77% 0.77 vs 0.78 0.78% 0.78), 可能是因为 F 0 F_0 F0’s were small in comparison to the sampling rate. 然而,在合成数据上的测试发现,抛物线插值可以减少所有 F 0 F_0 F0 的 fine error,而且避免高 F 0 F_0 F0 处的 gross errors.
F. 步骤 6: 最优局部估计
式 ( 1 ) (1) (1) 和 ( 6 ) (6) (6) 中积分的作用是为了确保估计是稳定的,并且不会在基本周期的时间尺度上波动。相反,如果观察到任何此类波动,则不应被视为真实的波动。有时候会发现,对于非平稳语音间隙,that the estimate fails at a certain phase of the period that usually coincides with a relatively high value of d ′ ( T t ) d^{'}(T_t) d′(Tt), 其中 T t T_{t} Tt 是时刻 t t t 估计出来的周期。而在另一个阶段(时刻 t ′ t^{'} t′), 估计出来的值可能是正确的,而且 d ′ ( T t ′ ) d^{'}(T_{t^{'}}) d′(Tt′) 的取值更小。步骤 6 6 6 利用这一事实,通过在每个分析点附近 “shopping”, 以获得更好的估计。
算法如下所述。对每个时刻 t t t, 在一个小的时间间隔 [ t − T m a x / 2 , t + T m a x / 2 ] [t-T_{max}/2, t+T_{max}/2] [t−Tmax/2,t+Tmax/2] 内寻找使得 d θ ′ ( T θ ) d_{\theta}^{'}(T_{\theta}) dθ′(Tθ) 取最小值的 θ \theta θ, 其中 T θ T_{\theta} Tθ 是在时刻 θ \theta θ 估计的周期,而 T m a x T_{max} Tmax 是期望的最大周期。基于该初始估计,在有限的搜索范围内再次使用估计算法来得到最终的估计。使用 T m a x = 25ms T_{max}=\text{25ms} Tmax=25ms,以及初始估计的 ± 20% \pm \text{20\%} ±20% 的最终搜索范围,步骤 6 将错误率从 0.77 % 0.77\% 0.77%降为 0.5 % 0.5\% 0.5%。步骤 6 使人想起中值平滑或动态规划技术,但不同之处在于它考虑了相对较短的时间间隔,并根据质量而不仅仅是连续性进行选择。
步骤 1~6 的组合构成了一个新的方法(YIN), 后续章节将其与其它方法进行比较以进行评估。值得注意的是这些步骤之间是如何相互构建的。使用差分函数(步骤 2)来代替 ACF(步骤 1)为累积均值归一化操作(步骤 3)铺平道路,阈值方案(步骤 4)和用于选择最优局部估计的测量值 d ′ ( T ) d^{'}(T) d′(T) 以此为基础。抛物线插值(步骤 5)独立于其它步骤,尽管它依赖于 ACF(步骤 1) 的谱特性。
5. 评估
到目前为止的错误率只是说明性的。本章节将新方法与以前的方法进行对比,以做一个更正式的评估。附录给出了测试集的详细情况。喉镜数据的 F 0 F0 F0 是自动估计出来的,而且人为剔除了那些看似不正确的值。该过程也去除了清音和不规则的浊音部分(diplophony, creak)。 在评估候选方法的时候,与喉镜数据的估计值相差超过 20% 的值被视为 “gross error”. 许多研究都使用了这种相对宽松的标准,并在以下假设下衡量任务的困难部分:如果初始估计的正确率在 20% 以内,则可以使用多种技术中的任意一种来改进它。Gross errors 进一步细分为 “too low” 错误(主要是次谐波)和 “too high” 错误。
错误率本身并不能提供信息,因为它取决于数据库的难度。为了得出有用的结论,必须在相同的数据集上对不同的方法做评估。幸运的是,可免费访问的数据库和软件使这件事变得容易。附录中给出了本文所对比的方法及一些参数的详细信息。简单来说,禁用后处理和 voiced–unvoiced 决策机制(如果可能的话),而且搜索的范围都是 40~800hz,但 YIN 除外,其上限为采样率的四分之一。

表 2 总结了每个方法在不同数据集上的错误率。这些数字不应被视为每种算法或实现的内在质量的一个准确衡量,因为评估条件与其优化条件不同。特别是搜索范围特别宽(40~800hz),可能会导致那些为较窄搜索范围设计的方法出现不稳定,几种方法的 “too low” 和 “too high” 错误率之间的不平衡就证明了这一点。相反,这些数字是对已知算法在这些困难条件下的“现成”实现的预期性能的抽样。值得注意的是,在不同的数据集上算法的排名有差异。比如 “acf” 和 “nacf” 算法在 DB1(一个包含 28 个说话人的大数据集 )上表现得很出色,但在别的数据集上表现得一般。这说明需要在广泛的数据集上进行测试。
在所有的数据集上,YIN 表现得最好。在所有数据集上平均之后,YIN 的错误率比其它算法中表现最好的小 3 倍左右。错误率取决于用于决定估计正确与否的容忍度。对于 YIN,大约 99% 的估计准确度在 20% 以内,94% 的估计准确度在 5% 以内,60% 的估计准确度在 1% 以内。
6. 对参数的敏感度
对于大多数方法而言, F 0 F_0 F0 的搜索上界和下界是一个很重要的参数。与其它方法相比,YIN 不需要上界限制(然而,对于 F 0 F_0 F0 超过采样率四分之一的情况,它往往会失败)。这使得它在音乐相关的应用中是十分有用的,在这些应用中, F 0 F_0 F0 会很高。较大的搜索范围往往会增加找到错误估计的可能性。因此尽管搜索范围较宽,但错误率相对较低,这表明了 YIN 算法的鲁棒性。
在一些方法中[基于谱的和基于公式 ( 2 ) (2) (2) 的自相关方法],窗长即决定了可以估计的最大周期( F 0 F_0 F0 搜索范围的下限),也决定了用来积分以获得任意特定估计的数据量。对于 YIN 来说,这两个量是解耦的( T m a x T_{max} Tmax 和 W W W)。然而,这两个量之间存在某种关系。为了使估计值随时间保持稳定,积分窗口必须不短于最大的期望周期。否则,one can construct stimuli for which the estimate would be incorrect over a certain phase of the period. 最大期望周期显然也决定了需要计算的滞后范围,这些考量一起证明了以下众所周知的经验法则: F 0 F_0 F0 估计需要足够的信号来覆盖两倍的最大期望周期。然而,窗长可能会很大,而且经常可以观察到:窗长越大,错误越少,但代价是估计的时间序列的时间分辨率降低。YIN 的统计报告是在积分窗口 25ms 和周期搜索范围 25ms 的情况下获得的,这是 F 0 F_0 F0 的下限 40hz 能兼容的最短时间。图 4(a) 给出了不同窗长下的错误数量。

YIN 特有的一个参数是步骤 4 中用到的阈值。图 4(b) 展示了它是如何影响错误率的。显然它不需要微调,至少对于这个任务来说是这样。此处使用的值是 0.1 0.1 0.1。最后一个参数是信号初始低通滤波的截止频率。通常观察到,低通滤波会使这些方法减少错误,但显然将截止频率设置在 F 0 F_0 F0 以下会导致估计失败。这里使用 1-ms 的方窗进行卷积(零点在 1kHz 处)。图 4(c) 给出了其它数值的错误率。总的来说,YIN 涉及到的参数较少,并且这些参数不需要微调。
7. 实现考虑
YIN 的基本组成部分是定义在 ( 1 ) (1) (1) 里面的函数。直接按照公式进行计算的话,其计算复杂度是非常高的,不过有两个方法可以降低其复杂度。第一种是在时间维度上使用递归的方式实现 ( 1 ) (1) (1)(每一步增加一个新的项,并减去一个旧的项目),窗是方窗,但可以通过递归获得三角窗或近似于高斯窗(但是没有什么理由不使用方窗)。
第二种方法是使用 ( 2 ) (2) (2),它可以使用 FFT 来高效地计算。不过这会引出两个问题。第一个问题是 ( 7 ) (7) (7) 中的能量项必须分开计算。它们与 r t ′ ( 0 ) r^{'}_t(0) rt′(0) 不同,而分别是窗口内第一个和最后一个 W − τ W-\tau W−τ 个采样点的平方和。必须在每个 τ \tau τ 值上都对它们进行计算,不过这可以通过在 τ \tau τ 上递归来高效实现。第二个问题是小的 τ \tau τ 值所涉及求和项比大的 τ \tau τ 要多。这会引入不必要的偏差,不过该偏差可以通过对 d ( τ ) d(\tau) d(τ) 的每个样本除以 W − τ W-\tau W−τ 来进行纠正。然而,当 τ \tau τ 取值较大时, d ( τ ) d(\tau) d(τ) 是从较短窗口的数据中计算得到的,因此不如 τ \tau τ 取较小值时稳定。在这个意义上,FFT 实现并不如第一种方法好。然而,在较低的帧率上进行估计时,第二种方法更快。如果需要高分辨率时间序列的估计,则第一种方法可能更快。
交互式音乐跟踪等实时应用需要低延迟。前面提到过,估计至少需要的信号样本量为 2 T m a x 2T_{max} 2Tmax。然而,步骤 4 允许计算从 τ = 0 \tau=0 τ=0 开始,直到找到可接受的候选结果为止,而不是在整个搜索范围上进行处理,所以延迟可以被降低到 T m a x + T T_{max} + T Tmax+T。仅当积分时间降低到 T m a x T_{max} Tmax 以下时,才有可能进一步减少延迟,which opens the risk of erroneously locking to the fine structure of a particularly long period.
d ′ ( T ) d^{'}(T) d′(T) 可以作为置信度指标(大的值表示 F 0 F0 F0 估计可能不太可靠),in postprocessing algorithms to correct the F 0 F0 F0 trajectory on the basis of the most reliable estimates, and in template-matching applications to prevent the distance between a pattern and a template from being corrupted by unreliable estimates within either. 另一个应用是在多媒体索引中, F 0 F_0 F0 的时间序列不得不被下采样以节省空间。置信度度量允许基于正确而不是错误的估计来进行下采样。该方案在 MPEG7 standard (ISO/IEC–JTC–1/SC–29, 2001) 中实现。
8. 扩展
第 4 章描述的 YIN 算法基于 ( 4 ) (4) (4) 的模型(周期信号)。模型的概念很有洞察力:“估计错误”仅仅意味着 that the model matched the signal for an unexpected set of parameters. 错误降低涉及修改模型以降低此类匹配的可能性。本章给出了扩展的模型,以解决信号系统性地偏离周期模型的情况。通过在语音数据库上的定量测试,这些扩展的模型均没有提高错误率,可能是因为 YIN 所使用的周期模型对这项任务来说足够准确。基于此,论文没有给出正式的评估结果。本章的目的是展示该方法的灵活性并为未来的发展开辟前景。
A. 变化的幅度
语音和音乐中经常出现的幅度变化会损害周期模型的拟合度,从而产生误差。为了处理这种情况,信号可以被建模成时变幅度的周期函数:
x t + T / a t + T = x t / a t . \begin{align} x_{t+T}/a_{t+T} = x_{t}/a_{t}. \end{align} xt+T/at+T=xt/at.
如果假设 α = a t + T / a t \alpha = a_{t+T}/a_{t} α=at+T/at 不依赖于 t t t (如指数增加或减少), α \alpha α 的值可以通过最小二乘拟合出来。将该值代入 ( 6 ) (6) (6) 中,可以得到:
d t ( τ ) = r t ( 0 ) [ 1 − r t ( τ ) 2 / r t ( 0 ) r t + τ ( 0 ) ] . \begin{align} d_{t}(\tau) = r_{t}(0)[1-r_{t}(\tau)^{2}/r_{t}(0)r_{t+\tau}(0)]. \end{align} dt(τ)=rt(0)[1−rt(τ)2/rt(0)rt+τ(0)].
图 5 说明了该结果。最上面的图展示了时变信号,中间的图展示了根据标准处理流程推导出的 d ′ ( τ ) d^{'}(\tau) d′(τ),最下面的图展示了使用 ( 12 ) (12) (12) 而不是 ( 6 ) (6) (6) 推导出的相同的函数。有趣的是, ( 12 ) (12) (12) 右边的第二项是归一化 ACF 的平方。

具有两个参数的模型 ( 12 ) (12) (12) 更加“宽容”,更容易拟合幅度变化的信号。然而,这也意味着会出现更多“不期望”的拟合,也就是出现更多错误。或许正是因为这个原因,其错误率确实有所增加(在受限数据库上 0.57% vs. 0.50%)。然而,它被成功地用于处理喉镜信号(见附录)。
B. 变化的 F 0 F_0 F0
幅度变化在语音和音乐中也很常见,是干扰 F 0 F_{0} F0 估计的第二个非周期性来源。当 F 0 F_{0} F0 为常量时,也许可以找到一个滞后 τ \tau τ,使得 ( x j − x j + τ ) 2 (x_{j} - x_{j+\tau})^2 (xj−xj+τ)2 在 d ( τ ) d(\tau) d(τ) 的整个积分窗口上都是 0 0 0,但是对于一个时变的 F 0 F_{0} F0,它只在某一点上等于 0 0 0。在任意一侧,( x j − x j + τ ) 2 x_{j}-x_{j+\tau})^{2} xj−xj+τ)2 的值随着距离该点的距离成二次方变化,因此, d ( τ ) d(\tau) d(τ) 随着窗长 W W W 成立方变化。
较短的窗可以改善匹配性能,但我们知道积分窗口不得短于特定限制(见第6 章)。一个解决办法是将窗口划分为两个或更多的片段,并允许片段之间的 τ \tau τ 在已有限制内取不同值,该已有限制取决于最大的期望变化率。Xu 和 Sun(2000) 给出 F 0 F_{0} F0 的最大变化率大约是 ± 6 oct/s \pm6 \, \text{oct/s} ±6oct/s, 但是在我们的数据库中,它通常不会超出 ± 1 oct/s \pm1 \, \text{oct/s} ±1oct/s (图 10)。使用划分后的窗口,搜索空间更大,但匹配得到改善(在两个片段的情况下,by a factor of up to 8 8 8)。同样,该模型比 ( 4 ) (4) (4) 更容易满足,因此可能会引入新的错误。
C. 加性噪声:缓慢变化的 DC
非周期性的一个常见来源是加性噪声,它有很多种形式。第一种形式是随时间变化的 DC,例如当麦克风太近,歌手呼吸时就会产生。图 6(b) 展示了 a DC ramp 的不利影响,不过可以使用以下公式消除该影响(如图 6(c) 所示),该公式是通过将 d t ( τ ) d_t(\tau) dt(τ) 对 DC 偏移的导数设置为 0 0 0 来得到的:
d t ( τ ) = r t ( 0 ) + r t + τ ( 0 ) − 2 r t ( τ ) + [ ∑ j = t + 1 t + W ( x j − x j + τ ) ] 2 \begin{align} d_{t}(\tau) = r_{t}(0) + r_{t+\tau}(0) - 2r_{t}(\tau) + [\sum_{j=t+1}^{t+W}(x_{j} - x_{j+\tau})]^{2} \end{align} dt(τ)=rt(0)+rt+τ(0)−2rt(τ)+[j=t+1∑t+W(xj−xj+τ)]2
同样,该模型比严格的周期性模型更宽松,因此也可能会引入新的错误。基于此并且因为语音数据不包含明显的 DC 偏移,所以它并没有带来任何改进,反而略微增加了错误率( 0.51 % 0.51\% 0.51% vs 0.5 % 0.5\% 0.5%)。然而,它可以用于处理喉镜信号,这些信号具有较大的缓慢变化的偏移。

D. 加性噪声:周期性的
加性噪声的第二种形式是并发的周期性声音,例如人声、乐器或嗡嗡声等。除了周期处于某些简单比率的不幸情况外,可以使用冲激响应为 h ( t ) = δ ( t ) − δ ( t + U ) h(t) = \delta(t) - \delta(t+U) h(t)=δ(t)−δ(t+U) 的梳状滤波器来消除干扰声的影响,其中 U U U 是干扰信号的周期。如果 U U U 已知,那么该处理过程就很简单。而如果 U U U 未知,那么它和周期 T T T 都可以通过联合估计算法找到。该联合估计算法搜索 ( τ , v ) (\tau, v) (τ,v) 参数空间以使下式取得最小值:
d d t ( τ , v ) = ∑ j = t + 1 t + W ( x j − x j + τ − x j + v + x j + τ + v ) 2 . \begin{align} dd_{t}(\tau, v) = \sum_{j=t+1}^{t+W}(x_{j} - x_{j+\tau} - x_{j+v} + x_{j+\tau+v})^{2}. \end{align} ddt(τ,v)=j=t+1∑t+W(xj−xj+τ−xj+v+xj+τ+v)2.
上述计算的复杂度较高,然而可以通过使用下式来大幅降低复杂度:
d d t ( τ , v ) = r t ( 0 ) + r t + τ ( 0 ) + r t + v ( 0 ) + r t + τ + v ( 0 ) − 2 r t ( τ ) − 2 r t ( v ) + 2 r t ( τ + v ) + 2 r t + τ ( v − τ ) − 2 r t + τ ( v ) − 2 r t + v ( τ ) . \begin{align} dd_{t}(\tau, v) &= r_{t}(0) + r_{t+\tau}(0) + r_{t+v}(0) + r_{t+\tau+v}(0) \notag \\ &- 2r_{t}(\tau) - 2r_{t}(v) + 2r_{t}(\tau+v) \notag \\ &+2r_{t+\tau}(v - \tau) - 2r_{t+\tau}(v) - 2r_{t+v}(\tau). \end{align} ddt(τ,v)=rt(0)+rt+τ(0)+rt+v(0)+rt+τ+v(0)−2rt(τ)−2rt(v)+2rt(τ+v)+2rt+τ(v−τ)−2rt+τ(v)−2rt+v(τ).
等式右边与用于单周期估计的 ACF 系数相同。如果它们已事先计算好,那么 ( 15 ) (15) (15) 的计算复杂度就相当低。两周期模型同样更加宽松,因此也可能会引入新的错误。
E. 加性噪声:与目标不同的频谱
现在假设加性噪声既不是 DC 也不是周期性的,但是它的谱包络不同于周期性目标信号的谱包络。如果这两个长时谱都是已知且稳定的,那么可以使用滤波的方法来增强目标信号,并且减弱干扰信号。低通滤波器是一种简单的方法,其影响如图 4(c) 所示。
如果目标信号和噪声的频谱仅在短期内有所不同,那么有两种技术可选。第一种技术首先使用滤波器(比如,听觉模型滤波器组)组对信号进行分带,然后计算每个输出的差分函数,最后将这些函数相加获得一个汇总的差分函数,可以从该汇总的差分函数中推导出周期性度量。然后将各个通道(笔者理解应该是划分后的子带)一一删除,直到周期性得到改善。

第二种技术对输入信号应用一个自适应滤波器,并且联合搜索周期和滤波器的参数。这对于冲激响应为 h ( t ) = δ ( t ) ± δ ( t + V ) h(t) = \delta(t) \pm \delta(t+V) h(t)=δ(t)±δ(t+V) 的滤波器来说很实用,其中 V V V 和符号决定了功率传递函数的形状,如图 7 所示。该算法基于这样的假设: V V V 和符号的一些值将使目标信号优于干扰信号,并改进周期性。通过搜索以下函数的最小值来确定参数 V V V、符号和周期 T T T:
d d t ′ ( τ , v ) = r t ( 0 ) + r t + τ ( 0 ) + r t + v ( 0 ) + r t + τ + v ( 0 ) ± 2 r t ( τ ) − 2 r t ( v ) ∓ 2 r t ( τ + v ) ∓ 2 r t + τ ( v − τ ) − 2 r t + τ ( v ) ± 2 r t + v ( τ ) , \begin{align} dd_{t}^{'}(\tau, v) &= r_{t}(0) + r_{t+\tau}(0) + r_{t+v}(0) + r_{t+\tau+v}(0) \notag \\ &\pm 2r_{t}(\tau) - 2r_{t}(v) \mp 2r_{t}(\tau+v) \notag \\ &\mp2r_{t+\tau}(v - \tau) - 2r_{t+\tau}(v) \pm 2r_{t+v}(\tau), \end{align} ddt′(τ,v)=rt(0)+rt+τ(0)+rt+v(0)+rt+τ+v(0)±2rt(τ)−2rt(v)∓2rt(τ+v)∓2rt+τ(v−τ)−2rt+τ(v)±2rt+v(τ),
T T T 和 V V V 的搜索空间应该是不相交的,以防止调谐到 V V V 的梳状滤波器干扰 T T T 的估计。同样,该模型也更加宽松。
F. 加性噪声:与目标相同的频谱
如果加性噪声在某个时刻与目标的谱包络相同,则先前的方法都无效。如果目标是稳态的并且持续时间足够长,那么仍然可以提高可靠性和准确性。想法是在给定可用数据的情况下,尽可能多地进行周期比较。令 D D D 表示持续时间,并将窗口大小 W W W 设置为至少与最大预期周期一样大,计算以下函数:
d k ( τ ) = ∑ j = 1 D − k W ( x j − x j − τ ) 2 , k = 1 , ⋯ , D / W . \begin{align} d_{k}(\tau) = \sum_{j=1}^{D-kW}(x_{j}-x_{j-\tau})^{2}, \quad k=1,\cdots,D/W. \end{align} dk(τ)=j=1∑D−kW(xj−xj−τ)2,k=1,⋯,D/W.
接着计算:
d ( τ ) = ∑ k = 1 D / W d k ( τ / ( D / W − k ) ) . \begin{align} d(\tau) = \sum_{k=1}^{D/W}d_{k}(\tau/(D/W-k)). \end{align} d(τ)=k=1∑D/Wdk(τ/(D/W−k)).
该函数是 ( D / W ) ( D / W 21 ) / 2 (D/W)(D/W21)/2 (D/W)(D/W21)/2 个差值之和。当 τ ≠ T \tau \neq T τ=T 时,每个差值包含一个确定的部分(目标)和噪声部分,当 τ = T \tau = T τ=T 时,只包含噪声部分。确定性部分同相相加,而噪声部分往往相互抵消, τ = T \tau = T τ=T 处下降的显著性得到增强。
总的来说,可以对基础模型通过多种方式扩展来处理特定形式的非周期性。在某些情况下,可以将这些扩展进行组合。尽管尚未探索所有组合,不过可以将该灵活性视为该方法的一个有用特征。
9. 与听觉感知模型的关系
正如第 3 章中所指出的那样,自相关模型是音调感知的一种流行解释,将该模型转变为准确的语音 F 0 F0 F0 估计方法的尝试取得了一定的成功。 这项研究展示了如何做到这一点。先前的一项研究表明,兴奋性巧合可以被抑制性“反巧合”所取代,从而产生在许多方面相当于自相关的“音调感知消除模型”。 目前的研究发现,消除实际上更有效,而且它可以准确地实现为自相关项的总和。

消除模型需要具有快速时间特性的兴奋性和抑制性突触。本项研究表明,仅使用快速兴奋性突触就可以获得相同的功能,如图 8 所示。有证据表明听觉系统中存在快速兴奋性相互作用,例如在 medial superior olive(MSO)内,以及快速抑制相互作用,例如在 lateral superior olive(LSO)内,其由来自耳蜗核的兴奋性输入和来自内侧梯形体的抑制性输入供给。然而,抑制性相互作用的时间准确性限制可能低于兴奋性相互作用。
上一章节展示了如何将一系列减法运算重新表述为自相关项之和。转移到神经领域,这表明 de Cheveigne´ 和 Kawahara 提出的级联消除阶段可以解释多种音高感知,或 de Cheveigne´ 为了考虑并发元音识别,可以在单个阶段中实现为等式 ( 15 ) (15) (15) 或 ( 16 ) (16) (16) 的神经等价物。取消级联时域处理可以避免一系列锁相神经元的假设,从而使此类模型更加合理。 类似的评论也适用于双耳处理的消除模型。
总而言之,信号处理和听觉感知之间可以得出有用的相似之处。 YIN 算法实际上是听觉模型工作的副产品。 相反,解决这个实际任务可能对听觉建模有益,因为它揭示了建模研究中不明显但听觉过程面临的困难。
10. 讨论
研究者们已经提出了数百种 F 0 F0 F0 估计方法,其中许多方法巧妙而复杂。 它们的数学基础通常假设周期性,而当周期性降低时,它们可能会以难以预测的方式崩溃。正如第 4 章 A 节所指出的,看似不同的估计方法是相关的,并且我们对误差机制的分析可能可以在经过必要的修改后转用到更广泛的方法中。 特别是,每种方法都面临着权衡过高与过低错误的问题。YIN 成功的关键可能是步骤 3,可以让它独立解决这两类错误。 其它步骤可以视为为此步骤做准备(步骤 1 和 2)或在此步骤的基础上进行构建(步骤 4 和 6)。抛物线插值(步骤 5)给出子样本分辨率。使用不大的信号间隔可以获得非常准确的估计。 准确地说,为了准确估计完美周期信号的周期 T T T,并确保真实周期不会大于 T T T,至少需要 2 T + 1 2T+1 2T+1 个数据样本。 如果这一点被认可,理论上精度就没有限制。 特别是,它不受熟悉的不确定性原理 △ T △ F = const \triangle T \triangle F = \text{const} △T△F=const 的限制。
我们避免使用熟悉的后处理方案,例如中值平滑或动态规划,因为包含它们会使评估和信用分配变得复杂。 没有什么可以阻止应用它们来进一步提高该方法的稳健性。 非周期性测量 d ′ ( T ) d^{'}(T) d′(T) 可用于确保估计值根据其可靠性而不是连续性本身进行校正。
还避免了声音检测的问题,同样是因为它使评估和信用分配变得非常复杂。非周期性测量 d ′ τ d^{'}\tau d′τ 似乎是发声检测的良好基础,也许与能量相结合。 然而,将发声等同于周期性并不令人满意,因为某些形式的发声本质上是不规则的。它们可能仍然带有语调线索,但如何量化它们尚不清楚。在另一篇论文中,我们提出了一种相当不同的 F 0 F0 F0 估计和声门事件检测方法,该方法基于瞬时频率以及沿着频率和时间轴的映射中搜索固定点。 这两篇论文共同为 F 0 F0 F0 估计的旧任务提供了新的视角。
YIN 仅在音乐方面进行过非正式评估,但有理由认为它适合该任务。 音乐特有的困难是 F 0 F0 F0 的范围宽且变化快。 YIN 的开放式搜索范围以及在没有连续性约束的情况下表现良好的事实使其比其它算法具有优势。 其它尚未测试的潜在优势包括交互式系统的低延迟或处理复调音乐的扩展。由于要测试的乐器和风格范围广泛,并且缺乏标记良好且具有代表性的数据库,音乐评估变得复杂。
有什么新内容?Licklider 提出自相关用于周期性分析,Hess 详细回顾了将其应用于语音的早期尝试,他还追溯了 AMDF 等差分函数方法的起源。Ney 分析了式 ( 7 ) (7) (7) 中利用的两者之间的关系。de Cheveigne´ 将步骤 3 和 4 分别应用于 AMDF。 步骤 5 是一项标准技术,例如应用于 Duifhuis 等人的 F 0 F0 F0 估计方法中的频谱峰值。 新的是步骤 6,将所描述的步骤组合起来的想法,分析其为何有效,以及最重要的正式评估。
11. 总结
本文提出了一种用于估计语音或音乐声音的基频的算法。从众所周知的自相关方法开始,引入了许多修改,以避免估计错误。当对与喉镜信号一起记录的语音的广泛数据库进行测试时,错误率比最佳竞争方法小 3 3 3 倍,且无需进行后处理。该算法参数很少,不需要微调。与大多数其他方法相比,不需要对 F 0 F0 F0 搜索范围设置上限。该方法相对简单并且可以以低延迟有效地实现,并且可以以多种方式扩展以处理在特定应用中出现的多种形式的非周期性。最后,听觉处理模型可以得出一个有趣的相似之处。
相关文章:
【论文笔记之 YIN】YIN, a fundamental frequency estimator for speech and music
本文对 Alain de Cheveigne 等人于 2002 年在 The Journal of the Acoustical Society of America 上发表的论文进行简单地翻译。如有表述不当之处欢迎批评指正。欢迎任何形式的转载,但请务必注明出处。 论文链接:http://audition.ens.fr/adc/pdf/2002_…...
水印相机小程序源码
水印相机前端源码,本程序无需后端,前端直接导入即可,没有添加流量主功能,大家开通后自行添加 源码搜索:源码软件库 注意小程序后台的隐私权限设置,前端需要授权才可使用 真实时间地址拍照记录,…...
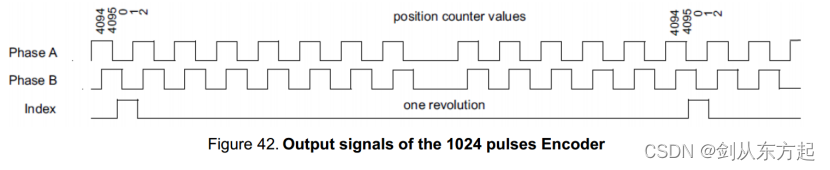
NXP实战笔记(八):S32K3xx基于RTD-SDK在S32DS上配置LCU实现ABZ解码
目录 1、概述 2、SDK配置 2.1、IO配置 2.2、TRGMUX配置 2.3、LCU配置 2.4、Trgmux配置 2.5、Emios配置 2.6、代码实现 1、概述 碰到光电编码器、磁编码器等,有时候传出来的位置信息为ABZ的方式,在S32K3里面通过TRGMUX、LCU、Emios结合的方式可以实现ABZ解码。 官方…...

【深度好文】simhash文本去重流程
对于类似于头条客户端而言,推荐的每一刷的新闻都必须是不同的新闻,这就需要对新闻文本进行排重。传统的去重一般是对文章的url链接进行排重,但是对于抓取的网页来说,各大平台的新闻可能存在重复,对于只通过文章url进行排重是不靠谱的,为了解决这个痛点于是就提出了用simh…...
主流的开发语言和开发环境介绍
个人浅见,不喜勿喷,谢谢 软件开发是一个涉及多个方面的复杂过程,其中包括选择合适的编程语言和开发环境。编程语言是软件开发的核心,它定义了程序员用来编写指令的语法和规则。而开发环境则提供了编写、测试和调试代码的工具和平台…...
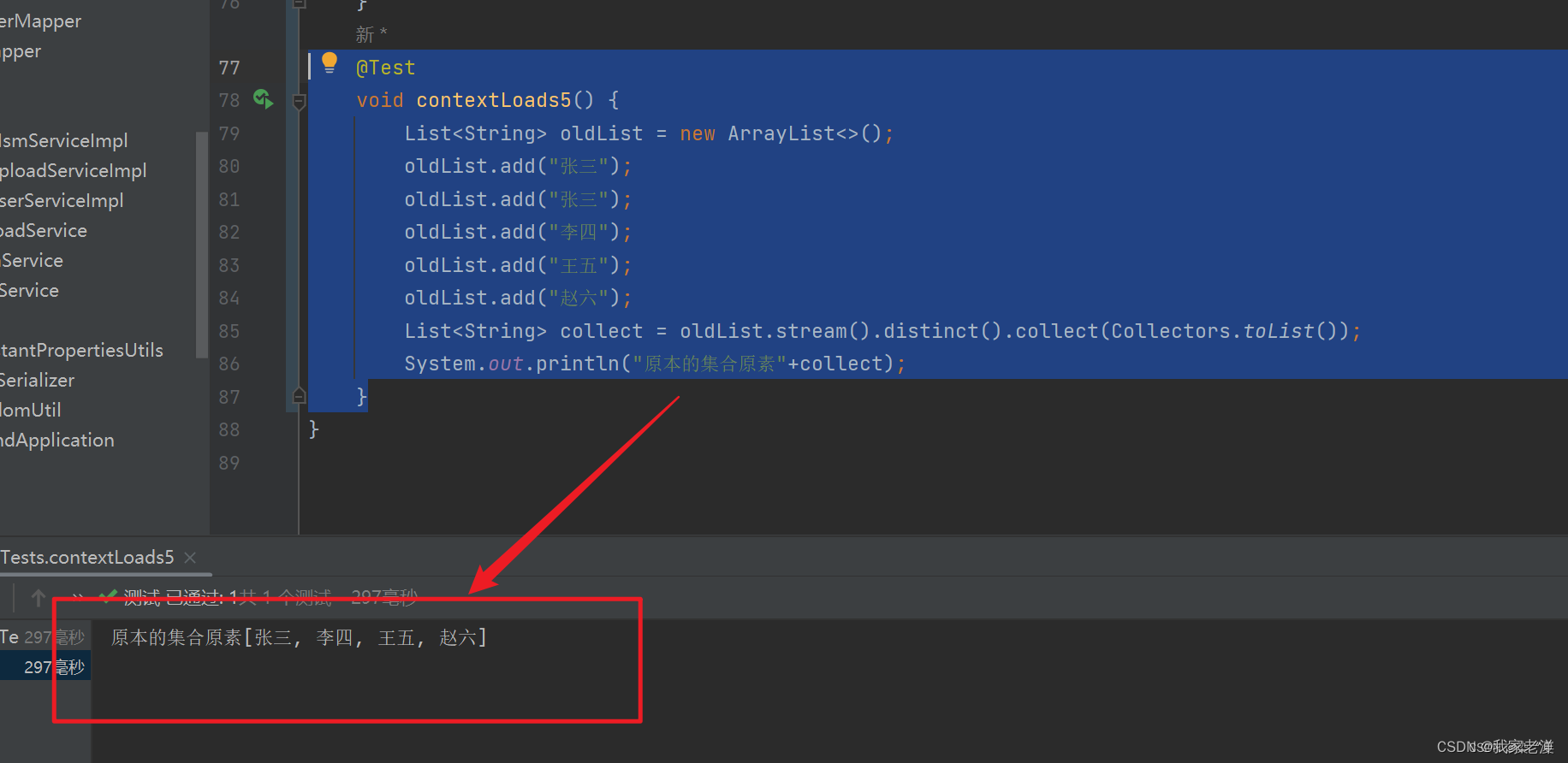
List去重有几种方式
目录 1、for循环添加去重 2、for 双循环去重 3、for 双循环重复坐标去重 4、Set去重 5、stream流去重 1、for循环添加去重 List<String> oldList new ArrayList<>();oldList.add("张三");oldList.add("张三");oldList.add("李四&q…...

使用C#+NPOI进行Excel处理,实现多个Excel文件的求和统计
一个简易的控制台程序,使用C#NPOI进行Excel处理,实现多个Excel文件的求和统计。 前提: 待统计的Excel格式相同统计结果表与待统计的表格格式一致 引入如下四个动态库: 1. NPOI.dll 2. NPOI.OOXML.dll 3. NPOI.OpenXml4Net.dll …...
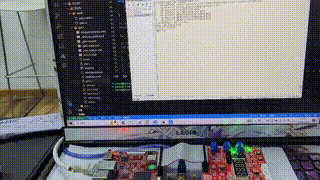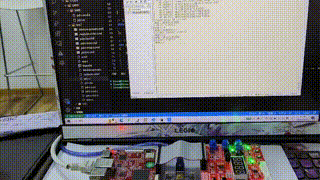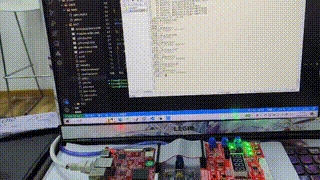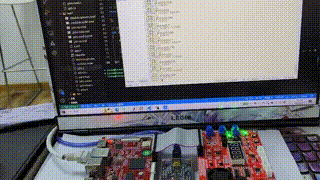
华清远见嵌入式学习——驱动开发——day9
目录 作业要求: 作业答案: 代码效果: 编辑 Platform总线驱动代码: 应用程序代码: 设备树配置: 作业要求: 通过platform总线驱动框架编写LED灯的驱动,编写应用程序测试&…...

formality:set_constant应用
我正在「拾陆楼」和朋友们讨论有趣的话题,你⼀起来吧? 拾陆楼知识星球入口 往期文章链接: formality:形式验证流程 scan mode func的功能检查需要把scan mode设置成0。...

sqllabs的order by注入
当我们在打开sqli-labs的46关发现其实是个表格,当测试sort等于123时,会根据列数的不同来进行排序 我们需要利用这个点来判断是否存在注入漏洞,通过加入asc 和desc判断页面有注入点 1、基于使用if语句盲注 如果我们配合if函数,表达…...

《The Art of InnoDB》第二部分|第4章:深入结构-磁盘结构-redo log
4.3 redo log 目录 4.3 redo log 4.3.1 redo log 介绍 4.3.2 redo log 的作用 4.3.3 redo log file 结构 4.3.4 redo log 提交逻辑 4.3.5 redo log 持久化逻辑 4.3.6 redo log 检查点 4.3.7 小结...

大模型安全相关论文
LLM对于安全的优势 “Generating secure hardware using chatgpt resistant to cwes,” Cryptology ePrint Archive, Paper 2023/212, 2023评估了ChatGPT平台上代码生成过程的安全性,特别是在硬件领域。探索了设计者可以采用的策略,使ChatGPT能够提供安…...

回归预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测
回归预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测 目录 回归预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测预测效果基本描述程序设计参考资料 预测效果…...

[算法沉淀记录] 排序算法 —— 堆排序
排序算法 —— 堆排序 算法基础介绍 堆排序(Heap Sort)是一种基于比较的排序算法,它利用堆这种数据结构来实现排序。堆是一种特殊的完全二叉树,其中每个节点的值都必须大于或等于(最大堆)或小于或等于&am…...

C++ //练习 9.33 在本节最后一个例子中,如果不将insert的结果赋予begin,将会发生什么?编写程序,去掉此赋值语句,验证你的答案。
C Primer(第5版) 练习 9.33 练习 9.33 在本节最后一个例子中,如果不将insert的结果赋予begin,将会发生什么?编写程序,去掉此赋值语句,验证你的答案。 环境:Linux Ubuntu࿰…...
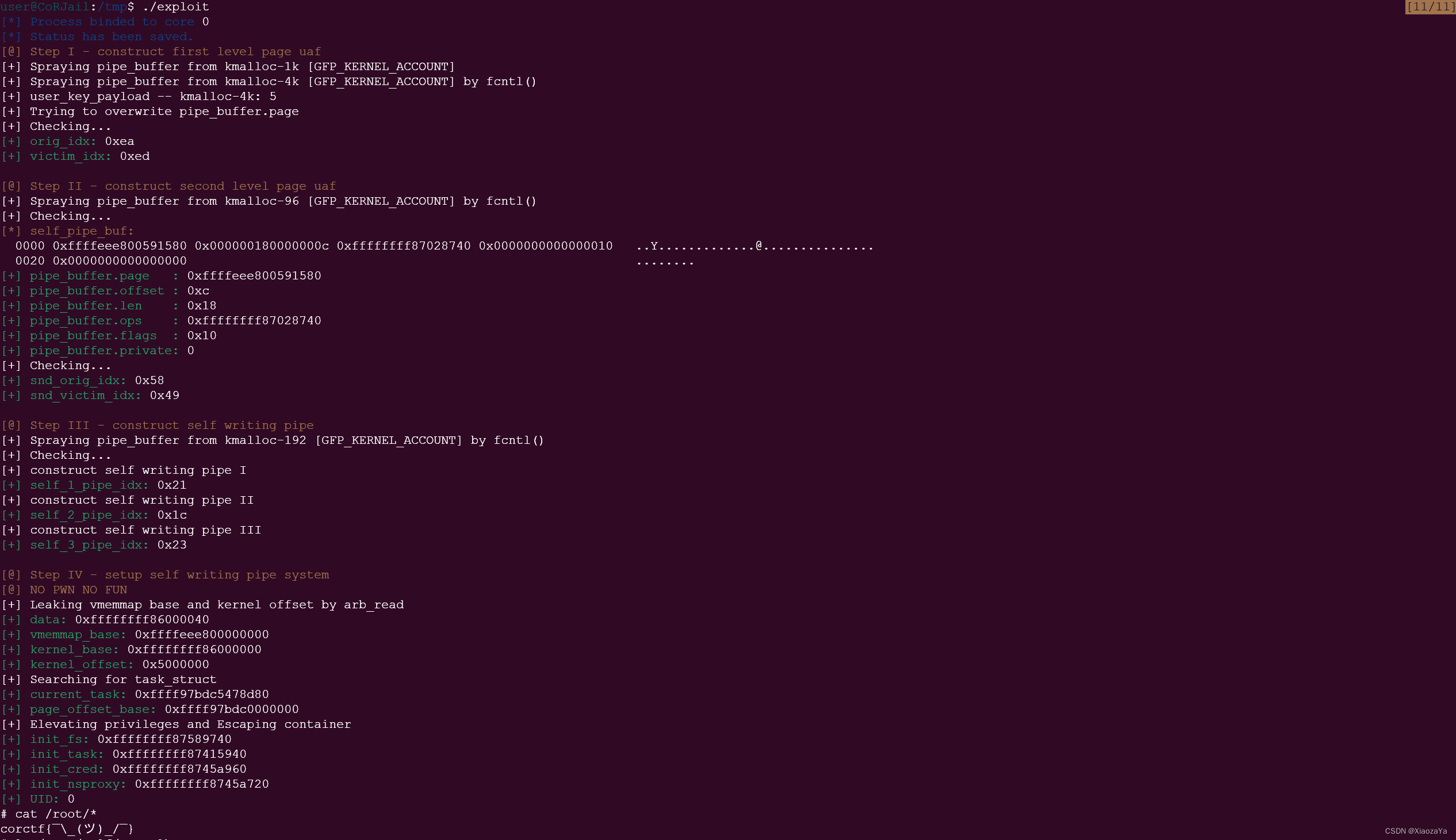
[corCTF 2022] CoRJail: From Null Byte Overflow To Docker Escape
前言 题目来源:竞赛官网 – 建议这里下载,文件系统/带符号的 vmlinux 给了 参考 [corCTF 2022] CoRJail: From Null Byte Overflow To Docker Escape Exploiting poll_list Objects In The Linux Kernel – 原作者文章,poll_list 利用方式…...
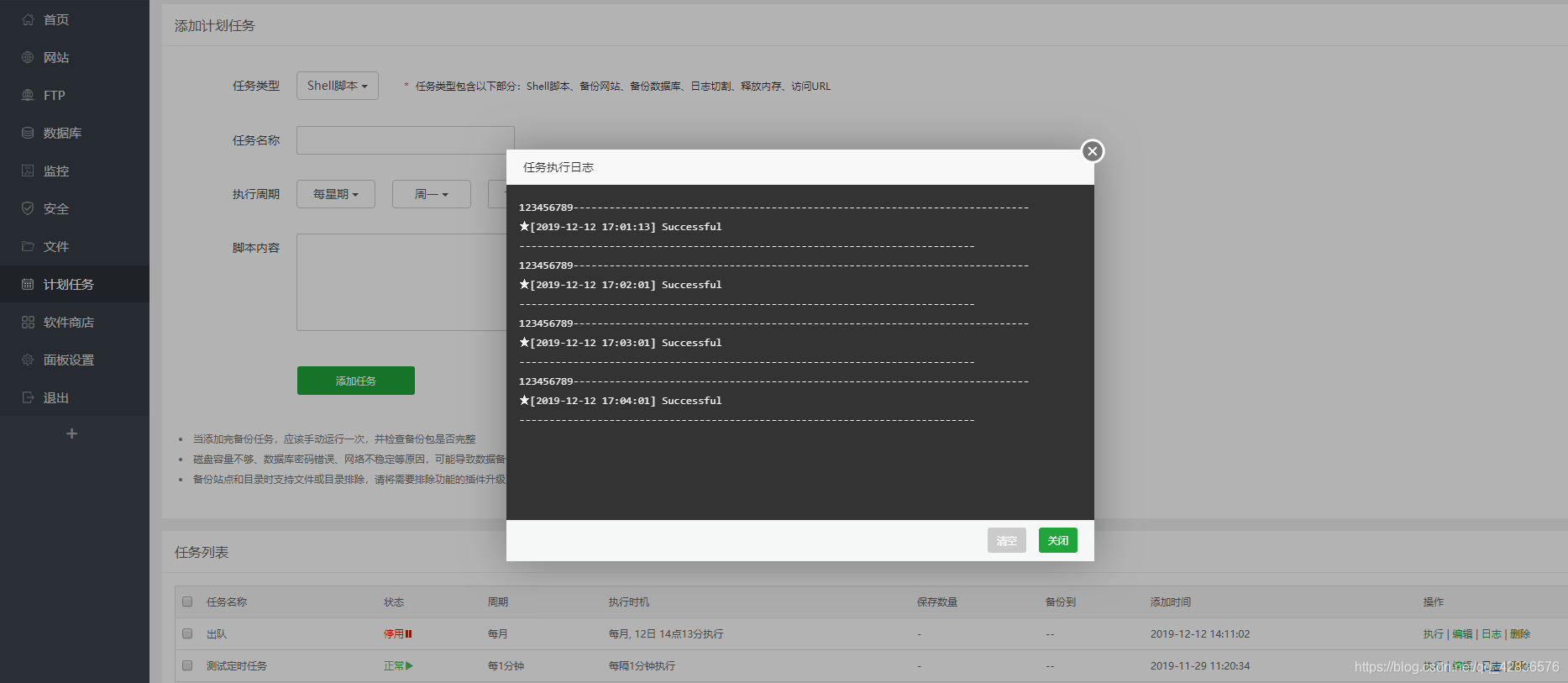
thinkphp6定时任务
这里主要是教没有用过定时任务没有头绪的朋友, 定时任务可以处理一些定时备份数据库等一系列操作, 具体根据自己的业务逻辑进行更改 直接上代码 首先, 是先在 tp 中的 command 方法中声明, 如果没有就自己新建一个, 代码如下 然后就是写你的业务逻辑 执行定时任务 方法写好了…...
)
支持国密ssl的curl编译和测试验证(上)
目录 1. 编译铜锁ssl库2. 编译nghttp2库3. 编译curl4. 验证4.1 查看版本信息4.2 验证国密ssl握手功能4.3 验证http2协议功能 以下以ubuntu 22.04环境为例进行编译 本次编译采用铜锁sslnghttp2curl,使得编译出来的curl可以支持国密ssl,并且可以支持http2…...

包装类详解
概述 Java提供了两个类型系统,基本类型与引用类型,使用基本类型在于效率,然而很多情况,会创建对象使用,因为对象可以做更多的功能,如果想要我们的基本类型像对象一样操作,就可以使用基本类型对…...

vue3与vue2的区别
Vue 3和Vue 2在以下几个方面有一些区别: 性能提升:Vue 3对渲染性能和内存占用进行了优化,使用了Proxy代理对象,比Vue 2的Object.defineProperty更高效。此外,Vue 3还引入了静态树提升(Static Tree Hoisting…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...