剖析G1 垃圾回收器
简单回顾
在Java当中,程序员在编写代码的时候只需要创建对象,从来不需要考虑将对象进行释放,这是因为Java中对象的垃圾回收全部由JVM替你完成了(所有的岁月静好都不过是有人替你负重前行)。

而JVM的垃圾回收由垃圾回收器来负责,在JDK的不断更新迭代过程中,JVM的垃圾回收器也经历了Serial 垃圾收集器、Serial Old 垃圾收集器、ParNew 垃圾收集器、Parallel Old垃圾收集器、CMS垃圾收集器,以及目前最流行的G1垃圾回收器(也就是本文重点要讲的)。
G1的诞生与发展
G1垃圾回收器最早在2004年发表论文提出(Garbage-First Garbage collection,doi:10.1145/1029873.1029879),在JDK6 中首次被应用,在JDK7中被正式支持,而到了2019年发布的JDK9中,G1垃圾收集器已经作为了官方默认的垃圾收集器,取代了之前的CMS。

G1有什么厉害的地方
先介绍两个词:硬实时性和软实时性。
硬实时性(hard real-time):每次处理的时间都不能超过最后期限,比如医疗机器人控制系统、航空管制系统。
软实时性(soft real-time):稍微超出几次最后期限也没有什么问题的系统,例如网络银行系统。
G1最大的特点就是非常重视高吞吐量与软实时性的最佳平衡,它让用户来设定期望最大暂停时间(Stop the word),也就是在垃圾回收时停止所有用户线程的时间,G1垃圾收集器可以预测下次 GC 会导致应用程序暂停多长时间。然后根据预测出的结果,G1会通过延迟执行GC、拆分 GC 目标对象等手段来尽量满足用户设置的期望最大暂停时间,默认的暂停目标是 200ms。你想让GC时暂停多久,它就能尽量的满足你。
G1垃圾收集器的应用场景最好需要包含以下特性(满足这些特性的话,则可能更适合G1出马,否则可能其他GC更合适):
-
堆内存大小超过10G,且存活对象占用比例超过50%
-
对象分配和晋升速率可能随时间有显著变化
-
堆中存在大量碎片
-
预测的最大停顿时间不超过几百毫秒
G1有什么特别牛逼的地方呢?
首先,以往的 GC 都是尽可能缩短最大暂停时间,缩短最大暂停时间很容易导致吞吐量下降。当然我们肯定希望是暂停时间越短约好呀,但是暂停时间过短很可能会导致频繁发生GC,从而把CPU全部都打满了,也就是吞吐量降低。所以并不是暂停时间越短机器性能越好。另外以往的 GC 无法预测暂停时间,GC 时可能会使应用程序长时间暂停的风险。G1的目的就是高效地实现软实时性,能够让用户设置期望暂停时间。在确保吞吐量比以往的 GC 更好的前提下,实现了软实时性。最大程度利用服务器上多处理器的优势,而且在处理巨大的堆时,也不会降低 GC 的性能。
G1垃圾收集模型
堆内存划分
G1垃圾收集器采取了和之前所有的垃圾收集器完全不一样的思路,可以说是一个开拓者。别人都在研究如何让马车能够把车拉的更快(改良马车结构,马车上多绑几匹马),G1相当于发明出来了蒸汽机来替代马车。

G1垃圾收集器开创了面向局部收集的设计思路和基于Region的内存布局形式。G1不再坚持固定大小以及固定数量的分代区域划分,而将内存结构划分成如图所示大小相等的块状区域,称为region,region是内存分配和内存回收的最小单位,每个Region都可以成为 Eden空间、Survivor空间、老年代空间。region的大小可以由用户进行调整,但是内部会将用户设置的值向上调整为 2 的指数幂来作为区域的大小。
图中绿色区域指代的是新生代中的伊甸园区(Eden),蓝色区域指代的是老年代(old generation),标注为S的橙色区域的为Suvivor Region,标注为H的蓝色区域为Humoungous Region(巨型对象,也属于老年代),灰色的区域为空闲区。我们从图中对象占用的内存都不是连续的,并且任何一个区域都没有特定的年代划分,可以将它分配成新生代也可以分配为老年代。由于分区的原因,G1可以只选取部分区域进行内存回收,这样缩小了回收的范围,因此对于全局停顿情况的发生也能得到较好的控制。这是G1和其他收集器在堆内存结构上的最大差别,也是为什么G1更适合处理堆中存在大量碎片场景的原因。

卡表与卡页
JVM将堆内存划分为了2次幂大小的卡页(Card Page),使用卡表来记录整个内存的状态。默认情况下,卡页的大小为512B。卡表(Card Table)是由1B组成的数组,卡表里的元素称为卡片(Card),每个卡片对应堆内存中的一个卡页,卡表中的卡片与卡页的映射关系:卡片数组位置为堆内存地址除卡页大小(向下取整)。在堆大小是 1GB 时,卡表大小为 2MB。
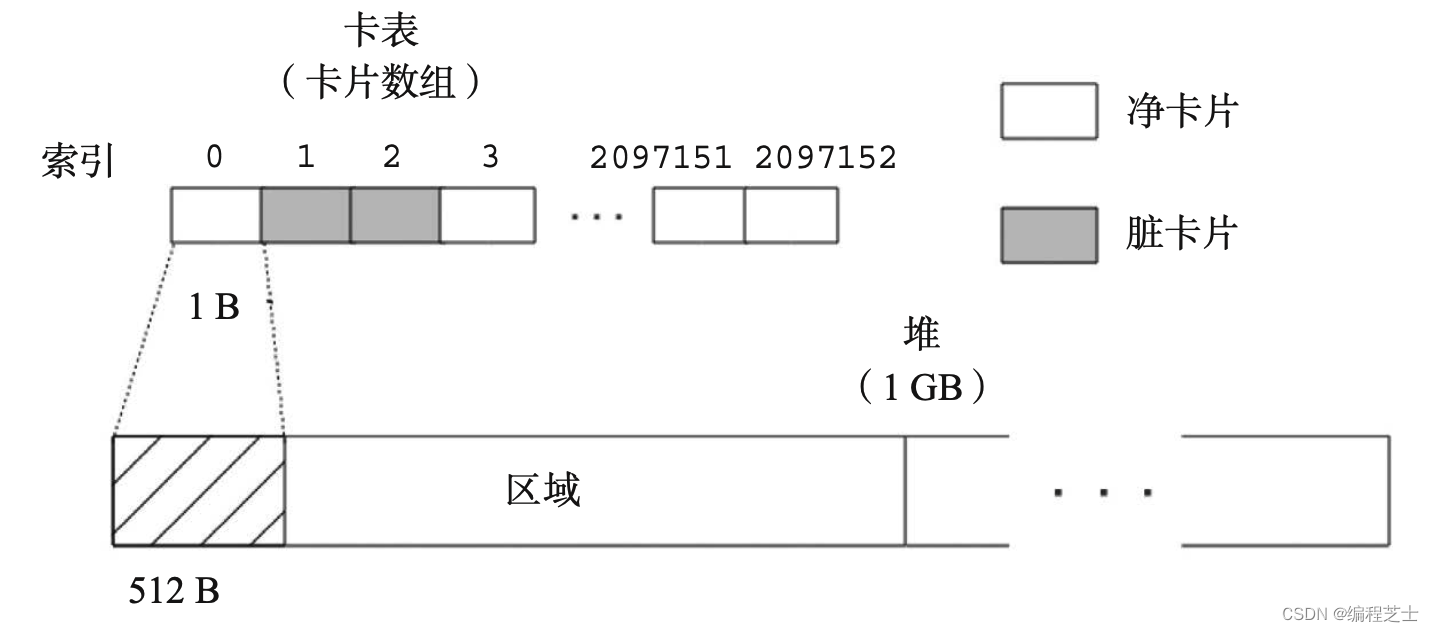
堆中对象所对应的卡片在卡表的索引值 = (对象的地址 - 堆的头部地址) / 512
因为卡片的大小是 1B,所有可以表示其对应卡页所处的很多状态,在后面只涉及到其中的两种:净卡片和脏卡片。
记忆集(RSet)
记忆集英文全称为RemerberSet,简称RSet,是一种抽象概念。其核心思想是通过卡表,记录对象在不同代际间的引用关系,加速垃圾回收的速度。
JVM会通过可达性分析算法标记存活对象来帮助进行垃圾回收,不过在分代GC中,新生代和老年代处于不同的回收阶段,如果仅仅只需要回收新生代,却标记了老年代的对象,那么这无疑是不必要的。但是如果只回收新生带的时候,新生代的对象有被老年代引用的情况,也就是出现跨区引用时,只扫描新生代显然是不行的。所以JVM设计了RSet这样的玩意来避免这种现象,将跨带引用的信息都记录到对应的记忆集中,使其即便不扫描全部对象,也可以查到待回收对象所在分区被其它分区引用的情况。

每个Region中都会开辟一小块的区域作为记忆集的存储位置,记忆集的结构为一个Hash表,Key为引用本分区的其它分区的地址,Value是卡片(Card)在卡表的索引值,即分区中的哪些卡页引用了本分区。

例如在下图中,区域 B 中的对象 b 引用了区域 A 中的对象 a。因为对象 b 不是区域 A 中的对象,所以必须记录这个引用关系。在记忆集合 A 中,以区域 B 的地址为键记录了卡片的索引 2048(对象 b 对应的卡片索引),此时对象 b 对对象 a 的引用被准确记录了下来。

那么是否是所有的引用关系都需要记录到记忆集中呢?答案不是的,分为以下几种情况来进行讨论。
无需记录引用关系:
-
Region内部间的引用:无需记录引用关系,Region是内存分配和回收的最小单位,要么都回收,要么都不回收,所以不需要进行记录。
-
新生代分区到新生代分区的引用:无需记录引用关系,无论哪种类型的回收,新生代都会全量回收。
-
新生代分区到老年代分区的引用:无需记录引用关系,对于YoungGC来说,针对的新生代,则无需关心;对于混合GC来说,会使用新生代分区作为根,那么遍历所有新生代分区自然能找到老年代;对于FullGC来说,所有分区都会被清理,无需关心引用关系。
需要记录引用关系:
-
老年代分区到新生代分区的引用:需要记录引用关系,新生代回收时,有两种根,一种是栈空间/全局变量的引用,另一种便是老年代到新生代的引用
-
老年代分区到老年代分区的引用:需要记录引用关系,混合回收时可能只回收部分Region,需要记录引用关系,快速找到活跃对象
写屏障
记忆集的主要作用是记录跨Region的引用关系,为保证其正确性,那么当引用关系变化时,我们需要及时更新记忆集,而记忆集写屏障则负责对记忆集进行更新。
每个应用程序线程都持有一个转移专用记忆集合日志的缓冲区,其中存放的是卡片索引的数组。当对象的域被修改时,写屏障就会感知,并会将对象 所对应的卡片索引添加到转移专用记忆集合日志中。
主要步骤:
-
从转移专用记忆集合日志的集合中取出转移专用记忆集合日志,从头开始扫描
-
将卡片变为净卡片
-
检查卡片所对应存储空间内的所有对象的域
-
向域中地址所指向的区域的记忆集合中添加卡片
G1 垃圾回收过程
G1的GC主要分为Young GC和Mixed GC两种模式,有些特殊场景可能会发生Full GC。不过如果按照垃圾回收的阶段来划分的话,G1的垃圾回收过程只包含两个阶段,Young-Only和Space Relcaimation阶段。
在Young Only阶段,G1只会回收新生代内存,即新生代回收,在Space Reclamation阶段,G1除了会全量回收新生代内存,还会回收老年代区域,即混合回收。Full GC是一种特殊的兜底回收逻辑,此处不考虑进来。所以G1的垃圾回收其实不是我们所想的Young GC和Mixed GC穿插进行,而是Young GC 持续一段时间,Mixed GC 再持续一段时间。

图中的圆圈表示G1回收过程中的暂停:蓝色圆圈表示Young-only GC导致的暂停,红色圆圈表示Mixed GC导致的暂停,黄色圆圈表示有并发标记导致的暂停。
全局并发标记
并发标记的时机是在Young GC后时,只有达到InitiatingHeapOccupancyPercent阈值后,才会触发并发标记。InitiatingHeapOccupancyPercent默认值是45。
整个过程分为四个步骤:
初始标记:标记处所有跟GC Roots直接关联的对象,这一阶段STW,并且耗时很短,主要是修改TAMS指针的值,让下一阶段分配对象能够使用Region内存。
并发标记:从GC Roots对堆中的对象进行可达性分析, 找出存活的对象,并发标记阶段产生的新的引用会被SATB的写屏障记录下来,并且还会定期更新和处理SATB局部缓存表的信息和记录,如果发现某一个Region中所有都是垃圾,那么就直接进行回收。
重新标记:标记在并发期间因为程序运作而改变的引用对象。
清除:进行价值衡量,回收最优价值的Region区。
转移存活对象
在并发标记完成后,G1能筛选出所有候选的回收集,并根据用户定义的期望最大停顿时间,筛选本次转移真正的回收集(CSet),标记回收集中的存活对象,将这些对象转移,完成垃圾回收。
参数介绍
| 参数 | 说明 |
| -XX:+UseG1GC | 使用 G1 收集器 |
| -XX:G1HeapRegionSize=n | 设置 G1区域Region的大小。范围从1 MB 到32MB之间,目标是根据最小的 Java 堆大小划分出大约2048个区域。 |
| -XX:MaxGCPauseMillis=200 | 设置最长暂停时间目标值,默认是200毫秒 |
| -XX:G1NewSizePercent=5 | 设置年轻代最小值占总堆的百分比,默认值是5% |
| -XX:G1MaxNewSizePercent=60 | 设置年轻代最大值占总堆的百分比,默认值是java堆的60% |
| -XX:ParallelGCThreads=n | 设置STW并行工作的GC线程数,一般推荐设置该值为逻辑处理器的数量,最大是8;如果逻辑处理器大于8,则取逻辑处理器数量的5/8;这适用于大多数情况,除非是较大的SPARC系统,其中的n值可以是逻辑处理器的5/16 |
| -XX:ConcGCThreads=n | 并发标记阶段,并发执行的线程数,一般n值为并行垃圾回收线程数(ParallelGCThreads)的1/4左右 |
| -XX:InitiatingHeapOccupancyPercent=45 | 设置触发全局并发标记周期的Java堆内存占用率阈值,默认占用率阈值是整个Java堆的45% |
| -XX:G1MixedGCLiveThresholdPercent=85 | 老年代Region中存活对象的占比,只有当占比小于此参数的Old Region,才会被选入CSet。这个值越大,说明允许回收的Region中的存活对象越多,可回收的空间就越少,gc效果就越不明显 |
| -XX:G1HeapWastePercent=5 | 设置G1中愿意浪费的堆的百分比,如果可回收region的占比小于该值,G1不会启动Mixed GC,默认值10%,主要用来控制Mixed GC的触发时机。在global concurrent marking结束之后,我们可以知道老年代regions中有多少空间要被回收,在每次YGC之后和再次Mixed GC之前,会检查垃圾占比是否达到此参数,只有达到了,下次才会触发Mixed GC。 |
| -XX:G1MixedGCCountTarget=8 | 一次全局并发标记后,最多执行Mixed GC的次数,次数越多,单次回收的老年代的Region个数就越少,暂停也就越短 |
| -XX:G1OldCSetRegionThresholdPercent=10 | 一次Mixed GC过程中老年代Region内存最多能被选入CSet中的占比 |
| -XX:G1ReservePercent=10 | 设置作为空闲空间的预留内存百分比,用来降低目标空间溢出的风险,默认是10%,一般增加或减少百分比时,需要确保也对java堆调整相同的量。 |
实例参考
下面是一台部署线上服务的4核10G的服务器的GC情况,其使用的垃圾回收器为G1:
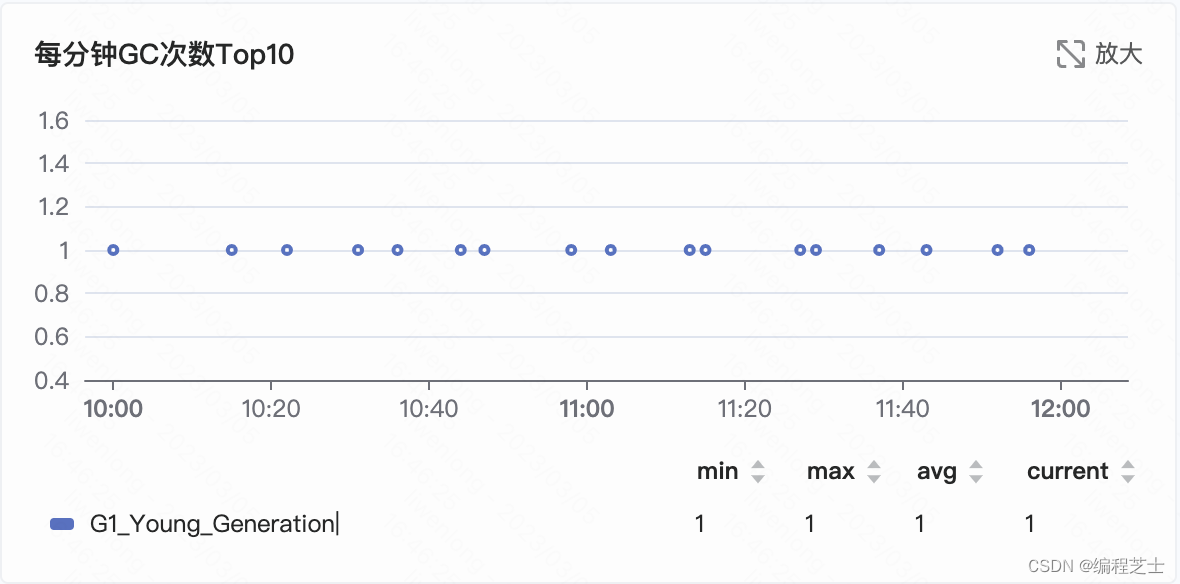
如图可得该实例在最近两小时共产生16次GC,平均每次间隔七八分钟。

每次GC耗时没有超过50ms,因此每分钟的吞吐量也超过了99%,符合MaxGCPauseMillis=200这个配置,所有的停顿时间都没有超出目标值。
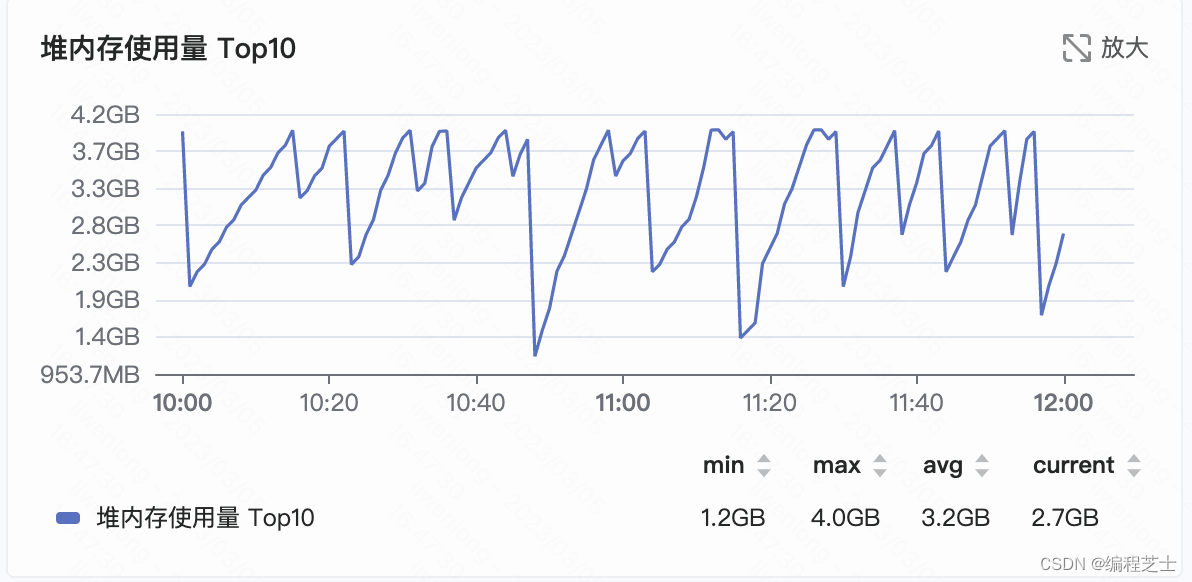
堆内存大约在到达4G的时候开始被回收,符合InitiatingHeapOccupancyPercent=40这个配置,在堆内存达到10*40%=4G的时候开始触发标记周期,然后进行内存回收工作.
相关文章:
剖析G1 垃圾回收器
简单回顾 在Java当中,程序员在编写代码的时候只需要创建对象,从来不需要考虑将对象进行释放,这是因为Java中对象的垃圾回收全部由JVM替你完成了(所有的岁月静好都不过是有人替你负重前行)。 而JVM的垃圾回收由垃圾回收器来负责,在…...
如何打造一款专属于自己的高逼格电脑桌面
作为一名电脑重度使用者,你是否拥有一款属于你自己的高逼格电脑桌面呢?你是不是也像大多数同学一样,会把所有的内容全部都堆积到电脑桌面,不仅找东西困难,由于桌面内容太多还会导致C盘空间不足,影响电脑的反…...

【C++】string的使用及其模拟实现
文章目录1. STL的介绍1.1 STL的六大组件1.2 STL的版本1.3 STL的缺陷2. string的使用2.1 为什么要学习string类?2.2 常见构造2.3 Iterator迭代器2.4 Capacity2.5 Modifiers2.6 String operations3. string的模拟实现3.1 构造函数3.2 拷贝构造函数3.3 赋值运算符重载和…...

怀念在青鸟的日子
时间过的可真快,一转眼来到了2023年!我初中上完就没有在念,下了学门步入社会,那时的我一片迷茫,不知道该去干什 么,父母说要不去学挖掘机、理发、修车...我思考再三,一个都没有我喜欢的…...

学习记录---Python内置类型
文章目录字符串split()列表常见操作列表相减字典创建普通创建eval(s)添加或更新元素d[t] 1d.update({c: 3}){**d1, **d2} **字典解包装运算符删除元素 d.pop(c)属性d.items()d.keys()d.values()访问元素d[Name]d.get(score)遍历字典for key in dictfor key, values in dict.it…...
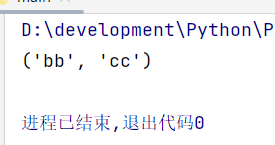
Python笔记 -- 列表
文章目录1、列表简介2、修改、添加、删除元素2.1、添加2.2、删除3、排序、倒序4、遍历列表5、创建数值列表6、列表切片7、列表复制8、元组1、列表简介 在Python中用方括号[]表示列表,用逗号隔开表示其元素 通过索引访问列表 names [aa,bb,cc,dd]print(names[0]) …...

谈谈UVM中的uvm_info打印
uvm_info宏的定义如下: define uvm_info(ID,MSG,VERBOSITY) \begin \if (uvm_report_enabled(VERBOSITY,UVM_INFO,ID)) \uvm_report_info (ID, MSG, VERBOSITY, uvm_file, uvm_line); \end 从这里可以看出uvm_info由两部分组成:uvm_report_enabled(VER…...
)
矩阵理论1 集合上的等价关系(equivalence relations on a set S)
定义 对于一个集合S, 如果集合E⊂SS\mathcal{E} \subset S\times SE⊂SS满足以下条件 自反性: 对于∀s∈S,都有(s,s)∈E\forall s\in S, 都有 (s, s) \in \mathcal{E}∀s∈S,都有(s,s)∈E对称性: (s,t)∈E⇔(t,s)∈E(s,t) \in \mathcal{E} \Leftrightarrow (t,s)\in \mathcal…...
【网络监控】Zabbix详细安装部署(最全)
文章目录Zabbix详细安装部署环境准备安装依赖组件访问初始化配置Zabbix详细安装部署 Zabbix 是一个高度集成的网络监控解决方案,可以提供企业级的开源分布式监控解决方案,由一个国外的团队持续维护更新,软件可以自由下载使用,运作…...

阿里云轻量服务器--Docker--Nacos安装(使用外部Mysql数据存储)
前言:docker 安装nacos 如果不设置外部的mysql 默认使用内嵌的内嵌derby为数据源,这个时候如果,重新部署nacos 则会造成原有数据丢失情况; 1 默认安装的nacos 启动后使用的是内嵌的存储: 2 使用外部mysql 作为存储&a…...
unity开发知识点小结01
unity对象生命周期函数 Awake():最早调用,所以可以实现单例模式 OnEnable():组件激活后调用,在Awake后调用一次 Stat():在Update()之前,OnEnable…...

软件系统[软件工程]
What’s the link? They all involve outdated (legacy) software technology. All have had huge socio-economical impact. Prompting national lockdowns. Spreadsheet workflow error led to thousands of preventable infections and deaths. Huge losses of citizen dat…...
电力系统稳定性的定义与分类
1电力系统稳定性的定义与分类 IEEE给出电力系统稳定性定义:电力系统稳定性是指电力系统这样的一种能力—对于给定的初始运行状态,经历物理扰动后,系统能够重新获得运行平衡点的状态,同时绝大多数系统变量有界,因此整个…...
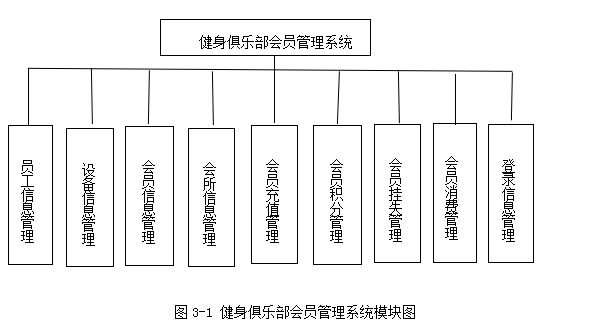
基于java的俱乐部会员管理系统
技术:Java、JSP等摘要:随着科学技术的飞速发展,科学技术在人们日常生活中的应用日益广泛,也给各行业带来发展的机遇,促使各个行业给人们提供更加优质的服务,有效提升各行业的管理水平。俱乐部通过使用一定的…...
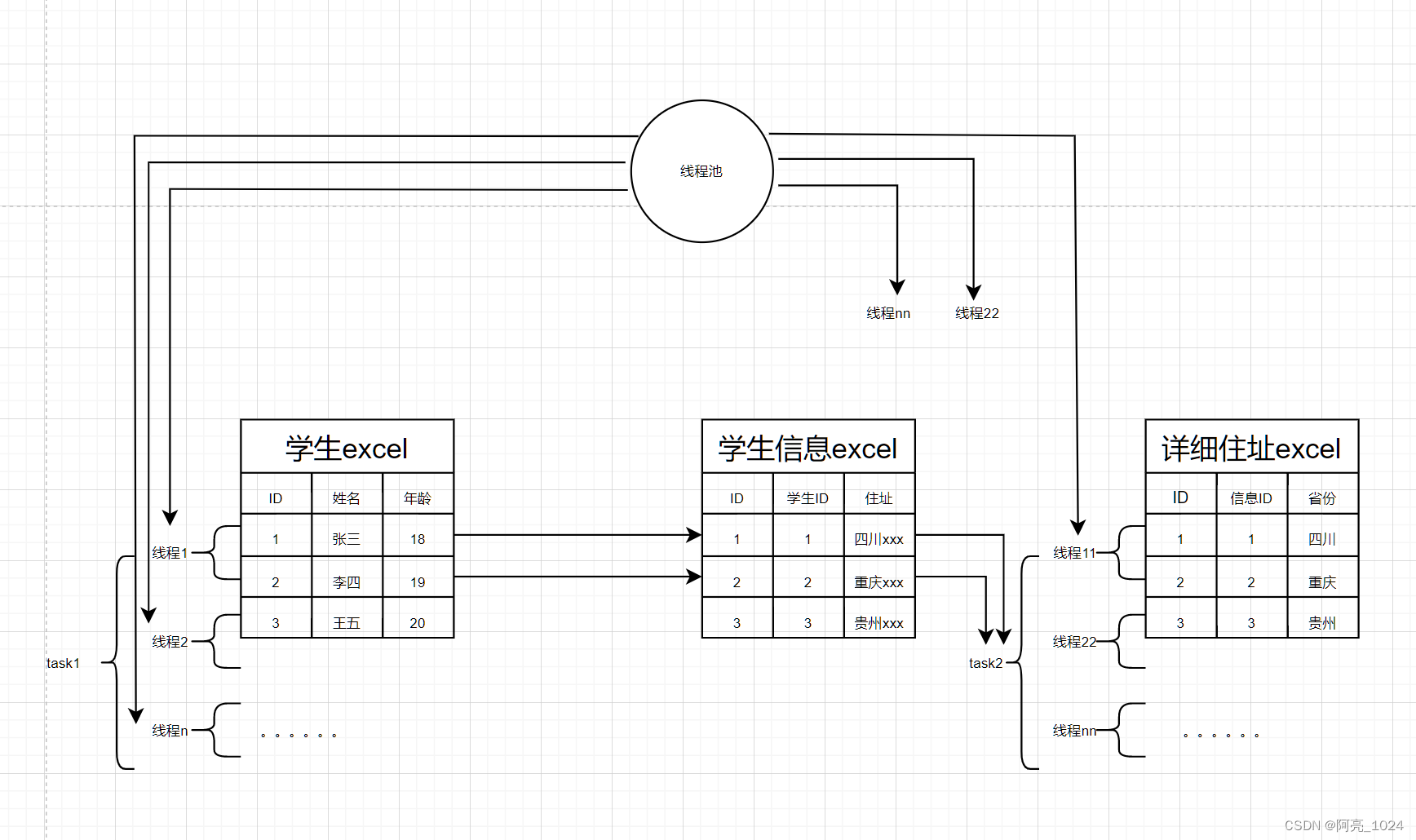
线程池执行父子任务,导致线程死锁
前言, 一次线程池的不当使用,导致了现场出现了线程死锁,接口一直不返回。而且由于这是一个公共的线程池,其他使用了次线程池的业务也一直阻塞,系统出现了OOM,不过是幸好是线程同事测试出来的,没…...

Ubuntu系统新硬盘挂载
Ubuntu系统新硬盘挂载 服务器通常会面临存储不足的问题,大部分服务器都是ubuntu系统,该篇博客浅浅记载一下在ubuntu系统上挂载新硬盘的步骤。本篇博文仅仅记载简单挂载一块新的硬盘,而没有对硬盘进行分区啥的。如果需要更加完善的教程&#…...
【亲测】Centos7系统非管理(root)权限编译NCNN
前言 由于使用的是集群,自己不具有管理员权限,所以以下所有的情况均在非管理员权限下进行安装,即该安装策略仅适用于普通用户构建自己的环境。 什么是NCNN ncnn是一款非常高效易用的深度学习推理框架,支持各种神经网络模型&#x…...

四种常见的异步请求方式
四种常见的异步请求方式 一、xhr异步老祖 XMLHttpRequest(简称XHR)是一种在JavaScript中创建异步请求的技术。XHR对象可以向服务器发送请求,并获取服务器返回的数据,而不会使页面刷新。 XHR对象的创建方式通常是通过构造…...
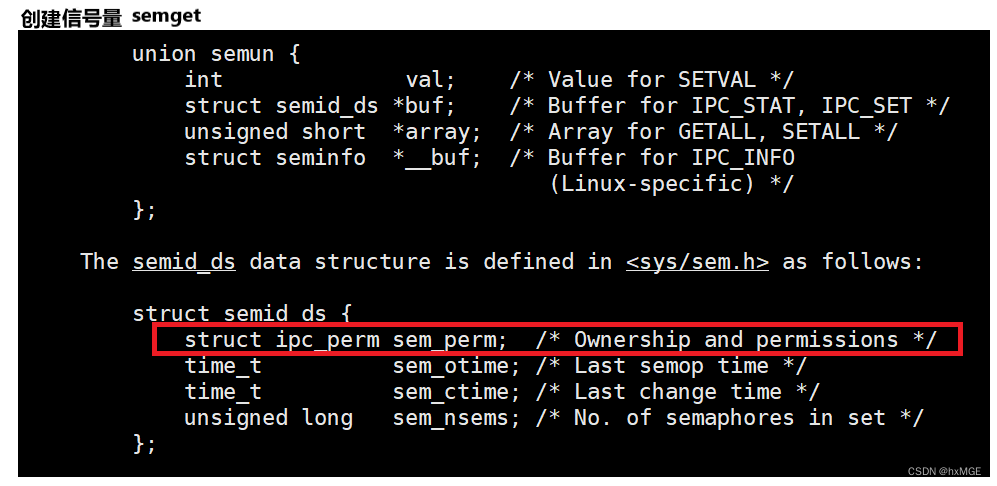
Linux操作系统学习(进程间通信)
文章目录进程间通信进程通信的意义进程通信的方式1.基于文件的方式匿名管道命名管道2.基于内存的通信方式共享内存验证内核相关的数据结构了解进程间通信 进程通信的意义 当我们和另一个人打电话时两部手机都是独立的,通过基站传递信号等等复杂的过程就实现了通…...
单目标追踪——【相关滤波】C-COT原理与ECO基于C-COT的改进
目录C-COT:Continuous Convolution Operator Tracker文章侧重点连续卷积算子目标追踪框架初始化过滤器:追踪流程ECO文章侧重点因式卷积因子生成采样空间模型模型更新策略论文链接:C-COT:Beyond Correlation Filters: Learning Con…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

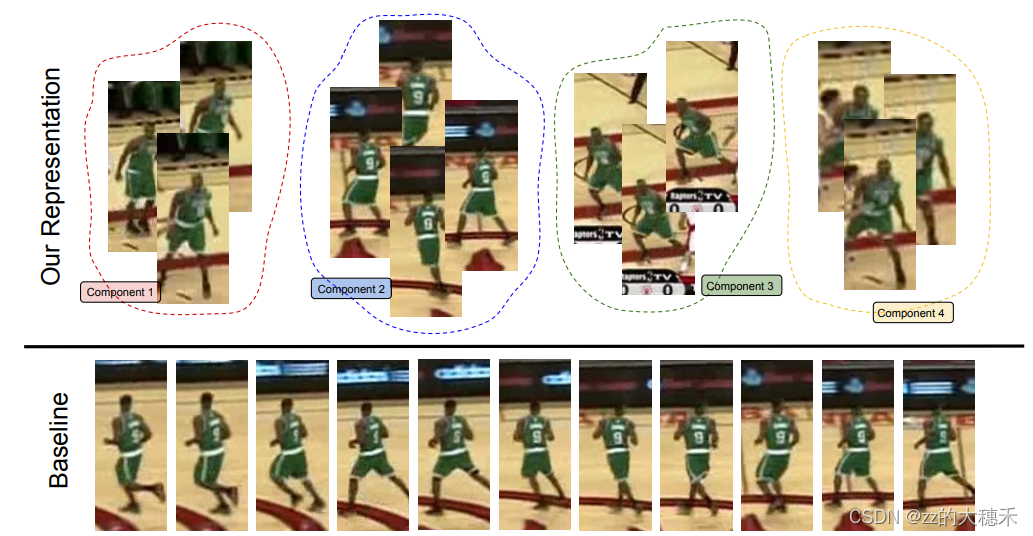
视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...