BiseNet v1论文及其代码详解
来源:投稿 作者:蓬蓬奇
编辑:学姐

BiSeNet v1说明:
文章链接:https://arxiv.org/abs/1808.00897
官方开源代码:https://github.com/CoinCheung/BiSeNet (本文未使用)
文章标题:BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
标题翻译:BiSeNet: 用于实时语义分割的双边分割网络
作者:ChangqianYu, JingboWang, ChaoPeng, Changxin Gao, GangYu, NongSan
单位:旷视科技
发表会议及时间:ECCV-2018
数据集:Cityscapes、CamVid、和COCO-Stuff
原论文的实验部分,在各种数据集上做对比,还做了很多消融实验,论文班的老师说,一篇好的论文应该做大量实验,投稿命中可能性更高,而这篇文章实验部分写的很好,想投论文的同学可以参考一下。
本文是论文班优秀学员的学习笔记~认真阅读很有帮助!
目录:
-
1 论文模型概述
1.1 引言
1.2 模型详解 -
2 代码详解(pytorch)
2.1 导入包
2.2 卷积模块
2.3 空间分支模块
2.4 ARM模块
2.5 FFM模块
2.6 上下文分支模块
2.7 BiSeNet模型
2.8 if 「name」 == '「main」
1、论文模型概述
1.1 引言
实时语义分割应用场景:可以广泛应用于增强现实设备(augmented reality devices)、自动驾驶(autonomous driving)和视频监控领域(video surveillance) 。这些应用对快速交互或响应的高效推理速度有很高的要求。
实时语义分割的算法[1, 17, 25, 39]表明,主要有三种方法来加速该模型:
-
[34, 39]尝试通过裁剪或调整输入大小以降低计算复杂度。虽然该方法简单有效,但是空间细节的丢失破坏了预测,尤其是在边界周围,导致指标和可视化的准确性下降。(不提倡,效果很差)
-
有些算法不是调整输入图像的大小,而是进行通道剪枝来提高推理速度[1, 8, 25],尤其是在骨干模型的早期阶段。然而,它会丢失空间信息。(推荐试一试)
-
对于最后一种情况,ENet[25]提出丢弃模型的最后一个阶段,以追求一个极其紧凑的框架。该方法的缺点也很明显:由于ENet抛弃了最后阶段的下采样,模型的感受野不足以涵盖大物体,导致判别能力较差。
总的来说,上述所有方法都在用精度换速度,这在实践中是不利的。下图1(a)给出了说明。
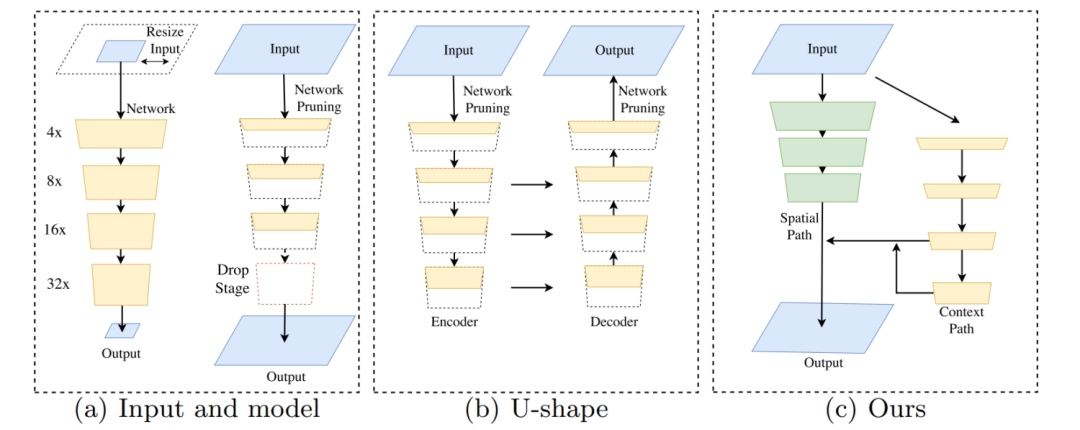
图1:语义分割加速的方法和本文提出的方法。
(a)左图表示对输入图像裁剪或调整大小,右图表示通过通道剪枝或丢弃模块得到的轻量化模型。
(b)表示U-shape结构。
(c)展示了本文中提出的双边分割网络(BiSeNet)。 黑色虚线表示破坏空间信息,而红色虚线表示减小感受野。绿色块是本文中提出的空间路径(SP)。
在网络部分,每个块代表不同下采样大小的特征图,并且块的长度代表空间分辨率,而厚度代表通道的数量。
为了弥补上述提到的空间细节的损失,研究人员广泛使用U-shape结构[1, 25, 35]。U-shape结构逐渐增加了空间分辨率(通过上采样),通过融合主干网络(backbone)的层次特征(hierarchical features),填充了一些缺失的细节。然而,这种技术有两个缺点:
-
完整的U-shape结构在高分辨率特征图上引入额外的计算,会降低模型速度。
-
更重要的是,通过裁减尺寸和剪枝丢失掉的空间信息无法简单的通过引入浅层信息修复,如图1(b)所示,因此性价比不高。换句话说,U-shape结构最好被视为一种缓解(relief),而不是一种基本的解决方案(essential solution)。
基于以上观察,我们提出的双边分割网络(Bilateral Segmentation Network,BiSeNet) 由两部分组成:空间路径(Spatial Path,SP)和上下文路径(Context Path,CP)。顾名思义,这两个组件被设计分别应对空间信息的丢失和感受野的减小。图1(c)显示了这两个组件的结构。
为了在不损失速度的情况下获得更好的准确率,我们还研究了两条路径的融合和最终预测的细化,分别提出了特征融合模块(Feature Fusion Module, FFM)和注意力细化模块(Attention Refinement Module, ARM)。
我们的主要贡献总结如下:
-
提出了一种新的方法,将保留空间信息和提供感受野的功能分离为两条路径。具体地说,我们提出了一个具有空间路径(SP)和上下文路径(CP)的双边分割网络。
-
设计了两个特定的模块,特征融合模块(FFM)和注意力细化模块(ARM),在可接受的成本下进一步提高准确率。
-
在Cityscapes、CamVid和COCO-Stuff的基准测试中取得了令人印象深刻的成绩。更具体地说,我们在速度为105 FPS的Cityscapes测试集上获得了68.4%的结果。
1.2 模型详解
算法主要包含三部分:空间分支、上下文分支和特征融合模块。
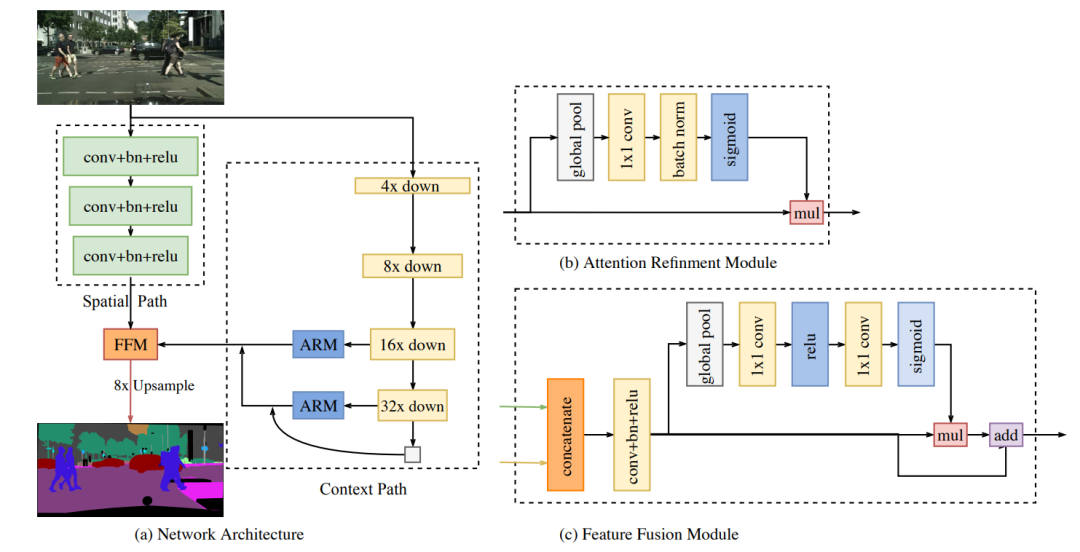
图2。双边分割网络综述。
(a)网络架构。块的长度表示空间(分辨率)大小,厚度表示通道的数量。
(b)注意力细化模块(ARM)的组件。
(c)特征融合模块(FFM)的组成部分。
-
空间分支(Spatial Path,SP):在语义分割的任务中,一些现有的方法[5, 6, 32, 40]试图用空洞卷积在保持输入图像的分辨率基础上编码足够的空间信息,而少数方法[5, 6, 26, 40]试图用金字塔池化模块、ASPP或“大卷积核”来捕获足够大的感受野。这些方法表明,空间信息和感受野是实现高精度的关键。然而,很难同时满足这两个需求,特别是在实时语义分割的情况下。
基于这一观察,我们提出了一种空间路径来保持原始输入图像的空间大小并编码丰富的空间信息。 空间路径包含三层,每一层都包含一个stride=2的3×3卷积,后跟批量归一化BN[15]和ReLU[11]。因此,该路径提取的输出特征图是原始图像的1/8。这种空间尺寸较大的特征图编码了丰富的空间信息。图2(a)显示了该结构的细节。 -
上下文分支(Context Path,CP):在语义分割任务中,感受野对于性能具有重要意义。为了扩大感受野,一些方法利用了金字塔池化模块[40],ASPP[5, 6]或“大卷积核”[26]。然而,这些操作计算量大,内存消耗大,导致速度慢。
为了兼顾感受野的大小和实时性两个因素,上下文分支采用轻量级模型和全局平均池化[5, 6, 21]去提供更大的感受野。轻量级模型可以快速的下采样从而获得更大的感受野,来编码高级特征的上下文信息;然后,使用全局平均池化提供具有全局上下文信息的最大感受野;最后,结合全局池化上采样输出的特征图和轻量级模型的特征图。
注意力细化模块(Attention refinement module,ARM):在上下文路径中,我们提出了特定的注意力细化模块(ARM)来细化每个阶段的特征,ARM使用全局平均池化去捕捉全局上下文并且计算一个注意力向量去引导特征学习,这个设计可以使特征图更加精细,如图2(b)所示。 -
特征融合模块(Feature Fusion Module,FFM):两个分支所提取的特征是不同level的,所以不能简单的把二者相加。空间分支捕捉空间信息编码更丰富的细节信息,上下文分支主要编码了上下文信息。换句话说,空间分支的特征是低级特征的,而上下文分支的特征是高级特征的,因此,本文提出了专门的特征融合模块。
给定不同level的特征,我们首先在通道维度concate空间路径和上下文路径的输出特征。然后经过BN层[15]进行归一化来平衡特征的尺度。接下来,将特征池化为一个特征向量,并计算一个权重向量,类似于SENet [13]。该权重向量可以对特征重新加权,这相当于特征选择和组合。图2(c)显示了这种设计的细节。
损失函数:在本文中,我们还利用辅助损失(auxiliary loss)函数来监督我们提出的方法的训练。我们使用主损失函数来监控整个网络BiseNet的输出。此外,我们添加了两个特定的辅助损失函数来监督上下文路径的输出,就像深度监督[35]一样。所有损失函数都是Softmax损失,如公式1所示。此外,我们使用参数来平衡主要损失和辅助损失的权重,如公式2所示。本文中
其中是网络的输出预测。
其中是级联输出(concatenated output)的主要损失。
是上下文分支模型第
的输出特征。
是
的辅助损失。在本文中,
。
是联合损失函数。在这里,我们只在训练阶段使用辅助损失。
2 代码详解
代码链接:https://github.com/ooooverflow/BiSeNet(这里CP部分没有使用原文Xception39,而是ResNet18-101)
下述以resnet18为例进行调试。
https://mmbiz.qpic.cn/mmbiz_svg/tqRiaNianNl1lf9WtUzq0kROStQymk9FF84EeWjWzibbBV33vqg9Ju3fTqq85VYqGNDsx0XAkIDMstA2ZmERWZ5B3Pde0oRFcuE/640?wx_fmt=svg&wxfrom=5&wx_lazy=1&wx_co=1
-
本图中将通道数放在了最后,即(H, W, C),代码调试时为(B, C, H, W)。
-
Conv2d_3×3_s2_p1_BN_ReLU (256, 256, 64)含义:卷积核kernel_size=3×3,stride=2,padding=1,后接BN层和ReLU激活函数。经过该卷积核后图像尺寸为(256, 256, 64)。
2.1 导入包
import torch
from torch import nn
from torchvision import modelsimport warnings
warnings.filterwarnings(action='ignore')
2.2 卷积模块
将Conv2d+BN+ReLU层封装为一个类,便于后续调用。
class ConvBlock(torch.nn.Module):def __init__(self, in_channels, out_channels,kernel_size=3, stride=2, padding=1):super().__init__()self.conv1 = nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size,stride=stride,padding=padding,bias=False)self.bn = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU()def forward(self, input):x = self.conv1(input)return self.relu(self.bn(x))

2.3 空间分支模块
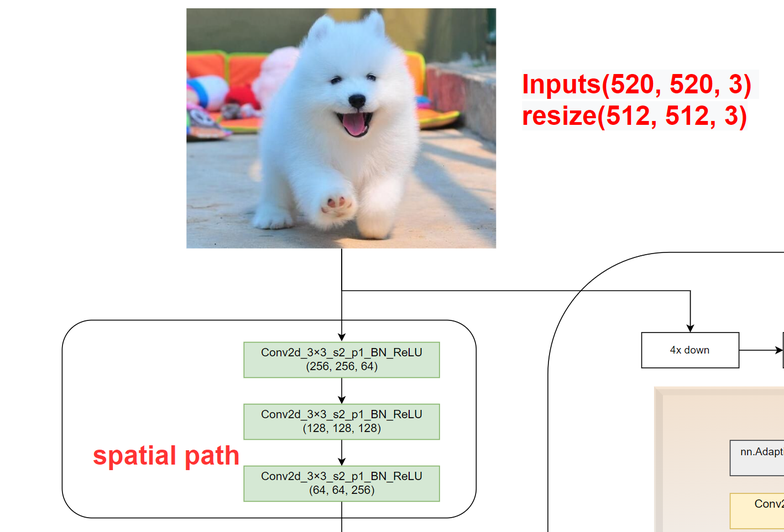
class Spatial_path(torch.nn.Module):def __init__(self):super().__init__()self.convblock1 = ConvBlock(in_channels=3, out_channels=64)self.convblock2 = ConvBlock(in_channels=64, out_channels=128)self.convblock3 = ConvBlock(in_channels=128, out_channels=256)def forward(self, input):x = self.convblock1(input)x = self.convblock2(x)x = self.convblock3(x)return x
可以看出空间分支就是三层卷积,调用上述ConvBlock类,只传入输入输出通道,图像尺寸每经过一层卷积变为原来一半,最后变为原来的1/8。通道数由3->64->128->256。
2.4 ARM模块
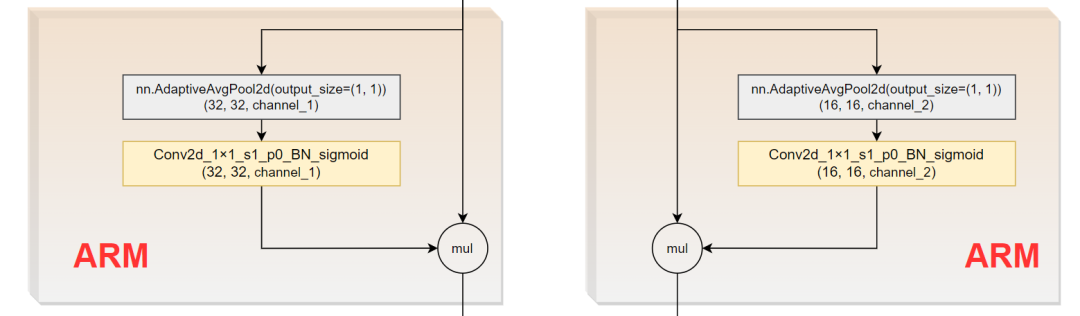
class AttentionRefinementModule(torch.nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)self.bn = nn.BatchNorm2d(out_channels)self.sigmoid = nn.Sigmoid()self.in_channels = in_channelsself.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))def forward(self, input): # input.shape=(16, 256, 32, 32)# global average poolingx = self.avgpool(input) # x.shape=(16, 256, 1, 1)assert self.in_channels == x.size(1), 'in_channels and out_channels should all be {}'.format(x.size(1))x = self.conv(x) # x.shape=(16, 256, 1, 1)# x = self.sigmoid(self.bn(x))x = self.sigmoid(x) # x.shape=(16, 256, 1, 1)# channels of input and x should be samex = torch.mul(input, x) # x.shape=(16, 256, 32, 32)return x
这里使用的是Conv2d+bn+sigmoid。可以看出,初始化类只需要传入输入通道和输出通道两个参数即可,二者一般数值相同。resnet18和resnet101差了四倍,具体见class BiSeNet(torch.nn.Module)模块:
if context_path == 'resnet101':self.attention_refinement_module1 = AttentionRefinementModule(1024, 1024)self.attention_refinement_module2 = AttentionRefinementModule(2048, 2048)
elif context_path == 'resnet18':# build attention refinement module for resnet 18self.attention_refinement_module1 = AttentionRefinementModule(256, 256)self.attention_refinement_module2 = AttentionRefinementModule(512, 512)
2.5 FFM模块

class FeatureFusionModule(torch.nn.Module):def __init__(self, num_classes, in_channels):super().__init__()# self.in_channels = input_1.channels + input_2.channels# resnet101 3328 = 256(from context path) + 1024(from spatial path) + 2048(from spatial path)# resnet18 1024 = 256(from context path) + 256(from spatial path) + 512(from spatial path)self.in_channels = in_channelsself.convblock = ConvBlock(in_channels=self.in_channels, out_channels=num_classes, stride=1)self.conv1 = nn.Conv2d(num_classes, num_classes, kernel_size=1)self.relu = nn.ReLU()self.conv2 = nn.Conv2d(num_classes, num_classes, kernel_size=1)self.sigmoid = nn.Sigmoid()self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))def forward(self, input_1, input_2): # input_1.shape=(16, 256, 64, 64) input_2.shape=(16, 768, 64, 64)x = torch.cat((input_1, input_2), dim=1) # x.shape=(16, 1024, 64, 64)assert self.in_channels == x.size(1), 'in_channels of ConvBlock should be {}'.format(x.size(1))feature = self.convblock(x) # feature.shape=(16, 10, 64, 64)x = self.avgpool(feature) # x.shape=(16, 10, 1, 1)x = self.relu(self.conv1(x)) # x.shape=(16, 10, 1, 1)x = self.sigmoid(self.conv2(x)) # x.shape=(16, 10, 1, 1)x = torch.mul(feature, x) # x.shape=(16, 10, 64, 64)x = torch.add(x, feature) # x.shape=(16, 10, 64, 64)return x
初始化类只需要传入类别数和输入通道数两个参数即可。resnet18和resnet101不一样,具体见class BiSeNet(torch.nn.Module)模块:
if context_path == 'resnet101':self.attention_refinement_module1 = AttentionRefinementModule(1024, 1024)self.attention_refinement_module2 = AttentionRefinementModule(2048, 2048)...# build feature fusion module, 1024+2048+256=3328, 256为上下文分支通道数self.feature_fusion_module = FeatureFusionModule(num_classes, 3328)
elif context_path == 'resnet18':# build attention refinement module for resnet 18self.attention_refinement_module1 = AttentionRefinementModule(256, 256)self.attention_refinement_module2 = AttentionRefinementModule(512, 512)....# build feature fusion module, 256+512+256=1024, 256为上下文分支通道数self.feature_fusion_module = FeatureFusionModule(num_classes, 1024)
2.6 上下文分支模块

这里可以选择使用resnet18还是resnet101,调用torchvision中models库模型。可加载预训练权重。可以看出resnet18和resnet101区别在于layer1-4层通道数扩大了四倍。
class resnet18(torch.nn.Module):def __init__(self, path_model=None):super().__init__()resnet18_model = models.resnet18()if path_model:resnet18_model.load_state_dict(torch.load(path_model, map_location="cpu"))print("load pretrained model , done!! ")self.features = resnet18_modelself.conv1 = self.features.conv1self.bn1 = self.features.bn1self.relu = self.features.reluself.maxpool1 = self.features.maxpoolself.layer1 = self.features.layer1self.layer2 = self.features.layer2self.layer3 = self.features.layer3self.layer4 = self.features.layer4def forward(self, input): # input.shape=(16, 3, 512, 512)x = self.conv1(input) # x.shape=(16, 64, 256, 256)x = self.relu(self.bn1(x)) # x.shape=(16, 64, 256, 256)x = self.maxpool1(x) # x.shape=(16, 64, 128, 128)feature1 = self.layer1(x) # 1 / 4 # feature1.shape=(16, 64, 128, 128)feature2 = self.layer2(feature1) # 1 / 8 # feature2.shape=(16, 128, 64, 64)feature3 = self.layer3(feature2) # 1 / 16 # feature3.shape=(16, 256, 32, 32)feature4 = self.layer4(feature3) # 1 / 32 # feature4.shape=(16, 512, 16, 16)# global average pooling to build tailtail = torch.mean(feature4, 3, keepdim=True) # tail.shape=(16, 512, 16, 1)tail = torch.mean(tail, 2, keepdim=True) # tail.shape=(16, 512, 1, 1)return feature3, feature4, tailclass resnet101(torch.nn.Module):def __init__(self, path_model=None):super().__init__()resnet101_model = models.resnet101()if path_model:resnet101_model.load_state_dict(torch.load(path_model, map_location="cpu"))self.features = resnet101_modelself.conv1 = self.features.conv1self.bn1 = self.features.bn1self.relu = self.features.reluself.maxpool1 = self.features.maxpoolself.layer1 = self.features.layer1self.layer2 = self.features.layer2self.layer3 = self.features.layer3self.layer4 = self.features.layer4def forward(self, input): # input.shape=(16, 3, 512, 512)x = self.conv1(input) # x.shape=(16, 64, 256, 256)x = self.relu(self.bn1(x)) # x.shape=(16, 64, 256, 256)x = self.maxpool1(x) # x.shape=(16, 64, 128, 128)feature1 = self.layer1(x) # 1 / 4 # feature1.shape=(16, 256, 128, 128)feature2 = self.layer2(feature1) # 1 / 8 # feature2.shape=(16, 512, 64, 64)feature3 = self.layer3(feature2) # 1 / 16 # feature3.shape=(16, 1024, 32, 32)feature4 = self.layer4(feature3) # 1 / 32 # feature4.shape=(16, 2048, 16, 16)# global average pooling to build tailtail = torch.mean(feature4, 3, keepdim=True) # tail.shape=(16, 2048, 16, 1)tail = torch.mean(tail, 2, keepdim=True) # tail.shape=(16, 2048, 1, 1)return feature3, feature4, taildef build_contextpath(name, path_model=False):assert name in ["resnet18", "resnet101"], "{} is not support! please use resnet18 or resnet101".format(name)if name == "resnet18":model = resnet18(path_model=path_model)elif name == "resnet101":model = resnet101(path_model=path_model)else:# raise "backbone is not defined!"passreturn model
两个torch.mean函数与nn.AdaptiveAvgPool2d等价。
tail = torch.mean(feature4, 3, keepdim=True) # tail.shape=(16, 512, 16, 1)
tail = torch.mean(tail, 2, keepdim=True) # tail.shape=(16, 512, 1, 1)# 与下述代码等价
avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
tail = avgpool(feature4)
打印resnet18的self.features结果如下,这里取出前四层conv1+bn1+relu+maxpool和layer1-4:
ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(1): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer2): Sequential((0): BasicBlock((conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer3): Sequential((0): BasicBlock((conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer4): Sequential((0): BasicBlock((conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))(fc): Linear(in_features=512, out_features=1000, bias=True)
)
2.7 BiSeNet模型
class BiSeNet(torch.nn.Module):def __init__(self, num_classes, context_path, path_model=None):super().__init__()# build spatial pathself.saptial_path = Spatial_path()# build context pathself.context_path = build_contextpath(name=context_path, path_model=path_model)# build attention refinement module for resnet 101if context_path == 'resnet101':self.attention_refinement_module1 = AttentionRefinementModule(1024, 1024)self.attention_refinement_module2 = AttentionRefinementModule(2048, 2048)# supervision block, 用于生成训练过程的辅助损失self.supervision1 = nn.Conv2d(in_channels=1024, out_channels=num_classes, kernel_size=1)self.supervision2 = nn.Conv2d(in_channels=2048, out_channels=num_classes, kernel_size=1)# build feature fusion moduleself.feature_fusion_module = FeatureFusionModule(num_classes, 3328)elif context_path == 'resnet18':# build attention refinement module for resnet 18self.attention_refinement_module1 = AttentionRefinementModule(256, 256)self.attention_refinement_module2 = AttentionRefinementModule(512, 512)# supervision block, 用于生成训练过程的辅助损失self.supervision1 = nn.Conv2d(in_channels=256, out_channels=num_classes, kernel_size=1)self.supervision2 = nn.Conv2d(in_channels=512, out_channels=num_classes, kernel_size=1)# build feature fusion moduleself.feature_fusion_module = FeatureFusionModule(num_classes, 1024)else:print('Error: unspport context_path network \n')# build final convolutionself.conv = nn.Conv2d(in_channels=num_classes, out_channels=num_classes, kernel_size=1)self.init_weight()self.mul_lr = []self.mul_lr.append(self.saptial_path)self.mul_lr.append(self.attention_refinement_module1)self.mul_lr.append(self.attention_refinement_module2)self.mul_lr.append(self.supervision1)self.mul_lr.append(self.supervision2)self.mul_lr.append(self.feature_fusion_module)self.mul_lr.append(self.conv)def init_weight(self):for name, m in self.named_modules():if 'context_path' not in name:if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')elif isinstance(m, nn.BatchNorm2d):m.eps = 1e-5m.momentum = 0.1nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def forward(self, input):# output of spatial pathsx = self.saptial_path(input)# output of context path# cx1.shape=(16, 256, 32, 32), cx2.shape=(16, 512, 16, 16), tail.shape=(16, 512, 1, 1)cx1, cx2, tail = self.context_path(input)cx1 = self.attention_refinement_module1(cx1) # cx1.shape=(16, 256, 32, 32)cx2 = self.attention_refinement_module2(cx2) # cx2.shape=(16, 512, 16, 16)cx2 = torch.mul(cx2, tail) # cx2.shape=(16, 512, 16, 16)# upsampling, 上采样到与空间模块输出图像尺寸相同cx1 = torch.nn.functional.interpolate(cx1, size=sx.size()[-2:], mode='bilinear') # cx1.shape=(16, 256, 64, 64)cx2 = torch.nn.functional.interpolate(cx2, size=sx.size()[-2:], mode='bilinear') # cx2.shape=(16, 512, 64, 64)cx = torch.cat((cx1, cx2), dim=1) # cx.shape=(16, 768, 64, 64)if self.training == True: # 训练独有辅助损失 # 注意,这里只进行了卷积计算, 没有接bn和激活函数cx1_sup = self.supervision1(cx1) # cx1_sup.shape=(16, 10, 64, 64)cx2_sup = self.supervision2(cx2) # cx2_sup.shape=(16, 10, 64, 64)cx1_sup = torch.nn.functional.interpolate(cx1_sup, size=input.size()[-2:], mode='bilinear') # cx1_sup.shape=(16, 10, 512, 512)cx2_sup = torch.nn.functional.interpolate(cx2_sup, size=input.size()[-2:], mode='bilinear') # cx2_sup.shape=(16, 10, 512, 512)# output of feature fusion module # sx.shape=(16, 256, 64, 64), cx.shape=(16, 768, 64, 64)result = self.feature_fusion_module(sx, cx) # result.shape=(16, 10, 64, 64)# upsamplingresult = torch.nn.functional.interpolate(result, scale_factor=8, mode='bilinear') # result.shape=(16, 10, 512, 512)result = self.conv(result) # result.shape=(16, 10, 512, 512)if self.training == True: # 训练过程return result, cx1_sup, cx2_sup # shape均为(16, 10, 512, 512)return result # result.shape=(16, 10, 512, 512)
2.8 if 「name」 == '「main」
if __name__ == '__main__':# 假设类别数为10, 上下文模块使用resnet18, 不加载预训练权重model = BiSeNet(num_classes=10, context_path='resnet18')# 16表示batch_size, 3表示图像的RGB三通道,512表示输入模型的图像尺寸x = torch.rand(16, 3, 512, 512)# 注意,训练和测试的输出是不同的,训练会有3个输出model.train()outputs, output_sup1, output_sup2 = model(x)print(outputs.shape)print(output_sup1.shape)print(output_sup2.shape)model.eval()output = model(x)print(type(output))print(output.shape)
输出结果:
torch.Size([16, 10, 512, 512])
torch.Size([16, 10, 512, 512])
torch.Size([16, 10, 512, 512])
<class 'torch.Tensor'>
torch.Size([16, 10, 512, 512])
点击下方卡片关注《学姐带你玩AI》🚀🚀🚀
180+篇AI必读论文讲解视频免费领
码字不易,欢迎大家点赞评论收藏!
相关文章:
BiseNet v1论文及其代码详解
来源:投稿 作者:蓬蓬奇 编辑:学姐 BiSeNet v1说明: 文章链接:https://arxiv.org/abs/1808.00897 官方开源代码:https://github.com/CoinCheung/BiSeNet (本文未使用) 文章标题&am…...

(超详细)Navicat的安装和激活,亲测有效
步骤一:准备安装包 下载Navicat,我用的v15最好一致(私信可以发你安装包和注册码)步骤二:关闭杀毒软件,然后需要断掉网络(一定断网) 步骤三:一路next安装,安装…...

JDY-31蓝牙模块使用指南
前言 本来是想买个hc-05,这种非常常用的模块,但是在优信电子买的时候,说有个可以替代的,没注意看,买回来折腾半天。 这个模块是从机模块,蓝牙模块分为主机从机和主从一体的,主机与从机的区别就…...

【2023】华为OD机试真题Java-题目0211-租车骑绿道
租车骑绿道 题目描述 部门组织绿道骑行团建活动。租用公共双人自行车骑行,每辆自行车最多坐两人、最大载重 M M M。 给出部门每个人的体重,请问最多需要租用多少双人自行车。 输入描述 第一行两个数字 m m m、...

leetcode: 3Sum
leetcode: 3Sum1. 题目描述2. 思考3. 解题3. 总结1. 题目描述 Given an integer array nums, return all the triplets [nums[i], nums[j], nums[k]] such that i ! j, i ! k, and j ! k, and nums[i] nums[j] nums[k] 0. Notice that the solution set must not contain …...
)
【Python学习笔记】26.Python3 输入和输出(2)
前言 本章节继续介绍Python的输入输出。 文件对象的方法 本节中剩下的例子假设已经创建了一个称为 f 的文件对象。 f.read() 为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。 size 是一个可选的数字类型的…...

vue项目第二天
项目中使用element-ui库中文网https://element.eleme.cn/#/zh-CN安装命令npm install element-ui安装按需加载babel插件npm install babel-plugin-component -Dnpm i //可以通过npm i 的指令让配置刷新重新配置一下项目中使用element-ui组件抽离文件中按需使用element ui &…...
)
Python爬虫零基础到进阶(课程说明)
Python爬虫零基础到进阶 课程介绍总结 学—练—问 跟着学、多做多练、不懂就问、坚持就是胜利! 作业 飞书布置,作业提交放到群里,老师批改。 代码量 python基础: 十一次课,学会python。环境安装(了…...
)
《C++ Primer Plus》第16章:string类和标准模板库(13)
复习题 考虑下面的声明: class RQ1{ private:char *st; // pointer to C-style string public:RQ1() { st new char [1];strcpy(st, "");}RQ1(const char * s) {st new char [strlen(s)1];strcpy(st, s);}RQ1(const RQ1 & rq) {st new char[strlen…...

材质笔记 - Simluate Solid Surface
光的行为 当光和物体相遇时,光会有三种行为:被物体反射、穿过物体(物体是透明或半透明的)或者被吸收。 高光反射和漫反射 高光反射(Specular Reflection)会在表面光滑且反光的物体上看到,比如镜…...

设计模式-值类型与引用类型、深拷贝与浅拷贝、原型模式详解
一. 值类型和引用类型 1. 前言 (1). 分类 值类型包括:布尔类型、浮点类型(float、double、decimal、byte)、字符类型(char)、整型(int、long、short等)、枚举(entum)、结构体(struct)。 引用类型:数组、字符串(string)、类、接口…...
ssm高校功能教室预约系统java idea maven
本网站所实现的是一个高校功能教室预约系统,该系统严格按照需求分析制作相关模块,并利用所学知识尽力完成,但是本人由于学识浅薄,无法真正做到让该程序可以投入市场使用,仅仅简单实现部分功能,希望日后还能…...

C语言学习笔记-强制类型转换
强制类型转换是通过类型转换运算来实现的。其一般形式为:(类型说明符)(表达式)其功能是把表达式的运算结果强制转换成类型说明符所表示的类型。自动转换是在源类型和目标类型兼容以及目标类型广于源类型时发生一个类型…...

docker数据卷插件
在docker中,对接外部存储我们通常需要docker的数据卷插件。docker中简要可分为两类 docker卷插件和CSI插件,其中docker卷插件分为两个版本,旧版的传统插件(legacy plugin/non-managed plugin)和新版的托管插件(managed plugin)。下面分章节讨…...
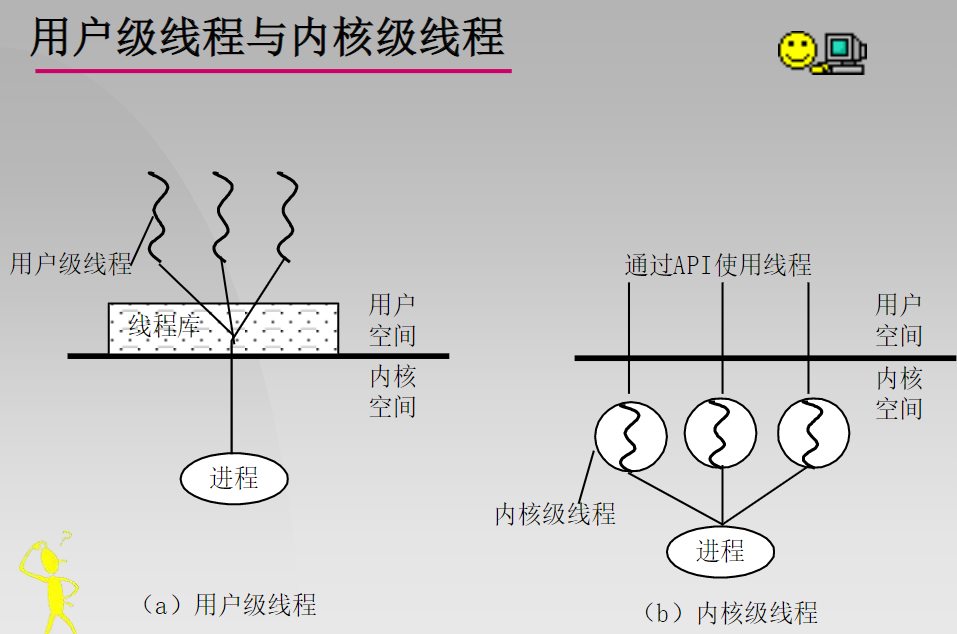
第二章-线程(3)
线程一、线程的定义二、线程的实现一、线程的定义 线程: 线程是进程中的一个实体,是系统独立调度和分派的基本单位。 进程是资源的拥有者,线程是系统独立调度和分配的基本单位。 进程与线程的比较: 调度:线程调度快…...
)
C++学习记录——칠 类和对象(4)
文章目录1、const成员2、取地址及const取地址操作符重载3、构造函数续集1、初始化列表2、explicit关键字4、static成员5、匿名对象6、友元1.友元函数2、友元类7、内部类1、const成员 看一段代码 class A { public:void Print(){cout << _a << endl;} private:int…...
)
Python-项目实战--飞机大战-碰撞检测(8)
目标了解碰撞检测方法碰撞实现1.了解碰撞检测方法pygame提供了两个非常方便的方法可以实现碰撞检测:pygame.sprite.groupcollide()两个精灵组中所有的精灵的碰撞检测groupcollide(group1, group2, dokill1, dokill2, collided None) -> Sprite_dict如果将dokill…...

T06 成绩排序
查找和排序 题目:输入任意(用户,成绩)序列,可以获得成绩从高到低或从低到高的排列,相同成绩 都按先录入排列在前的规则处理。 示例: jack 70 peter 96 Tom 70 smith 67 从高到低 成…...

【机器学习】Linear and Nonlinear Regression 线性/非线性回归讲解
文章目录一、回归问题概述二、误差项定义三、独立同分布的假设四、似然函数的作用五、参数求解六、梯度下降算法七、参数更新方法八、优化参数设置一、回归问题概述 回归:根据工资和年龄,预测额度为多少 其中,工资和年龄被称为特征࿰…...
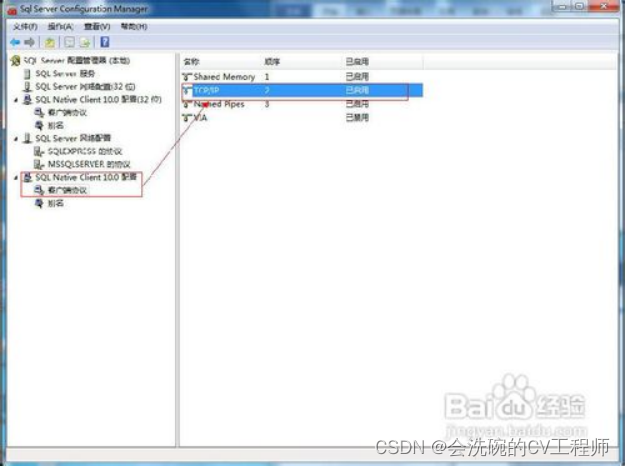
PyQt5数据库开发1 4.1 SQL Server 2008 R2如何开启数据库的远程连接
文章目录 前言 步骤/方法 1 使用windows身份登录 2 启用混合登录模式 3 允许远程连接服务器 4 设置sa用户属性 5 配置服务器 6 重新登录 7 配置SSCM 8 确认防火墙设置 注意事项 前言 SQL Server 2008 R2如何开启数据库的远程连接 SQL Server 2008默认是不允许远程连…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

Linux 内存管理实战精讲:核心原理与面试常考点全解析
Linux 内存管理实战精讲:核心原理与面试常考点全解析 Linux 内核内存管理是系统设计中最复杂但也最核心的模块之一。它不仅支撑着虚拟内存机制、物理内存分配、进程隔离与资源复用,还直接决定系统运行的性能与稳定性。无论你是嵌入式开发者、内核调试工…...

AirSim/Cosys-AirSim 游戏开发(四)外部固定位置监控相机
这个博客介绍了如何通过 settings.json 文件添加一个无人机外的 固定位置监控相机,因为在使用过程中发现 Airsim 对外部监控相机的描述模糊,而 Cosys-Airsim 在官方文档中没有提供外部监控相机设置,最后在源码示例中找到了,所以感…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...