Hadoop大数据应用:Linux 部署 HDFS 分布式集群
目录
一、实验
1.环境
2.Linux 部署 HDFS 分布式集群
3.Linux 使用 HDFS 文件系统
二、问题
1.ssh-copy-id 报错
2. 如何禁用ssh key 检测
3.HDFS有哪些配置文件
4.hadoop查看版本报错
5.启动集群报错
6.hadoop 的启动和停止命令
7.上传文件报错
8.HDFS 使用命令
一、实验
1.环境
(1)主机
表1 主机
| 主机 | 架构 | 软件 | 版本 | IP | 备注 |
| hadoop | NameNode SecondaryNameNode | hadoop | 2.7.7 | 192.168.204.50 | |
| node01 | DataNode | hadoop | 2.7.7 | 192.168.204.51 | |
| node02 | DataNode | hadoop | 2.7.7 | 192.168.204.52 | |
| node03 | DataNode | hadoop | 2.7.7 | 192.168.204.53 |
(2)安全机制
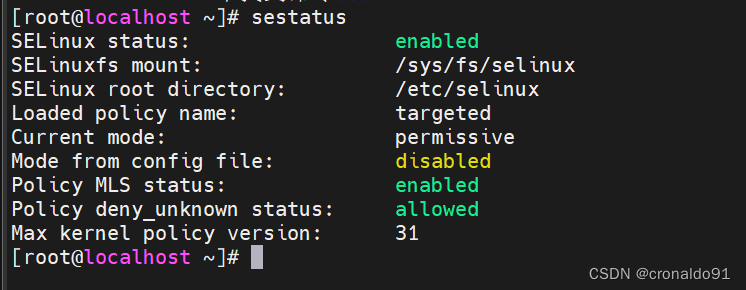
查看
[root@localhost ~]# sestatus
关闭
[root@localhost ~]# vim /etc/selinux/config
……
SELINUX=disabled
……

再次查看(需要reboot重启)
[root@localhost ~]# sestatus

(3)防火墙
关闭
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl mask firewalld

(4)安装java
[root@localhost ~]# yum install -y java-1.8.0-openjdk-devel.x86_64

查看
[root@localhost ~]# jps
hadoop

node01

node02

node03

(5)域名主机名
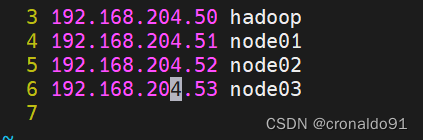
[root@localhost ~]# vim /etc/hosts
……
192.168.205.50 hadoop
192.168.205.51 node01
192.168.205.52 node02
192.168.205.53 node03
![]()
(6)修改主机名
[root@localhost ~]# hostnamectl set-hostname 主机名
[root@localhost ~]# bash




(7)hadoop节点创建密钥
[root@hadoop ~]# mkdir /root/.ssh
[root@hadoop ~]# cd /root/.ssh/
[root@hadoop .ssh]# ssh-keygen -t rsa -b 2048 -N ''

(8)添加免密登录
[root@hadoop .ssh]# ssh-copy-id -i id_rsa.pub hadoop[root@hadoop .ssh]# ssh-copy-id -i id_rsa.pub node01[root@hadoop .ssh]# ssh-copy-id -i id_rsa.pub node02[root@hadoop .ssh]# ssh-copy-id -i id_rsa.pub node03




2.Linux 部署 HDFS 分布式集群
(1)官网
https://hadoop.apache.org/查看版本
https://archive.apache.org/dist/hadoop/common/(2)下载
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
(3) 解压
tar -zxf hadoop-2.7.7.tar.gz
(3)移动
mv hadoop-2.7.7 /usr/local/hadoop
(4)更改权限
chown -R root.root hadoop

(5)验证版本
(需要修改环境配置文件hadoop-env.sh 申明JAVA安装路径和hadoop配置文件路径)
修改配置文件
[root@hadoop hadoop]# vim hadoop-env.sh



验证
[root@hadoop hadoop]# ./bin/hadoop version

(6)修改节点配置文件
[root@hadoop hadoop]# vim slaves

修改前:

修改后:
node01node02node03
(7)查看官方文档
https://hadoop.apache.org/docs/指定版本
https://hadoop.apache.org/docs/r2.7.7/
查看核心配置文件
https://hadoop.apache.org/docs/r2.7.7/hadoop-project-dist/hadoop-common/core-default.xml文件系统配置参数:

数据目录配置参数:

(8)修改核心配置文件
[root@hadoop hadoop]# vim core-site.xml
![]()
修改前:

修改后:
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop:9000</value><description>hdfs file system</description></property><property><name>hadoop.tmp.dir</name><value>/var/hadoop</value></property></configuration>

(9)查看HDFS配置文件
https://hadoop.apache.org/docs/r2.7.7/hadoop-project-dist/hadoop-hdfs/hdfs-default.xmlnamenode:

![]()
副本数量:

(10)修改HDFS配置文件
[root@hadoop hadoop]# vim hdfs-site.xml
![]()
修改前:

修改后:
<configuration><property><name>dfs.namenode.http-address</name><value>hadoop:50070</value><name>dfs.namenode.secondary.http-address</name><value>hadoop:50090</value><name>dfs.replication</name><value>2</value></property>
</configuration>

(11) 查看同步
[root@hadoop ~]# rpm -q rsync

同步
[root@hadoop ~]# rsync -aXSH --delete /usr/local/hadoop node01:/usr/local/
[root@hadoop ~]# rsync -aXSH --delete /usr/local/hadoop node02:/usr/local/
[root@hadoop ~]# rsync -aXSH --delete /usr/local/hadoop node03:/usr/local/

(12)初始化hdfs
[root@hadoop ~]# mkdir /var/hadoop

(13)查看命令
[root@hadoop hadoop]# ./bin/hdfs
Usage: hdfs [--config confdir] [--loglevel loglevel] COMMANDwhere COMMAND is one of:dfs run a filesystem command on the file systems supported in Hadoop.classpath prints the classpathnamenode -format format the DFS filesystemsecondarynamenode run the DFS secondary namenodenamenode run the DFS namenodejournalnode run the DFS journalnodezkfc run the ZK Failover Controller daemondatanode run a DFS datanodedfsadmin run a DFS admin clienthaadmin run a DFS HA admin clientfsck run a DFS filesystem checking utilitybalancer run a cluster balancing utilityjmxget get JMX exported values from NameNode or DataNode.mover run a utility to move block replicas acrossstorage typesoiv apply the offline fsimage viewer to an fsimageoiv_legacy apply the offline fsimage viewer to an legacy fsimageoev apply the offline edits viewer to an edits filefetchdt fetch a delegation token from the NameNodegetconf get config values from configurationgroups get the groups which users belong tosnapshotDiff diff two snapshots of a directory or diff thecurrent directory contents with a snapshotlsSnapshottableDir list all snapshottable dirs owned by the current userUse -help to see optionsportmap run a portmap servicenfs3 run an NFS version 3 gatewaycacheadmin configure the HDFS cachecrypto configure HDFS encryption zonesstoragepolicies list/get/set block storage policiesversion print the versionMost commands print help when invoked w/o parameters.

(14)格式化hdfs
[root@hadoop hadoop]# ./bin/hdfs namenode -format



查看目录
[root@hadoop hadoop]# cd /var/hadoop/
[root@hadoop hadoop]# tree .
.
└── dfs└── name└── current├── fsimage_0000000000000000000├── fsimage_0000000000000000000.md5├── seen_txid└── VERSION3 directories, 4 files

(15) 启动集群
查看目录
[root@hadoop hadoop]# cd ~
[root@hadoop ~]# cd /usr/local/hadoop/
[root@hadoop hadoop]# ls

启动
[root@hadoop hadoop]# ./sbin/start-dfs.sh

查看日志(新生成logs目录)
[root@hadoop hadoop]# cd logs/ ; ll

查看jps
[root@hadoop hadoop]# jps

datanode节点查看(node01)


datanode节点查看(node02)


datanode节点查看(node03)


(16)查看命令
[root@hadoop hadoop]# ./bin/hdfs dfsadmin
Usage: hdfs dfsadmin
Note: Administrative commands can only be run as the HDFS superuser.[-report [-live] [-dead] [-decommissioning]][-safemode <enter | leave | get | wait>][-saveNamespace][-rollEdits][-restoreFailedStorage true|false|check][-refreshNodes][-setQuota <quota> <dirname>...<dirname>][-clrQuota <dirname>...<dirname>][-setSpaceQuota <quota> [-storageType <storagetype>] <dirname>...<dirname>][-clrSpaceQuota [-storageType <storagetype>] <dirname>...<dirname>][-finalizeUpgrade][-rollingUpgrade [<query|prepare|finalize>]][-refreshServiceAcl][-refreshUserToGroupsMappings][-refreshSuperUserGroupsConfiguration][-refreshCallQueue][-refresh <host:ipc_port> <key> [arg1..argn][-reconfig <datanode|...> <host:ipc_port> <start|status>][-printTopology][-refreshNamenodes datanode_host:ipc_port][-deleteBlockPool datanode_host:ipc_port blockpoolId [force]][-setBalancerBandwidth <bandwidth in bytes per second>][-fetchImage <local directory>][-allowSnapshot <snapshotDir>][-disallowSnapshot <snapshotDir>][-shutdownDatanode <datanode_host:ipc_port> [upgrade]][-getDatanodeInfo <datanode_host:ipc_port>][-metasave filename][-triggerBlockReport [-incremental] <datanode_host:ipc_port>][-help [cmd]]Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.The general command line syntax is

(17)验证集群
查看报告,发现3个节点
[root@hadoop hadoop]# ./bin/hdfs dfsadmin -report
Configured Capacity: 616594919424 (574.25 GB)
Present Capacity: 598915952640 (557.78 GB)
DFS Remaining: 598915915776 (557.78 GB)
DFS Used: 36864 (36 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0-------------------------------------------------
Live datanodes (3):Name: 192.168.204.53:50010 (node03)
Hostname: node03
Decommission Status : Normal
Configured Capacity: 205531639808 (191.42 GB)
DFS Used: 12288 (12 KB)
Non DFS Used: 5620584448 (5.23 GB)
DFS Remaining: 199911043072 (186.18 GB)
DFS Used%: 0.00%
DFS Remaining%: 97.27%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Mar 14 10:30:18 CST 2024Name: 192.168.204.51:50010 (node01)
Hostname: node01
Decommission Status : Normal
Configured Capacity: 205531639808 (191.42 GB)
DFS Used: 12288 (12 KB)
Non DFS Used: 6028849152 (5.61 GB)
DFS Remaining: 199502778368 (185.80 GB)
DFS Used%: 0.00%
DFS Remaining%: 97.07%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Mar 14 10:30:18 CST 2024Name: 192.168.204.52:50010 (node02)
Hostname: node02
Decommission Status : Normal
Configured Capacity: 205531639808 (191.42 GB)
DFS Used: 12288 (12 KB)
Non DFS Used: 6029533184 (5.62 GB)
DFS Remaining: 199502094336 (185.80 GB)
DFS Used%: 0.00%
DFS Remaining%: 97.07%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Mar 14 10:30:18 CST 2024

(18)web页面验证
http://192.168.204.50:50070/
http://192.168.204.50:50090/
http://192.168.204.51:50075/
(19)访问系统

目前为空

3.Linux 使用 HDFS 文件系统
(1)查看命令
[root@hadoop hadoop]# ./bin/hadoop
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]CLASSNAME run the class named CLASSNAMEorwhere COMMAND is one of:fs run a generic filesystem user clientversion print the versionjar <jar> run a jar filenote: please use "yarn jar" to launchYARN applications, not this command.checknative [-a|-h] check native hadoop and compression libraries availabilitydistcp <srcurl> <desturl> copy file or directories recursivelyarchive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archiveclasspath prints the class path needed to get thecredential interact with credential providersHadoop jar and the required librariesdaemonlog get/set the log level for each daemontrace view and modify Hadoop tracing settingsMost commands print help when invoked w/o parameters.

[root@hadoop hadoop]# ./bin/hadoop fs
Usage: hadoop fs [generic options][-appendToFile <localsrc> ... <dst>][-cat [-ignoreCrc] <src> ...][-checksum <src> ...][-chgrp [-R] GROUP PATH...][-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...][-chown [-R] [OWNER][:[GROUP]] PATH...][-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>][-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-count [-q] [-h] <path> ...][-cp [-f] [-p | -p[topax]] <src> ... <dst>][-createSnapshot <snapshotDir> [<snapshotName>]][-deleteSnapshot <snapshotDir> <snapshotName>][-df [-h] [<path> ...]][-du [-s] [-h] <path> ...][-expunge][-find <path> ... <expression> ...][-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-getfacl [-R] <path>][-getfattr [-R] {-n name | -d} [-e en] <path>][-getmerge [-nl] <src> <localdst>][-help [cmd ...]][-ls [-d] [-h] [-R] [<path> ...]][-mkdir [-p] <path> ...][-moveFromLocal <localsrc> ... <dst>][-moveToLocal <src> <localdst>][-mv <src> ... <dst>][-put [-f] [-p] [-l] <localsrc> ... <dst>][-renameSnapshot <snapshotDir> <oldName> <newName>][-rm [-f] [-r|-R] [-skipTrash] <src> ...][-rmdir [--ignore-fail-on-non-empty] <dir> ...][-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]][-setfattr {-n name [-v value] | -x name} <path>][-setrep [-R] [-w] <rep> <path> ...][-stat [format] <path> ...][-tail [-f] <file>][-test -[defsz] <path>][-text [-ignoreCrc] <src> ...][-touchz <path> ...][-truncate [-w] <length> <path> ...][-usage [cmd ...]]Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]

(2)查看文件目录
[root@hadoop hadoop]# ./bin/hadoop fs -ls /

(3)创建文件夹
[root@hadoop hadoop]# ./bin/hadoop fs -mkdir /devops

查看

查看web

(4)上传文件
[root@hadoop hadoop]# ./bin/hadoop fs -put *.txt /devops/

查看
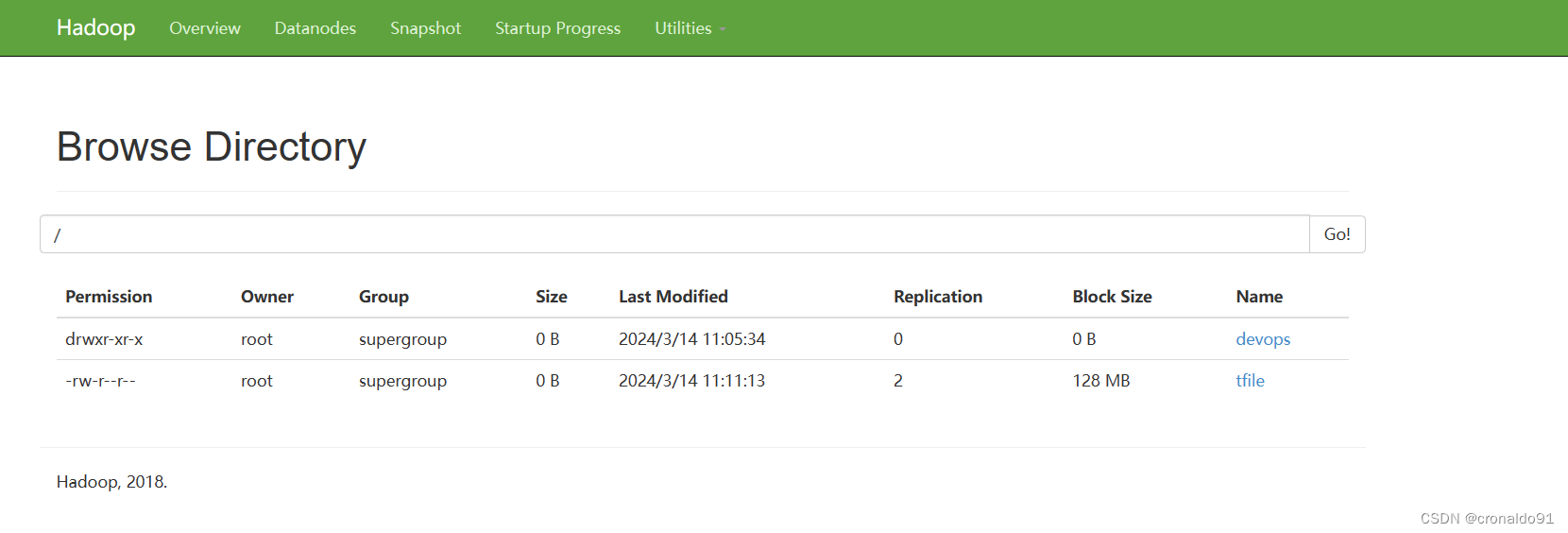
[root@hadoop hadoop]# ./bin/hadoop fs -ls /devops/

查看web
Permission Owner Group Size Last Modified Replication Block Size Name
-rw-r--r-- root supergroup 84.4 KB 2024/3/14 11:05:33 2 128 MB LICENSE.txt
-rw-r--r-- root supergroup 14.63 KB 2024/3/14 11:05:34 2 128 MB NOTICE.txt
-rw-r--r-- root supergroup 1.33 KB 2024/3/14 11:05:34 2 128 MB README.txt
下载

(5)创建文件
[root@hadoop hadoop]# ./bin/hadoop fs -touchz /tfile
![]()
查看
[root@hadoop hadoop]# ./bin/hadoop fs -ls /

(5)下载文件
[root@hadoop hadoop]# ./bin/hadoop fs -get /tfile /tmp/
![]()
查看
[root@hadoop hadoop]# ls -l /tmp/ | grep tfile

查看web
(6) 查看命令比较
之前的设置
![]()
所以查看功能相同
[root@hadoop hadoop]# ./bin/hadoop fs -ls /[root@hadoop hadoop]# ./bin/hadoop fs -ls hdfs://hadoop:9000/

另外官网默认是file ,使用的是本地文件目录
[root@hadoop hadoop]# ./bin/hadoop fs -ls file:///

二、问题
1.ssh-copy-id 报错
(1)报错
/usr/bin/ssh-copy-id: ERROR: ssh: connect to host hadoop port 22: Connection refused

(2)原因分析
主机解析错误。
(3)解决方法
修改前:

修改后:
成功:
2. 如何禁用ssh key 检测
(1)修改配置文件
[root@hadoop .ssh]# vim /etc/ssh/ssh_config
![]()
添加配置
StrictHostKeyChecking no

成功:

3.HDFS有哪些配置文件
(1)配置文件
1)环境配置文件
hadoop-env.sh2)核心配置文件
core-site.xml3)HDFS配置文件
hdfs-site.xml4)节点配置文件
slaves4.hadoop查看版本报错
(1) 报错

(2)原因分析
未申明JAVA环境。
(3)解决方法
申明JAVA环境。
查看
rpm -ql java-1.8.0-openjdk
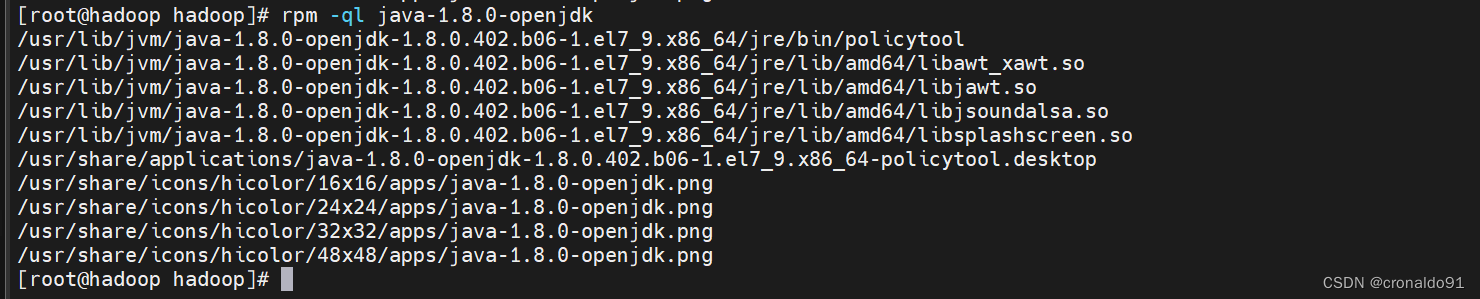
确定JAVA环境
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.402.b06-1.el7_9.x86_64/jre确定配置路径
/usr/local/hadoop/etc/hadoop修改配置文件
[root@hadoop hadoop]# vim hadoop-env.sh
修改前:


修改后:
成功:
[root@hadoop hadoop]# ./bin/hadoop version
5.启动集群报错
(1)报错
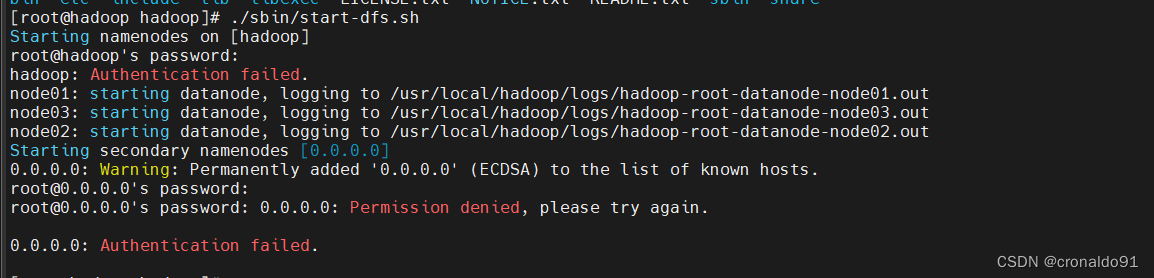
(2)原因分析
ssh-copy-id 未对本地主机验证。
(3)解决方法
ssh-copy-id 对本地主机验证。
[root@hadoop hadoop]# ssh-copy-id hadoop

如继续报错

需要停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
[root@hadoop hadoop]# ./sbin/stop-dfs.sh
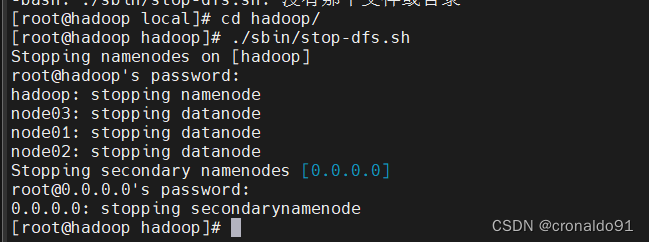
再次启动

6.hadoop 的启动和停止命令
(1)命令
sbin/start-all.sh 启动所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager
sbin/stop-all.sh 停止所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager
sbin/start-dfs.sh 启动Hadoop HDFS守护进程NameNode、SecondaryNameNode、DataNode
sbin/stop-dfs.sh 停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
sbin/hadoop-daemons.sh start namenode 单独启动NameNode守护进程
sbin/hadoop-daemons.sh stop namenode 单独停止NameNode守护进程
sbin/hadoop-daemons.sh start datanode 单独启动DataNode守护进程
sbin/hadoop-daemons.sh stop datanode 单独停止DataNode守护进程
sbin/hadoop-daemons.sh start secondarynamenode 单独启动SecondaryNameNode守护进程
sbin/hadoop-daemons.sh stop secondarynamenode 单独停止SecondaryNameNode守护进程
sbin/start-yarn.sh 启动ResourceManager、NodeManager
sbin/stop-yarn.sh 停止ResourceManager、NodeManager
sbin/yarn-daemon.sh start resourcemanager 单独启动ResourceManager
sbin/yarn-daemons.sh start nodemanager 单独启动NodeManager
sbin/yarn-daemon.sh stop resourcemanager 单独停止ResourceManager
sbin/yarn-daemons.sh stopnodemanager 单独停止NodeManager
sbin/mr-jobhistory-daemon.sh start historyserver 手动启动jobhistory
sbin/mr-jobhistory-daemon.sh stop historyserver 手动停止jobhistory7.上传文件报错
(1)报错

(2)原因分析
命令错误
(3)解决方法
使用正确命令
[root@hadoop hadoop]# ./bin/hadoop fs -put *.txt /devops/
8.HDFS 使用命令
(1)命令
ls 查看文件或目录cat 查看文件内容put 上传get 下载相关文章:
Hadoop大数据应用:Linux 部署 HDFS 分布式集群
目录 一、实验 1.环境 2.Linux 部署 HDFS 分布式集群 3.Linux 使用 HDFS 文件系统 二、问题 1.ssh-copy-id 报错 2. 如何禁用ssh key 检测 3.HDFS有哪些配置文件 4.hadoop查看版本报错 5.启动集群报错 6.hadoop 的启动和停止命令 7.上传文件报错 8.HDFS 使用命令 一…...

纯 CSS 实现文字换行环绕效果
实现效果 实现代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>Document</title><…...
【爬虫逆向】Python逆向采集猫眼电影票房数据
进行数据抓包,因为这个网站有数据加密 !pip install jsonpathCollecting jsonpathDownloading jsonpath-0.82.2.tar.gz (10 kB)Preparing metadata (setup.py) ... done Building wheels for collected packages: jsonpathBuilding wheel for jsonpath (setup.py) .…...

解析服务器下载速度:上行、下行与带宽之谜
在日常使用中,我们经常会遇到从服务器下载内容速度忽快忽慢的情况,即便服务器的硬件配置如4核CPU、8GB内存和12Mbps的带宽看似足够。为何会出现这种现象?这背后涉及到网络中的上行、下行以及带宽等关键概念。本文旨在揭开这些术语背后的含义&…...

计算机网络的概念
目录 <计算机网络的定义> <计算机网络的形成与发展> 1.第一阶段远程联机阶段----60年代以前: 2.第二阶段多机互联网络阶段----60年代中期: 3.第三阶段标准化网络阶段----70年代末: 4.第四阶段网络互联与高速网络阶段一90年代: <计算机网络的未来--下一代…...

MATLAB中的脚本和函数有什么区别?
MATLAB中的脚本和函数是两种不同的代码组织方式,它们在结构、功能和使用方式上有显著的区别。以下是对这两种方式的详细解释,总计约2000字。 一、MATLAB脚本 MATLAB脚本是一种包含多条MATLAB命令的文件,这些命令按照在文件中的顺序依次执行…...

从电影《沙丘》说起——对人工智能的思考
正文 从《沙丘》开始说起 之前看《沙丘》电影,里面有一类角色叫门泰特,这类人大脑可以飞快地运算,在电影设定里是替换人工智能、机器运算的存在。男主保罗也是这类型的人,但他可能基因更强大,吸食了香料后࿰…...

使用Python进行自然语言处理(NLP):NLTK与Spacy的比较【第133篇—NLTK与Spacy】
👽发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。 使用Python进行自然语言处理(NLP):NLTK与Spacy的比较 自…...
)
学习笔记--在线强化学习与离线强化学习的异同(3)
这篇博文很多部分仅代表个人学习观点,欢迎大家与我一起讨论 强化学习与离线强化学习的区别 强化学习和离线强化学习都是机器学习的分支,主要用于训练智能体以在不断尝试和错误的过程中学习如何最大化累积奖励。它们之间的主要区别在于数据的获取方式和训…...

使用Thymeleaf导出PDF,页眉插入图片与内容重叠?
CSS 打印分页功能 需求:打印 在第一页的内容被挤到第二页的时候,又想每一页页头都有相同的样式,使用页眉。 问题:第二页的内容与页眉重叠了? 查各路找出的原因:header 页眉不占空间 解决:不…...

python网络编程:通过socket实现TCP客户端和服务端
目录 写在开头 socket服务端(基础) socket客户端(基础) 服务端实现(可连接多个客户端) 客户端实现 数据收发效果 写在开头 近期可能会用python实现一些网络安全工具,涉及到许多关于网络…...

论文阅读——RSGPT
RSGPT: A Remote Sensing Vision Language Model and Benchmark 贡献:构建了一个高质量的遥感图像描述数据集(RSICap)和一个名为RSIEval的基准评估数据集,并在新创建的RSICap数据集上开发了基于微调InstructBLIP的遥感生成预训练…...

长连接技术
个人学习记录,欢迎指正 1.轮询 1.1 轮询的形式 短连接轮询 前端每隔一段时间向服务端发起一次Http请求来获取数据。 const shortPolling () > { const intervalHandler setInterval(() > {fetch(/xxx/yyy).then(response > response.json()).then(respo…...

供电系统分类详解
一、供电系统分类 电力供电系统一般有5种供电模式,常用的有:IT系统,TT系统,TN系统,其中TN系统又可以分为TN-C,TN-S,TN-C-S。 1、TN-C系统(三相四线制) 优点: 该系统中…...
基于centos7的k8s最新版v1.29.2安装教程
k8s概述 Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快速增长的生态,其服务、支持和工具的使用范围相当广泛。 Kubernetes 这个名字源于希腊语&…...

【赠书第20期】AI绘画与修图实战:Photoshop+Firefly从入门到精通
文章目录 前言 1 入门篇:初识Photoshop与Firefly 2 进阶篇:掌握Photoshop与Firefly的核心技巧 3 实战篇:运用Photoshop与Firefly进行创作 4 精通篇:提升创作水平,拓展应用领域 5 结语 6 推荐图书 7 粉丝福利 前…...

如何在并行超算云上玩转PWmat③:使用Q-Flow提交计算的案例演示
3月的每周二下午14:00我们将会在并行直播间为大家持续带来线上讲座。前面两期我们分享了”PWmat特色功能和应用“以及“如何在并行超算云平台使用PWmat计算软件”主题讲座,回看视频和PPT已上传至B站”龙讯旷腾“账号内。 本周张持讲师将继续带着大家手把手上机教学…...

html5cssjs代码 017样式示例
html5&css&js代码 017样式示例 一、代码二、解释 这段HTML代码定义了一个网页的基本结构,包括头部、主体和尾部。在头部中,设置了网页标题、字符编码和样式。主体部分包含一个标题和一个表格,表格内分为两个单元格,左侧为…...

Vue.js动画
Vue.js动画 Vue.js动画是指在Vue组件中通过添加/移除CSS类或应用CSS过渡/动画效果来实现的视觉效果。这些动画可以帮助改善用户体验,使界面更加生动和吸引人。 Vue.js提供了两种类型的动画:过渡和动画。 过渡:过渡是在元素插入、更新或删除…...

信号与系统学习笔记——信号的分类
目录 一、确定与随机 二、连续与离散 三、周期与非周期 判断是否为周期函数 离散信号的周期 结论 四、能量与功率 定义 结论 五、因果与反因果 六、阶跃函数 定义 性质 七、冲激函数 定义 重要关系 作用 一、确定与随机 确定信号:可以确定时间函数…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...
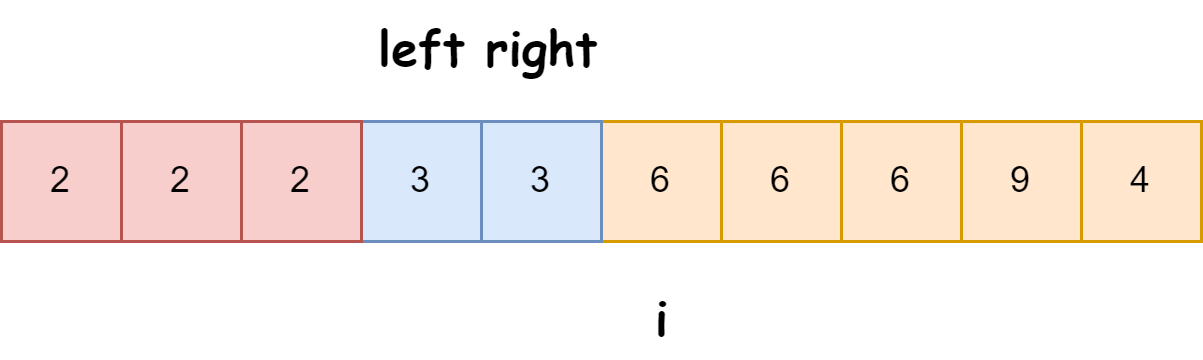
快速排序算法改进:随机快排-荷兰国旗划分详解
随机快速排序-荷兰国旗划分算法详解 一、基础知识回顾1.1 快速排序简介1.2 荷兰国旗问题 二、随机快排 - 荷兰国旗划分原理2.1 随机化枢轴选择2.2 荷兰国旗划分过程2.3 结合随机快排与荷兰国旗划分 三、代码实现3.1 Python实现3.2 Java实现3.3 C实现 四、性能分析4.1 时间复杂度…...
Spring AOP代理对象生成原理
代理对象生成的关键类是【AnnotationAwareAspectJAutoProxyCreator】,这个类继承了【BeanPostProcessor】是一个后置处理器 在bean对象生命周期中初始化时执行【org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization】方法时…...
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡 背景 我们以建设星云智控官网来做AI编程实践,很多人以为AI已经强大到不需要程序员了,其实不是,AI更加需要程序员,普通人…...

命令行关闭Windows防火墙
命令行关闭Windows防火墙 引言一、防火墙:被低估的"智能安检员"二、优先尝试!90%问题无需关闭防火墙方案1:程序白名单(解决软件误拦截)方案2:开放特定端口(解决网游/开发端口不通)三、命令行极速关闭方案方法一:PowerShell(推荐Win10/11)方法二:CMD命令…...