buffer它到底做了个啥,源码级分析linux内核的文件系统的缓冲区
最近一直在学习linux内核源码,总结一下
https://github.com/xiaozhang8tuo/linux-kernel-0.11 自己整理过的带注释的源码。
为什么要有buffer
高速缓冲区是文件系统访问块设备中数据的必经要道(PS:如果所有程序结果都不落盘,只是int a, a++直接在主存中搞事情,就不需要缓冲了,即使如此加载程序还是要读取文件系统的)。为了访问文件系统等块设备上的数据,内核可以每次都访问块设备,进行读或写操作。但是每次/O操作的时间与内存和CPU的处理速度相比是非常慢的。为了提高系统的性能,内核就在内存中开辟了一个高速数据冲区(池)(buffer cache),并将其划分成一个个与磁盘数据块大小相等的缓冲块来使用和管理,以期减少访问块设备的次数。
在linux内核中,高速缓冲区位于内核代码和主内存区之间。高速缓冲中存放着最近被使用过的各个块设备中的数据块。当需要从块设备中读取数据时,缓冲区管理程序首先会在高速缓冲中寻找。如果相应数据已经在缓冲中,就无需再从块设备上读。如果数据不在高速缓冲中,就发出读块设备的命令,将数据读到高速缓冲中。当需要把数据写到块设备中时,系统就会在高速缓冲区中申请一块空闲的缓冲块来临时存放这些数据。至于什么时候把数据真正地写到设备中去,则是通过设备数据同步实现的。Linux内核实现高速缓冲区的程序是buffer.c。文件系统中其他程序通过指定需要访问的设备号和数据逻辑块号来调用它的块读写函数。这些接口函数有:块读取函数bread、块提前预读函数breada和页块读取函数bread_page(全是b开头的函数,从buffer中读设备的block)。页块读取函数一次读取一页内存所能容纳的缓冲块数(4块)。
buffer在哪
main函数,mem_init ,初始化mem_map,buffer_init中初始化缓冲区
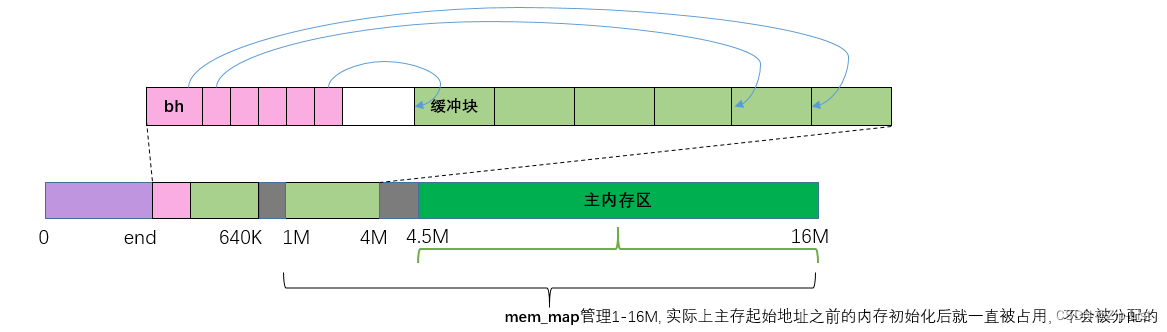
// 缓冲区初始化函数。
// 参数buffer_end是缓冲区内存末端。对于具有16MB内存的系统,缓冲区末瑞被设置为4MB.
// 对于有8MB内存的系统,缓冲区末瑞被设置为2MB。该函数从缓冲区开始位置start_buffer
// 处和缓冲区未端buffer_end处分别同时设置(初始化)缓冲块头结构和对应的数据块。直到
// 缓冲区中所有内存被分配完毕。参见程序列表前面的示意图。
void buffer_init(long buffer_end)
{struct buffer_head * h = start_buffer;void * b;int i;// 首先根据参数提供的缓冲区高端位置确定实际缓冲区高端位置b。如果缓冲区高端等于1Mb,// 则因为从640KB一1MB被显示内存和BIOS占用,所以实际可用缓冲区内存高端位置应该是// 640KB。否则缓冲区内存高端一定大于1MB。if (buffer_end == 1<<20)b = (void *) (640*1024);elseb = (void *) buffer_end;// 这段代码用于初始化缓冲区,建立空闲缓冲块循环链表,并获取系统中缓冲块数目。操作的// 过程是从缓冲区高瑞开始划分1KB大小的缓冲块,与此同时在缓冲区低端建立描述该缓冲块// 的结构buffer_head,并将这些buffer_head组成双向链表,// h是指向缓冲头结构的指针,而h+1是指向内存地址连续的下一个缓冲头地址,可以说是// 指向h缓冲头的末瑞外。为了保证有足够长度的内存来存储一个缓冲头结构,需要b所指向// 的内存块地址>=h缓冲头的末端,即要求>=h+1。// ------------------------------------------------------// ↑ (640KB)↑--------↑(1MB) ↑// start_buffer BIOS + 显存 buffer_endwhile ( (b -= BLOCK_SIZE) >= ((void *) (h+1)) ) { // 尽可能多的分配直到block不够了/buffer_head不够了(两者相交)h->b_dev = 0; // 使用该缓冲块的设备号h->b_dirt = 0; // 脏标志,缓冲修改标志h->b_count = 0; // 缓冲块引用计数h->b_lock = 0; // 缓冲块锁定标志h->b_uptodate = 0; // 缓冲块更新标志(或称有效标志)h->b_wait = NULL; // 指向等待该缓冲块解锁的进程。h->b_next = NULL; // 指向具有相同hash值的下一个缓冲头。h->b_prev = NULL; // 指向具有相同hash值的前一个缓冲头。h->b_data = (char *) b; // 指向对应缓冲块数据块(1024字节)。h->b_prev_free = h-1; // 指向链表中前一项。h->b_next_free = h+1; // 指向链表中下一项。h++;NR_BUFFERS++;if (b == (void *) 0x100000) // 若b递减到等于1MB,则跳过384KBb = (void *) 0xA0000; // 让b指向640KB}h--; //让h指向最后一个有效缓冲块头。 free_list = start_buffer; //让空闲链表头指向头一个缓冲块。free_list->b_prev_free = h; //链表头的b_prev_free指向前一项(即最后一项)。h->b_next_free = free_list; //h的下一项指针指向第一项,形成一个环链.// 初始化hash表(哈希表,散列数组),置表中所有指针为NULLfor (i=0;i<NR_HASH;i++)hash_table[i]=NULL;
}
buffer结构
struct buffer_head {char * b_data; /* pointer to data block (1024 bytes) */ // 指向该缓冲块中数据区(1024字节)的指针unsigned long b_blocknr; /* block number */ // 块号unsigned short b_dev; /* device (0 = free) */ // 数据源的设备号(0=free)unsigned char b_uptodate; // 更新标志,表示数据是否已经更新unsigned char b_dirt; /* 0-clean,1-dirty */ // 修改标志: 0-未修改(clean) 1-已修改(dirty)unsigned char b_count; /* users using this block */ // 使用该块的用户数unsigned char b_lock; /* 0 - ok, 1 -locked */ // 缓冲区是否被锁定 0-ok 1-lockedstruct task_struct * b_wait; // 指向等待该缓冲区解锁的任务struct buffer_head * b_prev; // buffer hash队列的前一块struct buffer_head * b_next; // buffer hash队列的后一块struct buffer_head * b_prev_free; // 空闲列表的前一块struct buffer_head * b_next_free; // 空闲列表的下一块
};// 变量end是由编译时的连接程序ld生成,用于表明内核代码的末端,即指明内核模块末端
// 位置。也可以从编译内核时生成的System.map文件中查出。这里用它来表明高速缓冲区开始于内核代码末瑞位置。
// buffer_wait变量是等待空闲缓冲块而睡眠的任务队列头指针。它与缓冲块头
// 部结构中b_wait指针的作用不同。当任务申请一个缓冲块而正好遇到系统缺乏可用空闲缓
// 冲块时,当前任务就会被添加到buffer_wait睡眠等待队列中。而b_wait则是专门供等待
// 指定缓冲块(即b_wait对应的缓冲块)的任务使用的等待队列头指针。
extern int end;
struct buffer_head * start_buffer = (struct buffer_head *) &end;
struct buffer_head * hash_table[NR_HASH];
static struct buffer_head * free_list; //空闲缓冲块链表头指针
static struct task_struct * buffer_wait = NULL; //等待空闲缓冲块而睡眠的任务队列
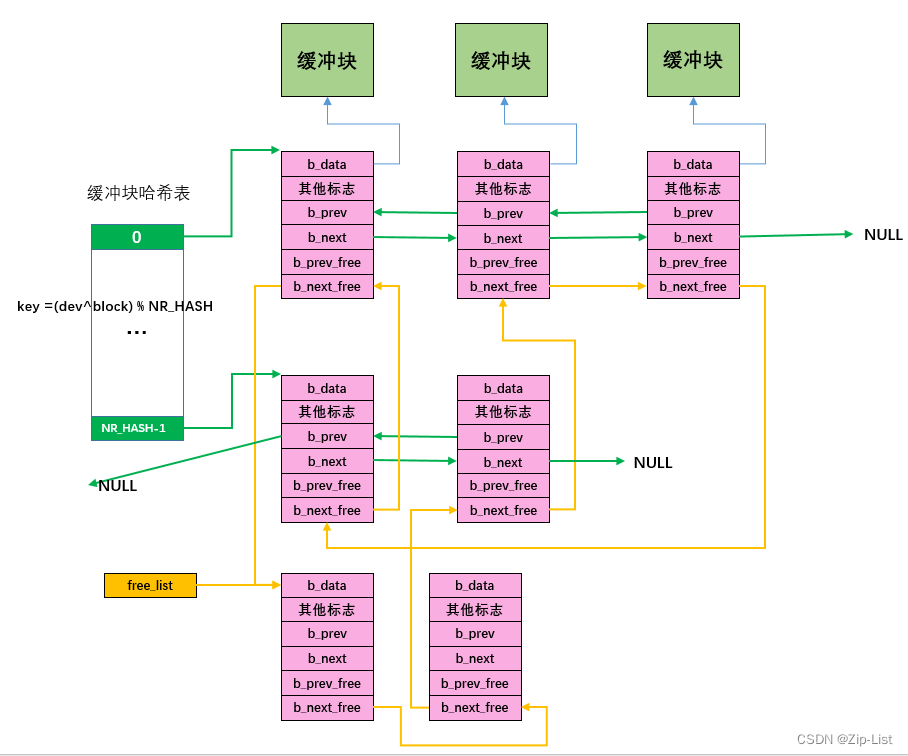
buffer
|bread, breada, bread_page || getblk | brelse || get_hash_table/find_buffer | |
缓冲块的获取和释放
remove_from_queues和insert_into_queues操作,hash_table o(1) 访问,free_listo(1) 添加/删除,其中free_list插入是尾插,LRU的思想。
find_buffer和get_hash_table 是哈希表中的find和get,其中get_hash_table成功后会让b_count++
getblk
返回值不为NULL时,能确定的是表项肯定在hash表中了,但是有没有dev,block的数据不一定,要看uptodate字段的值。没更新的话需要调缓冲块的读取函数
// 取高速缓冲中指定的缓冲块。
// 检查指定(设备号和块号)的缓冲区是否已经在高速缓冲中。如果指定块已经在高速缓冲中
// 则返回对应缓冲区头指针退出:如果不在,就需要在高速缓中中设置一个对应设备号和块号的
// 新项。返回相应缓冲区头指针。
struct buffer_head * getblk(int dev,int block)
{struct buffer_head * tmp, * bh;repeat:// 搜索hash表,如果指定块已经在高速缓冲中,则返回对应缓冲区头指针,退出。if (bh = get_hash_table(dev,block))return bh;// 扫描空闲数据块链表,寻找空闲缓冲区。// 首先让tmp指向空闲链表的第一个空闲缓冲区头。tmp = free_list;do {// 如果该缓冲区正被使用(引用计数不等于0),则继续扫描下一项。对于b_count=0的块,// 即高速缓冲中当前没有引用的块不一定就是干净的(b_dirt=0)或没有锁定的(b_lock=0)。// 因此,我们还是需要继续下面的判断和选择。例如当一个任务改写过一块内容后就释放了,// 于是该块b_count=0,但b_lock不等于0:当一个任务执行breada()预读几个块时,只要// ll_rw_block()命令发出后,它就会递减b_count:但此时实际上硬盘访问操作可能还在进行,// 因此此时b_lock=1,但b_count=0.if (tmp->b_count)continue;// 如果缓冲头指针bh为空,或者tmp所指缓冲头的标志(修改、锁定)权重小于bh头标志的权// 重,则让bh指向tmp缓冲块头。如果该tmp缓冲块头表明缓冲块既没有修改也没有锁定标// 志置位,则说明已为指定设备上的块取得对应的高速缓冲块,则退出循环。否则我们就继续// 执行本循环,看看能否找到一个BADNESS最小的缓冲快。if (!bh || BADNESS(tmp)<BADNESS(bh)) {bh = tmp;if (!BADNESS(tmp))break;}
/* and repeat until we find something good */} while ((tmp = tmp->b_next_free) != free_list);// 如果循环检查发现所有缓冲块都正在被使用(所有缓冲块的头部引用计数都>0)中,则睡服// 等待有空闲缓冲块可用。当有空闲缓冲块可用时本进程会被明确地唤醒。然后我们就跳转到// 函数开始处重新查找空闲缓冲块。if (!bh) {sleep_on(&buffer_wait);goto repeat;}// 执行到这里,说明我们已经找到了一个比较适合的空闲缓冲块了。于是先等待该缓冲区解锁// (如果已被上锁的话)。如果在我们睡眠阶段该缓冲区又被其他任务使用的话,只好重复上述寻找过程。wait_on_buffer(bh);if (bh->b_count)goto repeat;// 如果该缓冲区已被修改,则将数据写盘,并再次等待缓冲区解锁。同样地,若该缓冲区又被// 其他任务使用的话,只好再重复上述寻找过程。while (bh->b_dirt) {sync_dev(bh->b_dev);wait_on_buffer(bh);if (bh->b_count)goto repeat;}// 注意!!当进程为了等待该缓冲块而睡眠时,其他进程可能已经将该缓冲块加入进高速缓冲中,所以我们也要对此进行检查。// 在高速缓冲ash表中检查指定设备和块的缓冲块是否乘我们睡眠之即已经被加入进去。如果是的话,就再次重复上述寻找过程。if (find_buffer(dev,block))goto repeat;// 该缓冲块是指定参数的唯一一块,而且目前还没有被占用// (b_count=0),也未被上锁(b_lock=0),并且是干净的(b_dirt=0)// 占用此缓冲块。置引用计数为1,复位修改标志和有效(更新)标志。bh->b_count=1;bh->b_dirt=0;bh->b_uptodate=0;// 从hash队列和空闲块链表中移出该缓冲区头,让该缓冲区用于指定设备和其上的指定块.// 然后根据此新的设备号和块号重新插入空闲链表和hash队列新位置处。并最终返回缓冲头指针。remove_from_queues(bh);bh->b_dev=dev;bh->b_blocknr=block;insert_into_queues(bh); //LRUreturn bh;
}
brelse
// 释放指定缓冲块
// 等待该缓冲块解锁。引用计数-1,并明确的唤醒等待空闲缓冲块的进程
void brelse(struct buffer_head * buf)
{if (!buf)return;wait_on_buffer(buf);if (!(buf->b_count--))panic("Trying to free free buffer");wake_up(&buffer_wait);
}
缓冲块的读取
bread
b_uptodate,表明数据是否是最新的,只要bread返回的数据不是NULL,那它一定是最新的
/*
从设备上读取指定的数据块并返回含有数据的缓冲区。如果指定的块不存在
则返回NULL。*/
// 从设备上读取数据块。
// 该函数根据指定的设备号dev和数据块号block,首先在高速缓冲区中申请一块缓冲块。
// 如果该缓冲块中已经包含有有效的数据就直接返回该缓冲块指针,否则就从设备中读取
// 指定的数据块到该缓冲块中并返回缓冲块指针。
struct buffer_head * bread(int dev,int block)
{struct buffer_head * bh;// 在高速缓冲区中申请一块缓冲块。如果返回值是NULL,则表示内核出错,停机。然后我们// 判断其中是否已有可用数据。如果该缓冲块中数据是有效的(己更新的)可以直接使用,// 则返回。if (!(bh=getblk(dev,block)))panic("bread: getblk returned NULL\n");if (bh->b_uptodate)return bh;// 否则我们就调用底层块设备读写ll_rw_block函数,产生读设备块请求。然后等待指定// 数据块被读入,并等待缓冲区解锁。在睡眠醒来之后,如果该缓冲区已更新,则返回缓冲// 区头指针,退出。否则表明读设备操作失败,于是释放该缓冲区,返回NULL,退出。ll_rw_block(READ,bh);wait_on_buffer(bh);if (bh->b_uptodate)return bh;brelse(bh);return NULL;
}
bread_page
把dev的blocks数据通过buffer读到address物理地址处
1 缓冲区中先确保有数据,没有就去读
2 把buffer中的数据拷贝到物理地址处,释放buffer,因为已经放入了进程自己的物理地址中备份,buffer可以释放了
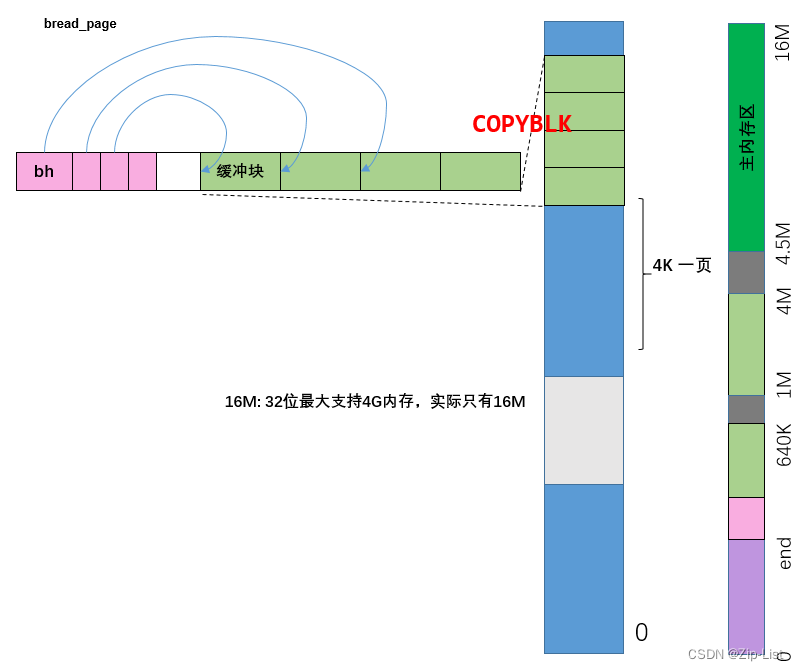
// bread_page一次读四个缓冲块数据读到内存指定的地址处。它是一个完整的函数
// 因为同时读取四块可以获得速度上的好处,不用等着读一块,再读一块了。
// 读设备上一个页面(4个缓冲块)的内容到指定内存地址处:
// 参数address是保存页面数据的地址:dev是指定的设备号:b[4]是含有4个设备数据块号
// 的数组。该函数仅用于mm/memory.c文件的do_no_page函数中(第386行)。
void bread_page(unsigned long address,int dev,int b[4])
{struct buffer_head * bh[4];int i;// 该函数循环执行4次,根据放在数组b[]中的4个块号从设备dev中读取一页内容放到指定// 内存位置address处。对于参数b[i]给出的有效块号,函数首先从高速缓冲中取指定设备// 和块号的缓冲块。如果缓冲块中数据无效(未更新)则产生读设备请求从设备上读取相应数// 据块。对于b[i]无效的块号则不用去理它了。因此本函数其实可以根据指定的b[]中的块号// 随意读取1一4个数据块。for (i=0 ; i<4 ; i++)if (b[i]) {if (bh[i] = getblk(dev,b[i]))if (!bh[i]->b_uptodate)ll_rw_block(READ,bh[i]);} elsebh[i] = NULL;// 随后将4个缓冲块上的内容顶序复制到指定地址处。在进行复削(使用)缓冲块之前我们// 先要睡眠等待缓冲块解锁(若被上锁的话)。另外,因为可能睡眠过了,所以我们还需要// 在复制之前再检查一下缓冲块中的数据是否是有效的。复制完后我们还需要释放缓冲块。for (i=0 ; i<4 ; i++,address += BLOCK_SIZE)if (bh[i]) {wait_on_buffer(bh[i]);if (bh[i]->b_uptodate)COPYBLK( (unsigned long)bh[i]->b_data, address );brelse(bh[i]);}
}
breada
传入的第一块数据肯定是要读的,预读随后的数据块,只需读进高速缓冲区但并不是马上就使用,tmp->b_count–,目的是发起尽量少的IO。
// 从指定设备读取指定的一些块。函数参数个数可变,是一系列指定的块号。成功时返回第1块的缓冲块头指针,否则返回NULL
struct buffer_head * breada(int dev,int first, ...)
{va_list args;struct buffer_head * bh, *tmp;// 首先取可变参数表中第1个参数(块号)。接着从高速缓冲区中取指定设备和块号的缓冲// 块。如果该缓冲块数据无效(更新标志未置位),则发出读设备数据块请求。va_start(args,first);if (!(bh=getblk(dev,first)))panic("bread: getblk returned NULL\n");if (!bh->b_uptodate)ll_rw_block(READ,bh);// 然后顺序取可变参数表中其他预读块号,并作与上面同样处理,但不引用。注意,483行上// 有一个bug。其中的bh应该是tmp。这个bug直到在0.96版的内核代码中才被纠正过来。// 因为这里是预读随后的数据块,只需读进高速缓冲区但并不是马上就使用,所以第484行语// 句需要将其引用计数递减释放掉该块(因为getblk函数会增加引用计数值)。while ((first=va_arg(args,int))>=0) {tmp=getblk(dev,first);if (tmp) {if (!tmp->b_uptodate)ll_rw_block(READA,bh);tmp->b_count--; //暂时释放该预读块}}// 此时可变参数表中所有参数处理完毕。于是等待第1个缓冲区解锁(如果已被上锁)。在等// 待退出之后如果缓冲区中数据仍然有效,则返回缓冲区头指针退出。否则释放该缓冲区返回NULL,退出。va_end(args);wait_on_buffer(bh);if (bh->b_uptodate)return bh;brelse(bh);return (NULL);
}
总结
- buffer的目的,设计的思想,减少IO
- buffer的管理,hash表+双链表,淘汰策略LRU
- buffer中
uptodate,dirt来控制是否发起IO读写,lock(只在lock_buffer中上锁,做保护),count有无引用作为分配空闲buffer的依据
相关文章:
buffer它到底做了个啥,源码级分析linux内核的文件系统的缓冲区
最近一直在学习linux内核源码,总结一下 https://github.com/xiaozhang8tuo/linux-kernel-0.11 自己整理过的带注释的源码。 为什么要有buffer 高速缓冲区是文件系统访问块设备中数据的必经要道(PS:如果所有程序结果都不落盘,只是int a, a直接在主存…...

【蓝桥杯刷题】盗版Huybery系列之手抓饼赛马
【蓝桥杯刷题】—— 盗版Huybery系列之手抓饼赛马😎😎😎 目录 💡前言🌞: 💛盗版Huybery系列之手抓饼赛马题目💛 💪 解题思路的分享💪 😊题…...

【微信小程序-原生开发】实用教程16 - 查看详情(含页面跳转的传参方法--简单传参 vs 复杂传参)
需在实现列表的基础上开发 【微信小程序-原生开发】实用教程15 - 列表的排序、搜索(含云数据库常用查询条件的使用方法,t-search 组件的使用)_朝阳39的博客-CSDN博客 https://sunshinehu.blog.csdn.net/article/details/129356909 效果预览 …...

论文精读:Ansor: Generating High-Performance Tensor Programs for Deep Learning
文章目录1. Abstract2. Introduction3. Background4. Design Overview5. Program Sampling5.1 Sketch Generation5.2 Random Annotation6. Performance Fine-tuning6.1 Evolutionary Search6.2 Learned Cost Model7. Task Scheduler7.1 Problem Formulation7.2 Optimizing with…...
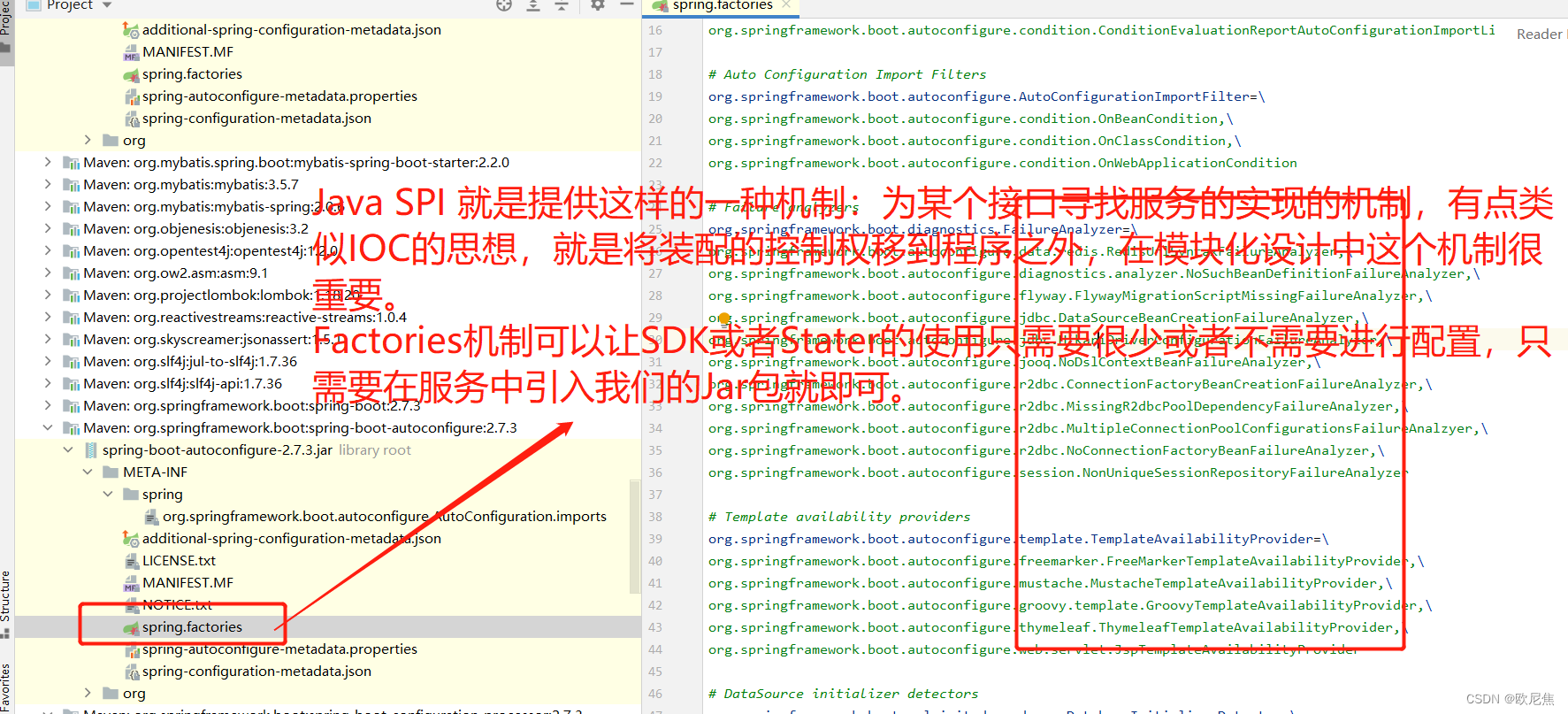
SpringBoot With IoC,DI, AOP,自动配置
文章目录1 IoC(Inverse Of Controller)2 DI(Dependency Injection)3 AOP(面向切面编程)3.1 什么是AOP?3.2 AOP的作用?3.3 AOP的核心概念3.4 AOP常见通知类型3.5 切入点表达式4 自动配…...
ggplot2的组图拓展包(1):patchwork(上篇)
专注系列化、高质量的R语言教程推文索引 | 联系小编 | 付费合集patchwork是ggplot绘图系统的拓展包,主要功能是将多个ggplot格式的图形组合成一幅大图,即组图。patchwork工具包十分好用,它主要利用几个类似四则运算符号的操作符进行组图&…...
)
Python 异步: 异步迭代器(15)
动动发财的小手,点个赞吧! 迭代是 Python 中的基本操作。我们可以迭代列表、字符串和所有其他结构。 Asyncio 允许我们开发异步迭代器。我们可以通过定义一个实现 aiter() 和 anext() 方法的对象来在 asyncio 程序中创建和使用异步迭代器。 1. 什么是异步…...
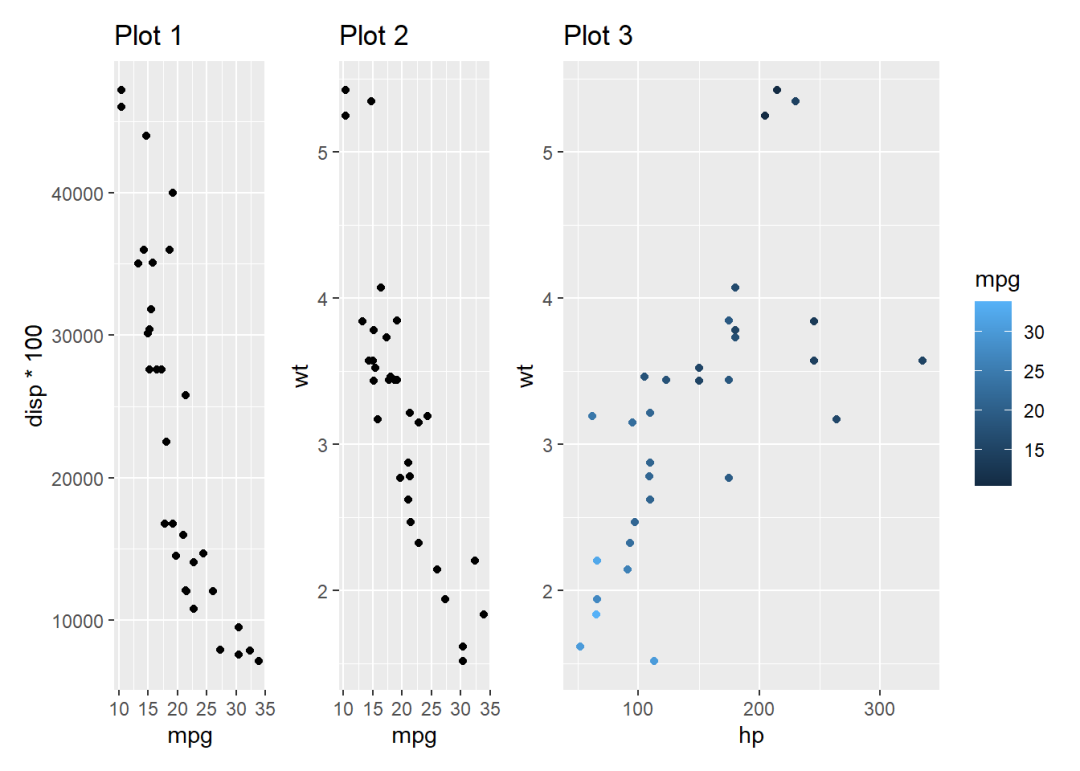
HD-G2L-IOT V2.0核心板MPU压力测试
1. 测试对象HD-G2L-IOT基于HD-G2L-CORE V2.0工业级核心板设计,双路千兆网口、双路CAN-bus、2路RS-232、2路RS-485、DSI、LCD、4G/5G、WiFi、CSI摄像头接口等,接口丰富,适用于工业现场应用需求,亦方便用户评估核心板及CPU的性能。H…...

scikit-image:遥感图像geotiff格式转mat格式
scikit-imagescikit-image 是一个专门用于图像处理的 Python 库,它可以与 Scipy 库和其他可能有助于计算的 Python 库一起使用。Github地址:https://github.com/scikit-image/scikit-image Star有5.3k首先pip安装scikit-image包,或者直接使用…...

吉利银河L7、长城哈弗B07、比亚迪宋Plus DM-i,自主品牌决战混动
2月23日,吉利推出全新的中高端新能源产品序列——吉利银河。当日,吉利推出了首款智能电混SUV「银河L7」,新车将在二季度交付。本月10日,长城汽车也计划举办智能新能源干货大会,其「颠覆技术」等宣传直面新一代的新能源…...

附录3:说一说 Ambari 视图编译相关
一、Ambari View Ambari 视图,即 Ambari Views 。其实 Ambari 视图并不是很好用,所以大部分人很自然地就把 Ambari 视图给忽略了,心里会冒出一句:“还有这东西?”。然而作为 Ambari 的一部分,今天还是要讲一下,万一有人追求 Ambari 完整性,要编译并安装汉化他们呢? …...

Arduino双色LED实验记录
接线图片:双色LED实物和布线有区别:代码:int RED_LED 11; //设置红色为11 int GREEN_LED 10; //设置绿色为10 int val 0;//全局变量val void setup() {// put your setup code here, to run once:pinMode(RED_LED,OUTPUT);//引脚配置pinMo…...

flex布局
十分简单灵活,区区几行代码都可以实现各种页面的布局,曾经学习页面布局时候,深受float、display、position这些属性的困扰,但是学习flex布局,只需要学习几个CSS属性,就可以写出简介优雅复杂的页面布局。 F…...
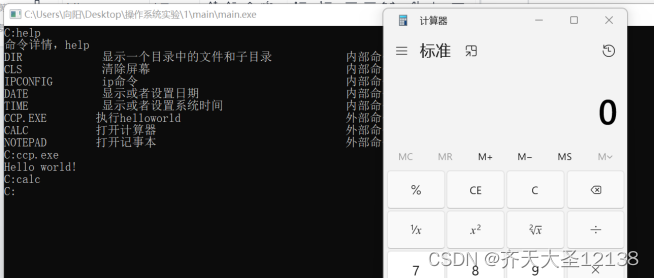
【操作系统原理实验】命令解释器模拟实现
选择一种高级语言如C/C等,编写一类似于DOS、UNIX中的命令行解释程序。 1)设计系统命名行提示符; 2)自定义命令集(8-10个); 3)用户输入help命令以查找命令的帮助; 4)列出命令的功能,区分内部命令…...
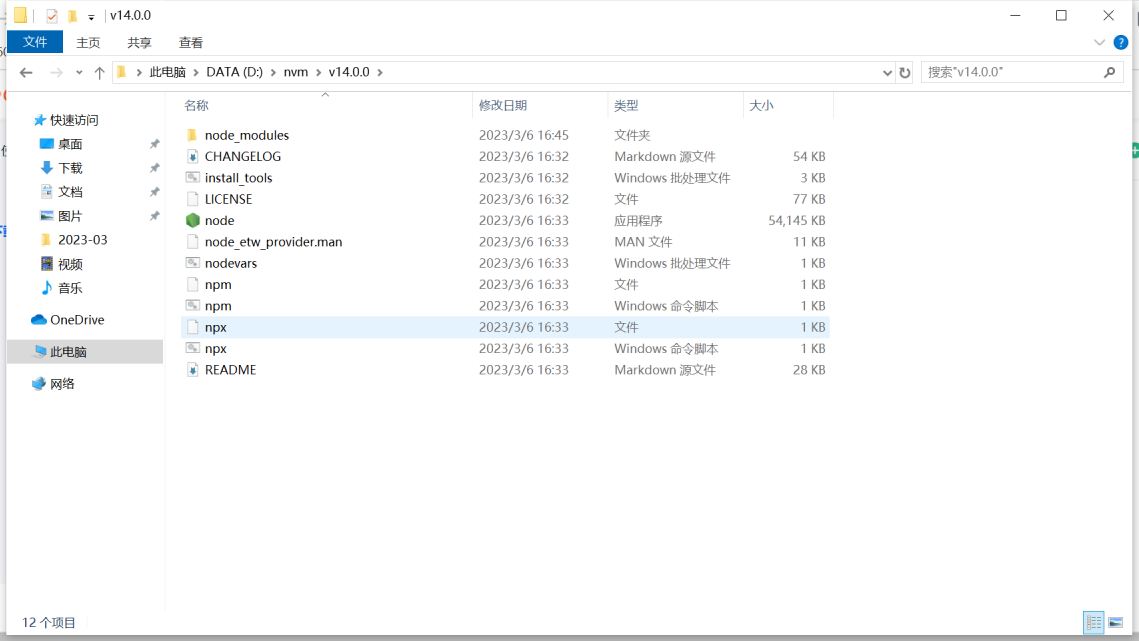
使用nvm管理node版本
下载nvm版本参考文章:https://blog.csdn.net/langmanboy/article/details/126357952下载安装选择nvm的目录为d:\nvm,nodejs的目录为d:\nodejs:v14.0.0:执行nvm install 14生成的目录v16.0.0:执行nvm install 16生成的目…...

jQuery BootStrap
1、jQuery的使用方式 1、下载jQuery库文件 网址 2、将下载好的js文件放到项目中,并引入到需要的HTML文件中 3、使用jQuery 注意:jQuery库文件的导入必须在自己写的代码之前。就绪函数在页面上可以写n个。 <!DOCTYPE html> <html lang"en…...

Vue2.0开发之——购物车案例-Footer组件封装(50)
一 概述 导入Footer子组件定义fullState计算属性把全选状态传递给Footer子组件实现全选功能 二 导入Footer子组件 2.1 App.vue中导入Footer组件 import Footer from "/components/Footer/Footer.vue";2.2 App.vue中注册Footer子组件 components: {Header,Goods,F…...

HTML基本概述
文章目录网站和网页浏览器的作用HTML标签元素注释乱码问题web系统是以网站形式呈现的,而前端是以网页形式呈现的。 网站和网页 网站(web site):互联网上用于展示特定内容的相关网页的集合。也就是说,一个网站包含多个…...

Vue 3.0 响应式 计算和侦听 【Vue3 从零开始】
本节使用单文件组件语法作为代码示例 #计算值 有时我们需要依赖于其他状态的状态——在 Vue 中,这是用组件计算属性处理的,以直接创建计算值,我们可以使用 computed 方法:它接受 getter 函数并为 getter 返回的值返回一个不可变的…...

1.mbedtls移植到STM32
mbedtls学习笔记 1.关于mbedtls2.STM32移植方法2.1STM32cubemx移植2.2手动移植12.3移植总结2.4手动移植22.4.1移植方式22.4.2测试SHA1加密1.关于mbedtls 1.主要提供了的 SSL/TLS 支持(在传输层对网络进行加密),各种加密算法,各种哈希算法,随机数生成以及 X.509(密码学里…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...