Chinese-LLaMA-Alpaca-2模型量化部署测试
简介
Chinese-LLaMA-Alpaca-2基于Meta发布的可商用大模型Llama-2开发, 是中文LLaMA&Alpaca大模型的第二期项目.
量化
模型的下载还是应用脚本
bash hfd.sh hfl/chinese-alpaca-2-13b --tool aria2c -x 8
应用llama.cpp进行量化, 主要参考该教程.
其中比较折腾的是与BLAS一起编译.
OpenBLAS
这个真是一言难尽, 非常折腾也没起作用(issue1 & issue2). 而且提升很小, 后续再尝试能不能成功.
cuBLAS
这个提升较为明显, 在有Nvidia GPU的情况下, 需要折腾应该就只有非root用户手动安装一下CUDA toolkit, 然后在CMakeLists.txt中指定一下路径即可.
手动安装CUDA toolkit和cuDnn后, 在CMakeLists.txt中加入:
# ${cuda path}示例: /home/orange/software/cuda-118
set(CUDA_TOOLKIT_ROOT_DIR ${cuda path})
进行编译即可
mkdir build
cd build
cmake .. -DLLAMA_CUBLAS=ON
cmake --build . --config Release
量化
编译完成llama.cpp后, 进行量化
python convert.py zh-models/chinese-alpaca-2-7b/
./build/bin/quantize ./zh-models/chinese-alpaca-2-7b/ggml-model-f16.gguf ./zh-models/chinese-alpaca-2-7b/ggml-model-q8_0.gguf q8_0
部署测试
直接使用./build/bin/main -m ./zh-models/chinese-alpaca-2-7b/ggml-model-q8_0.gguf不能进行对话, 加入参数-i表示交互模式, 也可以使用教程中的脚本形式.
按照tutorial, 新建chat.sh文件并填入以下内容
#!/bin/bash# temporary script to chat with Chinese Alpaca-2 model
# usage: ./chat.sh alpaca2-ggml-model-path your-first-instructionSYSTEM='You are a helpful assistant. 你是一个乐于助人的助手。'
FIRST_INSTRUCTION=$2./build/bin/main -m $1 \
--color -i -c 4096 -t 8 --temp 0.5 --top_k 40 --top_p 0.9 --repeat_penalty 1.1 \
--in-prefix-bos --in-prefix ' [INST] ' --in-suffix ' [/INST]' -p \
"[INST] <<SYS>>
$SYSTEM
<</SYS>>$FIRST_INSTRUCTION [/INST]"
运行
bash chat.sh ./zh-models/chinese-alpaca-2-7b/ggml-model-q8_0.gguf '请列举5条文明乘车的建议'
成功实现对话, 部署测试成功.
测试
下载并解压测试数据
chinese-alpaca-2-1.3b
测试命令:
./build/bin/perplexity -m ./zh-models/chinese-alpaca-2-1.3b/ggml-model-q8_0.gguf -f ./wikitext-2-raw/wiki.test.raw -ngl 20
由于使用cmake编译, 可执行文件位于build/bin下, 注意执行文件和模型, 数据的路径替换即可.
测试数据如下:
main: build = 2509 (50ccaf5e)
main: built with cc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0 for x86_64-linux-gnu
main: seed = 1711210157
llama_model_loader: loaded meta data with 23 key-value pairs and 39 tensors from ./zh-models/chinese-alpaca-2-1.3b/ggml-model-q8_0.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.vocab_size u32 = 55296
llama_model_loader: - kv 3: llama.context_length u32 = 4096
llama_model_loader: - kv 4: llama.embedding_length u32 = 4096
llama_model_loader: - kv 5: llama.block_count u32 = 4
llama_model_loader: - kv 6: llama.feed_forward_length u32 = 11008
llama_model_loader: - kv 7: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 8: llama.attention.head_count u32 = 32
llama_model_loader: - kv 9: llama.attention.head_count_kv u32 = 32
llama_model_loader: - kv 10: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 11: llama.rope.freq_base f32 = 10000.000000
llama_model_loader: - kv 12: general.file_type u32 = 7
llama_model_loader: - kv 13: tokenizer.ggml.model str = llama
llama_model_loader: - kv 14: tokenizer.ggml.tokens arr[str,55296] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 15: tokenizer.ggml.scores arr[f32,55296] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 16: tokenizer.ggml.token_type arr[i32,55296] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 17: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 18: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 19: tokenizer.ggml.padding_token_id u32 = 0
llama_model_loader: - kv 20: tokenizer.ggml.add_bos_token bool = true
llama_model_loader: - kv 21: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 22: general.quantization_version u32 = 2
llama_model_loader: - type f32: 9 tensors
llama_model_loader: - type q8_0: 30 tensors
llm_load_vocab: mismatch in special tokens definition ( 889/55296 vs 259/55296 ).
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 55296
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 4096
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 32
llm_load_print_meta: n_layer = 4
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 4096
llm_load_print_meta: n_embd_v_gqa = 4096
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 11008
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: model type = ?B
llm_load_print_meta: model ftype = Q8_0
llm_load_print_meta: model params = 1.26 B
llm_load_print_meta: model size = 1.25 GiB (8.50 BPW)
llm_load_print_meta: general.name = LLaMA v2
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: PAD token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: CUDA_USE_TENSOR_CORES: yes
ggml_cuda_init: found 2 CUDA devices:Device 0: NVIDIA A100-PCIE-40GB, compute capability 8.0, VMM: yesDevice 1: NVIDIA A100-PCIE-40GB, compute capability 8.0, VMM: yes
llm_load_tensors: ggml ctx size = 0.05 MiB
llm_load_tensors: offloading 4 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 5/5 layers to GPU
llm_load_tensors: CPU buffer size = 229.50 MiB
llm_load_tensors: CUDA0 buffer size = 615.28 MiB
llm_load_tensors: CUDA1 buffer size = 434.61 MiB
...............................
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CUDA0 KV buffer size = 96.00 MiB
llama_kv_cache_init: CUDA1 KV buffer size = 32.00 MiB
llama_new_context_with_model: KV self size = 128.00 MiB, K (f16): 64.00 MiB, V (f16): 64.00 MiB
llama_new_context_with_model: CUDA_Host output buffer size = 432.00 MiB
llama_new_context_with_model: pipeline parallelism enabled (n_copies=4)
llama_new_context_with_model: CUDA0 compute buffer size = 208.01 MiB
llama_new_context_with_model: CUDA1 compute buffer size = 200.01 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 24.02 MiB
llama_new_context_with_model: graph nodes = 136
llama_new_context_with_model: graph splits = 3system_info: n_threads = 76 / 152 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 |
perplexity: tokenizing the input ..
perplexity: tokenization took 1187.98 ms
perplexity: calculating perplexity over 655 chunks, n_ctx=512, batch_size=2048, n_seq=4
perplexity: 0.06 seconds per pass - ETA 0.17 minutes
[1]35.2055,[2]3151.7331,[3]9745.8526,[4]3056.9236
......
[653]1226.9638,[654]1219.7704,[655]1213.9217,
Final estimate: PPL = 1213.9217 +/- 16.09822llama_print_timings: load time = 2998.83 ms
llama_print_timings: sample time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: prompt eval time = 8371.13 ms / 335360 tokens ( 0.02 ms per token, 40061.49 tokens per second)
llama_print_timings: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: total time = 17937.28 ms / 335361 tokens
chinese-alpaca-2-13b
测试命令:
./build/bin/perplexity -m ./zh-models/chinese-alpaca-2-13b/ggml-model-q8_0.gguf -f ./wikitext-2-raw/wiki.test.raw -ngl 10
测试数据如下:
main: build = 2509 (50ccaf5e)
main: built with cc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0 for x86_64-linux-gnu
main: seed = 1711210012
llama_model_loader: loaded meta data with 21 key-value pairs and 363 tensors from ./zh-models/chinese-alpaca-2-13b/ggml-model-q8_0.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.vocab_size u32 = 55296
llama_model_loader: - kv 3: llama.context_length u32 = 4096
llama_model_loader: - kv 4: llama.embedding_length u32 = 5120
llama_model_loader: - kv 5: llama.block_count u32 = 40
llama_model_loader: - kv 6: llama.feed_forward_length u32 = 13824
llama_model_loader: - kv 7: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 8: llama.attention.head_count u32 = 40
llama_model_loader: - kv 9: llama.attention.head_count_kv u32 = 40
llama_model_loader: - kv 10: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 11: general.file_type u32 = 7
llama_model_loader: - kv 12: tokenizer.ggml.model str = llama
llama_model_loader: - kv 13: tokenizer.ggml.tokens arr[str,55296] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 14: tokenizer.ggml.scores arr[f32,55296] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 15: tokenizer.ggml.token_type arr[i32,55296] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 16: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 17: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 18: tokenizer.ggml.add_bos_token bool = true
llama_model_loader: - kv 19: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 20: general.quantization_version u32 = 2
llama_model_loader: - type f32: 81 tensors
llama_model_loader: - type q8_0: 282 tensors
llm_load_vocab: mismatch in special tokens definition ( 889/55296 vs 259/55296 ).
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 55296
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 4096
llm_load_print_meta: n_embd = 5120
llm_load_print_meta: n_head = 40
llm_load_print_meta: n_head_kv = 40
llm_load_print_meta: n_layer = 40
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 5120
llm_load_print_meta: n_embd_v_gqa = 5120
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 13824
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: model type = 13B
llm_load_print_meta: model ftype = Q8_0
llm_load_print_meta: model params = 13.25 B
llm_load_print_meta: model size = 13.12 GiB (8.50 BPW)
llm_load_print_meta: general.name = LLaMA v2
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: CUDA_USE_TENSOR_CORES: yes
ggml_cuda_init: found 2 CUDA devices:Device 0: NVIDIA A100-PCIE-40GB, compute capability 8.0, VMM: yesDevice 1: NVIDIA A100-PCIE-40GB, compute capability 8.0, VMM: yes
llm_load_tensors: ggml ctx size = 0.42 MiB
llm_load_tensors: offloading 10 repeating layers to GPU
llm_load_tensors: offloaded 10/41 layers to GPU
llm_load_tensors: CPU buffer size = 13431.58 MiB
llm_load_tensors: CUDA0 buffer size = 1607.23 MiB
llm_load_tensors: CUDA1 buffer size = 1607.23 MiB
..................................................................................................
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CUDA_Host KV buffer size = 1200.00 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 200.00 MiB
llama_kv_cache_init: CUDA1 KV buffer size = 200.00 MiB
llama_new_context_with_model: KV self size = 1600.00 MiB, K (f16): 800.00 MiB, V (f16): 800.00 MiB
llama_new_context_with_model: CUDA_Host output buffer size = 432.00 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 404.88 MiB
llama_new_context_with_model: CUDA1 compute buffer size = 204.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 24.00 MiB
llama_new_context_with_model: graph nodes = 1324
llama_new_context_with_model: graph splits = 335system_info: n_threads = 76 / 152 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 |
perplexity: tokenizing the input ..
perplexity: tokenization took 728.604 ms
perplexity: calculating perplexity over 655 chunks, n_ctx=512, batch_size=2048, n_seq=4
perplexity: 7.36 seconds per pass - ETA 20.08 minutes
[1]4.8998,[2]5.3381,[3]6.0623,
......
[654]6.3736,[655]6.3713,
Final estimate: PPL = 6.3713 +/- 0.03705llama_print_timings: load time = 17705.89 ms
llama_print_timings: sample time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: prompt eval time = 1130068.93 ms / 335360 tokens ( 3.37 ms per token, 296.76 tokens per second)
llama_print_timings: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: total time = 1137969.38 ms / 335361 tokens
相关文章:

Chinese-LLaMA-Alpaca-2模型量化部署测试
简介 Chinese-LLaMA-Alpaca-2基于Meta发布的可商用大模型Llama-2开发, 是中文LLaMA&Alpaca大模型的第二期项目. 量化 模型的下载还是应用脚本 bash hfd.sh hfl/chinese-alpaca-2-13b --tool aria2c -x 8应用llama.cpp进行量化, 主要参考该教程. 其中比较折腾的是与BLAS…...

flutter 打包成web应用后怎么通过url跳转页面
在 Flutter 中,如果你想要在打包成 Web 应用后通过 URL 跳转页面,你可以利用 Flutter 提供的路由导航系统和 URL 策略。以下是具体步骤: 1. 配置路由 在 Flutter 应用中定义路由,一种简单的方式是使用 MaterialApp 构造器的 rou…...
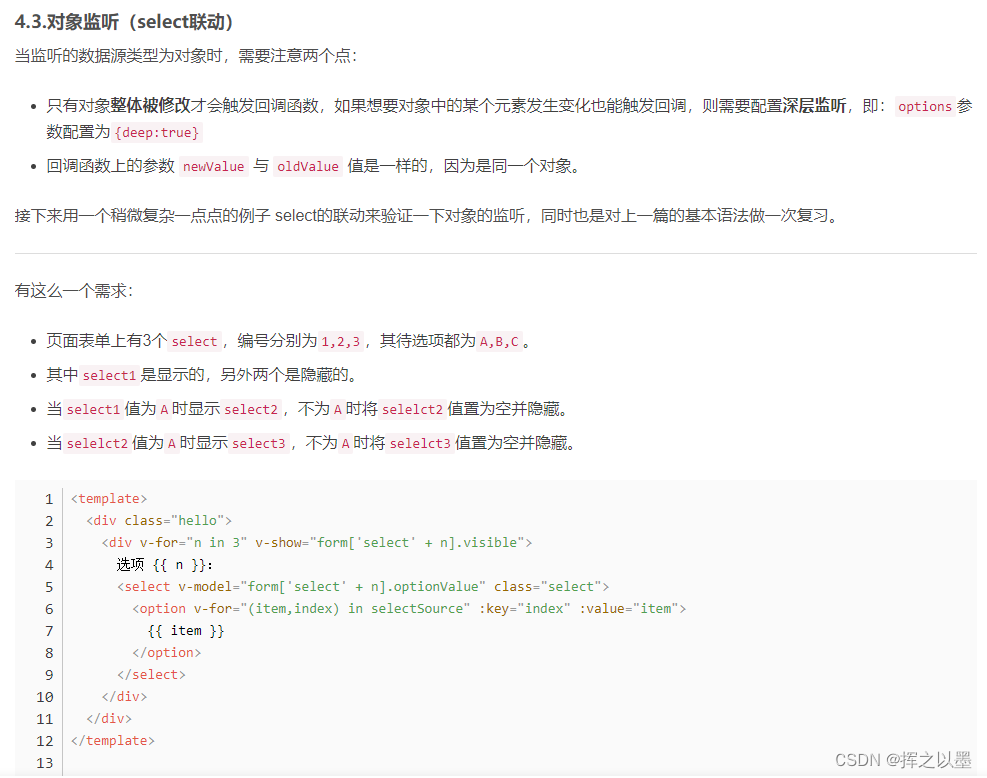
【设计模式】中介者模式的应用
文章目录 1.概述2.中介者模式的适用场景2.1.用户界面事件2.2.分布式架构多模块通信 3.总结 1.概述 中介者模式(Mediator Pattern)是一种行为型设计模式,它用于解决对象间复杂、过度耦合的问题。当多个对象(一般是两个以上的对象&…...

【微服务篇】分布式事务方案以及原理详解
分布式事务是指事务参与者、资源服务器、事务管理器分布在不同的分布式系统的多个节点之上的事务。在微服务架构、大型分布式系统和云计算等环境中,由于系统间调用和资源访问的复杂性,分布式事务变得尤为重要。 应用场景 跨系统交易:当交易…...

String 类的常用方法都有那些?
String 类在 Java 中是一个非常重要的类,用于处理文本数据。它提供了许多方法来操作字符串。以下是一些 String 类的常用方法: 构造方法 String(): 创建一个新的空字符串对象。String(byte[] bytes): 使用指定的字节数组来创建一个新的 String 对象。S…...

用XMLHttpRequest发送和接收JSON数据
百度的AI回答了一个案例: var xhr new XMLHttpRequest(); var url "your_endpoint_url"; // 替换为你的API端点 var data JSON.stringify({key1: "value1",key2: "value2" });xhr.open("POST", url, true); xhr.setReq…...
华为云使用指南02
5.使用GitLab进行团队及项目管理 GitLab旨在帮助团队进行项目开发协作,为软件开发和运营生命周期提供了一个完整的DevOps方案。GitLab功能包括:项目源码的管理、计划、创建、验证、集成、发布、配置、监视和保护应用程序等。该镜像基于CentOS操…...

halcon目标检测标注保存
* 创建一个新的字典 create_dict(ObjectDictionary) * 类别名称列表和对应的ID列表 class_names : [Defect1,Defect2,Defect3,Defect4,Defect5,Defect6,Defect7,Defect8,Defect9,Defect10,Defect11,Defect12,Defect13,Defect14,Defect15,Defect16,Defect17,Defect18] class_id…...
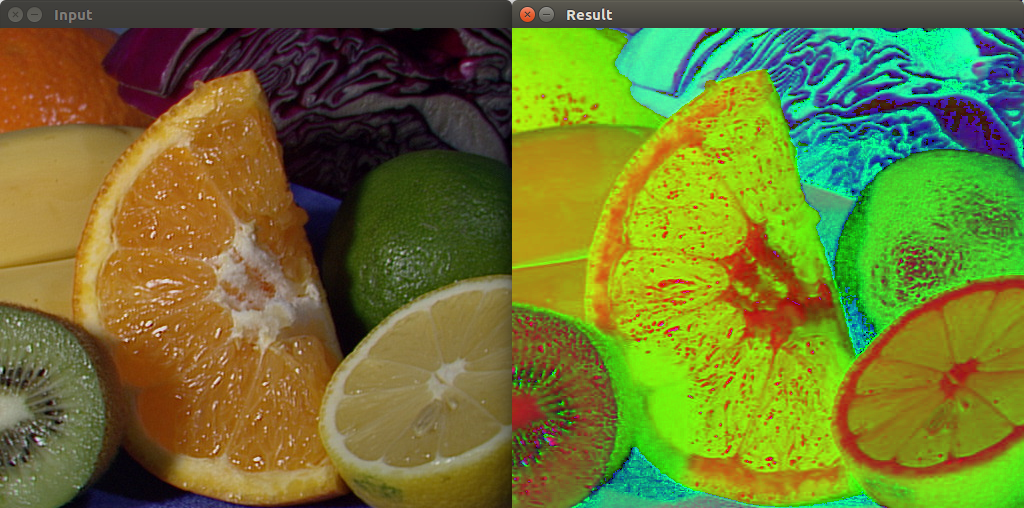
Python图像处理——计算机视觉中常用的图像预处理
概述 在计算机视觉项目中,使用样本时经常会遇到图像样本不统一的问题,比如图像质量,并非所有的图像都具有相同的质量水平。在开始训练模型或运行算法之前,通常需要对图像进行预处理,以确保获得最佳的结果。图像预处理…...

编译安装飞桨fastdeploy@FreeBSD(失败)
FastDeploy是一款全场景、易用灵活、极致高效的AI推理部署工具, 支持云边端部署。提供超过 🔥160 Text,Vision, Speech和跨模态模型📦开箱即用的部署体验,并实现🔚端到端的推理性能优化。包括 物…...
)
java组合总和(力扣Leetcode39)
组合总和 力扣原题链接 问题描述 给定一个无重复元素的整数数组 candidates 和一个目标整数 target,找出 candidates 中可以使数字和为目标数 target 的所有不同组合,并以列表形式返回。你可以按任意顺序返回这些组合。 示例 示例 1: 输…...

ZK友好代数哈希函数安全倡议
1. 引言 前序博客: ZKP中的哈希函数如何选择ZK-friendly 哈希函数?snark/stark-friendly hash函数Anemoi Permutation和Jive Compression模式:高效的ZK友好的哈希函数Tip5:针对Recursive STARK的哈希函数 随着Incrementally Ve…...
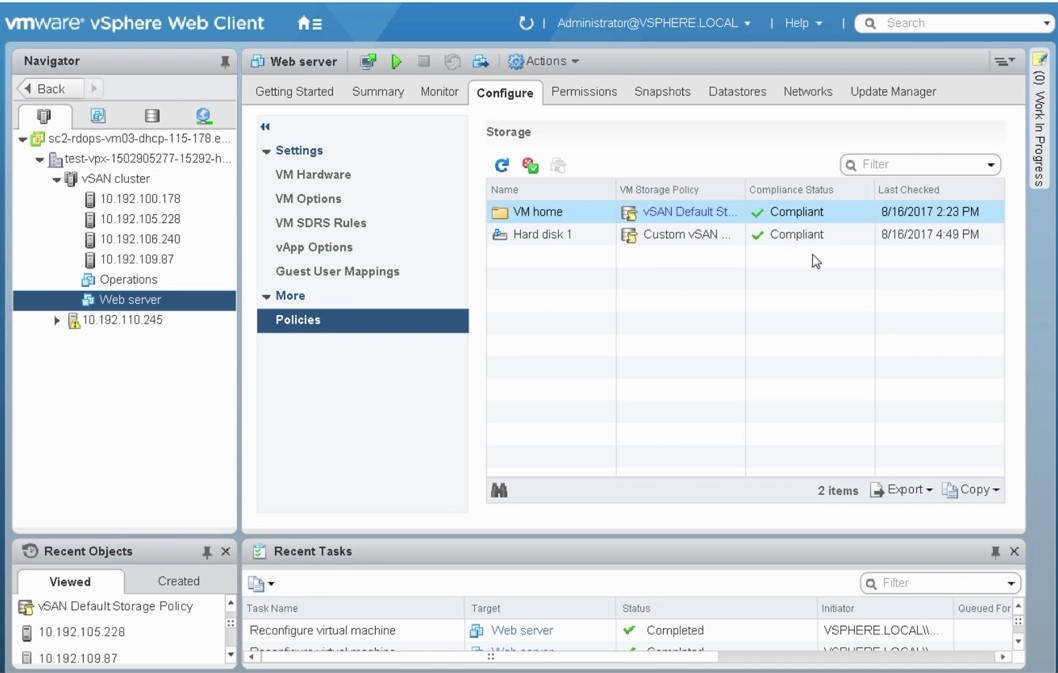
VMware vSAN OSA存储策略 - 基于虚拟机的分布式对象存储
简介 博客:https://songxwn.com/ 存储策略 (Storage Policy) 是管理员定义的一组规则,这组规则定义了数据对象在 vSAN 存储上是如何保存的,存储策略定义了数据存储的可靠性、访问性能等特性。vSAN 提供了基于存储策略的存储管理 SPBM (Stor…...
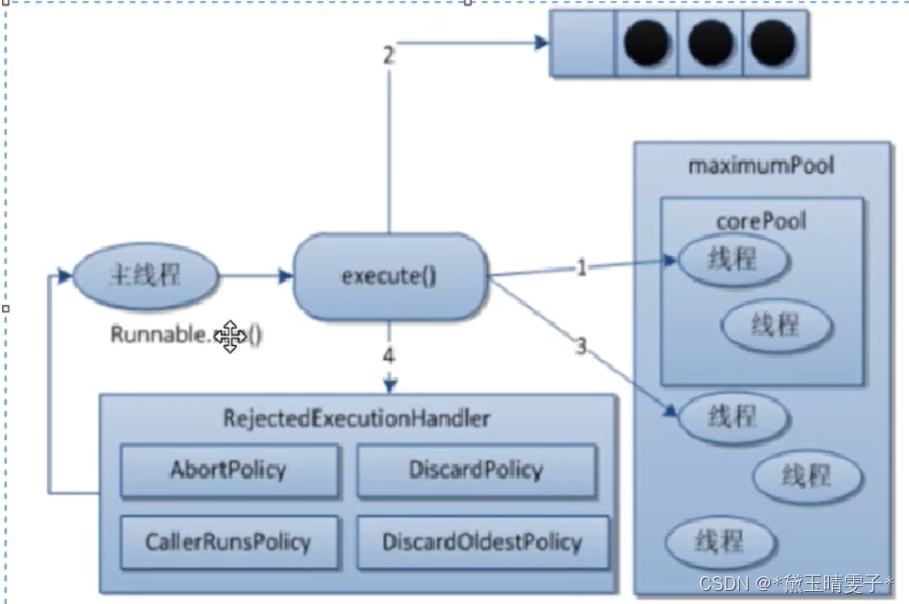
JUC内容概述
复习概念 Sleep和Wait的区别 Sleep是Thread的静态方法,wait是Object的方法,任何对象实例都可以使用sleep不会释放锁,他也不需要占用锁,暂停。wait会释放锁,但是调用他的前提是线程占有锁他们都可以被Interrupted方法…...

postcss安装和使用
要安装和使用 PostCSS,你可以按照以下步骤操作: 步骤一:安装 PostCSS 在项目目录下,通过 npm 初始化一个新的 package.json 文件(如果还没有): npm init -y 安装 PostCSS 和必要的插件&#x…...

macOS 13 Ventura (苹果最新系统) v13.6.6正式版
macOS 13 Ventura是苹果电脑的全新操作系统,它为用户带来了众多引人注目的新功能和改进。该系统加强了FaceTime和视频通话的体验,同时优化了邮件、Safari浏览器和日历等内置应用程序,使其更加流畅、快速和安全。特别值得一提的是,…...
WordPress Git主题 响应式CMS主题模板
分享的是新版本,旧版本少了很多功能,尤其在新版支持自动更新后,该主题可以用来搭建个人博客,素材下载网站,图片站等 主题特点 兼容 IE9、谷歌 Chrome 、火狐 Firefox 等主流浏览器 扁平化的设计加响应式布局&#x…...
安卓国内ip代理app,畅游网络
随着移动互联网的普及和快速发展,安卓手机已经成为我们日常生活和工作中不可或缺的一部分。然而,由于地理位置、网络限制或其他因素,我们有时需要改变或隐藏自己的IP地址。这时,安卓国内IP代理App便成为了一个重要的工具。虎观代理…...

Day53:WEB攻防-XSS跨站SVGPDFFlashMXSSUXSS配合上传文件添加脚本
目录 MXSS UXSS:Universal Cross-Site Scripting HTML&SVG&PDF&SWF-XSS&上传&反编译(有几率碰到) SVG-XSS PDF-XSS Python生成XSS Flash-XSS 知识点: 1、XSS跨站-MXSS&UXSS 2、XSS跨站-SVG制作&配合上传 3、XSS跨站-…...
k8s安装traefik作为ingress
一、先来介绍下Ingress Ingress 这个东西是 1.2 后才出现的,通过 Ingress 用户可以实现使用 nginx 等开源的反向代理负载均衡器实现对外暴露服务,以下详细说一下 Ingress,毕竟 traefik 用的就是 Ingress 使用 Ingress 时一般会有三个组件: …...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...
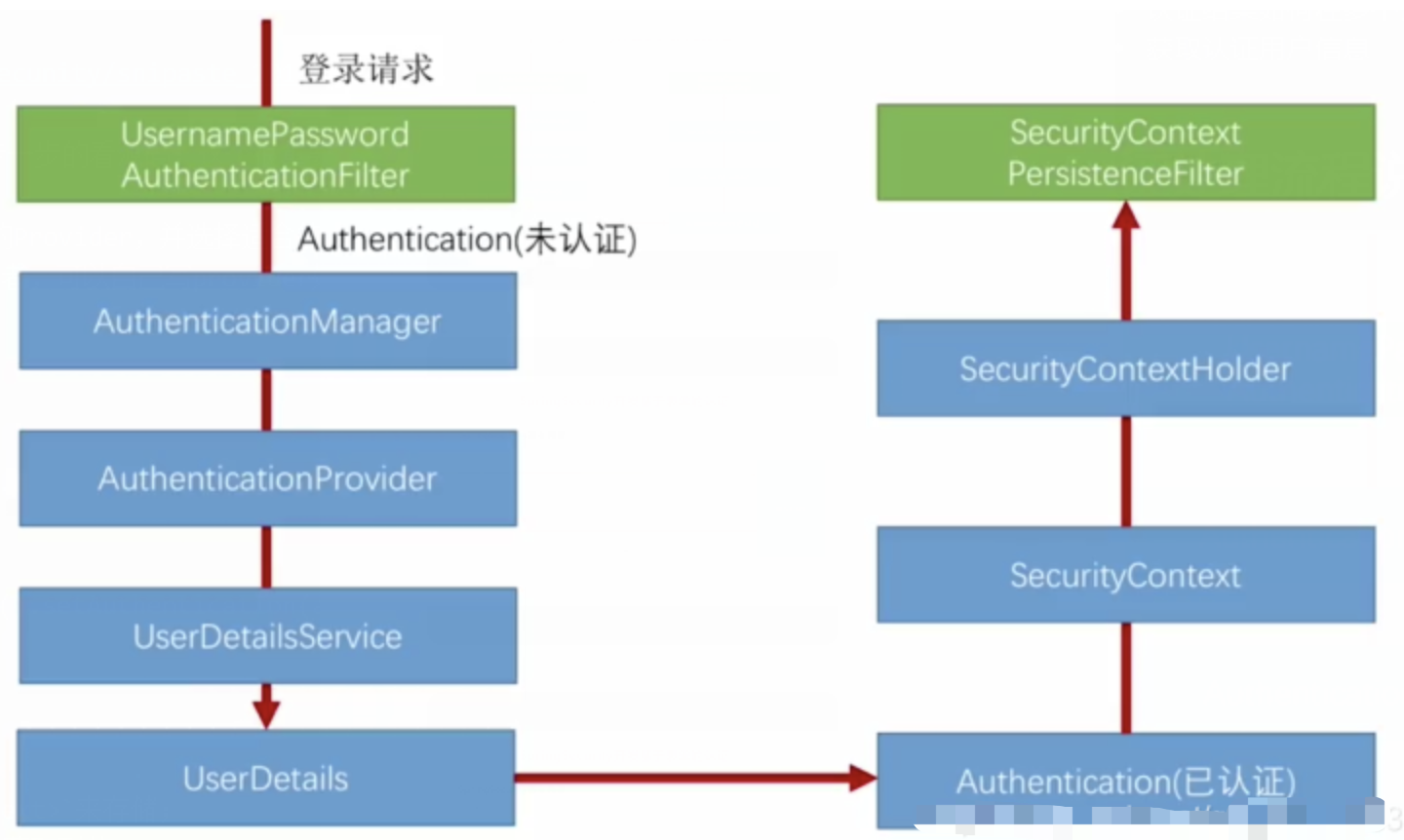
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...

如何在Windows本机安装Python并确保与Python.NET兼容
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...