asyncio和 aiohttp
文章目录
- asyncio和 aiohttp
- 3.8版本+ 特性
- aiohttp
- 案例
- 优化方案
asyncio和 aiohttp
asyncio即Asynchronous I/O是python一个用来处理并发(concurrent)事件的包,是很多python异步架构的基础,多用于处理高并发网络请求方面的问题。
为了简化并更好地标识异步IO,从Python 3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读。
asyncio 被用作多个提供高性能 Python 异步框架的基础,包括网络和网站服务,数据库连接库,分布式任务队列等等。
asyncio 往往是构建 IO 密集型和高层级 结构化 网络代码的最佳选择。
import asyncioasync def task(i):print(f"task {i} start")await asyncio.sleep(1)print(f"task {i} end")# 创建事件循环对象
loop = asyncio.get_event_loop()
# 直接将协程对象加入时间循环中
tasks = [task(1), task(2)]
# asyncio.wait:将协程任务进行收集,功能类似后面的asyncio.gather
# run_until_complete阻塞调用,直到协程全部运行结束才返回
loop.run_until_complete(asyncio.wait(tasks))
loop.close()task: 任务,对协程对象的进一步封装,包含任务的各个状态;asyncio.Task是Future的一个子类,用于实现协作式多任务的库,且Task对象不能用户手动实例化,通过下面2个函数loop.create_task() 或 asyncio.ensure_future()创建。
import asyncio, timeasync def work(i, n): # 使用async关键字定义异步函数print('任务{}等待: {}秒'.format(i, n))await asyncio.sleep(n) # 休眠一段时间print('任务{}在{}秒后返回结束运行'.format(i, n))return i + nstart_time = time.time() # 开始时间tasks = [asyncio.ensure_future(work(1, 1)),asyncio.ensure_future(work(2, 2)),asyncio.ensure_future(work(3, 3))]loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
loop.close()print('运行时间: ', time.time() - start_time)
for task in tasks:print('任务执行结果: ', task.result())
3.8版本+ 特性
async.run()运行协程
async.create_task()创建task
async.gather()获取返回值
import asyncio, timeasync def work(i, n): # 使用async关键字定义异步函数print('任务{}等待: {}秒'.format(i, n))await asyncio.sleep(n) # 休眠一段时间print('任务{}在{}秒后返回结束运行'.format(i, n))return i + ntasks = []
async def main():global taskstasks = [asyncio.create_task(work(1, 1)),asyncio.create_task(work(2, 2)),asyncio.create_task(work(3, 3))]await asyncio.wait(tasks) # 阻塞start_time = time.time() # 开始时间
asyncio.run(main())
print('运行时间: ', time.time() - start_time)
for task in tasks:print('任务执行结果: ', task.result())asyncio.create_task() 函数在 Python 3.7 中被加入。
asyncio.gather方法
# 用gather()收集返回值import asyncio, timeasync def work(i, n): # 使用async关键字定义异步函数print('任务{}等待: {}秒'.format(i, n))await asyncio.sleep(n) # 休眠一段时间print('任务{}在{}秒后返回结束运行'.format(i, n))return i + nasync def main():tasks = [asyncio.create_task(work(1, 1)),asyncio.create_task(work(2, 2)),asyncio.create_task(work(3, 3))]# 将task作为参数传入gather,等异步任务都结束后返回结果列表response = await asyncio.gather(tasks[0], tasks[1], tasks[2])print("异步任务结果:", response)start_time = time.time() # 开始时间asyncio.run(main())print('运行时间: ', time.time() - start_time)
aiohttp
爬虫最重要的模块requests,但它是阻塞式的发起请求,每次请求发起后需阻塞等待其返回响应,不能做其他的事情。本文要介绍的aiohttp可以理解成是和requests对应Python异步网络请求库,它是基于 asyncio 的异步模块,可用于实现异步爬虫,有点就是更快于 requests 的同步爬虫。安装方式,pip install aiohttp。
aiohttp是一个为Python提供异步HTTP 客户端/服务端编程,基于asyncio的异步库。asyncio可以实现单线程并发IO操作,其实现了TCP、UDP、SSL等协议,aiohttp就是基于asyncio实现的http框架, 使用方式如下。
import aiohttp
import asyncioasync def main():async with aiohttp.ClientSession() as session:async with session.get("http://httpbin.org/headers") as response:print(await response.text())asyncio.run(main())
案例
import asyncio
import os
import aiohttp
import time
from utils.aiorequests import aiorequest
from lxml import etreeheaders = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}url = "https://www.pkdoutu.com/photo/list/"base_url = "https://www.xr02.vip/"async def get_home_url():async with aiohttp.ClientSession() as session:async with session.get(url, headers=headers, ssl=False) as resp:res = await resp.content.read()selector = etree.HTML(res)urls = selector.xpath('//ul/li[@class="i_list list_n2"]/a/@href')return map(lambda i: base_url+i, urls)async def get_page_url(urls):async with aiohttp.ClientSession() as session:async with session.get(urls, headers=headers, ssl=False) as resp:res = await resp.content.read()selector = etree.HTML(res)page_urls = selector.xpath('//div[@class="page"]/a/@href')return map(lambda i: base_url+i, set(page_urls))async def get_img_url(urls):async with aiohttp.ClientSession() as session:async with session.get(urls, headers=headers, ssl=False) as resp:res = await resp.content.read()selector = etree.HTML(res)name = selector.xpath("//h1/text()")[0].replace("[XiuRen秀人网]",'')img_urls = selector.xpath('//p/img/@src')return name, map(lambda i: base_url+i, img_urls)async def download_img(urls, base_name):name = os.path.basename(urls)name = base_name + '_' + nametry:async with aiohttp.ClientSession() as session:async with session.get(urls, headers=headers, ssl=False) as resp:res = await resp.content.read()with open(f"./imgs/{name}","wb") as f:f.write(res)print(f"url: {urls} 下载成功,存储文件为{name}")except:print(f"url: {urls} 下载失败")return "success"async def main():tasks_1 = [asyncio.create_task(get_page_url(i)) for i in await get_home_url()]result_1 = await asyncio.gather(*tasks_1)result_list = []for i in result_1: result_list.extend(list(i))tasks_2 = [asyncio.create_task(get_img_url(i)) for i in result_list]result_2 = await asyncio.gather(*tasks_2)tasks_3 = []for name, img_url in result_2:tasks_3.extend(asyncio.create_task(download_img(url, name)) for url in img_url)await asyncio.gather(*tasks_3)if __name__ == '__main__':if not os.path.isdir("./imgs"):os.mkdir("./imgs")start = time.time()asyncio.run(main())print(time.time()-start)
通过这个案例,可以看到一个问题,那就是 aiohttp的使用,每次都需要写一堆重复代码,并且整个代码结构看起来复杂,作为一个高级开发,必须要会做的就是减少代码重复编写,要将其模块化,封装起来
优化方案
aiorequest.py
class AioRequest:async def request(self, method: str, url: str, data: Union[Dict, bytes, None] = None, **kwargs: Any) -> Any:async with aiohttp.ClientSession() as session:async with session.request(method, url, ssl=False, data=data, **kwargs) as response:if response.status != 200:raise Exception(f"{method.upper()} request failed with status {response.status}")# return await handler(await response.content.read()# return 这里必须带上await,但不支持 await ClientResponse 对象直接返回 必须要处理响应数据# 根据内容类型处理响应体content_type = response.headers.get('Content-Type')if content_type and ('image' in content_type or 'video' in content_type):return await response.read() # 返回图片或视频的二进制数据elif 'application/json' in content_type:return await response.json() # 假设响应是JSON格式else:return await response.text() # 读取文本内容async def get(self, url: str, **kwargs: Any):return await self.request("GET", url, **kwargs)async def post(self, url: str, data: Union[Dict, bytes], **kwargs: Any):return await self.request("POST", url, data=data, **kwargs)# 处理大文件async def save_binary_content(self, url: str, file_path: str, headers: Dict[str, str] = None, **kwargs: Any):async with aiohttp.ClientSession(headers=headers) as session:async with session.get(url, ssl=False, **kwargs) as response:if response.status != 200:raise Exception(f"GET request failed with status {response.status}")with open(file_path, 'wb') as f:while True:chunk = await response.content.read(1024) # 每次读取1024字节if not chunk:breakf.write(chunk)aiorequest = AioRequest() # 减少对象的重复创建消耗内存
使用aiorequest 后,代码就简洁明了多了,
import asyncio
import os
import time
from utils.aiorequests import aiorequest
from lxml import etreeheaders = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}base_url = "https://www.xr02.vip/"img_urls_dict = dict()async def get_home_url():res = await aiorequest.get(base_url)selector = etree.HTML(res)urls = selector.xpath('//ul/li[@class="i_list list_n2"]/a/@href')return map(lambda i: base_url+i, urls)async def get_page_url(urls):res = await aiorequest.get(urls)selector = etree.HTML(res)await get_img_url(res)page_urls = selector.xpath('//div[@class="page"]/a/@href')page_urls = list(map(lambda i: base_url + i, set(page_urls)))page_urls.remove(urls)return page_urlsasync def get_img_url(res):selector = etree.HTML(res)name = selector.xpath("//h1/text()")[0].replace("[XiuRen秀人网]",'')img_list = selector.xpath('//p/img/@src')img_list = map(lambda i: base_url+i, img_list)if name not in img_urls_dict:img_urls_dict.setdefault(name, list(img_list))else:img_urls_dict[name].extend(list(img_list))async def get_imgs_url(urls):res = await aiorequest.get(urls)await get_img_url(res)async def download_img(urls, base_name):name = os.path.basename(urls)name = base_name + '_' + nametry:res = await aiorequest.get(urls)with open(f"./imgs_2/{name}","wb") as f:f.write(res)print(f"url: {urls} 下载成功,存储文件为{name}")except:print(f"url: {urls} 下载失败")return "success"async def main():tasks_1 = [asyncio.create_task(get_page_url(i)) for i in await get_home_url()]result_1 = await asyncio.gather(*tasks_1)result_list = []for i in result_1: result_list.extend(i)tasks_2 = [asyncio.create_task(get_imgs_url(i)) for i in result_list]await asyncio.wait(tasks_2)tasks_3 = []for name, img_url in img_urls_dict.items():tasks_3.extend(asyncio.create_task(download_img(url, name)) for url in img_url)await asyncio.wait(tasks_3)if __name__ == '__main__':if not os.path.isdir("./imgs_2"):os.mkdir("./imgs_2")start = time.time()asyncio.run(main())print(time.time()-start)
相关文章:

asyncio和 aiohttp
文章目录 asyncio和 aiohttp3.8版本 特性aiohttp案例优化方案 asyncio和 aiohttp asyncio即Asynchronous I/O是python一个用来处理并发(concurrent)事件的包,是很多python异步架构的基础,多用于处理高并发网络请求方面的问题。 为了简化并更好地标识异…...
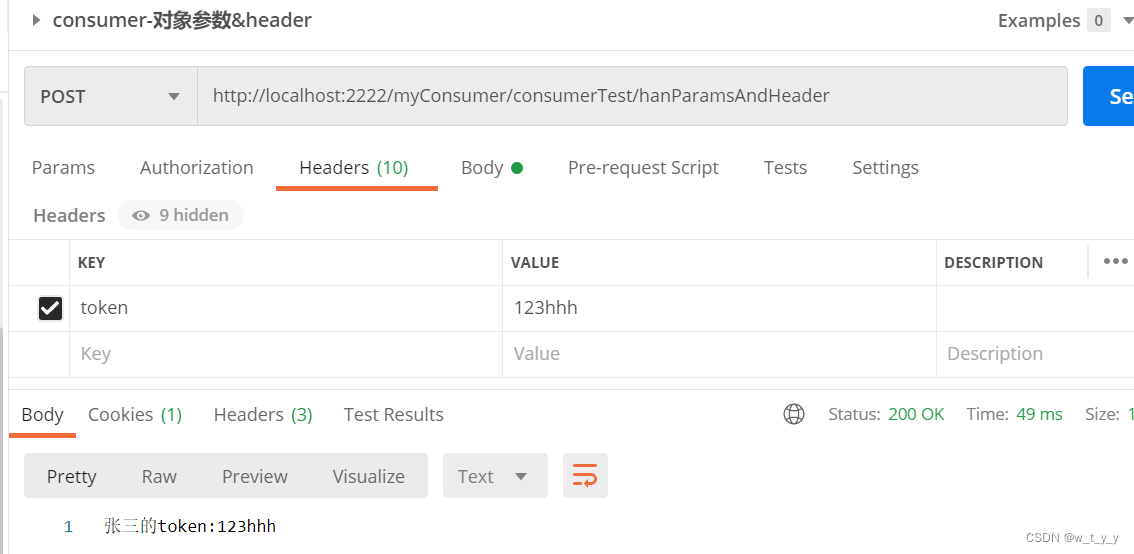
微服务demo(三)nacosfeign
一、feign使用 1、集成方法 1.1、pom consumer添加依赖 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId><version>2.2.6.RELEASE</version></dependency&…...
学浪视频如何录屏保存?
学浪软件对录屏进行了防范,不管什么录屏软件只要打开学浪就会黑屏,这里就教大家一个方法,可以使用网页版进行录屏 这里是学浪的网页版地址 https://student-api.iyincaishijiao.com/ep/pc/login 但是你们打开这个地址会直接跳转到这个页面…...

c++中2种返回变量类型名称的方法
std::string real_name abi::__cxa_demangle(typeid(*(*a)).name(), NULL, NULL, &status);必须使用#include <typeinfo> std::string real_name boost::core::demangle(typeid(*(*a)).name());必须使用 #include <boost/core/demangle.hpp> #include <t…...
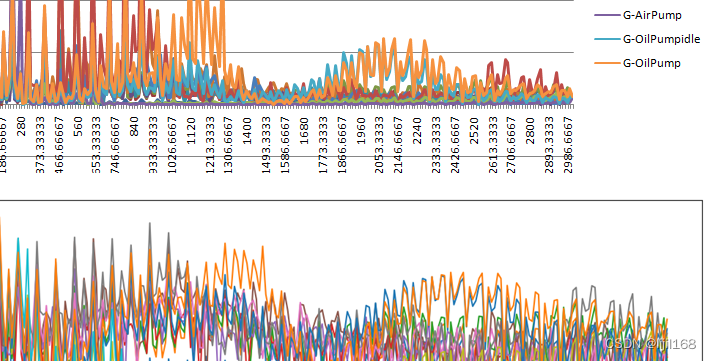
python仿真报告自动化——excite TD齿轮角加速度级计算
python仿真报告自动化——excite TD齿轮角加速度级计算 1 、问题-燃油泵相位优化2、难点-excite TD结果文件的提取3、代码 1 、问题-燃油泵相位优化 用excite TD对齿轮系进行仿真,模拟不同燃油泵相位对齿轮传动振动的影响,用齿轮角加速度级作为评价指标…...

如何系统的学习 C#
第一阶段:环境搭建与基础知识 1.1 安装开发环境 下载并安装Visual Studio或Visual Studio Code。若选用Visual Studio Code,记得安装C#扩展插件。 1.2 C#语言概述 了解C#的发展历程、特点以及应用场景。学习C#的基本语法规范,例如语句结尾…...

python爬虫----python列表高级
小伙伴们,大家好!今天学习的内容是python列表高级。 1、添加元素 append:在列表末尾添加元素 A [xiaoWang, xiaoZhang, xiaoHua] print("添加之前,列表A的数据:", A)temp input(请输入要添加的学生姓名:) A.append…...
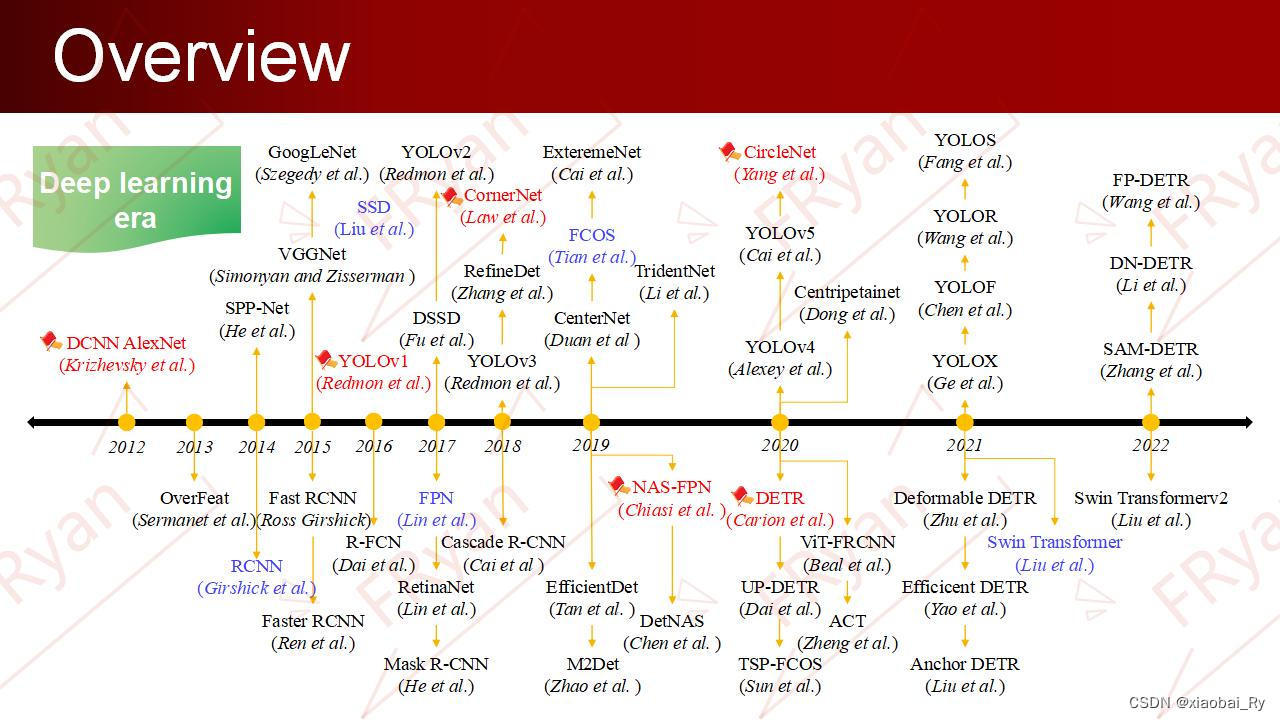
目标检测的相关模型图:YOLO系列和RCNN系列
目标检测的相关模型图:YOLO系列和RCNN系列 前言YOLO系列的图展示YOLOpassthroughYOLO2YOLO3YOLO4YOLO5 RCNN系列的图展示有关目标检测发展的 前言 最近好像大家也都在写毕业论文,前段时间跟朋友聊天,突然想起自己之前写画了一些关于YOLO、Fa…...

Linux基础命令2
目录 一.查看切换统计目录 1.Linux的文件属性 2. ls 命令 3.通配符 4.alias(别名) 5.du(disk use) 二.创建目录 1.mkdir (建立文件夹) 2.touch (建立文件) 三.Linux中的链接…...
IP组播基础
原理概述 IANA ( Internet Assigned Numbers Authority )将 IP 地址分成了 A 、 B 、 C 、 D 、 E5类,其中的 D 类为组播 IP 地址,范围是224.0.0.0~239.255.255.255。 一个 IP 报文,其目的地址如果是单播 IP 地址ÿ…...

Pytorch的named_children, named_modules和named_children
在 PyTorch 中,named_children、named_modules 和 named_parameters 是用于获取神经网络模型组件和参数的三种不同的方法。下面是它们各自的作用和区别: named_parameters:递归地列出所有参数名称和tensornamed_modules:递归地列…...

3.28总结
1.java学习记录 1.方法的重载 重载换而言之其实就是函数名不变,但是其中的参数需要改变,可以三个方面改变(参数类型,参数顺序,参数个数这三个方面入手,这样可以运用的) 但是:注意…...

C# 命名空间的两种定义哦写法与区别
这两种写法在C#中都是有效的,但是它们代表了不同的语法风格和C#版本特性。 第一种写法: namespace Nebula.PDF; public class PdfDocument {}这是C# 9.0及更高版本中引入的顶级语句(top-level statements)特性。它允许你直接在文…...

Rustdesk客户端编译后固定密码不稳定时好时坏
环境: rustdesk1.19 问题描述: Rustdesk客户端编译后固定密码不稳定时好时坏 解决方案: 出现固定密码不稳定的问题可能有多种原因,下面是一些可能的解决方法: 密码强度:确保所设置的固定密码足够强大…...
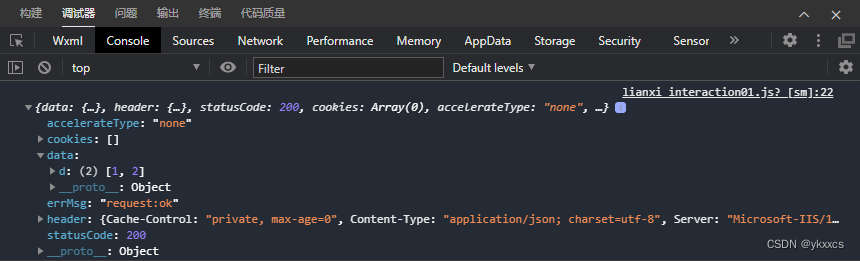
小程序利用WebService跟asp.net交互过程发现的问题并处理
最近在研究一个项目,用到asp.net跟小程序交互,简单的说就是小程序端利用wx.request发起请求。获取asp.net 响应回来的数据。但经常会报错。点击下图的测试按钮 出现如下错误: 百思不得其解,试了若干方法,都不行。 因为…...
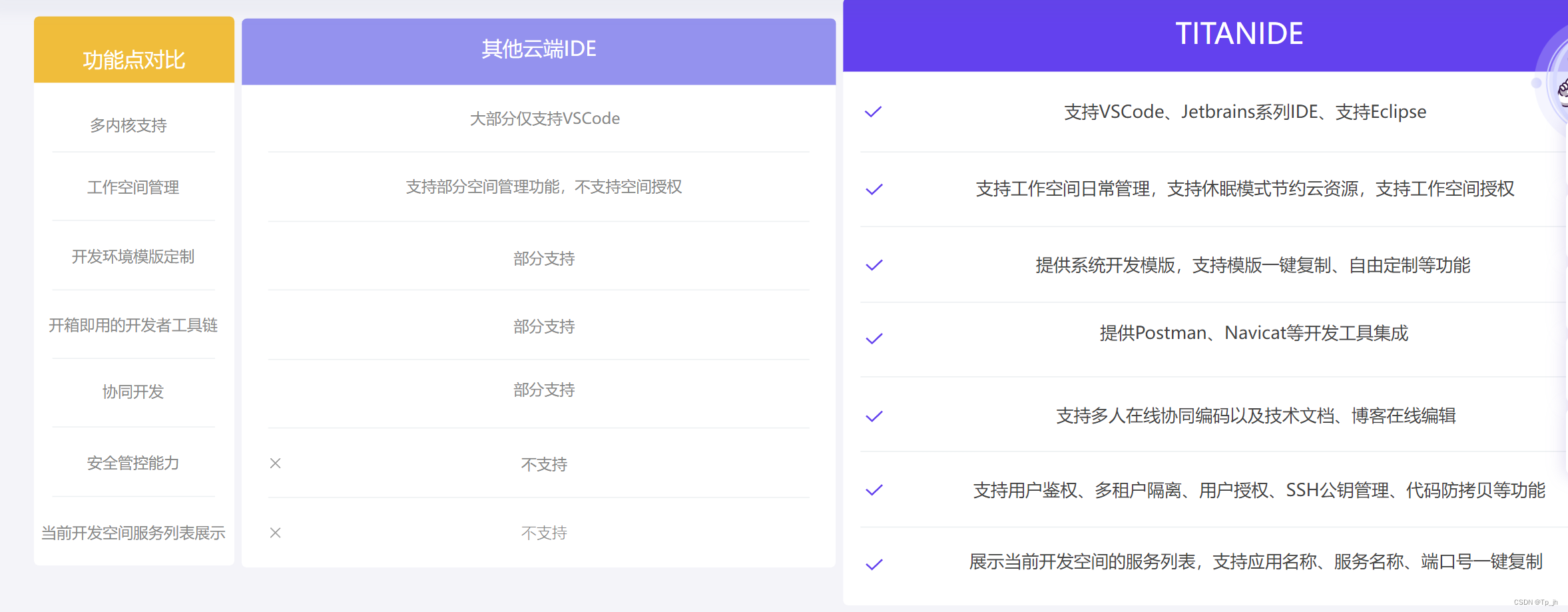
TitanIDE与传统 IDE 比较
与传统IDE的比较 TitanIDE 和传统 IDE 属于不同时代的产物,在手工作坊时代,一切都是那么的自然,开发者习惯 Windows 或 MacOS 原生 IDE。不过,随着时代的变迁,软件行业已经步入云原生时代,TitanIDE 是顺应…...
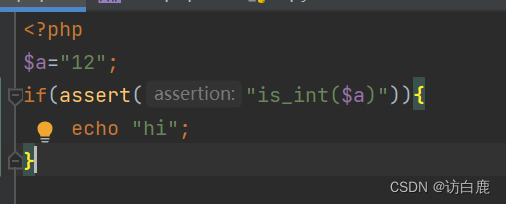
反序列化动态调用 [NPUCTF2020]ReadlezPHP1
在源代码上看到提示 访问一下看看 代码审计一下 <?php #error_reporting(0); class HelloPhp {public $a;public $b;public function __construct(){$this->a "Y-m-d h:i:s";$this->b "date";}public function __destruct(){$a $this->a;…...
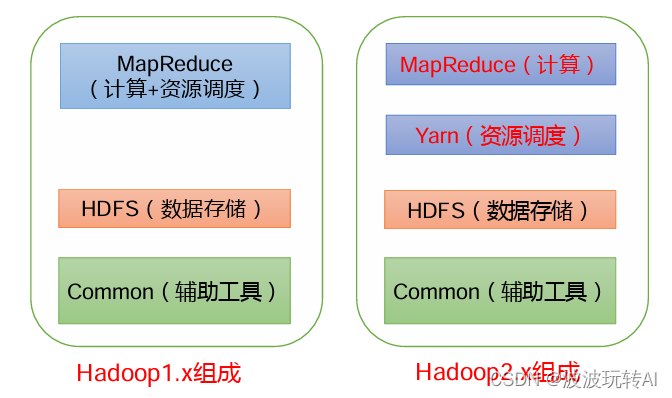
Hadoop面试重点
文章目录 1. Hadoop 常用端口号2.Hadoop特点3.Hadoop1.x、2.x、3.x区别 1. Hadoop 常用端口号 hadoop2.xhadoop3.x访问HDFS 端口500709870访问 MR 执行情况端口80888088历史服务器1988819888客户端访问集群端口90008020 2.Hadoop特点 高可靠:Hadoop底层维护多个数…...

【ONE·基础算法 || 分治·快排并归】
总言 主要内容:编程题举例,理解分治的思想(主要是对快排、并归的应用)。 文章目录 总言1、基本介绍2、颜色分类(medium)2.1、题解 3、快速排序(medium)3.1、题解ÿ…...
注册新用户)
Python 从0开始 一步步基于Django创建项目(11)注册新用户
1、修改C:\D\Python\Python310\study\snap_gram\users路径下的urls.py 添加‘注册新用户’URL。 #注册新用户 path(register/,views.register,nameregister), 2、修改C:\D\Python\Python310\study\snap_gram\users路径下的views.py 编写URL对应的视图函数register。 def r…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...