国产数据库中统计信息自动更新机制
数据库中统计信息描述的数据库中表和索引的大小数以及数据分布状况,统计信息的准确性对优化器选择执行计划时具有重要的参考意义。本文简要整理了下传统数据库和国产数据库中统计信息的自动更新机制,以加深了解。
1、数据库统计信息介绍
优化器是数据库中的重要模块,其作用是按照一定的判断原则为SQL语句找到在当前情形下的最高效执行路径。优化器的策略主要有基于成本的优化(CBO)和基于规则的优化(RBO):
- CBO根据SQL语句的代价进行最优执行计划的选择。它首先生成一组可能被使用的执行计划,然后估算每个执行计划的成本,并最终选择成本最小的执行计划。CBO依赖于统计信息来评估执行代价。
- RBO则基于硬编码在数据库中的一系列固定规则来决定SQL执行计划。随着数据库性能要求的提高,RBO逐渐向CBO发展,CBO能够根据数据的实际情况进行动态调整,在大多数情况下比RBO提供更好的性能。
在优化器CBO执行计划选择过程中,统计信息非常关键。统计信息主要是描述数据库中表、索引等对象的大小、规模以及数据分布状况的一类信息。主要包括以下几类:
- 表的统计信息:例如表的行数、块数、平均每行的大小等。这些信息描述了表的基本特征和规模。
- 索引的统计信息:包括索引的leaf blocks数量、索引字段的行数、不同值的大小等。索引的统计信息对于优化查询性能尤为重要,因为它们直接影响索引的访问方式和效率。
- 数据分布信息:如直方图(histograms)等,可以展示数据的分布情况,包括数据的最大值、最小值、平均值以及数据的频率分布等。这些信息有助于优化器评估查询条件的选择性,从而选择更高效的执行计划。
CBO优化器会根据这些统计信息来评估不同查询执行计划的成本,并选择成本最低的计划来执行查询。统计信息的准确性和实时性对于优化器的决策至关重要。因此,统计信息需要定期收集和维护,或是手动执行或是系统自动更新,以确保数据库的性能得到优化。本文将重点关注数据库中统计信息自动更新的策略。
除了优化SQL查询,通过统计信息还可以了解数据库中的数据分布情况、数据库的热点数据和冷数据。通过这些信息优化数据库的存储结构和访问策略,提高数据的访问效率
1.1 SQL语句执行流程
以MySQL数据库为例,一条SQL具体的执行过程,如下所示:

总的来说分为6个步骤:请求、缓存、SQL解析、优化SQL查询、调用引擎执行、返回结果。
- 连接:客户端向MySQL服务器发送一条查询请求,与connectors交互,连接池认证相关处理。请求会暂时存放在连接池(connection pool)中并由处理器(Management Serveices & Utilities)管理。当该请求从等待队列进入到处理队列,管理器会将该请求丢给SQL接口(SQL Interface)。
- 缓存:SQL接口接收到请求后会将请求进行hash处理,并与缓存中的结果进行比对,如果命中缓存,则立刻返回存储在缓存中的结果,否则进入下一阶段
- 解析:服务器进行SQL解析(词法语法)、预处理
- 优化:再由优化器生成对应的执行计划
- 执行:MySQL根据执行计划,调用存储引擎的API来执行查询
- 结果:将结果返回给客户端,同时缓存查询结果。
具体可参看“数据库系列之InnoDB存储引擎解密”
MySQL数据库是基于成本的优化,其中优化器使用了非常多的优化策略来生成一个最优的执行计划:
- 在表里面有多个索引的时候,决定使用哪个索引;
- 重新定义表的关联顺序(多张表关联查询时,并不一定按照SQL中指定的顺序进行,但有一些技巧可以指定关联顺序)
- 优化MIN()和MAX()函数(找某列的最小值,如果该列有索引,只需要查找B+Tree索引最左端,反之则可以找到最大值)
- 提前终止查询(比如:使用Limit时,查找到满足数量的结果集后会立即终止查询)
- 优化排序(在老版本MySQL会使用两次传输排序,即先读取行指针和需要排序的字段在内存中对其排序,然后再根据排序结果去读取数据行,而新版本采用的是单次传输排序,也就是一次读取所有的数据行,然后根据给定的列排序。对于I/O密集型应用,效率会高很多)
2、传统数据库中统计信息自动更新策略
2.1 MySQL数据库中统计信息自动更新机制
MySQL数据库中的统计信息分为持久化统计信息和非持久化统计信息,通过参数innodb_stats_persistent控制,默认是开启的。持久化统计信息将某一时刻的统计信息保存在磁盘中,避免每次查询时重新计算。如果表更新不是很频繁,或者没有达到MySQL必须重新计算统计信息的临界值,可直接从磁盘上获取。相比较非持久化统计信息,性能开销更小。
持久化统计信息还有一个参数innodb_stats_auto_recalc控制是否自动重新计算持久化统计信息,默认开启。统计信息自动更新策略:
当一张表数据变化超过10%后,MySQL会针对这张表统计信息的更新时间戳做一个判断,检查最后一次更新的时间是否超过10秒;如果不到10秒,把这张表加到一个统计信息更新队列中,到时间了再重新计算;如果超过了10秒,直接重新计算,并且更新时间戳。
另外参数innodb_stats_persistent_sample_pages 控制统计信息采样的页数,默认是20,页数越多,统计信息也就越准确,也就有助于查询优化器选择最优的查询计划。
统计信息更新完成后,会更新表mysql.innodb_table_stats和mysql.innodb_index_stats中的信息,包括表的行数n_rows、主键的数据页个数clustered_index_size、二级索引的数据页个数sum_of_other_index_sizes、索引采样页个数sample_size等重要信息。
mysql> SELECT * FROM mysql.innodb_table_stats WHERE table_name like 't1'\G
*************************** 1. row ***************************database_name: testtable_name: t1last_update: 2024-03-23 14:36:34n_rows: 5clustered_index_size: 1
sum_of_other_index_sizes: 2
2.2 PostgreSQL中统计信息自动更新机制
PostgreSQL数据库中统计信息自动更新主要是通过自动真空清理(autovacuum)和统计信息收集(analyze)来实现。
1)自动真空清理(autovacuum)
PostgreSQL默认启用了自动真空清理功能(autovacuum参数控制),它会定期扫描表和索引,清理不再需要的行版本(由于MVCC机制产生的),并释放空间。当表自上一次vacuum后更新记录数超过阈值后,会触发autovacuum动作,计算方法如下:
vacuum threshold = vacuum base threshold + vacuum scale factor * number of tuples
其中vacuum base threshold为autovacuum_vacuum_threshold(默认为50)、vacuum scale factor 为autovacuum_vacuum_scale_factor(默认为10%)、the number of tuples为pg_class.reltuples。
2)统计信息收集Analyze
当表或者索引的数据变化超过一定的阈值后,PostgreSQL也会自动进行统计信息收集操作。
analyze threshold = analyze base threshold + analyze scale factor * number of tuples
其中analyze base threshold为autovacuum_analyze_threshold(默认为50)、analyze scale factor 为autovacuum_analyze_scale_factor(默认为10%)、the number of tuples为pg_class.reltuples。
2.3 Oracle数据库统计信息自动更新机制
Oracle数据库中默认开启统计信息自动收集任务,使用的任务为gather_stats_prog。gather_stats_prog调用了DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC存储过程。在Oracle数据库中通过设置不同的维护窗口形式,设定窗口运行的开始时间、持续时间:
SQL> SELECT a.WINDOW_NAME,a.REPEAT_INTERVAL,a.duration FROM dba_scheduler_windows a WHERE ENABLED = 'TRUE';
WINDOW_NAME REPEAT_INTERVAL DURATION ------------------ ------------------------------------------------------- -----------------MONDAY_WINDOW freq=daily;byday=MON;byhour=22;byminute=0; bysecond=0 +000 04:00:00TUESDAY_WINDOW freq=daily;byday=TUE;byhour=22;byminute=0; bysecond=0 +000 04:00:00WEDNESDAY_WINDOW freq=daily;byday=WED;byhour=22;byminute=0; bysecond=0 +000 04:00:00THURSDAY_WINDOW freq=daily;byday=THU;byhour=22;byminute=0; bysecond=0 +000 04:00:00FRIDAY_WINDOW freq=daily;byday=FRI;byhour=22;byminute=0; bysecond=0 +000 04:00:00SATURDAY_WINDOW freq=daily;byday=SAT;byhour=6;byminute=0; bysecond=0 +000 20:00:00SUNDAY_WINDOW freq=daily;byday=SUN;byhour=6;byminute=0; bysecond=0 +000 20:00:00
————————————————
如果参数STATISTICS_LEVEL的值为TYPICAL(默认)或者ALL,则DBA_TAB_MODIFICATIONS会记录自上次自动统计信息收集完成之后对目标表的insert、update、delete的操作影响行数,并且还会记录自从上次自动收集统计信息之后是否发生过truncate。如果DBA_TAB_MODIFICATIONS中记录的INSERT+UPDATE+DELETE所影响的行记录之和超过了DBA_TABLES中目标表记录数的10%,或者是自上次统计信息收集完成之后目标表执行过truncate操作,那么Oracle会认为目标表的统计信息已经失效,自动统计信息收集作业就会对目标表重新收集统计信息。
如果想禁用或者开启统计信息自动收集任务:
#禁用统计信息自动收集
SQL> EXEC dbms_auto_task_admin.disable(client_name=> 'auto optimizer stats collection',operation=> NULL,window_name=> NULL);
#启用统计信息自动收集
SQL> EXEC dbms_auto_task_admin.enable(client_name=> 'auto optimizer stats collection',operation=> NULL,window_name=> NULL);
#禁用维护窗口中统计信息收集
EXEC dbms_auto_task_admin.disable(client_name=>'auto optimizer stats collection',operation=>NULL,window_name=>'TUESDAY_WINDOW');
#启用维护窗口中统计信息收集
EXEC dbms_auto_task_admin.enable(client_name=>'auto optimizer stats collection',operation=>NULL,window_name=>'TUESDAY_WINDOW');
2.4 DB2数据库统计信息自动更新机制
DB2数据库中支持统计信息的自动收集,有两种方式:一是通过配置auto_stmt_stats参数在语句编译时同步收集统计信息;另一种是RUNSTATS命令后台执行的时候,配置auto_runstats在后台自动收集统计信息。默认情况下,这两个参数都是启用状态。相比较异步统计信息收集,实时统计信息更为及时准确,为优化器生成最佳的执行计划以提升查询性能。
自动收集统计信息某些情况下可能会OLTP联机类业务的性能会产生影响,在实际使用过程中进行配置将影响降到最低:
- 使用RUNSTATS命令进行异步的统计信息收集操作
- 对于每个查询,同步统计信息收集操作的时间限制为5秒。如果同步收集操作超出时间限制,那么将提交异步收集请求。
- 实时同步的统计信息存储在高速缓存中,避免更新系统目录中涉及的内存使用情况和可能的锁定争用。后续SQL编译请求可以使用统计信息高速缓存中的统计信息。
- 对于每个表,只能执行一个同步统计信息收集操作。
另外,在开启统计信息自动收集需开启参数配置AUTO_MAINT和AUTO_TBL_MAINT,AUTO_MAINT用于指定自动维护任务的配置文件,AUTO_TBL_MAINT用于指定自动维护任务是否包括表级别的统计信息收集。
Automatic maintenance (AUTO_MAINT) = ONAutomatic database backup (AUTO_DB_BACKUP) = OFFAutomatic table maintenance (AUTO_TBL_MAINT) = ONAutomatic runstats (AUTO_RUNSTATS) = ONReal-time statistics (AUTO_STMT_STATS) = ONStatistical views (AUTO_STATS_VIEWS) = OFFAutomatic sampling (AUTO_SAMPLING) = OFFAutomatic column group statistics (AUTO_CG_STATS) = OFFAutomatic reorganization (AUTO_REORG) = OFF
3、国产数据库中统计信息更新策略
3.1 TiDB数据库
TiDB数据库中使用变量tidb_analyze_version 控制统计信息的收集,在 v5.3.0 及之后的版本中,该变量的默认值为 2。Version 2的统计信息避免了Version 1中因为哈希冲突导致的在较大的数据量中可能产生的较大误差,并保持了大多数场景中的估算精度。

TiDB中除了ANALYZE Table手动收集统计信息外,也支持自动更新。如果表发生增删改时,TiDB会自动更新表的总行数以及修改的行数,统计信息更新的周期为20*stats-lease。stats-lease默认配置为3s,如果将其指定为0,那么统计信息将不会自动更新。
另外如果表中修改的行数与总行数的比值大于tidb_auto_analyze_ratio(默认值为0.5),并且当前时间在tidb_auto_analyze_start_time和tidb_auto_analyze_end_time之间时,TiDB会在后台执行ANALYZE TABLE tbl语句自动更新这个表的统计信息。

为了避免小表因为少量数据修改而频繁触发自动更新,当表的行数小于1000时,TiDB不会触发对此表的自动更新。同时通过参数tidb_enable_auto_analyze也可以关闭统计信息自动更新机制,以避免自动更新统计信息消耗过多资源,影响在线业务。
3.2 OceanBase数据库
在OceanBase数据库优化器中,统计信息以普通数据的形式存储在内部表中,并且会在本地维护统计信息的缓存,以提高优化器对统计信息的访问速度。统计信息包含表统计信息(Table Level Statistics)和列统计信息(Column Level Statistics)两种类型。
OceanBase数据库中支持手动收集统计信息和自动收集统计信息,同时支持对应的视图查询收集的统计信息,包括Oracle模式和MySQL模式。其中OceanBase统计信息自动收集类似Oracle的任务窗口形式,基于DBMS_SCHEDULER系统包实现的MAINTENANCE WINDOW来实现每日的自动统计信息收集,如下所示:

自动统计信息收集任务的开启关闭也是通过设置MAINTENANCE WINDOW的属性:
DBMS_SCHEDULER.DISABLE($window_name);
DBMS_SCHEDULER.ENABLE($window_name);
OceanBase数据库中表的统计信息过期判断标准为:如果当前表增量的DML次数(上一次收集统计信息时DML次数到本次收集统计信息期间发生的增/删/改总次数)超过设置的阈值时就会过期。阈值的默认值是10%,阈值可以通过peres调整设置。具体的更新策略如下:
- 系统表和非分区用户表的自动收集策略:
- 如果表没有GLOBAL级别的统计信息,自动收集统计信息。
- 如果表有GLOBAL级别的统计信息,但是统计信息已经过期,则自动收集统计信息。
- 否则,OceanBase数据库优化器不会自动收集统计信息。
- OceanBase数据库分区用户表的自动收集策略:
- 如果表没有任何统计信息,自动收集所有的统计信息。
- 如果表有分区级别的统计信息,但是没有GLOBAL级别统计信息,则采用增量的方式自动收集统计信息。
- 如果表有GLOBAL级别统计信息,但是已经过期,则自动收集所有的统计信息。
- 如果表有GLOBAL级别统计信息,但是没有全部过期,只是部分分区的统计信息过期,则自动收集统计信息过期的分区统计信息,同时采用增量的方式推导GLOBAL级别统计信息。
3.3 OpenGauss数据库
OpenGauss数据库类似PostgreSQL数据库的做法,通过AutoVacuum机制来实现统计信息的自动更新。AutoVacuum后台有常驻线程AVClauncher,这个线程会定期唤起AVCWorker线程来执行实际的vacuum与analyze任务。一旦识别出过时数据,AutoVacuum会执行VACUUM操作,将过时数据行标记为可重用的空间,并更新表的统计信息,以确保查询优化器能够做出正确的执行计划。
当autovacuum设置为on时,系统会定时启动autovacuum线程(自动清理线程)自动执行VACUUM和ANALYZE命令,回收被标识为删除状态的记录空间,并更新表的统计数据。
- 对于空表而言,当表中插入数据的行数大于50时,会触发表自动进行ANALYZE。
- 对于表中已有数据的情况,阈值设定为
autovacuum_analyze_threshold+ autovacuum_analyze_scale_factor*reltuples
其中autovacuum_analyze_threshold表示当表上被删除、插入或更新的记录数超过设定的阈值时才会对这个表执行ANALYZE操作,默认值为50;autovacuum_analyze_scale_factor表示触发一个ANALYZE时增加到autovacuum_analyze_threshold的表大小的缩放系数,默认值为10%;reltuples是表的总行数。
同时,autovacuum生效还依赖于下面几个GUC参数:
- track_counts参数需要设置为on,表示开启收集收据库统计数据功能。
- autovacuum_max_workers参数需要大于0,该参数表示能同时运行的自动清理线程的最大数量。
- autovacuum_mode参需要配置允许进行analyze。
另外autoanalyze设置了超时时间,在对某张表做autoanalyze时,如果该表的analyze时长超过了autoanalyze_timeout,则自动取消该表此次analyze。
3.4 达梦数据库
在达梦数据库中统计信息包括表的行数、块数、平均每行的大小、索引的高度、叶子节点数以及索引字段的行数等描述数据库中表和索引的大小数以及数据分布状况等的一类信息。DM数据库中统计信息收集是通过DBMS_STATS包实现的,支持手动收集和自动收集,其自动收集统计信息配置如下:
--打开表数据量监控开关,参数值为 1 时监控所有表,2 时仅监控配置表
SP_SET_PARA_VALUE(1,'AUTO_STAT_OBJ',2);--设置 SYSDBA.T 表数据变化率超过 15% 时触发自动更新统计信息
DBMS_STATS.SET_TABLE_PREFS('SYSDBA','T','STALE_PERCENT',15);--配置自动收集统计信息触发时机
SP_CREATE_AUTO_STAT_TRIGGER(1, 1, 1, 1,'14:36', '2020/3/31',60,1);/*
函数各参数介绍
SP_CREATE_AUTO_STAT_TRIGGER(TYPE INT, --间隔类型,默认为天FREQ_INTERVAL INT, --间隔频率,默认 1FREQ_SUB_INTERVAL INT, --间隔频率,与 FREQ_INTERVAL 配合使用FREQ_MINUTE_INTERVAL INT, --间隔分钟,默认为 1440STARTTIME VARCHAR(128), --开始时间,默认为 22:00DURING_START_DATE VARCHAR(128), --重复执行的起始时间,默认 1900/1/1MAX_RUN_DURATION INT, --允许的最长执行时间(秒),默认不限制ENABLE INT --0 关闭,1 启用 --默认为 1
);
*/
4、各类数据库统计信息自动收集策略对比
上文对比了几种传统数据库和国产数据库中统计信息自动收集的策略,像Oracle和DB2数据库中统计信息的收集对性能和交易可能有潜在的风险,实际生产环境中默认是不开启的。像MySQL系列的数据库(TDSQL for MySQL、GoldenDB等),默认开启统计信息自动收集。在实际运行过程中,如果由于统计信息没更新导致应用出现慢SQL执行计划变化,建议手动触发统计信息的及时更新。

参考资料:
- https://dev.mysql.com/doc/refman/8.3/en/innodb-performance-optimizer-statistics.html
- https://www.postgresql.org/docs/15/runtime-config-autovacuum.html
- https://blog.csdn.net/weixin_30895723/article/details/106537408
- https://www.ibm.com/docs/zh/db2/11.5?topic=statistics-automatic-collection
- https://docs.pingcap.com/zh/tidb/stable/statistics
- https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/DatabaseReference
- https://eco.dameng.com/document/dm/zh-cn/pm/query-optimization
相关文章:
国产数据库中统计信息自动更新机制
数据库中统计信息描述的数据库中表和索引的大小数以及数据分布状况,统计信息的准确性对优化器选择执行计划时具有重要的参考意义。本文简要整理了下传统数据库和国产数据库中统计信息的自动更新机制,以加深了解。 1、数据库统计信息介绍 优化器是数据库…...

【C++】入门C++(中)
好的,我们继续,这是 C专栏的第二篇博客,还没读过上一篇博客可以进入我创建的专栏阅读 入门C(上)再回来哦~ 下面我们要讲的第一个概念就是函数重载 函数重载 1. 函数重载概念 什么是函数重载? 简单来说…...
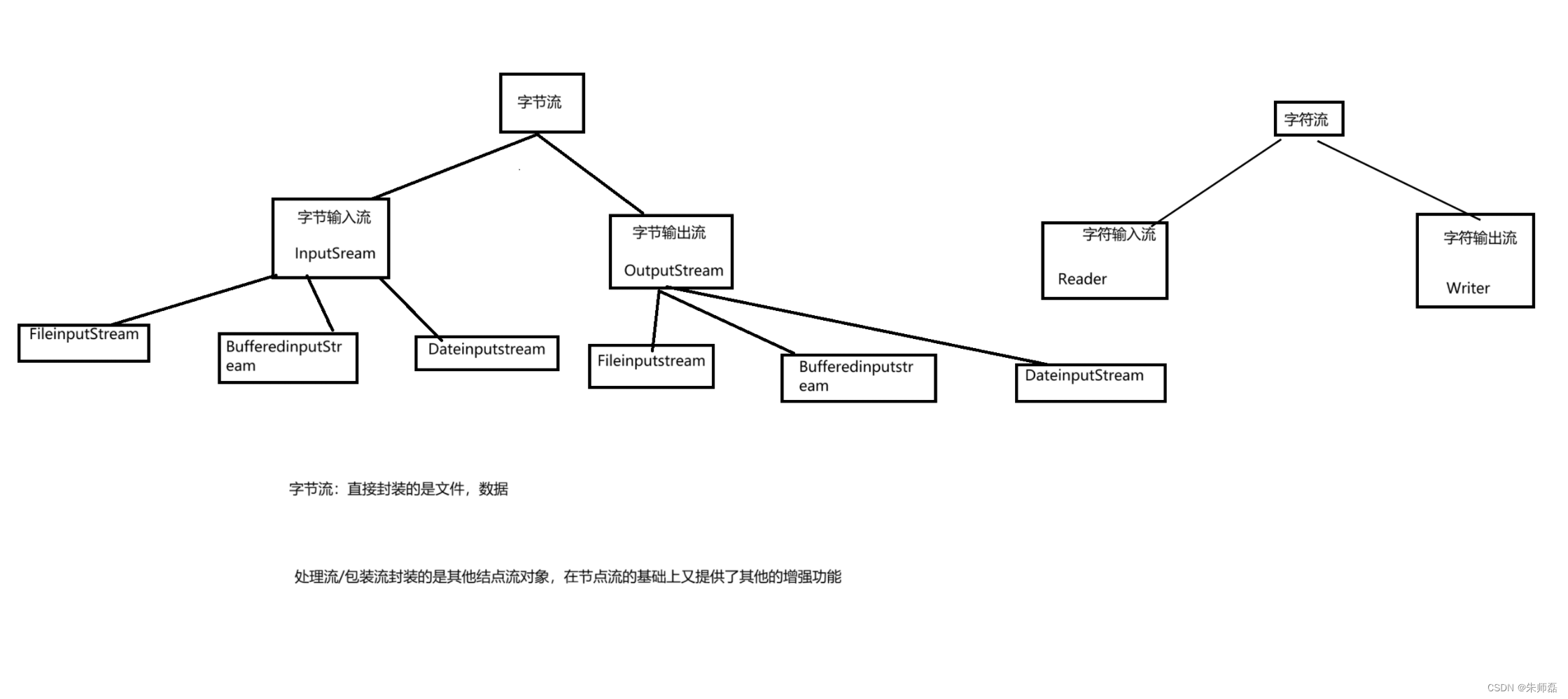
javaIO
file类 一个File类的对象可以表示一个具体的文件或目录 mkdir 创建单级文件夹 mkdirs 创建多级文件夹 delete 删除一个文件夹时,文件夹里面必须是空的 listfiles 将文件夹的子集放到一个file类型的数组中 输入及输出的概念 输入input 输出output 把jav…...
睿尔曼超轻量仿人机械臂之复合机器人底盘介绍及接口调用
机器人移动平台是一个包含完整成熟的感知、认知和定位导航能力的轮式机器人底盘产品级平台,产品致力于为各行业细分市场的商用轮式服务机器人提供一站式移动机器人解决方案,让合作伙伴专注在核心业务/人机交互的实现。以下是我司产品双臂机器人以及复合升…...
用JSch实现远程传输文件并打包成jar
本文将简单介绍一下 JSch 这个Java的第三方库的一个简单用法,并以此为实例,讲解 IntelliJ 中打包成 jar 包的2种方式。 实现目标 我们的目标是,做出一个jar包,它能够实现类似于 scp 命令的远程传输文件的功能。用法如下…...

2023年第十四届蓝桥杯大赛软件类省赛C/C++研究生组真题(代码完整题解)
C题-翻转⭐ 标签:贪心 简述:如果 S 中存在子串 101 或者 010,就可以将其分别变为 111 和 000,操作可以无限重复。最少翻转多少次可以把 S 变成和 T 一样。 链接: 翻转 思路:要求步骤最少->S每个位置最多修改一次->从头开始遍历不匹配就翻转->翻转不了就-1 …...
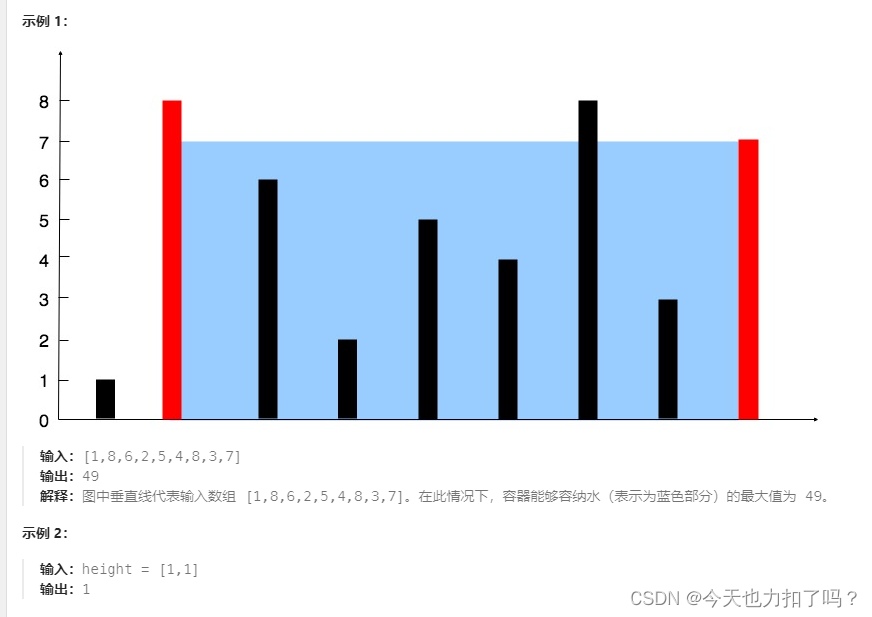
力扣刷题Days28-第二题-11.盛水最多的容器(js)
目录 1,题目 2,代码 3,学习与总结 3.1思路回顾 1,如何遍历 2,算法流程 3.2剖析问题 1,题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, h…...
文生图大模型三部曲:DDPM、LDM、SD 详细讲解!
1、引言 跨模态大模型是指能够在不同感官模态(如视觉、语言、音频等)之间进行信息转换的大规模语言模型。当前图文跨模态大模型主要有: 文生图大模型:如 Stable Diffusion系列、DALL-E系列、Imagen等 图文匹配大模型:如CLIP、Chinese CLIP、…...
算法学习——LeetCode力扣动态规划篇10(583. 两个字符串的删除操作、72. 编辑距离、647. 回文子串、516. 最长回文子序列)
算法学习——LeetCode力扣动态规划篇10 583. 两个字符串的删除操作 583. 两个字符串的删除操作 - 力扣(LeetCode) 描述 给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。 每步 可以删除任意一个字符串中的一个…...
TASKPROMPTER
baseline模型的预训练权重就有1.6G! 多吓人呐,当时我就暂停下载了,不建议复现...

C之易错注意点转义字符,sizeof,scanf,printf
目录 前言 一:转义字符 1.转义字符顾名思义就是转换原来意思的字符 2.常见的转义字符 1.特殊\b 2. 特殊\ddd和\xdd 3.转义字符常错点----计算字符串长度 注意 : 如果出现\890,\921这些的不是属于\ddd类型的,,不是一个字符…...
)
等级保护测评无补偿因素的高风险安全问题判例(共23项需整改)
层面 控制点 要求项 安全问题 适用范围 充分条件 整改建议简要 安全物理环境 基础设施位置 应保证云计算基础设施位于中国境内 1.云计算基础设施物理位置不当 二级及以上 相关基础设施不在中国境内 云平台相关基础设施在中国境内部署 安全通信网络 网络架构 应…...

JavaScript笔记 09
目录 01 DOM操作事件的体验 02 获取元素对象的五种方式 03 事件中this指向问题 04循环绑定事件 05 DOM节点对象的常用操作 06 点亮盒子的案例 07 节点访问关系 08 设置和获取节点内容的属性 09 以上内容的小总结 01 DOM操作事件的体验 js本身是受事件驱动的脚本语言 什…...

操作教程|在MeterSphere中通过SSH登录服务器的两种方法
MeterSphere开源持续测试平台拥有非常强大的插件集成机制,用户可以通过插件实现平台能力的拓展,借助插件或脚本实现多种功能。在测试过程中,测试人员有时需要通过SSH协议登录至服务器,以获取某些配置文件和日志文件,或…...

Swashbuckle.AspNetCore介绍
使用 ASP.NET Core 构建的 API 的 Swagger 工具。直接从您的路由、控制器和模型生成精美的 API 文档,包括用于探索和测试操作的 UI。 除了 Swagger 2.0 和 OpenAPI 3.0 生成器外,Swashbuckle 还提供了由生成的 Swagger JSON 提供支持的令人敬畏的 swagg…...

【Spring】通过Spring收集自定义注解标识的方法
文章目录 前言1. 声明注解2. 使用 Spring 的工厂拓展3. 收集策略4. 完整的代码后记 前言 需求: 用key找到对应的方法实现。使用注解的形式增量开发。 MyComponent public class Sample1 {MyMethod(key "key1")public String test2() {return "She…...

基于深度学习的图书管理推荐系统(python版)
基于深度学习的图书管理推荐系统 1、效果图 1/1 [] - 0s 270ms/step [13 11 4 19 16 18 8 6 9 0] [0.1780757 0.17474999 0.17390694 0.17207369 0.17157653 0.168248440.1668652 0.16665359 0.16656876 0.16519257] keras_recommended_book_ids深度学习推荐列表 [9137…...

MATLAB 点云随机渲染赋色(51)
MATLAB 点云随机渲染赋色(51) 一、算法介绍二、算法实现1.代码2.效果总结一、算法介绍 为点云中的每个点随机赋予一种颜色,步骤和效果如图: 1、读取点云 (ply格式) 2、随机为每个点的RGB颜色字段赋值 3、保存结果 (ply格式) 二、算法实现 1.代码 代码如下(示例):…...

通过一篇文章让你完全掌握VS和电脑常用快捷键的使用方法
VS常用快捷键 前言一、 VS常用快捷键常用VS运行调试程序快捷键常用VS编辑程序快捷键 二、常用windows系统操作快捷键 前言 VS(Visual Studio)是一款强大的开发工具,提供了许多常用快捷键,以提高开发效率。这些快捷键包括文件操作…...

ChatGPT指引:借助ChatGPT撰写学术论文的技巧
ChatGPT无限次数:点击直达 ChatGPT指引:借助ChatGPT撰写学术论文的技巧 在当今信息技术高度发达的时代,人工智能技术的不断发展为学术研究者提供了更多的便利和可能。其中,自然语言处理技术中的ChatGPT无疑是一种强大的工具,它能…...
)
收藏!小白程序员必看:轻松入门大模型(训练、微调与推理全解析)
本文系统梳理了大模型从训练、微调到推理的全过程,解析了Transformer架构、RLHF、RAG及推理加速等关键技术。通过介绍模型训练如何赋予知识、微调如何塑造专长、以及推理如何运用知识解决问题,帮助读者理解大模型的运作机制。同时,详细解释了…...

破局算力碎片化:基于K8s调度与Docker多架构镜像的GB28181/RTSP异构AI视频底座实践
引言:跨越“硬件巴别塔”的至暗时刻 在安防行业深耕十载,我目睹了无数优秀的项目因“硬件碎片化”而折戟沉沙。现场环境往往是“万国牌”混战:中心机房是x86架构的NVIDIA GPU集群,边缘端却是ARM架构的华为昇腾、瑞芯微或寒武纪NP…...

oneTBB安全编程规范终极指南:多线程环境下的数据保护策略
oneTBB安全编程规范终极指南:多线程环境下的数据保护策略 【免费下载链接】oneTBB 项目地址: https://gitcode.com/gh_mirrors/one/oneTBB oneTBB(oneAPI Threading Building Blocks)是一款强大的并行编程库,专为多核处理…...

VL53L0X飞行时间测距传感器嵌入式驱动详解
1. VL53L0X高精度飞行时间测距传感器嵌入式驱动深度解析1.1 器件本质与工程定位VL53L0X并非传统红外或超声波测距模块,而是STMicroelectronics推出的基于单光子雪崩二极管(SPAD)阵列与精密时间数字转换器(TDC)的飞行时…...

BEMD算法在图像去噪中的应用:原理与MATLAB实现对比传统方法
BEMD算法在图像去噪中的创新实践:从原理到MATLAB工程实现 当一张珍贵的医学影像被噪声污染,或是卫星传回的遥感图片出现干扰时,传统去噪方法往往面临保真度与去噪效果的权衡困境。二维经验模态分解(BEMD)作为一种自适应信号处理方法ÿ…...
:硬件电源设计)
英伟达系列芯片如何用于自动驾驶开发之(二):硬件电源设计
**作者 |**Jessie 出品 | 焉知 知圈 | 进“底盘社群”请加微yanzhi-6,备注底盘 往期回顾 英伟达系列芯片如何应用于智能汽车开发看这两篇文章就够了(一) 英伟达系列芯片如何应用于智能汽车开发看这两篇文章就够了(二) 英伟达…...

为什么你让 Claude 做网页,总是一股“AI味”?这 5 个办法,能把那股廉价感压下去
如果你直接丢一句话给 Claude,让它帮你生成一个网页,那么大概率,你最后拿到的会是一个“能用,但也就只是能用”的结果。比如,你只给它这样一条提示:Code a landing page of a SaaS service called Roxy tha…...

如何在AndroidStudio里面接入你的AI助手
1 寻找AndroidStudio的model接口处 在最左侧栏你会发现它自带的一个AI chat/agent 模型,点进去后 右下角有一个切换模型,默认的是Genimi,在Manage Model里面我们可以管理AI模型,也就是我们的接口处 不过细心的你也可以从这里的左…...

EtherCAT在工业机器人多轴同步控制中的关键技术与实践
1. 为什么工业机器人需要EtherCAT多轴同步? 想象一下交响乐团演奏的场景:小提琴手、大提琴手、管乐手必须严格遵循指挥的节拍,哪怕只有毫秒级的误差都会导致演奏混乱。工业机器人的多轴运动也是如此——六轴机械臂的每个关节电机、传送带的伺…...

深入解析PCIE数据链路层:DL_Active与DL_UP状态机制及其应用
1. PCIe数据链路层基础概念 PCIe(Peripheral Component Interconnect Express)作为现代计算机系统中最重要的高速串行总线标准之一,其架构采用分层设计理念。数据链路层(Data Link Layer)作为承上启下的关键层级&#…...