在 Amazon Timestream 上通过时序数据机器学习进行预测分析

由于不断变化的需求和现代化基础设施的动态性质,为大型应用程序规划容量可能会非常困难。例如,传统的反应式方法依赖于某些 DevOps 指标(如 CPU 和内存)的静态阈值,而这些指标在这样的环境中并不足以解决问题。在这篇文章中,我们展示了如何使用 Amazon SageMaker 内置算法,对存储在 Amazon Timestream 中的汇总 DevOps 数据(CPU、内存、每秒交易量)进行预测分析。这样可以实现主动式容量规划,防止潜在的业务中断。通过这种方法,您可以使用 Amazon SageMaker,对存储在 Amazon Timestream 中的任何时间序列数据运行机器学习。
Amazon Timestream 是一种快速、可扩展且无服务器的时间序列数据库服务,可轻松存储和分析每天数万亿个事件。Amazon Timestream 会自动纵向扩展或缩减以调整容量和性能,因此您无需管理底层基础设施。
Amazon SageMaker 是一项完全托管式机器学习(ML)服务。借助 Amazon SageMaker,数据科学家和开发人员可以轻松快速地构建和训练机器学习模型,然后直接将其部署到生产就绪型托管环境中。它提供了集成的 Jupyter 创作 Notebook 实例,可快速访问数据来源以进行探索和分析,因此您无需管理服务器。它还提供了常见的机器学习算法,这些算法经过优化,可高效地运行在分布式环境中的超大量数据上。
解决方案概览
DevOps 团队可以使用 Timestream 存储指标、日志和其它时间序列数据。然后,您可以查询这些数据,深入了解系统的行为。Timestream 能够以低延迟处理大量传入数据,这使团队能够执行实时分析。DevOps 团队可以实时分析性能指标和其它运营数据,以便快速制定决策。
以下参考架构展示了如何将 Timestream 用于 DevOps 应用场景。
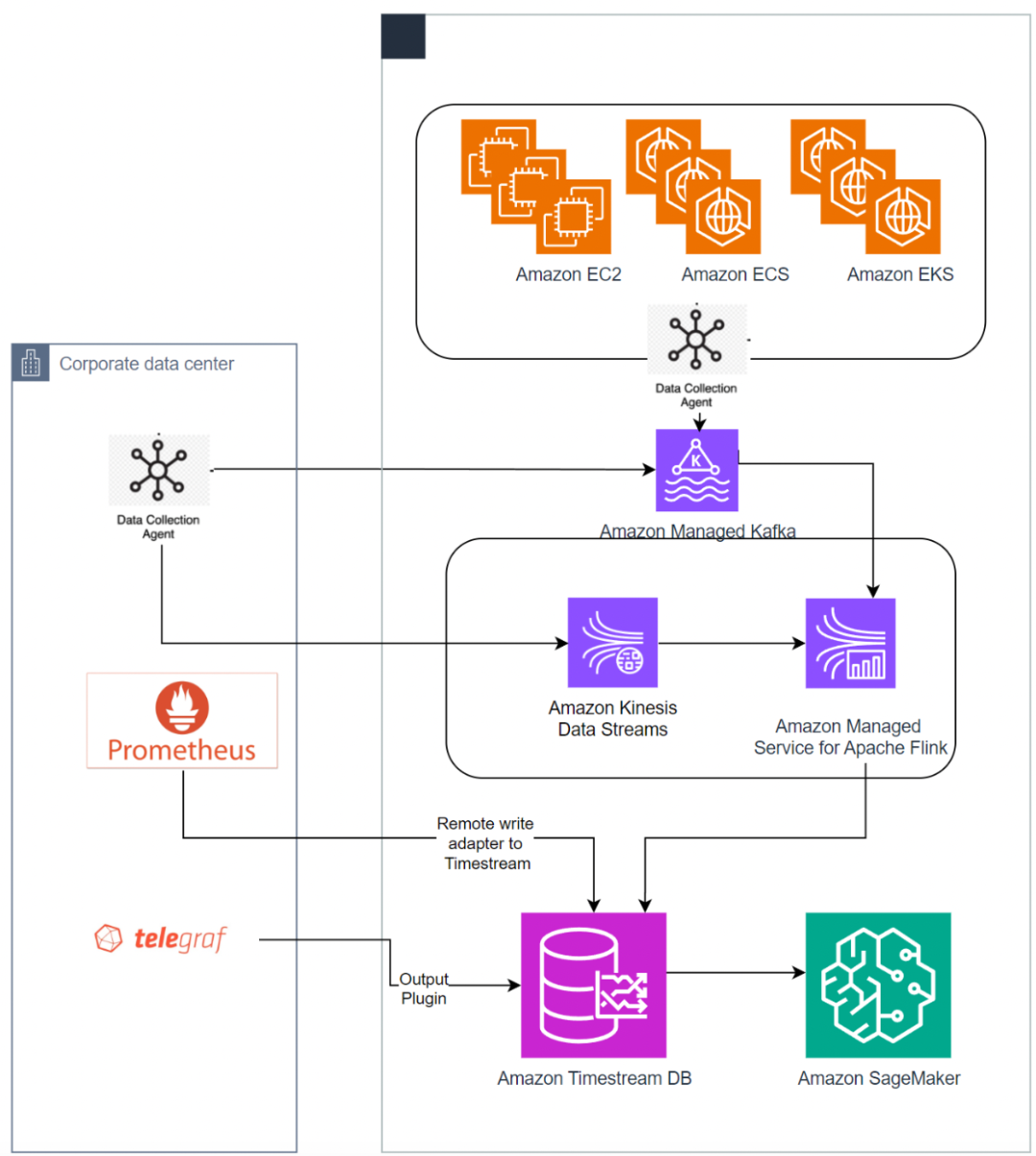
解决方案包含以下关键组件:
遥测数据,来自云端和本地运行的应用程序和服务器,使用开源收集代理(如 Prometheus 和 Telegraf)摄入。
数据也可以摄取自流式服务,例如 Amazon Managed Streaming for Apache Kafka (Amazon MSK) 和 Amazon Kinesis,使用适用于 Apache Flink 的亚马逊托管服务摄入。
摄取数据后,您可以使用可视化工具来分析数据和生成控制面板,这些工具包括 Grafana 和 Amazon QuickSight(有关详细信息,请参阅 Amazon QuickSight:
https://docs.aws.amazon.com/timestream/latest/developerguide/Quicksight.html),以及其它使用 JBDC 和 ODBC 驱动程序的工具。
Amazon SageMaker 用于运行预测分析。有关更多详细信息,请参阅 Amazon SageMaker:
https://docs.aws.amazon.com/timestream/latest/developerguide/Sagemaker.html
先决条件
要理解这篇文章,您应该熟悉 Timestream、Amazon SageMaker、Amazon Simple Storage Service (Amazon S3)、Amazon Identity and Access Management (IAM) 和 Python 的关键概念。这篇文章还包括一个动手试验室,使用 Amazon CloudFormation 模板和 Jupyter Notebook 预置,并与相关 Amazon 服务交互。这需要一个具有必要 IAM 权限的 Amazon 账户。
启动动手实验室
完成以下步骤以启动动手实验室:
1. 启动 CloudFormation 模板:
https://console.aws.amazon.com/cloudformation/home?#/stacks/create/review?templateURL=https://aws-blogs-artifacts-public.s3.amazonaws.com/artifacts/DBBLOG-3596/predictive_analytics.yaml
注意:此解决方案创建的亚马逊云科技资源会在账户中产生费用,请务必在完成后删除堆栈。
2. 提供堆栈名称,将所有其它选项保留为默认值。此堆栈创建 Timestream 数据库和表,并提取汇总 DevOps 数据示例。它还会创建一个 Amazon SageMaker Notebook 实例和 Amazon S3 存储桶。
3. 堆栈完成后,记下 Notebook 实例和 S3 存储桶的名称,这些信息在 Amazon CloudFormation 控制台上堆栈的输出选项卡中列出。
我们使用 Amazon SageMaker Notebook 实例来准备来自 Timestream 的数据、训练机器学习模型和运行预测。
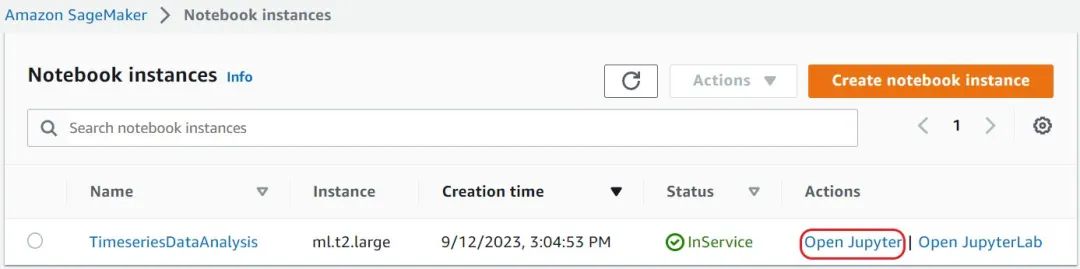
4. 要访问 Notebook 实例,请导航到 Amazon SageMaker 控制台,然后在导航窗格中选择 Notebook 实例。
5. 打开由 CloudFormation 堆栈创建的实例。
6. 当 Notebook 的状态为正在使用时,选择打开 Jupyter。
以下示例显示了一个名为 TimeseriesDataAnalysis 的 Notebook 实例。
7. 选择
timestream_predictive_analysis.ipynb 并将其标记为可信。
准备数据用于分析
现在,您可以运行 Notebook 中的单元格,来开始分析数据并准备数据用于训练。请完成以下步骤:
1. 以下代码设置 Amazon SageMaker 会话并创建 Amazon S3 和 Timestream 客户端。它还安装 Amazon SageMaker Data Wrangler 库,该库将 Pandas 库的功能扩展到亚马逊云科技,连接 DataFrames 与亚马逊云科技数据和分析服务,从而为 Timestream 和许多其它亚马逊云科技服务提供快速集成。
import time
import numpy as np
import pandas as pd
import json
import matplotlib.pyplot as plt
import boto3
import sagemaker
from sagemaker import get_execution_role
from IPython import display
%pip install awswrangler
import awswrangler as wrnp.random.seed(1)# 设置 Sagemaker 会话
prefix = "sagemaker/DEMO-deepar"
sagemaker_session = sagemaker.Session()
role = get_execution_role()
bucket = sagemaker_session.default_bucket()# 设置 S3 存储桶路径来上传训练数据集
s3_data_path = f"{bucket}/{prefix}/data"
s3_output_path = f"{bucket}/{prefix}/output"
print(s3_data_path)
print(s3_output_path)# 设置 S3 客户端
s3_client = boto3.client('s3') # Timestream 配置。
DB_NAME = "Demo_Predictive_Analysis" # <--- 指定在 Amazon Timestream 中创建的数据库
TABLE_NAME = "Telemetry_Aggregated_Data" # <--- 指定在 Amazon Timestream 中创建的表timestream_client = boto3.client('timestream-query')2. 在此步骤结束时,记下 S3 存储桶路径的输出。
分析完成后,您可以删除这些存储桶
3. 从 Timestream 查询数据:
query = """
SELECT *
FROM "Demo_Predictive_Analysis"."Telemetry_Aggregated_Data"
"""result = wr.timestream.query(sql=query,pagination_config={'PageSize': 1000})
display.display(result)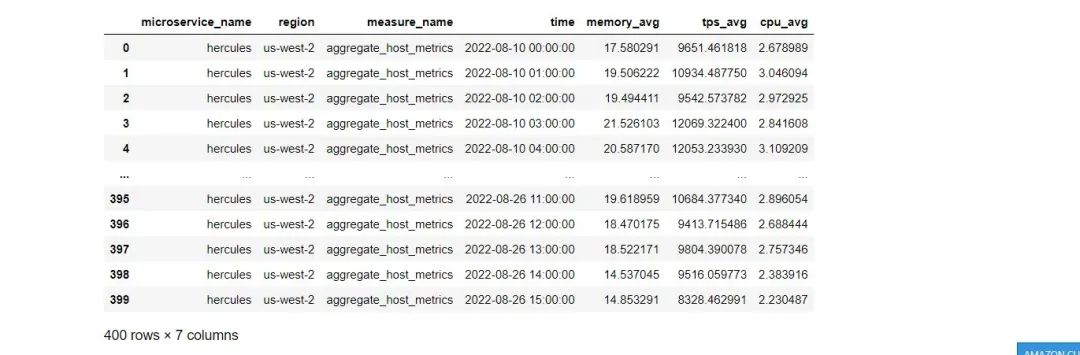
4. 可视化时间序列数据:
labels = ['cpu', 'memory', 'tps']cpu_series = pd.Series(data = result['cpu_avg'].values, index = pd.to_datetime(result['time']))
memory_series = pd.Series(data = result['memory_avg'].values, index = pd.to_datetime(result['time']))
tps_series = pd.Series(data = result['tps_avg'].values, index = pd.to_datetime(result['time']))## 收集列表中的所有序列
time_series = []
time_series.append(cpu_series)
time_series.append(memory_series)
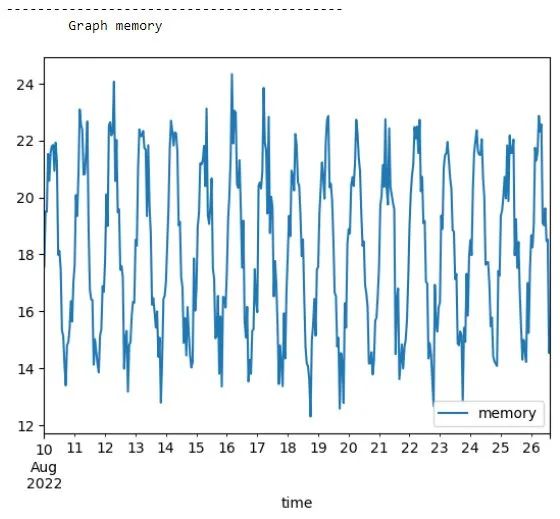
time_series.append(tps_series)for k in range(len(time_series)):print(f'-------------------------------------------\n\tGraph {labels[k]}')time_series[k].plot(label = labels[k])plt.legend(loc='lower right')plt.show()以下是 CPU 使用率图。

以下是内存使用情况图。
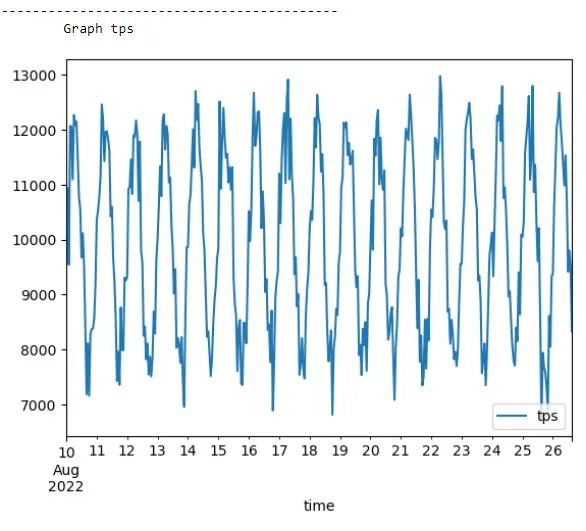
以下是每秒事务数(TPS,Transactions Per Second)图。
解决方案使用 Amazon SageMaker DeepAR 预测算法,之所以选择该算法,是因为它使用循环神经网络(RNN,Recurrent Neural Network)来高效地预测一维时间序列数据。DeepAR 因其适应不同时间序列模式的能力而脱颖而出,这些特性使其成为一种多功能且强大的选择。它采用有监督学习方法,使用已标注的历史数据进行训练,并利用 RNN 架构的优势来捕获顺序数据中的时间依赖关系。
5. 使用以下 DeepAR 超参数来初始化机器学习实例:
freq = "H" ## 时间,以小时为单位
prediction_length = 48
context_length = 72
data_length = 400
num_ts = 2
period = 24 hyperparameters = {"time_freq": freq,"context_length": str(context_length),"prediction_length": str(prediction_length),"num_cells": "40","num_layers": "3","likelihood": "gaussian","epochs": "20","mini_batch_size": "32","learning_rate": "0.001","dropout_rate": "0.05","early_stopping_patience": "10",
}查看之前的图表,您会发现所有三个指标的模式看起来都相似。因此,我们只使用 CPU 指标进行训练。但是,我们可以使用训练后的模型来预测 CPU 之外的其它指标。如果数据模式不同,那么我们必须分别训练每个数据集并相应进行预测。
我们有大约 16 天的 24 小时周期内的数据。我们使用前 14 天的数据,在 3 天(72 小时)的上下文窗口中训练模型,并使用最后 2 天(48 小时)来测试我们的预测。
6. 训练数据是数据的前面部分,截止到最近 2 天(48 小时):
time_series_training = []
for ts in time_series:time_series_training.append(ts[:-prediction_length])
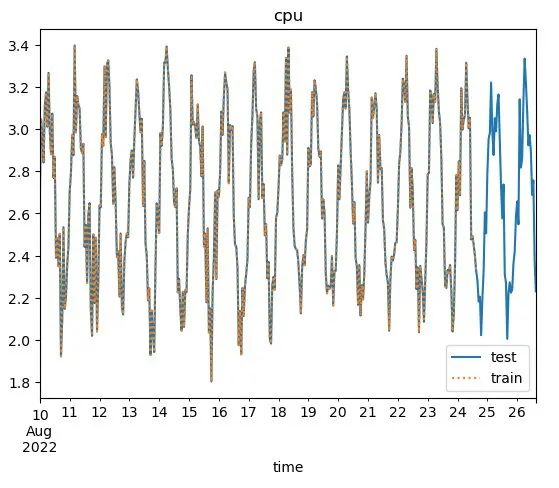
time_series[0].plot(label="test", title = "cpu")
time_series_training[0].plot(label="train", ls=":")
plt.legend()
plt.show()下图显示了数据并将其与测试数据叠加显示。
7. 下一步根据 DeepAR 输入格式对数据进行格式化,以便将数据用于训练模型。然后,该步骤将数据集保存到 Amazon S3。
def series_to_obj(ts, cat=None):obj = {"start": str(ts.index[0]), "target": list(ts)}if cat is not None:obj["cat"] = catreturn objdef series_to_jsonline(ts, cat=None):return json.dumps(series_to_obj(ts, cat))encoding = "utf-8"
FILE_TRAIN = "train.json"
FILE_TEST = "test.json"
with open(FILE_TRAIN, "wb") as f:for ts in time_series_training:f.write(series_to_jsonline(ts).encode(encoding))f.write("\n".encode(encoding))with open(FILE_TEST, "wb") as f:for ts in time_series:f.write(series_to_jsonline(ts).encode(encoding))f.write("\n".encode(encoding))
s3 = boto3.client("s3")
s3.upload_file(FILE_TRAIN, bucket, prefix + "/data/train/" + FILE_TRAIN)
s3.upload_file(FILE_TEST, bucket, prefix + "/data/test/" + FILE_TRAIN)您可以导航到 Amazon S3 控制台,然后查看先前创建的存储桶(例如 s3://sagemaker-<region>-<account_number>/sagemaker/DEMO-deepar/data)来验证文件 test.json 和 train.json。
使用 DeepAR 预测算法训练模型
此步骤使用通用估计器训练模型。它使用包含 DeepAR 算法的 SageMaker 镜像启动机器学习实例(实例类型为 ml.c4.xlarge):
image_uri = sagemaker.image_uris.retrieve("forecasting-deepar", boto3.Session().region_name)
estimator = sagemaker.estimator.Estimator(sagemaker_session=sagemaker_session,image_uri=image_uri,role=role,instance_count=1,instance_type="ml.c4.xlarge",base_job_name="DEMO-deepar",output_path=f"s3://{s3_output_path}",
)
estimator.set_hyperparameters(**hyperparameters)data_channels = {"train": f"s3://{s3_data_path}/train/", "test": f"s3://{s3_data_path}/test/"}estimator.fit(inputs=data_channels)等待模型训练完成(大约 5 分钟),然后再运行预测。
当训练作业完成后,您将看到以下响应。
生成预测见解
当模型训练阶段成功完成后,下一步就是通过部署端点来启动预测实例。
1. 使用以下代码部署端点:
job_name = estimator.latest_training_job.nameendpoint_name = sagemaker_session.endpoint_from_job(job_name=job_name,initial_instance_count=1,instance_type="ml.m4.xlarge",image_uri=image_uri,role=role,
)启动实例可能需要一段时间。最初,输出中只显示一个连字符(–)。等到状态行以感叹号(!)结尾。

2. 使用以下帮助程序类来运行预测:
class DeepARPredictor(sagemaker.predictor.RealTimePredictor):def set_prediction_parameters(self, freq, prediction_length):"""设置时间频率和预测长度参数。**必须** 调用此方法然后才能使用“predict”。Parameters:freq -- 表示时间频率的字符串prediction_length -- 整数,预测的时间点数量返回值:无。"""self.freq = freqself.prediction_length = prediction_lengthdef predict(self,ts,cat=None,encoding="utf-8",num_samples=100,quantiles=["0.1", "0.5", "0.9"],content_type="application/json",):"""请求对“ts”中列出的时间序列进行预测,每个时间序列带有(可选)对应的类别,在“cat”中列出。Parameters:ts -- “Pandas.Series”对象列表,要预测的时间序列cat -- 整数列表(默认值:无)encoding -- 字符串,用于请求的编码(默认值:“utf-8”)num_samples -- 整数,预测时要计算的样本数(默认值:100)quantiles -- 指定要计算的分位数的字符串列表(默认值:["0.1"、“0.5"、“0.9"])返回值:“pandas.DataFrame”对象的列表,每个对象中包含预测"""prediction_times = [x.index[-1] + pd.Timedelta(1, unit=self.freq) for x in ts]req = self.__encode_request(ts, cat, encoding, num_samples, quantiles)res = super(DeepARPredictor, self).predict(req, initial_args={"ContentType": content_type})return self.__decode_response(res, prediction_times, encoding)def __encode_request(self, ts, cat, encoding, num_samples, quantiles):instances = [series_to_obj(ts[k], cat[k] if cat else None) for k in range(len(ts))]configuration = {"num_samples": num_samples,"output_types": ["quantiles"],"quantiles": quantiles,}http_request_data = {"instances": instances, "configuration": configuration}return json.dumps(http_request_data).encode(encoding)def __decode_response(self, response, prediction_times, encoding):response_data = json.loads(response.decode(encoding))list_of_df = []for k in range(len(prediction_times)):prediction_index = pd.date_range(start=prediction_times[k], freq=self.freq, periods=self.prediction_length)list_of_df.append(pd.DataFrame(data=response_data["predictions"][k]["quantiles"], index=prediction_index))return list_of_dfpredictor = DeepARPredictor(endpoint_name=endpoint_name, sagemaker_session=sagemaker_session)
predictor.set_prediction_parameters(freq, prediction_length)list_of_df = predictor.predict(time_series_training[:3], content_type="application/json")
actual_data = time_series[:3]3. 最后,您可以将结果可视化:
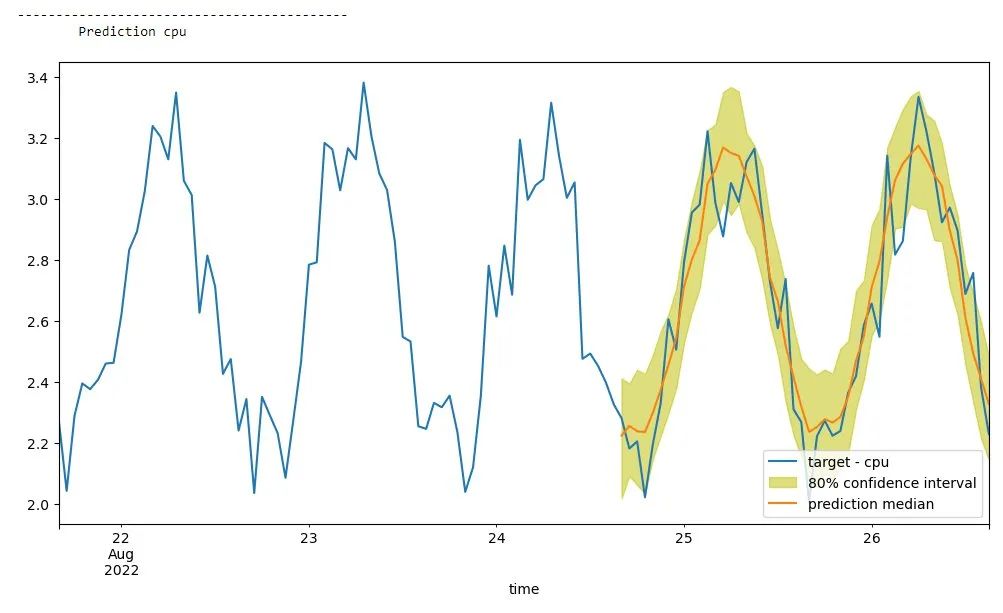
for k in range(len(list_of_df)):print(f'-------------------------------------------\n\tPrediction {labels[k]}')plt.figure(figsize=(12, 6))actual_data[k][-prediction_length - context_length :].plot(label=f'target - {labels[k]}')p10 = list_of_df[k]["0.1"]p90 = list_of_df[k]["0.9"]plt.fill_between(p10.index, p10, p90, color="y", alpha=0.5, label="80% confidence interval")list_of_df[k]["0.5"].plot(label="prediction median")plt.legend()plt.show()下图显示了我们的 CPU 预测。
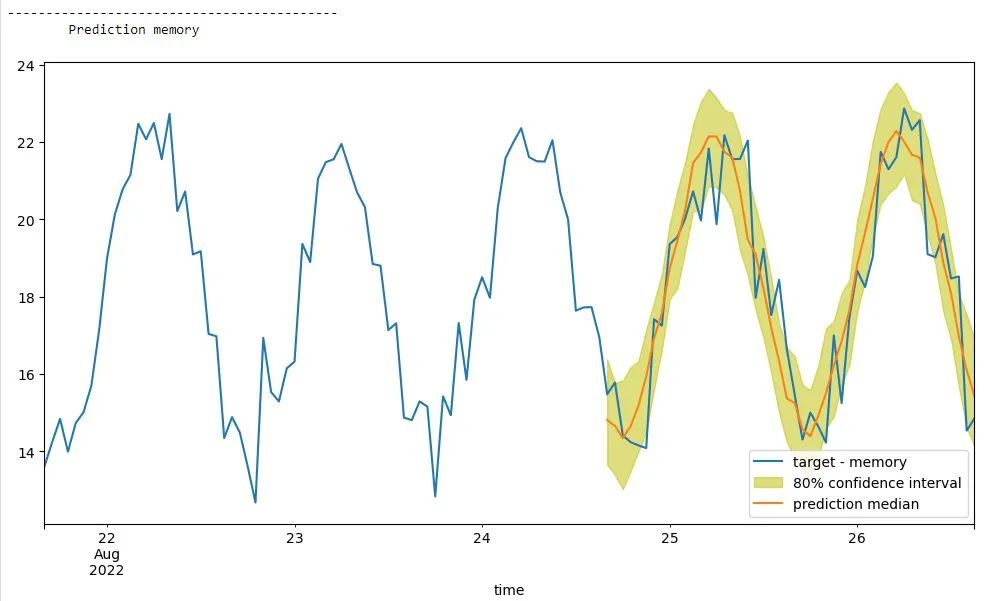
下图显示了我们的内存预测。
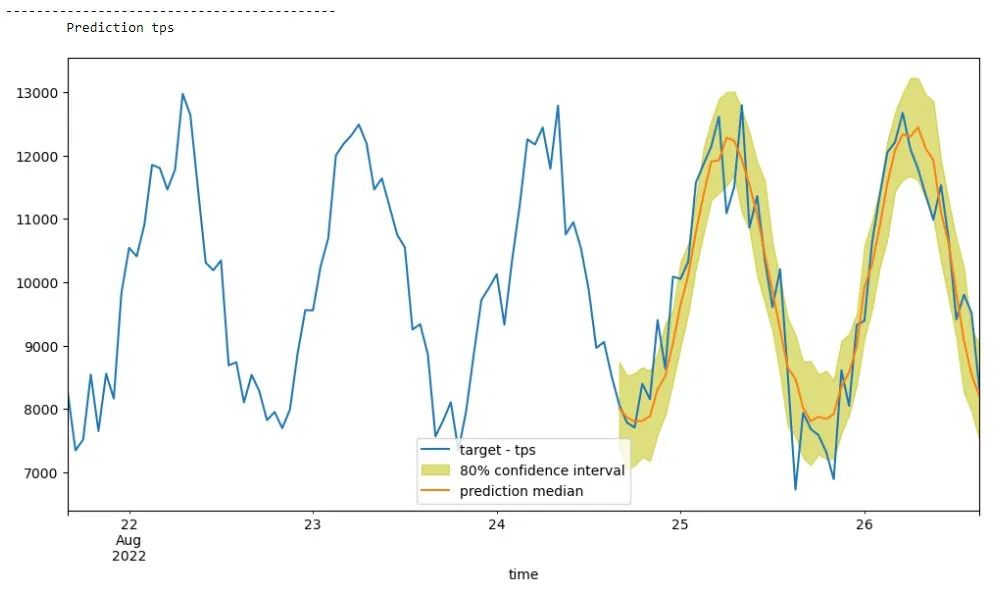
下图显示了我们的 TPS 预测。
4. 删除端点
sagemaker_session.delete_endpoint(endpoint_name)我们的预测结果与测试数据非常吻合,可以使用这些预测数据来规划容量。您可以按照本文中的步骤,无缝地扩展此解决方案,用于预测存储在 Timestream 中的其它时间序列数据。如果用户希望在现实场景中对一系列时间序列数据集进行准确预测,可以使用这种灵活且适用的解决方案。
Timestream 中的汇总
通常,最佳做法是在训练模型之前,以较低的频率汇总时间序列数据。使用原始数据会使模型运行缓慢且导致准确性降低。
使用 Timestream 计划查询功能,您可以汇总数据并将数据存储在不同的 Timestream 表中。您可以为业务报告使用计划查询,汇总应用程序中的最终用户活动,因此您可以训练机器学习模型来提供个性化的数据。您还可以使用计划查询提供警报,检测异常、网络入侵或欺诈活动,这样就可以立即采取补救措施。以下是 SQL 查询示例,该查询可以作为计划查询运行,以在 1 小时的时间间隔内汇总/向上采样数据:
select
microservice_name,
region,
'aggregate_host_metric' as measure_name,
bin(time, 1h) as time,
round(avg(memory),2) as memory_avg,
round(avg(tps),2) as tps_avg,
round(avg(cpu),2) as cpu_avg
from “Demo”.”source_metrics”
group by microservice_name, region, bin(time, 1h)清理
为避免产生费用,请使用亚马逊云科技管理控制台删除您在运行本练习时创建的资源:http://aws.amazon.com/console
删除在 CloudFormation 堆栈之外创建的 Amazon SageMaker 资源和 Amazon S3 存储桶。
清空创建的 Amazon S3 存储桶,这样在删除堆栈时就不会遇到问题。
删除为此解决方案创建的 CloudFormation 堆栈。
结论
在这篇文章中,我们向您演示了如何使用 Amazon SageMaker DeepAR 算法,对存储在 Timestream 中的 DevOps 时间序列数据运行预测分析,用于改善容量规划。通过结合 Amazon SageMaker 和 Timestream 的功能,您可以对时间序列数据集进行预测并获得宝贵的见解。
有关时间流聚合的更多信息,请参阅 Queries with aggregate functions(使用聚合函数进行查询):
https://docs.aws.amazon.com/timestream/latest/developerguide/sample-queries.iot-scenarios.html
有关高级时间序列分析函数,请参阅 Time-series functions(时间序列函数):
https://docs.aws.amazon.com/timestream/latest/developerguide/timeseries-specific-constructs.functions.html
要了解有关使用 DeepAR 算法的更多信息,请参阅使用 DeepAR 算法的最佳实践:
https://docs.aws.amazon.com/sagemaker/latest/dg/deepar.html#deepar_best_practices
本篇作者

Bobilli Balwanth
亚马逊云科技 Timestream SA,常驻犹他州。在加入亚马逊云科技之前,他曾在 Goldman Sachs 担任 Cloud Database Architect。他对数据库和云计算充满热情。对于在云端构建安全、可扩展和弹性的解决方案(尤其是云数据库)这个领域,他拥有丰富的经验。

Norbert Funke
亚马逊云科技 Timestream SA,常驻纽约。在加入亚马逊云科技之前,他曾在 PwC 旗下的一家数据咨询公司,从事有关数据架构和数据分析方面的工作。

Renuka Uttarala
亚马逊云科技资深 Neptune/Timestream SA,领导专门研究数据服务架构解决方案的全球团队。她拥有 20 多年的 IT 行业经验,专门从事高级分析和数据科学领域。在加入亚马逊云科技之前,她曾在多家公司担任产品开发、企业架构和解决方案工程领导职务,包括 HCL Technologies、Amdocs Openet、Warner Bros、Discovery 和 Oracle Corporation。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!

相关文章:
在 Amazon Timestream 上通过时序数据机器学习进行预测分析
由于不断变化的需求和现代化基础设施的动态性质,为大型应用程序规划容量可能会非常困难。例如,传统的反应式方法依赖于某些 DevOps 指标(如 CPU 和内存)的静态阈值,而这些指标在这样的环境中并不足以解决问题。在这篇文…...

【智能排班系统】快速消费线程池
文章目录 线程池介绍线程池核心参数核心线程数(Core Pool Size)最大线程数(Maximum Pool Size)队列(Queue)线程空闲超时时间(KeepAliveTime)拒绝策略(RejectedExecutionH…...
C语言——内存函数
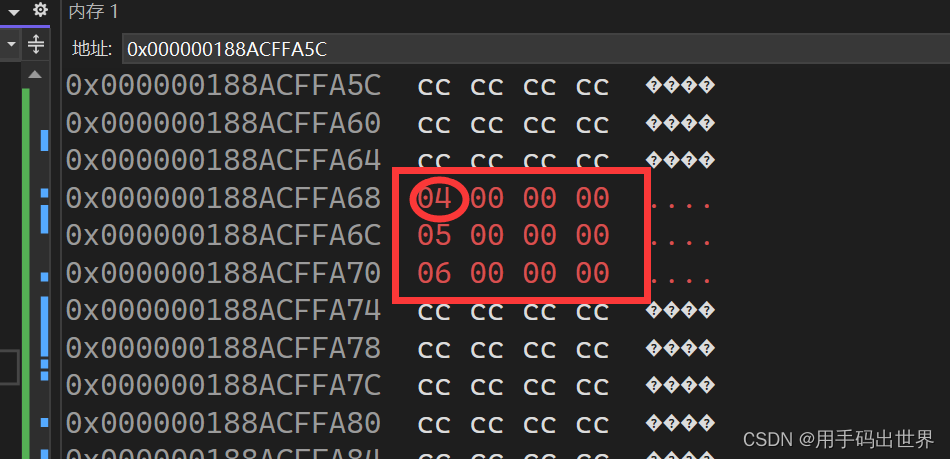
前言: C语言中除了字符串函数和字符函数外,还有一些函数可以直接对内存进行操作,这些函数被称为内存函数,这些函数与字符串函数都属于<string.h>这个头文件中。 一.memcpy()函数 memcpy是C语言中的…...
ideaSSM图书借阅管理系统VS开发mysql数据库web结构java编程计算机网页源码maven项目
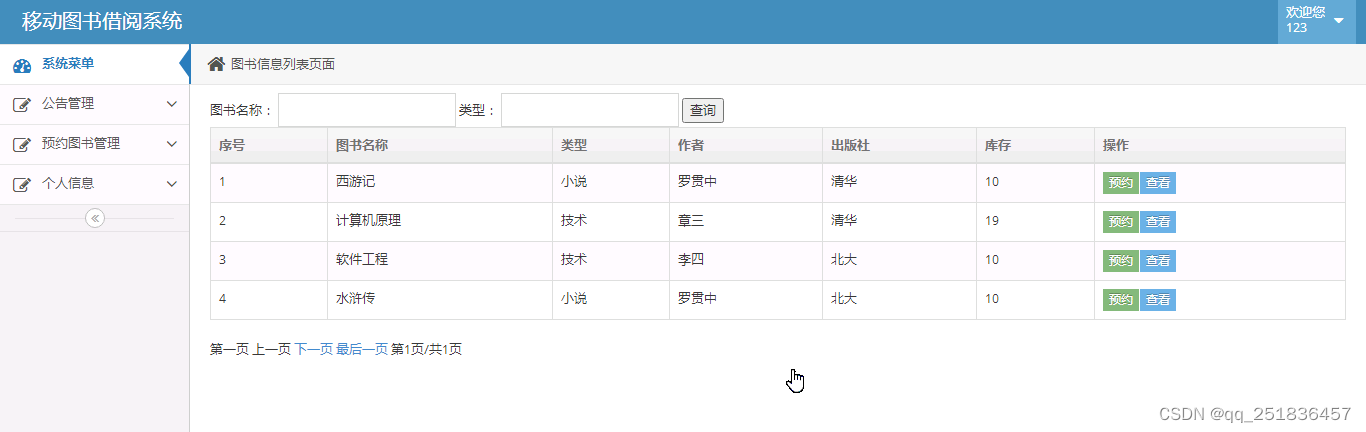
一、源码特点 SSM 图书借阅管理系统是一套完善的信息管理系统,结合SSM框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用SSM框架(MVC模式开发),系统具有完整的源代码 和数据库,系统主…...
普联一面4.2面试记录
普联一面4.2面试记录 文章目录 普联一面4.2面试记录1.jdk和jre的区别2.java的容器有哪些3.list set map的区别4.get和post的区别5.哪个更安全6.java哪些集合类是线程安全的7.创建线程有哪几种方式8.线程的状态有哪几种9.线程的run和start的区别10.什么是java序列化11.redis的优…...
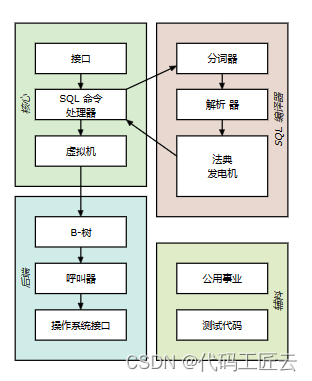
SQLite的架构(十一)
返回:SQLite—系列文章目录 上一篇:SQLite下一代查询规划器(十) 下一篇:SQLite—系列文章目录 介绍 本文档介绍SQLite库的架构。 这里的信息对那些想要了解或 修改SQLite的内部工作原理。 接口SQL 命令处理器虚拟机B-树…...

Vue2电商前台项目(一):项目前的初始化及搭建
一、项目初始化 创建项目:sudo vue create app 1.项目配置 (1)浏览器自动打开 在package.json文件中,serve后面加上 --open "scripts": {"serve": "vue-cli-service serve --open","buil…...
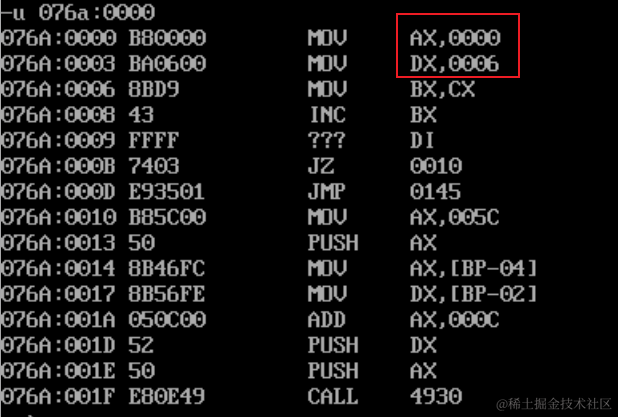
4.6 offset指令,jmp short指令,far,dword ptr各种跳转指令
4.6 offset指令,jmp short指令,far,dword ptr各种跳转指令 可以修改IP,或同时修改CS和IP的指令统称为转移指令。概括的讲,转移指令就是可以控制CPU执行内存中某处代码的指令 1. 转移指令 1.1 8086CPU的转移行为有以…...
【WEEK5】 【DAY5】DML语言【中文版】
2024.3.29 Friday 目录 3.DML语言3.1.外键(了解)3.1.1.概念3.1.2.作用3.1.3.添加(书写)外键的几种方法3.1.3.1.创建表时直接在主动引用的表里写(被引用的表的被引用的部分)3.1.3.2.先创建表后修改表以添加…...
媒体偏见从何而来?--- 美国MRC(媒体评级委员会)为何而生?
每天当我们打开淘宝,京东,步入超市,逛街或者逛展会,各种广告铺天盖地而来。从原来的平面广告,到多媒体广告,到今天融合AR和VR技术的数字广告,还有元宇宙虚拟世界,还有大模型加持的智…...

Solana 线下活动回顾|多方创新实践,引领 Solana“文艺复兴”新浪潮
Solana 作为在过去一年里实现突破式飞跃的头部公链,究竟是如何与 Web3 行业共振,带来全新的技术发展与生态亮点的呢?在 3 月 24 日刚结束的「TinTin Destination Moon」活动现场,来自 Solana 生态的的专家大咖和 Web3 行业的资深人…...

CSS3 实现文本与图片横向无限滚动动画
文章目录 1. 实现效果2.html结构3. css代码 1. 实现效果 gif录屏比较卡,实际很湿滑,因为是css动画实现的 2.html结构 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"…...
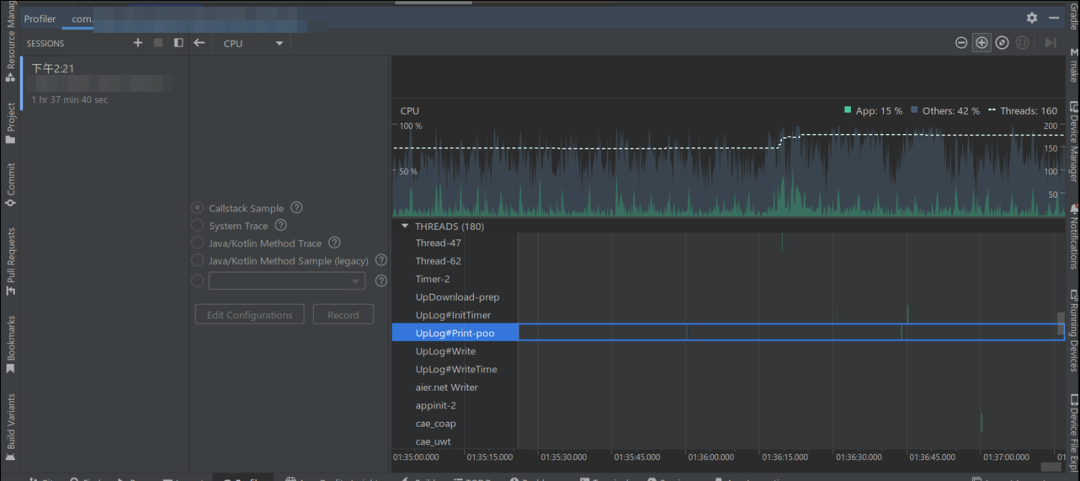
Android 性能优化之黑科技开道(一)
1. 缘起 在开发电视版智家 App9.0 项目的时候,发现了一个性能问题。电视系统原本剩余的可用资源就少,而随着 9.0 功能的进一步增多,特别是门铃、门锁、多路视频同屏监控后等功能的增加,开始出现了卡顿情况。 经过调研分析发现有…...

Successive Convex Approximation算法的学习笔记
文章目录 一、代码debug二、原理 本文主要参考了CSDN上的 另一篇文章,但规范了公式的推导过程和修缮了部分代码 一、代码debug 首先,我们将所有的代码放到MATLAB中,很快在命令行中出现了错误信息 很显然有问题,但是我不知道发生…...

IoT数采平台2:文档
IoT数采平台1:开篇IoT数采平台2:文档IoT数采平台3:功能IoT数采平台4:测试 【平台功能】 基础配置、 实时监控、 规则引擎、 告警列表、 系统配置 消息通知:Websocket 设备上线、设备下线、 数据变化、 告警信息、 实时…...

Vue监听器watch的基本用法
文章目录 1. 作用2. 格式3. 示例3.1 value 值为字符串3.2 value 值为函数3.3 value 值为对象 4. 与计算属性对比 1. 作用 监视数据变化,执行一些业务逻辑或异步操作。 2. 格式 监听器 watch 内部以 key :value 的形式定义,key 是 data 中的…...

MySQL UPDATE JOIN 根据一张表或多表来更新另一张表的数据
当使用MySQL时,经常需要根据一张表或多张表的数据来更新另一张表的数据。这种情况下,我们可以使用UPDATE语句结合JOIN操作来实现这一需求。本文将介绍MySQL中使用UPDATE JOIN的技术。 什么是UPDATE JOIN UPDATE JOIN是MySQL中一种结合UPDATE语句和JOIN…...

JS实现继承的方式ES6版
上一篇:JS实现继承的方式原生版 ES6的继承 主要是依赖extends关键字来实现继承,且继承的效果类似于寄生组合继承。 class Parent() { }class Child extends Parent {constructor(x, y, color) {super(x, y);this.color color;} }子类必须在construct…...
elementui 左侧或水平导航菜单栏与main区域联动
系列文章目录 一、elementui 导航菜单栏和Breadcrumb 面包屑关联 二、elementui 左侧导航菜单栏与main区域联动 三、elementui 中设置图片的高度并支持PC和手机自适应 四、elementui 实现一个固定位置的Pagination(分页)组件 文章目录 系列文章目录…...
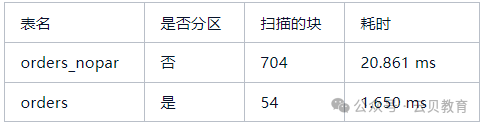
YUNBEE云贝-技术分享:PostgreSQL分区表
引言 PostgreSQL作为一款高度可扩展的企业级关系型数据库管理系统,其内置的分区表功能在处理大规模数据场景中扮演着重要角色。本文将深入探讨PostgreSQL分区表的实现逻辑、详细实验过程,并辅以分区表相关的视图查询、分区表维护及优化案例,…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...