java高性能并发计数器之巅峰对决
并发计数器各个方案介绍
方案概述
1. jdk5提供的原子更新长整型类 AtomicLong
2. synchronized
3. jdk8提供的 LongAdder 【单机推荐】
4. Redisson分布式累加器【分布式推荐】
方案介绍
jdk5提供的原子更新长整型类 AtomicLong
在JDK1.5开始就新增了并发的Integer/Long的操作工具类AtomicInteger和AtomicLong。
AtomicLong 利用底层操作系统的CAS来保证原子性,在一个死循环内不断执行CAS操作,直到操作成功。不过,CAS操作的一个问题是在并发量比较大的时候,可能很多次的执行CAS操作都不成功,这样性能就受到较大影响。
示例代码
AtomicLong value =newAtomicLong(0);//定义incrementAndGet();//递增1
```synchronized
synchronized是一个重量级锁,主要是因为线程竞争锁会引起操作系统用户态和内核态切换,浪费资源效率不高,在jdk1.5之前,synchronized没有做任何优化,但在jdk1.6做了性能优化,它会经历偏向锁,轻量级锁,最后才到重量级锁这个过程,在性能方面有了很大的提升,在jdk1.7的ConcurrentHashMap是基于ReentrantLock的实现了锁,但在jdk1.8之后又替换成了synchronized,就从这一点可以看出JVM团队对synchronized的性能还是挺有信心的。下面我们分别来介绍下无锁,偏向锁,轻量级锁,重量级锁。
jdk8提供的 LongAdder 【单机推荐】
在JDK8中又新增了LongAdder,这是一个针对Long类型的数据的操作工具类。
那我们知道,在ConcurrentHashMap中,对Map分割成多个segment,这样多个Segment的操作就可以并行执行,从而可以提高性能。在JDK8中,LongAdder与ConcurrentHashMap类似,将内部操作数据value分离成一个Cell数组,每个线程访问时,通过Hash等算法映射到其中一个Cell上。
计算最终的数据结果,则是各个Cell数组的累计求和。
LongAddr常用api方法
add(): //增加指定的数值;increament(): //增加1;decrement(): //减少1;intValue();//intValue();/floatValue()/doubleValue():得到最终计数后的结果sum()://求和,得到最终计数结果sumThenReset()://求和得到最终计数结果,并重置value。
```Redisson分布式累加器【分布式推荐】
基于Redis的Redisson分布式整长型累加器(LongAdder)采用了与java.util.concurrent.atomic.LongAdder类似的接口。通过利用客户端内置的LongAdder对象,为分布式环境下递增和递减操作提供了很高得性能。据统计其性能最高比分布式AtomicLong对象快 10000 倍以上。
RLongAddr itheimaLongAddr = redission.getLongAddr("itheimaLongAddr");
itheimaLongAddr.add(100);//添加指定数量
itheimaLongAddr.increment();//递增1
itheimaLongAddr.increment();//递减1
itheimaLongAddr.sum();//聚合求和
```基于Redis的Redisson分布式双精度浮点累加器(DoubleAdder)采用了与java.util.concurrent.atomic.DoubleAdder类似的接口。通过利用客户端内置的DoubleAdder对象,为分布式环境下递增和递减操作提供了很高得性能。据统计其性能最高比分布式AtomicDouble对象快 12000 倍。
示例代码
RLongDouble itheimaDouble = redission.getLongDouble("itheimaLongDouble");
itheimaDouble.add(100);//添加指定数量
itheimaDouble.increment();//递增1
itheimaDouble.increment();//递减1
itheimaDouble.sum();//聚合求和
```以上【整长型累加器】和【双精度浮点累加器】完美适用于分布式统计计量场景。
各个方案性能测试
测试代码
```
packagecom.itheima._01性能比较;importorg.junit.Test;importjava.util.ArrayList;importjava.util.List;importjava.util.concurrent.atomic.AtomicLong;importjava.util.concurrent.atomic.LongAdder;/*** @author 黑马程序员*/publicclassCountTest{privateint count =0;@TestpublicvoidstartCompare(){compareDetail(1,100*10000);compareDetail(20,100*10000);compareDetail(30,100*10000);compareDetail(40,100*10000);compareDetail(100,100*10000);}/*** @paramthreadCount 线程数* @paramtimes 每个线程增加的次数*/publicvoidcompareDetail(int threadCount,int times){try{System.out.println(String.format("threadCount: %s, times: %s", threadCount, times));long start =System.currentTimeMillis();testSynchronized(threadCount, times);System.out.println("testSynchronized cost: "+(System.currentTimeMillis()- start));start =System.currentTimeMillis();testAtomicLong(threadCount, times);System.out.println("testAtomicLong cost: "+(System.currentTimeMillis()- start));start =System.currentTimeMillis();testLongAdder(threadCount, times);System.out.println("testLongAdder cost: "+(System.currentTimeMillis()- start));System.out.println();}catch(Exception e){e.printStackTrace();}}publicvoidtestSynchronized(int threadCount,int times)throwsInterruptedException{List<Thread> threadList =newArrayList<>();for(int i =0; i < threadCount; i++){threadList.add(newThread(()->{for(int j =0; j < times; j++){add();}}));}for(Thread thread : threadList){thread.start();}for(Thread thread : threadList){thread.join();}}publicsynchronizedvoidadd(){count++;}publicvoidtestAtomicLong(int threadCount,int times)throwsInterruptedException{AtomicLong count =newAtomicLong();List<Thread> threadList =newArrayList<>();for(int i =0; i < threadCount; i++){threadList.add(newThread(()->{for(int j =0; j < times; j++){count.incrementAndGet();}}));}for(Thread thread : threadList){thread.start();}for(Thread thread : threadList){thread.join();}}publicvoidtestLongAdder(int threadCount,int times)throwsInterruptedException{LongAdder count =newLongAdder();List<Thread> threadList =newArrayList<>();for(int i =0; i < threadCount; i++){threadList.add(newThread(()->{for(int j =0; j < times; j++){count.increment();}}));}for(Thread thread : threadList){thread.start();}for(Thread thread : threadList){thread.join();}}}
```运行结果
threadCount: 1, times: 1000000
testSynchronized cost: 69
testAtomicLong cost: 16
testLongAdder cost: 15threadCount: 20, times: 1000000
testSynchronized cost: 639
testAtomicLong cost: 457
testLongAdder cost: 59threadCount: 30, times: 1000000
testSynchronized cost: 273
testAtomicLong cost: 538
testLongAdder cost: 70threadCount: 40, times: 1000000
testSynchronized cost: 312
testAtomicLong cost: 717
testLongAdder cost: 81threadCount: 100, times: 1000000
testSynchronized cost: 719
testAtomicLong cost: 2098
testLongAdder cost: 225
```结论
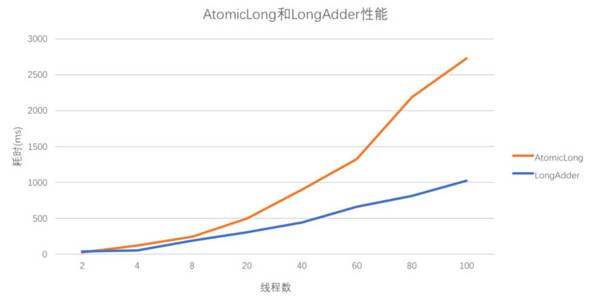
并发量比较低的时候AtomicLong优势比较明显,因为AtomicLong底层是一个乐观锁,不用阻塞线程,不断cas即可。但是在并发比较高的时候用synchronized比较有优势,因为大量线程不断cas,会导致cpu持续飙高,反而会降低效率
LongAdder无论并发量高低,优势都比较明显。且并发量越高,优势越明显
原理分析
AtomicLong 实现原子操作原理
非原子操作示例代码
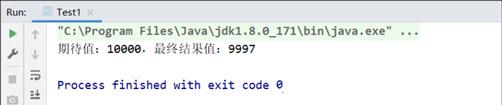
packagecom.itheima._02Unsafe测试;importjava.util.ArrayList;importjava.util.List;/*** @author 黑马程序员*/publicclassTest1{privateint value =0;publicstaticvoidmain(String[] args)throwsInterruptedException{Test1 test1 =newTest1();test1.increment();System.out.println("期待值:"+100*100+",最终结果值:"+ test1.value);//结果,期待值:10000,最终结果值:xxxx}privatevoidincrement()throwsInterruptedException{List<Thread> list =newArrayList<>();//启动100个线程,每个线程对value进行累加100次for(int i =0; i <100; i++){Thread t =newThread(()->{for(int j =0; j <100; j++){value++;}});list.add(t);t.start();}//保证所有线程运行完成for(Thread thread : list){thread.join();}}}
```运行效果
结论
> 可以发现输出的结果值错误,这是因为 `value++` 不是一个原子操作,它将 `value++` 拆分成了 3 个步骤 `load、add、store`,多线程并发有可能上一个线程 add 过后还没有 store 下一个线程又执行了 load 了这种重复造成得到的结果可能比最终值要小。
AtomicLong是JDK1.5提供的原子操作示例代码
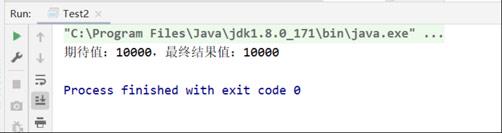
packagecom.itheima._03AtomicLong的CAS原子操作示例;importjava.util.ArrayList;importjava.util.List;importjava.util.concurrent.atomic.AtomicInteger;importjava.util.concurrent.atomic.AtomicLong;/*** @author 黑马程序员*/publicclassTest2{privateAtomicLong value =newAtomicLong(0);publicstaticvoidmain(String[] args)throwsInterruptedException{Test2 test1 =newTest2();test1.increment();System.out.println("期待值:"+100*100+",最终结果值:"+ test1.value);//结果,期待值:10000,最终结果值:10000}privatevoidincrement()throwsInterruptedException{List<Thread> list =newArrayList<>();//启动100个线程,每个线程对value进行累加100次for(int i =0; i <100; i++){Thread t =newThread(()->{for(int j =0; j <100; j++){value.incrementAndGet();}});list.add(t);t.start();}//保证所有线程运行完成for(Thread thread : list){thread.join();}}}
```运行效果
AtomicLong CAS原理介绍
1.使用volatile保证内存可见性,获取主存中最新的操作数据
2.使用CAS(Compare-And-Swap)操作保证数据原子性
CAS算法是jdk对并发操作共享数据的支持,包含了3个操作数
第一个操作数:内存值value(V)
第二个操作数:预估值expect(O)
第三个操作数:更新值new(N)
含义:CAS比较交换的过程可以通俗的理解为CAS(V,O,N),包含三个值分别为:V 内存地址(主存)存放的实际值;O 预期的值(旧值);N 更新的新值。当V和O相同时,也就是说旧值和内存中实际的值相同表明该值没有被其他线程更改过,即该旧值O就是目前来说最新的值了,自然而然可以将新值N赋值给V;当V和O不相同时,会一致循环下去直至修改成功。
AtomicLong底层CAS实现原子操作原理
查看incrementAndGet()方法源码
publicfinallongincrementAndGet(){return unsafe.getAndAddLong(this, valueOffset,1L)+1L;}
```getAndAddLong方法源码```java
publicfinallonggetAndAddLong(Object var1,long var2,long var4){long var6;do{var6 =this.getLongVolatile(var1, var2);}while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));return var6;}
```> 这里是一个循环CAS操作
compareAndSwapLong方法源码
publicfinalnativebooleancompareAndSwapLong(Object var1,long var2,long var4,long var6);
```我们发现调用的是 native 的 `unsafe.compareAndSwapLong(Object obj, long valueOffset, Long expect, Long update)`,我们翻看 Hotspot 源码发现在 unsafe.cpp 中定义了这样一段代码
> Unsafe中基本都是调用native方法,那么就需要去JVM里面找对应的实现。
>
> 到`http://hg.openjdk.java.net/` 进行一步步选择下载对应的hotspot版本,我这里下载的是`http://hg.openjdk.java.net/jdk8u/jdk8u60/hotspot/archive/tip.tar.gz`,
>
> 然后解hotspot目录,发现 `\src\share\vm\prims\unsafe.cpp`,这个就是对应jvm相关的c++实现类了。
>
> 比如我们对CAS部分的实现很感兴趣,就可以在该文件中搜索compareAndSwapInt,此时可以看到对应的JNI方法为`Unsafe_CompareAndSwapInt`
UNSAFE_ENTRY(jboolean,Unsafe_CompareAndSwapLong(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jlong e, jlong x))UnsafeWrapper("Unsafe_CompareAndSwapLong");Handle p(THREAD,JNIHandles::resolve(obj));jlong* addr =(jlong*)(index_oop_from_field_offset_long(p(), offset));#ifdefSUPPORTS_NATIVE_CX8return(jlong)(Atomic::cmpxchg(x, addr, e))== e;#elseif(VM_Version::supports_cx8())return(jlong)(Atomic::cmpxchg(x, addr, e))== e;else{jboolean success =false;MutexLockerEx mu(UnsafeJlong_lock, Mutex::_no_safepoint_check_flag);jlong val =Atomic::load(addr);if(val == e){Atomic::store(x, addr); success =true;}return success;}#endif
UNSAFE_END
```Atomic::cmpxchg c++源码
可以看到调用了“Atomic::cmpxchg”方法,“Atomic::cmpxchg”方法在linux_x86和windows_x86的实现如下。
linux_x86的实现:
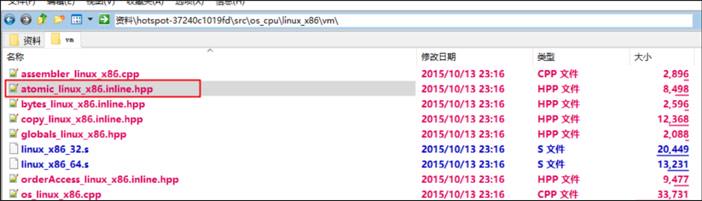
inline jint Atomic::cmpxchg(jint exchange_value,volatile jint* dest, jint compare_value){int mp = os::is_MP();__asm__ volatile(LOCK_IF_MP(%4)"cmpxchgl %1,(%3)":"=a"(exchange_value):"r"(exchange_value),"a"(compare_value),"r"(dest),"r"(mp):"cc","memory");return exchange_value;}
```windows_x86的实现(c++源文件):
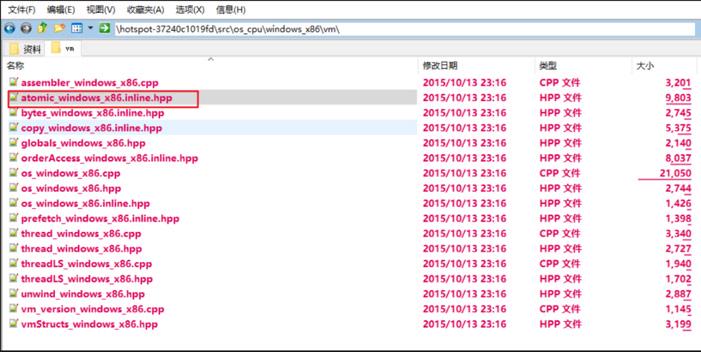
inline jint Atomic::cmpxchg(jint exchange_value,volatile jint* dest, jint compare_value){// alternative for InterlockedCompareExchangeint mp = os::is_MP();__asm {mov edx, destmov ecx, exchange_valuemov eax, compare_valueLOCK_IF_MP(mp)cmpxchg dword ptr [edx], ecx}}
```Atomic::cmpxchg方法解析:
mp是“os::is_MP()”的返回结果,“os::is_MP()”是一个内联函数,用来判断当前系统是否为多处理器。
如果当前系统是多处理器,该函数返回1。
否则,返回0。
LOCK_IF_MP(mp)会根据mp的值来决定是否为cmpxchg指令添加lock前缀。
如果通过mp判断当前系统是多处理器(即mp值为1),则为cmpxchg指令添加lock前缀。
否则,不加lock前缀。
这是一种优化手段,认为单处理器的环境没有必要添加lock前缀,只有在多核情况下才会添加lock前缀,因为lock会导致性能下降。cmpxchg是汇编指令,作用是比较并交换操作数。
> 底层会调用cmpxchg汇编指令,如果是多核处理器会加锁实现原子操作
反汇编指令查询
查看java程序运行的汇编指令资料
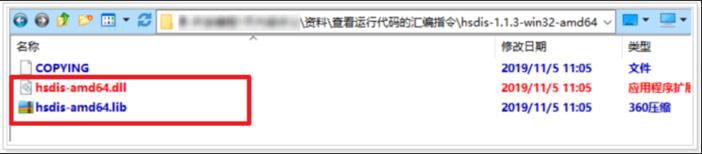
将上图2个文件拷贝到jre\bin目录下,如下图
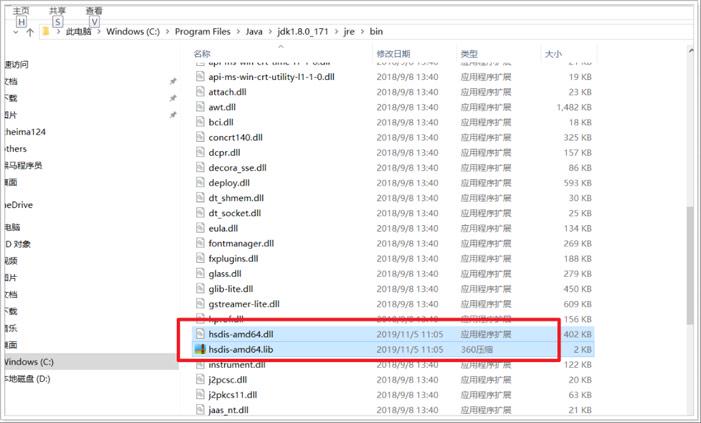
配置运行参数
```
-server -Xcomp -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:CompileCommand=compileonly,*
```
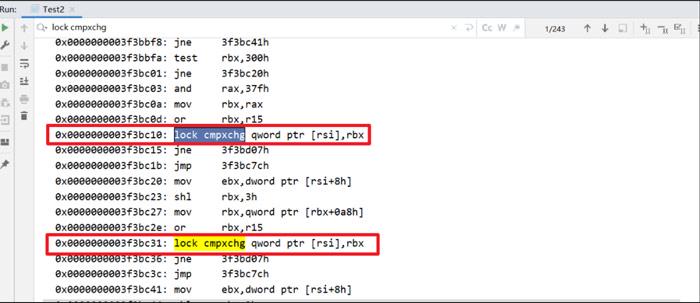
运行Test2效果
synchronized 实现同步操作原理
锁对象
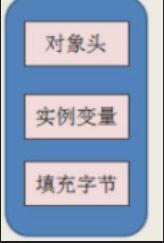
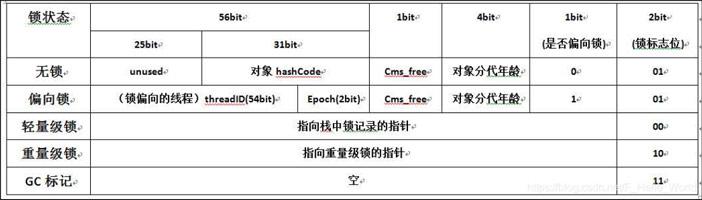
java中任何一个对象都可以称为锁对象,原因在于java对象在内存中存储结构,如下图所示:
在对象头中主要存储的主要是一些运行时的数据,如下所示:

其中 在Mark Work中存储着该对象作为锁时的一些信息,如下所示是Mark Work中在64位系统中详细信息:
偏向锁
在无竞争环境中(没有并发)使用一种锁
> 偏向锁的作用是当有线程访问同步代码或方法时,线程只需要判断对象头的Mark Word中判断一下是否有偏向锁指向线程ID.
>
> 偏向锁记录过程
>
> - 线程抢到了对象的同步锁(锁标志为01参考上图即无其他线程占用)
> - 对象Mark World 将是否偏向标志位设置为1
> - 记录抢到锁的线程ID
> - 进入偏向状态
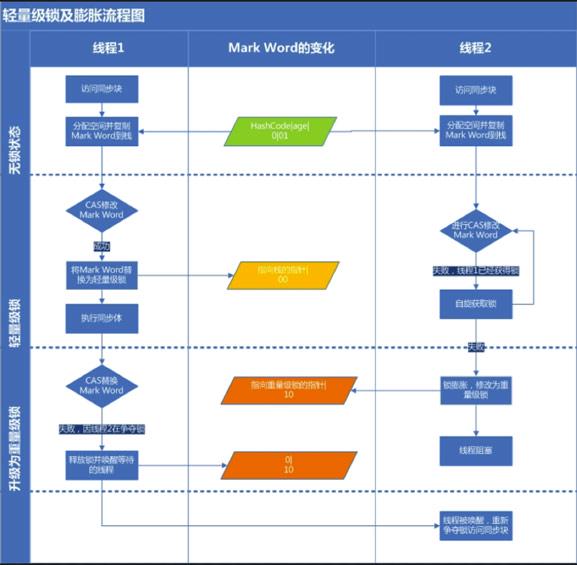
轻量级锁
当有另外一个线程竞争获取这个锁时,由于该锁已经是偏向锁,当发现对象头 Mark Word 中的线程 ID 不是自己的线程 ID,就会进行 CAS 操作获取锁,**如果获取成功**,直接替换 Mark Word 中的线程 ID 为自己的 ID,该锁会保持偏向锁状态;**如果获取锁失败**,代表当前锁有一定的竞争,偏向锁将升级为轻量级锁。
- 举个例子来说明一下什么时候需要升级偏向锁
假设A线程 持有锁 X(此时X是偏向锁) 这是有个B线程也同样用到了锁X,而B线程在检查锁对象的Mark World时发现偏向锁的线程ID已经指向了线程A。这时候就需要升级锁X为轻量级锁。轻量级锁意味着标示该资源现在处于竞争状态。
当有其他线程想访问加了轻量级锁的资源时,会使用自旋锁优化,来进行资源访问。
> 自旋策略
>
> JVM 提供了一种自旋锁,可以通过自旋方式不断尝试获取锁,从而避免线程被挂起阻塞。这是基于大多数情况下,线程持有锁的时间都不会太长,毕竟线程被挂起阻塞可能会得不偿失。
>
> 从 JDK1.7 开始,自旋锁默认启用,自旋次数由 JVM 设置决定,这里我不建议设置的重试次数过多,因为 CAS 重试操作意味着长时间地占用 CPU。自旋锁重试之后如果抢锁依然失败,同步锁就会升级至重量级锁,锁标志位改为 10。在这个状态下,未抢到锁的线程都会进入 Monitor,之后会被阻塞在 _WaitSet 队列中。
重量级锁
自旋失败,很大概率 再一次自选也是失败,因此直接升级成重量级锁,进行线程阻塞,减少cpu消耗。
当锁升级为重量级锁后,未抢到锁的线程都会被阻塞,进入阻塞队列。
重量级锁在高并发下性能就会变慢,因为所有没有获取锁的线程会进行阻塞等待,到获取锁的时候被唤醒,这些操作都是消耗很多资源。
轻量级锁膨胀流程图
LongAdder 实现原子操作原理
LongAdder实现高并发计数实现思路
LongAdder实现高并发的秘密就是用空间换时间,对一个值的cas操作,变成对多个值的cas操作,当获取数量的时候,对这多个值加和即可。

测试代码
```
packagecom.itheima._04LongAddr使用测试;importjava.util.ArrayList;importjava.util.List;importjava.util.concurrent.atomic.AtomicLong;importjava.util.concurrent.atomic.LongAccumulator;importjava.util.concurrent.atomic.LongAdder;importjava.util.function.LongBinaryOperator;/*** @author 黑马程序员*/publicclassTest3{privateLongAdder value =newLongAdder();//默认初始值0publicstaticvoidmain(String[] args)throwsInterruptedException{Test3 test1 =newTest3();test1.increment();System.out.println("期待值:"+100*100+",最终结果值:"+ test1.value.sum());//结果,期待值:10000,最终结果值:10000}privatevoidincrement()throwsInterruptedException{List<Thread> list =newArrayList<>();//启动100个线程,每个线程对value进行累加100次for(int i =0; i <100; i++){Thread t =newThread(()->{for(int j =0; j <100; j++){value.increment();}});list.add(t);t.start();}//保证所有线程运行完成for(Thread thread : list){thread.join();}}}
```源码分析
1. 先对base变量进行cas操作,cas成功后返回
2. 对线程获取一个hash值(调用getProbe),hash值对数组长度取模,定位到cell数组中的元素,对数组中的元素进行cas
增加数量源码
publicvoidincrement(){add(1L);}
``````java
publicvoidadd(long x){Cell[] as;long b, v;int m;Cell a;if((as = cells)!=null||!casBase(b = base, b + x)){boolean uncontended =true;if(as ==null||(m = as.length -1)<0||(a = as[getProbe()& m])==null||!(uncontended = a.cas(v = a.value, v + x)))longAccumulate(x,null, uncontended);}}
```当数组不为空,并且根据线程hash值定位到数组某个下标中的元素不为空,对这个元素cas成功则直接返回,否则进入longAccumulate方法
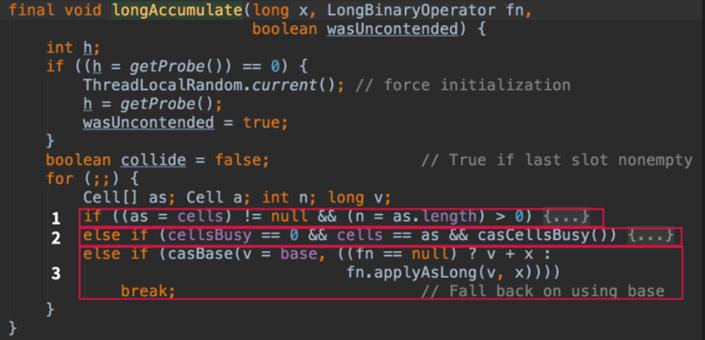
1. cell数组已经初始化完成,主要是在cell数组中放元素,对cell数组进行扩容等操作
2. cell数组没有初始化,则对数组进行初始化
3. cell数组正在初始化,这时其他线程利用cas对baseCount进行累加操作
完整代码
finalvoidlongAccumulate(long x,LongBinaryOperator fn,boolean wasUncontended){int h;if((h =getProbe())==0){ThreadLocalRandom.current();// force initializationh =getProbe();wasUncontended =true;}boolean collide =false;// True if last slot nonemptyfor(;;){Cell[] as;Cell a;int n;long v;if((as = cells)!=null&&(n = as.length)>0){if((a = as[(n -1)& h])==null){if(cellsBusy ==0){// Try to attach new CellCell r =newCell(x);// Optimistically createif(cellsBusy ==0&&casCellsBusy()){boolean created =false;try{// Recheck under lockCell[] rs;int m, j;if((rs = cells)!=null&&(m = rs.length)>0&&rs[j =(m -1)& h]==null){rs[j]= r;created =true;}}finally{cellsBusy =0;}if(created)break;continue;// Slot is now non-empty}}collide =false;}elseif(!wasUncontended)// CAS already known to failwasUncontended =true;// Continue after rehashelseif(a.cas(v = a.value,((fn ==null)? v + x :fn.applyAsLong(v, x))))break;elseif(n >= NCPU || cells != as)collide =false;// At max size or staleelseif(!collide)collide =true;elseif(cellsBusy ==0&&casCellsBusy()){try{if(cells == as){// Expand table unless staleCell[] rs =newCell[n <<1];for(int i =0; i < n;++i)rs[i]= as[i];cells = rs;}}finally{cellsBusy =0;}collide =false;continue;// Retry with expanded table}h =advanceProbe(h);}elseif(cellsBusy ==0&& cells == as &&casCellsBusy()){boolean init =false;try{// Initialize tableif(cells == as){Cell[] rs =newCell[2];rs[h &1]=newCell(x);cells = rs;init =true;}}finally{cellsBusy =0;}if(init)break;}elseif(casBase(v = base,((fn ==null)? v + x :fn.applyAsLong(v, x))))break;// Fall back on using base}}
```获取计算数量源码
publiclongsum(){Cell[] as = cells;Cell a;long sum = base;if(as !=null){for(int i =0; i < as.length;++i){if((a = as[i])!=null)sum += a.value;}}return sum;}
```需要注意的是,调用sum()返回的数量有可能并不是当前的数量,因为在调用sum()方法的过程中,可能有其他数组对base变量或者cell数组进行了改动,所以需要确保所有线程运行完再获取就是准确值
LongAdder 的前世今生
其实在 Jdk1.7 时代,LongAdder 还未诞生时,就有一些人想着自己去实现一个高性能的计数器了,比如一款 Java 性能监控框架 dropwizard/metrics 就做了这样事,在早期版本中,其优化手段并没有 Jdk1.8 的 LongAdder 丰富,而在 metrics 的最新版本中,其已经使用 Jdk1.8 的 LongAdder 替换掉了自己的轮子。在最后的测评中,我们将 metrics 版本的 LongAdder 也作为一个参考对象。
应用场景
AtomicLong等原子类的使用
并发少竞争少(读多写少)的计数原子操作
LongAdder 的使用
高性能计数器的首选方案, 单体项目建议使用LongAddr,分布式环境建议使用Redisson分布式累加器
应用场景功能:获取全局自增id值
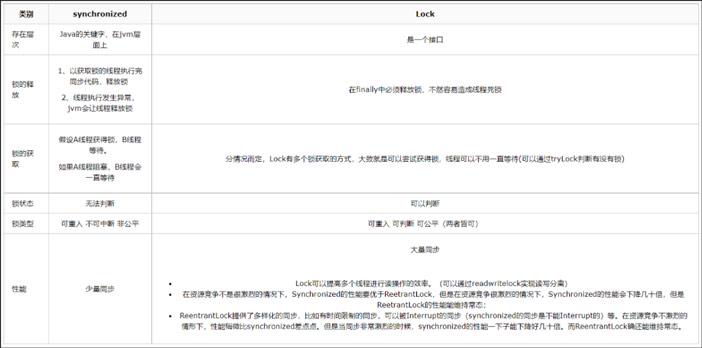
Synchronized与Lock的使用比较
Synchronized 适合少量的同步并发竞争
Lock 适合大量的同步并发竞争
总结
并发情况优化锁思路:
互斥锁 -> 乐观锁 -> 锁的粒度控制
在Java中对应的实现方式:
ReentrantLock或者Syschronized -> CAS + Volatile -> 拆分竞争点(longAddr,分布式累加器,ConcurrentHashMap等)
ReentrantLock或者Syschronized 在高并发时都存在获取锁等待、阻塞、唤醒等操作,所以在使用的使用注意拆分竞争点。
AtomicLong
1. 并发量非常高,可能导致都在不停的争抢该值,可能导致很多线程一致处于循环状态而无法更新数据,从而导致 CPU 资源的消耗过高。解决这个问题需要使用LongAdder
2. ABA 问题,比如说上一个线程增加了某个值,又改变了某个值,然后后面的线程以为数据没有发生过变化,其实已经被改动了。解决这个问题请参考《扩展:原子更新字段类-ABA问题解决》
synchronized
synchronized锁升级实际上是把本来的悲观锁变成了 在一定条件下 使用无所(同样线程获取相同资源的偏向锁),以及使用乐观(自旋锁 cas)和一定条件下悲观(重量级锁)的形式。
偏向锁:适用于单线程适用锁的情况
轻量级锁:适用于竞争较不激烈的情况(这和乐观锁的使用范围类似)
重量级锁:适用于竞争激烈的情况
LongAdder
- AtomicLong :并发场景下读性能优秀,写性能急剧下降,不适合作为高性能的计数器方案。内需求量少。
- LongAdder :并发场景下写性能优秀,读性能由于组合求值的原因,不如直接读值的方案,但由于计数器场景写多读少的缘故,整体性能在几个方案中最优,是高性能计数器的首选方案。由于 Cells 数组以及缓存行填充的缘故,占用内存较大。
最佳方案
高性能计数器的首选方案, 单体项目建议使用LongAddr,分布式环境建议使用Redisson分布式累加器
应用场景功能:获取全局自增id值
相关文章:
java高性能并发计数器之巅峰对决
并发计数器各个方案介绍方案概述1. jdk5提供的原子更新长整型类 AtomicLong2. synchronized3. jdk8提供的 LongAdder 【单机推荐】4. Redisson分布式累加器【分布式推荐】方案介绍jdk5提供的原子更新长整型类 AtomicLong在JDK1.5开始就新增了并发的Integer/Long的操作工具类Ato…...

HTTPS简介
HTTPS是HTTP开启TLS传输协议,客户端要拿到服务端的公钥,用公钥加密数据后再进行传输,防止数据泄露后背篡改。它要解决两个问题:怎么保证公钥可信怎么加密数据公钥可信问题客户端从服务端获取公钥的时候,存在请求被拦截…...

K-means聚类
原理说明 Kmeans是一种常见的聚类算法,用于将相似的数据点归类到不同的群组中。Kmeans的原理如下: 初始化:Kmeans算法首先需要初始化一个用户指定数量的聚类中心点,通常是随机选取K个数据点作为聚类中心点。 分配:对…...

04-SQL基础(表管理,约束,多表连接,子查询)
本文章主要内容 1、表的管理:创建表,修改表结构,删除字段,修改字段,添加字段,删除表,添加表约束; 2、数据管理:新增记录,修改记录,删除记录&…...
统计学 一元线性回归
统计学 一元线性回归 回归(Regression):假定因变量与自变量之间有某种关系,并把这种关系用适当的数学模型表达出来,利用该模型根据给定的自变量来预测因变量 线性回归:因变量和自变量之间是线性关系 非线…...

【软件开发】基于PyQt5开发的标注软件
这里是基于PyQt5写的面向目标检测的各类标注PC端软件系统。目前现有的labelme软件和labelImg开源软件无法满足特殊数据集的标注要求,而且没有标注顺序的报错提示。当然我设计的软件就会不具有适用性了(毕竟从下面开发的软件可以明显看出来我做的基本上是…...

CSS3新特性
CSS3新特性前言css3选择器边框特性背景参考前言 css3作为css的升级版本,css3提供了更加丰富实用的规范。新特性有: css3选择器边框特性多背景图颜色与透明度多列布局与弹性盒模型布局盒子的变形过渡与动画web字体媒体查询阴影 css3选择器 css3选择器…...

35 openEuler搭建repo(yum)服务器-创建、更新本地repo源
文章目录35 openEuler搭建repo(yum)服务器-创建、更新本地repo源35.1 获取ISO发布包35.2 挂载ISO创建repo源35.3 创建本地repo源35.4 更新repo源35 openEuler搭建repo(yum)服务器-创建、更新本地repo源 使用mount挂载,…...
【三.项目引入axios、申明全局变量、设置跨域】
根据前文《二.项目使用vue-router,引入ant-design-vue的UI框架,引入less》搭建好脚手架后使用 需求: 1.项目引入axios 2.申明全局变量 3.设置跨域 简介:axios本质上还是对原生XMLHttpRequest的封装,可用于浏览器和nodejs的HTTP客…...

启动u盘还原成普通u盘(Windows Diskpart)
使用windows系统的diskpart 命令解决系统盘恢复成普通U盘的问题:1. 按Windows R键打开运行窗口。在搜索框中输入“ Diskpart ”,然后按 Enter 键。2. 现在输入“ list disk ”并回车。3. 然后输入“ select disk X ”(将 X 替换为可启动U盘的…...
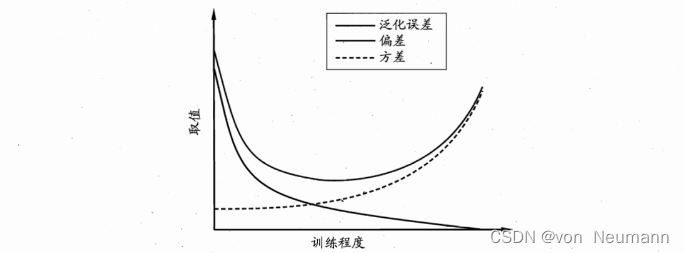
深入理解机器学习——偏差(Bias)与方差(Variance)
分类目录:《深入理解机器学习》总目录 偏差(Bias)与方差(Variance)是解释学习算法泛化性能的一种重要工具。偏差方差分解试图对学习算法的期望泛化错误率进行拆解,我们知道,算法在不同训练集上学…...

分布式新闻项目实战 - 13.项目部署_持续集成(Jenkins) ^_^ 完结啦 ~
欲买桂花同载酒,终不似,少年游。 系列文章目录 项目搭建App登录及网关App文章自媒体平台(博主后台)自媒体文章审核延迟任务kafka及文章上下架App端文章搜索后台系统管理Long类型精度丢失问题定时计算热点文章(xxl-Job…...

Linux c/c++技术方向分析
一、C与C介绍 1.1 说明 c语言是一门面向过程的、抽象化的通用程序设计语言,广泛应用于底层开发,如嵌入式。C语言能以简易的方式编译、处理低级存储器。是一种高效率程序设计语言。 c(c plus plus)是一种计算机高级程序设计语言&a…...
JavaScript 高级3 :函数进阶
JavaScript 高级3 :函数进阶 Date: January 19, 2023 Text: 函数的定义和调用、this、严格模式、高阶函数、闭包、递归 目标: 能够说出函数的多种定义和调用方式 能够说出和改变函数内部 this 的指向 能够说出严格模式的特点 能够把函数作为参数和返…...
【项目】Java树形结构集合分页,java对list集合进行分页
Java树形结构集合分页需求难点实现第一步:查出所有树形集合数据 (需进行缓存处理)selectTree 方法步骤:TreeUtil类:第二步:分页 GoodsCategoryController分页getGoodsCategoryTree方法步骤:第三…...
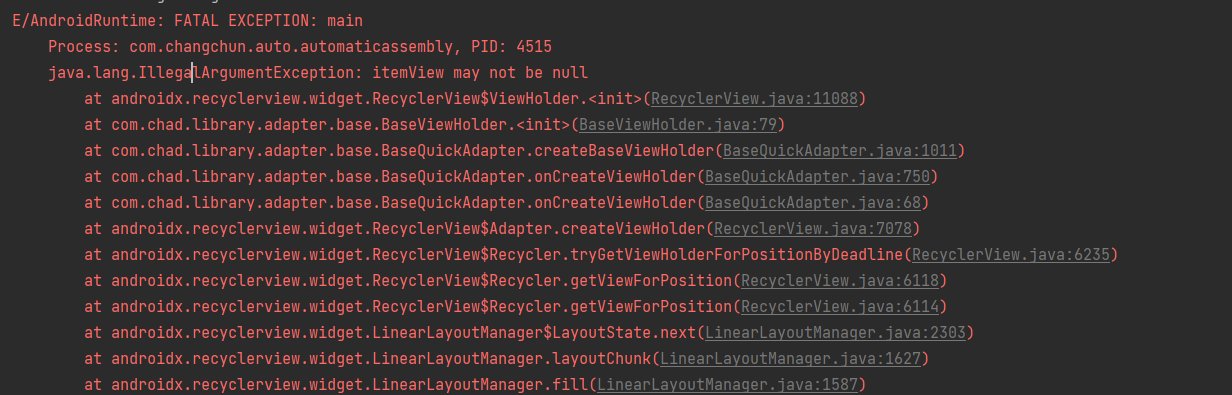
java.lang.IllegalArgumentException: itemView may not be null
报错截图:场景介绍:在使用recycleView 自动递增数据,且自动滚动到最新行; 当数据达到273条 时出现ANR;项目中 全部的列表适配器使用的三方库:BaseRecyclerViewAdapterHelper (很早之前的项目&am…...
[ 攻防演练演示篇 ] 利用 shiro 反序列化漏洞获取主机权限
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

达人合作加持品牌布局,3.8女神玩转流量策略!
随着迅猛发展的“她经济”,使社区本就作为内容种草的平台,自带“营销基因”。在3.8女神节即将到来之际,如何充分利用平台女性资源优势,借助达人合作等手段,实现迅速引流,来为大家详细解读下。一、小红书节日…...
观点丨Fortinet谈ChatGPT火爆引发的网络安全行业剧变
FortiGuard报告安全趋势明确指出“网络攻击者已经开始尝试AI手段”,ChatGPT的火爆之际的猜测、探索和事实正在成为这一论断的佐证。攻守之道在AI元素的加持下也在悄然发生剧变。Fortinet认为在攻击者利用ChatGPT等AI手段进行攻击的无数可能性的本质,其实…...

工业企业用电损耗和降损措施研究
来自用电设备和供配电系统的电能损耗。而供配电系统的电能损耗,包括企业变配电设备、控制设备企业在不断降低生产成本,追求经济效益的情况下,进一步降低供配电系统中的电能损耗,使电气设摘要:电网电能损耗是一个涉及面很广的综合性问题,主要包括管理损耗和技术损耗两部分…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

数据库正常,但后端收不到数据原因及解决
从代码和日志来看,后端SQL查询确实返回了数据,但最终user对象却为null。这表明查询结果没有正确映射到User对象上。 在前后端分离,并且ai辅助开发的时候,很容易出现前后端变量名不一致情况,还不报错,只是单…...

以太网PHY布局布线指南
1. 简介 对于以太网布局布线遵循以下准则很重要,因为这将有助于减少信号发射,最大程度地减少噪声,确保器件作用,最大程度地减少泄漏并提高信号质量。 2. PHY设计准则 2.1 DRC错误检查 首先检查DRC规则是否设置正确,然…...