数据结构(3)----栈和队列
目录
一.栈
1.栈的基本概念
2.栈的基本操作
3.顺序栈的实现
•顺序栈的定义
•顺序栈的初始化
•进栈操作
•出栈操作
•读栈顶元素操作
•若使用另一种方式:
4.链栈的实现
•链栈的进栈操作
•链栈的出栈操作
•读栈顶元素
二.队列
1.队列的基本概念
2.队列的基本操作
3.用顺序存储实现队列
•初始化
•入队操作
•出队操作
•获得队头元素的值
•判满/空方案
4.用链式存储实现队列
•初始化
•入队操作
•出队操作
•队列满的条件
三.双端队列
一.栈
1.栈的基本概念
栈(stack)是只允许在一端进行插入或删除操作的线性表。
栈顶:允许插入和删除的一端。最上面的元素被称为栈顶元素。
栈底:不允许插入和删除的一端。最下面的元素被称为栈底元素。
如下图所示:
进栈顺序:a1-->a2-->a3-->a4-->a5
出栈顺序:a5-->a4-->a3-->a2-->a1
所以栈的特点是后进先出(Last In First Out ( LIFO ))
补充:
n个不同元素进栈,出栈元素不同排列的个数为
。
上述公式称为卡特兰(Catalan)数,可采用数学归纳证明。

2.栈的基本操作
•Initstack(&S):初始化栈。构造一个空栈S,分配内存空间。
•DestroyStack(&L):销毁栈。销毁并释放栈s所占用的内存空间。
•Push(&S,x):进栈,若栈S未满,则将x加入使之成为新栈顶。•Pop(&S,&x):出栈,若栈S非空,则弹出栈顶元素,并用x返回。
•GetTop(S,&x):读栈顶元素。若栈S非空,则用x返回栈顶元素。
其他常用操作:
StackEmpty(S):判断一个栈S是否为空。若S为空,则返回true,否则返回false。
3.顺序栈的实现
•顺序栈的定义
#define Maxsize 10 //定义栈中元素的最大个数
typedef struct{ElemType data[Maxsize]; //静态数组存放栈中元素int top; //栈顶指针
} SqStack;void testStack(){SqStack S; //声明一个顺序栈(分配空间)
}
//这里使用声明的方式分配内存空间,并没有使用malloc函数。
//所以给这个栈分配的内存空间,会在函数结束之后又系统自动回收。声明顺序栈后,就会给各个数据元素分配连续的存储空间,大小为MaxSize*sizeof(ElemType)的空间。

•顺序栈的初始化
#define Maxsize 10 //定义栈中元素的最大个数
typedef struct{
ElemType data[Maxsize]; //静态数组存放栈中元素
int top; //栈顶指针
} SqStack;//初始化栈
void Initstack(Sqstack &S){S.top=-1; //初始化栈顶指针
}//判断栈空
bool StackEmpty(SqStack S){if(S.top==-1) //栈空return true ;else //不空return false;
}void testStack(){SqStack S;InitStack(S);
}•进栈操作
#define MaxSize 10
typedef struct{ElemType data[Maxsize];int top;
} Sqstack;//新元素入栈
bool Push(SqStack &S,ElemType x){if(S.top == MaxSize-1) //栈满,报错return false;S.top = S.top + 1; //指针先加1S.data[s.top]=x; //新元素入栈return true;
}//或者写为
bool Push(SqStack &S,ElemType x){if(S.top == MaxSize-1) //栈满,报错return false;S.data[++S.top]=x;return true;
}
//不能写为
bool Push(SqStack &S,ElemType x){if(S.top == MaxSize-1) //栈满,报错return false;S.data[S.top++]=x;return true;
}//这意味着
bool Push(SqStack &S,ElemType x){if(S.top == MaxSize-1) //栈满,报错return false; S.data[s.top]=x; //新进栈的元素会把以前的元素覆盖 S.top = S.top + 1;return true;
}•出栈操作
#define MaxSize 10
typedef struct{ElemType data[Maxsize];int top;
} Sqstack;//出栈操作
bool Pop(Sqstack &S,ElemType &x){if(S.top==-1) //栈空,报错return false;x=S.data[S.top]; //栈顶元素先出栈S.top=S.top-1; //指针再减1return true;
}
//删除操作中,top指针往下移,只是逻辑上被删除了,数据还残留在内存中。//出栈操作也可写为
bool Pop(Sqstack &S,ElemType &x){if(S.top==-1) //栈空,报错return false;x=S.data[S.top--];return true;
}//不能写为
bool Pop(Sqstack &S,ElemType &x){if(S.top==-1) //栈空,报错return false;x=S.data[--S.top];return true;
}//这意味着
bool Pop(Sqstack &S,ElemType &x){if(S.top==-1) //栈空,报错return false;S.top=S.top-1;x=S.data[S.top];return true;
}如果先减,再将top的值赋给x,那么x值就会返回"i",而不是"j"

•读栈顶元素操作
#define Maxsize 10
typedef struct{ElemType data[Maxsize];int top;
} Sqstack;//出栈澡作
bool Pop(Sqstack &S,ElemType &x){if(S.top==-1) //栈空,报错return false;x=S.data[s.top--]; //先出栈,指针再减1return true;
}//读栈顶元素
bool GetTop(Sqstack S,ElemType &x){if(S.top==-1) //栈空,报错return false;x=S.data[s.top]; //x记录栈顶元素return true;
}
//可以看到,出栈操作和读栈顶元素非常类似。•若使用另一种方式:
将top指针刚开始指向0,判断栈是否为空,即判断S.top==0,这样设计是将top指针指向下一个能插入元素的位置。

若进行入栈操作时,需要先把x放到top指针指向的位置,再让top+1,和之前的方式相反。
出栈操作也是,需要先让top-1,再把top指向的数据元素传回去。
代码如下:
#define Maxsize 10
typedef struct{ElemType data[Maxsize];int top;
} SqStack;//初始化栈
void Initstack(Sqstack &s){S.top=0; //初始化指向0
}bool StackEmpty(Sqstack S){if(S.top==0) //栈空return true;elsereturn false;
}//入栈操作
bool Push(SqStack &S,ElemType x){if(S.top == MaxSize) //栈满,报错return false;S.data[S.top++]=x;return true;
}//出栈操作
bool Pop(Sqstack &S,ElemType &x){if(S.top==0) //栈空,报错return false;x=S.data[--S.top];return true;
}void testStack(){ 判断栈空SqStacks;//声明一个顺序栈InitStack(S);
}顺序栈的缺点是栈的大小不可变,可以在刚开始就给栈分配大片的内存空间,但这样会导致内存空间的浪费,可以使用共享栈提高内存空间的利用率。共享栈即两个栈共享同一片内存空间。
代码如下:
#define MaxSize 10
typedef struct{ElemType data[Maxsize]; //静态数组存放栈中元素int top0; //0号栈栈顶指针int top1; //1号栈浅顶指针
} Shstack;//初始化栈
void InitStack(Shstack &S){S.top0=-1; //初始化栈顶指针S.top1=Maxsize;
}
可以看到,共享栈判断栈满的条件:top0+1=top1
总结:

4.链栈的实现
对于链栈而言,其进栈操作其实对应于链表中对头结点的"后插"操作,出栈操作对应于链表中对头结点的"后删"操作,就是将链头的一端看作栈顶的一端。
建议先看:http://t.csdnimg.cn/IknBJ
代码如下:
//链栈的定义和链表的定义是相同的,只是命名不同
typedef struct Linknode{ElemType data;struct Linknode *next;
}LiStack; //栈类型定义//带头结点
bool InitStack(LiStack &L){L=(Linknode *)malloc(sizeof(Linknode));if(L==NULL)return false; //内存不足,分配失败L->next=NULL;return true;
}bool Empty(LinkList L){return(L->next == NULL);
}//不带头结点
bool InitStack(LiStack &L){L=NULL;return true;
}bool Empty(LinkList L){return(L=NULL);
}•链栈的进栈操作
//带头结点
LiStack LiSPush(LiStack &L){Linknode *s;int x;L=(LiStack)malloc(size(Linknode));L->next=NULL;scanf("%d",&x);while(x!=9999){s=(Linknode *)malloc(sizeof(Linknode));s->data=x;s->next=L->next;L->next=s;scanf("%d",&x);}return L;
}//不带头结点
LiStack LisPush(LiStack &L){Linknode *s;int x;L=NULL;scanf("%d",&x);while(x!=9999){s=(Linknode *)malloc(sizeof(Linknode));s->data=x;s->next=L;L=s;scanf("%d",&x);}return L;
}•链栈的出栈操作
//带头结点
LiStack LisPop(LiStack &L, int &e) {if (L->next == NULL) {// 栈空,无法出栈return NULL;}Linknode *q = L->next;e = q->data;L->next = q->next;free(q);return L;
}//不带头结点
LiStack LisPop(LiStack &L, int &e) {if (L == NULL) {// 栈空,无法出栈return NULL;}Linknode *q = L;e = q->data;L = L->next;free(q);return L;
}
•读栈顶元素
//带头结点
int GetTop(LiStack &L) {if (L->next == NULL) {// 栈为空return -1; // 或者抛出异常}return L->next->data;
}//不带头结点
int GetTop(LiStack &L) {if (L == NULL) {// 栈为空return -1; // 或者抛出异常}return L->data;
}
二.队列
1.队列的基本概念
栈(stack)是只允许在一端进行插入或删除操作的线性表。队列(aueue)是只允许在一端进行插入,在另一端删除的线性表。
队头,队尾,空队列:
空队列:没有数据元素
队头:允许删除的一端
队尾:允许插入的一端

队列的特点:先进入队列的元素先出队,即先进先出(First In First Out,FIFO)。
2.队列的基本操作
Initaueue(&Q):初始化队列,构造一个空队列。
DestroyQueue(&Q):销毁队列。销毁并释放队列Q所占用的内存空间。
EnQueue(&Q,x):入队,若队列Q未满,将x加入,使之成为新的队尾。
DeQueue(&a,&x):出队,若队列Q非空,删除队头元素,并用x返回。
GetHead(a,&x):读队头元素,若队列Q非空,则将队头元素赋值给x。其他常用操作:
QueueEmpty(Q):判队列空,若队列Q为空返回true,否则返回false。
3.用顺序存储实现队列
•初始化
#define Maxsize 10 //定义队列中元素的最大个数
typedef struct{ElemType data[Maxsize]; //用静态数组存放队列元素int front,rear; //队头指针和队尾指针
}SqQueue;void testQueue(){SqQueue Q;//声明一个队列
}声明一个队列后,系统会分配一片连续的存储空间,大小为MaxSize*sizeof(ElemType),如下图所示:
队头指针:指向队头元素。
队尾指针:指向队尾元素的后一个位置。

所以还没有插入元素时,队头指针与队尾指针同时指向data[0]:

#define Maxsize 10 //定义队列中元素的最大个数
typedef struct{ElemType data[Maxsize]; //用静态数组存放队列元素int front,rear; //队头指针和队尾指针
}SqQueue;void InitQueue(SqQueue &Q){//初始时,队头和队尾指针指向0Q.rear=Q.front=0;
}//判空
bool QueueEmpty(SqQueue Q){if(Q.rear==Q.front) //队空条件return true;elsereturn false;void testQueue(){SqQueue Q;//声明一个队列InitQueue(Q);}
•入队操作
只能从队尾入队
#define MaxSize 10
typedef struct{ElemType data[Maxsize];int front,rear;
} SqQueue;//入队
bool EnQueue(SqQueue &Q,ElemType x){if(Q.rear==MaxSize) return false; //队满则报错Q.data[Q.rear]=x; //新元素插入队尾Q.rear=(Q.rear+1);return true;
}注:rear=MaxSize不能作为队列已满的判断条件,上面的写法是错误的。如下图所示,若前面的元素出队了,要再插入元素,可以从前面无数据元素的区域插入。

正确写法:
#define MaxSize 10
typedef struct{ElemType data[Maxsize];int front,rear;
} SqQueue;//入队
bool EnQueue(SqQueue &Q,ElemType x){if((Q.rear+1)%MaxSize=Q.front) //判满return false; //队满则报错Q.data[Q.rear]=x; //新元素插入队尾Q.rear=(Q.rear+1)%MaxSize; //队尾指针加1取模return true;
}这里的Q.rear=(Q.rear)%MaxSize实现的效果是:当(Q.rear+1)%MaxSize==0时,即“队满”时,会将rear指针重新指向data[0]。

这样用模运算,将存储空间在逻辑上变成了“环状。

如下图所示,队满条件是:队尾指针的再下一个位置是队头,即(Q.rear+1)%MaxSize==Q.front

为什么需要不能再插入一个元素,并且使rear和front指向同一个元素呢?
因为初始化队列的时候,rear指针与front指针就是指向同一个位置,同时我们也是通过判断rear和front指针是否指向同一个位置,判断队列是否为空的。
如果再插入一个元素,rear和front指针指向同一个位置,这样,判满与判空条件就会混淆起来。
所以必须牺牲一个存储单元,以区分队列满还是空。
•出队操作
只能让队头元素出队:
//出队(删除一个队头元素,并用x返回)
bool DeQueue(sqQueue &Q,ElemType &x){if(Q.rear==Q.front) //当队头指针与队尾指针再次指向同一个位置时,说明队空return false; //队空则报错x=Q.data[Q.front];Q.front=(Q.front+1)%Maxsize; //队头指针后移return true;
}
•获得队头元素的值
//获得队头元素的值,用x返回
bool GetHead(SqQueue Q,ElemType &x){if(Q.rear==Q.front) //队空则报错return false;x=Q.data[Q.front];return true;
}//相比于出队操作,获取队头的值不需要将队头指针后移
bool DeQueue(sqQueue &Q,ElemType &x){if(Q.rear==Q.front) //当队头指针与队尾指针再次指向同一个位置时,说明队空return false; x=Q.data[Q.front];Q.front=(Q.front+1)%Maxsize; return true;
}•判满/空方案
方案一:
以上方案中,判断队列已满的条件:队尾指针的再下一个位置是队头,即:
(Q.rear+1)%MaxSize==Q.front
队空条件:队头指针与队尾指针指向同一个地方,即:
Q.rear=Q.front
队列元素个数:
(rear+MaxSize-front)%MaxSize
例如下图,rear=2,front=3,那么队列元素个数就是:(2+10-3)%10 =9%10=9

其实也可以不用牺牲一个存储空间,下面两种方案可供参考。
方案二:
#define MaxSize 10
typedef struct{ElemType data[MaxSize];int front,rear;int size; //用size表示当前队列的长度,当入队成功size++,出队成功size--
}SqQueue;

具体代码如下:
#define MaxSize 10
typedef struct {ElemType data[MaxSize];int front, rear;int size; // 用size表示当前队列的长度,当入队成功size++,出队成功size--
} SqQueue;// 初始化队列
void InitQueue(SqQueue &Q) {Q.front = Q.rear = 0;Q.size = 0;
}// 判断队列是否为空
bool QueueIsEmpty(SqQueue Q) {return (Q.rear == Q.front) && (Q.size == 0);
}// 判断队列是否已满
bool QueueIsFull(SqQueue Q) {return (Q.rear == Q.front) && (Q.size == MaxSize);
}// 入队操作
bool EnQueue(SqQueue &Q, ElemType x) {if (QueueIsFull(Q))return false;Q.data[Q.rear] = x;Q.rear = (Q.rear + 1) % MaxSize;Q.size++;return true;
}// 出队操作
bool DeQueue(SqQueue &Q, ElemType &x) {if (QueueIsEmpty(Q)) // 队列为空return false;x = Q.data[Q.front];Q.front = (Q.front + 1) % MaxSize;Q.size--;return true;
}
方案三:
#define Maxsize 10
typedef struct{ElemType data[Maxsize];int front,rear;int tag; //记录最近进行的是删除/插入
//每次删除操作成功时,都令tag=0,每次插入成功时,都令tag=1;
} SqQueue;只有删除操作,才能导致队空,只有插入操作,才能导致队满。所以:

具体代码如下:
#define Maxsize 10
typedef struct{ElemType data[Maxsize];int front,rear;int tag; //记录最近进行的是删除/插入
//每次删除操作成功时,都令tag=0,每次插入成功时,都令tag=1;
} SqQueue;// 初始化队列
void InitQueue(SqQueue &Q) {Q.front = Q.rear = 0;Q.tag = 0; // 初始时没有进行过操作,设置tag为0
}// 判断队列是否为空
bool QueueIsEmpty(SqQueue Q) {return Q.front == Q.rear && Q.tag == 0;
}// 判断队列是否已满
bool QueueIsFull(SqQueue Q) {return Q.front == Q.rear && Q.tag == 1;
}// 入队操作
bool EnQueue(SqQueue &Q, ElemType x) {if (QueueIsFull(Q)) {return false;}Q.data[Q.rear] = x;Q.rear = (Q.rear + 1) % Maxsize;Q.tag = 1; // 插入成功,设置tag为1return true;
}// 出队操作
bool DeQueue(SqQueue &Q, ElemType &x) {if (QueueIsEmpty(Q)) {return false;}x = Q.data[Q.front];Q.front = (Q.front + 1) % Maxsize;Q.tag = 0; // 删除成功,设置tag为0return true;
}在考试时,也可能出现rear指向队尾元素的情况,如下图所示:
![]()
//rear指向队尾元素的后一个位置时入队操作:
Q.data[Q.rear]=x;
Q.rear=(Q.rear+1)%MaxSize;//rear指向队尾元素时入队操作:
Q.rear=(Q.rear+1)%MaxSize;
Q.data[Q.rear]=x;初始化操作:
![]()
void InitQueue(SqQueue &Q){//初始时,队头和队尾指针指向0Q.front=0;Q.rear=MaxSize-1;
}
判空操作:

//判空
bool QueueEmpty(SqQueue Q){if((Q.rear+1)%MaxSize==Q.front) //队空条件return true;elsereturn false;判满操作:
判满也不能用与判空相同的条件了:

可以牺牲一个存储空间,即队空时,队尾指针在队头指针后面一个位置,队满时,队尾指针在队头指针后面两个位置。

或者向上面说的一样,增加辅助变量,如size,tag
这里只演示牺牲一个存储空间的情况:
#define Maxsize 10
typedef struct{ElemType data[Maxsize];int front,rear;
} SqQueue;// 初始化队列
void InitQueue(SqQueue &Q) {Q.front = 0;Q.rear =MaxSze-1;}//判空
bool QueueEmpty(SqQueue Q){if((Q.rear+1)%MaxSize==Q.front) //队空条件return true;elsereturn false;//判满
bool QueueEmpty(SqQueue Q){if((Q.rear+2)%MaxSize==Q.front) //队空条件return true;elsereturn false;// 入队操作
bool EnQueue(SqQueue &Q, ElemType x) {if (QueueIsFull(Q)) {return false;}Q.rear=(Q.rear+1)%MaxSize; //先往后移一个存储空间,再赋值Q.data[Q.rear]=x;return true;
}// 出队操作
bool DeQueue(SqQueue &Q, ElemType &x) {if (QueueIsEmpty(Q)) {return false;}x = Q.data[Q.front]; Q.front = (Q.front + 1) % Maxsize;return true;
}总结:

4.用链式存储实现队列
•初始化
typedef struct LinkNode{ //链式队列结点ElemType data;struct LinkNode *next;
}LinkNode;typedef struct{ //链式队列LinkNode *front,*rear; //队列的队头和队尾指针
}LinkQueue;

typedef struct LinkNode{ //链式队列结点ElemType data;struct LinkNode *next;
}LinkNode;typedef struct{ //链式队列LinkNode *front,*rear; //队列的队头和队尾指针
}LinkQueue;//初始化队列(带头结点)
void InitQueue(LinkQueue &Q){//初始时 front、rear 都指向头结点Q.front=Q.rear=(LinkNode*)malloc(sizeof(LinkNode));Q.front->next=NULL;
}//判断队列是否为空
bool IsEmpty(LinkQueue Q){if(Q.front==Q.rear)return true;elsereturn false;
}void testLinkQueue(){LinkQueue Q; //声明一个队列InitQueue(Q); //初始化队列
}//初始化队列(不带头结点)
void InitQueue(LinkQueue &Q){//初始时 front、rear 都指向NULLQ.front=NULL;Q.rear=NULL;
}//判断队列是否为空(不带头结点)
bool IsEmpty(LinkQueue Q){if(Q.front==NULL)return true;elsereturn false;
}
•入队操作
//新元素入队(带头结点)
void EnQueue(LinkQueue &Q,ElemType x){LinkNode *s=(LinkNode *)malloc(sizeof(LinkNode));s->data=x;s->next=NULL; //新结点插入到rear之后 Q.rear->next=s; //修改表尾指针Q.rear=s;
首先申请一个新结点,并把数据元素放到这一新结点当中:s->data=x;
新插入的结点一定是队列的最后一个结点,所以该结点的next指针指向NULL:s->next=NULL
将rear指向的结点的next指针指向新申请的s结点:Q.rear->next=s;
最后表尾指针会指向新的表尾结点:Q.rear=s;
若不带头结点,在第一个元素入队时,就需要进行特殊的处理:
//新元素入队(不带头结点)
void EnQueue(LinkQueue &Q,ElemType x){LinkNode *s=(LinkNode *)malloc(sizeof(LinkNode));s->data=x;s->next=NULL;if(Q.front == NULL){ //在空队列中插入第一个元素Q.front = s; //修改队头队尾指针Q.rear=s; } else { Q.rear->next=s; //新结点插入到 rear 结点之后Q.rear=s; //修改 rear 指针}
}•出队操作
//队头元素出队(带头结点)
bool DeQueue(LinkQueue &Q,ElemType &x){if(Q.front==Q.rear)return false; //空队LinkNode *p=Q.front->next;x=p->data; //用变量x返回队头元素Q.front->next=p->next; //修改头结点的 next 指针if(Q.rear==p) //此次是最后一个结点出队Q.rear=Q.front; //修改rear指针free(p); //释放结点空间return true;
}首先用p指向要出队的结点,即头结点之后的结点:LinkNode *p=Q.front->next;
接着修改头结点的后项指针:Q.front->next=p->next;
最后释放结点p:free(p)
若此次出队的结点p是当前队列的最后一个元素,在修改完头结点的后项指针后:
还需要修改表尾指针,让其指向头结点:Q.rear=Q.front;
最后释放p:free(p)




对于不带头结点的队列:
//队头元素出队(不带头结点)
bool DeQueue(LinkQueue &Q,ElemType &x){if(Q.front==NULL) //空队return false;LinkNode *p=Q.front; //p指向此次出队的结点x=p->data; //用变量x返回队头元素Q.front=p->next; //修改 front 指针if(Q.rear==p){Q.front = NULL;Q.rear = NULL;}free(p);return true;
}每次出队的是front指针指向的结点:LinkNode *p=Q.front;
由于没有头结点,所以每一次队头出队时,就需要修改队头指针指向的结点:
Q.front=p->next;
最后一个结点出队后,将front和rear都指向NULL:Q.front=NULL;Q.rear=NULL;


•队列满的条件
对于顺序存储的队列,存储空间都是预分配的,预分配的存储空间耗尽,则队满。而对链式存储而言,一般不会对满,除非内存不足。
三.双端队列
之前学习的栈,只允许从一端插入和删除的线性表:

队列则只允许从一端插入,另一端删除的线性表:

双端队列则是允许从两端插入,也允许从两端删除的线性表:

若只使用其中一端的插入、删除操作,则效果等同于栈。所以,只要是栈能实现的功能,双端队列一定能够实现。
双端队列还可以分为:
输入受限的双端队列:只允许从一端插入、两端删除的线性表。

输出受限的双端队列:只允许从两端插入、一端删除的线性表。

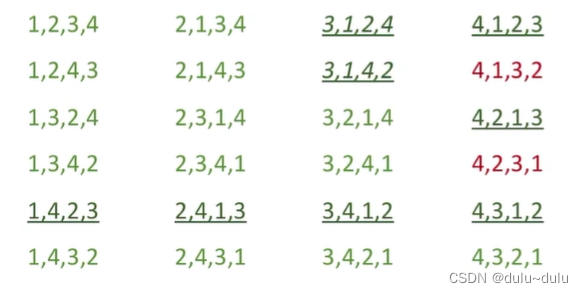
对于栈而言,合法的出栈序列有14种,可用卡特兰数计算:


对于输入受限的双端队列:

在栈中合法的序列,在双端队列中一定合法,所以只需要看“在栈中不合法”的输出队列即可。
可以得到以下结果,划线的是在栈中不合法,而在输入受限的双端队列中合法的序列:

对于输出受限的双端队列,同理:

相关文章:
数据结构(3)----栈和队列
目录 一.栈 1.栈的基本概念 2.栈的基本操作 3.顺序栈的实现 •顺序栈的定义 •顺序栈的初始化 •进栈操作 •出栈操作 •读栈顶元素操作 •若使用另一种方式: 4.链栈的实现 •链栈的进栈操作 •链栈的出栈操作 •读栈顶元素 二.队列 1.队列的基本概念 2.队列的基…...

nestjs 全栈进阶--module
视频教程 10_模块Module1_哔哩哔哩_bilibili 1. 模块Module 在 Nest.js 中,Module 是框架的核心概念之一,用于组织和管理应用程序的不同部分,包括服务、控制器、中间件以及其他模块的导入。每个 Nest.js 应用程序至少有一个根模块…...
jupyter python paramiko 网络系统运维
概述 通过使用jupyter进行网络运维的相关测试 设备为H3C 联通性测试 import paramiko import time import getpass import re import os import datetimeusername "*****" password "*****" ip "10.32.**.**"ssh_client paramiko.SSHCli…...

Windows Edge浏览器兼容性问题诊断与修复策略详解
随着Microsoft Edge浏览器的持续迭代与更新,其性能与兼容性已得到了显著提升。然而,在面对互联网上纷繁复杂的网页内容时,仍有可能遇到兼容性问题。本文旨在探讨Edge浏览器在处理网页兼容性问题时的常见场景、原因分析及相应的解决方案&#…...

EXCEL学习笔记
EXCEL学习笔记 小技巧 一键批量添加后缀名词/单词 单元格格式-自定义-通用格式后面输入相应的单位,比如“元”。 输入10000个序号,先输入1,点击开始-填充-序列,选中该列,终止值为10000; 按住shift选取多个…...
)
使用预训练的bert large model实现问答系统源码(本地实现 question answer system)
pre-trained bert model 预训练好的Bert模型 本地实现问答系统 用这条命令将bert下载到本地: model.save_pretrained("path/to/model") 具体代码 如下链接: https://download.csdn.net/download/qqqweiweiqq/89092005...

蓝桥杯 历届真题 杨辉三角形【第十二届】【省赛】【C组】
资源限制 内存限制:256.0MB C/C时间限制:1.0s Java时间限制:3.0s Python时间限制:5.0s 思路: 由于我第一写没考虑到大数据的原因,直接判断导致只得了40分,下面是我的代码: #…...

商务电子邮件: 在WorkPlace中高效且安全
高效和安全的沟通是任何组织成功的核心。在我们关于电子邮件类型的系列文章的第二期中,我们将重点关注商业电子邮件在促进无缝交互中的关键作用。当你身处重要的工作场环境时,本系列的每篇文章都提供了电子邮件的不同维度的视角。 “2024年,全…...

阿里云2024年优惠券领取及使用常见问题
阿里云是阿里巴巴旗下云计算品牌,服务涵盖云服务器、云数据库、云存储、域名注册等全方位云服务和各行业解决方案。为了吸引用户上云,阿里云经常推出各种优惠活动,其中就包括阿里云优惠券。本文将对阿里云优惠券领取及使用常见问题进行解答&a…...
90天玩转Python—05—基础知识篇:Python基础知识扫盲,使用方法与注意事项
90天玩转Python系列文章目录 90天玩转Python—01—基础知识篇:C站最全Python标准库总结 90天玩转Python--02--基础知识篇:初识Python与PyCharm 90天玩转Python—03—基础知识篇:Python和PyCharm(语言特点、学习方法、工具安装) 90天玩转Python—04—基础知识篇:Pytho…...

常见的常见免费开源绘图工具对比 draw.io/Excalidraw/Lucidchart/yEd Graph Editor/Dia/
拓展阅读 常见免费开源绘图工具 OmniGraffle 创建精确、美观图形的工具 UML-架构图入门介绍 starUML UML 绘制工具 starUML 入门介绍 PlantUML 是绘制 uml 的一个开源项目 UML 等常见图绘制工具 绘图工具 draw.io / diagrams.net 免费在线图表编辑器 绘图工具 excalidr…...
项目:自主实现Boost搜索引擎
文章目录 写在前面开源仓库和项目上线其他文档说明 项目背景项目的宏观原理技术栈与环境搜索引擎原理正排索引倒排索引 去标签和数据清洗模块html文件名路径保存函数html数据解析函数文件写入函数 建立索引模块检索和读取信息建立索引建立正排索引建立倒排索引jieba工具的使用倒…...
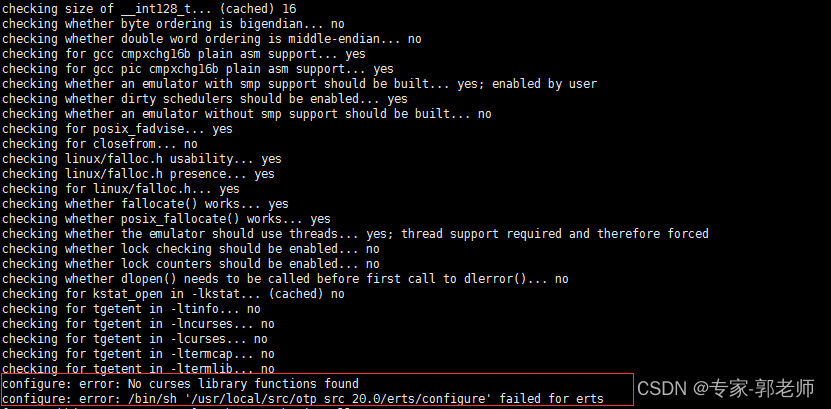
麒麟系统ARM安装rabbitmq
简单记录下,信创服务器:麒麟系统,安装rabbitmq的踩坑记录。 本文章参考了很多大佬文章,我整理后提供。 一、安装基础依赖 yum -y install make gcc gcc-c kernel-devel m4 ncurses-devel openssl-devel unixODBC-devel 二、下载…...

MongoDB数据更新大之大与小中小
学习mongodb,体会mongodb的每一个使用细节,欢迎阅读威赞的文章。这是威赞发布的第56篇mongodb技术文章,欢迎浏览本专栏威赞发布的其他文章。 数据更新中,往往要应对比较更新的场景。现在很多人喜欢跑步,规律跑步&…...

C语言开发实战:使用EasyX在Visual Studio 2022中创建井字棋游戏
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...
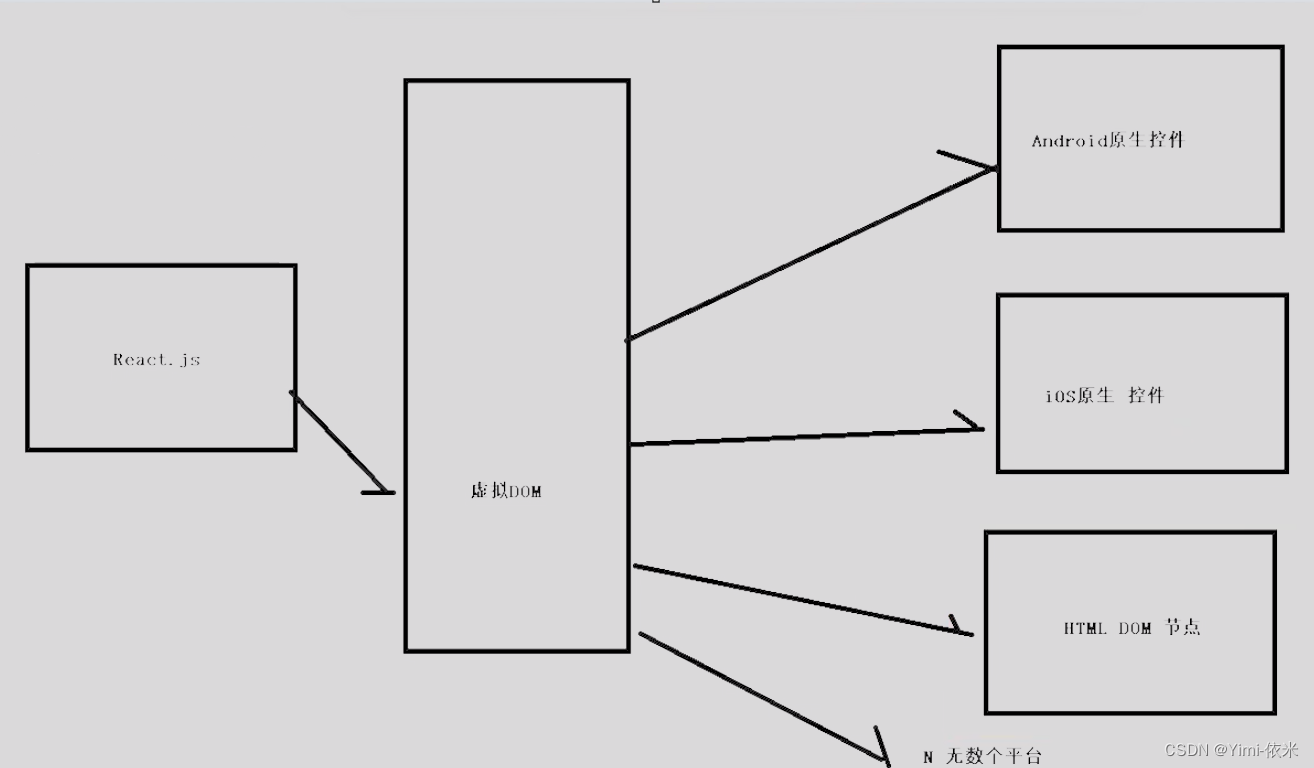
Android与RN远程过程调用的原理
Android与RN远程过程调用的原理是通过通信协议进行远程过程调用。RPC(Remote Procedure Call)是分布式系统常见的一种通信方式,从跨进程到跨物理机已经有几十年历史。 在React Native中,通信机制是一个C实现的桥,打通了Java和JS,实现了两者的…...

MySQL-主从复制:概述、原理、同步数据一致性问题、搭建流程
主从复制 1. 主从复制概述 1.1 如何提升数据库并发能力 一般应用对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,有一个思路就是采用数据库集群的方案,做主从架构、进行读写分离,这样同样可以提升数据库的并…...
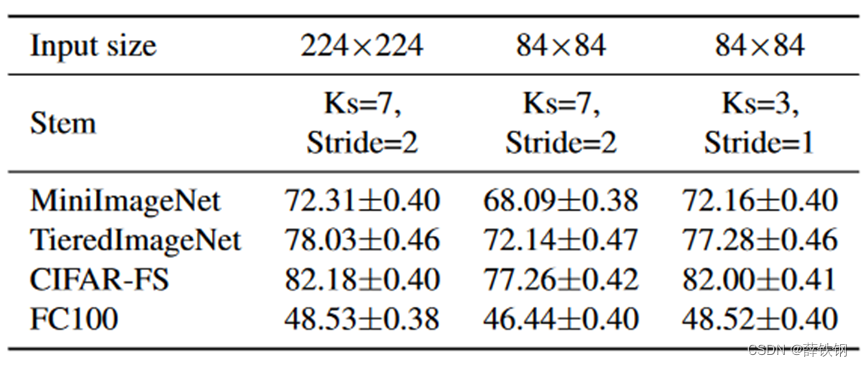
论文阅读《Semantic Prompt for Few-Shot Image Recognition》
论文地址:https://arxiv.org/pdf/2303.14123.pdf 论文代码:https://github.com/WentaoChen0813/SemanticPrompt 目录 1、存在的问题2、算法简介3、算法细节3.1、预训练阶段3.2、微调阶段3.3、空间交互机制3.4、通道交互机制 4、实验4.1、对比实验4.2、组…...
docker)
Linux初学(十七)docker
一、docker 1.1 简介 容器技术 容器其实就是虚拟机,每个容器可以运行不同的系统【系统以Linux为主的】 为什么要使用docker? docker容器之间互相隔离,可以提高安全性通过使用docker可以做靶场 1.2 安装配置docker 方法一:yum安装…...
Python---Numpy线性代数
1.数组和矩阵操作: 创建数组和矩阵:np.array, np.matrix 基本的数组操作:形状修改、大小调整、转置等 import numpy as np# 创建一个 2x3 的数组 A np.array([[1, 2, 3], [4, 5, 6]]) print("数组 A:\n", A)# 将数组 A 转换为矩阵…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

前端工具库lodash与lodash-es区别详解
lodash 和 lodash-es 是同一工具库的两个不同版本,核心功能完全一致,主要区别在于模块化格式和优化方式,适合不同的开发环境。以下是详细对比: 1. 模块化格式 lodash 使用 CommonJS 模块格式(require/module.exports&a…...
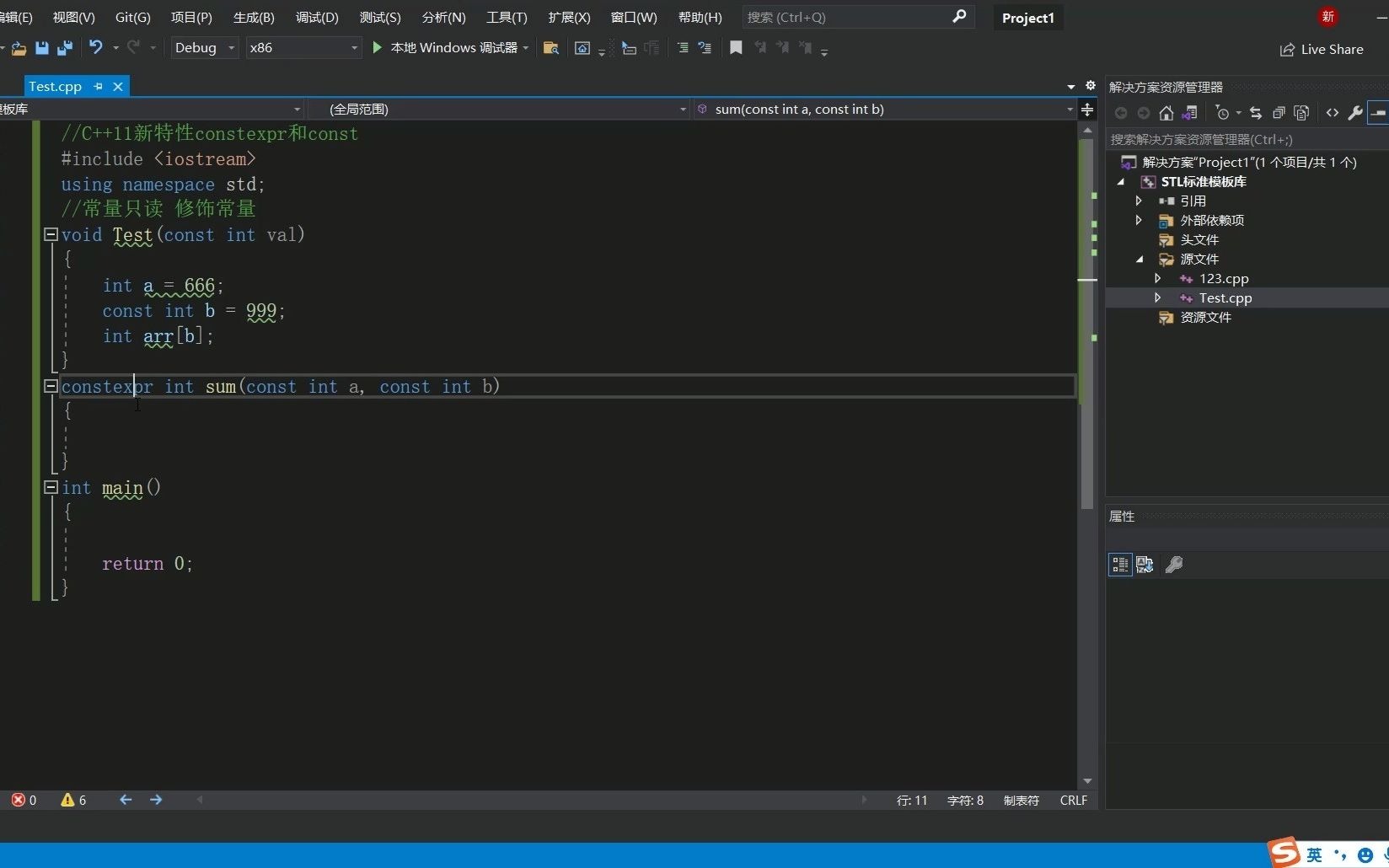
C++11 constexpr和字面类型:从入门到精通
文章目录 引言一、constexpr的基本概念与使用1.1 constexpr的定义与作用1.2 constexpr变量1.3 constexpr函数1.4 constexpr在类构造函数中的应用1.5 constexpr的优势 二、字面类型的基本概念与使用2.1 字面类型的定义与作用2.2 字面类型的应用场景2.2.1 常量定义2.2.2 模板参数…...

Clickhouse统计指定表中各字段的空值、空字符串或零值比例
下面是一段Clickhouse SQL代码,用于统计指定数据库中多张表的字段空值情况。代码通过动态生成查询语句实现自动化统计,处理逻辑如下: 从系统表获取指定数据库(替换your_database)中所有表的字段元数据根据字段类型动态…...

多层PCB技术解析:从材料选型到制造工艺的深度实践
在电子设备集成度与信号传输要求不断提升的背景下,多层PCB凭借分层布局优势,成为高速通信、汽车电子、工业控制等领域的核心载体。其通过导电层、绝缘层的交替堆叠,实现复杂电路的立体化设计,显著提升空间利用率与信号完整性。 一…...