AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.05-2024.04.10
文章目录~
- 1.BRAVE: Broadening the visual encoding of vision-language models
- 2.ORacle: Large Vision-Language Models for Knowledge-Guided Holistic OR Domain Modeling
- 3.MedRG: Medical Report Grounding with Multi-modal Large Language Model
- 4.InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
- 5.Can Feedback Enhance Semantic Grounding in Large Vision-Language Models?
- 6.Audio-Visual Generalized Zero-Shot Learning using Pre-Trained Large Multi-Modal Models
- 7.Anchor-based Robust Finetuning of Vision-Language Models
- 8.MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
- 9.Retrieval-Augmented Open-Vocabulary Object Detection
- 10.PromptAD: Learning Prompts with only Normal Samples for Few-Shot Anomaly Detection
- 11.Progressive Alignment with VLM-LLM Feature to Augment Defect Classification for the ASE Dataset
- 12.FGAIF: Aligning Large Vision-Language Models with Fine-grained AI Feedback
- 13.Hyperbolic Learning with Synthetic Captions for Open-World Detection
- 14.Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
- 15.ByteEdit: Boost, Comply and Accelerate Generative Image Editing
- 16.DifFUSER: Diffusion Model for Robust Multi-Sensor Fusion in 3D Object Detection and BEV Segmentation
- 17.Self-Training Large Language Models for Improved Visual Program Synthesis With Visual Reinforcement
- 18.Soft-Prompting with Graph-of-Thought for Multi-modal Representation Learning
- 19.ClickDiffusion: Harnessing LLMs for Interactive Precise Image Editing
- 20.Who Evaluates the Evaluations? Objectively Scoring Text-to-Image Prompt Coherence Metrics with T2IScoreScore (TS2)
- 21.Image-Text Co-Decomposition for Text-Supervised Semantic Segmentation
- 22.Label Propagation for Zero-shot Classification with Vision-Language Models
1.BRAVE: Broadening the visual encoding of vision-language models
标题:BRAVE:拓宽视觉语言模型的视觉编码
author:Oğuzhan Fatih Kar, Alessio Tonioni, Petra Poklukar, Achin Kulshrestha, Amir Zamir, Federico Tombari
publish:Project page at https://brave-vlms.epfl.ch/
date Time:2024-04-10
paper pdf:http://arxiv.org/pdf/2404.07204v1
摘要:
视觉语言模型(VLM)通常由一个视觉编码器(如 CLIP)和一个语言模型(LM)组成,前者解释编码特征,后者解决下游任务。尽管取得了显著进展,但由于视觉编码器的能力有限,VLM 仍然存在一些缺陷,例如对某些图像特征 “视而不见”、视觉幻觉等。为了解决这些问题,我们研究了如何拓宽 VLM 的视觉编码能力。我们首先对解决 VLM 任务的几种具有不同归纳偏差的视觉编码器进行了全面的基准测试。我们发现,没有一种编码配置能在不同任务中始终保持最佳性能,而具有不同偏置的编码器的性能却惊人地相似。受此启发,我们引入了一种名为 BRAVE 的方法,它能将来自多个冻结编码器的特征整合为一种更通用的表示方法,可直接作为输入输入到冻结 LM 中。BRAVE 在广泛的字幕和 VQA 基准上实现了最先进的性能,并显著减少了 VLMs 的上述问题,同时与现有方法相比,它所需的可训练参数数量更少,表示形式也更紧凑。我们的研究结果凸显了将不同的视觉偏差纳入对 VLMs 的更广泛、更情景化的视觉理解的潜力。
2.ORacle: Large Vision-Language Models for Knowledge-Guided Holistic OR Domain Modeling
标题:ORacle:用于知识引导的整体 OR 领域建模的大型视觉语言模型
author:Ege Özsoy, Chantal Pellegrini, Matthias Keicher, Nassir Navab
publish:11 pages, 3 figures, 7 tables
date Time:2024-04-10
paper pdf:http://arxiv.org/pdf/2404.07031v1
摘要:
每天,全世界都有无数的手术在不同的手术室(OR)中进行,这些手术室不仅在设置上各不相同,而且在人员、工具和设备的使用上也各不相同。这种固有的多样性给实现对手术室的整体理解带来了巨大挑战,因为它要求模型的泛化能力超越其初始训练数据集。为了缩小这一差距,我们引入了 ORacle,这是一种先进的视觉语言模型,专为手术室领域的整体建模而设计,具有多视角和时态功能,并能在推理过程中利用外部知识,使其能够适应以前未见过的手术场景。我们新颖的数据增强框架进一步增强了这一能力,大大丰富了训练数据集,确保 ORacle 能够熟练有效地应用所提供的知识。在 4D-OR 数据集的场景图生成和下游任务的严格测试中,ORacle 不仅展示了最先进的性能,而且与现有模型相比所需的数据更少。此外,ORacle 的适应性还体现在它能够解释未见过的视图、动作以及工具和设备的外观。这表明 ORacle 有潜力显著提高手术室领域建模的可扩展性和经济性,并为未来手术数据科学的发展开辟了道路。我们将在验收后发布我们的代码和数据。
3.MedRG: Medical Report Grounding with Multi-modal Large Language Model
标题:MedRG:利用多模态大语言模型实现医学报告落地
author:Ke Zou, Yang Bai, Zhihao Chen, Yang Zhou, Yidi Chen, Kai Ren, Meng Wang, Xuedong Yuan, Xiaojing Shen, Huazhu Fu
publish:12 pages, 4 figures
date Time:2024-04-10
paper pdf:http://arxiv.org/pdf/2404.06798v1
摘要:
医学报告基础是根据给定的短语查询识别医学图像中最相关区域的关键,是医学图像分析和放射诊断的一个重要方面。然而,现有的可视化接地方法需要人工从医疗报告中提取关键短语,给系统效率和医生都带来了沉重负担。在本文中,我们介绍了一个新颖的框架–医疗报告接地(MedRG),这是一个利用多模态大语言模型预测关键短语的端到端解决方案,方法是在词汇中加入一个独特的标记–BOX,作为解锁检测功能的嵌入。随后,视觉编码器-解码器联合解码隐藏的嵌入和输入的医学图像,生成相应的接地方框。实验结果验证了 MedRG 的有效性,其性能超过了现有最先进的医学短语接地方法。这项研究是对医疗报告接地任务的开创性探索,标志着这一领域的首次尝试。
4.InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
标题:InternLM-XComposer2-4KHD:处理从 336 像素到 4K 高清分辨率的开创性大型视觉语言模型
author:Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Songyang Zhang, Haodong Duan, Wenwei Zhang, Yining Li, Hang Yan, Yang Gao, Zhe Chen, Xinyue Zhang, Wei Li, Jingwen Li, Wenhai Wang, Kai Chen, Conghui He, Xingcheng Zhang, Jifeng Dai, Yu Qiao, Dahua Lin, Jiaqi Wang
publish:Code and models are publicly available at
https://github.com/InternLM/InternLM-XComposer
date Time:2024-04-09
paper pdf:http://arxiv.org/pdf/2404.06512v1
摘要:
大型视觉语言模型(LVLM)领域取得了长足的进步,但由于分辨率有限,在理解细粒度视觉内容方面面临挑战,阻碍了该领域的发展。最近,人们努力提高 LVLM 的高分辨率理解能力,但它们的分辨率上限仍然是大约 1500 x 1500 像素,而且受限于相对较窄的分辨率范围。本文介绍的 InternLM-XComposer2-4KHD 是将 LVLM 分辨率提升到 4K HD(3840 x 1600)及更高分辨率的开创性探索。同时,考虑到并非所有场景都需要超高分辨率,它支持从 336 像素到 4K 标准的各种不同分辨率,大大拓宽了其适用范围。具体来说,这项研究通过引入一种新的扩展功能:具有自动补丁配置功能的动态分辨率,推进了补丁划分范式的发展。它在保持训练图像纵横比的同时,还能根据预先训练的视觉变换器(ViT)(336 x 336)自动改变补丁数量和配置布局,从而实现从 336 像素到 4K 标准的动态训练分辨率。我们的研究表明,将训练分辨率提高到 4K HD 可以持续提升性能,而不会触及潜在改进的上限。在 16 项基准测试中,InternLM-XComposer2-4KHD 在 10 项测试中表现出了与 GPT-4V 和 Gemini Pro 相媲美甚至超越的超强能力。带有 7B 参数的 InternLM-XComposer2-4KHD 模型系列可在 https://github.com/InternLM/InternLM-XComposer 上公开获取。
5.Can Feedback Enhance Semantic Grounding in Large Vision-Language Models?
标题:反馈能否加强大型视觉语言模型的语义基础?
author:Yuan-Hong Liao, Rafid Mahmood, Sanja Fidler, David Acuna
publish:31 pages, 15 figures
date Time:2024-04-09
paper pdf:http://arxiv.org/pdf/2404.06510v1
摘要:
增强视觉语言模型(VLM)的语义基础能力通常需要收集特定领域的训练数据、完善网络架构或修改训练配方。在这项工作中,我们大胆尝试一个正交方向,探索视觉语言模型是否可以通过 "接收 "反馈来提高语义接地能力,而无需领域内数据、微调或修改网络架构。我们利用由二进制信号组成的反馈机制对这一假设进行了系统分析。我们发现,如果给予适当的提示,VLMs 可以在单步和迭代中利用反馈,从而展示了反馈作为一种替代技术来改善互联网规模 VLMs 接地的潜力。此外,VLM 和 LLM 一样,在开箱即用的情况下很难自我纠错。不过,我们发现可以通过二进制验证机制来缓解这一问题。最后,我们探讨了将这些发现综合起来并迭代应用以自动提高 VLMs 接地性能的潜力和局限性,结果表明,在所有被调查的环境中,所有模型的接地准确性在使用自动反馈后都得到了持续提高。总体而言,我们的迭代框架在无噪声反馈的情况下提高了VLM的语义接地精度15个点以上,在简单的自动二进制验证机制下提高了5个精度点。项目网站:https://andrewliao11.github.io/vlms_feedback
6.Audio-Visual Generalized Zero-Shot Learning using Pre-Trained Large Multi-Modal Models
标题:利用预训练的大型多模态模型进行视听通用零镜头学习
author:David Kurzendörfer, Otniel-Bogdan Mercea, A. Sophia Koepke, Zeynep Akata
publish:CVPRw 2024 (L3D-IVU)
date Time:2024-04-09
paper pdf:http://arxiv.org/pdf/2404.06309v1
摘要:
视听零镜头学习方法通常基于从预先训练的模型(如视频或音频分类模型)中提取的特征。然而,现有的基准早于 CLIP 和 CLAP 等大型多模态模型的普及。在这项工作中,我们探索了这种大型预训练模型来获取特征,即用于视觉特征的 CLIP 和用于音频特征的 CLAP。此外,CLIP 和 CLAP 文本编码器还提供了类标签嵌入,两者结合可提高系统的性能。我们提出了一个简单而有效的模型,该模型仅依赖于前馈神经网络,利用了新的音频、视觉和文本特征的强大泛化能力。我们的框架利用新特征在 VGGSound-GZSL、UCF-GZSL 和 ActivityNet-GZSL 上实现了最先进的性能。代码和数据请访问:https://github.com/dkurzend/ClipClap-GZSL。
7.Anchor-based Robust Finetuning of Vision-Language Models
标题:基于锚点的视觉语言模型稳健微调
author:Jinwei Han, Zhiwen Lin, Zhongyisun Sun, Yingguo Gao, Ke Yan, Shouhong Ding, Yuan Gao, Gui-Song Xia
publish:CVPR2024
date Time:2024-04-09
paper pdf:http://arxiv.org/pdf/2404.06244v1
摘要:
我们的目标是对视觉语言模型进行微调,同时不损害其分布外泛化(OOD)能力。我们研究了两种类型的 OOD 泛化,即:i) 领域转移,如从自然图像到素描图像;ii) 零拍摄能力,以识别微调数据中未包含的类别。可以说,微调后 OOD 泛化能力下降的原因是微调目标过于简化,只提供了类别信息,如 “一张[类别]的照片”。这与 CLIP 的预训练过程不同,在预训练过程中,有丰富的文本监督,包含丰富的语义信息。因此,我们建议使用具有丰富语义信息的辅助监督来补偿微调过程,作为锚来保持 OOD 的泛化。具体来说,我们的方法中阐述了两种类型的锚,包括 i) 文本补偿锚,它使用微调集中的图像,但丰富了来自预训练字幕机的文本监督;ii) 图像-文本-对锚,它根据下游任务从类似于 CLIP 预训练数据的数据集中检索,与具有丰富语义的 CLIP 原始文本相关联。这些锚点被用作辅助语义信息,以保持 CLIP 的原始特征空间,从而保持 OOD 的泛化能力。综合实验证明,我们的方法实现了与传统微调类似的内分布性能,同时在领域转移和零点学习基准上取得了新的一流成果。
8.MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
标题:MA-LMM:用于长期视频理解的记忆增强大型多模态模型
author:Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, Ser-Nam Lim
publish:Accepted at CVPR 2024
date Time:2024-04-08
paper pdf:http://arxiv.org/pdf/2404.05726v1
摘要:
随着大型语言模型(LLM)的成功,将视觉模型集成到 LLM 中以建立视觉语言基础模型的做法近来受到越来越多的关注。然而,现有的基于 LLM 的大型多模态模型(如 Video-LaMA、VideoChat)只能接收有限的帧数来理解短视频。在本研究中,我们主要关注为长期视频理解设计一种高效、有效的模型。我们并不像大多数现有研究那样试图同时处理更多帧,而是建议以在线方式处理视频,并将过去的视频信息存储在记忆库中。这样,我们的模型就能参考历史视频内容进行长期分析,而不会超出 LLM 的上下文长度限制或 GPU 内存限制。我们的内存库可以以现成的方式无缝集成到当前的多模态 LLM 中。我们在各种视频理解任务(如长视频理解、视频问题解答和视频字幕)上进行了广泛的实验,我们的模型可以在多个数据集上实现最先进的性能。代码见 https://boheumd.github.io/MA-LMM/。
9.Retrieval-Augmented Open-Vocabulary Object Detection
标题:检索增强型开放词汇对象检测
author:Jooyeon Kim, Eulrang Cho, Sehyung Kim, Hyunwoo J. Kim
publish:Accepted paper at CVPR 2024
date Time:2024-04-08
paper pdf:http://arxiv.org/pdf/2404.05687v1
摘要:
人们一直在研究利用视觉语言模型(VLM)进行开放词汇物体检测(OVD),以检测预先训练类别之外的新物体。以前的方法通过使用带有额外 "类别 "名称的 "正 "伪标签(如袜子、iPod 和鳄鱼)来提高泛化能力,以扩展检测器的知识。为了在两个方面扩展之前的方法,我们提出了检索-损失和视觉特征(RALF)。我们的方法会检索相关的 "负面 "类别并增强损失函数。此外,我们还利用类别的 "语言化概念 "来增强视觉特征,例如,脚上的磨损、手持音乐播放器和尖牙。具体来说,RALF 由两个模块组成:检索增强损失(RAL)和检索增强视觉特征(RAF)。RAL 包括两个损失,反映了与负面词汇的语义相似性。此外,RAF 利用大语言模型(LLM)中的口语化概念来增强视觉特征。我们的实验证明了 RALF 在 COCO 和 LVIS 基准数据集上的有效性。我们在 COCO 数据集的新类别上实现了高达 3.4 box AP 50 t e x t N _{50}^{text{N}} 50textN 的改进,在 LVIS 数据集上实现了 3.6 mask AP r _{\text{r}} r 的改进。代码见 https://github.com/mlvlab/RALF 。
10.PromptAD: Learning Prompts with only Normal Samples for Few-Shot Anomaly Detection
标题:PromptAD:仅使用正常样本学习提示,以实现少镜头异常检测
author:Xiaofan Li, Zhizhong Zhang, Xin Tan, Chengwei Chen, Yanyun Qu, Yuan Xie, Lizhuang Ma
publish:Accepted by CVPR2024
date Time:2024-04-08
paper pdf:http://arxiv.org/pdf/2404.05231v1
摘要:
视觉语言模型极大地改进了通常需要通过提示工程设计成百上千条提示信息的工业异常检测。针对自动化场景,我们首先使用传统的多类范式提示学习作为基线来自动学习提示,但发现它在单类异常检测中不能很好地发挥作用。针对上述问题,本文提出了一种适用于少拍异常检测的单类提示学习方法,称为 PromptAD。首先,我们提出了语义串联法,通过将正常提示语与异常后缀串联,可以将正常提示语转换为异常提示语,从而构建大量负样本,用于指导单类环境下的提示语学习。此外,为了减轻因缺乏异常图像而带来的训练挑战,我们引入了显式异常边际的概念,通过超参数来显式控制正常提示特征与异常提示特征之间的边际。在图像级/像素级异常检测方面,PromptAD 在 MVTec 和 VisA 上的 11/12 few-shot 设置中取得了第一名的成绩。
11.Progressive Alignment with VLM-LLM Feature to Augment Defect Classification for the ASE Dataset
标题:利用 VLM-LLM 特征逐步对齐,增强 ASE 数据集的缺陷分类功能
author:Chih-Chung Hsu, Chia-Ming Lee, Chun-Hung Sun, Kuang-Ming Wu
publish:MULA 2024
date Time:2024-04-08
paper pdf:http://arxiv.org/pdf/2404.05183v1
摘要:
传统的缺陷分类方法面临两个障碍。(1) 训练数据不足,数据质量不稳定。收集足够的缺陷样本既昂贵又费时,因此会导致数据集的差异。这给识别和学习带来了困难。(2) 过度依赖视觉模式。当给定数据集中所有缺陷类别的图像模式和纹理都是单调的,传统 AOI 系统的性能就无法得到保证。在由于机械故障或缺陷信息本身难以辨别而导致图像质量下降的情况下,深度模型的性能也无法得到保证。一个主要问题是:"当这两个问题同时出现时,如何解决?可行的策略是在数据集内探索另一种特征,并结合杰出的视觉语言模型(VLM)和大型语言模型(LLM)的惊人零拍能力。在这项工作中,我们提出了特殊的 ASE 数据集,其中包括记录在图像上的丰富数据描述,用于缺陷分类,但缺陷特征难以直接学习。其次,我们利用 ASE 数据集提出了针对缺陷分类的 VLM-LLM 提示,以激活图像中的模外特征来提高性能。然后,我们设计了新颖的渐进式特征配准(PFA)模块来细化图像-文本特征,从而缓解了在少镜头场景下配准的困难。最后,我们提出的跨模态注意力融合(CMAF)模块可以有效地融合不同的模态特征。实验结果表明,在 ASE 数据集上,我们的方法比几种缺陷分类方法更有效。
12.FGAIF: Aligning Large Vision-Language Models with Fine-grained AI Feedback
标题:FGAIF:用细粒度人工智能反馈调整大型视觉语言模型
author:Liqiang Jing, Xinya Du
date Time:2024-04-07
paper pdf:http://arxiv.org/pdf/2404.05046v1
摘要:
大型视觉语言模型(LVLM)在处理各种视觉语言任务方面表现出了很强的能力。然而,目前的大型视觉语言模型存在文本和图像模式不对齐的问题,这导致了三种幻觉问题,即对象存在、对象属性和对象关系。为解决这一问题,现有方法主要利用强化学习(RL)来对齐 LVLM 中的模态。然而,这些方法仍存在三大局限性:(1)一般反馈无法指出反应中包含的幻觉类型;(2)稀疏奖励只能给出整个反应的序列级奖励;(3)注释成本耗时耗力。为了解决这些局限性,我们提出了一种创新方法,通过细粒度人工智能反馈(FGAIF)来对齐 LVLM 中的模态:该方法主要包括三个步骤:基于人工智能的反馈收集、细粒度奖励模型训练和细粒度奖励强化学习。具体来说,我们首先利用人工智能工具预测反应中每个片段的幻觉类型,并获得细粒度反馈收集。然后,根据收集到的奖励数据,训练三个专门的奖励模型,以产生密集的奖励。最后,一个新颖的细粒度反馈模块被集成到近端策略优化(PPO)算法中。我们在幻觉和一般基准上进行了广泛的实验,证明我们提出的方法性能优越。值得注意的是,与之前使用基于 RL 的对齐方法训练的模型相比,我们提出的方法即使使用较少的参数也能取得很好的效果。
13.Hyperbolic Learning with Synthetic Captions for Open-World Detection
标题:利用合成字幕进行双曲线学习,实现开放世界检测
author:Fanjie Kong, Yanbei Chen, Jiarui Cai, Davide Modolo
publish:CVPR 2024
date Time:2024-04-07
paper pdf:http://arxiv.org/pdf/2404.05016v1
摘要:
开放世界检测是一项重大挑战,因为它要求使用对象类别标签或自由形式文本检测任何对象。现有的相关工作通常使用大规模的人工标注标题数据集进行训练,而这些数据集的收集成本极高。相反,我们建议从视觉语言模型(VLM)中获取知识,自动丰富开放词汇描述。具体来说,我们利用预先训练好的 VLM 引导出密集的合成标题,为图像中的不同区域提供丰富的描述,并结合这些标题来训练新型检测器,使其能够泛化到新概念。为了减轻合成字幕中幻觉造成的噪音,我们还提出了一种新颖的双曲视觉语言学习方法,在视觉和字幕嵌入之间建立层次结构。我们称这种检测器为 “HyperLearner”。我们在各种开放世界检测基准(COCO、LVIS、Object Detection in the Wild、RefCOCO)上进行了广泛的实验,结果表明,当使用相同的骨干网时,我们的模型始终优于现有的最先进方法,如 GLIP、GLIPv2 和 Grounding DINO。
14.Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
标题:用于可转移人工智能生成的图像检测的低等级专家混合物
author:Zihan Liu, Hanyi Wang, Yaoyu Kang, Shilin Wang
date Time:2024-04-07
paper pdf:http://arxiv.org/pdf/2404.04883v1
摘要:
生成模型在用最少的专业知识合成逼真图像方面取得了巨大飞跃,引发了人们对网络信息真实性的担忧。本研究旨在开发一种通用的人工智能生成图像检测器,能够识别来自不同来源的图像。现有的方法在提供有限的样本来源时,很难在未见过的生成模型中进行泛化。受预先训练的视觉语言模型的零点转移性的启发,我们试图利用 CLIP-ViT 的非微观视觉世界知识和描述能力来泛化未知领域。本文提出了一种新颖的参数高效微调方法,即低级专家混合方法,以充分挖掘 CLIP-ViT 的潜力,同时保留知识并扩展可转移检测的能力。我们通过在基于 MoE 的结构中整合共享和独立的 LoRA,只对更深的 ViT 块的 MLP 层进行调整。在公共基准上进行的大量实验表明,我们的方法在跨生成器泛化和对扰动的鲁棒性方面优于最先进的方法。值得注意的是,我们性能最好的 ViT-L/14 变体只需训练 0.08% 的参数,就能在未见过的扩散和自回归模型中以 +3.64% 的 mAP 和 +12.72% 的 avg.Acc 超越领先的基线。这甚至超过了仅使用 0.28% 训练数据的基线。我们的代码和预训练模型将发布在 https://github.com/zhliuworks/CLIPMoLE 网站上。
15.ByteEdit: Boost, Comply and Accelerate Generative Image Editing
标题:ByteEdit:提升、兼容并加速生成式图像编辑
author:Yuxi Ren, Jie Wu, Yanzuo Lu, Huafeng Kuang, Xin Xia, Xionghui Wang, Qianqian Wang, Yixing Zhu, Pan Xie, Shiyin Wang, Xuefeng Xiao, Yitong Wang, Min Zheng, Lean Fu
date Time:2024-04-07
paper pdf:http://arxiv.org/pdf/2404.04860v1
摘要:
基于扩散的生成式图像编辑技术的最新进展引发了一场深刻的革命,重塑了图像外绘和内绘任务的格局。尽管取得了这些长足进步,但该领域仍面临着固有的挑战,包括:i) 质量低劣;ii) 一致性差;iii) 不能充分遵守指令;iv) 生成效率不理想。为了解决这些障碍,我们提出了 ByteEdit,这是一个创新的反馈学习框架,经过精心设计,可提升、符合和加速生成图像编辑任务。ByteEdit 无缝集成了图像奖励模型,专门用于增强美感和图像-文本对齐,同时还引入了密集的像素级奖励模型,专门用于促进输出的一致性。此外,我们还提出了一种开创性的对抗和渐进反馈学习策略,以加快模型的推理速度。通过广泛的大规模用户评估,我们证明 ByteEdit 在生成质量和一致性方面都超越了 Adobe、Canva 和美图等领先的生成式图像编辑产品。与基线模型相比,ByteEdit-Outpainting 的质量和一致性分别显著提高了 388% 和 135%。实验还验证了我们的加速模型在质量和一致性方面保持了出色的性能。
16.DifFUSER: Diffusion Model for Robust Multi-Sensor Fusion in 3D Object Detection and BEV Segmentation
标题:DifFUSER:三维物体检测和 BEV 分段中鲁棒性多传感器融合的扩散模型
author:Duy-Tho Le, Hengcan Shi, Jianfei Cai, Hamid Rezatofighi
publish:23 pages
date Time:2024-04-06
paper pdf:http://arxiv.org/pdf/2404.04629v1
摘要:
作为强大的深度生成模型,扩散模型近来备受瞩目,在各个领域都表现出无与伦比的性能。然而,它们在多传感器融合方面的潜力在很大程度上仍未得到开发。在这项工作中,我们介绍了 DifFUSER,这是一种在三维物体检测和 BEV 地图分割中利用扩散模型进行多模态融合的新方法。得益于扩散固有的去噪特性,DifFUSER 能够在传感器出现故障时完善甚至合成传感器特征,从而提高融合输出的质量。在架构方面,我们的 DifFUSER 模块以分层 BiFPN(称为 cMini-BiFPN)的方式串联在一起,为潜在扩散提供了另一种架构。我们进一步引入了门控自调节(GSM)潜扩散模块和渐进式传感器辍学训练(PSDT)范式,旨在为扩散过程增加更强的调节能力,并提高传感器故障的鲁棒性。我们在 Nuscenes 数据集上进行的广泛评估表明,DifFUSER 不仅在 BEV 地图分割任务中实现了 69.1% 的 mIOU 的一流性能,而且在 3D 物体检测中与基于变压器的领先融合技术展开了有效竞争。
17.Self-Training Large Language Models for Improved Visual Program Synthesis With Visual Reinforcement
标题:自训练大型语言模型,利用视觉强化改进视觉程序合成
author:Zaid Khan, Vijay Kumar BG, Samuel Schulter, Yun Fu, Manmohan Chandraker
publish:CVPR 2024
date Time:2024-04-06
paper pdf:http://arxiv.org/pdf/2404.04627v1
摘要:
视觉程序合成是利用大型语言模型的推理能力来完成计算机视觉合成任务的一种很有前途的方法。以前的工作是利用冻结的 LLM 进行少量提示来合成视觉程序。训练 LLM 来编写更好的视觉程序是一个很有吸引力的前景,但目前还不清楚如何实现这一目标。目前还没有用于训练的可视化程序数据集,而且由于需要专家注释者,可视化程序数据集的获取也不容易以众包的方式进行。为了解决缺乏直接监督的问题,我们探索利用互动经验的反馈来提高 LLM 的程序合成能力。我们提出了一种方法,即利用视觉语言任务的现有注释来为该任务改进粗略的奖励信号,将 LLM 视为一个策略,并应用强化自我训练来提高 LLM 在该任务中的视觉程序合成能力。我们描述了一系列关于物体检测、合成视觉问题解答和图像文本检索的实验,结果表明,在每种情况下,自我训练的 LLM 都优于或与规模大一个数量级的几发冷冻 LLM 不相上下。网站: https://zaidkhan.me/ViReP
18.Soft-Prompting with Graph-of-Thought for Multi-modal Representation Learning
标题:利用思维图谱进行软提示,实现多模式表征学习
author:Juncheng Yang, Zuchao Li, Shuai Xie, Wei Yu, Shijun Li, Bo Du
publish:This paper is accepted to LREC-COLING 2024
date Time:2024-04-06
paper pdf:http://arxiv.org/pdf/2404.04538v1
摘要:
在多模式任务中,思维链技术一直广受好评。它是一个逐步推进的线性推理过程,通过调整思维链的长度来提高生成提示的性能。然而,人类的思维过程主要是非线性的,因为它们同时包含多个方面,并采用动态调整和更新机制。因此,我们提出了一种新颖的聚合思维图(AGoT)机制,用于多模式表征学习中的软提示调整。所提出的 AGoT 不仅将人类的思维过程建模为一个链条,还将每一步建模为一个推理聚合图,以应对单步推理中被忽视的多方面思维。这就把整个推理过程变成了及时聚合和及时流操作。实验表明,在文本-图像检索、视觉问题解答和图像识别等多项任务中,我们采用 AGoT 软提示增强的多模态模型取得了良好的效果。此外,我们还证明,由于推理能力更强,该模型具有良好的领域泛化性能。
19.ClickDiffusion: Harnessing LLMs for Interactive Precise Image Editing
标题:ClickDiffusion:利用 LLM 进行交互式精确图像编辑
author:Alec Helbling, Seongmin Lee, Polo Chau
publish:arXiv admin note: substantial text overlap with arXiv:2402.07925
date Time:2024-04-05
paper pdf:http://arxiv.org/pdf/2404.04376v1
摘要:
最近,研究人员提出了使用自然语言指令生成和处理图像的强大系统。然而,仅凭文字很难精确地指定许多常见的图像变换类别。例如,用户可能希望在一张有多只类似狗的图像中改变某只狗的位置和品种。这项任务仅靠自然语言是相当困难的,需要用户编写复杂的提示语,既要明确目标狗,又要描述目的地。我们提出的 ClickDiffusion 是一种用于精确操作和生成图像的系统,它将自然语言指令与用户通过直接操作界面提供的视觉反馈相结合。我们证明,通过将图像和多模态指令序列化为文本表示,可以利用 LLM 对图像的布局和外观进行精确转换。代码见 https://github.com/poloclub/ClickDiffusion。
20.Who Evaluates the Evaluations? Objectively Scoring Text-to-Image Prompt Coherence Metrics with T2IScoreScore (TS2)
标题:谁来评估评价?使用 T2IScoreScore (TS2) 客观评分文本到图像提示一致性指标
author:Michael Saxon, Fatima Jahara, Mahsa Khoshnoodi, Yujie Lu, Aditya Sharma, William Yang Wang
publish:15 pages main, 9 pages appendices, 16 figures, 3 tables
date Time:2024-04-05
paper pdf:http://arxiv.org/pdf/2404.04251v1
摘要:
随着文本到图像(T2I)模型质量的提高,人们开始关注其提示忠实度的基准测试–即生成的图像与提示语的语义一致性。利用跨模态嵌入和视觉语言模型(VLM)的进步,人们提出了多种 T2I 忠实度指标。然而,这些指标并没有经过严格的比较和基准测试,而是通过与一组易于区分的图像上的人类李克特评分的相关性,对照一些较弱的基线来提出。 我们引入了 T2IScoreScore (TS2),这是一组经过整理的语义错误图,包含一个提示和一组越来越多的错误图像。通过使用从既定统计测试中得出的元指标分数,我们可以严格判断给定的提示忠实度指标是否能根据客观错误数量对图像进行正确排序,并显著区分不同的错误节点。令人惊讶的是,我们发现我们测试过的最先进的基于 VLM 的度量(如 TIFA、DSG、LLMScore、VIEScore)未能明显优于 CLIPScore 等简单的基于特征的度量,特别是在自然出现的 T2I 模型错误的硬子集上。通过更严格地比较它们是否符合客观标准下的预期排序和分离,TS2 将有助于开发更好的 T2I 提示忠实度指标。
21.Image-Text Co-Decomposition for Text-Supervised Semantic Segmentation
标题:文本监督语义分割的图像-文本协同分解
author:Ji-Jia Wu, Andy Chia-Hao Chang, Chieh-Yu Chuang, Chun-Pei Chen, Yu-Lun Liu, Min-Hung Chen, Hou-Ning Hu, Yung-Yu Chuang, Yen-Yu Lin
publish:CVPR 2024
date Time:2024-04-05
paper pdf:http://arxiv.org/pdf/2404.04231v1
摘要:
本文针对文本监督下的语义分割,旨在学习一种模型,该模型能够仅使用无密集注释的图像-文本对来分割图像中的任意视觉概念。现有方法已经证明,图像-文本对的对比学习能有效地将视觉片段与文本的含义对齐。我们注意到,文本对齐和语义分割之间存在差异:文本通常由多个语义概念组成,而语义分割则致力于创建语义相同的片段。为了解决这个问题,我们提出了一个新颖的框架–图像-文本协同分解(CoDe),将配对图像和文本分别联合分解为一组图像区域和一组词段,并开发对比学习来执行区域-词对齐。为了与视觉语言模型配合使用,我们提出了一种提示学习机制,该机制可以衍生出一种额外的表示方法,以突出显示感兴趣的图像片段或词段,从而从该片段中提取出更有效的特征。综合实验结果表明,我们的方法在六个基准数据集上的表现优于现有的文本监督语义分割方法。
22.Label Propagation for Zero-shot Classification with Vision-Language Models
标题:利用视觉语言模型进行零镜头分类的标签传播
author:Vladan Stojnić, Yannis Kalantidis, Giorgos Tolias
publish:CVPR 2024
date Time:2024-04-05
paper pdf:http://arxiv.org/pdf/2404.04072v1
摘要:
视觉语言模型(VLM)在零镜头分类(即仅提供类别名称列表时的分类)方面表现出色。在本文中,我们要解决的是在无标记数据情况下的零镜头分类问题。我们利用未标记数据的图结构,引入了基于标签传播(LP)的 ZLaP 方法,该方法利用大地距离进行分类。我们对包含文本和图像特征的图进行了 LP 定制,并进一步提出了一种基于对偶解和稀疏化步骤进行归纳推理的高效方法。我们在 14 个常见数据集上进行了大量实验,以评估我们的方法的有效性,结果表明 ZLaP 优于最新的相关作品。代码:https://github.com/vladan-stojnic/ZLaP
相关文章:
:2024.04.05-2024.04.10)
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.05-2024.04.10
文章目录~ 1.BRAVE: Broadening the visual encoding of vision-language models2.ORacle: Large Vision-Language Models for Knowledge-Guided Holistic OR Domain Modeling3.MedRG: Medical Report Grounding with Multi-modal Large Language Model4.InternLM-XComposer2-4…...
【golang】动态生成微信小程序二维码实战下:golang 生成 小程序二维码图片 并通过s3协议上传到对象存储桶 | 腾讯云 cos
项目背景 在自研的系统,需要实现类似草料二维码的功能 将我们自己的小程序,通过代码生成相想要的小程序二维码 代码已经上传到 Github 需要的朋友可以自取 https://github.com/ctra-wang/wechat-mini-qrcode 一、生成Qrcode并提交到对象存储 通过源生A…...

kubeadm k8s 1.24之后版本安装,带cri-dockerd
最后编辑时间:2024/3/26 适用于1.24之后的版本 单节点配置 检查是否已经安装kubectl, kubelet, kubeadm直接输入命令确定,如果提示没有该指令则正确 kubectl kubelet kubeadm如果之前安装,首先reset,然后使用apt remove和snap r…...

13-pyspark的共享变量用法总结
目录 前言广播变量广播变量的作用 广播变量的使用方式 累加器累加器的作用累加器的优缺点累加器的使用方式 PySpark实战笔记系列第四篇 10-用PySpark建立第一个Spark RDD(PySpark实战笔记系列第一篇)11-pyspark的RDD的变换与动作算子总结(PySpark实战笔记系列第二篇))12-pysp…...

BI数据分析软件:行业趋势与功能特点剖析
随着数据量的爆炸性增长,企业对于数据的需求也日益迫切。BI数据分析软件作为帮助企业实现数据驱动决策的关键工具,在当前的商业环境中扮演着不可或缺的角色。本文将从行业趋势、功能特点以及适用场景等方面,深入剖析BI数据分析软件࿰…...
centos7上docker搭建vulhub靶场
1 vulhub靶场概述 VulHub是一个在线靶场平台,提供了丰富的漏洞环境供安全爱好者学习和实践。 该平台主要面向网络安全初学者和进阶者,通过模拟真实的漏洞环境,帮助用户深入了解漏洞的成因、利用方式以及防范措施。 此外,VulHub还…...

Flutter入门指南
文章目录 一、环境搭建二、基本概念三、创建一个简单的Flutter应用四、常用组件及代码示例五、总结推荐阅读 笔者项目中使用Flutter的模块并不多。虽然笔者还没有机会在项目中正式使用Flutter,但是也在学习Flutter的一些基本用法。本文就是一篇Flutter的入门介绍&am…...
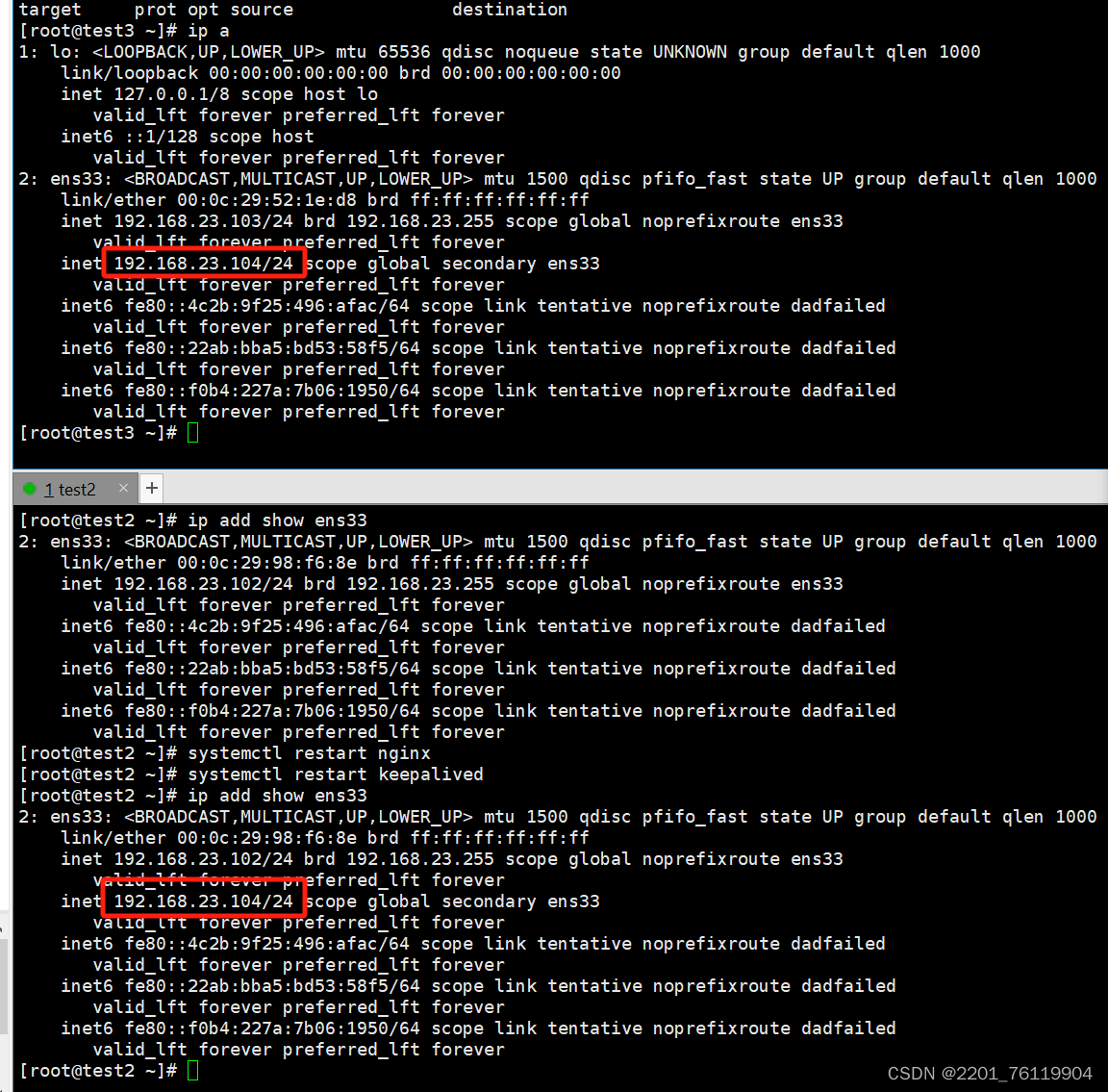
keepalived脑裂问题
脑裂问题产生的原因 就是vip同时存在 master和backup 就叫做脑裂 比如说 backup 机器的防火墙没关,并且没有允许vrrp通过,backup 没有收到master的心跳数据,就会抢夺资源,发生脑裂问题测试 我们打开test3的防火墙,此…...

【Linux笔记】编mysql库
说明当前编译条件:使用cmake 进行编译<当前编译为Ubuntu PC 版本 在虚拟机上面使用> 一、 cmake 库 【 cmake version 3.16.3 】 二、 openssl 库 【 libopenssl-1.1.1K 】 三、mysql 库 【mysql-5.7.36 】 四、boost 库 【boost_1_59_0 】 一、安装cmake 1.1…...

vscode远程免密登录ssh
vscode远程免密登录ssh 1. 安装vscode2. 安装ssh3. 本地vscode配置免密登录远端开发机1. 本地配置秘钥2. 远程开发机配置秘钥 4. vscode常用小工具1. vscode怎么设置ctrl加滚轮放大字体 1. 安装vscode 2. 安装ssh 设置符号打开config配置文件,点击符号ssh连接新的远…...
2024年MathorCup数模竞赛C题详解
C题持续更新中 问题一问题二代码混合ARIMA-LSTM模型构建完整数据与代码第一问第二问 问题一 问题一要求对未来30天每天及每小时的货量进行预测。首先,利用混合ARIMA-LSTM模型进行时间序列预测。ARIMA模型擅长捕捉线性特征和趋势,而LSTM模型处理非线性关…...

【简单讲解如何安装与配置Composer】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

深入理解Apache ZooKeeper与Kafka的协同工作原理
目录 引言 一、ZooKeeper基础概念 (一)ZooKeeper简介 (二)ZooKeeper数据结构 (三)ZooKeeper特点 (四)应用场景 二、ZooKeeper工作模式 (一)工作机制 …...
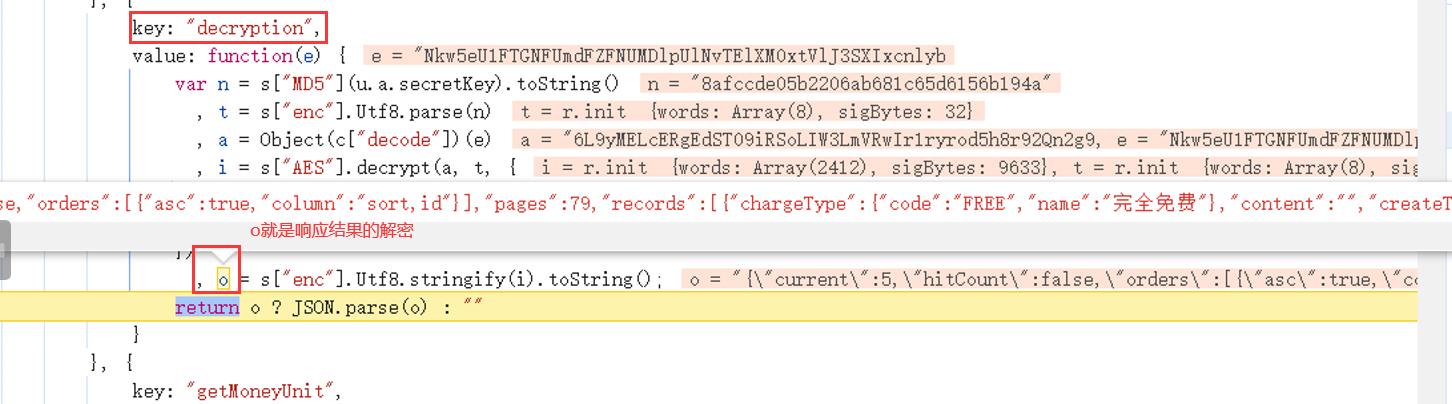
js解密心得,记录一次抓包vue解密过程
背景 有个抓包结果被加密了 1、寻找入口,打断点 先正常请求一次,找到需要的请求接口。 寻找入口,需要重点关注几个关键字:new Promise 、new XMLHttpRequest、onreadystatechange、.interceptors.response.use、.interceptors.r…...

redis-哨兵模式
一,哨兵的作用: 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配…...
自动化测试中的SOLID原则
自动化测试在软件质量保障手段中愈显重要 。但是随着自动化测试代码的规模和复杂性不断扩大,它也很容易出现测试代码重复、紧耦合等问题。而SOLID原则可以解决这一问题,作为自动化用例开发的指导原则。 探索SOLID原则 SOLID原则是一组指导软件开发人员…...

tencentcloud-sdk-python-iotexplorer和tencent-iot-device有什么区别
1. tencent-iot-device tencent-iot-device 是腾讯云提供的物联网设备 SDK,用于在物联网场景中开发和连接设备。这个 SDK 提供了丰富的功能和接口,可以帮助开发者快速构建稳定、高效的物联网应用。 主要功能和特点: 设备连接管理࿱…...

Spring day1
day01_eesy_01jdbc pom.xml<packaging>jar</packaging> <dependencies><!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --><!--依赖--><dependency><groupId>mysql</groupId><artifactId>mysql-…...
)
设计模式: 行为型之中介者模式(18)
中介者模式概述 中介者模式(Mediator Pattern)是一种行为设计模式,它用于减少对象之间的直接交互,从而使其可以松散耦合中介者模式通过引入一个中介者对象来协调多个对象之间的交互,使得这些对象不需要知道彼此的具体…...

计算机网络的起源与发展历程
文章目录 前言时代背景ARPANET 的诞生TCP/IP 协议簇与 Internet 的诞生HTTP 协议与 Web 世界结语 前言 在当今数字化时代,计算机网络已经成为我们生活中不可或缺的一部分。无论是在家庭、学校、还是工作场所,我们都能感受到网络的巨大影响。随着互联网的…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...