NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
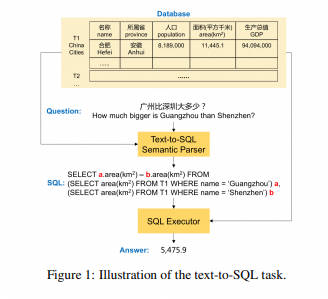
Text-to-SQL(或者Text2SQL),顾名思义就是把文本转化为SQL语言,更学术一点的定义是:把数据库领域下的自然语言(Natural Language,NL)问题,转化为在关系型数据库中可以执行的结构化询语言(Structured Query Language,SQL),因此Text-to-SQL也可以被简写为NL2SQL。
- 输入:自然语言问题,比如“查询表t_user的相关信息,结果按id降序排序,只保留前10个数据”
- 输出:SQL,比如“SELECT * FROM t_user ORDER BY id DESC LIMIT 10”
使用 NL2SQL 的技术方案,用户与数据库之间的距离可以进一步缩短,用户可以更自由地查询更多信息、表达自己更丰富的查询意图,还可以减轻目前技术方案的繁琐,解放开发人员。
1.NL2SQL情况
1.1 NL2SQL的发展历史
NL2SQL的历史要追溯到1973年,Woods等人开发了一个名为LUNAR的系统,主要用来回答从月球带回来的岩石相关的问题。1978年,Hendrix设计了一个名叫LIFER/LADDER的接口,可以通过自然语言查询数据库。但是上面提到的系统都是针对特定数据库开发的,而且只支持单表操作。2008年,Siasar等人基于句法和语义知识的基本概念提出了专家系统,并提出一个能够从多个结果中选择一个合适查询语句的算法。2010年,Rao等人提出了一个包含简单和隐式查询的系统。2013年,Chaudhari使用原型技术实现了一个能够处理简单查询和聚合函数的系统。虽然这些系统能够生成不同的查询语句,但依然无法支持多表关联的问题。2014年,Ghosh等人基于Chaudhari的研究成果,在其基础上又开发了一个自动查询生成器,它采用语音或自然语言文本作为输入,支持简单的嵌套查询和聚合操作,同时系统还能够处理那些明确指出的属性。同年,Reinaldha和Widagdo使用了不同的方法来研究用户不同形式的输入,他们采用语义规则来找出问题中出现的词与数据库中的属性之间的关系。2015年,Palakurthi等人提供了与属性类型和分类特征相关的信息,描述了不同属性出现在句子中的处理方式也是不一样的。2016年,Ghosal等人提出了一个系统,能够很好地处理多表简单查询,不过系统使用的数据字典有限。同年,Kaur and J, Jan 强化了系统的简单查询和连接操作,但不支持聚合函数、GROUPBY和HAVING等高级子句。Singh and Solanki也提出了一种将自然语言转为sql查询的算法。他们使用动词表、名词表和规则将属性和表映射到句子中的单词,系统还灵巧地处理了文本的模糊输入。2017年,Google开发了Analyza系统,一个以自然语言为人机交互的接口的系统,支持用户用自然语言做数据探索与数据分析。该系统已在Google两个产品中投入使用,一是Online Sheet产品的QA问答模块,二是提供了一个库存和收入数据数据库的一个访问入口。同年,Sukthankar, Nandan等人开发了nQuery系统,一个自然语言到SQL的查询生成器,支持聚合函数,以及where子句中的多个条件、高级子句(如order by、group by和having)操作。2018年,Utama, Prasetya等人开发了DBPal工具,一个面向数据库的端到端的自然语言接口。DBPal主要有两大特性,一是采用深度模型将自然语言语句转为SQL,二是在用户不知道数据库模式和查询特性的情况下,支持短语提问,同时支持用户查询扩展提示,有助于提高查询效果。
1.2 NL2SQL 业内情况
1.2.1 测评指标
Text-to-SQL任务的评价方法主要包含两种:精确匹配率(Exact Match, Accqm)、执行正确率(Execution Accuracy, Accex)
-
Execution Accuracy (EX) [paper]
- 定义:计算SQL执行结果正确的数量在数据集中的比例,结果存在高估的可能。
-
Exact Match (EM) [paper]
- 定义:计算模型生成的SQL和标注SQL的匹配程度,结果存在低估的可能。
精确匹配率指,预测得到的SQL语句与标准SQL语句精确匹配成功的问题占比。为了处理由成分顺序带来的匹配错误,当前精确匹配评估将预测的SQL语句和标准SQL语句按着SQL关键词分成多个子句,每个子句中的成分表示为集合,当两个子句对应的集合相同则两个子句相同,当两个SQL所有子句相同则两个SQL精确匹配成功;

执行正确指,执行预测的SQL语句,数据库返回正确答案的问题占比。

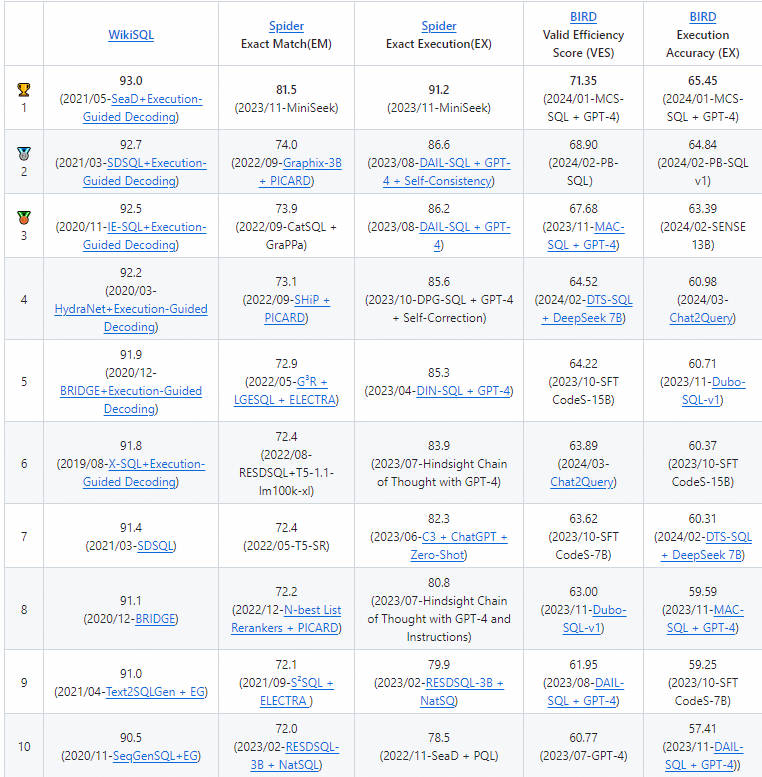
1.2.2 业界排行榜
1.3 相关论文综述
- (2023-International Conference on Very Large Data Bases, VLDB, CCF-A)A survey on deep learning approaches for text-to-SQL [paper]
- (2022-IEEE Transactions on Knowledge and Data Engineering, TKDE, CCF-A) A Survey on Text-to-SQL Parsing: Concepts, Methods, and Future Directions [paper]
- (2022-International Conference on Computational Linguistics, COLOING, CCF-B) Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect [paper]
- (2022-arXiv)Deep Learning Driven Natural Languages Text to SQL Query Conversion: A Survey [paper]
2.业内标准数据集介绍
2.1 数据集汇总

-
根据包含领域数量,数据集分为单领域和多领域。
-
根据每个数据库包含表的数量,数据集分为单表和多表模式。在多表模式中,SQL生成涉及到表格的选择。
-
根据问题复杂度,数据集分为简单问题和复杂问题模式,其中问题复杂度由SQL查询语句涉及到的关键词数量、嵌套层次、子句数量等确定。
-
根据完整SQL生成所需轮数,数据集分为单轮和多轮。
-
若SQL生成融进渐进式对话,则数据集增加“结合对话”标记。当前只有CoSQL数据集是融进对话的数据集。

-
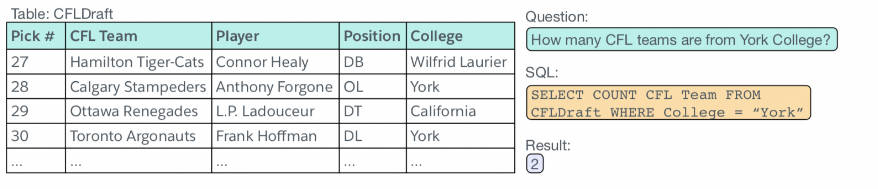
WikiSQL [paper] [code] [dataset]
-
2017年9月,Salesforce提出的一个大型的Text-to-SQL数据集,数据来源于Wikipedia,属于单领域,包含了80654个自然语言问题,77840个SQL语句,SQL语句形式比较简单,不包含排序、分组、子查询等复杂操作。包含了 24,241张表,80,645条自然语言问句及相应的SQL语句。由于该数据集的sql形式简单,不支持多列选择,or、group by、order by、limit等操作,而且只支持单表操作,所以相对而言任务比较简单,目前学术界的预测准确率最高可达93%+。
-
WikiSQL的问题长度815个词居多,查询长度811个词居多,表的列数5~7个居多,另外,大多数问题是what类型,其次是which、name、how many、who等类型。

-
-
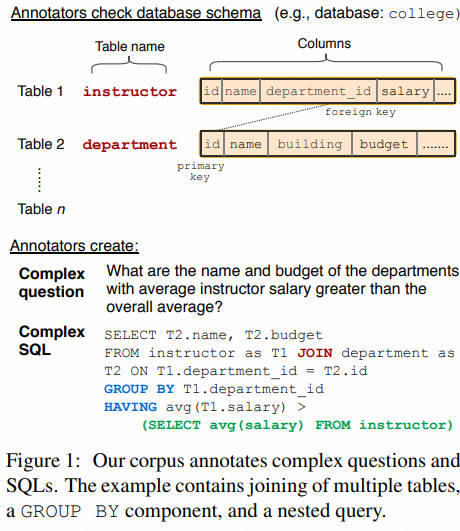
Spider [paper] [code] [dataset]
- 2018年9月,耶鲁大学提出的多数据库、多表、单轮查询的Text-to-SQL数据集,也是业界公认难度最大的大规模跨领域评测榜单,包含了10181个自然语言问题,5693个SQL语句,涉及138个不同领域的200多个数据库,难易程度分为:简单、中等、困难、特别困难。2024年2月,耶鲁大学开源了Spider1.0排行榜单的test数据集,并且他们将在3月开源Spider 2.0数据集。
-
SParC [paper] [code] [dataset]
- 2019年6月,耶鲁大学提出了一个大型数据集SParC,用于复杂、跨域、上下文相关(多轮)语义解析和Text-to-SQL任务,该数据集由4298个连贯的问题序列组成(有12k+个自然语言问题到SQL标注的Question-SQL对,由14名耶鲁大学学生标注),通过用户与138个领域的200个复杂数据库的交互获得。

-
CSpider [paper] [code] [dataset]
- 2019年9月,西湖大学提出了一个大型中文数据集CSpider,用于复杂和跨领域的语义解析和Text-to-SQL任务,由2位NLP研究人员和1位计算机专业学生从数据集Spider翻译而来,其中包含200个数据库上的10181个问题和5693个独特的复杂SQL查询,具有涵盖138个不同领域的多个表的数据库。

-
CoSQL [paper] [code] [dataset]
- 2019年9月,耶鲁大学和Salesforce Research提出了一种跨域数据库CoSQL,它由30k+轮次和10k+带注释的SQL查询组成,这些查询是从Wizard-of-Oz (WOZ)集合中获得的,该集合包含3k个对话,查询跨越 138个域的200个复杂数据库。它是Spider的升级版本,包含3w+轮对话和1w+带注释的SQL查询,这些查询来源于138个域的200个复杂数据库,每一轮对话都模拟了一个实际的数据库查询场景。因此需要结合多轮对话的内容生成最终的sql,是目前最复杂难度也最高的数据集之一。

-
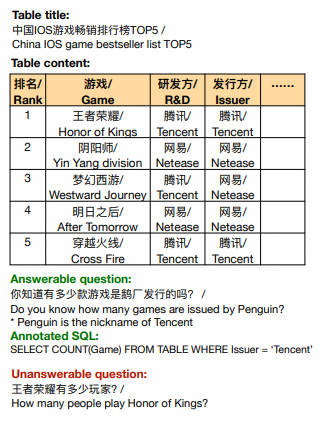
TableQA [paper] [dataset]
- 2020年6月,追一科技公司提出了一个大规模跨领域Text-to-SQL数据集TableQA,其中包含64891个问题和6000多个表的20311个唯一SQL查询。
-
DuSQL [paper] [dataset]
- 2020年11月,百度针对跨域文本到SQL任务提出了一个大规模、实用的中文数据集DuSQL,它包含200个数据库、813个表和23797个Question-SQL对。
-
CHASE [paper] [code] [dataset]
- 2021年8月,西安交通大学和微软等提出了首个跨领域、多轮Text-to-SQL中文数据集,包含了5459个多轮问题组成的列表,17940个<query, SQL>二元组。

-
BIRD-SQL [paper] [code] [dataset]
- 2023年5月,香港大学和阿里巴巴提出了一个大规模跨域数据集BIRD,其中包含超过12751个独特的问题 SQL、95个大数据库,总大小为33.4GB。它还涵盖区块链、曲棍球、医疗保健和教育等超过37个专业领域。

-
KaggleDBQA [paper] [code] [dataset]
- 2021年6月,华盛顿大学和微软研究院提出了KaggleDBQA,这是一个真实Web数据库的跨域评估数据集,具有特定领域的数据类型、原始格式和不受限制的问题。 它包括跨 8 个数据库的 272 个示例,每个数据库平均有 2.25 个表。 该数据集以其真实世界的数据源、自然的问题创作环境以及具有丰富领域知识的数据库文档而闻名。 主要统计数据:8.7% WHERE 子句、73.5% VAL、24.6% SELECT 和 6.8% NON-SELECT。

2.2 在Spider 和BIRD榜单情况
- Spider
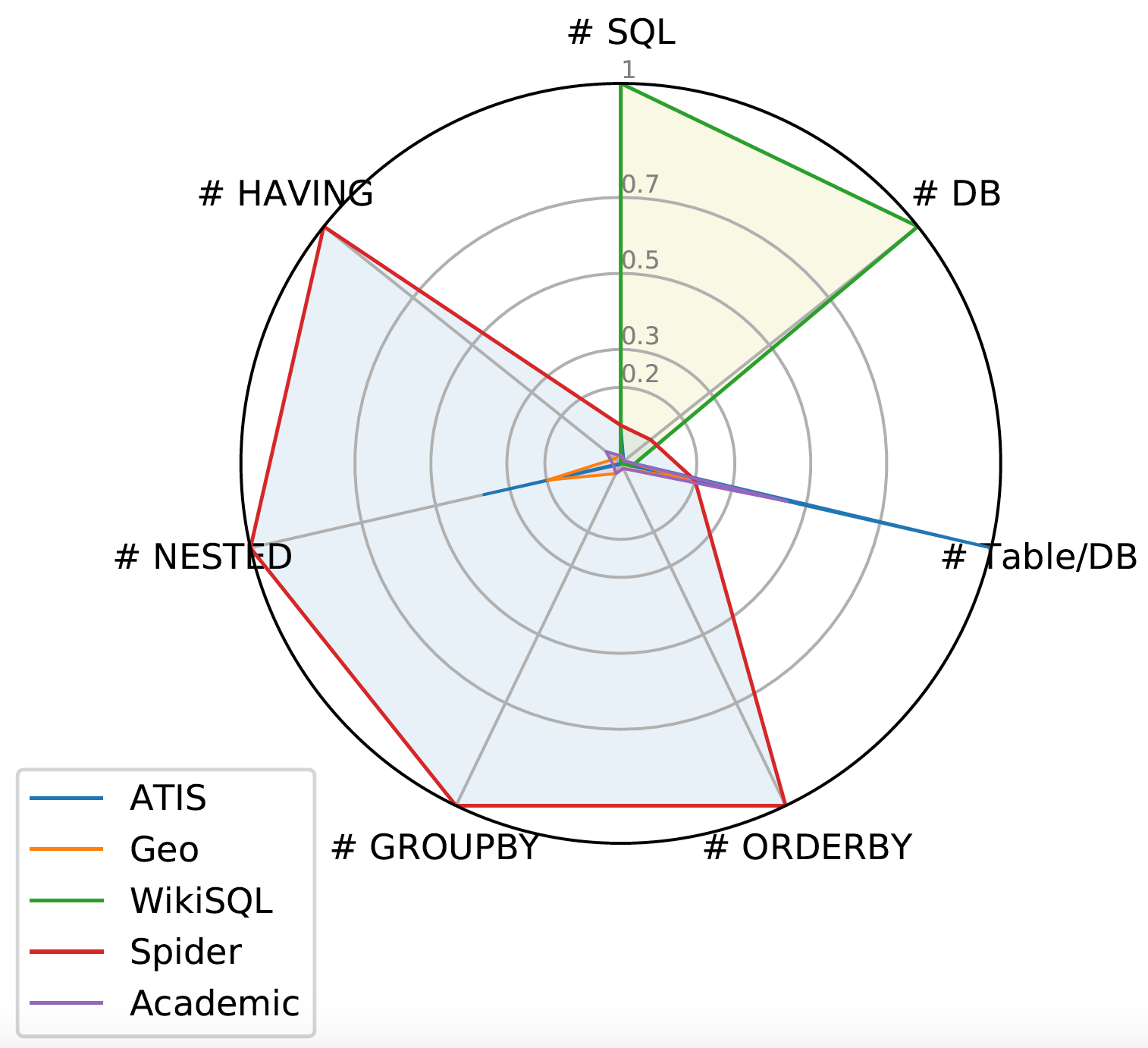
Spider 1.0与大多数先前的语义解析任务不同,因为:ATIS、Geo、Academic:它们各自仅包含一个数据库,SQL查询数量有限,且训练和测试集中SQL查询完全相同。WikiSQL:SQL查询和表的数量显著增多。但所有SQL查询都很简单,每个数据库仅是单一表,没有外键。Spider 1.0在图中占据最大面积,是首个复杂且跨领域的语义解析和文本到SQL数据集!
Leaderboard - Execution with Values
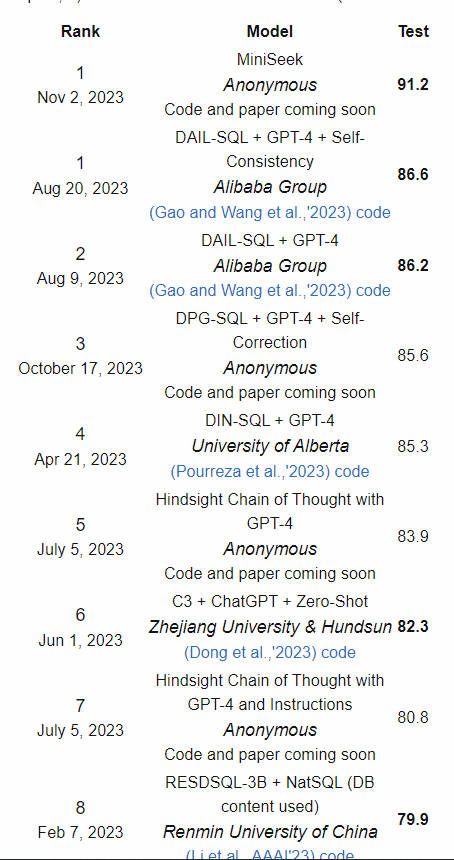
Leaderboard - Exact Set Match without Values

- BIRD


案例:

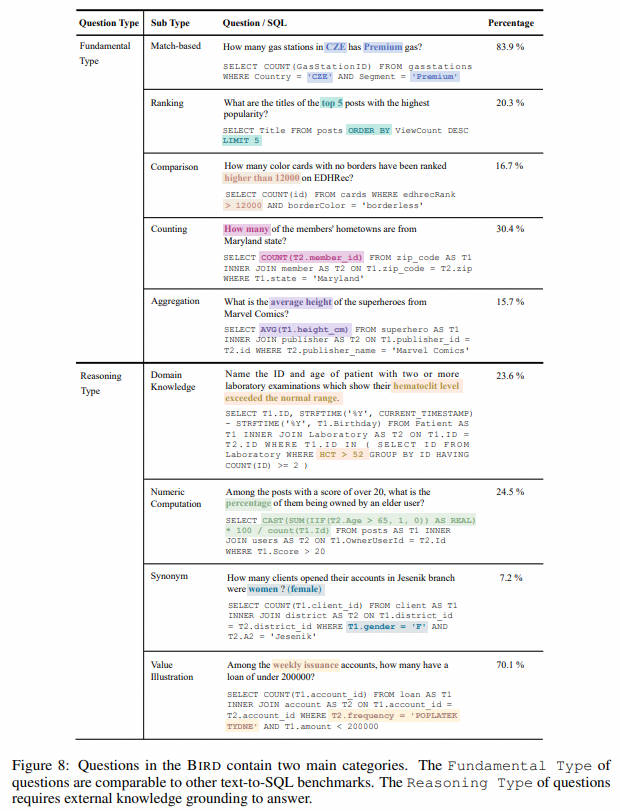
LLM排名:
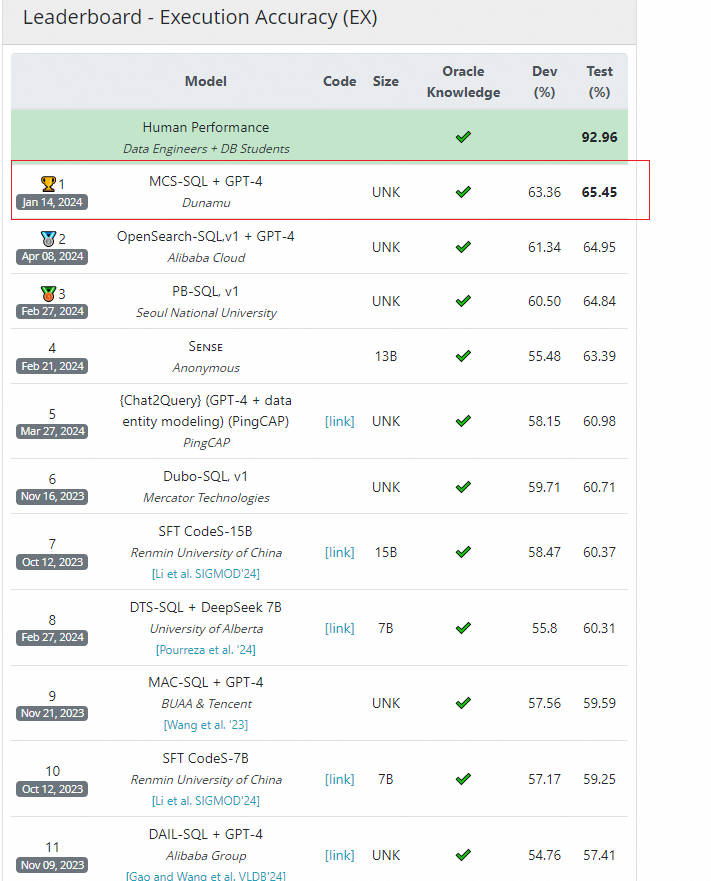
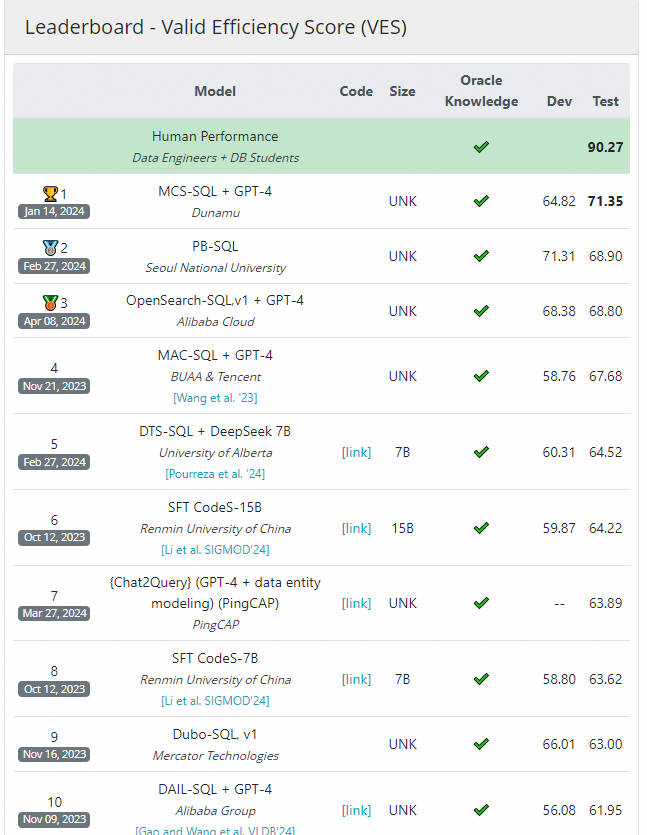
3.大模型在NL2SQL上对比
基于论文:Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT - A Text-to-SQL Parsing Comparison (2023.10)结果进行对比
本文对六种语言模型进行了综合评估:Dolly、LLaMA、Vicuna、Guanaco、Bard 和 ChatGPT,利用五种不同的提示策略,直接比较它们在九个基准数据集上的性能。
我们的主要发现是:
- 在大多数文本到 SQL 数据集中,开源模型的性能明显低于闭源模型。
- 虽然LLM在生成语法上有效的 SQL 语句方面表现出熟练程度,但他们通常很难生成语义上准确的查询。
- 事实证明,LLM 对用于小样本学习( few-shot learning)的示例高度敏感。
3.1 提示词策略
- Informal Schema (IS) :非正式模式 (IS) 策略以自然语言提供表及其关联列的描述。在这种方法中,模式信息以不太正式的方式表达。
- API Docs (AD) :相比之下,Rajkumar (2022)等人进行的评估中概述的 API 文档 (AD) 策略,遵循OpenAI 文档4中提供的默认 SQL 翻译提示。此提示遵循稍微更正式的数据库模式定义。
- Select 3 :Select 3 策略包括数据库中每个表的三个示例行。 此附加信息旨在提供每个表中包含的数据的具体示例,以补充模式描述。
- 1SL:1-Shot Learning (1SL),在提示中提供 1 个黄金示例。
- 5SL :5 Shot Learning (5SL) ,在提示中提供 5 个黄金示例。
3.2 在Spider和8大传统数据集表现
- 数据集简介

-
在spider 数据集表现

-
开源模型在 Spider 数据集上遇到了困难:尽管参数数量和模型性能之间存在正相关关系,但开源模型在 Spider数据集上实现高精度方面面临着挑战。 例如,尽管 Vicuna 7B 和 13B 已证明比原始预训练的 LLaMA 7B 和 13B模型有所改进,但与 Bard 和 GPT-3.5 相比,性能仍然存在显着差距。 此外,与 LLaMA 的 13B 版本相比,Dolly模型在不同的提示策略上也表现不佳。
-
LLM的表现对提示风格高度敏感:我们的实证研究结果证实,不存在适用于所有模型的通用提示策略。 虽然 IS 提示策略对于GPT-3.5、Bard、Vicuna 和guanaco 被证明是有效的,但对于 Dolly 和 LLaMA 来说却产生了次优的准确度。令人惊讶的是,LLaMA 在使用 S3 提示时实现了最佳结果,相比之下,GPT-3.5 的性能显著恶化。
-
使用随机示例的小样本学习提供的性能提升有限:从 1SL 和 5SL获得的大多数结果往往表现不佳,或者充其量只能达到与其他提示策略相当的结果。 然而,这种趋势也有一些例外。 Dolly 模型是一个例外,与12B 变体中的其他提示策略相比,该模型显示 1SL 提示策略的性能有所提高。 这个结果似乎是反常的,因为在其他 1SL 和 5SL结果中没有观察到类似的性能提升。 另一个例外是 LLaMA 模型,其中少样本提示策略优于一些零样本策略。 例如,30B LLaMA模型仅用 5 个给定示例就实现了 22.4% EX 和 19.9% TS 准确率,这接近于guanaco 模型的性能(24.4% EX 和19.0% TS)。
-
更多模型的表现:
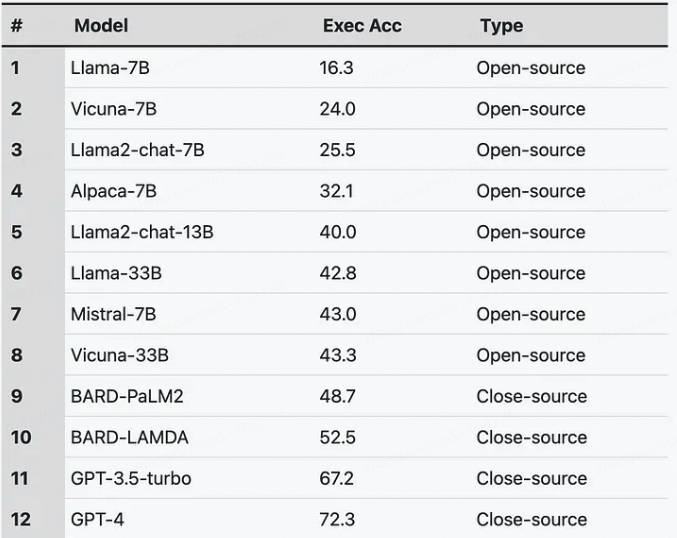
闭源模型如GPT和BARD在NL2SQL任务中显著优于开源模型,这得益于它们接受了更多的参数训练。通过额外的监督微调,模型性能得到显著提升,例如Alpaca-7B模型相比其前身Llama-7B改进了近16%,突显了微调对性能增强的潜力。与此同时,较新的开源模型如Mistral-7B和Llama2性能更优,正逐步缩小与闭源模型的差距。
-
经典数据集下情况
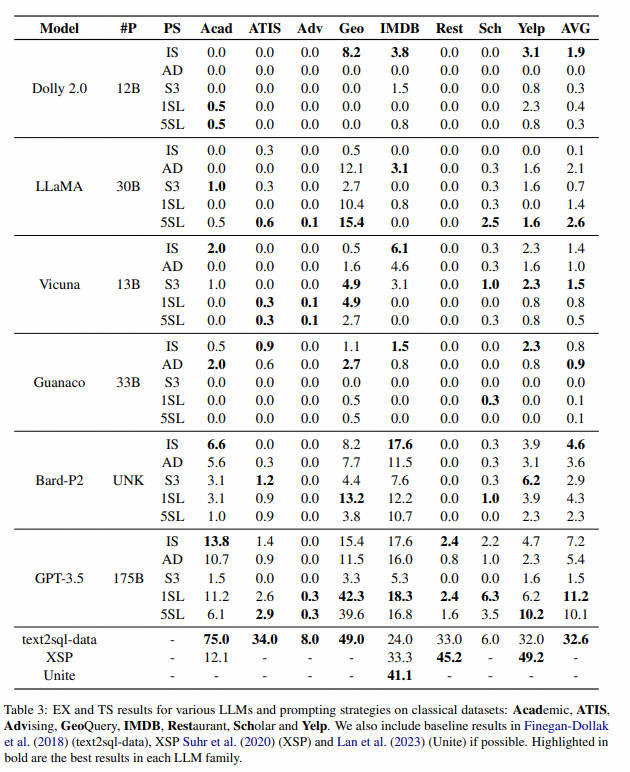
-
LLM在大多数经典数据集上表现不佳:特别是,与之前研究中报告的基线性能相比,这些数据集上达到的最高准确率分别仅为 2.9% 和 2.4%,明显低于使用 LSTM 或 BERT 的传统 seq2seq模型的其他研究中观察到的基线结果 34.0% 和 45.2%(Devlin 等人, 2019)。此外,即使进行了指令调整,Vicuna、Guanaco 和 Dolly 在经典数据集上也面临着相当大的挑战。它们在各种提示策略和数据集组合中的执行精度通常几乎为零。
-
不同模型的少样本学习的有效性有所不同:与 Spider 数据集的发现相比,我们观察到 LLaMA 和 GPT-3.5 在 1SL 和5SL 上的性能有所改进。 例如,使用 1SL,GPT-3.5 在 GeoQuery 数据集上的性能从 15.4% 提高到42.3%,而使用 5SL,LLaMA 在同一数据集上的性能也从 12.1% 显着提高到 15.4%。 然而,我们没有看到 Dolly、Vicuna 和 Bard 的 1SL或 5SL 具有类似的性能改进。
-
附加数据库示例行是无效的:就像使用Spider数据集观察到的结果一样,S3 提示策略在应用于不同模型的经典数据集时会产生低于标准的结果。因此,很明显,S3 提示策略在 Text-to-SQL 环境中可能并不有效。
-
3.3 大模型在SQL生成效果分析
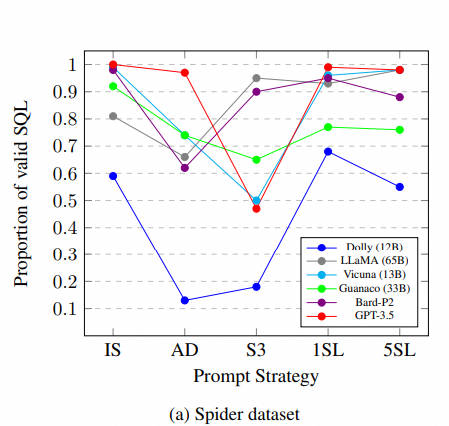
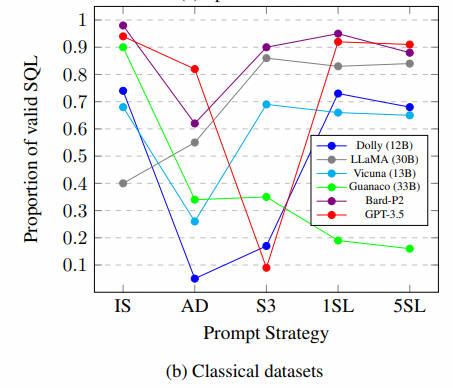
大型语言模型在生成SQL语句时常表现不佳,可能因为它们难以理解提示背后的真实意图。我们在多个数据集上测试了不同模型,发现除Dolly外,大多数模型在特定提示策略下能生成90%以上的有效SQL。尽管LLaMA未经指令数据集的微调,它仍能生成有效SQL。然而,开源模型如Vicuna和Dolly在达到高有效SQL百分比方面存在挑战。值得注意的是,LLaMA通过小样本学习提升性能,而guanaco则随着示例增多性能下降。另外,某些提示策略并不理想,尤其是S3策略,它显著降低了GPT-3.5在多个数据集上的有效SQL生成率。尽管模型能生成SQL,但语义不准确,导致执行精度低。
更多分析结果见原始论文
参考链接
- Awesome Text2SQL:https://github.com/eosphoros-ai/Awesome-Text2SQL/blob/main/README.zh.md
- NL2SQL :https://github.com/yechens/NL2SQL
- 语义解析 (Text-to-SQL) 技术研究及应用 上篇 https://mp.weixin.qq.com/s/FtsA4O_VTUqhhYS3Gq3G8Q
- Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT - A Text-to-SQL Parsing Comparison (2023.10)
- ODQA调研2:TableQA & Text2SQL:https://zhuanlan.zhihu.com/p/409001681
- https://bird-bench.github.io/
- https://yale-lily.github.io/spider
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
相关文章:
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL] Text-to-SQL(或者Text2SQL),顾名思义就是把文本转化为SQL语言,更学术一…...
深度学习基础——计算量、参数量和推理时间
深度学习基础——计算量、参数量和推理时间 在深度学习中,计算量、参数量和推理时间是评估模型性能和效率的重要指标。本文将介绍这三个指标的定义、计算方法以及如何使用Python进行实现和可视化展示,以帮助读者更好地理解和评估深度学习模型。 1. 定义…...
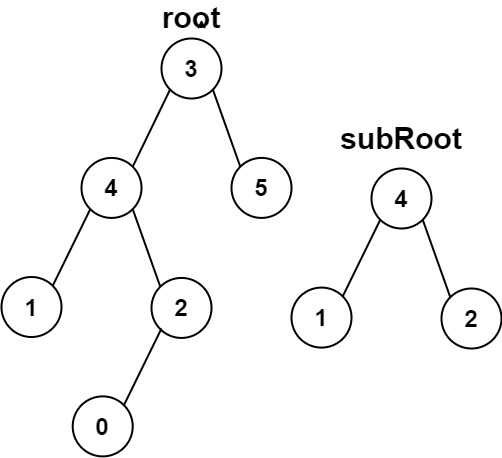
另一棵树的子树
目录 题目 思路 代码1 :相同的树 代码二:解题 注意点 题目 给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。 二叉树 tr…...

【hive】单节点搭建hadoop和hive
一、背景 需要使用hive远程debug,尝试使用无hadoop部署hive方式一直失败,无果,还是使用有hadoop方式。最终查看linux内存占用6GB,还在后台运行docker的mysql(bitnami/mysql:8.0),基本满意。 版本选择: &a…...
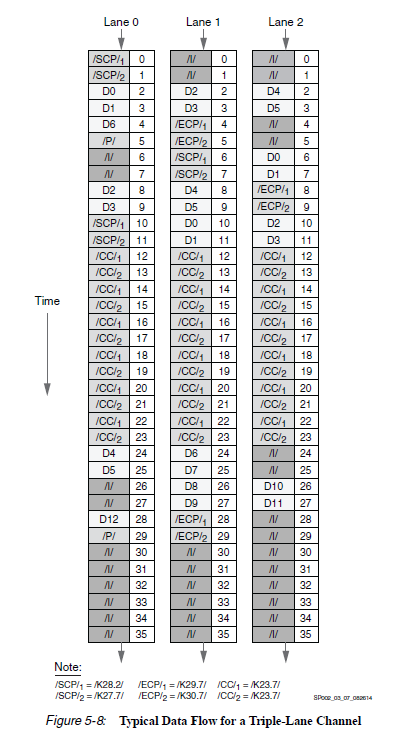
Aurora 协议学习理解与应用——Aurora 8B10B协议学习
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Aurora 8B10B协议学习之一,理解协议 概述8B10B数据发送和接收Symbol-Pairs传输调度用户PDU传输过程用户PDU接收过程 流控自然流量控制操作自然流量控制延迟自然流…...

Vue基础使用之V-Model绑定单选、复选、动态渲染选项的值
这里要说明一下,在v-model 绑定的值是id还是value是和<option>中的v-bind保持一致的,如第四个,如果是 <option :value"op[1]" 那v-model绑定的就是数组第二项的值2,4,6 如果是 <option :va…...
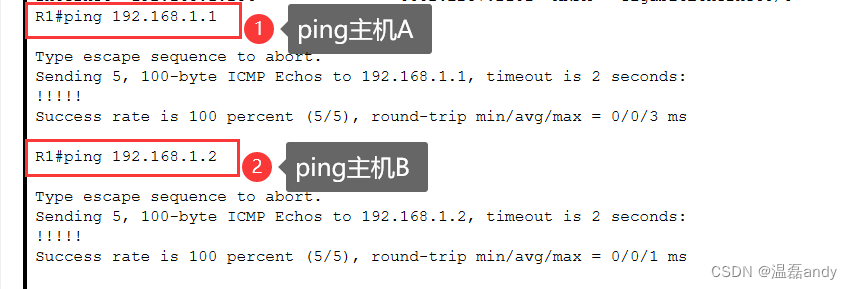
分析ARP解析过程
1、实验环境 主机A和主机B连接到交换机,并与一台路由器互连,如图7.17所示,路由器充当网关。 图7.17 实验案例一示意图 2、需求描述 查看 ARP 相关信息,熟悉在PC 和 Cisco 设备上的常用命令,设置主机A和主机B为同一个网段网关设置为路由接…...

为硬刚小米SU7,华为智界S7整出了「梅开二度」操作
如今国产中大型新能源轿车市场,在小米 SU7 加入后,可算彻底活了过来。 过去几年,咱们自主新能源品牌在 20-30 万元级轿车上发力明显不足,老牌车厂比亚迪汉几乎以一己之力扛起销量担当。 随着新能源汽车消费升级、竞争加剧&#x…...

408数据结构,怎么练习算法大题?
其实考研的数据结构算法题是有得分技巧的 得分要点 会写结构定义(没有就自己写上)写清楚解题的算法思想描述清楚算法实现最后写出时间和空间复杂度 以上这四步是完成一道算法题的基本步骤,也是其中得分的主要地方就是后面两步。但是前面两…...

imgcat 工具
如果经常在远程服务器或嵌入式设备中操作图片,要查看图片效果,就要先把图片dump到本地,比较麻烦。可以使用这个工具,直接在终端上显示。类似于这种效果。 imgcat 是一个终端工具,使用 iTerm2 内置的特性,允…...

Anaconda换清华源
1. 查看conda配置文件 sudo vim ~/.condarc2. 删除~/.condarc文件内容 使用vim中的dd命令 3. 打开并复制清华源的地址粘贴到~/.condarc文件中 https://mirrors4.tuna.tsinghua.edu.cn/help/anaconda/ channels:- defaults show_channel_urls: true default_channels:- https…...

react使用npm i @reduxjs/toolkit react-redux
npm i reduxjs/toolkit react-redux 创建一个 store文件夹,里面创建index.js文件和子模块文件夹 index,js文件写入以下代码 import {configureStore} from reduxjs/toolkit // 导入子模块 import counterReducer from ./modules/one import two from ./modules/tw…...

Nessus【部署 03】Docker部署漏洞扫描工具Nessus详细过程分享(下载+安装+注册+激活)文末福利
Docker部署漏洞扫描工具Nessus 1.安装2.配置2.1 添加用户2.2 获取Challenge code2.3 获取插件和许可证2.4 注册 3.使用4.进阶 整体流程: 1.安装 # 1.查询镜像 docker search nessus# 2.拉取镜像 docker pull tenableofficial/nessus# 3.启动镜像【挂载目录用于放置…...

2023年看雪安全技术峰会(公开)PPT合集(11份)
2023年看雪安全技术峰会(公开)PPT合集,共11份,供大家学习参阅。 1、MaginotDNS攻击:绕过DNS 缓存防御的马奇诺防线 2、从形式逻辑计算到神经计算:针对LLM角色扮演攻击的威胁分析以及防御实践 3、TheDog、0…...
Docker仅需3步搭建免费私有化的AI搜索引擎-FreeAskInternet
简介 FreeAskInternet 是一个完全免费、私有且本地运行的搜索引擎,并使用 LLM 生成答案,无需 GPU。用户可以提出问题,系统会进行多引擎搜索,并将搜索结果合并到ChatGPT3.5 LLM中,并根据搜索结果生成答案。 什么是 Fr…...

线程安全的单例模式
使用 synchronized 修饰 getInstance 方法 确保了只有一个线程可以同时访问 getInstance 方法。这意味着在任何时候只有一个线程可以执行 getInstance() 方法,从而避免了多个线程同时创建多个实例的情况,因此是线程安全的。 public class ClientUtil {…...
OpenHarmony实战开发-Grid和List内拖拽交换子组件位置。
介绍 本示例分别通过onItemDrop()和onDrop()回调,实现子组件在Grid和List中的子组件位置交换。 效果图预览 使用说明: 拖拽Grid中子组件,到目标Grid子组件位置,进行两者位置互换。拖拽List中子组件,到目标List子组件…...

设计模式:时序图
设计模式:时序图 设计模式:时序图时序图元素(Sequence Diagram Elements)角色(Actor)对象(Object)生命线(Lifeline)控制焦点(Focus of Control&am…...

前端性能监控(面试常见)
1. 用户体验优化 2. Web Vitals提取了几个核心网络指标 哇一头死 FCL 三大指标 FID被 INP干点 Largest Contentful Paint (LCP):最大内容绘制 衡量加载性能。 为了提供良好的用户体验,LCP 必须在网页首次开始加载后的 2.5 秒内发生。Interaction to Ne…...

react17 + antd4 如何实现Card组件与左侧内容对齐并撑满高度
在使用antd进行页面布局时,经常会遇到需要将内容区域进行左右分栏,并在右侧区域内放置一个或多个Card组件的情况。然而,有时我们会发现右侧的Card组件并不能与左侧的栏目对齐,尤其是当左侧栏目高度动态变化时。本文将介绍如何使用…...

段落自己改 vs 全文工具降:论文AI率哪种降得更彻底
段落自己改 vs 全文工具降:论文AI率哪种降得更彻底 降AI率的时候,很多人的直觉是"哪段被标红就改哪段"——这个思路乍一看很合理,精准处理、不动其他内容。 但实际操作下来,分段改写往往结果很差。 来说说为什么&…...

终端设备可靠性检测报告:读懂设备耐用密码
日常使用手机、智能手表、家用路由器等终端设备时,我们总希望它“扛造耐用”,不轻易出故障。这份终端设备可靠性检测报告,就用通俗的话拆解设备耐用的核心密码,让大家明白,一台靠谱的设备,背后都经过了哪些…...

5分钟零门槛搭建全功能免费AI接口:本地部署与场景化应用指南
5分钟零门槛搭建全功能免费AI接口:本地部署与场景化应用指南 【免费下载链接】kimi-free-api 🚀 KIMI AI 长文本大模型逆向API【特长:长文本解读整理】,支持高速流式输出、智能体对话、联网搜索、探索版、K1思考模型、长文档解读、…...

SEO如何提升网站权重_外链建设对SEO权重有什么作用
SEO如何提升网站权重_外链建设对SEO权重有什么作用 在当今互联网时代,网站的成功往往取决于其在搜索引擎上的排名。而搜索引擎优化(SEO)作为提升网站在搜索结果中排名的关键手段,其中的外链建设更是不可忽视的一环。SEO如何提升网…...

具备百万并发用户执行能力,静态页面加载的平均响应时间低于1.1毫秒, 事务请求处理成功率100%
在Tomcat性能测试与技术选型中,“具备百万并发用户执行能力”“静态页面加载平均响应时间低于1.1毫秒”“事务请求处理成功率100%”是常被提及的理想指标。这些指标看似彰显系统高性能,实则需结合计算机底层原理、操作系统限制、工程实践场景综合研判。本…...

如何通过SEO优化让网站排名首页_网站UX设计对SEO有什么影响
如何通过SEO优化让网站排名首页 在当今竞争激烈的互联网环境中,网站排名首页是每个网站主的共同目标。搜索引擎优化(SEO)作为提高网站流量和可见性的关键手段,不可忽视。SEO不仅仅是关于关键词、内容和链接的优化,网站…...

如何使用YimMenu提升GTA V体验:从部署到安全应用的完整指南
如何使用YimMenu提升GTA V体验:从部署到安全应用的完整指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi…...

高效Navicat密码找回工具:无需编程的数据库连接密码恢复方案
高效Navicat密码找回工具:无需编程的数据库连接密码恢复方案 【免费下载链接】navicat_password_decrypt 忘记navicat密码时,此工具可以帮您查看密码 项目地址: https://gitcode.com/gh_mirrors/na/navicat_password_decrypt 当数据库连接密码成为工作阻碍&a…...

一键解锁桌面窗口管理终极方案:告别遮挡烦恼,专注核心任务
一键解锁桌面窗口管理终极方案:告别遮挡烦恼,专注核心任务 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否曾因窗口层层叠叠而错失重要信息&#x…...

小米平板5变身Windows工作站:开源驱动如何重塑移动生产力边界?
小米平板5变身Windows工作站:开源驱动如何重塑移动生产力边界? 【免费下载链接】MiPad5-Drivers https://github.com/Project-Aloha/windows_oem_xiaomi_nabu 项目地址: https://gitcode.com/gh_mirrors/mi/MiPad5-Drivers 当一款Android平板遇上…...