AI大模型探索之路-训练篇16:大语言模型预训练-微调技术之LoRA
系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
AI大模型探索之路-训练篇14:大语言模型Transformer库-Trainer组件实践
AI大模型探索之路-训练篇15:大语言模型预训练之全量参数微调
目录
- 系列篇章💥
- 前言
- 一、微调技术分类
- 二、LoRA原理
- 三、在哪儿增加旁路
- 四、为什么微调少量参数就可以
- 五、如何对A和B进行初始化
- 六、增加旁路会增加推理时间吗?
- 七、R值为多少合适
- 八、如何注入LoRA
- 九、LoRA代码实践
- 学术资源加速
- 步骤1 导入相关包
- 步骤2 加载数据集
- 步骤3 数据集预处理
- 步骤4 创建模型
- 1、PEFT 步骤1 配置文件
- 2、PEFT 步骤2 创建模型
- 步骤5 配置训练参数
- 步骤6 创建训练器
- 步骤7 模型训练
- 步骤8 模型推理
- 十、主路合并旁路
- 1、加载基础模型
- 2、加载LoRA模型
- 3、模型推理
- 4、模型合并
- 5、模型推理
- 6、完整模型保存
- 总结
前言
在自然语言处理领域,大语言模型的预训练-微调技术已经成为一种常见的方法。其中,LoRA(Low-Rank Adaptation)是一种新颖的微调技术,通过引入低秩矩阵来调整模型的行为,以提高模型在新任务上的表现。本文将对LoRA的原理、优势以及应用进行详细介绍。
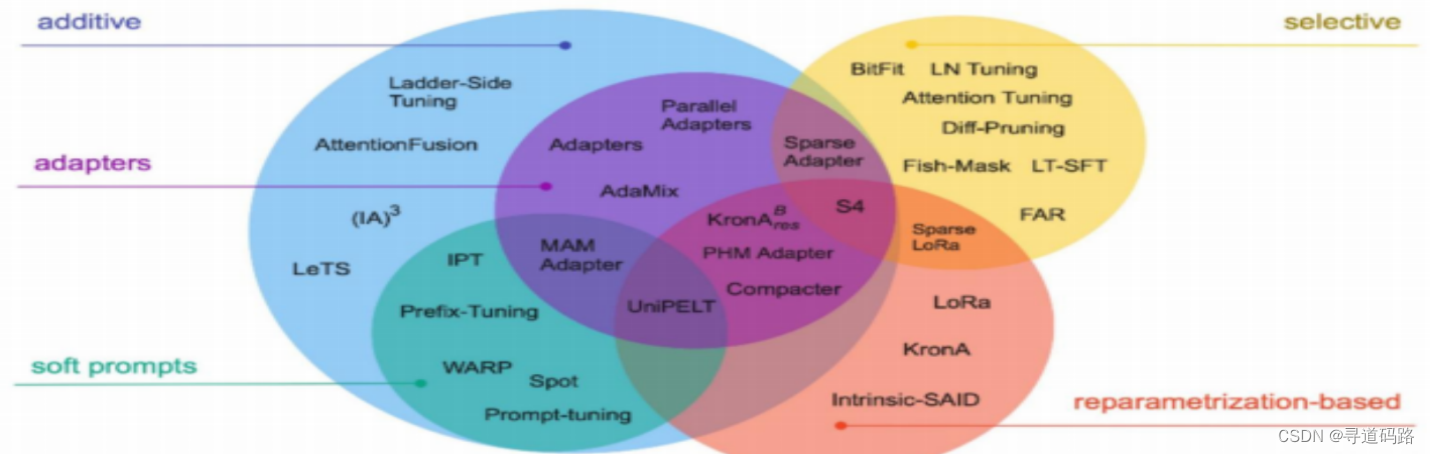
一、微调技术分类
微调技术主要分为以下几类:
1)增加额外参数(A):这种方法是在原有的预训练模型的基础上增加一些额外的参数,以改变模型的行为。
2)选取一部分参数更新(S):这种方法是在微调过程中只更新模型的一部分参数,而不是所有参数。这可以减少计算量,提高微调效率。
3)引入重参数化(R):这种方法是在模型的参数空间中引入一些新的变化,通常是一些线性变换或非线性变换,以改变模型的行为。这种方法可以使模型在新任务上有更好的表现。
常见的参数高效微调技术有Prefix Tuning、Prompt Tuning、P-Tuning、Adapter Tuning、LoRA等
二、LoRA原理
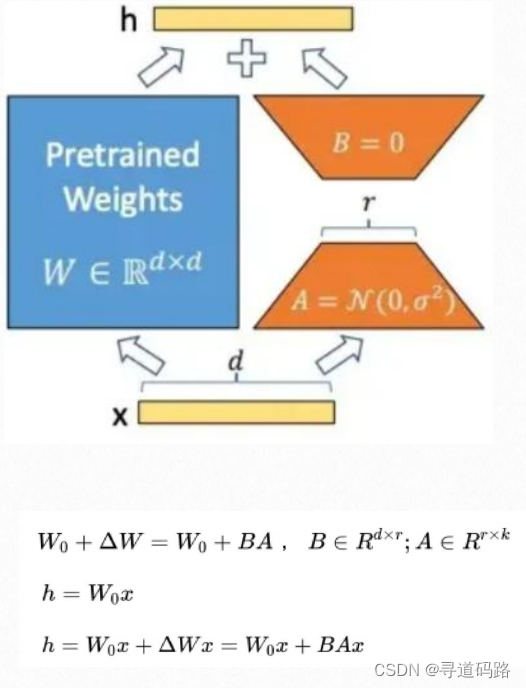
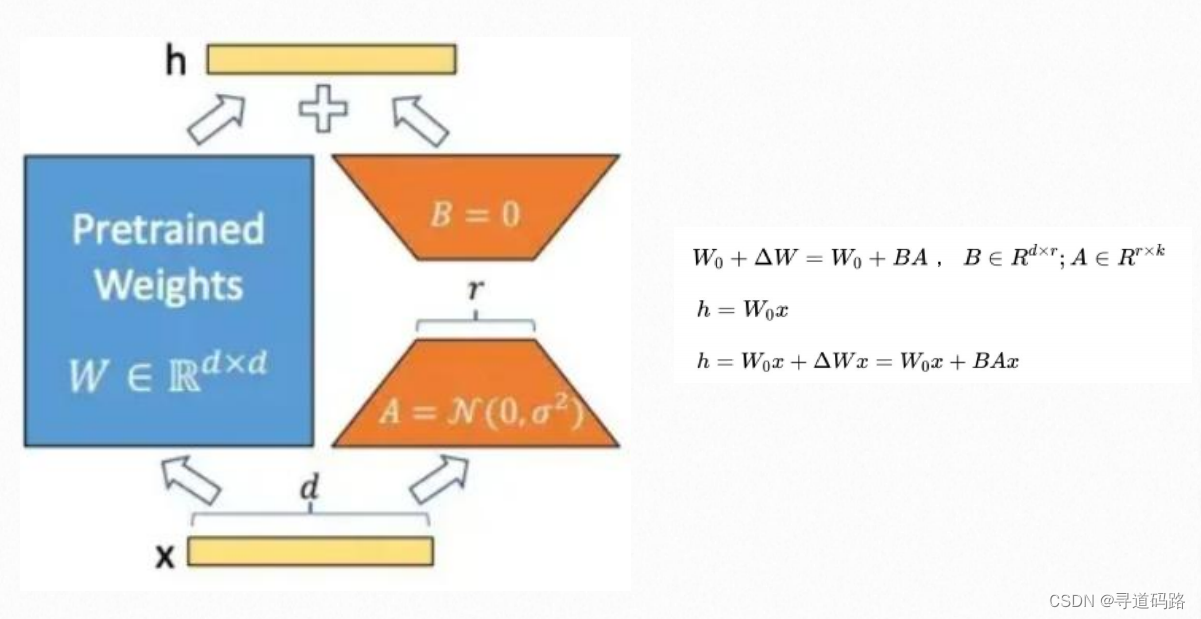
LoRA(Low-Rank Adaptation:低秩的适配器)是一种新颖的微调技术,它通过引入低秩矩阵来调整模型的行为,以提高模型在新任务上的表现。具体来说,LoRA在原有的预训练模型中增加了两个旁路矩阵A和B,这两个矩阵的维度远小于原始模型的输入输出维度,从而实现了参数的高效微调。
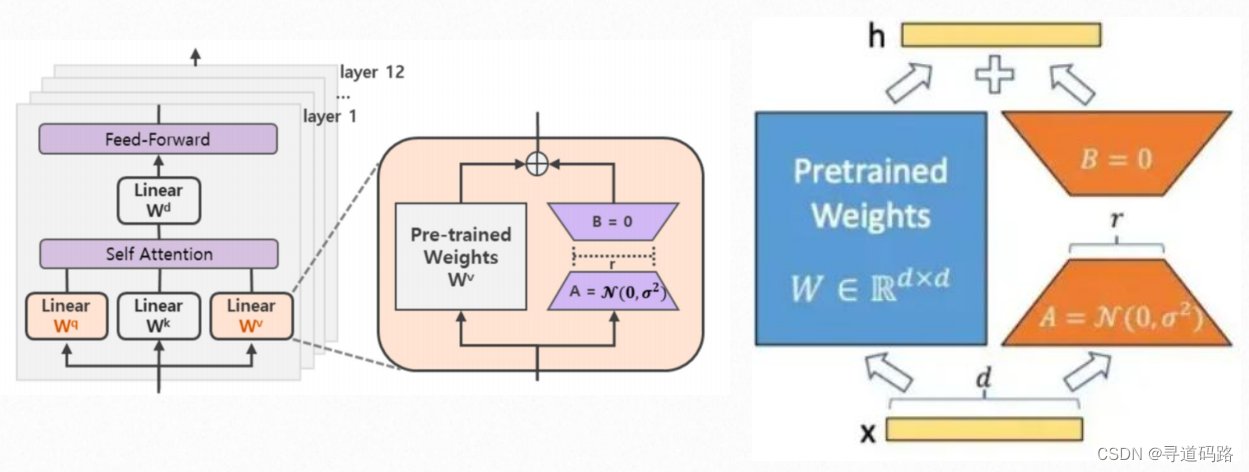
三、在哪儿增加旁路
在原有的预训练模型中,可以选择在任意两个相邻层之间增加旁路矩阵A和B。这样,模型在前向传播过程中,可以通过这两个旁路矩阵来引入新的信息,从而改变模型的行为。
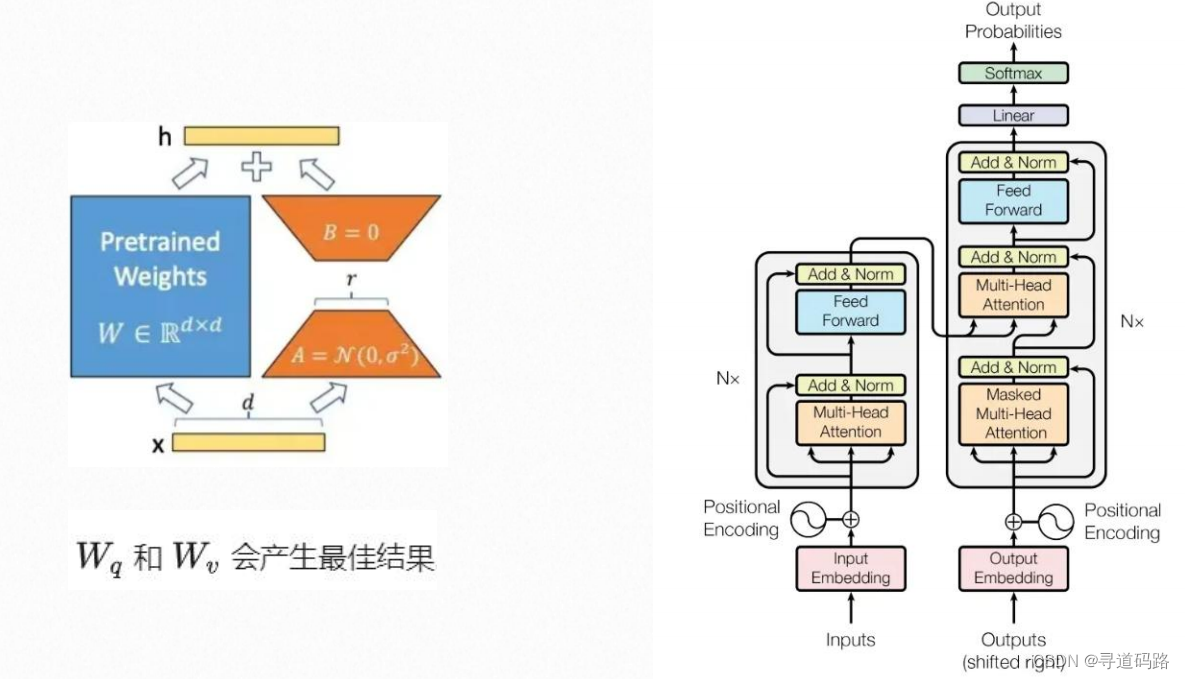
四、为什么微调少量参数就可以
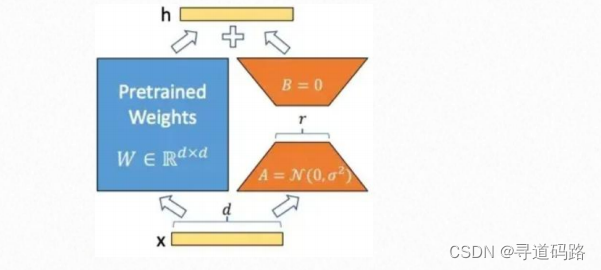
A的输入维度和B的输出维度分别与原始模型的输入输出维度相同,而A的输出维度和B的输入维度是一个远小于原始模型输入输出维度的值,这就是low-rank的体现,可以极大地减少待训练的参数
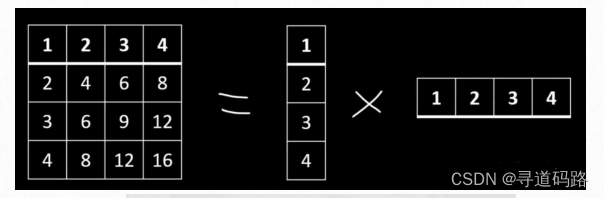
秩表示的是矩阵的信息量,这里的“秩”特指引入的旁路矩阵的规模,即它们的行数和列数。

在LoRA技术中,我们通过引入低秩矩阵来调整预训练模型的行为,同时保留大部分原有的参数不变。这样做可以在不牺牲太多性能的前提下,显著降低模型微调时的计算成本和内存需求。
通俗化解释:“秩”:
想象一下你有一个很大的包裹,你需要通过一个小门把它送出去。但是门太小了,你必须把包裹拆成几个小包裹才能通过。在这个比喻中,大包裹就像模型的权重矩阵,小门就像我们新增的低秩矩阵,而“秩”就是这些小包裹的数量。在LoRA中,我们通过创建一些小的(低秩)矩阵来传递信息,而不是使用原始的大矩阵。这样做的好处是我们可以只关注那些最重要的信息,忽略掉不重要的信息,从而减少计算量和内存需求。
五、如何对A和B进行初始化
A和B如何初始化?
对A采用高斯初始化,对B采用零初始化的目的是,让训练刚开始时的值为0,这样不会给模型带来额外的噪声。
六、增加旁路会增加推理时间吗?
虽然增加了旁路矩阵A和B,但是由于它们的维度远小于原始模型的输入输出维度,因此在推理过程中,计算量的增加是非常有限的。
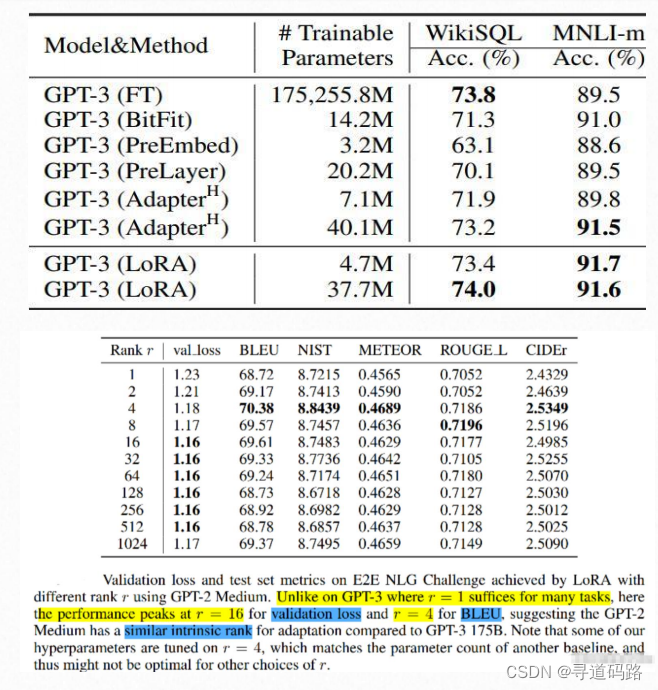
七、R值为多少合适
R值表示的是旁路矩阵A和B的秩。一般来说,R值的选择需要根据具体任务和模型结构来确定。在实际应用中,可以尝试不同的R值,以找到最佳的设置。
八、如何注入LoRA
要将LoRA应用于现有的预训练模型中,首先需要在相邻层之间插入旁路矩阵A和B。然后,在微调过程中,只需要调整这两个旁路矩阵的参数即可。这样,就可以实现模型行为的高效调整。
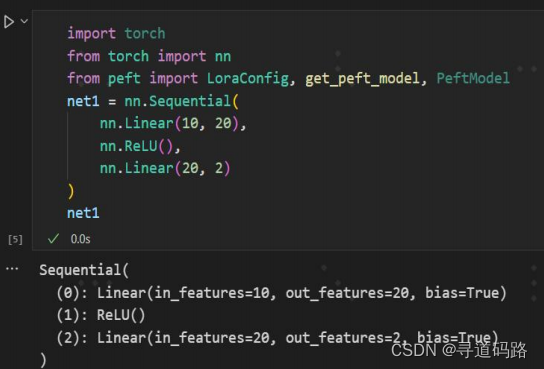
如上图中定义一个简单的3层的神经网络,在第1层增加旁路后效果如下:
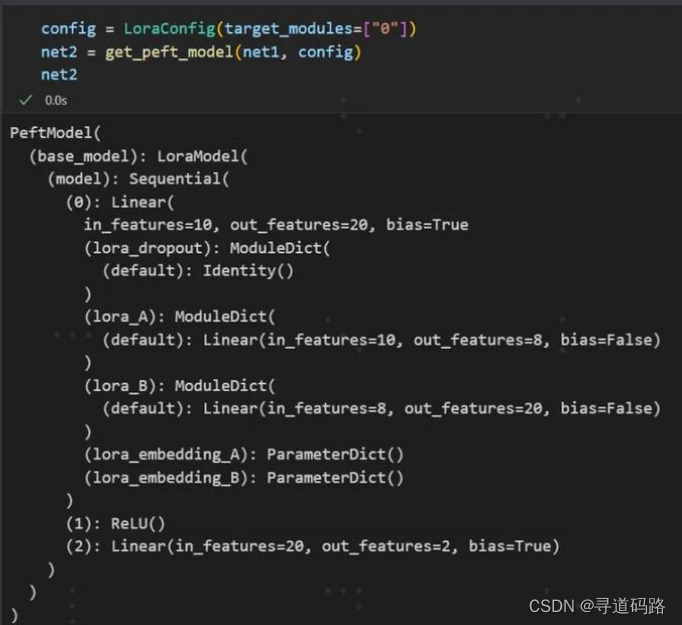
九、LoRA代码实践
PEFT文档资料地址
1)文档地址:https://huggingface.co/docs/peft/index
2)Github地址:https://github.com/huggingface/peft
PEFT(Parameter-Efficient Fine-Tuning)库是一个用于参数高效微调预训练语言模型的库,旨在降低大规模模型微调的计算和存储成本。
PEFT库的核心优势在于它能够仅通过微调少量额外模型参数来适应各种下游任务,避免了对整个大模型参数进行微调的需求。这种方法不仅降低了资源消耗,而且在很多情况下能达到与完全微调相当的性能
PEFT技术的支持:
学术资源加速
方便从huggingface下载模型,这云平台autodl提供的,仅适用于autodl。
import subprocess
import osresult = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():if '=' in line:var, value = line.split('=', 1)os.environ[var] = value
步骤1 导入相关包
开始之前,我们需要导入适用于模型训练和推理的必要库,如transformers。
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
步骤2 加载数据集
使用适当的数据加载器,例如datasets库,来加载预处理过的指令遵循性任务数据集。
ds = Dataset.load_from_disk("/root/tuning/lesson01/data/alpaca_data_zh/")
ds
输出
Dataset({features: ['output', 'input', 'instruction'],num_rows: 26858
})
数据查看
ds[:1]
输出
{'output': ['以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。'],'input': [''],'instruction': ['保持健康的三个提示。']}
步骤3 数据集预处理
利用预训练模型的分词器(Tokenizer)对原始文本进行编码,并生成相应的输入ID、注意力掩码和标签。
1)获取分词器
tokenizer = AutoTokenizer.from_pretrained("Langboat/bloom-1b4-zh")
tokenizer

输出:
BloomTokenizerFast(name_or_path='Langboat/bloom-1b4-zh', vocab_size=46145, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>', 'pad_token': '<pad>'}, clean_up_tokenization_spaces=False), added_tokens_decoder={0: AddedToken("<unk>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),1: AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),2: AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),3: AddedToken("<pad>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
2)定义数据处理函数
def process_func(example):# 设置最大长度为256MAX_LENGTH = 256# 初始化输入ID、注意力掩码和标签列表input_ids, attention_mask, labels = [], [], []# 对指令和输入进行编码instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")# 对输出进行编码,并添加结束符response = tokenizer(example["output"] + tokenizer.eos_token)# 将指令和响应的输入ID拼接起来input_ids = instruction["input_ids"] + response["input_ids"]# 将指令和响应的注意力掩码拼接起来attention_mask = instruction["attention_mask"] + response["attention_mask"]# 将指令的标签设置为-100,表示不计算损失;将响应的输入ID作为标签labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]# 如果输入ID的长度超过最大长度,截断输入ID、注意力掩码和标签if len(input_ids) > MAX_LENGTH:input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]# 返回处理后的数据return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}
3)对数据进行预处理
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds
输出:
Dataset({features: ['input_ids', 'attention_mask', 'labels'],num_rows: 26858
})
步骤4 创建模型
然后,我们实例化一个预训练模型,这个模型将作为微调的基础。对于大型模型,我们可能还需要进行一些特定的配置,以适应可用的计算资源。
#这行代码从Hugging Face Model Hub加载了一个预训练的Bloom模型,模型名称为"Langboat/bloom-1b4-zh",并且设置了low_cpu_mem_usage=True以减少CPU内存使用。
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh", low_cpu_mem_usage=True)
查看总共有哪些层,可以基于这些层添加LoRA
for name, parameter in model.named_parameters():print(name)
输出
base_model.model.transformer.word_embeddings.weight
base_model.model.transformer.word_embeddings_layernorm.weight
base_model.model.transformer.word_embeddings_layernorm.bias
base_model.model.transformer.h.0.input_layernorm.weight
base_model.model.transformer.h.0.input_layernorm.bias
base_model.model.transformer.h.0.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.0.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.0.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.0.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.0.self_attention.dense.weight
base_model.model.transformer.h.0.self_attention.dense.bias
base_model.model.transformer.h.0.post_attention_layernorm.weight
base_model.model.transformer.h.0.post_attention_layernorm.bias
base_model.model.transformer.h.0.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.0.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.0.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.0.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.1.input_layernorm.weight
base_model.model.transformer.h.1.input_layernorm.bias
base_model.model.transformer.h.1.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.1.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.1.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.1.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.1.self_attention.dense.weight
base_model.model.transformer.h.1.self_attention.dense.bias
base_model.model.transformer.h.1.post_attention_layernorm.weight
base_model.model.transformer.h.1.post_attention_layernorm.bias
base_model.model.transformer.h.1.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.1.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.1.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.1.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.2.input_layernorm.weight
base_model.model.transformer.h.2.input_layernorm.bias
base_model.model.transformer.h.2.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.2.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.2.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.2.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.2.self_attention.dense.weight
base_model.model.transformer.h.2.self_attention.dense.bias
base_model.model.transformer.h.2.post_attention_layernorm.weight
base_model.model.transformer.h.2.post_attention_layernorm.bias
base_model.model.transformer.h.2.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.2.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.2.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.2.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.3.input_layernorm.weight
base_model.model.transformer.h.3.input_layernorm.bias
base_model.model.transformer.h.3.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.3.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.3.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.3.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.3.self_attention.dense.weight
base_model.model.transformer.h.3.self_attention.dense.bias
base_model.model.transformer.h.3.post_attention_layernorm.weight
base_model.model.transformer.h.3.post_attention_layernorm.bias
base_model.model.transformer.h.3.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.3.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.3.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.3.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.4.input_layernorm.weight
base_model.model.transformer.h.4.input_layernorm.bias
base_model.model.transformer.h.4.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.4.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.4.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.4.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.4.self_attention.dense.weight
base_model.model.transformer.h.4.self_attention.dense.bias
base_model.model.transformer.h.4.post_attention_layernorm.weight
base_model.model.transformer.h.4.post_attention_layernorm.bias
base_model.model.transformer.h.4.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.4.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.4.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.4.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.5.input_layernorm.weight
base_model.model.transformer.h.5.input_layernorm.bias
base_model.model.transformer.h.5.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.5.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.5.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.5.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.5.self_attention.dense.weight
base_model.model.transformer.h.5.self_attention.dense.bias
base_model.model.transformer.h.5.post_attention_layernorm.weight
base_model.model.transformer.h.5.post_attention_layernorm.bias
base_model.model.transformer.h.5.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.5.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.5.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.5.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.6.input_layernorm.weight
base_model.model.transformer.h.6.input_layernorm.bias
base_model.model.transformer.h.6.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.6.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.6.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.6.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.6.self_attention.dense.weight
base_model.model.transformer.h.6.self_attention.dense.bias
base_model.model.transformer.h.6.post_attention_layernorm.weight
base_model.model.transformer.h.6.post_attention_layernorm.bias
base_model.model.transformer.h.6.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.6.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.6.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.6.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.7.input_layernorm.weight
base_model.model.transformer.h.7.input_layernorm.bias
base_model.model.transformer.h.7.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.7.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.7.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.7.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.7.self_attention.dense.weight
base_model.model.transformer.h.7.self_attention.dense.bias
base_model.model.transformer.h.7.post_attention_layernorm.weight
base_model.model.transformer.h.7.post_attention_layernorm.bias
base_model.model.transformer.h.7.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.7.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.7.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.7.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.8.input_layernorm.weight
base_model.model.transformer.h.8.input_layernorm.bias
base_model.model.transformer.h.8.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.8.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.8.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.8.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.8.self_attention.dense.weight
base_model.model.transformer.h.8.self_attention.dense.bias
base_model.model.transformer.h.8.post_attention_layernorm.weight
base_model.model.transformer.h.8.post_attention_layernorm.bias
base_model.model.transformer.h.8.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.8.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.8.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.8.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.9.input_layernorm.weight
base_model.model.transformer.h.9.input_layernorm.bias
base_model.model.transformer.h.9.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.9.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.9.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.9.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.9.self_attention.dense.weight
base_model.model.transformer.h.9.self_attention.dense.bias
base_model.model.transformer.h.9.post_attention_layernorm.weight
base_model.model.transformer.h.9.post_attention_layernorm.bias
base_model.model.transformer.h.9.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.9.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.9.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.9.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.10.input_layernorm.weight
base_model.model.transformer.h.10.input_layernorm.bias
base_model.model.transformer.h.10.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.10.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.10.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.10.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.10.self_attention.dense.weight
base_model.model.transformer.h.10.self_attention.dense.bias
base_model.model.transformer.h.10.post_attention_layernorm.weight
base_model.model.transformer.h.10.post_attention_layernorm.bias
base_model.model.transformer.h.10.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.10.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.10.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.10.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.11.input_layernorm.weight
base_model.model.transformer.h.11.input_layernorm.bias
base_model.model.transformer.h.11.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.11.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.11.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.11.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.11.self_attention.dense.weight
base_model.model.transformer.h.11.self_attention.dense.bias
base_model.model.transformer.h.11.post_attention_layernorm.weight
base_model.model.transformer.h.11.post_attention_layernorm.bias
base_model.model.transformer.h.11.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.11.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.11.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.11.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.12.input_layernorm.weight
base_model.model.transformer.h.12.input_layernorm.bias
base_model.model.transformer.h.12.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.12.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.12.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.12.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.12.self_attention.dense.weight
base_model.model.transformer.h.12.self_attention.dense.bias
base_model.model.transformer.h.12.post_attention_layernorm.weight
base_model.model.transformer.h.12.post_attention_layernorm.bias
base_model.model.transformer.h.12.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.12.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.12.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.12.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.13.input_layernorm.weight
base_model.model.transformer.h.13.input_layernorm.bias
base_model.model.transformer.h.13.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.13.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.13.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.13.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.13.self_attention.dense.weight
base_model.model.transformer.h.13.self_attention.dense.bias
base_model.model.transformer.h.13.post_attention_layernorm.weight
base_model.model.transformer.h.13.post_attention_layernorm.bias
base_model.model.transformer.h.13.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.13.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.13.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.13.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.14.input_layernorm.weight
base_model.model.transformer.h.14.input_layernorm.bias
base_model.model.transformer.h.14.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.14.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.14.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.14.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.14.self_attention.dense.weight
base_model.model.transformer.h.14.self_attention.dense.bias
base_model.model.transformer.h.14.post_attention_layernorm.weight
base_model.model.transformer.h.14.post_attention_layernorm.bias
base_model.model.transformer.h.14.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.14.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.14.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.14.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.15.input_layernorm.weight
base_model.model.transformer.h.15.input_layernorm.bias
base_model.model.transformer.h.15.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.15.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.15.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.15.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.15.self_attention.dense.weight
base_model.model.transformer.h.15.self_attention.dense.bias
base_model.model.transformer.h.15.post_attention_layernorm.weight
base_model.model.transformer.h.15.post_attention_layernorm.bias
base_model.model.transformer.h.15.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.15.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.15.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.15.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.16.input_layernorm.weight
base_model.model.transformer.h.16.input_layernorm.bias
base_model.model.transformer.h.16.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.16.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.16.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.16.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.16.self_attention.dense.weight
base_model.model.transformer.h.16.self_attention.dense.bias
base_model.model.transformer.h.16.post_attention_layernorm.weight
base_model.model.transformer.h.16.post_attention_layernorm.bias
base_model.model.transformer.h.16.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.16.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.16.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.16.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.17.input_layernorm.weight
base_model.model.transformer.h.17.input_layernorm.bias
base_model.model.transformer.h.17.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.17.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.17.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.17.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.17.self_attention.dense.weight
base_model.model.transformer.h.17.self_attention.dense.bias
base_model.model.transformer.h.17.post_attention_layernorm.weight
base_model.model.transformer.h.17.post_attention_layernorm.bias
base_model.model.transformer.h.17.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.17.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.17.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.17.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.18.input_layernorm.weight
base_model.model.transformer.h.18.input_layernorm.bias
base_model.model.transformer.h.18.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.18.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.18.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.18.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.18.self_attention.dense.weight
base_model.model.transformer.h.18.self_attention.dense.bias
base_model.model.transformer.h.18.post_attention_layernorm.weight
base_model.model.transformer.h.18.post_attention_layernorm.bias
base_model.model.transformer.h.18.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.18.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.18.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.18.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.19.input_layernorm.weight
base_model.model.transformer.h.19.input_layernorm.bias
base_model.model.transformer.h.19.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.19.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.19.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.19.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.19.self_attention.dense.weight
base_model.model.transformer.h.19.self_attention.dense.bias
base_model.model.transformer.h.19.post_attention_layernorm.weight
base_model.model.transformer.h.19.post_attention_layernorm.bias
base_model.model.transformer.h.19.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.19.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.19.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.19.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.20.input_layernorm.weight
base_model.model.transformer.h.20.input_layernorm.bias
base_model.model.transformer.h.20.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.20.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.20.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.20.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.20.self_attention.dense.weight
base_model.model.transformer.h.20.self_attention.dense.bias
base_model.model.transformer.h.20.post_attention_layernorm.weight
base_model.model.transformer.h.20.post_attention_layernorm.bias
base_model.model.transformer.h.20.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.20.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.20.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.20.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.21.input_layernorm.weight
base_model.model.transformer.h.21.input_layernorm.bias
base_model.model.transformer.h.21.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.21.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.21.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.21.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.21.self_attention.dense.weight
base_model.model.transformer.h.21.self_attention.dense.bias
base_model.model.transformer.h.21.post_attention_layernorm.weight
base_model.model.transformer.h.21.post_attention_layernorm.bias
base_model.model.transformer.h.21.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.21.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.21.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.21.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.22.input_layernorm.weight
base_model.model.transformer.h.22.input_layernorm.bias
base_model.model.transformer.h.22.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.22.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.22.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.22.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.22.self_attention.dense.weight
base_model.model.transformer.h.22.self_attention.dense.bias
base_model.model.transformer.h.22.post_attention_layernorm.weight
base_model.model.transformer.h.22.post_attention_layernorm.bias
base_model.model.transformer.h.22.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.22.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.22.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.22.mlp.dense_4h_to_h.bias
base_model.model.transformer.h.23.input_layernorm.weight
base_model.model.transformer.h.23.input_layernorm.bias
base_model.model.transformer.h.23.self_attention.query_key_value.base_layer.weight
base_model.model.transformer.h.23.self_attention.query_key_value.base_layer.bias
base_model.model.transformer.h.23.self_attention.query_key_value.lora_A.default.weight
base_model.model.transformer.h.23.self_attention.query_key_value.lora_B.default.weight
base_model.model.transformer.h.23.self_attention.dense.weight
base_model.model.transformer.h.23.self_attention.dense.bias
base_model.model.transformer.h.23.post_attention_layernorm.weight
base_model.model.transformer.h.23.post_attention_layernorm.bias
base_model.model.transformer.h.23.mlp.dense_h_to_4h.weight
base_model.model.transformer.h.23.mlp.dense_h_to_4h.bias
base_model.model.transformer.h.23.mlp.dense_4h_to_h.weight
base_model.model.transformer.h.23.mlp.dense_4h_to_h.bias
base_model.model.transformer.ln_f.weight
base_model.model.transformer.ln_f.bias
LoRA相关的配置(下面2个部分是LoRA相关的配置,其他的和全量微调代码一样)。
1、PEFT 步骤1 配置文件
在使用PEFT进行微调时,我们首先需要创建一个配置文件,该文件定义了微调过程中的各种设置,如学习率调度、优化器选择等。
from peft import LoraConfig, TaskType, get_peft_model
config = LoraConfig(task_type=TaskType.CAUSAL_LM)
##也可以不使用默认的,自己指定, 目标层 target_modules=["query_key_value"],秩 r=8
#config = LoraConfig(task_type=TaskType.CAUSAL_LM,r=8, target_modules=['query_key_value','dense_4h_to_h'])
config
2、PEFT 步骤2 创建模型
接下来,我们使用PEFT和预训练模型来创建一个微调模型。这个模型将包含原始的预训练模型以及由PEFT引入的低秩参数。
model = get_peft_model(model, config)
model
输出:
PeftModelForCausalLM((base_model): LoraModel((model): PeftModelForCausalLM((base_model): LoraModel((model): BloomForCausalLM((transformer): BloomModel((word_embeddings): Embedding(46145, 2048)(word_embeddings_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(h): ModuleList((0-23): 24 x BloomBlock((input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(self_attention): BloomAttention((query_key_value): lora.Linear((base_layer): Linear(in_features=2048, out_features=6144, bias=True)(lora_dropout): ModuleDict((default): Identity())(lora_A): ModuleDict((default): Linear(in_features=2048, out_features=8, bias=False))(lora_B): ModuleDict((default): Linear(in_features=8, out_features=6144, bias=False))(lora_embedding_A): ParameterDict()(lora_embedding_B): ParameterDict())(dense): Linear(in_features=2048, out_features=2048, bias=True)(attention_dropout): Dropout(p=0.0, inplace=False))(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(mlp): BloomMLP((dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)(gelu_impl): BloomGelu()(dense_4h_to_h): lora.Linear((base_layer): Linear(in_features=8192, out_features=2048, bias=True)(lora_dropout): ModuleDict((default): Identity())(lora_A): ModuleDict((default): Linear(in_features=8192, out_features=8, bias=False))(lora_B): ModuleDict((default): Linear(in_features=8, out_features=2048, bias=False))(lora_embedding_A): ParameterDict()(lora_embedding_B): ParameterDict()))))(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True))(lm_head): Linear(in_features=2048, out_features=46145, bias=False)))))
)
查看配置
config
输出
LoraConfig(peft_type=<PeftType.LORA: 'LORA'>, auto_mapping=None, base_model_name_or_path=None, revision=None, task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, inference_mode=False, r=8, target_modules={'query_key_value', 'dense_4h_to_h'}, lora_alpha=8, lora_dropout=0.0, fan_in_fan_out=False, bias='none', modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None, rank_pattern={}, alpha_pattern={}, megatron_config=None, megatron_core='megatron.core', loftq_config={})
步骤5 配置训练参数
定义训练参数,包括输出目录、学习率、批次大小、梯度累积步数、优化器选择等。
args = TrainingArguments(output_dir="/root/autodl-tmp/tuningdata/lora",# 指定模型训练结果的输出目录。per_device_train_batch_size=4, # 指定每个设备(如GPU)上的批次大小gradient_accumulation_steps=8,# 指定梯度累积步数。在本例子中,每8个步骤进行一次梯度更新。logging_steps=20, #指定日志记录的频率。在本例子中,每20个步骤记录一次日志num_train_epochs=4 #指定训练的总轮数
)步骤6 创建训练器
最后,我们创建一个训练器实例,它封装了训练循环。训练器将负责运行训练过程,并根据我们之前定义的参数进行优化。
trainer = Trainer(model=model,#指定训练模型args=args, #指定训练参数train_dataset=tokenized_ds, #指定数据集data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True) #指定数据收集器。其中tokenizer是分词器,padding=True表示对输入进行填充以保持批次大小一致。
)
步骤7 模型训练
通过调用训练器的train()方法,我们启动模型的训练过程。
trainer.train()
步骤8 模型推理
训练完成后,我们可以使用训练好的模型进行推理。这通常涉及到使用模型的inference方法,输入经过适当处理的问题,并得到模型的输出。
from transformers import pipelinepipe = pipeline("text-generation", model=model, tokenizer=tokenizer, device=0)ipt = "Human: {}\n{}".format("如何写好一个简历?", "").strip() + "\n\nAssistant: "
pipe(ipt, max_length=256, do_sample=True, )
输出
[{'generated_text': 'Human: 如何写好一个简历?\n\nAssistant: 一篇好的简历应包含以下内容:个人信息(姓名,出生日期,出生地,教育经历,工作经历)、求职理由、个人能力(如语言能力,英语水平,操作技能,编程能力,市场营销能力,分析归纳能力等)、学习经历、实践经历和经验、荣誉奖项、相关证书和荣誉、个人兴趣爱好以及在工作中遇到的瓶颈和障碍。\n\n在书写时,应注意文字简洁、条理清晰,突出重点,语言流畅。您也可以在简历中附上一些相关的个人照片或照片资料以供他人参考。如果您有任何疑问,请随时与我联系。'}]
十、主路合并旁路
1、加载基础模型
from transformers import AutoModelForCausalLM, AutoTokenizerfrom peft import PeftModelmodel = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh", low_cpu_mem_usage=True)
tokenizer = AutoTokenizer.from_pretrained("Langboat/bloom-1b4-zh")
2、加载LoRA模型
p_model = PeftModel.from_pretrained(model, model_id="/root/autodl-tmp/tuningdata/lora/checkpoint-500")
p_model
输出
PeftModelForCausalLM((base_model): LoraModel((model): BloomForCausalLM((transformer): BloomModel((word_embeddings): Embedding(46145, 2048)(word_embeddings_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(h): ModuleList((0-23): 24 x BloomBlock((input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(self_attention): BloomAttention((query_key_value): lora.Linear((base_layer): Linear(in_features=2048, out_features=6144, bias=True)(lora_dropout): ModuleDict((default): Identity())(lora_A): ModuleDict((default): Linear(in_features=2048, out_features=8, bias=False))(lora_B): ModuleDict((default): Linear(in_features=8, out_features=6144, bias=False))(lora_embedding_A): ParameterDict()(lora_embedding_B): ParameterDict())(dense): Linear(in_features=2048, out_features=2048, bias=True)(attention_dropout): Dropout(p=0.0, inplace=False))(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(mlp): BloomMLP((dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)(gelu_impl): BloomGelu()(dense_4h_to_h): lora.Linear((base_layer): Linear(in_features=8192, out_features=2048, bias=True)(lora_dropout): ModuleDict((default): Identity())(lora_A): ModuleDict((default): Linear(in_features=8192, out_features=8, bias=False))(lora_B): ModuleDict((default): Linear(in_features=8, out_features=2048, bias=False))(lora_embedding_A): ParameterDict()(lora_embedding_B): ParameterDict()))))(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True))(lm_head): Linear(in_features=2048, out_features=46145, bias=False)))
)
3、模型推理
from transformers import pipelinepipe = pipeline("text-generation", model=p_model, tokenizer=tokenizer, device=0)
ipt = "Human: {}\n{}".format("如何写好一个简历?", "").strip() + "\n\nAssistant: "
pipe(ipt, max_length=256, do_sample=True, )
4、模型合并
merge_model = p_model.merge_and_unload()
merge_model
输出
BloomForCausalLM((transformer): BloomModel((word_embeddings): Embedding(46145, 2048)(word_embeddings_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(h): ModuleList((0-23): 24 x BloomBlock((input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(self_attention): BloomAttention((query_key_value): Linear(in_features=2048, out_features=6144, bias=True)(dense): Linear(in_features=2048, out_features=2048, bias=True)(attention_dropout): Dropout(p=0.0, inplace=False))(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(mlp): BloomMLP((dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)(gelu_impl): BloomGelu()(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True))))(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True))(lm_head): Linear(in_features=2048, out_features=46145, bias=False)
)
5、模型推理
from transformers import pipelinepipe = pipeline("text-generation", model=merge_model, tokenizer=tokenizer, device=0)
ipt = "Human:如何写好一个简历?\n\nAssistant: "
pipe(ipt, max_length=256,)
6、完整模型保存
模型训练完后,可以将合并的模型进行保存到本地,进行备用
merge_model.save_pretrained("/root/autodl-tmp/tuningdata/merge_model")
总结
LoRA是一种新颖的微调技术,通过引入低秩矩阵来调整模型的行为,以提高模型在新任务上的表现。它具有参数高效、计算复杂度低等优点,因此在自然语言处理领域具有广泛的应用前景。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
相关文章:
AI大模型探索之路-训练篇16:大语言模型预训练-微调技术之LoRA
系列篇章💥 AI大模型探索之路-训练篇1:大语言模型微调基础认知 AI大模型探索之路-训练篇2:大语言模型预训练基础认知 AI大模型探索之路-训练篇3:大语言模型全景解读 AI大模型探索之路-训练篇4:大语言模型训练数据集概…...

mysql事务锁排查
-- mysql show full PROCESSLIST; -- 查看哪些表在锁。 show open tables where IN_use>0; -- 正在执行的事务: SELECT * FROM information_schema.INNODB_TRX;-- 8.0之前 查看正在锁的事务 select * from information_schema.innodb_locks;-- 查看等待锁的事务 …...

ChatGPT变懒原因:正在给自己放寒假!已被网友测出
ChatGPT近期偷懒严重,有了一种听起来很离谱的解释: 模仿人类,自己给自己放寒假了~ 有测试为证,网友Rob Lynch用GPT-4 turbo API设置了两个系统提示: 一个告诉它现在是5月,另一个告诉它现在是1…...
C#标签设计打印软件开发
1、新建自定义C#控件项目Custom using System; using System.Collections.Generic; using System.Text;namespace CustomControls {public class CommonSettings{/// <summary>/// 把像素换算成毫米/// </summary>/// <param name="Pixel">多少像素…...

Springboot+vue+小程序+基于微信小程序的在线学习平台
一、项目介绍 基于Spring BootVue小程序的在线学习平台从实际情况出发,结合当前年轻人的学习环境喜好来开发。基于Spring BootVue小程序的在线学习平台在语言上使用Java语言进行开发,在数据库存储方面使用的MySQL数据库,开发工具是IDEA。…...

正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-13-按键实验
前言: 本文是根据哔哩哔哩网站上“正点原子[第二期]Linux之ARM(MX6U)裸机篇”视频的学习笔记,在这里会记录下正点原子 I.MX6ULL 开发板的配套视频教程所作的实验和学习笔记内容。本文大量引用了正点原子教学视频和链接中的内容。…...
ubuntu与redhat的不同之处
华子目录 什么是ubuntu概述 ubuntu版本简介桌面版服务器版 安装部署部署后的设置设置root密码关闭防火墙启用允许root进行ssh登录更改apt源安装所需软件 安装nginx安装apache网络配置Netplan概述配置详解配置文件DHCP静态IP设置设置 软件安装方法apt安装软件作用常用命令配置ap…...
三岁孩童被家养大型犬咬伤 额部撕脱伤达10公分
近期,一名被家养大型犬咬伤了面部的3岁小朋友,在被家人紧急送来西安国际医学中心医院,通过24小时急诊门诊简单救治后,转至整形外科,由主治医师李世龙为他实施了清创及缝合手术。 “患者额部撕脱伤面积约为10公分&…...
“不会传递默认事件参数)
@click=“handleClick()“不会传递默认事件参数
当你使用click"handleClick()"这种形式绑定事件处理器时,Vue会将它视为一个函数调用,而不是一个事件监听器。在这种情况下,Vue不会自动传递原生事件对象作为默认参数。 如果你想让Vue自动传递原生事件对象作为默认参数,…...

KVM安装Ubuntu24.04简要坑点以及优点
本机环境是ubuntu22.04的环境,然后是8核16线程 ssd是500的 目前对于虚拟机的选择,感觉kvm确实会更加流畅,最重要的一点是简洁,然后实际安装效果也比较的好,如果对于速度方面希望快一点,并且流畅一点的话这…...
QT_day1
#include "mywidget.h"MyWidget::MyWidget(QWidget *parent): QWidget(parent) {//修改窗口标题this->setWindowTitle("4.6.0");//修改窗口图标this->setWindowIcon(QIcon("C:\\Users\\zj\\Desktop\\yuanshen\\icon"));//修改窗口大小this…...

AWS宣布推出Amazon Q :针对商业数据和软件开发的生成性AI助手
亚马逊网络服务(AWS)近日宣布推出了一项名为“Amazon Q”的新服务,旨在帮助企业利用生成性人工智能(AI)技术,优化工作流程和提升业务效率。这一创新平台的推出,标志着企业工作方式的又一次重大变…...
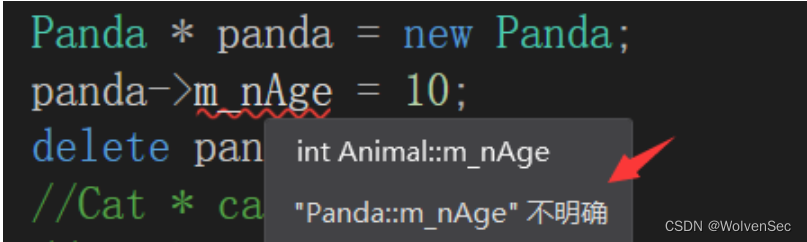
C++:多继承虚继承
在C中,虚继承(Virtual Inheritance)是一种特殊的继承方式,用于解决菱形继承(Diamond Inheritance)问题。菱形继承指的是一个类同时继承自两个或更多个具有共同基类的类,从而导致了多个实例同一个…...
Linux进程间通信
每个进程的用户空间都是独立的,不能相互访问。 所有进程的内核空间(32位系统3G-4G)都是共享的 应用场景 作为缓冲区,处理速度不同的进程之间的数据传输资源共享:多个进程之间共享同样的资源,一个进程对共享数据的修改,…...

【二叉树算法题记录】222. 完全二叉树的节点个数
题目描述 给你一棵 完全二叉树 的根节点root ,求出该树的节点个数。 完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位…...

每日新闻掌握【2024年5月6日 星期一】
2024年5月06日 星期一 农历三月廿八 大公司/大事件 多个品牌黄金优惠后价格重回600元/克以下 “五一”假期期间,记者走访调研黄金消费市场发现,受国际金价回落及“五一”假期促销等多重因素影响,终端黄金价格出现了较为明显的回落。包括周大…...

谈谈Tcpserver开启多线程并发处理遇到的问题!
最近在学习最基础的socket网络编程,在Tcpserver开启多线程并发处理时遇到了一些问题! 说明 在linux以及Windows的共享文件夹进行编写的,所以代码中有的部分使用 #ifdef WIN64 ... #else ... #endif 进入正题!!&…...

618好物节不知道买什么?快收下这份好物推荐指南!
随着618好物节的临近,你是否在为选择什么产品而犹豫不决?不用担忧,我精心准备了一份购物指南,旨在帮助你发现那些性价比高、口碑爆棚的商品。无论是科技新品还是生活小物件,这份指南都能帮你快速定位到那些值得投资的好…...

Django高级表单处理与验证实战
title: Django高级表单处理与验证实战 date: 2024/5/6 20:47:15 updated: 2024/5/6 20:47:15 categories: 后端开发 tags: Django表单验证逻辑模板渲染安全措施表单测试重定向管理最佳实践 引言: 在Web应用开发中,表单是用户与应用之间进行交互的重要…...

类和对象-Python-第一部分
初识对象 使用对象组织数据 class Student:nameNonegenderNonenationalityNonenative_placeNoneageNonestu_1Student()stu_1.name"林军杰" stu_1.gender"男" stu_1.nationality"中国" stu_1.native_place"山东" stu_1.age31print(stu…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...