使用QLoRA在自定义数据集上finetuning 大模型 LLAMA3 的数据比对分析
概述:
大型语言模型(LLM)展示了先进的功能和复杂的解决方案,使自然语言处理领域发生了革命性的变化。这些模型经过广泛的文本数据集训练,在文本生成、翻译、摘要和问答等任务中表现出色。尽管LLM具有强大的功能,但它可能并不总是与特定的任务或领域保持一致。
什么是LLM微调?
微调LLM涉及对预先存在的模型进行额外的训练,该模型之前使用较小的特定领域数据集从广泛的数据集中获取了模式和特征。在“LLM微调”的上下文中,LLM表示“大型语言模型”,例如OpenAI的GPT系列。这种方法具有重要意义,因为从头开始训练大型语言模型在计算能力和时间方面都是高度资源密集型的。利用嵌入预训练模型中的现有知识允许在显著减少数据和计算需求的情况下实现特定任务的高性能。
以下是LLM微调中涉及的一些关键步骤:
-
List item选择预训练模型:对于LLM微调,第一步是仔细选择符合我们所需架构和功能的基础预训练模型。预训练模型是在大量未标记数据的语料库上训练的通用模型。
-
收集相关数据集:然后我们需要收集与我们的任务相关的数据集。数据集应该以模型可以从中学习的方式进行标记或结构化。
-
预处理数据集:一旦数据集准备好,我们需要进行一些预处理以进行微调,方法是清理它,将其拆分为训练、验证和测试集,并确保它与我们想要微调的模型兼容。
-
微调:在选择了一个预训练的模型后,我们需要在预处理的相关数据集上对其进行微调,该数据集更适合手头的任务。我们将选择的数据集可能与特定的域或应用程序相关,从而允许模型针对该上下文进行调整和专门化。
-
特定任务的适应:在微调过程中,根据新的数据集调整模型的参数,帮助它更好地理解和生成与特定任务相关的内容。这个过程保留了在预训练期间获得的一般语言知识,同时根据目标领域的细微差别调整模型。
什么是LoRa?
LoRA是一种改进的微调方法,其中不是微调构成预训练的大型语言模型的权重矩阵的所有权重,而是微调近似于该较大矩阵的两个较小矩阵。这些矩阵构成了LoRA适配器。然后将这个经过微调的适配器加载到预先训练的模型中,并用于推理。
在针对特定任务或用例对LoRA进行微调后,结果是原始LLM不变,并且出现了相当小的“LoRA适配器”,通常表示原始LLM大小的个位数百分比(以MB而非GB为单位)。
在推理过程中,LoRA适配器必须与其原始LLM相结合。其优点在于许多LoRA适配器能够重用原始LLM,从而在处理多个任务和用例时降低总体内存需求。
什么是量化LoRA(QLoRA)?
QLoRA代表了LoRA的一种更具内存效率的迭代。QLoRA还通过将LoRA适配器(较小矩阵)的权重量化到较低精度(例如,4比特而不是8比特),使LoRA更进一步。这进一步减少了内存占用和存储需求。在QLoRA中,预训练的模型用量化的4位权重加载到GPU存储器中,而在LoRA中使用的是8位。尽管比特精度有所下降,QLoRA仍保持着与LoRA相当的有效性水平。
代码实现
依赖加载
from datasets import load_dataset
from transformers import (AutoModelForCausalLM,AutoTokenizer,BitsAndBytesConfig,HfArgumentParser,AutoTokenizer,TrainingArguments,Trainer,GenerationConfig
)
from tqdm import tqdm
from trl import SFTTrainer
import torch
import time
import pandas as pd
import numpy as np
from huggingface_hub import interpreter_login
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from functools import partialimport os
#禁用权重和偏差
os.environ['WANDB_DISABLED']="true"
数据加载
huggingface_dataset_name = "neil-code/dialogsum-test"#“neil代码/对话和测试
dataset = load_dataset(huggingface_dataset_name)
print(dataset['train'][0])

数据包含以下字段。
对话:对话的文本。
摘要:人类书写的对话摘要。
主题:人类书写的主题/对话的一行。
id:示例的唯一文件id。
加载模型
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type='nf4',bnb_4bit_compute_dtype=compute_dtype,bnb_4bit_use_double_quant=False,)model_name=r'D:\临时模型\Meta-Llama-3-8B-Instruct'
device_map = {"": 0}
original_model = AutoModelForCausalLM.from_pretrained(model_name, device_map=device_map,quantization_config=bnb_config,trust_remote_code=True,use_auth_token=True)
BitsAndBytesConfig 为量化配置
-
List itemload_in_4bit=True:这个参数指定模型在加载时是否应该以4位量化的格式进行。这意味着模型的权重将使用4位精度来存储,从而减少模型的内存占用和加速推理过程。 -
bnb_4bit_quant_type='nf4':这个参数定义了用于量化的数值格式。在这里,‘nf4’ 代表 “Normal Float 4”,它是一种4位量化的浮点数格式,用于量化模型的权重。 -
bnb_4bit_compute_dtype=compute_dtype:这个参数指定了在推理时用于计算的数据类型。compute_dtype 是一个变量,应该在这段代码之前定义,它通常是一个类似于 torch.bfloat16 的数据类型,表示在计算期间使用的半精度浮点数格式。 -
bnb_4bit_use_double_quant=False:这个参数控制是否使用双量化技术。双量化是一种技术,它在量化过程中使用两个不同的量化表(lookup table)来提高精度。在这里,False 表示不使用双量化。
数据预处理
#prompt 工程
def create_prompt_formats(sample):"""格式化示例的各个字段('instruction','output')然后使用两个换行符将它们连接起来:参数sample:样本字典这里主要对数据添加一个prompt 用于给到大模型更好的格式规范,这里是模型效果提升的第一个关键点"""INTRO_BLURB = "Below is an instruction that describes a task. Write a response that appropriately completes the request."INSTRUCTION_KEY = "### Instruct: Summarize the below conversation."RESPONSE_KEY = "### Output:"END_KEY = "### End"blurb = f"\n{INTRO_BLURB}"instruction = f"{INSTRUCTION_KEY}"input_context = f"{sample['dialogue']}" if sample["dialogue"] else Noneresponse = f"{RESPONSE_KEY}\n{sample['summary']}"end = f"{END_KEY}"parts = [part for part in [blurb, instruction, input_context, response, end] if part]formatted_prompt = "\n\n".join(parts)sample["text"] = formatted_promptreturn sample#数据截断
def get_max_length(model):conf = model.configmax_length = Nonefor length_setting in ["n_positions", "max_position_embeddings", "seq_length"]:max_length = getattr(model.config, length_setting, None)if max_length:print(f"Found max lenth: {max_length}")breakif not max_length:max_length = 1024print(f"Using default max length: {max_length}")相关文章:
使用QLoRA在自定义数据集上finetuning 大模型 LLAMA3 的数据比对分析
概述: 大型语言模型(LLM)展示了先进的功能和复杂的解决方案,使自然语言处理领域发生了革命性的变化。这些模型经过广泛的文本数据集训练,在文本生成、翻译、摘要和问答等任务中表现出色。尽管LLM具有强大的功能,但它可能并不总是与特定的任务或领域保持一致。 什么是LL…...
编译和链接(超详细)
✅博客主页:爆打维c-CSDN博客 🐾 🔹分享c语言知识及代码 一、编译和链接实例 假设我们有一个名为main.c的C语言源文件,它包含了一个简单的Hello World程序。我们可以使用gcc编译器对该源文件进行编译,生成一个可执行…...

Rust Turbofish 的由来
0x01 什么是 Turbofish 我们运行如下 Rust Snippet: fn main() {let numbers: Vec<i32> vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10];let even_numbers numbers.into_iter().filter(|n| n % 2 0).collect();println!("{:?}", even_numbers); }不出意…...
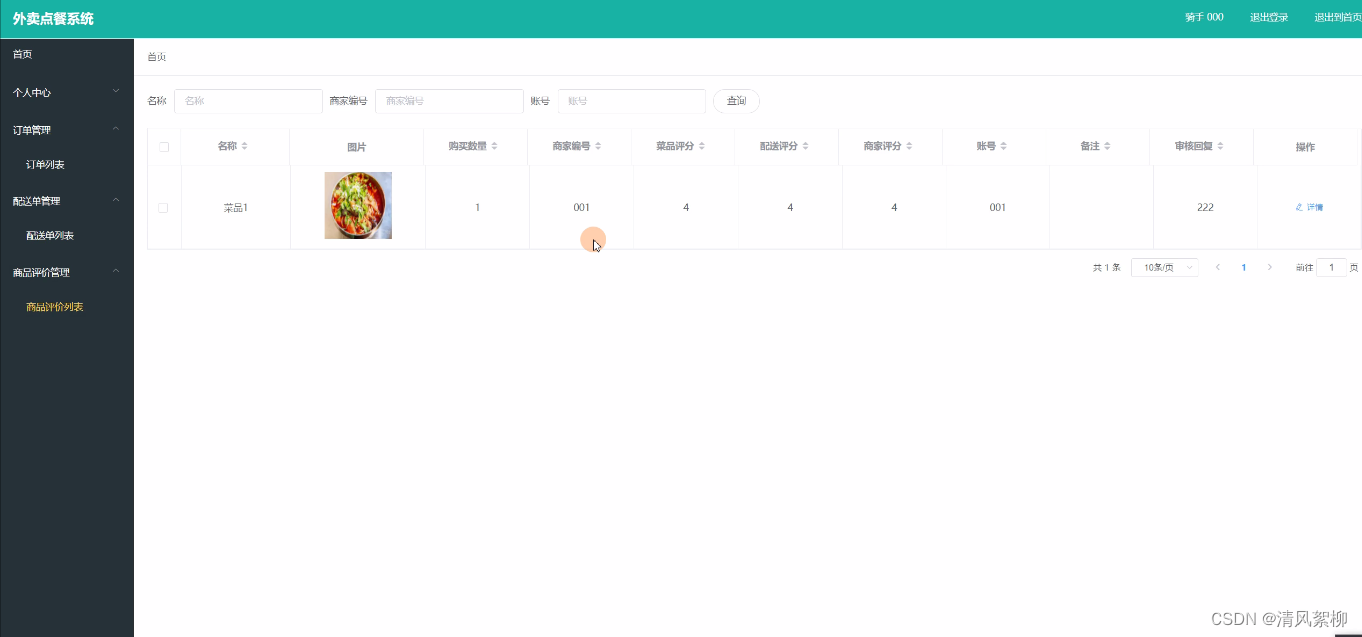
2.外卖点餐系统(Java项目 springboot)
目录 0.系统的受众说明 1.系统功能设计 2.系统结构设计 3.数据库设计 3.1实体ER图 3.2数据表 4.系统实现 4.1用户功能模块 4.2管理员功能模块 4.3商家功能模块 4.4用户前台功能模块 4.5骑手功能模块 5.相关说明 新鲜运行起来的项目:如需要源码数据库…...

Universal Thresholdizer:将多种密码学原语门限化
参考文献: [LS90] Lapidot D, Shamir A. Publicly verifiable non-interactive zero-knowledge proofs[C]//Advances in Cryptology-CRYPTO’90: Proceedings 10. Springer Berlin Heidelberg, 1991: 353-365.[Shoup00] Shoup V. Practical threshold signatures[C…...
【UE5学习笔记】编辑及运行界面:关闭眼部识别(自动曝光)
自动曝光,也就是走进一个黑暗的环境,画面会逐渐变量,以模拟人眼进入黑暗空间时瞳孔放大,进光量增加的一种真实视觉感受: 制作过程中是否关闭自动曝光,取决于游戏的性质,但是个人认为,…...

未来科技的前沿:深入探讨人工智能的进展、机器学习技术和未来趋势
文章目录 一、人工智能的定义和概述1. 人工智能的基本概念2. 人工智能的发展历史 二、技术深入:机器学习、深度学习和神经网络1. 机器学习2. 深度学习3. 神经网络 三、人工智能的主要目标和功能1. 自动化和效率提升2. 决策支持和风险管理3. 个性化服务和预测未来 本…...

3-qt综合实例-贪吃蛇的游戏程序
引言: 如题,本次实践课程主要讲解贪吃蛇游戏程序。 qt贪吃蛇项目内容: 一、功能需求 二、界面设计 各组件使用: 对象名 类 说明 Widget QWidge 主窗体 btnRank QPushButton 排行榜-按钮 groupBox QGroupBox 难…...

QGraphicsView实现简易地图12『平移与偏移』
前文链接:QGraphicsView实现简易地图11『指定层级-定位坐标』 提供地图平移与偏移功能。地图平移是指将地图的中心点更改为给定的点,即移动地图到指定位置。地图偏移是指将当前视口内的地图向上/下/左/右/进行微调,这里偏移视口宽/高的四分之…...

深入探索 Vue 中的 createVNode 与 resolveComponent
在 Vue 开发中,createVNode和resolveComponent是两个至关重要的工具,它们为我们提供了强大的能力来灵活地创建和操控组件。 一、首先,让我们深入了解一下createVNode。 这是一个用于创建虚拟节点的关键函数,通过它,我…...
【记录42】centos 7.6安装nginx教程详细教程
环境:腾讯云centos7.6 需求:安装nginx-1.24.0 1. 切入home文件 cd home 2. 创建nginx文件 mkdir nginx 3. 切入nginx文件 cd nginx 4. 下载nginx安装包 wget https://nginx.org/download/nginx-1.24.0.tar.gz 5. 解压安装包 tar -zxvf nginx-1.24.0.…...

C语言程序设计(不熟悉的点)
一、switch多路分支语句 二、条件表达式 三、循环 for循环: for循环的三个表达式不是必须的,第一个表达式之前声明过,可以不写,第三个表达式可以放在循环体里面;第二个表达式可以不写,为死循环。 空循环…...

DAO是什么?有什么用途?
DAO(Decentralized Autonomous Organization,去中心化自治组织)是一种基于区块链技术的组织形式,它没有中央管理层,而是通过智能合约和区块链上的代码来运作。DAO 的决策过程是透明的,通常由组织的成员通过…...
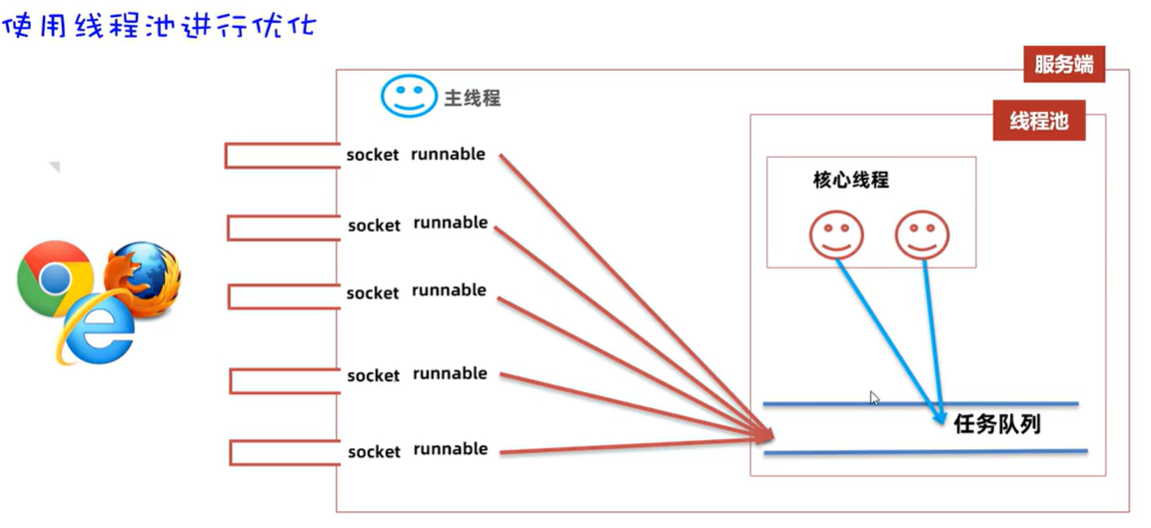
Socket学习记录
本次学习Socket的编程开发,该技术在一些通讯软件,比如说微信,QQ等有广泛应用。 网络结构 这些都是计算机网络中的内容,我们在这里简单回顾一下: UDP(User Datagram Protocol):用户数据报协议;TCP(Transmission Contr…...

黑马 - websocket搭建在线聊天室
这里写自定义目录标题 一、消息推送常见方式二、websocket 是什么?三、websocket api的介绍1、客户端 (浏览器)2、服务端api 四、实现在线聊天室1、需求2、聊天室流程分析3、消息格式4、代码实现 一、消息推送常见方式 1、轮训方式 2、SSE…...
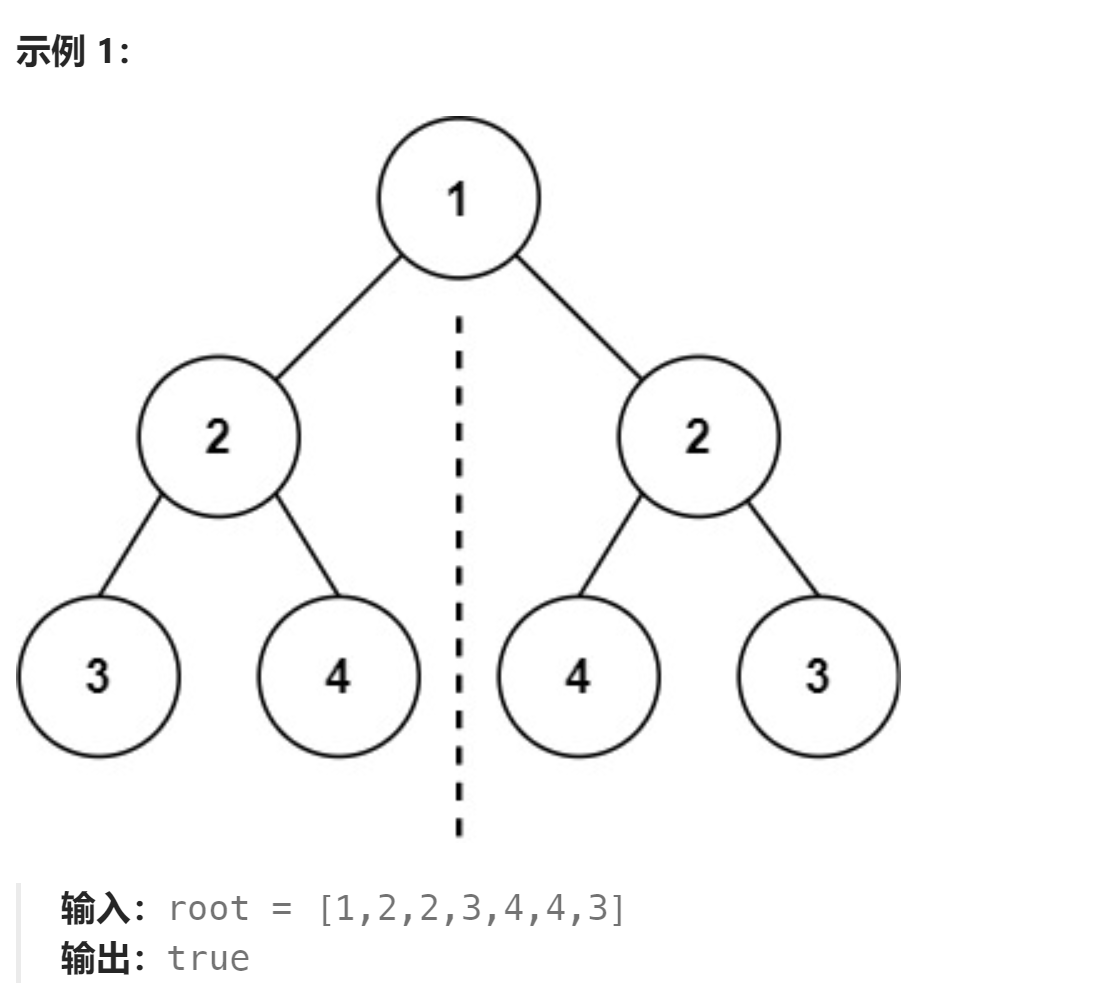
【每日力扣】543. 二叉树的直径与101. 对称二叉树
🔥 个人主页: 黑洞晓威 😀你不必等到非常厉害,才敢开始,你需要开始,才会变的非常厉害 543. 二叉树的直径 给你一棵二叉树的根节点,返回该树的 直径 。 二叉树的 直径 是指树中任意两个节点之间最长路径的…...

【linux】——日志分析
1. 日志文件 1.1 日志文件的分类 日志文件: 是用于记录Linux系统中各种运行消息的文件,相当于Linux主机的“日记". 日志文件对于诊断和解决系统中的问题很有帮助,系统一旦出现问题时及时分析日志就会“有据可查”。此外。当主机遭受攻…...
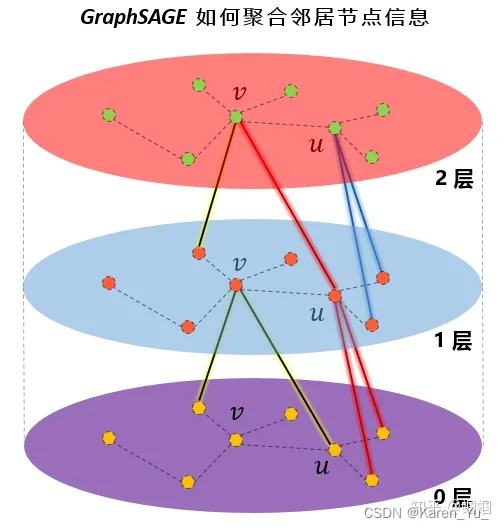
【intro】GraphSAGE
论文 https://arxiv.org/pdf/1706.02216 abstract 大图中节点的低维embedding已经被证明在各种预测任务中非常有用,然而,大多数现有的方法要求在embedding训练期间图中的所有节点都存在;这些先前的方法属于直推式(transductive)…...
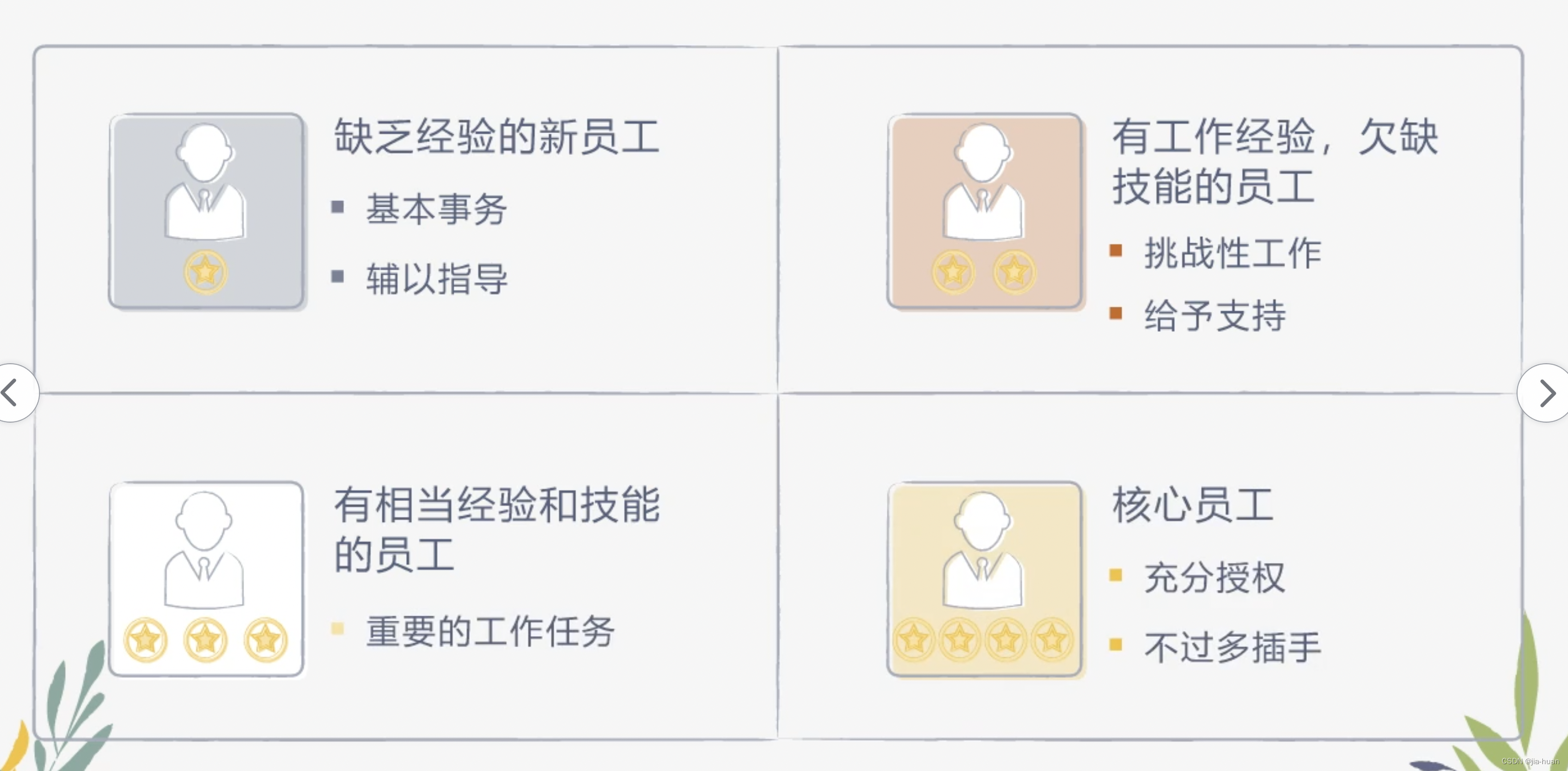
管理能力学习笔记九:授权的常见误区和如何有效授权
授权的常见误区 误区一:随意授权 管理者在授权工作时,需要依据下属的能力、经验、意愿问最自己:这项工作适合授权给Ta做吗?如果没有,可以通过哪些方法进行培训呢? 误区二:缺乏信任 心理暗示…...

第21天 反射
反射概述 想象一下,你在一个房间里边,但你看不见自己,也不知道自己是谁。这时候你面前有一个镜子,你可以通过镜子的反射来观察自己。反射就像这面镜子。它让你能够检查、分析、修改Java中的对象、类、方法等 使用情况࿱…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...

Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement
Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement 1. LAB环境2. L2公告策略2.1 部署Death Star2.2 访问服务2.3 部署L2公告策略2.4 服务宣告 3. 可视化 ARP 流量3.1 部署新服务3.2 准备可视化3.3 再次请求 4. 自动IPAM4.1 IPAM Pool4.2 …...