MongoDB学习(java版)
MongoDB概述
结构化数据库
结构化数据库是一种使用结构化查询语言(SQL)进行管理和操作的数据库,它们的数据存储方式是基于表格和列的。结构化数据库要求数据预先定义数据模式和结构,然后才能存储和查询数据。结构化数据库通常具有以下特点:
-
数据预定义:在存储数据之前,需要先定义数据结构和数据类型。这些定义通常存储在数据库的元数据中,并用于确保数据库中的数据一致性和完整性。
-
数据之间的关系:结构化数据库使用表格来存储数据,并且通常有多个表格之间的关系。通过在表格之间建立外键关系,可以在查询时轻松地检索相关数据。
-
SQL支持:结构化数据库使用SQL进行管理和查询。SQL是一种标准化的查询语言,能够使用户轻松地检索和操作数据。
-
ACID事务支持:结构化数据库支持ACID事务,确保数据的一致性和完整性。
常见的结构化数据库包括MySQL、Oracle、SQL Server等。结构化数据库主要用于事务性应用程序和数据处理应用程序,例如企业资源计划(ERP)和客户关系管理(CRM)系统。这些应用程序需要处理结构化数据,并且需要确保数据的一致性和完整性。
非结构化数据库
非结构化数据库是一种没有预定义数据结构的数据库,它们的数据存储方式是基于文档、键值对或图形的,不同的非结构化数据库使用的数据存储方式可能不同。非结构化数据库不需要事先定义数据结构,它们的数据可以动态添加和删除,非常适合存储大量复杂和多层次的数据。
非结构化数据库的特点如下:
-
数据灵活性:非结构化数据库的数据存储格式更灵活,可以存储各种类型的数据,包括文本、图像、音频、视频等。
-
高性能:非结构化数据库通常能够更快地访问和处理数据,因为它们的数据存储方式更为灵活,使得查询效率更高。
-
可扩展性:非结构化数据库通常可以更好地扩展,因为它们不需要预定义表结构。
-
没有固定查询语言:非结构化数据库没有像SQL一样的标准化查询语言,而是使用API和查询语句来访问和操作数据。
非结构化数据库可以分为几种不同的类型,包括:
-
文档数据库:文档数据库存储的是基于文档的数据,例如JSON或XML格式。文档数据库的查询通常是基于键值对的。常见的文档数据库包括MongoDB、Couchbase、RavenDB等。
-
键值数据库:键值数据库存储的是基于键值对的数据,通常用于缓存和存储大量的简单数据。常见的键值数据库包括Redis、Amazon DynamoDB、Riak等。
-
列式数据库:列式数据库将数据存储在列中,而不是行中,这使得它们能够快速地查询和分析大量数据。常见的列式数据库包括Apache Cassandra、HBase等。
-
图形数据库:图形数据库存储的是基于图形结构的数据,通常用于存储和查询关系和连接。常见的图形数据库包括Neo4j、ArangoDB等。
以下是常见的几种 NoSQL 数据库之间的对比:
特性 MongoDB Cassandra Redis Couchbase HBase 数据模型 文档型 列族型 键值型 文档型 列族型 支持 ACID 事务 支持 仅在单独的分区上支持 不支持 支持 不支持 数据分布 支持分片 支持分布式集群 不支持分片 支持分片 支持分布式集群 备份与恢复 支持备份和恢复 支持增量备份和快照 支持备份和恢复 支持备份和恢复 支持备份和恢复 索引 支持二级索引 支持二级索引 支持多种索引 支持二级索引 支持二级索引 适合场景 大数据量、高性能读写 分布式、高吞吐量写入 内存缓存、高速读写 强一致性、高可用性 适合实时读写大规模数据
结构化数据库和非结构化数据库
以下是结构化数据库和非结构化数据库的对比表格:
| 特性 | 结构化数据库 | 非结构化数据库 |
|---|---|---|
| 数据模型 | 关系型模型,基于表格的结构 | 非关系型模型,没有固定的结构,可以是文档、键值、图形等 |
| 数据存储 | 通常使用 SQL 语言存储和检索数据 | 不使用 SQL 语言存储和检索数据 |
| 数据规模 | 适合处理小规模、高度结构化的数据 | 适合处理大规模、非结构化的数据 |
| 数据一致性 | 强一致性,可以保证数据的完整性和准确性 | 最终一致性,数据的一致性和准确性不能保证 |
| 数据处理 | 常用于在线事务处理(OLTP)场景 | 常用于在线分析处理(OLAP)场景 |
| 可扩展性 | 通常采用垂直扩展(增加更强大的硬件) | 通常采用水平扩展(增加更多的节点) |
| 代表性数据库 | MySQL、Oracle、SQL Server | MongoDB、Cassandra、Redis |
MongoDB介绍
MongoDB是一种流行的文档型数据库管理系统,它是一个开源、跨平台的数据库系统,支持在分布式集群上进行横向扩展。MongoDB使用类似于JSON的BSON(二进制JSON)格式来存储数据,它支持复杂的查询和索引,可以处理大量数据并具有高可用性和自动分片等特性。MongoDB的灵活性和可扩展性使得它在各种不同的应用场景中被广泛使用,如Web应用程序、大数据、物联网等。
MongoDB的主要特点如下:
- 数据模型灵活:MongoDB使用文档型数据库模型,可以存储各种类型的数据,如文本、图像、视频、音频等,且可以随时添加、删除、修改数据结构,极大地提高了开发效率。
- 横向扩展性强:MongoDB支持在分布式集群上进行横向扩展,通过将数据和负载分散到多台服务器上,提高了系统的可用性和吞吐量。
- 高性能:MongoDB通过内存映射和其他技术实现了高效的数据访问和查询,能够快速地处理大量数据。
- 高可用性:MongoDB通过副本集和分片技术实现了高可用性和容错性,即使某台服务器出现故障,整个系统也能够继续正常运行。
- 开源和社区支持:MongoDB是一个完全开源的项目,拥有庞大的社区支持和开发者基础,使得它能够快速地适应新的技术和应用场景。
安装与配置
下载安装包
MongoDB官网的下载页面上下载本地版本的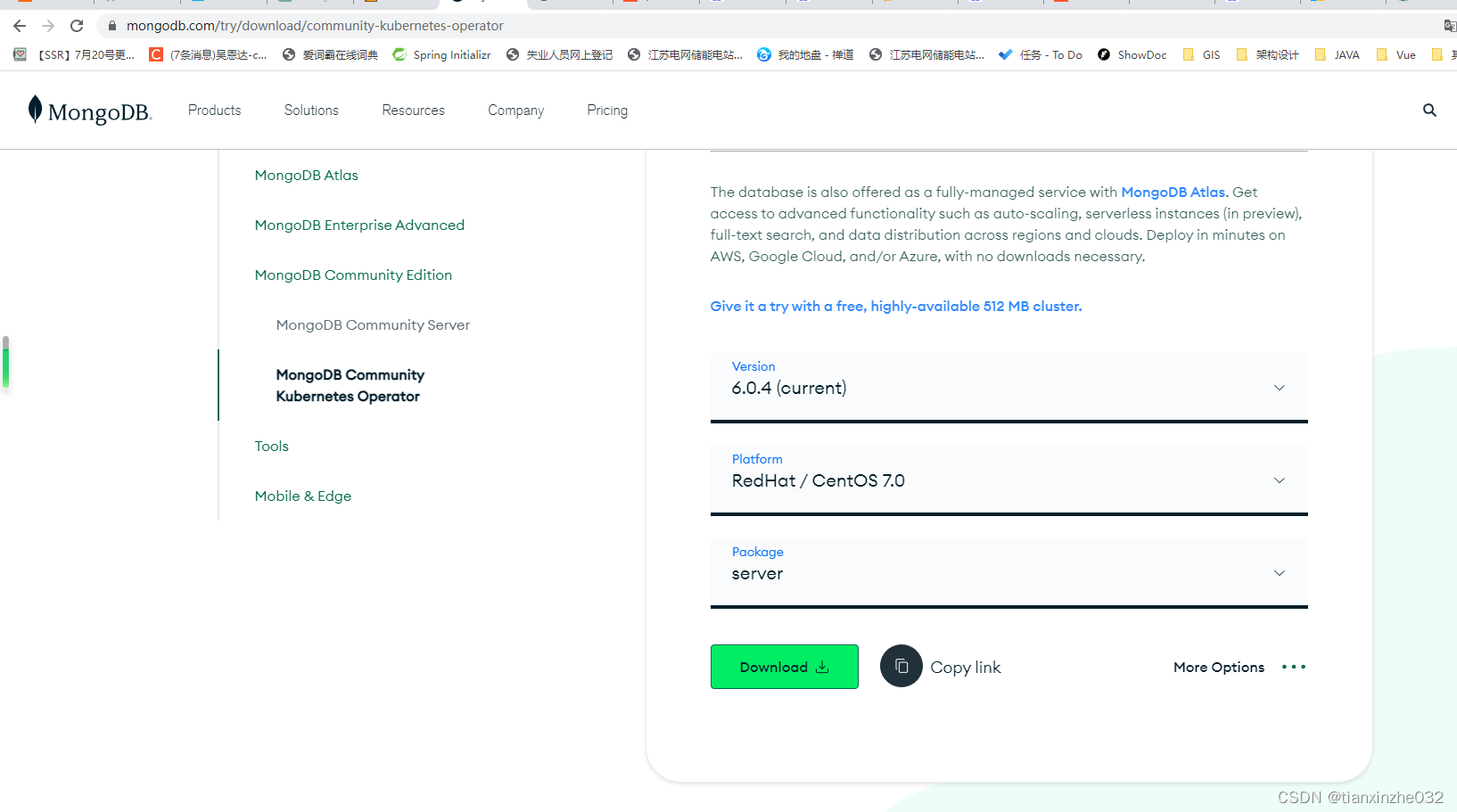
MongoDB。以下是下载MongoDB本地版本的步骤:
打开MongoDB官网https://www.mongodb.com/try/download/community 点击“Download”进入下载页面。
-
在下载页面中,选择适合的操作系统(如Windows、macOS或Linux)和MongoDB的版本号。如果不确定应该选择哪个版本,可以选择最新版本。
-
选择需要下载的版本后,会看到两个可用的下载选项:MSI和ZIP。如果使用的是Windows操作系统,建议下载MSI版本。如果使用的是Linux或macOS操作系统,建议下载ZIP版本。
安装
Windows
-
msi
-
双击安装包
mongodb-windows-x86_64-4.4.4-signed.msi进行安装,根据提示完成安装过程。 -
将MongoDB的安装目录添加到系统环境变量中。默认情况下,MongoDB会被安装到
C:\Program Files\MongoDB\Server\<version>目录下,其中<version>是您所安装的MongoDB版本号。您可以按以下步骤将MongoDB的安装目录添加到系统环境变量中:a. 右键单击“此电脑”(或“我的电脑”),选择“属性”。
b. 点击“高级系统设置”。
c. 在“系统属性”窗口中,点击“环境变量”。
d. 在“环境变量”窗口中,找到“系统变量”下的“Path”变量,双击打开。
e. 在“编辑环境变量”窗口中,点击“新建”。
f. 输入MongoDB的安装路径,例如
C:\Program Files\MongoDB\Server\<version>\bin,然后点击“确定”。 -
打开命令提示符,输入以下命令以启动MongoDB:
mongod --dbpath C:\mongodb\data\db其中,
--dbpath参数指定MongoDB数据文件的存储路径。如果未指定该参数,则MongoDB会默认使用C:\data\db目录作为数据文件存储路径。 -
-
zip
-
下载MongoDB的Zip格式包,例如
mongodb-win32-x86_64-4.4.4.zip。 -
解压MongoDB的Zip格式包到一个目录,例如
C:\mongodb。 -
将MongoDB的安装目录添加到系统环境变量中。您可以按以下步骤将MongoDB的安装目录添加到系统环境变量中:
a. 右键单击“此电脑”(或“我的电脑”),选择“属性”。
b. 点击“高级系统设置”。
c. 在“系统属性”窗口中,点击“环境变量”。
d. 在“环境变量”窗口中,找到“系统变量”下的“Path”变量,双击打开。
e. 在“编辑环境变量”窗口中,点击“新建”。
f. 输入MongoDB的安装路径,例如
C:\mongodb\bin,然后点击“确定”。 -
打开命令提示符,输入以下命令以启动MongoDB:
-
mongod --dbpath C:\mongodb\data\db
其中,--dbpath参数指定MongoDB数据文件的存储路径。如果未指定该参数,则MongoDB会默认使用C:\data\db目录作为数据文件存储路径。
Linux
- 打开终端,并切换到包含MongoDB压缩包的目录。
- 使用以下命令解压MongoDB压缩包:
tar -zxvf mongodb-linux-x86_64-<version>.tgz
其中<version>是您下载的MongoDB版本号。
- 将解压后的文件夹移动到指定位置。例如,将MongoDB文件夹移动到
/usr/local/目录下,使用以下命令:
sudo mv mongodb-linux-x86_64-<version> /usr/local/mongodb
- 配置环境变量。打开
~/.bashrc或~/.bash_profile文件,并添加以下行:
export PATH=/usr/local/mongodb/bin:$PATH
- 保存并关闭文件,然后使用以下命令使环境变量生效:
source ~/.bashrc
- 启动MongoDB。使用以下命令启动MongoDB:
mongod --dbpath \home\data\mongodb
Mongodb 配置项
下面是一份mongod.conf的示例代码,包括了各个配置项的详细说明:
yamlCopy code# mongod.conf# 系统日志配置
systemLog:destination: file # 日志输出到文件path: /var/log/mongodb/mongod.log # 日志文件路径logAppend: true # 采用追加模式quiet: false # 关闭安静模式,开启详细日志输出# 网络配置
net:port: 27017 # 监听的端口号bindIp: 127.0.0.1 # 监听的IP地址,默认为所有可用IP地址# 存储引擎配置
storage:dbPath: /var/lib/mongodb # 数据文件存储路径engine: wiredTiger # 存储引擎# 进程管理配置
processManagement:fork: true # 是否在后台运行# 复制集配置
replication:replSetName: rs0 # 复制集名称# 安全认证配置
security:authorization: enabled # 启用认证机制
在这个示例中,我们配置了系统日志、网络、存储引擎、进程管理、复制集和安全认证等多个方面的配置项。具体说明如下:
- 系统日志配置:将日志输出到文件,并指定了日志文件的存储路径。我们采用追加模式,并关闭了安静模式,以便输出详细的日志信息。
- 网络配置:指定了MongoDB监听的端口号为27017,并默认监听本地地址127.0.0.1。
- 存储引擎配置:指定了数据文件的存储路径为
/var/lib/mongodb,并使用了wiredTiger存储引擎。 - 进程管理配置:将MongoDB配置为后台运行。
- 复制集配置:指定了复制集的名称为
rs0。 - 安全认证配置:启用了认证机制,以增强MongoDB的安全性。
具体的配置项根据实际需求进行修改。修改mongod.conf文件后,需要重启MongoDB才能使新的配置生效。
数据结构
数据库(Database)
数据库(Database)是 MongoDB 的最高级别的数据存储单位,可以包含多个集合(Collection),类似于关系型数据库中的数据库(Database)。
| 数据结构 | 描述 |
|---|---|
| 集合(Collection) | 每个数据库可以包含多个集合,类似Mysql的表 |
| 文档(Document) | 每个集合包含多个文档,文档是 MongoDB 的最小数据单元 |
| 字段(Field) | 每个文档包含多个字段,类似于关系型数据库中的列 |
-
集合(Collection):
在 MongoDB 中,集合(Collection)是一组文档(Document)的无序集合。与关系型数据库中的表(Table)相比,集合不需要提前定义结构(Schema),也不需要定义表之间的关系。在集合中可以存储各种不同结构的文档,这使得 MongoDB 数据模型非常灵活,适用于各种类型的应用场景。
MongoDB 中的集合类似于关系型数据库中的表,但有以下区别:
- 集合不需要提前定义结构,文档可以有不同的字段和值。
- 集合是动态的,即当第一个文档插入时自动创建集合,不需要提前创建。
- 集合中的文档不需要有相同的字段,也不需要遵循相同的数据类型。
- 集合是基于文档的,而不是基于行的。
-
文档(Document):
文档(Document)是数据的基本单元,类似于关系型数据库中的行(Row)。文档是一个由字段和值组成的键值对(Key-Value Pair),可以存储各种不同的数据类型,例如字符串、整数、浮点数、布尔值、数组、日期等等。
与关系型数据库中的行相比,文档的结构非常灵活,可以随时添加或删除字段,也可以包含嵌套的文档和数组。这种灵活性使得 MongoDB 在处理非结构化数据时非常方便。
-
字段(Field):
在 MongoDB 中,一个文档(Document)就是一个数据记录,每个文档都由一个或多个字段(Field)组成。字段是文档中的最小单位,每个字段都包含一个键值对,键是字符串类型的字段名称,值可以是任何 BSON 数据类型,例如字符串、数字、布尔值、数组、日期时间等。
以下是 MongoDB 支持的常见数据类型以及它们的描述:
数据类型 描述 String 存储文本数据,最大长度为 16 MB Integer 存储整数,包括 32 位整数和 64 位整数 Double 存储浮点数 Boolean 存储布尔值 Object 存储嵌套文档 Array 存储数组 Date 存储日期和时间 ObjectId 存储文档的唯一标识符 Binary 存储二进制数据 Regular Expression 存储正则表达式 除了上述数据类型外,MongoDB 还支持一些高级数据类型,例如 GeoJSON、MinKey、MaxKey 等。这些数据类型在特定场景下会非常有用。
在 MongoDB 中,文档的字段类型是动态的,也就是说,在同一个集合中,不同的文档可以拥有不同的字段,而且这些字段的类型可以不同。这种灵活性使得 MongoDB 非常适合存储非结构化数据和半结构化数据。同时,这也带来了一些挑战,例如需要进行数据验证和数据一致性的管理。
基本操作
Shell操作
MongoDB 4.4版本之前使用mongo来操作数据库,后期版本使用mongosh 。
mongosh 是 MongoDB 官方推出的命令行工具,支持 MongoDB 4.4 及更高版本,提供了更好的交互体验和更多的功能,例如语法高亮、自动完成、内置实用程序等。
mongosh下载地址https://www.mongodb.com/try/download/shell,下载完成之后解压后,保存到上面配置的安装目录下,或者按照自己的想法放到任意位置。
- 连接 MongoDB 数据库
使用 mongosh 命令行工具连接 MongoDB 数据库,格式为:
mongosh mongodb://<username>:<password>@<host>/<database>
其中:
<username>:用户名<password>:密码<host>:主机名或 IP 地址<database>:要连接的数据库名称
例如,连接本地 MongoDB 数据库可以使用以下命令:
mongosh mongodb://localhost/test
#或者直接使用
mongosh
- 查看所有数据库
使用以下命令可以查看 MongoDB 中的所有数据库:
show databases
# 或者
show dbs
- 切换数据库
使用以下命令可以切换当前数据库:
use <database>
例如,切换到名为 mydb 的数据库:
use mydb
- 查看当前数据库中的所有集合
使用以下命令可以查看当前数据库中的所有集合:
show collections
- 插入数据insertOne / insertMany
使用以下命令可以向集合中插入一条文档:
db.<collection>.insertOne(<document>)
其中:
<collection>:集合名称<document>:要插入的文档数据,格式为 JSON 对象
例如,向名为 users 的集合中插入一条文档:
db.users.insertOne({ name: 'Alice', age: 30 })
在 mongosh 中进行批量插入数据可以使用 insertMany() 方法。例如,插入多个文档到 test 数据库中的 students 集合中:
db.users.insertMany([{ name: "Alice", age: 20, gender: "female" },{ name: "Bob", age: 21, gender: "male" },{ name: "Charlie", age: 19, gender: "male" }
])
上述代码将会向 users集合中插入三个文档,每个文档都包含 name、age 和 gender 三个字段。insertMany() 方法可以接受一个包含多个文档的数组作为参数,并且会返回一个包含插入结果的对象。
{acknowledged: true,insertedIds: {'0': ObjectId("6405aa49d335c2829403f6a2"),'1': ObjectId("6405aa49d335c2829403f6a3"),'2': ObjectId("6405aa49d335c2829403f6a4")}
}
- 查询数据
使用以下命令可以查询集合中的文档:
db.<collection>.find(<query>)
其中:
<collection>:集合名称<query>:查询条件,格式为 JSON 对象
例如,查询名为 Alice 的文档:
db.users.find({ name: 'Alice' })
db.users.find({ })
[{ _id: ObjectId("6405a63ed335c2829403f6a1"), name: 'Alice', age: 30 },{_id: ObjectId("6405aa49d335c2829403f6a2"),name: 'Alice',age: 20,gender: 'female'},{_id: ObjectId("6405aa49d335c2829403f6a3"),name: 'Bob',age: 21,gender: 'male'},{_id: ObjectId("6405aa49d335c2829403f6a4"),name: 'Charlie',age: 19,gender: 'male'}
]
- 更新数据updateOne/updataMany
使用以下命令可以更新集合中的文档:
updateOne() 是 MongoDB 提供的更新单个文档的方法。
语法:
db.collection.updateOne(<filter>,<update>,{upsert: <boolean>,writeConcern: <document>,collation: <document>}
)
参数说明:
-
<filter>:查询需要更新的文档的筛选条件。常用的筛选符号如下:
$eq: 匹配等于指定值的文档。$ne: 匹配不等于指定值的文档。$gt: 匹配大于指定值的文档。$gte: 匹配大于或等于指定值的文档。$lt: 匹配小于指定值的文档。$lte: 匹配小于或等于指定值的文档。$in: 匹配指定数组中任意值的文档。$nin: 不匹配指定数组中任意值的文档。$and: 逻辑与,同时满足多个条件。$or: 逻辑或,满足多个条件之一。$not: 反转筛选条件,匹配不符合条件的文档。$nor: 逻辑非或,不满足多个条件之一。
-
<update>:指定如何更新文档。 -
upsert:可选,如果设置为true,当查询条件的文档不存在时,会创建一个新文档。默认为false。 -
writeConcern:可选,指定写入操作的写入安全性。 -
collation:可选,指定语言特定的比较规则。
例如,将名为 Alice 的文档的年龄更新为 31:
db.users.updateOne({ name: 'Alice' }, { $set: { age: 31 } })
updateMany()是MongoDB用于更新多个文档的方法,可以将一个或多个文档的字段值更新为指定的值,或者使用更新操作符进行更新。
语法:
db.collection.updateMany(<filter>,<update>,{upsert: <boolean>,writeConcern: <document>,collation: <document>,arrayFilters: [ <filterdocument1>, ... ]}
)
参数说明:
-
filter:指定更新文档的条件,与find方法的query参数类似。 -
update:指定要更新的文档字段及值,可以使用更新操作符。 -
upsert:可选,如果设置为true,表示如果没有符合条件的文档则插入新的文档,默认为false。 -
writeConcern:可选,指定写入操作的安全级别。 -
collation:可选,指定对文档进行排序、大小写不敏感的比较和字符映射的规则。 -
arrayFilters:可选,如果更新的文档中包含嵌套数组,则使用该参数指定更新哪些子文档。update 更新操作符:
$set:用于指定更新字段及其值。$unset:用于从文档中删除一个或多个字段。$inc:用于增加或减少一个数字型字段的值。$push:用于将一个值添加到数组字段中。$addToSet:用于将一个唯一的值添加到数组字段中。$pop:用于从数组字段中删除第一个或最后一个元素。$pull:用于从数组字段中删除指定的元素。$rename:用于重命名一个字段。
示例:
将集合users中年龄为25岁的用户的姓名改为“Tom”:
db.users.updateMany({ age: 25 },{ $set: { name: "Tom" } }
)
将集合users中年龄为25岁的用户的年龄加1:
db.users.updateMany({ age: 25 },{ $inc: { age: 1 } }
)
将集合users中所有用户的年龄减1:
db.users.updateMany({},{ $inc: { age: -1 } }
)
- 删除数据
deleteOne(filter, options) 方法删除集合中匹配过滤条件的单个文档。如果多个文档匹配,只删除第一个匹配的文档。
db.collection.deleteOne(<filter>,{writeConcern: <document>,collation: <document>}
)
<filter>:(可选)删除条件,表示要删除的文档。writeConcern:(可选)写入操作的写入安全性级别。collation:(可选)指定要用于字符串比较的规则。
示例:
db.users.deleteOne({name: "John"})
deleteMany(filter, options) 方法从集合中删除匹配过滤条件的多个文档。
db.collection.deleteMany(<filter>,{writeConcern: <document>,collation: <document>}
)
<filter>:(可选)删除条件,表示要删除的文档。writeConcern:(可选)写入操作的写入安全性级别。collation:(可选)指定要用于字符串比较的规则。
示例:
db.users.deleteMany({age: {$lt: 18}})
在进行删除操作时,需要小心,因为它是永久性操作,一旦删除,数据将无法恢复。在删除之前,建议创建数据备份或在操作之前进行确认。
Java操作(MongoDB Java Driver)
Java 可以通过 MongoDB 官方提供的 Java 驱动程序(MongoDB Java Driver)来操作 MongoDB 数据库。
导入MongoDB Java Driver库文件
<!-- Maven依赖 -->
<dependency><groupId>org.mongodb</groupId><artifactId>mongodb-driver-sync</artifactId><version>4.7.1</version>
</dependency>
import com.mongodb.MongoClient;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;public class MongoDBExample {public static void main(String[] args) {// 创建 MongoClient 对象,并连接到 MongoDB 服务器MongoClient mongoClient = MongoClients.create("mongodb://localhost:27017");// 选择要操作的数据库MongoDatabase database = mongoClient.getDatabase("mydb");// 选择要操作的集合MongoCollection<Document> collection = database.getCollection("mycollection");// 插入文档Document doc1 = new Document("name", "Alice").append("age", 25);Document doc2 = new Document("name", "Bob").append("age", 30);collection.insertMany(Arrays.asList(doc1, doc2));// 关闭连接mongoClient.close();}}
这个程序会连接到本地 MongoDB 服务器,并在名为 “mydb” 的数据库中的 “mycollection” 集合中插入两个文档,其中一个文档包含 “name” 和 “age” 两个字段,另一个文档也包含这两个字段。然后关闭连接。
- 插入文档
Document doc = new Document("name", "John Doe").append("age", 30).append("email", "johndoe@example.com");
collection.insertOne(doc);
- 查询文档
Document result = collection.find(Filters.eq("name", "John Doe")).first();
Filters类提供了很多静态方法,这些方法可以用来创建各种查询条件,如相等、不相等、小于、大于等比较运算符、逻辑运算符(与、或、非)等。
下面是一些常用的Filters静态方法:
-
eq(String fieldName, Object value):相等比较,返回符合指定字段等于指定值的文档。 -
ne(String fieldName, Object value):不等比较,返回符合指定字段不等于指定值的文档。 -
gt(String fieldName, Object value):大于比较,返回符合指定字段大于指定值的文档。 -
gte(String fieldName, Object value):大于等于比较,返回符合指定字段大于等于指定值的文档。 -
lt(String fieldName, Object value):小于比较,返回符合指定字段小于指定值的文档。 -
lte(String fieldName, Object value):小于等于比较,返回符合指定字段小于等于指定值的文档。 -
and(Bson... filters):逻辑与运算符,返回符合所有指定查询条件的文档。 -
or(Bson... filters):逻辑或运算符,返回符合任意指定查询条件的文档。 -
not(Bson filter):逻辑非运算符,返回符合指定查询条件取反后的文档。 -
regex():正则查询,用于在查询中匹配指定的正则表达式。
Bson query = Filters.and(Filters.eq("name", "John"),Filters.gt("age", 18)
);
// Execute the query
FindIterable<Document> results = collection.find(query);
这个查询将返回所有 name 字段等于 “John” 且 age 字段大于 18 的文档。
- 更新文档
collection.updateOne(Filters.eq("name", "John Doe"), new Document("$set", new Document("age", 31)));
- 删除文档
collection.deleteOne(Filters.eq("name", "John Doe"));
- 导出文本
FileWriter writer = new FileWriter("d:\\output.txt");
MongoCursor<Document> cursor = collection.find().projection(Projections.exclude("_id" )).cursor();
JsonWriterSettings settings = JsonWriterSettings.builder().indent(false).build();
while (cursor.hasNext()) {Document document = cursor.next();System.out.println(document.toJson(settings));writer.write(document.toJson() + "\n");
}
writer.close();
Projections是MongoDB驱动程序中的一个类,用于在查询结果中只返回指定的字段,而不是返回整个文档。
常用的Projections方法及其含义如下:
include:指定返回结果中需要包含哪些字段。如果还需要包含_id字段,则需要使用excludeId()方法。exclude:指定返回结果中不需要包含哪些字段。excludeId:指定返回结果中不需要包含_id字段。elemMatch:指定返回结果中数组类型的字段只返回满足条件的元素,条件使用Filters.eq、Filters.gt、Filters.lt等方法构建。
下面是一个使用Projections进行投影查询的例子:
MongoCollection<Document> collection = database.getCollection("mycollection");
Bson filter = Filters.eq("age", 30);
Bson projection = Projections.fields(Projections.include("name", "age"), Projections.excludeId());
FindIterable<Document> result = collection.find(filter).projection(projection);
在上述代码中,通过Projections.fields()方法指定了需要返回的字段(name和age),并且排除了_id字段。最后使用projection()方法将该投影查询应用于find()方法的结果中。
JsonWriterSettings 是 MongoDB Java Driver 中的一个类,用于配置 JsonWriter 的行为。JsonWriter 是将 MongoDB 文档序列化为 JSON 格式的类。在 MongoDB 4.4 以前的版本中,JsonWriter 与 BsonWriter 是分开的,分别用于序列化为 JSON 格式和 BSON 格式。而在 MongoDB 4.4 以后的版本中,它们被合并为一个类,名为 BsonDocumentWriter,并且支持将文档序列化为多种格式。
以下是 JsonWriterSettings 中一些重要的属性:
indent:是否缩进输出,默认为 false。indentCharacters:缩进使用的字符,默认为空格。newLineCharacters:换行使用的字符,默认为系统默认的换行符。maxLength:JSON 字符串最大长度,默认为 0,表示不限制长度。escapeNonAsciiCharacters:是否将非 ASCII 字符进行转义,默认为 false。dateTimeConverter:日期转换器,默认为DefaultDateTimeConverter,可以通过实现DateTimeConverter接口来实现自定义的日期转换。outputMode:输出模式,默认为STRICT,可以选择RELAXED或SHELL模式。
使用 JsonWriterSettings,可以对 MongoDB 文档的序列化行为进行灵活的配置,以满足不同的需求。
待续。。。
Spring boot 操作
高级操作
数据聚合操作
索引的创建与使用
数据备份与恢复
安全性配置
实际应用场景
社交网络应用
物联网应用
数据存储与查询
日志分析
相关文章:
MongoDB学习(java版)
MongoDB概述 结构化数据库 结构化数据库是一种使用结构化查询语言(SQL)进行管理和操作的数据库,它们的数据存储方式是基于表格和列的。结构化数据库要求数据预先定义数据模式和结构,然后才能存储和查询数据。结构化数据库通常…...

RK3568平台开发系列讲解(显示篇)什么是DRM
🚀返回专栏总目录 文章目录 一、DRM介绍二、DRM与framebuffer的区别沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇文章将介绍什么是DRM。 一、DRM介绍 DRM 是 Linux 目前主流的图形显示框架,相比FB架构,DRM更能适应当前日益更新的显示硬件。 比如FB原生不支…...

Python蓝桥杯训练:基本数据结构 [二叉树] 上
Python蓝桥杯训练:基本数据结构 [二叉树] 上 文章目录Python蓝桥杯训练:基本数据结构 [二叉树] 上一、前言二、有关二叉树理论基础1、二叉树的基本定义2、二叉树的常见类型3、二叉树的遍历方式三、有关二叉树的层序遍历的题目1、[二叉树的层序遍历](http…...
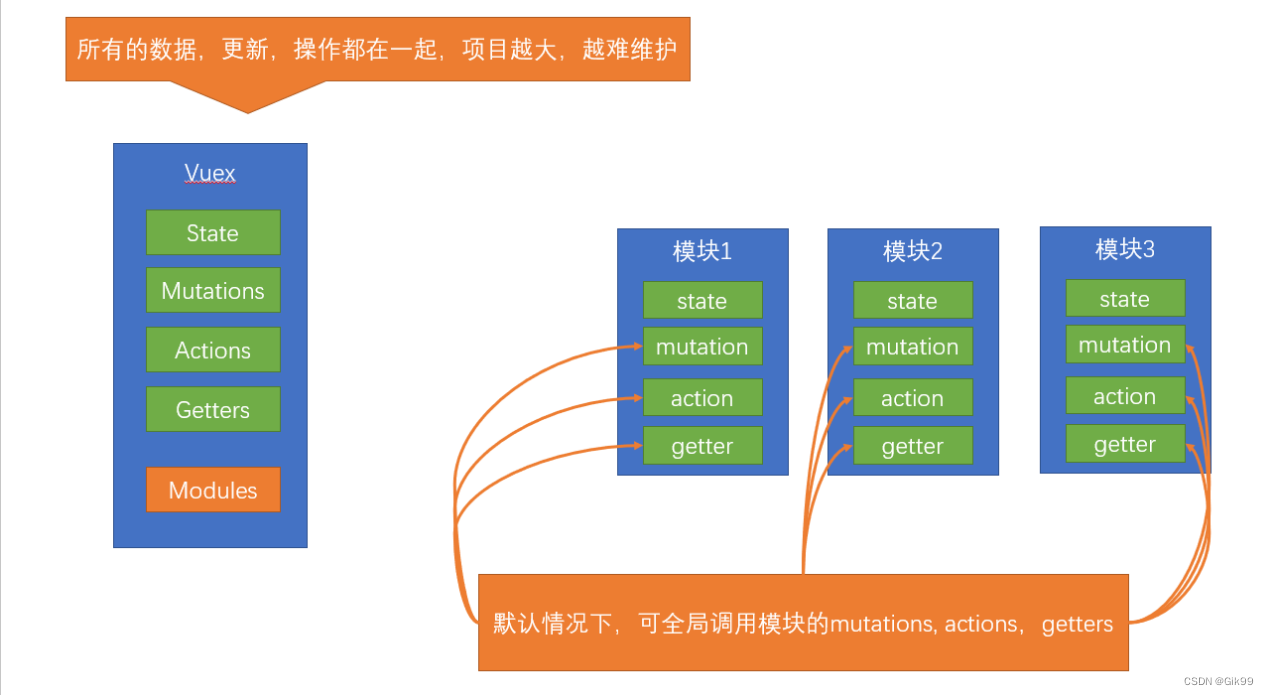
vuex基础之初始化功能、state、mutations、getters、模块化module的使用
vuex基础之初始化功能、state、mutations、getters、模块化module的使用一、Vuex的介绍二、初始化功能三、state3.1 定义state3.2 获取state3.2.1 原始形式获取3.2.2 辅助函数获取(mapState)四、mutations4.1 定义mutations4.2 调用mutations4.2.1 原始形式调用($store)4.2.2 辅…...

WebSphere中间件漏洞总结
WebSphere中间件漏洞总结 一、WebSphere简介 WebSphere为SOA(面向服务架构)环境提供软件,以实现动态的、互联的业务流程,为所有业务情形提供高度有效的应用程序基础架构。WebSphere是IBM的应用程序和集成软件平台,包含所有必要的中间件基础架构(包括服务器、服务和工具)…...

Unity之ASE实现影魔灵魂收集特效
前言 我们今天来实现一下Dota中的影魔死亡后,灵魂收集的特效。效果如下: 实现原理 1.先添加一张FlowMap图,这张图的UV是根据默认UV图,用PS按照我们希望的扭曲方向修改的如下图所示: 2.通过FlowMap图,我…...

半入耳式耳机运动会不会掉、佩戴超稳固的运动耳机推荐
现在越来越多的人开始意识到运动的重要性,用运动给身体增加一道“防护墙”是最好的生活方式了,不过,日复一日做着几乎相同的动作,难免索然无味,所以很多人都会选择在运动时戴上耳机听歌解闷,这时候也有不少…...
使用Tensorflow完成一个简单的手写数字识别
Tensorflow中文手册 介绍TensorFlow_w3cschool 模型结构图: 首先明确模型的输入及输出(先不考虑batch) 输入:一张手写数字图(28x28x1像素矩阵) 1是通道数 输出:预测的数字(1x10的one…...

OpenGL三种向着色器传递数据的方法 attributes,uniform,texture以及中间产物
(1)属性,使在顶点着色器中使用的变量,用于描述顶点的属性,如位置、颜色、法向量等,attributes通常用于描述每个顶点的属性,因此在顶点缓冲对象中存储,渲染的时候,openGL会…...

详解package.json和package-lock
详解package.json和package-lockpackage.json和package-lock.json作用首先要明确一点,package.json不会自动生成,需要我们使用 npm init 创建。package-lock.json是自动生成的,我们使用 npm install 安装包后就会自动生成。在我们执行 npm in…...

02-CSS
一、emmet语法1、简介Emmet语法的前身是Zen coding,它使用缩写,来提高html/css的编写速度, Vscode内部已经集成该语法。快速生成HTML结构语法快速生成CSS样式语法2、快速生成HTML结构语法生成标签 直接输入标签名 按tab键即可 比如 div 然后tab 键, 就可以生成 <…...

JavaScript 中的类型转换机制以及==和===的区别
目录一、概述二、显示转换Number()parseInt()String()Boolean()三、隐式转换自动转换成字符串自动转换成数值四、 和 区别1、等于操作符2、全等操作符3、区别小结一、概述 我们知道,JS中有六种简单数据类型:undefined、null、boolean、string、number、…...
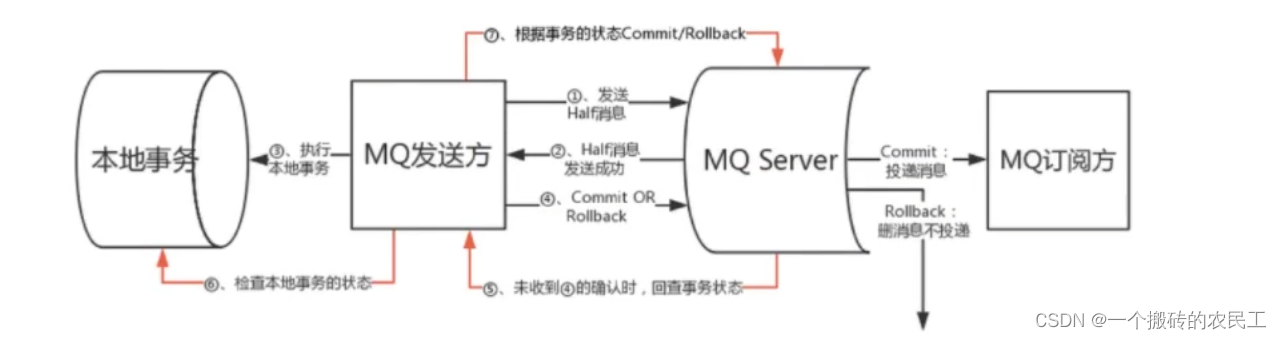
RocketMQ基础篇(一)
目录一、发送消息类型1、同步消息2、异步消息3、单向消息4、顺序消费5、延迟消费二、消费模式1、集群模式2、广播模式3、消费模式扩展4、如何配置三、其他用法1、事务消息2、过滤消息1)Tag过滤2)SQL方式过滤源码放到了GitHub仓库上,地址 http…...

Android前沿技术—gradle中的build script详解
build.gradle是gradle中非常重要的一个文件,因为它描述了gradle中可以运行的任务,今天本文将会带大家体验一下如何创建一个build.gradle文件和如何编写其中的内容。 project和task gradle是一个构建工具,所谓构建工具就是通过既定的各种规则…...

深入浅出PaddlePaddle函数——paddle.zeros_like
分类目录:《深入浅出PaddlePaddle函数》总目录 相关文章: 深入浅出PaddlePaddle函数——paddle.Tensor 深入浅出PaddlePaddle函数——paddle.ones 深入浅出PaddlePaddle函数——paddle.zeros 深入浅出PaddlePaddle函数——paddle.full 深入浅出Padd…...

物料-零部件分类属性
离散制造业的研发、生产跟产品零部件紧密联系在一起,从企业业务流程来说零部件涉及研发、采购、仓储、生产、质量、售后和配件等多个部门,为了更好地管理零部件,下面我们一起来看看零部件概念及分类。 1、按行业属性分类 (1&…...

TypeError: cannot pickle ‘module‘ object
创建python对象时报错: TypeError: cannot pickle module object 原因: 很大可能是类成员错误的使用了第三方包(别名)等,具体排查方法可参考: import redisimport pickle from pprint import pformat as …...
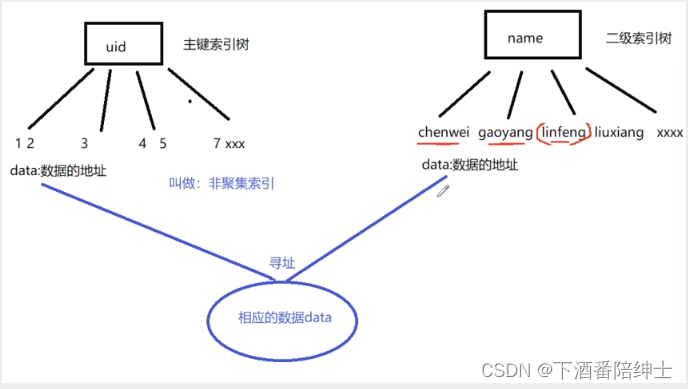
[MySQL索引]3.索引的底层原理(二)
索引的底层原理(二)InnoDB的主键和二级/辅助索引树(涉及回表)MyISAM存储引擎的主键和二级索引树InnoDB的主键和二级/辅助索引树(涉及回表) 看下面这张student数据库表: 场景一:uid…...

JavaScript混淆——逆向思维的艺术
在本文中我们将介绍三种常见的JavaScript混淆技术。 1.混合名称 通过将函数名称和变量名混合使用,我们可以使代码更难读。下面是一个使用名称混合的JavaScript函数。 function c(a){var b[2,4,8,a],db[0]b[1]b[2]b[3],ed""a;return e}混合名称技术通过…...
数据库管理-第六十期 监听(20230309)
数据库管理 2023-03-09第六十期期 监听1 无法访问2 监听配置3 问题复现与解决4 静态监听5 记不住配置咋整总结第六十期期 监听 不知不觉又来到了一个整10期数,我承认上一期有很大的划水的。。。嫌疑吧,本期内容是从帮群友解决ADG前置配置时候的一个问题…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

OCR MLLM Evaluation
为什么需要评测体系?——背景与矛盾 能干的事: 看清楚发票、身份证上的字(准确率>90%),速度飞快(眨眼间完成)。干不了的事: 碰到复杂表格(合并单元…...

前端调试HTTP状态码
1xx(信息类状态码) 这类状态码表示临时响应,需要客户端继续处理请求。 100 Continue 服务器已收到请求的初始部分,客户端应继续发送剩余部分。 2xx(成功类状态码) 表示请求已成功被服务器接收、理解并处…...

大数据治理的常见方式
大数据治理的常见方式 大数据治理是确保数据质量、安全性和可用性的系统性方法,以下是几种常见的治理方式: 1. 数据质量管理 核心方法: 数据校验:建立数据校验规则(格式、范围、一致性等)数据清洗&…...
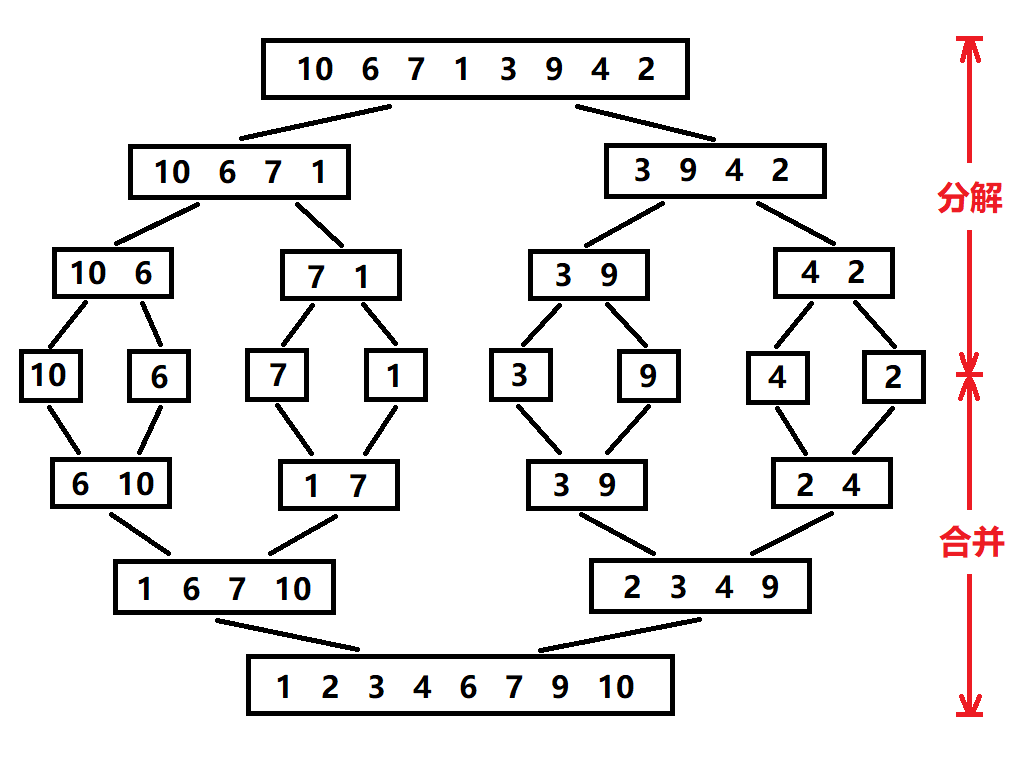
归并排序:分治思想的高效排序
目录 基本原理 流程图解 实现方法 递归实现 非递归实现 演示过程 时间复杂度 基本原理 归并排序(Merge Sort)是一种基于分治思想的排序算法,由约翰冯诺伊曼在1945年提出。其核心思想包括: 分割(Divide):将待排序数组递归地分成两个子…...