自然语言处理中的BERT模型深度剖析
自然语言处理(NLP)是人工智能领域的一个重要分支,它致力于让计算机理解和生成人类语言。近年来,BERT(Bidirectional Encoder Representations from Transformers)模型的出现,极大地推动了NLP领域的发展。BERT模型由Google在2018年提出,它通过预训练和微调的方式,在多种NLP任务上取得了突破性的成果。本文将深入剖析BERT模型的架构、训练过程以及其在文本分类、命名实体识别等任务中的应用。
一、BERT模型架构
BERT(Bidirectional Encoder Representations from Transformers)模型架构的核心是基于Transformer的编码器,它采用了多层的自注意力(self-attention)和前馈神经网络结构,以此捕获文本数据的复杂语义信息。下面,我们将对BERT模型架构的关键组成部分进行更加详细的解析。
1.Transformer 编码器
Transformer编码器是BERT架构的基石,由多个相同的层(Layer)堆叠而成。每一层都包含两个核心部分:多头自注意力机制(Multi-Head Self-Attention Mechanism)和前馈神经网络(Feed-Forward Neural Network)。这两个部分都采用了残差连接(Residual Connection)和层归一化(Layer Normalization),这有助于避免在深层网络中出现的梯度消失问题。
1)多头自注意力机制
自注意力机制允许输入序列中的每个词都直接与其他所有词相互作用和学习,这样能有效捕获长距离依赖信息。而多头自注意力进一步拓展了这种能力,它将注意力机制分割为多个“头”,每个头学习序列的不同部分,从而能够让模型从多个子空间角度学习信息。
在具体实现中,多头自注意力首先会将输入的词嵌入表示投影到不同的查询(Q)、键(K)和值(V)空间,每个头对应一组Q、K、V。然后,通过计算Q和K的点积,得到不同词之间的注意力权重,随后这些权重会和V相乘,得到最终的输出。这个过程允许模型动态地调整不同词之间的交互重要性。
2)位置全连接前馈网络
在每个自注意力层后面,BERT采用了一个简单的两层前馈神经网络(Feed-Forward Neural Network, FFNN),包括ReLU激活函数。这个网络对每个位置的输出都是独立的,意味着它以相同的方式作用于所有位置的输出。这一设计增加了模型处理每个词向量的能力,让模型能够进一步学习词之间的复杂关系。
2.输入表示
BERT的输入表示是其另一个重要特点。每个输入元素的表示由三部分组成:词嵌入、段落嵌入和位置嵌入。
- 词嵌入(Token Embeddings):将每个词转换为固定长度的向量表示,捕获词的语义信息。
- 段落嵌入(Segment Embeddings):BERT能够处理单个文本或一对文本(如问答对)。段落嵌入用于区别这两种情况,标识每个词属于哪个文本。
- 位置嵌入(Positional Embeddings):由于Transformer模型本身不具有捕获序列顺序的能力,位置嵌入用于提供词在序列中的位置信息,使模型能够理解词序。
这三种嵌入的向量会被相加,得到每个词的最终输入表示,这样不仅带来了丰富的语义信息,还包含了位置和句子层面的信息,为模型提供了全面的输入视角。
3.层归一化和残差连接
每个子层(自注意力和前馈网络)的输出都会经过层归一化和残差连接。残差连接帮助缓解了深度网络中的梯度消失问题,而层归一化则用于稳定深层网络的训练过程。
BERT模型的架构通过引入Transformer编码器,结合独特的多头自注意力机制和深度前馈网络,实现了对文本深层次语义的理解。其创新的输入表示法,以及网络中的层归一化和残差连接设计,进一步提升了模型的性能和训练稳定性。这些特点共同构成了BERT在各种NLP任务中取得卓越成绩的基础。
二、BERT模型的训练过程
BERT模型的训练过程是其成功的关键之一,它采用了独创性的预训练和微调两阶段策略,允许模型在广泛的文本数据上学习通用的语言表示,然后针对具体任务进行微调,大幅提升了模型的适应性和性能。
1.预训练
BERT的预训练阶段涉及两种创新的任务:掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。这两种任务共同训练BERT模型,使其能够理解语言的深层次结构和含义。
1)掩码语言模型(MLM)
在MLM任务中,输入文本的一部分词被随机选中并替换为一个特殊的[MASK]标记,模型的任务是预测这些被掩码的词。这种方法允许BERT学习到双向的文本表示,与传统的单向语言模型(只能从左到右或从右到左)相比,BERT能够整合上下文的全部信息进行预测。为了实现这一点,大约15%的词汇被选为目标,其中80%被替换为[MASK],10%被替换为随机词,剩下的10%保持不变。这种策略避免了模型仅仅学会填充[MASK]。
2)下一句预测(NSP)
NSP任务旨在让模型学习理解两个句子之间的关系。在预训练过程中,模型被给予一对句子,需要预测第二个句子是否是第一个句子在原始文本中的紧接着的下一句。这项任务通过随机选择50%的正样本(实际相连的句子对)和50%的负样本(随机组合的句子对)来进行训练。NSP任务对于理解句子间逻辑关系、提高问答系统和自然语言推理系统的性能非常有帮助。
2.微调
在完成了预训练之后,BERT模型可以被用于特定的下游NLP任务,如文本分类、命名实体识别、问答系统等。在微调阶段,预训练得到的模型参数被用作初始化参数,然后在特定任务的数据集上进行进一步的训练。这一阶段通常需要相对较少的数据和较短的训练时间。
微调过程中,模型的架构会针对特定任务做出相应的调整。例如,在文本分类任务中,BERT模型的输出会被连接到一个额外的全连接层,该层的输出大小与分类类别的数量相匹配。在命名实体识别任务中,BERT的输出则会被用于每个输入词的实体类别预测。
BERT模型的训练过程通过预训练和微调两个阶段的策略,有效地学习了广泛的语言表示,这些通用的表示能够被轻易地调整以适应各种下游任务。预训练阶段的掩码语言模型和下一句预测任务使得BERT模型能够理解复杂的语言结构和上下文关系,而微调阶段则确保了模型在特定任务上的高性能表现。这种灵活性和高效性是BERT模型在多个NLP任务中取得优异成绩的关键。
三、BERT在NLP任务中的应用
BERT(Bidirectional Encoder Representations from Transformers)模型自2018年推出以来,因其在自然语言处理(NLP)领域中的卓越性能而受到广泛关注。BERT通过预训练一个大型的双向Transformer编码器,在广泛的NLP任务中实现了当时的最先进(state-of-the-art)性能。它的成功推动了预训练模型在NLP领域的广泛应用,以下是BERT在NLP任务中的几个关键应用案例。
1.文本分类(Text Classification)
文本分类是将文本分配给一个或多个类别的任务,例如垃圾邮件检测、情感分析等。BERT在这类任务中通过预训练获得的强大语言理解能力,能够抓住文本的细微情感和语境,从而提高分类的准确性。例如,在情感分析任务中,BERT能够准确地区分正面和负面评论,甚至能够捕捉到讽刺等复杂情绪。
2.命名实体识别(Named Entity Recognition, NER)
命名实体识别是识别文本中特定实体(如人名、地名、组织名等)的任务。BERT利用其深度双向语境理解,可以更准确地识别和分类文本中的实体。与传统的基于规则或统计的方法相比,BERT能够更好地处理实体的多义性和上下文依赖性。
3.问答系统(Question Answering, QA)
问答系统旨在理解用户的问题并从给定的文本中提取或生成答案。BERT在阅读理解方面的强大能力使其在这项任务上表现出色。通过预训练,BERT学会了理解和表示复杂的问题和答案的语境,从而能够精准地从文本中提取出正确的答案。
4.文本摘要(Text Summarization)
文本摘要的任务是生成文本的简短且具有代表性的摘要。尽管BERT主要是作为编码器设计的,但通过与其他模型(如解码器)的结合使用,它也能被应用于文本摘要任务。BERT能够理解文本的主要内容和结构,帮助生成连贯且紧密的摘要。
5.机器翻译(Machine Translation)
机器翻译是将一种语言的文本自动翻译成另一种语言。虽然BERT本身不是为机器翻译而设计,但其预训练的语言理解能力可以作为机器翻译系统中的一个强大组件,特别是在理解源语言文本方面。结合适当的解码器,BERT可以帮助提高翻译的准确性和流畅性。
BERT在多个NLP任务中的应用展示了预训练模型的强大潜力,它通过在大量文本数据上学习语言的深层次特征,显著提高了NLP系统的性能。随着研究的深入和技术的进步,BERT及其变种(如RoBERTa、ALBERT等)将继续推动NLP领域的发展,解决更多复杂的语言处理问题。
结论
BERT模型通过其深层的Transformer架构和创新的预训练策略,在多种NLP任务上展现了卓越的性能。它的出现不仅提高了NLP任务的基准,也为后续模型的研究和开发提供了新的思路。随着研究的深入,BERT及其变体将继续在自然语言处理领域发挥重要作用。
通过本文的介绍,我们希望读者能够对BERT模型的架构、训练过程及其在NLP任务中的应用有一个全面的了解。随着技术的不断进步,我们有理由相信,BERT模型及其后续发展将继续推动NLP领域的进步。
相关文章:

自然语言处理中的BERT模型深度剖析
自然语言处理(NLP)是人工智能领域的一个重要分支,它致力于让计算机理解和生成人类语言。近年来,BERT(Bidirectional Encoder Representations from Transformers)模型的出现,极大地推动了NLP领域…...
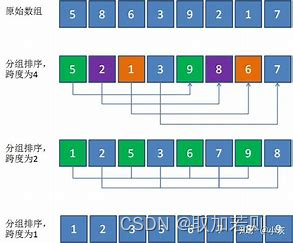
数据结构:希尔排序
文章目录 前言一、排序的概念及其运用二、常见排序算法的实现 1.插入排序2.希尔排序总结 前言 排序在生活中有许多实际的运用。以下是一些例子: 购物清单:当我们去超市购物时,通常会列出一份购物清单。将购物清单按照需要购买的顺序排序&…...
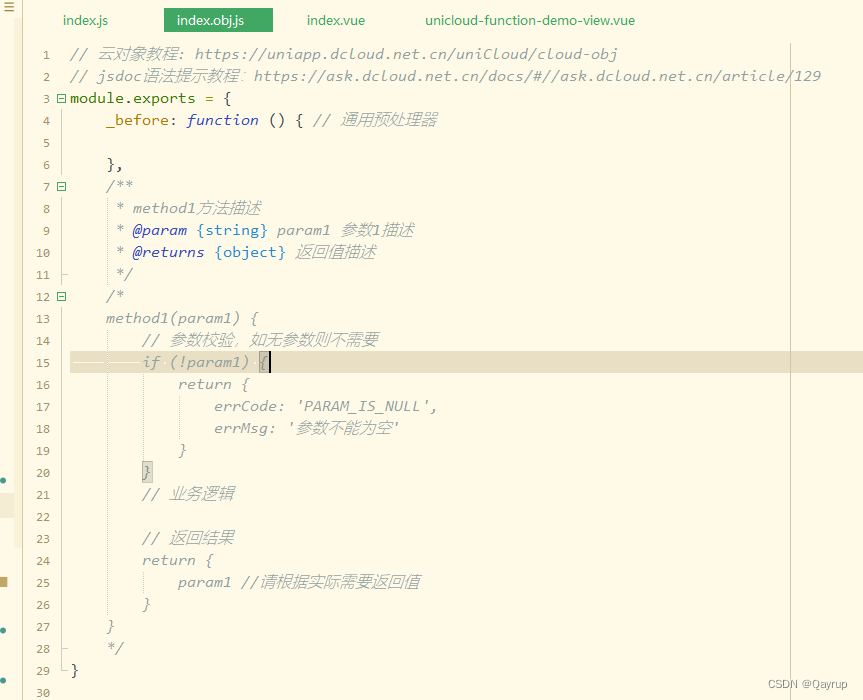
unicloud 云对象
背景和优势 20年前,restful接口开发开始流行,服务器编写接口,客户端调用接口,传输json。 现在,替代restful的新模式来了。 云对象,服务器编写API,客户端调用API,不再开发传输json…...

【车载开发系列】常用专业术语汇总
【车载开发系列】常用专业词汇汇总 英语全称说明详细HILSHardware In the Loop Simulation车硬件仿真模拟器精密仪器,价格昂贵,机能测试时一定要小心使用。使用简易HILS不能模拟电气故障。要模拟电气故障需要外接故障BoxLSBLeast Significant Bit单位精…...

如何实现Docker容器的自动化升级:不再为手动更新烦恼!
要升级 Docker 容器,你可以按照以下步骤操作,这些步骤涵盖了从拉取最新镜像到重启容器的整个过程。 步骤一:拉取最新的镜像 首先,确保你有最新版本的镜像。例如,如果你要升级一个 Spring Boot 应用的镜像,…...

SwiftUI 5.0(iOS 17)进一步定制 TipKit 外观让撸码如虎添翼
概览 在之前 SwiftUI 5.0(iOS 17)TipKit 让用户更懂你的 App 这篇博文里,我们已经初步介绍过了 TipKit 的基本知识。 现在,让我们来看看如何进一步利用 SwiftUI 对 TipKit 提供的细粒度外观定制技巧,让 Tip 更加“明眸…...
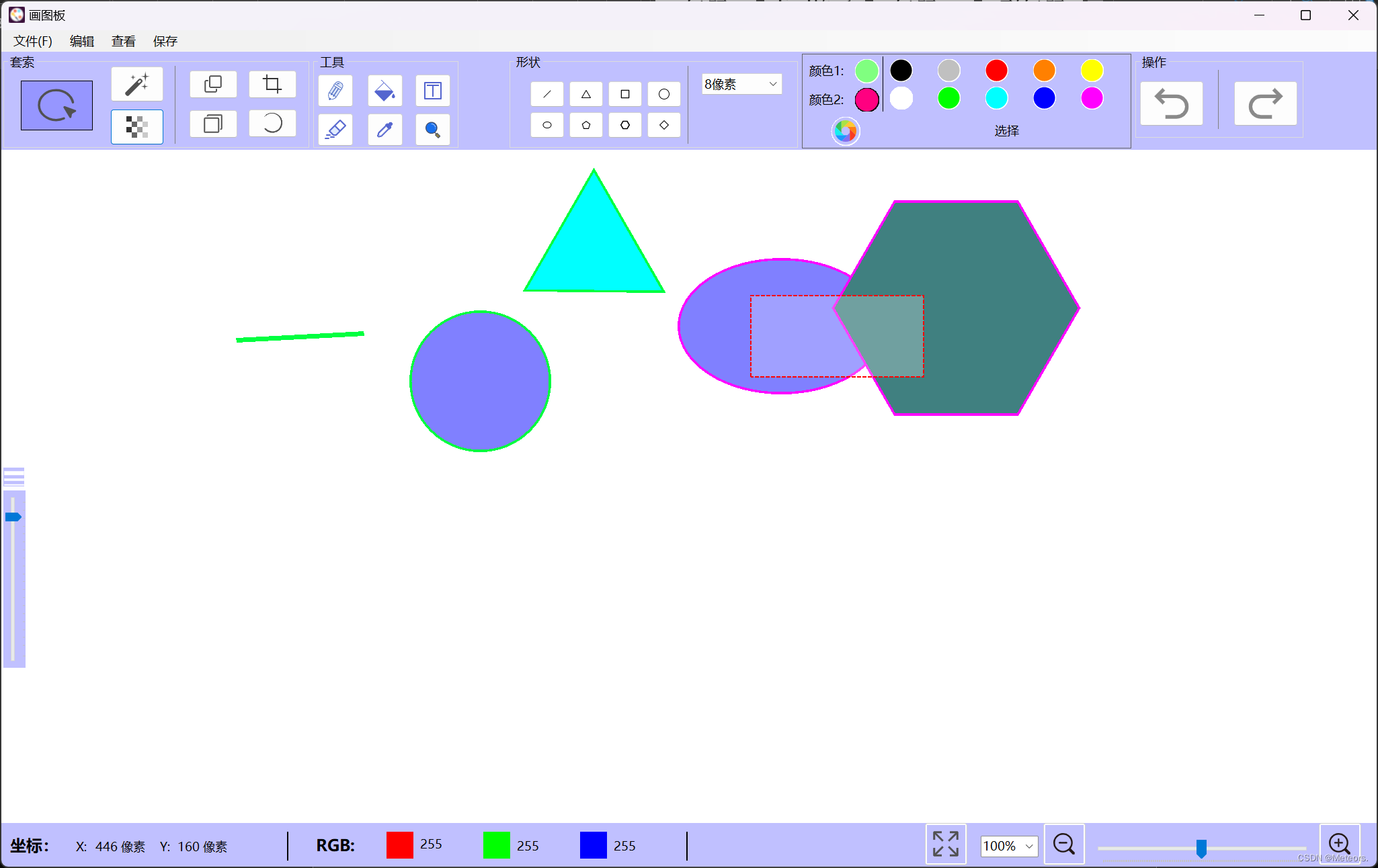
使用C#实现VS窗体应用——画图板
✅作者简介:大家好,我是 Meteors., 向往着更加简洁高效的代码写法与编程方式,持续分享Java技术内容。🍎个人主页:Meteors.的博客💞当前专栏:小项目✨特色专栏: 知识分享🥭…...
)
flutter 自定义本地化-GlobalMaterialLocalizations(重写本地化日期转换)
1. 创建自定义 GlobalMaterialLocalizations import package:flutter_localizations/flutter_localizations.dart; import package:kittlenapp/utils/base/date_time_util.dart;///[auth] kittlen ///[createTime] 2024-05-31 11:40 ///[description]class MyMaterialLocaliza…...

HTTPS 原理技术
HTTPS原理技术 背景简介原理总结 背景 随着年龄的增长,很多曾经烂熟于心的技术原理已被岁月摩擦得愈发模糊起来,技术出身的人总是很难放下一些执念,遂将这些知识整理成文,以纪念曾经努力学习奋斗的日子。本文内容并非完全原创&am…...

Linux基础指令及其作用之压缩与解压
压缩与解压targzip示例输出解释 gunzipzipunzip 压缩与解压 tar tar xzf 是一个常用的命令组合,用于解压缩由 gzip 压缩的 tarball 文件。下面是对这个命令的详细说明: tar:这是一个用于在 Linux 和类 Unix 系统上创建、查看或提取归档文件…...

ORA-08189: 因为未启用行移动功能, 不能闪回表问题
在执行闪回恢复误删数据出现“ORA-08189: 因为未启用行移动功能, 不能闪回表”的错误提示。 ORA-08189 错误表示你尝试对一个表执行闪回操作,但该表没有启用行移动(ROW MOVEMENT)功能。行移动是Oracle中的一个特性,它允许表中的行…...
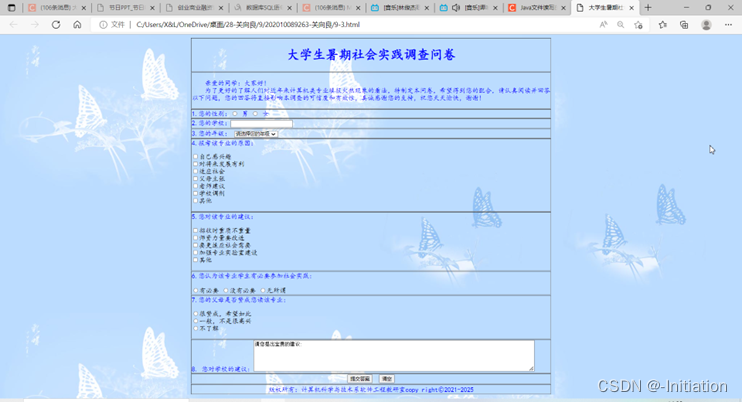
html+CSS部分基础运用9
项目1 参会注册表 1.设计参会注册表页面,效果如图9-1所示。 图9-1 参会注册表页面 项目2 设计《大学生暑期社会实践调查问卷》 1.设计“大学生暑期社会实践调查问卷”页面,如图9-2所示。 图9-2 大学生暑期社会调查表页面 2.调查表前导语的…...

五大元素之一,累不累——Java内部类
目录 简略版: 详解版: 使用场景: 内部类的优点: 内部类的分类: 一. 成员内部类 1.创建对象 2.访问方法 3. 外部类名.this. 二. 静态内部类 1. 创建对象 2. 访问特点 三. 局部内部类 四. 匿名内部类 …...
YAML快速编写示例
一、案例 1.1 自主式创建service关联上方的pod 资源名称my-nginx-kkk命名空间my-kkk容器镜像nginx:1.21容器端口80标签njzb:my-kkk 1.1.1 创建一个demo文件夹 1.1.2 创建并获取模版文件 1.1.3 查看服务并编写yaml文件 1.1.4 编写yaml文件并部署,查看服务是否运行成…...
)
2024 江苏省大学生程序设计大赛 2024 Jiangsu Collegiate Programming Contest(FGKI)
题目来源:https://codeforces.com/gym/105161 文章目录 F - Download Speed Monitor题意思路编程 G - Download Time Monitor题意思路编程 K - Number Deletion Game题意思路编程 I - Integer Reaction题意思路编程 写在前面:今天打的训练赛打的很水&…...

【C语言】基于C语言实现的贪吃蛇游戏
【C语言】基于C语言实现的贪吃蛇游戏 🔥个人主页:大白的编程日记 🔥专栏:C语言学习之路 文章目录 【C语言】基于C语言实现的贪吃蛇游戏前言一.最终实现效果一.Win32 API介绍1.1Win32 API1.2控制台程序1.3控制台屏幕上的坐标COORD…...
代码审计(工具Fortify 、Seay审计系统安装及漏洞验证)
源代码审计 代码安全测试简介 代码安全测试是从安全的角度对代码进行的安全测试评估。(白盒测试;可看到源代码) 结合丰富的安全知识、编程经验、测试技术,利用静态分析和人工审核的方法寻找代码在架构和编码上的安全缺陷…...
cocos creator 3.x 手搓背包拖拽装备
项目背景: 游戏背包 需要手动 拖拽游戏装备到 装备卡槽中,看了下网上资料很少。手搓了一个下午搞定,现在来记录下实现步骤; 功能拆分: 一个完整需求,我们一般会把它拆分成 几个小步骤分别造零件。等都造好了…...

运维开发.Kubernetes探针与应用
运维系列 Kubernetes探针与应用 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this article:https://blog.csdn.net/qq_28550263…...

Spring 框架:Java 企业级开发的基石
文章目录 序言Spring 框架的核心概念Spring 框架的主要模块Spring Boot:简化 Spring 开发Spring Cloud:构建微服务架构实际案例分析结论 序言 Spring 框架自 2002 年发布以来,已经成为 Java 企业级开发的标准之一。它通过提供全面的基础设施…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

LabVIEW双光子成像系统技术
双光子成像技术的核心特性 双光子成像通过双低能量光子协同激发机制,展现出显著的技术优势: 深层组织穿透能力:适用于活体组织深度成像 高分辨率观测性能:满足微观结构的精细研究需求 低光毒性特点:减少对样本的损伤…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...