Postgresql | 执行计划
SQL优化主要从三个角度进行:
(1)扫描方式;
(2)连接方式;
(3)连接顺序。
如果解决好这三方面的问题,那么这条SQL的执行效率就基本上是靠谱的。看懂SQL的执行计划的关键也是要首先了解这三方面的基本概念,只有搞清楚了这些基本概念,才能够更好的看懂SQL的执行计划,下面我们分别来学习这些预备知识。
要想让SQL语句有好的执行效果,首先要采用正确的扫描方式。PG的扫描方式与Oracle等其他数据库类似,但也存在较大的不同,为了掌握好SQL语句优化的技术,我们首先要学会看SQL语句的执行计划,而看执行计划的最为基础的能力就是看懂每一步的扫描方式。下表是一个PG常用的表扫描方式的清单,大家一定要熟练掌握。
| 扫描方式简称 | 解释 |
|---|---|
| Seq Scan | 顺序扫描整个对象 |
| Parallel Seq Scan | 采用并行方式顺序扫描整个对象 |
| Index Scan | 采用离散读的方式,利用索引访问某个对象 |
| Index Only Scan | 仅通过索引,不访问表快速访问某个对象 |
| Bitmap Index Scan | 通过多个索引扫描后形成位图找到符合条件的数据 |
| Bitmap Heap Scan | 往往跟随bitmap index scan,使用该扫描生成的位图访问对象 |
| CTE Scan | 从CTE(Common Table Expression)中扫描数据 (WITH Block) |
| Function Scan | 从存储过程中扫描数据 |
顺序扫描(Seq Scan)
顺序扫描(Seq Scan)往往是开销最大的扫描方式,其方式是针对一个关系(表)从头到尾进行扫描,从而找到所需要的数据。如果这张表上的数据量比较大,那么这种扫描方式可能会产生较大的IO,消耗较多的CPU资源,持续较长的时间。如果某条SQL语句扫描某张表的时候返回的记录数较少(或者返回记录的比例较少,比如小于5%)。
而SQL语句的WHERE条件中具有针对某几个字段的某些条件的,那么在这张表上创建适当的索引可能会大大提高这条SQL的执行效率。如果扫描返回的记录数占表的比例比较大,比如超过50%,那么,通过索引扫描该表可能效率还不如直接进行顺序扫描。因此我们不能看到顺序扫描就认为这条SQL扫描数据的方式存在问题,而是要根据实际情况来判断扫描方式是否合理。
并行顺序扫描(Parallel Seq Scan)
并行顺序扫描(Parallel Seq Scan)是一种改良的顺序扫描,从PG 9.6开始支持的一种新的扫描功能。如果对于某张表的扫描无法使用索引,必须进行顺序扫描,那么我们如何提高这样的扫描的性能呢?答案就是Parallel Seq Scan,通过并行扫描的方式对大表进行扫描,从而减少扫描所需的时间。
采用并行扫描时应该注意两个问题:第一个问题是,并行扫描会增加系统的资源开销,比如在SQL执行时会消耗更多的CPU/IO/内存等资源。如果系统资源本身存在瓶颈,那么就要尽可能限制并行扫描的数量;第二是并行扫描并不一定具有更高的效率,在不同的系统环境与数据情况下,有时候并行顺序扫描效率并不会比普通的顺序扫描更快。这取决于并行扫描的协同工作成本是否较高。
索引扫描(Index Scan)
索引扫描(Index Scan)是我们希望遇到的扫描方式,不过索引唯一扫描(Index Only Scan)具有更高的效率,因为Index Only Scan不需要再进行回表操作,就可以完成执行工作,获得到所需要的数据,因为索引中已经包含了SQL执行所需要的所有数据。不过我们要注意的是,有些时候,索引扫描的效率还不一定比顺序扫描高,比如某个扫描需要返回的行数较多,底层存储的顺序读性能远高于离散读,这种情况下,如果我们还一味追求索引扫描,那么可能会起到副作用。
CTE SCAN
CTE SCAN是一种特殊的扫描,当SQL语句中存在CTE结构(语法上的WITH …),那么在SQL的执行计划中会看到CTE SCAN的内容。相当于从一个固化的子查询体中获得数据。CTE结构在一次SQL执行中只执行一次,但是可以给SQL中的子查询多次使用,从而减少响应的开销。
Function Scan
Function Scan也是一种特殊的扫描方式,是从函数中获取数据。
针对一个单表的访问,我们只要选择最适合的表扫描方式就可以实现优化了,不过我们面对的SQL往往不是一张单表访问的,很多SQL涉及多张表的关联操作。因此仅仅了解PG数据库的扫描方式是不够的,我们需要认真学习一下PG数据库的表连接方式。和其他关系型数据库类似,PostgreSQL 支持三种连接操作:
(1)嵌套循环连接(Nested Loop Join)
(2)合并连接(Merge Join)
(3)散列连接(Hash Join)
PostgreSQL 中的嵌套循环连接和合并连接有几种变体。要注意的是这里所说的PG数据库的表连接方式与SQL语句中的表连接不是一码事。PostgreSQL支持的三种join方法都可以进行所有的join操作,不仅是INNER JOIN,还有LEFT/RIGHT OUTER JOIN、FULL OUTER JOIN等。
Nested Loop Join(嵌套循环连接)
Nested Loop Join(嵌套循环连接)是最基本的连接操作,它可以用于任何连接条件。PostgreSQL 支持嵌套循环连接,包括其多种变体。参与Nested Loop Join的两张表分为外表(Outer)和内表(Inner),首先找出外表符合条件的数据集,然后针对这个数据集的每一行进行一次循环,找出内表中符合条件的数据。针对内表的扫描可能是Index Scan,也可能是Seq Scan。如果内表数据量不大,那么Seq Scan是可以接受的,如果内表比较大,那么进行Seq Scan的成本太高,就可能导致Nested Loop的成本过高。因此这种情况下,就需要在内表上创建适当的索引来进行优化。如果关联条件使用索引的效果不佳,那么Nested Loop连接的性能就无法优化了。另外如果外表的结果集太大,有上万甚至几十万条记录,那么Nested Loop的循环次数就很大,哪怕内表扫描使用Index Scan,总体效率也不高。
每当读取外部表的每个元组时,上述嵌套循环连接必须扫描内部表的所有元组。如果上面所说的情况出现,由于为每个外表元组扫描整个内表是一个昂贵的过程,PostgreSQL 通过一种变种的Nested Loop连接方式-物化嵌套循环连接(Materialized Nested Loop Join)以降低内表的总扫描成本,从而解决这个问题。
=# explain select o.o_c_id,i.apd from test_outer o,test_inner i where o.o_id=i.o_id and o.o_w_id=29 and o.o_c_id=1831 and i.o_id<3000;< span="">QUERY PLAN
----------------------------------------------------------------------------------Nested Loop (cost=1000.00..180434.51 rows=2 width=8)Join Filter: (o.o_id = i.o_id)-> Seq Scan on test_inner i (cost=0.00..691.75 rows=2971 width=8)Filter: (o_id < 3000)-> Materialize (cost=1000.00..178450.45 rows=29 width=8)-> Gather (cost=1000.00..178450.31 rows=29 width=8)Workers Planned: 2-> Parallel Seq Scan on test_outer o (cost=0.00..177447.41 rows=12 width=8)Filter: ((o_w_id = 29) AND (o_c_id = 1831))
(9 rows)
从上面的执行计划看,针对表的过滤条件比较好,筛选后只有29条记录,因此针对这张表的条件建立了一个物化视图,用test_inner作为外表,执行nested loop。
Merge Join(合并连接)
第二种常用的表连接方式是Merge Join(合并连接)在一些其他数据库中也叫Sort Merge Join,是因为两个结果集做JOIN之前,都需要对连接字段进行排序,然后再进行连接。如果结果集数量不大,所有元组都可以存储在内存中,那么排序操作就可以在内存中进行;否则,将使用临时文件。使用临时文件排序的效率远低于内存排序,因此要确保work_mem的配置足够大,从而提高合并连接的性能。与嵌套循环连接一样,合并连接也支持物化合并连接来物化内表,使内表扫描更加高效。Merge Join往往在内外表的大小相差较小的情况下有较好的效果。
Hash Join(哈希连接)
第三种常用的表连接方式是Hash Join(哈希连接)。与Merge Join类似,Hash Join只能用于自然连接和等连接。PostgreSQL 中的Hash Join的行为取决于表的大小。如果目标表足够小(更准确地说,内表的大小是 work_mem 的 25% 或更少),它将是一个简单的两阶段内存哈希连接;否则需要采用具有倾斜处理的混合哈希连接。
内存中哈希连接(In-memory Hash Join)是在work_mem上处理的,这个hash表区在PostgreSQL中称为batch。一批具有散列槽,内部称为桶。外表上构建好Hash桶之后,内表的连接字段逐个探测Hash桶,完成连接操作。
当内表的元组无法在work_mem中存储为一个batch时,PostgreSQL使用了混合散列连接和skew算法,这是基于混合散列连接的一种变体。在构建和探测阶段,PostgreSQL 准备多个批次。批次数与桶数相同,在这个阶段,work_mem中只分配了一个batch,其他batch作为临时文件创建;并将属于这些批次的元组写入相应的文件并使用临时元组存储功能进行保存。在混合哈希联接中,构建和探测阶段执行的次数与批次数相同,因为内表和外表存储在相同的批次数中。在构建和探测阶段的第一轮中,不仅创建了每个批次,而且处理了内部表和外部表的第一批。另一方面,第二轮和后续轮次的处理需要向/从临时文件写入和重新加载,因此这些是昂贵的过程。因此,PostgreSQL 还准备了一个名为skew的特殊批处理,以在第一轮更有效地处理更多的元组。
了解了表的扫描方式与表连接的方式之后,我们就可以来分析SQL的执行计划了。不过在看执行计划之前,我们还需要了解一下执行计划中的每个节点的操作。常见的操作包括如下几种:
| 操作 | 解释 |
|---|---|
| ljoin | 采用某种方法把两个node的数据连接起来 |
| lsort | 进行排序操作 |
| llimit | 通过limit结束扫描,限制返回的数据量 |
| laggregate | 进行汇总 |
| lhash aggregate | 通过hash分组数据 |
| lunique | 对于已经排序的数据进行除重 |
| lgather | 从不同的并发worker中汇总数据 |
学习了每个节点的操作符,我们基本上就能看懂PG的执行计划了。我们可以使用explain命令来查看PG的SQL语句的执行计划。Explain命令的语法如下:
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
EXPLAIN [ ( option [, ...] ) ] statementANALYZE 执行SQL并且显示执行细节VERBOSE 详细输出COSTS 显示执行计划开销BUFFERS 显示查询的buffers操作信息TIMING 显示执行消耗的时间SUMMARY 在最后显示汇总信息FORMAT TEXT/XML/JSON/YAML 显示格式选择
下面我们还是以上面举例的那条SQL来看看SQL的执行计划。通过explain命令我们可以获得某条SQL语句的执行计划。比如下面的SQL:
PG=# explain select o.o_c_id,i.apd from test_outer o,test_inner i where o.o_id=i.o_id and o.o_w_id=29 and o.o_c_id=1831 and i.o_id<3000;< span="">QUERY PLAN
-------------------------------------------------------------------------------------------Nested Loop (cost=1000.00..180434.51 rows=2 width=8)Join Filter: (o.o_id = i.o_id)-> Seq Scan on test_inner i (cost=0.00..691.75 rows=2971 width=8)Filter: (o_id < 3000)-> Materialize (cost=1000.00..178450.45 rows=29 width=8)-> Gather (cost=1000.00..178450.31 rows=29 width=8)Workers Planned: 2-> Parallel Seq Scan on test_outer o (cost=0.00..177447.41 rows=12 width=8)Filter: ((o_w_id = 29) AND (o_c_id = 1831))
(9 rows)
我们看到最下面的两行,只针对test_outer表做并行Seq Scan,条件正是SQL语句中针对该表的两个过滤条件。Parallel Sequence Scan的成本为:
(cost=0.00…177447.41 rows=12 width=8)
从上面的数据可以看出,Parallel Seq Scan的成本是177447.41。经过Gather后生成了一个物化视图,成本变为178450.45。rows=12指出了本操作返回的行数,而width=8指出了每行数据的长度,rows*width可以计算出操作涉及的字节数。
然后执行了一个和物化视图同等级的Seq Scan,是针对test_inner表的,这个扫描操作:
-> Seq Scan on test_inner i (cost=0.00..691.75 rows=2971 width=8)
这个操作的成本为691.75,返回2971条记录。然后这两个结果集之间进行Join,方式采用的是Nested Loop。
读懂了执行计划,就可以判断执行计划中那些地方存在问题了。我们看到对于test_outer表的扫描采用Parallel Seq Scan的成本占比很高,如果要优化这条SQL,可以考虑创建一个o_c_id和o_w_id的索引来进一步优化。
highgo=# create index idx_outer1 on test_outer(o_c_id,o_w_id);
CREATE INDEX
highgo=# explain select o.o_c_id,i.apd from test_outer o,test_inner i where o.o_id=i.o_id and o.o_w_id=29 and o.o_c_id=1831 and i.o_id<3000;< span="">QUERY PLAN
---------------------------------------------------------------------------------------Hash Join (cost=729.32..760.00 rows=2 width=8)Hash Cond: (o.o_id = i.o_id)-> Index Scan using idx_outer1 on test_outer o (cost=0.43..30.98 rows=29 width=8)Index Cond: ((o_c_id = 1831) AND (o_w_id = 29))-> Hash (cost=691.75..691.75 rows=2971 width=8)-> Seq Scan on test_inner i (cost=0.00..691.75 rows=2971 width=8)Filter: (o_id < 3000)
(7 rows)
可以看出,执行计划中使用了这个索引,而且表连接方式也变成了Hash Join,Cost也下降了上百倍。这是PG数据库SQL优化最为常用的方法。
一个顺序磁盘页面操作的cost值由系统参数seq_page_cost (floating point)参数指定的,由于这个参数默认为1.0,所以我们可以认为一次顺序磁盘页面操作的cost值为1。
osdba=# explain select * from t;
QUERY PLAN
———————————————————-
Seq Scan on t (cost=0.00 ..4621.00 rows=300000 width=10 )
(1 row)
cost 说明:
第一个数字0.00表示启动cost,这是执行到返回第一行时需要的cost值。
第二个数字4621.00表示执行整个SQL的cost
可以explain后加analyze来通过真实执行这个SQL来获得真实的执行计划和执行时间:.
osdba=# EXPLAIN ANALYZE SELECT * FROM t;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------
Seq Scan on t (cost=0.00..4621.00 rows=300000 width=10) (actual time=0.022 ..355.380rows=300000 loops=1)
Total runtime: 696.074 ms
actual time中的第一个数字表示返回第一行需要的时间(叫启动时间),第二个数字表示执行这个整个花的时间。后面的rows=300000是实际的行数。
表顺序扫描由于是立即可以获得第一行,所以启动时间一般都是0,而如果是排序操作,则需要处理完所有行后才能返回第一行,所以排序操作是需要启动时间的,下表列出了哪些操作是需要启动时间的,哪些操作不是需要的:
| 执行计划运算类型 | 操作说明 | 是否有启动时间 |
|---|---|---|
| Seq Scan | 扫描表 | 无启动时间 |
| Index Scan | 索引扫描 | 无启动时间 |
| Bitmap Index Scan | 索引扫描 | 有启动时间 |
| Bitmap Heap Scan | 索引扫描 | 有启动时间 |
| Subquery Scan | 子查询 | 无启动时间 |
| Tid | Scan ctid = …条件 | 无启动时间 |
| Function Scan | 函数扫描 | 无启动时间 |
| Nested Loop | 循环结合 | 无启动时间 |
| Merge Join | 合并结合 | 有启动时间 |
| Hash Join | 哈希结合 | 有启动时间 |
| Sort | 排序,ORDER BY操作 | 有启动时间 |
| Hash | 哈希运算 | 有启动时间 |
| Result | 函数扫描,和具体的表无关 | 无启动时间 |
| Unique | DISTINCT,UNION操作 | 有启动时间 |
| Limit | LIMIT,OFFSET操作 | 有启动时间 |
| Aggregate | count, sum,avg, stddev集约函数 | 有启动时间 |
| Group | GROUP BY分组操作 | 有启动时间 |
| Append | UNION操作 | 无启动时间 |
| Materialize | 子查询 | 有启动时间 |
| SetOp | INTERCECT,EXCEPT | 有启动时间 |
explain select distinct course_id from course where course_term = 'Fal02';
NOTICE: QUERY PLAN:
Unique (cost=12223.09..12339.76 rows=4667 width=4)-> Sort (cost=12223.09..12223.09 rows=46666 width=4)-> Seq Scan on course (cost=0.00..8279.99 rows=46666 width=4)
1.从下往上读
2.explain报告查询的操作,开启的消耗,查询总的消耗,访问的行数 访问的平均宽度
3.开启时间消耗是输出开始前的时间例如排序的时间
4.消耗包括磁盘检索页,cpu时间
5.注意,每一步的cost包括上一步的
6.重要的是,explain 不是真正的执行一次查询 只是得到查询执行的计划和估计的花费
7.索引有用条件 当满足特定条件的元组数小于总的数目
cost
(1)含义:这个计划节点的预计的启动开销和总开销
(2)描述:启动开销是指一个计划节点在返回结果之前花费的开销,如果是在一个排序节点里,那就是指执行排序花费的开销。 总开销是指一个计划节点从开始到运行完成,即所有可用行被检索完后,总共花费的开销。实际上,一个节点的父节点可能会在子节点返回一部分结果后,停止继续读取剩余的行,如Limit节点。
rows
(1)含义:这个计划节点的预计输出行数
(2)描述:在带有ANALYZE选项时,SQL语句会实际运行,这时一个计划节点的代价输出会包含两部分,前面部分是预计的代价,后面部分是实际的代价。前面部分中rows是指预计输出行数,后面部分是指实际输出行数。如果中间节点返回的数据量过大,最终返回的数据量很小,或许可以考虑将中间节点以下的查询修改成物化视图的形式。
width
(1)含义:这个计划节点返回行的预计平均宽度(以字节计算)
(2)描述:如果一个扫描节点返回行的平均宽度明显小于子节点返回行的平均宽度,说明从子节点读取的大部分数据是无用的,或许应该考虑一下调整SQL语句或表的相关设计,比如让执行计划尽量选择Index Only Scan,或者对表进行垂直拆分。
actual time
(1)含义:这个计划节点的实际启动时间和总运行时间
(2)描述:启动时间是指一个计划节点在返回第一行记录之前花费的时间。 总运行时间是指一个计划节点从开始到运行完成,即所有可用行被检索完后,总共花费的时间。
loops
(1)含义:这个计划节点的实际重启次数
(2)描述:如果一个计划节点在运行过程中,它的相关参数值(如绑定变量)发生了变化,就需要重新运行这个计划节点。
Filter
(1)含义:这个扫描节点的过滤条件
(2)描述:对于一个表的扫描节点,如果相关的条件表达式不能对应到表上的某个索引,可能需要分析一下具体的原因和影响,比如该表相关的字段在表达式中需要进行隐式类型转换,那么即使在该字段上存在索引,也不可能被使用到。如:((b.intcol)::numeric > 99.0)
Index Cond
(1)含义:这个索引扫描节点的索引匹配条件
(2)描述:说明用到了表上的某个索引。
Rows Removed by Filter
(1)含义:这个扫描节点通过过滤条件过滤掉的行数
(2)描述:如果一个扫描节点的实际输出行数明显小于通过过滤条件过滤掉的行数,说明这个计划节点在运行过程中的大量计算是无用的,或者说是没有实际产出的,那么这个SQL语句或者表的相关设计可能不是特别好。
相关文章:

Postgresql | 执行计划
SQL优化主要从三个角度进行: (1)扫描方式; (2)连接方式; (3)连接顺序。 如果解决好这三方面的问题,那么这条SQL的执行效率就基本上是靠谱的。看懂SQL的执行计…...

Vue3之父子组件通过事件通信
前言 组件间传值的章节我们知道父组件给子组件传值的时候,使用v-bind的方式定义一个属性传值,子组件根据这个属性名去接收父组件的值,但是假如子组件想给父组件一些反馈呢?就不能使用这种方式来,而是使用事件的方式&a…...

在云服务器安装tomcat和mysql
将 linux 系统安装包解压到指定目录进入 bin 目录执行./startup.sh 命令启动服务器执行./shutdown.sh 关闭服务器在浏览器中访问虚拟机中的 tomcat ip端口具体操作入下解压tomcat压缩包解压,输入tom按table键自动补全tar -zxvf 启动tomcat进入bin目录在linux启动to…...
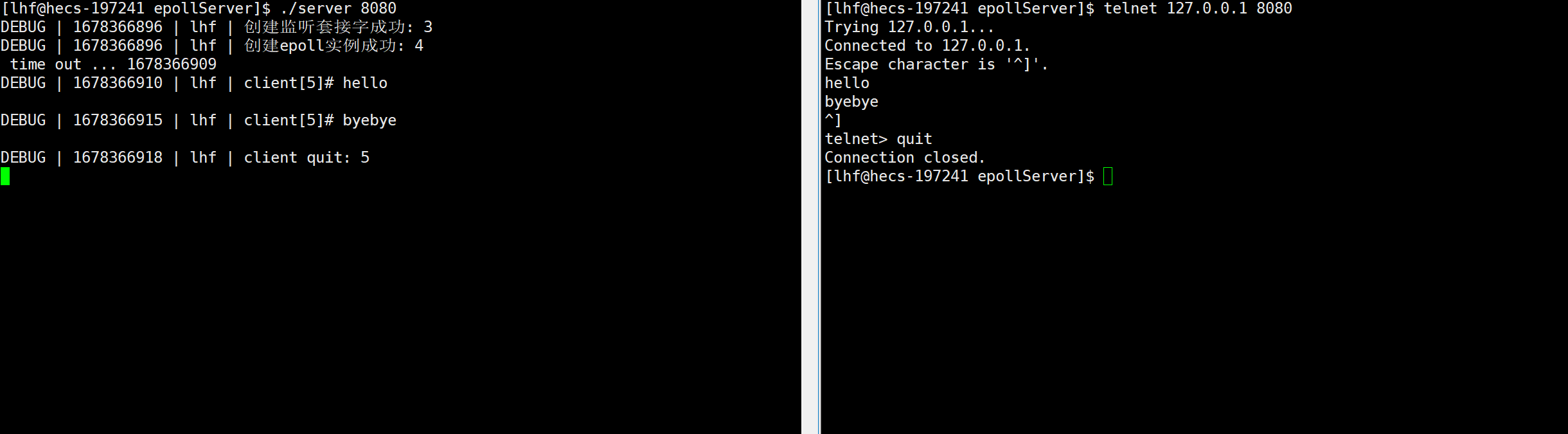
IO多路复用(select、poll、epoll网络编程)
目录一、高级IO相关1.1 同步通信和异步通信1.2 阻塞与非阻塞1.3 fcntl 函数二、五种IO模型2.1 阻塞式IO模型2.2 非阻塞式IO模型2.3 多路复用IO模型2.4 信号驱动式IO模型2.5 异步IO模型三、认识IO多路复用四、select4.1 认识select函数4.2 select函数原型4.3 select网络编程4.4 …...

Spark单机伪分布式环境搭建、完全分布式环境搭建、Spark-on-yarn模式搭建
搭建Spark需要先配置好scala环境。三种Spark环境搭建互不关联,都是从零开始搭建。如果将文章中的配置文件修改内容复制粘贴的话,所有配置文件添加的内容后面的注释记得删除,可能会报错。保险一点删除最好。Scala环境搭建上传安装包解压并重命…...
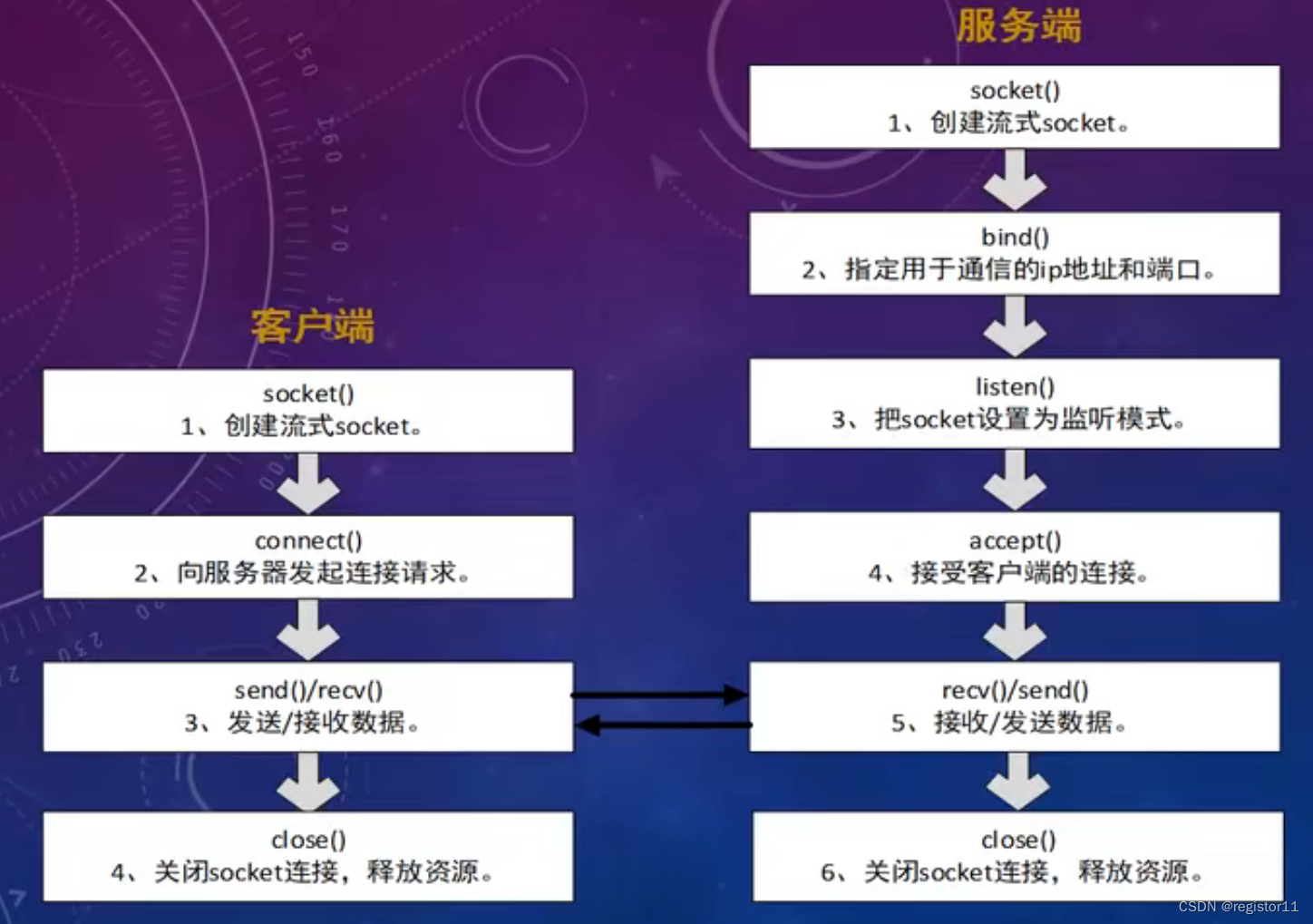
C++网络编程(一)本地socket通信
C网络编程(一) socket通信 前言 本次内容简单描述C网络通信中,采用socket连接客户端与服务器端的方法,以及过程中所涉及的函数概要与部分函数使用细节。记录本人C网络学习的过程。 网络通信的Socket socket,即“插座”,在网络中译作中文“套接字”,应…...

【Docker】Linux下Docker安装使用与Docker-compose的安装
【Docker】的安装与启动 sudo yum install -y yum-utils device-mapper-persistent-data lvm2 sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo sudo yum install docker-cesudo systemctl enable dockersudo systemct…...
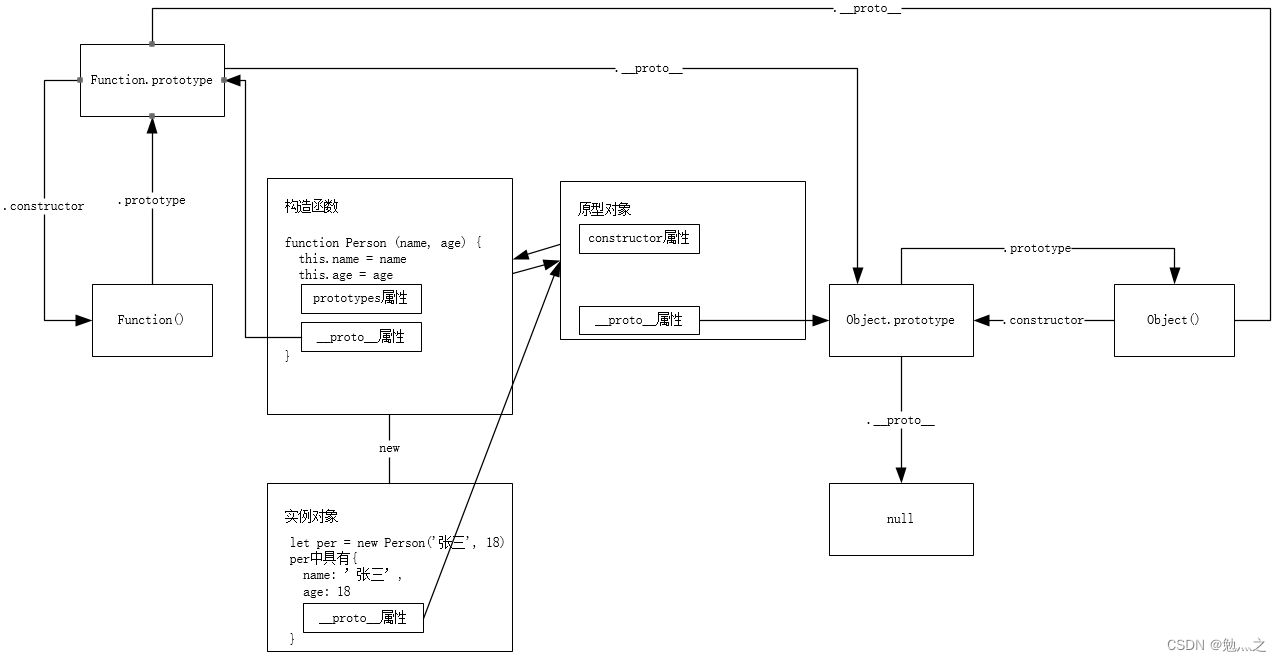
构造函数与普通函数,显式原型与隐式原型,原型与原型链
原型与原型链1 学前先了解一些概念1.1 构造函数和普通函数的区别1.1.1 调用方式1.1.2 函数中this的指向不同1.1.3 写法不同1.2 问题明确2 原型与原型链2.1 原型2.2 显式原型与隐式原型2.3 原型链3 原型链环形结构1 学前先了解一些概念 1.1 构造函数和普通函数的区别 构造函数…...

跨过社科院与杜兰大学金融管理硕士项目入学门槛,在金融世界里追逐成为更好的自己
没有人不想自己变得更优秀,在职的我们也是一样。当我们摸爬滚打在职场闯出一条路时,庆幸的是我们没有沉浸在当下,而是继续攻读硕士学位,在社科院与杜兰大学金融管理硕士项目汲取能量,在金融世界里追逐成为更好的自己。…...
macOS 13.3 Beta 3 (22E5236f)With OpenCore 0.9.1开发版 and winPE双引导分区原版镜像
原文地址:http://www.imacosx.cn/112494.html(转载请注明出处)镜像特点完全由黑果魏叔官方制作,针对各种机型进行默认配置,让黑苹果安装不再困难。系统镜像设置为双引导分区,全面去除clover引导分区&#x…...
InceptionTime 复现
下载数据集: https://www.cs.ucr.edu/~eamonn/time_series_data/ 挂梯子,开全局模式即可 配置环境 虚拟环境基于python3.9, tensorflow下载:pip install tensorflow,不需要tensorflow-gpu(高版本python&…...
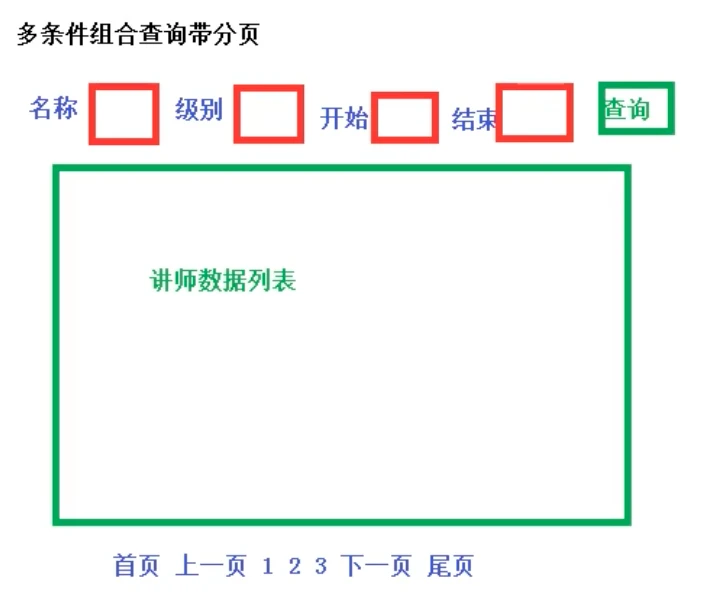
谷粒学院开发(二):教师管理模块
前后端分离开发 前端 html, css, js, jq 主要作用:数据显示 ajax后端 controller service mapper 主要作用:返回数据或操作数据 接口 讲师管理模块(后端) 准备工作 创建数据库,创建讲师数据库表 CREATE TABLE edu…...

2021牛客OI赛前集训营-提高组(第三场) T4扑克
2021牛客OI赛前集训营-提高组(第三场) 题目大意 小A和小B在玩扑克牌游戏,规则如下: 从一副52张牌(没有大小王)的扑克牌中随机发3张到每个玩家手上,每个玩家可以任意想象另外两张牌࿰…...

【OJ比赛日历】快周末了,不来一场比赛吗? #03.11-03.17 #12场
CompHub 实时聚合多平台的数据类(Kaggle、天池…)和OJ类(Leetcode、牛客…)比赛。本账号同时会推送最新的比赛消息,欢迎关注!更多比赛信息见 CompHub主页 或 点击文末阅读原文以下信息仅供参考,以比赛官网为准目录2023-03-11&…...

C++-说一说异常机制
C异常机制是一种处理程序错误的高级方法。当程序出现错误时,可以通过抛出异常来通知调用者进行处理,或者在异常对象被捕获之后终止程序执行。 异常处理语法 在C中,可以使用 throw 抛出异常, try-catch 处理异常,try块中…...

k8s CSI插件浅析
Kubernetes CSI (Container Storage Interface)插件是一种可插拔的存储插件,可以将外部存储系统的功能集成到Kubernetes集群中。它允许Kubernetes管理员动态地将外部存储系统映射到容器中,以满足应用程序对持久化存储的需求。 CSI插件基于一组规范定义的…...

九、CSS3新特性三
文章目录一、逐帧动画二、flex弹性盒子三、少量元素侧轴对齐方式四、折行侧轴对齐方式五、项目属性六、网格布局七、网格布局的对齐方式八、网格布局的项目合并一、逐帧动画 一张背景图,改变back-position-x的位置让他动起来 step-start 逐帧动画 animation: play …...

Dynamics365 本地部署整体界面
昨天已经登陆上去了然后今天开机突然又登陆不上去了 具体原因也不知道 然后我把注册插件删除又重新下载结果还是登陆不上去于是返回之前的断点就可以登陆上去了重复昨天的操作这里就不截图了6、注册新步骤右键单击(插件)BasicPlugin.FollowUpPlugin&…...
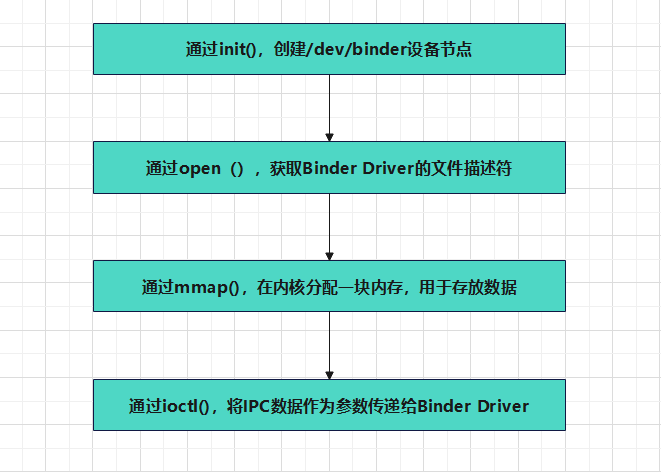
Binder ——binder的jni注册和binder驱动
环境:Android 11源码Android 11 内核源码源码阅读器 sublime textbinder的jni方法注册zygote启动1-1、启动zygote进程zygote是由init进程通过解析init.zygote.rc文件而创建的,zygote所对应的可执行程序是app_process,所对应的源文件是app_mai…...

Python+Yolov8目标识别特征检测
Yolov8目标识别特征检测如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助!前言这篇博客针对<<Yolov8目标识别特征检测>>编写代码,代码整洁,规则,易读。 学习与应用推荐…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...

C语言中提供的第三方库之哈希表实现
一. 简介 前面一篇文章简单学习了C语言中第三方库(uthash库)提供对哈希表的操作,文章如下: C语言中提供的第三方库uthash常用接口-CSDN博客 本文简单学习一下第三方库 uthash库对哈希表的操作。 二. uthash库哈希表操作示例 u…...