经典回归模型及Python实现方法
文章目录
- 1. 引言
- 2. 经典回归模型及Python实现
- 2.1 线性回归 Linear Regression
- 2.2 多项式回归 Polynomial Regression
- 2.3 逻辑回归 Logistic Regression
- 2.4 岭回归 Ridge Regression
- 2.5 套索回归 LASSO Regression
- 2.6 弹性网络回归 Elastic Net
- 2.7 决策树回归 Decision Tree Regression
- 2.8 随机森林回归 Random Forest Regression
1. 引言
回归分析 是一种预测性的统计技术,用于研究和建模两个或多个变量之间的关系,通过回归分析,能够预测一个或多个自变量(也称为特征或解释变量)对因变量(也称为目标或响应变量)的影响。回归分析为实际决策提供灵活且强力的支持,广泛应用于经济学、工程学、社会科学等领域。
回归分析的步骤:
- 数据准备:收集和预处理数据,将数据集划分为训练集、验证集和测试集;
- 模型选择:根据数据特征和研究问题选择合适的回归模型;
- 模型训练:使用训练数据拟合回归模型,估计模型参数;
- 模型评估:使用测试数据评估模型的性能,常用评估指标包括均方误差、均方根误差、 R 2 R^2 R2等;
- 模型优化:调整模型参数和特征,可能使用正则化等方法,优化模型性能;
- 模型预测和解释:使用优化后的模型进行预测,并解释模型结果。
最早的回归分析应用可以追溯到19世纪,经过学界业界的发展,回归分析出现大量分支,不同回归技术具有不同的特点和适应性,例如线性回归的可解释性较强,但线性关系假设可能不适用于所有的数据。
本文接下来就对回归分析中经典的回归模型进行介绍,并介绍如何用Python现有的库进行简单实现。
2. 经典回归模型及Python实现
2.1 线性回归 Linear Regression
线性回归假设因变量(目标变量)与自变量(特征)之间存在如下形式的线性关系:
y = β 0 + β 1 x + ϵ y=\beta_0+\beta_1x+\epsilon y=β0+β1x+ϵ
其中, y y y 是因变量, x x x 是自变量, β 0 \beta_0 β0 是截距, β 1 \beta_1 β1 是斜率, ϵ \epsilon ϵ 是误差项。当自变量 x x x 的个数 n = 1 n=1 n=1 时称为一元线性回归, n > 1 n>1 n>1 时称为多元线性回归。通过最小二乘法来最小化残差平方和,来找到最佳的拟合直线(回归线)。这里提到的残差指的是观测值与模型预测值之差。
特点:线性回归简单易理解,且计算成本低,但不能处理非线性关系的数据,以及对异常值非常敏感。此外,多元线性回归存在多重共线性、自相关性等特点,会导致回归系数估计值不稳定等问题。
这里我们定义简单的数据并基于sklearn库进行多元线性回归计算:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score# 假设我们有一个包含多元数据的 DataFrame
data = pd.DataFrame({'X1': [1, 2, 3], # 自变量 x1'X2': [2, 5, 8], # 自变量 x2'X3': [1, 6, 11], # 自变量 x3'Y': [11, 20, 30] # 因变量 y
})# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data[['X1', 'X2', 'X3']], data['Y'], test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 基于测试数据得到预测值
y_pred = model.predict(X_test)# 输出结果
print(f"Coefficients: {model.coef_}")
print(f"Intercept: {model.intercept_}")
print(f"Mean squared error: {mean_squared_error(y_test, y_pred)}")
print(f"R^2 score: {r2_score(y_test, y_pred)}")
上述代码中,构建回归模型就三步,(随机)划分训练数据,创建线性回归模型,训练模型。并可以通过 sklearn 自带的工具计算训练的模型在测试数据集上的性能指标。
2.2 多项式回归 Polynomial Regression
如前面提到的,实际中的数据间关系并不总是线性关系的,而多项式回归能通过曲线来拟合非线性关系的数据。多项式回归曲线的表达式中自变量的最高次幂大于 1 1 1,具体形式如下:
y = a 0 x m + a 1 x m − 1 + . . . + a m − 1 x 1 + a m x 0 y=a_0x^m+a_1x^{m-1}+...+a_{m-1}x^1+a_mx^0 y=a0xm+a1xm−1+...+am−1x1+amx0
其中, y y y 是因变量, x x x 是自变量, a m x 0 a_mx^0 amx0 是常数项。上述单项式中的最高项次数 m m m,就是多项式的次数。同样的,当自变量 x x x 有多个,则称为多元多项式回归模型,区别于线性模型,多元会导致多项式函数形式变得很复杂,因此本文主要以上述的一元多项式模型举例。
特点:相比于线性回归,多项式回归更加灵活,能够处理更复杂的非线性关系数据,且理论上多项式函数可以逼近任一类型的函数,因此多项式回归具有广泛的应用性,但也常常会导致过拟合的问题,在实际中需要不断实验以选择合适的多项式指数。
这里我们基于sklearn库进行多项式回归计算,值得注意的是,多项式回归可以看成是线性回归的扩展,例如一元二次回归,可以看成是自变量为 [ x 2 , x ] [x^2,x] [x2,x] 的二元线性回归,在代码中实现如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegressionX = np.random.uniform(-3, 3, size=(100, 1))
y = 0.5 * X ** 2 + X + 2 + np.random.normal(0, 1, size=(100, 1))# 转化为多元线性回归的自变量
X_new = np.c_[X ** 2, X]
# 视作线性回归进行计算
model = LinearRegression()
model.fit(X_new, y)
y_pred = model.predict(X_new)# 绘制图形
plt.plot(np.sort(X, axis=0), y_pred[np.argsort(X, axis=0)].flat, color="red")
plt.scatter(X, y)
plt.show()

同理,输出拟合后曲线的系数 [ [ 0.428130630.92657404 ] ] [[0.42813063 0.92657404]] [[0.428130630.92657404]] 和截距 [ 2.25250732 ] [2.25250732] [2.25250732],发现与我们代码中生成随机点的函数系数非常接近,说明多项式回归的准确性较高。
2.3 逻辑回归 Logistic Regression
逻辑回归 也是一种广义上的线性回归分析模型,它是在线性回归基础上加一个 Sigmoid 函数对线性回归结果进行压缩,令其最终预测值 y y y 落在指定范围内,它最大的应用场景是解决多分类问题。
以二分类问题为例,首先训练线性回归函数:
z = β 0 + β 1 x + ϵ z=\beta_0+\beta_1x+\epsilon z=β0+β1x+ϵ
通过 Sigmoid 函数( 1 1 + e − y \frac{1}{1+e^{-y}} 1+e−y1)能够将实数范围内的值的取值映射在 ( 0 , 1 ) (0,1) (0,1) 之间(实质上就是完成了二分类任务)。此时得到:
y = 1 1 + e − ( β 1 x + β 0 + ϵ ) ⇒ 1 y − 1 = e − ( β 1 x + β 0 + ϵ ) ⇒ l n ( 1 y − 1 ) = l n ( e − ( β 1 x + β 0 + ϵ ) ) ⇒ l n ( y 1 − y ) = β 1 x + β 0 + ϵ y=\frac{1}{1+e^{-(\beta_1x+\beta_0+\epsilon)}}\\ \Rightarrow \frac{1}{y}-1=e^{-(\beta_1x+\beta_0+\epsilon)}\\ \Rightarrow ln(\frac{1}{y}-1)=ln(e^{-(\beta_1x+\beta_0+\epsilon)}) \\ \Rightarrow ln(\frac{y}{1-y})=\beta_1x+\beta_0+\epsilon y=1+e−(β1x+β0+ϵ)1⇒y1−1=e−(β1x+β0+ϵ)⇒ln(y1−1)=ln(e−(β1x+β0+ϵ))⇒ln(1−yy)=β1x+β0+ϵ
根据上述 y y y 的定义,令 y y y 为观测数据 x x x 为正例的概率, 1 − y 1-y 1−y 为 x x x 作为反例的概率,则可得:
h β ( x ) = P ( y = 1 ∣ x ) = 1 1 + e − ( β 1 x + β 0 + ϵ ) 1 − h β ( x ) = P ( y = 0 ∣ x ) = 1 1 + e β 1 x + β 0 + ϵ h_{\beta}(x)=P(y=1|x)=\frac{1}{1+e^{-(\beta_1x+\beta_0+\epsilon)}} \\ 1-h_{\beta}(x)=P(y=0|x)=\frac{1}{1+e^{\beta_1x+\beta_0+\epsilon}} hβ(x)=P(y=1∣x)=1+e−(β1x+β0+ϵ)11−hβ(x)=P(y=0∣x)=1+eβ1x+β0+ϵ1
基于最大似然估计推导相关的损失函数,如下:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( h β ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h β ( x ( i ) ) ) ] J(θ)=−\frac{1}{m}\sum_{i=1}^m [y^{(i)} log(h_{\beta}(x^{(i)}))+(1−y^{(i)})log(1−h_{\beta} (x^{(i)} ))] J(θ)=−m1i=1∑m[y(i)log(hβ(x(i)))+(1−y(i))log(1−hβ(x(i)))]
其中, m m m 是训练样本的数量; y ( i ) ∈ { 0 , 1 } y^{(i)}\in\{0,1\} y(i)∈{0,1} 是第 i i i 个训练样本的实际标签, x ( i ) x^{(i)} x(i) 是第 i i i 个训练样本的特征向量; h β ( x ) h_{\beta}(x) hβ(x) 表示给定特征 x x x 的预测概率(如上所示,逻辑回归该函数为逻辑函数),也就是模型的假设函数。
显然的,当 y ( i ) = 1 y^{(i)}=1 y(i)=1,上述式子的只考虑 log ( h β ( x ) ) \log (h_{\beta}(x)) log(hβ(x)) 这一项,如果 h h h 值越接近于 1 1 1,则损失值越小(系数为负数);同理,当 y ( i ) = 0 y^{(i)}=0 y(i)=0,上述式子的只考虑 log ( 1 − h β ( x ) ) \log (1-h_{\beta}(x)) log(1−hβ(x)) 这一项,如果 h h h 值越接近于 0 0 0,则损失值越小。
这里我们基于 sklearn 库实现逻辑回归:
from sklearn.linear_model import LogisticRegression# 假设我们有一个包含两列数据的 DataFrame
data = pd.DataFrame({'x1': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],'x2': [23, 23, 33, 6, 55, 22, 4, 87, 9, 21],'y': [1, 0, 0, 1, 1, 1, 1, 0, 1, 0]
})# 将数据分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(data[['x1', 'x2']], data['y'], test_size=0.2)Model = LogisticRegression()
Model.fit(x_train, y_train)
Model.score(x_train,y_train)
# Equation coefficient and Intercept
print("Coefficient:", Model.coef_)
print("Intercept:", Model.intercept_)
基于训练好的模型 Model,使用模型的 predict() 方法可以返回测试数据的预测值,预测值的范围是 { 0 , 1 } \{0,1\} {0,1}。
2.4 岭回归 Ridge Regression
在线性回归的介绍当中,我们提到,多元线性回归由于存在多重共线性(自变量高度相关)的特点,会导致用最小二乘法估计的不稳定性,使得模型的预测性能下降。
而岭回归(又称L2正则化)是一种用于解决多重共线性问题的线性回归技术。在线性回归中,最小二乘法的目标是最小化观测值与预测值之间的残差平方和来估计系数,而岭回归是在此基础上,引入L2正则化项来解决多重共线性问题,具体形式如下:
min β ( ∑ i = 1 n ( y i − x i β ) 2 + λ ∑ j = 1 p β j 2 ) \min_{\beta}\left( \sum_{i=1}^n(y_i-x_i\beta)^2+\lambda \sum_{j=1}^p \beta_j^2 \right) βmin(i=1∑n(yi−xiβ)2+λj=1∑pβj2)
其中, y y y 是因变量, x x x 是自变量, β \beta β 是待估计的回归系数, λ \lambda λ 是正则化参数,用于控制正则化的强度。
根据正则项的形式可知,岭回归是在线性回归的损失函数基础上,增加了对所有估计参数的求和项(最小化),因此L2正则项也称为权重衰减,可以用来减小模型泛化误差,防止模型过拟合。显然的,如果 λ \lambda λ 的值越大,正则项相对于损失函数的比重就越大,当 λ = 0 \lambda=0 λ=0,则转变为线性回归,如果 λ → + ∞ \lambda\rightarrow+\infin λ→+∞,则估计系数会趋于0,此时回归线会趋向于一条平行于 x 轴的直线。
特点:如上所述,岭回归在线性回归的损失函数基础上,添加了L2正则项,能解决多重共线性的问题,防止回归线过拟合的问题,以及收缩系数,使模型更稳健。但也恰恰因为添加了正则项,使得模型的解释性降低,并需要手动调整正则化参数 λ \lambda λ,增加了调参的复杂性。
这里我们基于 sklearn 库进行岭回归计算:
from sklearn.linear_model import Ridge
import pandas as pd
from sklearn.model_selection import train_test_split# 假设我们有一个包含两列数据的 DataFrame
data = pd.DataFrame({'stop_time': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],'passenger_flow': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000]
})# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data[['stop_time']], data['passenger_flow'], test_size=0.2)# 创建岭回归模型
model = Ridge(alpha=1.0)
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)# 评估模型
print(model.coef_)
print(model.intercept_)
输出的结果为:变量系数 [ 98.23 ] [98.23] [98.23],截距 11.06 11.06 11.06。很接近数据本身的关系,通过线性回归得到的系数和截距分别为 100 , 0 100,0 100,0。当我们增大正则化参数(上述代码 Ridge 函数的参数 alpha改为 10 10 10),得到新的结果系数和截距分别为 88.87 , 62.59 88.87, 62.59 88.87,62.59,可以看到随着 λ \lambda λ 的增大,回归系数的值被缩小。
2.5 套索回归 LASSO Regression
LASSO回归(又称L1正则化)是另一种用于解决多重共线性问题的线性回归技术,与岭回归仅区别于损失函数中的正则项形式,具体形式如下:
min β ( ∑ i = 1 n ( y i − x i β ) 2 + λ ∑ j = 1 p ∣ β j ∣ ) \min_{\beta}\left( \sum_{i=1}^n(y_i-x_i\beta)^2+\lambda \sum_{j=1}^p |\beta_j| \right) βmin(i=1∑n(yi−xiβ)2+λj=1∑p∣βj∣)
其中, y y y 是因变量, x x x 是自变量, β \beta β 是待估计的回归系数,同样, λ \lambda λ 是正则化参数,用于控制正则化的强度。由于L1正则化项是用对参数绝对值进行求和,能够直接对回归系数的绝对值进行压缩,对于较小且趋近于 0 0 0的回归系数可以压缩至 0 0 0,而 L2正则化项由于平方的存在,回归系数越大则限制越大,回归系数越小限制也越小,因此难以将回归系数压缩到 0 0 0,除非 λ \lambda λ 无穷大,而LASSO回归能将回归系数压缩到 0 0 0,相比岭回归最大的特点就是能够进行特征选择。
特点:如上所述,LASSO回归能将回归系数的估计值最小压缩至 0 0 0,因此具有特征选择的能力,也因此能用于系数数据集的建模,非常适用于希望通过模型进行特征选择的场景。但如果训练数据当中,存在高度相关的变量,则LASSO回归只会(随机)选择其中之一,其他的变量系数为 0 0 0,这会表现出一定的不稳定性。
这里我们基于 sklearn 库进行LASSO回归计算:
from sklearn.linear_model import Lasso# 假设我们有一个包含两列数据的 DataFrame
data = pd.DataFrame({'stop_time1': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],'stop_time2': [12, 23, 33, 44, 55, 66, 78, 87, 99, 101],'passenger_flow': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000]
})# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data[['stop_time1', 'stop_time2']], data['passenger_flow'], test_size=0.2)# 创建岭回归模型
model = Lasso(alpha=10)
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)# 评估模型
print(model.coef_)
print(model.intercept_)
当 λ = 10 \lambda=10 λ=10 时, 输出的结果为:变量系数 [ 0 , 9.19 ] [0, 9.19] [0,9.19],截距 − 8.087 -8.087 −8.087,其中第一个自变量的回归系数估计值为 0 0 0,可以在建模和预测中舍弃该变量。
2.6 弹性网络回归 Elastic Net
弹性网络回归 是岭回归技术和LASSO回归通过加权平均混合得到一种广泛使用的线性回归方法,其具体的损失函数形式如下:
min β ( ∑ i = 1 n ( y i − x i β ) 2 + λ ( 1 − α 2 ∣ ∣ β ∣ ∣ 2 + α ∣ ∣ β ∣ ∣ 1 ) ) \min_{\beta}\left( \sum_{i=1}^n(y_i-x_i\beta)^2+\lambda\left( \frac{1-\alpha}{2}||\beta||^2+\alpha ||\beta||_1 \right) \right) βmin(i=1∑n(yi−xiβ)2+λ(21−α∣∣β∣∣2+α∣∣β∣∣1))
其中, ∣ ∣ β ∣ ∣ 2 ||\beta||^2 ∣∣β∣∣2 是 L2正则项, ∣ ∣ β ∣ ∣ 1 ||\beta||_1 ∣∣β∣∣1 是 L1正则项, λ \lambda λ 用于控制正则化的比重, α \alpha α 控制 L1 和 L2 正则化项的相对贡献。该回归方法具有LASSO回归的变量选择能力,也具有岭回归处理多重共线性的能力(保持稳定性),同时能有效减少模型的过拟合情况。
基于 sklearn 库进行弹性网络回归计算的代码如下:
from sklearn.linear_model import ElasticNet# 假设我们有一个包含两列数据的 DataFrame
data = pd.DataFrame({'stop_time1': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],'stop_time2': [12, 23, 33, 44, 55, 66, 78, 87, 99, 101],'passenger_flow': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000]
})# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data[['stop_time1', 'stop_time2']], data['passenger_flow'], test_size=0.2)# 创建弹性网络回归模型
model = ElasticNet(alpha=0.5, l1_ratio=0.8)
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)# 评估模型
print(model.coef_) # [34.44286334 6.27563407]
print(model.intercept_) # -14.139040117979903
在创建弹性网络回归模型时,参数 l1_ratio 即 L1正则项的系数 α \alpha α,当 l1_ratio=1 时,回归模型转变为 LASSO回归模型,该参数是调节模型性能的重要指标,而参数 alpha 则是损失函数中的 λ \lambda λ,当增加该值时,模型结果能体现特征选择的能力。
2.7 决策树回归 Decision Tree Regression
前面提到的回归模型,输出都是连续的,即能够将数据间关系用连续的曲线进行表示。然而,对于非线性关系等的复杂数据场景,则可以用到 决策树回归,这是一种基于树结构的回归模型,通过递归地划分输入空间来进行预测,具有较好的可解释性和可视化效果,但极易过拟合,以及对输入数据的变量非常敏感,常通过剪支等方法进行处理。
树结构的构建,包括优先以哪些特征进行分支等,可以自行了解机器学习中的决策树算法,这里仅介绍决策树回归以及如何利用Python实现:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor# 生成示例数据
np.random.seed(0)
X = np.sort(5 * np.random.rand(80, 1), axis=0)
y = np.sin(X).ravel() + np.random.randn(80) * 0.1# 使用决策树回归进行建模
tree_model = DecisionTreeRegressor(max_depth=4)
tree_model.fit(X, y)# 预测新数据点
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_pred = tree_model.predict(X_test)# 绘制数据点和决策树回归曲线
plt.scatter(X, y, s=20, edgecolor='black', c='darkorange', label='data')
plt.plot(X_test, y_pred, color='cornflowerblue', label='prediction')
plt.xlabel('data')
plt.ylabel('target')
plt.title('Decision Tree Regression')
plt.legend()
plt.show()

上述代码参考自公开资料,其中,创建决策树回归模型当中的 max_depth 设置了树结构的深度,这是需要自行给定的参数,权衡了回归模型的拟合程度。理论上,树结构深度越大,数结构越复杂,预测的准确度越高,然而,这极易造成过拟合,损害了模型的泛化性能。如下是树结构深度为 100 100 100 的拟合效果。

因此,需要控制决策树回归模型当中的 max_depth ,以限制树结构的过度生长,牺牲拟合精度来换取泛化性能。
2.8 随机森林回归 Random Forest Regression
随机森林回归 通过集成多棵决策树来提高预测的准确性和鲁棒性,它结合了决策树的思想和集成学习的优势,能够处理大规模数据集。在随机森林中,每个决策树都是一个弱学习器(基评估器),都是基于对训练数据的随机子集进行训练而生成的,在预测时,随机森林会对每棵树的预测结果进行平均或投票,以得到最终的预测结果。
随机森林通常比于单个决策树回归更加准确,以及对异常值和噪声数据有更好的鲁棒性,但由于多个决策树都需要进行训练,因此具有较高的训练成本,且模型更加复杂不易解释。
随机森林回归的Python实现代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor# 生成示例数据
np.random.seed(0)
X = np.sort(5 * np.random.rand(80, 1), axis=0)
y = np.sin(X).ravel() + np.random.randn(80) * 0.1# 使用随机森林回归进行建模
tree_model = RandomForestRegressor(n_estimators=100, random_state=42)
tree_model.fit(X, y)# 预测新数据点
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_pred = tree_model.predict(X_test)# 绘制数据点和决策树回归曲线
plt.scatter(X, y, s=20, edgecolor='black', c='darkorange', label='data')
plt.plot(X_test, y_pred, color='cornflowerblue', label='prediction')
plt.xlabel('data')
plt.ylabel('target')
plt.title('Decision Tree Regression')
plt.legend()
plt.show()

上述代码中,创建随机森林回归器的传入参数 n_estimators 控制随机森林回归器中的回归树数量,设置的值越大模型效果往往越好,但有边界,n_estimators 大到一定程度后,模型的精确性开始波动而不再上升,但计算资源的消耗却会一直增大,因此需要权衡相应的收益和代价。
除了上述回归模型,还有大量不同类型的模型,例如逐步回归、贝叶斯线性回归、人工神经网络、XGBoost回归等,在选择回归方法时,需要依据数据特征、问题复杂性,以及对模型解释性等方面的要求来决定。
相关文章:
经典回归模型及Python实现方法
文章目录 1. 引言2. 经典回归模型及Python实现2.1 线性回归 Linear Regression2.2 多项式回归 Polynomial Regression2.3 逻辑回归 Logistic Regression2.4 岭回归 Ridge Regression2.5 套索回归 LASSO Regression2.6 弹性网络回归 Elastic Net2.7 决策树回归 Decision Tree Re…...

Git 保留空文件夹结构
假设有如下 helloworld 项目结构: helloworld|--.git|--.gitignore|--Builds|--WebGL|--iOS|--Android现在有个需求,在上传到 github 仓库时,只想保留 WebGL、iOS、Android 文件夹的结构,不想要里面的内容,可以按以下…...

【吊打面试官系列】MySQL 中有哪几种锁?
大家好,我是锋哥。今天分享关于 【MySQL 中有哪几种锁?】面试题,希望对大家有帮助; MySQL 中有哪几种锁? 1、表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,…...

小巧、免费高级分类整理桌面图标和文件程序
一、简介 1、专为Windows操作系统设计的桌面整理工具,旨在帮助用户更好地管理和整理桌面上的图标和文件。这款软件以其小巧、免费且无广告的特点受到用户的欢迎,尤其适合那些希望保持桌面整洁、提高工作效率的用户。 二、下载 1、下载地址: 官网链接:https://www.coodesker…...

Elasticsearch挂掉后,如何快速恢复数据
目录 一、Elasticsearch使用 二、实体类 2.1 mysql 实体类 2.2 Elasticsearch实体类 三、XXL-job定时执行 一、Elasticsearch使用 当我们做搜索功能时,如果为了提高查询效率,通常使用Elasticsearch搜索引擎加快搜索效率。以搜索商品为例,我…...
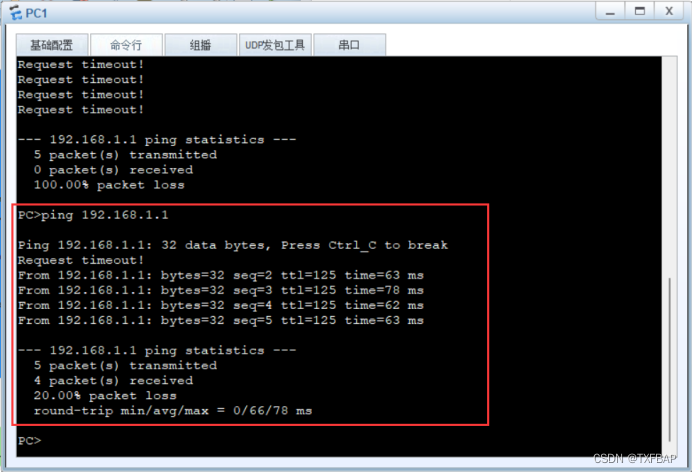
eNSP学习——连接RIP与OSPF网络、默认路由
目录 相关主要命令 实验一、连接RIP与OSPF网络 原理概述 实验目的 实验内容 实验拓扑 实验编址 实验步骤 1、基本配置 2、搭建RIP和OSPF网络 3、配置双向路由引入 4、手工配置引入时的开销值 实验二、使用OSPF、RIP发布默认路由 原理介绍 实验目的 实验内容 实…...
)
工具MyBatis Generator(MBG)
MyBatis Generator(MBG),这是官方帮我们提供的一个自动生成代码的工具,前面的课程中,我们都是脑袋里想好,pojo有哪些属性,属性的类型是什么,对应的数据表中的字段名字是什么,匹配的类型是什么..…...

NeuralForecast 模型的参数 windows_batch的含义
NeuralForecast 模型的参数 windows_batch的含义 flyfish import pandas as pd import numpy as npAirPassengers np.array([112.0, 118.0, 132.0, 129.0, 121.0, 135.0, 148.0, 148.0, 136.0, 119.0],dtypenp.float32, )AirPassengersDF pd.DataFrame({"unique_id&qu…...
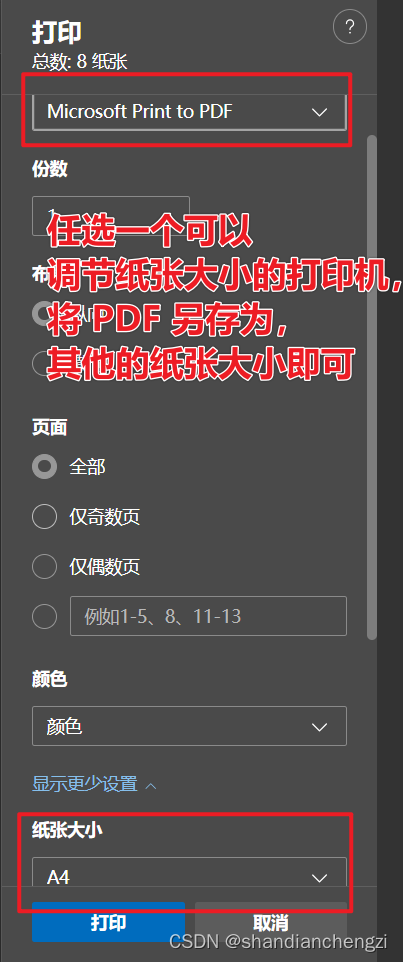
【记录】打印|用浏览器生成证件照打印PDF,打印在任意尺寸的纸上(简单无损!)
以前我打印证件照的时候,我总是在网上找在线证件照转换或者别的什么。但是我今天突然就琢磨了一下,用 PDF 打印应该也可以直接打印出来,然后就琢磨出来了,这么一条路大家可以参考一下。我觉得比在线转换成一张 a4 纸要方便的多&am…...

【python实现】实时监测GPU,空闲时自动执行脚本
文章目录 代码 代码 # author: muzhan # contact: levio.pkugmail.com import os import sys import time cmd nohup python -u train_post_2d_aut.py > output1.log & # gpu空闲时,需要执行的脚本命令 def gpu_info():gpu_status os.popen(nvidia-smi…...

chrome 浏览器历史版本下载
最近做一个项目,要使用到chrome浏览器比较久远的版本,在网上查找资源时,发现chrome比较老的版本的安装包特别难找,几经寻找,总算找到,具体方法如下 打开百度,搜索关键字【chrome版本号‘浏览迷’】,例如“chrome41浏览迷”,找到“全平台”开头的链接&am…...
⭐⭐⭐)
【设计模式】工厂模式(创建型)⭐⭐⭐
文章目录 1.概念1.1 什么是工厂模式1.2 优点与缺点 2.实现方式2.1 简单工厂模式(Simple Factory)2.2 简单工厂模式缺点2.3 抽象工厂模式(Abstract Factory Pattern) 3 Java 哪些地方用到了工厂模式4 Spring 哪些地方用到了工厂模式…...

Postman 连接数据库 利用node+xmysql
1、准备nodejs环境 如果没有安装,在网上找教程,安装好后,在控制台输入命令查看版本,如下就成功了 2、安装xmysql 在控制台输入 npm install -g xmysql 3、连接目标数据库 帮助如下: 示例: 目标数据库…...
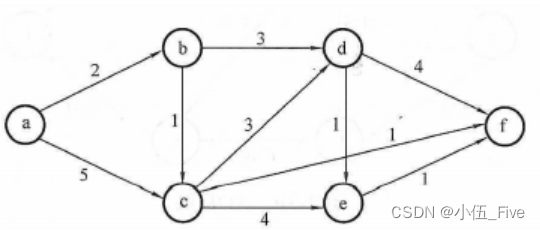
挑战你的数据结构技能:复习题来袭【6】
1. (单选题)设无向图的顶点个数为n,则该图最多有()条边 A. n-1 B. n(n-1)/2 C. n(n1)/2 D. 0 答案:B 分析: 2. (单选题)含有n个顶点的连通无向图,其边的个数至少为()。 A. n-1 B. n C. n1 D. nlog2n 答案:A…...

如何反编译jar并修改后还原为jar
如何反编译jar并修改后还原为jar 目标:修改jar包中某个类的某个方法后还原为新的jar 1.新建android工程,把旧的jar添加为lib 2.用jadx-gui打开旧的jar并保存所有资源 3.找到保存的资源中想修改的.java类 4.复制类中的内容, 在android工程中新建一个同样路径的包,并在包下创建…...
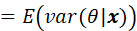
统计信号处理基础 习题解答10-5
题目 通过令 并进行计算来重新推导MMSE估计量。提示:利用结果 解答 首先需要明确的是: 上式是关于观测值x 的函数 其次需要说明一下这个结果 和教材一样,我们用求期望,需要注意的是,在贝叶斯情况下,是个…...
—从零开始:一步步搭建Vue 3自定义插件)
Vue3实战笔记(60)—从零开始:一步步搭建Vue 3自定义插件
文章目录 前言一、自定义插件二、使用步骤总结 前言 在开发和学习中,经常使用一些好用的插件,那么如何创建一个自己的插件呢?在 Vue 3 中,你可以通过创建一个包含 install 方法的对象来定义自定义插件。install 方法接收两个参数…...

Java面向对象笔记
多态 一种类型的变量可以引用多种实际类型的对象 如 package ooplearn;public class Test {public static void main(String[] args) {Animal[] animals new Animal[2];animals[0] new Dog();animals[1] new Cat();for (Animal animal : animals){animal.eat();}} }class …...
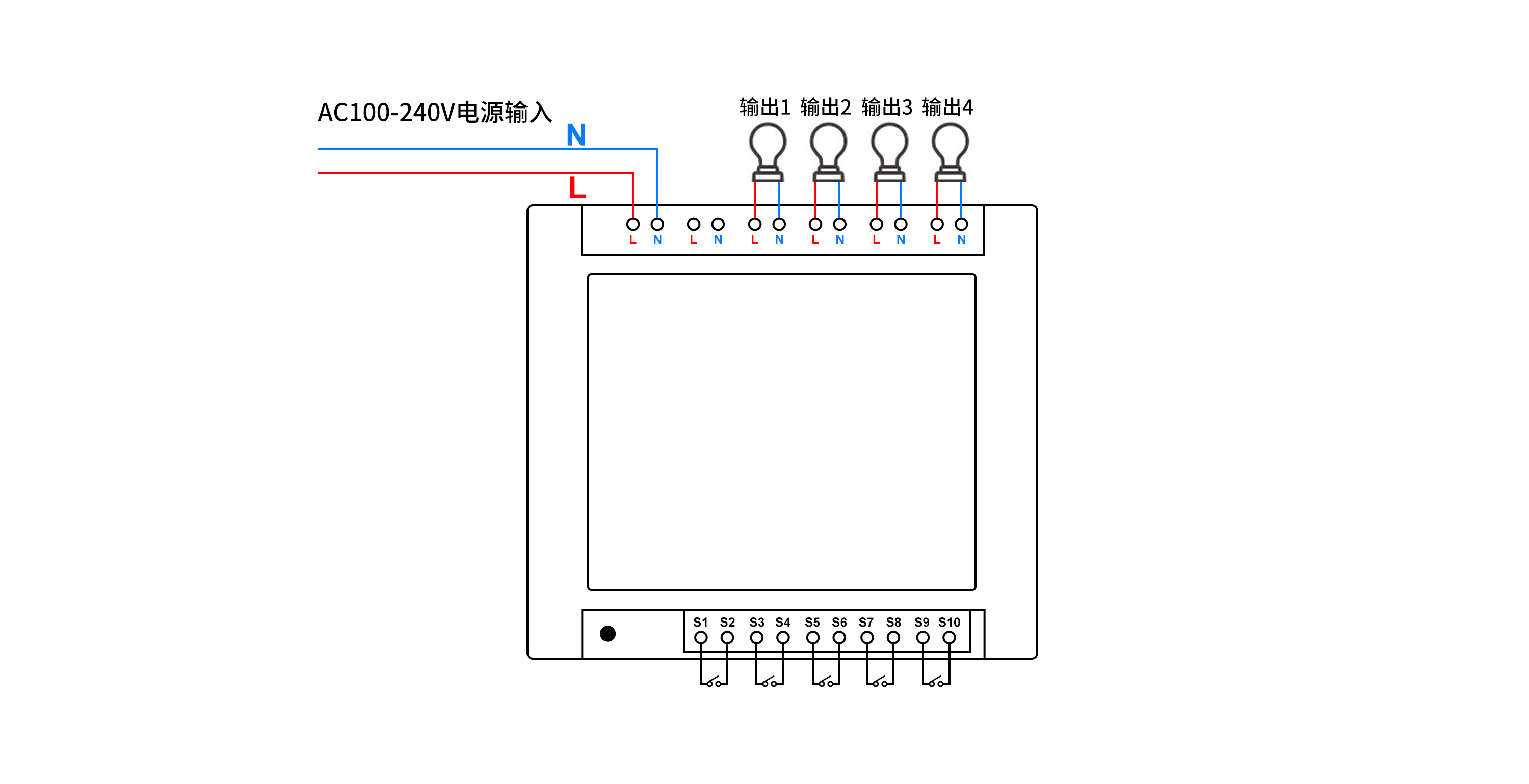
如何通过PHP语言实现远程控制多路照明
如何通过PHP语言实现远程控制多路照明呢? 本文描述了使用PHP语言调用HTTP接口,实现控制多路照明,通过多路控制器,可独立远程控制多路照明。 可选用产品:可根据实际场景需求,选择对应的规格 序号设备名称厂…...

Capture One Pro 23:专业 Raw 图像处理的卓越之选
在当今的数字摄影时代,拥有一款强大的图像处理软件至关重要。而 Capture One Pro 23 for Mac/Win 无疑是其中的佼佼者,为摄影师和图像爱好者带来了前所未有的体验。 Capture One Pro 23 以其出色的 Raw 图像处理能力而闻名。它能够精准地解析和处理各种…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...