使用 Node.js 和 Azure Function App 自动更新 Elasticsearch 索引
作者:来自 Elastic Jessica Garson

维护最新数据至关重要,尤其是在处理频繁变化的动态数据集时。这篇博文将指导你使用 Node.js 加载数据,并通过定期更新确保数据保持最新。我们将利用 Azure Function Apps 的功能来自动执行这些更新,从而确保你的数据集始终是最新且可靠的。
对于这篇博文,我们将使用 Near Earth Object Web 服务 (NeoWs),这是一种 RESTful Web 服务,提供有关近地小行星的详细信息。通过将 NeoWs 与作为 Azure 无服务器函数集成的 Node.js 服务集成,此示例将为你提供一个强大的框架来有效处理管理动态数据的复杂性。这种方法将帮助你最大限度地降低使用过时信息的风险,并最大限度地提高数据的准确性和实用性。
先决条件
- 此示例使用 Elasticsearch 版本 8.13;如果你是 Elasticsearch 新手,请查看我们的 Elasticsearch 快速入门。任何 8.0 版本都适用于此博客文章。
- 下载最新的 NPM 和 Node.js 版本。本教程使用 Node v21.6.1 和 npm 10.5.0。
- NASA API 的 API 密钥。
- 具有创建 Function App 权限的有效 Azure 帐户。
- 访问 Azure 门户或 Azure CLI
本地设置
在开始索引和本地加载数据之前,设置环境至关重要。首先,创建一个目录并初始化它。然后,下载必要的软件包并创建一个 .env 文件来存储你的配置设置。此初步设置可确保你的本地环境已准备好有效处理数据。
mkdir Introduction-to-Data-Loading-in-Elasticsearch-with-Nodejs
cd Introduction-to-Data-Loading-in-Elasticsearch-with-Nodejs
npm init你将使用 Elasticsearch nodejs 客户端连接到 Elastic,使用 Axios 连接到 NASA API,使用 dotenv 解析你的凭据(secrets)。你需要运行以下命令下载所需的软件包:
npm install @elastic/elasticsearch axios dotenv下载所需的软件包后,你可以在项目目录的根目录中创建一个 .env 文件。.env 文件允许你在本地保护你的凭据。查看示例 .env 文件以了解更多信息。要了解有关连接到 Elasticsearch 的更多信息,请务必查看有关该主题的文档。
要创建 .env 文件,你可以在项目根目录中使用此命令:
touch .env在你的 .env 中,请确保输入以下内容。请确保添加完整的端点:
ELASTICSEARCH_ENDPOINT="https://...."
ELASTICSEARCH_API_KEY="YOUR_ELASTICSEARCh_API_KEY"
NASA_API_KEY="YOUR_NASA_API_KEY"你还需要创建一个新的 JavaScript 文件:
touch loading_data_into_a_index.js
创建索引并加载数据
现在你已经设置了正确的文件结构并下载了所需的包,你可以创建一个脚本来创建索引并将数据加载到索引中。如果你在此过程中遇到困难,请务必查看本节中创建的文件的完整版本。
在文件 loading_data_into_a_index.js 中,配置 dotenv 包以使用存储在 .env 文件中的密钥和令牌。你还应该导入 Elasticsearch 客户端以连接到 Elasticsearch 和 Axios 并发出 HTTP 请求。
require('dotenv').config();const { Client } = require('@elastic/elasticsearch');
const axios = require('axios');由于你的密钥和令牌当前存储为环境变量,你将需要检索它们并创建客户端来向 Elasticsearch 进行身份验证。
const elasticsearchEndpoint = process.env.ELASTICSEARCH_ENDPOINT;
const elasticsearchApiKey = process.env.ELASTICSEARCH_API_KEY;
const nasaApiKey = process.env.NASA_API_KEY;const client = new Client({node: elasticsearchEndpoint,auth: {apiKey: elasticsearchApiKey}
});
你可以开发一个函数来异步检索 NASA 的 NEO(Near Earth Object - 近地天体)Web 服务中的数据。首先,你需要为 NASA API 请求配置基本 URL,并创建今天和上周的日期对象以建立查询周期。将这些日期格式化为 API 请求所需的 YYYY-MM-DD 格式后,将日期设置为查询参数并向 NASA API 执行 GET 请求。此外,该函数还包括错误处理机制,以便在出现任何问题时帮助进行调试。
async function fetchNasaData() {const url = "https://api.nasa.gov/neo/rest/v1/feed";const today = new Date();const lastWeek = new Date(today);lastWeek.setDate(today.getDate() - 7);const startDate = lastWeek.toISOString().split('T')[0];const endDate = today.toISOString().split('T')[0];const params = {api_key: nasaApiKey,start_date: startDate,end_date: endDate,};try {const response = await axios.get(url, { params });return response.data;} catch (error) {console.error('Error fetching data from NASA:', error);return null;}
}
现在,你可以创建一个函数,将 NASA API 中的原始数据转换为结构化格式。由于你返回的数据目前嵌套在复杂的 JSON 响应中。更直接的对象数组使处理数据变得更容易。
function createStructuredData(response) {const allObjects = [];const nearEarthObjects = response.near_earth_objects;Object.keys(nearEarthObjects).forEach(date => {nearEarthObjects[date].forEach(obj => {const simplifiedObject = {close_approach_date: date,name: obj.name,id: obj.id,miss_distance_km: obj.close_approach_data.length > 0 ? obj.close_approach_data[0].miss_distance.kilometers : null,};allObjects.push(simplifiedObject);});});return allObjects;
}
你将需要创建一个索引来存储来自 API 的数据。Elasticsearch 中的索引是你可以将数据存储在文档中的地方。在此函数中,你将检查索引是否存在,并在需要时创建一个新索引。你还将为索引指定正确的字段映射。此函数还将数据作为文档加载到索引中,并将 NASA 数据中的 id 字段映射到 Elasticsearch 中的 _id 字段。
async function indexDataIntoElasticsearch(data) {const indexExists = await client.indices.exists({ index: 'nasa-node-js' });if (!indexExists.body) {await client.indices.create({index: 'nasa-node-js',body: {mappings: {properties: {close_approach_date: { type: 'date' },name: { type: 'text' },miss_distance_km: { type: 'float' },},},},});}const body = data.flatMap(doc => [{ index: { _index: 'nasa-node-js', _id: doc.id } }, doc]);await client.bulk({ refresh: false, body });
}
你需要创建一个主函数来获取、构造和索引数据。此函数还将打印出正在上传的记录数,并记录数据是否已编入索引、是否没有要编入索引的数据,或者是否无法从 NASA API 获取数据。创建 run 函数后,你需要调用该函数并捕获可能出现的任何错误。
async function run() {const rawData = await fetchNasaData();if (rawData) {const structuredData = createStructuredData(rawData);console.log(`Number of records being uploaded: ${structuredData.length}`);if (structuredData.length > 0) {await indexDataIntoElasticsearch(structuredData);console.log('Data indexed successfully.');} else {console.log('No data to index.');}} else {console.log('Failed to fetch data from NASA.');}
}run().catch(console.error);
你现在可以通过运行以下命令从命令行运行该文件:
node loading_data_into_a_index.js
要确认你的索引已成功加载,你可以通过执行以下 API 调用来检查 Elastic Dev Tools:
GET /nasa-node-js/_search
使用 Azure 函数应用程序保持数据更新
现在你已成功将数据加载到本地索引中,但这些数据很快就会过时。为确保你的信息保持最新,你可以设置 Azure 函数应用程序以自动每天获取新数据并将其上传到 Elasticsearch 索引。
第一步是在 Azure 门户中配置你的函数应用程序。Azure 快速入门指南是入门的有用资源。
设置函数后,你可以确保已为 ELASTICSEARCH_ENDPOINT、ELASTICSEARCH_API_KEY 和 NASA_API_KEY 设置环境变量。在函数应用程序中,环境变量称为应用程序设置(Application settings)。在函数应用程序中,单击左侧面板中 “Configuration” 下的 “Settings” 选项。在 “Application settings” 选项卡下,单击“+ New application setting”。
你还需要确保安装了所需的库。如果你转到 Azure 门户上的终端,可以通过输入以下内容来安装必要的软件包:
npm install @elastic/elasticsearch axios
你正在安装的软件包看起来应该与之前的安装非常相似,只是你将使用 moment 来解析日期,并且你不再需要加载 env 文件,因为你只需将 secrets 设置为应用程序设置即可。
你可以单击 create 的位置以在函数应用程序中创建新函数,选择名为 “Timer trigger”” 的模板。现在你将拥有一个名为 function.json 的文件。你需要将其调整为如下所示,以便每天上午 10 点运行此应用程序。
{"bindings": [{"name": "myTimer","type": "timerTrigger","direction": "in","schedule": "0 0 10 * * *"}]}
你还需要上传 package.json 文件并确保其显示如下:
{"name": "introduction-to-data-loading-in-elasticsearch-with-nodejs","version": "1.0.0","description": "A simple script for loading data in Elasticsearch","main": "loading_data_into_a_index.js","scripts": {"test": "echo \"Error: no test specified\" && exit 1"},"repository": {"type": "git","url": "git+https://github.com/JessicaGarson/Introduction-to-Data-Loading-in-Elasticsearch-with-Nodejs.git"},"author": "Jessica Garson","license": "Apache-2.0","bugs": {"url": "https://github.com/JessicaGarson/Introduction-to-Data-Loading-in-Elasticsearch-with-Nodejs/issues"},"homepage": "https://github.com/JessicaGarson/Introduction-to-Data-Loading-in-Elasticsearch-with-Nodejs#readme","dependencies": {"@elastic/elasticsearch": "^8.12.0","axios": "^0.21.1"}
}
下一步是创建一个 index.js 文件。此脚本旨在每天自动更新数据。它通过每天系统地获取和解析新数据,然后无缝地更新数据集来实现这一点。Elasticsearch 可以使用相同的方法来提取时间序列或不可变数据,例如 webhook 响应。此方法可确保信息保持最新和准确,反映最新的可用数据。你也可以查看完整代码。
你在本地运行的脚本与此脚本之间的主要区别如下:
- 你不再需要加载 .env 文件,因为你已经设置了环境变量
- 还有不同的日志记录,更多旨在创建更可持续的脚本
- 你可以根据最近的收盘价日期保持索引更新
- 有一个 Azure 函数应用程序的入口点
你首先需要设置库并向 Elasticsearch 进行身份验证,如下所示:
const elasticsearchEndpoint = process.env.ELASTICSEARCH_ENDPOINT;
const elasticsearchApiKey = process.env.ELASTICSEARCH_API_KEY;
const nasaApiKey = process.env.NASA_API_KEY;const client = new Client({node: elasticsearchEndpoint,auth: {apiKey: elasticsearchApiKey}
});
之后,你将需要从 Elasticsearch 获取最新的更新日期,并配置备份方法以便在出现任何问题时获取过去一天的数据。
async function getLastUpdateDate() {try {const response = await client.search({index: 'nasa-node-js',body: {size: 1,sort: [{ close_approach_date: { order: 'desc' } }],_source: ['close_approach_date']}});if (response.body && response.body.hits && response.body.hits.hits.length > 0) {return response.body.hits.hits[0]._source.close_approach_date;} else {// Default to one day ago if no records foundconst today = new Date();const lastWeek = new Date(today);lastWeek.setDate(today.getDate() - 1);return lastWeek.toISOString().split('T')[0];}} catch (error) {console.error('Error fetching last update date from Elasticsearch:', error);throw error;}
}
以下函数连接到 NASA 的 NEO(近地天体)Web 服务以获取数据,使你的索引保持更新。还有一些额外的错误处理功能,可以捕获可能出现的任何 API 错误。
async function fetchNasaData(startDate) {const url = "https://api.nasa.gov/neo/rest/v1/feed";const today = new Date();const endDate = today.toISOString().split('T')[0];const params = {api_key: nasaApiKey,start_date: startDate,end_date: endDate,};try {// Perform the GET request to the NASA API with query parametersconst response = await axios.get(url, { params });return response.data;} catch (error) {// Log any errors encountered during the requestconsole.error('Error fetching data from NASA:', error);return null;}
}
现在,你将需要创建一个函数,通过迭代每个日期的对象来组织数据。
function createStructuredData(response) {const allObjects = [];const nearEarthObjects = response.near_earth_objects;Object.keys(nearEarthObjects).forEach(date => {nearEarthObjects[date].forEach(obj => {const simplifiedObject = {close_approach_date: date,name: obj.name,id: obj.id,miss_distance_km: obj.close_approach_data.length > 0 ? obj.close_approach_data[0].miss_distance.kilometers : null,};allObjects.push(simplifiedObject);});});return allObjects;
}
现在,你需要使用批量(bulk)索引操作将数据加载到 Elasticsearch 中。此功能应与上一节中的功能类似。
async function indexDataIntoElasticsearch(data) {const body = data.flatMap(doc => [{ index: { _index: 'nasa-node-js', _id: doc.id } }, doc]);await client.bulk({ refresh: false, body });
}
最后,你需要为将根据你设置的计时器运行的函数创建一个入口点。此函数类似于主函数,因为它调用文件中先前创建的函数。还有一些额外的日志记录,例如打印记录数并通知你数据是否已正确编入索引。
module.exports = async function (context, myTimer) {try {const lastUpdateDate = await getLastUpdateDate();context.log(`Last update date from Elasticsearch: ${lastUpdateDate}`);const rawData = await fetchNasaData(lastUpdateDate);if (rawData) {const structuredData = createStructuredData(rawData);context.log(`Number of records being uploaded: ${structuredData.length}`);if (structuredData.length > 0) {const flatFileData = JSON.stringify(structuredData, null, 2);context.log('Flat file data:', flatFileData);await indexDataIntoElasticsearch(structuredData);context.log('Data indexed successfully.');} else {context.log('No data to index.');}} else {context.log('Failed to fetch data from NASA.');}} catch (error) {context.log('Error in run process:', error);}
结论
使用 Node.js 和 Azure 的 Function App,你应该能够确保你的索引定期更新。通过结合使用 Node.js 的功能和 Azure 的 Function App,你可以有效地维护索引的定期更新。这种强大的组合提供了一个简化的自动化流程,减少了定期更新索引所需的手动工作量。此示例的完整代码可在 Search Labs GitHub 上找到。如果你基于此博客构建了任何内容,或者你对我们的论坛和社区 Slack 频道有疑问,请告诉我们。
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证吗?了解下一次 Elasticsearch 工程师培训何时举行!
原文:Elasticsearch index updates: Automatically update your index using Node.js and an Azure Function App — Elastic Search Labs
相关文章:
使用 Node.js 和 Azure Function App 自动更新 Elasticsearch 索引
作者:来自 Elastic Jessica Garson 维护最新数据至关重要,尤其是在处理频繁变化的动态数据集时。这篇博文将指导你使用 Node.js 加载数据,并通过定期更新确保数据保持最新。我们将利用 Azure Function Apps 的功能来自动执行这些更新…...
UE4_Ben_图形52_水下效果处理
学习笔记,不喜勿喷,欢迎指正,侵权立删!祝愿生活越来越好! 在这个后期处理的效果中,我们可以看到有很多不同的,这里有浓雾,波纹扭曲,镜头扭曲和边缘模糊,在第4…...
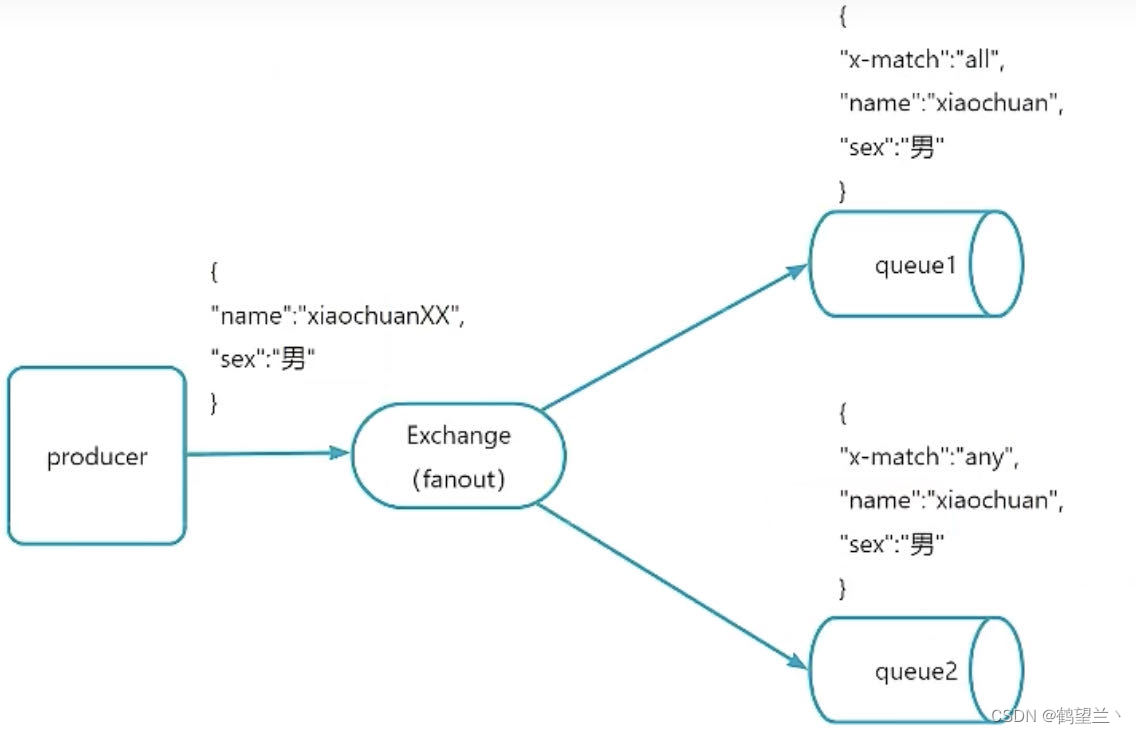
RabbitMQ小结
MQ分类 Acitvemq kafka 优点:性能好,吞吐量高百万级,分布式,消息有序 缺点:单机超过64分区,cpu会飙高,消费失败不支持重试 , Rocket 阿里的mq产品 优点:单机吞吐量也…...

中国自动气象站:现代气象观测的中流砥柱
引言 气象观测是人类认识和预报天气的重要手段。在现代科技的推动下,自动气象站成为气象观测的重要工具,为天气预报、防灾减灾和气候研究提供了宝贵的数据支持。本文将介绍中国自动气象站的发展历程、技术特点及其在气象观测中的重要作用。 中国自动气象…...

【微信小程序】连接蓝牙设备
1、检查小程序是否授权蓝牙功能 initBluetooth() {const that thiswx.getSetting({success: (res) > {if (res.authSetting.hasOwnProperty(scope.bluetooth)) {//scope.bluetooth属性存在,且为falseif (!res.authSetting[scope.bluetooth]) {wx.showModal({tit…...

基于R语言BIOMOD2 及机器学习方法的物种分布模拟与案例分析实践技术
BIOMOD2是一个R软件包,用于构建和评估物种分布模型(SDMs)。它集成了多种统计和机器学习方法,如GLM、GAM、SVM等,允许用户预测和分析物种在不同环境条件下的地理分布。通过这种方式,BIOMOD帮助研究者评估气候…...

Objective-C之通过协议提供匿名对象
概述 通过协议提供匿名对象的设计模式,遵循了面向对象设计的多项重要原则: 接口隔离原则:通过定义细粒度的协议来避免实现庞大的接口。依赖倒置原则:高层模块依赖于抽象协议,而不是具体实现。里氏替换原则࿱…...

C语言基础(一)
C语言基础 一、标准输出(格式化输出):1、概念:2、注意语法点:3、格式控制符:4、调试技巧:5、代码风格:6、实例: 二、数据类型:1、整型概念:语法&a…...

机器学习_决策树与随机森林
决策树是一种常用的监督学习算法,既可以用于分类任务也可以用于回归任务。决策树通过递归地将数据集划分成更小的子集,逐步建立树结构。每个节点对应一个特征,树的叶子节点表示最终的预测结果。构建决策树的关键是选择最佳的特征来分割数据&a…...

嵌入式系统日志轮转:实现与性能考量
日志轮转是嵌入式系统中管理日志文件的一种常用技术,它通过创建新的日志文件来替代旧的日志文件,从而避免日志文件无限增长,占用过多存储空间。本文将探讨日志轮转的实现方法以及在嵌入式系统中实现日志轮转时需要考虑的性能因素。 一、日志…...

麦肯锡:ChatGPT等生成式AI应用激增,大中华区增长最快
全球顶级咨询公司麦肯锡(McKinsey & Company)在官网发布了《he state of AI in early 2024:Gen AI adoption spikes and starts to generate value》,一份关于生成式AI应用的调查报告。 麦肯锡对多个国家/地区的1,363位管理者进行了调查…...

Vue Router 使用教程
Vue Router 是 Vue.js 的官方路由管理器,它提供了一种方便的方式来管理应用的路由。在本教程中,我们将介绍 Vue Router 的一些常见用法和示例。 一、安装 Vue Router 使用 Vue Router 之前,需要先安装它。可以使用以下命令通过 npm 安装&am…...

银河麒麟解压命令
银河麒麟(Kylin)操作系统是基于Linux的操作系统分支之一,其使用的解压命令与Linux系统中的命令基本相同。 在银河麒麟系统中,常用的解压命令有以下几种: 对于.tar文件: tar -xvf file.tar对于.tar.gz或.…...

VSCode打开文件总是在当前标签页打开,不是新增标签页
修改 VS Code 设置 打开设置: 按 Ctrl , 或者点击右下角的齿轮图标,然后选择 “Settings”。 搜索设置: 在设置搜索栏中输入 workbench.editor.enablePreview。 禁用预览模式: 找到 Workbench > Editor: Enable Preview 选…...

Django redirect()函数实现页面重定向
1,通过路由反向解析进行重定向 1.1 添加视图函数 myshop/app2/views.py from django.http import HttpResponse from django.shortcuts import render from django.urls import reverse def index(request):return HttpResponse("app2 的index")# 反向…...

【运维项目经历|029】NTP精准时间同步系统优化项目
🍁博主简介: 🏅云计算领域优质创作者 🏅2022年CSDN新星计划python赛道第一名 🏅2022年CSDN原力计划优质作者 🏅阿里云ACE认证高级工程师 🏅阿里云开发者社区专家博主 💊交流社区:CSDN云计算交流社区欢迎您的加入! 目...

机房网络运维服务项目难点与关键点分析
随着信息技术的飞速发展,机房作为支撑企业信息化建设的核心枢纽,其网络运维服务的重要性日益凸显。然而,在实际运维过程中,运维团队常常面临诸多难点和挑战。本文将围绕机房网络运维服务项目的难点和关键点进行深入分析࿰…...

MKS AX7680 SERIES 电源使用说明手侧
MKS AX7680 SERIES 电源使用说明手侧...
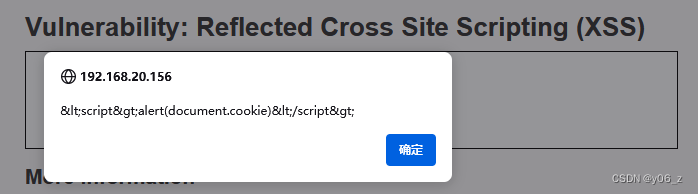
DVWA-XSS(Reflected)
反射型XSS可以用来窃取cookie Low 输入1111进行测试,发现1111被打印 输入<script>alert(document.cookie)</script>,出现弹窗,获得cookie Medium 查看后端代码,发现对<script>进行了转义,但是…...
Python自动化办公2.0 即将发布
第一节课:数据整理与清洗 第二节课:数据筛选、过滤与排序 第三节课:高级数据处理技巧 第四节课:数据可视化与实践案例 第五节课:统计分析与报表 第六节:常见的Excel报表 与下方的课程形成知识体系&…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...