Cognita RAG:模块化、易用与可扩展的开源框架
Cognita RAG是一个开源框架,它通过模块化设计、用户友好的界面和可扩展性,简化了将领域特定知识整合到通用预训练语言模型中的过程。本文介绍了Cognita的特点、优势、应用场景以及如何帮助开发者构建适合生产环境的RAG应用程序。
文章目录
- Cognita RAG介绍
- Cognita RAG的定义与作用
- Cognita RAG的技术基础
- Cognita RAG的核心优势
- 模块化设计
- 用户友好的UI
- 中心化仓库
- 完全API驱动
- 支持本地和可扩展部署
- Cognita RAG的功能与特性
- 支持多种文档检索器
- 支持最新的开源嵌入和重排序方法
- 支持增量索引
- 与现有系统通过API集成
- Cognita RAG的使用场景
- 不同用户的使用场景
- 研究人员
- 开发者
- 企业用户
- 社区反馈与建议
- Cognita RAG的部署与集成
- 本地部署
- 部署步骤
- 注意事项
- 云部署
- 部署步骤
- 注意事项
- Truefoundry集成
- 部署步骤
- 注意事项
- Cognita RAG的技术架构
- Cognita RAG的组件
- 数据索引与查询处理
- 代码结构
- Cognita RAG与现有RAG框架的比较
- Cognita RAG与RAGFlow的比较
- RAGFlow 简介
- Cognita RAG 的优势
- Cognita RAG 如何帮助生产化 RAG
- Cognita RAG的未来展望
- 新功能的引入
- 1. 更强大的嵌入和重排序算法
- 2. 增强的多语言支持
- 3. 高级数据隐私和安全功能
- 4. 可视化工具和仪表板
- 未来贡献范围规划
- 1. 社区驱动的功能开发
- 2. 教育和文档资源
- 3. 开发者工具和插件
- 4. 跨平台支持
- 5. 持续的社区支持和反馈
- Cognita RAG的开源贡献
- 贡献指南
- 1. 了解项目结构和代码库
Cognita RAG介绍
Cognita RAG是一个开源框架,它通过模块化设计、用户友好的界面和可扩展性,简化了将领域特定知识整合到通用预训练语言模型中的过程。以下是关于Cognita RAG的定义与作用以及其技术基础的详细介绍。
Cognita RAG的定义与作用
Cognita RAG的核心是一个开源框架,它为开发者提供了一个组织RAG(Retrieval Augmented Generation)代码库的方法,并且通过一个前端界面允许用户尝试不同的RAG定制。RAG是一种结合了检索和生成的方法,用于增强语言模型的功能,特别是在处理复杂或特定领域的问题时。
Cognita RAG的作用主要体现在以下几个方面:
- 代码库组织:Cognita为RAG相关的代码提供了一个结构化的存储库,使得代码更加模块化,易于管理和维护。
- 前端界面:通过提供前端界面,Cognita使得非技术用户也能够通过用户界面上传文档并执行问答,极大地提高了框架的可用性。
- 集成与扩展:Cognita的设计允许它轻松地与现有的系统进行集成,并且可以扩展以适应不同的应用场景和需求。
Cognita RAG的技术基础
Cognita RAG的技术基础建立在以下几个关键点上:
- Langchain/LlamaIndex:Cognita底层使用了Langchain和LlamaIndex技术。Langchain是一个用于构建基于语言的应用程序的工具链,而LlamaIndex是一个用于构建、搜索和检索文档索引的框架。这些技术为Cognita提供了强大的文档处理和管理能力。
- 模块化设计:Cognita的设计哲学是模块化,这意味着每个RAG组件,如解析器、加载器、嵌入器和检索器,都是独立的模块。这种设计使得每个组件都可以单独开发和更新,而不会影响其他组件。
- API驱动:Cognita完全由API驱动,这为与其他系统的集成提供了极大的灵活性。开发者可以通过API来控制Cognita的所有功能,从而可以根据需要定制和扩展框架。
- 增量索引:Cognita支持增量索引,这种索引方式可以批量地摄入整个文档,同时跟踪已索引的文档,防止它们被重新索引。这种方法减轻了计算负担,提高了索引的效率。
通过这些技术基础,Cognita RAG为开发者提供了一个强大、灵活且易于使用的工具,以构建和部署RAG应用程序。
Cognita RAG的核心优势
Cognita RAG作为一个开源框架,其核心优势在于它通过模块化设计、用户友好的界面、中心化仓库、完全API驱动以及支持本地和可扩展部署,极大地简化了将领域特定知识整合到通用预训练语言模型中的过程。
模块化设计

Cognita RAG的模块化设计是其最大的优势之一。它将RAG流程分解为一系列可插拔的模块化组件,每个组件都可以根据用户的需求进行定制和控制。这种设计使得系统更易于维护,可以轻松添加新功能,例如与其他AI库的互操作性,并且允许用户根据自己的特定需求来定制平台。开发者可以根据实际需求自由选择和组合不同的组件,例如数据加载器、解析器、嵌入器、向量数据库等,轻松实现定制化开发。
用户友好的UI
Cognita RAG提供了用户友好的界面,方便非技术人员上传文档、执行问答等操作,降低了RAG技术的使用门槛。用户友好的UI使得Cognita RAG不仅适用于开发者,也适用于非技术人员。这使得Cognita RAG成为了一个更加通用的工具,可以用于各种不同的场景。
中心化仓库
Cognita RAG提供了一个中心化仓库,用于存储和管理文档、嵌入和查询结果。这使得开发者可以轻松地管理和访问他们的数据,而无需担心数据的一致性和完整性。中心化仓库还提供了版本控制功能,使得开发者可以轻松地跟踪和管理他们的数据变化。
完全API驱动
Cognita RAG是一个完全API驱动的框架,所有的操作都可以通过API来完成。这种设计使得Cognita RAG可以轻松地与其他系统集成,例如与现有的应用程序或服务集成。完全API驱动的设计使得Cognita RAG更加灵活和可扩展,可以满足各种不同的需求。
支持本地和可扩展部署
Cognita RAG支持多种部署方式,包括本地部署和云部署。本地部署可以直接在用户自己的机器上运行Cognita RAG,适用于私有用例。云部署可以利用TrueFoundry的云平台轻松部署和管理Cognita RAG实例,适用于需要可扩展性和协作的场景。Cognita RAG还支持Truefoundry集成,使得开发者可以更轻松地测试不同的模型并以可扩展的方式部署系统。
总之,Cognita RAG的核心优势在于其模块化设计、用户友好的UI、中心化仓库、完全API驱动以及支持本地和可扩展部署。这些优势使得Cognita RAG成为一个强大、灵活、易用的工具,可以用于各种不同的场景,并帮助开发者构建适合生产环境的RAG应用程序。
Cognita RAG的功能与特性
Cognita RAG作为一个先进的开源框架,不仅提供了模块化设计和用户友好的界面,还具备一系列强大的功能和特性,这些功能和特性使得它在构建和部署 Retrieval-Augmented Generation (RAG) 应用程序时表现出色。以下是Cognita RAG的一些核心功能和特性:
支持多种文档检索器
Cognita RAG支持多种文档检索器,这意味着开发者可以根据自己的需求选择最合适的检索工具。这些检索器包括但不限于:
- Elasticsearch:一种广泛使用的开源搜索引擎,能够快速、高效地检索大量数据。
- SQLite:轻量级的数据库,适用于小型或中等规模的数据存储和检索。
- Solr:Apache Solr是一个强大的搜索平台,基于Lucene构建,适用于复杂的搜索需求。
开发者可以根据数据量、查询复杂性和性能要求来选择合适的检索器,从而优化应用程序的性能。
支持最新的开源嵌入和重排序方法
Cognita RAG紧跟最新的开源嵌入和重排序方法,使得开发者能够利用最先进的技术来提升模型的性能。以下是一些支持的特性:
- 嵌入模型:Cognita RAG支持多种嵌入模型,如Word2Vec、BERT、GPT等,这些模型能够将文本转换为高维空间的向量,便于相似度计算和检索。
- 重排序算法:框架支持各种重排序算法,如基于上下文的排序、基于用户意图的排序等,这些算法能够根据特定的需求调整检索结果。
通过这些技术,Cognita RAG能够提供更加精准和相关的搜索结果。
支持增量索引
Cognita RAG支持增量索引,这是一种高效的数据更新策略,允许开发者仅对新增或修改的数据进行索引,而不是重新索引整个数据集。这种策略大大提高了索引的效率,尤其是在处理大量数据时。
增量索引的工作流程通常包括以下步骤:
- 数据监控:监控系统会实时监控数据源的变化,如新增、修改或删除操作。
- 数据提取:提取变化的数据,并将其发送到索引更新模块。
- 索引更新:索引更新模块对提取的数据进行处理,并更新到现有的索引中。
这种增量更新机制确保了数据的实时性和索引的高效性。
与现有系统通过API集成
Cognita RAG提供了丰富的API接口,使得它能够与现有的系统无缝集成。以下是一些集成的关键点:
- RESTful API:Cognita RAG提供了标准的RESTful API,使得开发者可以通过HTTP请求与框架进行交互。
- Webhooks:框架支持Webhooks,允许开发者在不直接修改代码的情况下,实现自定义的事件处理逻辑。
- SDK支持:Cognita RAG提供了多种编程语言的SDK,如Python、Java、JavaScript等,使得开发者可以更方便地在自己的应用程序中调用API。
通过这些集成方式,Cognita RAG能够灵活地适应不同的业务场景和需求,为开发者提供极大的便利。
总之,Cognita RAG的功能与特性使其成为一个强大且灵活的开源框架,能够满足各种复杂的应用场景,帮助开发者构建高效、可扩展的RAG应用程序。
Cognita RAG的使用场景
Cognita RAG作为一个模块化、易用与可扩展的开源框架,其设计理念是为了满足不同用户的需求,无论是在研究、开发还是生产环境中。以下是Cognita RAG在不同使用场景下的应用,以及社区反馈与建议的汇总。
不同用户的使用场景
研究人员
研究人员可以利用Cognita RAG来探索和实验各种 Retrieval-Augmented Generation (RAG) 技术的应用。例如,他们可以:
- 构建原型:快速搭建RAG原型,测试不同的嵌入和重排序方法,以及文档检索器。
- 数据集准备:使用Cognita RAG的模块化特性来准备和索引大规模数据集,以便进行模型训练和评估。
- 模型评估:通过集成的API,研究人员可以轻松地评估模型的性能,并进行A/B测试。
开发者
开发者在使用Cognita RAG时,可以专注于构建和部署生产级别的RAG应用程序。以下是一些具体的使用场景:
- 集成现有系统:通过Cognita RAG提供的API,开发者可以将RAG功能集成到现有的应用程序中,如问答系统、聊天机器人或内容推荐系统。
- 定制化开发:利用Cognita RAG的模块化设计,开发者可以根据项目需求定制化开发,如添加新的文档检索器或集成特定的嵌入模型。
- 性能优化:开发者可以利用Cognita RAG的增量索引功能,优化数据索引和查询处理,提高应用程序的响应速度和效率。
企业用户
企业用户可以利用Cognita RAG来提升业务流程的智能化水平,以下是一些典型的应用场景:
- 客户服务:通过集成Cognita RAG,企业可以构建智能的客户服务系统,自动检索相关文档和知识库,提供快速准确的回答。
- 知识管理:企业可以利用Cognita RAG来构建内部知识管理系统,帮助员工快速找到所需信息,提高工作效率。
- 数据分析:企业可以运用Cognita RAG对大量非结构化数据进行索引和分析,从中提取有价值的信息。
社区反馈与建议
Cognita RAG的开源特性吸引了一个活跃的社区,社区成员的反馈与建议对于框架的持续改进至关重要。以下是一些社区反馈与建议的汇总:
- 功能请求:社区成员经常提出新的功能请求,如支持更多的嵌入模型、增加新的文档检索器等。
- 性能优化:针对Cognita RAG的性能问题,社区成员提供了许多优化建议,包括改进索引算法、提高查询效率等。
- 文档完善:社区成员认为,完善文档对于新用户来说至关重要,建议增加更多的教程、示例和最佳实践。
- 错误报告:社区成员积极报告在使用Cognita RAG时遇到的问题和错误,以便开发团队能够及时修复。
通过不断收集和分析社区反馈,Cognita RAG的开发团队可以更好地理解用户需求,不断优化框架,使其更加完善和强大。
Cognita RAG的部署与集成
Cognita RAG作为一个模块化、易用与可扩展的开源框架,提供了多种部署与集成方式,以满足不同用户和场景的需求。以下是Cognita RAG的三种主要部署与集成方法。
本地部署
本地部署是指将Cognita RAG应用程序部署在用户的本地服务器或个人计算机上。这种部署方式适合那些对数据安全和隐私有严格要求,或者需要完全控制基础设施的用户。
部署步骤
- 环境准备:确保本地服务器或计算机满足Cognita RAG的硬件和软件要求,包括操作系统、Python版本、相关依赖库等。
- 安装Cognita RAG:通过pip等包管理工具安装Cognita RAG及其依赖。
pip install cognita-rag - 配置文件:根据实际情况配置Cognita RAG的配置文件,包括数据库连接、模型路径、API端口等。
- 启动服务:运行Cognita RAG的启动脚本或命令,启动后端服务。
cognita-rag start - 测试验证:通过访问本地API端口,测试Cognita RAG是否正常工作。
注意事项
- 确保本地网络环境可以访问Cognita RAG所需的远程服务,如模型仓库、文档数据库等。
- 定期更新Cognita RAG及其依赖库,以获得最新的功能和安全性修复。
云部署
云部署是指将Cognita RAG部署在云服务提供商上,如AWS、Azure或Google Cloud。这种方式适合需要高可用性、弹性扩展和易于维护的用户。
部署步骤
- 选择云服务提供商:根据需求选择合适的云服务提供商。
- 创建虚拟机或容器实例:在云平台上创建虚拟机或容器实例,并安装必要的操作系统和依赖。
- 部署Cognita RAG:将Cognita RAG部署到虚拟机或容器中,配置环境变量和配置文件。
- 设置自动扩展:根据负载情况配置自动扩展策略,确保服务的稳定性和响应性。
- 监控与日志:配置云服务的监控和日志功能,以便于问题追踪和性能优化。
注意事项
- 选择合适的云服务套餐,以平衡成本和性能。
- 确保云服务的安全组设置正确,以防止未授权访问。
Truefoundry集成
Truefoundry是一个平台,可以帮助开发者快速部署和扩展应用程序。通过Truefoundry,Cognita RAG可以轻松集成到复杂的系统中。
部署步骤
- 注册Truefoundry账户:在Truefoundry上创建账户并登录。
- 创建新项目:在Truefoundry上创建一个新项目,并设置项目的基本信息。
- 部署Cognita RAG:通过Truefoundry的界面或CLI工具将Cognita RAG部署到平台。
- 配置环境:在Truefoundry中配置Cognita RAG所需的环境变量和资源。
- 集成其他服务:利用Truefoundry的集成功能,将Cognita RAG与其他服务(如数据库、存储服务等)集成。
注意事项
- 熟悉Truefoundry的界面和操作流程。
- 确保Truefoundry的API访问权限正确设置,以避免安全风险。
通过这三种部署与集成方式,Cognita RAG可以灵活地适应不同的使用场景,为开发者提供便捷、高效的服务。
Cognita RAG的技术架构
Cognita RAG的技术架构是其能够提供强大功能的基础。它由多个关键组件构成,这些组件协同工作,确保了系统的稳定性和可扩展性。以下是Cognita RAG的主要组件及其功能:
Cognita RAG的组件
-
数据源:这是文档存储的位置,可以是本地硬盘、云存储或内部数据库。数据源是Cognita处理文档的起点。
-
元数据存储:类似于图书馆目录,用于跟踪文档集合的信息。它会记录集合名称、文档存储位置以及用于分析的所选嵌入模型等详细信息。
-
LLM网关(可选):充当于来自不同提供商的各种大语言模型(LLM)和嵌入模型交互的中心枢纽。它可以被视为一个通用翻译器,允许Cognita与不同的AI服务进行无缝通信。
-
向量数据库:这是一个高性能数据库,存储由分析器生成的文档嵌入。它允许Cognita根据用户查询有效地检索相关文档,可以视为一个超级强大的搜索引擎。
-
索引作业:在后台运行,自动处理文档。它从数据源检索文档、分析它们、创建嵌入,并将它们存储在向量数据库中。
-
API服务器:系统的核心。它接收用户查询,与其他组件交互以查找相关信息,并使用LLM网关(如果适用)生成响应。
数据索引与查询处理
Cognita RAG的数据索引与查询处理是其核心功能之一。它通过以下步骤实现:
-
文档解析:Cognita会自动解析上传的文档,提取文本内容,为后续的嵌入和索引做准备。
-
嵌入生成:使用预训练的嵌入模型(如OpenAI的text-embedding-ada-002)将文档内容转换为高维向量,这些向量能够捕捉文档的语义信息。
-
索引构建:将生成的嵌入存储在向量数据库中,构建索引。索引允许Cognita快速检索与用户查询最相关的文档。
-
查询处理:当用户提出查询时,Cognita会使用向量数据库来检索最相关的文档,并使用LLM网关(如果适用)生成响应。
代码结构
Cognita RAG的代码结构设计得非常清晰,便于开发者理解和扩展。以下是Cognita RAG的主要代码模块:
-
数据加载器:负责从数据源加载文档,支持多种数据格式和来源。
-
解析器:用于解析文档内容,提取文本信息。
-
嵌入器:使用预训练的嵌入模型将文本内容转换为向量。
-
向量数据库接口:提供与向量数据库交互的API,用于索引构建和查询处理。
-
API服务器:处理用户查询,调用其他组件生成响应。
-
用户界面:提供用户友好的界面,方便用户上传文档、执行问答等操作。
通过这些模块的协同工作,Cognita RAG能够提供一个完整、高效、易用的RAG解决方案,帮助开发者构建适合生产环境的RAG应用程序。
Cognita RAG与现有RAG框架的比较
在自然语言处理领域,Retrieval Augmented Generation (RAG) 技术通过结合检索和生成能力,显著提升了预训练语言模型的应用效果。Cognita RAG 作为一种新兴的开源框架,与现有的 RAG 框架相比,展现出其独特的优势和特点。本文将重点探讨 Cognita RAG 与 RAGFlow 的比较,以及 Cognita RAG 如何帮助开发者将 RAG 技术应用于生产环境。
Cognita RAG与RAGFlow的比较
RAGFlow 简介
RAGFlow 是一个流行的 RAG 框架,它提供了一个基础的框架来整合检索和生成过程。RAGFlow 的主要特点包括:
- 基本的模块化设计:允许开发者自定义和组合不同的组件。
- 简单的数据索引和查询处理:支持基本的数据索引和查询功能。
- 有限的扩展性:虽然提供了基本的扩展点,但扩展性相对有限。
Cognita RAG 的优势
与 RAGFlow 相比,Cognita RAG 在以下几个方面具有显著的优势:
-
更高级的模块化设计:Cognita RAG 提供了一套更为完善的模块化设计,包括数据加载器、解析器、嵌入器、重排序器和向量数据库等组件,这些组件可以灵活地组合和重用,大大提高了开发效率。
-
用户友好的 UI:Cognita RAG 通过一个精心设计的用户界面,使得非技术用户也能够轻松上传文档、执行查询和与系统交互,这一点是 RAGFlow 所不具备的。
-
完全 API 驱动:Cognita RAG 提供了全面的 API 支持,使得与其他系统的集成变得更加流畅,而 RAGFlow 在这方面则相对较弱。
-
支持多种向量数据库:Cognita RAG 与多种向量数据库(如 Qdrant 和 SingleStore)集成,提供了更高的灵活性和性能。
-
社区支持和开源贡献:作为开源框架,Cognita RAG 拥有一个活跃的社区,不断有新的功能和改进被集成进来,而 RAGFlow 的社区活跃度相对较低。
Cognita RAG 如何帮助生产化 RAG
Cognita RAG 的设计理念是为了简化将领域特定知识整合到通用预训练语言模型中的过程,以下是 Cognita RAG 如何帮助生产化 RAG 的几个方面:
-
简化开发流程:通过提供一系列可重用的组件和模块,Cognita RAG 大大简化了开发流程,使得开发者可以快速构建和部署 RAG 应用程序。
-
易于集成:Cognita RAG 的完全 API 驱动设计使得它可以轻松地与现有系统集成,无论是本地部署还是云部署,都能够灵活适应。
-
提高生产效率:Cognita RAG 的模块化设计不仅提高了开发效率,还使得维护和更新变得更加容易,这对于生产环境中的 RAG 应用程序至关重要。
-
增强性能和可扩展性:通过支持多种向量数据库和最新的嵌入和重排序方法,Cognita RAG 能够提供高性能和可扩展的解决方案,满足生产环境中的需求。
-
社区支持和持续改进:Cognita RAG 的开源特性吸引了广泛的社区支持,这意味着开发者可以依赖社区的贡献来不断改进和扩展框架的功能。
总之,Cognita RAG 通过其模块化设计、用户友好的界面、中心化仓库、完全 API 驱动和支持本地和可扩展部署等特性,为开发者提供了一个强大的工具,以构建适合生产环境的 RAG 应用程序。与现有的 RAG 框架相比,Cognita RAG 提供了更多的灵活性和易用性,使得开发者能够更高效地构建和部署 RAG 应用程序。
Cognita RAG的未来展望
Cognita RAG作为一个开源框架,其模块化设计、用户友好的界面和可扩展性使其在AI领域具有巨大的发展潜力。以下是Cognita RAG未来展望的两个关键方面:新功能的引入和未来贡献范围的规划。
新功能的引入
Cognita RAG的未来发展将集中在引入一系列新功能,以进一步提升其性能、灵活性和易用性。以下是一些即将到来的新功能:
1. 更强大的嵌入和重排序算法
随着AI技术的不断进步,Cognita RAG计划集成最新的嵌入和重排序算法。这些算法将提高检索的准确性和生成响应的相关性,使得Cognita RAG能够生成更加精确和有深度的回答。
2. 增强的多语言支持
为了满足全球用户的需求,Cognita RAG将扩展其多语言支持功能。这包括对更多语言的嵌入和解析支持,以及为不同语言环境提供本地化的用户界面。
3. 高级数据隐私和安全功能
随着数据隐私和安全性的重要性日益增加,Cognita RAG将引入更高级的数据加密和访问控制功能。这些功能将确保用户数据的安全性和合规性。
4. 可视化工具和仪表板
为了提高用户体验,Cognita RAG计划开发可视化工具和仪表板,帮助用户更直观地理解系统的工作流程和性能。
未来贡献范围规划
Cognita RAG的开源特性为其未来的发展提供了广阔的空间。以下是未来贡献范围的规划:
1. 社区驱动的功能开发
Cognita RAG将鼓励社区成员参与新功能的开发和优化。社区驱动的开发模式将加速创新,确保框架能够快速适应市场需求和技术进步。
2. 教育和文档资源
为了帮助新用户更好地理解和使用Cognita RAG,将提供更多的教育和文档资源。这包括详细的用户手册、教程视频、案例分析等。
3. 开发者工具和插件
Cognita RAG将开发一系列开发者工具和插件,以简化开发流程。这些工具和插件将帮助开发者快速集成Cognita RAG到他们的项目中,并提高开发效率。
4. 跨平台支持
为了扩大Cognita RAG的应用范围,将致力于实现跨平台支持。这意味着Cognita RAG不仅可以在云端运行,还可以在本地环境和各种操作系统上运行。
5. 持续的社区支持和反馈
Cognita RAG将建立一个活跃的社区,鼓励用户分享他们的经验和反馈。社区的支持和反馈将帮助Cognita RAG不断改进和优化,以满足用户的需求。
总之,Cognita RAG的未来展望充满了无限可能。通过不断引入新功能和规划未来的贡献范围,Cognita RAG将继续在AI领域发挥重要作用,为开发者提供更加强大、灵活和易用的工具。
Cognita RAG的开源贡献
Cognita RAG作为一个开源框架,不仅为开发者提供了强大的功能和灵活性,还鼓励和欢迎社区成员的参与和贡献。以下是关于如何为Cognita RAG做出贡献的指南以及社区参与的详细介绍。
贡献指南
1. 了解项目结构和代码库
在开始贡献之前,首先需要熟悉Cognita RAG的项目结构和代码库。Cognita RAG的代码库通常包括以下核心组件:
- Chunking and Embedding Job:负责将文档分割成小块并生成嵌入向量。
- Query Service:处理查询请求,并从索引中检索相关信息。
- LLM / Embedding Model Deployment:部署语言模型和嵌入模型,以便进行查询和检索。
通过阅读官方文档和代码库的README文件,可以更好地理解每个组件的作用和如何与之交互。
相关文章:
Cognita RAG:模块化、易用与可扩展的开源框架
Cognita RAG是一个开源框架,它通过模块化设计、用户友好的界面和可扩展性,简化了将领域特定知识整合到通用预训练语言模型中的过程。本文介绍了Cognita的特点、优势、应用场景以及如何帮助开发者构建适合生产环境的RAG应用程序。 文章目录 Cognita RAG介…...

linux虚拟机免密登录配置
1、假设A服务器要免密登录B服务器 2、在A服务器上执行命令: cd /root/.ssh/ ssh-keygen -t rsa #这里会生成两个文件 一个是id_rsa私钥和公钥rsa.pub2、我们把公钥的内容复制粘贴到B服务器的/root/.ssh/authorized_keys文件下 #在A服务器上执行命令记录内容 cat …...
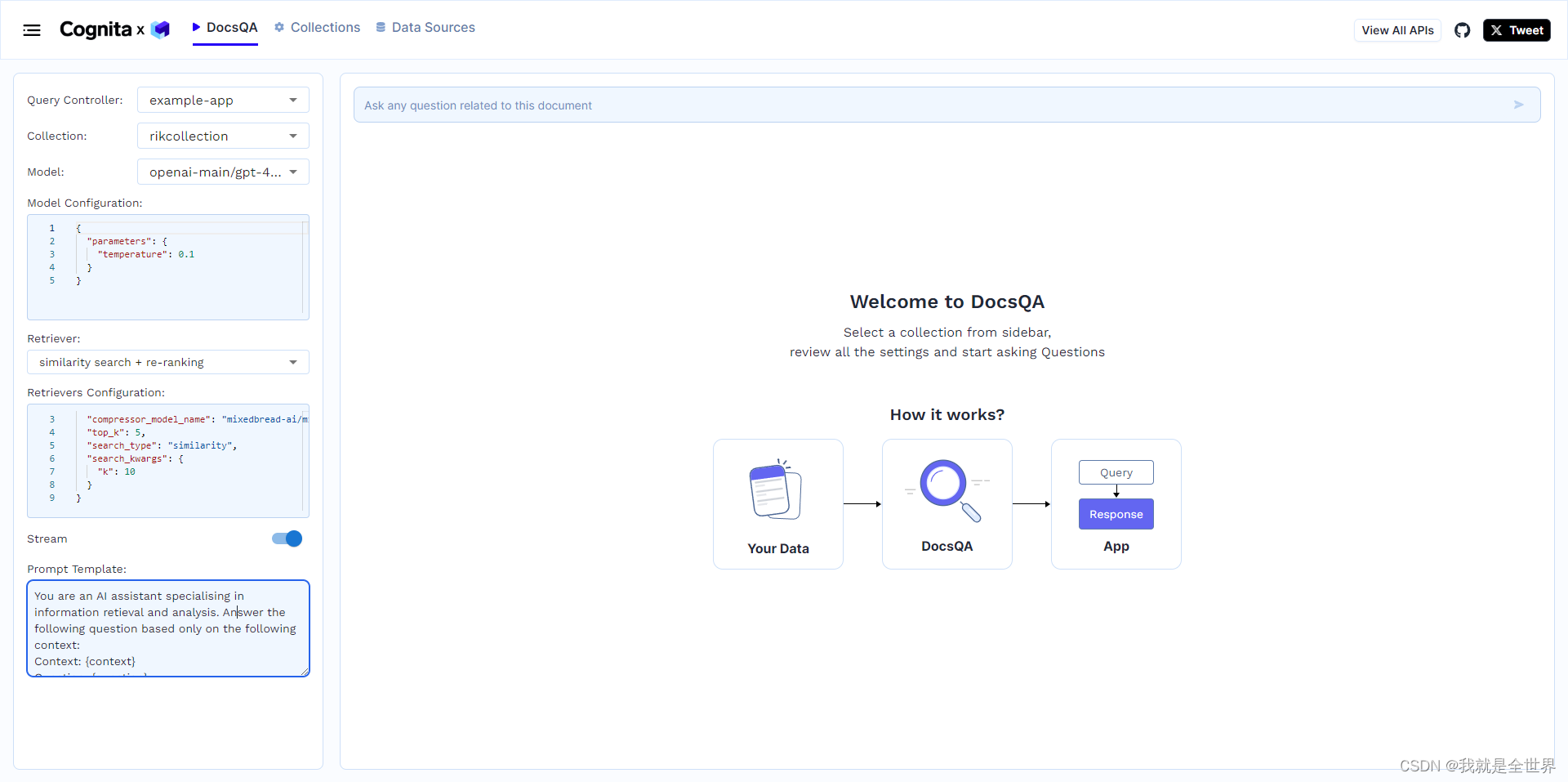
Qt_C++ RFID网络读卡器Socket Udp通讯示例源码
本示例使用的设备: WIFI/TCP/UDP/HTTP协议RFID液显网络读卡器可二次开发语音播报POE-淘宝网 (taobao.com) #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <QHostInfo> #include <QNetworkInterface> #include <…...

C++ 实现Python 列表list 的两种方法
1、vector里面放多种参数。在C中,如果你想要在std::vector中存储不同类型的参数,你可以使用std::any(C17及以上)或std::variant(C17以前的版本需要使用Boost库或者C17及以上标准)。以下是使用std::vector&l…...
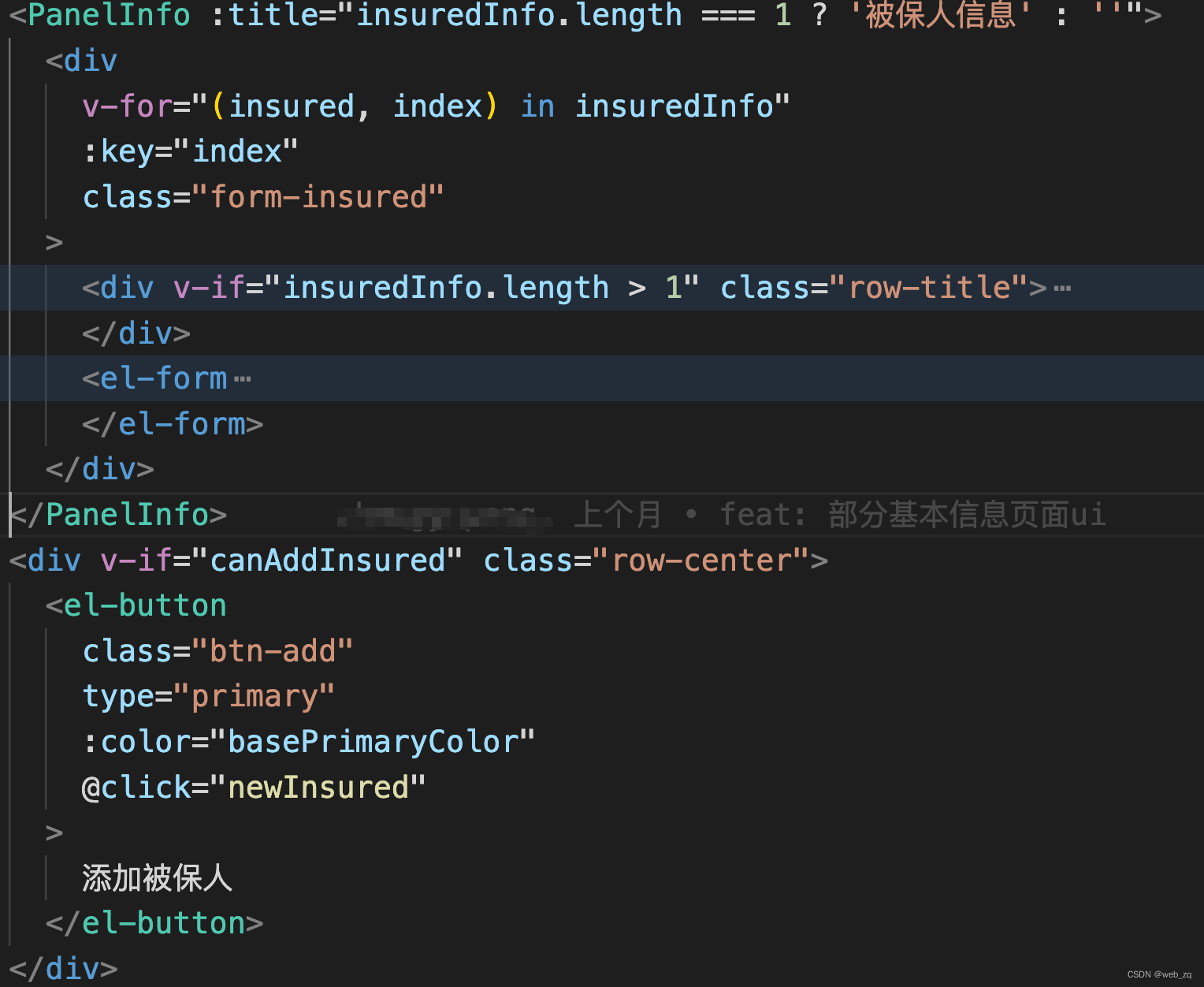
vue3+ elementPlus PC端开发 遇到页面已进入就form校验了的问题
form表单一进页面就校验了 rules里配置的 require 提示语 如图所示代码是这样的 最后发现是form表单下面的一个按钮的展示规则 会导致规则校验 canAddInsured 这个字段的变化会导致form表单校验 这个字段是computed maxInsureds 也是个computed监听 maxInsured.value >1 就…...
transformers DataCollator介绍
本博客主要介绍 transformers DataCollator的使用 from transformers import AutoTokenizer, AutoModel, \DataCollatorForSeq2Seq, DataCollatorWithPadding, \DataCollatorForTokenClassification, DefaultDataCollator, DataCollatorForLanguageModelingPRETRAIN_MODEL &qu…...
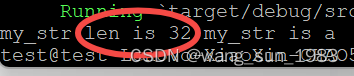
rust学习(字节数组转string)
最新在写数据传输相关的操作,发现string一个有趣的现象,代码如下: fn main() {let mut data:[u8;32] [0;32];data[0] a as u8;let my_str1 String::from_utf8_lossy(&data);let my_str my_str1.trim();println!("my_str len is…...
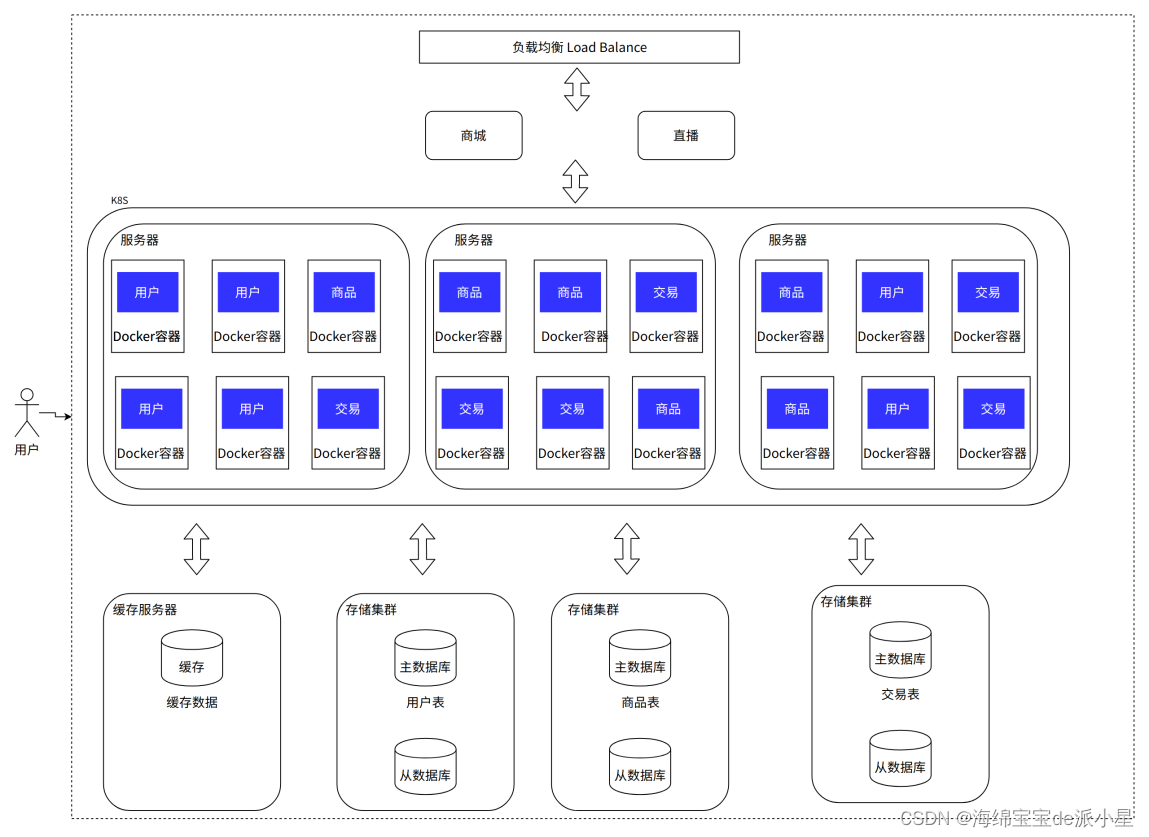
Docker:技术架构演进
文章目录 基本概念架构演进单机架构应用数据分离架构应用服务集群架构读写分离/主从分离架构冷热分离架构垂直分库微服务容器编排架构 本篇开始进行对于Docker的学习,Docker是一个陌生的词汇,那么本篇开始就先从技术架构的角度出发,先对于技术…...
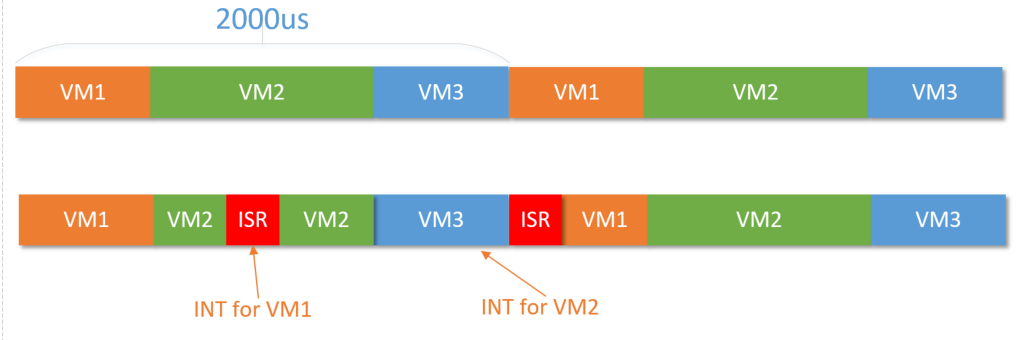
汽车MCU虚拟化--对中断虚拟化的思考(2)
目录 1.引入 2.TC4xx如何实现中断虚拟化 3.小结 1.引入 其实不管内核怎么变,针对中断虚拟化无非就是上面两种,要么透传给VM,要么由Hypervisor统一分发。汽车MCU虚拟化--对中断虚拟化的思考(1)-CSDN博客 那么,作为车规MCU龙头…...

python的继承
本章正式开始之前,先让我们回顾一下什么是 对象 ? 什么是 类 ? 小贝 喜欢 猫咪,今年领养了一只名叫 Kitty 的 布偶猫。则下列哪项是 对象 呢? A. 猫咪 B. Kitty C. 布偶猫 相比之下,闻闻 更喜欢 犬科 动…...

组件的注册和引用
在Vue中,开发者可以将页面中独立的、可重用的部分封装成组件,对组件的结构,样式和行为进行设置。组件是 Vue 的基本结构单元,组件之间可以相互引用。 一.注册组件 当在Vue项目中定义了一个新的组件后,要想在其他组件中…...
诊所如何赢得患者?做好这两点很关键!
大家都知道,社区周边的诊所原本是居民看病的第一选择,方便又快捷。但现在很多诊所服务都差不多,没有自己的特色,这就让患者有点难选择了。那诊所怎么做才能更吸引患者呢?其实,关键是要抓住患者的心…...

Qwen2本地部署的实战教程
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…...
html+CSS+js部分基础运用15
1、完成输入框内容的实时反向输出。 2、银行账户余额变动自动通知项目。 设计要求:单击按钮后,余额按照输入框的数额减少,同时将按钮式的提示信息(金额)同步改变。利用侦听属性实现余额发生变化时发出提示信息&#x…...

从零开始学JAVA
一、编写Hello world程序 public class JavaMain1 {//主程序执行入口,main方法public static void main(String[] args){System.out.println("Hello world!");} } 运行结果 Hello world! java编写主程序常见错误: 1、System ---首字母没有…...
查询)
MySQL(四)查询
1、MySQL限性约束 —非空、唯一(自增)、主外键、检查(MySQL存在但是不能用)。 约束主要完成对数据的校验,保证数据库数据的完整性;如果有相互依赖数据,保证该数据不被删除。 1)常用五类约束 not null :非空约束,指定某列不为空。 unique:唯一约束,指定某列和几列组…...
——day31)
嵌入式学习——网络编程(TCP)——day31
1. TCP和UDP的区别 TCP(Transmission Control Protocol,传输控制协议) UDP(User Datagram Protocol,用户数据报协议) 1.1 连接方式 TCP 是面向连接的协议,它在数据传输前需要通过三次握手建立…...

[STM32]定位器与PWM的LED控制
目录 1. 深入了解STM32定时器原理,掌握脉宽调制pwm生成方法。 (1)STM32定时器原理 原理概述 STM32定时器的常见模式 使用步骤 (2)脉宽调制pwm生成方法。 2. 实验 (1)LED亮灭 代码 测试效果 (2)呼吸灯 代码 测试效果 3.总结 1. 深入了解STM32定时器原…...

可视化数据科学平台在信贷领域应用系列五:零代码可视化建模
信贷风控模型是金融机构风险管理的核心工具,在信贷风险管理工作中扮演着至关重要的角色。随着信贷市场的环境不断变化,信贷业务的风险日趋复杂化和隐蔽化,开发和应用准确高效的信贷风控模型显得尤为重要。信贷风险控制面临着越来越大的挑战和…...

Windows 11广告植入“另辟蹊径”:PC Manager暗示若不使用必应搜索,你的系统可能需要“修复”
Edge浏览器近期增添了许多实用的新功能,如侧边栏、休眠标签页和沉浸式阅读器。话虽如此,浏览器中仍有一部分功能被部分用户视为“冗余软件”和不必要的累赘。 随着Windows 11用户逐渐习惯操作系统关键位置出现越来越多的广告,微软似乎正尝试以…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...

MinIO Docker 部署:仅开放一个端口
MinIO Docker 部署:仅开放一个端口 在实际的服务器部署中,出于安全和管理的考虑,我们可能只能开放一个端口。MinIO 是一个高性能的对象存储服务,支持 Docker 部署,但默认情况下它需要两个端口:一个是 API 端口(用于存储和访问数据),另一个是控制台端口(用于管理界面…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...

Python网页自动化Selenium中文文档
1. 安装 1.1. 安装 Selenium Python bindings 提供了一个简单的API,让你使用Selenium WebDriver来编写功能/校验测试。 通过Selenium Python的API,你可以非常直观的使用Selenium WebDriver的所有功能。 Selenium Python bindings 使用非常简洁方便的A…...
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...