详解 Flink 的状态管理
一、Flink 状态介绍
1. 流处理的无状态和有状态
- 无状态的流处理:根据每一次当前输入的数据直接转换输出结果的过程,在处理中只需要观察每个输入的独立事件。例如, 将一个字符串类型的数据拆分开作为元组输出或将每个输入的数值加 1 后输出。Flink 中的基本转换算子 (map、filter、flatMap 等) 在计算时不依赖其他数据,所以都属于无状态的算子。

-
有状态的流处理:根据每一次当前输入的数据和一些其他已处理的数据共同转换输出结果的过程,这些其他已处理的数据就称之为状态(state),状态由任务维护,可以被任务的业务逻辑访问。例如,做求和(sum)计算时,需要当前输入的数据和保存的之前所有输入数据的和共同计算;窗口操作中会将当前达到的数据和保存的之前已经到达的所有数据共同处理。Flink 中的聚合算子和窗口算子都属于有状态的算子。

2. Flink 的状态管理
- 在传统的事务型处理架构中,状态数据一般是保存在数据库中的,在业务处理过程中与数据库交互进行状态的读取和更新;但对于大数据实时处理架构来说,在业务处理时频繁地读写外部数据库会造成性能达不到要求,因此不能使用数据库进行状态管理
- 在实时流处理中一般将状态直接保存在内存中来保证性能,但必须使用分布式架构来做扩展,在低延迟、高吞吐的基础上还要保证容错性,一系列复杂的问题随之产生
- Flink 拥有一套完整的状态管理机制,将底层一些核心功能全部封装起来,包括状态一致性、状态的高效存储和访问、持久化保存和故障恢复以及资源扩展时的调整。开发者只需要调用相应的 API 就可以很方便地使用状态,或对应用的容错机制进行配置,从而将更多的精力放在业务逻辑的开发上
二、Flink 状态分类
1. 托管状态
Managed State,所有的托管状态都由 Flink 统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由 Flink 实现
1.1 算子状态
Operator State,状态作用范围限定为当前的算子任务实例,只对当前的并行子任务实例有效;使用较少

- 由同一并行任务所处理的所有数据都可以访问到相同的算子状态
- 算子状态对于同一任务而言是共享的
- 算子状态不能由相同或不同算子的另一个任务访问
1.1.1 算子状态数据结构
- 列表状态(List state):将状态表示为一组数据的列表
- 联合列表状态(Union list state):也是将状态表示为一组数据的列表。与列表状态的区别在于,在发生故障时或者从保存点(savepoint)启动应用程序时恢复的方式不同
- 广播状态(Broadcast state):如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态
1.1.2 案例
public class TestFlinkOperatorState {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> inputStream = env.socketTextStream("localhost", 7777);DataStream<SensorReading> dataStream = inputStream.map(line -> {String[] fields = line.split(",");return new SensorReading(fileds[0], new Long(fields[1]), new Double(fields[2]));});//定义一个有状态的map算子,用于统计输入数据个数DataStream<Integer> resultStream = dataStream.map(new MyCountMapper());resultStream.print();env.execute();}//定义有状态的 map 操作//实现 ListCheckpointed 接口,泛型为状态数据类型public static class MyCountMapper implements MapFunction<SensorReading, Integer>, ListCheckpointed<Integer> {//定义一个本地变量作为状态private Integer count = 0;@Overridepublic Integer map(SensorReading value) throws Exception {count++;return count;}//对状态做快照@Overridepublic List<Integer> snapshotState(long checkpointId, long timestamp) throws Exception {return Collections.singletonList(count);}//容错恢复状态@Overridepublic void restoreState(List<Integer> state) throws Exception {for(Integer num : state) {count += num;}}}}
1.2 按键分区状态
Keyed State,状态的作用范围以 key 来隔离,是根据输入流中定义的键(key)来维护和访问的,所以只能定义在按键分区流(KeyedStream)中,即 keyBy 之后才可以使用

- 在进行按键分区(keyBy)之后,具有相同 key 的所有数据,都会分配到同一个并行子任务中,这个任务会维护和处理这个 key 对应的状态实例
- 一个并行子任务可能会处理多个 key 的数据,所以该任务会为每个 key 都维护一个状态实例
- 在底层,同一个并行子任务的所有 KeyedState 会根据 key 保存成键值对(key-value)的形式,当一条数据到来时,任务会自动将状态的访问范围限定为当前数据的 key,并从键值对(key-value)存储中读取出对应的状态值
- 具有相同 key 的所有数据都会到访问相同的状态,而不同 key 的状态之间是彼此隔离的
- 在应用的并行度改变时,状态也需要随之进行重组。不同 key 对应的 Keyed State 可以进一步组成所谓的键组(key groups),每一组都对应着一个并行子任务。键组是 Flink 重新分配 Keyed State 的单元,键组的数量就等于定义的最大并行度。当算子并行度发生改变时,Keyed State 就会按照当前的并行度重新平均分配,保证运行时各个子任务的负载相同
1.2.1 按键分区状态数据结构
//按键分区状态的实例化方法:在富函数中,调用 getRuntimeContext() 方法获取到运行时上下文之后
ValueState<T> getState(ValueStateDescriptor<T>)
MapState<UK, UV> getMapState(MapStateDescriptor<UK, UV>)
ListState<T> getListState(ListStateDescriptor<T>)
ReducingState<T> getReducingState(ReducingStateDescriptor<T>)
AggregatingState<IN, OUT> getAggregatingState(AggregatingStateDescriptor<IN, ACC, OUT>)
- 值状态:
ValueState<T>,将状态表示为单个的值,值的类型为 TValueState.value():获取状态值ValueState.update(T value):添加或更新状态值ValueState.clear():清空操作
- 列表状态:
ListState<T>,将状态表示为一组数据的列表,列表里的元素的数据类型为 TListState.add(T value):追加状态值ListState.addAll(List<T> values):追加状态值列表ListState.get():获取状态值的Iterable<T>ListState.update(List<T> values):更新状态值列表ListState.clear():清空操作
- 映射状态:
MapState<K, V>,将状态表示为一组 Key-Value 对MapState.get(UK key):获取状态值MapState.put(UK key , UV value):添加或更新状态值MapState.contains(UK key):判断状态值是否存在MapState.remove(UK key):删除状态值MapState.clear():清空操作
- 聚合状态:
ReducingState<T>和AggregatingState<I, O>,将状态表示为一个用于聚合操作的列表ReducingState.add():聚合状态值,调用实例化 ReducingState 时自定义 ReduceFunction 中的方法;AggregatingState 同理ReducingState.clear():清空操作,AggregatingState 同理
1.2.2 案例
/**按键分区状态的使用步骤:1. 在自定义算子Function中声明一个按键分区数据结构,由于声明时需要使用 getRuntimeContext(),因此要使用继承富函数类的方式自定义算子Function2. 在自定义算子Function的对应算子方法中进行状态的读写等相关操作
*/
public class TestFlinkKeyedState {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> inputStream = env.socketTextStream("localhost", 7777);DataStream<SensorReading> dataStream = inputStream.map(line -> {String[] fields = line.split(",");return new SensorReading(fileds[0], new Long(fields[1]), new Double(fields[2]));});/*需求:自定义有状态的map算子,按sensor_id统计个数*///使用按键分区状态必须先进行keyByDataStream<Integer> resultStream = dataStream.keyBy("id").map(new MyKeyCountMapper());resultStream.print();env.execute();}//使用继承富函数类的方式自定义MapFunctionpublic static class MyKeyCountMapper extends RichMapFunction<SensorReading, Integer> {//定义一个值状态属性private ValueState<Integer> myValueState;//在open方法中实例化值状态@Overridepublic void open(Configuration parameters) throws Exception {myValueState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("value-state", Integer.class));}@Overridepublic Integer map(SensorReading value) throws Exception {//获取状态值Integer count = myValueState.value();if(count == null) {count = 0;}count++;//更新状态值myValueState.update(count);return count;}}
}
2. 原始状态
Raw State,原始状态是自定义的,相当于开辟了一块内存,需要开发者自己管理,实现状态的序列化和故障恢复
- Flink 不会对原始状态进行任何自动操作,也不知道状态的具体数据类型,只会把它当作最原始的字节(Byte)数组来存储
- 只有在遇到托管状态无法实现的特殊需求时,才考虑使用原始状态;一般情况下不推荐使用
三、Flink 状态编程案例
/**需求:检测同一个传感器的温度值,如果连续的两个温度差值超过 10 度,就输出报警信息
*/
public class FlinkKeyedStateCase {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> inputStream = env.socketTextStream("localhost", 7777);DataStream<SensorReading> dataStream = inputStream.map(line -> {String[] fields = line.split(",");return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));});//定义一个有状态的 flatMap 操作,若同一个传感器连续两个温度的差值超过 10 度,则输出报警//报警信息:sensor_id,前一次温度值,当前温度值DataStream<Tuple3<String, Double, Double>> warningStream = dataStream.keyBy("id").flatMap(new TempChangeWarning(10.0));warningStream.print();env.execute();}//使用继承富函数类的方式自定义FlatMapFunctionpublic static class TempChangeWarning extends RichFlatMapFunction<SensorReading, Tuple3<String, Double, Double>> {//定义温度差阈值属性private Double threshold;//定义值状态属性,保存上一次的温度值private ValueState<Double> lastTempState;public TempChangeWarning(Double threshold) {this.threshold = threshold;}//在open方法中实例化值状态@Overridepublic void open(Configuration parameters) throws Exception {lastTempState = getRuntimeContext().getState(new ValueStateDescriptor("last-temp", Double.class));}//重写flatMap方法@Overridepublic void flatMap(SensorReading value, Collector<Tuple3<String, Double, Double>> out) throws Exception {//获取上一次温度状态值Double lastTemp = lastTempState.value();//如果状态值不为null,则进行差值判断if(lastTemp != null) {Double diff = Math.abs(lastTemp - value.getTemperature());//差值超过阈值,则输出报警信息if(diff >= threshold) {out.collect(new Tuple3<>(value.getId(), lastTemp, value.getTemperature()));}}//更新状态值lastTempState.update(value.getTemperature());}//在close方法中清空状态@Overridepublic void close() throws Exception {lastTempState.clear();}}
}
四、Flink 状态后端
State Backends,一个可插入的决定状态的存储、访问以及维护等工作的组件
1. 介绍
在 Flink 中,状态的存储、访问以及维护,都是由一个可插拔的组件决定的,这个组件就叫作状态后端(state backends)。状态后端主要负责两件事:一是本地的状态管理,二是将检查点(checkpoint)写入远程的持久化存储。
2. 分类
-
MemoryStateBackend:内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储
在 TaskManager 的 JVM 堆上;而将 checkpoint 存储在 JobManager 的内存中。 -
FsStateBackend:文件系统级的状态后端,对于本地状态,跟 MemoryStateBackend 一样,也会存储在 TaskManager 的 JVM 堆上,但会将 checkpoint 存储到远程的持久化文件系统(FileSystem)中,如 HDFS。
-
RocksDBStateBackend:将所有状态和 checkpoint 序列化后,存入本地的 RocksDB 中存储。RocksDBStateBackend 的支持并不直接包含在 flink 中,需要引入依赖。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_2.12</artifactId><version>1.10.1</version> </dependency>
3. 配置
3.1 配置文件配置
-
进入 flink 安装目录下的 conf 目录,打开
flink-conf.yaml文件cd /opt/module/flink/conf vim flink-conf.yaml -
在文件中的
Fault tolerance and checkpointing部分进行配置#Fault tolerance and checkpointing #============================================================ state.backend: filesystem #默认值为 filesystem,可选值为 jobmanager/filesystem/rocksdb#state.checkpoints.dir: hdfs://namenode:port/flink/checkpointsjobmanager.execution.failover-strategy: region #容错恢复策略,默认是按区域恢复
3.2 代码配置
在代码中为每个作业单独配置状态后端
public class TestStatebackend {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//配置状态后端//1.MemoryStateBackendenv.setStateBackend(new MemoryStateBackend());//2.FsStateBackendenv.setStateBackend(new FsStateBackend("hdfs://......"));//3.RocksDBStateBackend,需要先引入依赖env.setStateBackend(new RocksDBStateBackend("checkpointDataUri"));DataStream<String> inputStream = env.socketTextStream("localhost", 7777);DataStream<SensorReading> dataStream = inputStream.map(line -> {String[] fields = line.split(",");return new SensorReading(fileds[0], new Long(fields[1]), new Double(fields[2]));});dataStream.print();env.execute();}
}
相关文章:
详解 Flink 的状态管理
一、Flink 状态介绍 1. 流处理的无状态和有状态 无状态的流处理:根据每一次当前输入的数据直接转换输出结果的过程,在处理中只需要观察每个输入的独立事件。例如, 将一个字符串类型的数据拆分开作为元组输出或将每个输入的数值加 1 后输出。…...

手机怎么压缩视频?归纳了三种快速压缩方案
手机怎么压缩视频?在数字时代,手机已经成为我们记录生活的重要工具,而视频作为其中的一种主要形式,更是占据了极大的存储空间。然而,随着手机拍摄的视频越来越多,如何高效压缩视频以节省存储空间࿰…...
【实战】kafka3.X kraft模式集群搭建
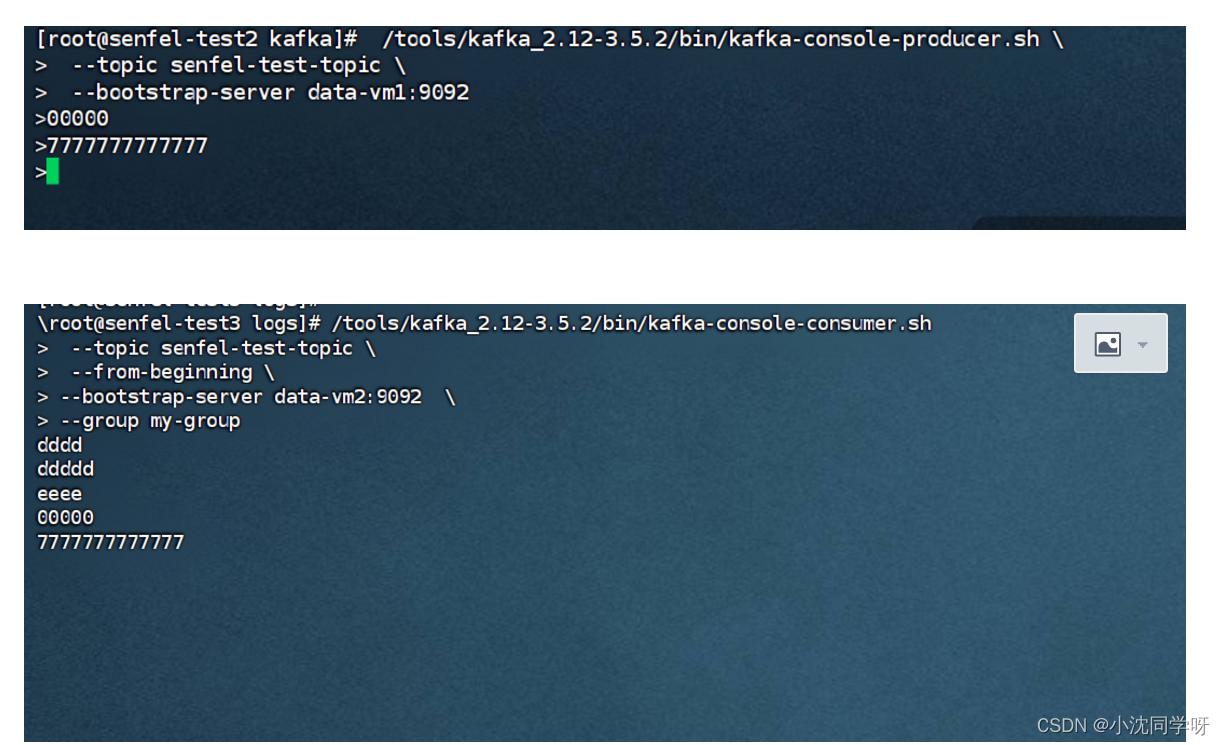
文章目录 前言kafka2.0与3.x对比准备工作JDK安装kafka安装服务器增加hosts 修改Kraft协议配置文件格式化存储目录 启动集群停止集群测试Kafka集群创建topic查看topic列表查看消息详情生产消息消费消息查看消费者组查看消费者组列表 前言 相信很多同学都用过Kafka2.0吧…...
华为防火墙配置 SSL VPN
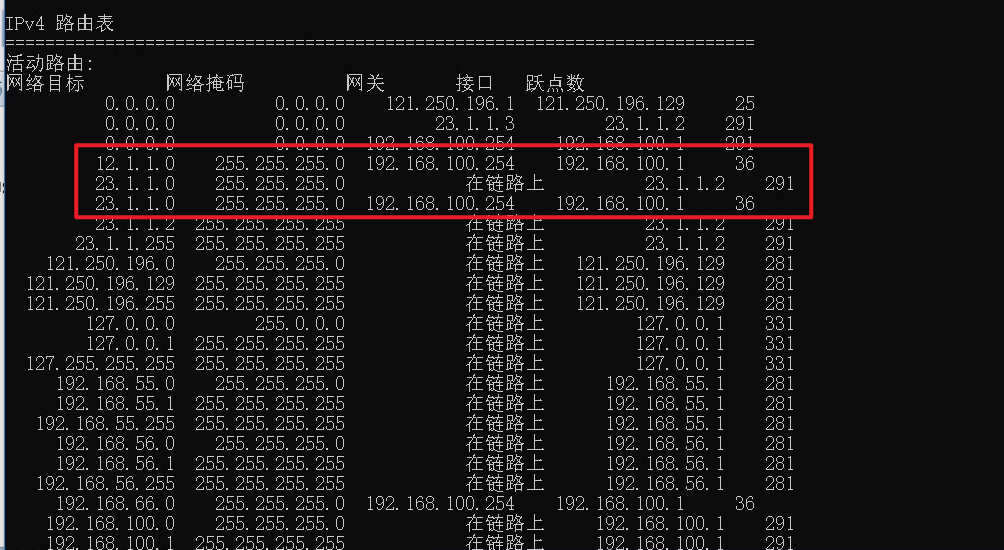
前言 哈喽,我是ICT大龙。本期给大家更新一次使用华为防火墙实现SSL VPN的技术文章。 本次实验只需要用到两个软件,分别是ENSP和VMware,本次实验中的所有文件都可以在文章的末尾获取。话不多说,教程开始。 什么是VPN 百度百科解…...
Redis的删除策略与内存淘汰
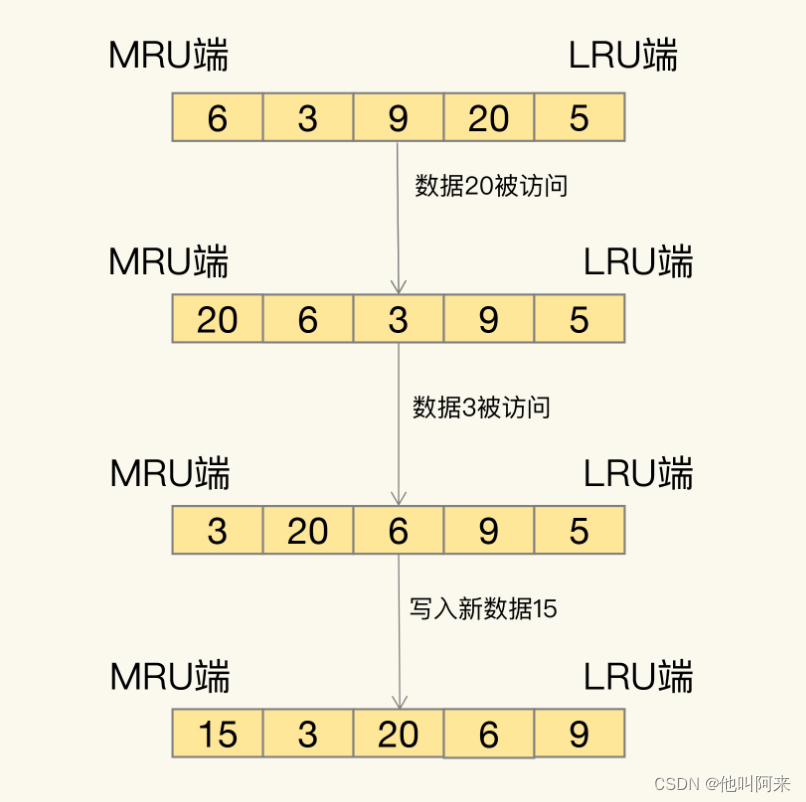
文章目录 删除策略设置过期时间的常用命令过期删除策略 内存淘汰相关设置LRU算法LFU 总结 在redis使用过程中,常常遇到以下问题: 如何设置Redis键的过期时间?设置完一个键的过期时间后,到了这个时间,这个键还能获取到么…...

《一心体系至善算法》“人文+AI”成果
《一心体系至善算法》“人文AI”成果 人工智能(AI)和通用人工智能(AGI)的伦理与安全问题: 在《中法联合声明》中,着重强调了AI向善问题。在探讨人工智能(AI)和通用人工智能(AGI&…...

C#面:阐述对DDD的理解
C#是一种面向对象的编程语言,而领域驱动设计(Domain-Driven Design,简称DDD)是一种软件开发方法论,它强调将业务领域的知识和逻辑直接融入到软件设计和开发中。 在C#中实施DDD的关键是将业务领域划分为不同的领域模型…...
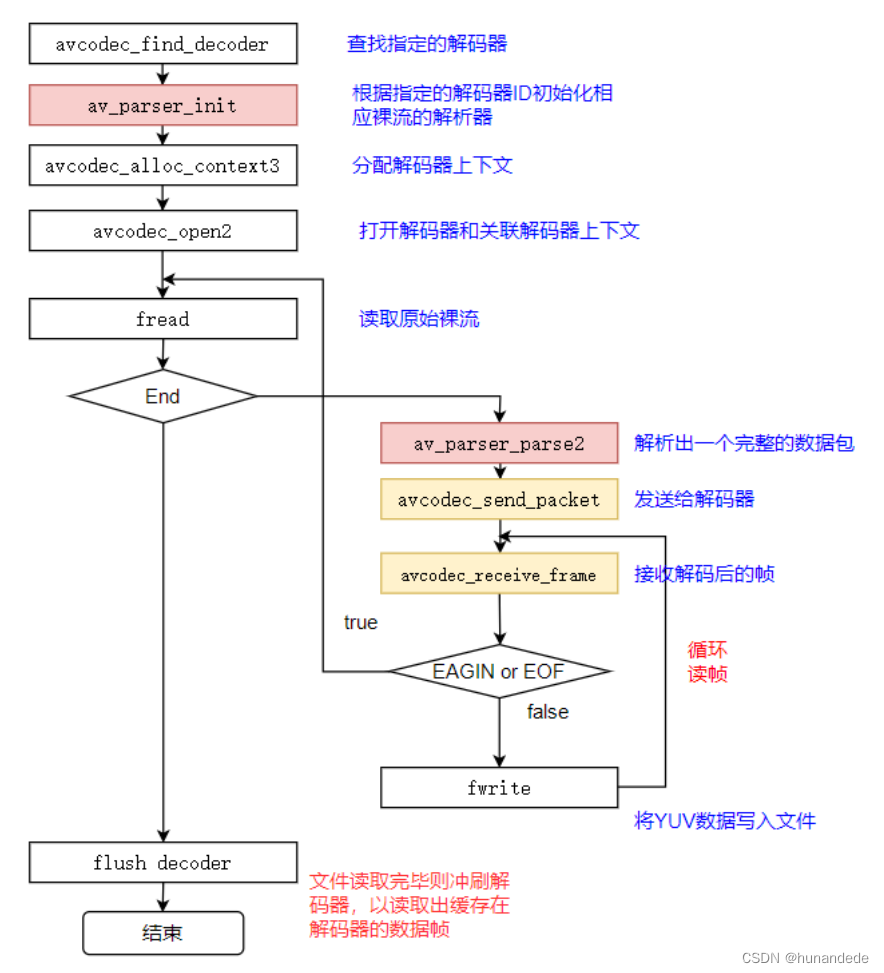
音视频开发19 FFmpeg 视频解码- 将 h264 转化成 yuv
视频解码过程 视频解码过程如下图所示: ⼀般解出来的是420p FFmpeg流程 这里的流程是和音频的解码过程一样的,不同的只有在存储YUV数据的时候的形式 存储YUV 数据 如果知道YUV 数据的格式 前提:这里我们打开的h264文件,默认是YU…...
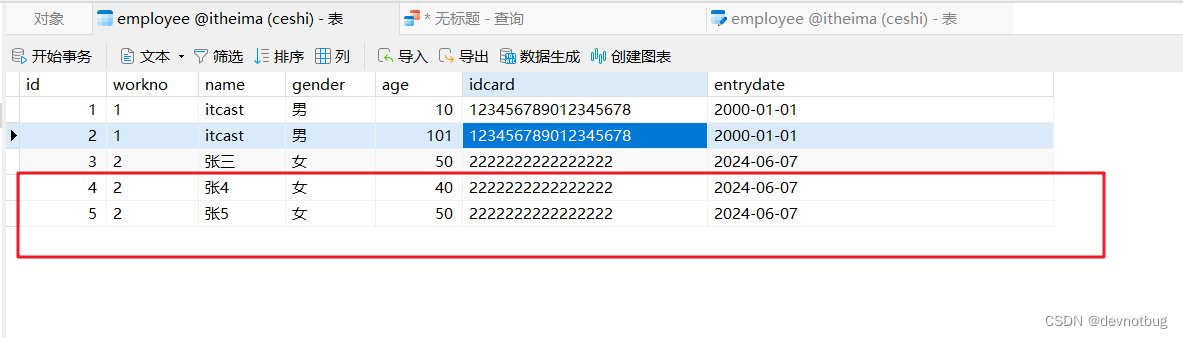
Mysql 常用命令 详细大全【分步详解】
1、启动和停止MySQL服务 // 暂停服务 默认 80 net stop mysql80// 启动服务 net start mysql80// 任意地方启动 mysql 客户端的连接 mysql -u root -p 2、输入密码 3、数据库 4、DDL(Data Definition Language )数据 定义语言, 用来定义数据库对象(数…...
基于百度接口的实时流式语音识别系统
目录 基于百度接口的实时流式语音识别系统 1. 简介 2. 需求分析 3. 系统架构 4. 模块设计 4.1 音频输入模块 4.2 WebSocket通信模块 4.3 音频处理模块 4.4 结果处理模块 5. 接口设计 5.1 WebSocket接口 5.2 音频输入接口 6. 流程图 程序说明文档 1. 安装依赖 2.…...

AIGC作答《2024年高考作文|新课标I卷》能拿多少分?
AIGC作答《2024年高考作文|新课标I卷》能拿多少分? 一、前言二、题目三、作答 一、前言 如火如荼的2024年高考圆满落幕,在如此Happy的时刻,AIGC技术正以其前所未有的热度席卷全球。它不仅改变了我们获取信息的方式,也…...

WHAT - 发布订阅
目录 一、常见实现方案1.1 使用事件发射器(Event Emitter)1.2 自定义事件系统(EventBus)1.3 使用库如 PubSubJS1.4 使用框架内置的状态管理工具Vue.jsReact (使用 Context API 或 Redux) 二、先后关系2.1 缓存事件数据2.2 使用 Re…...
useEffect)
React@16.x(23)useEffect
目录 1,介绍作用介绍 2,注意点2.1,参数1,副作用函数2.1.1,运行时间点2.1.2,返回值2.1.3,闭包的影响2.1.4,严禁出现在代码块中(判断,循环)2.1.5&am…...

算法竞赛一句话解题经典问题分析 ©ntsc 2024
原名:算法竞赛一句话解题&经典问题分析 ©ntsc 2024 处理进度 绿:P1381【~P(今日进度)】蓝:P1099 致CSDN网友: 本文章不定期更新!文章链接: 经典问题分析 基础知识与编程…...

【TensorFlow深度学习】强化学习中的贝尔曼方程及其应用
强化学习中的贝尔曼方程及其应用 强化学习中的贝尔曼方程及其应用:理解与实战演练贝尔曼方程简介应用场景代码实例:使用Python实现贝尔曼方程求解状态价值结语 强化学习中的贝尔曼方程及其应用:理解与实战演练 在强化学习这一复杂而迷人的领…...

牛客 NC129 阶乘末尾0的数量【简单 基础数学 Java/Go/PHP/C++】
题目 题目链接: https://www.nowcoder.com/practice/aa03dff18376454c9d2e359163bf44b8 https://www.lintcode.com/problem/2 思路 Java代码 import java.util.*;public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改ÿ…...

【Spring Boot】异常处理
异常处理 1.认识异常处理1.1 异常处理的必要性1.2 异常的分类1.3 如何处理异常1.3.1 捕获异常1.3.2 抛出异常1.3.4 自定义异常 1.4 Spring Boot 默认的异常处理 2.使用控制器通知3.自定义错误处理控制器3.1 自定义一个错误的处理控制器3.2 自定义业务异常类3.2.1 自定义异常类3…...

Laravel学习-自定义辅助函数
因为laravel框架的辅助函数helpers不会进入版本库,被版本库忽略的,只有自己创建一个helpers辅助函数。 可以在任意文件下创建helpers.php文件,建议在app目录下, 然后在composer.json文件中,autoload 中间,…...

LLVM Cpu0 新后端6
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章: LLVM 后端实践笔记 代码在这里(还没来得及准备,先用网盘暂存一下): 链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?…...
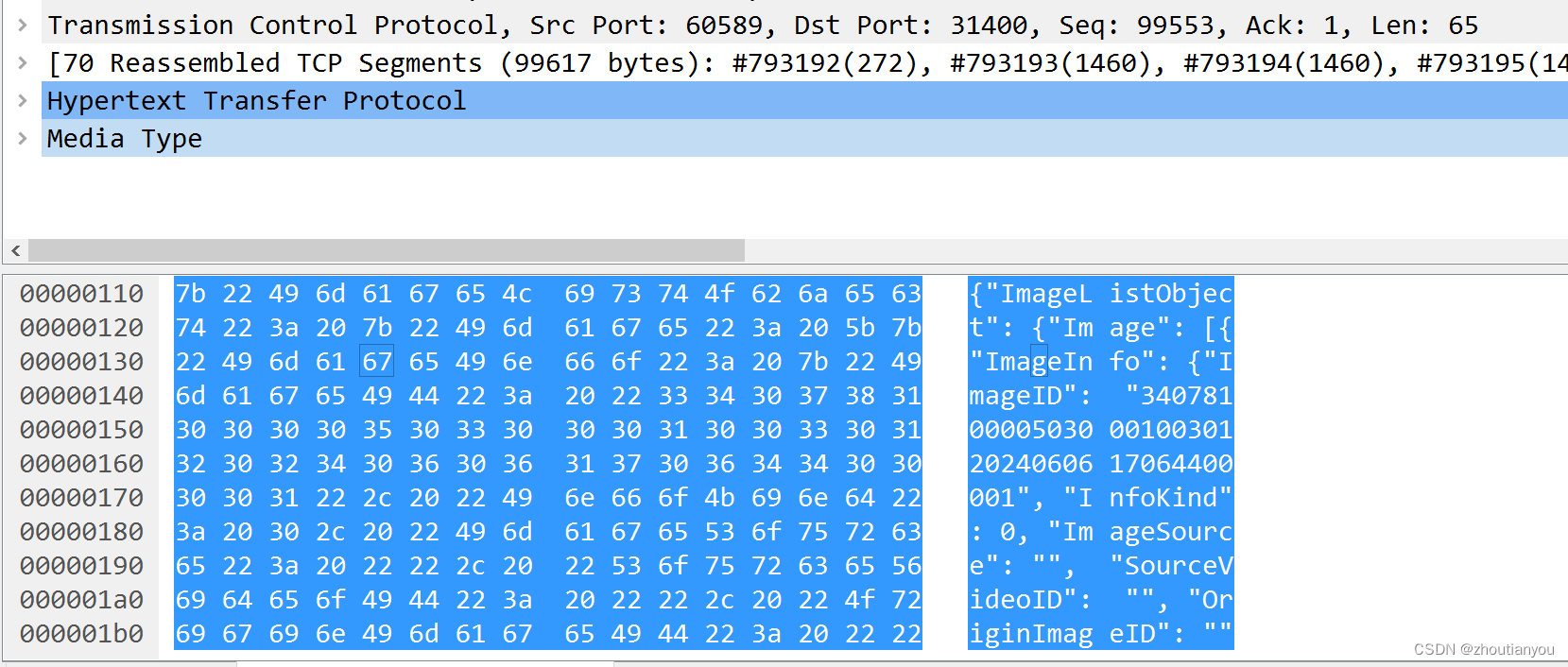
GAT1399协议分析(9)--图像上传
一、官方定义 二、wirechark实例 有前面查询的基础,这个接口相对简单很多。 请求: 文本化: POST /VIID/Images HTTP/1.1 Host: 10.0.201.56:31400 User-Agent: python-requests/2.32.3 Accept-Encoding: gzip, deflate Accept: */* Connection: keep-alive content-type:…...
)
SpringBoot项目用Maven插件一键部署到Docker(WSL2环境)
SpringBoot项目用Maven插件一键部署到Docker(WSL2环境) 在当今快节奏的开发环境中,如何高效地将SpringBoot应用部署到Docker容器中成为了开发者关注的焦点。传统的手动部署方式不仅耗时耗力,还容易出错。本文将介绍如何利用Maven插…...

Java学习笔记_Day8
拼图游戏设计主界面JFrame 最外层的窗体JMenuBar 最上面的菜单JLabel 管理图片和文字的容器有登录界面,注册界面,游戏界面游戏主界面初始化界面private void initJframe() {//宽高this.setSize(603,680);this.setTitle("拼图游戏");//置顶t…...

ECBS多机器人路径规划:从理论到实践的优化策略
1. 多机器人路径规划的核心挑战 想象一下让10个外卖机器人在商场里送餐,或者让50个仓储机器人在仓库搬运货物。每个机器人都有自己的起点和目的地,但通道宽度只够1-2台机器并行。这就是典型的多机器人路径规划(MAPF)问题——既要保证所有机器人按时到达目…...
)
KLayout新手必看:5分钟搞定圆形、文字和复杂图案绘制(附实例截图)
KLayout新手必看:5分钟搞定圆形、文字和复杂图案绘制(附实例截图) 作为一名芯片设计工程师,我深知KLayout在版图设计中的重要性。这款开源工具虽然功能强大,但对新手来说却有些门槛。记得我第一次使用时,光…...

【快速上手】KH Coder:从安装到文本分析的完整指南
1. KH Coder是什么?能帮你解决什么问题? 第一次听说KH Coder时,我也是一头雾水——这到底是个什么工具?直到用它完成了我的第一篇论文文本分析,才发现这简直是文科生的"编程救星"。简单来说,KH …...
)
IE11卸载翻车实录:Win10下这些隐藏设置你必须知道(避坑指南)
IE11卸载与系统组件管理的深度解析:Win10用户必知的技术内幕 每次Windows系统更新后,总有些"钉子户"组件让人又爱又恨——IE11就是其中最典型的代表。上周帮同事处理一台无法运行企业内网系统的笔记本时,我再次深刻体会到微软在系统…...

如何在Java中设计高内聚低耦合的类
单一职责的判断标准是看每个public方法是否服务于同一业务概念;如果方法变化的原因不同(如sendemail和generatereport),则违反了这一原则,应通过委托、界面抽象等方式安全拆分,并确保测试重点关注单一职责。如何判断单一职责是否“…...

实时跟踪算法比较研究:PDA与JPDA在多目标杂波环境下的应用与分析
信息融合项目matlab仿真代码及说明 针对杂波环境多目标跟踪问题,设计目标稀疏的目标运动场景,分别采用PDA和JPDA方法,对目标的状态进行有效估计和实时跟踪。 以航迹丢失百分率,位置状态估计精度,计算效率为指标&#x…...

ngx_shmtx_create
1. 定义 ngx_shmtx_create 函数 定义在 ./nginx-1.24.0/src/core/ngx_shmtx.cngx_int_t ngx_shmtx_create(ngx_shmtx_t *mtx, ngx_shmtx_sh_t *addr, u_char *name) { mtx->lock &addr->lock;if (mtx->spin (ngx_uint_t) -1) {return NGX_OK;}mtx->spin 204…...

MySQL 中 DELETE、DROP 和 TRUNCATE 的区别是什么?
在 MySQL 中,DELETE、DROP 和 TRUNCATE 都用于删除数据或表结构,但它们的作用对象、执行机制、事务特性以及使用场景有显著区别。 以下是详细的对比分析: 1. 核心区别总结 | 特性 | DELETE | TRUNCATE | DROP | | :— | :— | :— | : | | SQ…...