Redis系列之淘汰策略介绍
Redis系列之淘汰策略介绍
文章目录
- 为什么需要Redis淘汰策略?
- Redis淘汰策略分类
- Redis数据淘汰流程
- 源码验证淘汰流程
- Redis中的LRU算法
- Redis中的LFU算法
为什么需要Redis淘汰策略?
由于Redis内存是有大小的,当内存快满的时候,又没有过期数据,这个时候就会导致内存被占满,内存满了,自然就不能再放入新的数据。所以,就需要Redis的淘汰策略来保证可用性。
Redis淘汰策略分类
在Redis中提供了好几种淘汰策略,查看官方文档
https://redis.io/docs/latest/operate/rs/databases/memory-performance/eviction-policy/,找到如下几种淘汰策略:
| Eviction Policy | Description |
|---|---|
| noeviction | New values aren’t saved when memory limit is reached When a database uses replication, this applies to the primary database // 默认策略,默认不淘汰数据,能读不能写 |
| allkeys-lru | Keeps most recently used keys; removes least recently used (LRU) keys // 基于伪LRU算法,在所有的key中去淘汰 |
| allkeys-lfu | Keeps frequently used keys; removes least frequently used (LFU) keys // 基于伪LRU算法,在所有的key中去淘汰 |
| allkeys-random | Randomly removes keys // 基于随机算法,在所有的key中去淘汰 |
| volatile-lru | Removes least recently used keys with expire field set to true // 基于伪LRU算法,在设置了过期时间的key中去淘汰 |
| volatile-lfu | Removes least frequently used keys with expire field set to true // 基于伪LFU算法,在设置了过期时间的key中去淘汰 |
| volatile-random | Randomly removes keys with expire field set to true // 基于随机算法,在设置了过期时间的key中去淘汰 |
| volatile-ttl | Removes least frequently used keys with expire field set to true and the shortest remaining time-to-live (TTL) value // 根据过期时间来,淘汰即将过期的 |
我们发现redis提供了8种不同的策略,只要在我们的config中配置maxmemory-policy即可指定相关的淘汰策略。
maxmemory-policy noeviction # 默认淘汰策略,只能读不能写
Redis数据淘汰流程
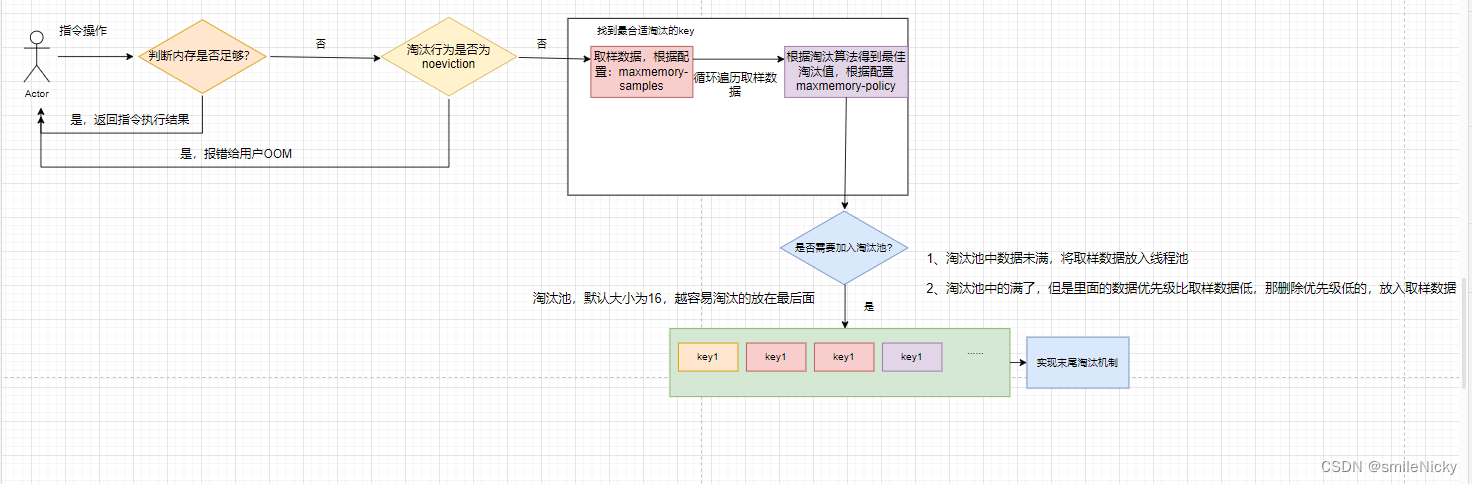
淘汰流程:
- 首先,我们会有一个淘汰池,默认大小是16,并且里面的数据都是末尾淘汰机制。
- 每次指令操作的时候,会自旋判断当前的内存是否满足指令所需要的内存,内存满足,继续指令操作
- 如果当前内存不能满足时,判断淘汰机制是否为
noeviction,是默认的noeviction机制,OOM报错给用户,只能读不能写,如果不是默认的noeviction机制会从淘汰池中的尾部拿取一个最适合淘汰的数据。- 取样,从Redis中随机获取取样的数据,不一次性读取所有的数据。
- 在取样的数据中,根据淘汰算法,找到最适合淘汰的数据
- 将最合适淘汰的取样数据跟淘汰池中的数据比较,是否比淘汰池中的数据更适合淘汰,如果更合适,才放入淘汰池
- 淘汰池按照适合的程度进行排序,最适合的数据放在尾部
- 将需要淘汰的数据从redis中删除,并且从淘汰池移除
源码验证淘汰流程
每次执行操作指令都会走freeMemoryIfNeeded函数(evict.c文件)
/* This function is periodically called to see if there is memory to free* according to the current "maxmemory" settings. In case we are over the* memory limit, the function will try to free some memory to return back* under the limit.** The function returns C_OK if we are under the memory limit or if we* were over the limit, but the attempt to free memory was successful.* Otherwise if we are over the memory limit, but not enough memory* was freed to return back under the limit, the function returns C_ERR. */
int freeMemoryIfNeeded(void) {int keys_freed = 0;/* By default replicas should ignore maxmemory* and just be masters exact copies. *//* 从库是否忽略内存淘汰机制,server.masterhost有配置,说明是从库 */if (server.masterhost && server.repl_slave_ignore_maxmemory) return C_OK;size_t mem_reported, mem_tofree, mem_freed;mstime_t latency, eviction_latency, lazyfree_latency;long long delta;int slaves = listLength(server.slaves);int result = C_ERR;/* When clients are paused the dataset should be static not just from the* POV of clients not being able to write, but also from the POV of* expires and evictions of keys not being performed. */if (clientsArePaused()) return C_OK;/* 判断内存是否满,如果没有超过内存,直接返回 */if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK)return C_OK;mem_freed = 0;latencyStartMonitor(latency);/* 如果策略为noeviction,默认不淘汰数据,直接报错OOM */if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION)goto cant_free; /* We need to free memory, but policy forbids. *//* 内存不够的情况,一直自旋释放内存 */while (mem_freed < mem_tofree) {int j, k, i;static unsigned int next_db = 0;sds bestkey = NULL; // 定义最好的删除keyint bestdbid;redisDb *db;dict *dict;dictEntry *de;if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) ||server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL){ // 如果淘汰算法是LRU、LFU、TTLstruct evictionPoolEntry *pool = EvictionPoolLRU; // 淘汰池,默认大小为16// 自旋,找到合适的要淘汰的keywhile(bestkey == NULL) {unsigned long total_keys = 0, keys;/* We don't want to make local-db choices when expiring keys,* so to start populate the eviction pool sampling keys from* every DB. *//* 去不同的DB查找 */for (i = 0; i < server.dbnum; i++) {db = server.db+i;dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ?db->dict : db->expires; // 判断需要淘汰的范围,是所有数据还是过期的数据if ((keys = dictSize(dict)) != 0) { evictionPoolPopulate(i, dict, db->dict, pool);// 关键方法,从范围中取样,拿到最适合淘汰的数据total_keys += keys;}}if (!total_keys) break; /* No keys to evict. */ /*没有过期的key*//* Go backward from best to worst element to evict. */for (k = EVPOOL_SIZE-1; k >= 0; k--) {if (pool[k].key == NULL) continue;bestdbid = pool[k].dbid;if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) {de = dictFind(server.db[pool[k].dbid].dict,pool[k].key);} else {de = dictFind(server.db[pool[k].dbid].expires,pool[k].key);}/* Remove the entry from the pool. */if (pool[k].key != pool[k].cached)sdsfree(pool[k].key);pool[k].key = NULL;pool[k].idle = 0;/* If the key exists, is our pick. Otherwise it is* a ghost and we need to try the next element. */if (de) {bestkey = dictGetKey(de);break;} else {/* Ghost... Iterate again. */}}}}/* volatile-random and allkeys-random policy */else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM ||server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM){/* When evicting a random key, we try to evict a key for* each DB, so we use the static 'next_db' variable to* incrementally visit all DBs. */for (i = 0; i < server.dbnum; i++) {j = (++next_db) % server.dbnum;db = server.db+j;dict = (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM) ?db->dict : db->expires;if (dictSize(dict) != 0) {de = dictGetRandomKey(dict);bestkey = dictGetKey(de);bestdbid = j;break;}}}/* Finally remove the selected key. *//* 移除这个key */if (bestkey) {db = server.db+bestdbid;robj *keyobj = createStringObject(bestkey,sdslen(bestkey));propagateExpire(db,keyobj,server.lazyfree_lazy_eviction);/* We compute the amount of memory freed by db*Delete() alone.* It is possible that actually the memory needed to propagate* the DEL in AOF and replication link is greater than the one* we are freeing removing the key, but we can't account for* that otherwise we would never exit the loop.** Same for CSC invalidation messages generated by signalModifiedKey.** AOF and Output buffer memory will be freed eventually so* we only care about memory used by the key space. */delta = (long long) zmalloc_used_memory();latencyStartMonitor(eviction_latency);/* 如果是异步淘汰,进行异步淘汰*/if (server.lazyfree_lazy_eviction)dbAsyncDelete(db,keyobj);// 异步淘汰机制elsedbSyncDelete(db,keyobj); // 同步淘汰机制latencyEndMonitor(eviction_latency);latencyAddSampleIfNeeded("eviction-del",eviction_latency);delta -= (long long) zmalloc_used_memory();mem_freed += delta;server.stat_evictedkeys++;signalModifiedKey(NULL,db,keyobj);notifyKeyspaceEvent(NOTIFY_EVICTED, "evicted",keyobj, db->id);decrRefCount(keyobj);keys_freed++;/* When the memory to free starts to be big enough, we may* start spending so much time here that is impossible to* deliver data to the slaves fast enough, so we force the* transmission here inside the loop. */if (slaves) flushSlavesOutputBuffers();/* Normally our stop condition is the ability to release* a fixed, pre-computed amount of memory. However when we* are deleting objects in another thread, it's better to* check, from time to time, if we already reached our target* memory, since the "mem_freed" amount is computed only* across the dbAsyncDelete() call, while the thread can* release the memory all the time. */if (server.lazyfree_lazy_eviction && !(keys_freed % 16)) {if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {/* Let's satisfy our stop condition. */mem_freed = mem_tofree;}}} else {goto cant_free; /* nothing to free... */}}result = C_OK;cant_free:/* We are here if we are not able to reclaim memory. There is only one* last thing we can try: check if the lazyfree thread has jobs in queue* and wait... */if (result != C_OK) {latencyStartMonitor(lazyfree_latency);while(bioPendingJobsOfType(BIO_LAZY_FREE)) {if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {result = C_OK;break;}usleep(1000);}latencyEndMonitor(lazyfree_latency);latencyAddSampleIfNeeded("eviction-lazyfree",lazyfree_latency);}latencyEndMonitor(latency);latencyAddSampleIfNeeded("eviction-cycle",latency);return result;
}
evictionPoolPopulate方法(evict.c文件)
/* This is an helper function for freeMemoryIfNeeded(), it is used in order* to populate the evictionPool with a few entries every time we want to* expire a key. Keys with idle time smaller than one of the current* keys are added. Keys are always added if there are free entries.** We insert keys on place in ascending order, so keys with the smaller* idle time are on the left, and keys with the higher idle time on the* right. */void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {int j, k, count;// 需要取样的数据dictEntry *samples[server.maxmemory_samples];// 随机从需要取样的范围中得到取样的数据count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);// 循环取样数据for (j = 0; j < count; j++) {unsigned long long idle;sds key;robj *o;dictEntry *de;de = samples[j];key = dictGetKey(de);/* If the dictionary we are sampling from is not the main* dictionary (but the expires one) we need to lookup the key* again in the key dictionary to obtain the value object. */if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL) { // 如果是ttl,只能从带有过期时间的数据中获取,所以不需要获取对象,其它的淘汰策略都需要去我们的键值对中获取值对象if (sampledict != keydict) de = dictFind(keydict, key);o = dictGetVal(de);}/* Calculate the idle time according to the policy. This is called* idle just because the code initially handled LRU, but is in fact* just a score where an higher score means better candidate. */if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) { // 如果是LRU算法,采用LRU算法得到最长时间没访问的idle = estimateObjectIdleTime(o);} else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { // 如果是LFU算法,根据LFU算法得到最少访问的,idle越大,越容易淘汰,因为是用255-LFUDecrAndReturn(o);/* When we use an LRU policy, we sort the keys by idle time* so that we expire keys starting from greater idle time.* However when the policy is an LFU one, we have a frequency* estimation, and we want to evict keys with lower frequency* first. So inside the pool we put objects using the inverted* frequency subtracting the actual frequency to the maximum* frequency of 255. */idle = 255-LFUDecrAndReturn(o);} else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) { // ttl 直接根据时间来/* In this case the sooner the expire the better. */idle = ULLONG_MAX - (long)dictGetVal(de);} else {serverPanic("Unknown eviction policy in evictionPoolPopulate()");}/* Insert the element inside the pool.* First, find the first empty bucket or the first populated* bucket that has an idle time smaller than our idle time. *//* 取样的数据,计算好淘汰的idle后,放入淘汰池中 */k = 0;while (k < EVPOOL_SIZE &&pool[k].key &&pool[k].idle < idle) k++; // 自旋,找到淘汰池中比当前key的idle小的最后一个下标// k=0说明上面循环没进,也就是淘汰池中的所有数据都比当前数据的idle大,并且淘汰池的最后一个不为空,说明淘汰池也是满的,所以优先淘汰淘汰池中的数据if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL) {/* Can't insert if the element is < the worst element we have* and there are no empty buckets. */continue;} else if (k < EVPOOL_SIZE && pool[k].key == NULL) { // 插入到桶后面/* Inserting into empty position. No setup needed before insert. */} else { // 插入到中间,会进行淘汰池的数据移动/* Inserting in the middle. Now k points to the first element* greater than the element to insert. */if (pool[EVPOOL_SIZE-1].key == NULL) {/* Free space on the right? Insert at k shifting* all the elements from k to end to the right. *//* Save SDS before overwriting. */sds cached = pool[EVPOOL_SIZE-1].cached;memmove(pool+k+1,pool+k,sizeof(pool[0])*(EVPOOL_SIZE-k-1));// 假如当前数据比淘汰池的有些数据大,那么淘汰最小的pool[k].cached = cached;} else {/* No free space on right? Insert at k-1 */k--;/* Shift all elements on the left of k (included) to the* left, so we discard the element with smaller idle time. */sds cached = pool[0].cached; /* Save SDS before overwriting. */if (pool[0].key != pool[0].cached) sdsfree(pool[0].key);memmove(pool,pool+1,sizeof(pool[0])*k);pool[k].cached = cached;}}/* Try to reuse the cached SDS string allocated in the pool entry,* because allocating and deallocating this object is costly* (according to the profiler, not my fantasy. Remember:* premature optimization bla bla bla. *//* 将当前的放入淘汰池 */int klen = sdslen(key);if (klen > EVPOOL_CACHED_SDS_SIZE) {pool[k].key = sdsdup(key);} else {memcpy(pool[k].cached,key,klen+1);sdssetlen(pool[k].cached,klen);pool[k].key = pool[k].cached;}pool[k].idle = idle;pool[k].dbid = dbid;}
}
简要看了一遍源码,我们对redis数据的淘汰机制有了一定的理解,并且知道淘汰算法有8种,所以下面主要介绍一下Redis中比较重要的LRU算法和LFU算法
Redis中的LRU算法
LRU,Least Recently Used翻译过来就是最久未使用,LRU算法根据使用时间淘汰数据,越久没使用的数据越容易淘汰。
- 实现原理
- 首先,LRU算法是根据这个对象的操作访问时间来进行淘汰的,所以我们就需要知道这个对象最后的访问时间。
- 知道了对象的最后访问时间后,我们就需要跟当前的系统时间进行对比,计算出这个对象已经多久没访问
- 源码验证
在Redis源码中,有一个redisObject对象,这个对象就是我们redis中所有数据结构的对外对象,它里面有个字段叫做lru
redisObject对象 (server.h文件)
typedef struct redisObject {unsigned type:4;unsigned encoding:4;unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or* LFU data (least significant 8 bits frequency* and most significant 16 bits access time). */int refcount;void *ptr;
} robj;
看注释,大概也能猜出来,redis去实现lru淘汰算法跟这个lru对象有关,这个字段大小为24bit,记录的是对象操作访问时候的秒单位的后24位(bit),然后怎么获取秒单位的后24位?看一下例子:
long currentTimeMillis = System.currentTimeMillis();
System.out.println(currentTimeMillis/1000); // 获取当前秒
System.out.println(currentTimeMillis/1000 & ((1<<24)-1));// 获取秒的后24位
控制台打印一下,得到两个10进制参数

用二进制转换平台转换一下,1715915460二进制1100110010001101100101011000100
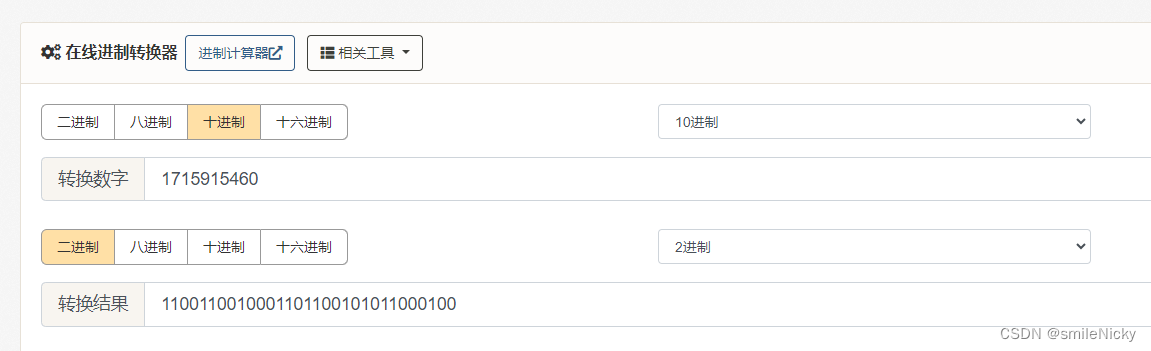
4639428二进制10001101100101011000100
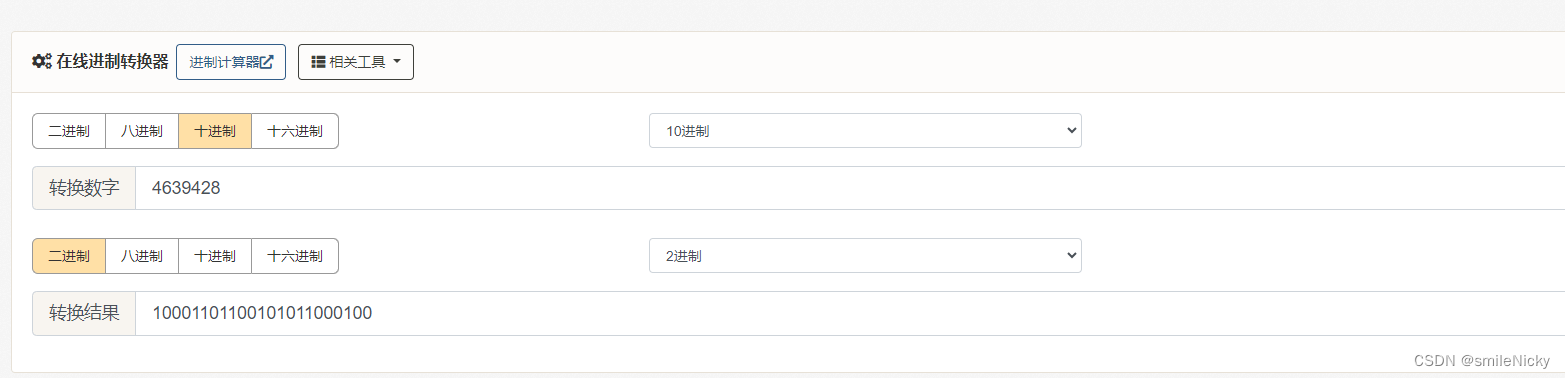
两个参数对比一下,确实是拿到了最后24位
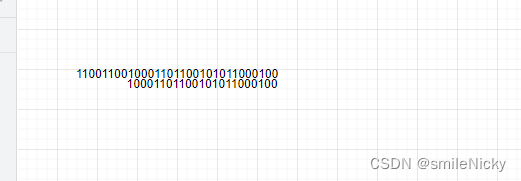
currentTimeMillis/1000 & ((1<<24)-1)为什么能获取到当前时间(二进制)的最后24位?还是画图看看,一个数和24个1进行二进制的与运算,就是获取最后24位数,如图所示

然后怎么获取24个1?细心的读者可能已经知道了,没错,就是(1<<24)-1,1左移24位再减1,如图所示:

二进制不熟悉,可以参考二进制运算
生活中的例子:
场景一:数据在5月份被访问,现在是8月份,我们可以通过8-3=5,得到这个对象3个月没访问
场景二:数据在5月份被访问,现在是3月份,我们可以通过:3+12-5得到这个对象10个月没访问
同理:
如果redisObject.lru < lruclock,直接通过lruclock-redisObject.lru得到这个对象多久没访问。
如果redisObject.lru > lruclock,直接通过lruclock+(24bit的最大值-redisObject.lru)
通过redis源码验证一下,发现源码的思路和我们上面所说是差不多的,查看estimateObjectIdleTime方法(evict.c)
/* Given an object returns the min number of milliseconds the object was never* requested, using an approximated LRU algorithm. */
unsigned long long estimateObjectIdleTime(robj *o) {// 获取秒单位时间的最后24位unsigned long long lruclock = LRU_CLOCK();// 因为只有24位,所有最大值为2的24次方-1// 超过最大值从0开始,所以需要判断lruclock(当前系统时间)跟缓存对象的lru字段的大小if (lruclock >= o->lru) {// 如果lruclock>=robj.lru,返回lruclock->lru,再转换单位return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;} else {// 否则,lruclock+(LRU_CLOCK_MAX - o->lru),得到的对象的值越小,返回的值越大,越大越容易被淘汰return (lruclock + (LRU_CLOCK_MAX - o->lru)) *LRU_CLOCK_RESOLUTION;}
}
Redis中的LFU算法
LFU,英文Least Frequently Used,翻译成中文就是最不常用的优先淘汰。不常用,它的衡量标准就是次数,次数越少的越容易淘汰。
- LFU的时效性问题
LFU算法有个问题需要去考虑,就是这个时效性问题,什么是时效性问题?就是去统计这个次数的时候,不能仅仅只考虑数量,而不考虑时间
举个例子,假如去年有一个新闻,很火,假如点击量是3000w,那么今年再有一个新闻出来,刚出来,点击量是1000w,本来我们应该让今年这个新闻显示出来的,去年的新闻虽然太火,但是也是去年的,我们推荐系统肯定不希望这个新闻继续上热搜的,所以推荐系统就需要考虑到数量同时兼顾这个时间问题
所以,如果根据LFU来做的话,仅根据使用次数来淘汰数据,很容易淘汰今年的新闻,所以容易导致新的数据进不去,旧的数据出不来,不过Redis里的LFU算法肯定是有考虑到这个问题的,具体是怎么实现的?
- 源码分析
来看redisObject的结构体,在server.h代码里,看里面注释,大概也知道在LFU算法的时候,里面这个lru,它前面16位代表的是时间,后8位代表的是一个数值,frequenct频率,应该就是代表这个对象的访问次数,我们先给它叫做counter
typedef struct redisObject {unsigned type:4;unsigned encoding:4;unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or* LFU data (least significant 8 bits frequency* and most significant 16 bits access time). */int refcount;void *ptr;
} robj;
前16bits代表时间,有啥用?跟时间相关,可以猜想应该和时效性有关。大胆猜测,这个时间是不是去记录对象多久没访问,如果多久没访问,就去减少对应的次数
找到Redis源码里的evict.c的LFUDecrAndReturn函数:
/* If the object decrement time is reached decrement the LFU counter but* do not update LFU fields of the object, we update the access time* and counter in an explicit way when the object is really accessed.* And we will times halve the counter according to the times of* elapsed time than server.lfu_decay_time.* Return the object frequency counter.** This function is used in order to scan the dataset for the best object* to fit: as we check for the candidate, we incrementally decrement the* counter of the scanned objects if needed. */
unsigned long LFUDecrAndReturn(robj *o) {// lru字段右移8位,得到前面16位的时间unsigned long ldt = o->lru >> 8;// lru字段与255进行&运算,255代表8位的最大值,也就是二进制的8个1,得到8位counter值unsigned long counter = o->lru & 255;// 如果配置了lfu_decay_time,用LFUTimeElapsed(ldt)除以配置的值,总的没访问的分钟时间除以配置值,得到每分钟没访问,需要减少多少访问次数unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;if (num_periods)// 不能减少为负数counter = (num_periods > counter) ? 0 : counter - num_periods;return counter;
}
redis配置
lfu-decay-time 1 // 多少分钟没操作访问就减1次
而对应8bit的次数,最大值是255,可以看下redis源码LFULongIncr函数,在evict.c
/* Logarithmically increment a counter. The greater is the current counter value* the less likely is that it gets really implemented. Saturate it at 255. */
uint8_t LFULogIncr(uint8_t counter) {// 如果等于255,直接返回255,8位的最大值if (counter == 255) return 255;// 得到随机数,0到1之间double r = (double)rand()/RAND_MAX;// LFU_INIT_VAL表示基数值,默认为5,在server.h配置double baseval = counter - LFU_INIT_VAL;// 如果当前counter小于基数,那么p=1,r肯定小于p,所以counter肯定加if (baseval < 0) baseval = 0;// 不然,按照几率来校验counter是否加,跟baseval和lfu_log_factor这两个参数相关,因为都是在分母,所以两个值越大,p越小,也就是counter++的概率越小double p = 1.0/(baseval*server.lfu_log_factor+1);if (r < p) counter++;// p越小,counter++的几率就越小,反之亦然return counter;
}
所以,LFU的实现逻辑,可以总结一下:
- 如果达到255最大值,
counter就不加,因为达到255的几率不是很高,可以支撑很大的数据量 counter是随机添加,添加的概率和已有的counter值和配置的lfu-log-factor两个参数相关,已有的counter值越大,添加的几率越小,配置的lfu-log-factor值越大,添加的几率也越小
在redis官网找到如图的压测数据图,里面facror就是配置的lfu_log_factor,可以看到配置的值越大,需要达到255的最大值就需要更多的hits
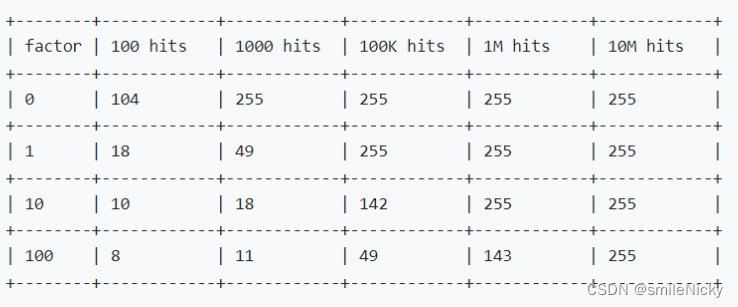
相关文章:
Redis系列之淘汰策略介绍
Redis系列之淘汰策略介绍 文章目录 为什么需要Redis淘汰策略?Redis淘汰策略分类Redis数据淘汰流程源码验证淘汰流程Redis中的LRU算法Redis中的LFU算法 为什么需要Redis淘汰策略? 由于Redis内存是有大小的,当内存快满的时候,又没有…...

sql 调优
sql 调优 SQL调优是一个复杂的过程,涉及多个方面,包括查询优化、索引优化、表结构优化等。以下是一些基本的SQL调优策略: 使用索引:确保查询中涉及的列都有适当的索引。 查询优化:避免使用SELECT *,只选取…...
【UML用户指南】-13-对高级结构建模-包
目录 1、名称 2、元素 3、可见性 4、引入与引出 用包把建模元素安排成可作为一个组来处理的较大组块。可以控制这些元素的可见性,使一些元素在包外是可见的,而另一些元素要隐藏在包内。也可以用包表示系统体系结构的不同视图。 狗窝并不复杂&#x…...

前端面试题日常练-day63 【面试题】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末 1. TypeScript中,以下哪个关键字用于声明一个类的构造函数? a) constructor b) init c) create d) initialize 2. 在TypeScript中,以下哪个符号用于声明可选的函…...
GAN的入门理解
这一篇主要是关于生成对抗网络的模型笔记,有一些简单的证明和原理,是根据李宏毅老师的课程整理的,下面有链接。本篇文章主要就是梳理基础的概念和训练过程,如果有什么问题的话也可以指出的。 李宏毅老师的课程链接 1.概述 GAN是…...

43【PS 作图】颜色速途
1 通过PS让画面细节模糊,避免被过多的颜色干扰 2 分析画面的颜色 3 作图 参考网站: 色感不好要怎么提升呢?分享一下我是怎么练习色感的!_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1h1421Z76p/?spm_id_from333.1007.…...

定个小目标之刷LeetCode热题(13)
今天来看看这道题,介绍两种解法 第一种动态规划,代码如下 class Solution {public int maxSubArray(int[] nums) {int pre 0, maxAns nums[0];for (int x : nums) {// 计算当前最大前缀和pre Math.max(pre x, x);// 更新最大前缀和maxAns Math.ma…...
【AI大模型】Prompt Engineering
目录 什么是提示工程(Prompt Engineering) Prompt 调优 Prompt 的典型构成 「定义角色」为什么有效? 防止 Prompt 攻击 攻击方式 1:著名的「奶奶漏洞」 攻击方式 2:Prompt 注入 防范措施 1:Prompt 注…...
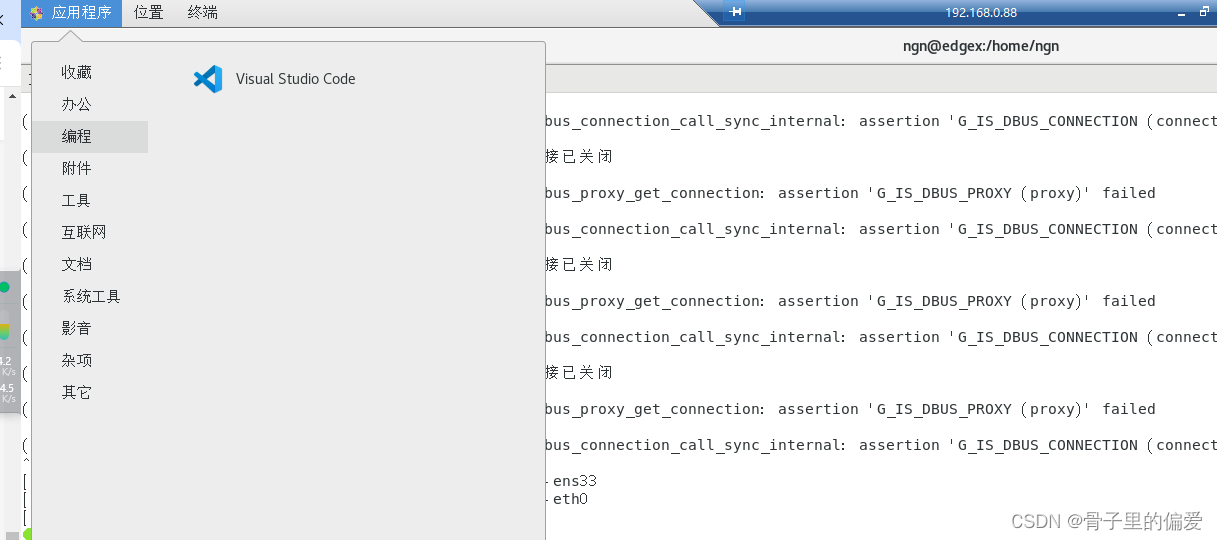
centos安装vscode的教程
centos安装vscode的教程 步骤一:打开vscode官网找到历史版本 历史版本链接 步骤二:找到文件下载的位置 在命令行中输入(稍等片刻即可打开): /usr/share/code/bin/code关闭vscode后,可在应用程序----编程…...

面试题------>MySQL!!!
一、连接查询 ①:左连接left join (小表在左,大表在右) ②:右连接right join(小表在右,大表在左) 二、聚合函数 SQL 中提供的聚合函数可以用来统计、求和、求最值等等 COUNT&…...

英伟达:史上最牛一笔天使投资
200万美元的天使投资,让刚成立就面临倒闭风险的英伟达由危转安,并由此缔造了一个2.8万亿美元的市值神话。 这是全球风投史上浓墨重彩的一笔。 前不久,黄仁勋在母校斯坦福大学的演讲中,提到了人生中的第一笔融资——1993年&#x…...

PDF分页处理:技术与实践
引言 在数字化办公和学习中,PDF文件因其便携性和格式稳定性而广受欢迎。然而,处理大型PDF文件时,我们经常需要将其拆分成单独的页面,以便于管理和分享。本文将探讨如何使用Python编程语言和一些流行的库来实现PDF文件的分页处理。…...
数据可视化——pyecharts库绘图
目录 官方文档 使用说明: 点击基本图表 可以点击你想要的图表 安装: 一些例图: 柱状图: 效果: 折线图: 效果: 环形图: 效果: 南丁格尔图(玫瑰图&am…...

Python的return和yield,哪个是你的菜?
目录 1、return基础介绍 📚 1.1 return用途:数据返回 1.2 return执行:函数终止 1.3 return深入:无返回值情况 2、yield核心概念 🍇 2.1 yield与迭代器 2.2 生成器函数构建 2.3 yield的暂停与续行特性 3、retur…...
)
持续总结中!2024年面试必问 20 道分布式、微服务面试题(七)
上一篇地址:持续总结中!2024年面试必问 20 道分布式、微服务面试题(六)-CSDN博客 十三、请解释什么是服务网格(Service Mesh)? 服务网格(Service Mesh)是一种用于处理服…...

AJAX 跨域
这里写目录标题 同源策略JSONPJSONP 是怎么工作的JSONP 的使用原生JSONP实践CORS 同源策略 同源: 协议、域名、端口号 必须完全相同、 当然网页的URL和AJAX请求的目标资源的URL两者之间的协议、域名、端口号必须完全相同。 AJAX是默认遵循同源策略的,不…...

3 数据类型、运算符与表达式-3.1 C语言的数据类型和3.2 常量与变量
数据类型 基本类型 整型字符型实型(浮点型) 单精度型双精度型 枚举类型 构造类型 数组类型结构体类型共用体类型 指针类型空类型 #include <stdio.h> #include <string.h> #include <stdbool.h> // 包含布尔类型定义 // 常量和符号常量 #define PRICE 30//…...
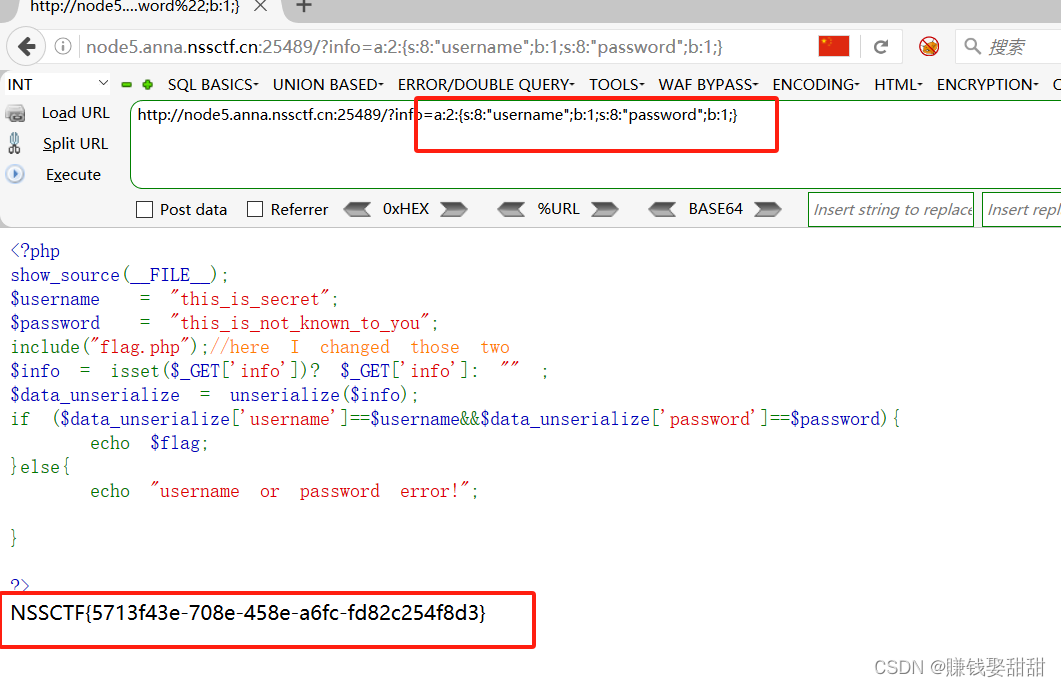
NSSCTF-Web题目5
目录 [SWPUCTF 2021 新生赛]error 1、题目 2、知识点 3、思路 [LitCTF 2023]作业管理系统 1、题目 2、知识点 3、思路 [HUBUCTF 2022 新生赛]checkin 1、题目 2、知识点 3、思路 [SWPUCTF 2021 新生赛]error 1、题目 2、知识点 数据库注入、报错注入 3、思路 首先…...

cnvd_2015_07557-redis未授权访问rce漏洞复现-vulfocus复现
1.复现环境与工具 环境是在vulfocus上面 工具:GitHub - vulhub/redis-rogue-getshell: redis 4.x/5.x master/slave getshell module 参考攻击使用方式与原理:https://vulhub.org/#/environments/redis/4-unacc/ 2.复现 需要一个外网的服务器做&…...

免费,C++蓝桥杯等级考试真题--第7级(含答案解析和代码)
C蓝桥杯等级考试真题--第7级 答案:D 解析:步骤如下: 首先,--a 操作会使 a 的值减1,因此 a 变为 3。判断 a > b 即 3 > 3,此时表达式为假,因为 --a 后 a 并不大于 b。因此,程…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...