【openGauss实战9】深度分析分区表
📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前服务于工业互联网
擅长主流Oracle、MySQL、PG、高斯及GP 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
- 前言
- 📣 1.何为分区表
- 📣 2.分区表类型
- ✨ 2.1 范围分区表
- ✨ 2.2 列表分区表
- ✨ 2.3 间隔分区表
- ✨ 2.4 哈希分区表
- 📣 3.分区表维护
- ✨ 3.1 常用语法
- ✨ 3.2 案例
前言
本篇介绍了openGauss的分区表的实践应用📣 1.何为分区表
一张表内的数据过多时,就会严重影响到数据的查询和操作效率。openGauss支持把一张表从逻辑上分成多个小的分片,从而避免一次处理大量数据,提高处理效率。随着现代信息数据的快速增长,数据库的数据量也不断增长。对于庞大的数据如何管理呢?从数据库角度看,分区表无疑是一种很好的选择。
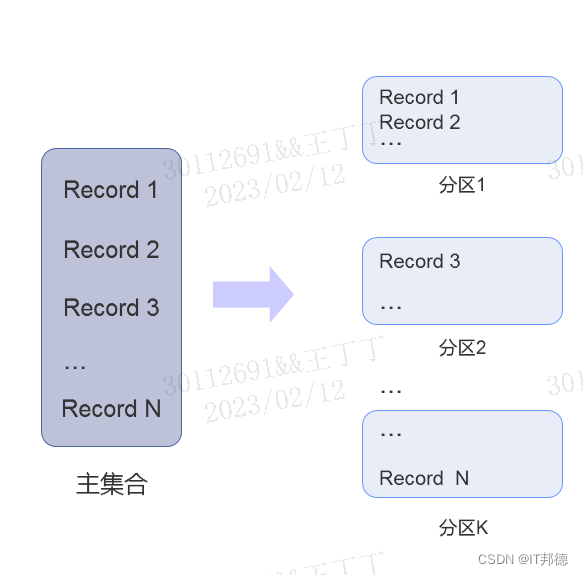
对于大多数用户使用场景,分区表和普通表相比具有以下优点:
改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索效率。
增强可用性:如果分区表的某个分区出现故障,表在其他分区的数据仍然可用。
均衡I/O:可以把不同的分区映射到不同的磁盘以平衡I/O,改善整个系统性能。
📣 2.分区表类型
openGauss数据库支持这些划分类型:
(1) 范围分区表:指定一个或多个列划分为多个范围,每个范围创建一个分区,用来存储相应的数据。
例如可以采用日期划分范围,将销售数据按照月份进行分区。
(2) 列表分区表:直接按照一个列上的值来划分出分区。例如可以采用销售门店划分销售数据。
(3) 间隔分区表:是一种特殊的范围分区,新增了间隔值定义。当插入记录找不到匹配的分区时可以根据间隔值自动创建分区。
(4) 哈希分区表:根据表的一列,为每个分区指定模数和余数,将要插入表的记录划分到对应的分区中。
✨ 2.1 范围分区表
范围分区表按照划分范围的方式,分为以下类别:
(1) VALUES LESS THAN:通过给出每个分区的上限来确定分区范围。上个分区的上限<=分区的范围<本分区的上限。
(2) START END:通过以下方式划分:
分区的起点和终点;
仅给出分区起点;
仅给出分区终点;
给出分区起点和终点后,再给出该范围内的间隔值。
📢📢📢 创建VALUES LESS THAN范围分区
1.语法格式
CREATE TABLE partition_table_name
( [column_name data_type ][, ... ]
)PARTITION BY RANGE (partition_key)(PARTITION partition_name VALUES LESS THAN (partition_value | MAXVALUE})[, ... ]);2.参数说明
partition_table_name:分区表的名称
column_name:新表中要创建的字段名。
data_type:字段的数据类型。
partition_key:partition_key为分区键的名称。
注:对于从句是VALUE LESS THAN的语法格式,范围分区策略的分区键最多支持4列。
partition_name:partition_name为范围分区的名称。
VALUES LESS THAN:分区中的数值必须小于上边界值。
partition_value:范围分区的上边界,取值依赖于partition_key的类型。
MAXVALUE:表示分区的上边界,它通常用于设置最后一个范围分区的上边界。3.分区表示例
示例1:创建范围分区表sales_table,含有4个分区,分区键为DATE类型。
分区的范围分别为:
sales_date<2022-04-01,
2022-04-01<= sales_date<2022-07-01,
2022-07-01<=sales_date< 2022-10-01,
2022-10-01 <= sales_date< MAXVALUE--创建分区表sales_table。
openGauss=# CREATE TABLE sales_table
(order_no INTEGER NOT NULL,goods_name CHAR(20) NOT NULL,sales_date DATE NOT NULL,sales_volume INTEGER,sales_store CHAR(20)
)
PARTITION BY RANGE(sales_date)
(PARTITION season1 VALUES LESS THAN('2022-04-01 00:00:00'),PARTITION season2 VALUES LESS THAN('2022-07-01 00:00:00'),PARTITION season3 VALUES LESS THAN('2022-10-01 00:00:00'),PARTITION season4 VALUES LESS THAN(MAXVALUE)
);
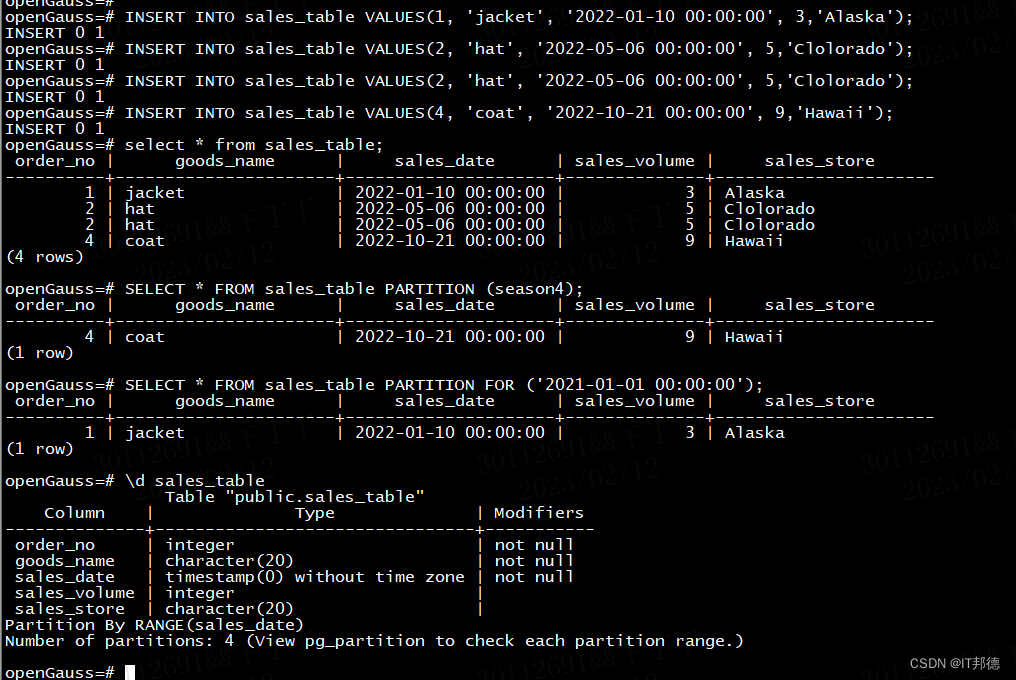
-- 数据插入分区season1
openGauss=# INSERT INTO sales_table VALUES(1, 'jacket', '2022-01-10 00:00:00', 3,'Alaska');-- 数据插入分区season2
openGauss=# INSERT INTO sales_table VALUES(2, 'hat', '2022-05-06 00:00:00', 5,'Clolorado');-- 数据插入分区season3
openGauss=# INSERT INTO sales_table VALUES(3, 'shirt', '2022-09-17 00:00:00', 7,'Florida');-- 数据插入分区season4
openGauss=# INSERT INTO sales_table VALUES(4, 'coat', '2022-10-21 00:00:00', 9,'Hawaii');--查询sales_table的数据
openGauss=# select * from sales_table;order_no | goods_name | sales_date | sales_volume | sales_store
----------+----------------------+---------------------+--------------+----------------------1 | jacket | 2022-01-10 00:00:00 | 3 | Alaska 2 | hat | 2022-05-06 00:00:00 | 5 | Clolorado 2 | hat | 2022-05-06 00:00:00 | 5 | Clolorado 4 | coat | 2022-10-21 00:00:00 | 9 | Hawaii --查询sales_table的4季度数据
openGauss=# SELECT * FROM sales_table PARTITION (season4);order_no | goods_name | sales_date | sales_volume | sales_store
----------+----------------------+---------------------+--------------+----------------------4 | coat | 2022-10-21 00:00:00 | 9 | Hawaii --查询sales_table的1季度数据
openGauss=# SELECT * FROM sales_table PARTITION FOR ('2021-01-01 00:00:00'); order_no | goods_name | sales_date | sales_volume | sales_store
----------+----------------------+---------------------+--------------+----------------------1 | jacket | 2022-01-10 00:00:00 | 3 | Alaska
📢📢📢 创建START END范围分区
START END范围分区表有多种表达方式,而且这些方式可以在一个分区表内组合使用。
方式一:START(partition_value) END (partition_value | MAXVALUE)方式CREATE TABLE partition_table_name
( [column_name data_type ][, ... ]
)PARTITION BY RANGE (partition_key)(PARTITION partition_name START(partition_value) END (partition_value | MAXVALUE)[, ... ]);参数说明:
A.partition_name:partition_name为范围分区的名称或者范围分区的名称前缀。
1)若该定义是“START(partition_value) END (partition_value) EVERY (interval_value)”从句,假定其中的partition_name是p1,
则分区的名称依次为p1_1, p1_2, …2)对于完整定义“PARTITION p1 START(1), PARTITION p2 START(2)”,生成的分区是:
(MINVALUE, 1), [1, 2) 和 [2, MAXVALUE),其名称依次为p1_0, p1_1和p2,即此处p1是名称前缀,p2是分区名称。
这里MINVALUE表示最小值B.interval_value:对[START,END) 表示的范围进行切分,interval_value是指定切分后每个分区的宽度。
如果(END-START)值不能整除以EVERY值,则仅最后一个分区的宽度小于EVERY值示例1:以“START(partition_value) END (partition_value | MAXVALUE)”方式创建START END范围分区表graderecord。
含有3个分区,分区键为INTEGER类型。分区的范围分别为:0<= grade<60,60<= grade<90,90<=grade< MAXVALUE。--创建分区表graderecord。
openGauss=# CREATE TABLE graderecord(number INTEGER,name CHAR(20),class CHAR(20),grade INTEGER)PARTITION BY RANGE(grade)(PARTITION pass START(60) END(90),PARTITION excellent START(90) END(MAXVALUE));-- 数据插入分区。
openGauss=# insert into graderecord values('210101','Alan','21.01',92);
openGauss=# insert into graderecord values('210102','Ben','21.01',62);
openGauss=# insert into graderecord values('210103','Brain','21.01',26);
openGauss=# insert into graderecord values('210204','Carl','21.02',77);
openGauss=# insert into graderecord values('210205','David','21.02',47);
openGauss=# insert into graderecord values('210206','Eric','21.02',97);
openGauss=# insert into graderecord values('210307','Frank','21.03',90);
openGauss=# insert into graderecord values('210308','Gavin','21.03',100);
openGauss=# insert into graderecord values('210309','Henry','21.03',67);
openGauss=# insert into graderecord values('210410','Jack','21.04',75);
openGauss=# insert into graderecord values('210311','Jerry','21.04',60);--查询graderecord的数据。
openGauss=# SELECT * FROM graderecord;number | name | class | grade
--------+----------------------+----------------------+-------210103 | Brain | 21.01 | 26210205 | David | 21.02 | 47210102 | Ben | 21.01 | 62210204 | Carl | 21.02 | 77210309 | Henry | 21.03 | 67210410 | Jack | 21.04 | 75210311 | Jerry | 21.04 | 60210101 | Alan | 21.01 | 92210206 | Eric | 21.02 | 97210307 | Frank | 21.03 | 90210308 | Gavin | 21.03 | 100
(11 rows)--查询graderecord的pass分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (pass);
ERROR: partition "pass" of relation "graderecord" does not exist
查询失败。
原因是“PARTITION pass START(60) END(90),”是第一个分区定义,且该定义有START值,
则范围(MINVALUE, 60)将自动作为第一个实际分区,其名称为“pass_0”。
而该定义语义描述的“60<= grade<90”分区的名称为“pass_1”。--查询graderecord的pass_0分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (pass_0);number | name | class | grade
--------+----------------------+----------------------+-------210103 | Brain | 21.01 | 26210205 | David | 21.02 | 47
(2 rows)--查询graderecord的pass_1分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (pass_1);number | name | class | grade
--------+----------------------+----------------------+-------210102 | Ben | 21.01 | 62210204 | Carl | 21.02 | 77210309 | Henry | 21.03 | 67210410 | Jack | 21.04 | 75210311 | Jerry | 21.04 | 60
(5 rows)--查询graderecord的execllent分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (excellent);number | name | class | grade
--------+----------------------+----------------------+-------210101 | Alan | 21.01 | 92210206 | Eric | 21.02 | 97210307 | Frank | 21.03 | 90210308 | Gavin | 21.03 | 100
(4 rows)示例2:以“START(partition_value) END (partition_value) EVERY (interval_value)”
方式创建START END范围分区表metro_ride_record。
含有7个分区,分区键为INTEGER类型。总范围是ride_stations_number<21, 每3站为一个分区。
--创建分区表metro_ride_record。记录乘车人、上下车站点、乘坐站点数量。并按照乘坐站点数量,每3站建立一个分区。
openGauss=# CREATE TABLE metro_ride_record(record_number INTEGER,name CHAR(20),enter_station CHAR(20),leave_station CHAR(20),ride_stations_number INTEGER)PARTITION BY RANGE(ride_stations_number)(PARTITION cost START(3) END(21) EVERY (3));-- 数据插入分区。
openGauss=# insert into metro_ride_record values('120101','Brain','Tung Chung','Tsing Yi',2);
openGauss=# insert into metro_ride_record values('120102','David','Po Lam','Yau Tong',4);
openGauss=# insert into metro_ride_record values('120103','Ben','Yau Ma Tei','Wong Tai Sin',6);
openGauss=# insert into metro_ride_record values('120104','Carl','Tai Wo Hau','Prince Edward',8);
openGauss=# insert into metro_ride_record values('120105','Henry','Admiralty','Lai King',10);
openGauss=# insert into metro_ride_record values('120106','Jack','Chai Wan','Central',12);
openGauss=# insert into metro_ride_record values('120107','Jerry','Central','Tai Wo Hau',14);
openGauss=# insert into metro_ride_record values('120108','Alan','Diamond Hill','Kwai Hing',16);
openGauss=# insert into metro_ride_record values('120109','Eric','Jordan','Shek Kip Mei',18);
openGauss=# insert into metro_ride_record values('120110','Frank','Lok Fu','Sunny Bay',20);--查询metro_ride_record的数据。
openGauss=# SELECT * FROM metro_ride_record;record_number | name | enter_station | leave_station | ride_stations_number
---------------+----------------------+----------------------+----------------------+----------------------120101 | Brain | Tung Chung | Tsing Yi | 2120102 | David | Po Lam | Yau Tong | 4120103 | Ben | Yau Ma Tei | Wong Tai Sin | 6120104 | Carl | Tai Wo Hau | Prince Edward | 8120105 | Henry | Admiralty | Lai King | 10120106 | Jack | Chai Wan | Central | 12120107 | Jerry | Central | Tai Wo Hau | 14120108 | Alan | Diamond Hill | Kwai Hing | 16120109 | Eric | Jordan | Shek Kip Mei | 18120110 | Frank | Lok Fu | Sunny Bay | 20
(10 rows)“PARTITION cost START(3) END(21) EVERY (3)”是第一个分区定义,且该定义有START值,则范围(MINVALUE, 3)将自动作为第一个实际分区,其名称为“cost_0”。
其余分区依次为“cost_1”、...、“cost_6”.--查询metro_ride_record的cost_0分区数据。
openGauss=# SELECT * FROM metro_ride_record PARTITION (cost_0);record_number | name | enter_station | leave_station | ride_stations_number
---------------+----------------------+----------------------+----------------------+----------------------120101 | Brain | Tung Chung | Tsing Yi | 2
(1 row)--查询metro_ride_record的cost_1分区数据。
openGauss=# SELECT * FROM metro_ride_record PARTITION (cost_1);record_number | name | enter_station | leave_station | ride_stations_number
---------------+----------------------+----------------------+----------------------+----------------------120102 | David | Po Lam | Yau Tong | 4
(1 row)--查询metro_ride_record的cost_6分区数据。
openGauss=# SELECT * FROM metro_ride_record PARTITION (cost_6);record_number | name | enter_station | leave_station | ride_stations_number
---------------+----------------------+----------------------+----------------------+----------------------120109 | Eric | Jordan | Shek Kip Mei | 18120110 | Frank | Lok Fu | Sunny Bay | 20
(2 rows)示例3:以“START(partition_value) ”方式创建START END范围分区表graderecord。
含有3个分区,分区键为INTEGER类型。分区的范围分别为:0<= grade<60,60<= grade<90,90<=grade< MAXVALUE。--创建分区表graderecord。
openGauss=# CREATE TABLE graderecord(number INTEGER,name CHAR(20),class CHAR(20),grade INTEGER)PARTITION BY RANGE(grade)(PARTITION pass START(60),PARTITION excellent START(90));-- 数据插入分区。
openGauss=# insert into graderecord values('210101','Alan','21.01',92);
openGauss=# insert into graderecord values('210102','Ben','21.01',62);
openGauss=# insert into graderecord values('210103','Brain','21.01',26);
openGauss=# insert into graderecord values('210204','Carl','21.02',77);
openGauss=# insert into graderecord values('210205','David','21.02',47);
openGauss=# insert into graderecord values('210206','Eric','21.02',97);
openGauss=# insert into graderecord values('210307','Frank','21.03',90);
openGauss=# insert into graderecord values('210308','Gavin','21.03',100);
openGauss=# insert into graderecord values('210309','Henry','21.03',67);
openGauss=# insert into graderecord values('210410','Jack','21.04',75);
openGauss=# insert into graderecord values('210311','Jerry','21.04',60);--查询graderecord的数据。
openGauss=# SELECT * FROM graderecord;number | name | class | grade
--------+----------------------+----------------------+-------210103 | Brain | 21.01 | 26210205 | David | 21.02 | 47210102 | Ben | 21.01 | 62210204 | Carl | 21.02 | 77210309 | Henry | 21.03 | 67210410 | Jack | 21.04 | 75210311 | Jerry | 21.04 | 60210101 | Alan | 21.01 | 92210206 | Eric | 21.02 | 97210307 | Frank | 21.03 | 90210308 | Gavin | 21.03 | 100
(11 rows)--查询graderecord的pass分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (pass);
ERROR: partition "pass" of relation "graderecord" does not exist
查询失败。
原因是“PARTITION pass START(60),”是第一个分区定义,且该定义有START值,则范围(MINVALUE, 60)将自动作为第一个实际分区,
其名称为“pass_0”。
而该定义语义描述的“60<= grade<90”分区的名称为“pass_1”。--查询graderecord的pass_0分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (pass_0);number | name | class | grade
--------+----------------------+----------------------+-------210103 | Brain | 21.01 | 26210205 | David | 21.02 | 47
(2 rows)--查询graderecord的pass_1分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (pass_1);number | name | class | grade
--------+----------------------+----------------------+-------210102 | Ben | 21.01 | 62210204 | Carl | 21.02 | 77210309 | Henry | 21.03 | 67210410 | Jack | 21.04 | 75210311 | Jerry | 21.04 | 60
(5 rows)--查询graderecord的execllent分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (excellent);number | name | class | grade
--------+----------------------+----------------------+-------210101 | Alan | 21.01 | 92210206 | Eric | 21.02 | 97210307 | Frank | 21.03 | 90210308 | Gavin | 21.03 | 100
(4 rows)示例4:以“END(partition_value | MAXVALUE) ”方式创建START END范围分区表graderecord。
含有3个分区,分区键为INTEGER类型。
分区的范围分别为:0<= grade<60,60<= grade<90,90<=grade< MAXVALUE。--创建分区表graderecord。
openGauss=# CREATE TABLE graderecord(number INTEGER,name CHAR(20),class CHAR(20),grade INTEGER)PARTITION BY RANGE(grade)(PARTITION no_pass END(60),PARTITION pass END(90),PARTITION excellent END(MAXVALUE));-- 数据插入分区。
openGauss=# insert into graderecord values('210101','Alan','21.01',92);
openGauss=# insert into graderecord values('210102','Ben','21.01',62);
openGauss=# insert into graderecord values('210103','Brain','21.01',26);
openGauss=# insert into graderecord values('210204','Carl','21.02',77);
openGauss=# insert into graderecord values('210205','David','21.02',47);
openGauss=# insert into graderecord values('210206','Eric','21.02',97);
openGauss=# insert into graderecord values('210307','Frank','21.03',90);
openGauss=# insert into graderecord values('210308','Gavin','21.03',100);
openGauss=# insert into graderecord values('210309','Henry','21.03',67);
openGauss=# insert into graderecord values('210410','Jack','21.04',75);
openGauss=# insert into graderecord values('210311','Jerry','21.04',60);--查询graderecord的数据。
openGauss=# SELECT * FROM graderecord;number | name | class | grade
--------+----------------------+----------------------+-------210103 | Brain | 21.01 | 26210205 | David | 21.02 | 47210102 | Ben | 21.01 | 62210204 | Carl | 21.02 | 77210309 | Henry | 21.03 | 67210410 | Jack | 21.04 | 75210311 | Jerry | 21.04 | 60210101 | Alan | 21.01 | 92210206 | Eric | 21.02 | 97210307 | Frank | 21.03 | 90210308 | Gavin | 21.03 | 100
(11 rows)--查询graderecord的no_pass分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (no_pass);number | name | class | grade
--------+----------------------+----------------------+-------210103 | Brain | 21.01 | 26210205 | David | 21.02 | 47
(2 rows)--查询graderecord的pass分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (pass);number | name | class | grade
--------+----------------------+----------------------+-------210102 | Ben | 21.01 | 62210204 | Carl | 21.02 | 77210309 | Henry | 21.03 | 67210410 | Jack | 21.04 | 75210311 | Jerry | 21.04 | 60
(5 rows)--查询graderecord的execllent分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (excellent);number | name | class | grade
--------+----------------------+----------------------+-------210101 | Alan | 21.01 | 92210206 | Eric | 21.02 | 97210307 | Frank | 21.03 | 90210308 | Gavin | 21.03 | 100
(4 rows)
✨ 2.2 列表分区表
1.语法
CREATE TABLE partition_table_name
( [column_name data_type ][, ... ]
)PARTITION BY LIST (partition_key)(PARTITION partition_name VALUES (list_values_clause)[, ... ]);list_values_clause:对应分区存在的一个或者多个键值。多个键值之间以逗号分隔。
VALUES (DEFAULT):加入的数据如有“list_values_clause”中未列出的键值,存放在VALUES (DEFAULT)对应的分区。
MAXVALUE:MAXVALUE表示分区的上边界,它通常用于设置最后一个范围分区的上边界。2.示例:
创建列表分区表graderecord。含有4个分区,分区键为CHAR类型。分区的范围分别为:21.01,21.02,21.03,21.04。--创建分区表graderecord。
openGauss=# CREATE TABLE graderecord(number INTEGER,name CHAR(20),class CHAR(20),grade INTEGER)PARTITION BY LIST(class)(PARTITION class_01 VALUES ('21.01'),PARTITION class_02 VALUES ('21.02'),PARTITION class_03 VALUES ('21.03'),PARTITION class_04 VALUES ('21.04'));-- 数据插入分区。
openGauss=# insert into graderecord values('210101','Alan','21.01',92);
openGauss=# insert into graderecord values('210102','Ben','21.01',62);
openGauss=# insert into graderecord values('210103','Brain','21.01',26);
openGauss=# insert into graderecord values('210204','Carl','21.02',77);
openGauss=# insert into graderecord values('210205','David','21.02',47);
openGauss=# insert into graderecord values('210206','Eric','21.02',97);
openGauss=# insert into graderecord values('210307','Frank','21.03',90);
openGauss=# insert into graderecord values('210308','Gavin','21.03',100);
openGauss=# insert into graderecord values('210309','Henry','21.03',67);
openGauss=# insert into graderecord values('210410','Jack','21.04',75);
openGauss=# insert into graderecord values('210311','Jerry','21.04',60);--查询graderecord的数据。
openGauss=# SELECT * FROM graderecord;number | name | class | grade
--------+----------------------+----------------------+-------210410 | Jack | 21.04 | 75210311 | Jerry | 21.04 | 60210307 | Frank | 21.03 | 90210308 | Gavin | 21.03 | 100210309 | Henry | 21.03 | 67210204 | Carl | 21.02 | 77210205 | David | 21.02 | 47210206 | Eric | 21.02 | 97210101 | Alan | 21.01 | 92210102 | Ben | 21.01 | 62210103 | Brain | 21.01 | 26
(11 rows)--查询graderecord的class_01分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (class_01);number | name | class | grade
--------+----------------------+----------------------+-------210101 | Alan | 21.01 | 92210102 | Ben | 21.01 | 62210103 | Brain | 21.01 | 26
(3 rows)--查询graderecord的class_04分区数据。
openGauss=# SELECT * FROM graderecord PARTITION (class_04);number | name | class | grade
--------+----------------------+----------------------+-------210410 | Jack | 21.04 | 75210311 | Jerry | 21.04 | 60
(2 rows)✨ 2.3 间隔分区表
间隔分区是在范围分区的基础上,增加了间隔值
1.VALUES LESS THAN间隔分区语法格式
CREATE TABLE partition_table_name
( [column_name data_type ][, ... ]
)PARTITION BY RANGE (partition_key)(INTERVAL ('interval_expr')PARTITION partition_name VALUES LESS THAN (partition_value | MAXVALUE})[, ... ]);interval_expr自动创建分区的间隔,例如:自动创建分区的间隔,例如:1 day、1 month。2.示例:
--创建分区表sales_table。
openGauss=# CREATE TABLE sales_table
(order_no INTEGER NOT NULL,goods_name CHAR(20) NOT NULL,sales_date DATE NOT NULL,sales_volume INTEGER,sales_store CHAR(20)
)
PARTITION BY RANGE(sales_date)INTERVAL ('1 month')(PARTITION start VALUES LESS THAN('2021-01-01 00:00:00'),PARTITION later VALUES LESS THAN('2021-01-10 00:00:00'));
-- 数据插入分区later
openGauss=# INSERT INTO sales_table VALUES(1, 'jacket', '2021-01-8 00:00:00', 3,'Alaska');-- 不在已有分区的数据插入,系统会新建分区sys_p1。
openGauss=# INSERT INTO sales_table VALUES(2, 'hat', '2021-04-06 00:00:00', 255,'Clolorado');-- 不在已有分区的数据插入,系统会新建分区sys_p2。
openGauss=# INSERT INTO sales_table VALUES(3, 'shirt', '2021-11-17 00:00:00', 7000,'Florida');-- 数据插入分区start
openGauss=# INSERT INTO sales_table VALUES(4, 'coat', '2020-10-21 00:00:00', 9000,'Hawaii');--查询sales_table的数据。
openGauss=# SELECT * FROM sales_table;order_no | goods_name | sales_date | sales_volume | sales_store
----------+----------------------+---------------------+--------------+----------------------4 | coat | 2020-10-21 00:00:00 | 9000 | Hawaii1 | jacket | 2021-01-08 00:00:00 | 3 | Alaska2 | hat | 2021-04-06 00:00:00 | 255 | Clolorado3 | shirt | 2021-11-17 00:00:00 | 7000 | Florida
(4 rows)--查询sales_table的start分区数据。这里采用“sales_table PARTITION (start);”来引用分区。
openGauss=# SELECT * FROM sales_table PARTITION (start);order_no | goods_name | sales_date | sales_volume | sales_store
----------+----------------------+---------------------+--------------+----------------------4 | coat | 2020-10-21 00:00:00 | 9000 | Hawaii
(1 row)--查询sales_table的later分区数据。这里采用“sales_table PARTITION (later);”来引用分区。
openGauss=# SELECT * FROM sales_table PARTITION (later);order_no | goods_name | sales_date | sales_volume | sales_store
----------+----------------------+---------------------+--------------+----------------------1 | jacket | 2021-01-08 00:00:00 | 3 | Alaska
(1 row)--查询sales_table的sys_p1分区数据。这里采用“sales_table PARTITION (sys_p1);”来引用分区。
openGauss=# SELECT * FROM sales_table PARTITION (sys_p1);order_no | goods_name | sales_date | sales_volume | sales_store
----------+----------------------+---------------------+--------------+----------------------2 | hat | 2021-04-06 00:00:00 | 255 | Clolorado
(1 row)--查询sales_table的sys_p2分区数据。这里采用“sales_table PARTITION (sys_p2);”来引用分区。
openGauss=# SELECT * FROM sales_table PARTITION (sys_p2);order_no | goods_name | sales_date | sales_volume | sales_store
----------+----------------------+---------------------+--------------+----------------------3 | shirt | 2021-11-17 00:00:00 | 7000 | Florida
(1 row)
✨ 2.4 哈希分区表
1.语法
CREATE TABLE partition_table_name
( [column_name data_type ][, ... ]
)PARTITION BY HASH (partition_key)(PARTITION partition_name )[, ... ]);partition_name:哈希分区的名称。希望创建几个哈希分区就给出几个分区名。2.创建哈希分区表hash_partition_table
openGauss=# create table hash_partition_table (
col1 int,
col2 int)
partition by hash(col1)
(
partition p1,
partition p2
);-- 数据插入
openGauss=# INSERT INTO hash_partition_table VALUES(1, 1);
INSERT 0 1
openGauss=# INSERT INTO hash_partition_table VALUES(2, 2);
INSERT 0 1
openGauss=# INSERT INTO hash_partition_table VALUES(3, 3);
INSERT 0 1
openGauss=# INSERT INTO hash_partition_table VALUES(4, 4);
INSERT 0 1-- 查看数据
openGauss=# select * from hash_partition_table partition (p1);col1 | col2
------+------3 | 34 | 4
(2 rows)openGauss=# select * from hash_partition_table partition (p2);col1 | col2
------+------1 | 12 | 2
(2 rows)📣 3.分区表维护
✨ 3.1 常用语法
删除分区:
ALTER TABLE partition_table_name DROP PARTITION partition_name;
增加分区:
ALTER TABLE partition_table_name ADD {partition_less_than_item | partition_start_end_item| partition_list_item };
重命名分区:
ALTER TABLE partition_table_name RENAME PARTITION partition_name TO partition_new_name;
分裂分区(指定切割点split_partition_value的语法):
ALTER TABLE partition_table_name SPLIT PARTITION partition_name AT ( split_partition_value ) INTO ( PARTITION partition_new_name1, PARTITION partition_new_name2);
分裂分区(指定分区范围的语法):
ALTER TABLE partition_table_name SPLIT PARTITION partition_name INTO { ( partition_less_than_item [, …] ) | ( partition_start_end_item [, …] ) };
合并分区:
ALTER TABLE partition_table_name MERGE PARTITIONS { partition_name } [, …] INTO PARTITION partition_name;
✨ 3.2 案例
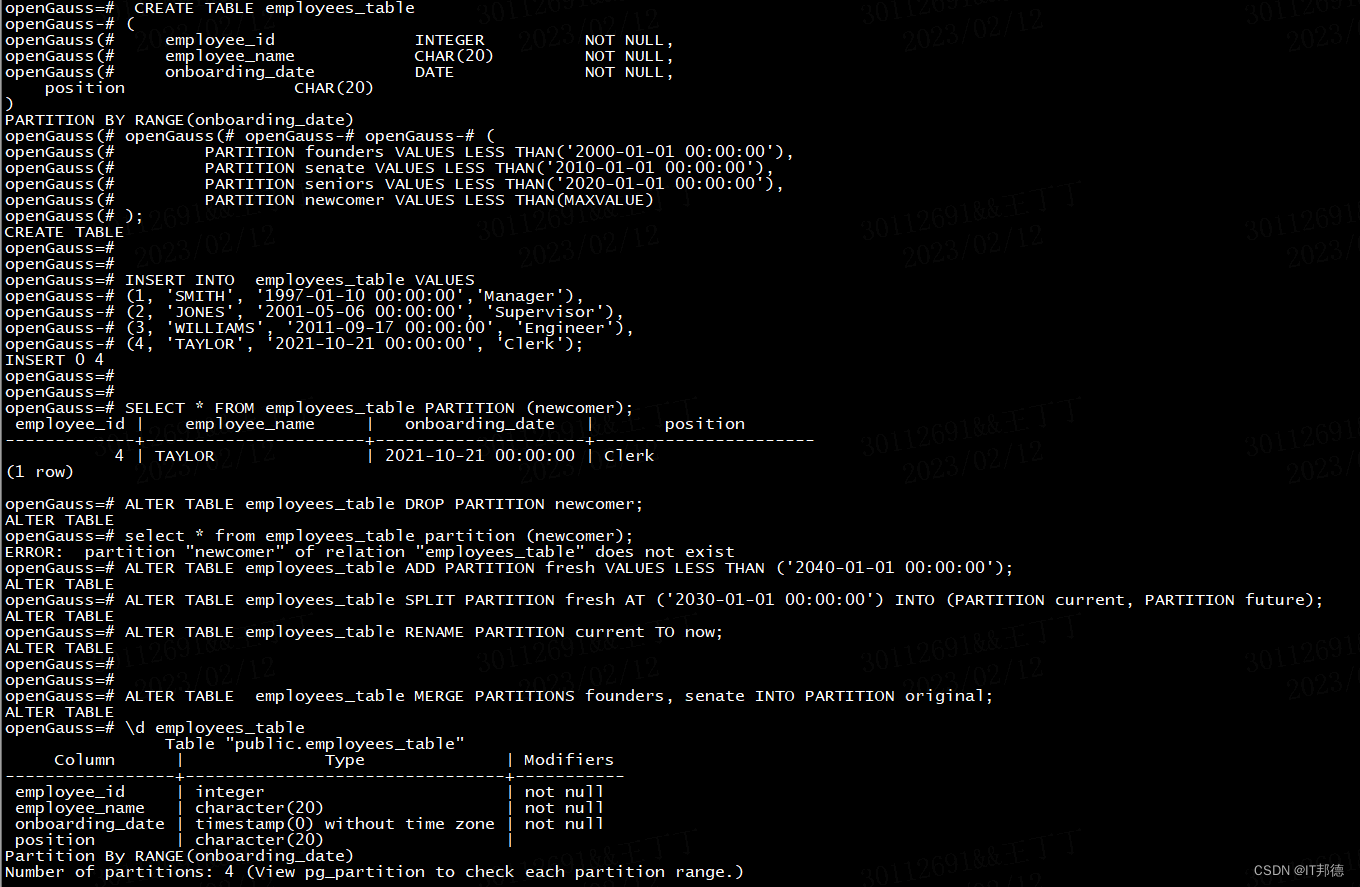
--创建分区表employees_table。
openGauss=# CREATE TABLE employees_table
(employee_id INTEGER NOT NULL,employee_name CHAR(20) NOT NULL,onboarding_date DATE NOT NULL,position CHAR(20)
)
PARTITION BY RANGE(onboarding_date)
(PARTITION founders VALUES LESS THAN('2000-01-01 00:00:00'),PARTITION senate VALUES LESS THAN('2010-01-01 00:00:00'),PARTITION seniors VALUES LESS THAN('2020-01-01 00:00:00'),PARTITION newcomer VALUES LESS THAN(MAXVALUE)
);-- 插入数据
openGauss=# INSERT INTO employees_table VALUES
(1, 'SMITH', '1997-01-10 00:00:00','Manager'),
(2, 'JONES', '2001-05-06 00:00:00', 'Supervisor'),
(3, 'WILLIAMS', '2011-09-17 00:00:00', 'Engineer'),
(4, 'TAYLOR', '2021-10-21 00:00:00', 'Clerk');查看newcomer分区
openGauss=# SELECT * FROM employees_table PARTITION (newcomer);employee_id | employee_name | onboarding_date | position
-------------+----------------------+---------------------+----------------------4 | TAYLOR | 2021-10-21 00:00:00 | Clerk
(1 row)--删除newcomer分区。
openGauss=# ALTER TABLE employees_table DROP PARTITION newcomer;-- 查看newcomer分区数据
openGauss=# select * from employees_table partition (newcomer);--增加fresh分区。
openGauss=# ALTER TABLE employees_table ADD PARTITION fresh VALUES LESS THAN ('2040-01-01 00:00:00');
ALTER TABLE--以2030-01-01 00:00:00为分割点,分裂fresh分区为current、future两个分区
openGauss=# ALTER TABLE employees_table SPLIT PARTITION fresh AT ('2030-01-01 00:00:00') INTO (PARTITION current, PARTITION future);--将分区current改名为now
openGauss=# ALTER TABLE employees_table RENAME PARTITION current TO now;--将founders,senate合并为一个分区original。
openGauss=# ALTER TABLE employees_table MERGE PARTITIONS founders, senate INTO PARTITION original;openGauss=# select w.relname,w.parttype from pg_partition w;relname | parttype
-----------------+----------sales_table | rseason1 | pseason2 | pseason3 | pseason4 | pemployees_table | rseniors | pfuture | pnow | poriginal | p


相关文章:
【openGauss实战9】深度分析分区表
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

XSS跨站脚本攻击剖析与防御:初识XSS
目录 跨站脚本介绍 1. 什么是XSS跨站脚本 2. XSS跨站脚本实例 3. XSS漏洞的危害 XSS的分类 1. 反射型XSS 2. 持久性XSS XSS构造 1. 利用< >标记注射Html /Javascript 2. 利用HTML标签属性值执行XSS 3. 空格回车Tab 4. 对标签属性值转码 5. 产生自己的事件…...
Python 高级编程之网络编程 Socket(六)
文章目录一、概述二、Python socket 模块1)Socket 类型1、创建 TCP Socket2、创建 UDP Socket2)Socket 函数1、服务端socket函数2、客户端socket函数3、公共socket函数三、单工,半双工以及全双工通信方式的区别四、单工,半双工以及…...
centos学习记录
遇到的问题及其解决办法 centos7安装图形化界面 yum groupinstall ‘X Window System’ yum groupinstall -y ‘GNOME Desktop’ 安装完成后输入init 5进入图形化界面 centos7安装vmware-tools 第一步卸载open-vm-tools 输入命令 yum remove open-vm-tools 输入命令 reboot 在…...

为什么说网络安全是风口行业?
前言 “没有网络安全就没有国家安全”。当前,网络安全已被提升到国家战略的高度,成为影响国家安全、社会稳定至关重要的因素之一。 网络安全行业特点 1、就业薪资非常高,涨薪快 2021年猎聘网发布网络安全行业就业薪资行业最高人均33.77万&…...

12-PHP使用过的函数 111-120
111、rowCount if ($stmt->execute($data)) {//true//读:select//写:insert,update,delete,成功后会返回表中受影响的记录数量//!rowCount() 返回受影响的记录数量if ($stmt->rowCount() > 0) {echo 新增成功,id . $db->lastInsertId() . <hr>;} else {//…...
【JavaWeb项目】简单搭建一个前端的博客系统
博客系统项目 本项目主要分成四个页面: 博客列表页博客详情页登录页面博客编辑页 该系统公共的CSS样式 common.css /* 放置一些各个页面都会用到的公共样式 */* {margin: 0;padding: 0;box-sizing: 0; }/* 给整个页面加上背景 */ html, body{height: 100%; }body {backgrou…...

iPerf3 -M参数详解,场景分析
本文目录iPerf3 -M参数说明几个典型测试场景中应该如何设定合适的-M参数值理想局域网模型(无丢包,无抖动)高丢包,无抖动模型高丢包,高抖动模型(网络质量比较差,IP转发路径变化频繁)总…...

java的基本语法以及注意事项
Java 基础语法一个 Java 程序可以认为是一系列对象的集合,而这些对象通过调用彼此的方法来协同工作。下面简要介绍下类、对象、方法和实例变量的概念。对象:对象是类的一个实例,有状态和行为。例如,一条狗是一个对象,它…...
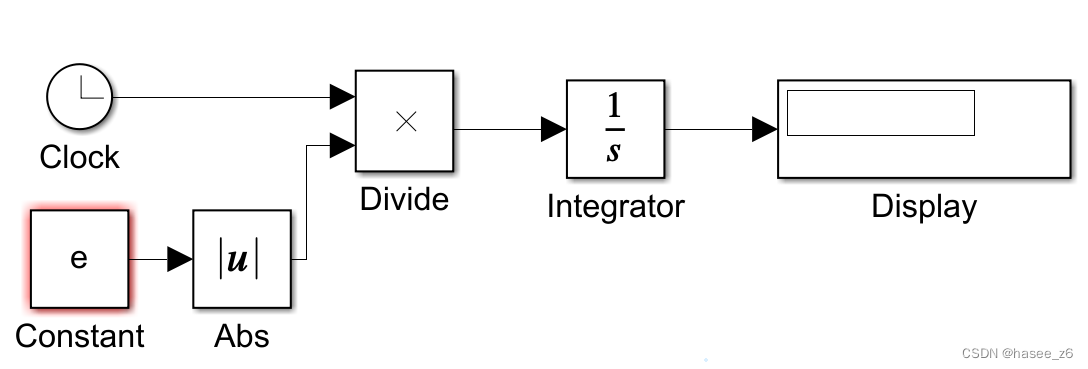
matlab搭建IAE,ISE,ITAE性能指标
目录前言准备IAEISEITAE前言 最近在使用matlab搭建控制系统性能评价指标模型,记录一下 准备 MATLAB R2020 IAE IAE函数表达式如下所示: IAE函数模型如下所示: ISE ISE函数表达式如下所示: ISE函数模型如下所示ÿ…...
docker安装mysql
在安装Mysql之前,我们可以先查看一下我们的镜像,输入命令: docker images 能发现,镜像里面只有一个Nginx,并没有Mysql 然后我们可以像上一篇安装Nginx一样,安装Mysql镜像。 输入以下命令,安装…...
Leetcode 回溯详解
回溯法 回溯法有“通用解题法”之称,用它可以系统地搜索问题的所有解。回溯法是一个既带有系统性又带有跳跃性的搜索算法。 在包含问题的所有解的解空间树中,按照深度优先搜索(DFS))的策略,从根结点出发深度探索解空间树。当探索…...
AI_Papers:第一期
2023.02.06—2023.02.12 文摘词云 Top Papers Subjects: cs.CL 1.Multimodal Chain-of-Thought Reasoning in Language Models 标题:语言模型中的多模式思维链推理 作者:Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Sm…...
C/C++内存管理
C/C内存管理C/C内存分布C语言中内存管理的方式:malloc/calloc/realloc/freeC内存管理方式内置类型自定义类型operator new 与operator deletenew和delete的实现原理内置类型自定义类型定位new表达式(placement-new)new/delete与malloc/free的区别C/C内存分布 我们先…...
【大数据hive】hive 函数使用详解
一、前言 在任何一种编程语言中,函数可以说是必不可少的,像mysql、oracle中,提供了很多内置函数,或者通过自定义函数的方式进行定制化使用,而hive作为一门数据分析软件,随着版本的不断更新迭代,…...
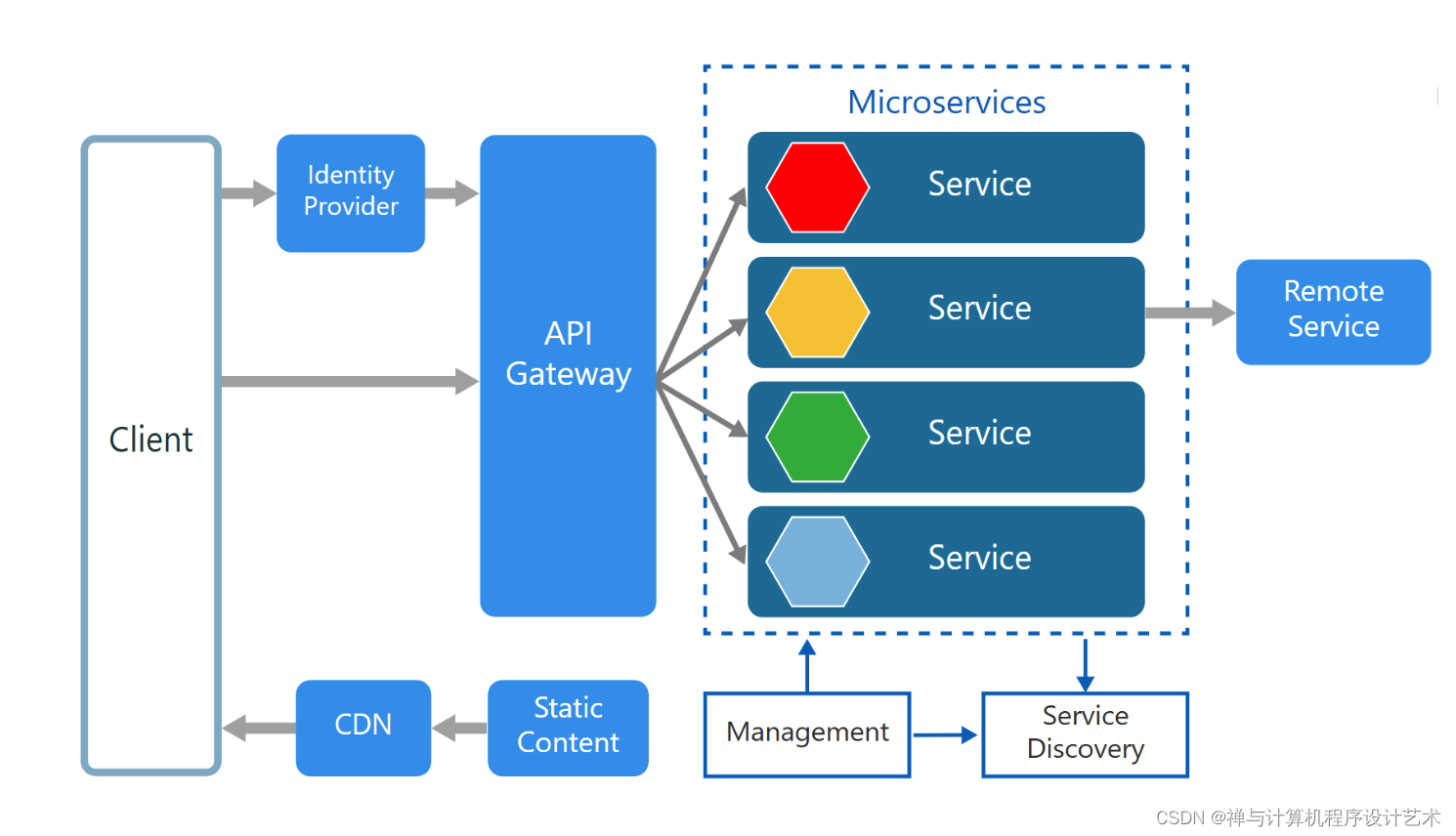
彻底搞懂分布式系统服务注册与发现原理
目录 引入服务注册与发现组件的原因 单体架构 应用与数据分离...

安卓Camera2用ImageReader获取NV21源码分析
以前如何得到Camera预览流回调 可以通过如下方法,得到一路预览回调流 Camera#setPreviewCallbackWithBuffer(Camera.PreviewCallback),可以通过如下方法,设置回调数据的格式,比如 ImageFormat.NV21 Camera.Parameters#setPreview…...

24. 两两交换链表中的节点
文章目录题目描述迭代法递归法参考文献题目描述 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1: 输入&a…...

linux006之帮助命令
linux帮助命令简介: linux的命令是非常多的,光靠人是记不住的,在工作中一般都会去网上查,这是有外网的情况下,如果项目中不允许访问外网,那么linux的帮助命令就可以派上用场了, linux帮助命令是…...

【C++初阶】十三、模板进阶(总)|非类型模板参数|模板的特化|模板分离编译|模板总结(优缺点)
目录 一、非类型模板参数 二、模板的特化 2.1 模板特化概念 2.2 函数模板特化 2.3 类模板特化 2.3.1 全特化 2.3.2 偏特化 三、模板分离编译 四、模板总结(优缺点) 前言:之前模板初阶并没有把 C模板讲完,因为当时没有接触…...

BYD 高通8155 OTA项目 我写的一篇专利
草根不要在BYD写专利,我24年1月初开始撰写,24年6月份才提交到专利公司,被驳回是因为有对比文件公开了我的发明点,是重庆赛力斯 4月份公开的,部门内部流程审核极慢,集团IPR找各种理由能拖上你半年࿰…...

ai辅助部署openclaw:让快马智能适配ubuntu环境与反爬策略
AI辅助部署OpenClaw:让快马智能适配Ubuntu环境与反爬策略 最近在尝试用OpenClaw抓取一些动态加载的网站数据,发现直接部署基础版本根本行不通。目标网站不仅有动态渲染的内容,还设置了各种反爬机制。好在发现了InsCode(快马)平台的AI辅助开发…...

C++ 性能评测工程:基于 Google Benchmark 的 C++ 函数级性能基准测试方法论
各位技术同仁,下午好!今天,我们将深入探讨一个在C开发中至关重要的话题:C 函数级性能基准测试。尤其是在追求极致性能的C世界里,仅仅依靠经验和直觉来优化代码是远远不够的。我们需要一套科学、严谨的方法论来量化和评…...

Qwen3.5-2B边缘部署教程:ARM架构服务器上运行多模态模型详细步骤
Qwen3.5-2B边缘部署教程:ARM架构服务器上运行多模态模型详细步骤 1. 引言 Qwen3.5-2B是阿里云推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。这款模型主打低功耗、低门槛部署,特别适配端侧和边…...

从‘迷失’到‘秒达’:我用PyCharm的‘符号搜索’和‘调用链查看’重构了老项目
从‘迷失’到‘秒达’:我用PyCharm的‘符号搜索’和‘调用链查看’重构了老项目 接手一个缺乏文档的遗留代码库,就像被扔进一座没有地图的迷宫。上周我面对的就是这样一个Python项目——3万行代码,零文档,函数命名随意得像临时起意…...
Pixelorama:从像素小白到艺术大师的完整指南
Pixelorama:从像素小白到艺术大师的完整指南 【免费下载链接】Pixelorama Unleash your creativity with Pixelorama, a powerful and accessible open-source pixel art multitool. Whether you want to create sprites, tiles, animations, or just express yours…...
)
若依框架实战:如何优雅地实现静态资源权限校验(附完整代码)
若依框架静态资源权限校验实战指南 在企业级应用开发中,静态资源的安全访问控制是一个常见需求。无论是小程序图片资源管理,还是企业内部文档权限控制,都需要确保只有授权用户才能访问特定资源。本文将深入探讨如何在若依(RuoYi)框架中实现静…...

DeepSeek句式重构指令怎么用?手把手教你降AI率超过30%
第一次操作的话,照着下面的步骤来,15分钟内搞定DeepSeek句式重构指令、降AI、降AIGC率。 工具选嘎嘎降AI(www.aigcleaner.com),达标率99.26%,有退款保障,操作也不复杂。 准备工作 需要准备的&…...

[AI/应用/MCP] MCP Server/Tool 开发指南
1. 智能软件工程的范式转移:从库集成到原生框架演进 在生成式人工智能(Generative AI)从单纯的文本生成向具备自主规划与执行能力的“代理化(Agentic)”系统跨越的过程中,.NET 生态系统正在经历一场自该平台…...

Phi-3-mini-4k-instruct-gguf实战案例:用轻量模型替代Llama3-8B做高频短任务降本
Phi-3-mini-4k-instruct-gguf实战案例:用轻量模型替代Llama3-8B做高频短任务降本 1. 为什么选择轻量模型 在AI应用落地的过程中,我们常常面临一个困境:大模型效果虽好,但部署成本高、响应速度慢。特别是在处理大量高频短任务时&…...