【Week-R3】天气预测,引入探索式数据分析方法(EDA)
文章目录
- 1. 导入模块
- 2. 导入数据
- 3.探索式数据分析方法(EDA)
- 3.1 数据相关性探索
- 3.2 是否会下雨
- 3.3 地理位置与下雨的关系
- 3.4 湿度和压力对下雨的影响
- 3.5 气温对下雨的影响
- 4.数据预处理
- 4.1 处理缺损值
- 4.2 构建数据集
- 5 预测是否会下雨
- 5.1 构建神经网络
- 5.2 模型训练
- 5.3 结果可视化
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
本次学习引入了探索式数据分析(EDA),可用于分析数据表内各数据之间的关系
本次学习使用的数据集:来自澳大利亚许多地点的大约10年的每日天气观测数据。
本次学习的任务:根据提供的数据,对明天是否下雨(RainTomorrow)进行预测。
语言环境:Python 3.12
编译器:VSCode
深度学习框架:Tensorflow 2.11.0
1. 导入模块
print("*****************# 1. 导入模块************************")
# 1. 导入模块
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warningswarnings.filterwarnings('ignore')import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout
from keras.callbacks import EarlyStopping
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error, mean_squared_error
print("*****************# 1. 导入模块 End************************")2. 导入数据
# 2. 导入数据
print("*****************# 2. 导入数据************************")
data = pd.read_csv("D:\\jupyter notebook\\DL-100-days\\RNN\\weatherAUS.csv")
df = data.copy()
print("data.head():\n", data.head())

print("data.describe():\n", data.describe())

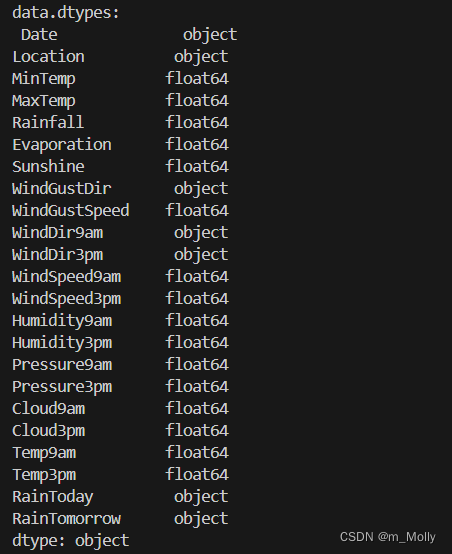
print("data.dtypes:\n", data.dtypes)
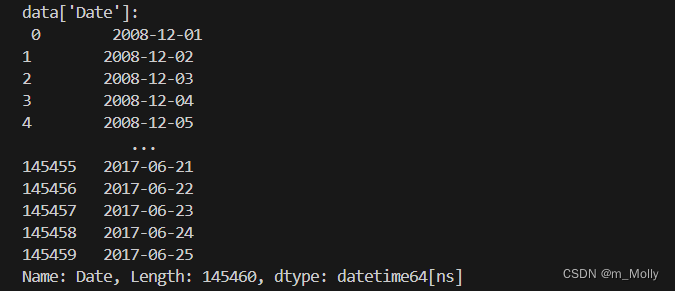
data['Date'] = pd.to_datetime(data['Date'])
print("data['Date']:\n", data['Date'])
data['year'] = data['Date'].dt.year
data['Month'] = data['Date'].dt.month
data['day'] = data['Date'].dt.day
print("data.head():\n", data.head())

data.drop('Date', axis=1, inplace=True)
print("data.columns:\n", data.columns)
print("*****************# 2. 导入数据 End************************")
3.探索式数据分析方法(EDA)
探索性数据分析(Exploratory Data Analysis,简称EDA),是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律了解数据集,了解变量间的相互关系以及变量与预测值之间的关系的一种数据分析方法。
【探索式数据分析方法(EDA)】
3.1 数据相关性探索
print("*****************3.探索式数据分析方法(EDA)************************")
# 3.探索式数据分析方法(EDA)
# 3.1 数据相关性探索
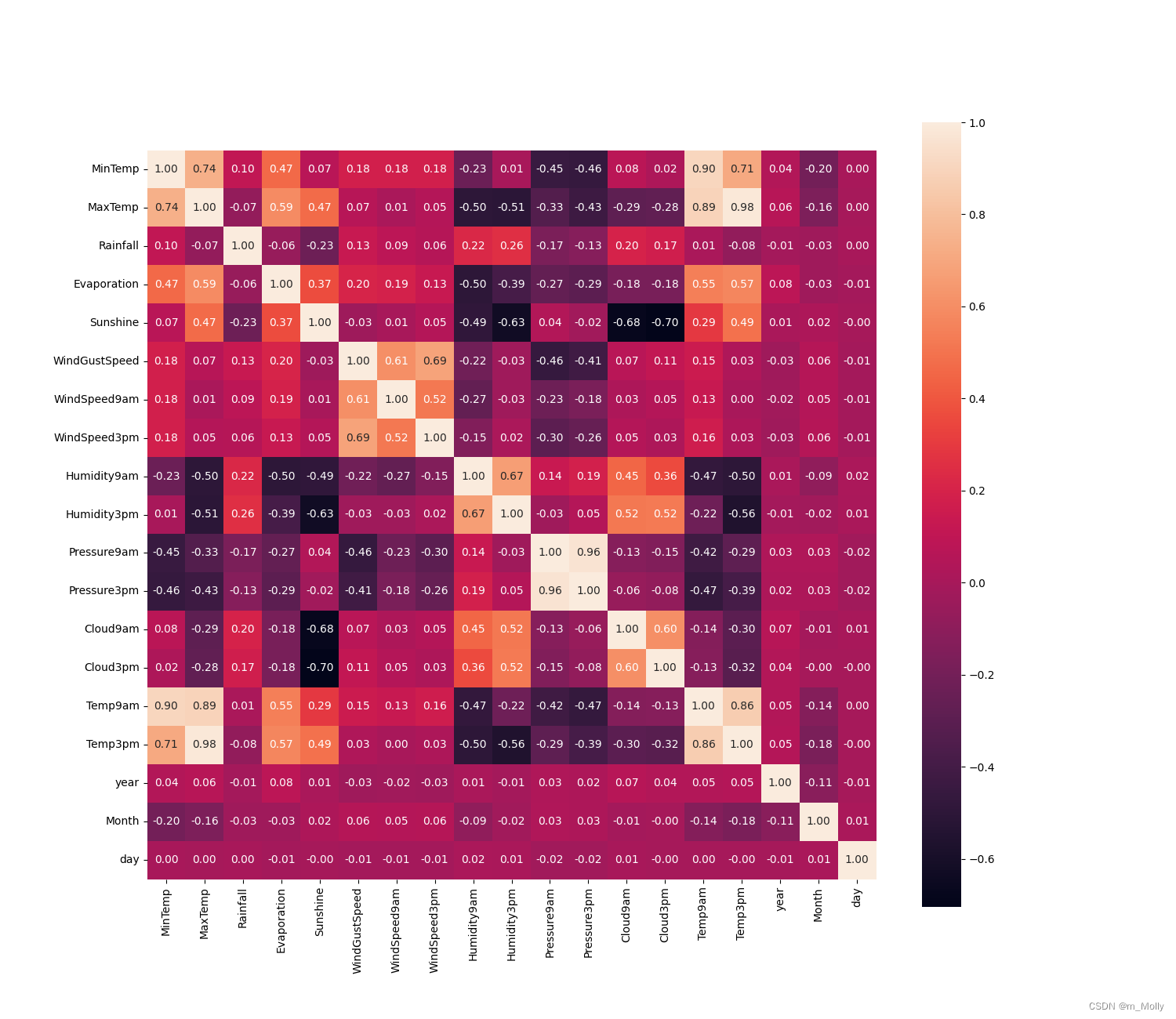
plt.figure(figsize=(15,13))
# data.corr()表示了data中的两个变量之间的相关性
ax = sns.heatmap(data.corr(),square=True, annot=True, fmt='.2f')
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
plt.savefig("3.1 数据相关性探索热力图.png")
plt.show()
3.2 是否会下雨
# 3.2 是否会下雨
fig,ax = plt.subplots(1,3,constrained_layout = True , figsize = (14,3))
sns.set_theme(style="darkgrid")
#plt.figure(figsize=(4,3))
sns.countplot(x='RainTomorrow', data=data, ax=ax[0])
#plt.savefig("3.2 明天是否会下雨.png")#plt.figure(figsize=(4,3))
sns.countplot(x='RainToday', data=data, ax=ax[1])
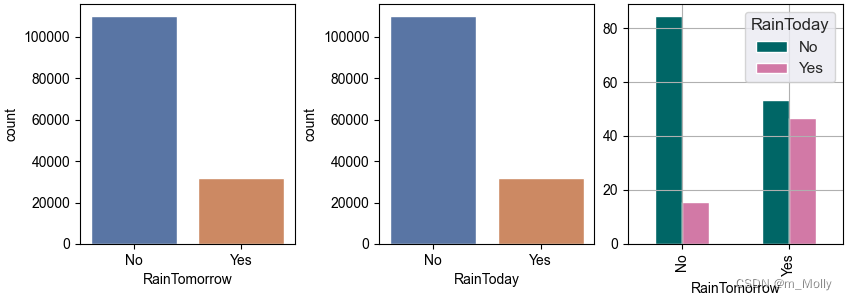
#plt.savefig("3.2 今天是否会下雨.png")x = pd.crosstab(data['RainTomorrow'], data['RainToday'])
print("x: \n", x)
# 计算百分比
y = x/x.transpose().sum().values.reshape(2,1)*100
print("y: \n", y)y.plot(kind="bar", figsize=(4,3), color=['#006666','#d279a6'], ax=ax[2])
plt.savefig("3.2 是否会下雨.png")
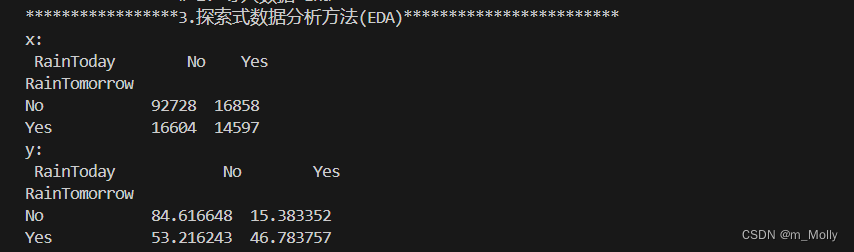
(左)明天是否下雨
(中)今天是否下雨
(右)今天是否下雨 & 明天是否下雨 的关系
3.3 地理位置与下雨的关系
plt.figure(figsize=(15,20))
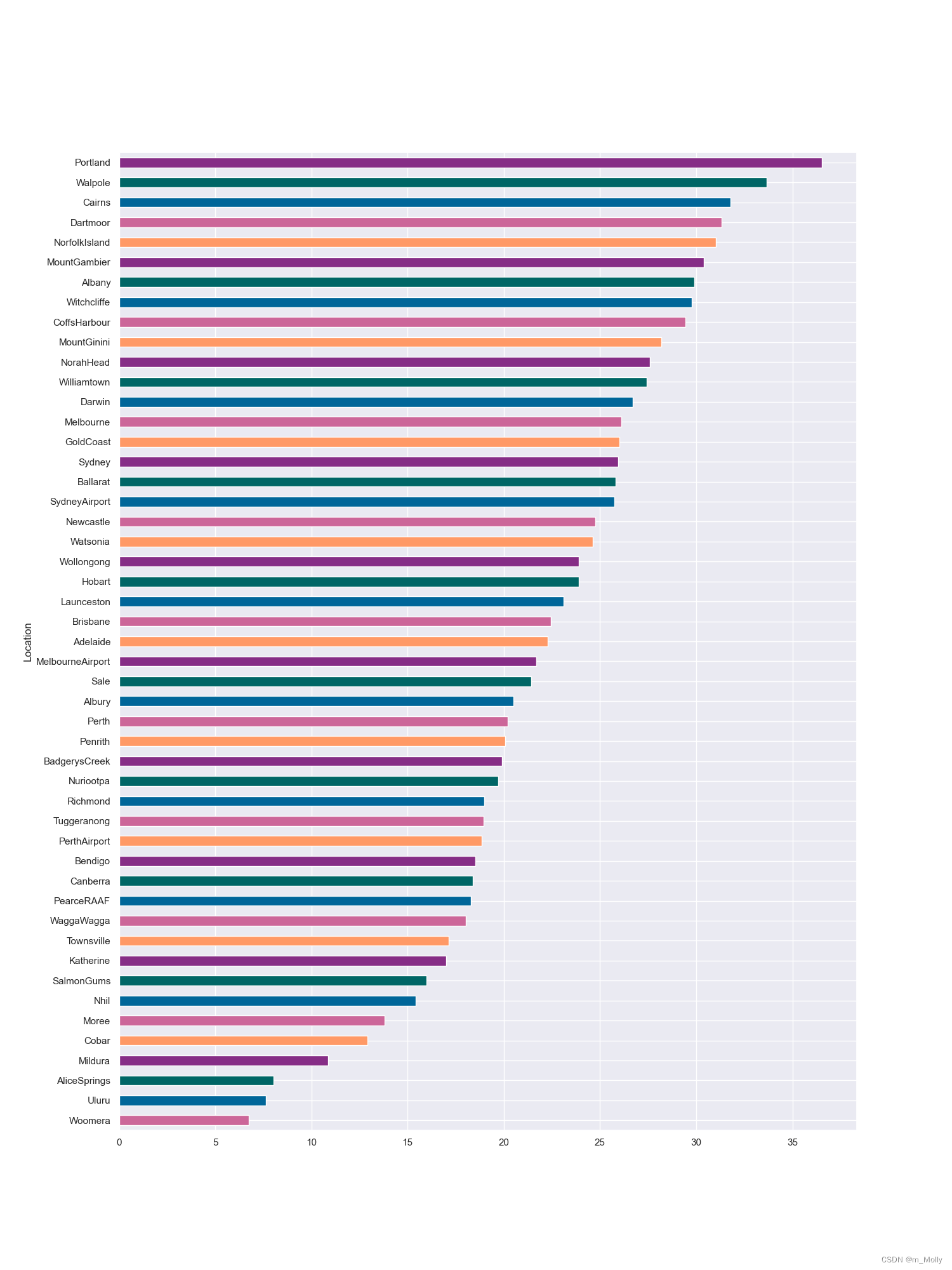
# 3.3 地理位置与下雨的关系
x = pd.crosstab(data['Location'], data['RainToday'])
# 获取每个城市下雨天数和非下雨天数的百分比
y = x/x.transpose().sum().values.reshape((-1,1))*100
# 按每个城市雨天的百分比排序
y = y.sort_values(by='Yes', ascending=True)
color = ['#cc6699', '#006699', '#006666', '#862d86', '#ff9966']
y.Yes.plot(kind="bath", figsize=(15,20), color=color)
plt.savefig("3.3 地理位置与下雨的关系.png")
3.4 湿度和压力对下雨的影响
# 3.4 湿度和压力对下雨的影响
data.columns
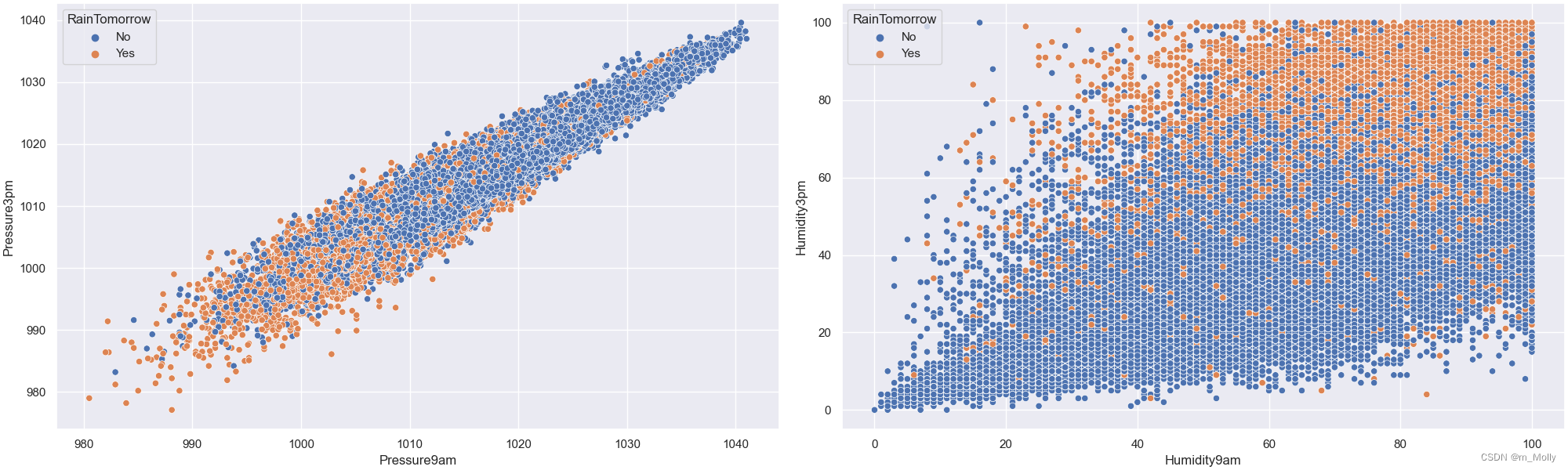
# 绘制明天早上9点到下午3点的气压下是否下雨的散点图
fig,ax = plt.subplots(1,2,constrained_layout = True , figsize = (20,6))
#plt.figure(figsize=(8,6))
sns.scatterplot(data=data, x='Pressure9am', y='Pressure3pm',hue='RainTomorrow', ax=ax[0])
#plt.savefig("3.4 压力对下雨的影响.png")
# 绘制明天早上9点到下午3点的湿度下是否下雨的散点图
#plt.figure(figsize=(8,6))
sns.scatterplot(data=data, x='Humidity9am', y='Humidity3pm',hue='RainTomorrow', ax=ax[1])
plt.savefig("3.4 压力、湿度对下雨的影响.png")
输出:(左)压力对下雨的影响 (右)湿度对下雨的影响
3.5 气温对下雨的影响
# 3.5 气温对下雨的影响
plt.figure(figsize=(8,6))
sns.scatterplot(data=data, x='MinTemp', y='MaxTemp',hue='RainTomorrow')
plt.savefig("3.5 气温对下雨的影响.png")
print("*****************3.探索式数据分析方法(EDA) End************************")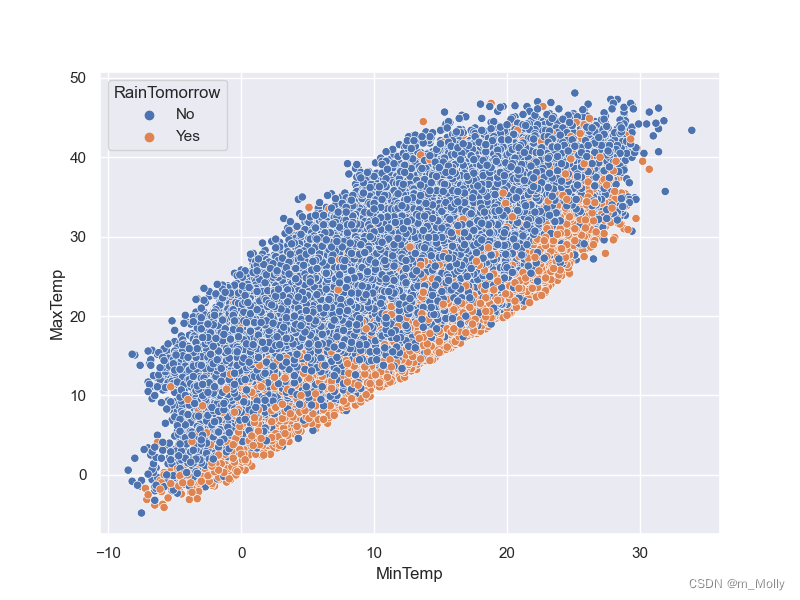
4.数据预处理
4.1 处理缺损值
print("*****************# 4.数据预处理************************")
# 4.数据预处理
# 4.1 处理缺损值
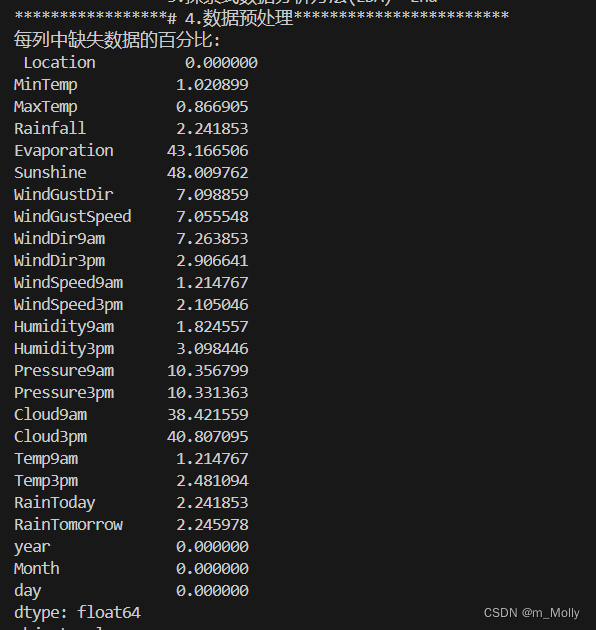
# 每列中缺失数据的百分比
print("每列中缺失数据的百分比: \n", data.isnull().sum()/data.shape[0]*100)
# 在该列中随机选择数进行填充
lst = ['Evaporation', 'Sunshine', 'Cloud9am', 'Cloud3pm']
for col in lst:fill_list = data[col].dropna()data[col] = data[col].fillna(pd.Series(np.random.choice(fill_list, size=len(data.index))))
s = (data.dtypes == "object")
object_cols = list(s[s].index)
print("object_cols: \n", object_cols)

# inplace=True: 直接修改原对象,不创建副本
# data[i].mode()[0]: 返回频率出现最高的选项,众数
for i in object_cols:data[i].fillna(data[i].mode()[0], inplace=True)
t = (data.dtypes == "float64")
num_cols = list(t[t].index)
print("num_cols: \n", num_cols)

# .median(): 中位数
for i in num_cols:data[i].fillna(data[i].median(), inplace=True)
data.isnull().sum()
4.2 构建数据集
LabelEncoder 是 sklearn.preprocessing 模块中的一个工具,用于将分类特征的标签转换为整数。
# 4.2 构建数据集
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
for i in object_cols:data[i] = label_encoder.fit_transform(data[i])
x = data.drop(['RainTomorrow', 'day'], axis=1).values
y = data['RainTomorrow'].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=101)
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
print("*****************# 4.数据预处理 End************************")报错:

原因:LabelEncoder是sklearn的模块,不是keras的。

5 预测是否会下雨
5.1 构建神经网络
print("*****************# 5 预测是否会下雨************************")
# 5 预测是否会下雨
# 5.1 构建神经网络
from keras.optimizers import Adam
model = Sequential()
model.add(Dense(units=24, activation='tanh',))
model.add(Dense(units=18, activation='tanh'))
model.add(Dense(units=23, activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(units=12, activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(units=1, activation='tanh'))
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(loss='binary_crossentropy',optimizer=optimizer,metrics="accuracy")
early_stop = EarlyStopping(monitor='val_loss',mode='min',min_delta=0.001,verbose=1,patience=25,restore_best_weights=True)
5.2 模型训练
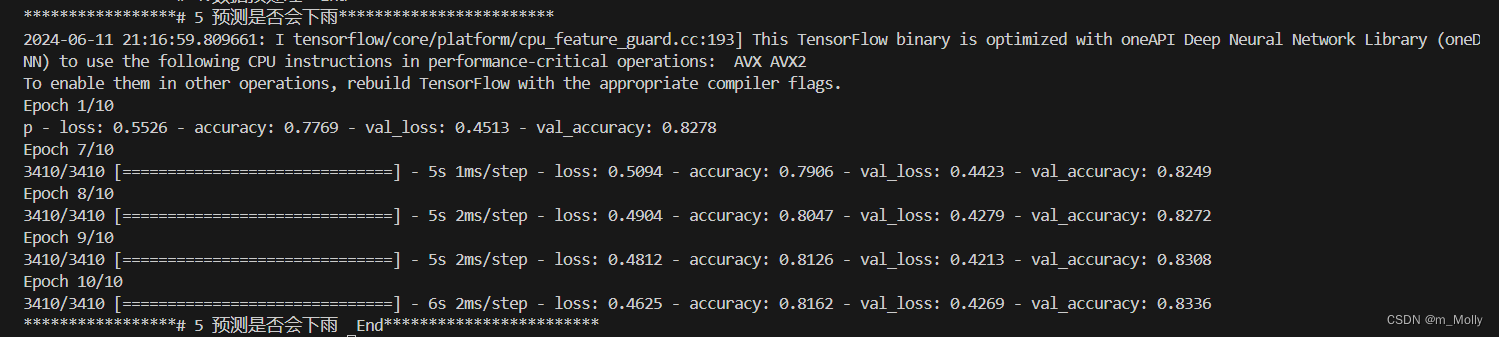
# 5.2 模型训练
model.fit(x=x_train,y=y_train,validation_data=(x_test, y_test), verbose=1,callbacks=[early_stop],epochs=10,batch_size=32)
5.3 结果可视化
# 5.3 结果可视化
acc = model.history.history['accuracy']
val_acc = model.history.history['val_accuracy']
loss = model.history.history['loss']
val_loss = model.history.history['val_loss']
epochs_range = range(10)plt.figure(figsize=(14,4))plt.subplot(1,2,1)
plt.plot(epochs_range, acc, label="Training Accuracy")
plt.plot(epochs_range, val_acc, label="Validation Accuracy")
plt.legend(loc="lower right")
plt.title("Training and Validation Accuracy")plt.subplot(1,2,2)
plt.plot(epochs_range, loss, label="Training Loss")
plt.plot(epochs_range, val_loss, label="Validation Loss")
plt.legend(loc="lower right")
plt.title("Training and Validation Loss")
plt.savefig("# 5.3 结果可视化.png")
plt.show()
print("*****************# 5 预测是否会下雨 End************************")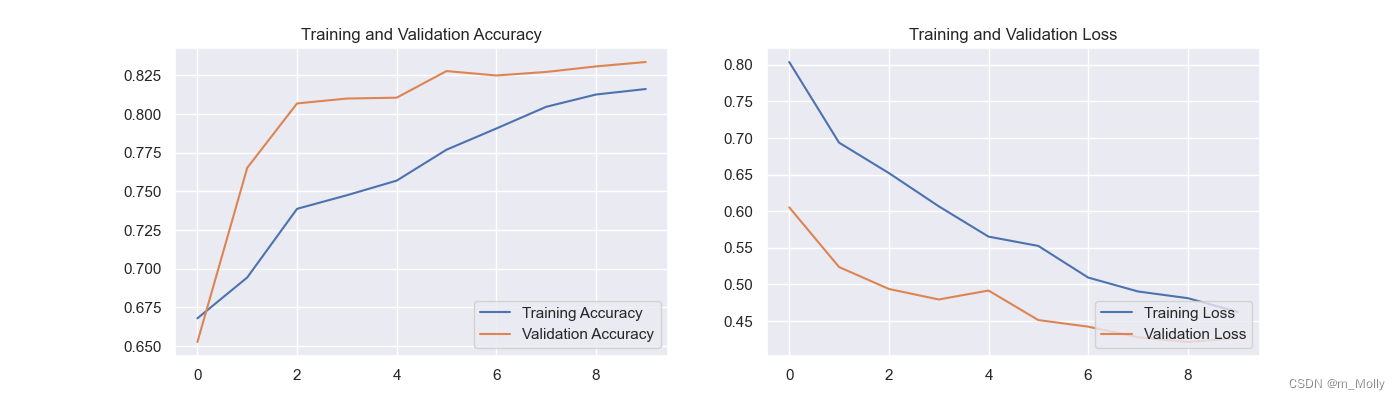
相关文章:
【Week-R3】天气预测,引入探索式数据分析方法(EDA)
文章目录 1. 导入模块2. 导入数据3.探索式数据分析方法(EDA)3.1 数据相关性探索3.2 是否会下雨3.3 地理位置与下雨的关系3.4 湿度和压力对下雨的影响3.5 气温对下雨的影响 4.数据预处理4.1 处理缺损值4.2 构建数据集 5 预测是否会下雨5.1 构建神经网络5.…...
VBA excel 表格将多行拆分成多个表格或 文件 或者合并 多个表格
excel 表格 拆分 合并 拆分工作表按行拆分为工作表工作表按行拆分为工作薄 合并操作步骤 拆分 为了将Excel中的数万行数据拆分成多个个每个固定行数的独立工作表,并且保留每个工作表的表头,你可以使用以下VBA脚本。这个脚本会复制表头到每个新的工作表&…...

利用Redis的队列模式实现消息的发送和订阅,适合分布式场景,Java实现代码
在Redis中,通常使用发布/订阅模式(Pub/Sub)来进行消息的实时通信。然而,标准的Redis发布/订阅模式并不直接支持确保一条消息只被一台机器消费。在这种模式下,所有订阅了特定频道的客户端都会收到发布的消息。 但是&…...

软件下载安装【汇总】
软件下载安装【汇总】 前言版权推荐软件安装【汇总】最后 前言 2024-5-12 21:38:34 以下内容源自《【汇总】》 仅供学习交流使用 版权 禁止其他平台发布时删除以下此话 本文首次发布于CSDN平台 作者是CSDN日星月云 博客主页是https://jsss-1.blog.csdn.net 禁止其他平台发布…...
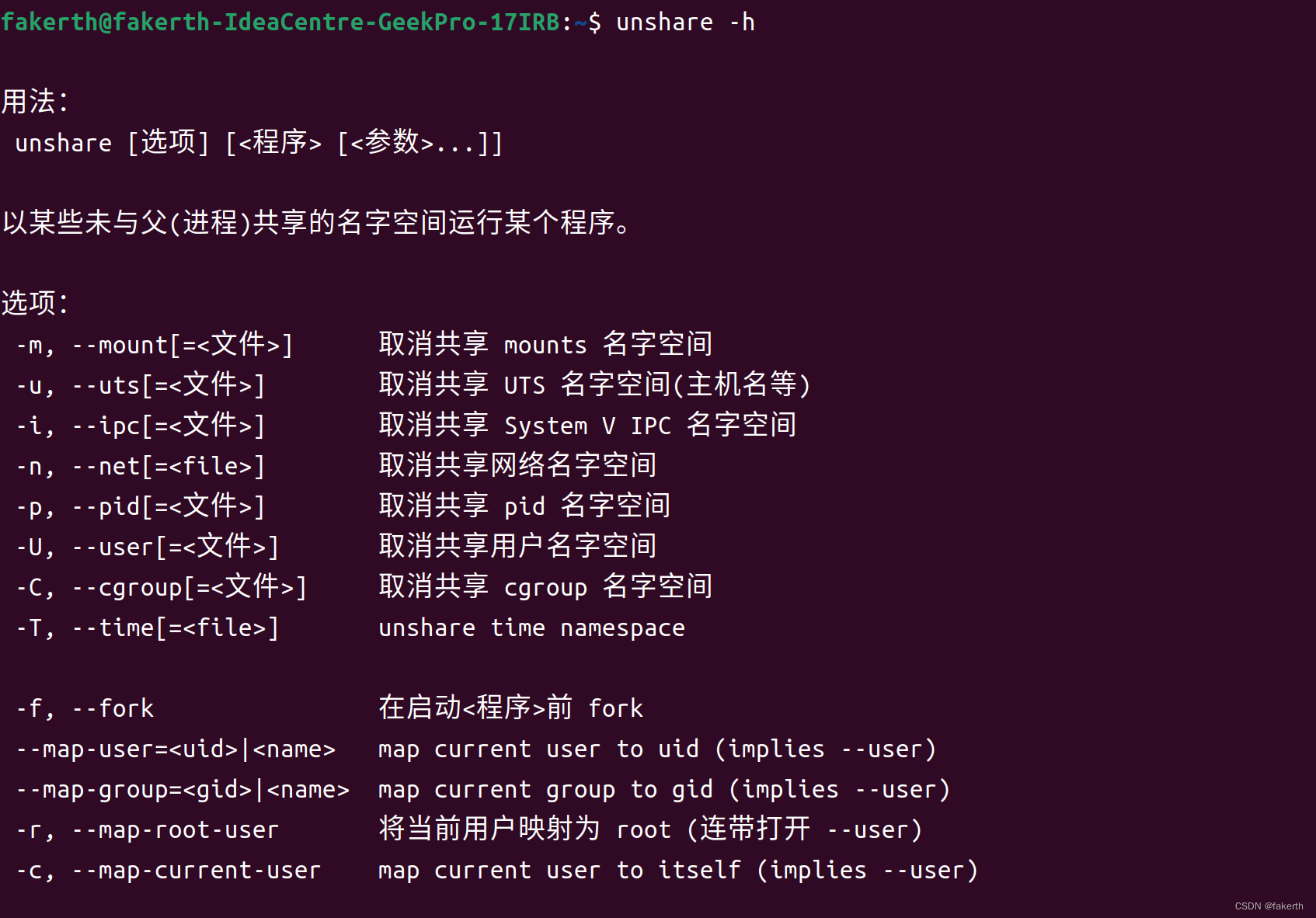
重定向文件访问(Redirect file access)
重定向文件访问 重定向文件访问是指通过修改文件系统的路径,使对某个文件或目录的访问请求被转到另一个文件或目录。这在系统管理、测试和开发中非常有用,因为它允许您在不修改应用程序或服务配置的情况下,改变文件的实际存储位置。 proot …...
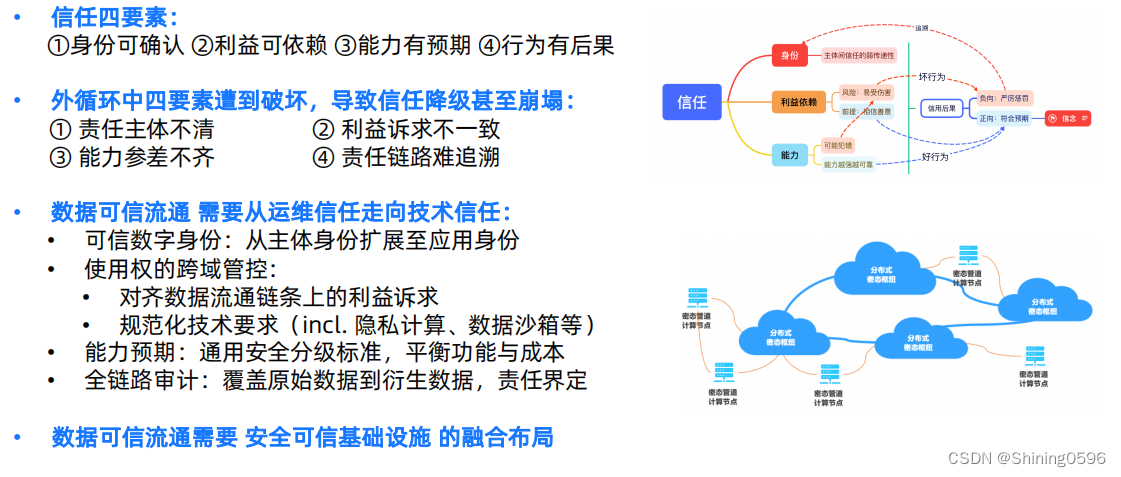
隐私计算(1)数据可信流通
目录 1. 数据可信流通体系 2. 信任的基石 3.数据流通中的不可信风险 可信链条的级联失效,以至于崩塌 4.数据内循环与外循环:传统数据安全的信任基础 4.1内循环 4.2外循环 5. 技术信任 6. 密态计算 7.技术信任 7.1可信数字身份 7.2 使用权跨域…...

果汁机锂电池充电,5V升压12.7V 升压恒压芯片SL1571B
在现代化的日常生活中,果汁机已经逐渐成为了许多家庭厨房的必备电器。随着科技的不断进步,果汁机的性能也在不断提升,其中锂电池的应用更是为果汁机带来了前所未有的便利。而5V升压12.7V升压恒压芯片SL1571B,作为果汁机锂电池充电…...

多个线程多个锁:如何确保线程安全和避免竞争条件
目录 前言 一、确定需要多个锁的场景 1.独立资源保护 2.部分依赖资源 二、避免死锁 三、锁粒度与并发性能 1. 粗粒度锁定 2.细粒度锁定 四、设计策略:减少资源依赖 1.资源分离 2.无锁设计 3.锁合并 五、Demo讲解 总结: 前言 当多个线程需要…...

Linux-笔记 设备树插件
目录 前言: 设备树插件的书写规范: 设备树插件的编译: 内核配置: 应用背景: 举例: 前言: 设备树插件(Device Tree Blob Overlay,简称 DTBO)是Linux内核和嵌入式系统…...

【排序算法】总结篇
✨✨这些 排序算法都是指的 需要进行比较的排序算法 ✨✨下面都是略微讲解一下思路,如果需要详细了解哪一个排序,点击👉链接即可 ✨✨对于时间、空间复杂度、稳定性,希望你🧑🎓能够理解记忆🧑…...

鸿蒙开发文件管理:【@ohos.fileio (文件管理)】
文件管理 该模块提供文件存储管理能力,包括文件基本管理、文件目录管理、文件信息统计、文件流式读写等常用功能。 说明: 本模块首批接口从API version 6开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 impor…...

硬件工程师学习规划
背景介绍 当前电子行业中,互联网因为中国人口基数大,得到很快的发展,一越成为世界第一梯队,互联网软件薪资要高于传统制造业硬件的薪资,从各大招聘软件上就能看到,那么为什么软件发展要好于硬件࿱…...

esp32 8行代码实现蓝牙音响
目录 硬件准备: 具体代码: 接线: 备注: 八行代码实现简易版蓝牙音响,亲测有效: esp32 DIY蓝牙音响_哔哩哔哩_bilibili 硬件准备: ESP32-wroom、MAX98357音频放大器模块、4欧3瓦小喇叭、杜…...

注册用户如何防止缓存穿透?
注册用户如何防止缓存穿透? 先说明用户注册为什么会发送缓存穿透:用户注册时,需要验证用户名是否已存在,先查缓存,没有再查数据库,还没有才验证通过。高并发的情况下就可能有大量用户同时注册,…...

Presto基础知识
Presto缓存 引入Presto缓存之前 BackgroundHiveSplitLoader 使用底层的文件系统直接进行数据的读写; 引入Presto缓存机制之后,底层的文件系统被被CachingFileSystem 代理一层 CachingFileSystem 有两个子类,根据你选用的底层缓存引擎的不同…...

Ajax + Easy Excel 通过Blob实现导出excel
前端代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><script src"./js/jquery-3.6.0.min.js"></script></head><body><div><button onclick"exportF…...

Qt+qss动态属性改变控件状态切换的样式
先说点基础的吧,qt的样式实现,常见的主要有三种方式,分别为: 1.ui界面中右键样式表直接添加 2.代码中对控件设置样式setStyleSheet 3.外部预设好qss文件,代码中加载后设置样式 实际工作开发中,我推荐使用优…...

纷享销客安全体系:安全运维运营
安全运维运营(Security Operations,SecOps)是指在信息安全管理中负责监控、检测、响应和恢复安全事件的一系列运营活动。它旨在保护组织的信息系统和数据免受安全威胁和攻击的损害。 通过有效的安全运维运营,组织可以及时发现和应对安全威胁,减少安全事…...

富瀚微FH8322 ISP图像调试—BLC校正
1、简单介绍 目录 1、简单介绍 2、调试方法 3、输出结果 富瀚微平台调试有一段时间了,一直没有总结,我们调试ISP的时候,首先一步时确定好sensor的黑电平值,黑电平如果不准,则会影响到后面的颜色及对比度相关模块。…...
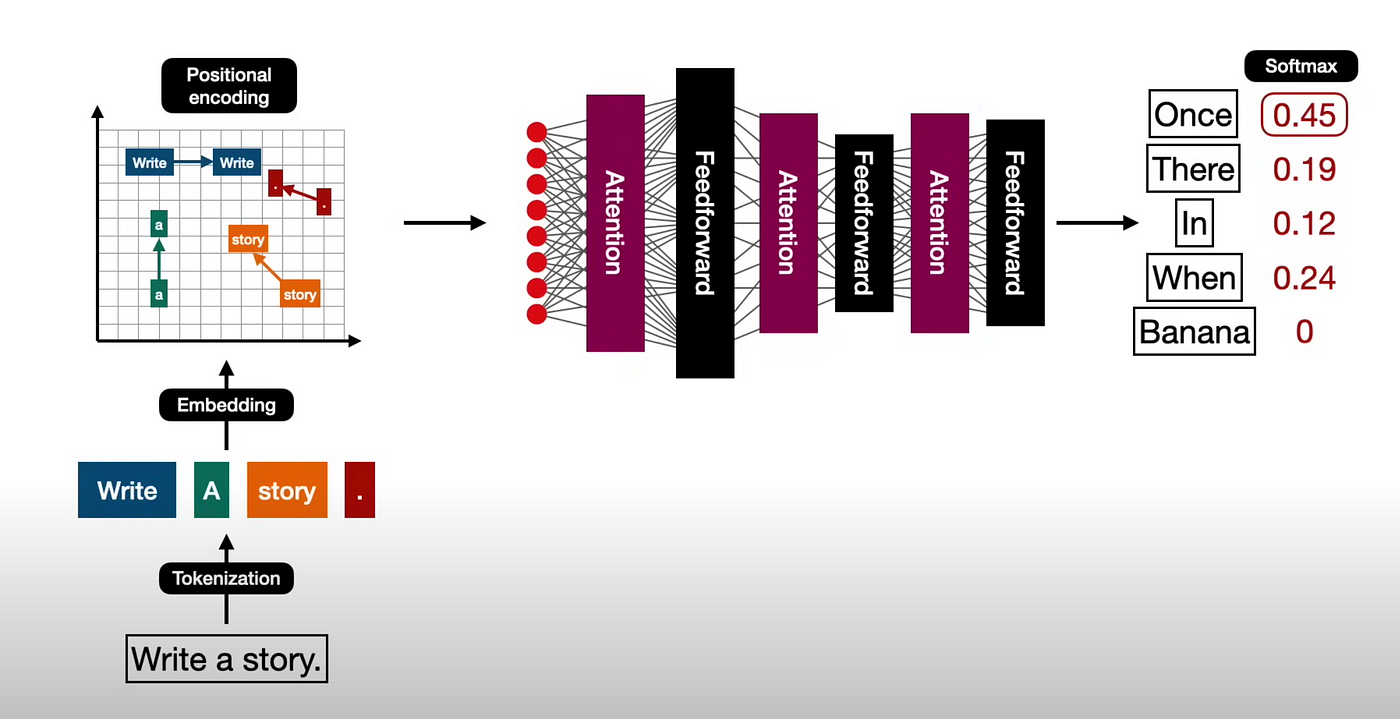
什么是大型语言模型 ?
引言 在本文[1]中,我们将从高层次概述大型语言模型 (LLM) 的具体含义。 背景 2023年11月,我偶然间听闻了OpenAI的开发者大会,这个大会展示了人工智能领域的革命性进展,让我深深着迷。怀着对这一领域的浓厚兴趣,我加入了…...

基于Fluent的SLM过程模拟:涵盖案例研究、热源UDF及粉末导入技术详解
基于fluent的slm过程模拟,包含案例,热源udf,粉末的导入都有涉及。在增材制造领域,选择性激光熔化(SLM)技术因其高精度和复杂形状的制造能力而备受关注。今天,我们就来聊聊如何基于Fluent进行SLM…...

python python-telegram-bot
# 聊聊Python-Telegram-Bot:一个让机器人活起来的工具 如果你曾经用过Telegram,可能会注意到上面有各种各样的机器人,有的能帮你查天气,有的能管理群组,还有的甚至能陪你聊天。这些机器人背后,很多时候都是…...

MySQL数据库(基础语法篇
MySQL数据库(基础语法篇 这份文档详细梳理了MySQL数据库的核心语法体系,涵盖了从基础的数据定义、操纵、查询,到进阶的多表连接、视图、存储过程以及最佳实践。 一、MySQL优势 MySQL作为世界上最流行的开源数据库之一,具有诸多显著特点与优势…...
)
避坑指南:Ubuntu20.04下用Python3.8搞定Carla 0.9.13预编译版与ROS Bridge(解决卡死问题)
Ubuntu 20.04下Python 3.8与Carla 0.9.13的完美联姻:ROS Bridge避坑全指南 当自动驾驶仿真遇上机器人操作系统,Carla与ROS的集成堪称绝配。但这对黄金搭档的联姻之路却布满荆棘——Python版本冲突、依赖库不兼容、环境变量混乱,每一个坑都可能…...

MATLAB绘图中文乱码终极解决方案:3种方法让你的图表告别方框
MATLAB绘图中文乱码终极解决方案:3种方法让你的图表告别方框 科研图表中的中文显示问题一直是MATLAB用户的痛点。当精心准备的论文图表出现"口口口"方框时,不仅影响数据呈现效果,更可能让研究成果的专业性大打折扣。本文将深入剖析…...

JAVA面试-JVM内存结构详解
Java虚拟机(JVM)内存结构,也称内存模型,是程序运行时的数据存储区域。根据《Java虚拟机规范》,可划分为线程私有和线程共享两大部分,以实现高效的内存管理和线程安全。其主要构成如下表所示: 内…...

Modelsim 10.7/2019.5 破解后启动报错:HostID格式异常排查与修复
1. 破解后启动报错的典型现象 最近在折腾Modelsim 10.7和2019.5版本时,遇到了一个让人抓狂的问题:明明按照网上的破解教程一步步操作,环境变量也设置正确,但启动软件时还是弹出了license报错。这个错误提示特别有意思,…...
)
NAS不只是存文件!极空间Docker部署汉化游戏全攻略(含避坑技巧)
极空间NAS变身游戏主机:Docker部署汉化游戏的完整实践指南 你是否曾想过,那台安静躺在角落里的NAS设备,除了存储照片和电影外,还能摇身一变成为你的私人游戏服务器?极空间NAS凭借其出色的硬件性能和友好的操作界面&…...

从Python到Maple:给程序员的数据结构与函数包迁移避坑手册
从Python到Maple:给程序员的数据结构与函数包迁移避坑手册 当你习惯了Python的灵活与简洁,突然切换到Maple的数学王国时,那种感觉就像从喧闹的都市搬进了严谨的实验室。作为一款专注于符号计算和数学建模的工具,Maple有着独特的思…...

毕业项目技术辅导:前后端与数据分析模块协作
毕业项目进入冲刺期,功能点多、时间紧、还要准备演示与答辩? 我这边提供毕业项目技术协作,主要做: 前端页面与交互实现(可配合你现有框架)后端接口、数据库与联调支持数据清洗、分析与可视化展示既有代码 b…...